Apple Inc. (NASDAQ:AAPL) の一日後の予測と検証
【概要】
Apple Inc.の過去10年間の株価データを用いて、LSTM深層学習モデルによる翌日の終値予測を行う。過去60日間のデータから13種類の特徴量を生成し、3層LSTMモデルで学習する。ウォークフォワード検証により時系列データにおける予測性能を評価し、RMSE、MAPE、方向予測精度の3つの指標で定量化する。訓練では1,972日分、予測は直近494日分のデータを使用する。
10年間データを使用。訓練では1,972日分を使用。予測は直近494日分。
本プログラムはAIによる将来予測を学ぶためのものである。実際の将来予測に使用することはリスクが高く推奨できない。
【目次】
【関連する外部ページ】
Colab のページ(ソースコードと説明): https://colab.research.google.com/drive/1cQqBvawPcU8YTnXh4R7NRUcAnI4i4X6f?usp=sharing
第1章 用語リスト
-
LSTM(Long Short-Term Memory)
再帰型ニューラルネットワークの一種で、時系列データにおける長期依存関係を学習する。メモリセルと3つのゲート機構により勾配消失問題を解決する。
-
ウォークフォワード検証
時系列データに対するモデル評価手法。データを時間順に分割し、訓練期間を段階的に拡大しながら予測性能を評価する。
-
時系列データ
時間順に並んだデータ。株価予測では過去のデータのみを用いて未来を予測するため、データの順序を維持する必要がある。
-
多変量特徴量
複数の種類の特徴量。このプログラムでは終値、移動平均比率、テクニカル指標など13種類を使用する。
-
MinMaxスケーリング
全特徴量を0から1の範囲に正規化する手法。異なる尺度の特徴量を統一的に扱い、学習の安定性を確保する。
-
Early Stopping
検証損失を監視し、改善が見られない場合に学習を停止する仕組み。過学習を抑制し、汎化性能(未知のデータに対する予測性能)を維持する。
-
過学習
モデルが訓練データに過度に適合し、未知のデータに対する予測性能が低下する現象。
-
RMSE(二乗平均平方根誤差)
予測値と実際の値の誤差を評価する指標。値が小さいほど予測精度が高い。
-
MAPE(平均絶対パーセント誤差)
予測誤差をパーセンテージで表す指標。値が小さいほど予測精度が高い。
-
方向予測精度
価格の上昇・下降という方向性の予測精度を示す指標。実際の取引における有用性を評価する。
第2章 プログラム利用ガイド
1. このプログラムの利用シーン
株価の時系列データを用いて、深層学習による予測モデルを構築し評価するためのプログラムである。Apple Inc.の過去10年間の株価データから翌日の終値を予測し、その精度を複数の指標で評価する。機械学習を用いた株価予測の研究や、LSTMによる時系列予測の学習に活用できる。本プログラムはAIによる将来予測を学ぶためのものである。実際の将来予測に使用することはリスクが高く推奨できない。
2. 主な機能
- 株価データの自動取得:yfinanceライブラリを用いてApple Inc.の10年間の株価データを取得する
- 特徴量の自動生成:移動平均比率、RSI、MACD、ボリンジャーバンド位置など13種類の特徴量を自動計算する
- LSTMモデルによる予測:過去60日間のデータから翌日の終値を予測する3層LSTMモデルを学習する
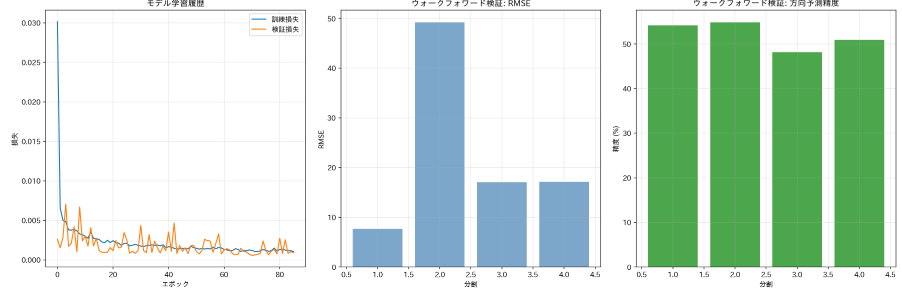
- ウォークフォワード検証:4分割のウォークフォワード検証により時系列データにおける予測性能を評価する
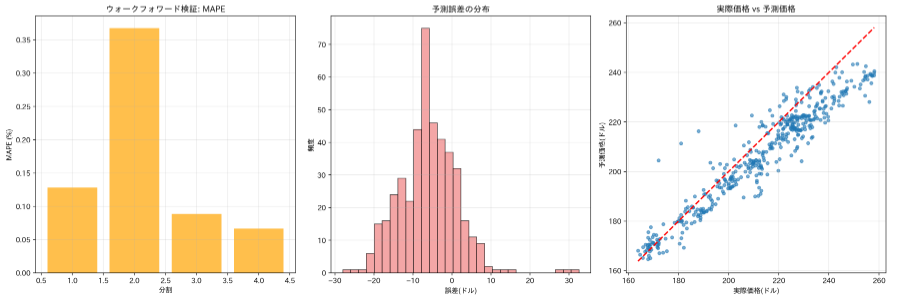
- 包括的な評価:RMSE、MAPE、方向予測精度の3つの指標で予測性能を定量化する
- 詳細な可視化:全期間の予測結果、学習履歴、検証結果、誤差分布など7つのグラフを生成する
3. 基本的な使い方
- Colab のページを開く
Colab のページ(ソースコードと説明): https://colab.research.google.com/drive/1cQqBvawPcU8YTnXh4R7NRUcAnI4i4X6f?usp=sharing
- コードセルを実行する(データ取得、特徴量生成、モデル学習、評価が順に自動実行される)
- セルの出力で各段階の進捗とウォークフォワード検証の結果を確認する
- 生成されたグラフで予測精度を視覚的に評価する
4. 便利な機能
- データ取得から評価まで一連の処理が自動化されており、手動での設定は不要である
- japanize-matplotlibにより、グラフの凡例や軸ラベルが日本語で表示される
- 各グラフについて、何を示しているか、どう解釈するかの説明が出力される
- 訓練データとテストデータを時系列順序を維持したまま分割し、未来のデータが過去の予測に影響しない仕組みとなっている
第3章 プログラムの説明
概要
このプログラムはApple Inc.の10年間の株価データを用いて、LSTM深層学習モデルによる1日先予測を行うものである。過去60日間のデータを入力として翌日の終値を予測し、ウォークフォワード検証により予測精度を評価する。訓練データとテストデータを時系列順に分割することで、実際の運用環境における予測性能を検証する。
主要技術
LSTM(Long Short-Term Memory)
LSTMはHochreiterとSchmidhuberが1997年に発表した再帰型ニューラルネットワーク(RNN)の一種である[1]。従来のRNNが抱える勾配消失問題を解決するため、メモリセルと3つのゲート機構(入力ゲート、忘却ゲート、出力ゲート)を導入している。この構造により、時系列データにおける長期依存関係を学習できる。株価予測のような時系列データ解析において、過去の情報を保持しながら将来の値を予測する能力を持つ。
ウォークフォワード検証(Walk-Forward Validation)
ウォークフォワード検証は時系列データに対するモデル評価手法である[2]。データを時間順に分割し、訓練期間を段階的に拡大しながら予測性能を評価する。このプログラムでは4分割のウォークフォワード検証を実施し、各分割において訓練データで学習したモデルをテストデータで評価する。この手法により、将来データに対する予測性能をより現実的に評価できる。
技術的特徴
多変量時系列データの活用
終値、騰落率(前日からの価格の変化率)、高値安値比率に加え、5日・10日・20日・50日移動平均の価格比率、ボリンジャーバンド位置(移動平均線の上下に標準偏差の幅を取った帯の中での価格の位置)、RSI(相対力指数。一定期間の値上がり幅と値下がり幅の比率から買われすぎ・売られすぎを判断する指標)、MACD(移動平均収束拡散法。短期と長期の指数移動平均の差)、出来高比率、ボラティリティ(価格変動の大きさ)を含む13種類の特徴量を使用している。これらを統合することで価格動向を多面的に捉えている。
MinMaxスケーリングによる正規化
全特徴量を0から1の範囲に正規化することで、異なる尺度の特徴量を統一的に扱い、学習の安定性を確保している。
Early Stoppingによる過学習防止
検証損失を監視し、10エポック(エポックは訓練データ全体を1回学習する単位)改善が見られない場合に学習を停止する。この仕組みにより過学習を抑制し、汎化性能を維持している。
3層LSTM構造とドロップアウト
64-64-32ユニットの3層LSTM構造を採用し、各層の後に0.1から0.2のドロップアウト層(学習中に一部のユニットを無効化して過学習を防ぐ層)を配置している。この構成により特徴抽出能力と汎化性能のバランスを実現している。
実装の特色
時系列順序の維持
データ分割において訓練データとテストデータの時系列順序を厳密に維持し、未来のデータが過去の予測に影響を与えない設計となっている。この制約により、実運用環境における予測性能を正確に評価できる。
包括的な評価指標
RMSE(二乗平均平方根誤差)、MAPE(平均絶対パーセント誤差)、方向予測精度の3種類の指標を用いて予測性能を多角的に評価している。方向予測精度は価格の上昇・下降という方向性の予測精度を示し、実際の取引における有用性を評価する指標である。
テクニカル指標の統合
taライブラリを使用してRSI、MACD、ボリンジャーバンドなどのテクニカル指標を計算し、価格データと組み合わせることで市場の状態を表現する特徴量を構築している。
詳細な可視化機能
全期間の時系列プロット、学習履歴、ウォークフォワード検証結果、予測誤差分布、散布図など7つのグラフを生成する。各グラフには読み方の説明が付属し、モデルの挙動と予測精度を視覚的に把握できる。
参考文献
[1] Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780. https://doi.org/10.1162/neco.1997.9.8.1735
[2] Machine Learning Mastery (2019). How To Backtest Machine Learning Models for Time Series Forecasting. https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
第4章 実験・研究スキルの基礎:Google Colabで学ぶ株価予測実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは株価の時系列データが実験用データである。Apple Inc.の過去10年間の株価データ(終値、高値、安値、始値、出来高)をyfinanceライブラリを通じて取得する。データは日次単位で記録されており、約2,500日分のデータが含まれる。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- シーケンス長(過去何日分のデータを使用するか)が予測精度に与える影響を確認する
- LSTM層の構成(層数、ユニット数)が予測精度に与える影響を確認する
- 特徴量の種類と数が予測精度に与える影響を確認する
- 訓練エポック数が予測精度と過学習に与える影響を確認する
- ドロップアウト率が汎化性能に与える影響を確認する
- ウォークフォワード検証の分割数が評価の安定性に与える影響を確認する
1.3 プログラム
実験を実施するためのツールである。このプログラムはTensorFlow/KerasのLSTMモデルとウォークフォワード検証を使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加できる
- パラメータを変更することで異なる実験条件を設定できる
1.4 プログラムの機能
このプログラムは複数のパラメータで株価予測モデルを制御する。
入力パラメータ:
- シーケンス長(sequence_length):過去何日分のデータを使用するか(デフォルト:60日)
- 訓練エポック数:モデルを何回学習させるか(最終モデル:100エポック、ウォークフォワード:50エポック)
- LSTM層の構成:各層のユニット数(64-64-32の3層構造)
- ドロップアウト率:過学習防止のための値(0.1から0.2)
- 訓練データとテストデータの分割比率(80:20)
- ウォークフォワード検証の分割数(n_splits:4)
出力情報:
- 3つの評価指標(RMSE、MAPE、方向予測精度)
- 訓練データとテストデータでの予測結果
- ウォークフォワード検証の各分割における性能
- 7つのグラフ(全期間時系列プロット、学習履歴、検証結果、誤差分布、散布図など)
- 使用した特徴量の一覧
実験の実行では、プログラムを実行するとデータ取得、特徴量生成、モデル学習、評価が自動的に順次実行される。各段階の進捗状況はセルの出力に表示される。実験結果は数値とグラフの両方で出力される。
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、パラメータの影響を考察する。
基本認識:
- パラメータを変えると結果が変わる。その変化を観察することが実験である
- 良い結果かどうかは、複数の評価指標を総合的に判断する必要がある
観察のポイント:
- RMSEの値はどの程度か(テストRMSEが訓練RMSEより大幅に高い場合は過学習の可能性がある)
- MAPEは何パーセントか(一般に10%以下であれば良好な予測とされる)
- 方向予測精度は50%以上か(50%を下回る場合はランダムより悪い予測である)
- ウォークフォワード検証の結果は分割ごとに大きくばらついていないか
- 学習曲線(訓練損失と検証損失)は適切に収束しているか
- 予測誤差の分布は0を中心に対称的か、偏りがあるか
- 散布図で実際価格と予測価格は対角線に沿っているか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
データ取得に失敗する
- 原因:インターネット接続の問題、またはYahoo Financeのサービス障害
- 対処方法:インターネット接続を確認し、しばらく時間をおいて再実行する。別の銘柄(例:"MSFT")で試してみる
メモリ不足のエラーが発生する
- 原因:大量のデータや複雑なモデルによりメモリが不足している
- 対処方法:ランタイムタイプをGPUに変更する、またはsequence_lengthを小さくする(例:60から30)
2.2 期待と異なる結果が出る場合
予測精度が極端に低い(MAPE > 20%)
- 原因:シーケンス長が短すぎる、特徴量が不足している、または過学習が発生している
- 対処方法:sequence_lengthを増やす(例:60から90)。学習曲線を確認し、検証損失が上昇している場合はエポック数を減らす
訓練精度は高いがテスト精度が低い
- 原因:過学習が発生している
- 対処方法:ドロップアウト率を上げる(0.2から0.3)、またはEarly Stoppingのpatience値(何エポック改善がなければ停止するかの設定値)を小さくする(10から5)。LSTM層のユニット数を減らすことも有効である
方向予測精度が50%程度またはそれ以下
- 原因:モデルが価格の方向性を学習できていない。これはランダム予測と同等である
- 対処方法:特徴量を見直す。特に方向性に関連する特徴量(returns、macd)の重要性が高い。シーケンス長を変更して再実験する
ウォークフォワード検証の結果が分割ごとに大きく異なる
- 原因:モデルの安定性が低い、または市場環境の変化が激しい期間を含んでいる
- 対処方法:これは時系列データでは起こりうる現象である。分割数を増やして(4から8)より詳細に評価する。各分割の期間を確認し、特定の期間で性能が低下している理由を考察する
学習曲線で検証損失が訓練損失より常に高い
- 原因:これは正常な動作である。訓練データは学習済み、テストデータは未知のデータであるためである
- 対処方法:問題ではない。両方の損失が減少していれば学習は進んでいる。ただし差が大きすぎる場合は過学習の兆候であるため、ドロップアウト率を調整する
3. 実験レポートのサンプル
シーケンス長が予測精度に与える影響の検証
実験目的(記載例)
過去何日分のデータを使用するか(シーケンス長)が株価予測の精度に与える影響を明らかにする。最適なシーケンス長を見つける。
実験計画(記載例)
他のパラメータを固定し、シーケンス長のみを変化させて予測精度を比較する。LSTM層の構成(64-64-32)、エポック数(50)、訓練データ比率(80%)は固定する。
実験方法(記載例)
プログラムのsequence_length変数を変更して実行し、以下の指標を記録する:
- テストRMSE:予測誤差の大きさ
- テストMAPE:予測誤差の割合
- 方向予測精度:価格の上昇・下降の予測精度
- 学習時間:モデルの訓練に要した時間
実験結果(記載例)
| シーケンス長 | テストRMSE | テストMAPE (%) | 方向予測精度 (%) | 学習時間 (秒) | 総合評価 |
|---|---|---|---|---|---|
| 30日 | x.xx | x.xx | xx.x | xx | x |
| 60日 | x.xx | x.xx | xx.x | xx | x |
| 90日 | x.xx | x.xx | xx.x | xx | x |
| 120日 | x.xx | x.xx | xx.x | xx | x |
考察(記載例)
- (例文)シーケンス長xxx日では学習時間は短いが予測精度は最も低かった。過去の情報が不足しており、長期的なトレンドを捉えられていないと考えられる
- (例文)シーケンス長xxx日ではRMSEとMAPEが改善され、方向予測精度も向上した。学習時間も妥当な範囲でありバランスの取れた設定である
- (例文)シーケンス長xxx日では予測精度がさらに向上したが学習時間も増加した。特に方向予測精度の向上が顕著であった
- (例文)シーケンス長xxx日では予測精度の改善は限定的であり学習時間のみが大幅に増加した。長すぎるシーケンスは効率が悪いことが確認できた
- (例文)シーケンス長を長くするほど予測精度は向上する傾向が見られたが、xxx日を超えると効果が頭打ちになる。これは株価がxxx日程度より古い情報にはあまり依存しないことを示唆している
結論(記載例)
(例文)本実験においては、シーケンス長xxx日からxxx日が最適であると判断できる。予測精度と計算効率のバランスを考慮するとxxx日が実用的な設定である。より高い精度が必要で計算時間に余裕がある場合はxxx日が適切である。シーケンス長の選択は予測精度に大きな影響を与えることが確認でき、適切な過去データの範囲を設定することの重要性が理解できた。