YOLO11を用いたCOCOインスタンスセグメンテーション Colab プログラムによる実験・研究スキルの基礎
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1TLO0Bthg-NDqfTQkz_oB5l__G9OfMkLH?usp=sharing
【目次】
プログラム利用ガイド
1. このプログラムの利用シーン
画像内の複数の物体を自動的に識別し、それぞれの物体の正確な輪郭を抽出するためのプログラムである。自動運転システムにおける歩行者や車両の認識、医療画像における臓器や病変部位の識別、小売店舗での商品在庫管理など、物体の個別認識が必要な場面で利用できる。Google Colab環境で動作するため、特別なハードウェアを用意することなく、ウェブブラウザから利用できる。
2. 主な機能
- 物体検出とセグメンテーション: 画像内の複数の物体を検出し、各物体の輪郭をピクセル単位で抽出する。
- 検出結果の可視化: 検出された物体に色分けされたマスクとバウンディングボックスを重ねて表示する。
- 検出情報の出力: 各物体のクラス名、信頼度スコア、バウンディングボックス座標を日本語で表示する。
- サンプル画像での動作確認: 公式提供のサンプル画像を使用して、プログラムの動作を確認できる。
- ユーザー画像の処理: 手元の画像ファイルをアップロードして、インスタンスセグメンテーションを実行できる。
3. 基本的な使い方
- Google Colabでコードセルを実行:
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1TLO0Bthg-NDqfTQkz_oB5l__G9OfMkLH?usp=sharing
- サンプル画像での動作確認:
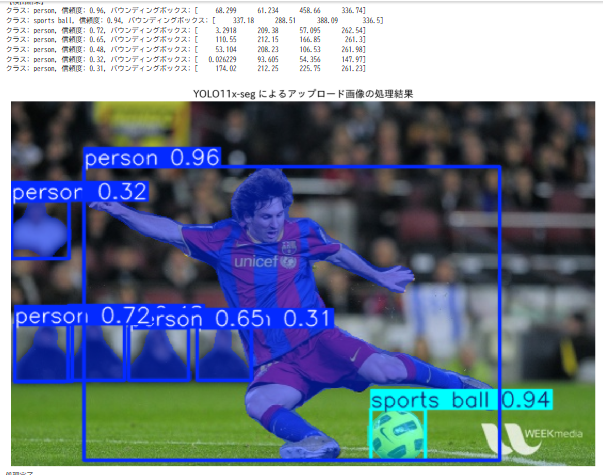
プログラムを実行すると、公式サンプル画像(バスの画像)に対してインスタンスセグメンテーションが実行される。検出された物体のクラス名、信頼度、バウンディングボックス座標がテキストで表示され、続いてアノテーション済みの画像が表示される。
- ユーザー画像のアップロード:
ファイル選択ダイアログが表示されるので、処理したい画像ファイルを選択してアップロードする。
- 結果の確認:
アップロードした画像に対する検出結果が、サンプル画像と同様の形式で表示される。
4. 便利な機能
- GPUの自動利用: CUDAが利用可能な環境では、自動的にGPUを使用して処理する。
- 複数物体の同時検出: 1枚の画像に複数の物体が含まれる場合でも、すべての物体を同時に検出して個別にセグメンテーションする。
- 80クラスの物体認識: COCOデータセットで学習された80種類の物体クラス(人、車、動物、家具など)を認識できる。
- 日本語での結果表示: 検出結果とグラフのラベルが日本語で表示されるため、理解しやすい。
- 大規模モデルの使用: YOLO11x-segは、YOLO11シリーズの中で最大規模のモデルであり、より正確なセグメンテーション結果を得られる。
プログラムコードの説明
1. 概要
このプログラムは、YOLO11フレームワークを用いて画像内の物体を検出し、各物体のピクセル単位のセグメンテーションマスクを生成する。Google Colab環境で動作し、公式サンプル画像とユーザーがアップロードした画像の両方に対してインスタンスセグメンテーションを実行する。
2. 主要技術
YOLO11 (You Only Look Once 11)
Ultralyticsが開発したリアルタイム物体検出・セグメンテーションモデルである[1]。物体検出、インスタンスセグメンテーション、画像分類、姿勢推定など複数のコンピュータビジョンタスクに対応する。改良されたバックボーンとネック構造により、前世代のYOLOv8mと比較してパラメータ数を22%削減しながらCOCOデータセットでより高いmAP(mean Average Precision)を達成している[1]。
インスタンスセグメンテーション
画像内の個々の物体を識別し、ピクセルレベルで輪郭を抽出するコンピュータビジョン技術である[2][3]。物体検出とセマンティックセグメンテーションを同時に解決する手法であり、同一クラスに属する複数の物体インスタンスに対して異なるラベルを割り当てる[3]。
3. 技術的特徴
- 事前学習済みモデルの利用
YOLO11x-segモデルはCOCOデータセットで事前学習されており、80種類の物体クラスを認識できる[4]。COCOデータセットは330K枚の画像を含み、物体検出とセグメンテーションのベンチマークとして広く使用されている[4]。
- バウンディングボックスとマスクの同時出力
各検出物体に対して矩形の境界ボックス(xyxy座標形式)とピクセル単位のセグメンテーションマスクを同時に生成する。
- 信頼度スコアの付与
各検出結果に0.0から1.0の範囲の信頼度スコアを付与し、モデルの確信度を示す。
- マルチデバイス対応
CUDAが利用可能な環境ではGPUを、そうでない環境ではCPUを自動的に選択して処理を実行する。
4. 実装の特色
Google Colab環境に特化した実装となっており、以下の機能を備える。
- Ultralyticsライブラリとjapanize_matplotlibの自動インストール
- 公式サンプル画像(バス画像)での動作確認機能
- ユーザー画像のアップロード機能
- 検出結果の日本語表示(クラス名、信頼度、バウンディングボックス座標)
- アノテーション済み画像のmatplotlibによる表示
- IPython環境での対話的な出力設定
5. 参考文献
[1] Ultralytics. (2024). YOLO11 Documentation. https://docs.ultralytics.com/models/yolo11/
[2] Hafiz, A. M., & Bhat, G. M. (2020). A Survey on Instance Segmentation: State of the art. arXiv preprint arXiv:2007.00047. https://arxiv.org/abs/2007.00047
[3] Tian, D., Han, Y., Wang, B., Guan, T., Gu, H., & Wei, W. (2021). Review of object instance segmentation based on deep learning. Journal of Electronic Imaging, 31(4), 041205. https://doi.org/10.1117/1.JEI.31.4.041205
[4] Lin, T.-Y., et al. (2014). Microsoft COCO: Common Objects in Context. COCO Dataset. https://cocodataset.org/
実験・研究スキルの基礎:Google Colabで学ぶインスタンスセグメンテーション実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは画像ファイルが実験用データである。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- 異なる画像で検出される物体クラスの種類と数を比較する
- 複数の物体が重なっている場合のセグメンテーション精度を確認する
- 物体の大きさ(ピクセル数)と検出信頼度の関係を調べる
- 同一クラスの複数インスタンス(複数の人物など)が正しく区別されるか確認する
- 背景が複雑な画像での検出精度を評価する
1.3 プログラム
実験を実施するためのツールである。このプログラムはUltralyticsのYOLO11x-segモデルを使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムは画像に対してインスタンスセグメンテーションを実行する。
入力データ:
- 公式サンプル画像(バスの画像)
- ユーザーがアップロードした画像ファイル
出力情報:
- 検出された各物体のクラス名
- 各物体の信頼度スコア(0.0〜1.0)
- 各物体のバウンディングボックス座標(左上x、左上y、右下x、右下y)
- アノテーション済み画像(物体ごとに色分けされたマスクと矩形を重畳表示)
処理の特徴:
- 1枚の画像内の複数物体を同時に検出する
- 同一クラスの物体であっても個別のインスタンスとして区別する
- 各物体のピクセル単位の輪郭(セグメンテーションマスク)を生成する
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、インスタンスセグメンテーションの特性を考察する。
基本認識:
- 画像の内容によって検出結果が変わる。その変化を観察することが実験である
- 良い結果、悪い結果は目的によって異なる
観察のポイント:
- どのような物体クラスが検出されたか
- 同一クラスの複数インスタンスが正しく区別されているか
- セグメンテーションマスクは物体の輪郭を正確に捉えているか
- 物体が重なっている部分のマスクはどのように表現されているか
- 小さい物体と大きい物体で信頼度に差があるか
- 誤検出(存在しない物体の検出)は発生しているか
- 見逃し(本来検出すべき物体の未検出)は発生しているか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する
- 原因: 構文エラー、必要なライブラリがインストールされていない
- 対処方法: エラーメッセージを確認し、提供されたコードと比較する
画像がアップロードできない
- 原因: ファイル選択ダイアログで画像を選択していない、またはファイル形式が対応していない
- 対処方法: JPG、PNG形式の画像ファイルを選択する
モデルのダウンロードに時間がかかる
- 原因: 初回実行時にYOLO11x-segモデルをダウンロードしている
- 対処方法: これは正常な動作である。ダウンロードが完了するまで待つ
結果の画像が表示されない
- 原因: matplotlibの表示設定の問題、またはメモリ不足
- 対処方法: ランタイムを再起動して最初から実行する
2.2 期待と異なる結果が出る場合
明らかに存在する物体が検出されない
- 原因: 物体がCOCOデータセットの80クラスに含まれていない、または物体が小さすぎる
- 対処方法: COCOデータセットに含まれる物体クラスを確認する。小さい物体は検出されにくいことを理解する
同じ物体が複数のインスタンスとして検出される
- 原因: 物体が視覚的に分離して見える、または部分的に隠れている
- 対処方法: これは正常な動作である。インスタンスセグメンテーションのアルゴリズムが視覚的な分離を検出している
セグメンテーションマスクが物体の輪郭からずれている
- 原因: 物体の境界が不明瞭、または複雑な形状である
- 対処方法: これはモデルの限界である。境界が明瞭な物体ほど正確なマスクが得られることを理解する
信頼度が低い検出結果が含まれる
- 原因: 物体が部分的に隠れている、または背景と区別しにくい
- 対処方法: これは正常な動作である。信頼度の値を記録し、どのような場合に低くなるか観察する
3. 実験レポートのサンプル
複数人物画像におけるインスタンス識別精度の評価
実験目的:
複数の人物が写っている画像において、各人物が個別のインスタンスとして正しく区別されるか、またセグメンテーションマスクの精度を評価する。
実験計画:
人物が複数含まれる画像を用意し、検出されたインスタンス数、各インスタンスの信頼度、マスクの精度を記録する。
実験方法:
プログラムを実行し、以下の基準で評価する。
- 検出された人物インスタンス数
- 正しく区別された人物の数
- 各インスタンスの信頼度スコア
- セグメンテーションマスクの精度(目視評価: 良好、普通、不良)
- 重なりがある人物の検出状況
実験結果:
| 画像内の実際の人物数 | 検出されたインスタンス数 | 正しく区別された数 | 平均信頼度 | マスク精度評価 | 見逃し数 |
|---|---|---|---|---|---|
| x | x | x | x.xx | 良好/普通/不良 | x |
| x | x | x | x.xx | 良好/普通/不良 | x |
| x | x | x | x.xx | 良好/普通/不良 | x |
| x | x | x | x.xx | 良好/普通/不良 | x |
考察:
- (例文)人物が重なっていない画像では、すべての人物が個別のインスタンスとして正しく検出され、信頼度もxxxx以上であった
- (例文)人物が部分的に重なっている画像では、手前の人物は正確に検出されたが、後ろの人物の一部が見逃される傾向が見られた
- (例文)セグメンテーションマスクは、人物の輪郭が明瞭な部分では正確であったが、髪の毛などの細かい部分では精度が低下した
- (例文)画像の端に位置する人物や、身体の一部のみが写っている人物は、信頼度が低くなる傾向が確認できた
- (例文)同じクラス(人物)であっても、個別のインスタンスとして色分けされたマスクが生成されることを確認できた
結論:
(例文)YOLO11x-segモデルは、複数人物の個別識別において良好な結果を示した。特に人物が重ならず、全身が写っている場合の検出は良好であった。一方、重なりがある場合や身体の一部のみが写っている場合は、検出率が低下することが確認された。インスタンスセグメンテーションは物体検出と比較して、各物体の正確な輪郭情報が得られる利点があるが、境界が不明瞭な部分ではマスクの正確性に限界があることも明らかになった。