BERTopic による日本語トピックモデリング
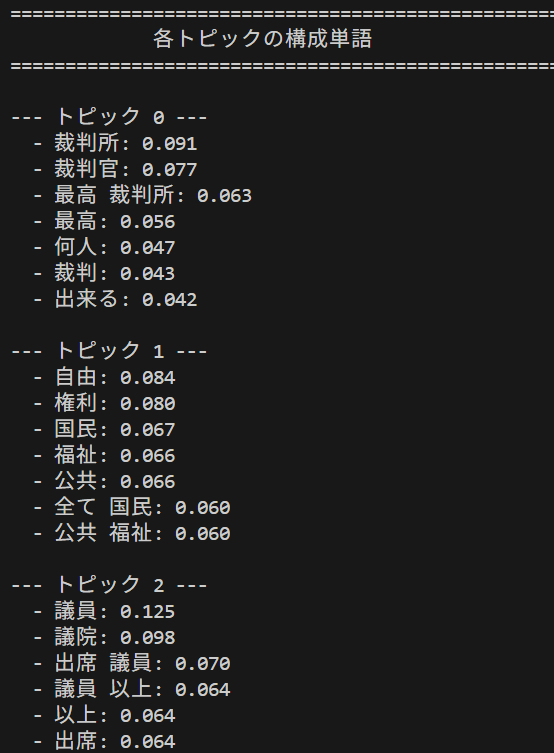
日本国憲法の分析結果
【目次】
はじめに
BERTopicは、Transformer埋め込みとc-TF-IDF(class-based TF-IDF)を組み合わせたトピックモデリング手法である。従来のLDAやTF-IDFを改良し、意味的に一貫したトピック抽出を実現する。
技術名: BERTopic(Neural topic modeling with a class-based TF-IDF procedure)
出典: Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794.
技術的特徴: c-TF-IDFは従来のTF-IDFが個別文書内での用語重要度を計算するのに対し、クラスタ全体を一つの文書として扱い、クラスタ間での用語の識別力を重視する。この技術的差異により、トピック表現の解釈性が向上し、意味的に一貫したトピック抽出が可能になる。
活用例: カスタマーフィードバック分析、ニュース記事の自動分類、学術論文の研究動向分析、SNS投稿の感情・話題分析
体験内容: 日本語テキストデータから意味的に一貫したトピックを自動抽出し、従来手法との精度差を確認できる。多言語Transformerモデルによる意味理解と、HDBSCANクラスタリングによる話題分離を体験できる。
使用技術・アルゴリズム
BERTopicの構成要素:
- BERTopic: Transformer埋め込み、UMAP次元削減、HDBSCANクラスタリング、c-TF-IDFを統合したトピックモデリングフレームワーク
- c-TF-IDF(class-based TF-IDF): クラスタ内文書を単一文書として扱い、クラスタ間で用語重要度を比較する手法
- paraphrase-multilingual-MiniLM-L12-v2: 多言語対応のTransformer文書埋め込みモデル(384次元ベクトル出力)
- HDBSCAN: 密度ベースの階層クラスタリングアルゴリズム(ノイズ耐性、可変クラスタ数)
- UMAP: 高次元データの非線形次元削減手法(t-SNEの改良版)
日本語処理技術:
- fugashi: MeCabベースの日本語形態素解析ライブラリ
- ipadic: 日本語形態素解析用辞書
事前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install bertopic sentence-transformers umap-learn sudachipy sudachidict-core
プログラムコード
使用技術・アルゴリズム詳細
- BERTopic: Transformer埋め込み、UMAP次元削減、HDBSCANクラスタリング、c-TF-IDFを統合したトピックモデリングフレームワーク
- c-TF-IDF(class-based TF-IDF): クラスタ内文書を単一文書として扱い、クラスタ間で用語重要度を比較する手法
- paraphrase-multilingual-MiniLM-L12-v2: 多言語対応のTransformer文書埋め込みモデル(384次元ベクトル出力)
- HDBSCAN: 密度ベースの階層クラスタリングアルゴリズム(ノイズ耐性、可変クラスタ数)
- UMAP: 高次元データの非線形次元削減手法(t-SNEの改良版)
- fugashi: MeCabベースの日本語形態素解析ライブラリ
- ipadic: 日本語形態素解析用辞書
ソースコード
# プログラム名: BERTopic日本語トピックモデリング
# 特徴技術名: BERTopic [Transformerベースのトピックモデリング技術]
# 出典: Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794.
# 特徴機能: c-TF-IDF(class-based TF-IDF)[各クラスタ(トピック)内の全文書を1つの文書として扱い、トピック特有の重要語を抽出。従来のTF-IDFと異なり、トピック間の差異を明確化]
# 学習済みモデル: paraphrase-multilingual-MiniLM-L12-v2 [多言語対応Sentence-BERTモデル、50言語以上対応、384次元の文書埋め込み生成、https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2]
# 方式設計:
# - 関連利用技術: [Sentence Transformers(文書埋め込み生成、多言語対応)、UMAP(次元削減、トポロジー保持)、HDBSCAN(密度ベースクラスタリング、外れ値検出)、SudachiPy(日本語形態素解析、品詞分解)]
# - 入力と出力: [入力: テキスト(複数行の日本語文書、Enterキーのみで入力終了)、出力: コンソール出力(トピック一覧、各トピックの構成単語、文書とトピックの対応、分析結果概要)]
# - 処理手順: [1.文書埋め込み生成(Sentence Transformers)、2.次元削減(UMAP)、3.クラスタリング(HDBSCAN)、4.トピック表現生成(c-TF-IDF)]
# - 前処理、後処理: [前処理: Unicode正規化(NFKC)、記号除去、日本語ストップワード除去、品詞フィルタリング(名詞・動詞・形容詞)、2文字以上フィルタ。後処理: 外れ値トピック(-1)の分離表示]
# - 追加処理: [n-gram活用(1-2gram)による複合語認識、頻度フィルタリング(min_df=1, max_df=0.8)によるノイズ除去、語彙数制限(max_features=200)による計算効率化]
# - 調整を必要とする設定値: [MIN_TOPIC_SIZE(トピック最小文書数、デフォルト3、小さいほど細分化)、NUM_TOPICS(最大トピック数、Noneで自動決定)]
# 将来方策: [MIN_TOPIC_SIZEの自動最適化: 文書数の平方根を基準に、外れ値割合が10-20%になるよう反復的に調整する機能の実装]
# その他の重要事項: 再現性確保のためrandom_state=42を設定、外れ値割合10-20%が適切な指標
# 前準備: pip install bertopic sentence-transformers umap-learn sudachipy sudachidict-core
import os
import re
import unicodedata
import numpy as np
# Numbaのキャッシュディレクトリを設定(Windows権限問題回避)
os.environ['NUMBA_CACHE_DIR'] = os.path.expanduser('~/.numba_cache')
# ==============================================================================
# ユーザーが調整可能なパラメータ
# ==============================================================================
# BERTopicモデル設定
NUM_TOPICS = None # 生成するトピックの最大数。NoneにするとBERTopicが自動決定。
MIN_TOPIC_SIZE = 3 # 1つのトピックに最低限必要な文書数。小さいほど細かくトピックが分かれる。
# 前処理設定
MIN_DOC_LEN = 0 # 短い文書をフィルタリングする際の最小文字数。0にするとフィルタリングしない。
# CountVectorizer設定
MAX_FEATURES = 200 # トピックモデリングに使用する最大語彙数。
MIN_DF = 1 # 語彙の出現頻度の下限(文書数)。これより少ない文書にしか出現しない語は除外。
MAX_DF = 0.8 # 語彙の出現頻度の上限(割合)。これより多くの文書に出現する語は除外。
NGRAM_RANGE = (1, 2) # (1,1) は単一の単語のみ、(1,2) は単一と2連語、(1,3) は単一と2,3連語
# UMAPモデル設定 (BERTopic内部の次元削減)
UMAP_N_COMPONENTS = 5 # 埋め込みの次元数。大きいほど意味の違いを保持しやすい。
UMAP_N_NEIGHBORS = 15 # 近傍点の数。小さいほど局所的な構造を重視し、多くのクラスタ形成を促す。
UMAP_MIN_DIST = 0.0 # 埋め込みの密度の度合い。小さいほどクラスタが密になる。
# SudachiPy設定
SUDACHI_SPLIT_MODE = 'C' # SudachiPyの分割モード: 'A' (基本)、'B' (短単位)、'C' (粗い)
# その他
SEED = 42 # 再現性のための乱数シード
# 表示設定
SEP_LINE = '=' * 50 # セクション区切り線
TOP_WORDS_NUM = 7 # 各トピックで表示する上位単語数
TOP_COMMON_WORDS = 3 # 最頻出トピックで表示する代表単語数
# 正規表現パターン
SYMBOL_PATTERN1 = r'[\u2000-\u206F\u2E00-\u2E7F\u3000-\u303F]' # Unicode記号
SYMBOL_PATTERN2 = r'[!"#$%&\'()*+,-./:;<=>?@\[\\\]^_`{|}~¥€£™©®™℠]' # ASCII記号等
SYMBOL_PATTERN3 = r'[、。「」()【】『』〔〕【】 々〇〆]' # 日本語記号
SYMBOL_PATTERN4 = r'[—–‐\--]' # ダッシュ類
DIGIT_PATTERN = r'[0-9]' # アラビア数字
SPACE_PATTERN = r'\s+' # 空白文字
KANJI_PATTERN = r'[一-龯]{1,}' # 漢字(1文字以上)
HIRAGANA_PATTERN = r'[ぁ-ん]{2,}' # ひらがな(2文字以上)
KATAKANA_PATTERN = r'[ァ-ヶ]{2,}' # カタカナ(2文字以上)
# ==============================================================================
# SudachiPyの利用可能性チェック
# ==============================================================================
SUDACHIPY_AVAILABLE = False
try:
from sudachipy import tokenizer, dictionary
SUDACHIPY_AVAILABLE = True
except ImportError:
print('SudachiPyが利用できません。代替の正規表現ベースの処理を使用します。')
# ==============================================================================
# 日本語ストップワード
# ==============================================================================
JAPANESE_STOPWORDS = list(set([
'の', 'に', 'は', 'を', 'が', 'で', 'と', 'から', 'まで', 'より', 'へ',
'も', 'か', 'や', 'など', 'なお', 'また', 'さらに', 'ただし', 'しかし',
'すなわち', 'つまり', 'そして', 'それで', 'だから', 'したがって',
'である', 'です', 'ます', 'だ', 'でも', 'けれど', 'けれども',
'あの', 'その', 'この', 'それ', 'これ', 'あれ', 'どの', 'どれ', 'なに',
'なん', 'いつ', 'どこ', 'だれ', 'どう', 'なぜ', 'いかに',
'て', 'な', 'し', 'れ', 'い',
'る', 'す', 'た', 'ある', 'いる', 'なる', 'する', 'できる',
'される', 'られる', 'こと', 'もの', 'ため', 'について', 'において', 'に関し',
'に対し', 'により', 'によって', 'その他', 'すべて', 'または', 'もしくは',
'および', 'ならびに'
]))
# ==============================================================================
# プログラム本体
# ==============================================================================
print('BERTopic日本語トピックモデリング')
print(SEP_LINE)
print('\n【概要】')
print('このプログラムは、日本語文書からトピック(話題)を自動抽出します。')
print('BERTopicという技術を使用し、文書の意味的な類似性に基づいてグループ化します。')
print('\n【操作方法】')
print('1. 分析したい文章を入力してください(複数行可)')
print('2. 入力終了は空行(Enterキーのみ)で判定します')
print('3. その後、自動的に分析が開始されます')
print('\n【注意事項】')
print('- 日本語の文章を入力してください')
print('- 最低3つ以上の文書を入力することを推奨します')
print('- 処理には数秒から数十秒かかる場合があります')
print(SEP_LINE)
# 文書入力
print('\n分析対象の文章を入力してください:')
print()
docs = []
while True:
line = input()
if line == '':
break
docs.append(line)
# 元の文書リストを保持
original_docs = list(docs)
if not docs:
print('処理可能な文書がありません')
exit()
## 前処理関数とトークナイザー関数の定義
def preprocess_document(text):
"""文書から記号を除去し、半角・全角変換の統一処理を行う"""
# Unicode正規化 (NFKC形式)
text = unicodedata.normalize('NFKC', text)
# 記号の除去
text = re.sub(SYMBOL_PATTERN1, '', text)
text = re.sub(SYMBOL_PATTERN2, '', text)
text = re.sub(SYMBOL_PATTERN3, '', text)
text = re.sub(SYMBOL_PATTERN4, '', text)
# 空白文字を単一の半角スペースに変換
text = re.sub(SPACE_PATTERN, ' ', text)
# 短すぎる文書の除外
if MIN_DOC_LEN > 0 and len(text) < MIN_DOC_LEN:
return None
return text.strip()
def advanced_tokenize_japanese(text):
"""日本語テキストをトークン化し、品詞フィルタリング等を行う"""
tokens_list = []
if SUDACHIPY_AVAILABLE:
tokenizer_obj = dictionary.Dictionary().create()
mode = getattr(tokenizer.Tokenizer.SplitMode, SUDACHI_SPLIT_MODE, tokenizer.Tokenizer.SplitMode.A)
tokens = tokenizer_obj.tokenize(text, mode)
for token in tokens:
pos = token.part_of_speech()[0]
surface = token.surface()
normalized = token.normalized_form()
# 基本形または正規化された形を優先
word = re.sub(SPACE_PATTERN, '', normalized if normalized else surface)
word = word.strip()
# 数字の除去
word = re.sub(DIGIT_PATTERN, '', word)
# 品詞フィルタリング
if pos in ['名詞', '動詞', '形容詞'] and len(word) >= 2 and word not in JAPANESE_STOPWORDS:
tokens_list.append(word)
else:
# 正規表現ベースのフォールバック処理
pattern = f'{KANJI_PATTERN}|{HIRAGANA_PATTERN}|{KATAKANA_PATTERN}'
words_found = re.findall(pattern, text)
for word in words_found:
word = re.sub(SPACE_PATTERN, '', word).strip()
word = re.sub(DIGIT_PATTERN, '', word)
if word and len(word) >= 2 and word not in JAPANESE_STOPWORDS:
tokens_list.append(word)
return tokens_list if tokens_list else ['文書']
def strict_clean_tokenizer(text):
"""CountVectorizer用のトークナイザー関数"""
tokens = advanced_tokenize_japanese(text)
if not tokens or (len(tokens) == 1 and tokens[0] == '文書'):
return ['未分類文書']
return tokens
## 文書の前処理とフィルタリング
print('\n文書の前処理とフィルタリングを実行します...')
orig_count = len(docs)
# 前処理実行(元のインデックスを常に保持)
proc_docs = []
original_indices = []
for i, d in enumerate(docs):
processed_doc = preprocess_document(d)
if processed_doc is not None:
proc_docs.append(processed_doc)
original_indices.append(i)
docs = proc_docs
if len(original_indices) < orig_count:
print(f'前処理完了。{orig_count}件中{len(docs)}件の有効な文書を分析します。')
else:
print(f'前処理完了。{len(docs)}件の文書を分析します。')
if not docs:
print('フィルタリングの結果、処理可能な文書がありませんでした。')
exit()
## メイン処理: BERTopicモデル構築と分析
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import CountVectorizer
from umap import UMAP
print('多言語Transformerモデル読み込み中...')
embed_model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# CountVectorizer設定
print('CountVectorizer設定中...')
vectorizer = CountVectorizer(
tokenizer=strict_clean_tokenizer,
min_df=MIN_DF,
max_df=MAX_DF,
ngram_range=NGRAM_RANGE,
max_features=MAX_FEATURES,
token_pattern=None,
lowercase=False
)
# UMAPモデル設定
umap_model = UMAP(
n_neighbors=UMAP_N_NEIGHBORS,
n_components=UMAP_N_COMPONENTS,
min_dist=UMAP_MIN_DIST,
metric='cosine',
random_state=SEED
)
# BERTopicモデル作成
topic_model = BERTopic(
embedding_model=embed_model,
umap_model=umap_model,
vectorizer_model=vectorizer,
language='multilingual',
min_topic_size=MIN_TOPIC_SIZE,
nr_topics=NUM_TOPICS,
calculate_probabilities=False,
verbose=False
)
print('BERTopicトピック分析開始...')
# トピック抽出実行
topics, _ = topic_model.fit_transform(docs)
## 結果出力
print('\n' + SEP_LINE)
print(' トピック抽出結果')
print(SEP_LINE + '\n')
info = topic_model.get_topic_info()
# 表示したい列を選択し、新しい列名で出力
display_info = info[['Topic', 'Count', 'Name']].rename(columns={
'Topic': 'トピック番号',
'Count': '文書数',
'Name': '代表語句'
})
print(display_info.to_string(index=False))
print('\n' + SEP_LINE)
print(' 各トピックの構成単語')
print(SEP_LINE + '\n')
# -1 (外れ値) トピックは除外し、昇順にソートして表示
sorted_topics = sorted([t for t in info['Topic'].values if t >= 0])
for topic_id in sorted_topics:
words = topic_model.get_topic(topic_id)
print(f'--- トピック {topic_id} ---')
if words:
for word, weight in words[:TOP_WORDS_NUM]:
print(f' - {word}: {weight:.3f}')
else:
print(' (このトピックには特徴語がありません)')
print()
print('\n' + SEP_LINE)
print(' 文書とトピックの対応')
print(SEP_LINE + '\n')
print(f'全 {len(docs)} 件の文書結果を表示します。')
# numpy配列として扱う
topics_array = np.array(topics)
# 元の文書番号を表示
for i, processed_doc in enumerate(docs):
# 元の文書番号を取得(常にoriginal_indicesを使用)
orig_num = original_indices[i] + 1
if topics_array[i] >= 0:
print(f'文書 {orig_num}: トピック {topics_array[i]}')
print(f' 内容 (前処理後): {processed_doc[:50]}...')
else:
print(f'文書 {orig_num}: 外れ値トピック (-1)')
print(f' 内容 (前処理後): {processed_doc[:50]}...')
if len(original_indices) < orig_count:
print('\n【注意】フィルタリングにより一部の文書が除外されました。文書番号は元の入力順を保持しています。')
print('\n' + SEP_LINE)
print(' 分析結果概要')
print(SEP_LINE + '\n')
print(f' **処理文書数**: {len(docs)} 件')
# トピック数のカウント
unique_topics = set(topics_array)
num_topics = len([t for t in unique_topics if t >= 0])
print(f' **発見トピック数**: {num_topics} 個 (外れ値を除く)')
# 外れ値割合の計算
if len(topics_array) > 0:
outlier_count = np.sum(topics_array == -1)
outlier_pct = (outlier_count / len(topics_array) * 100)
print(f' **外れ値割合**: {outlier_pct:.1f}% (目安: 10-20%が適切)')
else:
print(' **外れ値割合**: 0.0%')
# 最頻出トピック表示
if num_topics > 0:
filtered_topics = topics_array[topics_array >= 0]
if len(filtered_topics) > 0:
unique_topics, counts = np.unique(filtered_topics, return_counts=True)
common_topic = int(unique_topics[np.argmax(counts)])
print(f'\n**最も多く出現したトピック**: トピック {common_topic}')
words = topic_model.get_topic(common_topic)
if words:
print(' 代表単語:')
for word, weight in words[:TOP_COMMON_WORDS]:
print(f' - {word}: {weight:.3f}')
print('\n' + SEP_LINE)
print(' 結果の読み方とヒント')
print(SEP_LINE + '\n')
print(' - **トピック番号**: 抽出されたトピックの識別番号です。')
print(' - **文書数**: そのトピックに分類された文書の数を示します。')
print(' - **代表語句**: トピックを表す単語と、その重み(重要度)です。')
print(' - **外れ値割合**: トピックに分類されなかった文書の割合です。')
print(' - 10-20%が適切な目安とされます(低すぎると過学習、高すぎるとノイズが多い可能性)。')
print(' - **トピック数**: 分析対象の文書数の10-20%が一般的な目安です。')
print('\n' + SEP_LINE)
print(' BERTopicの技術的特徴')
print(SEP_LINE + '\n')
print(' - **Transformer埋め込み**: 文書の意味内容を理解し、表現を生成します。')
print(' - **c-TF-IDF**: 各トピックに特有の重要な単語を識別し、分かりやすいトピック名を生成します。')
print(' - **HDBSCAN**: クラスタリング手法で、意味的に近い文書をまとめます。')
print('\n分析完了しました!')
print('より良いトピックを得るには、冒頭のパラメータや日本語ストップワードを調整してみてください。')
使用方法
- 上記のプログラムを実行する
- 分析対象の文章を複数行で入力する(日本語テキスト推奨)
- 空行(Enterキーのみ)で入力を終了する
- 自動的にトピック分析が実行され、結果が表示される
実験・探求のアイデア
モデル選択の指針
paraphrase-multilingual-MiniLM-L12-v2: 多言語対応、処理速度と精度のバランス良好、日本語を含む100言語対応、384次元ベクトル出力により効率的な処理が可能
all-MiniLM-L6-v2: 英語特化、軽量モデル、処理速度最高、メモリ使用量少、日本語処理精度は劣る
paraphrase-multilingual-mpnet-base-v2: 高精度、768次元ベクトル出力、処理時間長、大規模データ分析に適合
段階的実験プロセス
基礎レベル(動作確認):
- 文書数の影響:10文書での基本動作確認、結果の妥当性判定
- 文書長の影響:短文(1行)での処理能力確認、基本的なトピック抽出の理解
応用レベル(比較検証):
- 文書数の影響:50文書、100文書での精度比較、スケーラビリティ検証
- 文書長の影響:中文(段落)、長文(記事)での分析結果比較、文書長による精度変化の観察
- 言語混在の影響:日本語のみ、英語のみ、混在テキストでの処理能力検証
発展レベル(独自分析):
- モデル比較:異なるTransformerモデルでの同一データ分析、精度と処理時間のトレードオフ評価
- パラメータ調整:min_df、ngram_range等のパラメータ変更による結果への影響分析
具体的実験アイデア
意味的類似性の検証: 同一話題の異なる表現を用いた文章を分析し、BERTopicが意味的類似性を正しく認識するか検証する
時系列分析: 同一分野の文書を時系列で分析し、話題の変遷を追跡する
外れ値分析: トピック-1(外れ値)に分類された文書の特徴を分析し、ノイズ検出能力を評価する
分類精度評価: 手動でラベル付けした文書群をBERTopicで分析し、自動分類の精度を定量評価する
多言語処理能力: 日本語、英語、中国語の混在文書での言語横断的トピック抽出能力を検証する
専門分野適用: 技術文書、医学文書、法律文書など専門性の高い文書での用語認識精度を評価する