第1章 Google Colaboratoryの概要
1.1 基本概念の定義
ノートブックは、プログラムコードと説明文を組み合わせた文書である。セルは、ノートブック内の編集可能な個別の単位であり、コードを記述する「コードセル」と、説明文を記述する「テキストセル」の2種類がある。ランタイムは、プログラムが実行される環境である。
1.2 Google Colaboratoryとは
Google Colaboratory(以下、Colab)は、Googleが提供するクラウドベースのノートブック環境である。URLは https://colab.research.google.com/ である。ブラウザ上でPythonコードを編集・実行できる。セットアップ不要で無料利用可能であり、利用にはGoogleアカウントが必要である。他者が公開したノートブックの閲覧のみであれば、Googleアカウントは不要である。
クラウド上で動作するため、利用者のPCには特別なセットアップが不要である。GPU(Graphics Processing Unit、グラフィックス処理装置)やTPU(Tensor Processing Unit、機械学習専用プロセッサ)を含む計算リソースを利用できる。GPUおよびTPUは大量のデータを並列処理できるため、機械学習モデルの学習時間を短縮できる。
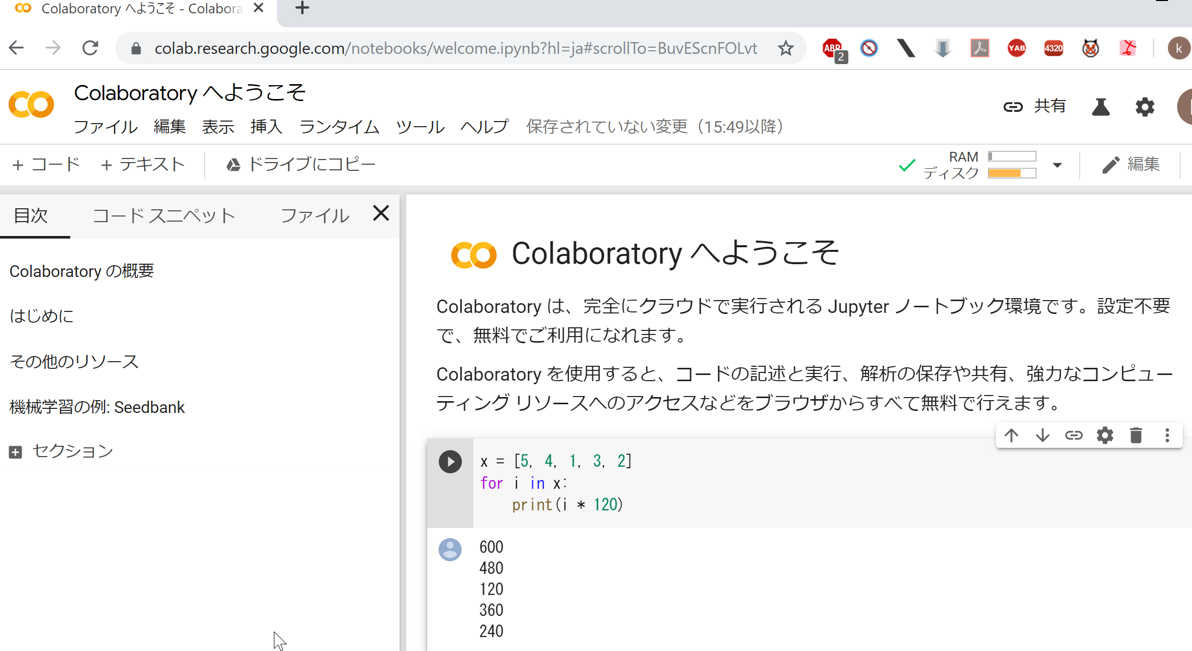
1.3 ノートブックの構造
ノートブックは2種類のセルで構成される。コードセルは、Pythonプログラムやコマンドを記述し、実行結果を表示する。テキストセルは、説明文や図表を表示する。

1.4 画面構成
ブラウザ上の画面は、左側メニュー(目次、検索と置換、変数、ファイル)、上部メニューバー、コードセルとテキストセルの追加ボタン、およびセルの配置エリアで構成される。
1.5 システム制約
Colabのセッション(実行環境が起動している状態)には時間制限がある。無料版では連続実行時間は最大12時間程度であり、一定時間(目安として90分程度)の非アクティブ状態が続くとセッションは自動切断される。これらの制限値は利用状況により変動し、Googleにより予告なく変更される場合がある。セッションが切断されると、保存していないデータが失われる。
セッション内の一時的なファイル(/contentディレクトリ)はセッション終了時に削除されるため、重要なデータはGoogle Driveに保存する必要がある。
GPU使用量には上限があり、無料版では使用時間や頻度に応じた動的制限が適用される。上限に達すると一時的に利用できなくなる。
1.6 計算リソースと料金体系
Colabには無料版と有料版がある。有料版には、サブスクリプション形式のColab Pro、Colab Pro+、および従量課金形式のPay As You Goがある。有料版では、コンピュートユニット(計算資源の利用量を表す単位。利用に応じて消費される)の購入により、より長時間の利用、優先的なGPUアクセス、大容量メモリの利用が可能となる。
無料版では連続実行時間が最大12時間程度に制限される(利用状況により変動する)。Colab Pro+では、コンピュートユニットの残高が十分にある場合、最大24時間の連続実行が可能である。
提供されるGPU・TPUの種類、メモリ容量、使用時間制限は時期により変動するため、最新情報は公式サイト(https://colab.research.google.com/signup)で確認する。
1.7 共有機能とデータ保存
Googleアカウントでログインして編集する場合、作成したノートブックはGoogle Driveの「Colab Notebooks」フォルダに自動保存される。変更履歴も自動保存される。
Google Driveと統合されており、Google Driveに保存されたデータを利用できる。複数人での共同編集が可能であり、編集中は他の編集者の変更がリアルタイムで反映される。
1.8 事前インストールされているライブラリ
NumPy、Pandas、Matplotlib、TensorFlow、PyTorchなど、科学計算および機械学習に使用される主要なライブラリが事前にインストールされている。
事前にインストールされていないライブラリは!pipコマンドでインストールできる。インストールしたライブラリはセッション終了後に使用できなくなるため、新しいセッションでは再インストールが必要である。
1.9 対応ブラウザ
Google Colaboratoryは以下のブラウザの最新版で動作する。
- Google Chrome
- Firefox
- Safari
1.10 他の開発環境との比較
Jupyter Notebookは、ローカル環境で動作し、セットアップが必要であるが、時間制限はない。VS Codeおよびその派生版(Windsurfなど)は、統合開発環境であり、多言語対応で拡張機能が豊富である。Google Colaboratoryは、クラウド環境で動作し、セットアップが不要で、GPU・TPUを利用できる。
第2章 Googleアカウントの設定
2.1 Googleアカウントの概要
Googleアカウントは、Googleが提供するオンラインサービスを利用するためのアカウントである。ユーザーIDとパスワードで構成され、利用者自身が設定する。Gmail、Google Drive、Google Cloudなど各種Googleサービスと連携する。
2.2 Google ColaboratoryとGoogleアカウント
Google Colaboratoryの利用にはGoogleアカウントが必要である。
Googleアカウントで利用できる機能は以下の通りである。
- ノートブックの新規作成、編集、保存、公開
- Pythonプログラムの編集、実行
- システム操作コマンド(!pip、%cdなど)の実行
- ファイルのアップロード、ダウンロード
Googleアカウントなしで利用できる機能は、他者が公開したノートブックの閲覧のみである。公開ノートブックのセルを実行・編集しようとするとログインが求められ、編集する場合は自分のGoogle Driveへのコピー作成が必要となる。
2.3 Googleアカウントの取得
Googleアカウントは無料で取得できる。登録に必要な情報は、氏名、メールアドレス、パスワード、電話番号(本人確認用)、生年月日、性別である。
個人情報の取り扱いについて各自で確認し、不安がある場合は取得を控える。
2.4 セキュリティ対策と注意事項
- 二段階認証を設定する
- 公開ノートブックでは個人情報を記載しない
- アカウント乗っ取り防止のため強固なパスワードを使用する
- 企業や組織での利用時は機密情報の取り扱いに注意する
2.5 Googleアカウント取得手順
- GoogleのWebページを開く(https://www.google.com/)
- 右上のメニューで「アカウント」を選択する
- 「アカウントを作成する」をクリックする
- 表示された画面で「自分用」を選択する
- 以下の情報を登録する
- 姓、名
- 希望するメールアドレス(<ユーザー名>@gmail.com)
- パスワード(2か所に入力)
- 電話番号
- 生年月日、性別
- 本人確認のための電話番号を入力し、「次へ」をクリックする(スマートフォンの番号を使用する)
- 電話番号認証により本人確認を行う。電話番号は国際電話形式で入力するため、日本の場合は先頭の0を+81に置き換える(例:080-1234-5678は+81-80-1234-5678となる)
第3章 基本的な使用方法
3.1 アクセスとログイン
3.1.1 Google Colaboratoryへのアクセス
ブラウザでGoogle Colaboratoryにアクセスする。
アクセスURL:https://colab.research.google.com/?hl=ja
3.1.2 ログイン手順
Google Colaboratoryの使用中に「Googleへのログインが必要」と表示された場合、以下の手順でログインする。
- 表示されたログイン画面でGoogleアカウントのIDを入力する
- パスワードを入力する
- 必要に応じて二段階認証を実行する
- ログイン完了後、ノートブックの編集と実行が可能になる
3.2 ノートブックの作成と基本操作
新規ノートブックは、Colabのトップページから「ファイル」→「ノートブックを新規作成」で作成できる。作成されたノートブックは、Untitled*.ipynbという名前でGoogle Driveの「Colab Notebooks」フォルダに自動保存される。
基本的なセル操作は以下の通りである。
- セルの実行:
Shift+Enterで実行して次のセルに移動、Ctrl+Enterで実行のみ - セルの追加:ツールバーの「+ コード」「+ テキスト」ボタンをクリックする(ショートカットは環境により異なる場合があるが、
Ctrl+Mに続けてAで上に、Bで下にコードセルを挿入できる) - セルの種類変更:ツールバーのセル種類切り替えボタンを使用するか、セル選択時に
Ctrl+Mに続けてMでテキストセルに、Ctrl+Mに続けてYでコードセルに変換する
3.3 実行の流れ
ノートブックの基本的な実行の流れは以下の通りである。
- ブラウザでGoogle Colaboratoryにアクセスする
- Googleアカウントでログインする
- セルの編集と実行を行う
- テキストセルでは説明文を作成する
- コードセルではPythonプログラムを作成し実行する
- セルは上から下へ順次実行する
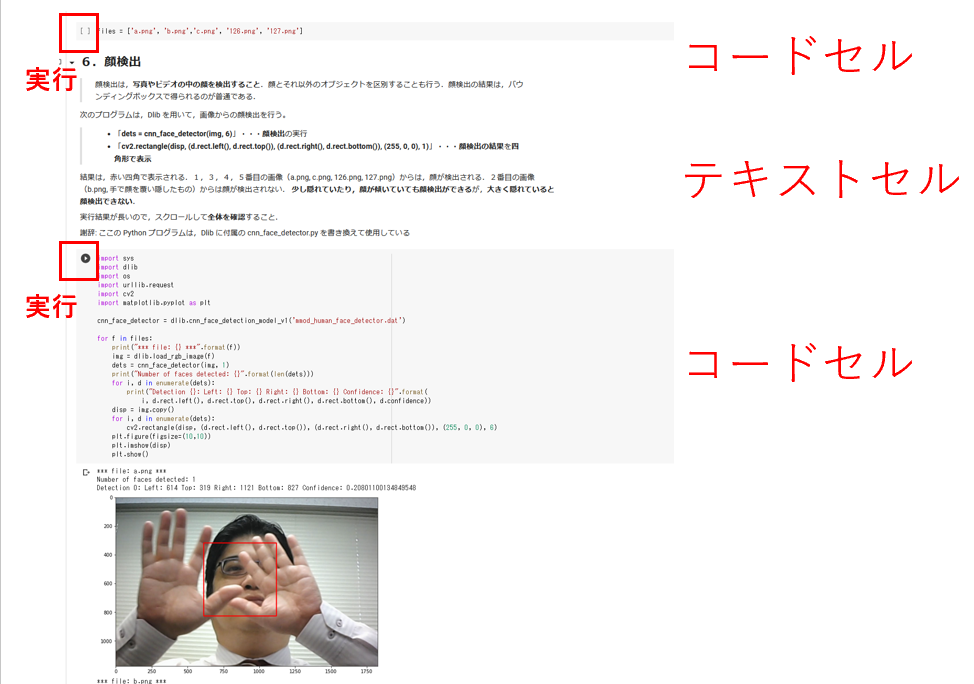
3.4 プログラムの実行
3.4.1 コードセルの実行
コードセルでは、Pythonプログラムやシステムコマンドを編集・実行できる(Googleアカウントでのログインが必要である)。
実行方法は以下の通りである。
- セルを選択する
- 実行ボタンをクリックする、または
Shift+Enterを押す - 実行結果がセルの下に表示される

3.4.2 すべてのセルの実行
メニューバーで「ランタイム」をクリックし、ドロップダウンメニューから「すべてのセルを実行」を選択する。Googleアカウントでのログインが求められた場合はログインする。
3.4.3 実行がうまくいかない場合の対処法
以下の手順を実行する。
- Googleアカウントでログインしていない場合は、ログインを行う。その後、すべてのセルを再実行する。
- すべてのアクティブなセッション(現在実行中のセッション)を停止する。メニューの「ランタイム」から「セッションの管理」を選択し、アクティブなセッション一覧で「終了」をクリックしてすべてのセッションを終了する。その後、すべてのセルを再実行する。
第4章 実践演習
4.1 演習の目的
本章では、Google Colaboratoryでのノートブック作成、コードセルの作成、Pythonプログラムの実行を実践する。演習1で環境を準備し、演習2〜4で変数の代入・条件分岐・ループ処理を順に作成し、演習5で実行結果を確認する。
4.2 演習1:ノートブックの新規作成
手順
- Google ColaboratoryのWebページを開く(https://colab.research.google.com)
- 「ファイル」メニューから「ノートブックを新規作成」を選択する
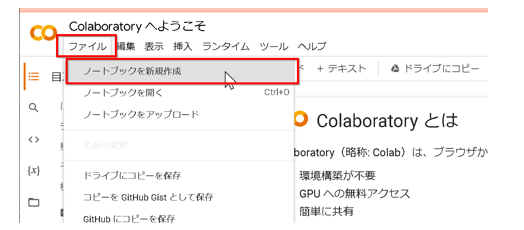
- Googleアカウントでのログインが求められた場合はログインする

ヒント:作成したノートブックはGoogle Driveの「Colab Notebooks」フォルダに自動保存される。
考察ポイント:新規作成直後に空のコードセルが1つ表示されることを確認する。
4.3 演習2:変数の代入
手順
- コードセルを新規作成する(ツールバーの「+ コード」をクリックする)

- コードセルに以下のPythonプログラムを記述する
x = 100
ヒント:このプログラムは、変数xに整数値100を代入する。
考察ポイント:このセル単体では画面に出力が表示されない。代入だけでは結果が表示されないことを確認する。
4.4 演習3:条件分岐
手順
- コードセルを新規作成する(ツールバーの「+ コード」をクリックする)

- コードセルに以下のPythonプログラムを記述する
if x > 20:
print("big")
else:
print("small")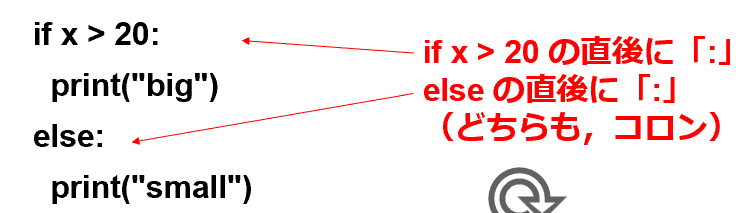
ヒント
- このプログラムは、変数xの値が20より大きい場合は"big"、そうでなければ"small"を出力する。
- if行とelse行の直後に「:」(コロン)を記述する。
考察ポイント:演習2でxに100を代入したため、出力は"big"となる。条件分岐の結果が変数xの値で決まることを確認する。
4.5 演習4:ループ処理
手順
- コードセルを新規作成する(ツールバーの「+ コード」をクリックする)

- コードセルに以下のPythonプログラムを記述する
# ループ処理
s = 0
for i in [1, 2, 3, 4, 5]:
s = s + i
print(s)
ヒント
- このプログラムは、リスト[1, 2, 3, 4, 5]の各要素を順番に変数sに加算し、最終結果を出力する。
- for行の直後に「:」(コロン)を記述する。
- 字下げ(インデント)は半角スペース2つである。
考察ポイント:出力は15(1+2+3+4+5の合計)となる。ループ内のsへの加算が要素ごとに繰り返されることを確認する。
4.6 演習5:実行と結果の確認
手順:コードセルを上から順番に実行する。
- 演習2のコードセル(変数代入)の実行ボタンをクリックする
- 演習3のコードセル(条件分岐)の実行ボタンをクリックする
- 演習4のコードセル(ループ処理)の実行ボタンをクリックする

ヒント:セルは上から順番に実行する。
考察ポイント:条件分岐で"big"、ループ処理で15が出力される。演習3・4は演習2で代入したxに依存するため、実行順序を入れ替えるとエラーや異なる結果になることを確認する。
第5章 データ保護の重要事項
5.1 セッション切断のリスク
Colabのセッションは、以下の条件で自動的に切断される。
- 連続実行時間が上限(無料版では最大12時間程度)に達した場合
- 一定時間(目安として90分程度)の非アクティブ状態が続いた場合
これらの制限値は利用状況により変動する。セッション切断時、/contentディレクトリに保存されたファイルはすべて削除され、保存していないデータやモデルが失われる。
5.2 Google Driveへの定期保存
重要なデータは、Google Driveに保存する必要がある。以下にデータ保護の方法を示す。
5.2.1 Google Driveのマウント
Google Driveをマウント(接続)すると、クラウドストレージのファイルに直接アクセスできる。セッションが切断されてもGoogle Drive上のデータは保持される。
from google.colab import drive
# Google Driveをマウント
drive.mount('/content/drive')
# マウント確認
!ls /content/drive/MyDrive/初回実行時は認証画面が表示されるため、指示に従って認証を行う。
5.2.2 モデルの定期保存
機械学習モデルの学習中に定期的に保存することで、セッション切断時のデータ損失を防ぐ。ModelCheckpoint(学習の各段階でモデルを自動保存する機能)を使用する。保存形式は、現行Colabの既定であるKeras 3で推奨される.keras形式を用いる(.h5はレガシー形式)。save_best_only=Trueは、monitorで指定した指標(例:検証データの損失val_loss)が改善したときのみ保存する設定であるため、検証データの指定が前提となる。
from tensorflow.keras.callbacks import ModelCheckpoint
# 事前にGoogle Driveをマウントしておく(5.2.1参照)
# save_best_only=True: monitorの指標が改善したときのみ保存
# save_freq='epoch': エポック(学習データ全体を1回処理する単位)ごとに保存
checkpoint = ModelCheckpoint(
'/content/drive/MyDrive/model_checkpoint.keras',
monitor='val_loss',
save_best_only=True,
save_freq='epoch'
)
# callbacks: 学習中に特定のタイミングで実行される処理
# validation_dataを渡すことでval_lossが計算され、最良判定が機能する
model.fit(train_data, validation_data=val_data, epochs=100, callbacks=[checkpoint])5.2.3 重要データの即時保存
処理結果や重要なデータを即時にGoogle Driveに保存することで、セッション切断によるデータ損失を防ぐ。
import json
import numpy as np
# 事前にGoogle Driveをマウントしておく(5.2.1参照)
# 結果辞書の保存
results = {'accuracy': 0.95, 'loss': 0.05}
with open('/content/drive/MyDrive/results.json', 'w') as f:
json.dump(results, f)
# 処理済みデータの保存
np.save('/content/drive/MyDrive/processed_array.npy', processed_array)5.3 データ保護のベストプラクティス
- 作業開始時:最初にGoogle Driveをマウントする
- 学習中:ModelCheckpointなどで定期的に保存する
- 処理完了後:結果を即時にGoogle Driveに保存する
- 長時間処理:定期的にブラウザを確認し、セッションが切断されていないか確認する
第6章 パッケージ管理とファイル操作
6.1 パッケージのインストール
事前にインストールされていないライブラリは、!pipコマンドでインストールできる。
# 基本的なインストール
!pip install package_name
# 出力を抑制してインストール(-q: quiet、進捗表示を省略)
!pip install -q package_name
# 特定バージョンを指定してインストール
!pip install package_name==1.2.3
# アップグレード
!pip install package_name --upgradeインストールしたライブラリはセッション終了後に使用できなくなるため、新しいセッションでは再インストールが必要である。
6.2 ファイルのアップロードとダウンロード
6.2.1 画面操作によるファイルアップロード
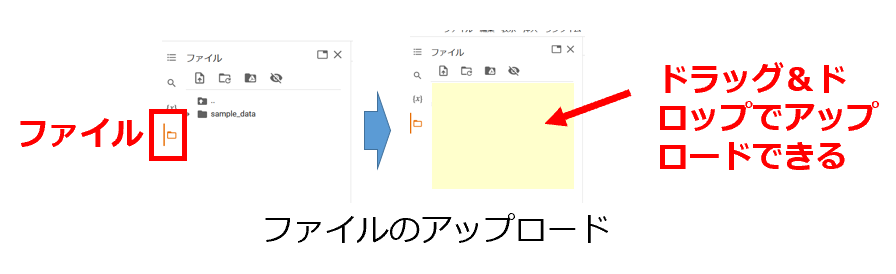
ローカルPCからColabにファイルを転送する方法である。
- 左側メニューから「ファイル」アイコンをクリックする
- 「アップロード」ボタンをクリックする、またはファイルをドラッグ&ドロップする
- アップロードされたファイルは一時的に保存され、セッション終了時に削除される
6.2.2 コードによるファイルアップロード
ローカルファイルをColabにアップロードするには、以下のコードを使用する。
from google.colab import files
uploaded = files.upload()実行すると、ファイル選択ダイアログが表示され、ブラウザ経由でファイルを選択できる。アップロードされたファイルは、/contentディレクトリに配置される。なお、files.upload()およびfiles.download()は、一部のブラウザやポップアップブロックが有効な環境では動作しないことがある。その場合は、画面操作(6.2.1)またはGoogle Drive経由での受け渡しを利用する。
6.2.3 ファイルのダウンロード
処理結果をローカルPCに保存するには、以下のコードを使用する。
from google.colab import files
files.download('filename.txt')6.3 作業ディレクトリの変更
マジックコマンド(Jupyter Notebook系の環境で使用できる特殊なコマンド)を使用して、Google Drive内のフォルダに作業ディレクトリを変更できる。作業ディレクトリを変更すると、ファイルパスの指定が簡潔になる。
# 事前にGoogle Driveをマウントし、対象フォルダ(project)を作成しておく
# 作業ディレクトリをGoogle Drive内に変更
%cd /content/drive/MyDrive/project第7章 日本語環境と可視化
7.1 日本語フォントの設定
Colabには標準で日本語フォントが含まれていないため、設定しないと日本語が文字化けする。日本語を含むグラフを作成するには、日本語フォントを導入し、matplotlibに登録する。フォントを一度導入すれば、そのセッション中は繰り返し有効である。
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 日本語フォント(Noto Sans CJK JP)を導入する
!apt-get -y install fonts-noto-cjk
# 導入したフォントをmatplotlibに登録する
font_path = '/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc'
fm.fontManager.addfont(font_path)
# 既定のフォントを日本語フォントに設定する
plt.rcParams['font.family'] = 'Noto Sans CJK JP'!apt-getで始まる行は、日本語フォントを導入するコマンドであり、そのまま実行すればよい。fm.fontManager.addfontでフォントをmatplotlibに認識させ、plt.rcParams['font.family']で既定のフォントに指定する。以降のグラフでは日本語が正しく表示される。なお、フォントのパスやフォント名は環境の更新により変わる場合がある。設定後に日本語が表示されないときは、[f.name for f in fm.fontManager.ttflist if 'Noto' in f.name]を実行して、登録されたフォント名を確認する。
7.2 画像の表示
7.2.1 matplotlibによる基本的なグラフ表示
日本語ラベルを含むグラフを表示する基本的な方法を示す(7.1の日本語フォント設定を実行済みであること)。
import matplotlib.pyplot as plt
import numpy as np
# サンプルデータの作成
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 6, 8, 10])
# グラフの作成と表示
plt.figure(figsize=(8, 6))
plt.plot(x, y, marker='o')
plt.xlabel('X軸のラベル')
plt.ylabel('Y軸のラベル')
plt.title('日本語タイトル')
plt.grid(True)
plt.show()7.2.2 OpenCVで読み込んだ画像の表示
OpenCVで読み込んだ画像をmatplotlibで表示する方法を示す(7.1の日本語フォント設定を実行済みであること)。OpenCVはBGR形式(青・緑・赤の順)で画像を読み込むが、matplotlibはRGB形式(赤・緑・青の順)を使用するため、変換が必要である。変換しないと色が正しく表示されない。
import cv2
import matplotlib.pyplot as plt
# 画像の読み込み(BGR形式)
img = cv2.imread('sample_image.jpg')
# BGR形式からRGB形式に変換
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 画像の表示
plt.figure(figsize=(10, 8))
plt.imshow(img_rgb)
plt.title('画像のタイトル')
plt.axis('off') # 軸を非表示
plt.show()7.3 動画の表示
MP4形式の動画をColab上で表示する方法である。ノートブック内で動画を再生でき、処理結果の確認に利用できる。
from IPython.display import HTML
from base64 import b64encode
def show_mp4(video_path, width=640, height=480):
"""MP4動画をノートブック内に表示する関数"""
with open(video_path, "rb") as video_file:
video_data = video_file.read()
video_base64 = b64encode(video_data).decode()
video_url = f"data:video/mp4;base64,{video_base64}"
video_html = f"""
<video width="{width}" height="{height}" controls>
<source src="{video_url}" type="video/mp4">
</video>
"""
return HTML(video_html)
# 使用例
show_mp4("sample_video.mp4")この関数は、動画ファイルをBase64エンコードしてHTML内に埋め込むことで、ノートブック内で再生可能にする。Base64埋め込みはファイル全体をHTMLに展開するため、サイズの大きい動画では表示が重くなる。短い動画での利用を推奨する。
第8章 GPU利用
8.1 GPUとは
GPU(Graphics Processing Unit)は、機械学習の計算を高速化するために利用される専用ハードウェアである。GPUは並列計算に適しており、深層学習で用いられる大規模な行列演算を高速に処理できる。
Colabでは無料でGPUを利用できるが、使用時間には制限がある。割り当てられるGPUの種類は無料版と有料版(Colab Pro/Pro+)で異なり、実際に割り当てられたGPUは付録A.2の方法で確認できる。
8.2 GPUの有効化
GPUを使用すると、機械学習の学習時間を短縮できる。使用するには、ランタイムの設定を変更する。
- メニューバーから「ランタイム」→「ランタイムのタイプを変更」を選択する
- 「ハードウェアアクセラレータ」のドロップダウンから「GPU」を選択する
- 「保存」をクリックする
設定変更後、セッションが再起動される。変数やインストールしたライブラリは初期化されるため、必要なセルを再実行する。
8.3 GPU利用可能性の確認
GPUが正しく認識されているか確認する方法を示す。PyTorchとTensorFlowの両方で確認しているのは、使用するフレームワークによってGPU認識状況が異なる場合があるためである。GPUが割り当てられていない場合(CPUのみの場合)も、以下のコードはエラーにならず、GPUが利用できないことを表示する。
import torch
import tensorflow as tf
# PyTorchでのGPU確認
print(f"PyTorch GPU利用可能: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU名: {torch.cuda.get_device_name(0)}")
# TensorFlowでのGPU確認
print(f"TensorFlow GPU: {tf.config.list_physical_devices('GPU')}")8.4 GPU使用時の注意事項
- 使用時間制限:無料版では、GPU使用時間に制限があり、使用状況に応じて一時的にアクセスが制限される
- セッション切断:GPU使用中でも、連続実行時間および非アクティブ状態による切断は適用される
- データ保護:GPU使用中の学習結果は、Google Driveに保存する
TPU(Tensor Processing Unit)の利用方法は変更が頻繁であるため、利用する場合は公式ドキュメント(https://research.google.com/colaboratory/faq.html)を参照する。
第9章 AI支援機能(Gemini)
9.1 AI支援機能の概要
現在のGoogle Colaboratoryには、Geminiを基盤としたAI支援機能が統合されている。会話形式でのコード生成、コードの説明、エラーの修正提案、入力中のコード自動補完などを利用できる。これらの機能は、対象となる利用者には既定で有効化されている。
AI支援機能の利用には、Googleアカウントの年齢が18歳以上であることと、対応する地域(ロケール)であることが条件となる。条件を満たさない場合、後述の機能(Geminiアイコンや自動補完など)は表示されない。
9.2 主な機能
- 会話によるコード生成・説明:自然言語で指示すると、コードの生成や概念の説明を行う。
- コードの変換・修正:既存のコードを自然言語の指示で修正できる。エラー発生時は、修正案を差分(変更箇所)の形で提示する。
- 自動補完:コードの入力中に、続きのコードの候補を提示する。
- データサイエンスエージェント:高レベルの目標を与えると、分析の計画を立て、コードを実行し、結果を提示する。CSV、TSV、JSON、Excelなどのファイルを扱える。
9.3 使い方
ノートブック下部のGeminiアイコン(スパークアイコン)をクリックすると、チャットパネルが開く。ここで指示を入力すると、コードの生成や説明を行える。コードの入力中には、自動補完の候補が表示される。
9.4 利用上の注意
- 生成コードの検証:AIが生成したコードは、実行前に内容を確認し、正確性と安全性を検証する。生成コードの利用についての責任は利用者にある。
- 機密情報の入力禁止:AI機能に入力したプロンプト、コード、生成された出力はGoogleにより収集され、品質改善のために人間のレビュー担当者が確認する場合がある。個人を特定できる情報や機密情報は入力しない。
- インターネットアクセス:AI自体は直接インターネットを閲覧しないが、インターネットにアクセスするコード(APIの呼び出しやファイルのダウンロードなど)を生成・実行できる。
- Google Driveやシークレットへのアクセス:既定では、AIは利用者のGoogle Driveのファイルやシークレットにアクセスしない。利用者が明示的に要求した場合にのみ、それらにアクセスするコードを生成する。
第10章 トラブルシューティング
10.1 セッション管理
システムの混雑時や長時間実行時に処理が停止し、再開しない場合がある。対処方法は以下の通りである。
- メニューから「ランタイム」を選択する
- 「セッションの管理」をクリックする
- アクティブなセッション一覧から「終了」をクリックし、すべてのセッションを終了する
- 最初からコードを再実行する
10.2 エラー対処法
よくあるエラーと対処法は以下の通りである。
- ライブラリインストールエラー:
!pip install ライブラリ名でインストールする - メモリ不足エラー:「ランタイム」から「ファクトリーリセット」で環境を初期化する
- ファイル読み込みエラー:ファイルパスとファイル名を確認する
エラー解決の基本手順は以下の通りである。
- エラーメッセージを最後の行から読む
- エラーの種類(SyntaxError、NameErrorなど)を特定する
- 「ランタイム」から「すべての出力を表示」でログ全体を確認する
- 公式ドキュメント(https://colab.research.google.com/notebooks/)で解決策を検索する
10.3 セッション再開時の復旧
セッションが切断された後に作業を再開する際の復旧方法を以下に示す。Google Driveに保存したデータを読み込むことで、作業を途中から再開できる。保存時と同じ.keras形式で読み込む。
# 中断したトレーニングの再開
try:
model = tf.keras.models.load_model('/content/drive/MyDrive/model_checkpoint.keras')
print("モデルを復旧しました")
except Exception:
print("新しいモデルを作成します")
model = create_new_model()
# データの復旧
try:
processed_array = np.load('/content/drive/MyDrive/processed_array.npy')
print("データを復旧しました")
except Exception:
print("データを再処理します")
processed_array = preprocess_data()第11章 制限事項と制約
11.1 実行時間と計算資源の制限
無料版では連続実行時間が最大12時間程度に制限される(利用状況により変動する)。Colab Pro+では、コンピュートユニットの残高が十分にある場合、最大24時間の連続実行が可能である。
提供されるCPU、メモリ、ストレージ、GPU、TPUの種類および容量は時期や利用状況により変動する。最新の仕様および制限値は公式FAQ(https://research.google.com/colaboratory/faq.html)で確認する。
11.2 禁止されている使用方法
Colabは、ノートブック上での対話的な計算を目的としたサービスである。これに該当しない用途は公式FAQで禁止されており、違反するとアカウントが制限される可能性がある。具体的には、暗号通貨のマイニング、ファイル配信やメディア配信などのサーバー的な利用、torrentのダウンロードなどのP2Pファイル共有、不正アクセスやパスワード解析、リソースを長時間占有する用途、複数アカウントによる制限回避、ディープフェイクの作成などが禁止されている。詳細は公式FAQ(https://research.google.com/colaboratory/faq.html)で確認する。