FastTextによる日本語文章類似度計算
【目次】
1. はじめに
FastTextを用いた日本語文書の意味的類似度計算を体験する。単語埋め込みとは、単語を数値ベクトルに変換する技術である。単語を高次元空間の点として表現することで、単語間の意味的関係を計算可能にする。FastTextは、Meta AI Research(旧Facebook Research)が開発した単語埋め込み技術である。技術名:FastText、出典:Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146。この技術は単語を文字n-gramに分解して学習することで、学習データに含まれていない未知語に対しても、その文字構成からベクトル表現を生成する。文書検索システムや推薦システムなど、意味的な類似性判定が必要なアプリケーションで活用できる。
2. 事前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なPythonライブラリのインストール:
コマンドプロンプトを管理者として実行(手順:Windowsキー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install gensim numpy matplotlib seaborn sudachipy sudachidict_core japanize-matplotlib
3. プログラムコード
- コサイン類似度は、2つのベクトル間の角度の余弦値で、-1から1の値を取る。1に近いほど類似性が高い。計算式:similarity = (A・B) / (||A|| × ||B||)
- 日本語は単語間にスペースがないため、文を単語に分割する形態素解析が必要である。また、動詞や形容詞の活用形を原形に戻すことで、同じ意味の単語を統一的に扱える。
- 文書ベクトルの生成には複数の方法がある。本プログラムでは単語ベクトルの平均を採用している。これは、文書を構成する全単語の意味を均等に反映させる方法である。
# プログラム名: FastText日本語文書類似度計算プログラム
# 特徴技術名: FastText(サブワード情報を用いた単語埋め込み)
# 出典: Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146.
# 特徴機能: サブワード(文字n-gram)情報を活用した未知語対応。単語を文字n-gramに分解し、それらの埋め込みを合成することで、学習データに存在しない単語でもベクトル表現を生成可能
# 学習済みモデル: Common Crawl + Wikipedia日本語FastTextモデル(cc.ja.300.vec.gz)、300次元ベクトル、Meta AI提供、157言語対応、URL: https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz
# 方式設計:
# - 関連利用技術:
# - Gensim(4.3.2): トピックモデリングライブラリ、FastTextモデルの読み込みと操作
# - SudachiPy(0.6.8): 日本語形態素解析器、文書を単語に分割
# - NumPy: 数値計算、ベクトル演算とコサイン類似度計算
# - Matplotlib/Seaborn: 可視化、類似度マトリックスのヒートマップ表示
# - 入力と出力: 入力: メニュー選択(0:固定文書セット、1:テキスト入力)、出力: コンソールに類似度結果表示、result.txtファイルに結果保存、類似度マトリックスのヒートマップ画像
# - 処理手順: 1.FastTextモデルのダウンロードと読み込み、2.日本語文書の形態素解析(内容語抽出)、3.各単語のベクトル取得と文書ベクトルの計算(平均)、4.クエリ文書と各文書間のコサイン類似度計算、5.全文書間の類似度マトリックス作成と可視化
# - 前処理、後処理: 前処理: 形態素解析による内容語(名詞・動詞・形容詞)抽出、動詞・形容詞の原形化。後処理: 類似度の降順ソートと上位結果の表示
# - 追加処理: 語彙数制限(VOCAB_LIMIT=500000)によるメモリ使用量の抑制、モデルに存在しない単語のスキップ処理
# - 調整を必要とする設定値: VOCAB_LIMIT(読み込む語彙数の上限、デフォルト500000。メモリ容量に応じて調整)
# 将来方策: VOCAB_LIMITの自動調整機能。利用可能メモリを検出し、最適な語彙数を自動設定することで、メモリエラーを回避しつつ最大限の語彙を活用
# その他の重要事項: FastTextの未知語対応機能を完全に活用するには、バイナリ形式(.bin)のモデルが必要。現在使用のテキスト形式(.vec)では既知語のみ対応
# 前準備:
# - pip install gensim numpy matplotlib seaborn sudachipy sudachidict_core japanize-matplotlib
from gensim.models import KeyedVectors
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
from sudachipy import tokenizer, dictionary
import urllib.request
import os
import datetime
# 定数定義
RANDOM_SEED = 42
MODEL_PATH = 'cc.ja.300.vec.gz'
MODEL_URL = 'https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz'
VOCAB_LIMIT = 500000
CONTENT_POS = ['名詞', '動詞', '形容詞']
DATE_FORMAT = '%Y-%m-%d %H:%M:%S'
RESULT_FILE = 'result.txt'
np.random.seed(RANDOM_SEED)
# プログラム開始時の説明
print('=== FastText日本語文書類似度計算プログラム ===')
print('このプログラムは、FastTextを使用して日本語文書間の意味的類似度を計算します。')
print('サブワード情報により未知語にも対応可能な類似度計算を実現します。')
print()
# 結果保存用リスト
results = []
results.append(f'実行日時: {datetime.datetime.now().strftime(DATE_FORMAT)}')
results.append('=== FastText日本語文書類似度計算プログラム ===')
results.append('')
# 日本語形態素解析器の初期化
tokenizer_obj = dictionary.Dictionary().create()
mode = tokenizer.Tokenizer.SplitMode.C
# 学習済みモデルのダウンロード
if not os.path.exists(MODEL_PATH):
print('日本語FastTextモデルをダウンロード中...')
try:
urllib.request.urlretrieve(MODEL_URL, MODEL_PATH)
print('ダウンロード完了')
except Exception as e:
print(f'モデルのダウンロードに失敗しました: {MODEL_URL}')
print(f'エラー: {e}')
exit()
print('FastTextモデルを読み込み中...')
try:
model = KeyedVectors.load_word2vec_format(MODEL_PATH, binary=False, limit=VOCAB_LIMIT)
print(f'モデル読み込み完了(語彙数: {len(model)})')
except Exception as e:
print(f'モデルの読み込みに失敗しました: {e}')
exit()
# 形態素解析関数
def tokenize_doc(text, tokenizer_obj, mode):
tokens = []
for token in tokenizer_obj.tokenize(text, mode):
pos = token.part_of_speech()[0]
if pos in CONTENT_POS:
if pos in ['動詞', '形容詞']:
tokens.append(token.dictionary_form())
else:
tokens.append(token.surface())
return tokens
# 文書ベクトル計算関数
def calc_doc_vector(tokens, model):
vectors = [model[token] for token in tokens if token in model]
return np.mean(vectors, axis=0) if vectors else np.zeros(model.vector_size)
# 入力方式の選択
print()
print('入力方式を選択してください:')
print('0: 固定文書セット(デモ用)')
print('1: テキスト入力')
choice = input('選択 (0 or 1): ')
if choice == '0':
# 固定文書セット
documents = [
'機械学習は人工知能の重要な分野です',
'深層学習はニューラルネットワークを多層化した技術です',
'自然言語処理により日本語の文章を解析できます',
'画像認識技術はコンピュータビジョンの応用例です',
'データサイエンスは統計学と情報工学を融合した分野です',
'ニューラルネットワークは脳の神経回路を模倣しています',
'Pythonはデータ分析で広く使われるプログラミング言語です',
'テキストマイニングで大量の文書から知識を抽出します'
]
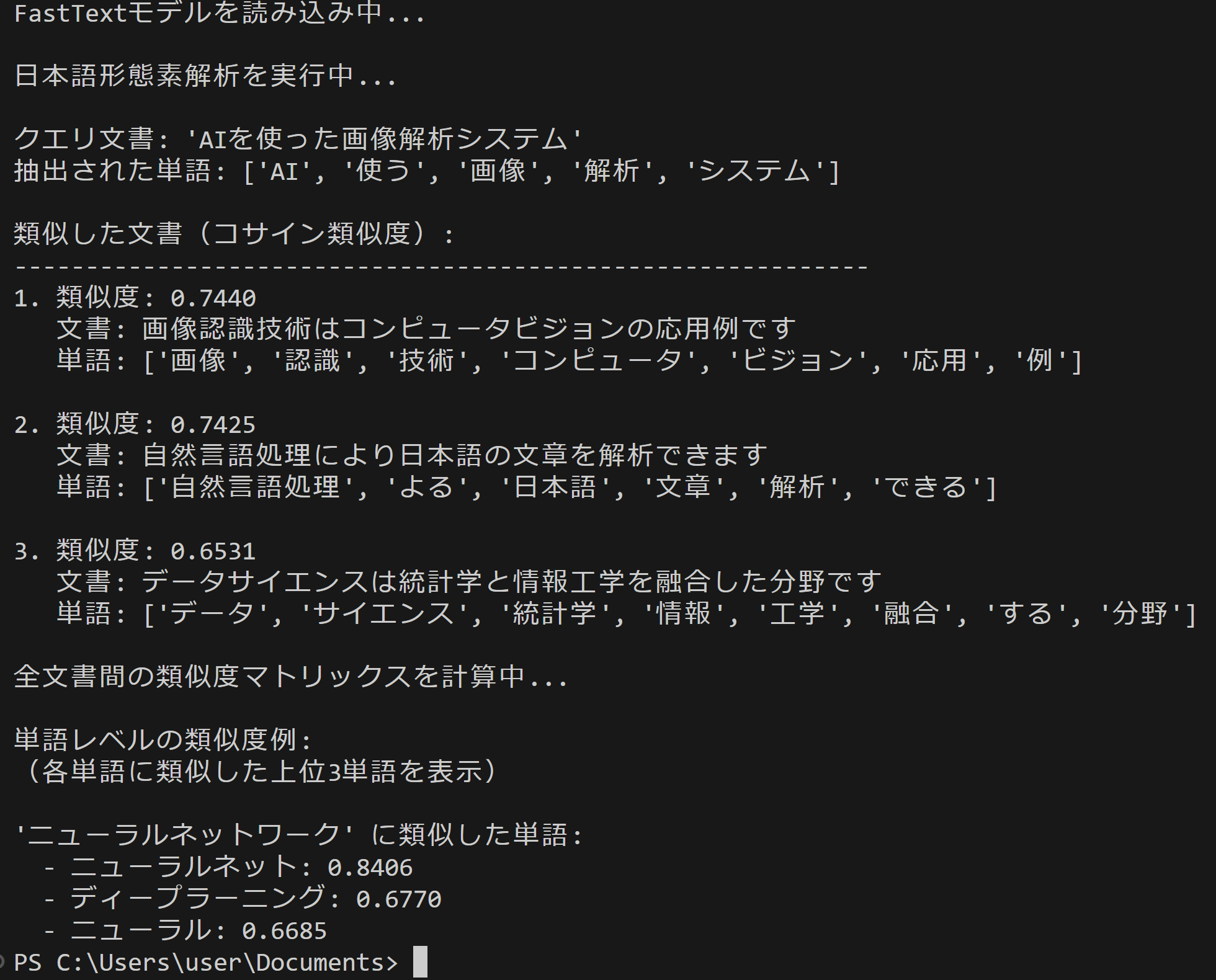
query = 'AIを使った画像解析システム'
elif choice == '1':
# テキスト入力
print()
print('文書を入力してください(空行で入力終了):')
documents = []
while True:
doc = input(f'文書{len(documents)+1}: ')
if doc == '':
break
documents.append(doc)
if len(documents) == 0:
print('文書が入力されていません')
exit()
query = input('クエリ文書を入力してください: ')
else:
print('無効な選択です')
exit()
# 形態素解析
print()
print('日本語形態素解析を実行中...')
results.append('入力文書:')
for i, doc in enumerate(documents):
results.append(f'{i+1}. {doc}')
results.append('')
results.append(f'クエリ文書: {query}')
results.append('')
# 文書の形態素解析
tokenized_docs = [tokenize_doc(doc, tokenizer_obj, mode) for doc in documents]
# クエリの形態素解析
query_tokens = tokenize_doc(query, tokenizer_obj, mode)
# ベクトル計算
query_vector = calc_doc_vector(query_tokens, model)
doc_vectors = [calc_doc_vector(tokens, model) for tokens in tokenized_docs]
print(f'クエリ文書: "{query}"')
print(f'抽出された単語: {query_tokens}')
print()
print('類似した文書(コサイン類似度):')
print('-' * 60)
results.append(f'クエリ文書の抽出単語: {query_tokens}')
results.append('')
results.append('類似度計算結果:')
results.append('-' * 60)
# 類似度計算
similarities = []
for i, doc_vec in enumerate(doc_vectors):
if np.any(query_vector) and np.any(doc_vec):
sim = np.dot(query_vector, doc_vec) / (np.linalg.norm(query_vector) * np.linalg.norm(doc_vec))
similarities.append((i, sim))
# 類似度でソート
similarities.sort(key=lambda x: x[1], reverse=True)
# 上位結果の表示
for rank, (idx, sim) in enumerate(similarities[:3], 1):
print(f'{rank}. 類似度: {sim:.4f}')
print(f' 文書: {documents[idx]}')
print(f' 単語: {tokenized_docs[idx]}')
print()
results.append(f'{rank}. 類似度: {sim:.4f}')
results.append(f' 文書: {documents[idx]}')
results.append(f' 単語: {tokenized_docs[idx]}')
results.append('')
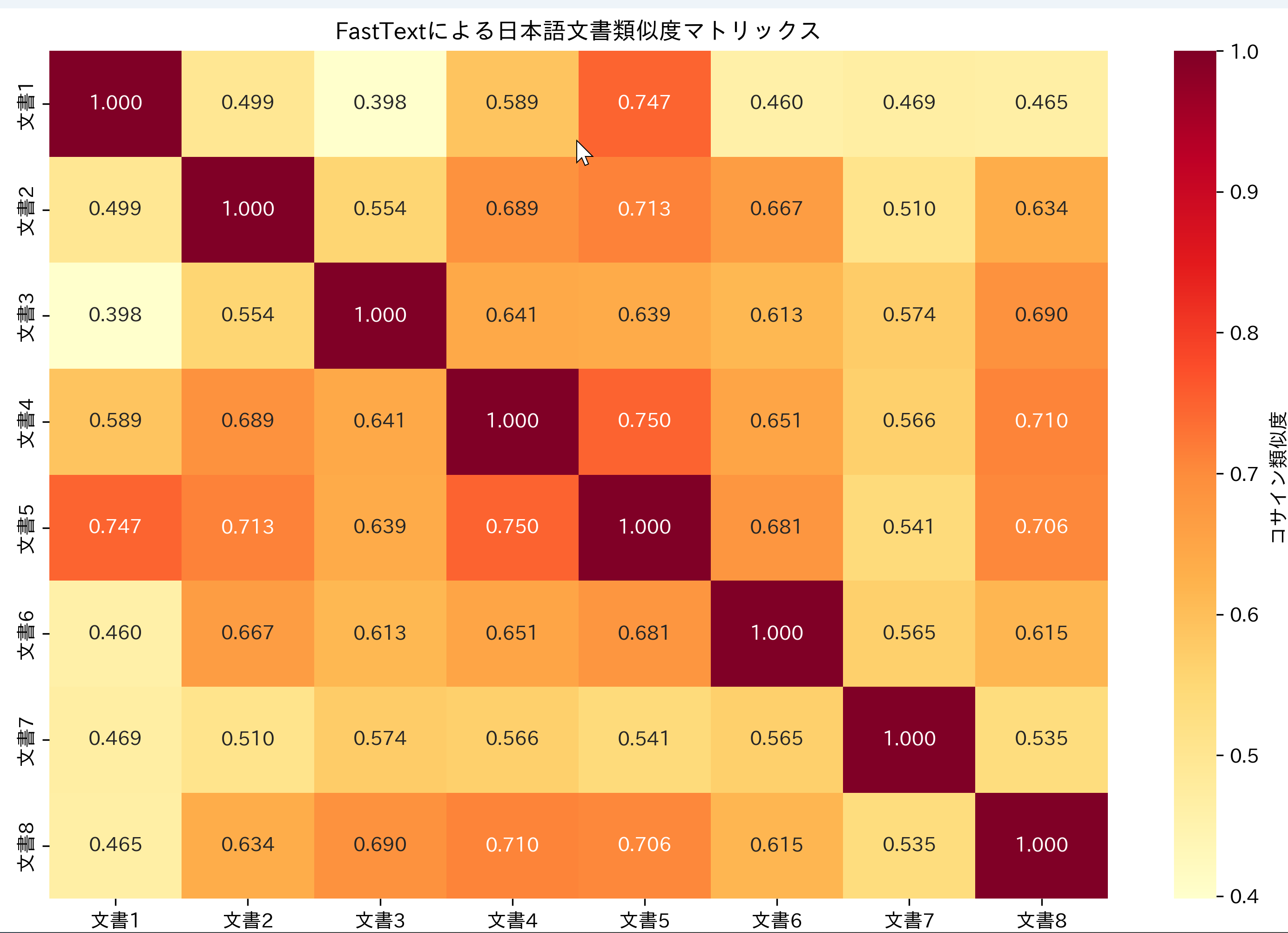
# 全文書間の類似度マトリックス
print('全文書間の類似度マトリックスを計算中...')
n_docs = len(documents)
similarity_matrix = np.zeros((n_docs, n_docs))
for i in range(n_docs):
for j in range(n_docs):
if np.any(doc_vectors[i]) and np.any(doc_vectors[j]):
similarity_matrix[i][j] = np.dot(doc_vectors[i], doc_vectors[j]) / (np.linalg.norm(doc_vectors[i]) * np.linalg.norm(doc_vectors[j]))
# ヒートマップの表示
plt.figure(figsize=(10, 8))
sns.heatmap(similarity_matrix,
xticklabels=[f'文書{i+1}' for i in range(n_docs)],
yticklabels=[f'文書{i+1}' for i in range(n_docs)],
annot=True, fmt='.3f', cmap='YlOrRd',
cbar_kws={'label': 'コサイン類似度'})
plt.title('FastTextによる日本語文書類似度マトリックス')
plt.tight_layout()
plt.show()
# 単語レベルの類似度例(固定文書セットの場合のみ)
if choice == '0':
print()
print('単語レベルの類似度例:')
print('(各単語に類似した上位3単語を表示)')
results.append('')
results.append('単語レベルの類似度例:')
test_words = ['機械学習', '深層学習', 'ニューラルネットワーク']
for word in test_words:
if word in model:
similar_words = model.most_similar(word, topn=3)
print(f'\n"{word}" に類似した単語:')
results.append(f'"{word}" に類似した単語:')
for similar_word, score in similar_words:
print(f' - {similar_word}: {score:.4f}')
results.append(f' - {similar_word}: {score:.4f}')
# 結果をファイルに保存
with open(RESULT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(results))
print()
print(f'{RESULT_FILE}に保存しました')
4. 使用方法
- 上記のプログラムを実行する
- 初回実行時は学習済みモデル(約4GB)のダウンロードに時間がかかる。実行結果として、クエリ文書に対する類似文書の順位、全文書間の類似度ヒートマップ、単語レベルの類似度が表示される。
実行結果の解釈:
- 類似度0.8以上:意味的に関連性の高い文書
- 類似度0.5-0.8:関連性のある文書
- 類似度0.5未満:関連性の低い文書
ヒートマップでは、赤色が濃いほど類似度が高いことを示す。
5. 実験・探求のアイデア
AIモデル選択
プログラム内のコメントに記載された学習済みモデルの利用を検討
実験要素
- 文書セットの変更:専門分野の文書(医療、法律、技術文書など)に変更して、分野特有の類似度パターンを観察する。
- 品詞フィルタリングの調整:CONTENT_POSを変更して名詞のみ、動詞のみで類似度を計算し、品詞が類似度判定に与える影響を分析する。
- ベクトル集約方法の変更:単語ベクトルの平均ではなく、最大値や重み付き平均を使用して文書ベクトルを生成する。
体験・実験・探求のアイデア
- 同義語・類義語の発見:単語レベルの類似度機能を使って、専門用語の同義語辞書を自動生成する実験を行う。
- 文書クラスタリング実験:類似度マトリックスを使って文書を自動的にグループ化し、教師なし学習による文書分類を体験する。
- 多言語対応の探求:FastTextの多言語モデルを使用して、日本語と英語の文書間の類似度計算に挑戦できる。