SucachiPy による形態素解析
【目次】
はじめに
ここでは、SudachiPyという日本語形態素解析技術を体験することを目的とする。
SudachiPyは、株式会社Works Applicationsが開発した日本語形態素解析器である。その技術は「Sudachi: A Japanese Tokenizer for Improving Text Analysis」という論文で発表されている。
新規性・特徴: SudachiPyは、一般的な形態素解析器が単一の辞書を使用するのに対し、従来の形態素解析器が抱えていた複合語の過剰分割や未登録語への対応の難しさを解決するため、複数の粒度(単語の分割の細かさ)の辞書を組み合わせることで、文脈に応じた柔軟な単語分割を可能にする。
特徴を活かせるアプリ例: ニュース記事の自動要約、チャットボットの応答精度向上、検索エンジンの関連性向上など、日本語のテキストデータを深く理解する必要があるアプリケーションでその特徴が活かされる。
体験価値: 本プログラムを実行することで、入力した日本語の文章がどのように単語に分割され、それぞれの単語がどのような品詞や原型を持つのかを直接確認できる。これにより、日本語の構造や形態素解析の仕組みに対する理解を深め、AIがどのように日本語を処理しているかを体験できる。
事前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリのインストール
本プログラムはSudachiPyを使用する。SudachiPyがインストールされていない場合は、以下のコマンドを管理者権限のコマンドプロンプトで実行する。
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install sudachipy sudachidict-core
プログラムコード
本プログラムは、日本語の形態素解析を行うためにSudachiPyライブラリを使用している。SudachiPyは、日本語の文章を「形態素」と呼ばれる最小単位に分割し、それぞれの形態素の品詞や原型などの情報を取得するツールである。
- 形態素解析: 自然言語処理(NLP)において、文章を意味を持つ最小単位(形態素)に分割する技術である。例えば、「私は学生です」という文章は、「私」「は」「学生」「です」という形態素に分割される。
- SudachiPy: 従来の形態素解析器が抱えていた複合語の分割粒度(単語の分割の細かさ)の問題や、辞書にない語の処理能力を改善するために開発された。複数の辞書を組み合わせることで、文脈に応じた柔軟な単語分割を実現する。
本プログラムでは、SudachiPyのCモードを利用している。SudachiPyにはA, B, Cの3つの異なる分割モードがあり、利用者が用途に応じて適切な粒度でテキストを分析できる柔軟性を持つ。
- Aモード (SplitMode.A): 最も短い単位に区切る(UniDic shot unit と等価)
- Bモード (SplitMode.B): 中程度の単位に区切る
- Cモード (SplitMode.C): 名称を区切る
ソースコード
# プログラム名: SudachiPy日本語形態素解析プログラム
# 特徴技術名: SudachiPy(日本語形態素解析器)
# 出典: Takaoka, K., Hisamoto, S., Kawahara, N., Sakamoto, M., Uchida, Y., & Matsumoto, Y. (2018). Sudachi: a Japanese Tokenizer for Business. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
# 特徴機能: 多段階分割モード(A/B/Cモード)による柔軟な形態素解析。Cモードでは複合語を一つの単位として扱い、文脈に応じた適切な分割を実現
# 学習済みモデル: 該当なし(辞書ベースの形態素解析器)
# 方式設計:
# - 関連利用技術: なし
# - 入力と出力: 入力: テキスト(標準入力から複数行の日本語文章)、出力: 形態素解析結果(表層形、品詞、原形、正規化形、読み)
# - 処理手順: 1. SudachiPy辞書の初期化、2. 分割モードの選択、3. 入力文章の取得、4. 各文章の形態素解析、5. 解析結果の表示
# - 前処理、後処理: 前処理: なし、後処理: なし
# - 追加処理: なし
# - 調整を必要とする設定値: 分割モード(A/B/Cモード)- 解析粒度を調整可能
# 将来方策: 分割モードを実行時にユーザが選択できるメニュー機能の実装により、用途に応じた解析粒度の選択を可能にする
# その他の重要事項: 辞書データのサイズが大きいため、初回起動時に時間がかかる場合がある
# 前準備: pip install sudachipy sudachidict-core
from sudachipy import tokenizer
from sudachipy import dictionary
# 設定値
DEFAULT_SPLIT_MODE = 'C' # デフォルトの分割モード(A:最小単位, B:中間, C:最大単位)
print('SudachiPy日本語形態素解析プログラム')
print('概要: 入力された日本語文章を形態素解析し、単語ごとに詳細(表層形、品詞、原形、正規化形、読み)を表示します')
print('操作: 解析したい文章を入力してください。複数行の入力が可能です。空行(Enterキーのみ)で入力を終了します')
print('=' * 40)
# SudachiPyの辞書とトークナイザーを初期化
tokenizer_obj = dictionary.Dictionary().create()
# 分割モード選択
print('分割モードを選択してください:')
print('A: 最小単位での分割(短単位)')
print('B: 中間的な分割')
print('C: 最大単位での分割(長単位)')
mode_choice = input('選択 (A/B/C) [デフォルト: C]: ').upper()
if mode_choice not in ['A', 'B', 'C']:
mode_choice = DEFAULT_SPLIT_MODE
if mode_choice == 'A':
split_mode = tokenizer.Tokenizer.SplitMode.A
elif mode_choice == 'B':
split_mode = tokenizer.Tokenizer.SplitMode.B
else:
split_mode = tokenizer.Tokenizer.SplitMode.C
print(f'\n選択された分割モード: {mode_choice}')
print('=' * 40)
print('解析対象の文章を入力してください(複数行可)')
print('入力終了は空行(Enterキーのみ)で判定します。')
input_documents = []
while True:
line = input()
# 空行で入力を終了
if not line:
break
input_documents.append(line)
# 入力された文章がない場合は、メッセージを表示して終了
if not input_documents:
print('処理対象の文章がありません。')
exit()
print('\n' + '=' * 40)
print(' 解析結果')
print('=' * 40 + '\n')
# 結果を保存するリスト
results = []
# 統計情報用の変数
total_morphemes = 0
pos_counter = {}
# 各文書を形態素解析し、結果を表示
for i, doc in enumerate(input_documents):
result_line = f'--- 文書 {i+1} ---'
print(result_line)
results.append(result_line)
# 形態素解析を実行
morphemes = tokenizer_obj.tokenize(doc, split_mode)
# 解析結果を表示
for m in morphemes:
total_morphemes += 1
# 品詞情報を取得(タプルの場合とstring の場合の両方に対応)
pos_info = m.part_of_speech()
if isinstance(pos_info, tuple):
pos = pos_info[0]
else:
pos = pos_info.split(',')[0]
pos_counter[pos] = pos_counter.get(pos, 0) + 1
# 読み仮名を取得
reading = m.reading_form()
# 表層形、品詞、原形、正規化された形、読みを表示
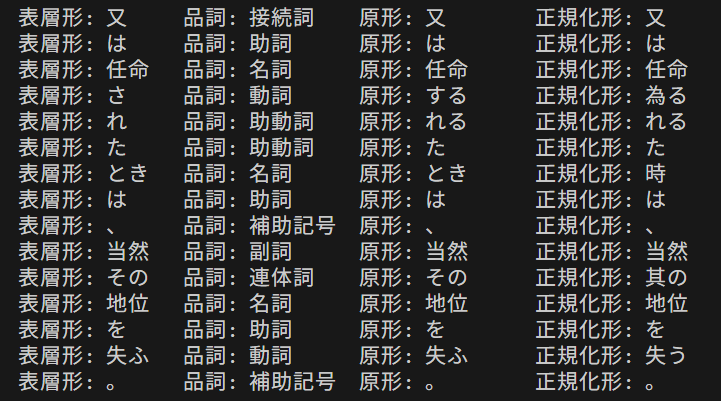
result_detail = f' 表層形: {m.surface()}\t 品詞: {pos}\t 原形: {m.dictionary_form()}\t 正規化形: {m.normalized_form()}\t 読み: {reading}'
print(result_detail)
results.append(result_detail)
print() # 各文書の後に改行
results.append('')
# 統計情報を表示
print('=== 統計情報 ===')
print(f'総単語数: {total_morphemes}')
print('品詞別集計:')
stat_info = [f'=== 統計情報 ===', f'総単語数: {total_morphemes}', '品詞別集計:']
for pos, count in sorted(pos_counter.items(), key=lambda x: x[1], reverse=True):
stat_line = f' {pos}: {count}'
print(stat_line)
stat_info.append(stat_line)
# 統計情報も結果に追加
results.extend(stat_info)
# 結果をファイルに保存
with open('result.txt', 'w', encoding='utf-8') as f:
for line in results:
f.write(line + '\n')
print('\nresult.txtに保存しました')
使用方法
- 上記のプログラムを実行する
- プログラムが起動すると、「解析対象の文章を入力してください(複数行可)」というメッセージが表示される。
- 解析したい日本語の文章を入力し、Enterキーを押す。複数行入力する場合は、1行入力するごとにEnterキーを押し、全ての入力が終わったら空行でEnterキーを再度押す。
- 入力が終了すると、解析結果が表示される。各形態素の表層形(実際に表示される形)、品詞、原形(辞書形)、正規化形(表記ゆれを吸収した形)が確認できる。
実験・探求のアイデア
本プログラムを様々な文章で実行し、以下のような実験を通してSudachiPyの特性や日本語の構造を探求することができる。
AIモデル選択
本プログラムでは、SudachiPyのCモードを利用している。SudachiPyには他にも以下の分割モードが存在する。
実験のアイデア: プログラムコード内のsplit_mode = tokenizer.Tokenizer.SplitMode.Cの部分をsplit_mode = tokenizer.Tokenizer.SplitMode.Aやsplit_mode = tokenizer.Tokenizer.SplitMode.Bに変更し、同じ文章を解析してみる。各モードで単語の分割のされ方や品詞情報がどのように変化するかを比較することで、SudachiPyの柔軟な分割能力を体験できる。
実験要素
- 複合語の解析: 「国立競技場」「日本語形態素解析」「自動運転技術」のような複合語を入力し、どのように分割されるかを確認する。特にCモードでの分割に注目し、どの部分までが1つの単語として扱われるか、あるいは分割されるかを確認する。
- 同音異義語の解析: 「はし(橋、箸、端)」や「き(木、気、器)」のように、同じ読みで異なる意味を持つ単語を入力し、品詞や原形がどのように識別されるかを確認する。
- 新語・流行語の解析: インターネットスラングや最近の流行語を入力し、SudachiPyがどのように処理するかを確認する。辞書にない単語がどのように扱われるか(未知語として扱われるか、あるいは近い単語に分割されるか)を観察する。
- 文体の違いによる解析: 硬い文章(論文、ニュース記事)と柔らかい文章(SNSの投稿、会話文)を入力し、形態素解析結果の違いを比較する。
体験・実験・探求のアイデア(新発見を促す)
- 意味の曖昧さと形態素解析: 意図的に意味が複数取れる文章(例: 「走る人が多い」と「走る車が多い」)を入力し、形態素解析の結果がその曖昧さをどの程度反映しているかを観察する。人間の言語理解とAIの言語処理の違いについて考察するきっかけとなる。
- 外来語・カタカナ語の処理: 「スマートフォン」「オンラインゲーム」などの外来語やカタカナ語を複数組み合わせた文章を入力し、SudachiPyがどのように分割し、品詞を付与するかを確認する。日本語における外来語の定着度合いが形態素解析にどう影響するかを探求する。