日本語文のコーパス(ドキュメントの集まり)から 辞書,Bag of Words, Latent Semantic Indexing (LSI),Latent Dirichlet Allocation (LDA) を作る(Python,gensim を使用)
次のページで公開されているプログラムを日本語が扱えるように書き替えて, 文書(ドキュメント)についての,単語の切り出し,ストップワードの除去,頻出単語の抽出とIDの付与,Bag of Words,LSI,LDA の作成を行う.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
【サイト内の関連ページ】
- 英文の場合について: 別ページ »で説明
謝辞:このページで使用しているソフトウェア類の作者に感謝します.
前準備
Python のインストール(Windows上)
注:既にPython(バージョン3.12を推奨)がインストール済みの場合は,この手順は不要である.
winget(Windowsパッケージマネージャー)を使用してインストールを行う
- Windowsで,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。 - winget(Windowsパッケージマネージャー)が利用可能か確認する:
winget --version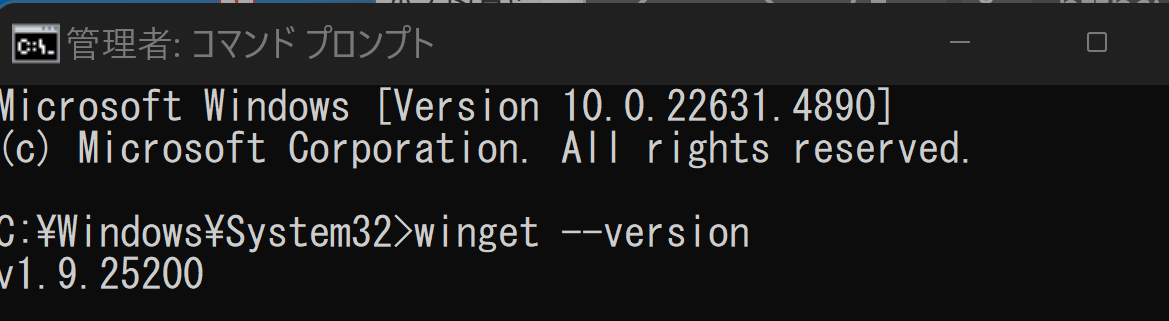
- Pythonのインストール(下のコマンドにより Python 3.12 がインストールされる).
REM Python 3.12 をシステム領域にインストール winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements REM パス長制限の解除 reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem" /v LongPathsEnabled /t REG_DWORD /d 1 /f reg query "HKLM\SYSTEM\CurrentControlSet\Control\FileSystem" /v LongPathsEnabled REM Python のパス set "INSTALL_PATH=C:\Program Files\Python312" echo "%PATH%" | find /i "%INSTALL_PATH%" >nul if errorlevel 1 setx PATH "%PATH%;%INSTALL_PATH%" /M >nul echo "%PATH%" | find /i "%INSTALL_PATH%\Scripts" >nul if errorlevel 1 setx PATH "%PATH%;%INSTALL_PATH%\Scripts" /M >nul - Python詳細ガイド:Pythonまとめ »
- Windows
Windows では,コマンドプロンプトを管理者として実行する.
次のコマンドを実行.
python -m pip install mecab gensim - Ubuntu
sudo pip3 install mecab gensim - ストップワード(.,。,,,、,EOS,は,の,を,に,が,と,も,で,ば,し,て,う,た,ふ,記号-空白,for,a,of,the,and,to,in)は除去する.
- 英語の大文字は小文字に変える(lower() を使用)
- -Owakati で行う場合
import sys import MeCab m = MeCab.Tagger("-Owakati") stoplist = set('.,。,,,、,EOS,は,の,を,に,が,と,も,で,ば,し,て,う,た,ふ,これ,それ,あれ,この,その,あの,こと,する,ら,〔,〕,「,」,【,】,(,),記号-空白,記号-括弧開,記号-括弧閉,for,a,of,the,and,to,in'.split(',')) a = [m.parse(document.lower()).split() for document in text_corpus] texts = [[word for word in document if word not in stoplist] for document in a] print(texts)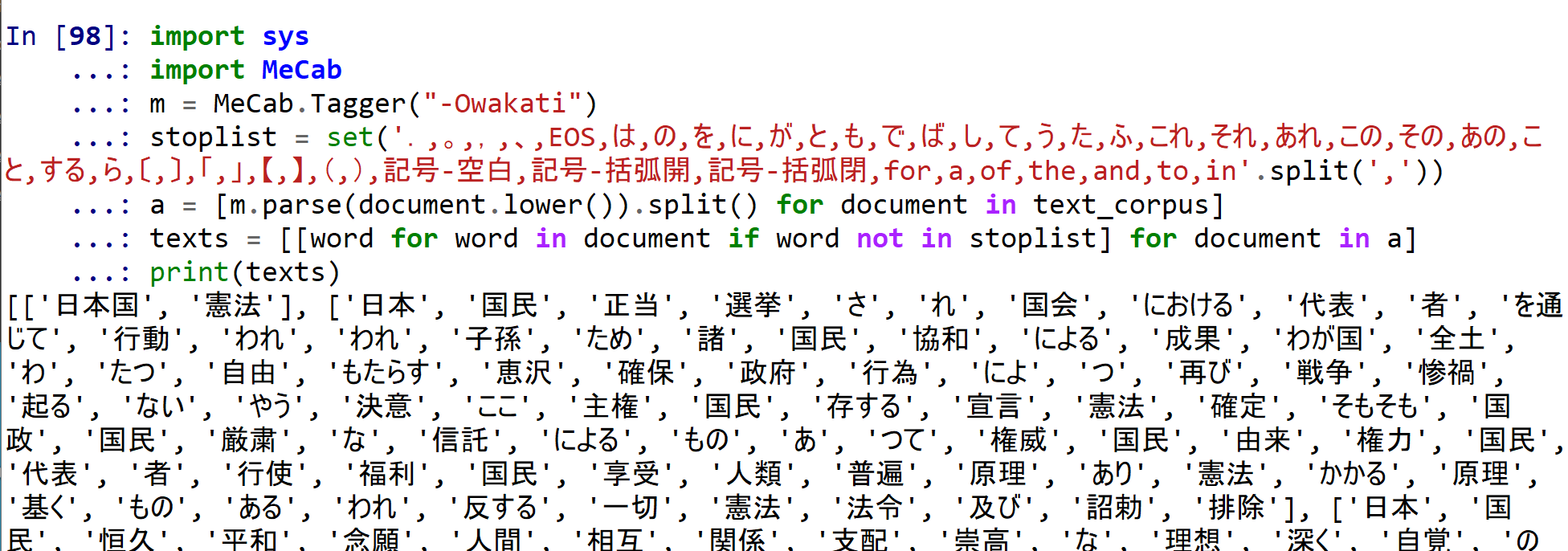
- -Ochasen で行う場合
上と同じことを行っているが,将来,品詞の情報を使いたい場合に備えている.
import sys import MeCab m = MeCab.Tagger("-Ochasen") stoplist = set('.,。,,,、,EOS,は,の,を,に,が,と,も,で,ば,し,て,う,た,ふ,これ,それ,あれ,この,その,あの,こと,する,ら,〔,〕,「,」,【,】,(,),記号-空白,記号-括弧開,記号-括弧閉,for,a,of,the,and,to,in'.split(',')) a = [[i.split()[0] for i in m.parse(document.lower()).splitlines()] for document in text_corpus] texts = [[word for word in document if word not in stoplist] for document in a] print(texts)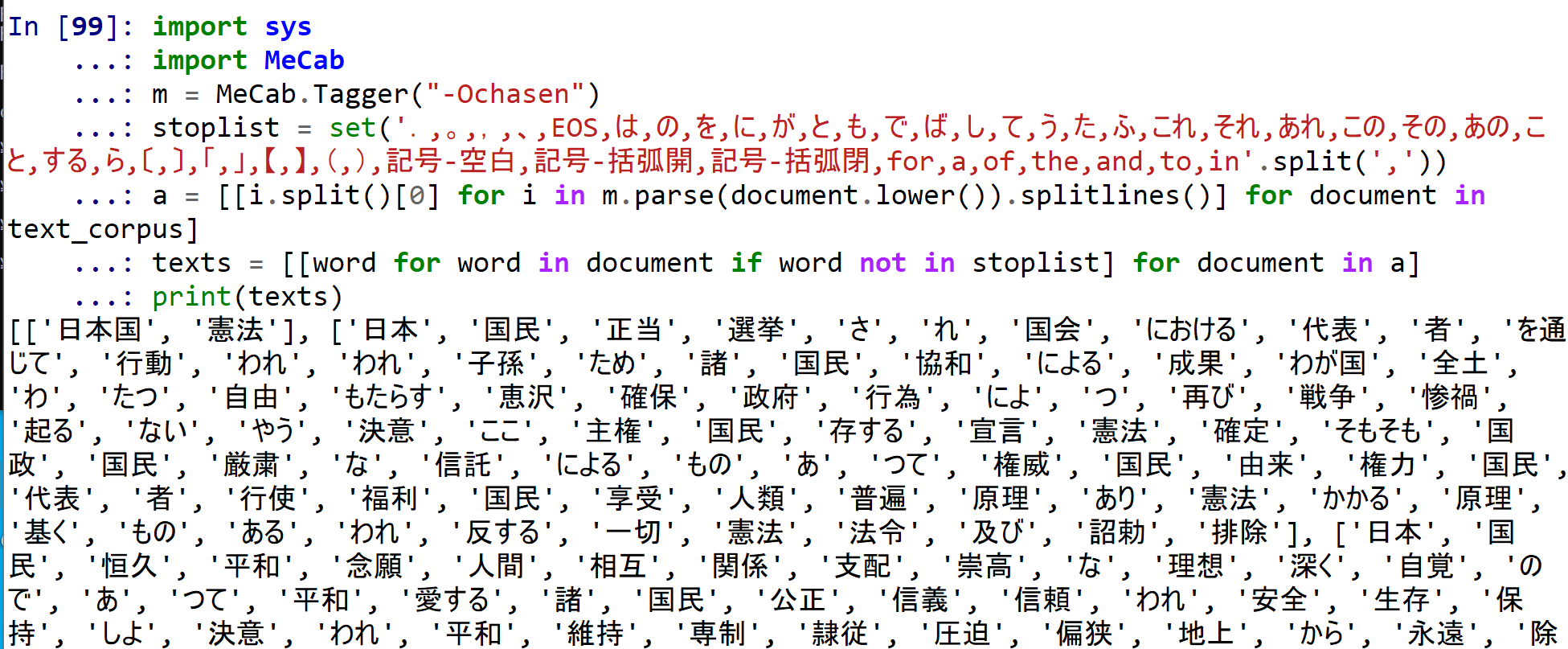
【関連する外部サイト】
【サイト内の関連ページ】
MeCab のインストール
python の mecab, gensim のインストール
日本語文書からの単語の切り出し,品詞の判定
Python 処理系の起動
Python 処理系として,Jupyter Qt Console を起動
jupyter qtconsole

ここでは,Jupyter Qt Console を使っている. 他の開発環境(Spyder,PyCharm,PyScripter など)も便利である.
ここから先は,Jupyter Qt Console の画面で説明する.
コーパス
文書(ドキュメントの集まり)をコーパスという.
次は,元のテキストファイルを改行のところで区切って,コーパスを作成する. なお,空の行はコーパスから取り除く.
plain='''
日本国憲法
日本国民は、正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民との協和による成果と、わが国全土にわたつて自由のもたらす恵沢を確保し、政府の行為によつて再び戦争の惨禍が起ることのないやうにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する。そもそも国政は、国民の厳粛な信託によるものであつて、その権威は国民に由来し、その権力は国民の代表者がこれを行使し、その福利は国民がこれを享受する。これは人類普遍の原理であり、この憲法は、かかる原理に基くものである。われらは、これに反する一切の憲法、法令及び詔勅を排除する。
日本国民は、恒久の平和を念願し、人間相互の関係を支配する崇高な理想を深く自覚するのであつて、平和を愛する諸国民の公正と信義に信頼して、われらの安全と生存を保持しようと決意した。われらは、平和を維持し、専制と隷従、圧迫と偏狭を地上から永遠に除去しようと努めてゐる国際社会において、名誉ある地位を占めたいと思ふ。われらは、全世界の国民が、ひとしく恐怖と欠乏から免かれ、平和のうちに生存する権利を有することを確認する。
われらは、いづれの国家も、自国のことのみに専念して他国を無視してはならないのであつて、政治道徳の法則は、普遍的なものであり、この法則に従ふことは、自国の主権を維持し、他国と対等関係に立たうとする各国の責務であると信ずる。
日本国民は、国家の名誉にかけ、全力をあげてこの崇高な理想と目的を達成することを誓ふ。
第一章 天皇
〔天皇の地位と主権在民〕
第一条 天皇は、日本国の象徴であり日本国民統合の象徴であつて、この地位は、主権の存する日本国民の総意に基く。
〔皇位の世襲〕
第二条 皇位は、世襲のものであつて、国会の議決した皇室典範の定めるところにより、これを継承する。
〔内閣の助言と承認及び責任〕
第三条 天皇の国事に関するすべての行為には、内閣の助言と承認を必要とし、内閣が、その責任を負ふ。
〔天皇の権能と権能行使の委任〕
第四条 天皇は、この憲法の定める国事に関する行為のみを行ひ、国政に関する権能を有しない。
2 天皇は、法律の定めるところにより、その国事に関する行為を委任することができる。
〔摂政〕
第五条 皇室典範の定めるところにより摂政を置くときは、摂政は、天皇の名でその国事に関する行為を行ふ。この場合には、前条第一項の規定を準用する。
〔天皇の任命行為〕
第六条 天皇は、国会の指名に基いて、内閣総理大臣を任命する。
2 天皇は、内閣の指名に基いて、最高裁判所の長たる裁判官を任命する。
〔天皇の国事行為〕
第七条 天皇は、内閣の助言と承認により、国民のために、左の国事に関する行為を行ふ。
一 憲法改正、法律、政令及び条約を公布すること。
二 国会を召集すること。
三 衆議院を解散すること。
四 国会議員の総選挙の施行を公示すること。
五 国務大臣及び法律の定めるその他の官吏の任免並びに全権委任状及び大使及び公使の信任状を認証すること。
六 大赦、特赦、減刑、刑の執行の免除及び復権を認証すること。
七 栄典を授与すること。
八 批准書及び法律の定めるその他の外交文書を認証すること。
九 外国の大使及び公使を接受すること。
十 儀式を行ふこと。
〔財産授受の制限〕
第八条 皇室に財産を譲り渡し、又は皇室が、財産を譲り受け、若しくは賜与することは、国会の議決に基かなければならない。
第二章 戦争の放棄
〔戦争の放棄と戦力及び交戦権の否認〕
第九条 日本国民は、正義と秩序を基調とする国際平和を誠実に希求し、国権の発動たる戦争と、武力による威嚇又は武力の行使は、国際紛争を解決する手段としては、永久にこれを放棄する。
2 前項の目的を達するため、陸海空軍その他の戦力は、これを保持しない。国の交戦権は、これを認めない。
'''
text_corpus = [i for i in plain.split('\n') if len(i) > 0]
print(text_corpus)

単語の切り出し
コーパスのそれぞれの文書(ドキュメント)から,単語を切り出す. そのために,ドキュメントごとに,MeCab の parse() で解析を行う. Mecab での解析結果の先頭列に単語が入っているので,split()[0] で取り出して使う. 次のことも行う.
同じことを行うプログラムを 2通り示す.
単語の出現数を数え上げ,単語の切り出し結果について頻出する単語のみを残す.
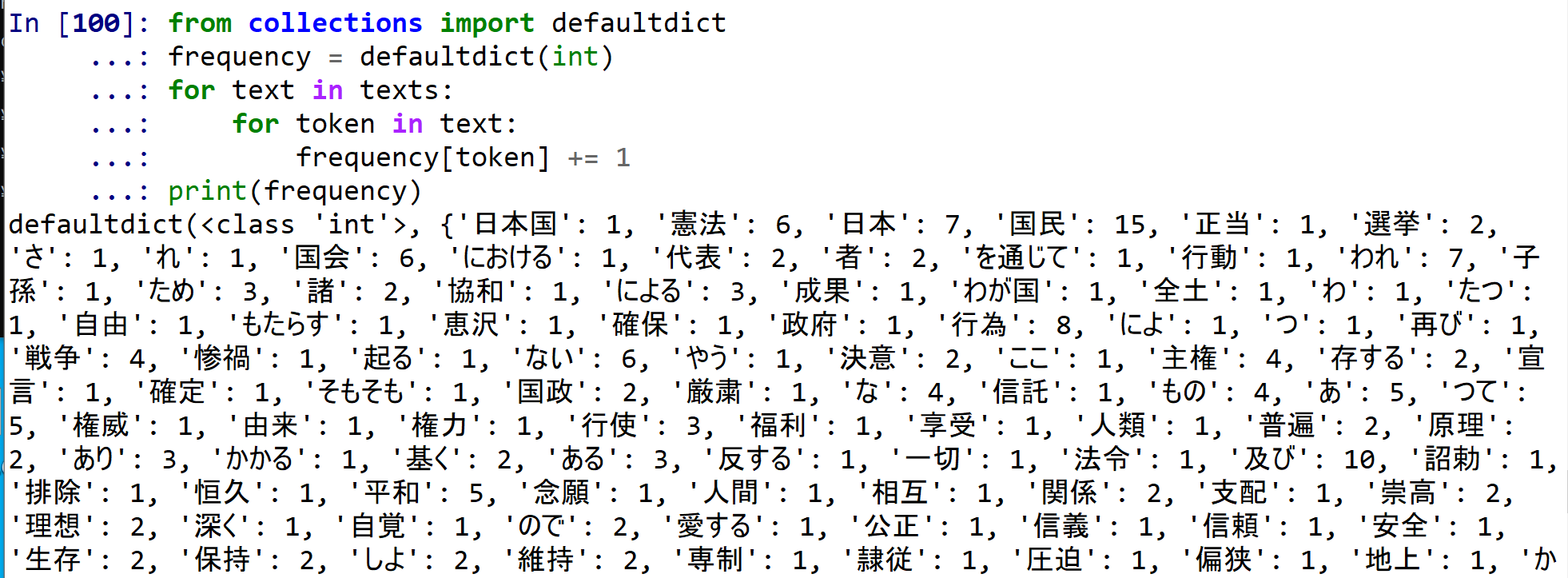
単語の出現数の数え上げは次で行う.
* 日本語を扱うが,次のページで公開されているプログラムからの変更なし.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
from collections import defaultdict
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
print(frequency)
単語の切り出し結果について,頻出する単語(出現回数 2回以上のみ)を残す.
* 日本語を扱うが,次のページで公開されているプログラムからの変更なし.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
processed_corpus = [[token for token in text if frequency[token] > 1] for text in texts]
print(processed_corpus)

単語の切り出し結果を使い,単語ごとに ID を割り振る
単語に,整数の ID を割り振る(辞書を作る).
* 日本語を扱うが,次のページで公開されているプログラムからの変更なし.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
from gensim import corpora
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary.token2id)

Bag of Words
Bag of Words は,単語IDと出現回数のペアを文書(ドキュメント)ごとに作ったもの.
* 日本語を扱うが,次のページで公開されているプログラムからの変更なし.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
bow_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
print(bow_corpus)

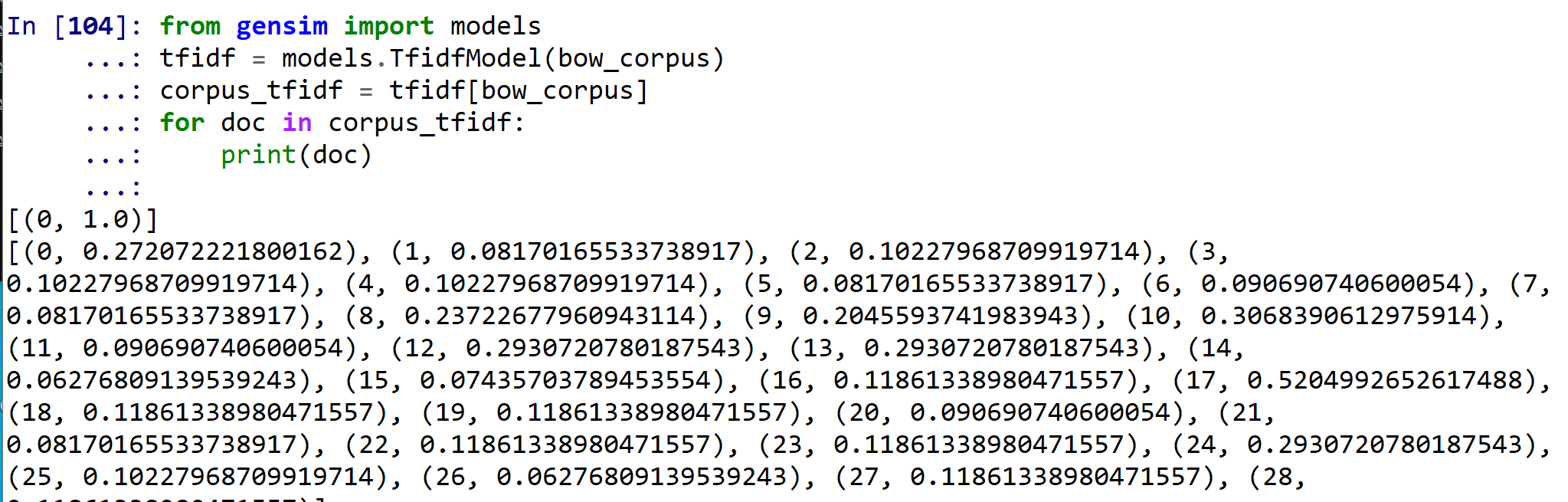
TF/IDF コーパスの作成
先ほど作成した bow_corpus (Bag of Words) をTF/IDF値に変換する.
gensim の次のページで公開されている Python プログラムを使用
from gensim import models
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
for doc in corpus_tfidf:
print(doc)
Latent Semantic Indexing (LSI)
先ほど作成した corpus_tfidf (TF/IDF コーパス) をLatent Semantic Indexing に変換する. ここでは, トピックス数を 2 に設定.
gensim の次のページで公開されている Python プログラムを使用
N = 2
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=N)
corpus_lsi = lsi_model[corpus_tfidf]
for doc, as_text in zip(corpus_lsi, text_corpus):
print(doc, as_text)

Latent Dirichlet Allocation (LDA)
先ほど作成した bow_corpus (Bag of Words) をLatent Dirichlet Allocation (LDA) に変換する. ここでは, トピックス数を 2 に設定.
gensim の次のページで公開されている Python プログラムを使用
N = 2
lda_model = models.LdaModel(bow_corpus, id2word=dictionary, num_topics=N)
corpus_lda = lda_model[bow_corpus]
for doc, as_text in zip(corpus_lda, text_corpus):
print(doc, as_text)

lda_model.print_topics()
