Windows での gpt-oss 実行と Chain of Thought (ソースコードと実行結果)
- 特徴:21Bパラメータ、推論レベル設定(Low/Medium/High)、Chain of Thought機能。
- 実行環境 ・Windows上のWSL2 + Ubuntu 、CUDA 12.6 + PyTorch
- GPU のメモリ使用量 12.8G (実測)
- 回答はRTX 3090で1~2分以上程度。
Python開発環境,ライブラリ類
次の手順で,WSL上でのGPT-OSSプログラム実行ができるように準備する
- WindowsにLinux環境を追加
管理者権限のコマンドプロンプトでwsl --installを実行し,再起動。WSL2+Ubuntu LTSが自動インストールされ、Hyper-V仮想化とGPUパススルー対応のLinux環境が利用可能になる。
操作:管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行
wsl --install
- Python3.12、AIコードエディタWindsurf、GPU高速化用CUDA Toolkit 12.6をWSL内にインストール
所定のコマンドをコピペ実行して,NVIDIA GPU対応のAI開発環境が準備できる。
操作:WSLが起動するので、次のコマンドを実行(WSLの初回実行ではアカウントを設定)
sudo apt update sudo apt install python3 python3-pip python3-venv curl -fsSL "https://windsurf-stable.codeiumdata.com/wVxQEIWkwPUEAGf3/windsurf.gpg" | sudo gpg --dearmor -o /usr/share/keyrings/windsurf-stable-archive-keyring.gpg echo "deb [signed-by=/usr/share/keyrings/windsurf-stable-archive-keyring.gpg arch=amd64] https://windsurf-stable.codeiumdata.com/wVxQEIWkwPUEAGf3/apt stable main" | sudo tee /etc/apt/sources.list.d/windsurf.list > /dev/null sudo apt update sudo apt install windsurf wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.0-1_all.deb sudo dpkg -i cuda-keyring_1.0-1_all.deb sudo apt-get update sudo apt-get install -y cuda-toolkit-12-6
- GPT-OSSプログラム専用の独立Python環境を作成
CUDA12.6対応PyTorch、Transformers、Triton3.4 などをインストール。MXFP4量子化とMoE推論の環境を整える。独立 Python環境であり、他プログラムと干渉しない。
操作:引き続き,WSLで次のコマンドを実行し仮想環境を作成する
python3 -m venv gpt-oss-env source gpt-oss-env/bin/activate pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 pip install wheel transformers accelerate triton==3.4 kernels huggingface_hub
GPT-OSSプログラム
概要
GPT-OSS-20Bは、OpenAIが公開したオープンウェイトモデル(21Bパラメータ、3.6Bアクティブパラメータ)である。Apache 2.0ライセンスで利用でき、Harmonyレスポンス形式を使用する。
特徴技術
-
推論レベル設定(Reasoning Effort)
OpenAIの公式発表およびHugging Faceの公式モデルページで、3つの推論レベルが説明されている(https://huggingface.co/openai/gpt-oss-20b、https://huggingface.co/openai/gpt-oss-120b)
- Low: 高速な汎用対話用
- Medium: 速度と詳細のバランス
- High: 深い詳細分析
設定方法: システムプロンプトで「
Reasoning: high」のように設定可能である。 -
Transformersライブラリのコード例
OpenAIの公式GitHubおよびHugging Faceページに記載されている公式コード例(https://github.com/openai/gpt-oss、https://cookbook.openai.com/articles/gpt-oss/run-transformers)
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1]) -
Harmonyフォーマット
OpenAIが公式に開発したgpt-oss専用の応答フォーマットである(https://cookbook.openai.com/articles/openai-harmony)
- 必須要件: GPT-OSSモデルはharmonyフォーマットでのみ動作する
- 自動適用: Transformersのチャットテンプレートを使用すると自動的にharmonyフォーマットが適用される
- 公式ライブラリ: openai-harmonyパッケージで細かな制御が可能である(https://pypi.org/project/openai-harmony/、https://github.com/openai/harmony)
- 機能: 推論出力、ツール呼び出し、チェーンオブソート(CoT)の構造化
-
Chain of Thought(思考の連鎖)
GPT-OSS 20BはChain of Thought(思考の連鎖)の機能を提供する。(https://openai.com/index/introducing-gpt-oss/):
- 機能: モデルの推論プロセスへのアクセスを提供、出力の信頼性向上
- チャンネル分離: 「analysis」チャンネル(エンドユーザー向けではない思考過程)と「final」チャンネル(実際のメッセージ)に分離
- 安全性の注意: GPT-OSS の CoT が生成するデータには有害なコンテンツが含まれる可能性があるため、エンドユーザーには直接提供すべきではないとされる(https://cookbook.openai.com/articles/gpt-oss/handle-raw-cot)
-
MXFP4量子化
OpenAIが公式に採用した4ビット量子化技術である(https://openai.com/index/introducing-gpt-oss/、https://ollama.com/blog/gpt-oss):
- 技術仕様: 4.25ビット/パラメータのMixture-of-Experts (MoE)重み量子化
- 適用範囲: MoE重み(全パラメータの90%以上)に適用される
関連する外部ページ
- OpenAI公式発表: https://openai.com/index/introducing-gpt-oss/
- OpenAI GitHub: https://github.com/openai/gpt-oss
- OpenAI Cookbook: https://cookbook.openai.com/articles/openai-harmony
- Hugging Face モデルページ: https://huggingface.co/openai/gpt-oss-20b
- Harmony ライブラリ: https://pypi.org/project/openai-harmony/
- モデルカード: https://openai.com/index/gpt-oss-model-card/
ソースコード
# GPT-OSS 20B プログラム
# 前準備
# pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install transformers accelerate triton kernels flash-attn huggingface_hub
from transformers import pipeline
import torch
import os
# メモリ最適化
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# モデル読み込み
pipe = pipeline(
"text-generation",
model="openai/gpt-oss-20b",
torch_dtype="auto",
device_map="auto"
)
# 推論パラメータの一元管理
INFERENCE_PARAMS = {
"temperature": 0.7,
"top_p": 1.0,
"top_k": 40,
"repetition_penalty": 1.1,
"do_sample": True
}
# VRAM監視関数
def show_vram_usage():
if torch.cuda.is_available():
gpu_count = torch.cuda.device_count()
total_vram = 0
for i in range(gpu_count):
vram_gpu = torch.cuda.memory_allocated(i) / 1024**3
print(f"GPU{i} VRAM使用量: {vram_gpu:.1f}GB")
total_vram += vram_gpu
print(f"合計VRAM使用量: {total_vram:.1f}GB")
torch.cuda.empty_cache()
# 推論実行(全実行で共通使用)
def generate(prompt, reasoning="medium", max_tokens=1024, system_content=None):
if system_content is None:
system_content = f"Reasoning: {reasoning}"
messages = [
{"role": "system", "content": system_content},
{"role": "user", "content": prompt}
]
result = pipe(
messages,
max_new_tokens=max_tokens,
pad_token_id=pipe.tokenizer.eos_token_id,
**INFERENCE_PARAMS
)
show_vram_usage()
return result[0]["generated_text"]
# 推論レベル比較(4回実行)
def compare_reasoning_levels(prompt):
print(f"質問: {prompt}\n")
# 1-3回目:標準推論レベル
for level in ["low", "medium", "high"]:
print(f"=== {level.upper()} ===")
response = generate(prompt, reasoning=level)
print(response)
print("\n" + "-"*50 + "\n")
# 4回目:CoT最大化設定
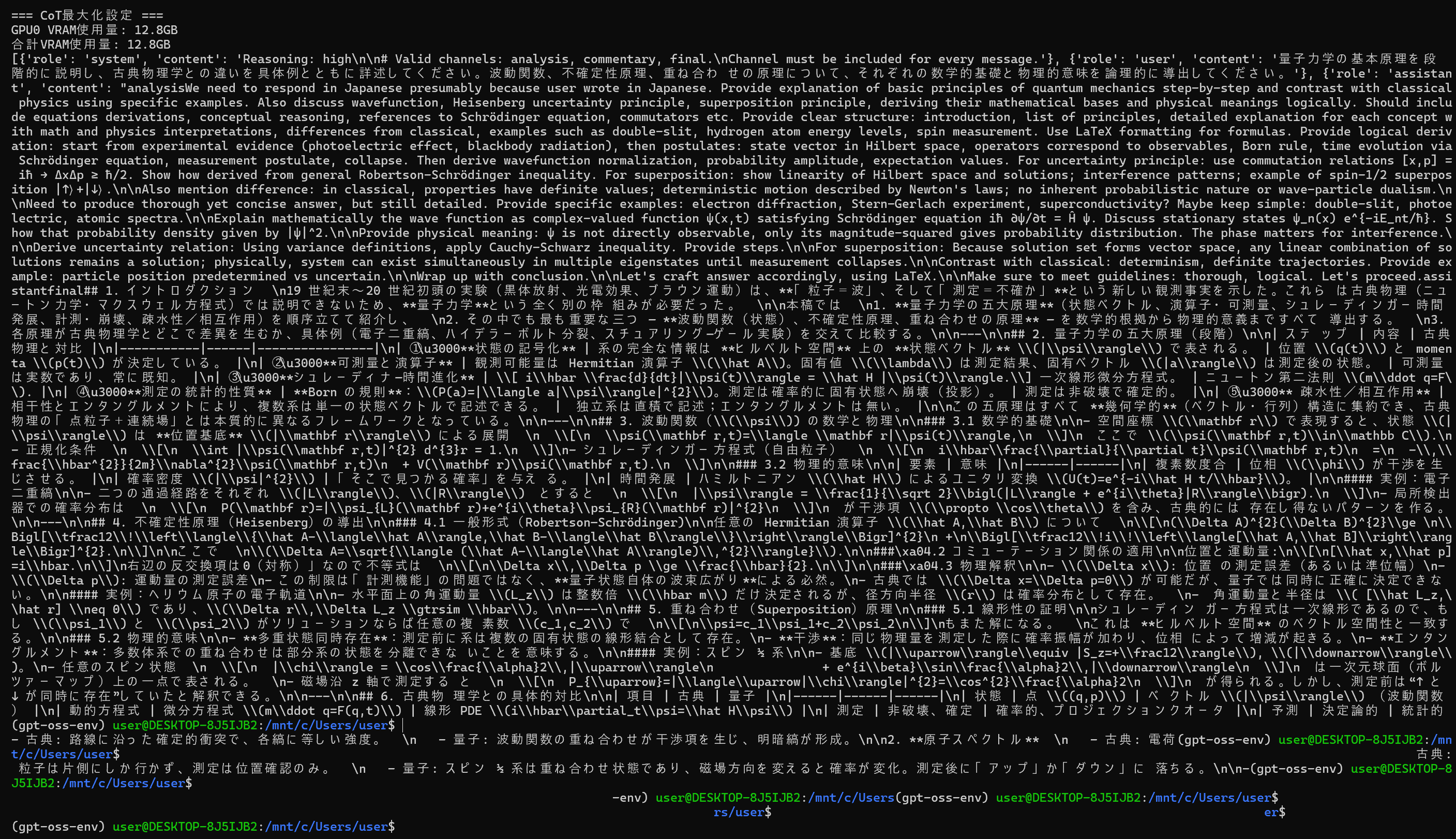
print("=== CoT最大化設定 ===")
enhanced_prompt = "量子力学の基本原理を段階的に説明し、古典物理学との違いを具体例とともに詳述してください。波動関数、不確定性原理、重ね合わせの原理について、それぞれの数学的基礎と物理的意味を論理的に導出してください。"
enhanced_system = "Reasoning: high\n\n# Valid channels: analysis, commentary, final.\nChannel must be included for every message."
response = generate(enhanced_prompt, max_tokens=30000, system_content=enhanced_system)
print(response)
# 使用例
if __name__ == "__main__":
# 4回の推論レベル比較実行
compare_reasoning_levels("量子力学を説明して")