Streamlit Community Cloud(無料枠)活用ガイド&AIアプリ体験
Streamlit を用いたアプリの公開手順。
【目次】
- 1. Pythonプログラムの公開方法
- 2. 他の人が公開しているプログラムURLの実行方法・無料利用の制限
- 3. 使用可能な主要 pip パッケージとインストール方法
- 4. ローカルのカメラを Streamlit で表示する方法
- 5. 動的パラメータ変更と関数処理(ガウシアンフィルタの実装例)
- 【前準備】演習を始める前に必要な環境
- 【実践】演習1:Streamlitで「Hello, World」アプリを公開する
- 【実践】演習2:カメラ画像にガウシアンフィルタをかけるアプリを作る
- 【実践】演習3:YOLO26で画像から物体を検出する
- 【実践】演習4:YOLO26でインスタンスセグメンテーションを行う
- 【実践】演習5:YOLO26で姿勢推定を行う
1. Pythonプログラムの公開方法
Streamlit Community Cloudでアプリを公開する手順は、GitHubを経由して行う。初回のデプロイ(プログラムをクラウドに配置して実行可能な状態にすること)はブラウザからの操作を要するが、以降の更新はローカルのコマンド操作で完結する。
① ローカルでの動作確認
コード(app.py)と requirements.txt を作成後、ローカル環境で起動して確認する。
streamlit run app.py② GitHubへプッシュ(コマンド操作)
ローカルのファイル群をGitHubのリポジトリ(プログラムを保管する場所)にプッシュ(アップロード)する。
git add .
git commit -m "Initial commit"
git push origin main③ Streamlit Cloudでのデプロイ(初回のみWeb画面操作)
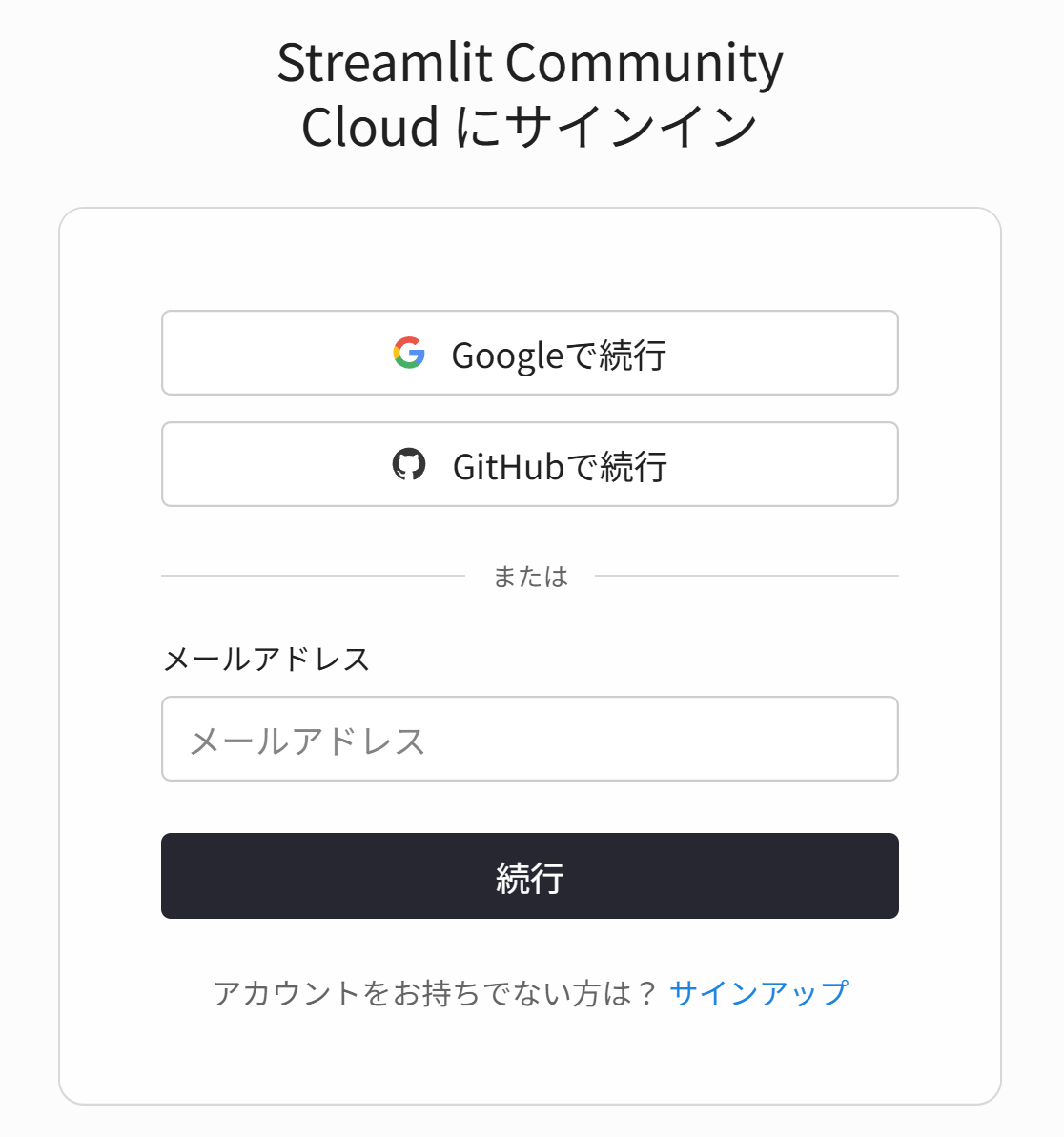
- Streamlit Community Cloud にGitHubアカウントでログインする。
- 画面右上の「New app」をクリックする。
- 対象の「Repository」「Branch」「Main file path(
app.py)」を選択し、「Deploy!」をクリックすると公開される。
更新時の動作:2回目以降のプログラム修正は、上記②の
git pushをコマンドで実行すると、クラウド上のアプリへ反映される。
2. 他の人が公開しているプログラムURLの実行方法・無料利用の制限
実行方法
公開されたURL(例:https://[アプリ名].streamlit.app)をブラウザで開いて実行する。閲覧者側でのPythonのインストールや環境構築は不要である。
無料枠の制限と注意点
- リソース制限(メモリ・CPU・ストレージ):無料枠のアプリは共通のリソース上限の範囲で動作する。Streamlit公式の記載では、メモリは約690MB〜2.7GB、CPUは0.078〜2コア、ストレージは最大50GBである(これらの値は予告なく変更される)。上限に達すると、アプリの処理が遅くなる、または「This app has gone over its resource limits.」と表示されて停止する。大規模なデータセットの読み込みや、大規模なAIモデル(LLMや大型の画像認識モデル)のロードは、メモリ上限を超える原因となる。
- スリープ機能:アプリへのアクセス(トラフィック)がない状態が12時間続くと、スリープモードに入る。閲覧者がURLにアクセスして「Yes, get this app back up!」ボタンを押すと再起動する。再起動には時間を要する。再起動の操作は、アプリの開発者に限らず、アプリを閲覧する権限を持つ者が実行できる。
- ストレージの揮発性:アプリの再起動・スリープ復帰のたびに、クラウド上の環境に一時保存したファイル(生成した画像やCSVなど)は消去される。
3. 使用可能な主要 pip パッケージとインストール方法
AI関連パッケージ(ultralytics, mediapipe等)の扱い
Streamlit Community Cloudの環境には、標準でPythonとStreamlitのみがインストールされている。そのため、ultralytics や mediapipe などのAIパッケージは、明示的に指定してインストールさせる必要がある。
インストール方法
GitHubリポジトリの直下に requirements.txt という名前のテキストファイルを作成し、必要なパッケージ名を記述する。デプロイ時にこのファイルが読み込まれ、インストールが実行される。
requirements.txt の記述例:
streamlit
opencv-python-headless
ultralytics
mediapipe注意点:OpenCVを利用する場合、クラウド環境(Linux)でのグラフィックライブラリ欠如によるエラーを防ぐため、
opencv-pythonではなくopencv-python-headlessを指定する。また、ultralyticsの大型モデルはメモリ上限を超える原因となるため、軽量モデル(YOLO26nなど)を選定する。
4. ローカルのカメラを Streamlit で表示する方法
Streamlitの標準機能である st.camera_input を使用する。
- 動作:この関数を呼び出すと、ユーザーのブラウザ上でカメラの使用許可が求められ、PCやスマートフォンのカメラ映像がブラウザ内にプレビュー表示される。
- データの取得方法:リアルタイムの動画ストリームを常時Python側に送るのではなく、ユーザーが「Take Photo(撮影)」ボタンを押して静止画(スナップショット)を撮影したタイミングで、その画像データがサーバー側に送信される。
- 特徴:標準機能であり、ネットワークの追加設定を要さない。モバイル・PCのいずれのブラウザでも動作する。取得データはメモリ上のバッファ(一時的なデータ置き場)として扱われ、PillowやOpenCVで画像処理を行える。
5. 動的パラメータ変更と関数処理(ガウシアンフィルタの実装例)
Streamlitは、スライダーなどのUIを操作するたびに、スクリプト全体を上から下へ再実行(リラン)する。再実行を跨いでパラメータを保持・更新するため、状態管理機能である st.session_state を使用する。具体的なコードは、演習2で実行して確認する。
【前準備】演習を始める前に必要な環境
演習を進める前に、PCに次の環境が整っていることを確認する。
- GitHubアカウント:プログラムを管理・公開するために必要である。
- Gitのインストール:コマンドライン(コマンドプロンプトなど、文字でPCに命令を送る画面)からGitHubへプログラムをアップロードするために必要である。
- テキストエディタ:VS Code、メモ帳など、コードを編集できるエディタを用意する。
- Python環境:ローカルPC(手元のPC)で事前に動作確認を行う場合に必要である。
【実践】演習1:Streamlitで「Hello, World」アプリを公開する
ローカルPCで作成したプログラムを、ローカルで動作確認したうえでGitHubへアップロードし、Streamlit Community CloudでWeb公開する。さらに、公開後にソースコードを書き換え、その変更をクラウドへ反映するまでの手順を実行する。
考察ポイント:ローカルでの起動とクラウドへの公開で、必要な操作がどう異なるかを確認する。requirements.txt に記述したパッケージが、クラウド側でインストールされることを確認する。公開後の更新が git push のみで反映されることを確認する。
手順1:ローカルでのファイル準備
- ターミナル(またはコマンドプロンプト)を開き、
st_helloというフォルダを作成して移動する。mkdir st_hello cd st_hello - そのフォルダ内に
app.pyというファイルを作成し、次のコードを記述して保存する。import streamlit as st # 画面に文字を表示する(printではなくst.writeを使用する) st.write("Hello, World") - 同じフォルダ内に
requirements.txtというファイルを作成し、次の1行を記述して保存する。streamlit
手順2:ローカルでの動作確認
st_helloフォルダ内で次のコマンドを実行し、ローカル環境でアプリを起動する。streamlit run app.py- 初回実行時には、メールアドレスの登録画面が表示される

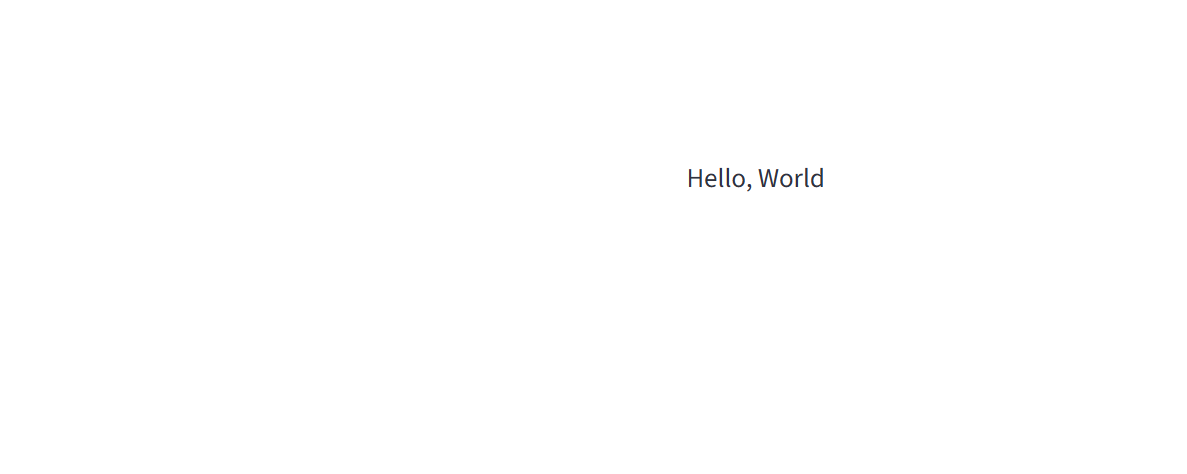
- 自動的に開いたブラウザのページに「Hello, World」と表示されることを確認する。確認後、ターミナルで
Ctrl + Cを押してアプリを停止する。
手順3:GitHubへのアップロード
Git のコミット時に使用される「メールアドレス」と「名前」の設定。 名前は本名でなくても構わない。 この設定は毎回ではなく、一度だけで十分である。git config --global user.email "<メールアドレス>"
git config --global user.name "<名前>"
手順3:GitHubへのアップロード
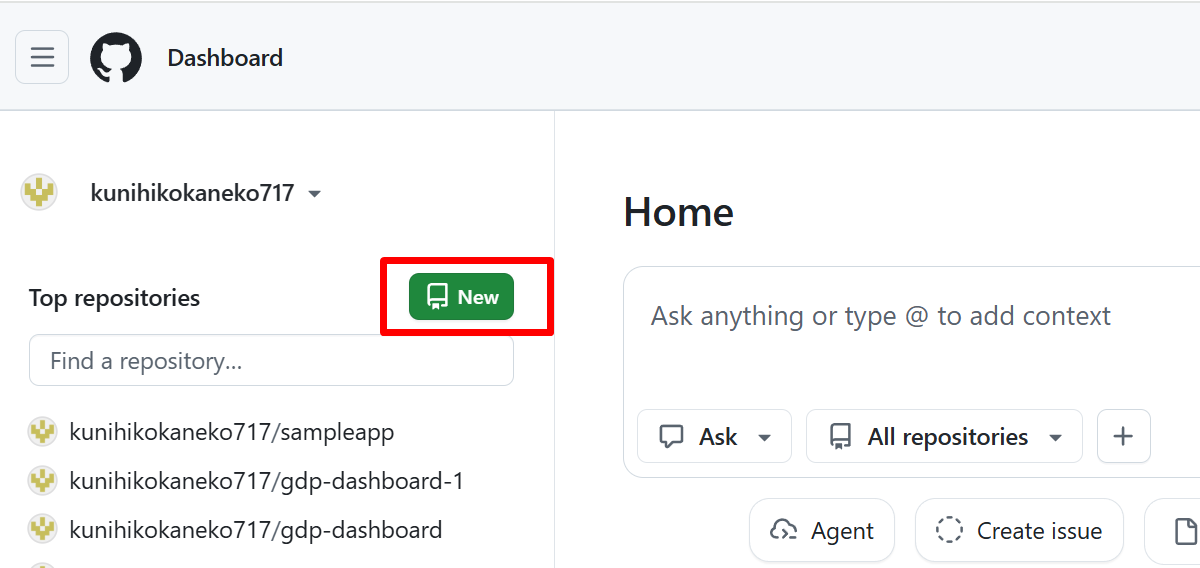
- ブラウザでGitHubにログイン
- 右上の「New」をクリックする。
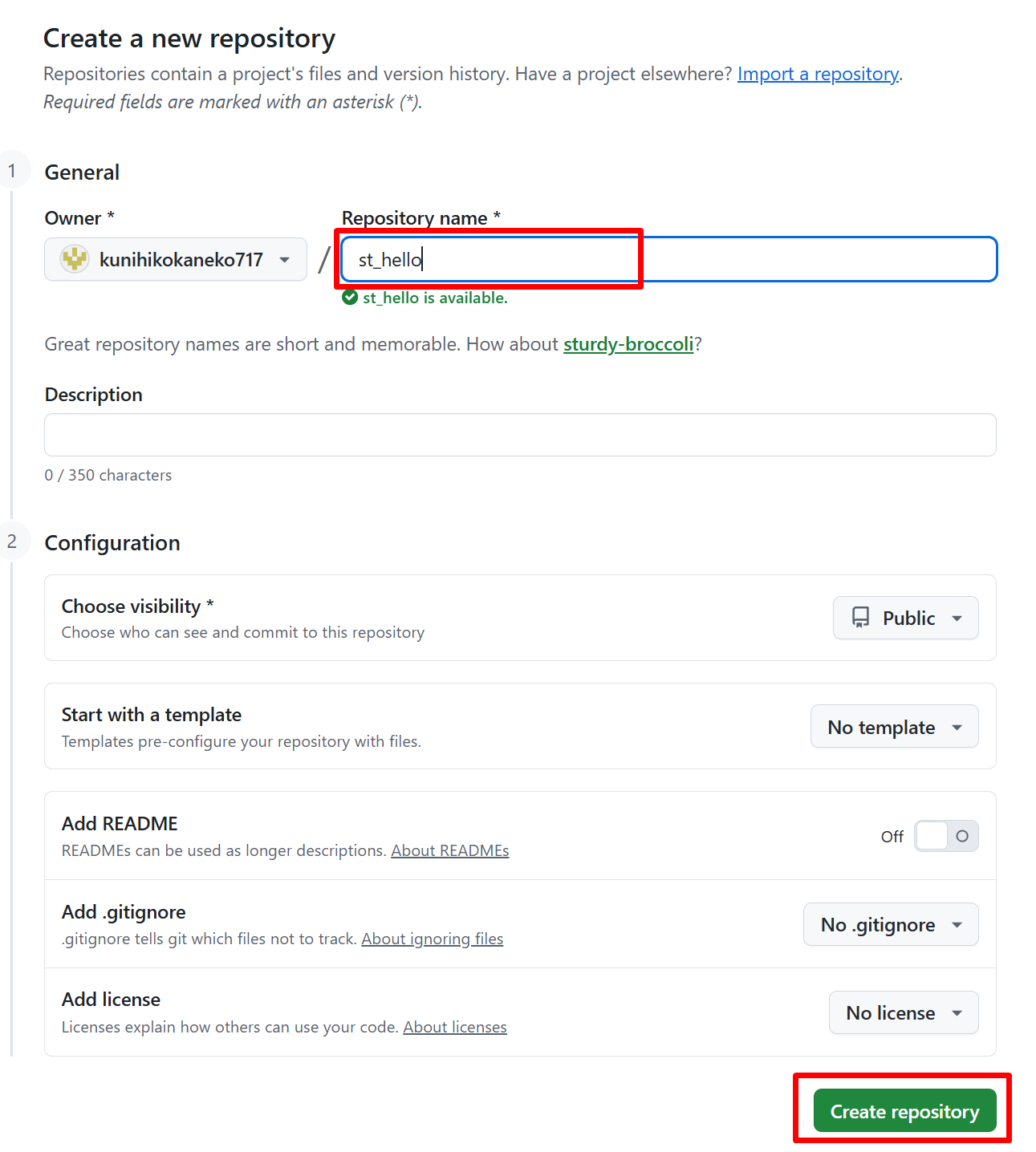
- Repository name に
st_helloと入力する。他の設定は変更せず、一番下の「Create repository」をクリックする。 - 結果を確認する
- コマンドプロンプトに戻り、
st_helloフォルダ内で次のコマンドを順に実行する(URLの部分は、自身のGitHubのURLに書き換える)。git init git add . git commit -m "first commit" git branch -M main git remote add origin https://github.com/あなたのユーザー名/st_hello.git git push -u origin main
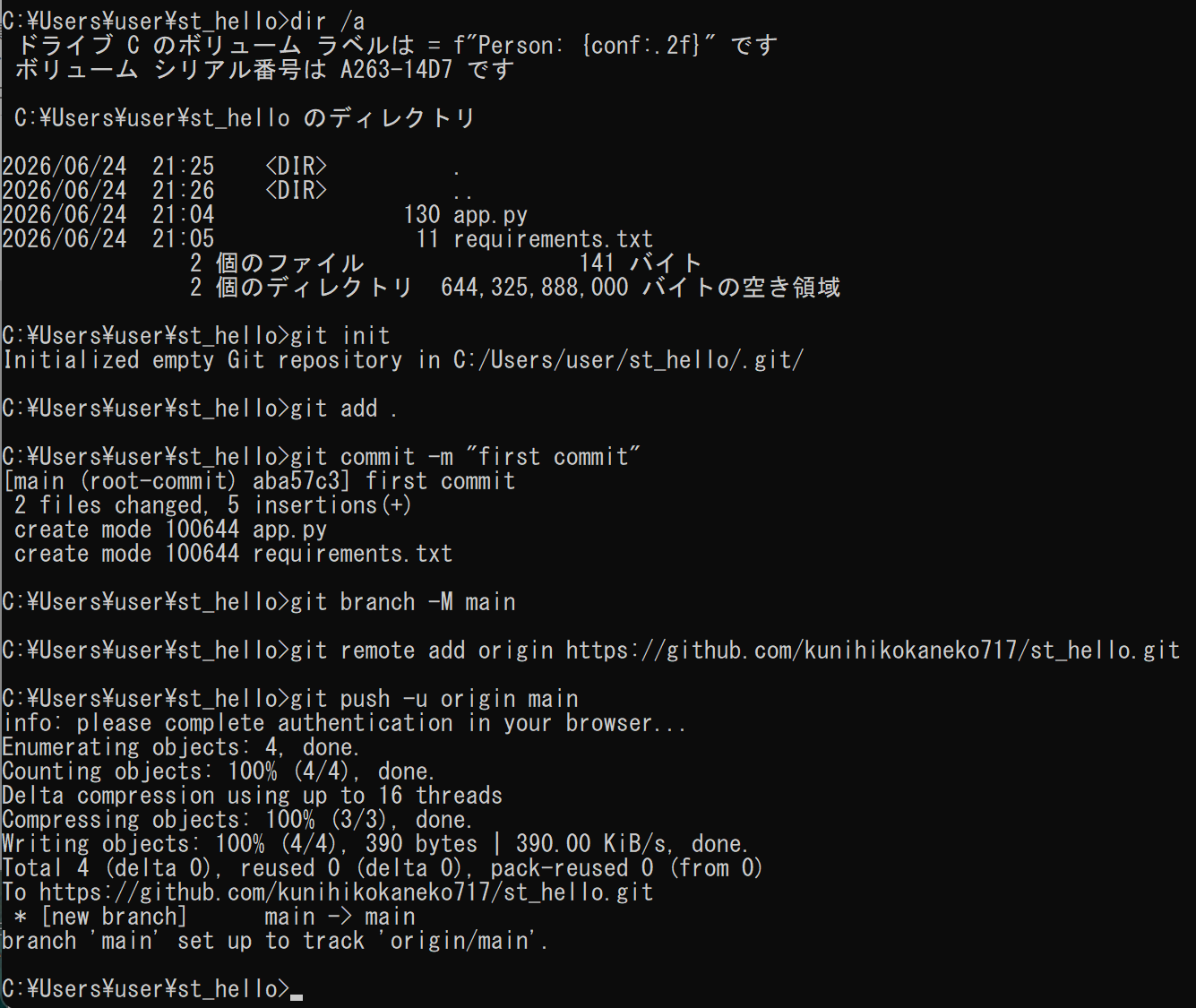
手順4:Streamlitでの公開(デプロイ)
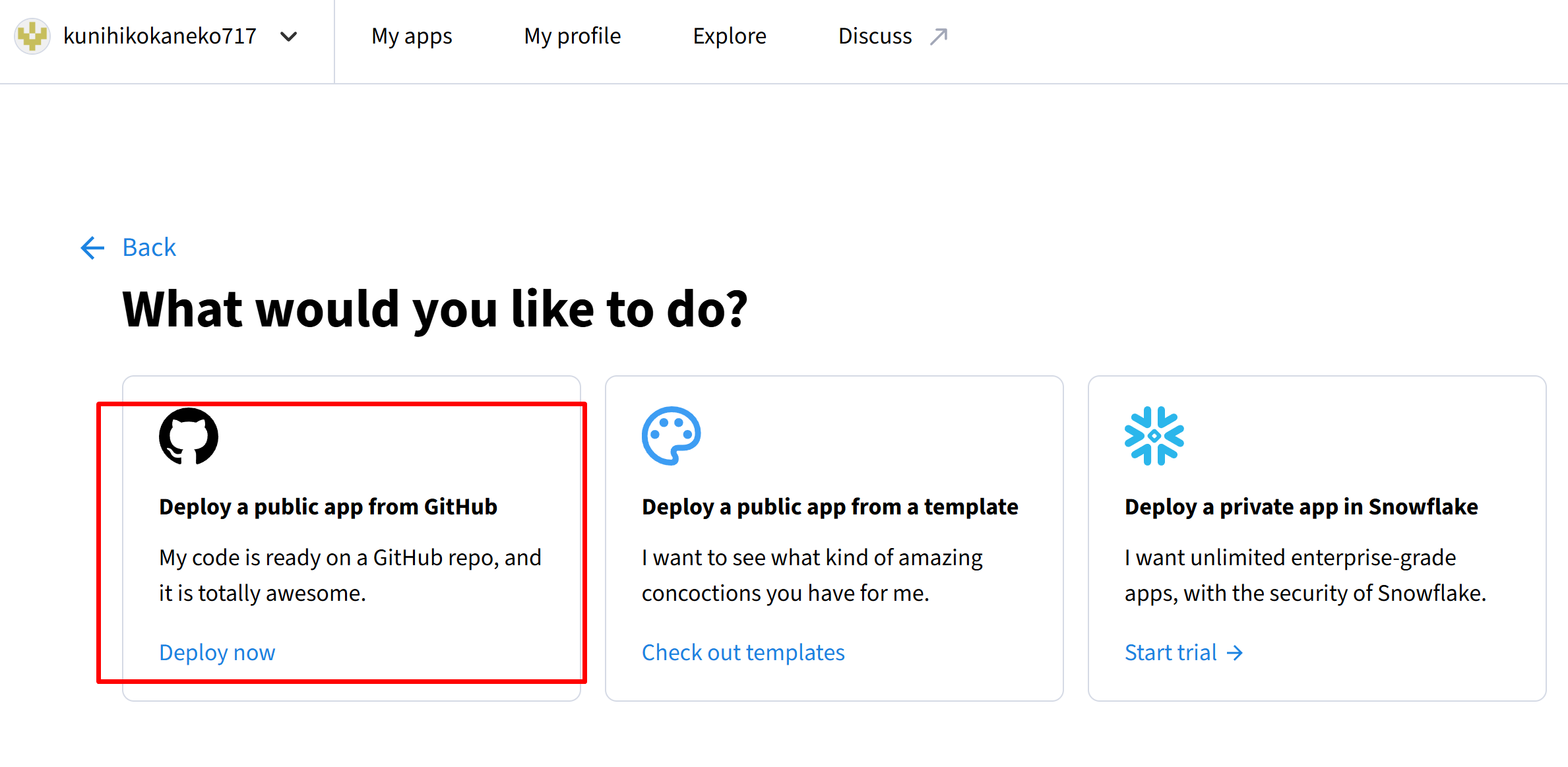
- ブラウザで Streamlit Community Cloud にアクセス
- GitHubアカウントでログインする。
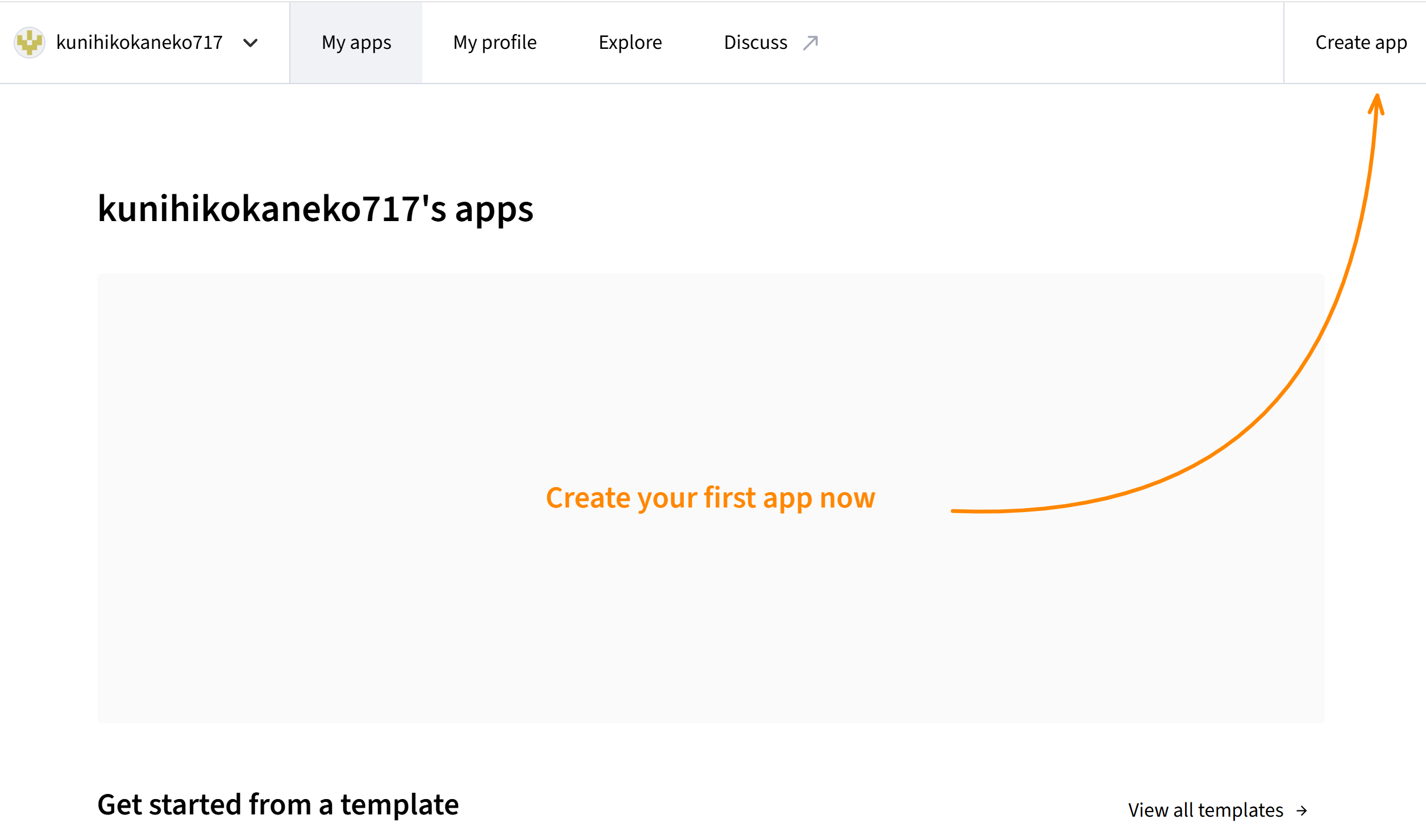
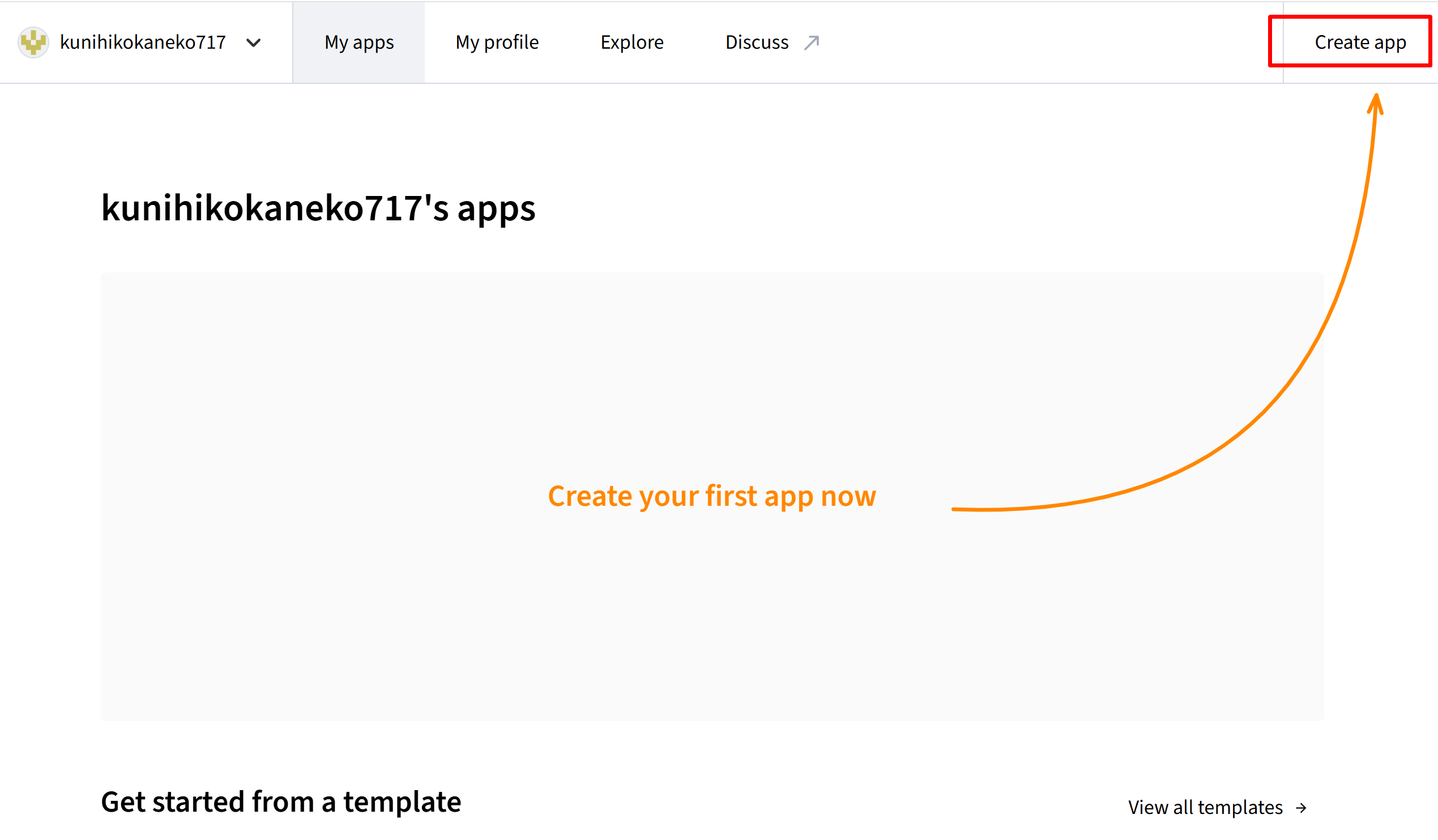
- 画面右上の「Create app」をクリックする。
- 「Deploy a public app from GitHub」を選ぶ
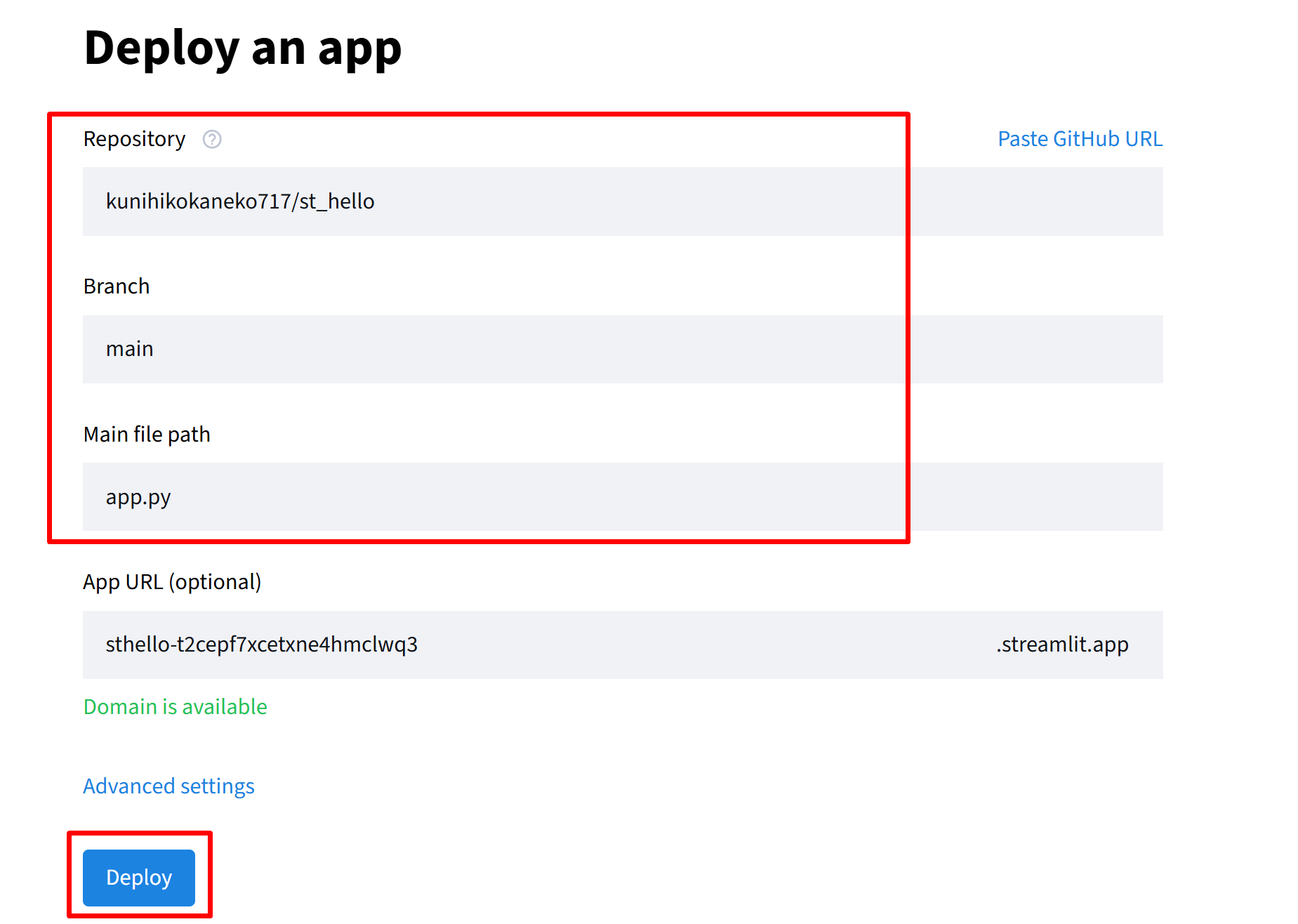
- デプロイ設定画面で、次の3項目を指定する。「Deploy!」をクリックする。
- Repository:
あなたのユーザー名/st_helloを選択 - Branch:
mainを選択 - Main file path:
app.pyと入力
- Repository:
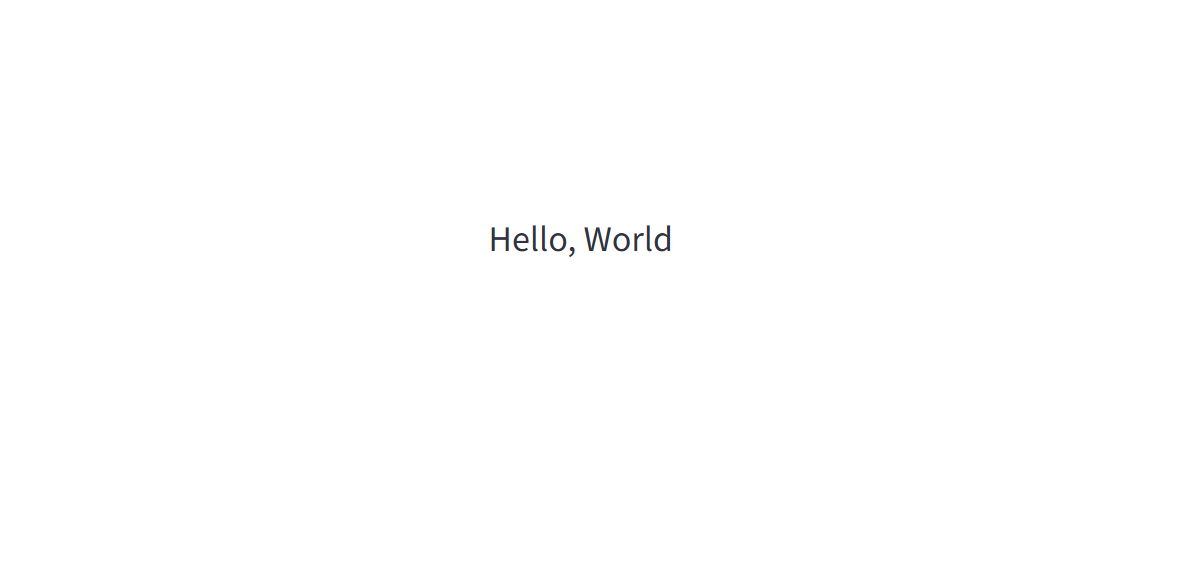
- 風船が飛ぶアニメーションのあと、画面に「Hello, World」と表示されれば成功である。ブラウザのURLを共有すると、他者もアプリにアクセスできる。
手順5:ソースコードの書き換えと反映
- ローカルの
app.pyを開き、表示する文字列を書き換えて保存する。import streamlit as st # 画面に文字を表示する(printではなくst.writeを使用する) st.write("Hello, Streamlit") st_helloフォルダ内で次のコマンドを順に実行し、変更をGitHubへプッシュする。git add . git commit -m "update message" git push origin main- 演習1と同じ手順で公開する
- 公開中のアプリのURLをブラウザで再読み込みし、表示が「Hello, Streamlit」に変わることを確認する。初回のデプロイと異なり、Web画面での操作は不要である。
ヒント
公開が完了しない場合は、requirements.txt がリポジトリの直下にあるか、ファイル名が正確かを確認する。
【実践】演習2:カメラ画像にガウシアンフィルタをかけるアプリを作る
カメラで撮影した画像に対し、スライダーでガウシアンフィルタ(画像をぼかす処理)の強度を変えるアプリを作成して実行する。第5章で説明した st.session_state と、第4章で説明した st.camera_input を組み合わせる。
手順
- この演習用のフォルダ
st_filterを作成して移動する。mkdir st_filter cd st_filter - そのフォルダ内に
requirements.txtというファイルを作成し、次の1行を記述して保存する。streamlit opencv-python-headless numpy pillow - そのフォルダ内に次のコードを保存(メモ帳を用いる場合は app.py のようなファイル名で保存)する。
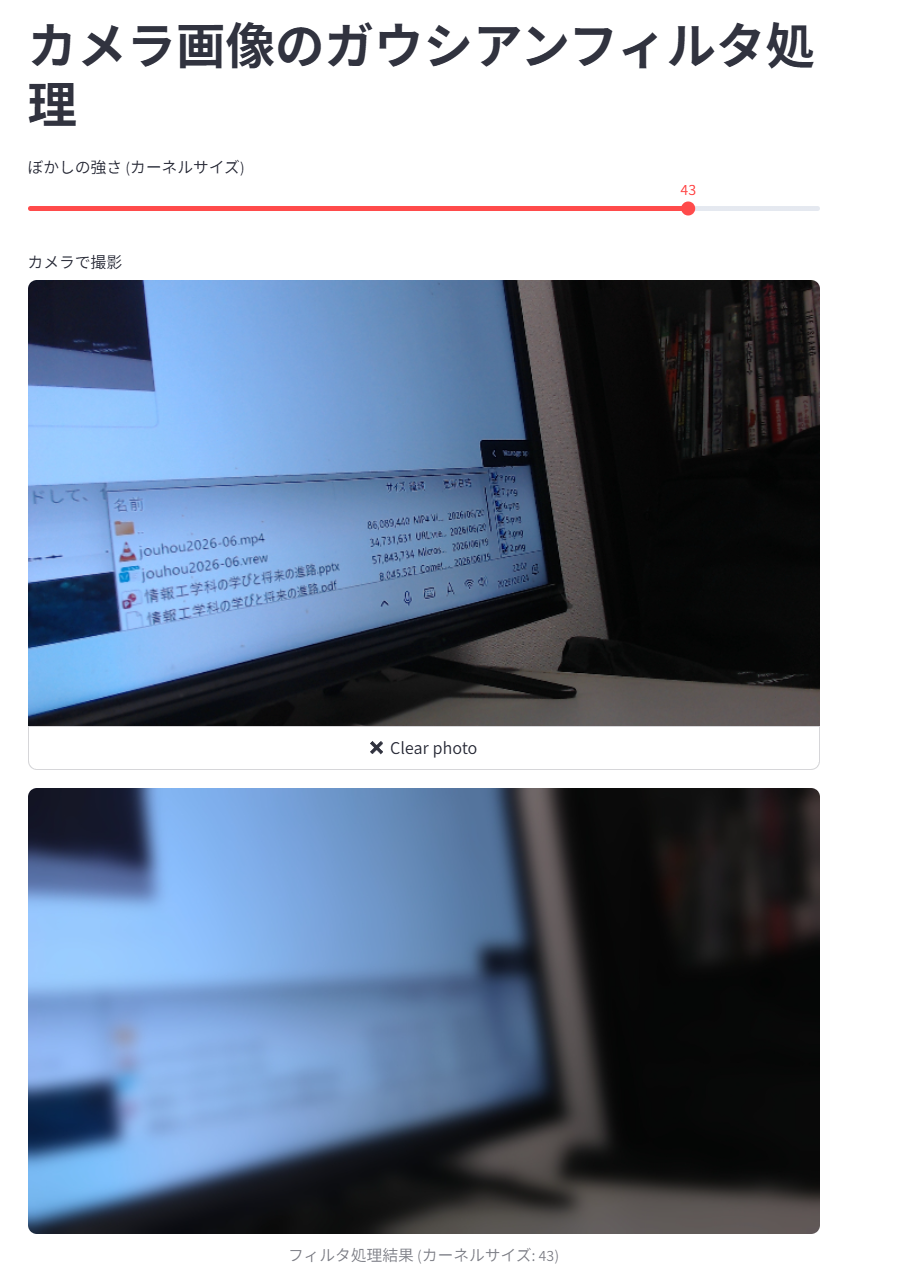
import streamlit as st import cv2 import numpy as np from PIL import Image def apply_gaussian_filter(image_array, ksize): # ガウシアンブラーのカーネルサイズは正の奇数である必要があるための補正処理 if ksize % 2 == 0: ksize += 1 blurred_image = cv2.GaussianBlur(image_array, (ksize, ksize), 0) return blurred_image st.title("カメラ画像のガウシアンフィルタ処理") # Session State を初期化し、デフォルト値を設定 if "blur_strength" not in st.session_state: st.session_state.blur_strength = 5 # スライダーの配置(動的パラメータ変更) # スライダーを動かすとスクリプトが再実行され、新しい値が session_state に保存される st.session_state.blur_strength = st.slider( "ぼかしの強さ (カーネルサイズ)", min_value=1, max_value=51, step=2, value=st.session_state.blur_strength ) # ローカルカメラの起動と静止画の取得 img_file_buffer = st.camera_input("カメラで撮影") # 画像が撮影された場合のみ処理を実行 if img_file_buffer is not None: # 画像データをPillowで開き、OpenCVで処理できるNumPy配列に変換 image = Image.open(img_file_buffer) img_array = np.array(image) # session_state に保持されているスライダーの値を引数にして関数を呼び出す processed_img = apply_gaussian_filter(img_array, st.session_state.blur_strength) # 処理結果の表示 st.image( processed_img, caption=f"フィルタ処理結果 (カーネルサイズ: {st.session_state.blur_strength})", width="stretch" ) - 演習1と同じ手順で公開する
- スライダーを動かしてから「Take Photo」で撮影し、ぼかしの強さが変わることを確認する。
ヒント
- 同じStreamlit クラウド・アプリを、次のURLで公開している。動作確認のみであれば次のURLですぐに確認できる。
- カーネルサイズは正の奇数である。スライダーの
step=2と関数内の補正処理が、この条件を満たす。
考察ポイント
スライダーを動かすたびにスクリプトが上から再実行されること、その再実行を跨いで st.session_state がスライダーの値を保持することを、動作から確認する。
【実践】演習3:YOLO26で画像から物体を検出する
YOLO26は、物体検出、インスタンスセグメンテーション、セマンティックセグメンテーション、画像分類、姿勢推定、回転バウンディングボックス検出(OBB)に対応する統一モデルである。タスクごとに専用の重みファイルが用意されており、この演習では物体検出用の軽量モデルである yolo26n.pt を用いる。カメラで撮影した画像から物体を検出し、検出した物体のクラス名とバウンディングボックス(物体を囲む枠)を画面に表示する。スライダーで信頼度しきい値(検出を採用する確信度の下限)を変える。
手順
- この演習用のフォルダ
st_detectを作成して移動する。mkdir st_detect cd st_detect - そのフォルダ内に
requirements.txtというファイルを作成し、次の1行を記述して保存する。streamlit opencv-python-headless ultralytics numpy pillow - そのフォルダ内に次のコードを保存(メモ帳を用いる場合は app.py のようなファイル名で保存)する。初回実行時にモデルの重みファイルが取得される。
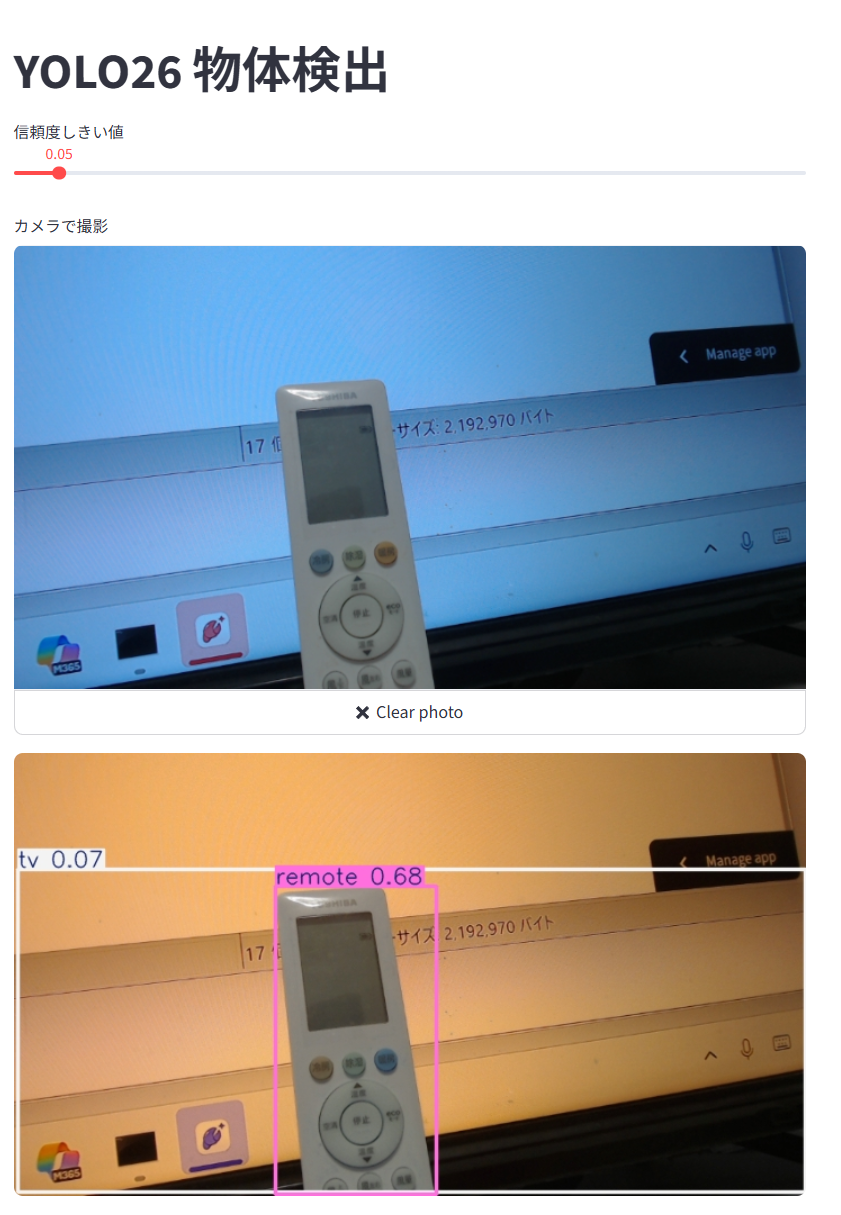
import streamlit as st import numpy as np from PIL import Image from ultralytics import YOLO st.title("YOLO26 物体検出") # Session State を初期化し、信頼度しきい値のデフォルト値を設定 if "conf" not in st.session_state: st.session_state.conf = 0.25 # スライダーで信頼度しきい値を変更する st.session_state.conf = st.slider( "信頼度しきい値", min_value=0.0, max_value=1.0, step=0.05, value=st.session_state.conf ) # 物体検出用の軽量モデル YOLO26n を取得する model = YOLO("yolo26n.pt") # ローカルカメラの起動と静止画の取得 img_file_buffer = st.camera_input("カメラで撮影") # 画像が撮影された場合のみ処理を実行 if img_file_buffer is not None: # 画像データをPillowで開き、NumPy配列に変換する image = Image.open(img_file_buffer) img_array = np.array(image) # スライダーの信頼度しきい値を指定して物体検出を実行する results = model(img_array, conf=st.session_state.conf) # 検出結果(クラス名とバウンディングボックス)を描画した画像を取得する # plot() は BGR 順の NumPy 配列を返す annotated_img = results[0].plot() # BGR 順の画像を指定して表示する st.image(annotated_img, channels="BGR", width="stretch") - 演習1と同じ手順で公開する
- スライダーで信頼度しきい値を変えてから「Take Photo」で撮影し、検出された物体に枠とクラス名が描画されることを確認する。
ヒント
- 同じStreamlit クラウド・アプリを、次のURLで公開している。動作確認のみであれば次のURLですぐに確認できる。
- 信頼度しきい値を上げると、確信度の低い検出が除外されて検出数が減る。下げると検出数が増える。物体検出以外のタスクを行う場合は、対応する重みファイル(セグメンテーションは
yolo26n-seg.pt、姿勢推定はyolo26n-pose.ptなど)を指定する。
考察ポイント
信頼度しきい値を変えると、検出される物体の数がどう変わるかを確認する。各物体に、クラス名と信頼度の値が付与されることを確認する。
【実践】演習4:YOLO26でインスタンスセグメンテーションを行う
インスタンスセグメンテーションは、物体検出の枠に加えて、各物体の形状をマスク(領域)として切り出すタスクである。この演習では、インスタンスセグメンテーション用の軽量モデルである yolo26n-seg.pt を用いる。カメラで撮影した画像から物体ごとのマスクを求め、クラス名とともに画面に表示する。スライダーで信頼度しきい値を変える。
手順
- この演習用のフォルダ
st_segmentを作成して移動する。mkdir st_segment cd st_segment - そのフォルダ内に
requirements.txtというファイルを作成し、次の1行を記述して保存する。streamlit opencv-python-headless ultralytics numpy pillow - そのフォルダ内に次のコードを保存(メモ帳を用いる場合は app.py のようなファイル名で保存)する。初回実行時にモデルの重みファイルが取得される。
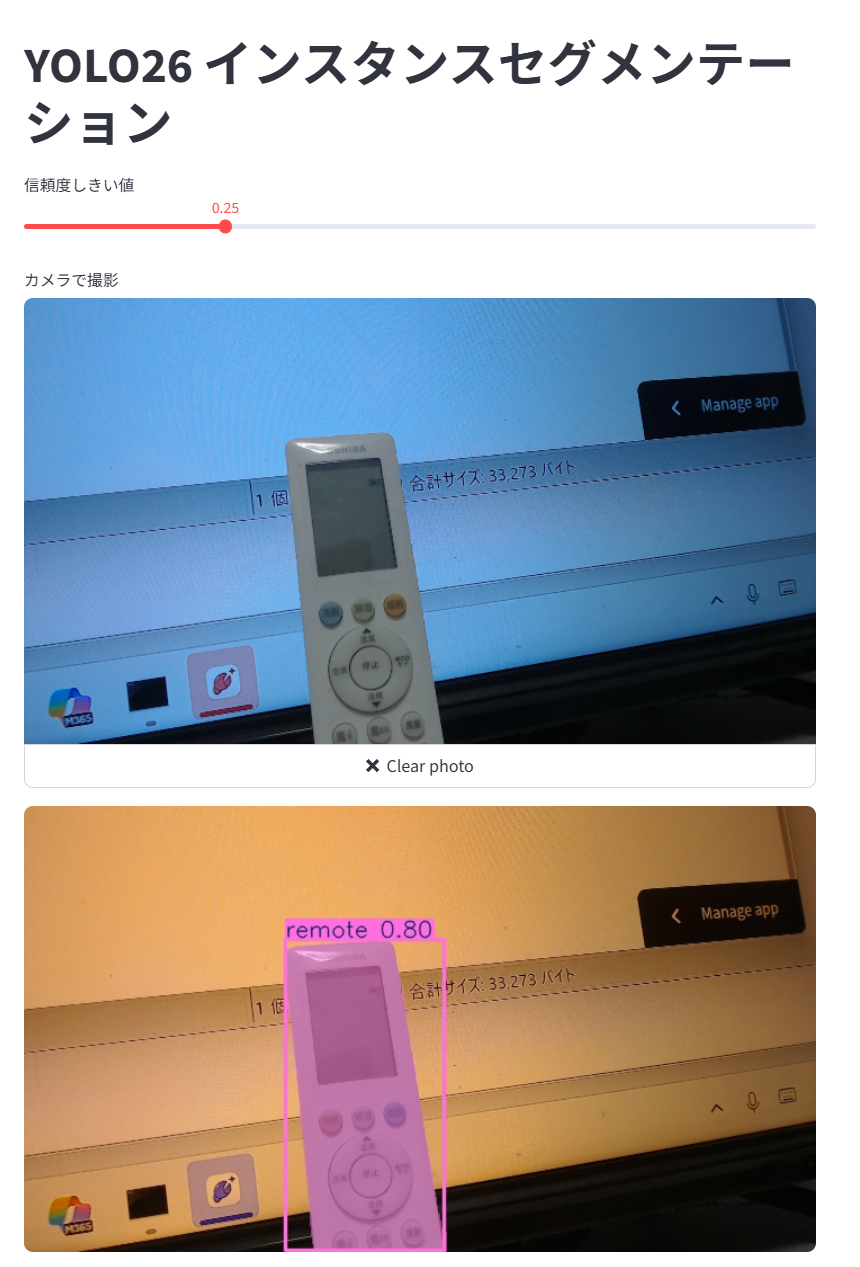
import streamlit as st import numpy as np from PIL import Image from ultralytics import YOLO st.title("YOLO26 インスタンスセグメンテーション") # Session State を初期化し、信頼度しきい値のデフォルト値を設定 if "conf" not in st.session_state: st.session_state.conf = 0.25 # スライダーで信頼度しきい値を変更する st.session_state.conf = st.slider( "信頼度しきい値", min_value=0.0, max_value=1.0, step=0.05, value=st.session_state.conf ) # インスタンスセグメンテーション用の軽量モデル YOLO26n-seg を取得する model = YOLO("yolo26n-seg.pt") # ローカルカメラの起動と静止画の取得 img_file_buffer = st.camera_input("カメラで撮影") # 画像が撮影された場合のみ処理を実行 if img_file_buffer is not None: # 画像データをPillowで開き、NumPy配列に変換する image = Image.open(img_file_buffer) img_array = np.array(image) # スライダーの信頼度しきい値を指定してセグメンテーションを実行する results = model(img_array, conf=st.session_state.conf) # 検出結果(マスク・枠・クラス名)を描画した画像を取得する # plot() は BGR 順の NumPy 配列を返す annotated_img = results[0].plot() # BGR 順の画像を指定して表示する st.image(annotated_img, channels="BGR", width="stretch") - 演習1と同じ手順で公開する
- スライダーで信頼度しきい値を変えてから「Take Photo」で撮影し、検出された物体ごとにマスクとクラス名が描画されることを確認する。
ヒント
- 同じStreamlit クラウド・アプリを、次のURLで公開している。動作確認のみであれば次のURLですぐに確認できる。
- 物体検出(演習3)との違いは、各物体の形状がマスクとして示される点である。コードの構造は演習3と同じで、読み込む重みファイルが
yolo26n-seg.ptに変わる。
考察ポイント
物体検出が枠で位置を示すのに対し、インスタンスセグメンテーションが各物体の形状を領域で示すことを、結果の画像から確認する。
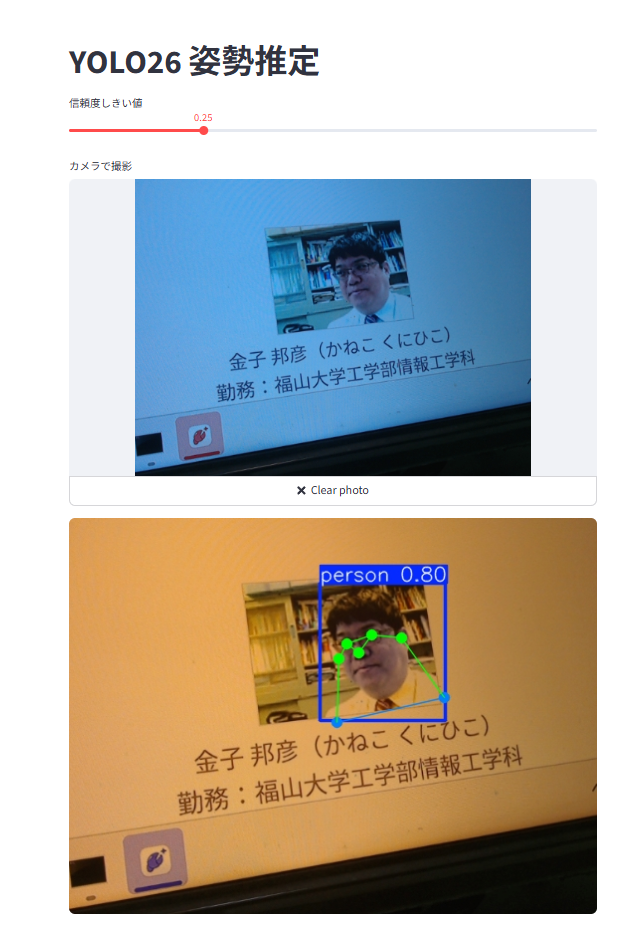
【実践】演習5:YOLO26で姿勢推定を行う
姿勢推定は、人物などの体の関節点(キーポイント)の位置を求めるタスクである。この演習では、姿勢推定用の軽量モデルである yolo26n-pose.pt を用いる。カメラで撮影した画像から人物のキーポイントを求め、骨格として画面に表示する。スライダーで信頼度しきい値を変える。
手順
- この演習用のフォルダ
st_poseを作成して移動する。mkdir st_pose cd st_pose - そのフォルダ内に
requirements.txtというファイルを作成し、次の1行を記述して保存する。streamlit opencv-python-headless ultralytics numpy pillow - そのフォルダ内に次のコードを保存(メモ帳を用いる場合は app.py のようなファイル名で保存)する。初回実行時にモデルの重みファイルが取得される。
import streamlit as st import numpy as np from PIL import Image from ultralytics import YOLO st.title("YOLO26 姿勢推定") # Session State を初期化し、信頼度しきい値のデフォルト値を設定 if "conf" not in st.session_state: st.session_state.conf = 0.25 # スライダーで信頼度しきい値を変更する st.session_state.conf = st.slider( "信頼度しきい値", min_value=0.0, max_value=1.0, step=0.05, value=st.session_state.conf ) # 姿勢推定用の軽量モデル YOLO26n-pose を取得する model = YOLO("yolo26n-pose.pt") # ローカルカメラの起動と静止画の取得 img_file_buffer = st.camera_input("カメラで撮影") # 画像が撮影された場合のみ処理を実行 if img_file_buffer is not None: # 画像データをPillowで開き、NumPy配列に変換する image = Image.open(img_file_buffer) img_array = np.array(image) # スライダーの信頼度しきい値を指定して姿勢推定を実行する results = model(img_array, conf=st.session_state.conf) # 検出結果(キーポイントと骨格)を描画した画像を取得する # plot() は BGR 順の NumPy 配列を返す annotated_img = results[0].plot() # BGR 順の画像を指定して表示する st.image(annotated_img, channels="BGR", width="stretch") - 人物が写るように「Take Photo」で撮影し、体の関節点が点と線(骨格)で描画されることを確認する。
ヒント
- 同じStreamlit クラウド・アプリを、次のURLで公開している。動作確認のみであれば次のURLですぐに確認できる。
- 姿勢推定モデルは、人物の体の関節点を17個のキーポイント(鼻、両目、両肩、両肘、両手首、両腰、両膝、両足首など)として求める。コードの構造は演習3・演習4と同じで、読み込む重みファイルが
yolo26n-pose.ptに変わる。
考察ポイント
姿勢推定が、物体の位置や形状ではなく、体の関節点の位置を求めるタスクであることを、結果の画像から確認する。