SQL 問い合わせ(Python, pandas, DuckDB を使用)
【概要】
本記事では,Python の pandas および DuckDB を使用して,データフレームに対し SQL で問い合わせを行う方法を説明する。選択(selection),射影(projection),グループごとの集計,ソート(ORDER BY),条件付き集計といった操作を扱う。データセットには seaborn が提供する Iris データセットおよび titanic データセットを使用する。
【目次】
- 1. 前準備
- 2. 必要なライブラリのインストール
- 3. 実行のための準備とその確認手順(Windows 前提)
- 4. 概要・使い方・実行上の注意
- 5. 演習1:iris, titanic データセットの読み込み
- 6. 演習2:データの確認
- 7. 演習3:選択(selection)
- 8. 演習4:射影(projection)
- 9. 演習5:グループごとの数え上げ
- 10. 演習6:グループごとの最大値
- 11. 演習7:ソート(ORDER BY)
- 12. 演習8:条件付き集計
- 13. まとめ
【関連する外部ページ】
なし
【サイト内の関連情報】
なし
1. 前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする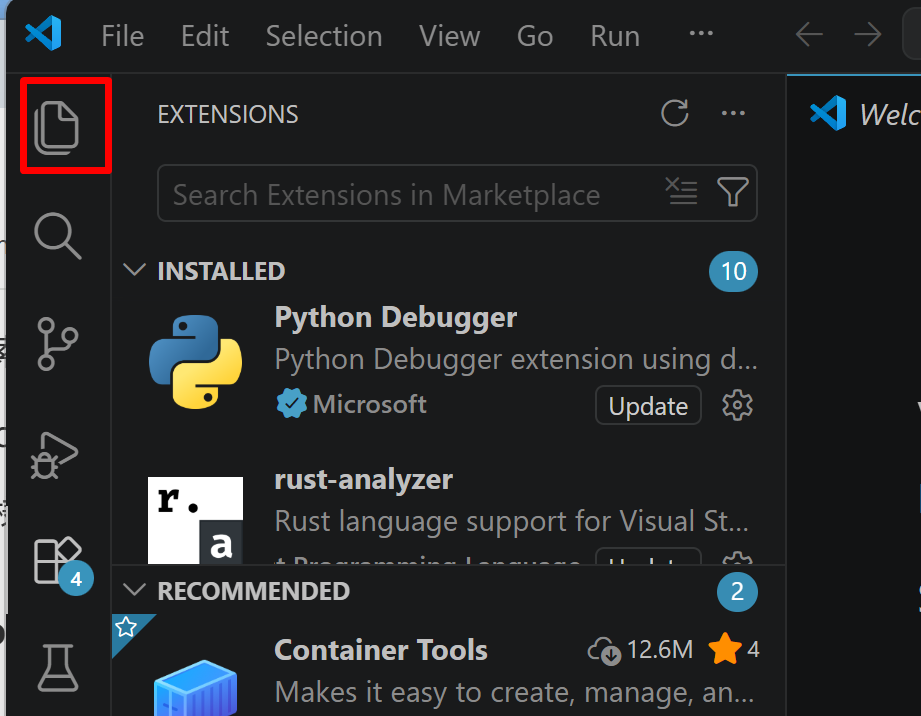
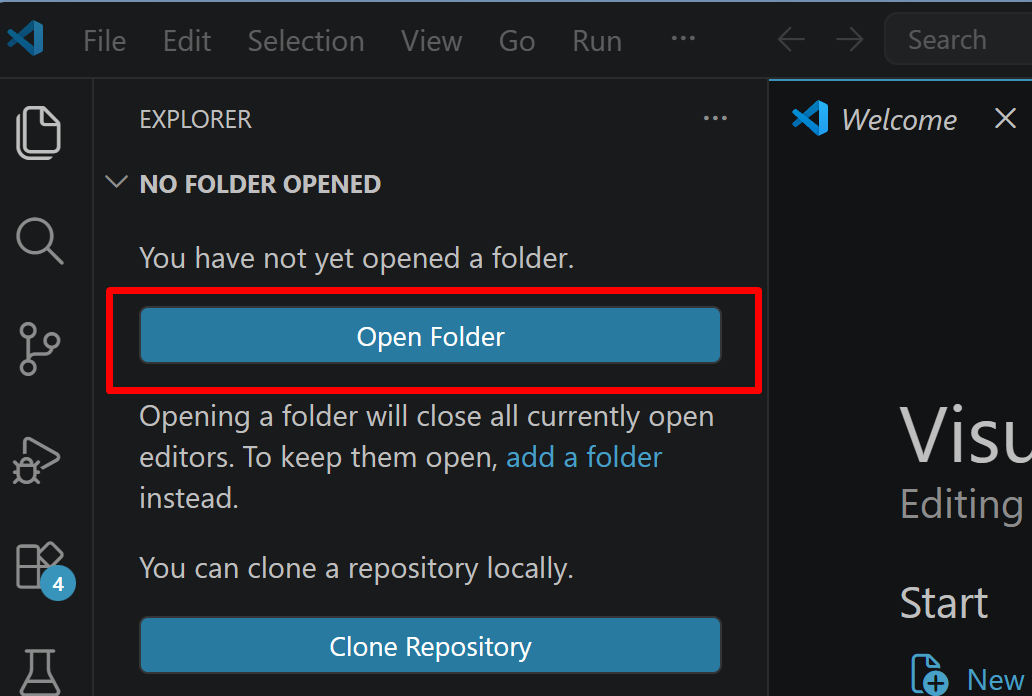
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
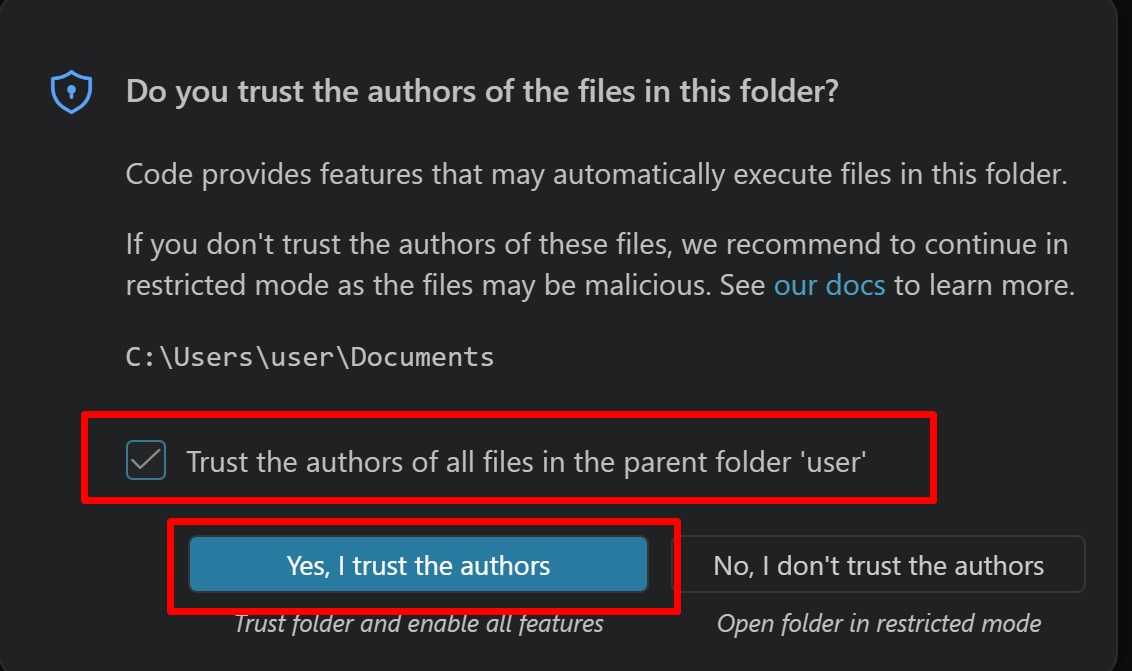
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
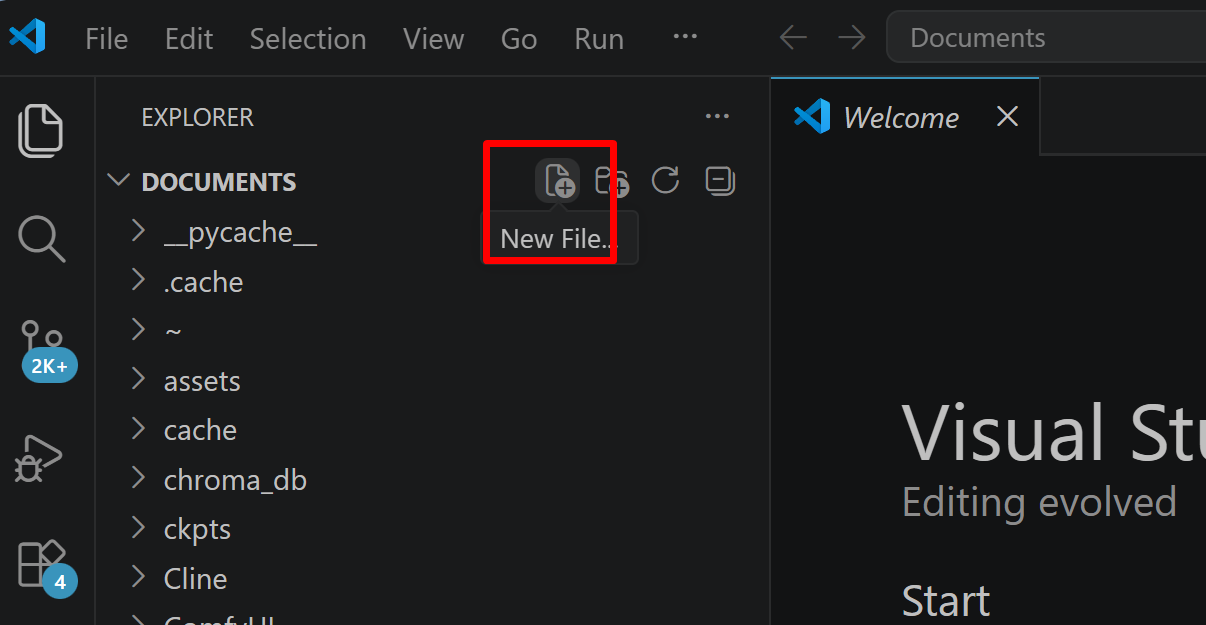
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される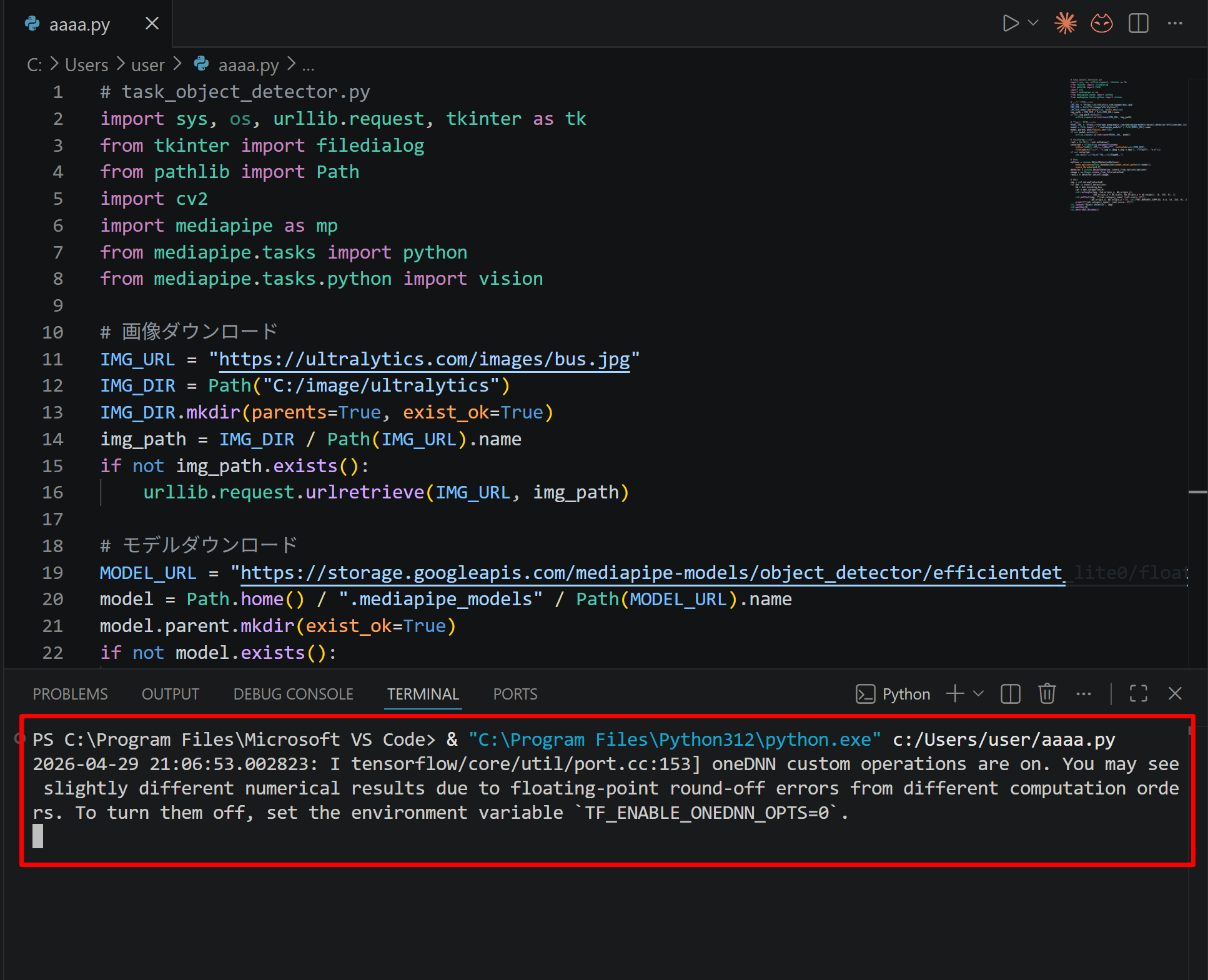
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


2. 必要なライブラリのインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
起動したコマンドプロンプトで以下を実行する。
python -m pip install -U --no-user pip setuptools numpy pandas duckdb matplotlib seaborn scikit-learn scikit-learn-intelex
3. 実行のための準備とその確認手順(Windows 前提)
3.1 プログラムファイルの準備
本記事では複数の独立した Python コード例を掲載している。各演習のコードをテキストエディタ(Visual Studio Code やメモ帳など)に貼り付け,文字コード UTF-8 で保存する。
3.2 実行コマンド
コマンドプロンプトでファイルの保存先ディレクトリに移動し,保存したファイルを python ファイル名.py の形式で実行する(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)。
3.3 動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
| データセットの読み込み | エラーなく実行が完了する |
| データの確認 | iris と titanic それぞれの先頭5行が表示される |
| 選択(selection) | sepal_length が 5 より大きいレコードが表示される |
| 射影(projection) | sepal_length と sepal_width の2列のみが条件付きで表示される |
| グループごとの数え上げ | iris の species 別件数と titanic の embark_town 別件数が表示される |
| グループごとの最大値 | iris の species ごとに各列の最大値が表示される |
| ソート | sepal_length の降順で先頭10件が表示される |
| 条件付き集計 | 乗船地ごとの生存者数,総数,生存率が表示される |
4. 概要・使い方・実行上の注意
4.1 データセットの準備
seaborn の sns.load_dataset() で Iris データセットと titanic データセットを読み込む。初回実行時にはインターネット経由でデータがダウンロードされる。読み込み後,head() で先頭5行を表示してデータの構造と列名を確認する。
4.2 SQL 問い合わせの各操作
DuckDB の sql 関数を使用すると,pandas のデータフレームに対して SQL で問い合わせを実行できる。DuckDB は,変数に格納されたデータフレームをテーブルとして直接参照して問い合わせを処理する(replacement scan という仕組み)。本記事では以下の操作を扱う。
選択(selection)は,WHERE 句で条件に合致するレコードを抽出する操作である。
射影(projection)は,SELECT 句で特定の列のみを取得する操作である。WHERE 句と組み合わせることで,条件を満たすレコードの特定列のみを取得できる。
グループごとの数え上げでは,列を1つ選んでグループを作り,各グループの要素数を求める。GROUP BY 句と count(*) を組み合わせて使用する。
グループごとの最大,最小,平均,和では,集約関数(max, min, avg, sum)を GROUP BY 句と組み合わせる(これらは DuckDB の標準の集約関数である。なお median も DuckDB では集約関数として利用できる)。本記事では各グループの最大値を求める例を載せる。
ソート(ORDER BY)では,ORDER BY 句で結果を並べ替える。LIMIT 句と組み合わせることで上位 N 件を取得できる。
条件付き集計では,SUM,COUNT,AVG,ROUND,WHERE(NULL 除外),GROUP BY,ORDER BY を組み合わせて,乗船地ごとの生存者数を集計する。
5. 演習1:iris, titanic データセットの読み込み
テーマ名:iris, titanic データセットの読み込み
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,2つのデータセットがエラーなく読み込まれることを確認する。
ヒント:sns.load_dataset() の引数にデータセット名を文字列で渡す。
考察ポイント:読み込みの段階では画面に出力が出ないことを確認する。
import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
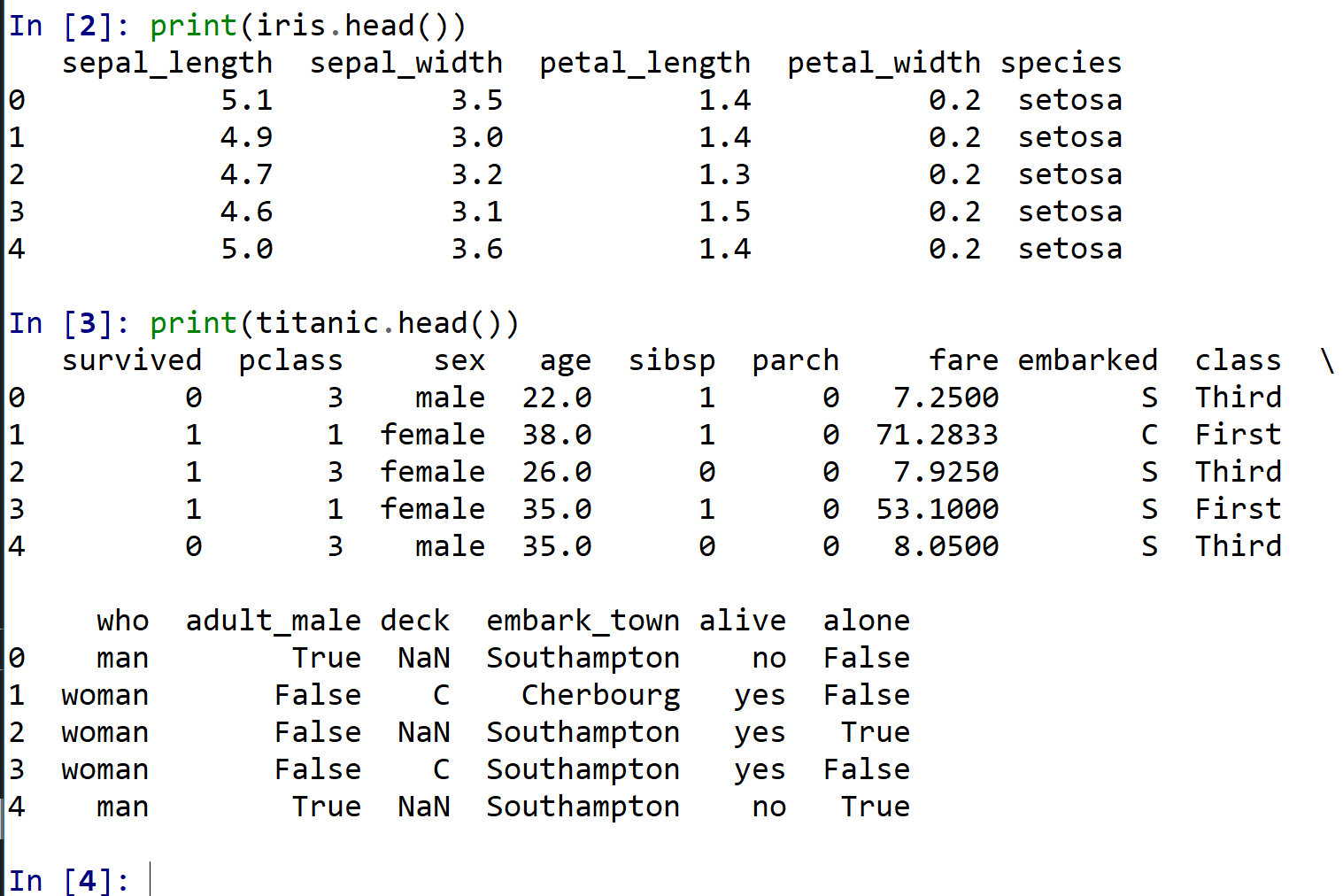
6. 演習2:データの確認
テーマ名:データの確認
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,iris と titanic の先頭5行を表示する。
ヒント:head() は先頭5行を返す。
考察ポイント:各データセットの列名と値の型を読み取る。
import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print(iris.head())
print(titanic.head())
7. 演習3:選択(selection)
テーマ名:選択(selection)
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,sepal_length が 5 より大きいレコードを抽出する。
ヒント:WHERE 句で条件を指定する。
考察ポイント:抽出後の行数が元の行数より少ないことを読み取る。
import pandas as pd
import duckdb
import seaborn as sns
iris = sns.load_dataset('iris')
print(duckdb.sql("SELECT * FROM iris WHERE sepal_length > 5;").df())

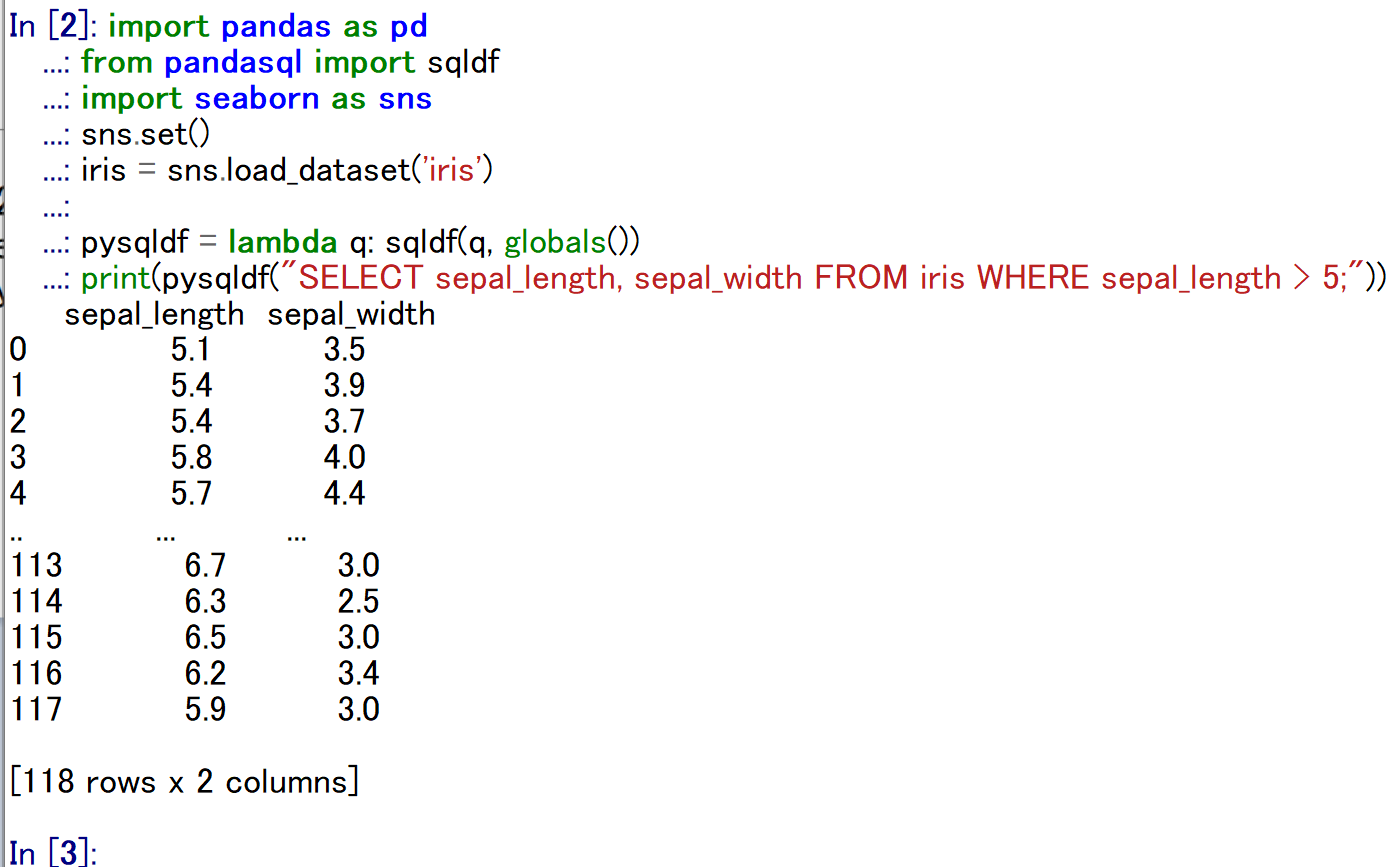
8. 演習4:射影(projection)
テーマ名:射影(projection)
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,条件を満たすレコードの sepal_length と sepal_width の2列のみを取得する。
ヒント:SELECT 句に取得したい列名を並べる。
考察ポイント:選択(演習3)との違い,すなわち取得される列が絞られている点を読み取る。
import pandas as pd
import duckdb
import seaborn as sns
iris = sns.load_dataset('iris')
print(duckdb.sql("SELECT sepal_length, sepal_width FROM iris WHERE sepal_length > 5;").df())
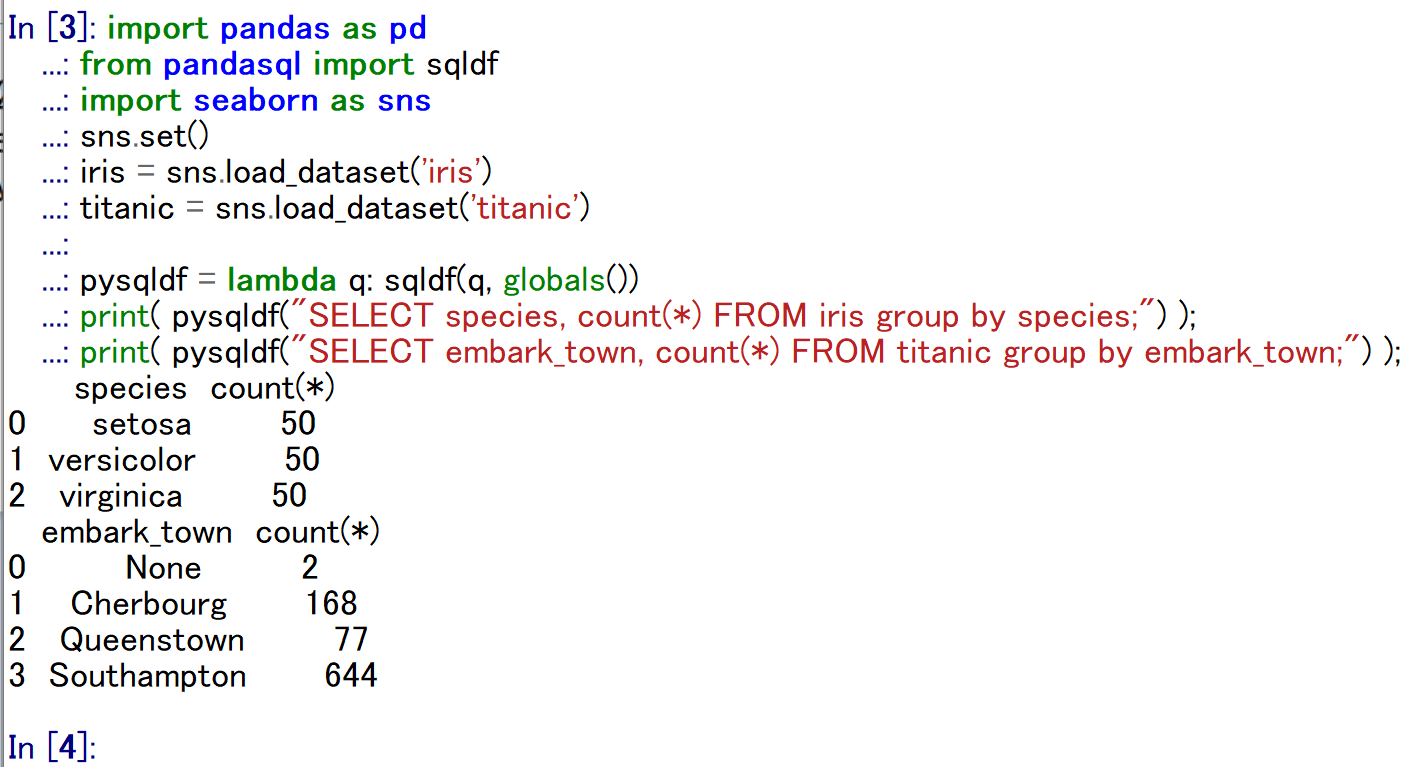
9. 演習5:グループごとの数え上げ
テーマ名:グループごとの数え上げ
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,iris の species 別件数と titanic の embark_town 別件数を求める。
ヒント:GROUP BY 句と count(*) を組み合わせる。
考察ポイント:グループごとに件数が分かれて表示されることを読み取る。
import pandas as pd
import duckdb
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print(duckdb.sql("SELECT species, count(*) FROM iris GROUP BY species;").df())
print(duckdb.sql("SELECT embark_town, count(*) FROM titanic GROUP BY embark_town;").df())
10. 演習6:グループごとの最大値
テーマ名:グループごとの最大値
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,iris の species ごとに各列の最大値を求める。
ヒント:集約関数 max を GROUP BY 句と組み合わせる。
考察ポイント:species ごとに各列の最大値が異なることを読み取る。
import pandas as pd
import duckdb
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print(duckdb.sql("SELECT species, max(sepal_length), max(sepal_width), max(petal_length), max(petal_width) FROM iris GROUP BY species;").df())

11. 演習7:ソート(ORDER BY)
テーマ名:ソート(ORDER BY)
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,sepal_length の降順で先頭10件を取得する。
ヒント:ORDER BY 句に DESC を付けると降順になる。LIMIT 句で件数を絞る。
考察ポイント:先頭の行ほど sepal_length が大きいことを読み取る。
import pandas as pd
import duckdb
import seaborn as sns
iris = sns.load_dataset('iris')
print(duckdb.sql("SELECT * FROM iris ORDER BY sepal_length DESC LIMIT 10;").df())
12. 演習8:条件付き集計
テーマ名:条件付き集計
手順:次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)し,乗船地ごとの生存者数,総数,生存率を集計する。
ヒント:SUM,COUNT,AVG,ROUND,WHERE,GROUP BY,ORDER BY を1つの SELECT 文で組み合わせる。生存率は AVG(survived) * 100 を ROUND で丸める。
考察ポイント:乗船地によって生存率に差があることを読み取る。
import pandas as pd
import duckdb
import seaborn as sns
titanic = sns.load_dataset('titanic')
print(duckdb.sql("SELECT embark_town, SUM(survived) AS survived_count, COUNT(*) AS total, ROUND(AVG(survived) * 100, 1) AS survival_rate FROM titanic WHERE embark_town IS NOT NULL GROUP BY embark_town ORDER BY survival_rate DESC;").df())
13. まとめ
- DuckDB による SQL 問い合わせ:DuckDB の
sql関数により,pandas のデータフレームに対して SQL で問い合わせを実行できる。 - 選択と射影:選択(selection)は WHERE 句で条件に合致するレコードを抽出し,射影(projection)は SELECT 句で特定の列のみを取得する。両者を組み合わせることで,必要なデータを絞り込める。
- GROUP BY による集計:列を1つ選んでグループを作り,
count,max,min,avg,sumなどの集約関数で各グループの統計量を求めることができる。 - ORDER BY によるソート:ORDER BY 句で結果を並べ替え,LIMIT 句で上位 N 件を取得できる。
- 複合的な SQL 問い合わせ:SUM,COUNT,AVG,ROUND,WHERE,GROUP BY,ORDER BY を組み合わせることで,条件付き集計を単一の SELECT 文で実現できる。