日本語文書トピックモデリング・固有表現抽出 Colab プログラム
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1EbjqpewsIEXVYgOEO_NqhAvMHhaOo3dD?usp=sharing




【目次】
プログラム利用ガイド
1. このプログラムの利用シーン
日本語小説のテキストファイルを分析し、主要なテーマと登場人物・地名を自動抽出するプログラムである。小説の内容を客観的に把握したい場合や、複数の作品を比較分析したい場合に利用できる。
2. 主な機能
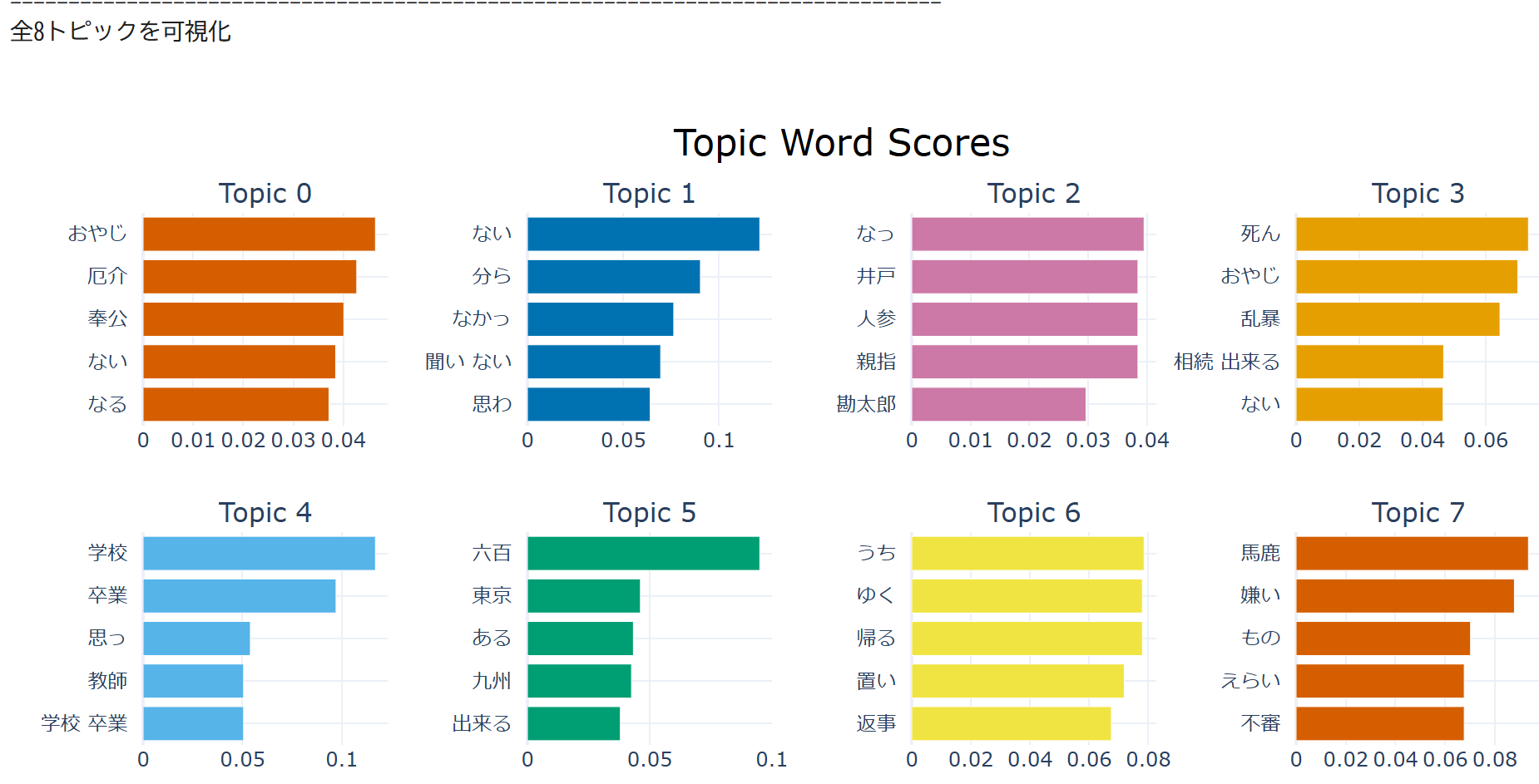
- トピックモデリング:小説内の主要テーマを自動抽出し、各テーマに関連する単語をスコア付きで表示する
- c-TF-IDF分析:各トピック内の重要単語を定量的に評価し、トピックを特徴づける単語を抽出する
- 固有表現抽出:人名・組織名・地名・日付などの固有表現を自動的に検出し、出現頻度を集計する
- 可視化:トピック分布を棒グラフで表示し、視覚的に理解できる
- 統計情報:各トピックの文章数、固有表現のタイプ別集計、頻出固有表現Top10などを出力する
3. 基本的な使い方
- Colabのページを開く
- 「テキストファイルをアップロードしてください」と表示されたら、分析対象のテキストファイルを選択する
- 自動的に分析が実行され、結果が表示される
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1EbjqpewsIEXVYgOEO_NqhAvMHhaOo3dD?usp=sharing
4. 便利な機能
- パラメータ調整:コード上部のパラメータ設定セクションで、UMAP_N_NEIGHBORS、HDBSCAN_MIN_CLUSTER_SIZE_RATIO、NER_BATCH_SIZE、VISUALIZE_ALL_TOPICSを変更できる
- 全トピック表示:VISUALIZE_ALL_TOPICS=Trueに設定すると、全トピックを可視化する(デフォルトは全トピック表示)
- バッチサイズ調整:NER_BATCH_SIZEを変更すると、固有表現抽出の処理速度を調整できる
プログラムの説明
概要
このシステムは、日本語小説のテキストを分析するプログラムである。BERTopic、c-TF-IDF、spaCyの3つのAI技術を統合し、テキストの主題抽出と固有表現(人名・地名等)の抽出を行う。
主要技術
BERTopic(トピックモデリング)
BERTopicは、BERT埋め込みとc-TF-IDFを組み合わせたトピックモデリング手法である[1][2]。文章を数値ベクトルに変換し、クラスタリングによってテーマを自動抽出する。以下の5段階で処理を行う。
- Sentence-BERT埋め込み:文章を384次元ベクトルに変換
- UMAP次元削減:高次元データを5次元に圧縮
- HDBSCANクラスタリング:密度ベースで文章をグループ化
- Bag-of-Words:単語の出現頻度を集計
- c-TF-IDF重み付け:トピックを代表する単語を抽出
c-TF-IDF(クラスベースTF-IDF)
c-TF-IDFは、BERTopicの内部で使用される重み付けアルゴリズムである[1][2]。従来のTF-IDFを拡張し、クラス(トピック)単位で単語の重要度を計算する。各トピック内の全文書を1つの文書として扱い、トピックを特徴づける単語を抽出する。
計算式:
$$c\text{-}TF\text{-}IDF(x,c) = tf(x,c) \times \log(1 + A/freq(x))$$- tf(x,c):クラスc内での単語xの頻度(L1正規化済み)
- A:全クラスの平均単語数
- freq(x):全クラスにおける単語xの出現頻度
技術的特徴
- 多言語対応の埋め込みモデル
paraphrase-multilingual-MiniLM-L12-v2を使用する[6][7]。このモデルは50以上の言語に対応し、文章を384次元の密ベクトル空間にマッピングする。
- 次元削減とクラスタリング
UMAP(Uniform Manifold Approximation and Projection)により、384次元のベクトルを5次元に削減する。HDBSCANは、データの密度に基づいてクラスタを形成し、外れ値(どのトピックにも属さない文章)を検出する。
- 日本語トークン化
Fugashiを用いて日本語をトークン化する。名詞・動詞・形容詞のみを抽出し、2文字以上の単語に制限する。1文字のひらがな・カタカナを除外することで、意味の薄い単語を排除する。
- 固有表現抽出
spaCy ja_core_news_lgモデルを使用する[4][5]。480,443キーワード、300次元の単語ベクトルを含む大規模モデルで、Universal Dependencies Japanese GSDコーパスで学習されている。NER(固有表現抽出)のF1スコアは約71.2%、品詞タグ付け精度は約97.4%である。
実装の特色
- バッチ処理による効率化
spaCyのnlp.pipe()関数を使用し、固有表現抽出を効率化する。一度に100文ずつ処理する。
- パラメータの自動調整
文章数に応じてUMAPとHDBSCANのパラメータを動的に調整する。UMAP_N_NEIGHBORSは文章数-1を上限とし、HDBSCAN_MIN_CLUSTER_SIZEは文章数を20で割った値を使用する。
- 詳細な統計出力
c-TF-IDF行列の情報(行列サイズ、非ゼロ要素数、密度)、各トピックの上位5単語とスコア、トピック別文章分布、固有表現のタイプ別集計、頻出固有表現Top10を出力する。
参考文献
[1] Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794. https://arxiv.org/abs/2203.05794
[2] BERTopic公式ドキュメント. https://maartengr.github.io/BERTopic/
[3] BERTopic GitHub Repository. https://github.com/MaartenGr/BERTopic
[4] Explosion AI. (2024). spaCy - Industrial-strength Natural Language Processing. https://spacy.io/
[5] spaCy ja_core_news_lg モデル. https://spacy.io/models/ja
[6] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. https://arxiv.org/abs/1908.10084
[7] Hugging Face. sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2. https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
実装技術の概要
本システムは3つのAI技術を組み合わせた日本語小説分析システムである。
- c-TF-IDF:クラスベースのTF-IDF(BERTopicの重み付けアルゴリズム)
- BERTopic:トピックモデリング(テーマ抽出)
- spaCy ja_core_news_lg:固有表現抽出(人名・地名等の抽出)
1. c-TF-IDF(BERTopicで使用)
公式情報
- 論文:Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv:2203.05794
- 公式GitHub:https://github.com/MaartenGr/BERTopic
- 公式ドキュメント:https://maartengr.github.io/BERTopic/
- アルゴリズム詳細:https://maartengr.github.io/BERTopic/algorithm/algorithm.html
- c-TF-IDF API:https://maartengr.github.io/BERTopic/api/ctfidf.html
2. BERTopic(トピックモデリング)
公式情報
- GitHub:https://github.com/MaartenGr/BERTopic
- 公式ドキュメント:https://maartengr.github.io/BERTopic/
- 論文:Grootendorst, M. (2022). arXiv:2203.05794
- インストール:
pip install bertopic
3. spaCy ja_core_news_lg(固有表現抽出)
モデル概要
spaCy公式の日本語大規模モデルである。統計的機械学習ベースのNERモデルで、Universal Dependencies Japanese GSD コーパスで学習されている。
- 単語ベクトル:480,443キーワード、300次元
- 学習データ:UD Japanese GSD、日本語Wikipedia
- 品詞タグ付け精度:約97-98%
- 依存構造解析:約88-90%
抽出可能な固有表現
- PERSON(人名)
- ORG(組織名)
- GPE(地政学的実体:国・都市など)
- LOC(場所)
- DATE(日付)
- TIME(時刻)
- MONEY(金額)
- PERCENT(パーセンテージ)
- QUANTITY(数量)
- ORDINAL(序数)
- FAC(施設)
- NORP(国籍・宗教・政治団体)
- WORK_OF_ART(作品名)
- LANGUAGE(言語)
公式情報
- 公式サイト:https://spacy.io/models/ja
- モデルページ:https://github.com/explosion/spacy-models/releases/tag/ja_core_news_lg-3.8.0
- spaCy公式:https://spacy.io/
- ライセンス:CC BY-SA 4.0
実験・研究スキルの基礎:Google Colabで学ぶ日本語小説分析実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは日本語小説のテキストファイルが実験用データである。テキストファイルは文章数が50以上あることが望ましい。文章数が少なすぎると、トピック分析の精度が低下する。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- UMAP_N_NEIGHBORSの値がトピック数に与える影響を確認する
- HDBSCAN_MIN_CLUSTER_SIZE_RATIOの値がトピック分割の細かさに与える影響を確認する
- 外れ値(どのトピックにも属さない文章)の割合とパラメータの関係を調べる
- 固有表現抽出の精度と文章の長さの関係を調べる
- 異なる小説で同じパラメータを使用した場合の結果の違いを比較する
1.3 プログラム
実験を実施するためのツールである。このプログラムはBERTopic、c-TF-IDF、spaCy ja_core_news_lgの3つの技術を使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムは4つのパラメータで分析を制御する。
入力パラメータ:
- UMAP_N_NEIGHBORS:次元削減時の近傍点数(デフォルト:15)
- HDBSCAN_MIN_CLUSTER_SIZE_RATIO:クラスタサイズの最小値を決定する比率(デフォルト:20)
- NER_BATCH_SIZE:固有表現抽出のバッチサイズ(デフォルト:100)
- VISUALIZE_ALL_TOPICS:全トピックを表示するかどうか(デフォルト:True)
出力情報:
- c-TF-IDF分析結果:各トピックの重要単語とスコア
- BERTopic分析結果:トピック数、外れ値の割合、トピック別文章分布
- 固有表現抽出結果:人名、地名、組織名などの出現頻度
- 可視化:トピック分布の棒グラフ
パラメータの影響:
- UMAP_N_NEIGHBORSを大きくすると、グローバルな構造が保持され、トピック数が減少する傾向がある
- UMAP_N_NEIGHBORSを小さくすると、ローカルな構造が保持され、トピック数が増加する傾向がある
- HDBSCAN_MIN_CLUSTER_SIZE_RATIOを大きくすると、トピック数が減少し、外れ値が増加する
- HDBSCAN_MIN_CLUSTER_SIZE_RATIOを小さくすると、トピック数が増加し、小さなトピックが多く生成される
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、パラメータの影響を考察する。
基本認識:
- パラメータを変えると結果が変わる。その変化を観察することが実験である
- 「良い結果」「悪い結果」は分析の目的によって異なる
観察のポイント:
- トピック数はどう変化するか
- 外れ値の割合を確認する(20-40%の範囲が一般的である。50%を超える場合は設定を見直す)
- 各トピックの代表単語は小説の内容を正確に表現しているか
- トピック間に区別があるか、それとも重複しているか
- 固有表現抽出で登場人物や地名が正しく抽出されているか
- c-TF-IDFスコアの高い単語は各トピックを特徴づけているか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する
- 原因:必要なライブラリがインストールされていない、またはファイルの読み込みに失敗している
- 対処方法:エラーメッセージを確認し、ランタイムを再起動して最初から実行する
ファイルのアップロードができない
- 原因:ファイル形式が対応していない、またはファイルサイズが大きすぎる
- 対処方法:テキストファイル(.txt)をUTF-8エンコーディングで保存し、ファイルサイズを確認する
モデルのダウンロードに時間がかかる
- 原因:初回実行時にspaCyモデルとBERTopicの埋め込みモデルをダウンロードしている
- 対処方法:これは正常な動作である。ダウンロードが完了するまで待つ
メモリ不足のエラーが発生する
- 原因:テキストファイルが大きすぎる、またはNER_BATCH_SIZEが大きすぎる
- 対処方法:NER_BATCH_SIZEを50に減らす、またはテキストファイルを分割する
2.2 期待と異なる結果が出る場合
トピック数が1つしか生成されない
- 原因:HDBSCAN_MIN_CLUSTER_SIZE_RATIOが大きすぎる、または文章数が少なすぎる
- 対処方法:HDBSCAN_MIN_CLUSTER_SIZE_RATIOを10-15程度まで下げる。文章数が50未満の場合は、より長いテキストを使用する
外れ値の割合が30-40%程度になる
- 原因:デフォルト設定(RATIO=20)では、文章数が200-300程度の場合、30-40%の外れ値が発生することがある。これは必ずしも異常ではない
- 対処方法:外れ値を減らしたい場合はHDBSCAN_MIN_CLUSTER_SIZE_RATIOを25-30程度まで上げる。ただし、トピック数が減少する
外れ値の割合が50%を超える
- 原因:HDBSCAN_MIN_CLUSTER_SIZE_RATIOが大きすぎる、またはテキストのトピックが明確でない
- 対処方法:HDBSCAN_MIN_CLUSTER_SIZE_RATIOを10-15程度まで下げる
トピックの代表単語が意味不明である
- 原因:トークン化の設定が正しくない、または文章が短すぎる
- 対処方法:これはトークン化関数の改善が必要である。現在の設定では2文字以上の名詞・動詞・形容詞のみを抽出している
固有表現が全く抽出されない
- 原因:テキストに固有名詞が含まれていない、またはspaCyモデルが認識できない
- 対処方法:テキストの内容を確認する。古典文学や創作された固有名詞はspaCyが認識できない場合がある
同じトピックが複数生成される
- 原因:UMAP_N_NEIGHBORSが小さすぎる、またはHDBSCAN_MIN_CLUSTER_SIZE_RATIOが小さすぎる
- 対処方法:UMAP_N_NEIGHBORSを20-30程度まで増やす。これは正常な動作であり、トピック分割のメカニズムを理解する良い機会である
3. 実験レポートのサンプル
実験例1:トピック数とパラメータの関係調査
実験目的:
同一の日本語小説テキストに対して、HDBSCAN_MIN_CLUSTER_SIZE_RATIOの値を変化させることで、トピック数と外れ値の割合がどのように変化するかを調査する。
実験計画:
UMAP_N_NEIGHBORSを15に固定し、HDBSCAN_MIN_CLUSTER_SIZE_RATIOを15、20、25、30の4段階で変化させて結果を比較する。
実験方法:
プログラムのパラメータ設定セクションでHDBSCAN_MIN_CLUSTER_SIZE_RATIOの値を変更し、各設定で以下の項目を記録する。
- トピック数:外れ値を除く発見されたトピックの数
- 外れ値の割合:全文章に対する外れ値の割合
- 各トピックの平均文章数:トピック数が変化することで、各トピックに含まれる文章数がどう変化するか
- 代表単語の妥当性:各トピックの上位3単語が小説の内容を適切に表現しているかを主観評価する
実験結果:
| RATIO値 | トピック数 | 外れ値割合 | 平均文章数 | 代表単語の妥当性 |
|---|---|---|---|---|
| 15 | x | x% | x文 | x |
| 20 | x | x% | x文 | x |
| 25 | x | x% | x文 | x |
| 30 | x | x% | x文 | x |
考察:
- (例文)HDBSCAN_MIN_CLUSTER_SIZE_RATIO=xxでは、トピック数が多く生成されたが、類似したトピックが複数存在していた。各トピックの文章数が少なく、代表単語の妥当性が低かった
- (例文)HDBSCAN_MIN_CLUSTER_SIZE_RATIO=xxでは、トピック数が適度に減少し、各トピックの区別が明確になった。外れ値の割合は約xx%で、許容範囲内であった
- (例文)HDBSCAN_MIN_CLUSTER_SIZE_RATIO=xxでは、トピック数がさらに減少し、大きなテーマごとに分類された。代表単語は小説の主要なテーマを反映していた
- (例文)HDBSCAN_MIN_CLUSTER_SIZE_RATIO=xxでは、トピック数が少なすぎて、異なるテーマが同一トピックに統合されていた。外れ値の割合がxx%を超え、多くの文章が分類されなかった
結論:
(例文)本実験のテキスト(文章数xx)においては、HDBSCAN_MIN_CLUSTER_SIZE_RATIO=xxが最もバランスの取れた設定であった。トピック数はxx個生成され、各トピックは小説の異なる場面や主題を適切に反映していた。細かいテーマの違いを捉えたい場合はxx、大まかなテーマ分類で十分な場合はxx-xxが適切である。文章数に応じてパラメータを調整する必要性が確認できた。
実験例2:固有表現抽出の精度検証
実験目的:
spaCy ja_core_news_lgモデルによる固有表現抽出の精度を検証し、どのタイプの固有表現が正確に抽出され、どのタイプで誤抽出や見逃しが発生するかを調査する。
実験計画:
プログラムの固有表現抽出結果を目視で確認し、正しく抽出された固有表現と誤って抽出された固有表現を分類する。特に人名(PERSON)と地名(GPE)に注目して精度を評価する。
実験方法:
プログラムを実行して固有表現抽出結果を取得し、以下の手順で検証する。
- 頻出固有表現Top10をテキストで確認し、正しく抽出されているか判定する
- 抽出例(最初の10件)について、各固有表現のタイプが正しいか確認する
- テキストを読み、抽出されるべきだが見逃されている固有表現を探す
- 誤抽出の傾向(どのような語が誤って固有表現と判定されるか)を分析する
実験結果:
| 固有表現タイプ | 抽出数 | 正解数 | 誤抽出数 | 精度 |
|---|---|---|---|---|
| PERSON(人名) | xx件 | xx件 | xx件 | xx% |
| GPE(地名等) | xx件 | xx件 | xx件 | xx% |
| DATE(日付) | xx件 | xx件 | xx件 | xx% |
| QUANTITY(数量) | xx件 | xx件 | xx件 | xx% |
具体的な抽出例の検証:
| 抽出された表現 | 判定タイプ | 正誤 | 備考 |
|---|---|---|---|
| 清 | PERSON | ○ | 人名として正しく抽出 |
| 勘太郎 | PERSON | ○ | 人名として正しく抽出 |
| 西洋 | LOC | △ | 抽象的な地理概念 |
| 三年間 | DATE | ○ | 期間表現として正しく抽出 |
| 二階 | FAC | × | 一般名詞を誤抽出 |
考察:
- (例文)PERSON(人名)の抽出精度は比較的高く、主要な登場人物は正しく抽出された。ただし、古風な名前や漢字表記の揺れがある場合、一部で見逃しが発生した
- (例文)GPE(地名等)の抽出数が最も多かったが、「西洋」のような抽象的な地理的概念がLOCとして分類されるなど、タイプの判定に揺れが見られた
- (例文)DATE(日付)とQUANTITY(数量)は比較的正確に抽出されたが、「三年間」のような期間表現と「三年」のような時点表現の区別が曖昧であった
- (例文)FAC(施設)タイプで「二階」が抽出されたが、これは建物の一部であり、固有名詞ではない。一般名詞が誤って抽出される傾向が確認できた
- (例文)ルビ付き表記(例:「譲おやゆずり」)では、ルビ部分も含めて抽出されるため、表記の正規化が必要であることが分かった
結論:
(例文)spaCy ja_core_news_lgモデルは、人名と地名の抽出において実用的な精度を示した。特に現代的な固有名詞や一般的な地名については高い精度で抽出できた。一方で、古典文学特有の表現、ルビ付き表記、一般名詞との境界が曖昧な語については誤抽出や見逃しが発生した。固有表現抽出の結果を利用する際は、頻出表現を目視で確認し、明らかな誤抽出を除外する後処理が必要である。また、文学作品の分析では、作品の時代背景に応じてモデルの精度が変動することを考慮すべきである。