日本語文のドキュメントの類似検索(Latent Semantic Indexing による)(Python,gensim を使用)
日本語文のドキュメントの類似検索を行う.
Latent Semantic Indexing による.
次のページで公開されている Python プログラムを使用している.
【サイト内の関連ページ】
- 日本語文のドキュメントの類似検索(Latent Dirichlet Allocation による)(Python,gensim を使用): 別ページ »で説明
謝辞:このページで使用しているソフトウェア類の作者に感謝します.
Latent Semantic Indexing による類似検索
前準備
別ページ »で説明手順で,辞書,Bag of Words,TF/IDF,Latent Semantic Indexing (LSI) の作成を終えていること.索引(インデックス)の作成
from gensim import similarities
index = similarities.MatrixSimilarity(lsi_model[bow_corpus])
print(index)

類似度
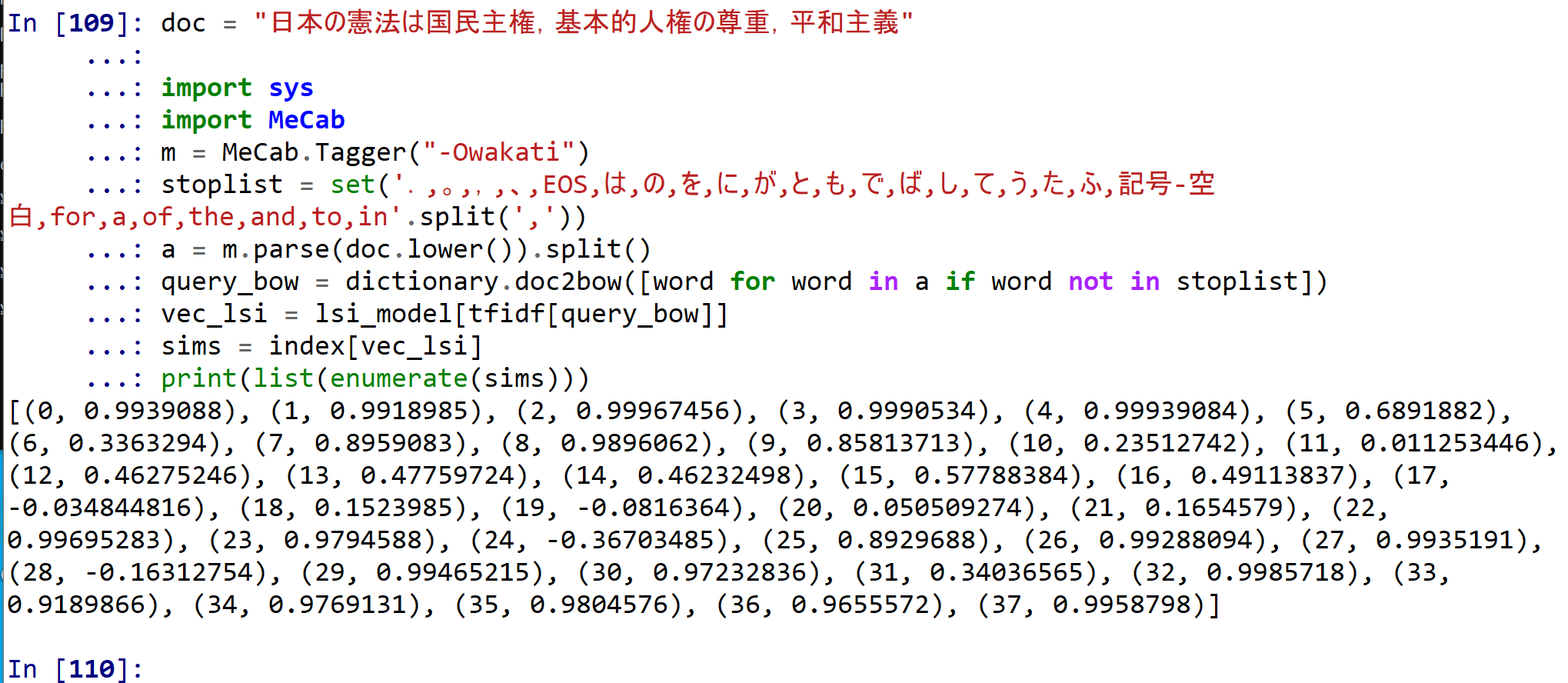
問い合わせを行う文書を doc にセットしている. そして,doc と,コーパス内の全ドキュメントとの類似度を求めている.
doc = "日本の憲法は国民主権,基本的人権の尊重,平和主義"
import sys
import MeCab
m = MeCab.Tagger("-Owakati")
stoplist = set('.,。,,,、,EOS,は,の,を,に,が,と,も,で,ば,し,て,う,た,ふ,これ,それ,あれ,この,その,あの,こと,する,ら,〔,〕,「,」,【,】,(,),記号-空白,記号-括弧開,記号-括弧閉,for,a,of,the,and,to,in'.split(','))
a = m.parse(doc.lower()).split()
query_bow = dictionary.doc2bow([word for word in a if word not in stoplist])
vec_lsi = lsi_model[tfidf[query_bow]]
sims = index[vec_lsi]
print(list(enumerate(sims)))
類似度順に文書を並べ替えて表示
sim_result = sorted(enumerate(sims), key=lambda item: -item[1])
for i, s in enumerate(sim_result):
print(s[1], text_corpus[s[0]])
