人工知能のプログラム実行体験と探求(Windows上)
コード及び説明文の作成ではAIを使用している。
* 人工知能のプログラム実行体験と探求(Google Colaboratory上): 別ページ »で説明、
目次
実用ツール集
技術深堀り
- ローカルLLM
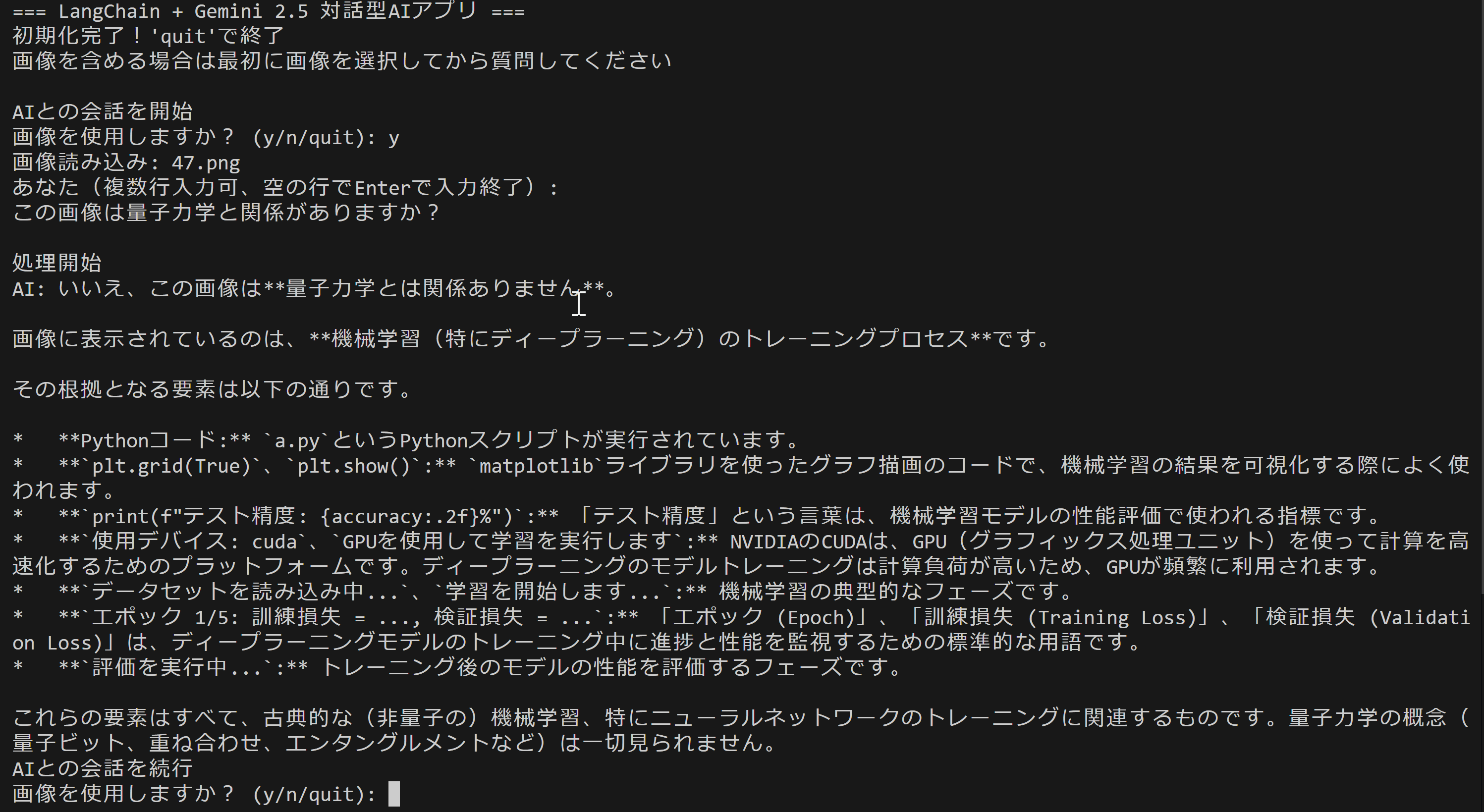
- マルチモーダルLLMの利用:Gemini による対話,翻訳,画像理解,Visual Question Answering
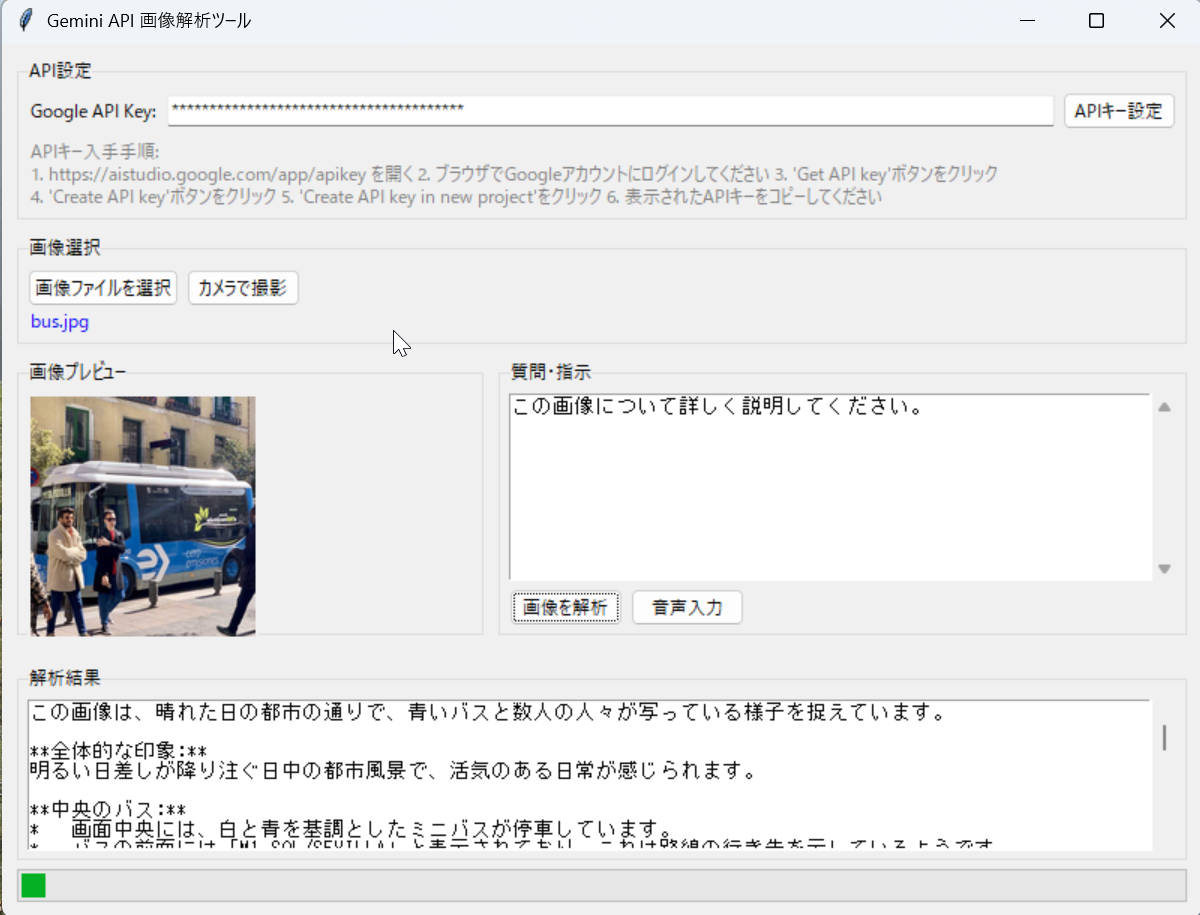
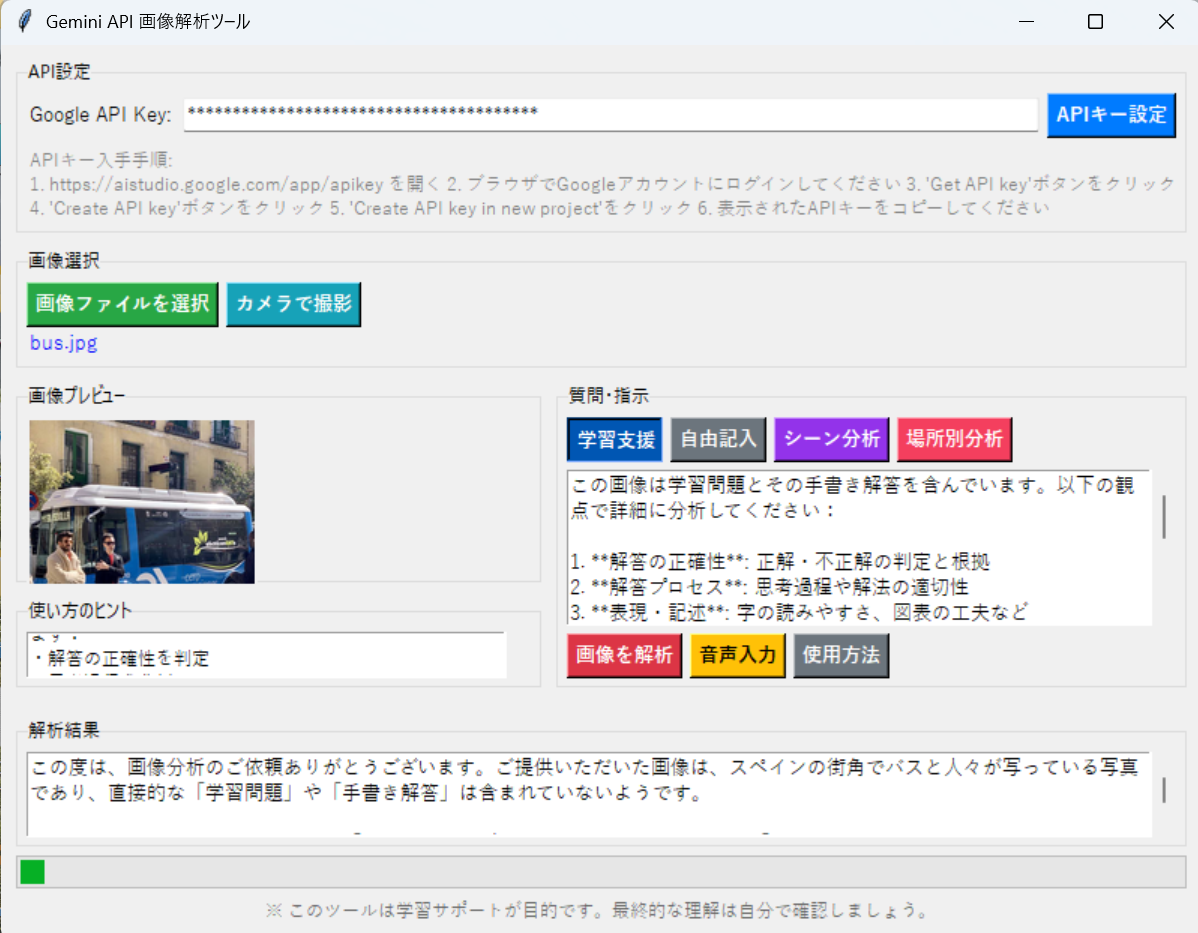
- マルチモーダルLLMの利用:ローカルLLMによる画像理解,Visual Question Answering
- マルチモーダル基盤モデル:画像とテキストの類似性,画像キャプション生成
- 文字認識・音声認識
- 自然言語処理
- 画像処理,動画像処理
- コンピュータビジョン:画像分類,画像タギング(入力:動画像)
- コンピュータビジョン:画像分類,画像タギング(入力:静止画像)
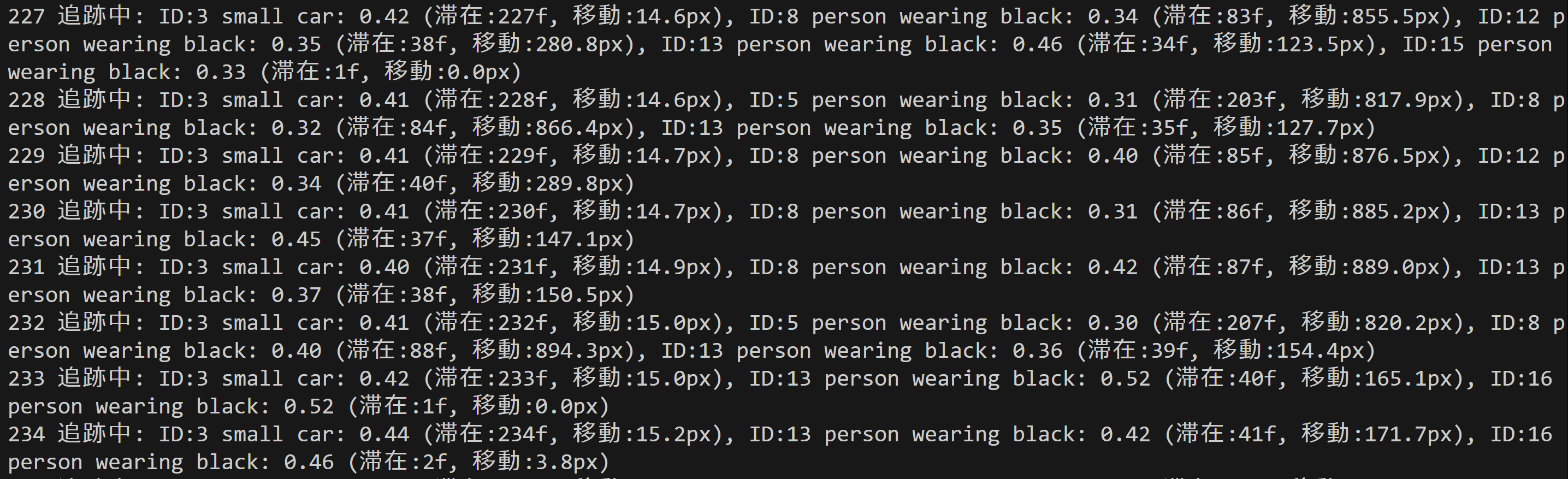
- コンピュータビジョン:物体検出(ByteTrackによる追跡とTTAの機能付き)
- コンピュータビジョン:物体検出
- コンピュータビジョン:人物検出(ByteTrackによる追跡とTTAの機能付き)
- コンピュータビジョン:インスタンスセグメンテーション
- コンピュータビジョン:セマンティックセグメンテーション
- コンピュータビジョン:前景背景分離
- コンピュータビジョン:顔情報処理
- コンピュータビジョン:人物動作認識
- コンピュータビジョン:手指の姿勢推定
- コンピュータビジョン:頭部姿勢推定
- コンピュータビジョン:人体姿勢推定
- コンピュータビジョン:眼球運動
- コンピュータビジョン:エッジ検出
- コンピュータビジョン:異常検知,微細変化検出
- コンピュータビジョン:画像からの深度推定
- コンピュータビジョン:動画像のトラッキングビジョン
- コンピュータビジョン:人物再識別
- コンピュータビジョン:線分検出,消失点推定
- 画像生成(Text-to-Image)
- 画質改善
- 音声処理
- シミュレーション・応用技術
- ゲームAI
- クラスタリング
- 機械学習・深層学習の基礎実習
- 機械学習の最適化と評価技術
- オープンデータ:標高データとDepthMap
- AI技術の基礎理論と解説
- パワーポイントファイルの処理
AI支援について: 記載のプログラムや説明は AIの支援を受けて作成している.
実用ツール
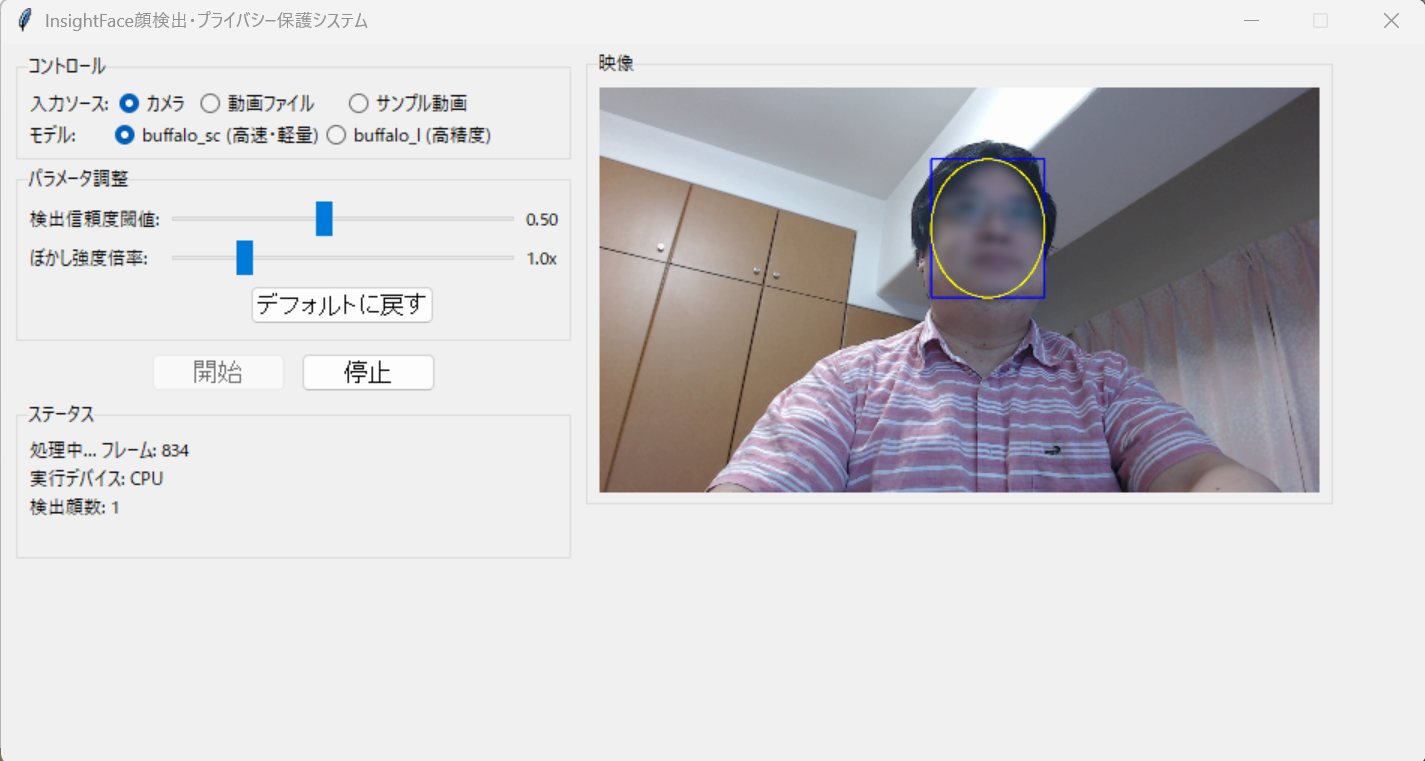
- InsightFace顔検出・プライバシー保護と動画保存(ソースコードと説明と利用ガイド)
【ツール説明】 動画の顔を自動ぼかし(プライバシ保護)、動画で保存。 InsightFaceのSCRFDを利用。リアルタイム処理、GUIで顔検出閾値、ぼかし強度調整可能、保存動画は枠線なしのぼかしのみ。CUDA/DirectML/CPU対応。
- ノイズ除去 (バイラテラルフィルタ)、彩度調整、ガンマ補正、コントラスト調整 (CLAHE)によるリアルタイム動画補正(ソースコードと説明と利用ガイド)
【ツール説明】このページのリアルタイム動画補正プログラムは、動画ファイルやウェブカメラ映像に対し、GUIスライダーを用いて以下の画質補正を対話的に適用できるものである。調整したパラメータはプリセットとしてファイルに保存・読み込みが可能。画像処理の学習教材としての活用も意図している。
【主な調整項目】 ・ノイズ除去 (バイラテラルフィルタ) ・彩度調整 ・ガンマ補正 (明るさ) ・コントラスト調整 (CLAHE)

- yt_dlp によるダウンロード
十分に確認の上で実行すること.
プロンプト例

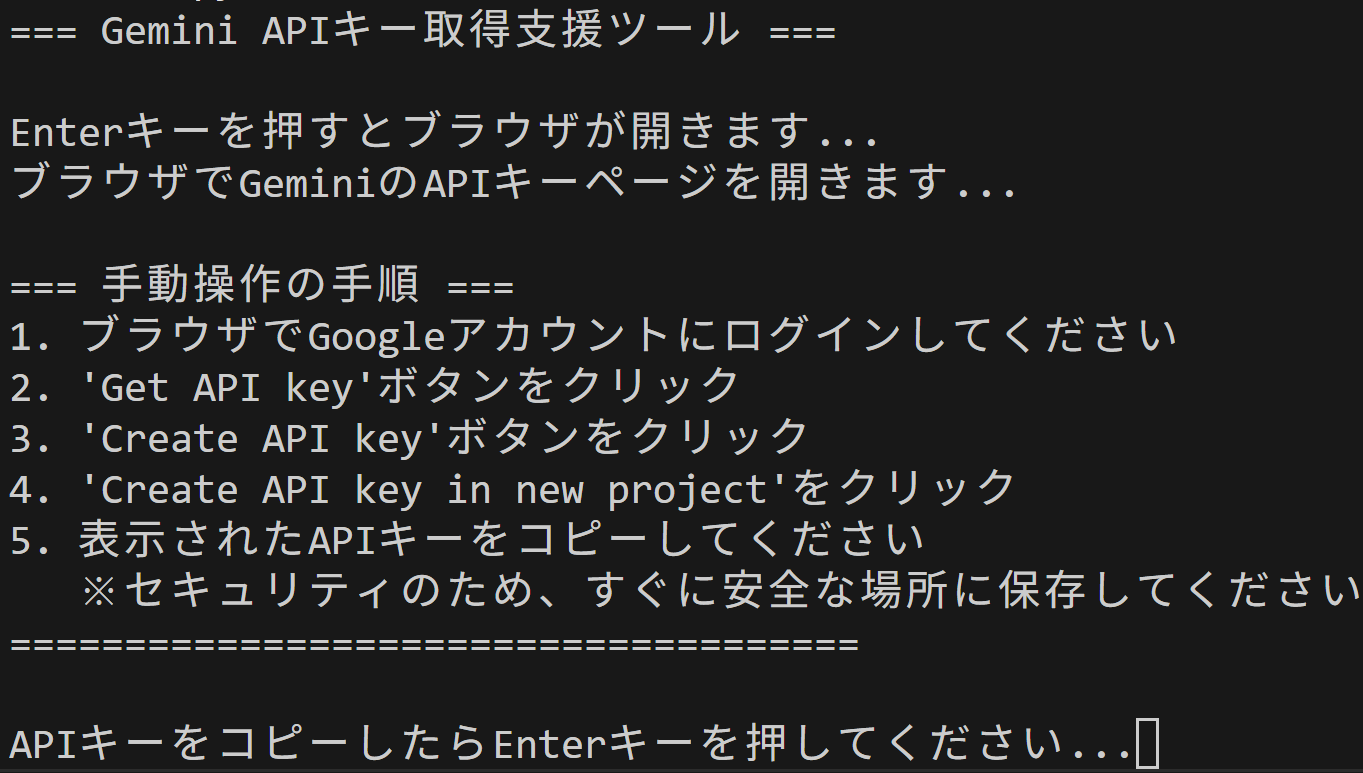
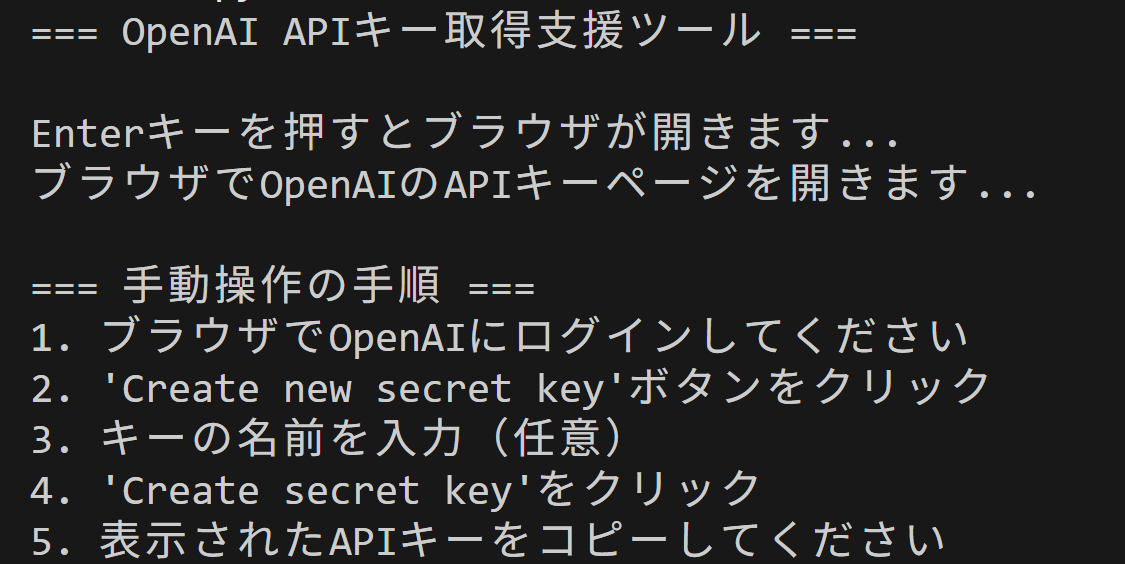
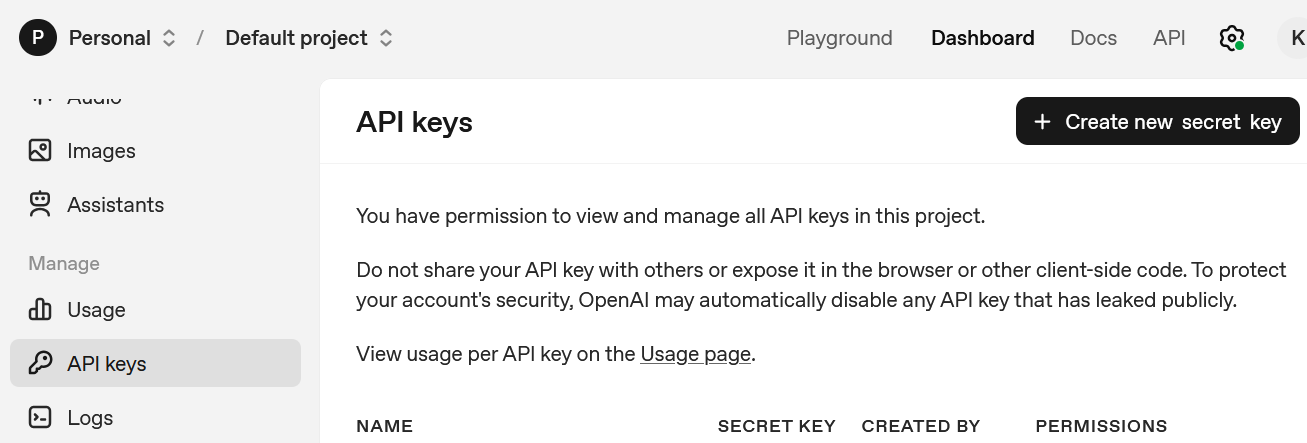
実用ツール: APIキー取得支援ツール
ローカルLLM
マルチモーダルLLMの利用:Gemini による対話,翻訳,画像理解,Visual Question Answering


マルチモーダルLLMの利用:ローカルLLMによる画像理解,Visual Question Answering
- Qwen3-VL-4B/8B:Windows環境での実践ガイド
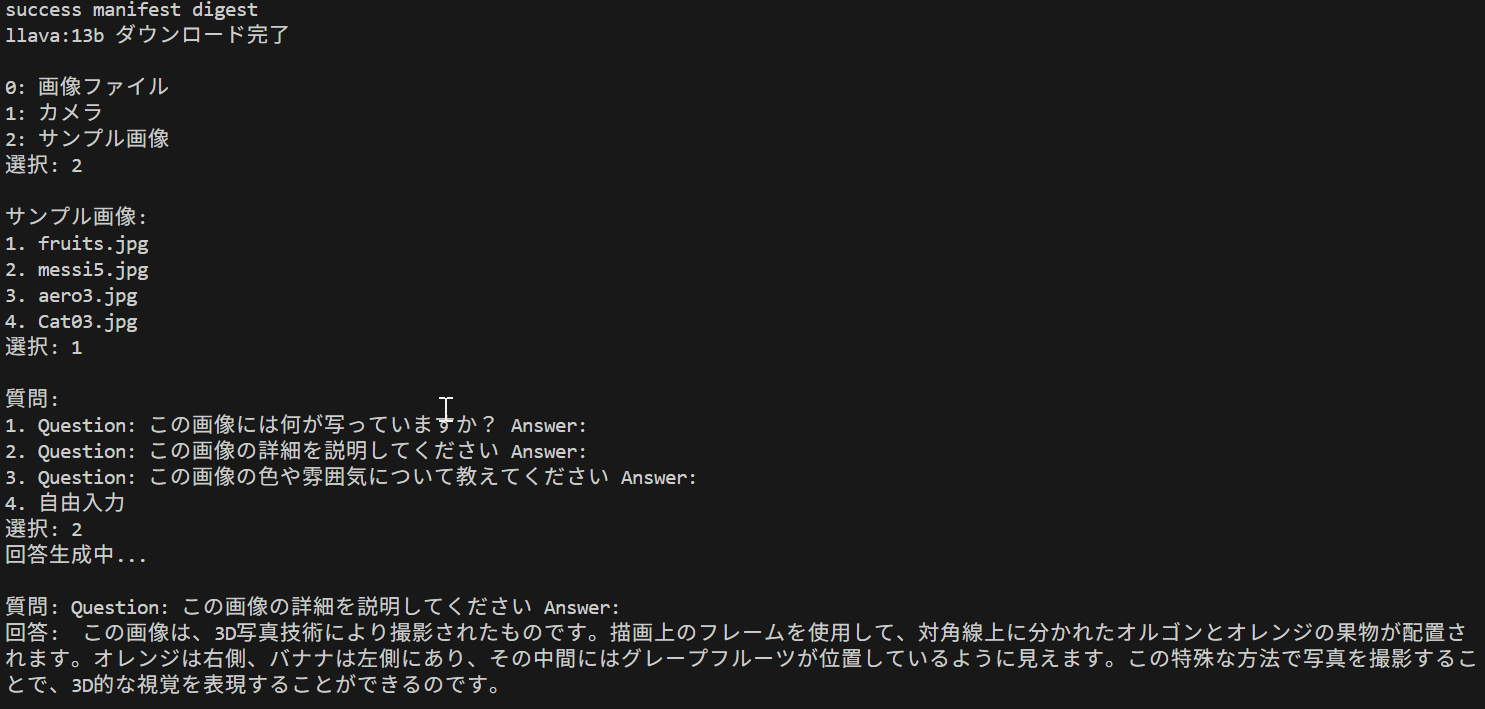
- OLLAMA LLaVA 1.6 による Visual Question Answering(ソースコードと実行結果)
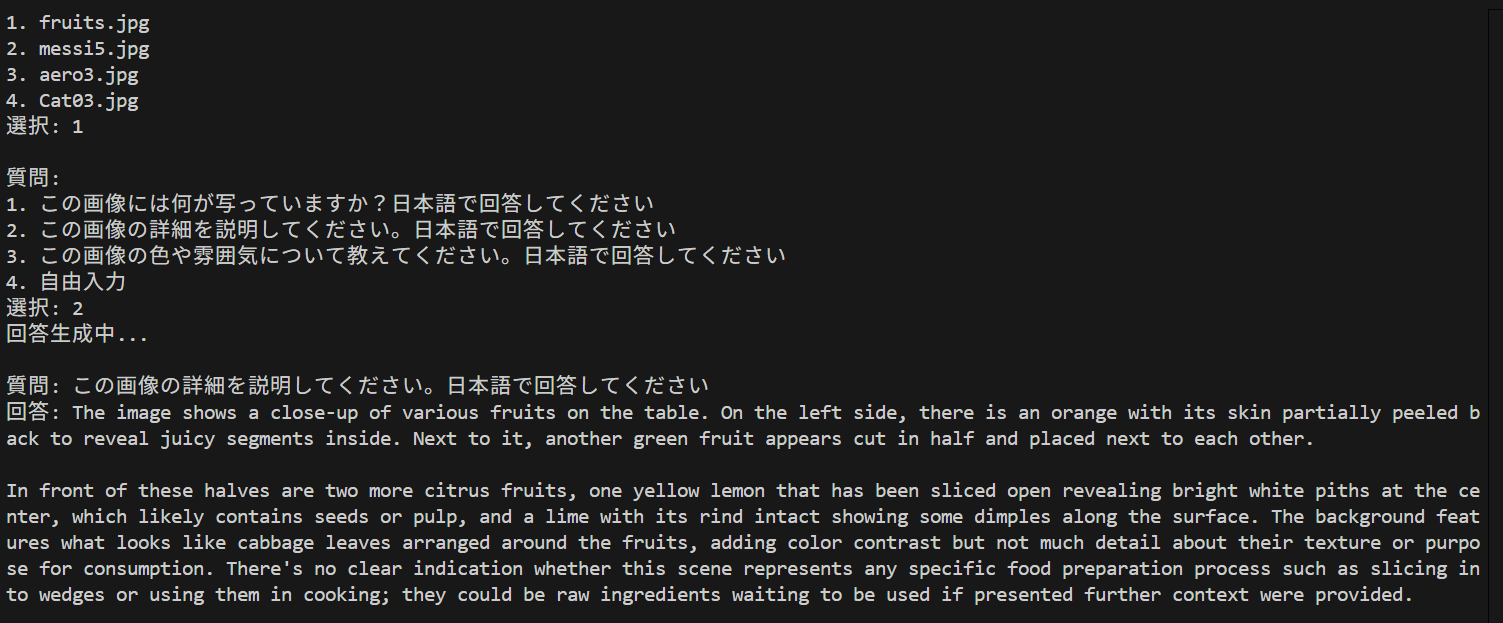
- Hugging Face LLaVA OneVision による Visual Question Answering (ソースコードと実行結果)
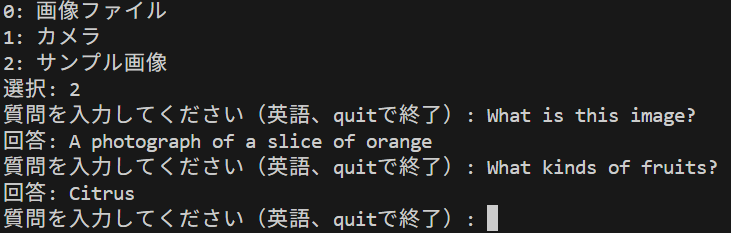
- BLIP-2 による Visual Question Answering(ソースコードと実行結果)
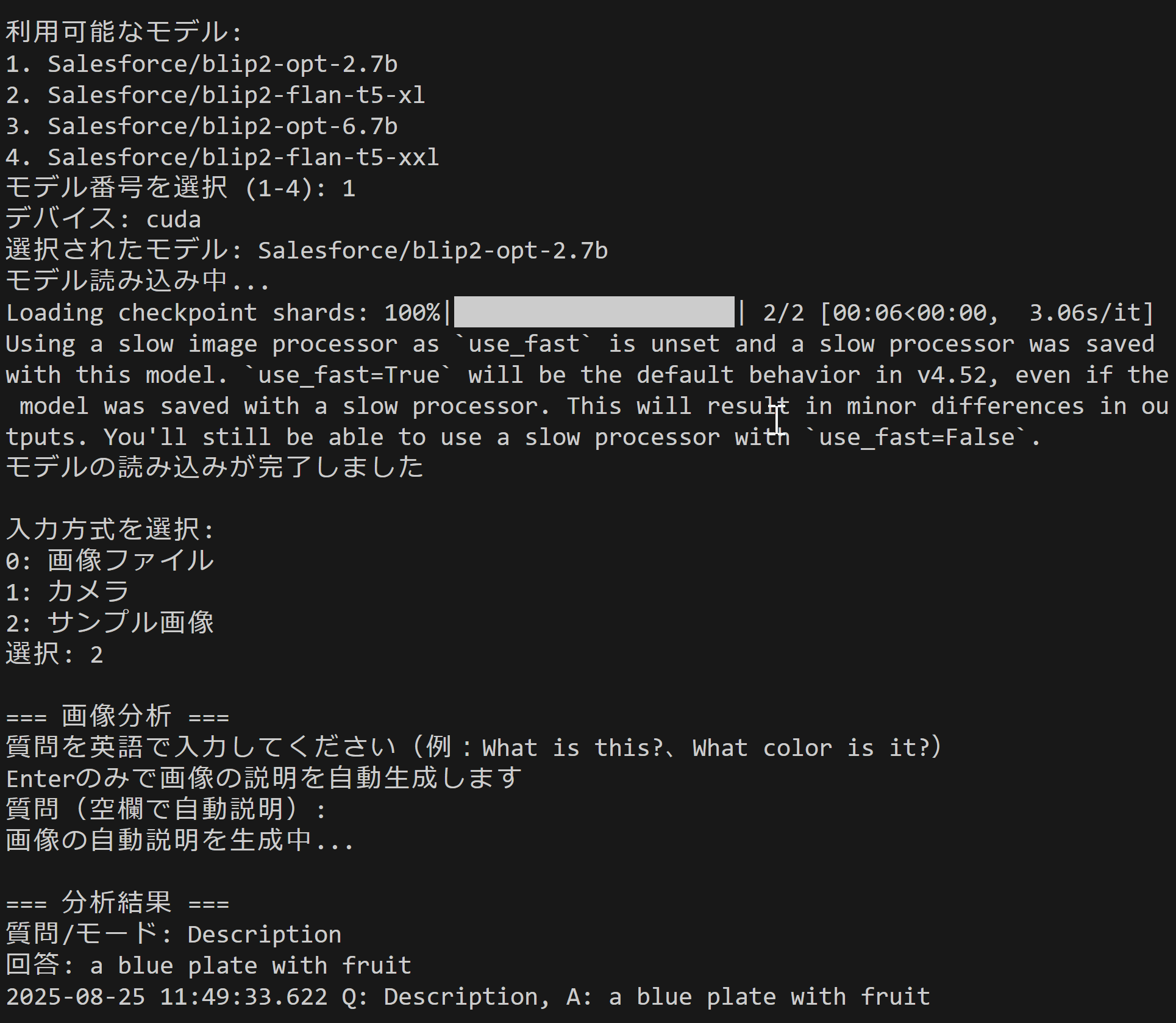
- BLIP-2による画像質問応答・説明生成(ソースコードと実行結果)

- InstructBLIP による Visual Question Answering(ソースコードと実行結果)
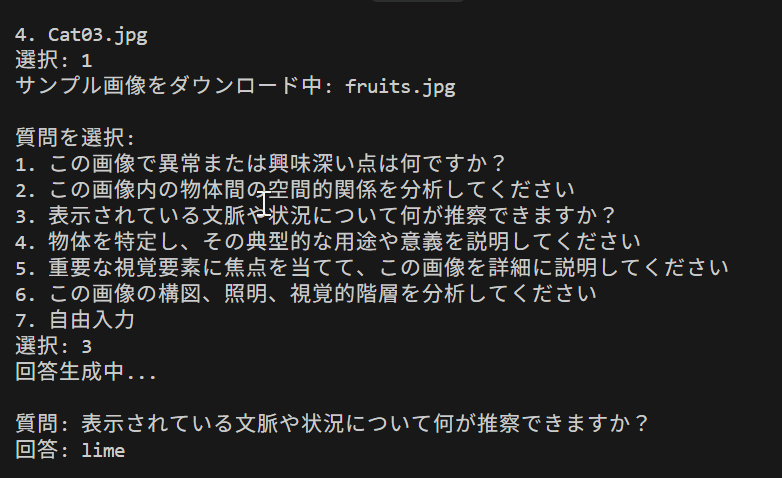
- LLaVA-NeXTによる商業施設向けAI案内(ソースコードと実行結果)

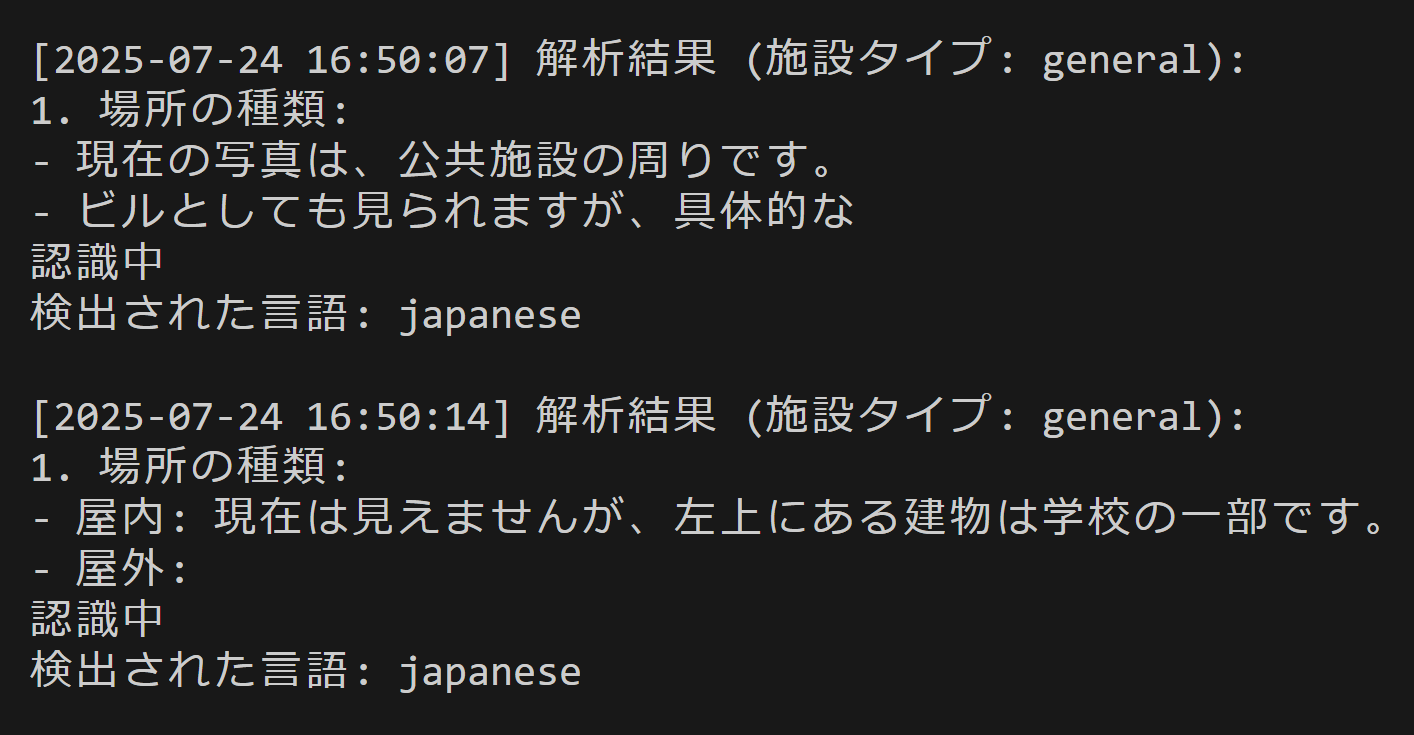
- LLaVa による画像理解(静止画用)(ソースコードと実行結果)

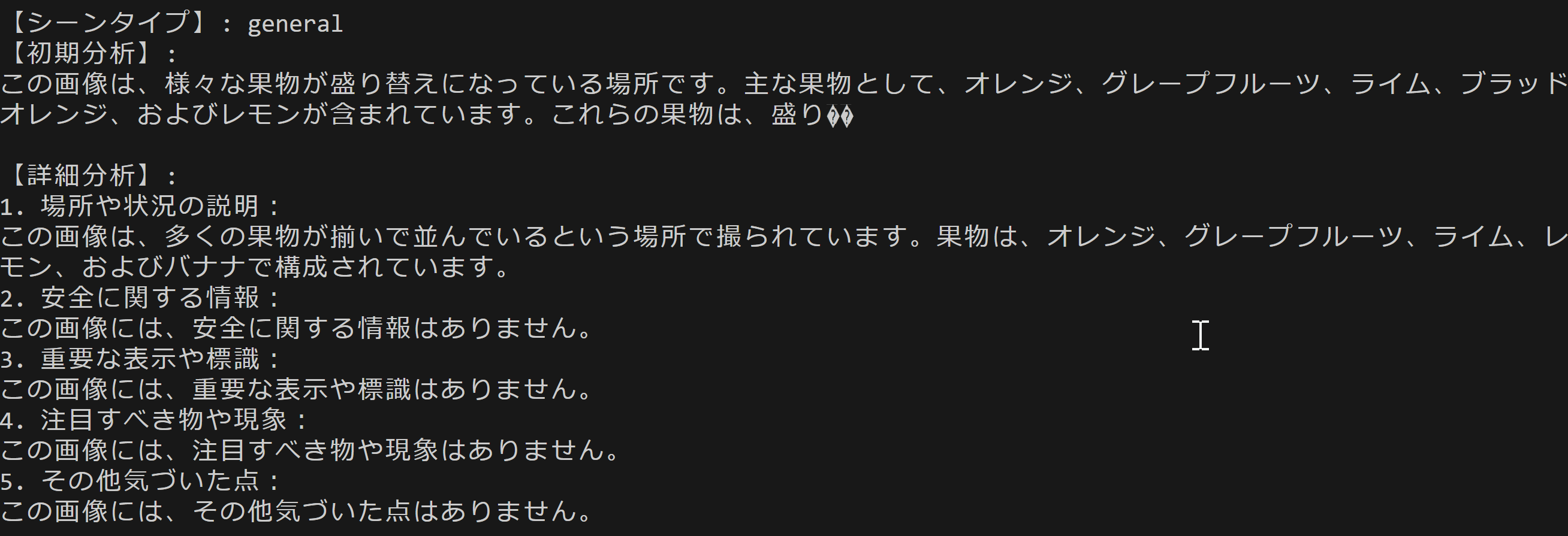
マルチモーダル基盤モデル:画像とテキストの類似性,画像キャプション生成
- SigLIP2による画像とテキストの類似性判定
SigLIP2(Vision Transformerベース)を用いて事前学習なしの単語等による画像分類を行うゼロショット学習。SigLIP2の4種類のモデル(base-patch16-224からso400m-patch14-384)の性能比較ができるPythonプログラム、画像とテキストの埋め込み空間や類似度計算などの解説付き。

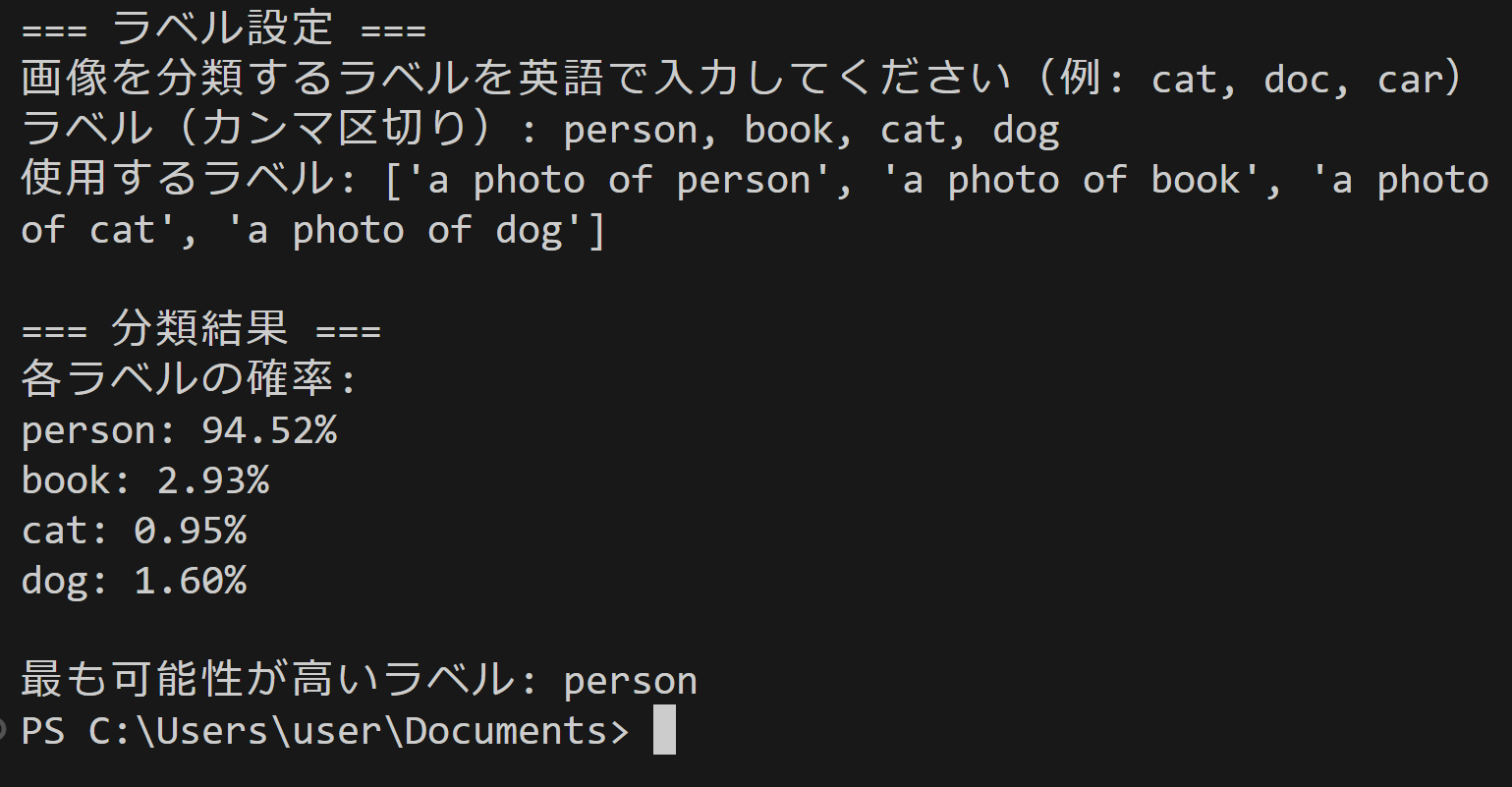
- CLIPによる画像とテキストの類似性算出(ソースコードと実行結果)

- YOLOE によるオープンボキャブラリ物体検出・追跡

文字認識・音声認識
- DeepSeek-OCR によるPDF・画像OCR(ソースコードと説明と利用ガイド)

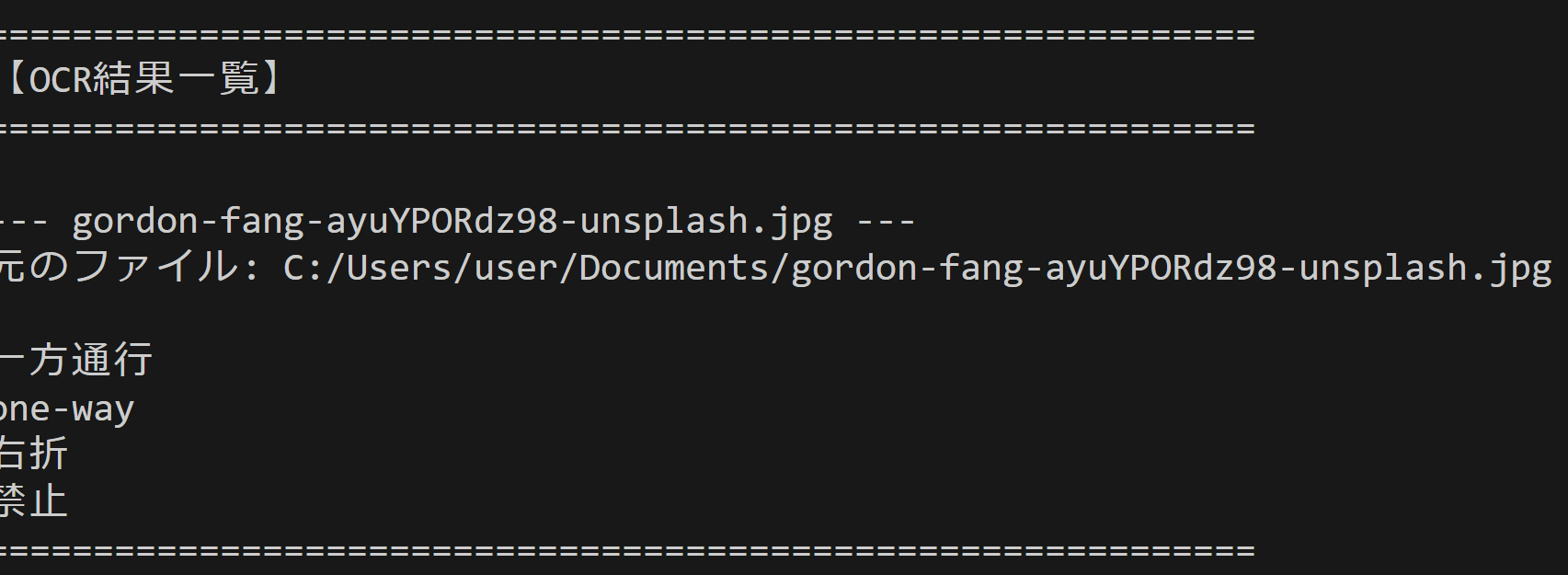
- YomiTokuによる印刷・手書き文字認識
【概要】Yomitokuを用いた文字認識を行う。7000文字超の日本語文字認識と縦書き・手書き文字に対応する。

- EasyOCR によるシーンテキスト検出・認識(英語・日本語対応)(ソースコードと実行結果)

- Tesseract OCR 日本語・英語文字認識(ソースコードと実行結果)

- OpenALPR による英語ナンバープレート認識(ソースコードと実行結果)
 rew
rew 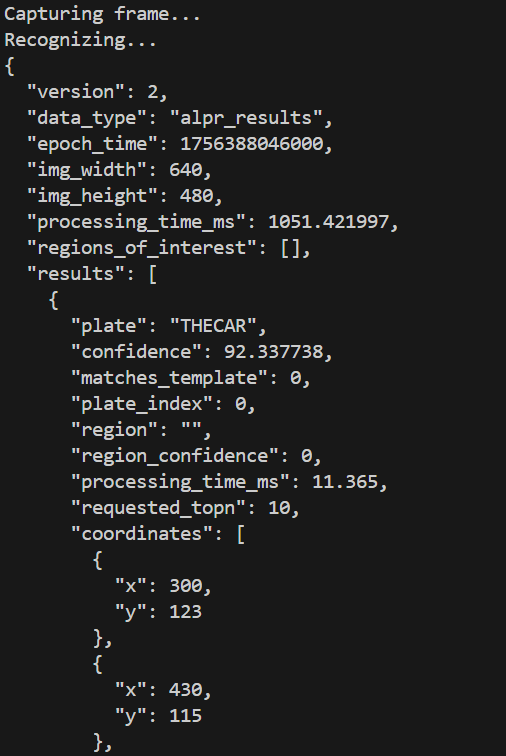
- OpenAI Whisperによる日本語の音声・動画ファイルやマイクの文字起こしツール(ソースコードと実行結果)
- OpenAI Whisperによる日本語の音声・動画ファイル文字起こし・pyannoteによる話者特定(ソースコードと実行結果)
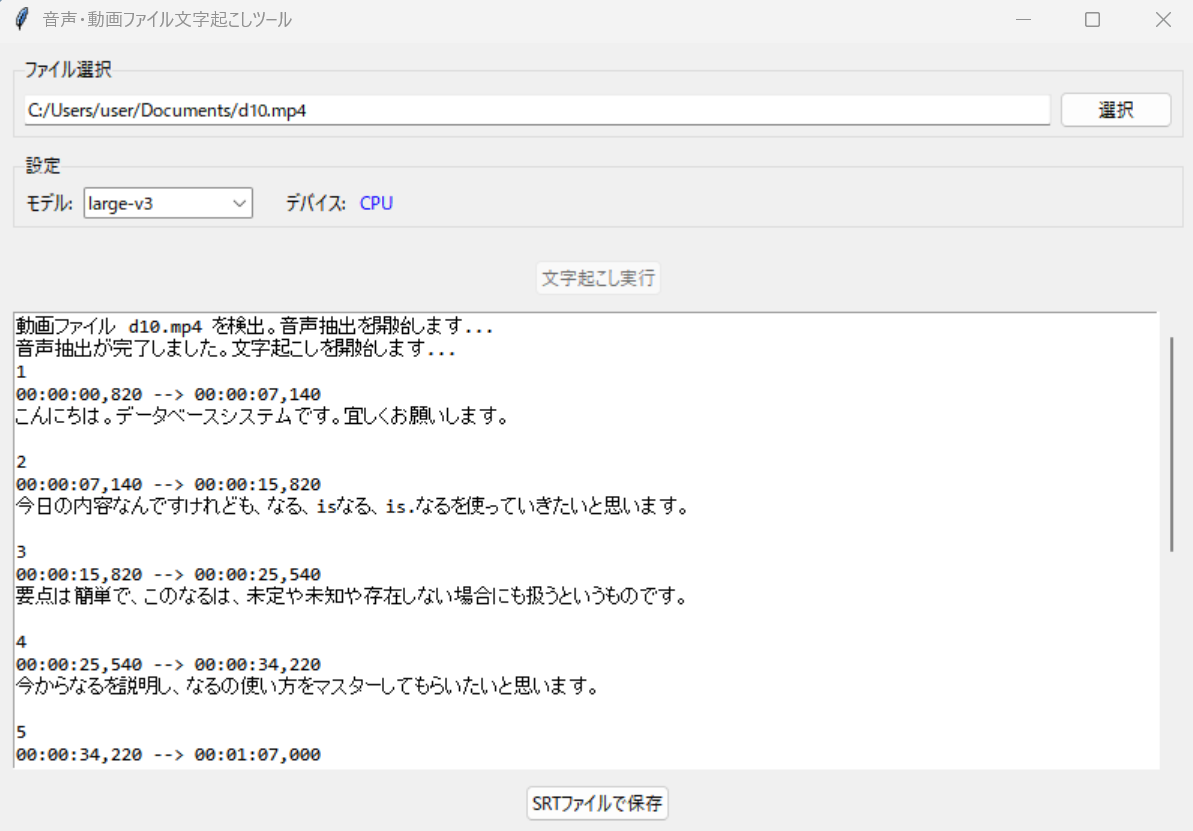
- OpenAI Whisperによる日本語の音声・動画ファイル文字起こし(ソースコードと実行結果)
現在,声の大きさやトーンを解析し議論が白熱した「熱量の高い部分」の発言を自動で赤字強調表示する機能はなくしています(調整中)。
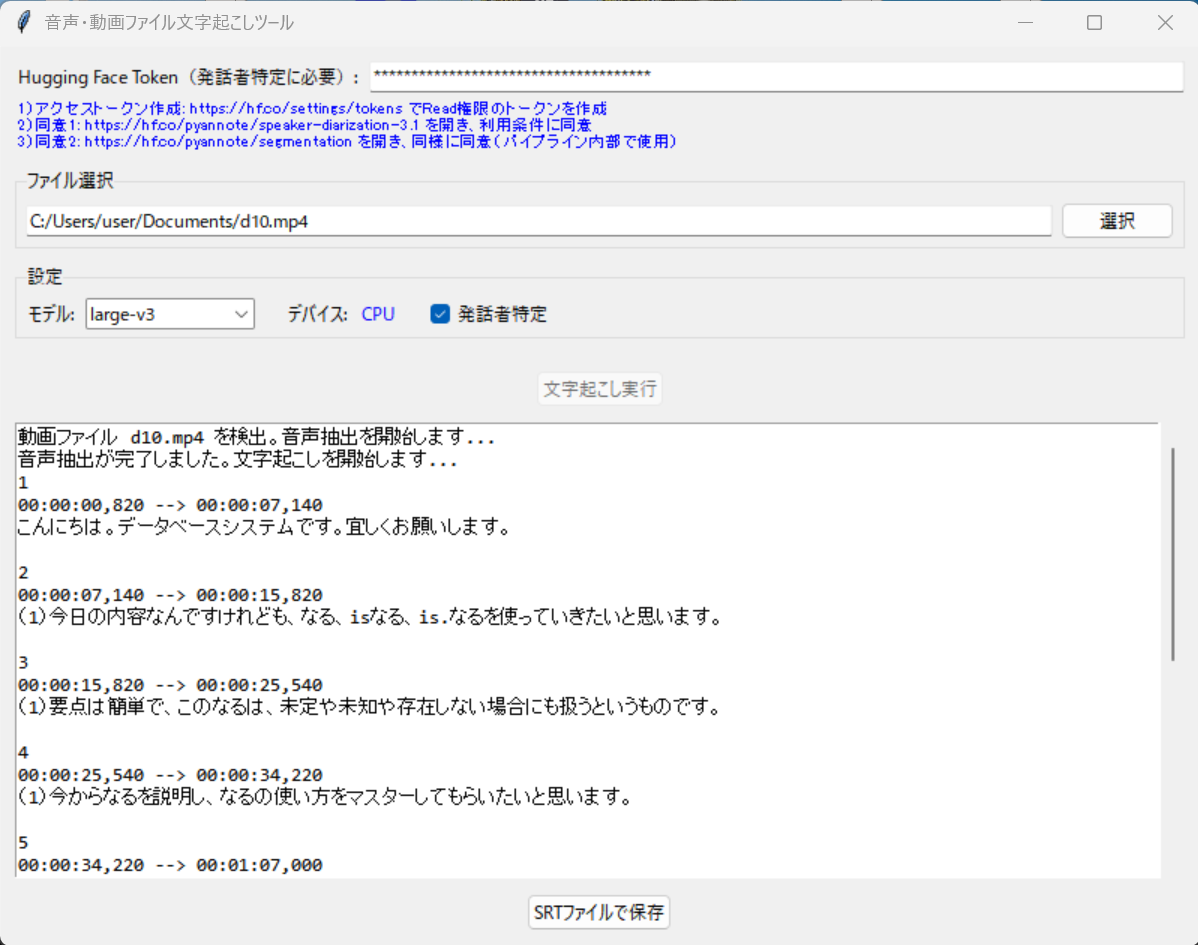
【概要】OpenAI Whisperを使用して日本語の音声・動画ファイルをテキスト(字幕)に変換する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
自然言語処理
- EmbeddingGemma による文書の意味的検索(ソースコードと実行結果)
- LUKEによる日本語感情分析プログラム(ソースコードと実行結果)

日本国憲法の分析結果 - SucachiPy による形態素解析
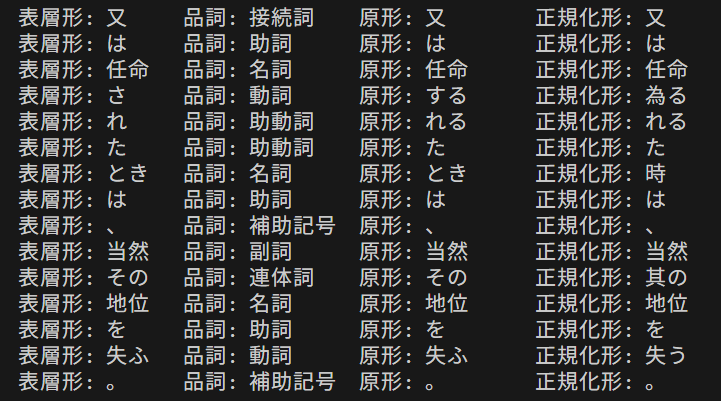
【概要】 日本語形態素解析ツール「SudachiPy」の体験を通じ、その技術と応用を学ぶ。SudachiPyは、多様な辞書と分割モードにより、日本語テキスト分析を実現する。プログラム実行で単語分割や品詞情報を確認でき、日本語処理の仕組みを理解できる。
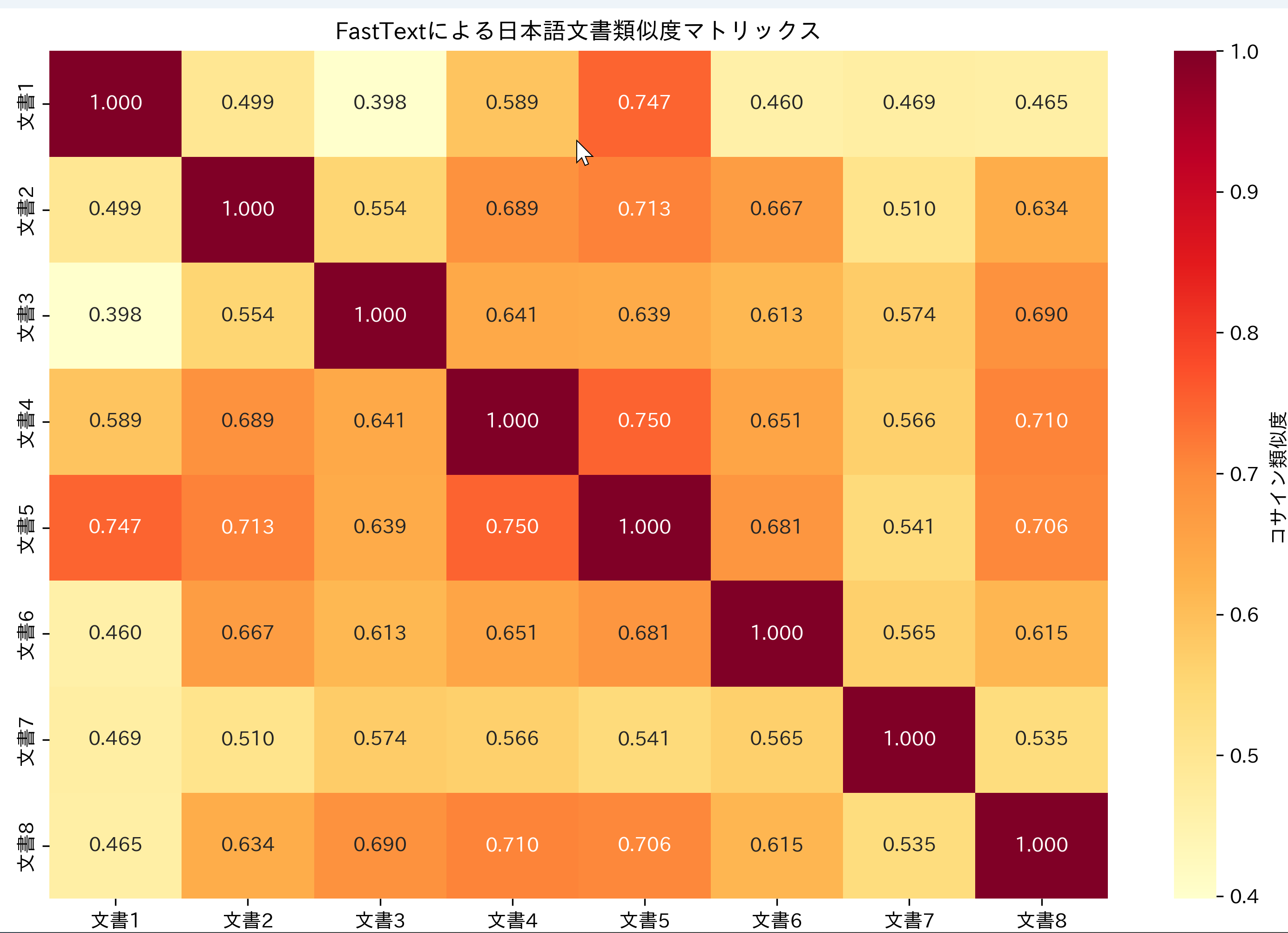
日本国憲法の分析結果 - FastTextによる日本語文章類似度計算
【概要】 FastTextは単語を数値ベクトルに変換する単語埋め込み技術で、部分文字列情報により未知語にも対応できる。本教材では、日本語文書を形態素解析で単語分割し、各単語のベクトルを平均して文書ベクトルを生成、コサイン類似度で文書間の意味的類似性を計算する。実行結果はヒートマップで可視化され、AIによる文書理解の仕組みを体験できる。
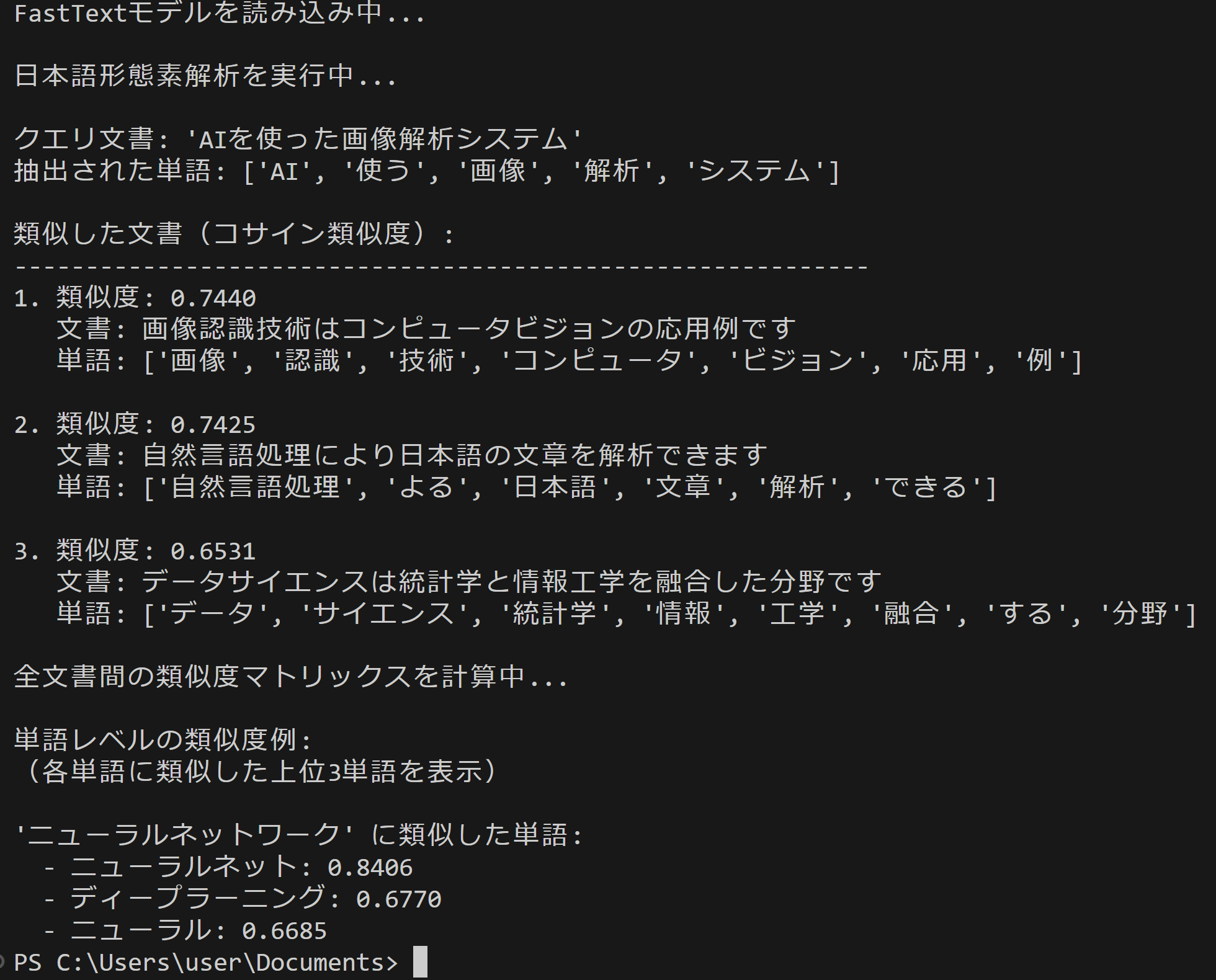
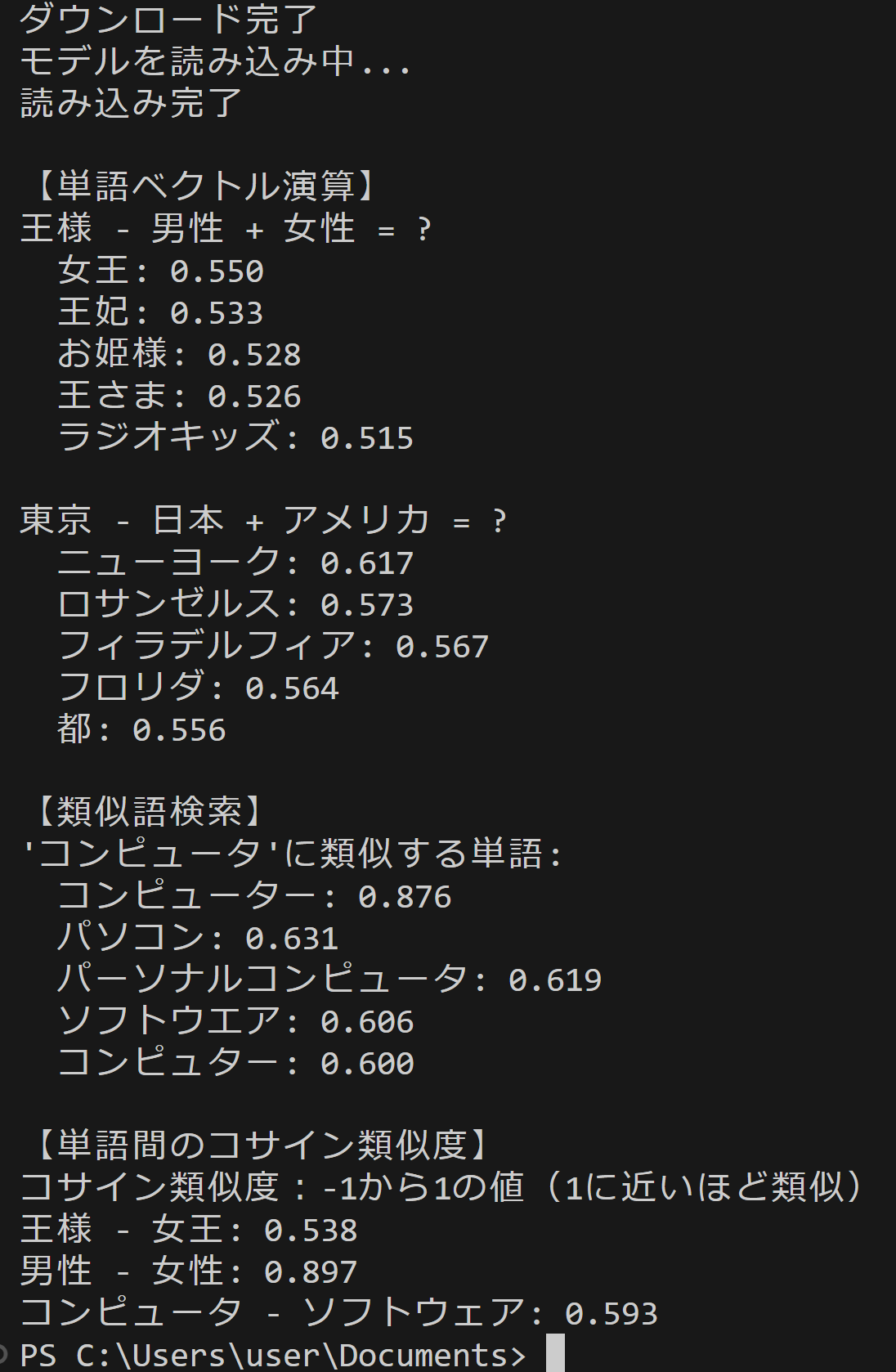
- FastText日本語単語ベクトル演算
【概要】FastText技術を確認する。FastTextは、Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146.で提案された単語埋め込み手法である。この技術は単語を文字n-gramに分解して学習することで、学習データに含まれていない未知語に対しても、その文字構成からベクトル表現を生成。機械翻訳、感情分析、文書分類などの自然言語処理で活用される。ここでは、日本語単語ベクトルの演算を実行し、「王様-男性+女性=女王」のような意味的関係を確認する。
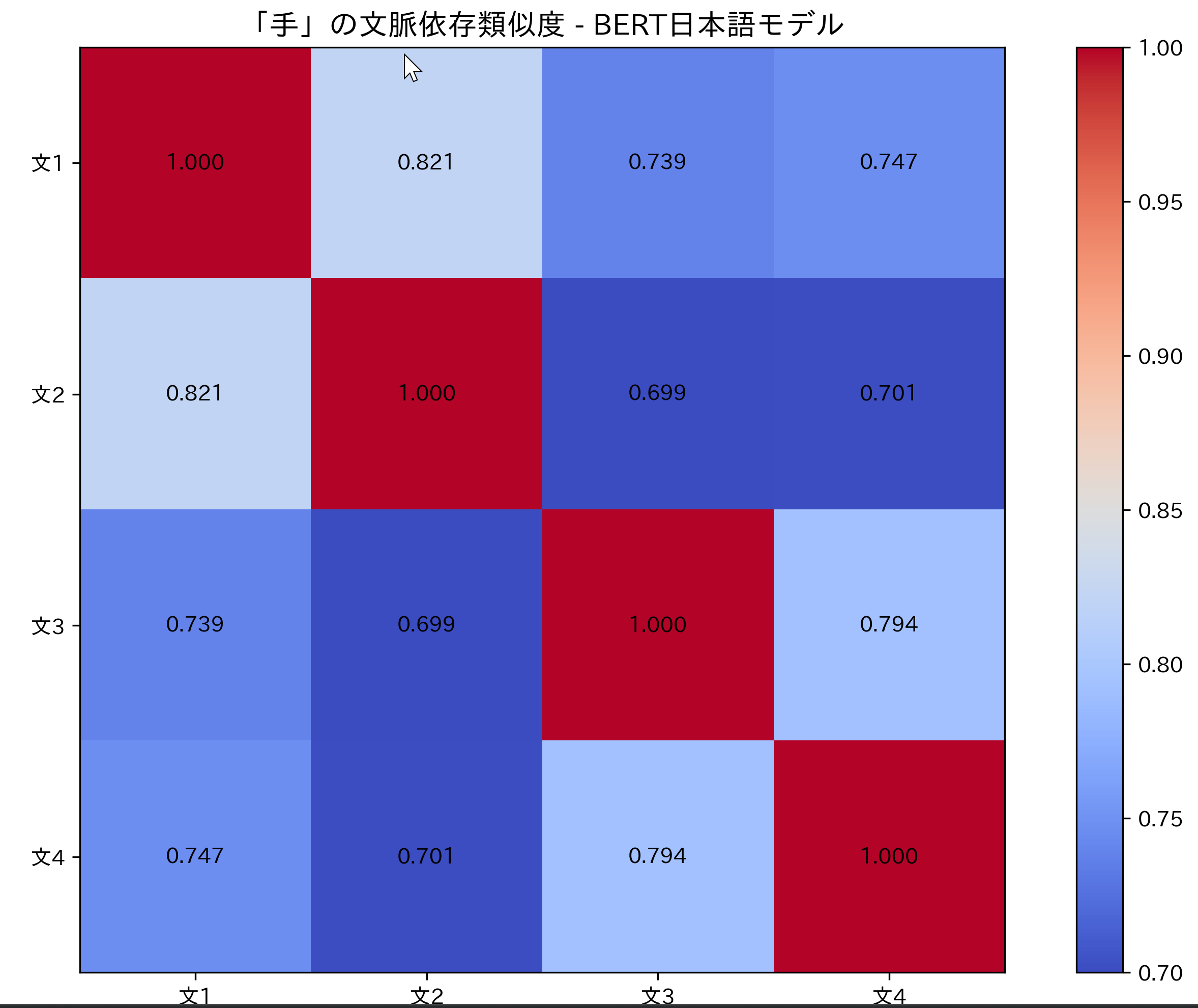
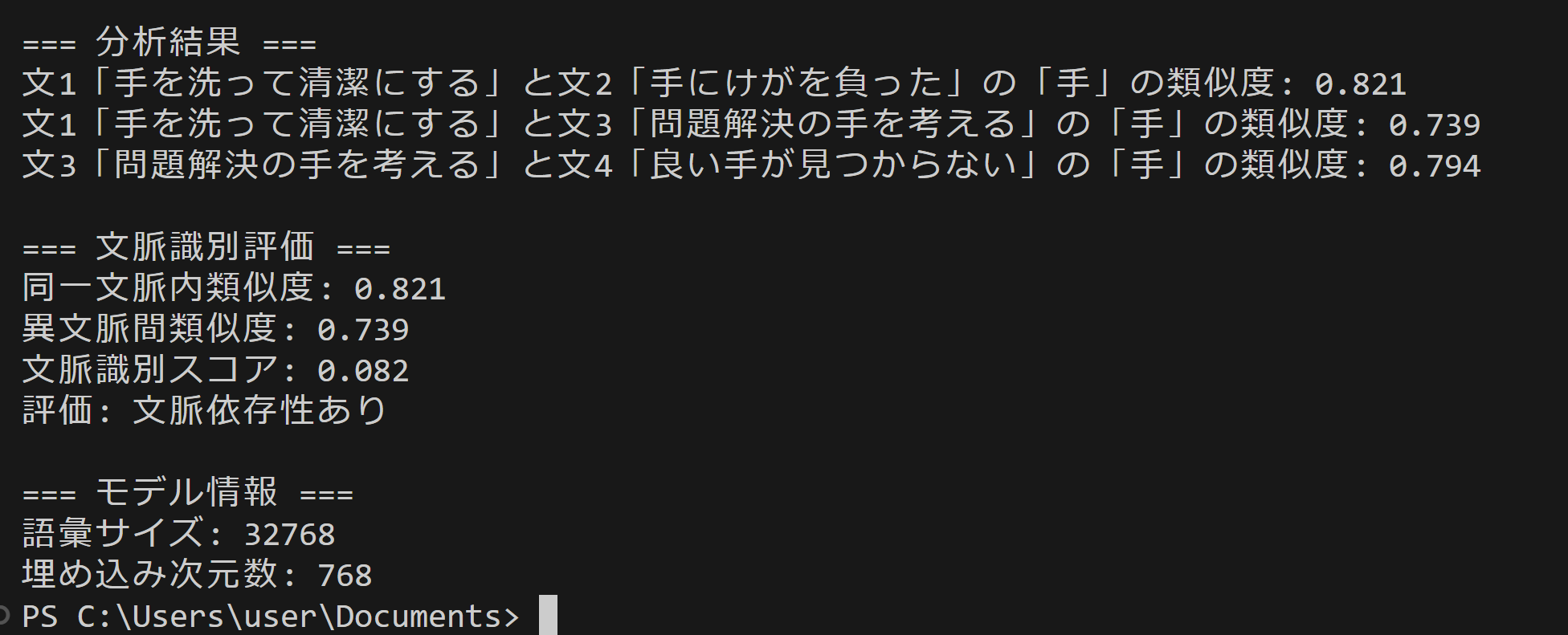
- 日本語BERT文脈埋め込み分析
【概要】 BERTは文脈を考慮した単語埋め込み技術で、同一単語でも文脈により異なるベクトル表現を生成する。日本語BERT(tohoku-nlp/bert-base-japanese-v3)を用いて「手」の多義性を分析。身体部位としての「手」と方法・手段としての「手」のベクトル類似度を計算し、文脈による意味の違いを数値化。コサイン類似度とヒートマップで可視化し、BERTの文脈理解能力を実験的に確認する。
- 多言語対応文埋め込み技術を用いた意味的類似性による単語クラスタリング(ソースコードと実行結果)
【概要】 単語抽出 → 埋め込み → K-means → クラスタ表示を行う.Sentence Transformers/E5の利用により,文脈を考慮した意味理解(多義語対応: 文脈により異なる意味を区別可能)が可能.日英混在テキストでも統一的に処理可能.このプログラムでは,他のモデルとも比較できるようにしている 多義語対応: 文脈により異なる意味を区別可能)が可能.日英混在テキストでも統一的に処理可能.このプログラムでは,他のモデルとも比較できるようにしている.

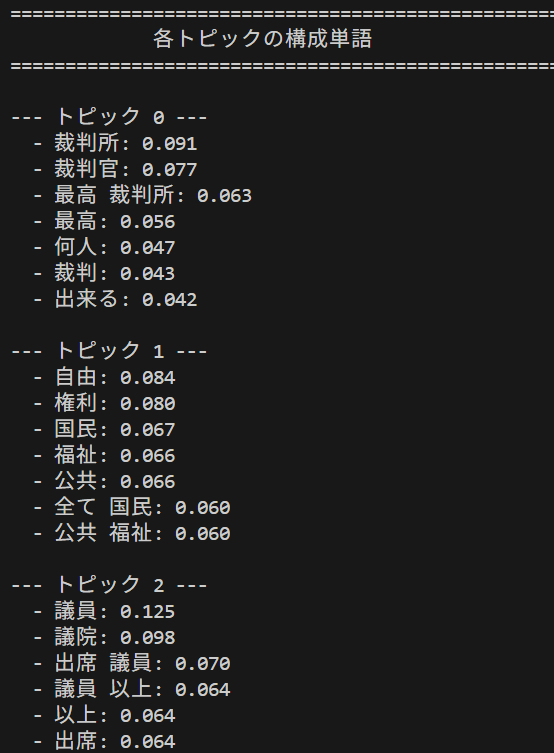
- BERTopic による日本語トピックモデリング
【概要】 BERTopicは、Transformer埋め込みとc-TF-IDFを組み合わせた日本語対応トピックモデリング手法である。従来のLDAより意味的に一貫したトピック抽出を実現し、カスタマーフィードバック分析や学術論文の研究動向分析に活用できる。
日本国憲法の分析結果 - ModernBERT による話者帰属句検出(ソースコードと実行結果)

画像処理,動画像処理
- OpenCV ガウシアンフィルタによるぼかし(入力:静止画)(ソースコードと説明と利用ガイド)
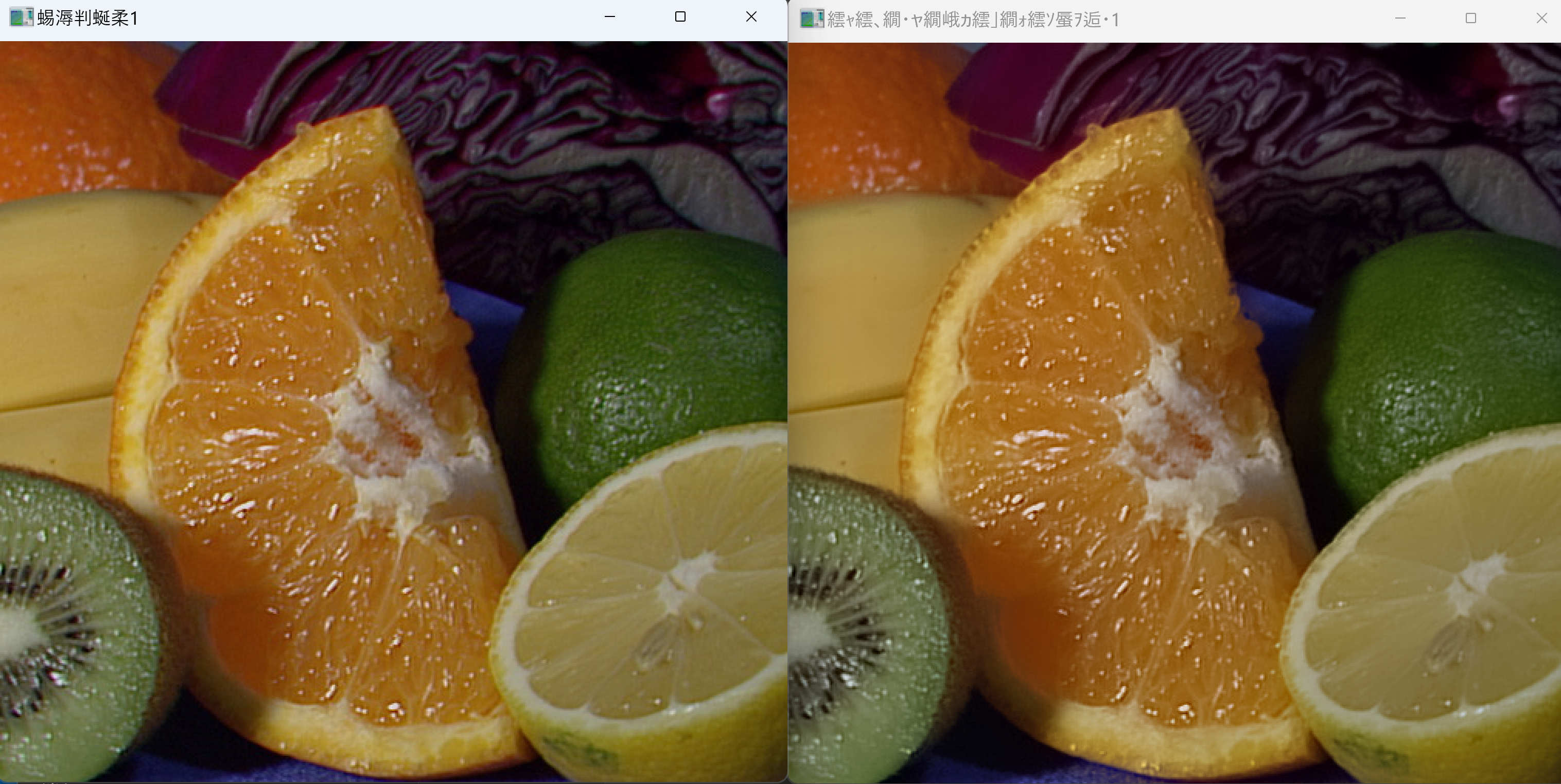
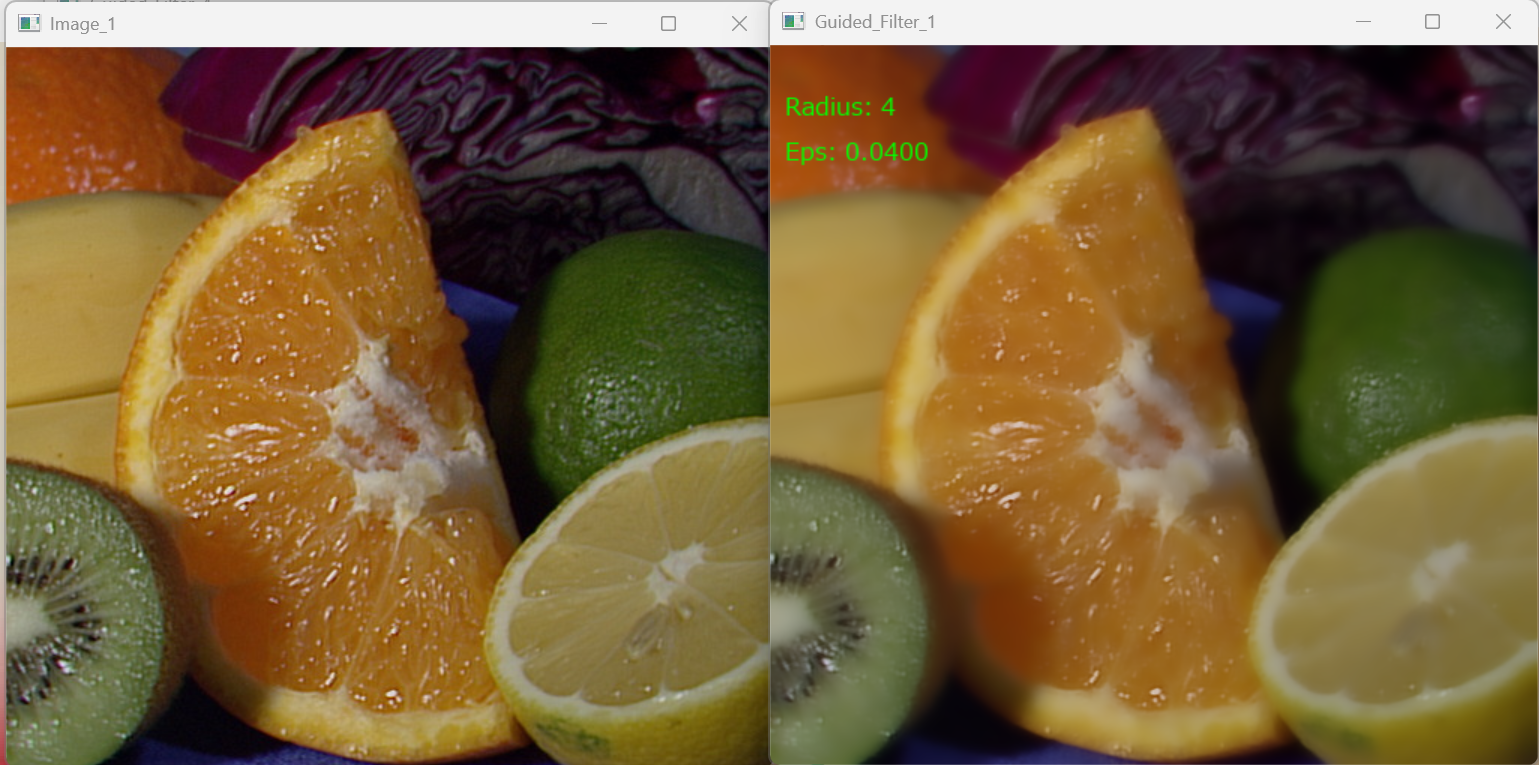
- SVDベースガイデッドフィルタ画像処理(入力:静止画)(ソースコードと説明と利用ガイド)

- ガイデッドフィルタ画像処理(入力:静止画)(ソースコードと説明と利用ガイド)
- vidstabによる動画手ぶれ補正

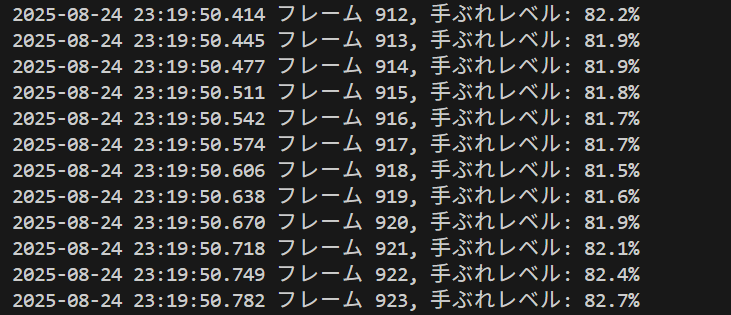
- ORB特徴点検出カメラキャプチャプログラム
Webカメラから映像を取得し、ORB特徴点検出により画像間の重なり面積を計算、設定した閾値(80%)以下になった時点で新しい視点のフレームとして保存するカメラキャプチャプログラム
コンピュータビジョン:画像分類,画像タギング(入力:動画像)
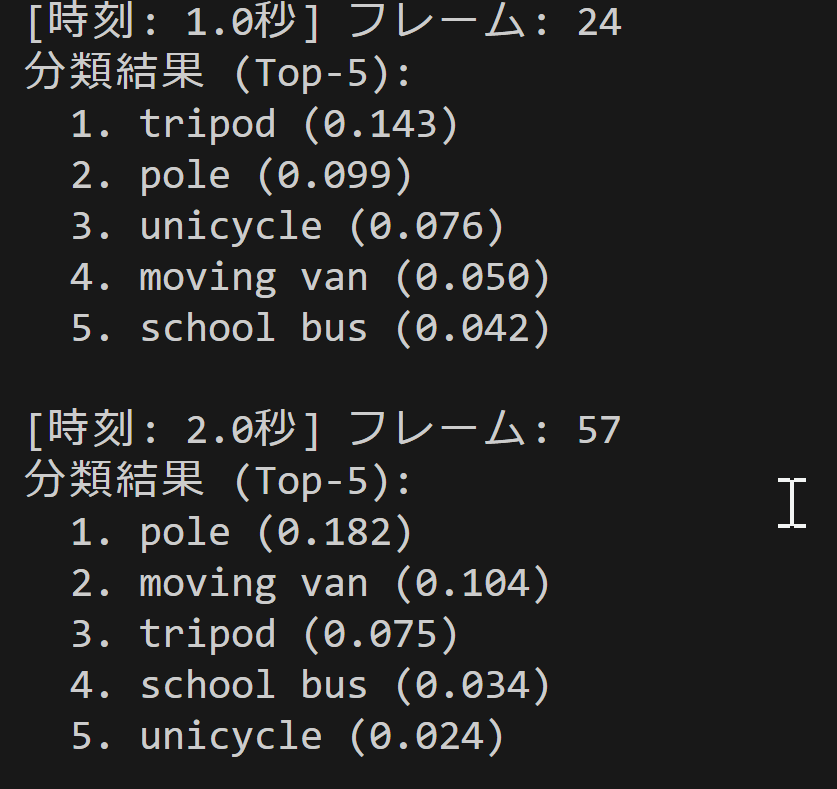
- ConvNeXt V2による画像分類(入力:動画像)(ImageNet 1000クラス)(ソースコードと説明と利用ガイド)
【概要】 ConvNeXt V2による動画のリアルタイム画像分類プログラム。ImageNet 1000クラスで分類し、Top-5結果を確信度別に色分け表示する。動画ファイル、カメラ、サンプル動画に対応。Tiny~Largeの4モデルから選択可能。分類結果を自動保存。

- EfficientNetV2による画像分類(入力:動画像)(ImageNet 1000クラス)(ソースコードと説明と利用ガイド)
【概要】EfficientNetV2-Sを用いたリアルタイム画像分類システム。ImageNet 1000クラスに対応し、動画ファイル・ウェブカメラ・サンプル動画から物体を認識する。Progressive Learning技術により学習。上位5位の分類結果表示、処理結果の自動保存機能を搭載。

- MambaOut による画像分類(入力:動画像)(ImageNet 1000クラス)(ソースコードと説明と利用ガイド)
【概要】 MambaOutモデルを用いた動画像からの物体分類システム。ImageNet 1000クラスの分類をリアルタイム実行し、4種類のモデル(Tiny/Small/Base/Kobe)から選択可能。動画ファイル、ウェブカメラ、サンプル動画の3つの入力に対応し、Top-5分類結果を確信度に応じて色分け表示する。MambaOutはSSM(状態空間モデル)を除去しGated CNNブロックのみで構成される階層的アーキテクチャ。分類結果は画面表示とファイル保存が可能
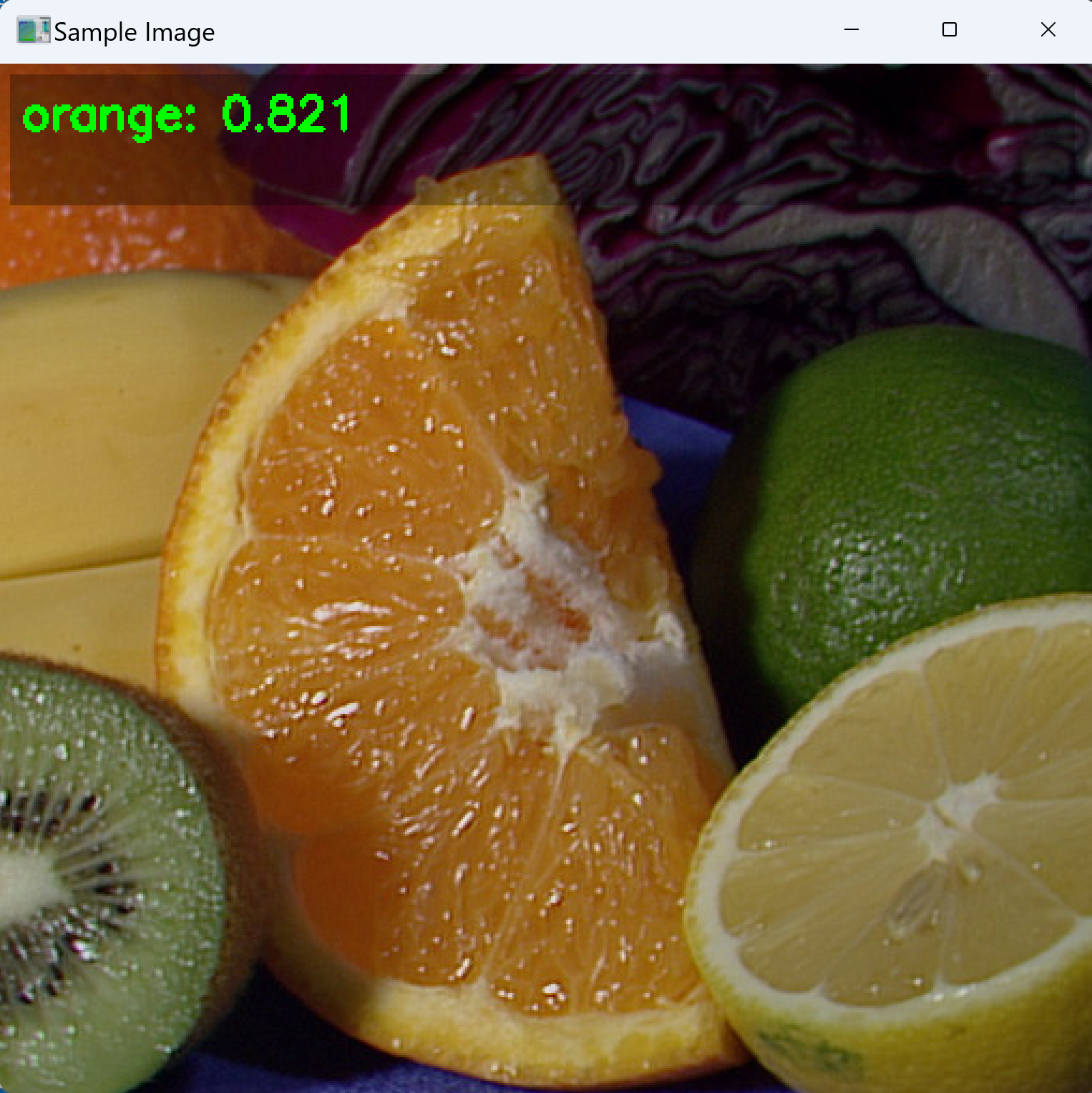
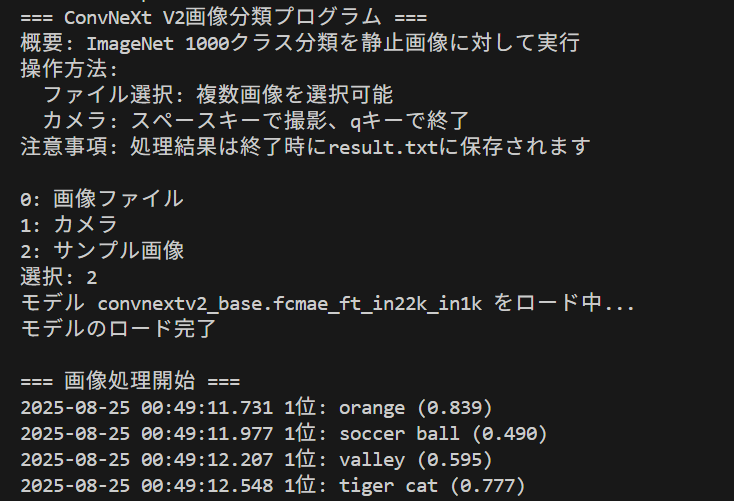
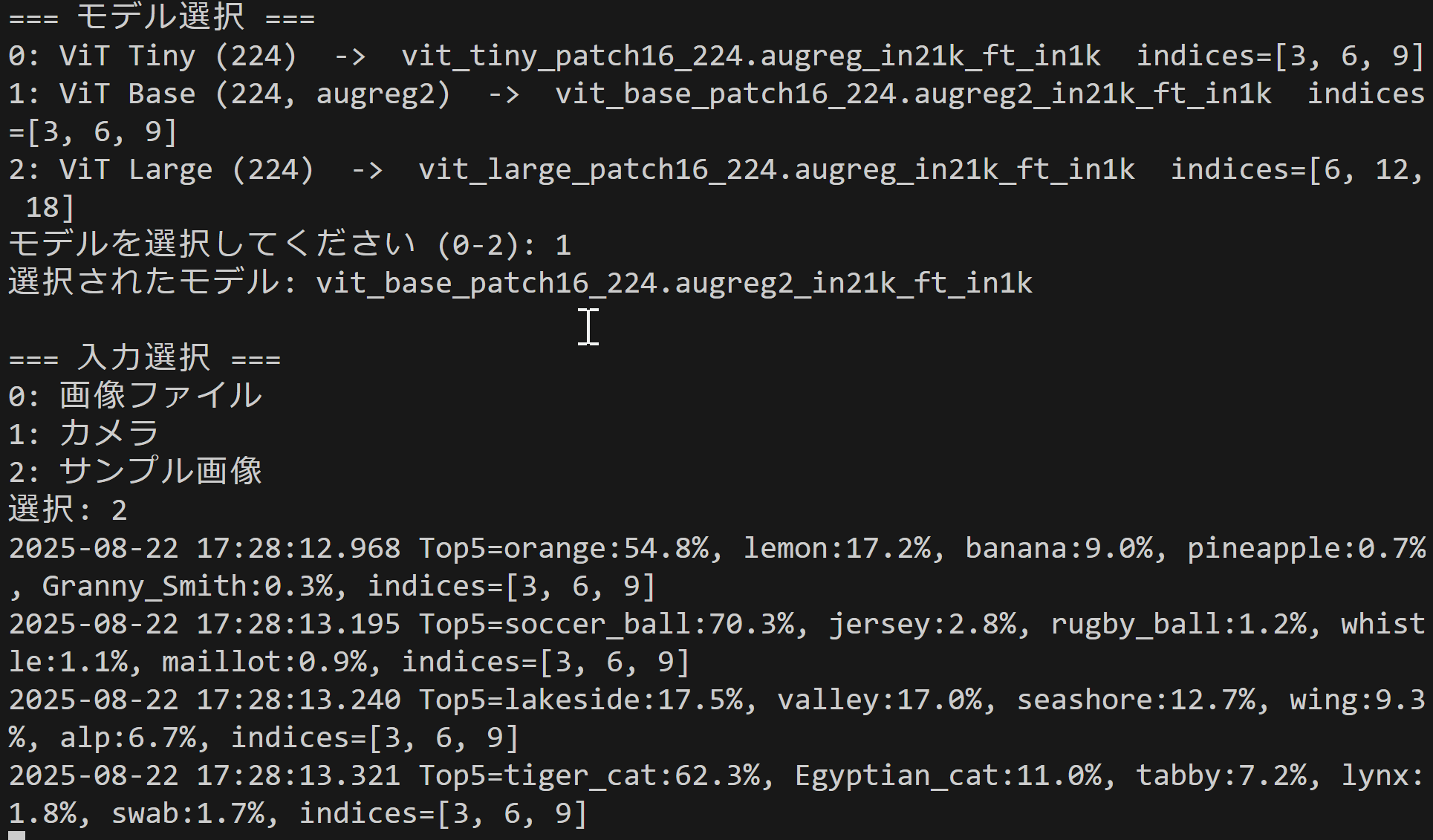
コンピュータビジョン:画像分類,画像タギング(入力:静止画像)


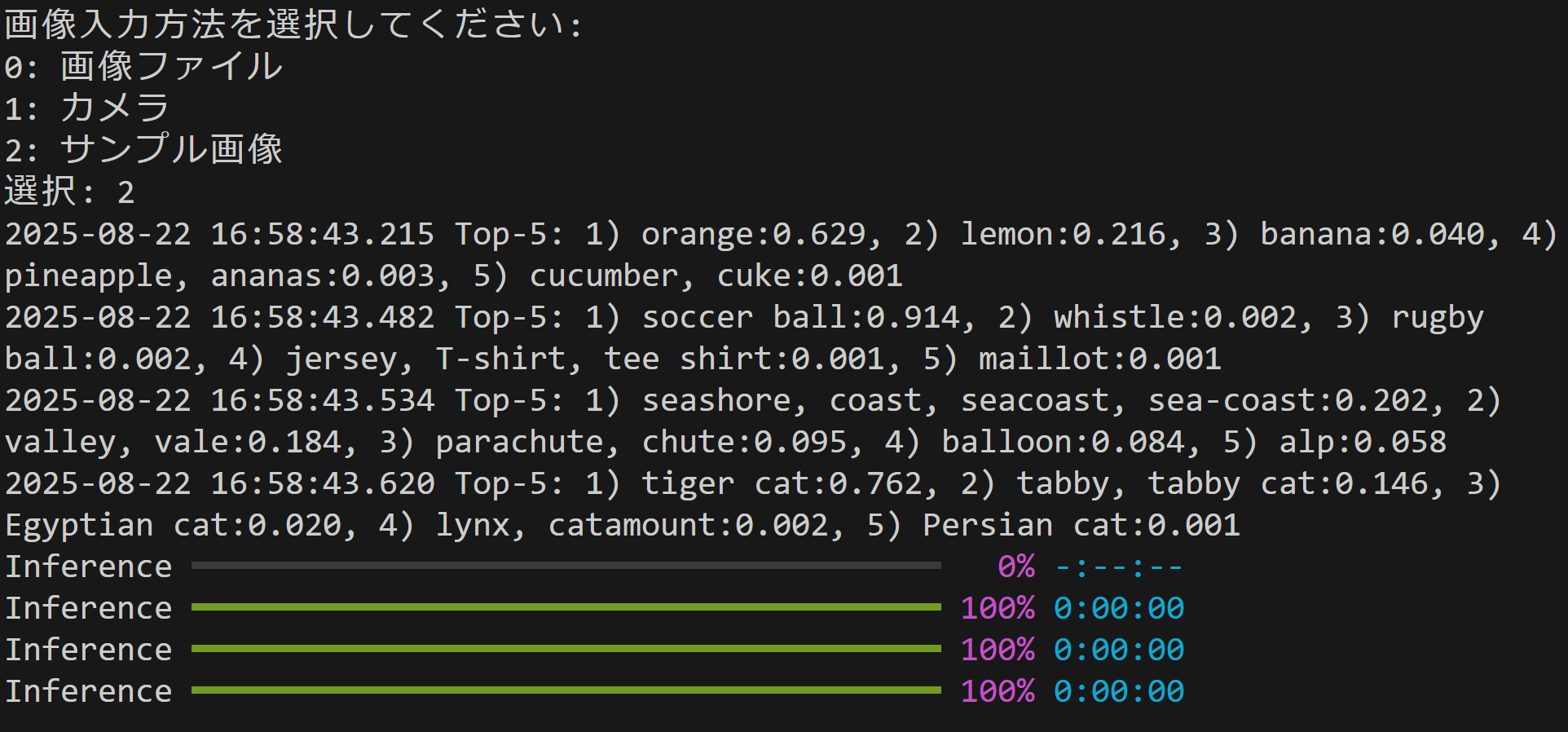
コンピュータビジョン:物体検出(ByteTrackによる追跡とTTAの機能付き)
- RT-DETRv2による物体検出・ByteTrackによる追跡とTTAの機能付き(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】 RT-DETRv2を用いた物体検出システムで、動画やウェブカメラからCOCO 80クラスの物体をリアルタイムで検出する。CLAHE前処理とTTAにより暗所でも高精度な検出が可能。ByteTrackによる物体追跡機能を搭載し、フレーム間での継続的な追跡を実現。3種類のバックボーン選択、日本語表示対応、検出結果の自動保存機能を備える。

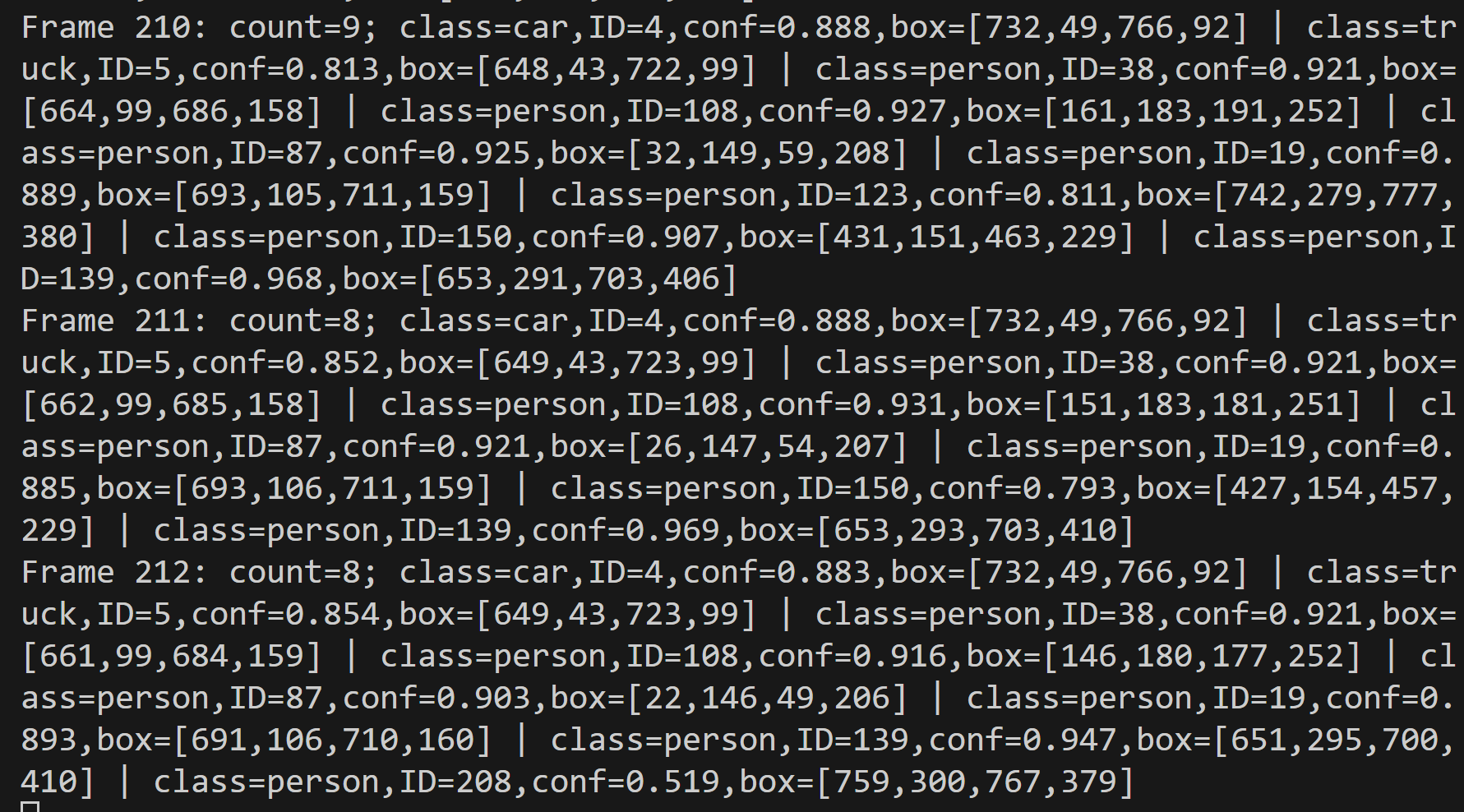
- MediaPipeによる物体検出・ByteTrackによる追跡とTTAの機能付き(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】 MediaPipeを用いた物体検出システムで、動画やウェブカメラからCOCO 80クラスの物体をリアルタイムで検出する。CLAHE前処理とTTAにより暗所でも高精度な検出が可能。ByteTrackによる物体追跡機能を搭載し、フレーム間での継続的な追跡を実現。3種類のバックボーン選択、日本語表示対応、検出結果の自動保存機能を備える。

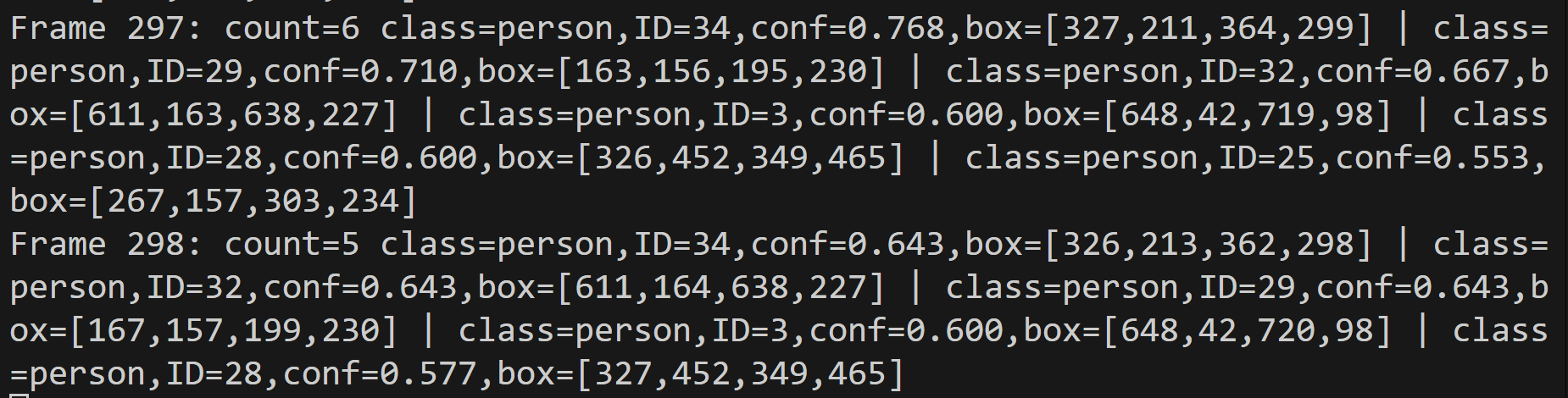
- YOLOv10による物体検出・ByteTrackによる追跡とTTAの機能付き(COCO 80クラス)(ソースコードと説明と利用ガイド)

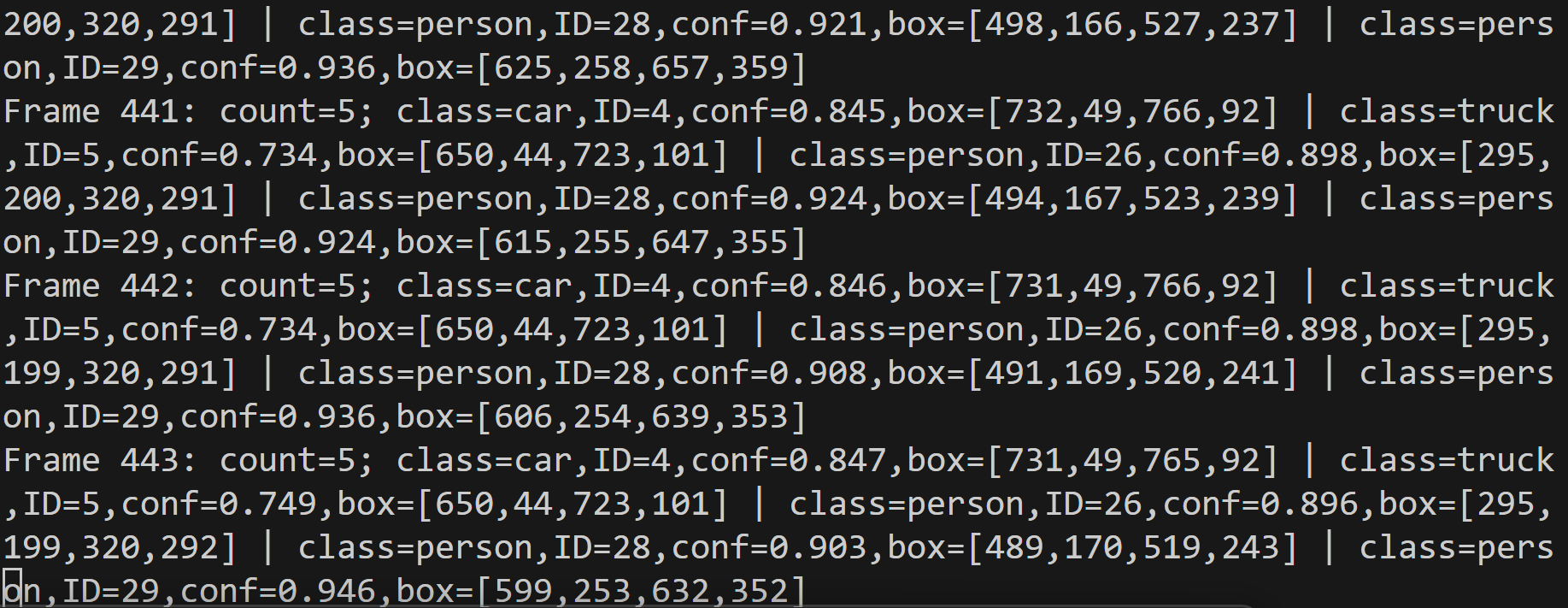
- YOLO11による物体検出・ByteTrackによる追跡とTTAの機能付き(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】YOLO11による物体検出システム。動画やウェブカメラから人・車・動物など80クラスの物体をリアルタイム検出する。CLAHE前処理で暗所でも安定動作し、TTAとByteTrackで精度と追跡性能を向上。5種類のモデルサイズから選択可能。日本語表示対応、検出結果の自動保存機能を備える。

- YOLOv12による物体検出・ByteTrackによる追跡とTTAの機能付き(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】YOLOv12による物体検出システム。動画やウェブカメラから人・車・動物など80クラスの物体をリアルタイム検出する。CLAHE前処理で暗所でも安定動作し、TTAとByteTrackで精度と追跡性能を向上。5種類のモデルサイズから選択可能。日本語表示対応、検出結果の自動保存機能を備える。

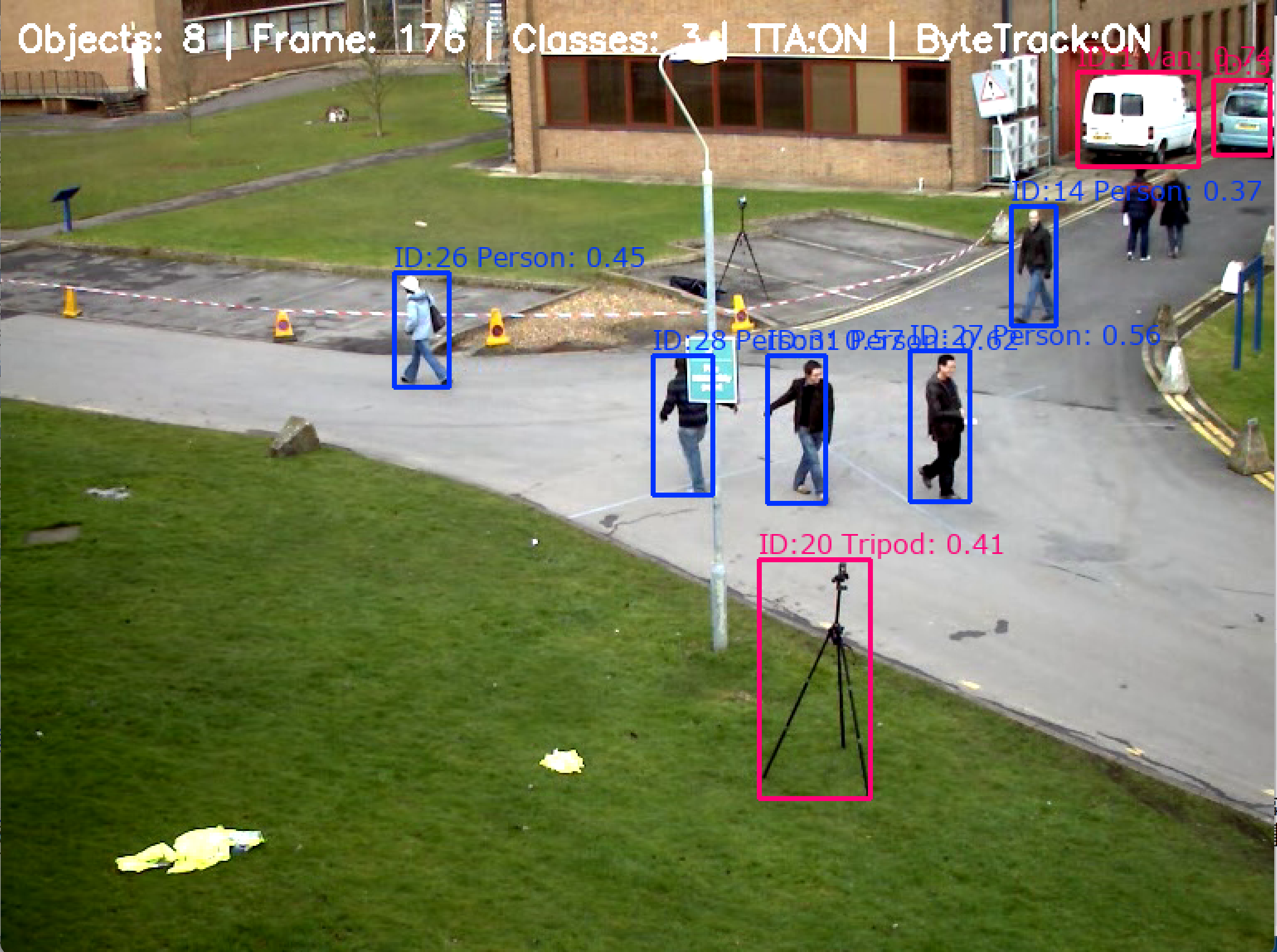
- YOLOv8による物体検出(Open Images V7)(ソースコードと説明と利用ガイド)
【概要】YOLOv8とOpen Images V7データセットを用いたリアルタイム物体検出プログラム。600クラスの物体を識別可能で、動画ファイルやカメラ映像から物体を検出・追跡する。CLAHE前処理により低照度環境での視認性を向上させ、ByteTrackアルゴリズムでオクルージョン発生時も追跡を継続。TTA実装により検出精度を向上。5種類のモデルサイズ(n,s,m,l,x)から選択可能。検出結果の自動保存機能を備える。
コンピュータビジョン:物体検出
- RT-DETRv2による物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】RT-DETRv2は、Transformerベースのリアルタイム物体検出技術で、動画やカメラ映像からCOCO 80クラスの物体を自動検出。CLAHE画像処理により検出精度を向上させ、ResNet-50D、ResNet-101D、HGNetv2-Lの3つのモデルから選択可能。日本語表示対応、検出結果の自動保存機能を備える。


- MMDetection と RTMDet による物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】MMDetectionとRTMDetを用いた物体検出プログラム。動画ファイル、ウェブカメラ、サンプル動画から人や車など80種類の物体をリアルタイムで検出。5段階のモデルサイズ選択が可能。検出結果の自動保存機能を備える。

- MMDetection と Co-DINO(Swin-L) による物体検出プログラム(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】MMDetectionとCo-DINO(Swin-L)を用いた物体検出プログラムである。動画ファイル、ウェブカメラ、サンプル動画の3つの入力に対応し、COCO 80クラスの物体をリアルタイムで検出する。Transformerアーキテクチャによるエンドツーエンド検出を実現し、CLAHE前処理により画像品質を向上させる。検出結果の自動保存機能を備える。

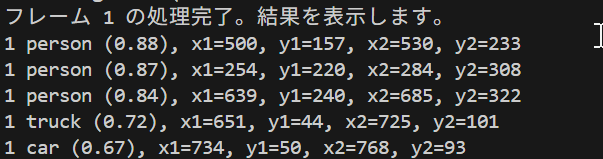
- MediaPipeとEfficientDet-Liteによる物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】MediaPipeとEfficientDet-Liteを用いた物体検出システムである。動画やウェブカメラからCOCO 80クラス(人、車、動物等)の物体をリアルタイムで検出し、バウンディングボックスで表示する。3種類のモデル(EfficientDet-Lite0/2、SSD MobileNetV2)から用途に応じて選択可能である。CLAHE技術により暗所での検出精度を向上。日本語表示対応、検出結果の自動保存機能を備える。

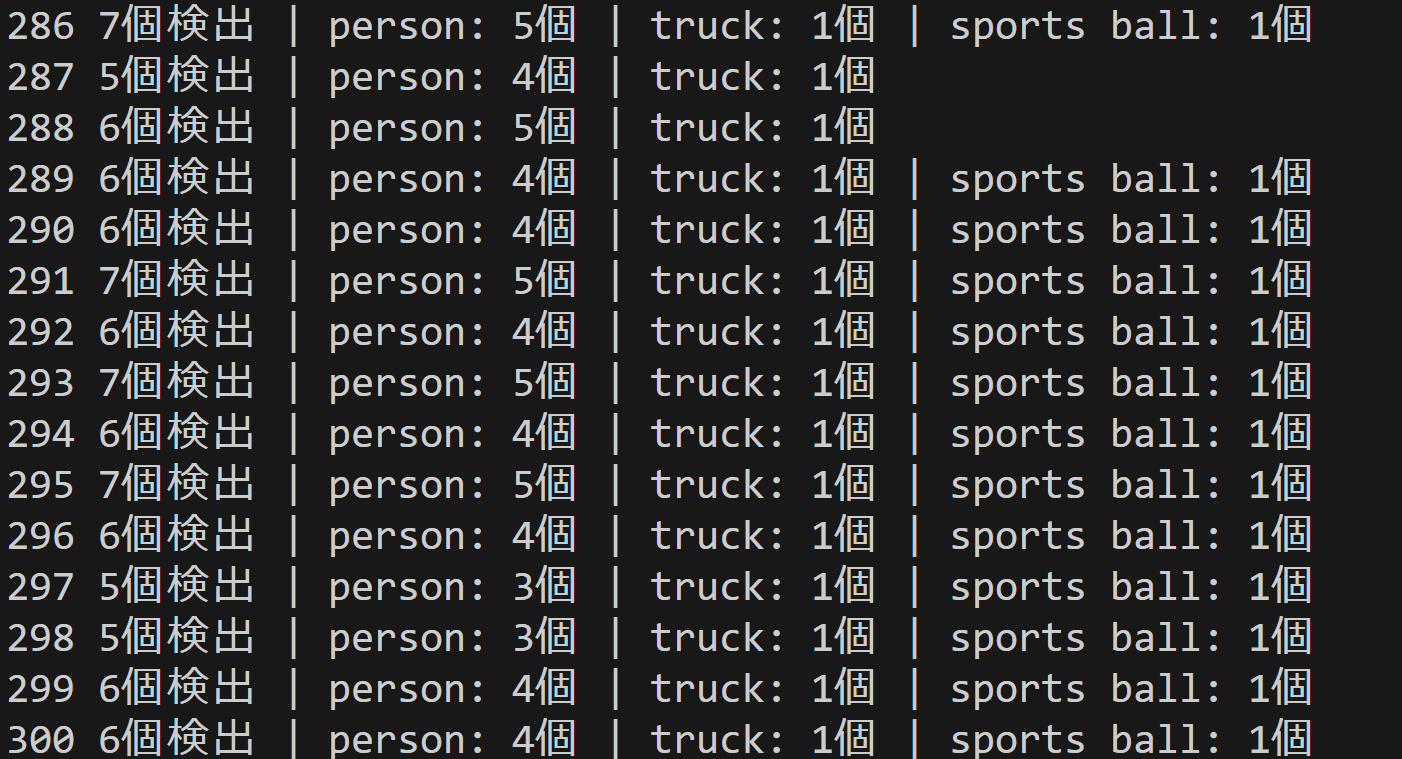
- YOLOv10による物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】YOLOv10は、物体検出アルゴリズムである。従来のYOLOシリーズが使用していたNon-Maximum Suppressionを不要とし、エンドツーエンド設計により後処理なしで物体検出を実現する。本プログラムは、動画やウェブカメラ映像から人、車、動物、家具などCOCO 80クラスの物体をリアルタイムで検出し、矩形とラベルで可視化する。CLAHE前処理によるコントラスト強化、6種類のモデルサイズ選択。日本語表示対応、検出結果の自動保存機能を備える。

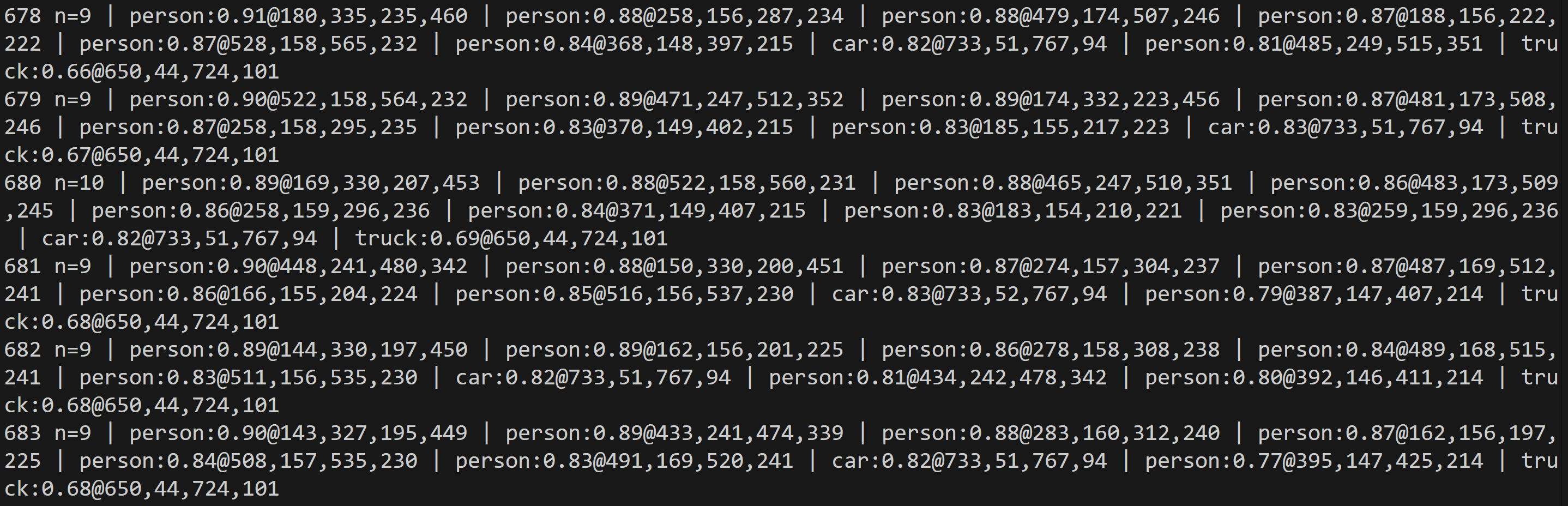
- YOLO11による物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】YOLO11を用いた物体検出プログラムは、動画やウェブカメラから人や車などCOCO80クラスの物体をリアルタイムで検出する。CLAHE前処理により暗所や逆光環境での検出精度が向上する。動画ファイル、ウェブカメラ、サンプル動画の3種類の入力ソースに対応。5種類のモデルから選択可能。日本語表示対応、検出結果の自動保存機能を備える。
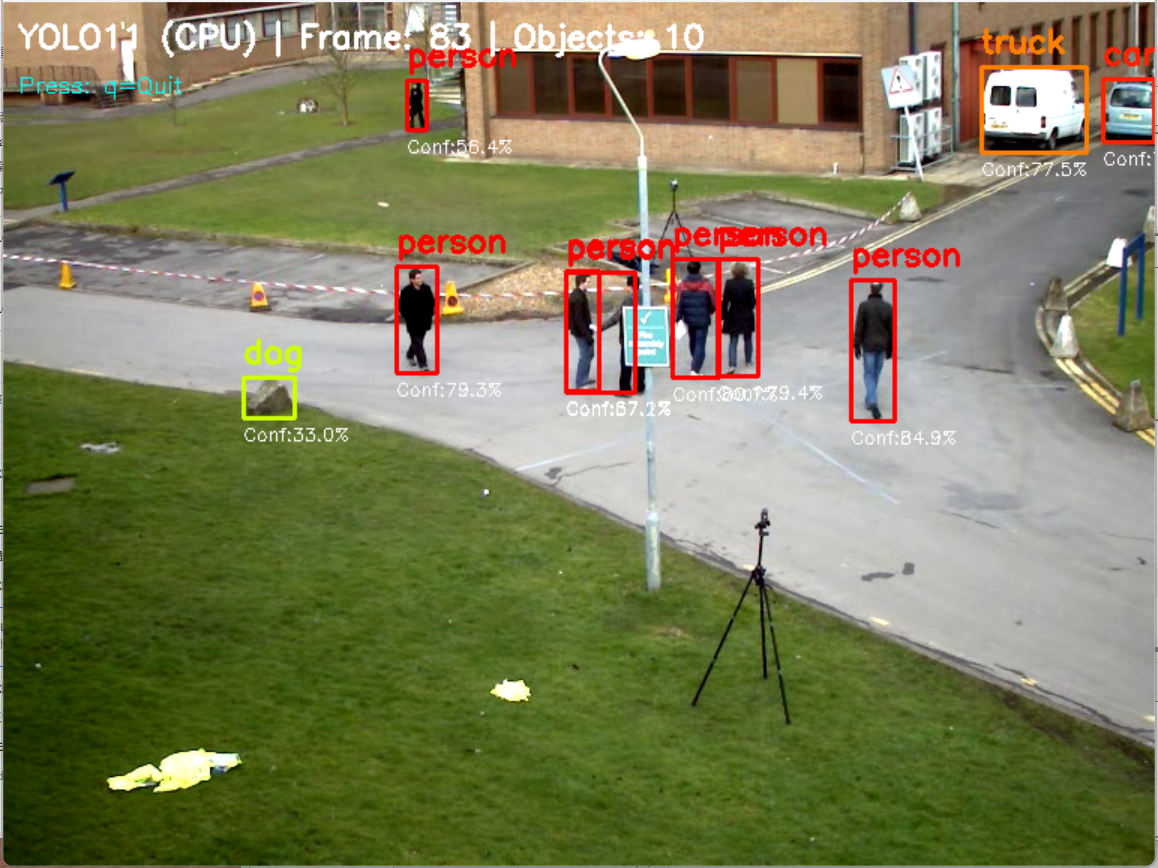
- YOLO12による物体検出(COCO 80クラス)(ソースコードと説明と利用ガイド)
【概要】 YOLOv12を用いた物体検出プログラムである。動画ファイル、ウェブカメラ、サンプル動画から80種類の物体をリアルタイムで検出する。Area Attention機構により計算量を削減しながら高精度を実現。5段階のモデルサイズから選択可能である。CLAHE技術による画質前処理で低照度環境にも対応する。日本語表示対応、検出結果の自動保存機能を備える。

- YOLO11によるOBB(回転物体検出)(ソースコードと説明と利用ガイド)
【概要】YOLO11-OBBは、物体の向きに合わせて回転可能な境界ボックスを用いた物体検出技術である。従来の軸平行な矩形と異なり、任意の角度で回転した物体を正確に検出できる。DOTAv1データセットで学習され、航空・衛星画像における飛行機、船舶、車両など15種類の物体を検出する。C3k2ブロックやSPPFモジュールにより特徴抽出能力が向上。CLAHE前処理により低照度環境でも高精度な検出が可能である。日本語表示対応、検出結果の自動保存機能を備える。

- Albumentations物体検出データ拡張
本プログラムでは、Albumentationsライブラリを使用してサンプル画像に対して複数の変換手法を組み合わせたデータ拡張を実行する。幾何学的変換(回転、スケール、平行移動)、色彩変換(明度、コントラスト調整)、ノイズ追加などの処理を適用し、バウンディングボックス座標を変換に合わせて自動調整する。拡張前後の画像とバウンディングボックスの変化を可視化することで、データ拡張の効果を確認できる。
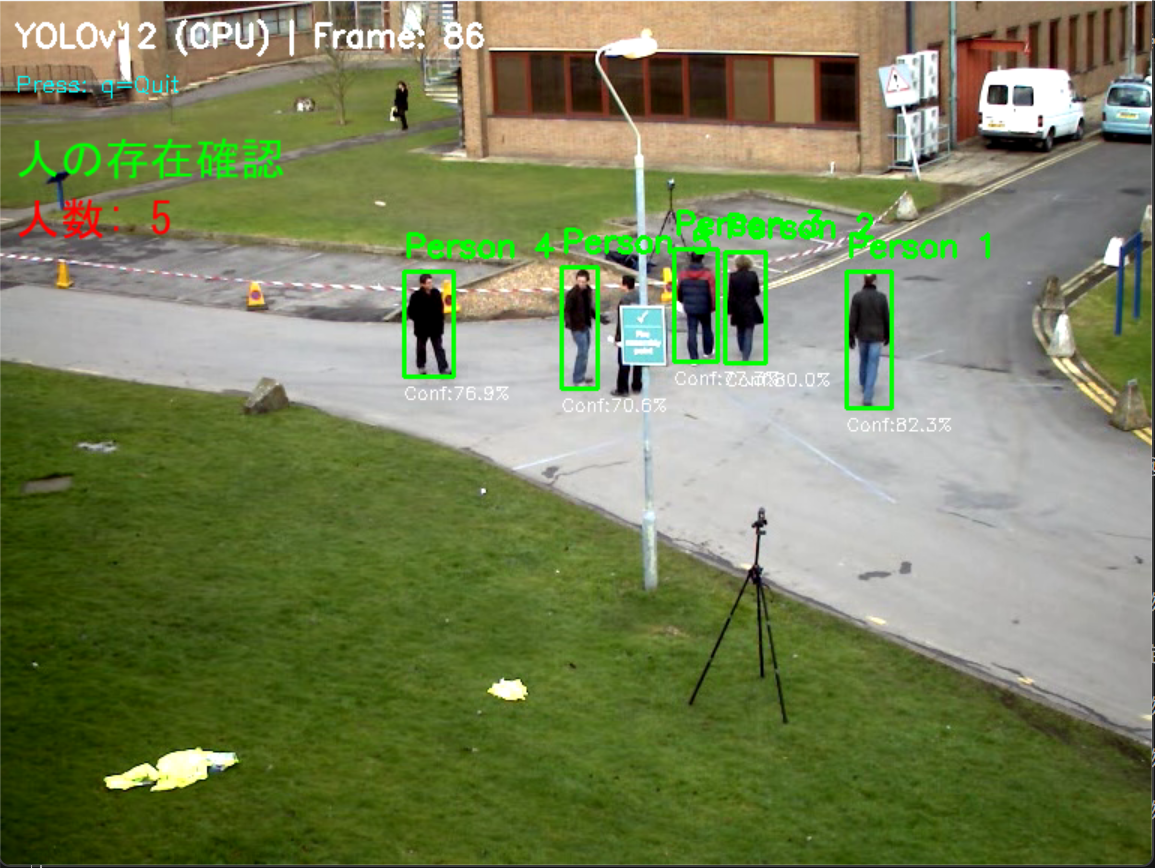
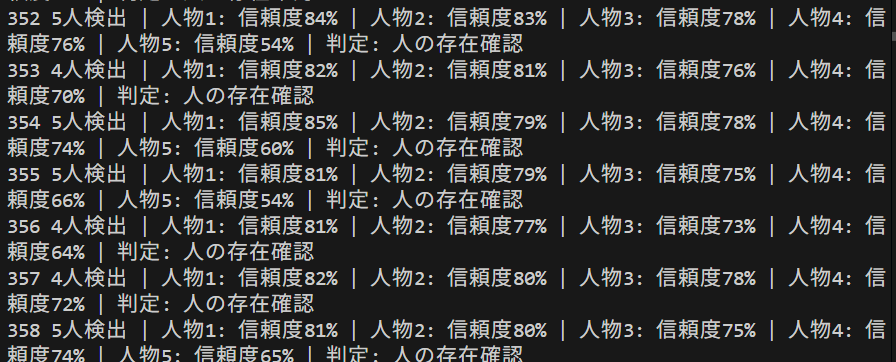
コンピュータビジョン:人物検出(ByteTrackによる追跡とTTAの機能付き)

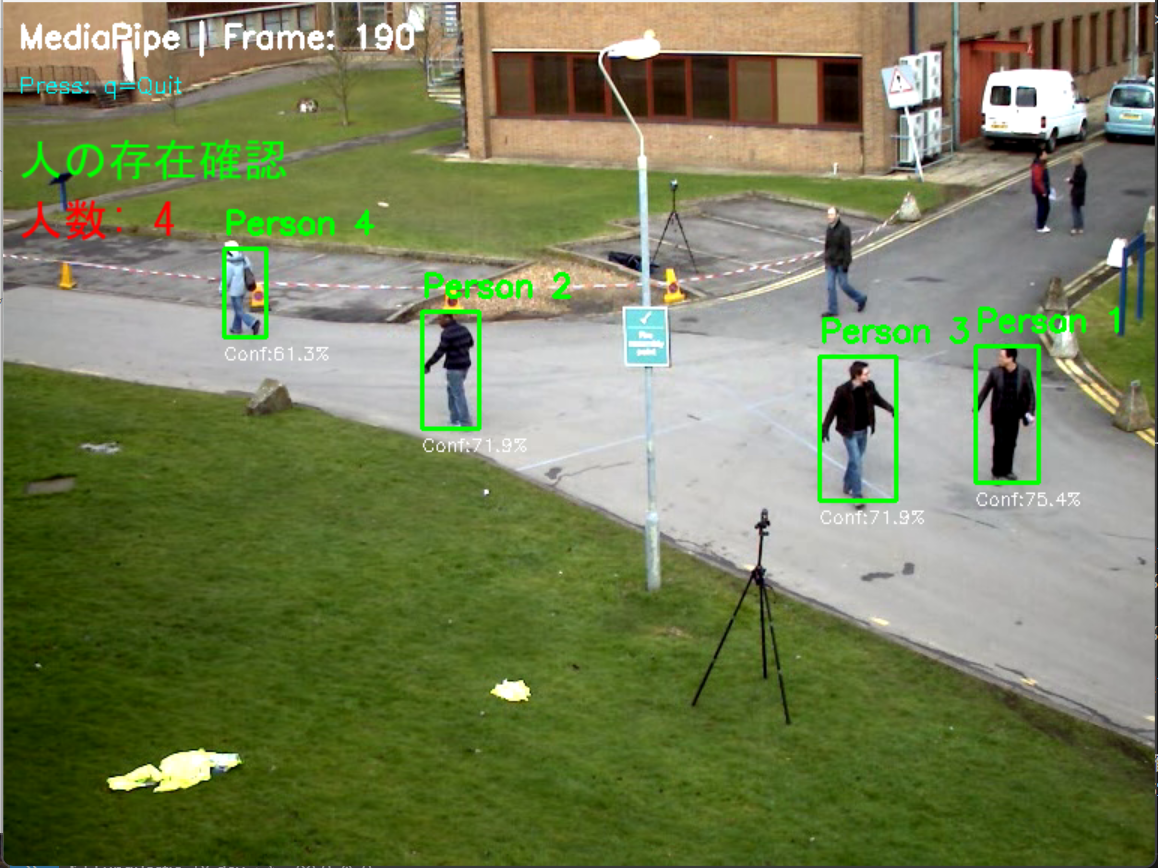


コンピュータビジョン:インスタンスセグメンテーション
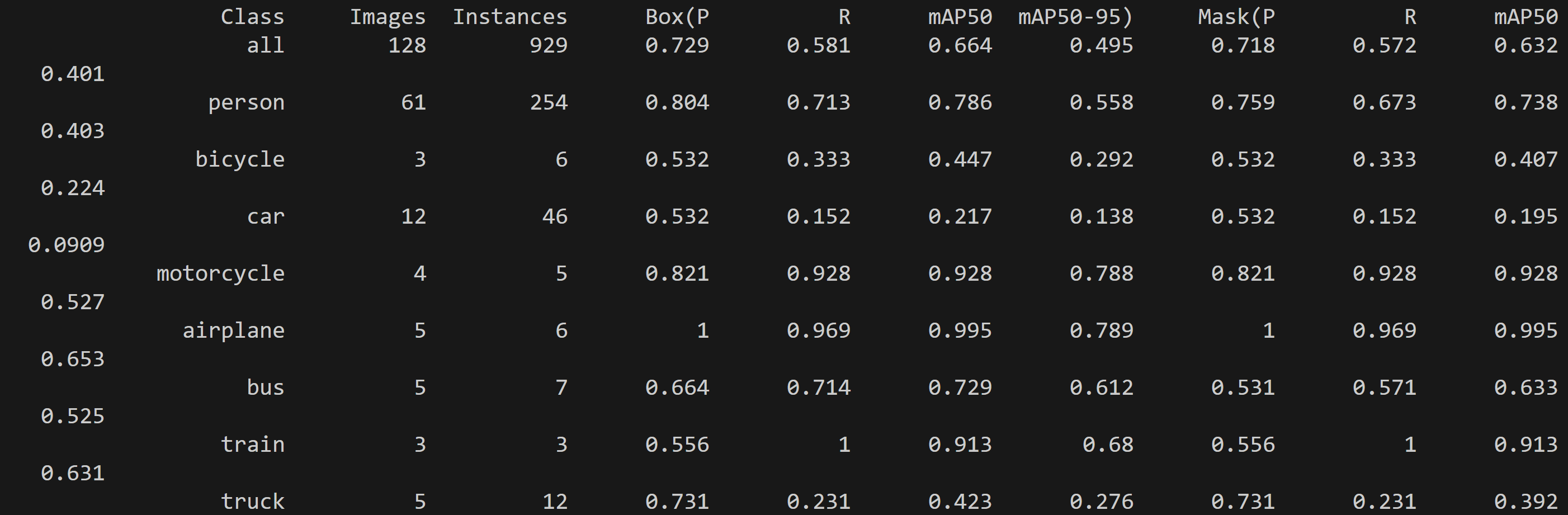
- YOLO11によるインスタンスセグメンテーション(ソースコードと説明と利用ガイド)
【概要】YOLO11-segを使用してリアルタイムインスタンスセグメンテーションを実行。Enhanced Feature Extractionにより物体検出と同時にピクセルレベルのセグメンテーションを学習し、5種類のモデルサイズによる精度と速度の比較実験が可能。Windows環境での実行手順、プログラムコード、実験アイデアを含む。


- YOLOE オープンボキャブラリ物体検出・セグメンテーション(ソースコードと実行結果)

- SAM2による画像セグメンテーション

- SAMによる画像セグメンテーション
【概要】Meta AI ResearchのSAM(Segment Anything Model)は、画像内の任意物体を分割するセグメンテーションモデルである。ゼロショット転移学習により未知の物体や環境でもセグメンテーションを実現。Windows環境での実行手順、プログラムコード、実験アイデアを含む。

- YOLOv11インスタンスセグメンテーションのためのデータオーグメンテーション
【概要】YOLO11セグメンテーションモデル用のデータオーグメンテーションの実装。COCO128データセットからの元画像128枚を回転・スケーリング・色調変更等により数千パターンに拡張し学習効果を向上させる。拡張画像は保存されず学習時のみ使用される。

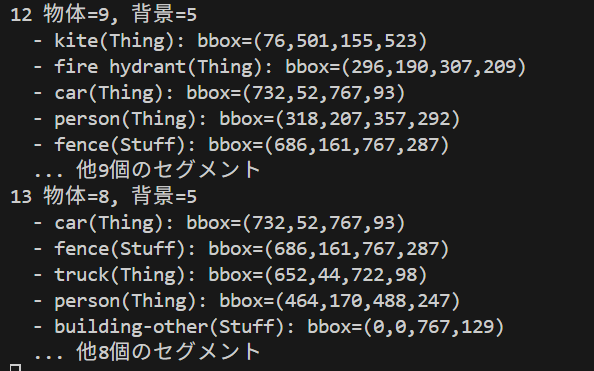
コンピュータビジョン:セマンティックセグメンテーション



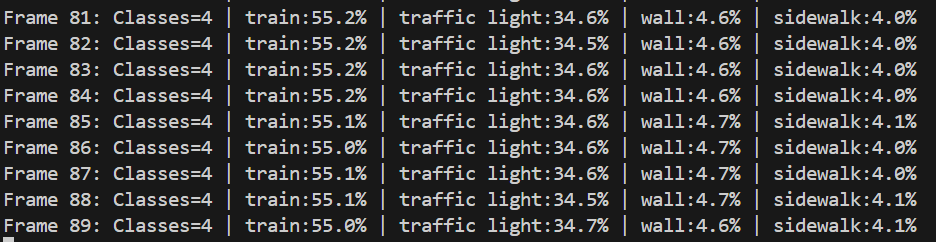
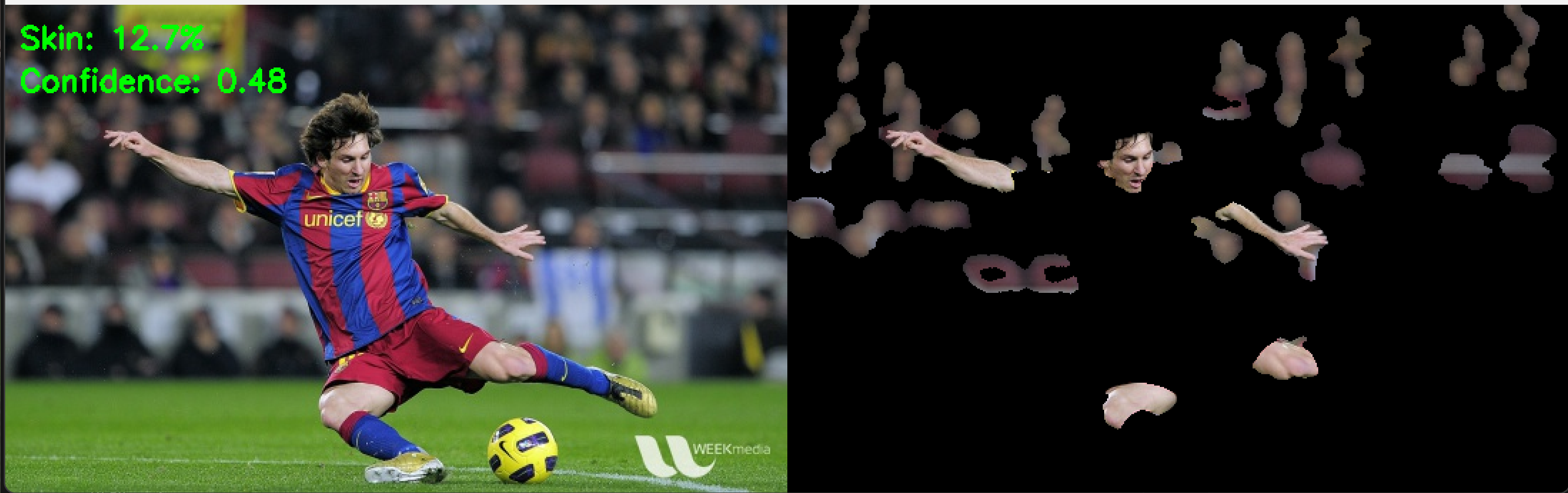
コンピュータビジョン:前景背景分離
- rembgによる背景除去(静止画像向けプログラム)(ソースコードと実行結果)
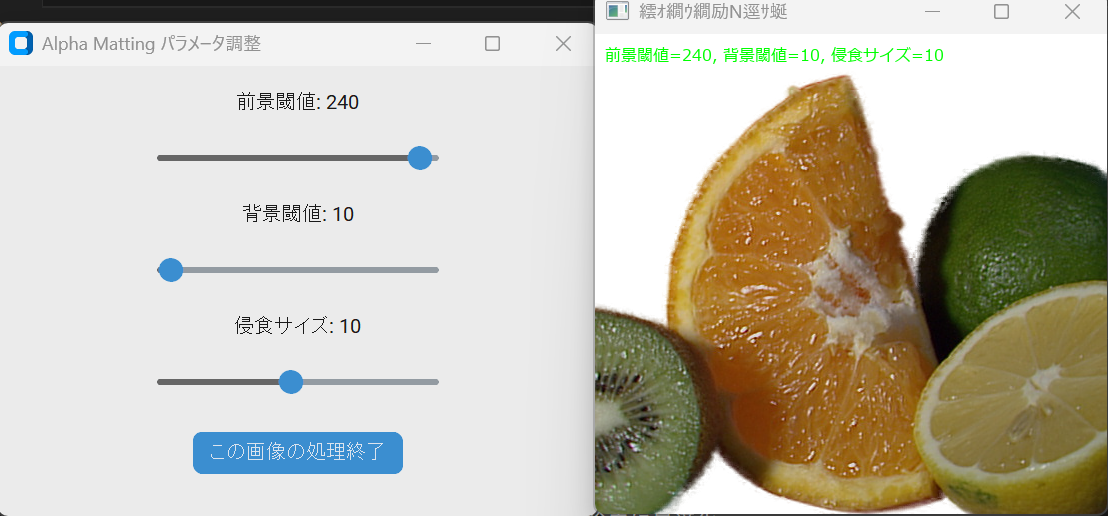
- MediaPipe前景・背景セグメンテーション(ソースコードと実行結果)

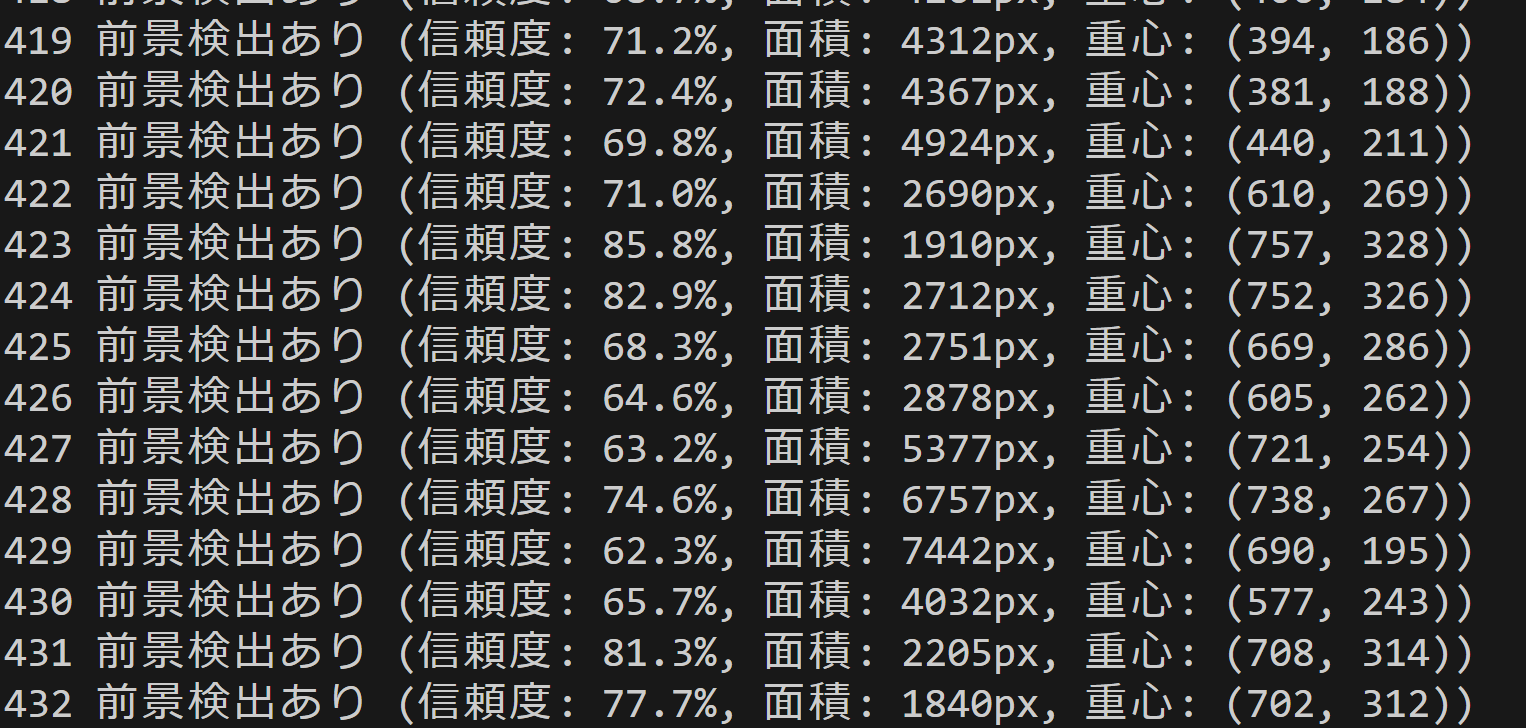
- U-2-Net (U Square Net) による動画用オブジェクト顕著性検出(ソースコードと実行結果)
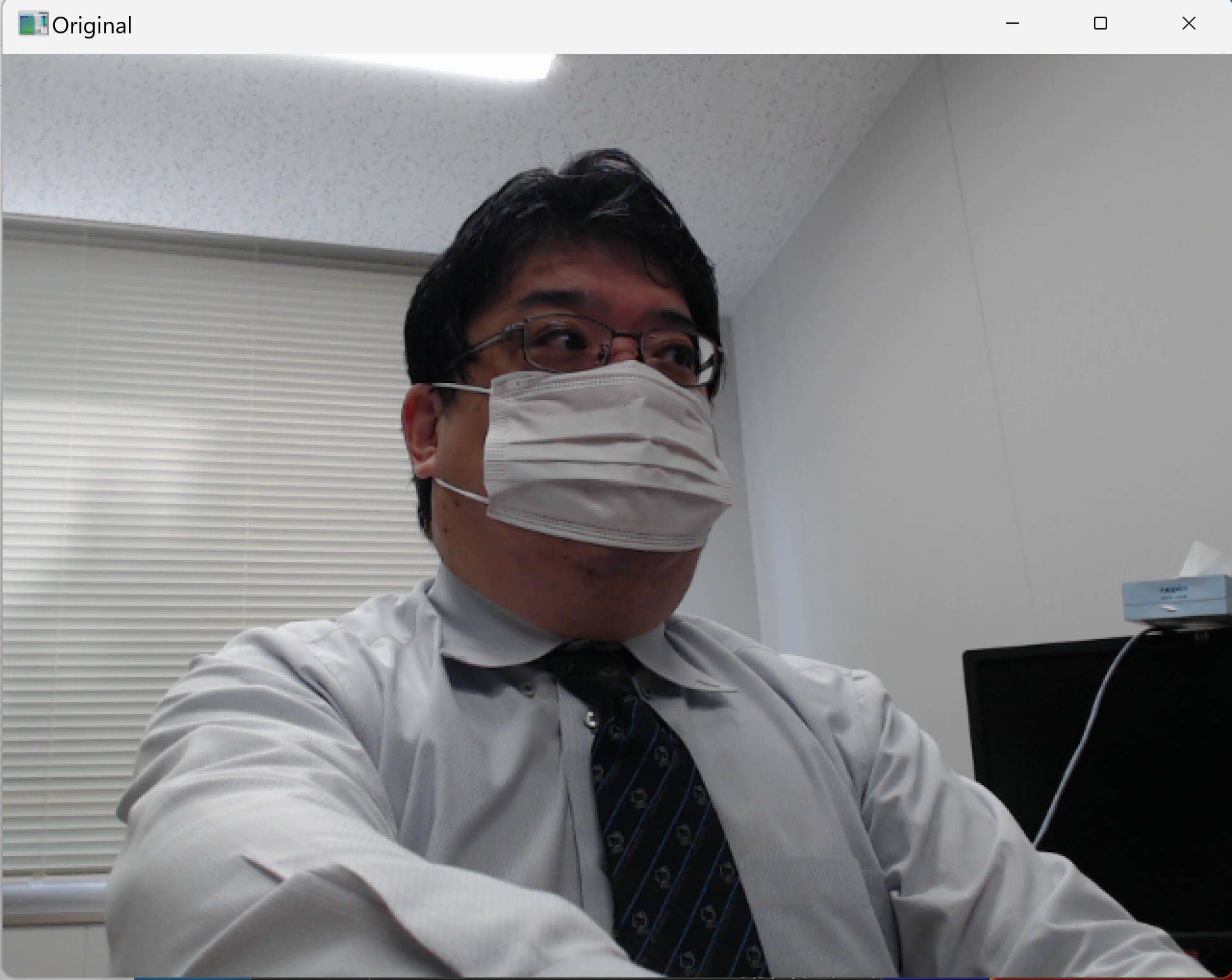
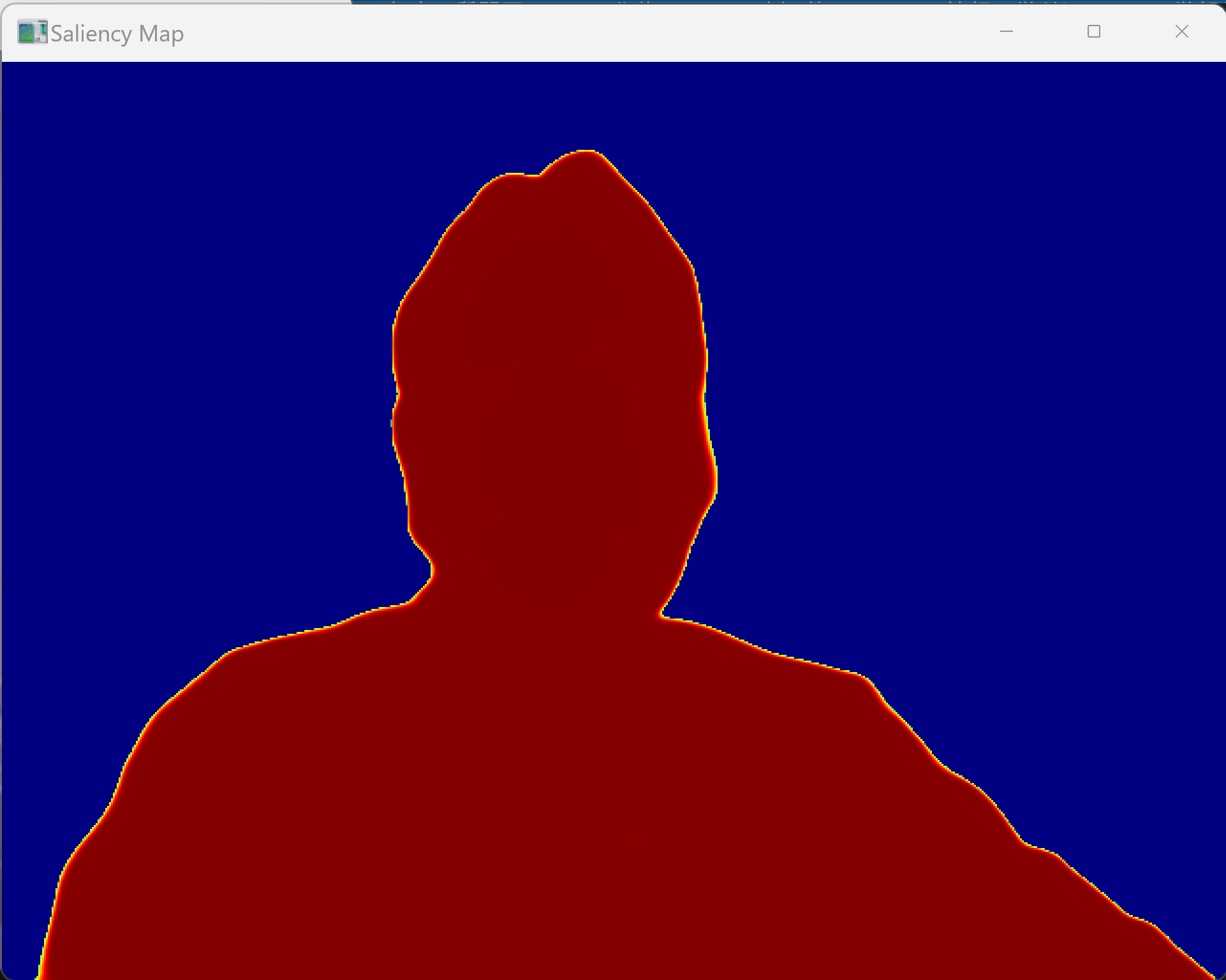
- SAM2による前景背景分離(ソースコードと実行結果)

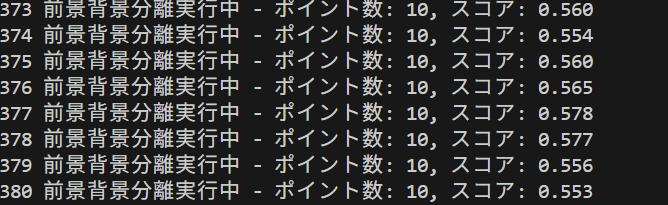
コンピュータビジョン:顔情報処理
- InsightFace と SCRFD による顔検出
【概要】 InsightFaceフレームワークのSCRFD技術を用いた顔検出プログラムの実装と実験を行う。SCRFDはサンプル分布を再配分することを特徴とする顔検出技術である。Webカメラから顔と5点キーポイントを検出する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。


- InsightFaceとSCRFDによる顔検出・年齢・性別推定
- DeepFace による顔検出・年齢・性別・感情推定
- YOLOv11-Face 顔検出(ソースコードと実行結果)
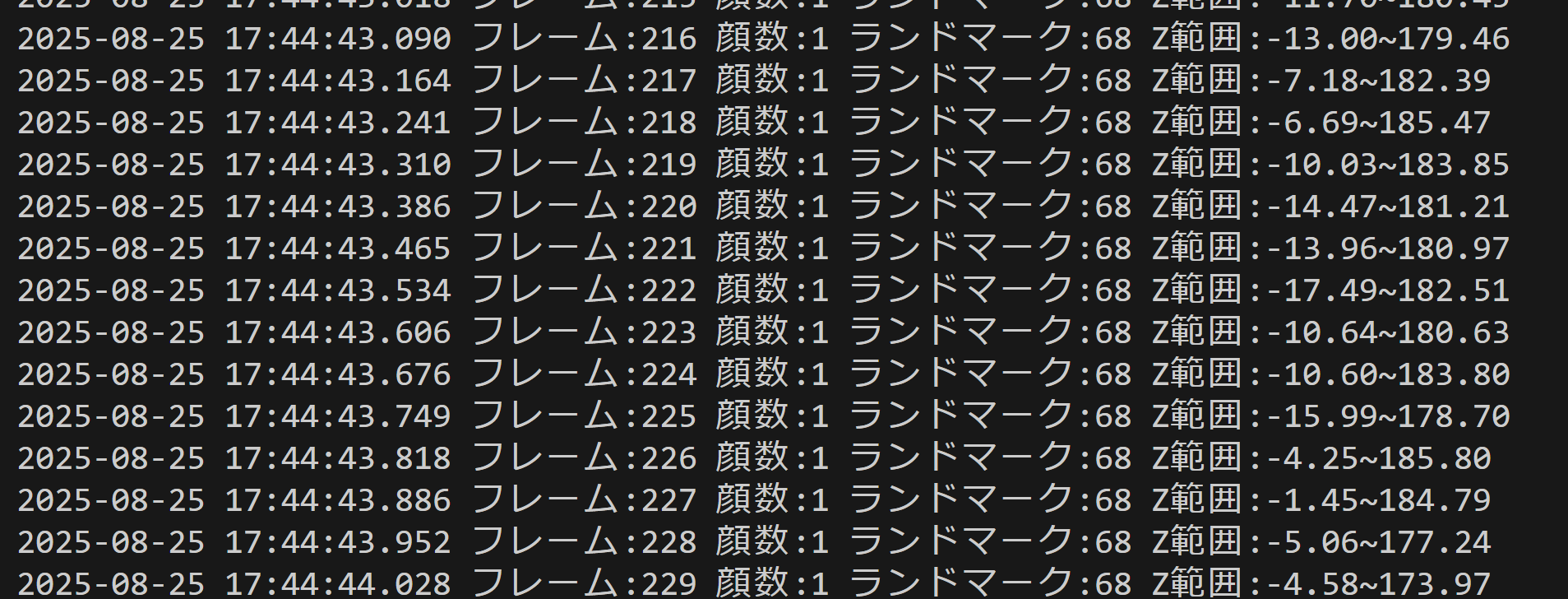
- InsightFaceによる68点3Dランドマーク検出
【概要】 InsightFaceフレームワークの68点3Dランドマーク検出技術を用いた顔解析プログラムの実装と実験を行う。68点3Dランドマーク検出は顔の主要な特徴点を3次元座標で特定する技術である。Webカメラから顔と68点ランドマークを検出する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。

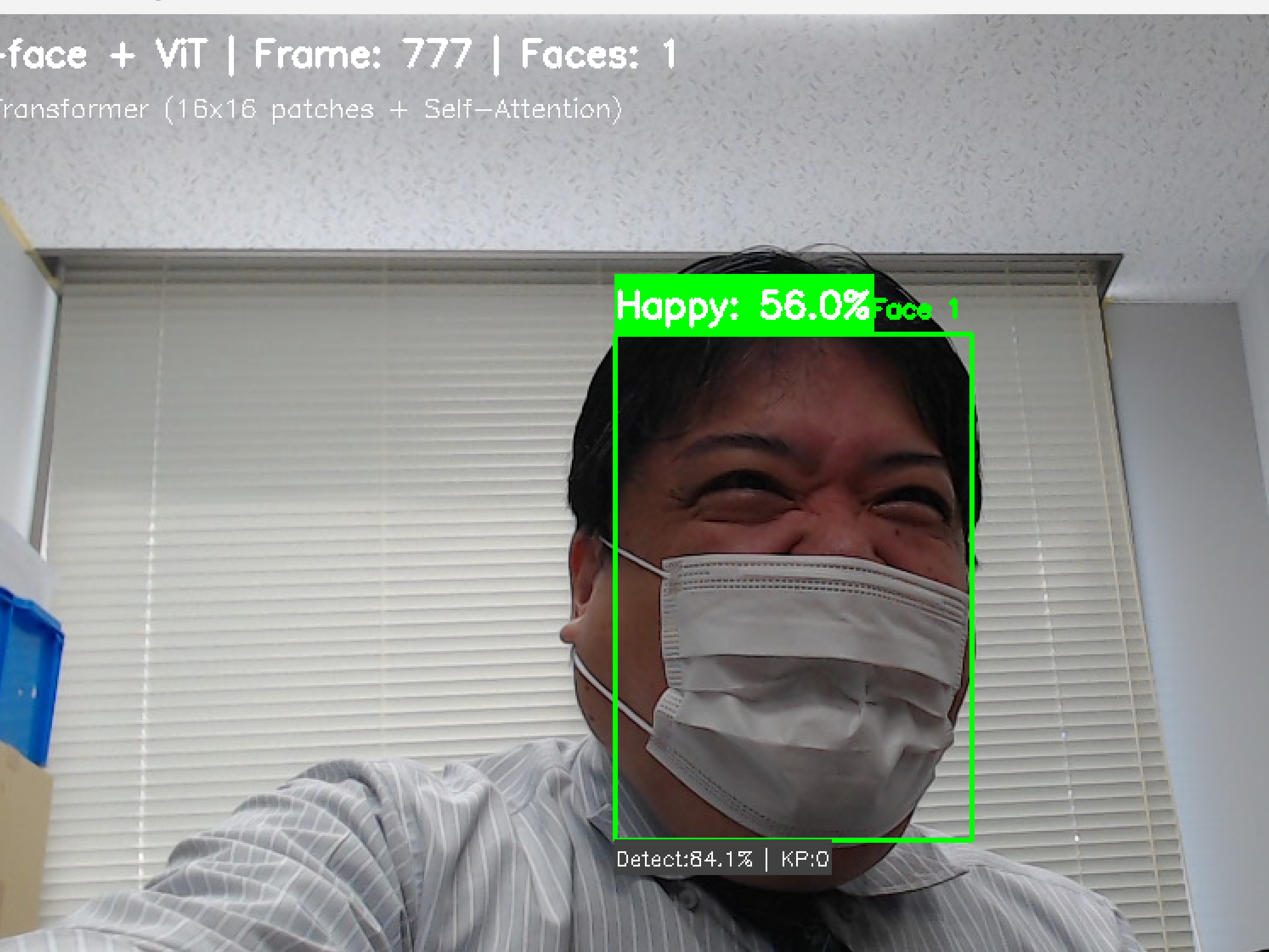
- Vision Transormer による表情推定システム
【概要】YOLOv11ベースの顔検出とVision Transformerを組み合わせた表情推定システム。顔を検出し、Ekmanの6基本感情+中性状態(怒り、嫌悪、恐怖、幸福、悲しみ、驚き、中性)を認識。68点顔キーポイント、16x16パッチ分割によるViTの文脈理解で、顔の向きや照明に頑健な感情分析を目指す。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
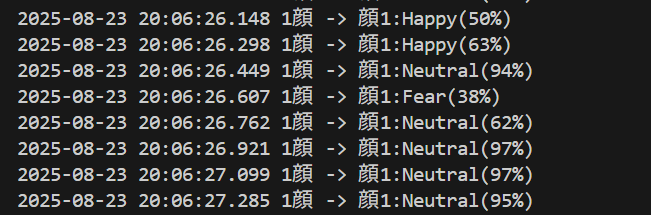
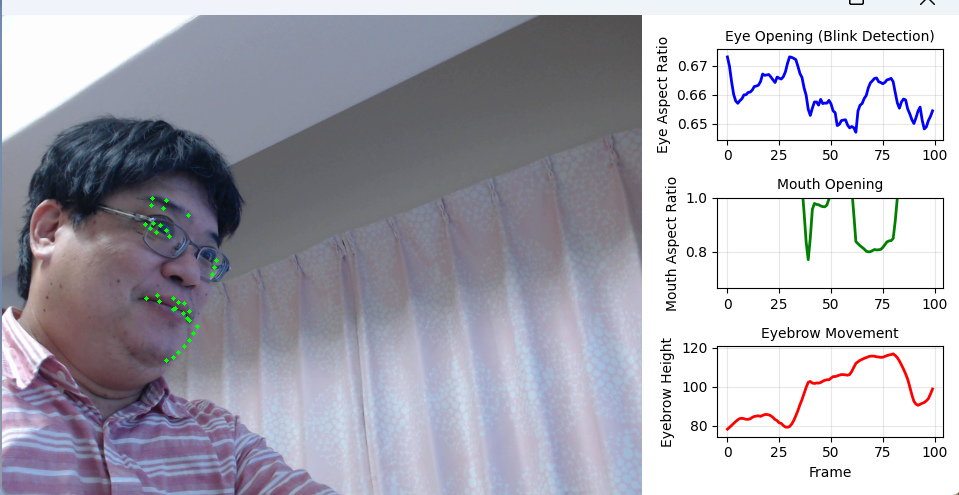
- MediaPipe Face Landmarker による顔の変化分析(ソースコードと実行結果)
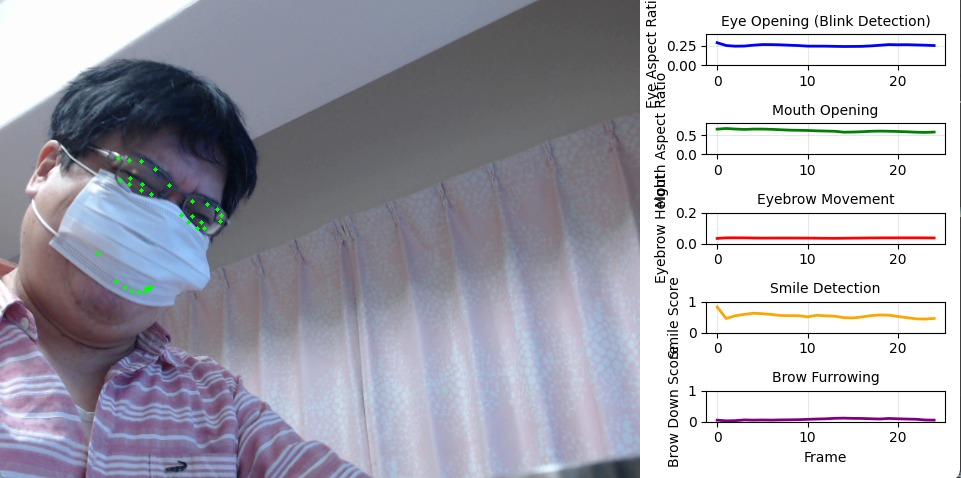
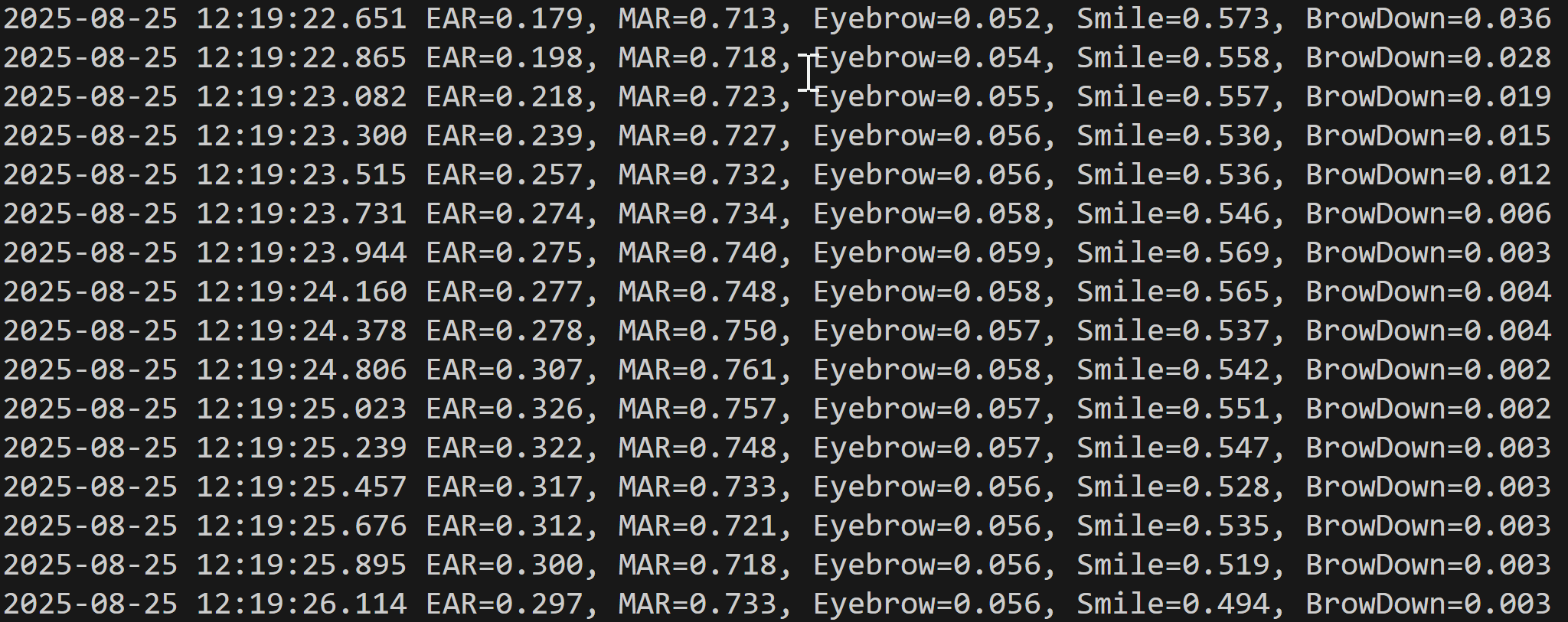
- InsightFace による顔の変化分析(ソースコードと実行結果)
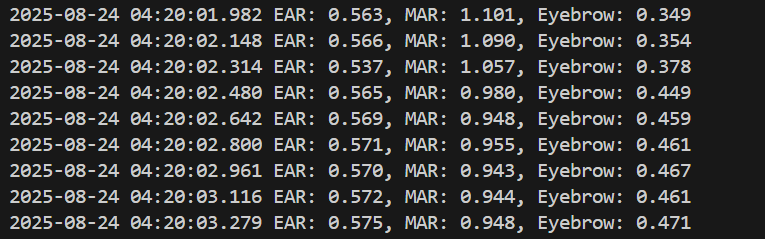

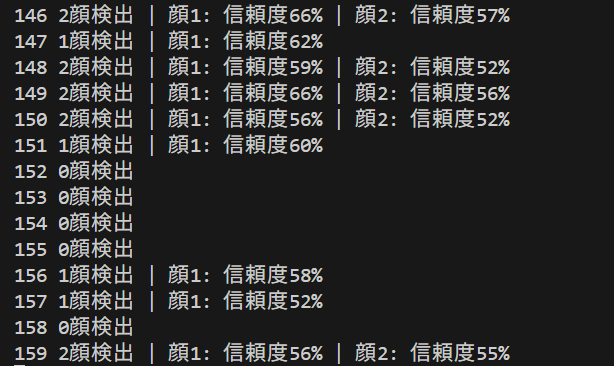
コンピュータビジョン:人物動作認識
- TimeSformer による人物動作認識(ソースコードと説明と利用ガイド)
- VideoMAE による人物動作認識(ソースコードと説明と利用ガイド)
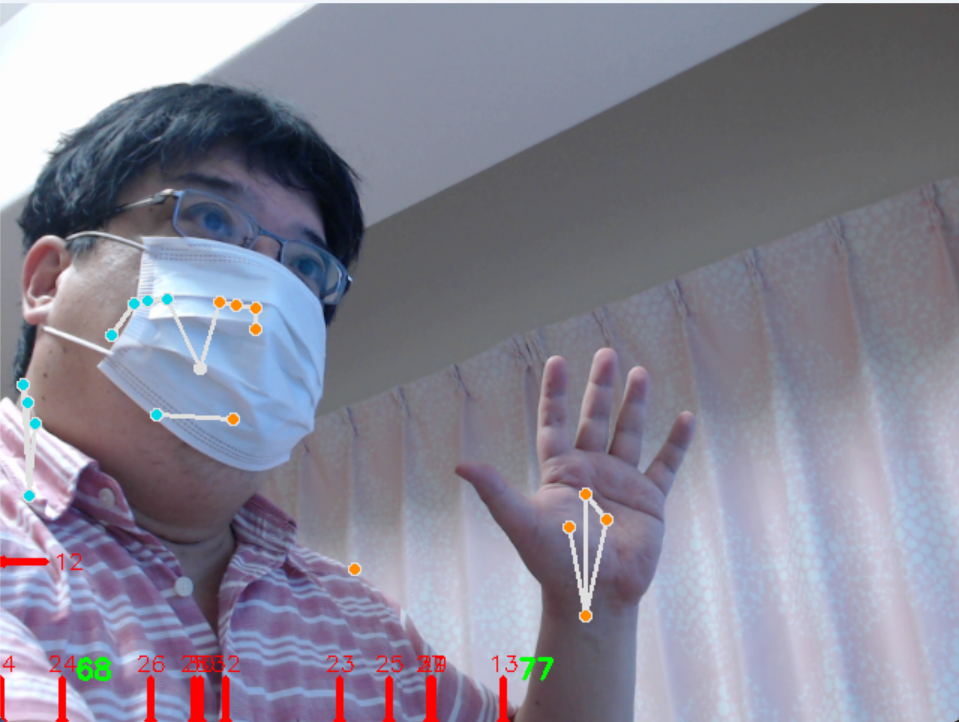
- MediaPipe Hands による手指ジェスチャー分析システム(ソースコードと実行結果)
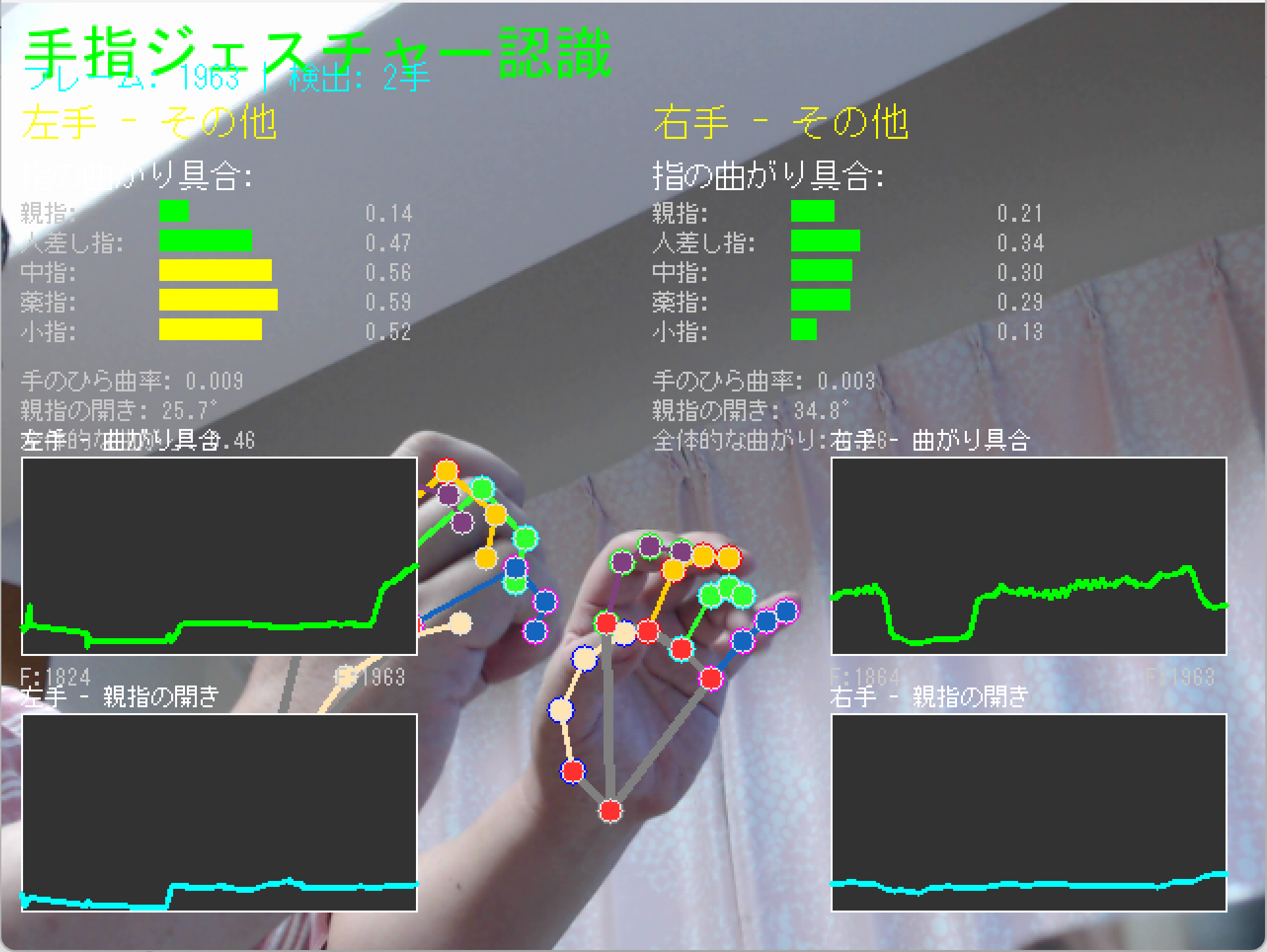
- MediaPipe Hands による3次元手指ランドマーク検出と指接触判定
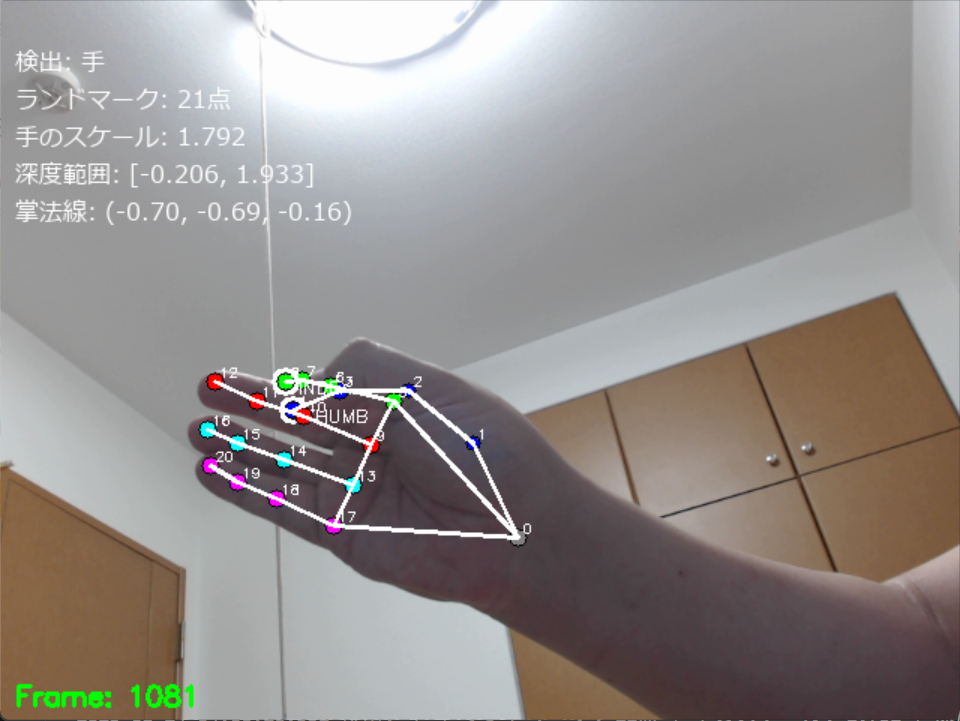
【概要】MediaPipe Handsは、カメラの映像から手の21点の3次元座標を推定する技術である。機械学習モデルにより単一のRGB画像から手の位置を検出し、各指の関節位置を3次元座標として出力する。手の姿勢を可視化し、関節角度の計算や手のスケール測定などの実験を通じて、コンピュータビジョンとジェスチャー認識の基礎を確認するWindows環境での実行手順、プログラムコード、実験アイデアを含む。


- MediaPipe Hands による3次元手指ランドマーク検出

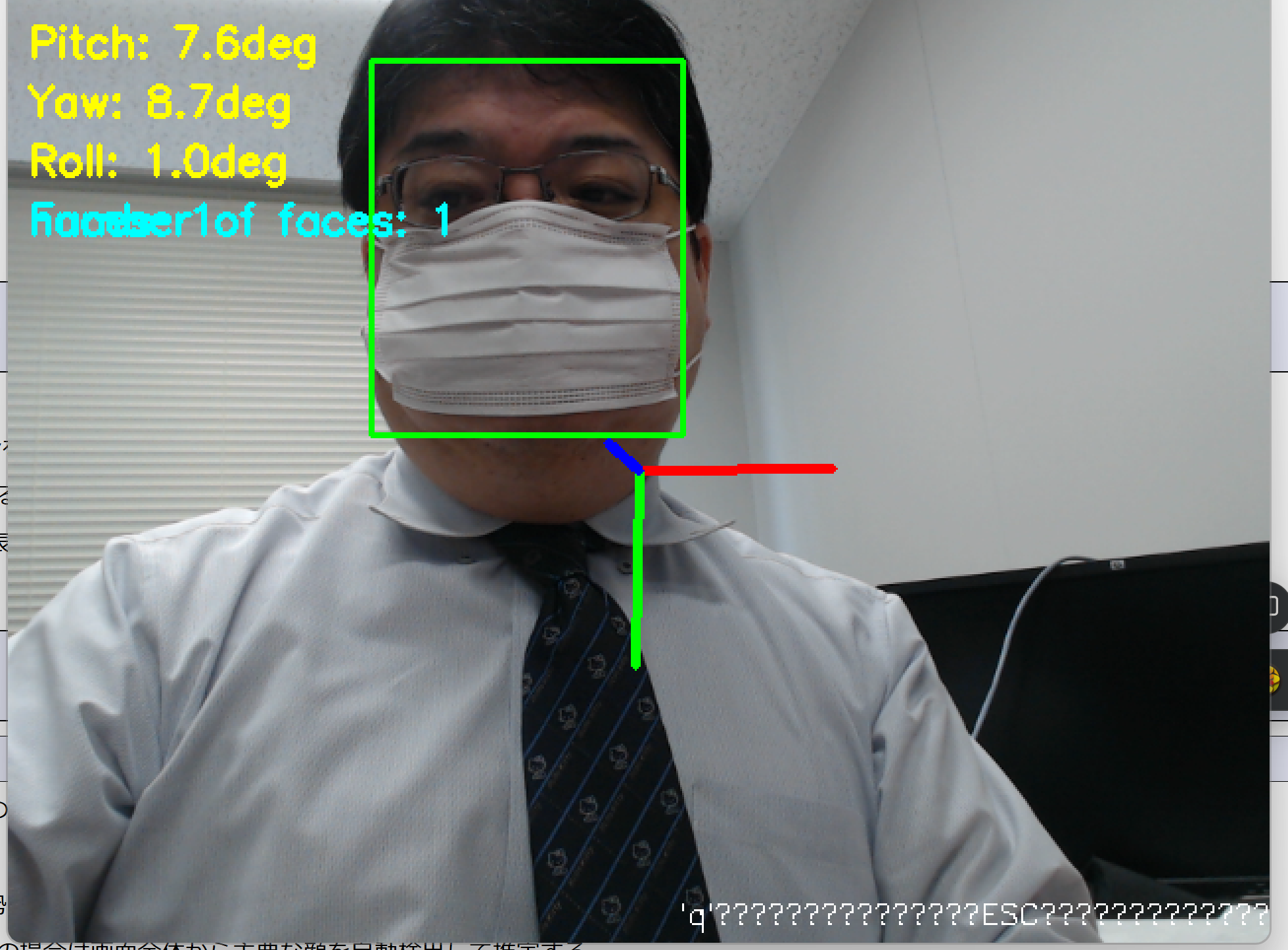
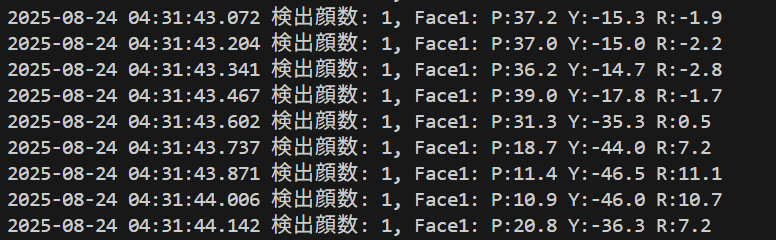
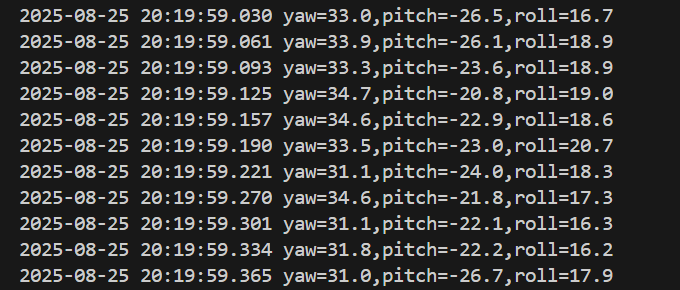
- 6DRepNet頭部3次元姿勢推定
【概要】6DRepNetは人間の頭部姿勢を推定するAI技術である。従来のEuler角表現と異なり、6次元回転表現を採用することで角度の曖昧性問題を解決し、推定を実現している。パソコンカメラを使用して頭部の向きを検出し、ピッチ・ヨー・ロール角度を数値とグラフィカルな軸表示で確認できる。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
- OpenVINO OMZ による頭部姿勢推(ソースコードと実行結果)
- TRG 6DoF頭部姿勢推定(プログラム作成中 trg6dof.html)
- MediaPipe Pose Landmarker (Tasks API) による3次元人体姿勢推定(ソースコードと実行結果)
【概要】MediaPipe Poseを用いた人体姿勢推定システム。動画やカメラ映像から33個の身体ランドマークを検出し、2D/3D座標をリアルタイム推定する。時系列平滑化と骨格長の物理的制約により精度を向上。3Dプロット表示、信頼度評価、結果の自動保存機能を搭載。スポーツフォーム分析や姿勢矯正の評価に活用可能。
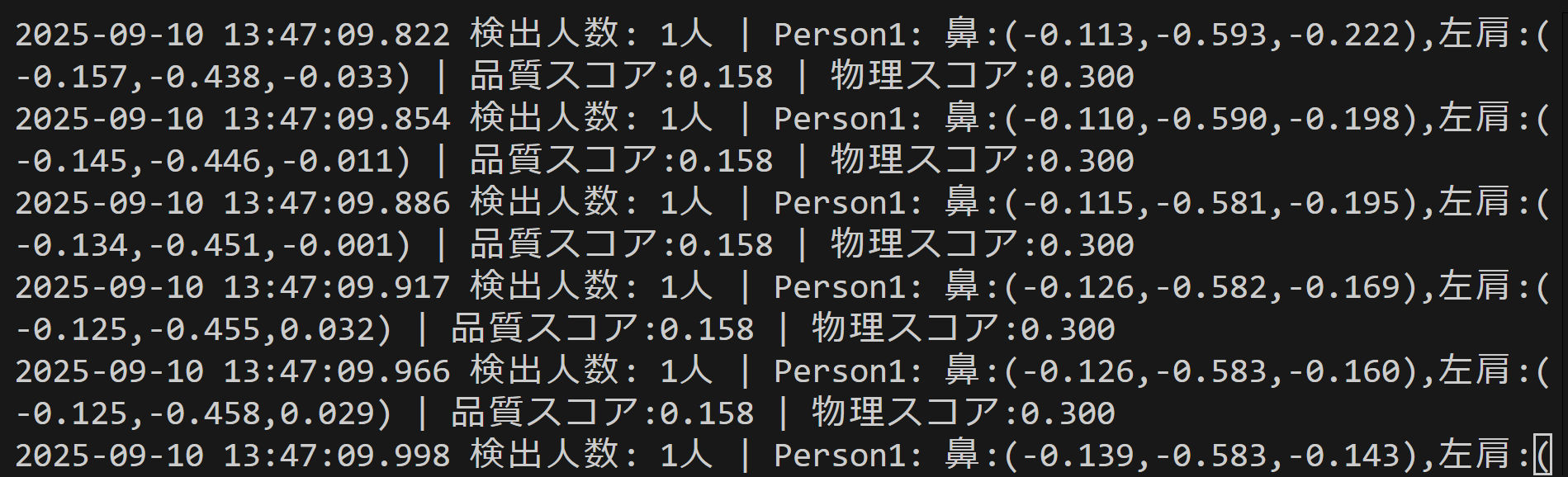
- MediaPipe BlazePose による人間の無意識の姿勢からの感情予測(ソースコードと実行結果)

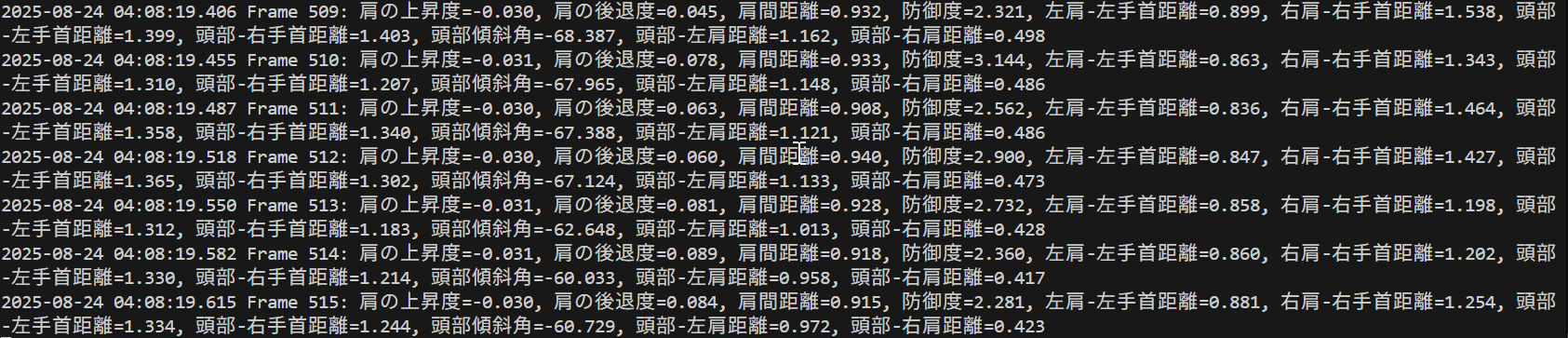
- MediaPipeによるしぐさ検出(ソースコードと実行結果)

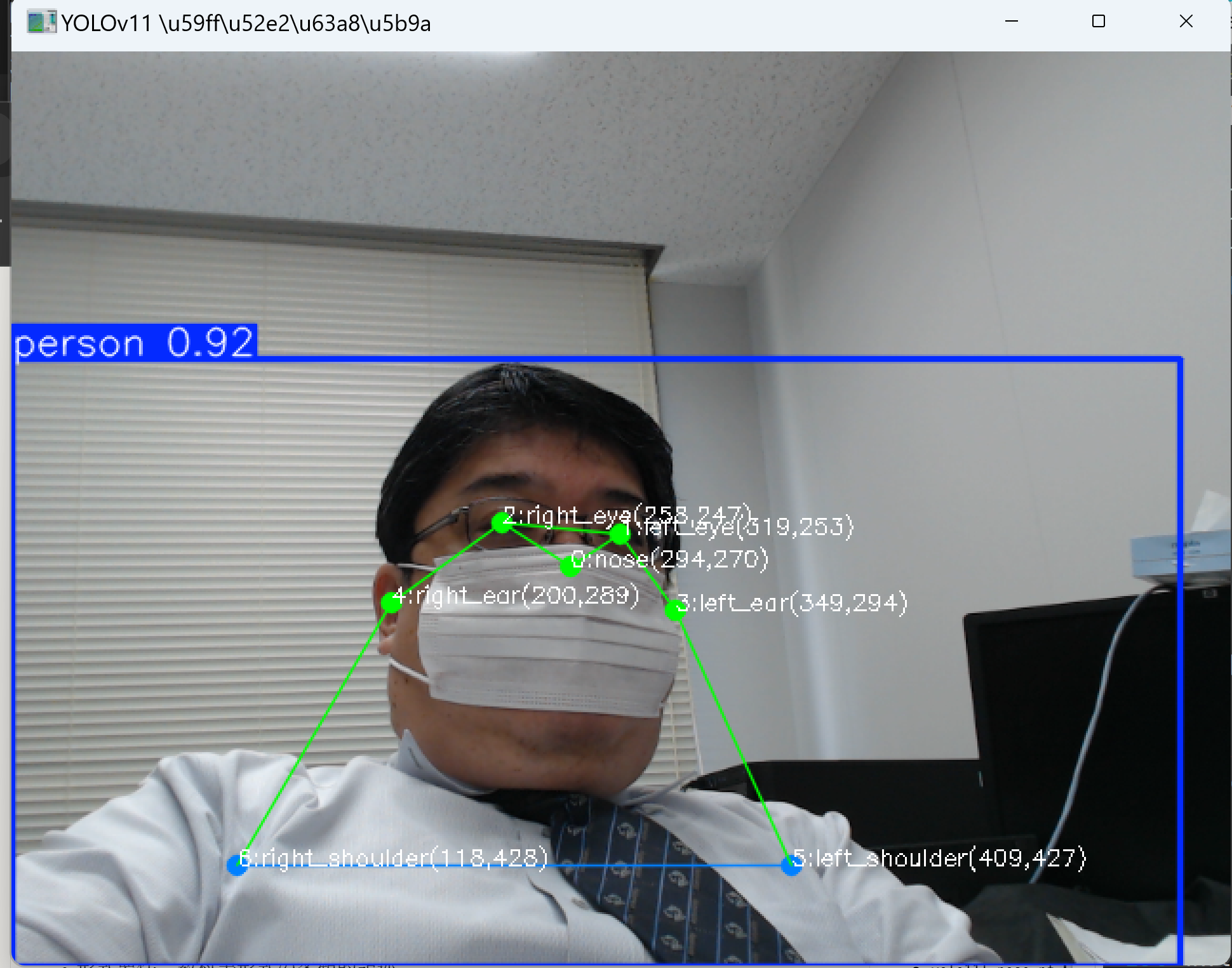
- YOLOv11による2次元姿勢推定
【概要】YOLO11-poseを使用して、カメラから人体17箇所のキーポイント(鼻、目、耳、肩、肘、手首、腰、膝、足首)をリアルタイム検出。Nano・Small・Medium・Large・Extra-Largeの5種類のモデルサイズで精度と処理速度のトレードオフを比較実験可能。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
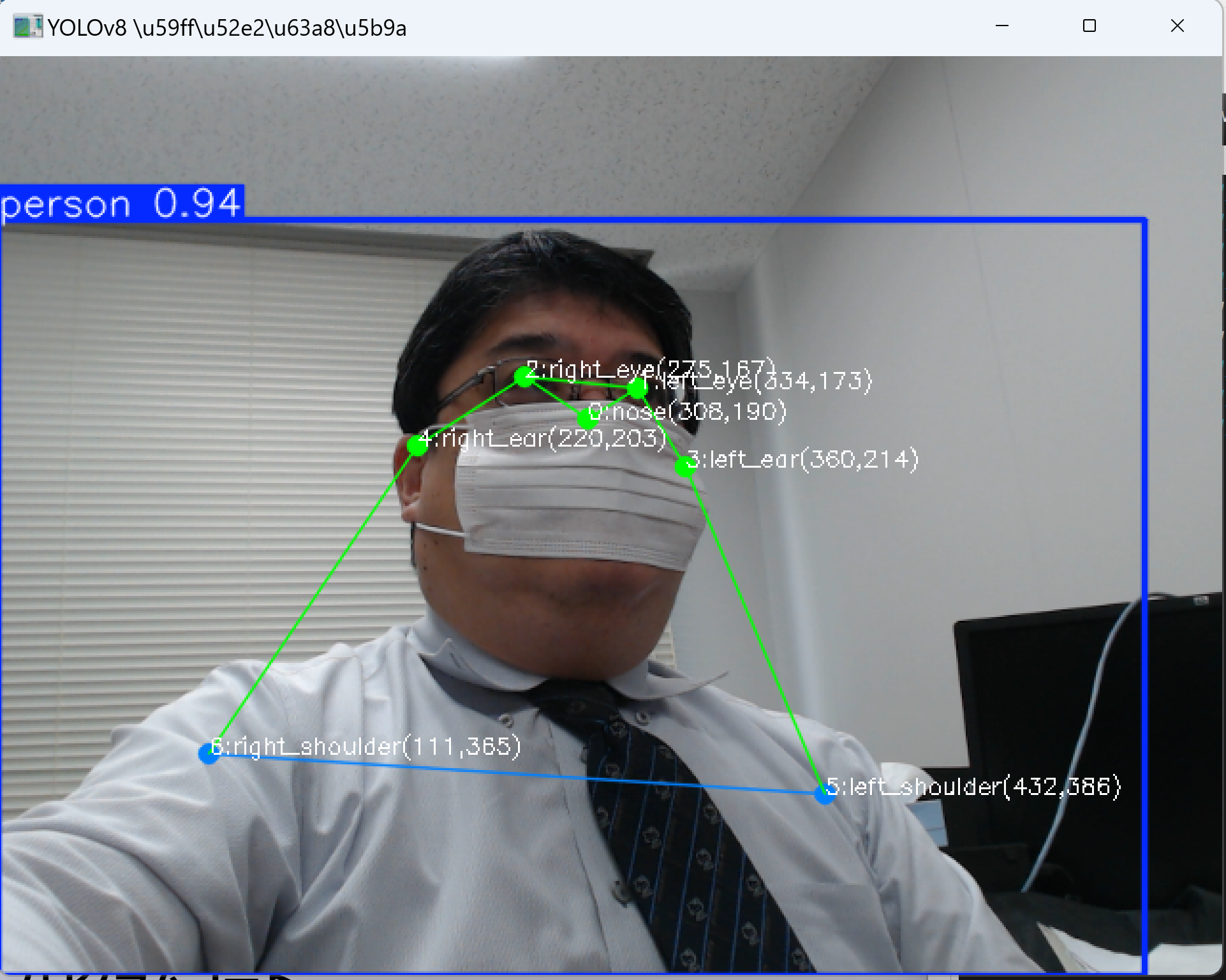
- YOLOv8による2次元姿勢推定
【概要】YOLOv8-poseを使用してリアルタイム姿勢推定を実行。人体17箇所のキーポイント検出技術を学習し、5種類のモデルサイズによる精度と速度の比較実験が可能。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
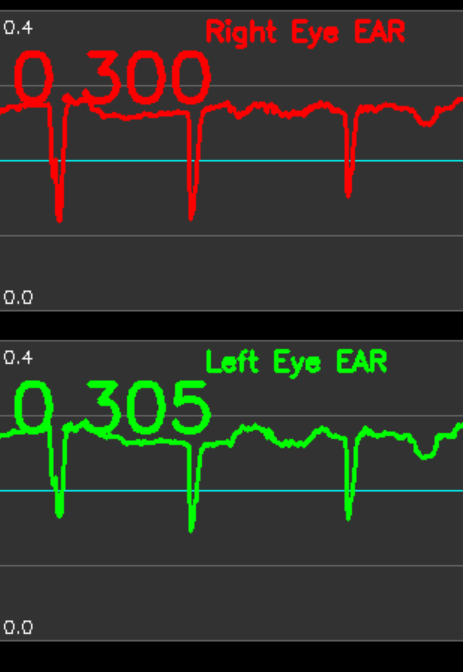
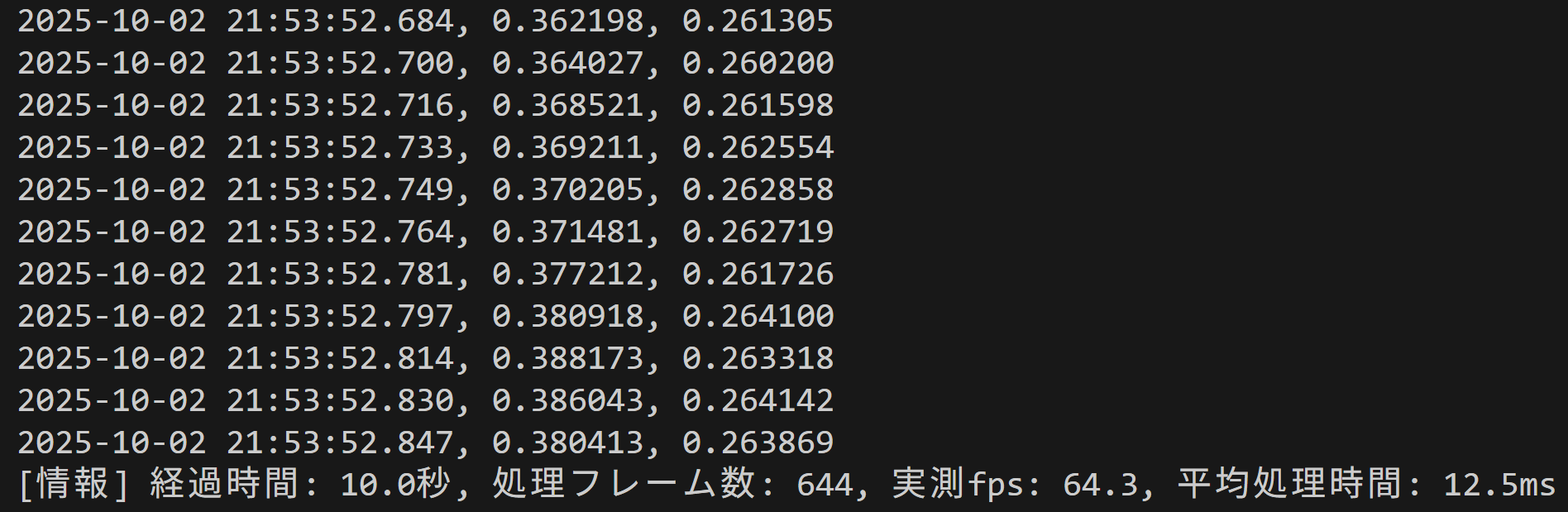
- MediaPipe Face Landmarker(新API)によるリアルタイムEAR(Eye Aspect Ratio)算出(ソースコードと説明と利用ガイド))
【概要】MediaPipe新APIでリアルタイムEAR算出。 目の開閉状態を数値化するEAR(Eye Aspect Ratio)をリアルタイム計算し、瞬き検出を実現。 特徴: • 顔478点検出→目12点からEAR算出 • 時系列グラフで可視化 • 60fps動作(スレッド化フレーム取得) • 動画/カメラ対応。 用途: 眠気検出、集中度測定
- MediaPipe Face Landmarkerによる瞳孔と虹彩追跡(ソースコードと実行結果)
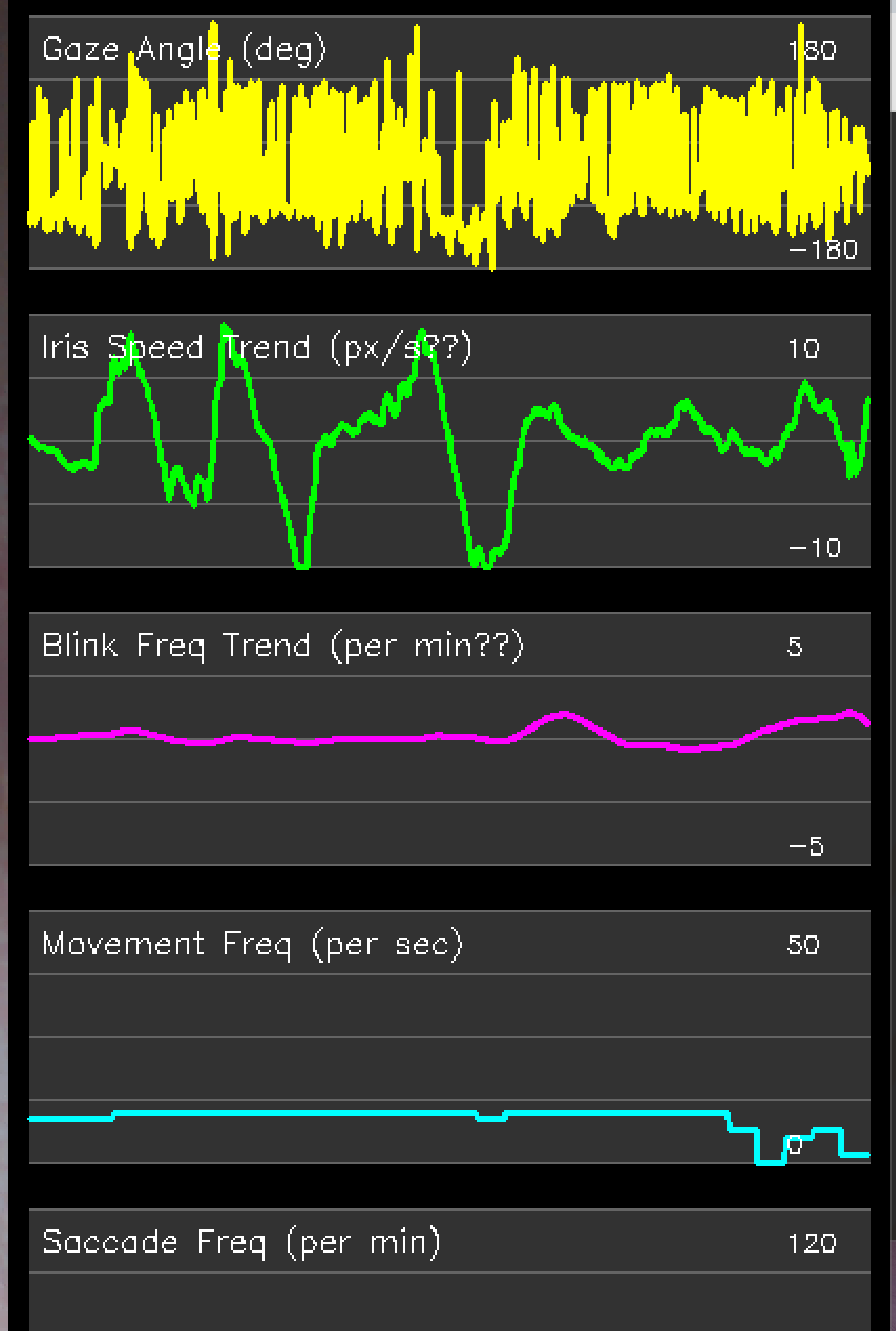
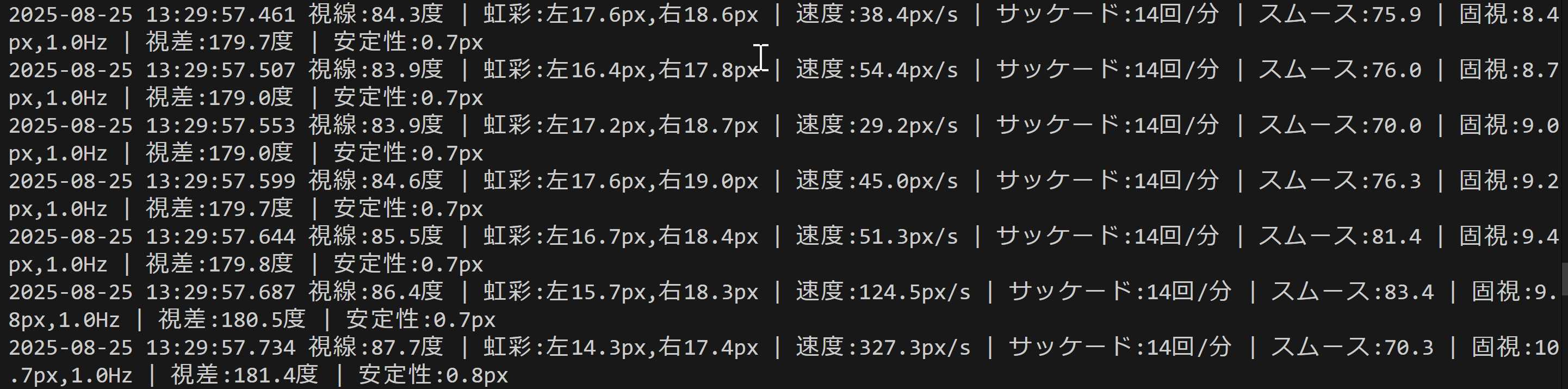
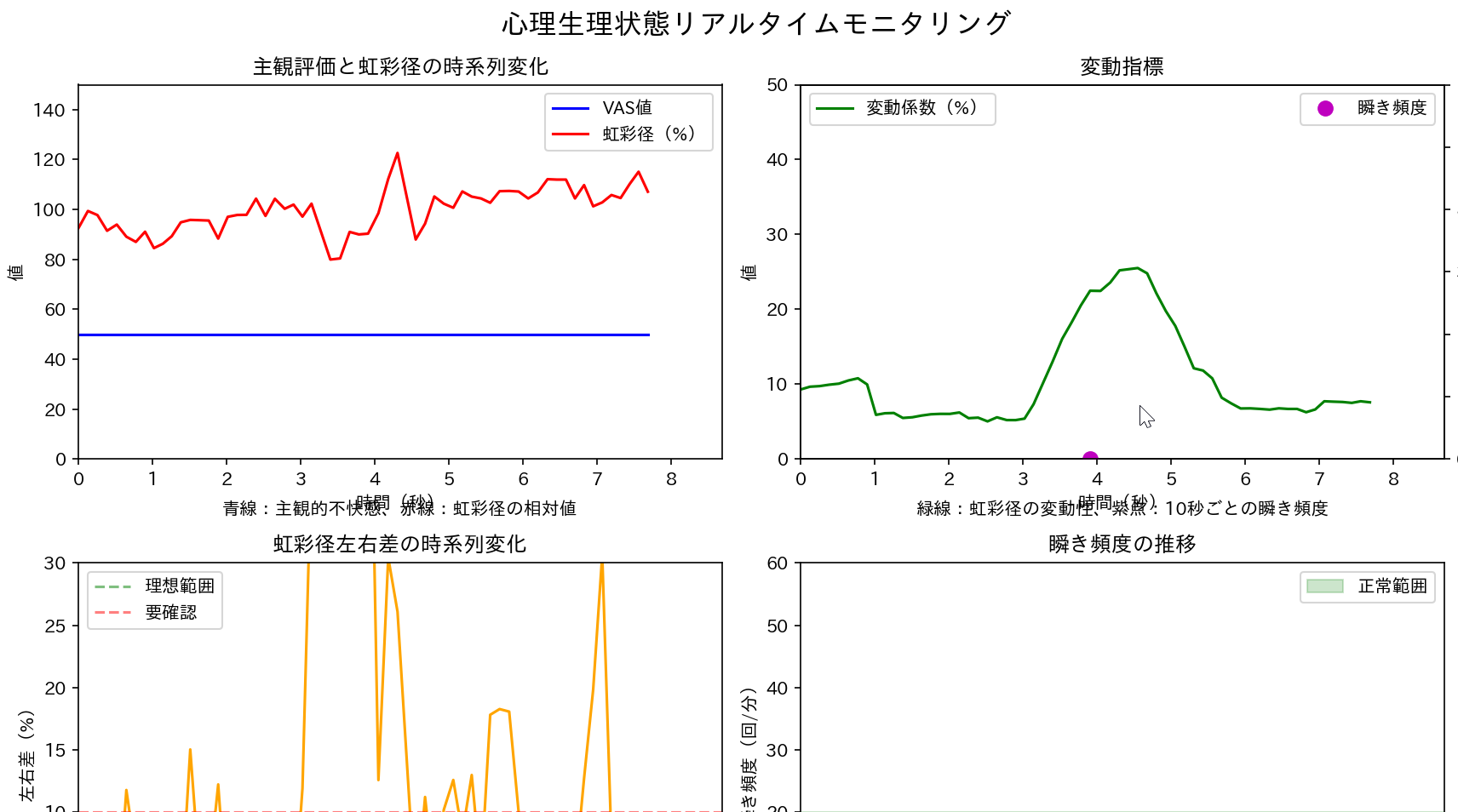
- VAS値・左右瞳孔径・瞬き検出による計測(ソースコードと実行結果)

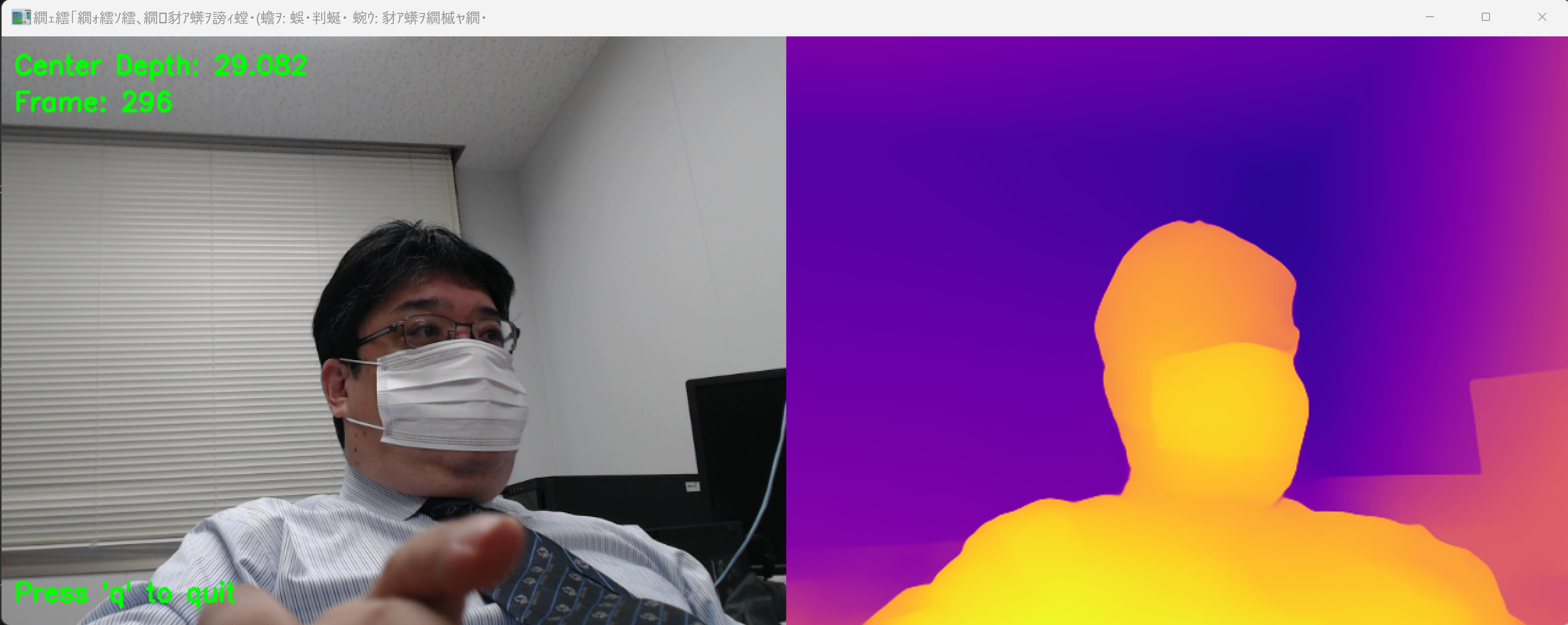
- MiDaSによる深度推定
【概要】MiDaSは単眼カメラから深度情報を推定するAI技術である。Webカメラを用いたリアルタイム深度推定プログラムにより、深度マップの可視化と単眼深度推定を確認する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
- 深度画像からのステレオペア画像生成
- LSD とカラー画像の勾配情報による直線検出(ソースコードと実行結果)

- DeepLSDによる線分検出(ソースコードと実行結果)

- LCNNによる消失点推定
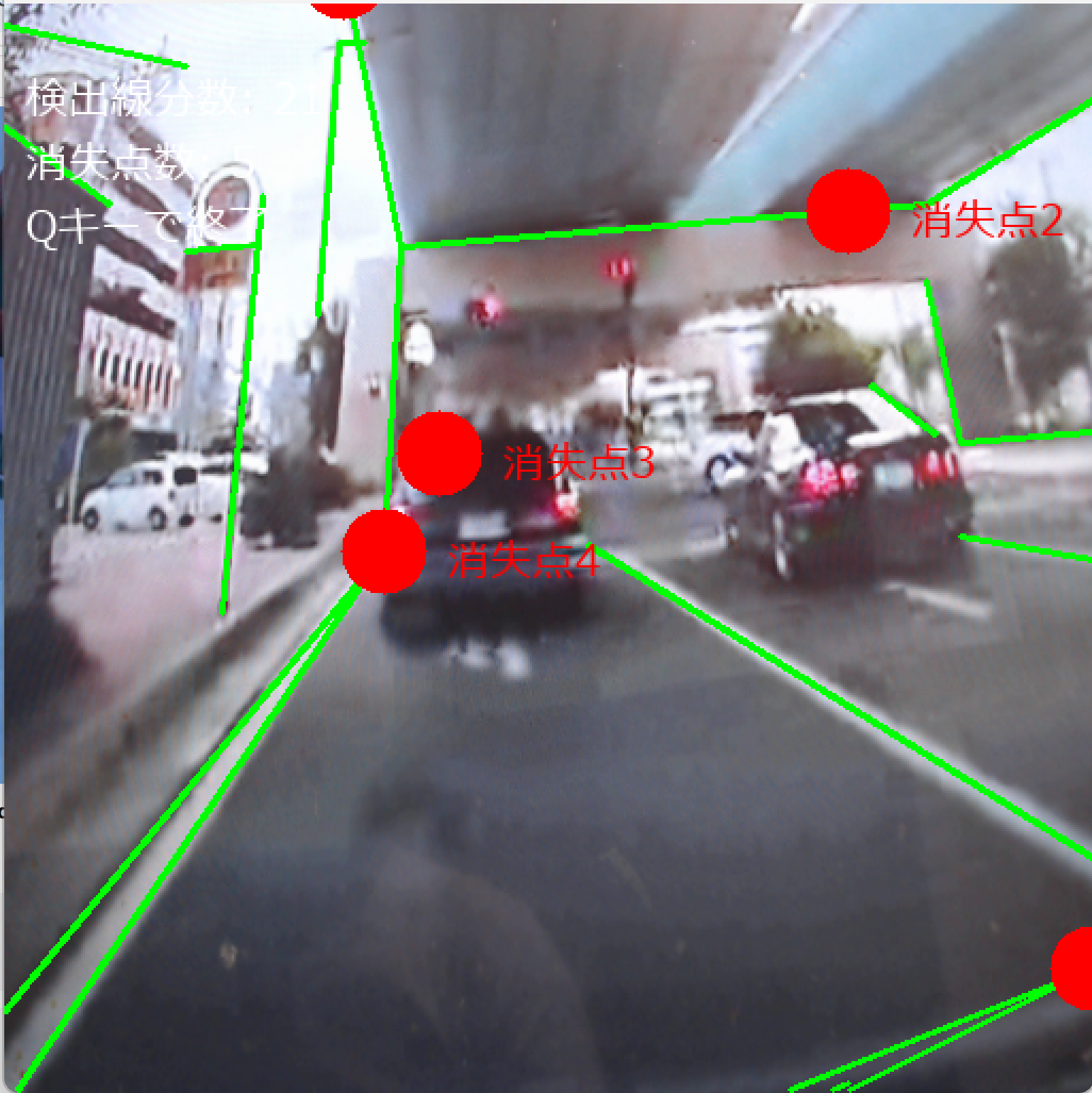
- LSD-VP消失点検出【概要】LSD(Line Segment Detector)は画像から線分を検出するアルゴリズムである。Hough変換より計算効率が高く、パラメータ調整不要という特徴を持つ。消失点は3次元空間の平行線が2次元画像上で収束する点である。処理は以下の手順で行われる。まず、LSDで画像から線分を検出する。次に、検出された線分の延長線の交点を計算する。そして、DBSCANで近接する交点をクラスタリングし、最後に各クラスタの中心を消失点として推定する。

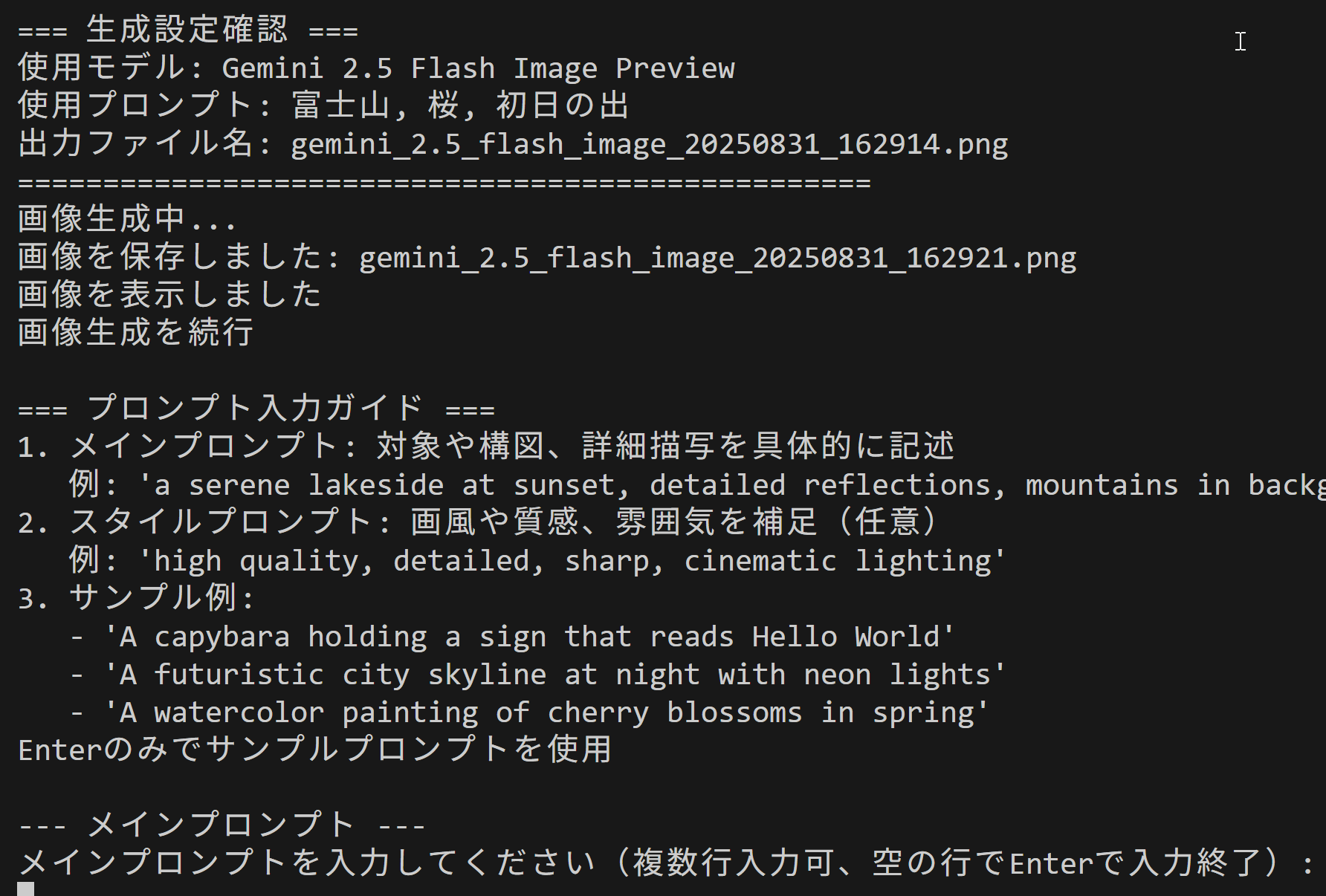
- Gemini 2.5 Flash Text-to-Image(画像生成)(ソースコードと実行結果)
【概要】テキストプロンプトからの画像生成(Text-to-Image)を行うPythonアプリケーション。メイン・スタイルプロンプト分離入力、複数行対応、タイムスタンプ付き保存機能。API版なので料金に注意.

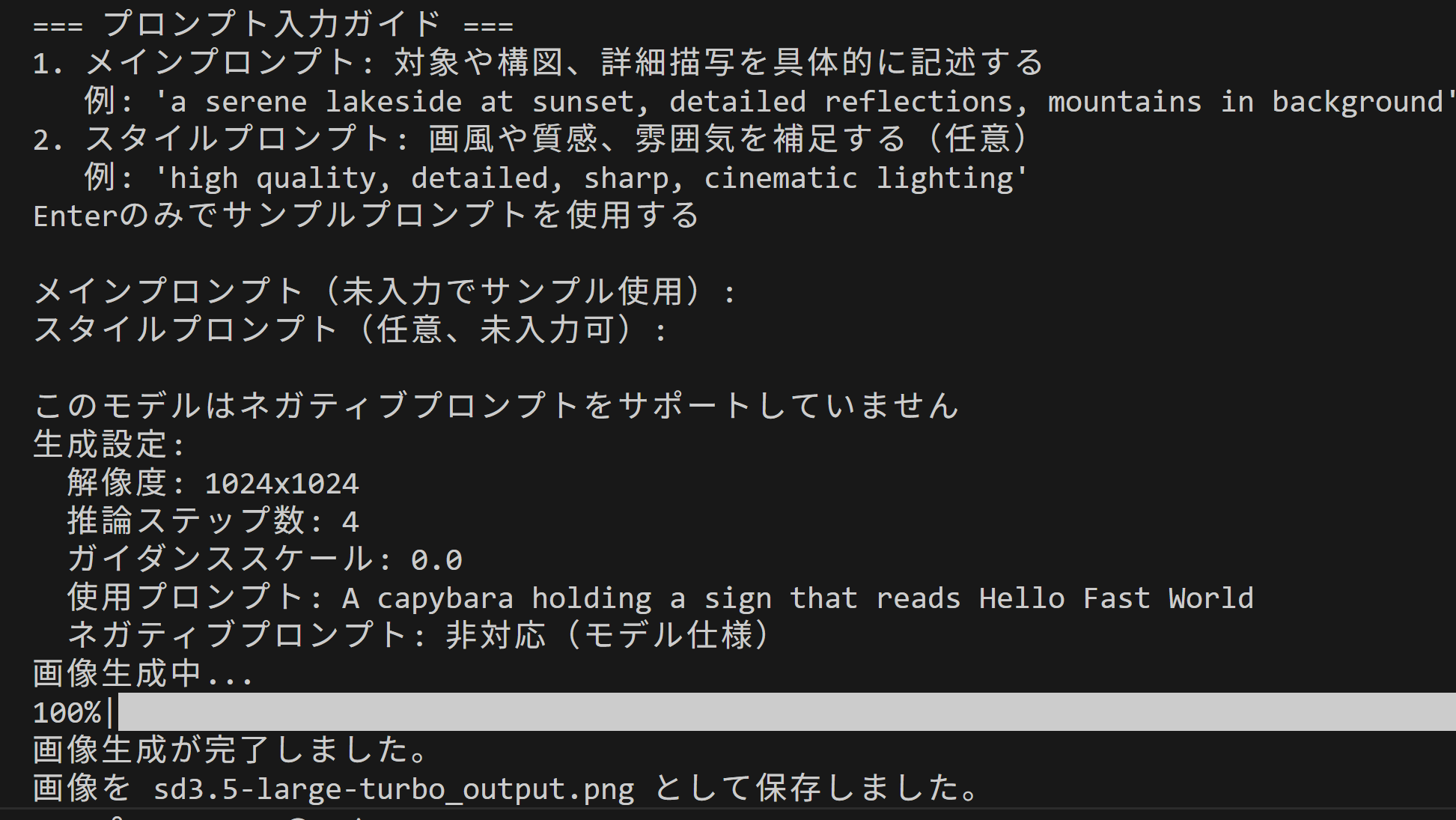
- Stable Diffusion 3.5 Large による Text-to-Image (GUI付き)(ソースコードと実行結果)
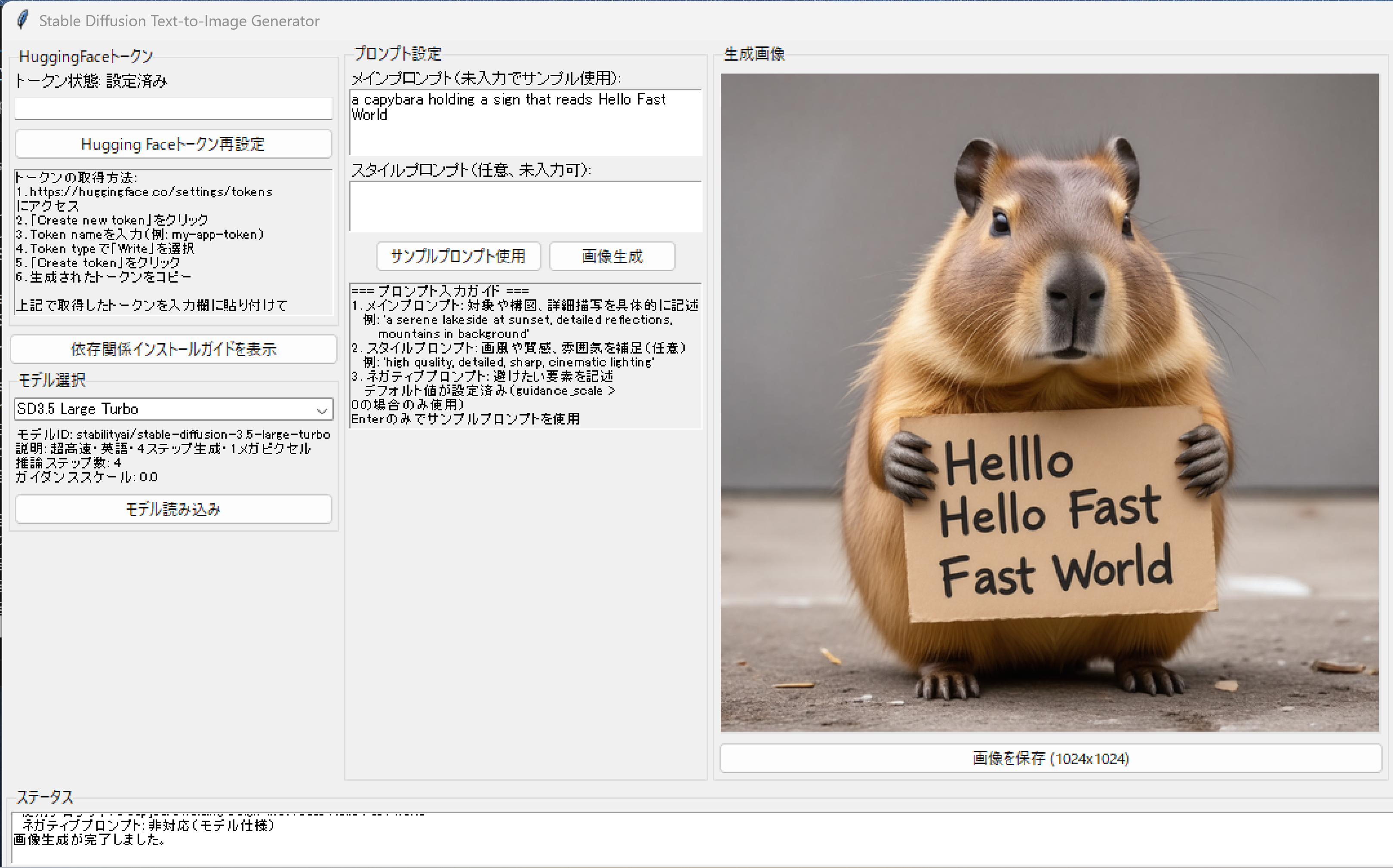

- Stable Diffusion 3.5 Large による Text-to-Image (ソースコードと実行結果)

- Nitro-E によるテキストからの画像生成(ソースコードと説明と利用ガイド)
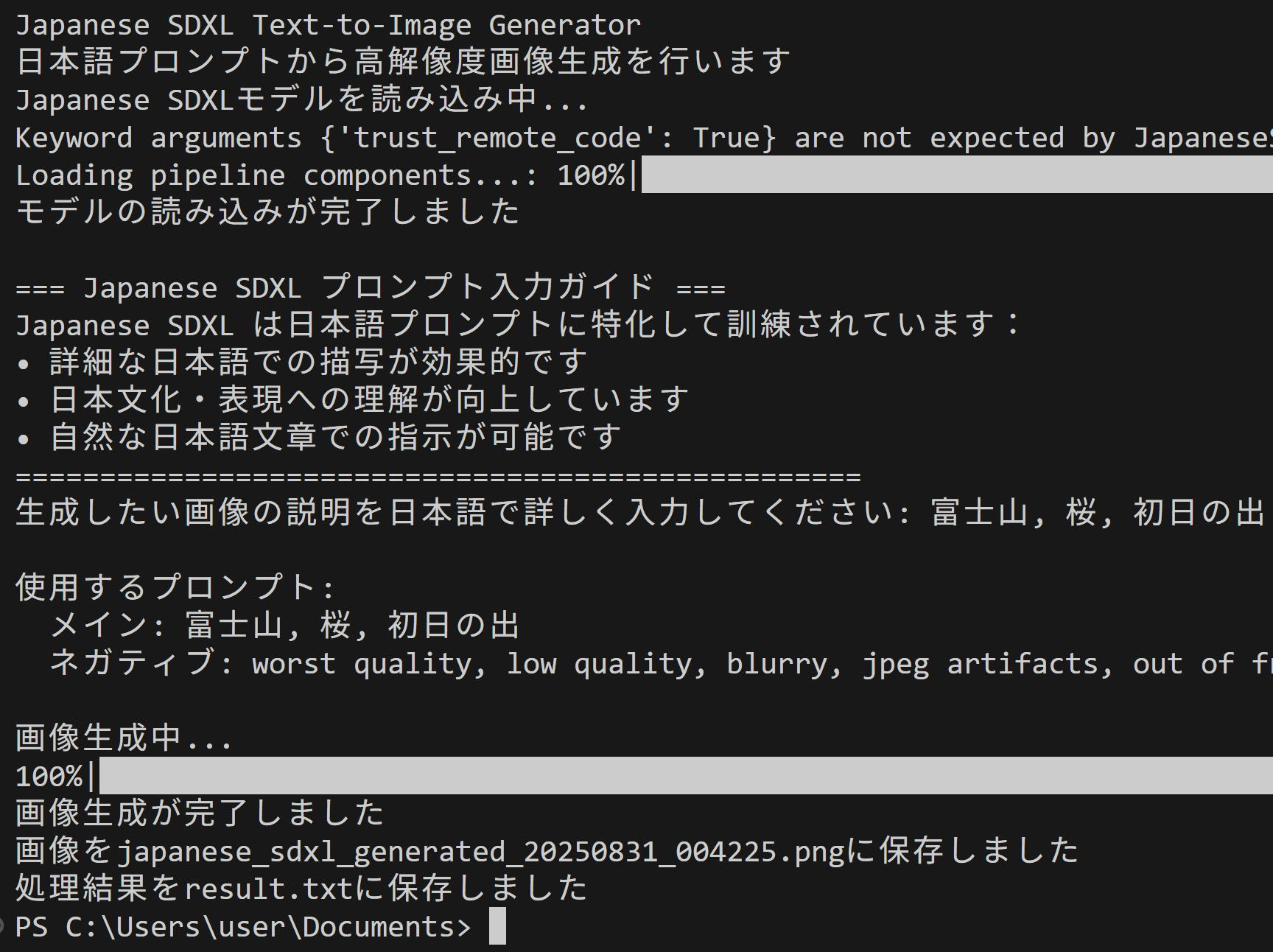
- Japanese SDXL Text-to-Image Generator による日本語テキストからの画像生成(ソースコードと実行結果)

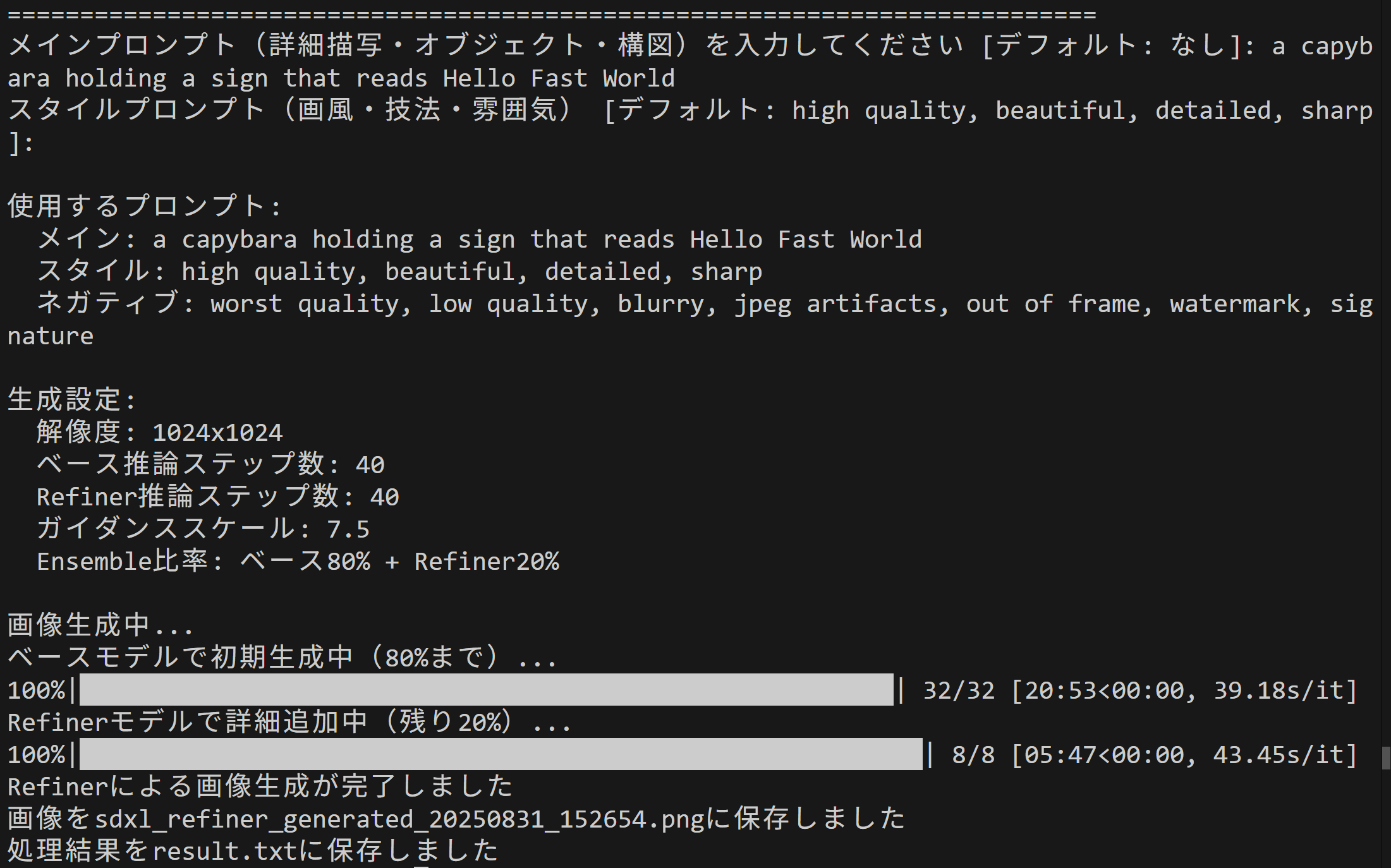
- SDXL Text-to-Image Generator with Refiner and Dual Text Encoders によるテキストからの画像生(ソースコードと実行結果)

- 地形侵食シミュレーション
【概要】Python + NumPyによる物理ベースの水力侵食シミュレーション。fBmノイズで初期地形を生成し、降雨・水流・土砂運搬・堆積の物理プロセスを統合計算。128×128グリッドで100m×100mスケールの地形を数百年の侵食過程で変化させ、自然な河川パターンと谷地形を生成する。

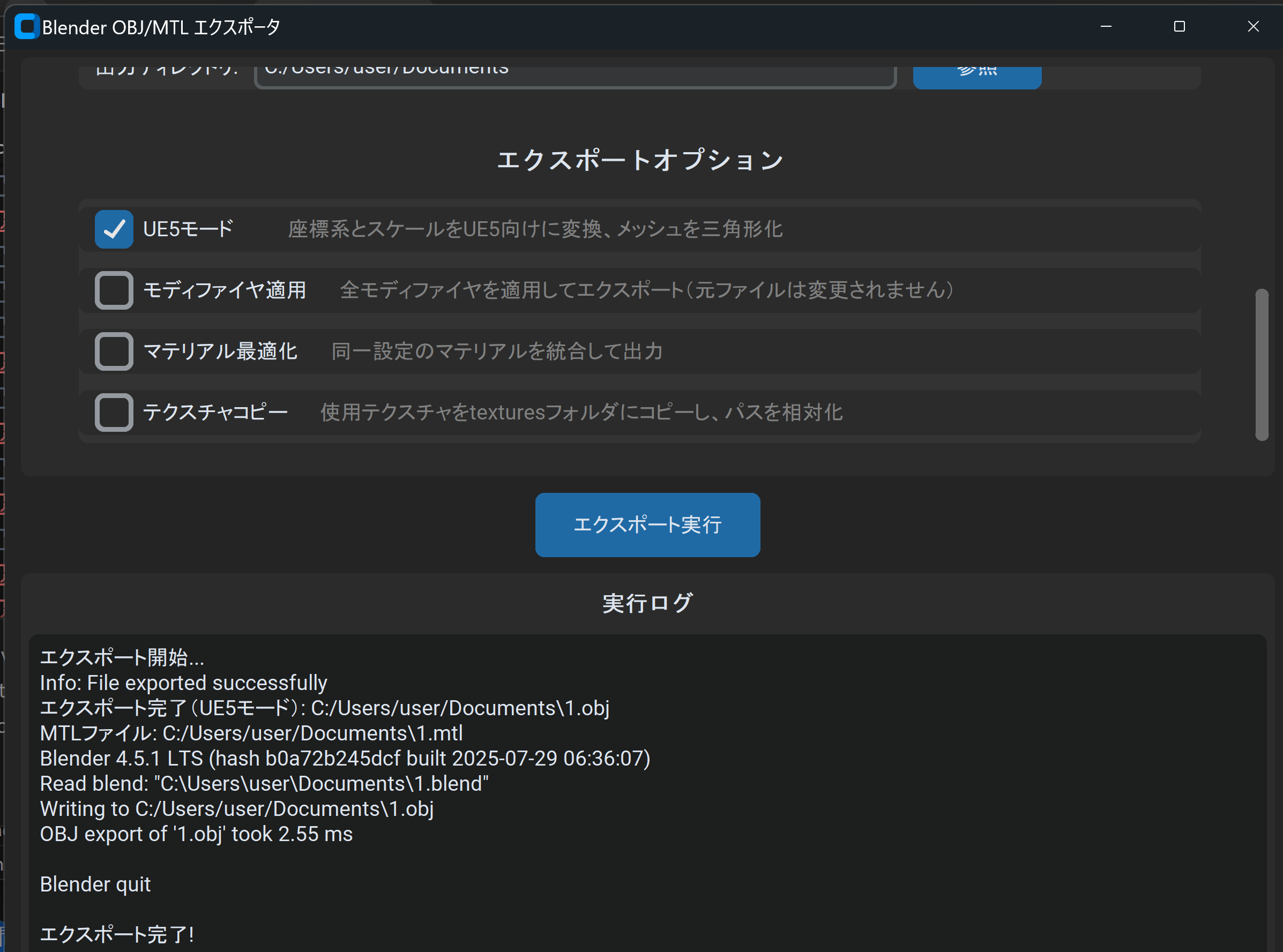
- Blender OBJ/MTL エクスポータ(UE5モード付き)(ソースコードと実行結果)
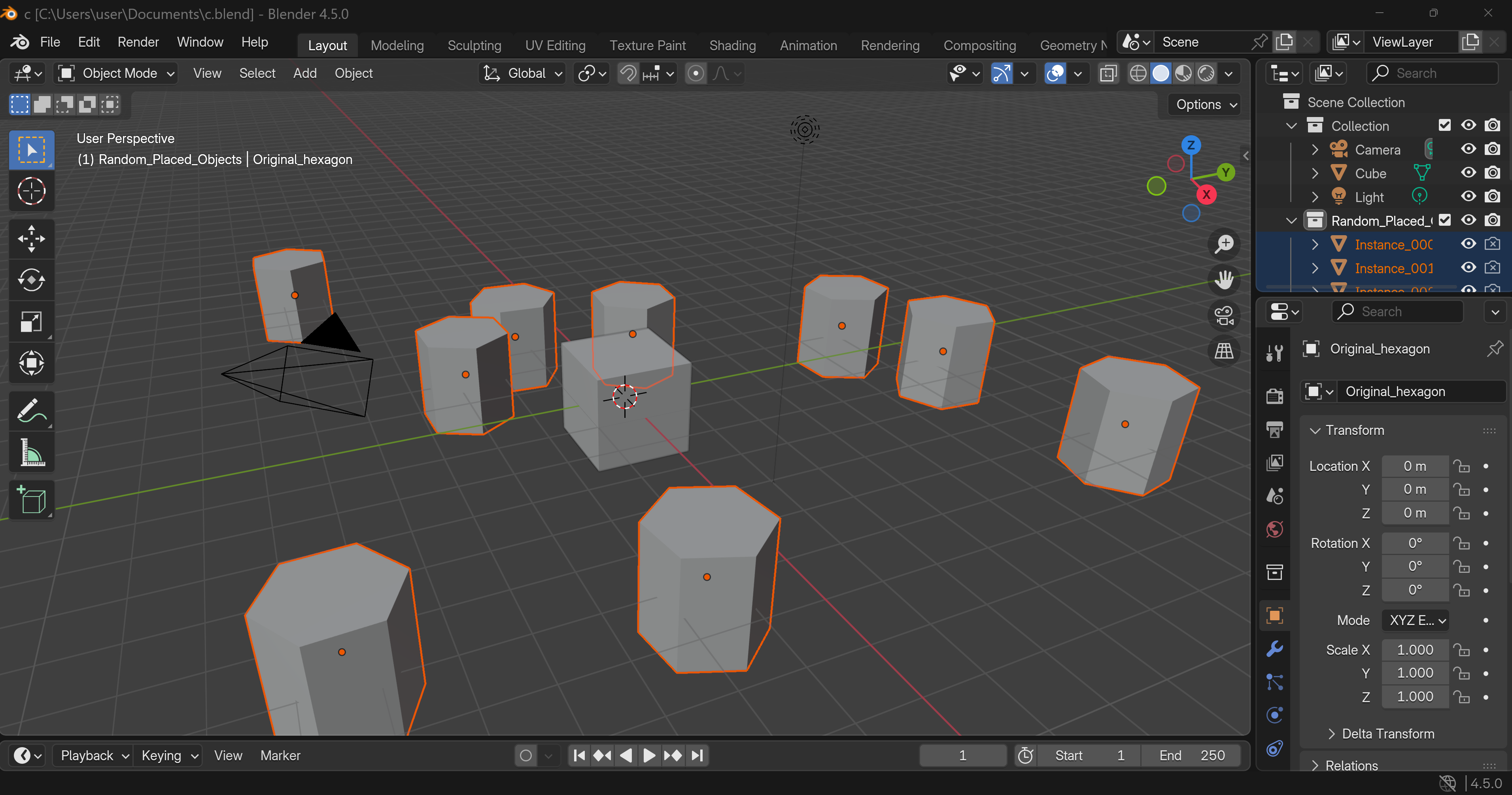
- Blender に3Dアセット(obj,mtl)の配置(ソースコードと実行結果)
- VGGT による多視点画像からの3次元再構成デモ
- TRELLIS による画像から3Dアセットへの変換(ソースコードと実行結果)
- TripoSR による単一画像からの3次元モデル推定
- Shap-E Text-to-3D Generator
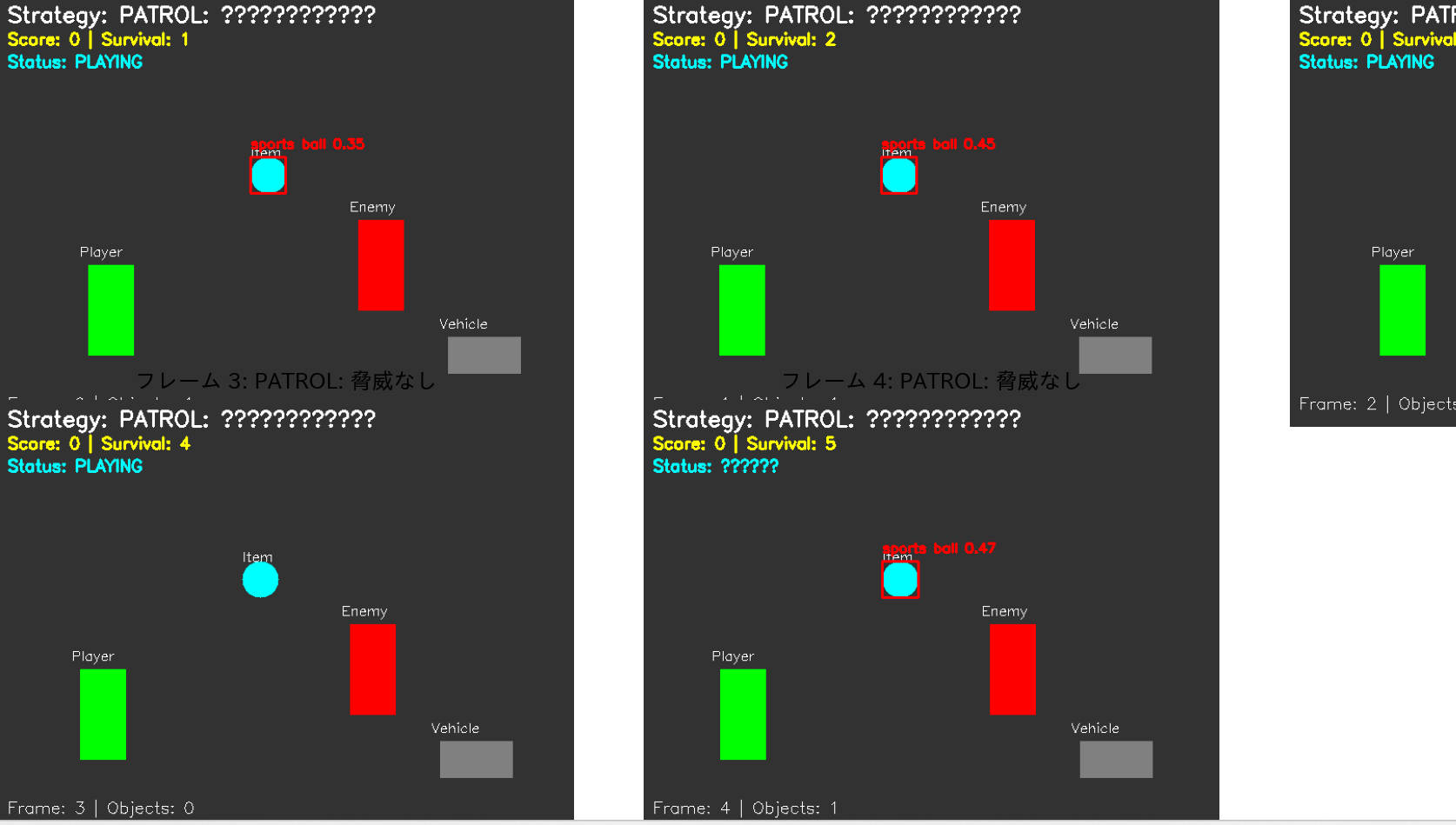
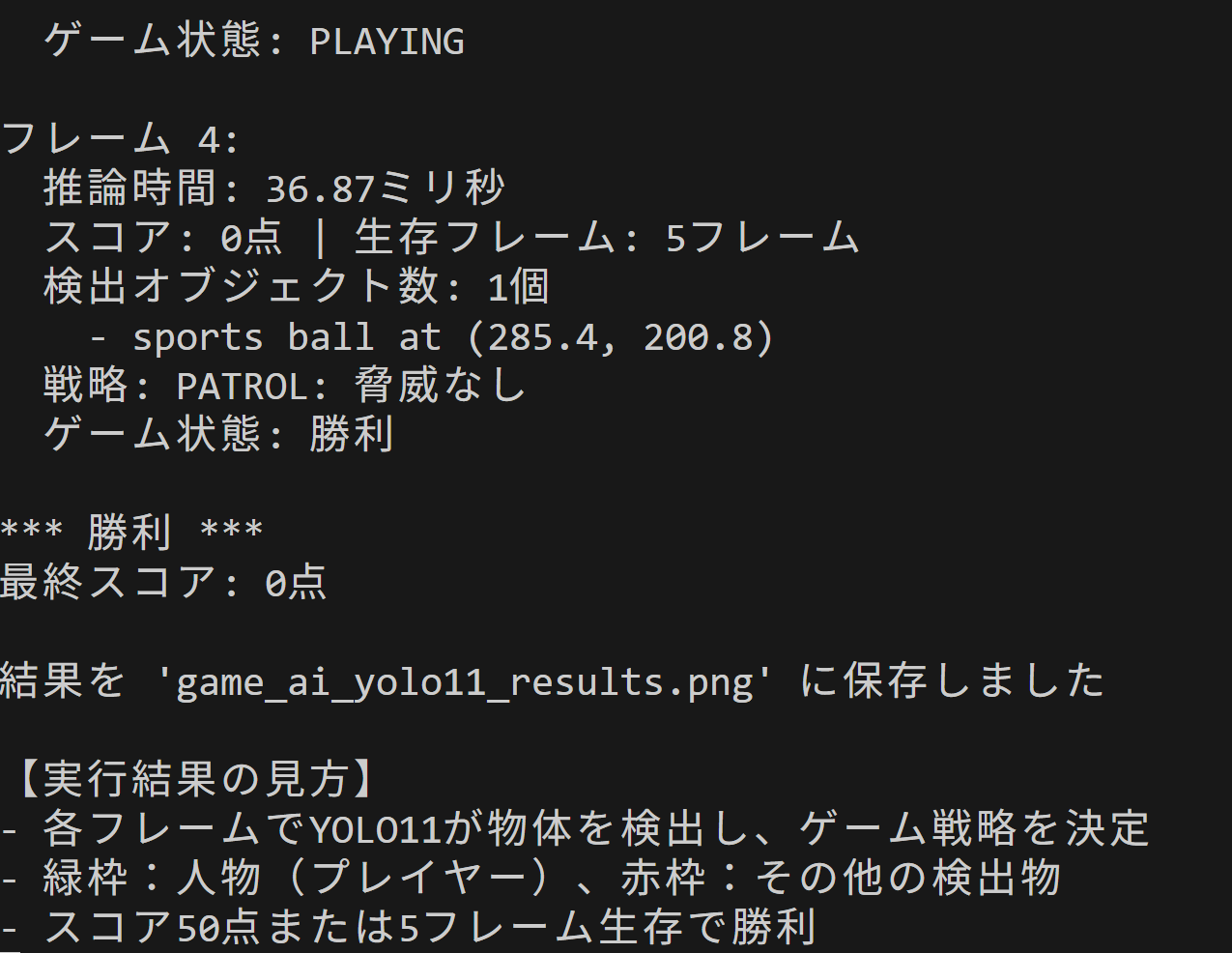
- ゲーム画面でのアイテム認識と戦略決定
【概要】 物体検出AI「YOLO11」を用いたゲームAI実装を体験する。YOLO11を活用し、ゲーム画面内の物体をリアルタイムで検出・分析するシステムを構築する。プレイヤー、敵、アイテムの認識から戦略決定まで、AIがゲーム状況を理解する過程を実際のコードで学習する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
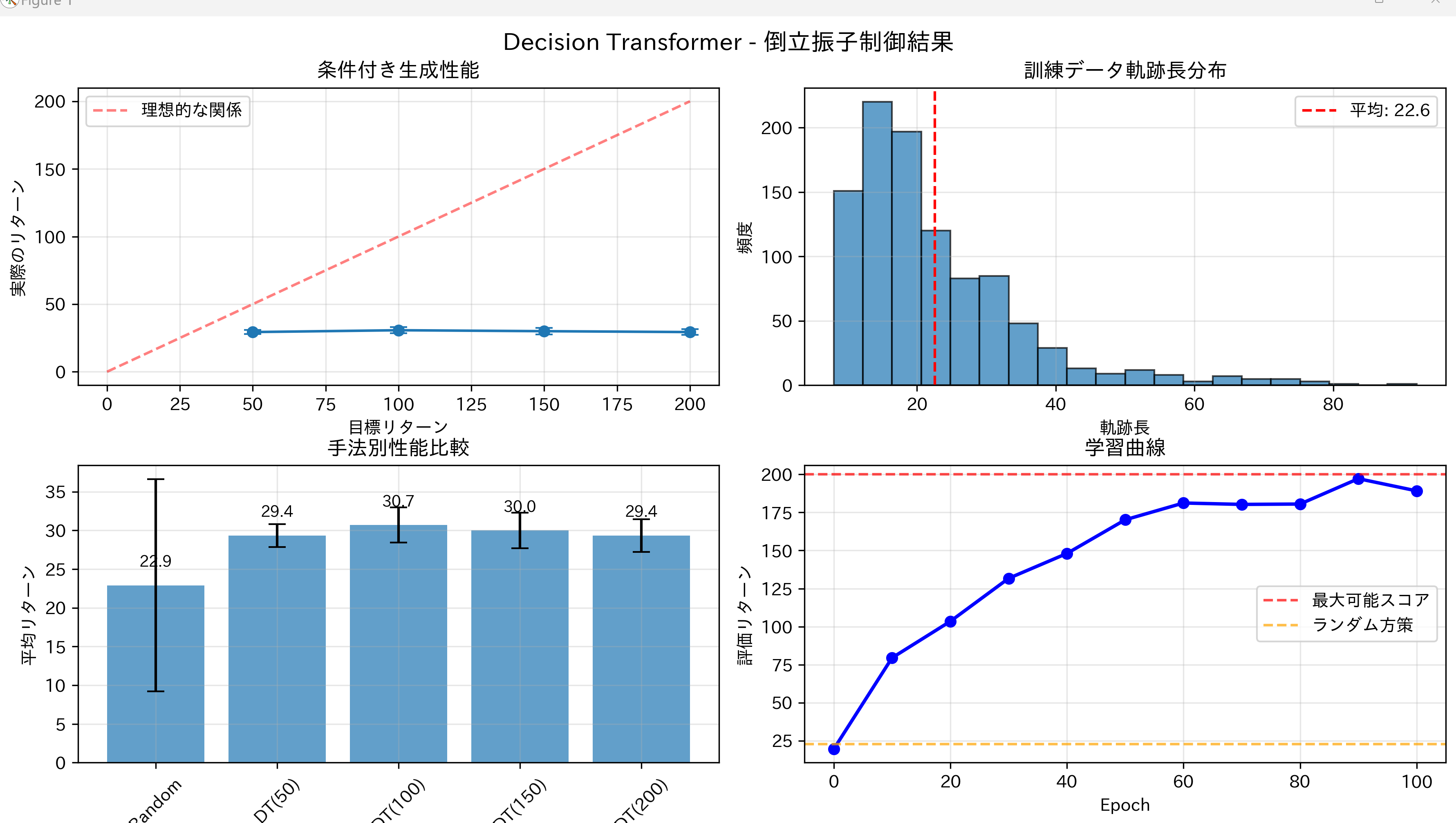
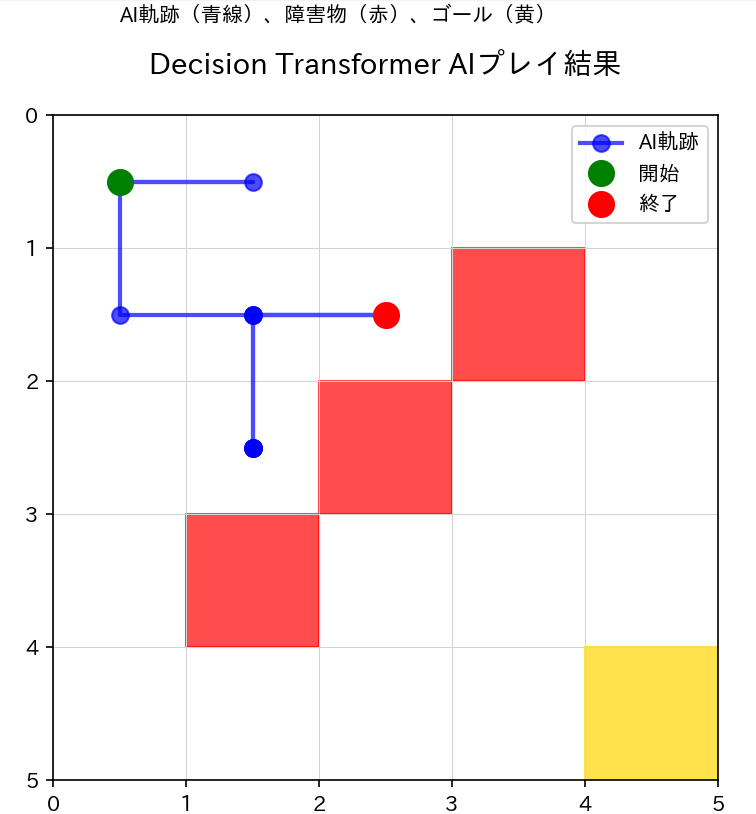
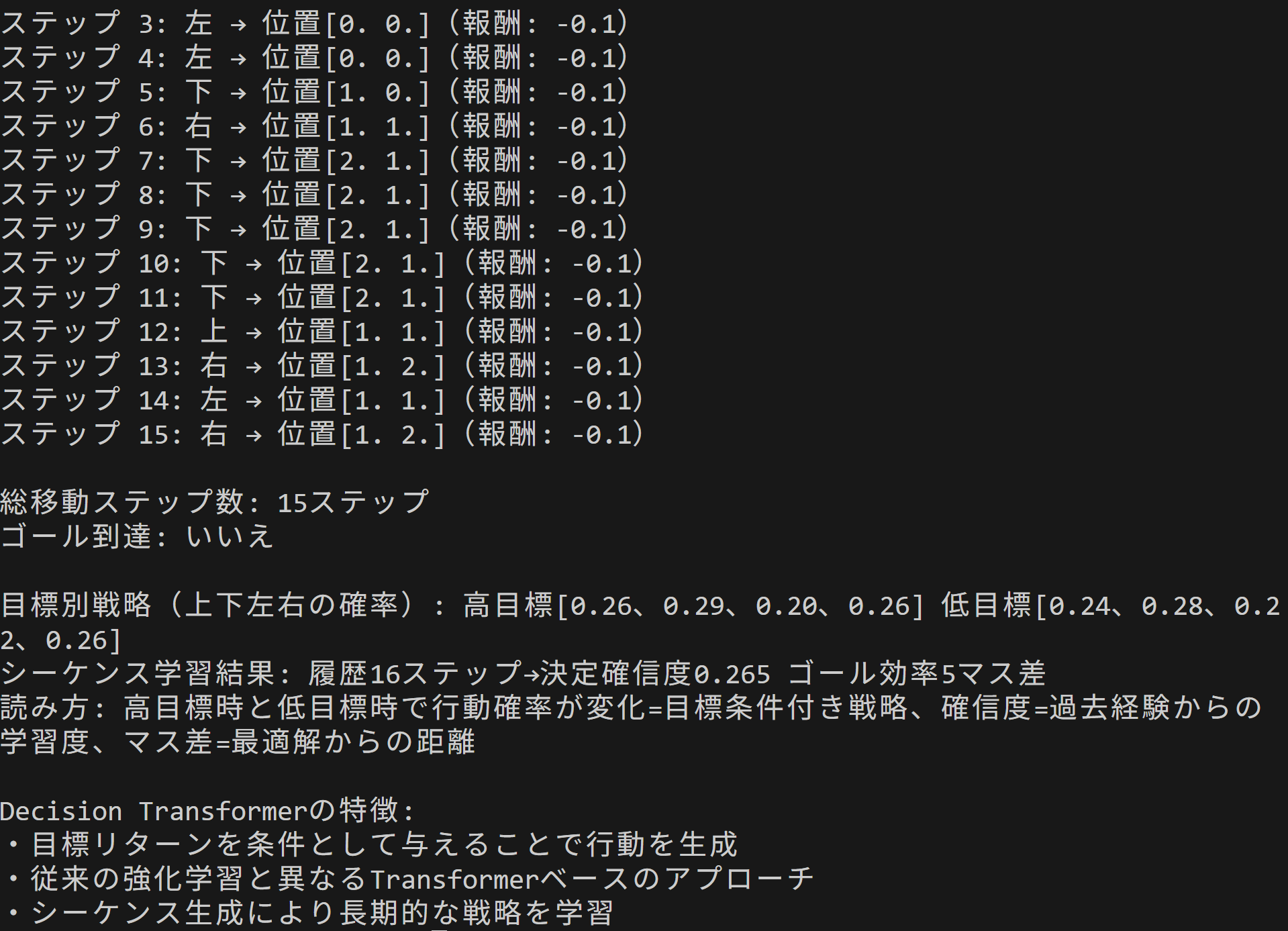
- Decision Transformerによる倒立振子制御エージェント




- Decision TransformerによるゲームAI
【概要】 Decision Transformerは強化学習を条件付きシーケンス生成問題として定式化する手法である。目標リターン(将来の累積報酬)を条件として与えることで、その目標を達成する行動系列を生成する。ここでは、5×5グリッドワールドゲームを題材に、AIが目標に応じて異なる戦略を選択する様子を実際に確認できる。
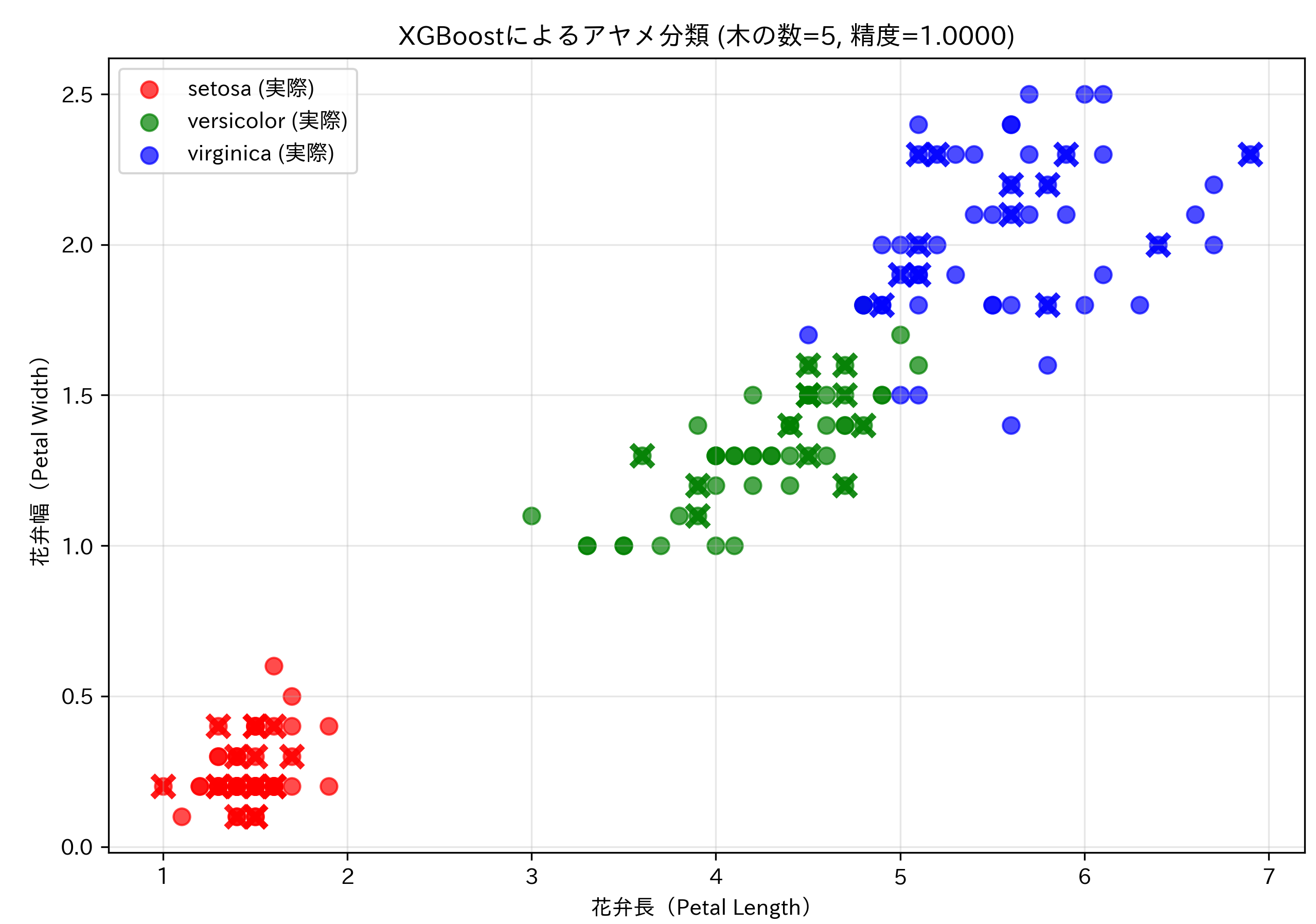
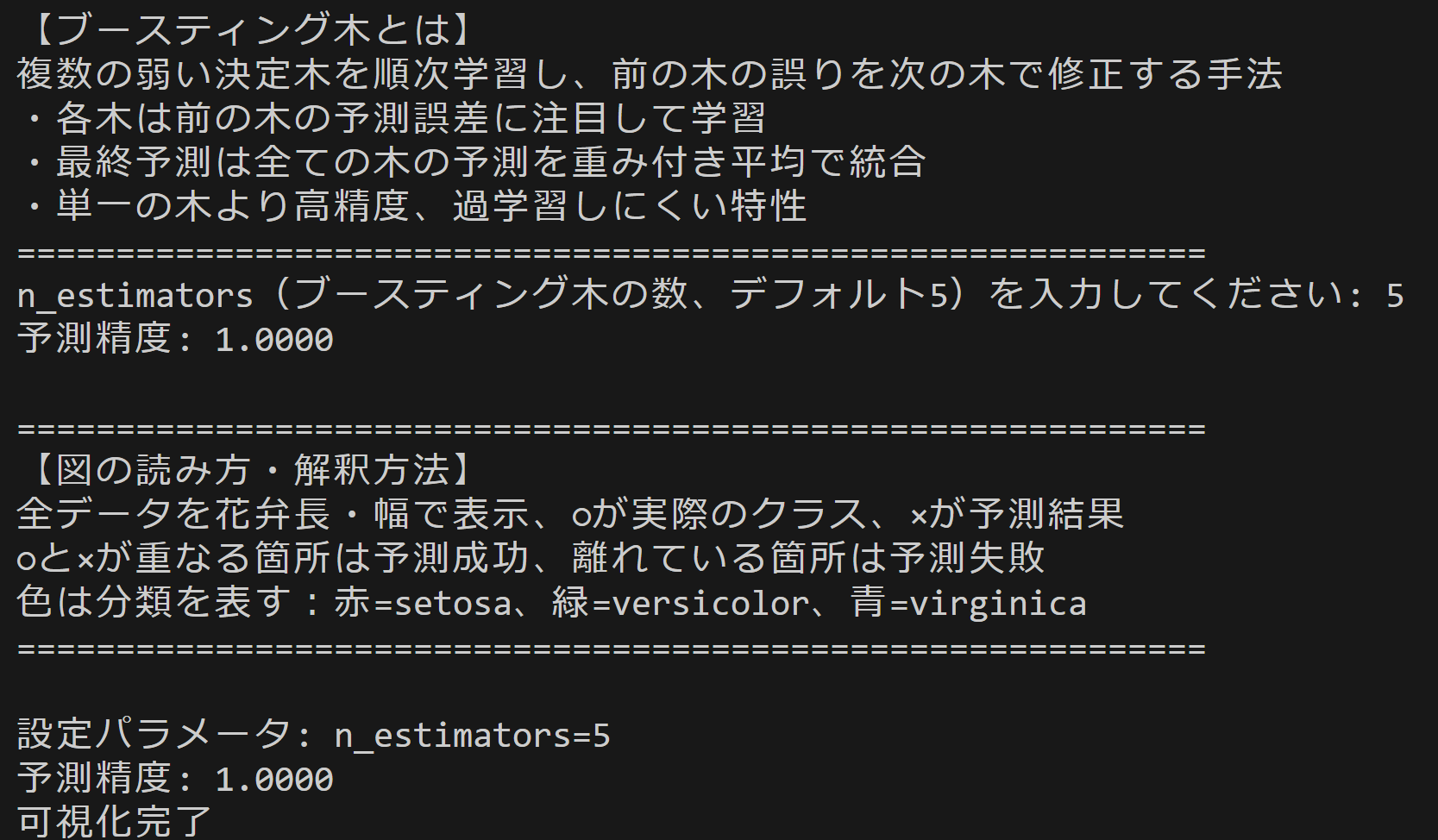
- XGBoost機械学習体験
【概要】XGBoostによるIrisデータセットの分類。決定木の数を変更して予測精度の変化を観察。機械学習の弱学習器組み合わせ概念を体験する。
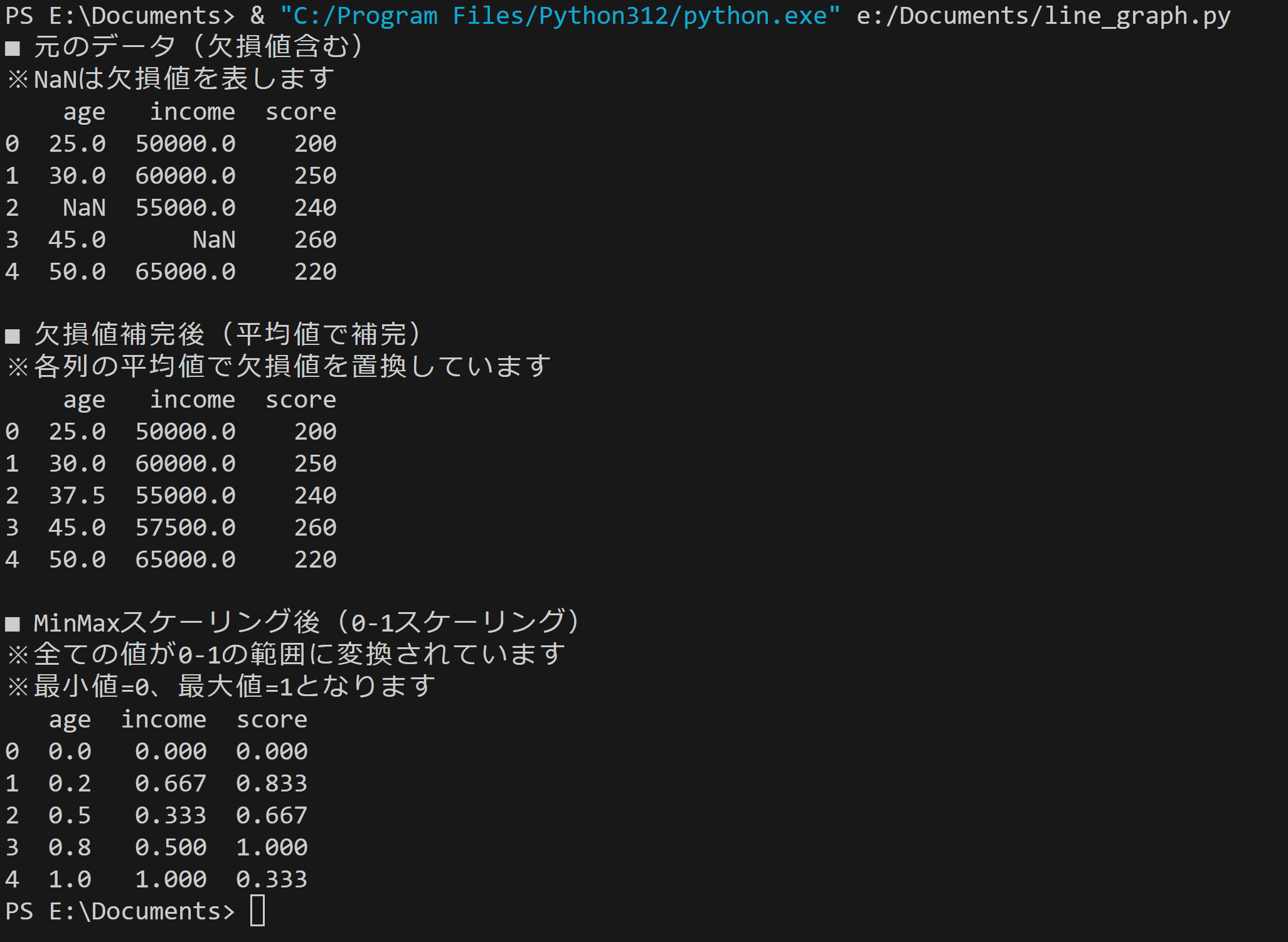
- データ前処理の例:欠損値補完とMinMaxスケーリング
【概要】scikit-learnを使用。データ前処理として、欠損値補完とMinMaxスケーリングを実行し、データの変化を観察。機械学習での前処理の重要性を確認する。
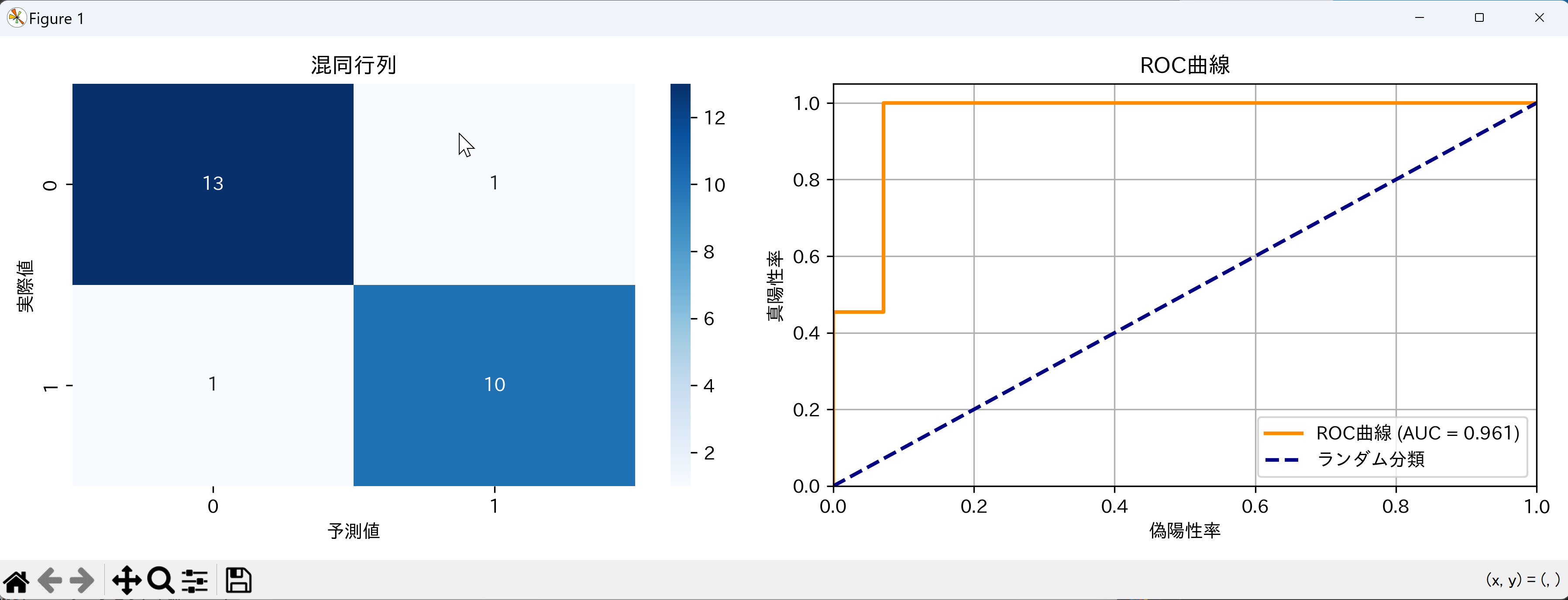
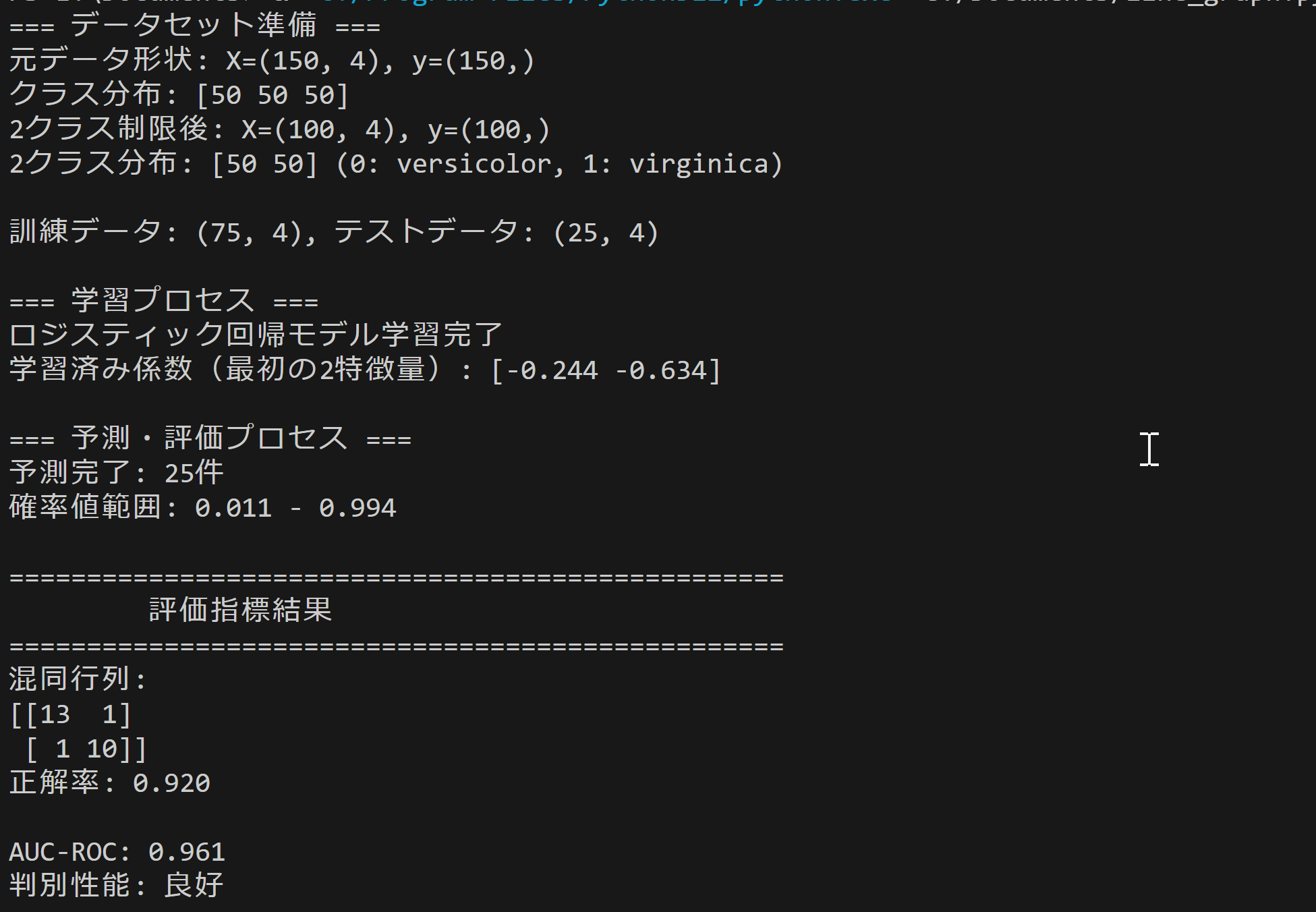
- ロジスティック回帰による分類性能の確認
【概要】ロジスティック回帰による二値分類の性能評価を確認する。混同行列、AUC-ROC、分類レポートによる評価手法。Irisデータセット(特徴量が明確で分類境界が適度に複雑な標準的二値分類問題)を使用し、異なる評価指標の意味と解釈方法を確認する。
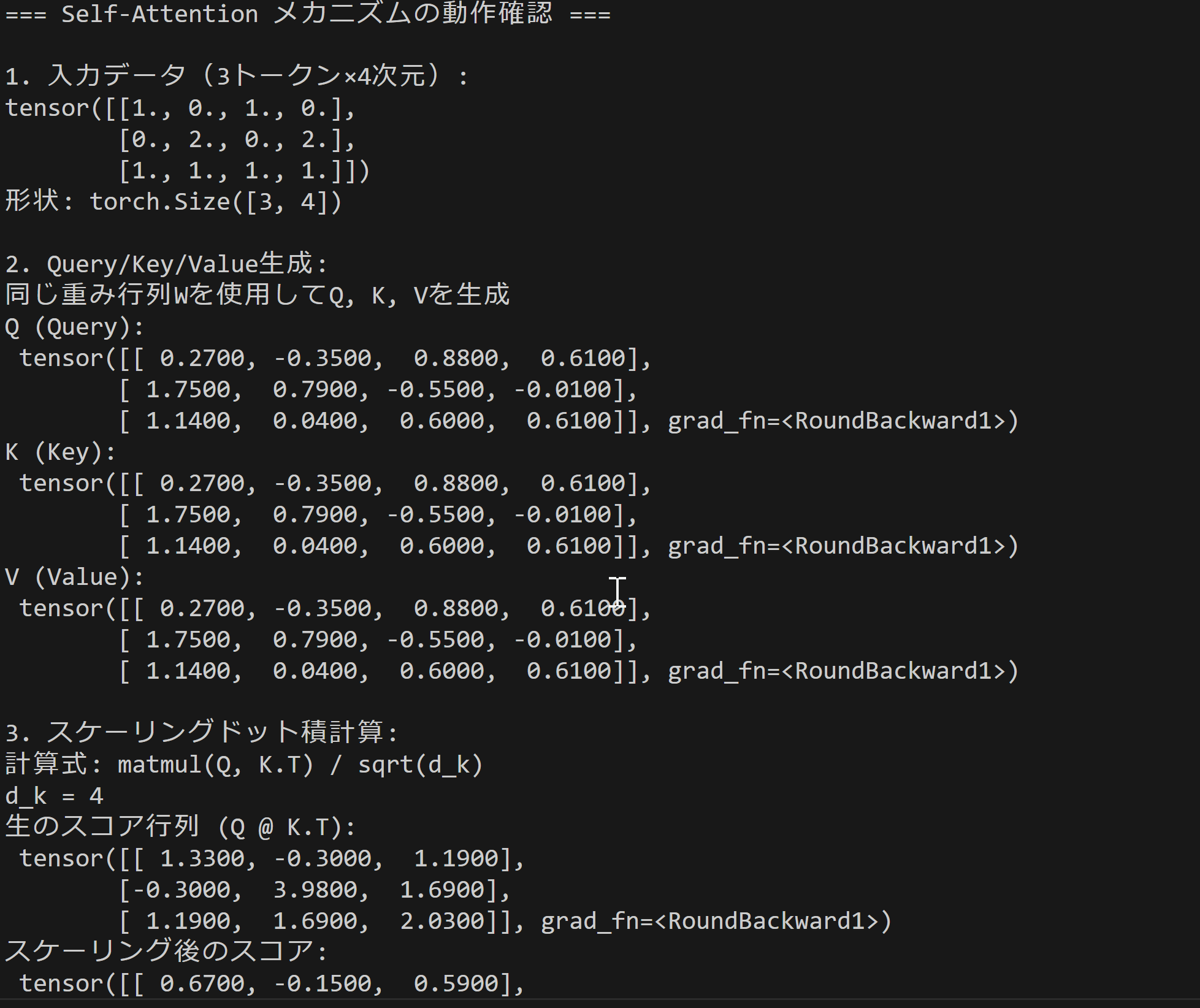
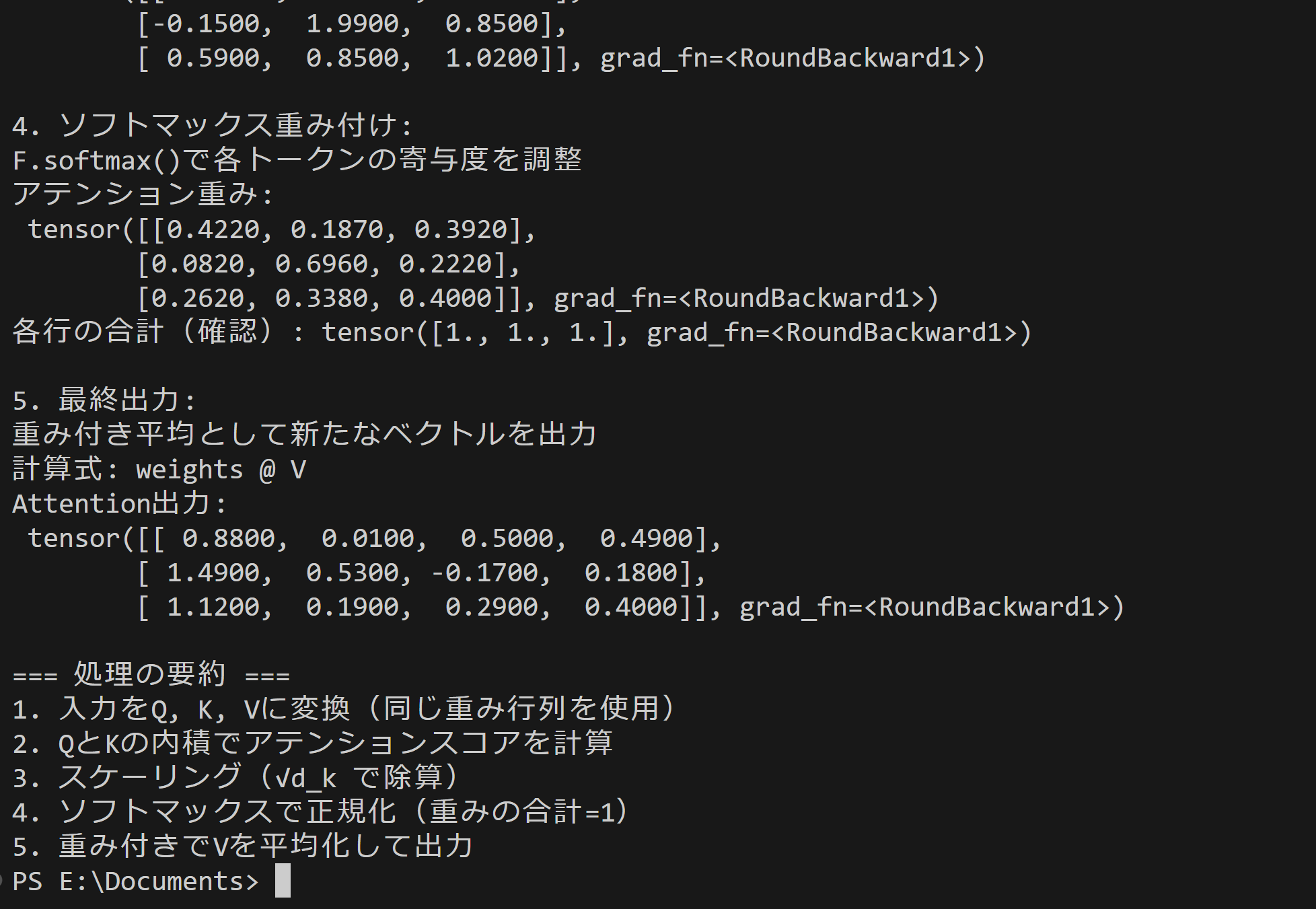
- Self-Attentionメカニズムの確認
【概要】PyTorchによるSelf-Attentionの基本動作を体験する。TransformerのQuery・Key・Valueによる重み付き平均計算を実習し、アテンション重みの変化を数値で確認する。
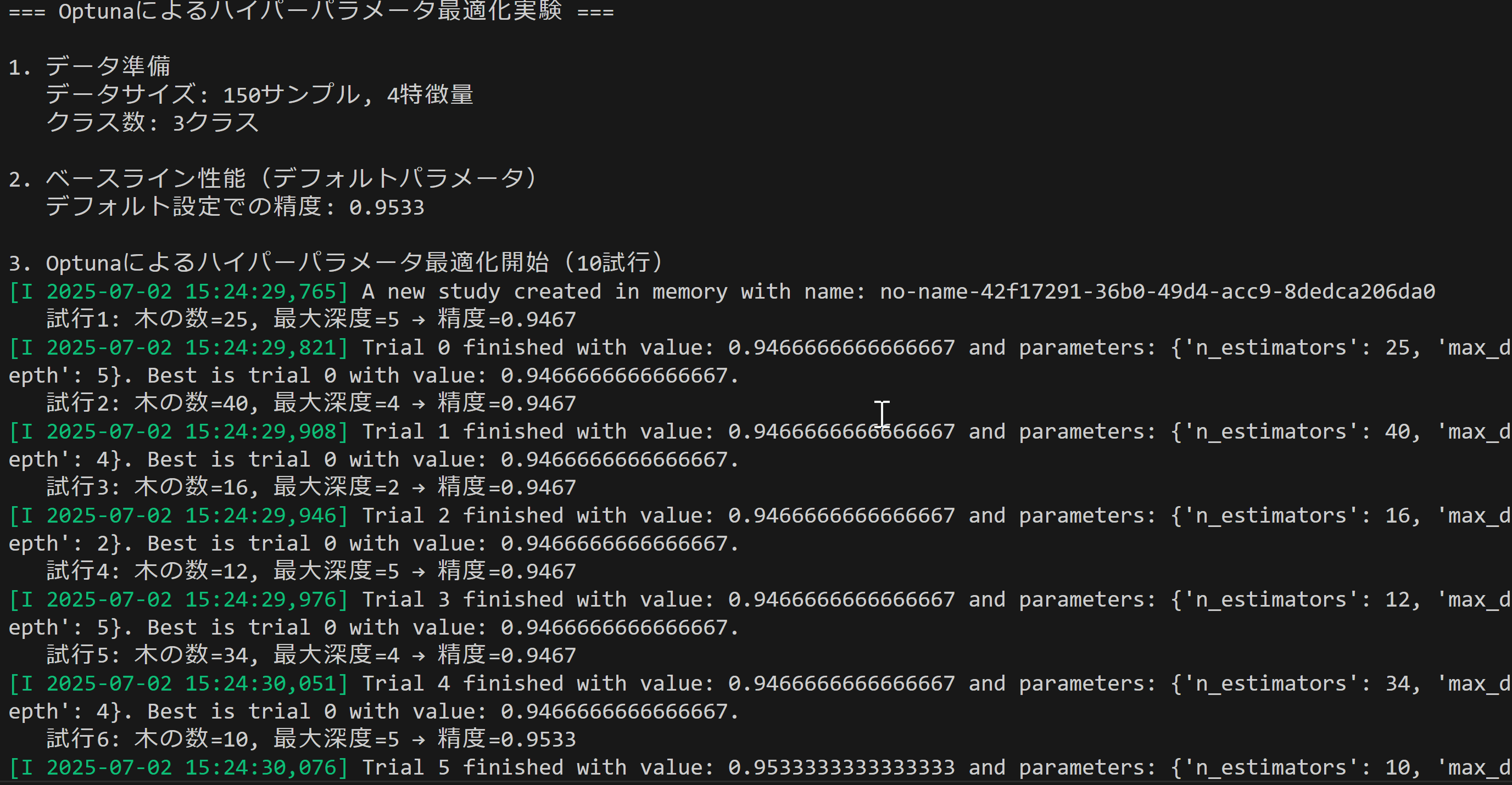
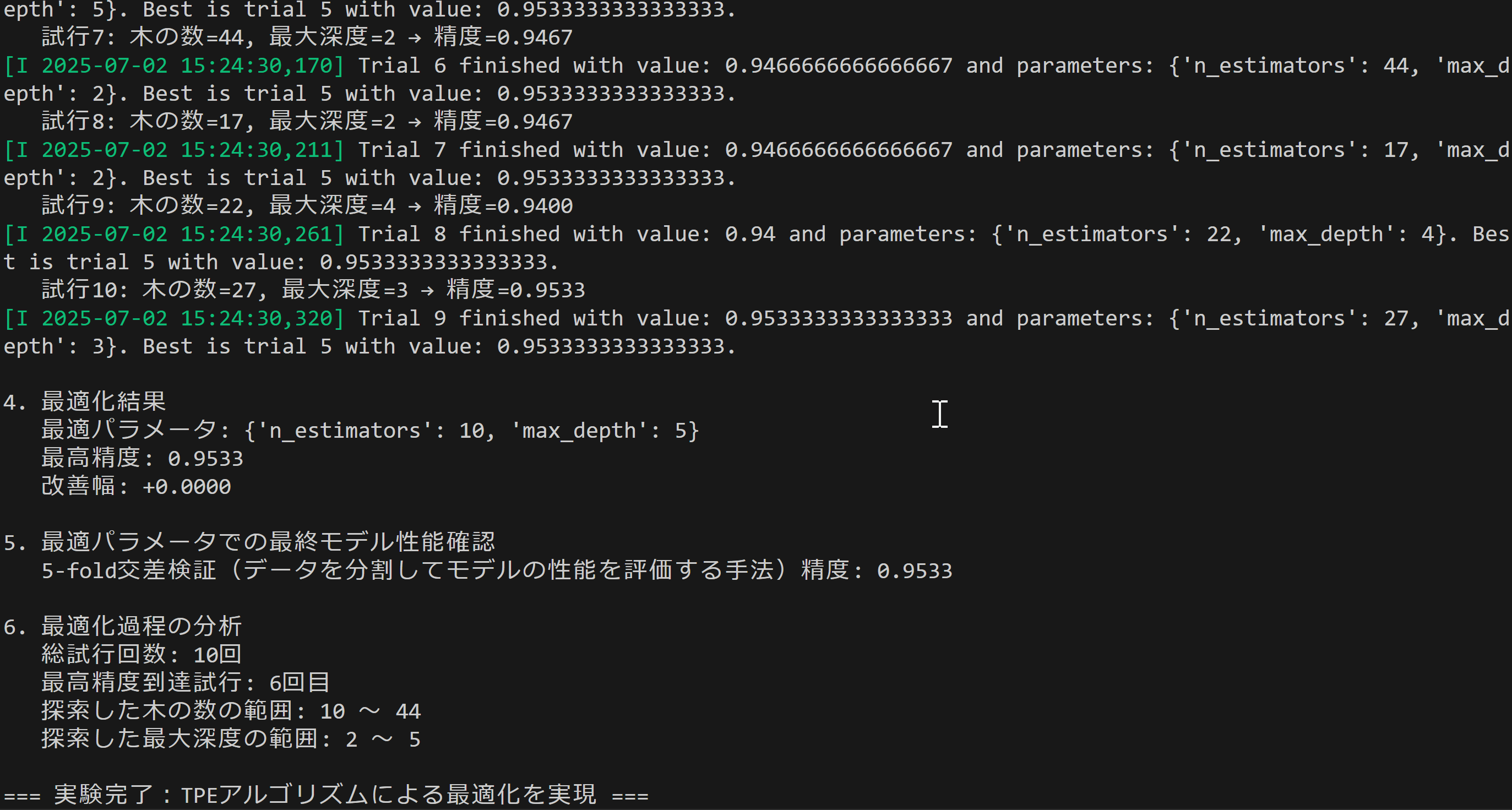
- Optunaによるハイパーパラメータ最適化
【概要】TPEアルゴリズムによるハイパーパラメータ最適化技術を体験。従来手法との比較実験により最適化を確認でき、機械学習モデルの性能向上手法を確認できる。
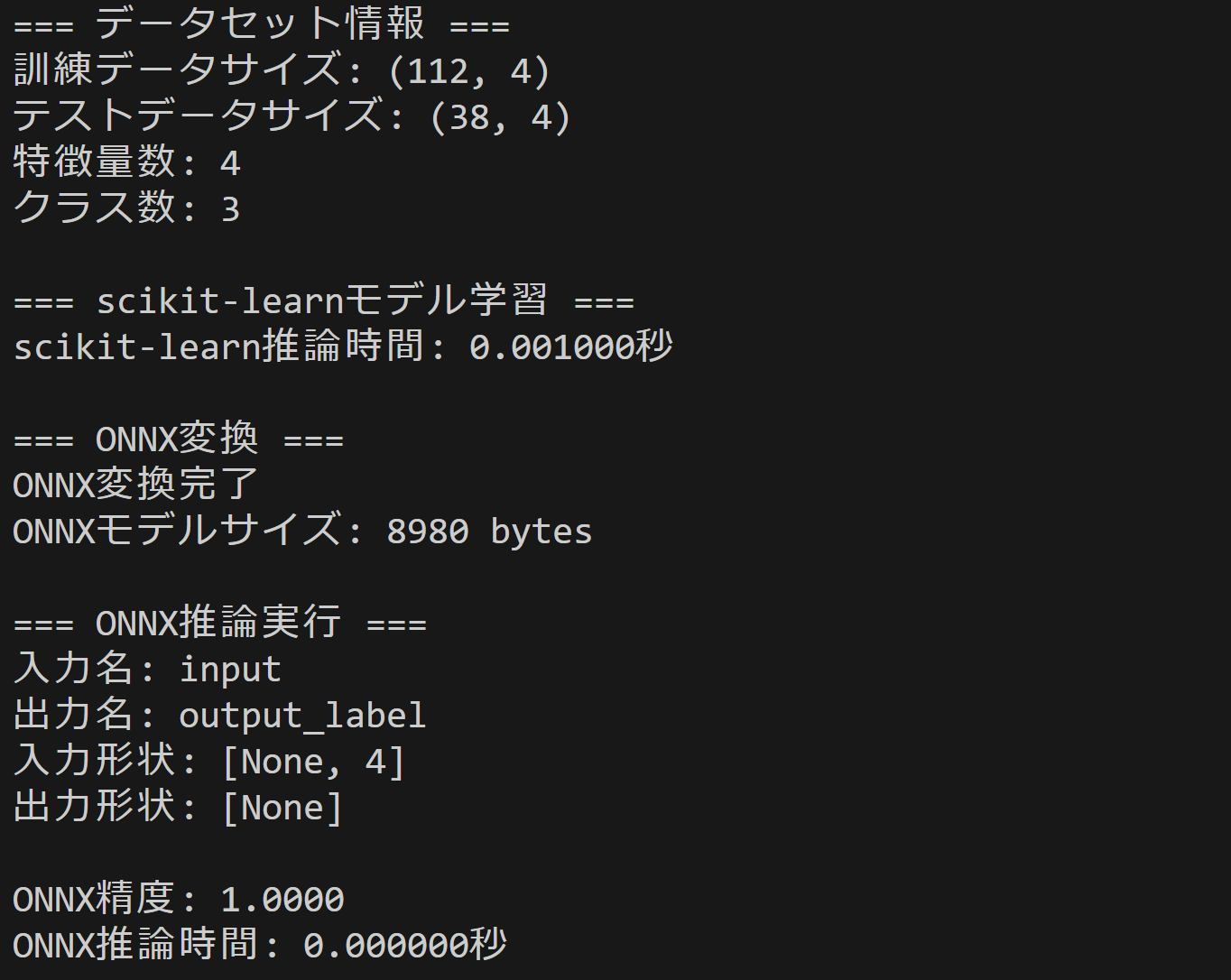
- ONNX機械学習モデル変換・推論
【概要】scikit-learnモデルをONNX形式に変換し推論性能を比較する。ONNXの相互運用性と効果を確認。RandomForestClassifierでの変換精度と速度変化を確認。

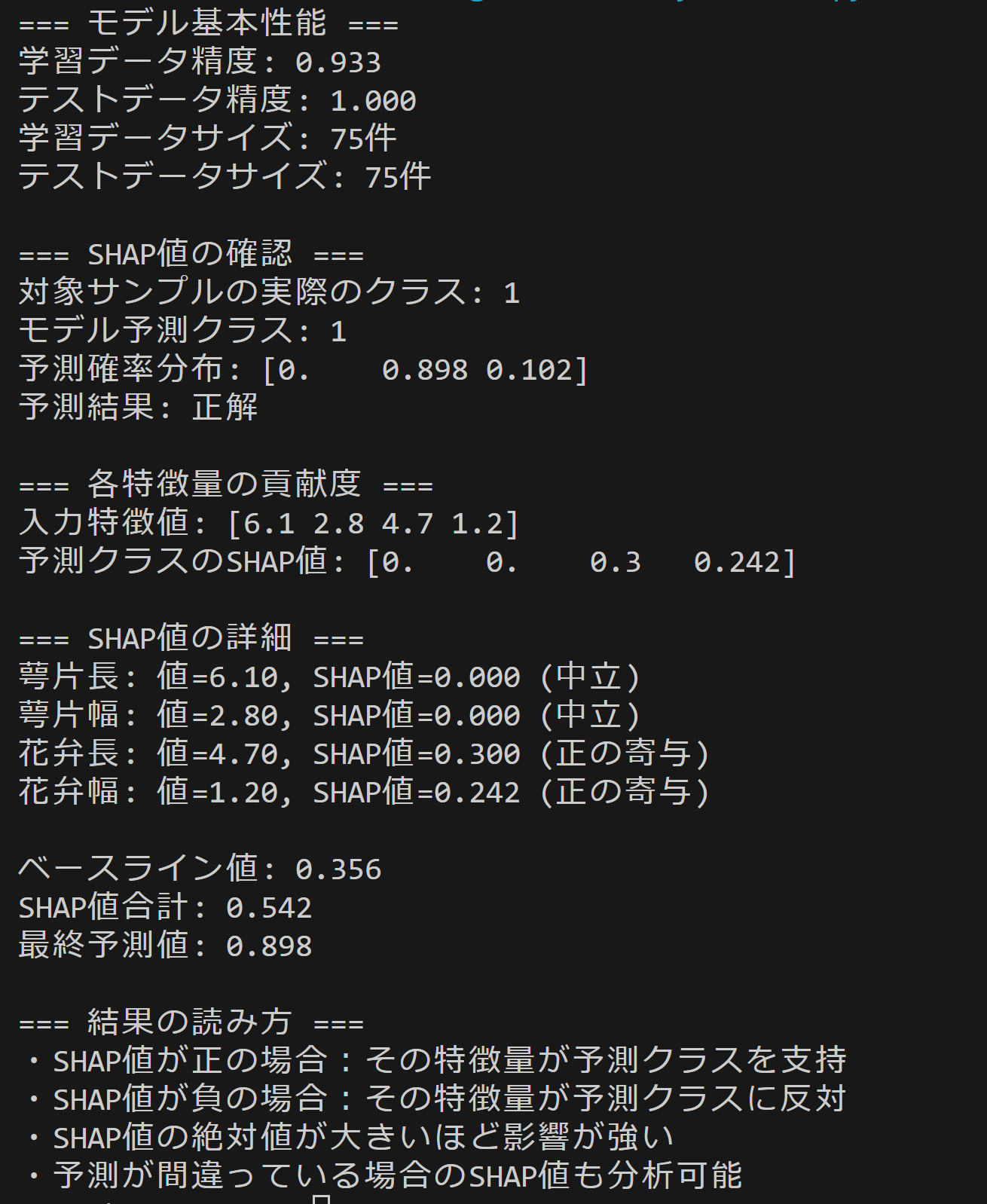
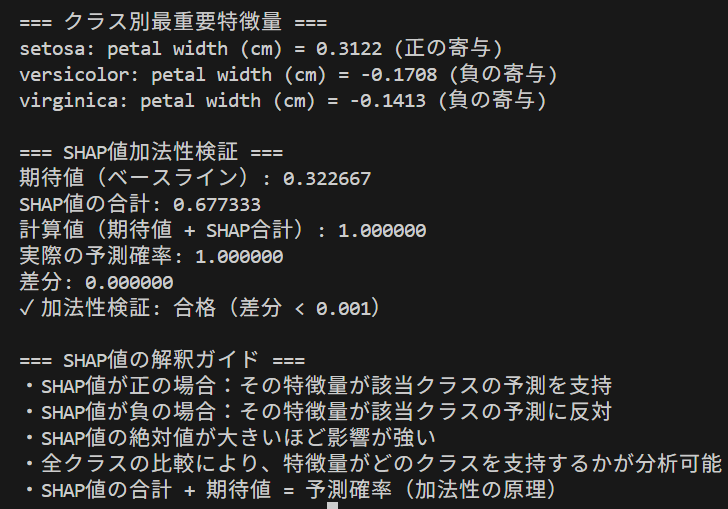
- SHAP説明可能性
【概要】SHAPはゲーム理論のシャプレイ値を用いて機械学習モデルの各特徴量の貢献度を定量化する手法である。医療診断支援や金融審査などで活用される。
- 深層学習による画像分類・タギングのテキスト
【概要】深層学習による画像分類では、CNN(例:ResNet)の畳み込み演算で局所特徴を抽出する。Vision Transformer(ViT)は画像パッチ間の関係性を計算する。ViTの一種であるEVA-02は、自己教師あり学習で精度の改善を達成している。用途に応じてモデル選択が重要で、高精度用途にはEVA-02、リアルタイム処理にはResNetを選択する。
- InsightFace顔情報処理のテキスト
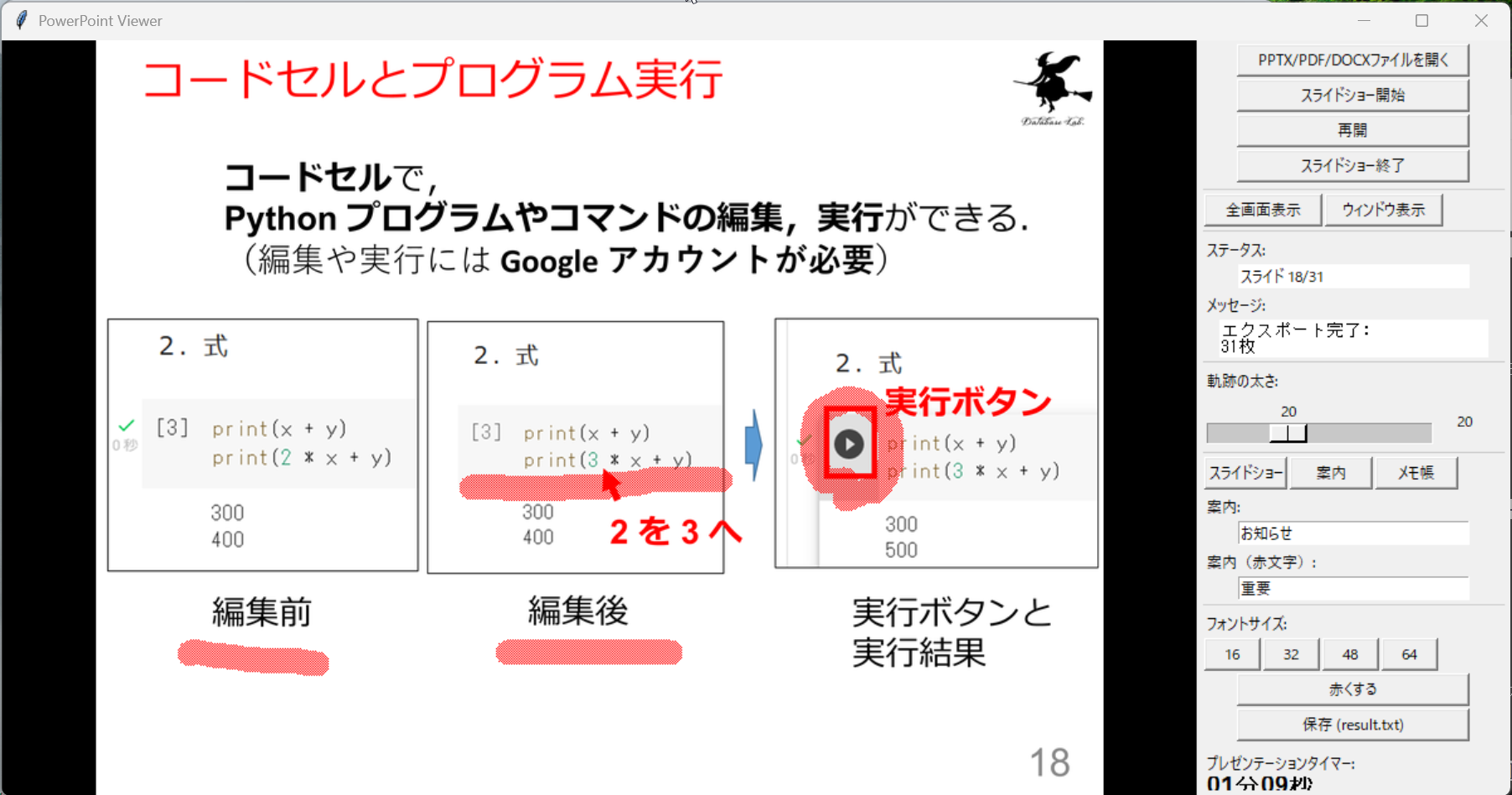
- PowerPointファイルビューワ・Windows用(動作にPowerPointが必要)
【概要】PowerPoint、PDF文書を画像変換してスライド表示するWindowsデスクトップアプリケーション。スライド表示中にマウスで赤い線を描画でき、案内表示モードやメモ帳モードを搭載。全画面対応、プレゼンテーションタイマー付き。
- PowerPoint差分検出
【概要】2つのPowerPointファイル間の変更を自動検出するPythonプログラム。python-pptxライブラリとMD5ハッシュを使用して、テキスト変更・位置変更・サイズ変更・書式変更を検出し、レポートを生成する。
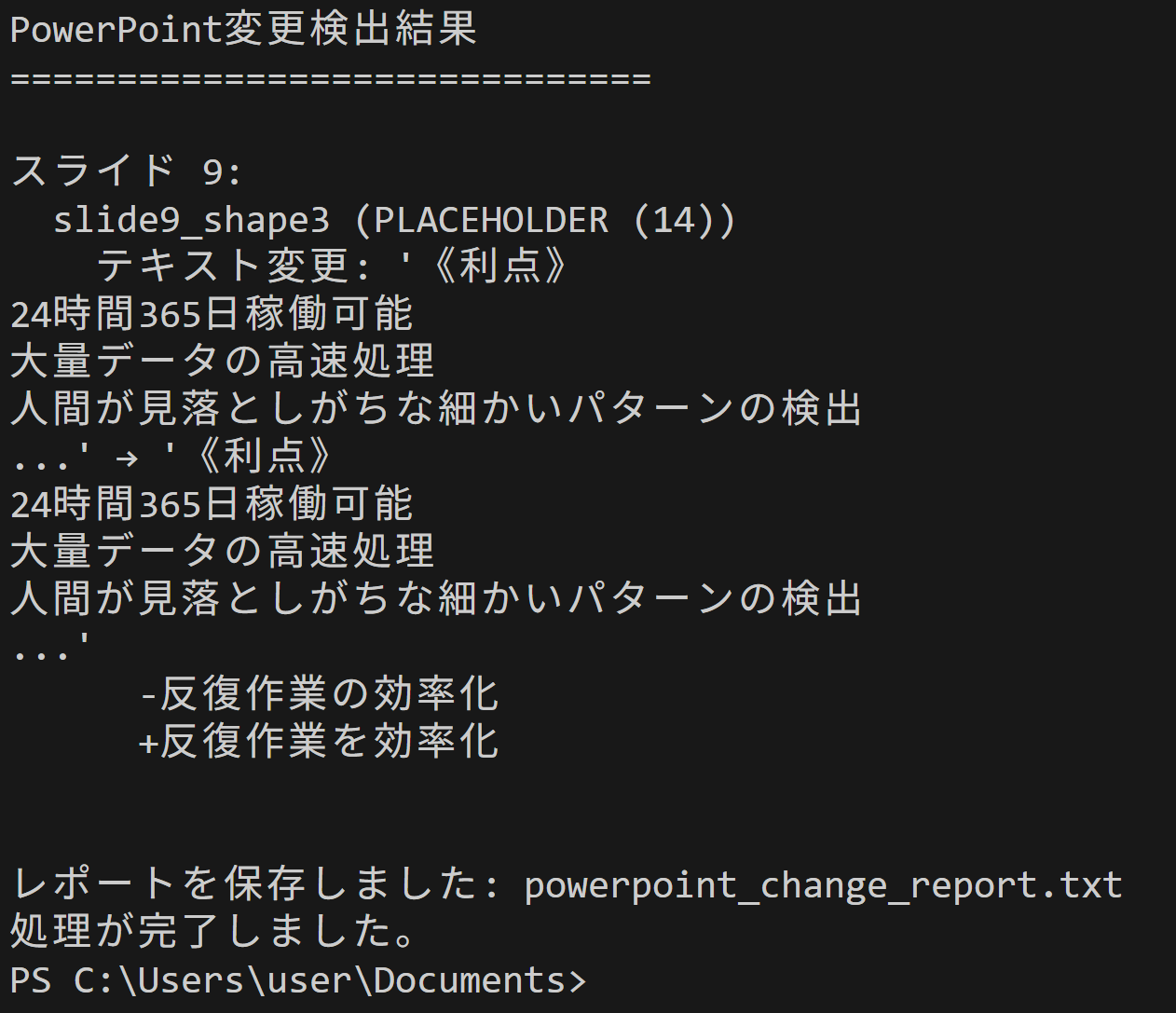
- PowerPointテキスト置換ツール
【概要】python-pptxライブラリを使用したPowerPointファイルのテキスト置換ツールを体験する。本ツールは、Office Open XML形式のファイル内部構造を直接操作し、フォント書式を保持しながら一括置換を実現する。プレゼンテーション資料の更新作業を効率化できるツールである。

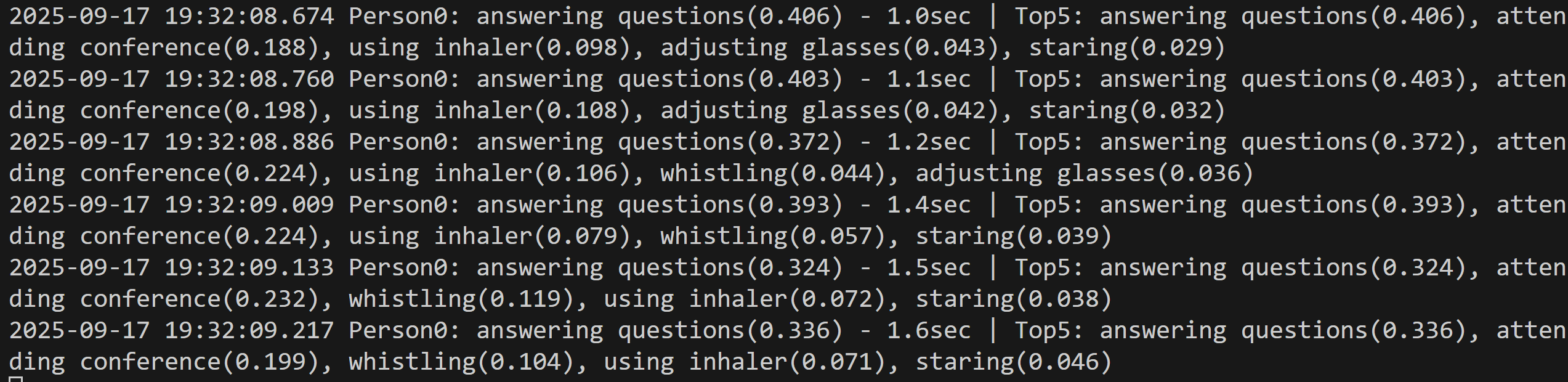
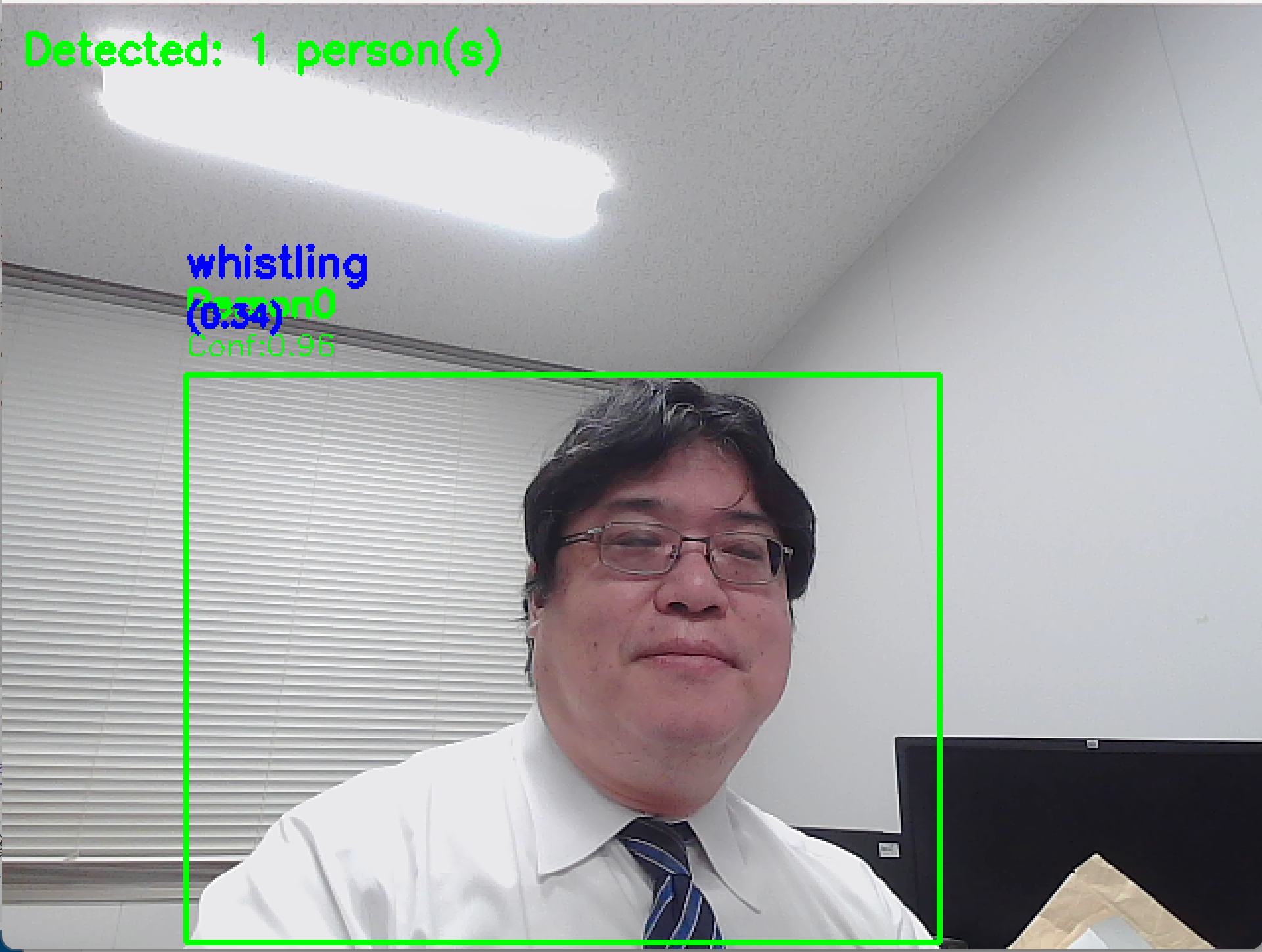
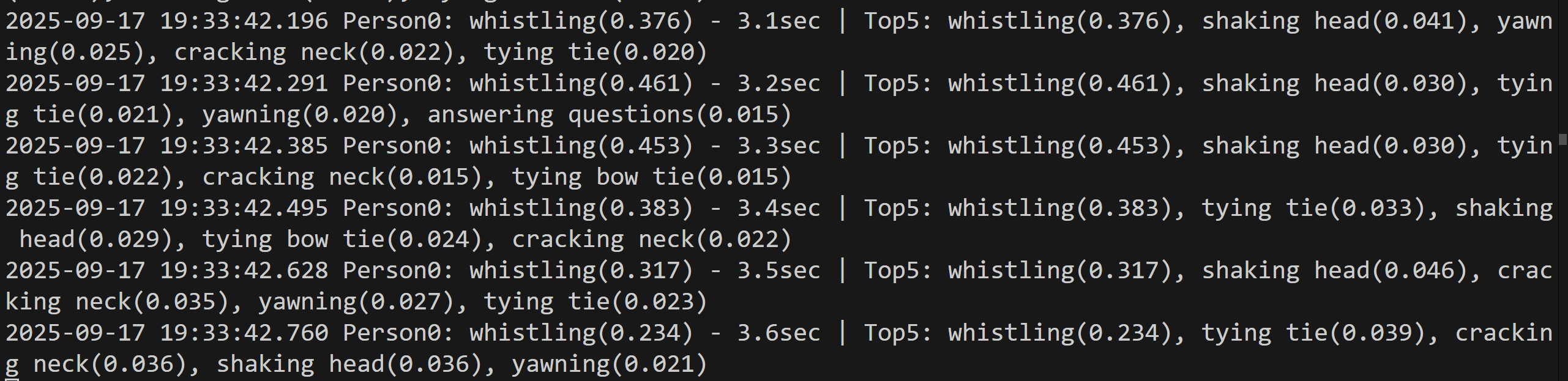
コンピュータビジョン:手指の姿勢推定
コンピュータビジョン:頭部姿勢推定
コンピュータビジョン:人体姿勢推定
コンピュータビジョン:眼球運動
コンピュータビジョン:エッジ検出




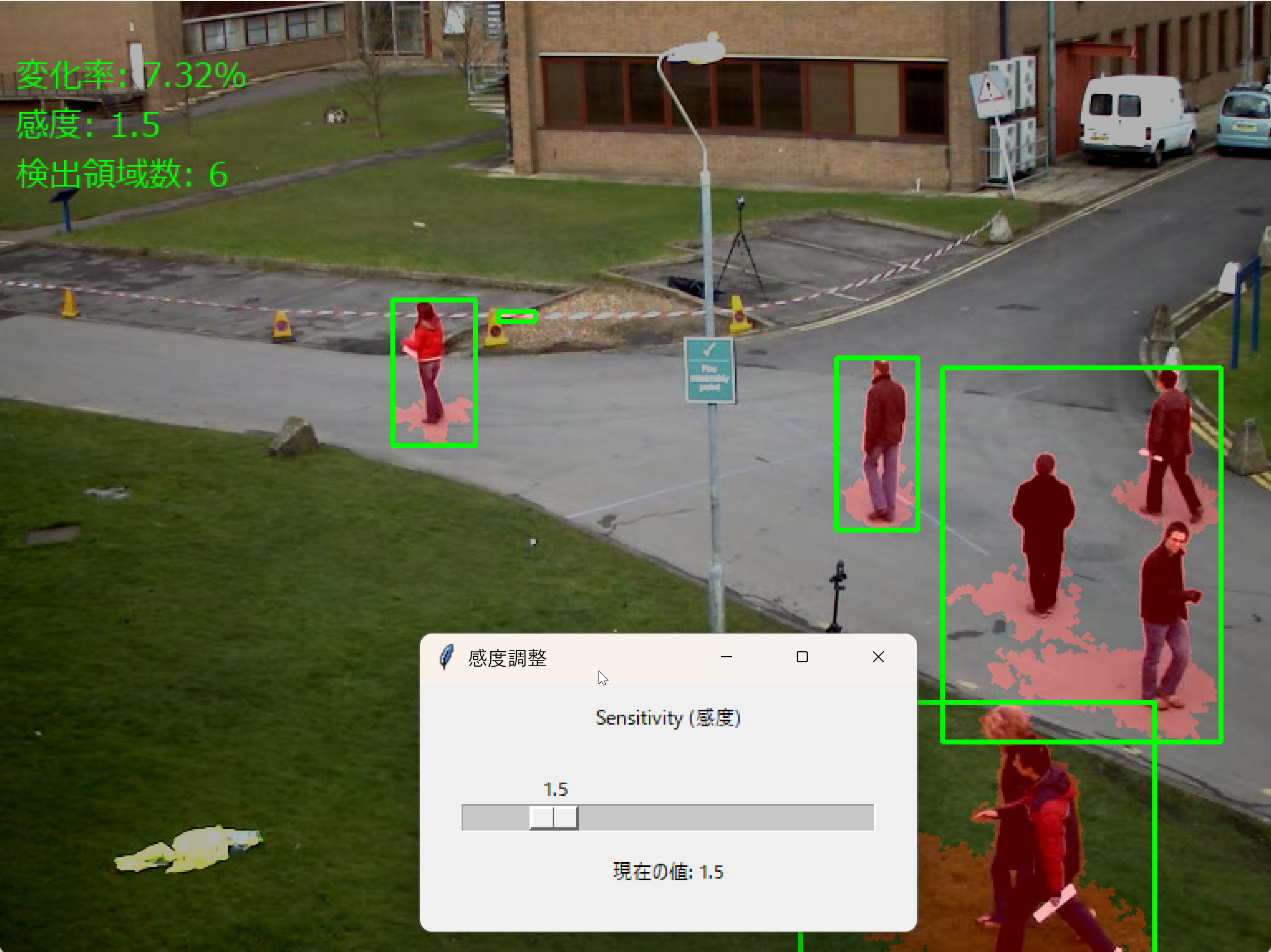
コンピュータビジョン:異常検知,微細変化検出






コンピュータビジョン:画像からの深度推定
コンピュータビジョン:動画像のトラッキングビジョン

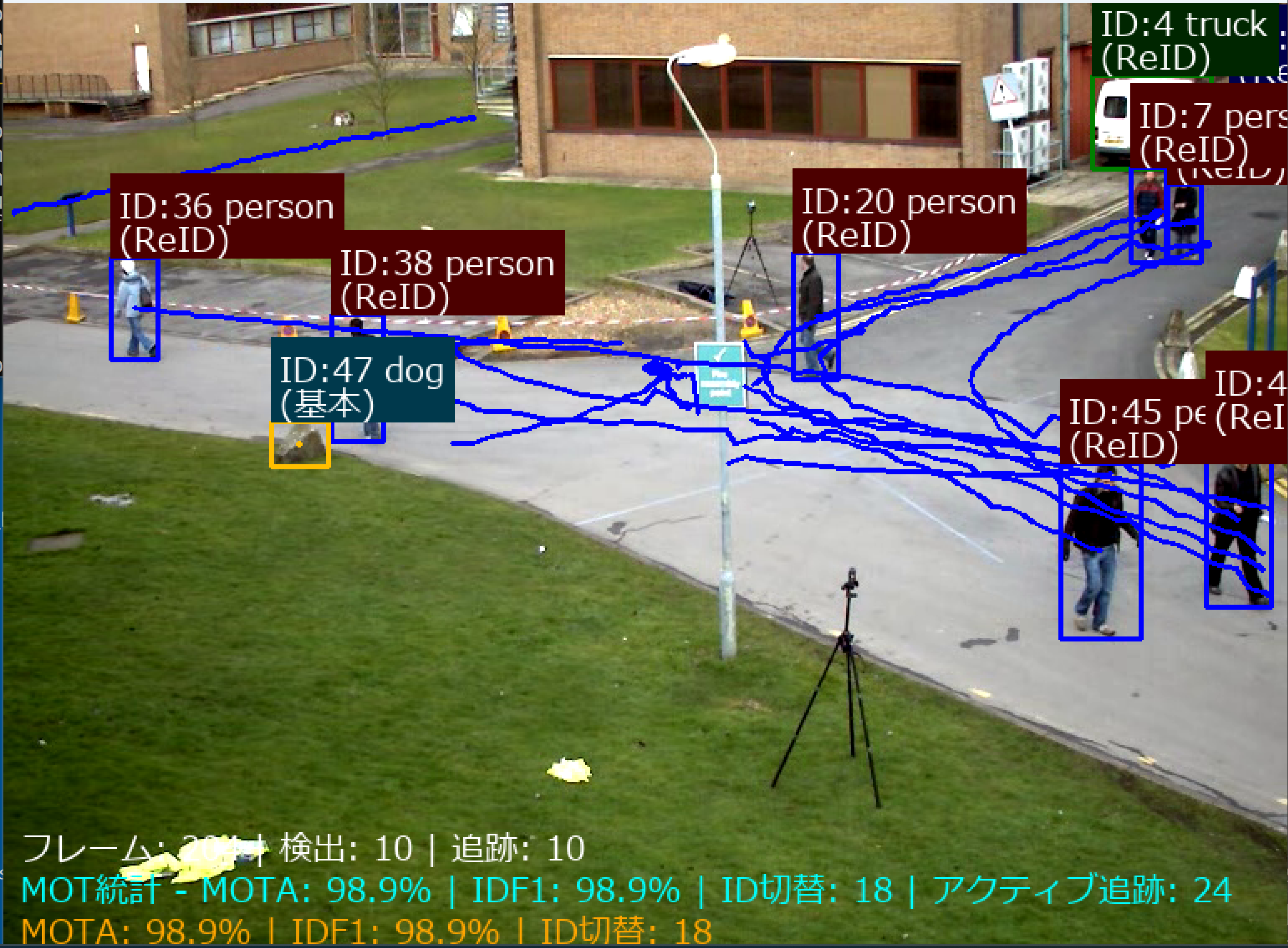

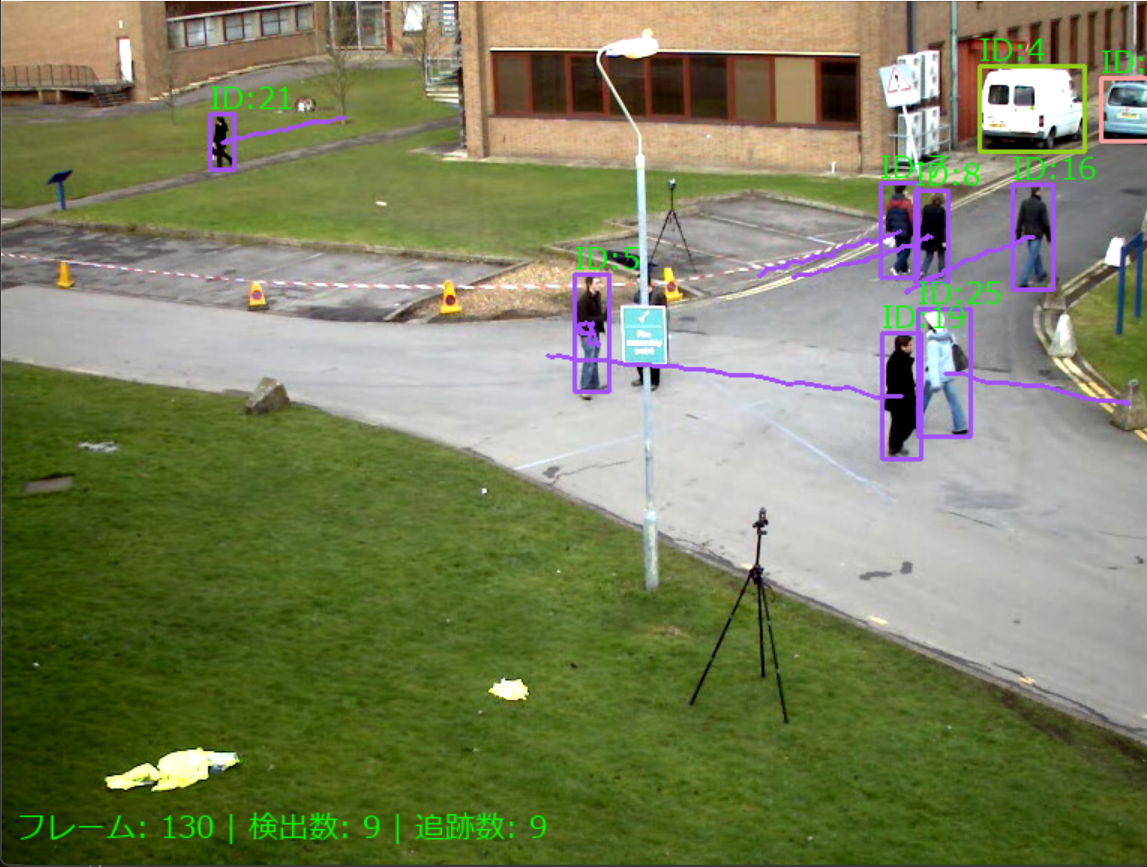
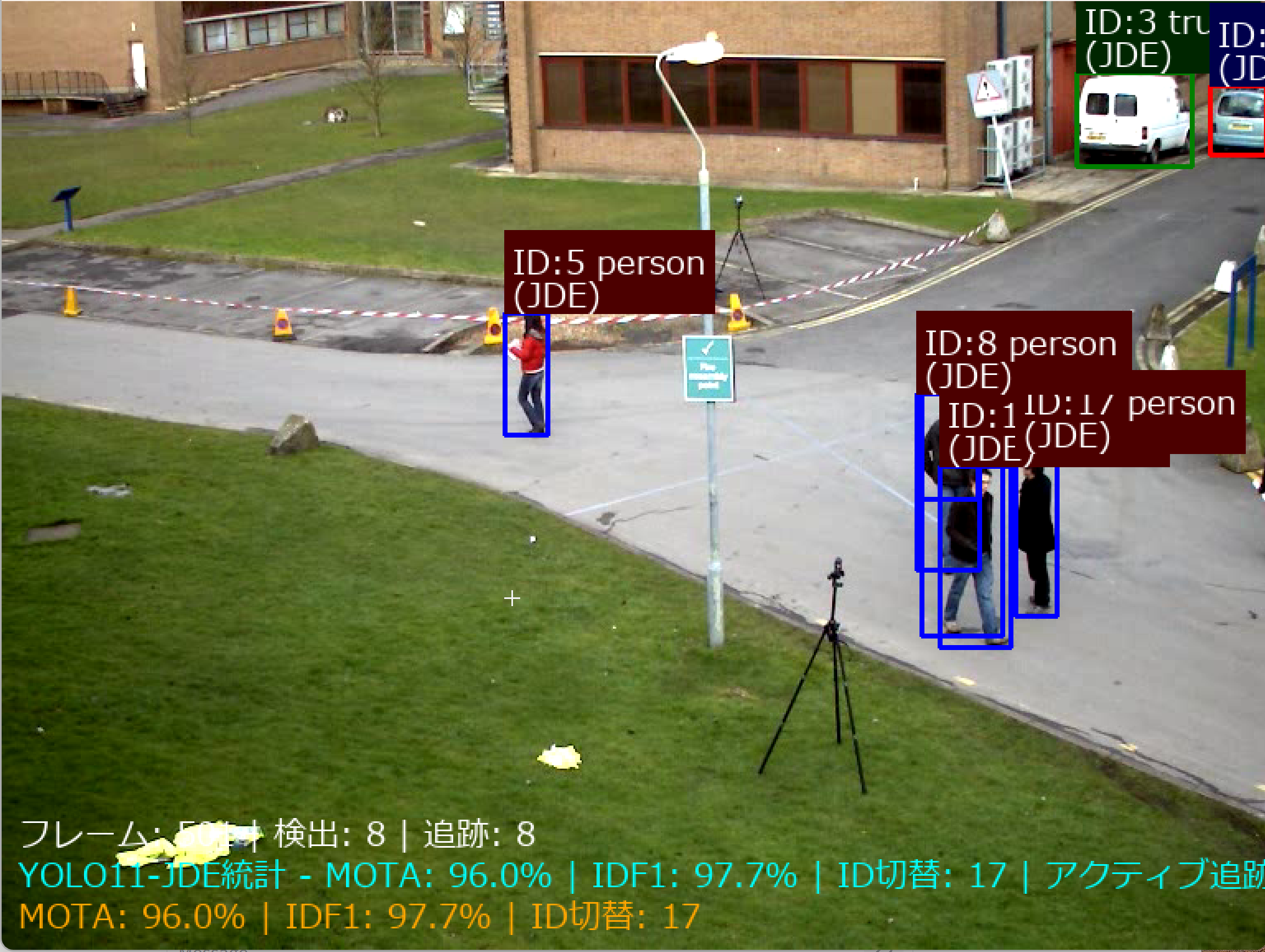
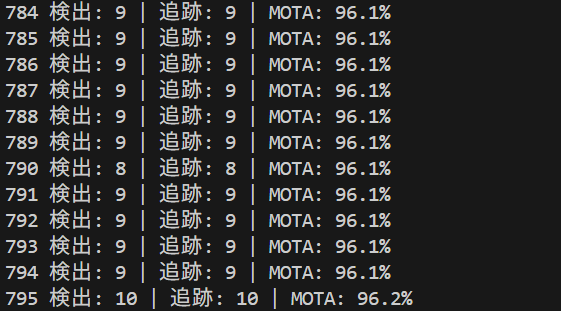

コンピュータビジョン:人物再識別


コンピュータビジョン:線分検出,消失点推定
画像生成(Text-to-Image)
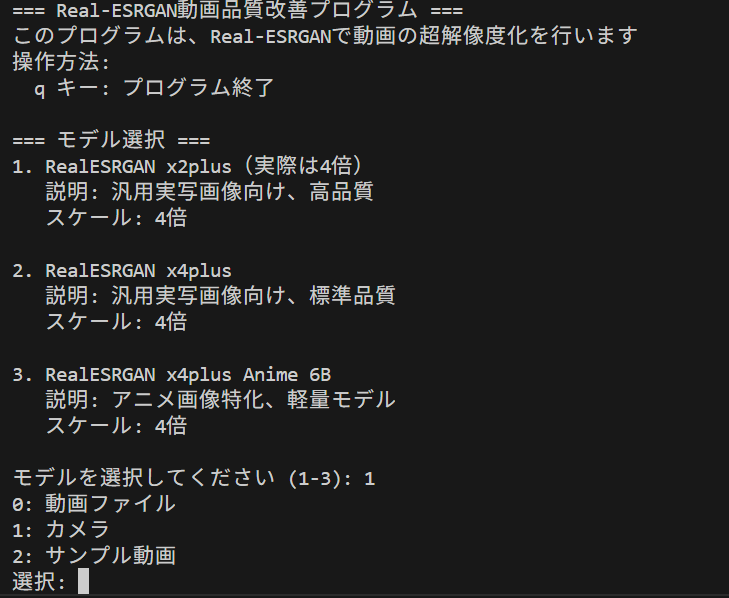
画質改善




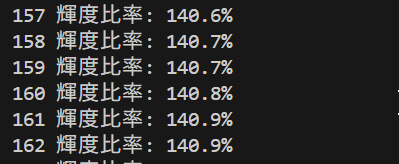
音声処理
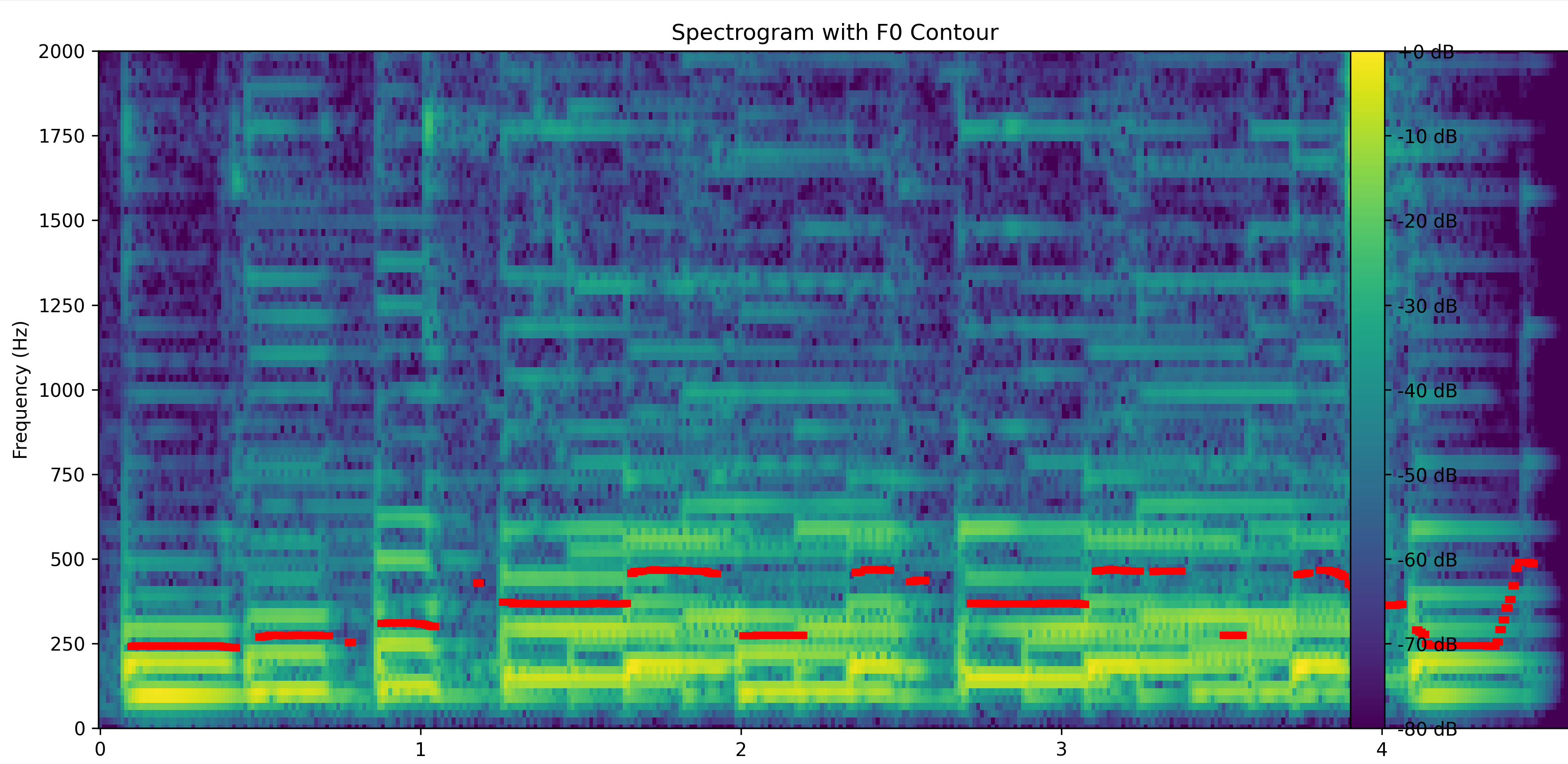
シミュレーション・応用技術
ゲームAI


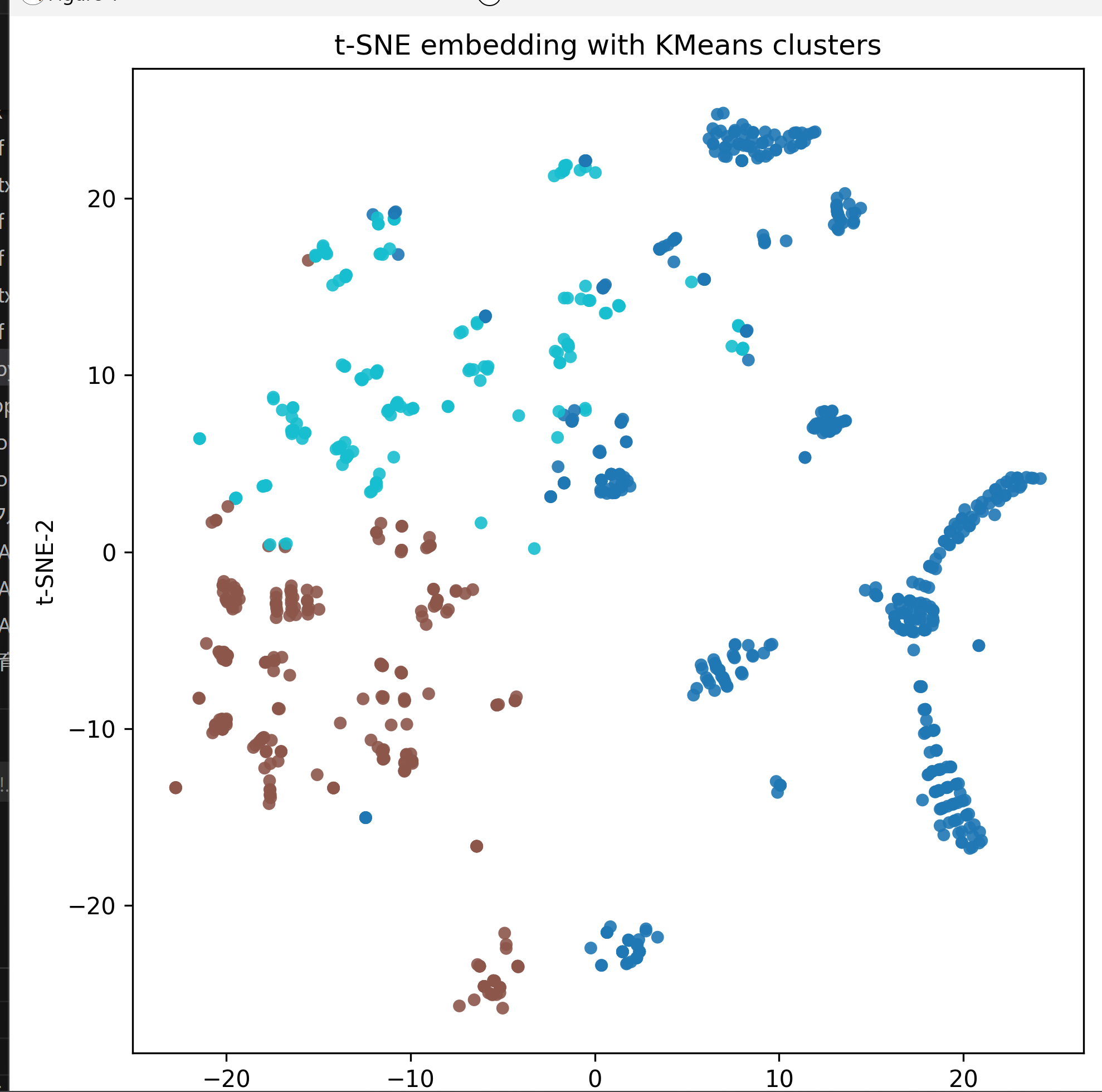
クラスタリング
機械学習・深層学習の基礎実習
機械学習の最適化と評価技術
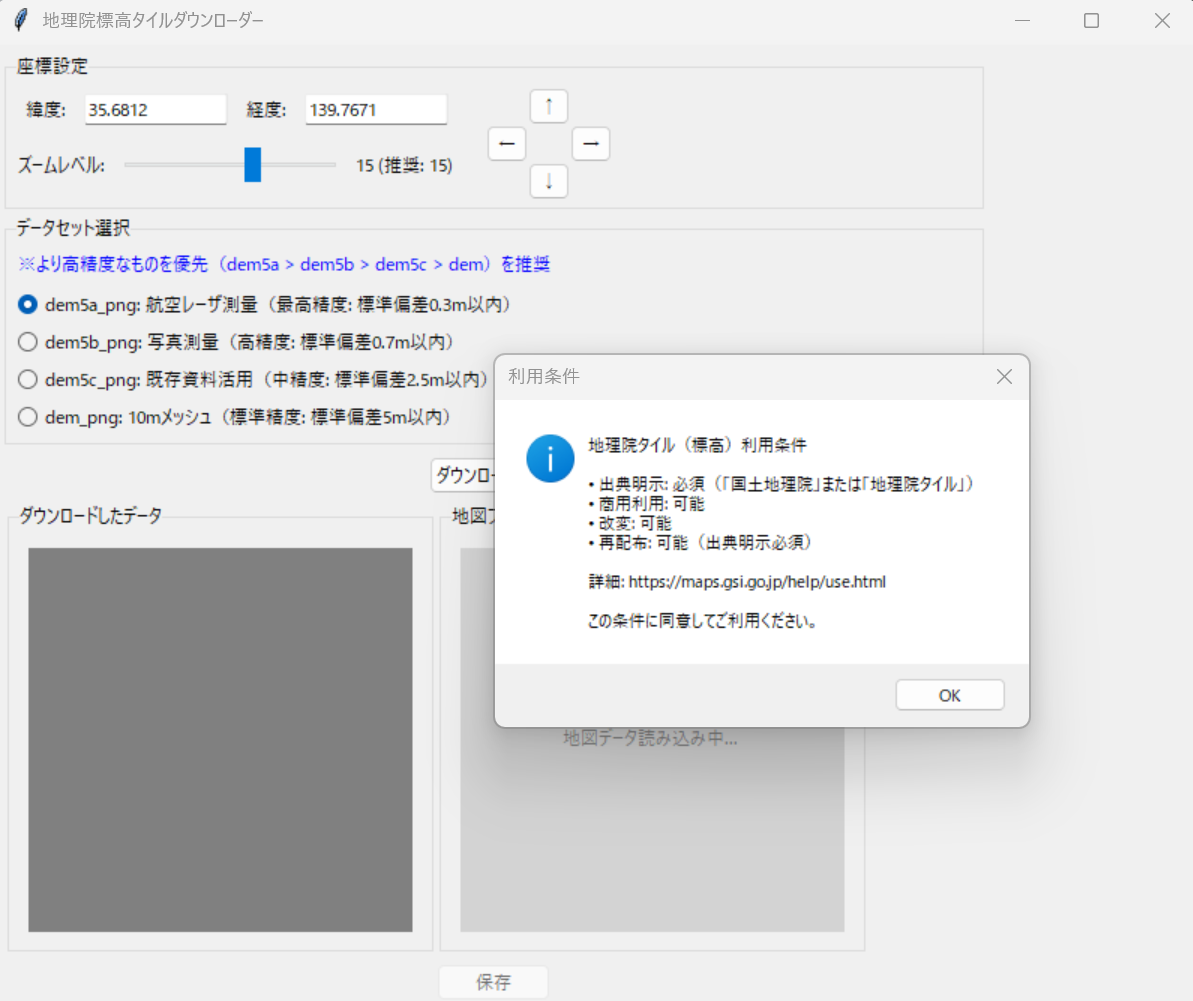
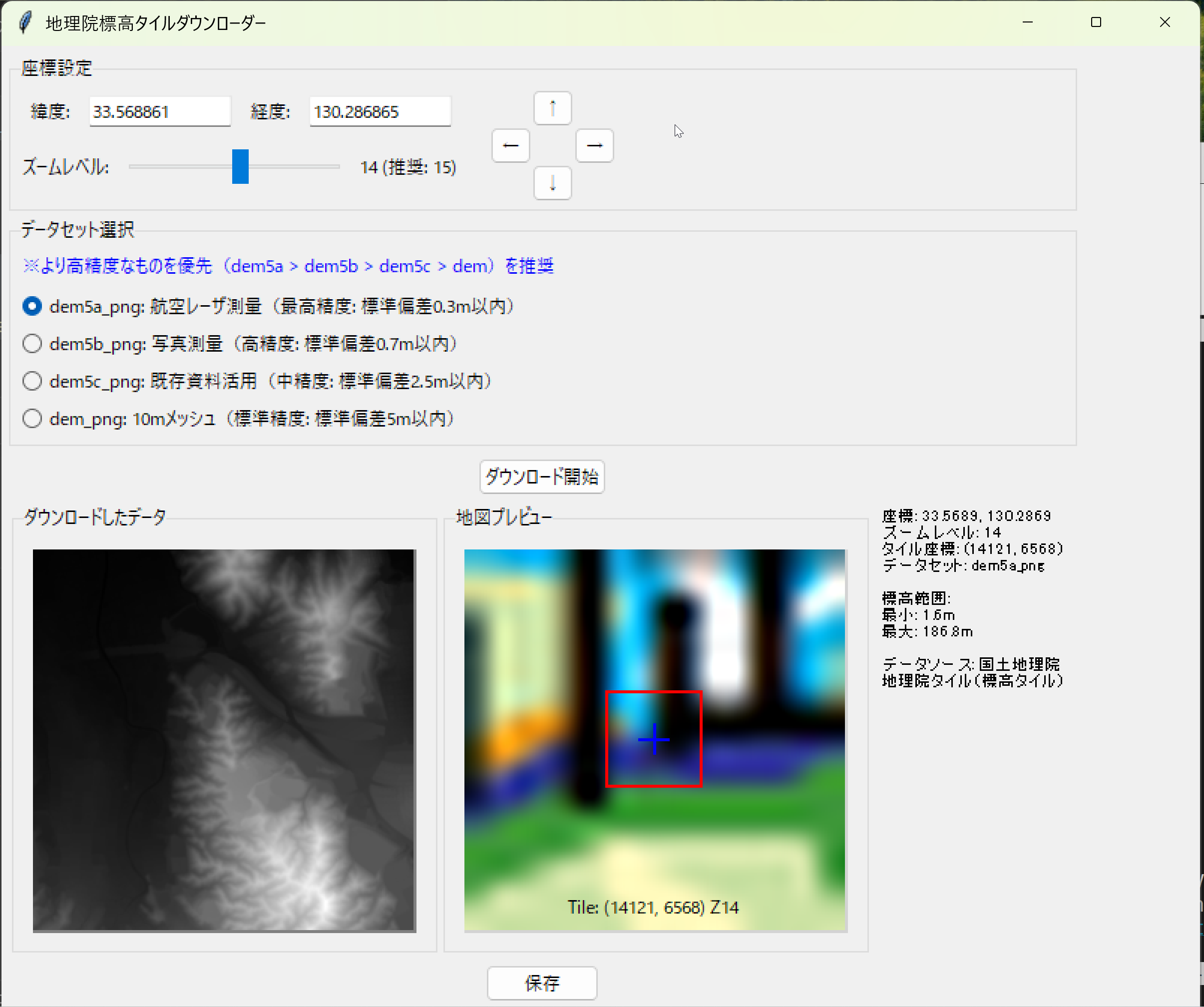
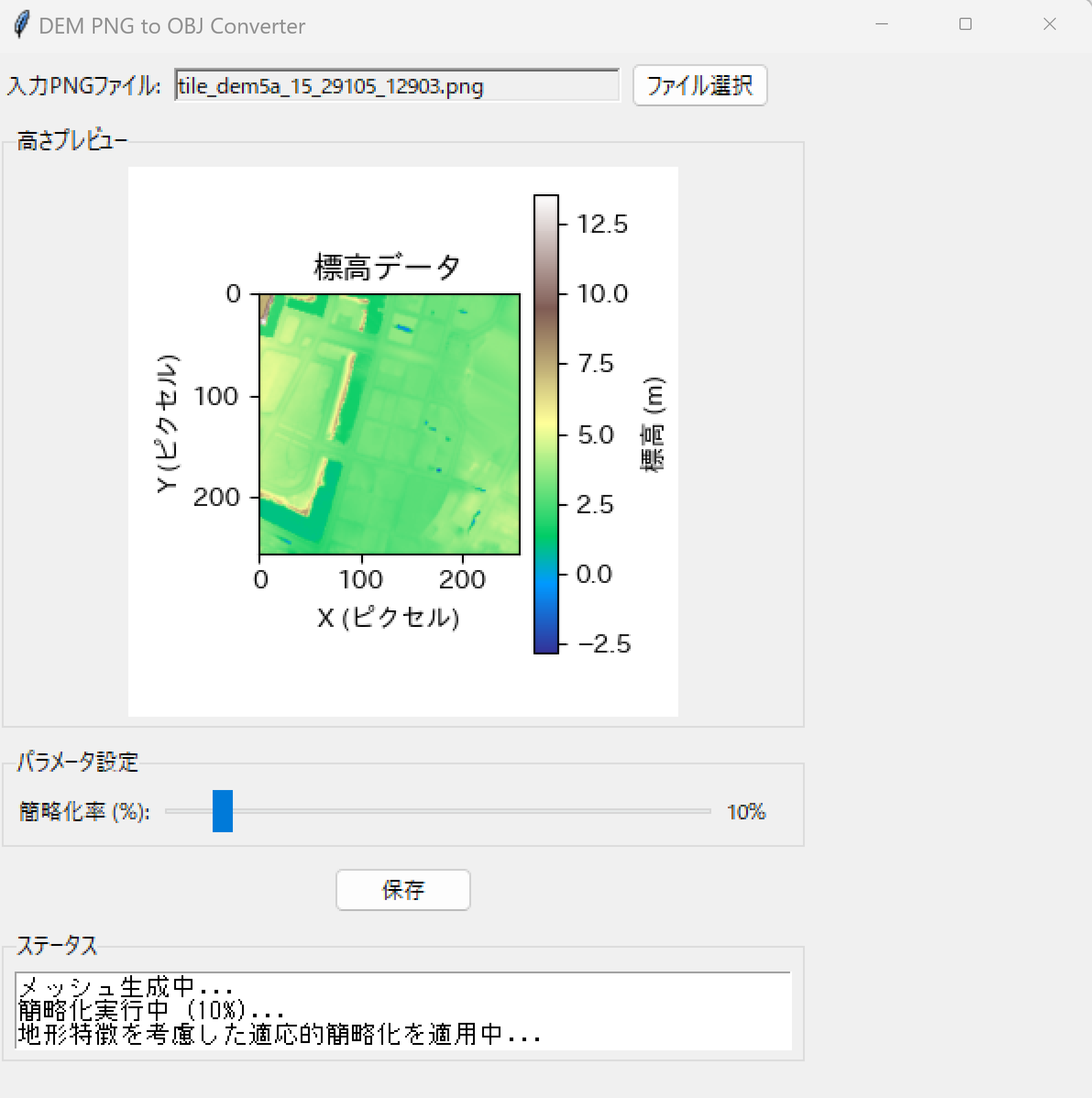
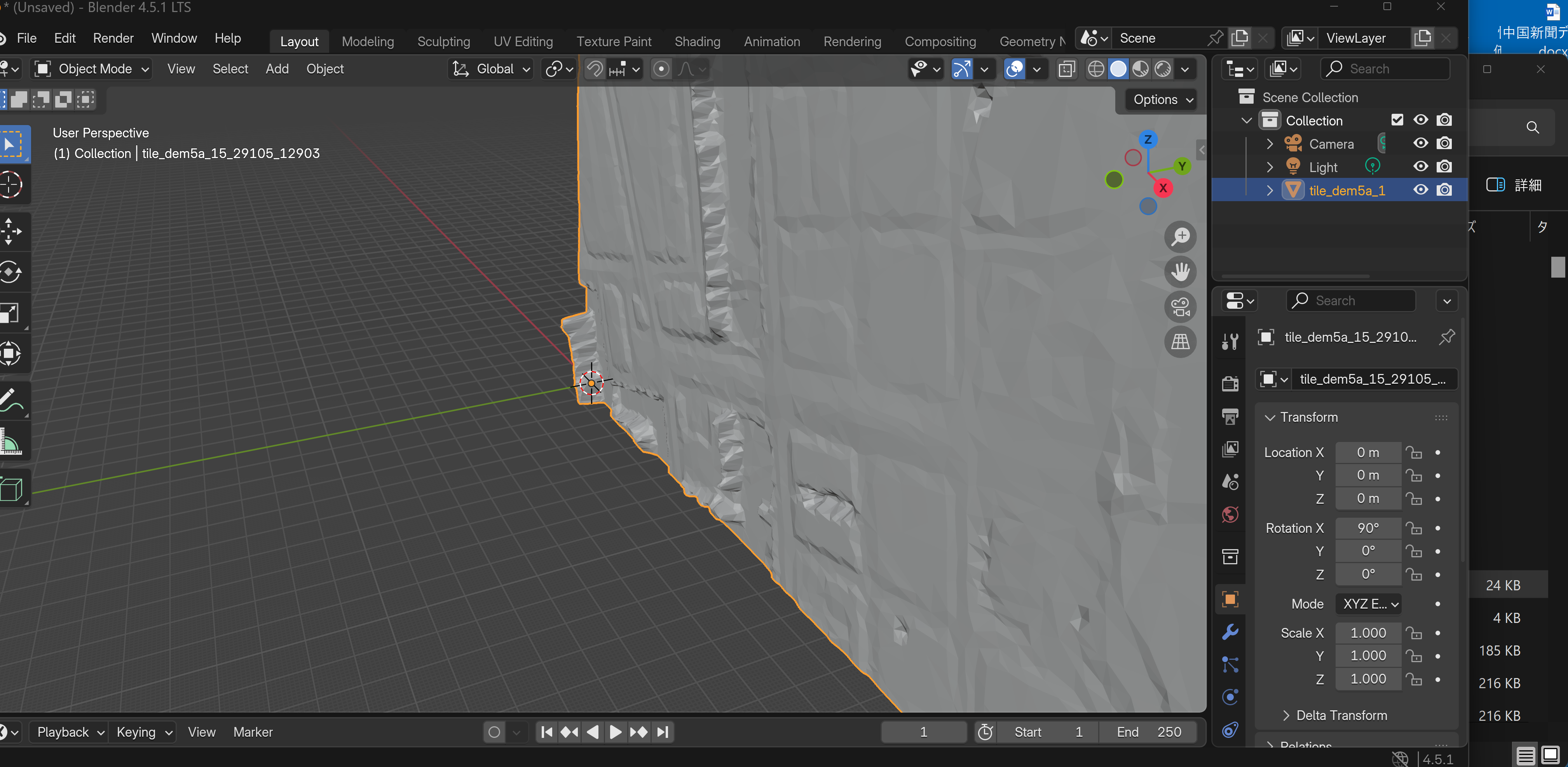
オープンデータ:標高データとDepthMap
AI技術の基礎理論と解説
【概要】InsightFaceは、オープンソースの2D&3D顔解析フレームワーク。顔検出(RetinaFace・SCRFD),顔認識(ArcFace)の機能を持つ。512次元の特徴ベクトルで顔を数値化してコサイン類似度により類似判定を行う。