YOLOv10物体検出実験 Colab プログラムによる実験・研究スキルの基礎
【概要】
Google Colabで動作する物体検出AI(YOLOv10)を用いた実験プログラムの解説である。画像から人や車、動物など80種類の物体を自動検出する。プログラミング初心者の学生を対象に、実験・研究の基礎スキルを含めて説明する。
【目次】
【関連する外部ページ】
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1VYEaaWa731OcMfr4YnzsvIbybDHtrnUM?usp=sharing
【サイト内の関連情報】
1. プログラムの使用法
1.1 このプログラムの利用シーン
画像内の物体を自動的に検出し、その位置とクラスを特定する用途に使用される。研究開発、教育、プロトタイピングなど、物体検出技術の実験や検証を必要とする場面で活用される。
1.2 主な機能
画像ファイルのアップロードによる物体検出
自分のパソコンやスマートフォンに保存されている写真を、Google Colabにアップロード(転送)する。プログラムはアップロードされた画像を読み込み、その中に何が写っているかを自動的に探し出す。
80クラスのCOCOデータセット物体の検出
このプログラムは80種類の物体を認識できる。これらの物体は、COCOデータセット(大規模な物体検出用の画像データベース)で定義されている。人物、車両、動物など、日常的に見かける物体が含まれている。検出できる物体の例は「3.1.4 プログラムの機能」に示す。
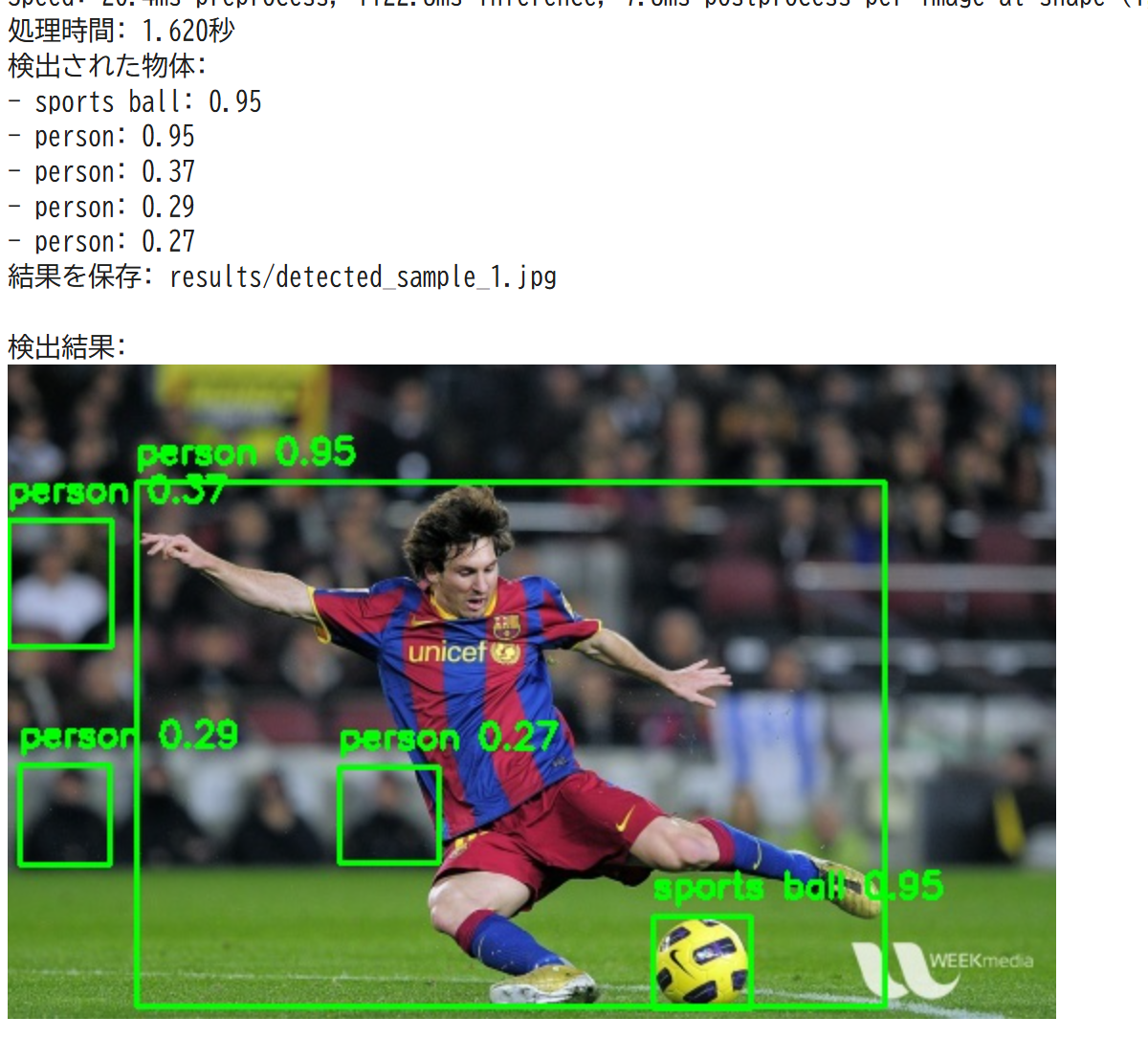
検出結果の視覚化(バウンディングボックスとラベル)
プログラムは検出した物体を画像上に表示する。物体の周りに緑色の矩形の枠(バウンディングボックス)を描き、その上に物体の名前(ラベル)を表示する。これにより、どこに何が検出されたかを視覚的に確認できる。
検出物体の詳細情報表示(クラス名、信頼度)
プログラムは検出した物体について、以下の情報をテキストで出力する。
- クラス名:物体の種類の名前(例:「人」「車」「犬」)
- 信頼度:モデルがその物体であると判断した確信の度合いを0.0から1.0の数値で表したもの。1.0に近いほど確信度が高い。統計的な確率そのものではなく、モデル内部の指標である
1.3 基本的な使い方
- 処理画像を準備しておく
- Colabのページを開く
Colabのページ: https://colab.research.google.com/drive/1VYEaaWa731OcMfr4YnzsvIbybDHtrnUM?usp=sharing
- セルを実行する
- 表示されるファイル選択ダイアログから検出対象の画像ファイルを選択する
- 処理が完了すると、検出結果がノートブック上に表示される
1.4 便利な機能
- 複数の画像形式に対応(JPEG、PNG)
- 検出結果のコンソール出力により、各物体の情報を確認可能
- resultsフォルダへの自動保存により、処理結果の管理が容易
- 処理時間の表示により、性能評価が可能
2. プログラムの説明
2.1 概要
このプログラムは、Google Colab環境でYOLOv10モデルを使用した物体検出を実行する。アップロードした画像に対して物体検出を行い、検出結果を視覚化して表示する機能を提供する。
2.2 主要技術
YOLOv10 (You Only Look Once version 10)
物体検出アルゴリズムである[1]。2024年5月に清華大学の研究者らが公開した。訓練時に用いる一対多ヘッド(one-to-many head)と、推論時に用いる一対一ヘッド(one-to-one head)を組み合わせることで、従来のYOLOシリーズで必要だったNMS後処理を不要としている。
Ultralytics
YOLOモデルの実装と展開を支援するPythonパッケージである[2]。YOLOv3からYOLO26まで複数のYOLOバージョンをサポートし、訓練、検証、推論、エクスポートの機能を統合したフレームワークを提供する。
2.3 技術的特徴
- NMSフリー推論
YOLOv10は一対一マッチング機構を採用し、後処理としてのNMSを不要とする。これにより推論パイプラインが簡素化され、エンドツーエンドの展開が可能になる。
- 信頼度閾値によるフィルタリング
検出結果に対して信頼度0.25の閾値を適用し、低信頼度の検出を除外する。これにより誤検出を抑制し、有意な検出結果のみを出力する。この値はUltralyticsの既定値と同じである。
- バウンディングボックス可視化
検出された物体に対して矩形枠とラベル(クラス名、信頼度)を描画する。OpenCVの描画機能を使用し、元画像に検出結果を重畳表示する。
2.4 実装の特色
Google Colab環境に特化した実装として、以下の機能を備える。
- ファイルアップロードAPIによるインタラクティブな画像入力
- IPython.displayモジュールを使用したノートブック内での結果表示
- 検出結果の自動保存(resultsフォルダ)
- 処理時間の計測機能
- 検出物体の詳細情報(クラス名、信頼度)のコンソール出力
2.5 参考文献
[1] Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J., & Ding, G. (2024). YOLOv10: Real-Time End-to-End Object Detection. Advances in Neural Information Processing Systems (NeurIPS 2024). arXiv:2405.14458. https://arxiv.org/abs/2405.14458
[2] Jocher, G., & Qiu, J. (2024). Ultralytics YOLO11 (Version 11.0.0) [Computer software]. https://github.com/ultralytics/ultralytics
3. 実験・研究スキルの基礎
3.1 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
3.1.1 実験用データ
このプログラムでは画像ファイルが実験用データである。自分で撮影した写真やインターネットから取得した画像(JPEG、PNG形式)を使用する。
3.1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例は次のとおりである。
- 日常的な物体の検出精度を確認する
- 照明条件が検出精度に与える影響を調査する
- 物体のサイズが検出精度に与える影響を調査する
3.1.3 プログラム
実験を実施するためのツールである。このプログラムはYOLOv10(ヨーロー・バージョン10:リアルタイム物体検出アルゴリズム)を使用した物体検出を行う。
プログラムが提供される場合、プログラムの機能を理解して活用することが基本である。基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる。
例として、現在は1枚の画像を処理する機能が提供されている。これを理解すれば、将来的には複数画像の一括処理機能を自分で追加できる。信頼度閾値(検出結果の確信度の基準値、現在0.25)の意味を理解すれば、将来的には目的に応じて調整できる。
3.1.4 プログラムの機能
このプログラムは80種類の物体を検出できる。
検出できる物体の例は次のとおりである。
- 人物:人
- 乗り物:自転車、車、バイク、飛行機、バス、電車、トラック、ボート
- 動物:鳥、猫、犬、馬、羊、牛、象、熊、シマウマ、キリン
- 屋外の物体:信号機、消火栓、停止標識、ベンチ
- 家具:椅子、ソファ、ベッド、ダイニングテーブル
- 食品:バナナ、リンゴ、サンドイッチ、オレンジ、ピザ
- 電子機器:テレビ、ノートPC、マウス、キーボード、携帯電話
- その他:本、時計、花瓶、はさみ
このモデルは事前に大量の画像で訓練されているため、上記80種類の物体を自動的に認識できる。
出力情報は次のとおりである。
- 検出された物体のクラス名(物体の種類の名前、例:「人」「車」)
- 信頼度(検出結果の確信度を示す0.0から1.0の値、1.0に近いほど確信度が高い)
- バウンディングボックス(物体の位置を示す矩形の枠)
- 処理時間
3.1.5 検証(結果の確認と考察)
プログラムの実行結果が正しいか確認し、誤りがあれば原因を考察する。
実行結果には間違いがありえる。間違いの原因は2種類に分けられる。
- プログラムのミス(人為的エラー)
- AIの限界(技術的限界)
3.2 間違いの原因と対処方法
3.2.1 プログラムのミス(人為的エラー)
検出される物体が多すぎる、または少なすぎる場合、原因は信頼度閾値が適切でないことである。対処方法は、閾値を調整する(0.1から0.9の範囲)ことである。
画像を読み込めない場合、原因は対応していないファイル形式である。対処方法は、JPEG、PNG形式に変換することである。
3.2.2 AIの限界(技術的限界)
小さすぎる物体が検出されない場合、原因はアルゴリズムの解像度限界である。対処方法は、カメラを近づけることである。
重なった物体が誤認識される場合、原因はオクルージョン(遮蔽、物体の一部が他の物体に隠れること)への対応困難である。対処方法は、物体が重ならないように配置することである。
80クラスにない物体が検出されない場合、原因は訓練されていない物体であることである。対処方法は、検出したい物体が80クラスに含まれるか確認することである。
暗い場所で検出精度が低下する場合、原因は訓練データと異なる照明条件である。対処方法は、適切な照明条件で撮影することである。
3.3 実験レポートのサンプル
以下は実験結果を記録する際のサンプルである。
サンプル1:基本的な動作確認
実験目的は、YOLOv10による物体検出プログラムの基本的な動作を確認することである。
実験計画は、自分で撮影した画像を1枚用意し、プログラムを実行して物体検出を行うことである。
使用した画像は、大学の教室で撮影した写真(机、椅子、人物が写っている)である。
実験結果は次のとおりである。
- 検出された物体1:人、信頼度=x.xx
- 検出された物体2:椅子、信頼度=x.xx
- 検出された物体3:椅子、信頼度=x.xx
- 処理時間=x.xxx秒
考察は次のとおりである。
- (例文)人物と椅子は正しく検出された。
- (例文)机は検出されなかった(COCOデータセットの80クラスに「机」が含まれていない、または「ダイニングテーブル」として分類される可能性がある)。
- (例文)信頼度はいずれもx.xx以上であり、閾値0.25を上回っている。
結論は次のとおりである。
- (例文)プログラムは正常に動作し、画像内の物体を検出できることが確認された。
- (例文)ただし、検出される物体はCOCOデータセットの80クラスに限定される。
サンプル2:照明条件の影響調査
実験目的は、明るい環境と暗い環境で、YOLOv10の検出精度がどのように変化するか調査することである。
実験計画は、同じ物体(椅子)を3つの照明条件で撮影し、検出結果を比較することである。
- 条件A:明るい室内
- 条件B:通常の室内
- 条件C:暗い室内
実験結果は次のとおりである。
- 条件A(明るい):検出結果=椅子、信頼度=x.xx、処理時間=x.xxx秒
- 条件B(通常):検出結果=椅子、信頼度=x.xx、処理時間=x.xxx秒
- 条件C(暗い):検出結果=椅子、信頼度=x.xx、処理時間=x.xxx秒
考察は次のとおりである。
- (例文)明るい環境では信頼度がx.xxであった。
- (例文)暗い環境では信頼度がx.xxまで低下した。
- (例文)照明条件が物体の特徴抽出に影響することが確認された。
結論は次のとおりである。
- (例文)照明条件は物体検出精度に影響する。
- (例文)実用的なシステムを構築する際は、適切な照明環境を確保する必要がある。