fastTextを使用した日本語単語の特徴ベクトルと類似検索の Colab プログラムによる実験・研究スキルの基礎
【概要】fastTextライブラリを用いて日本語単語の300次元ベクトル表現を取得し、コサイン類似度計算や類似語検索を行うプログラムである。辞書にない新語にも対応し、単語埋め込み技術の動作原理を実践的に学習できる。
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1HtjErY_mM2YEaAWrVCqYFklNyoerFtrI?usp=sharing
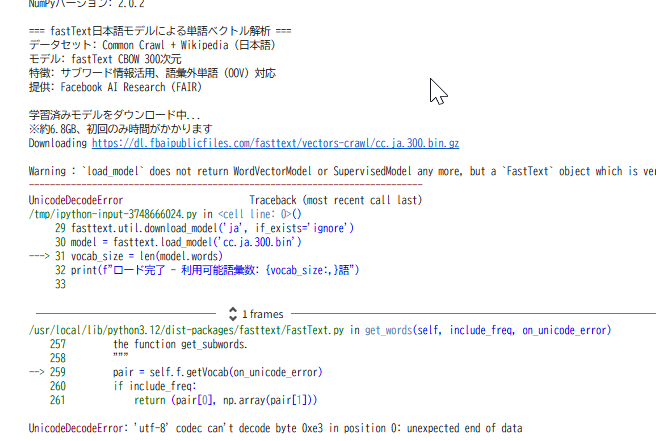 現在デバッグ中
現在デバッグ中
【目次】
プログラム利用ガイド
1. このプログラムの利用シーン
日本語の単語間の意味的な類似性を定量的に分析するためのソフトウェアである。自然言語処理の研究や教育において、単語埋め込み技術の動作原理を理解し、単語の意味的関係を可視化することができる。辞書にない新語や造語であっても、その意味的な位置づけを推定できる。
2. 主な機能
単語ベクトルの取得では、日本語の単語を300個の数値(300次元ベクトル)で表現する。意味的に類似した単語は、この数値空間で近い位置に配置される。類似度の計算では、2つの単語がどれだけ意味的に近いかを数値(-1から1の範囲)で示す。1に近いほど類似度が高い。類似語の検索では、ある単語に意味的に近い単語を自動的に探索する。指定した数(K個)の最も近い単語を取得できる。新語への対応では、辞書に登録されていない単語であっても、その構成文字から意味を推定し、ベクトル表現を生成する。
3. 基本的な使い方
環境の準備では、Google ColabやJupyter Notebook環境で実行する。初回実行時は学習済みモデル(約6.8GB)が自動的にダウンロードされる。
プログラムの実行では、ノートブックのコードセルを実行する。
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1HtjErY_mM2YEaAWrVCqYFklNyoerFtrI?usp=sharin
各セクションで以下の結果が表示される。単語ベクトルの例(東京、大阪、京都の300次元数値配列)、単語間の類似度(東京と大阪、東京と京都のコサイン類似度)、類似語の検索結果(寿司、ラーメン、天ぷらに近い単語トップ10)、語彙外単語の処理結果(ChatGPT、スマホ、ググるのベクトル表現)が表示される。
結果の解釈では、各単語の300次元ベクトルは、その単語の意味を数値で表現したものである。類似度が高い(1に近い)ほど、2つの単語の意味が近いことを示す。類似検索では、食べ物なら関連する料理名が上位に表示される。
4. 便利な機能
任意の単語で試すには、プログラム内の単語リスト(['東京', '大阪', '京都']や['寿司', 'ラーメン', '天ぷら'])を編集することで、興味のある単語で分析できる。検索数の調整では、K近傍探索のK値(デフォルト10)を変更することで、表示する類似語の数を調整できる。新語の分析では、辞書にない単語(例:新しい流行語や専門用語)を入力し、既存の単語との類似性を調べることができる。モデルの理解では、実行結果を通じて、単語埋め込み技術とベクトル空間モデルの動作原理を実践的に学習できる。
プログラムコードの説明
1. 概要
このプログラムは、fastTextライブラリを用いて日本語単語の特徴ベクトル表現を取得し、単語間の意味的類似度を計算する。学習済みモデル(Common Crawl + Wikipedia)を利用し、300次元のベクトル空間における単語ベクトル表示、コサイン類似度計算、K近傍探索、語彙外単語への対応をデモンストレーションする。
2. 主要技術
fastText
Facebook AI Research(FAIR)が開発した単語埋め込みライブラリである[1][2]。文字n-gram(サブワード)単位でベクトル表現を学習することで、形態素情報を捉え、訓練データに含まれない単語にも対応できる[1]。本プログラムでは、Common CrawlとWikipediaで事前学習されたCBOW(Continuous Bag of Words)モデルを使用し、各単語を300次元のベクトルで表現する[3]。
コサイン類似度
ベクトル空間における2つのベクトル間の角度の余弦を測定する類似度指標である。単語ベクトル間の意味的類似性を定量化する手法として自然言語処理で広く使用される。値の範囲は-1から1で、1に近いほど類似度が高いことを示す。
3. 技術的特徴
サブワード情報の活用
fastTextは文字n-gram(3〜6文字)でベクトル表現を学習し、これらのベクトルの総和として単語を表現する[1]。接頭辞・接尾辞・語幹などの形態素情報を捉えることができる。
語彙外単語への対応
訓練データに含まれない単語でも、その構成文字n-gramから意味的なベクトル表現を生成できる[1]。これにより、新語や造語にも柔軟に対応する。
CBOW学習モデル
周辺語から中心語を予測する学習手法により、文脈情報を反映した単語表現を獲得する[3]。位置重み付けを適用し、300次元の密なベクトル空間で表現する。
K近傍探索
ベクトル空間で最も近いK個の単語を探索するアルゴリズムである。コサイン類似度を距離尺度として用い、意味的に関連する単語を検索する。
4. 実装の特色
本プログラムは、日本語単語の意味的関係を分析するための4つのデモンストレーションを提供する。単語ベクトルの表示では、任意の単語(例:東京、大阪、京都)を300次元ベクトルに変換して表示する。類似度計算では、2単語間のコサイン類似度を計算し、意味的近接性を定量化する。類似検索では、指定単語に最も近い10単語をK近傍探索により取得する。OOV処理では、訓練データに存在しない単語(ChatGPT、スマホ、ググる)に対してもサブワード情報からベクトルを推定する。
学習済みモデル(cc.ja.300.bin、約6.8GB)を自動ダウンロードし、NumPyとfastTextライブラリを使用して実装される。
5. 参考文献
[1] Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146. https://doi.org/10.1162/tacl_a_00051
[2] Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2017). Bag of Tricks for Efficient Text Classification. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 427-431.
[3] Grave, E., Bojanowski, P., Gupta, P., Joulin, A., & Mikolov, T. (2018). Learning Word Vectors for 157 Languages. Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018).
実験・研究スキルの基礎:Google Colabで学ぶ単語ベクトル実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは日本語の単語が実験用データである。プログラムには具体的な単語例(東京、大阪、京都、寿司、ラーメン、天ぷら、ChatGPT、スマホ、ググる)が含まれているが、これらを任意の単語に変更して実験できる。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例としては、特定のカテゴリ(都市、食べ物、職業など)の単語同士の類似度を比較する、同義語や類義語がどの程度の類似度を示すか確認する、新語や造語が既存の単語とどの程度類似しているか調べる、K近傍探索における検索数K(5、10、20など)が結果に与える影響を確認する、文字の一部を共有する単語(例:「走る」と「走行」)の類似度を調べる、コサイン類似度と人間の直感的な類似性判断の一致度を検証するといったものが挙げられる。
1.3 プログラム
実験を実施するためのツールである。このプログラムはfastTextライブラリとNumPyを使用している。プログラムの機能を理解して活用することが基本である。基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる。
1.4 プログラムの機能
このプログラムは日本語単語の意味的関係を数値化する4つの機能を提供する。
入力データとしては、任意の日本語単語(ひらがな、カタカナ、漢字に対応)、K近傍探索における検索数K(デフォルト10)がある。
出力情報としては、単語ベクトル(各単語を300個の数値、すなわち300次元ベクトルで表現)、コサイン類似度(2つの単語間の類似度を-1から1の数値で表現、1に近いほど類似)、類似単語リスト(指定単語に最も近いK個の単語とその類似度)、語彙外単語の推定(辞書にない単語でもベクトル表現を生成)がある。
実験可能な操作としては、単語リスト(例:['東京', '大阪', '京都'])を編集して、興味のある単語群で実験すること、類似度計算の対象単語を変更して、異なる単語ペアを比較すること、K近傍探索のK値を変更して、表示する類似語の数を調整することが挙げられる。
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、単語間の意味的関係を考察する。
基本認識としては、単語を変えると結果が変わり、その変化を観察することが実験である。「意味的に近い」という判断は文脈や用途によって異なる。数値化された類似度は、人間の直感と必ずしも一致しない場合がある。
観察のポイントとしては、類似度の数値は人間の直感と一致しているか、同じカテゴリの単語同士は高い類似度を示すか、K近傍探索で得られた類似語は妥当か、新語や造語がどのような既存単語と近いと判定されるか、文字が似ている単語と意味が似ている単語で類似度に違いはあるか、類似度の範囲(0.3〜0.5、0.5〜0.7、0.7〜1.0など)によって意味的関係はどう異なるかといったことが挙げられる。
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する場合、原因はfastTextライブラリがインストールされていない、または構文エラーである。対処方法として、エラーメッセージを確認し、提供されたコードと比較する。最初のセル(!pip install -q fasttext-wheel)を実行したか確認する。
モデルのダウンロードが進まない場合、原因は初回実行時に学習済みモデル(約6.8GB)をダウンロードしていることである。対処方法として、これは正常な動作である。ダウンロードが完了するまで待つ(数分〜十数分)。
単語が見つからないというエラーが出る場合、原因は入力した単語の表記が間違っている、または空白や特殊文字が含まれていることである。対処方法として、単語の綴りを確認する。全角・半角の違いにも注意する。
2.2 期待と異なる結果が出る場合
明らかに関係のない単語同士の類似度が高い場合、原因はfastTextが文脈での共起関係を学習しているため、人間の直感と異なる場合があることである。対処方法として、これは正常な動作である。なぜその単語が近いと判定されたか、文脈的な関係を考察する機会として活用する。
同義語なのに類似度が低い場合、原因は使用頻度が異なる、または訓練データでの共起が少ないことである。対処方法として、複数の類義語ペアで実験し、傾向を観察する。類似度0.5以上であれば意味的に関連していると考えられる。
K近傍探索で意外な単語が上位に来る場合、原因はベクトル空間での距離は多次元的であり、人間が考える1つの側面だけでは説明できないことである。対処方法として、これは正常な動作である。なぜその単語が近いのか、複数の観点から考察する。
新語のベクトルが既存の単語と全く関連がない場合、原因はその新語を構成する文字n-gramが訓練データに少なかったことである。対処方法として、K値を増やして(例:20や30)より多くの類似語を観察する。または、似た構成の既存単語を探してみる。
3. 実験レポートのサンプル
食べ物カテゴリにおける単語の意味的類似性の分析
実験目的として、日本の伝統的な料理名(寿司、天ぷら、そば、うどん)と外来語の料理名(ラーメン、カレー、ハンバーグ)の類似度を比較し、fastTextモデルがどのように料理を分類しているかを確認する。
実験計画として、「寿司」を基準単語として、他の料理名との類似度を計算する。また、K近傍探索(K=10)で「寿司」に類似する単語を抽出し、その妥当性を評価する。
実験方法として、プログラムを実行し、calc_similarity関数を使用して以下の単語ペアの類似度を計算する。寿司 - 天ぷら、寿司 - そば、寿司 - うどん、寿司 - ラーメン、寿司 - カレー、寿司 - ハンバーグの各ペアである。
実験結果(以下の表の数値はすべて架空の値):
| 単語ペア | コサイン類似度 | カテゴリ | 評価 |
|---|---|---|---|
| 寿司 - 天ぷら | xxx | 伝統的和食 | xxx |
| 寿司 - そば | xxx | 伝統的和食 | xxx |
| 寿司 - うどん | xxx | 伝統的和食 | xxx |
| 寿司 - ラーメン | xxx | 外来語料理 | xxx |
| 寿司 - カレー | xxx | 外来語料理 | xxx |
| 寿司 - ハンバーグ | xxx | 外来語料理 | xxx |
K近傍探索の結果(寿司に類似する上位5単語、以下の表の数値はすべて架空の値):
| 順位 | 単語 | 類似度 | 関連性の評価 |
|---|---|---|---|
| 1 | xxx | xxx | xxx |
| 2 | xxx | xxx | xxx |
| 3 | xxx | xxx | xxx |
| 4 | xxx | xxx | xxx |
| 5 | xxx | xxx | xxx |
考察:
(例文)伝統的な和食同士(寿司-天ぷら、寿司-そば)はxxx以上の高い類似度を示し、fastTextモデルが日本料理というカテゴリを捉えていることが確認できた。(例文)外来語の料理(カレー、ハンバーグ)との類似度はxxx程度と低く、料理の起源や文化的背景が類似度に影響している可能性が示唆された。(例文)ラーメンは外来語であるが比較的高い類似度(xxx)を示した。これは日本で広く定着した料理として、寿司などの和食と同じ文脈で使われることが多いためと考えられる。(例文)K近傍探索では料理名だけでなく「xxx」「xxx」といった関連語も抽出された。これは単に料理名という枠を超えて、食文化全般の文脈でベクトルが学習されていることを示している。(例文)一部予想外の単語(xxx)が上位に現れたが、これはその単語が寿司と同じ文脈(例:観光、日本文化など)で頻繁に言及されるためと推測される。
結論:
(例文)fastTextの単語ベクトルは、料理名の意味的関係をある程度捉えているが、人間の直感的な分類とは異なる側面も含んでいることが確認できた。特に、文化的カテゴリ(伝統的和食 vs 外来料理)が類似度に影響を与えている。また、K近傍探索により、単に料理名だけでなく、その周辺の文脈(食文化、観光など)も含めた意味的関連性が捉えられていることが明らかになった。実験を通じて、単語ベクトルは多次元空間での距離であり、単一の意味的側面だけでは説明できない複雑な関係を表現していることが理解できた。