zipall
◆ bash プログラム
#!/bin/bash
cat >/tmp/a.$$.sql <<-SQL
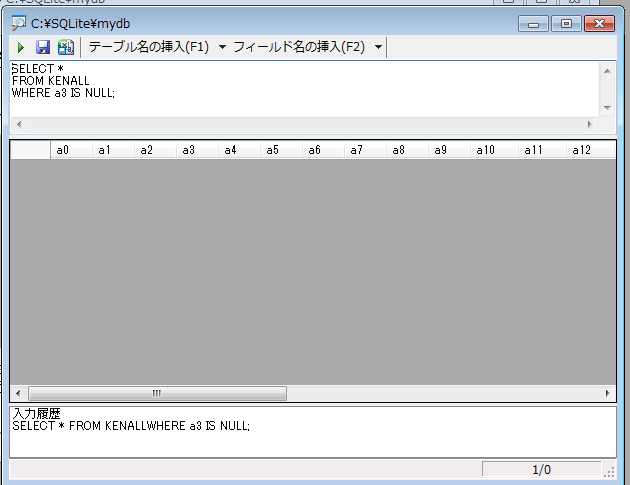
SELECT *
FROM KEN_ALL
WHERE a4 = '""';
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
* (注意)なお,町域については、「小谷」を「コヤト」,「オオタニ」などいろんな読み方をすることがある.都道府県や市区町村と同じというわけにはいかない.
郵便番号テーブルを定義します.テーブル名は ken_all
【テーブル定義の方針】
- 半角数字は INTEGER
- 半角カタカナと漢字は TEXT
【作業手順】
- テーブル定義
◆ bash プログラム
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL drop table ken_all; SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb cat >/tmp/a.$$.sql <<-SQL create table ken_all ( jiscode INTEGER not null CHECK ( jiscode >= 1000 AND jiscode <= 50000 ), zip_old text, zipcode text, ken_kana TEXT not null, shichoson_kana TEXT not null, choiki_kana TEXT not null, ken_kanji TEXT not null, shichoson_kanji TEXT not null, choiki_kanji text, num_ken_kana INTEGER not null, num_shichoson_kana INTEGER not null, num_choiki_kana INTEGER not null, num_ken_kanji INTEGER not null, num_shichoson_kanji INTEGER not null, num_choiki_kanji INTEGER not null, flag10 INTEGER not null, flag11 INTEGER not null CHECK ( flag11 >= 0 AND flag11 <= 1 ), flag12 INTEGER not null CHECK ( flag12 >= 0 AND flag12 <= 3 ), flag13 INTEGER not null CHECK ( flag13 >= 0 AND flag13 <= 1 ), info14 integer, info15 integer, org_choiki_kana text, org_choiki_kanji text, comment_kanji text, comment_kana text, kaisyamei_kana text, kaisyamei_kanji TEXT ); SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb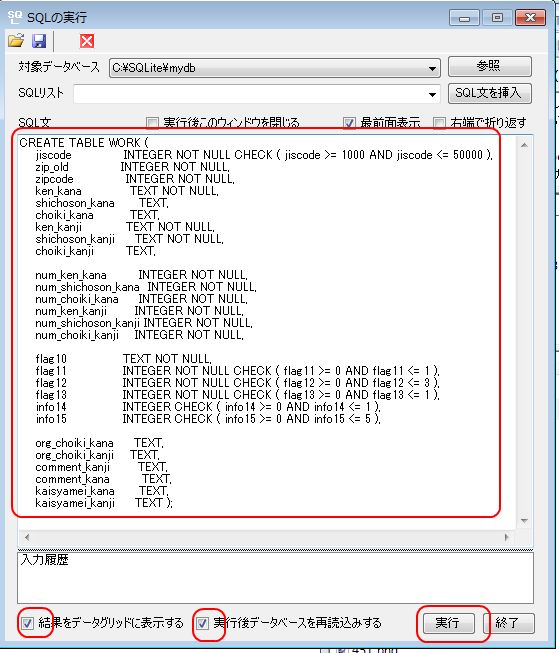
- 郵便番号テーブル ken_all の作成
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL drop table hoge2; SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb cat >/tmp/a.$$.sql <<-SQL create table hoge2 AS SELECT * FROM KEN_ALL UNION ALL SELECT * FROM JIGYOSYO; insert into ken_all SELECT * FROM hoge2; SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb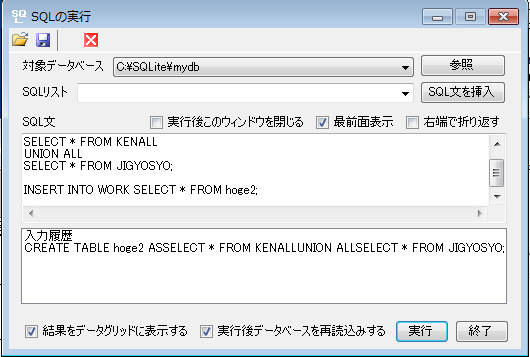
- 郵便番号テーブル ken_all の中身の確認
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL select * from ken_all limit 3; SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb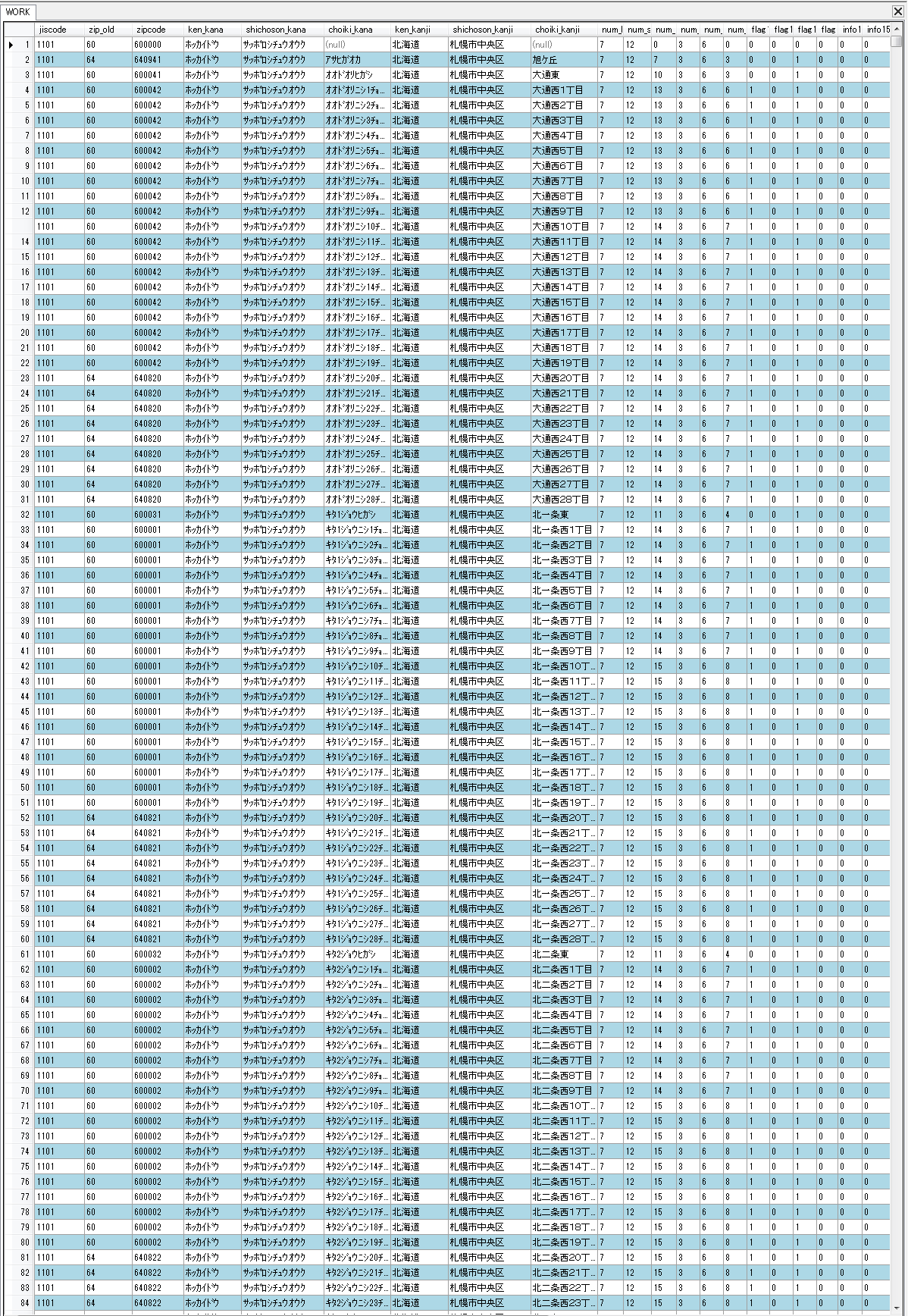
- (オプション) ダンプ操作
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL .output /tmp/ken_all.sql .dump ken_all .exit SQL # cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb(参考) 郵便番号テーブル ken_all の各列の説明
jiscode 全国地方公共団体コード(JIS X0401、X0402)……… 半角数字 zip_old (旧)郵便番号(5桁)……………………………………… 半角数字 zipcode 郵便番号(7桁)……………………………………… 半角数字 ken_kana 都道府県名カタカナ ………… 半角カタカナ(コード順に掲載) (注1) shichoson_kana 市区町村名カタカナ ………… 半角カタカナ(コード順に掲載) (注1) choiki_kana 町域名カタカナ ……………… 半角カタカナ(五十音順に掲載) (注1) ※「郵便番号CSVデータ作成プログラム」による自動編集後のもの ken_kanji 都道府県名漢字 ………… 漢字(コード順に掲載) (注1,2) shichoson_kanji 市区町村名漢字 ………… 漢字(コード順に掲載) (注1,2) choiki_kanji 町域名漢字 ……………… 漢字(五十音順に掲載) (注1,2) ※「郵便番号CSVデータ作成プログラム」による自動編集後のもの num_ken_kana 都道府県名カタカナ文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 num_shichoson_kana 市区町村名カタカナ文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 num_choiki_kana 町域名カタカナ文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 num_ken_kanji 都道府県名漢字文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 num_shichoson_kanji 市区町村名漢字文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 num_choiki_kanji 町域名漢字文字数 ※「郵便番号CSVデータ作成プログラム」により追加された属性 flag10 一町域が二以上の郵便番号で表される場合の表示 (「1」は該当、「0」は該当せず) ※ 事業所の個別郵便番号では「北海道」のような文字列が入る flag11 小字毎に番地が起番されている町域の表示 (「1」は該当、「0」は該当せず) flag12 丁目を有する町域の場合の表示 (「1」は該当、「0」は該当せず) flag13 一つの郵便番号で二以上の町域を表す場合の表示 (「1」は該当、「0」は該当せず) info14 更新の表示 (「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用)) ※ 事業所の個別郵便番号では空値(NULL)になることがある. info15 変更理由 (「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整、集配局新設、「5」訂正、「6」廃止(廃止データのみ使用)) ※ 事業所の個別郵便番号では空値(NULL)になることがある. org_choiki_kana org町域名カタカナ ※「郵便番号CSVデータ作成プログラム」による自動編集前のもの org_choiki_kanji org町域名漢字 ※「郵便番号CSVデータ作成プログラム」による自動編集前のもの comment_kanji コメント漢字 comment_kana コメントカタカナ kaisyamei_kana 会社名カタカナ kaisyamei_kanji 会社名漢字日本郵政「ゆうびんホームページ」で公開されている郵便番号データについて, もし
- 住所の郵便番号(CSV形式)(ken_all.csv) だけを使う, かつ,
- 「郵便番号CSVデータ作成プログラム」を使っての自動編集は行いたくない
という場合には,下記のテーブル定義を使ってください.そのこと以外は,ほぼ、この Web ページの手順が使える.
create table zips ( jiscode INTEGER not null, zip_old INTEGER not null, zipcode INTEGER not null, ken_kana TEXT not null, shichoson_kana TEXT not null, choiki_kana TEXT not null, ken_kanji TEXT not null, shichoson_kanji TEXT not null, choiki_kanji TEXT not null, flag10 TEXT not null, flag11 INTEGER not null, flag12 INTEGER not null, flag13 INTEGER not null, info14 integer, info15 INTEGER );
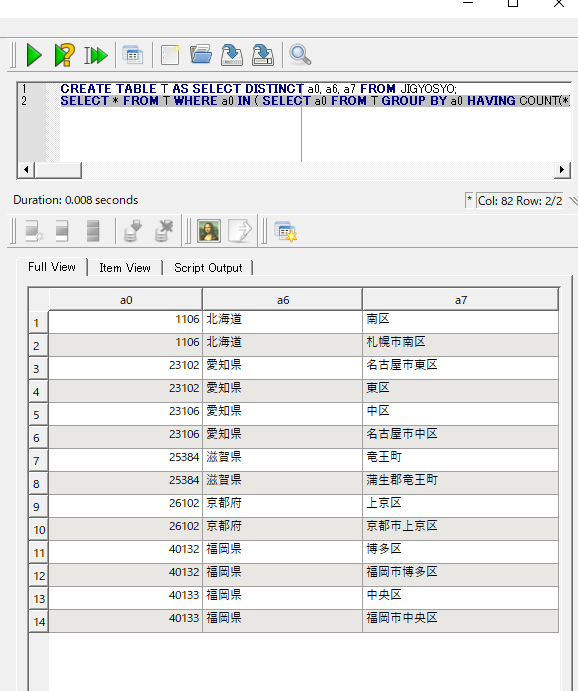
◆ 次のSQL プログラムを実行し,この問題を解消します
begin transaction;
UPDATE JIGYOSYO SET a7='札幌市南区' WHERE a0=1106;
UPDATE JIGYOSYO SET a7='名古屋市東区' WHERE a0=23102;
UPDATE JIGYOSYO SET a7='名古屋市中区' WHERE a0=23106;
UPDATE JIGYOSYO SET a7='名古屋市名東区' WHERE a0=23115;
UPDATE JIGYOSYO SET a7='蒲生郡竜王町' WHERE a0=25384;
UPDATE JIGYOSYO SET a7='京都市上京区' WHERE a0=26102;
UPDATE JIGYOSYO SET a7='福岡市博多区' WHERE a0=40132;
UPDATE JIGYOSYO SET a7='福岡市中央区' WHERE a0=40133;
commit;

次のを実行して確認します.
create table T2 AS select distinct a0, a6, a7 FROM JIGYOSYO;
SELECT * FROM T2 WHERE a0 IN ( SELECT a0 FROM T2 group by a0 HAVING COUNT(*) > 1 );
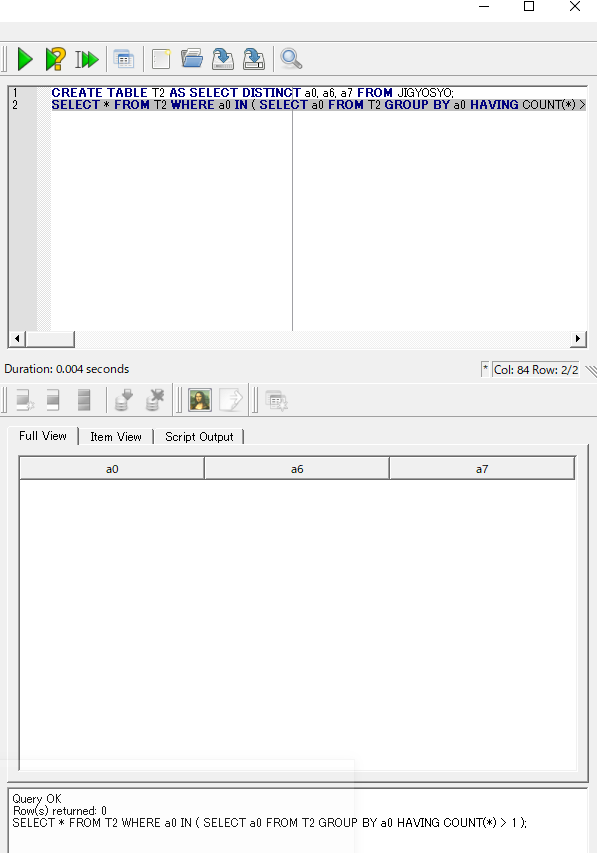
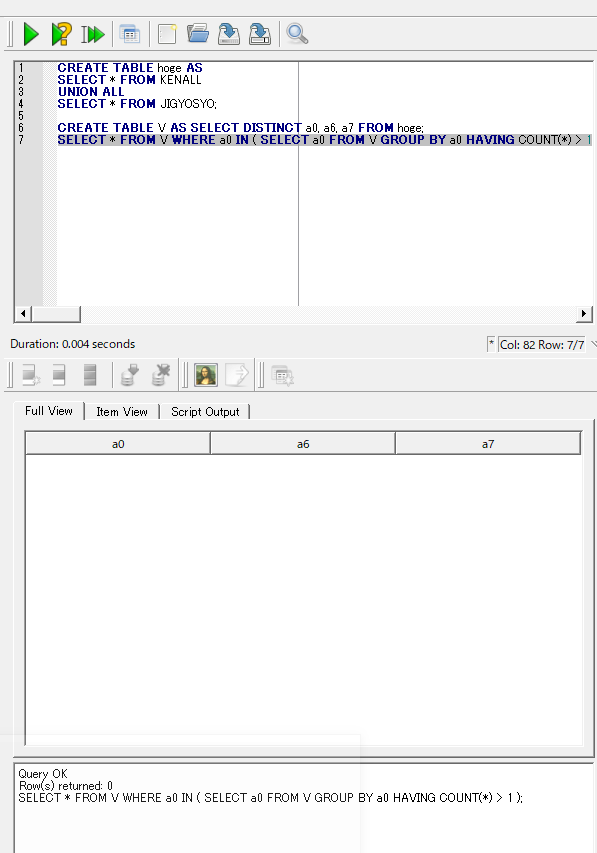
2. jiscode の一意性について
次に、「KEN_ALL テーブルと JIGYOSO テーブルの UNION ALL をとって,新しいテーブルを作ると, また,同じ a0 の値に対して,2つの違う a7 の値が出ている」 という問題がないことを確認します
create table hoge AS
SELECT * FROM KEN_ALL
UNION ALL
SELECT * FROM JIGYOSYO;
create table V AS select distinct a0, a6, a7 FROM hoge;
SELECT * FROM V WHERE a0 IN ( SELECT a0 FROM V group by a0 HAVING COUNT(*) > 1 );
begin transaction;
UPDATE JIGYOSYO SET a7='鳩ヶ谷市' WHERE a0=11226;
UPDATE JIGYOSYO SET a7='羽咋郡宝逹志水町' WHERE a0=17386;
UPDATE KEN_ALL SET a7='鳩ヶ谷市' WHERE a0=11226;
UPDATE KEN_ALL SET a7='羽咋郡宝逹志水町' WHERE a0=17386;
commit;
3. テーブル JIGYOSYO の「都道府県名カタカタ」,「市区町村名カタカナ」の空文字列
説明
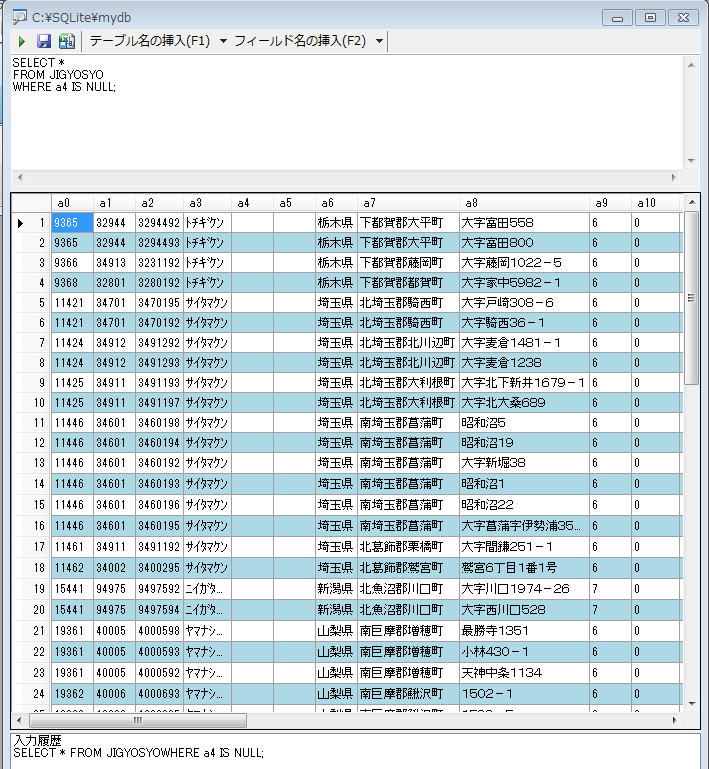
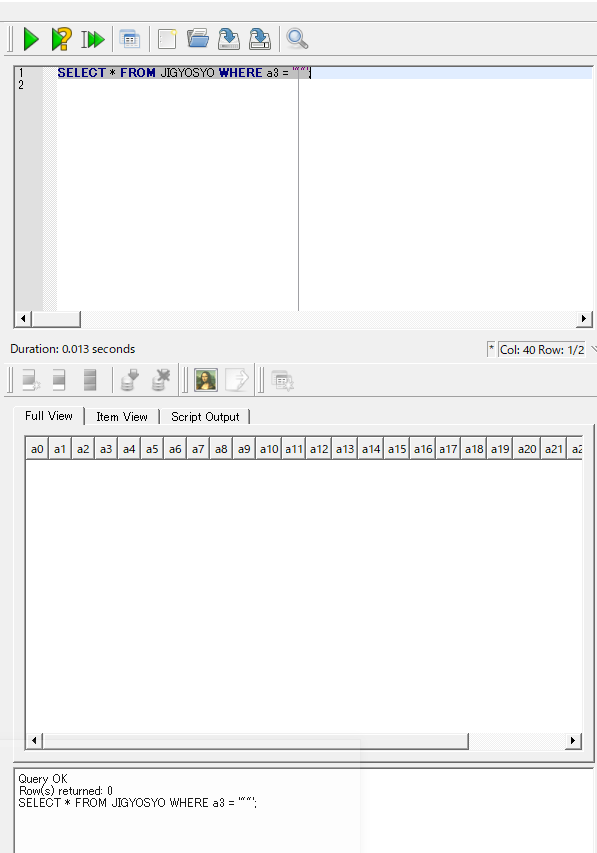
生成されたテーブル JIGYOSYO で, 「都道府県名カタカタ」,「市区町村名カタカナ」が「""」になっているレコードを確認します.
下の実行例では、「そのようなレコードが存在しない」と分かり、問題ありません.
SELECT * FROM JIGYOSYO WHERE a3 = '""';
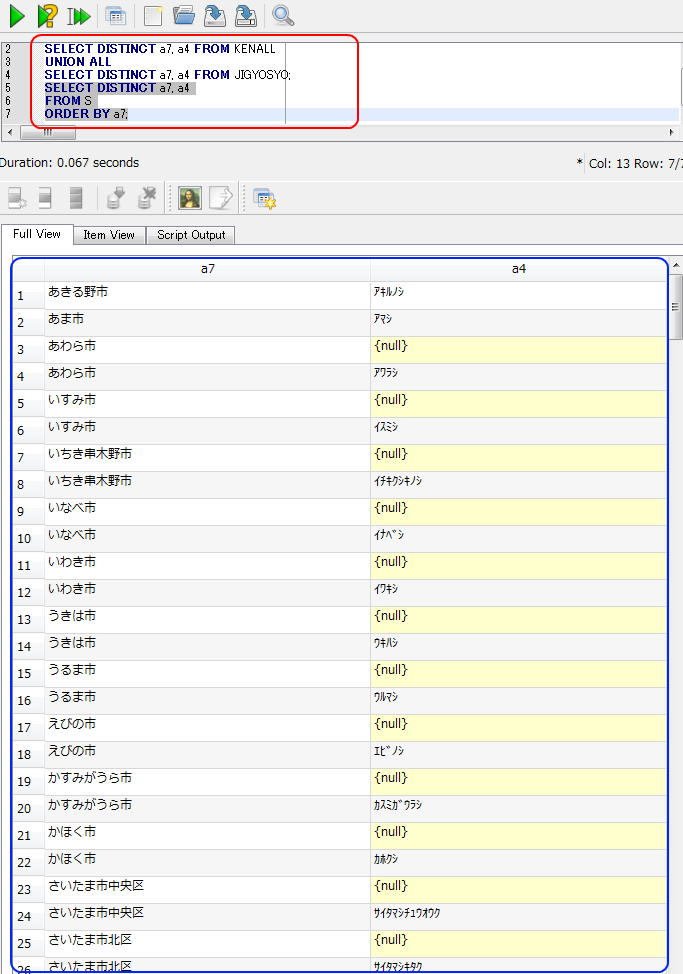
JIGYOSYO テーブルで, 「都道府県名カタカタ」,「市区町村名カタカナ」が「""」になっているレコードは,他のレコードを使って転記を行うことができる.
下記の例で分かる通り,「都道府県名漢字」,「市区町村名漢字」の値が同じ値になっているような別のレコードに, 「都道府県名カタカタ」,「市区町村名カタカナ」が書いてあります.
* a3 ・・・ 都道府県名カタカナ, a4 ・・・ 市区町村名カタカナ, a6 ・・・ 都道府県名漢字, a7 ・・・ 市区町村名漢字,
create table S AS
select distinct a7, a4 FROM KEN_ALL
UNION ALL
select distinct a7, a4 FROM JIGYOSYO;
select distinct a7, a4
FROM S
ORDER BY a7;
これを転記するというのが方針です. ここで言っている「転記」を,SQL でどう行うか,以下,説明する. ここでは,説明のため,郵便番号テーブルでなく,仮の簡略化したテーブルを使って説明する. 例えば,あるテーブルがあって,「漢字」,「カタカナ」,「文字数」が次のようになっているとしましょう. 説明用に,テーブル名,列名を日本語にしている.
create table 元の表 (
漢字 text,
カタカナ text,
文字数 INTEGER
);
begin transaction;
insert into 元の表 values('北', 'キタ', 2);
insert into 元の表 values('北', 'キタ', 2);
insert into 元の表 values('北', "", 0);
insert into 元の表 values('北', "", 0);
insert into 元の表 values('北', "", 0);
insert into 元の表 values('青', "", 0);
insert into 元の表 values('青', "", 0);
insert into 元の表 values('福', 'フク', 2);
insert into 元の表 values('福', 'フク', 2);
insert into 元の表 values('福', "", 0);
insert into 元の表 values('福', "", 0);
commit;
上記のテーブルを,下記のように変更したいという問題です.「漢字」が「北」,「福」になっていて,かつ, 「カタカナ」が "" になっているレコードには,「カタカナ」,「文字数」を転記したい! ということです. 一方で,「漢字」が「青」のレコードは,転記のしようがないので,手を付けずに残します.
漢字 カタカナ 文字数 ====================== 北 キタ 2 北 キタ 2 北 キタ 2 北 キタ 2 北 キタ 2 青 0 青 0 福 フク 2 福 フク 2 福 フク 2 福 フク 2 ----------------------
転記後のテーブルの例
さて,元のテーブルから,変更後のテーブルを得る SQL を段階的に考えましょう. 「select distinct 漢字, カタカナ, 文字数 FROM 元の表;」を実行して,同一値を持つレコードの重複を取り除くと,次のようになる.
select distinct 漢字, カタカナ, 文字数
FROM 元の表;
「青」のように,レコードが1つしかないもの, 「福」,「北」のように,レコードが2個あるものが見て取れます. では,「青」のように,レコードが1つしかないものを選ぶ SQL はどう書けるかというと, これは,副問い合わせを使うのが簡単です.
-
まずは,「漢字」で集約して,個々の「漢字」ごとに,「カタカナ」の異なり数がいくつあるかを調べ,異なり数が1のレコードだけを選びます.
これは,「『カタカナ』が全部 "" になっている」.言い換えると「
ある『漢字』に対して,『カタカナ』として,""そうでないレコードが混ざっている場合には,異なり数は2以上になる」という意味です.
そのために,
「HAVING COUNT(DISTINCT(カタカナ)) = 1;」という条件を SQL 内に含めることになる.
* なお,属性「文字数」は,「カタカナ」に依存する,つまり,関数従属なので, HAVING のところに「文字数」を指定する必要はありません.
- 副問い合わせの結果,{「青」} のような,漢字の集合が得られますので,それを使って,元の表からレコードを選び出す.
SQL とその実行結果は,次のようになる.
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 1 );
同様に, 「福」,「北」のように,カタカナの値が "" であるレコード,ある1つの値を持つものという2種類だけあるものを選ぶ(3種類以上は除外します.) SQL も書けます.SQL とその実行結果は,次のようになる. 先ほどの SQL の「= 1」を「= 2」に変えただけです.
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 2 );
この SQL に少し手を加えて,「カタカタ」が空文字列でないものだけを出力するようにします.(WHERE に,「カタカナ IS not null」を追加している).
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE カタカナ <> ''
AND 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 2 );
以上をまとめて,次のような UNION (和)を考えます.
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 1 )
UNION
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE カタカナ <> ''
AND 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 2 );
出力される表は,次のことをあらわしている.
- 「青」のレコードには,もともと「カタカナ」の情報が無いので,転記しない.
- 「福」のレコードには,「フク」,「2」を転記する
- 「北」のレコードには,「アオ」,「2」を転記する
こうして出来た表を,元の表における転記用に使いたいので, 「create table ... AS ...」を使って,「作業用」という名前のテーブルに保存します.そして,「作業用」と「元の表」の2つのテーブルを使い,「元の表」における転記を行う.
SQL とその実行結果は,次のようになる.期待通りの結果です.
create table 作業用リスト AS
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 1 )
UNION
select distinct 漢字, カタカナ, 文字数
FROM 元の表
WHERE カタカナ <> ''
AND 漢字 IN
( SELECT 漢字
FROM 元の表
group by 漢字
HAVING COUNT(DISTINCT(カタカナ)) = 2 );
UPDATE 元の表 SET
文字数 = (SELECT 作業用リスト.文字数 FROM 作業用リスト WHERE 元の表.漢字 = 作業用リスト.漢字 )
WHERE カタカナ = '';
UPDATE 元の表 SET
カタカナ = (SELECT 作業用リスト.カタカナ FROM 作業用リスト WHERE 元の表.漢字 = 作業用リスト.漢字 )
WHERE カタカナ = '';