深層学習による画像分類・タギングのテキスト
【目次】
画像認識
画像認識とは、コンピューターが画像の内容を自動的に理解・分類する技術である。人間が写真を見て「これは猫だ」と判断するのと同様に、機械が画像から特徴を抽出し、事前に定義されたカテゴリに分類する。
第1章:深層学習の基礎理論と用語
基礎用語
深層学習(Deep Learning):多層ニューラルネットワークによる機械学習手法
事前学習(Pre-training):大規模データセットで汎用的な特徴を学習する段階。少ないデータでも高性能を実現し、計算コストを削減する。事前学習なしでは数百万枚の画像が必要な場合も、事前学習済みモデルなら数千枚で同等の性能を達成可能。
ファインチューニング(Fine-tuning):特定タスクに合わせて事前学習モデルを調整する段階。事前学習で獲得した汎用的な特徴表現を活用し、新しいタスクに適応させる。
ImageNet:1,400万枚の画像からなる大規模画像データセット。1000のカテゴリに分類され、画像認識研究の標準的なベンチマーク
Top-1精度:モデルが最も確信度の高いクラスを予測した際の正解率。例えば85%の場合、100枚中85枚を正しく分類する。一般用途では80%以上、高精度要求用途では90%以上が目安。
FLOPS効率:浮動小数点演算数(FLOPS)あたりの精度を示す効率指標。同じ精度でもFLOPSが少ないモデルほど高速・省電力で動作する。リアルタイム処理では特に重要な指標。
畳み込み(Convolution):画像の局所的な特徴を抽出するための数学的操作
受容野(Receptive Field):ニューラルネットワークの各ニューロンが入力画像のどの範囲の情報を統合して処理しているかを示す領域
自己注意機構(Self-Attention):入力の各要素が他の全ての要素との関係を計算する機構
マスク画像モデリング(MIM):画像の一部を隠して、その部分を予測する自己教師あり学習手法
ゼロショット学習:訓練時に見たことのないクラスに対して、事前学習で獲得した知識のみで分類を行う手法
物体検出:画像内の物体の位置と種類を同時に特定するタスク
セマンティックセグメンテーション:画像の各ピクセルにクラスラベルを割り当てるタスク
深層学習の数学的基礎
画像認識における深層学習は、数学的な計算によって人間の視覚的判断を模倣する。コンピューターが画像の数値データから意味のあるパターンを抽出するために、以下の数学的概念を使用する。
ソフトマックス関数
複数のクラスから1つを選ぶ分類問題では、各クラスの確率を計算する必要がある。ソフトマックス関数は実数値を0と1の間の確率値に変換し、すべての確率の合計を1にする。
数式:softmax(x_i) = exp(x_i) / Σexp(x_j)
ここで、x_iは第iクラスの出力値(ロジット)、exp()は指数関数、Σは全クラスに対する総和を表す。指数関数により大きな値がより強調され、正規化により確率分布となる。
ソフトマックス関数の動作例:
入力値: [2.0, 1.0, 0.1] → 確率分布: [0.66, 0.24, 0.10]
計算過程: exp(2.0)=7.39, exp(1.0)=2.72, exp(0.1)=1.11
総和=11.22, 確率=[7.39/11.22, 2.72/11.22, 1.11/11.22]
勾配降下法
機械学習では予測誤差を最小化するためのパラメータ調整が必要である。勾配降下法は誤差の勾配を計算し、誤差が減少する方向にパラメータを更新する。
数式:θ = θ - α(∂L/∂θ)
ここで、θはパラメータ、αは学習率(0.001~0.1程度)、∂L/∂θは損失関数の勾配を表す。学習率が大きすぎると最適解を飛び越え、小さすぎると学習が遅くなる。適切な学習率の選択が重要である。
画像データの数値表現
グレースケール画像(3×3ピクセル):
[0.2, 0.5, 0.8]
[0.1, 0.9, 0.3]
[0.7, 0.4, 0.6]
カラー画像(RGB 3チャンネル):
R: [0.8, 0.2, ...] G: [0.3, 0.7, ...] B: [0.1, 0.9, ...]
第2章:主要技術の概要と性能比較
技術発展の概要
- 2012年:CNN(AlexNet)による深層学習の突破 - 従来の手法より精度向上を実現
- 2016年:ResNetによる深層ネットワークの実現 - 勾配消失問題を解決
- 2021年:Vision Transformerによるアーキテクチャ革新 - CNNの局所性制約を克服
- 2022年:ConvNeXtによるCNNの現代化 - Transformer手法をCNNに適用
- 2023年:EVA-02による高精度の達成 - 自己教師あり学習で事前学習を活用
技術系統の分類
画像認識技術
├── CNN系(畳み込みベース)
│ ├── AlexNet (2012) → VGG (2014) → ResNet (2016)
│ └── ConvNeXt (2022) ← Transformerとの融合
└── Transformer系(注意機構ベース)
├── ViT (2021) → DeiT → Swin Transformer
└── EVA-02 (2023) ← 自己教師あり学習の活用
主要技術の統合比較
- ResNet-50 (2016): Top-1精度 76.1%, パラメータ数 25M, 特徴: 残差接続による深層化
- ViT-Base (2021): Top-1精度 84.5%, パラメータ数 86M, 特徴: グローバル self attention
- ConvNeXt-Tiny (2022): Top-1精度 82.1%, パラメータ数 28M, 特徴: Transformerとの融合重視
- EVA-02 Large (2023): Top-1精度 90.0%, パラメータ数 304M, 特徴: MIM事前学習
モデル選択指針
精度要求 > 85% ?
├─ Yes → 計算資源は潤沢?
│ ├─ Yes → EVA-02 Large (大容量メモリ必要)
│ └─ No → ViT-Base (中程度メモリ)
└─ No → リアルタイム処理が必要?
├─ Yes → ResNet-18, 50, 101
└─ No → ConvNeXt
用途別推奨技術
高精度要求用途(医療診断、精密検査)
- 推奨:EVA-02 Large
- 理由:最高精度、豊富な事前学習知識
一般的な業務用途(商品分類、文書処理)
- 推奨:ViT-BaseまたはConvNeXt-Tiny
- 理由:精度と効率のバランス
リアルタイム用途(監視カメラ、IoTデバイス)
- 推奨:ResNet-18, 50, 101
- 理由:高速処理、軽量
第3章:CNN(ResNet)
CNNの基礎
畳み込み演算の原理
画像の局所的なパターンを効率的に検出する。小さなフィルタを画像全体に適用することで、エッジやテクスチャなどの特徴を抽出する。
数式:(f * g)(x, y) = ΣΣ f(m, n) × g(x-m, y-n)
CNNの処理フロー:
入力画像 → 畳み込み層 → 活性化関数 → プーリング層 →
畳み込み層 → 活性化関数 → プーリング層 → 全結合層 → 出力
受容野の概念
各層のニューロンが入力画像のどの範囲の情報を統合して処理しているかを示す領域を受容野と呼ぶ。深い層ほど広い範囲の情報を統合できるが、全画像を見ることは困難である。受容野の大きさは認識性能に直接影響し、小さな受容野では細かな特徴を、大きな受容野では大域的なパターンを捉える。
受容野の拡大:
入力層: 1×1 → 第1層: 3×3 → 第2層: 5×5 → 第3層: 7×7
CNNでは層を重ねることで受容野を段階的に拡大するが、Transformerは最初の層から画像全体(グローバル受容野)を捉える点で根本的に異なる。
ResNetの技術的革新
従来のCNNの勾配消失問題を残差接続(スキップ接続)により解決し、152層の超深層ネットワークを実現した。
第4章:Vision Transformer(ViT・EVA-02)
ViTの理論的基礎
自己注意機構の原理
画像をパッチに分割してTransformerを適用する。各パッチ間の関係性を直接計算することで、最初の層から画像全体を捉える。
数式:Attention(Q, K, V) = softmax(QK^T/√d_k)V
ViTの処理フロー:
入力画像(224×224×3)→ パッチ分割(16×16パッチ×196個)→
パッチ埋め込み → 位置埋め込み追加 → Transformer Encoder×12層 →
[CLS]トークン出力 → 分類ヘッド → クラス確率
EVA-02の技術革新
マスク画像モデリング(MIM)による事前学習
画像の一部を隠してその部分を予測させることで、モデルに画像の構造的理解を促す。ラベルなしデータからも学習可能な自己教師あり学習手法である。
数式:L_MIM = E[||f(x_masked) - x_original||²]
MIMの学習プロセス:
原画像 → マスク適用 → 隠した部分の予測 → 画像の構造的理解
第5章:実践応用、技術別実装例
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
NVIDIA CUDA Toolkit 12.8のインストール
- 前提条件(NVIDIA CUDA Toolkit インストール前): NVIDIA GPU,NVIDIA ドライバ,および Build Tools for Visual Studio もしくは Visual Studio が必要である.
- インストール中の注意: なるべく他のウインドウはすべて閉じておくこと.
以下のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール
winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n"
REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更)
mkdir C:\TEMP
set "TEMP_PATH=C:\TEMP"
setx TEMP "%TEMP_PATH%" /M >nul
setx TMP "%TEMP_PATH%" /M >nulPyTorch のインストール
PyTorch がインストール済みの場合、この手順は不要である。管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM PyTorch をインストール
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%必要なライブラリのインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install transformers pillow requests matplotlib japanize-matplotlib
ResNet-18, 50, 101による画像分類
Pythonプログラム
# プログラム名: ResNet画像分類モデル比較プログラム
# 特徴技術名: ResNet (Residual Networks)
# 出典: He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
# 特徴機能: 残差接続による深層ネットワーク学習。入力を出力に直接加算するスキップ接続により、勾配消失問題を解決し、152層までの深層ネットワークを効果的に学習可能にする技術
# 学習済みモデル: Microsoft ResNet (ImageNet-1k事前学習済み、1000クラス分類モデル)
# - ResNet-18: 18層、11.7Mパラメータ、高速推論向け (https://huggingface.co/microsoft/resnet-18)
# - ResNet-50: 50層、25.6Mパラメータ、精度と速度のバランス (https://huggingface.co/microsoft/resnet-50)
# - ResNet-101: 101層、44.5Mパラメータ、高精度向け (https://huggingface.co/microsoft/resnet-101)
# 方式設計:
# - 関連利用技術:
# - Hugging Face Transformers: 事前学習済みモデルの読み込みと推論API提供
# - PyTorch: テンソル演算と深層学習の基盤フレームワーク
# - PIL (Pillow): 画像ファイルの読み込みと前処理
# - OpenCV: 画像表示とカメラ入力処理
# - 入力と出力: 入力: 静止画像(ユーザは「0:画像ファイル,1:カメラ,2:サンプル画像」のメニューで選択.0:画像ファイルの場合はtkinterで複数ファイル選択可能.1の場合はOpenCVでカメラが開き,スペースキーで撮影(複数回可能).2の場合はhttps://github.com/opencv/opencv/raw/master/samples/data/fruits.jpg とhttps://github.com/opencv/opencv/raw/master/samples/data/messi5.jpgとhttps://github.com/opencv/opencv/raw/master/samples/data/aero3.jpgを使用)、出力: OpenCV画面でリアルタイム表示、処理結果をテキストで表示
# - 処理手順: 1.画像入力→2.3つのResNetモデル(18/50/101層)を順次読み込み→3.各モデルで画像特徴抽出と分類→4.予測クラスと確信度を計算→5.性能比較結果を表示
# - 前処理、後処理: 前処理:画像を224x224にリサイズ、正規化(ImageNet平均・標準偏差)。後処理:logitsをsoftmaxで確率化、最大確率のクラスを選択
# - 追加処理: なし
# - 調整を必要とする設定値: MODELS配列(比較するResNetモデルの選択。デフォルトはResNet-18/50/101の3モデル)
# 将来方策: MODELS配列の自動最適化。画像の内容に応じて最適なモデルを自動選択する機能(例:単純な物体はResNet-18、複雑なシーンはResNet-101)
# その他の重要事項: ImageNet-1kの1000クラスのみ分類可能。日本語クラス名は非対応
# 前準備: pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install transformers pillow opencv-python
import cv2
import tkinter as tk
from tkinter import filedialog
import urllib.request
import os
import torch
from transformers import AutoImageProcessor, ResNetForImageClassification
from PIL import Image
import numpy as np
import time
# 定数定義
MODELS = [
('microsoft/resnet-18', 'ResNet-18'),
('microsoft/resnet-50', 'ResNet-50'),
('microsoft/resnet-101', 'ResNet-101')
]
# 表示設定
FONT_SCALE = 0.7
FONT_THICKNESS = 2
INFO_HEIGHT = 400
TEXT_COLOR = (255, 255, 255)
HIGHLIGHT_COLOR = (0, 255, 0)
BEST_COLOR = (0, 255, 255)
# デバイス設定(GPU/CPU自動選択)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用デバイス: {device}')
# プログラム開始
print('=== ResNet画像分類モデル比較プログラム ===')
print('3つのResNetモデル(ResNet-18/50/101)で画像分類を実行し、性能を比較します')
print('操作方法: カメラモードではスペースキーで撮影、qキーで終了')
print('')
# モデルの事前読み込み
print('モデルを読み込み中...')
loaded_models = []
for model_name, display_name in MODELS:
processor = AutoImageProcessor.from_pretrained(model_name)
model = ResNetForImageClassification.from_pretrained(model_name).to(device)
model.eval() # 評価モードに設定
loaded_models.append((processor, model, display_name))
print('モデルの読み込み完了')
print('')
def image_processing(img):
"""画像分類処理を実行"""
# OpenCVからPIL形式に変換
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
pil_image = Image.fromarray(img_rgb)
# 結果表示用の画像を作成
result_img = img.copy()
height, width = result_img.shape[:2]
result_img = cv2.copyMakeBorder(result_img, 0, INFO_HEIGHT, 0, 0, cv2.BORDER_CONSTANT, value=(0, 0, 0))
# 処理中表示
cv2.putText(result_img, 'Processing...', (10, height + 30), cv2.FONT_HERSHEY_SIMPLEX, FONT_SCALE, TEXT_COLOR, FONT_THICKNESS)
cv2.imshow('ResNet Classification', result_img)
cv2.waitKey(1)
# 各モデルで分類実行
results = []
for processor, model, display_name in loaded_models:
# 推論実行
inputs = processor(pil_image, return_tensors='pt')
inputs = {k: v.to(device) for k, v in inputs.items()}
start_time = time.time()
with torch.no_grad():
outputs = model(**inputs)
inference_time = time.time() - start_time
# 結果取得
predicted_idx = outputs.logits.argmax(-1).item()
confidence = outputs.logits.softmax(dim=-1).max().item()
predicted_class = model.config.id2label[predicted_idx]
total_params = sum(p.numel() for p in model.parameters())
# 結果保存
result = {
'model': display_name,
'class': predicted_class,
'confidence': confidence,
'params': total_params,
'inference_time': inference_time
}
results.append(result)
# コンソール出力
print(f'{display_name}: {predicted_class} ({confidence:.1%}) - {inference_time:.3f}s')
# 結果を画像に描画
result_img = img.copy()
result_img = cv2.copyMakeBorder(result_img, 0, INFO_HEIGHT, 0, 0, cv2.BORDER_CONSTANT, value=(0, 0, 0))
cv2.putText(result_img, '=== ResNet Classification Results ===', (10, height + 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, TEXT_COLOR, 2)
# 各モデルの結果表示
for i, result in enumerate(results):
y_pos = height + 70 + i * 100
cv2.putText(result_img, f'{result["model"]}:', (10, y_pos), cv2.FONT_HERSHEY_SIMPLEX, FONT_SCALE, HIGHLIGHT_COLOR, FONT_THICKNESS)
cv2.putText(result_img, f'Class: {result["class"][:30]}', (10, y_pos + 25), cv2.FONT_HERSHEY_SIMPLEX, 0.6, TEXT_COLOR, 1)
cv2.putText(result_img, f'Confidence: {result["confidence"]:.1%}', (10, y_pos + 50), cv2.FONT_HERSHEY_SIMPLEX, 0.6, TEXT_COLOR, 1)
cv2.putText(result_img, f'Time: {result["inference_time"]:.3f}s', (10, y_pos + 75), cv2.FONT_HERSHEY_SIMPLEX, 0.6, TEXT_COLOR, 1)
# 最高確信度のモデルを特定
best_result = max(results, key=lambda x: x['confidence'])
cv2.putText(result_img, f'Best: {best_result["model"]} ({best_result["confidence"]:.1%})',
(10, height + 380), cv2.FONT_HERSHEY_SIMPLEX, FONT_SCALE, BEST_COLOR, FONT_THICKNESS)
return result_img
def show_processed_image(img, window_name):
if img is None:
print('画像の読み込みに失敗しました')
return
cv2.imshow(window_name, image_processing(img))
cv2.waitKey(0)
print('0: 画像ファイル')
print('1: カメラ')
print('2: サンプル画像')
choice = input('選択: ')
if choice == '0':
root = tk.Tk()
root.withdraw()
paths = filedialog.askopenfilenames()
if not paths:
exit()
for path in paths:
show_processed_image(cv2.imread(path), 'ResNet Classification')
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
try:
while True:
cap.grab()
ret, frame = cap.retrieve()
if not ret:
break
cv2.imshow('Camera', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
show_processed_image(frame, 'ResNet Classification')
elif key == ord('q'):
break
finally:
cap.release()
elif choice == '2':
urls = [
'https://github.com/opencv/opencv/raw/master/samples/data/fruits.jpg',
'https://github.com/opencv/opencv/raw/master/samples/data/messi5.jpg',
'https://github.com/opencv/opencv/raw/master/samples/data/aero3.jpg'
]
downloaded_files = []
for i, url in enumerate(urls):
filename = f'sample_{i}.jpg'
try:
urllib.request.urlretrieve(url, filename)
downloaded_files.append(filename)
show_processed_image(cv2.imread(filename), 'ResNet Classification')
except Exception as e:
print(f'画像のダウンロードに失敗しました: {url}')
print(f'エラー: {e}')
exit()
# ダウンロードしたファイルの削除
for filename in downloaded_files:
try:
os.remove(filename)
except OSError:
pass
cv2.destroyAllWindows()
概要
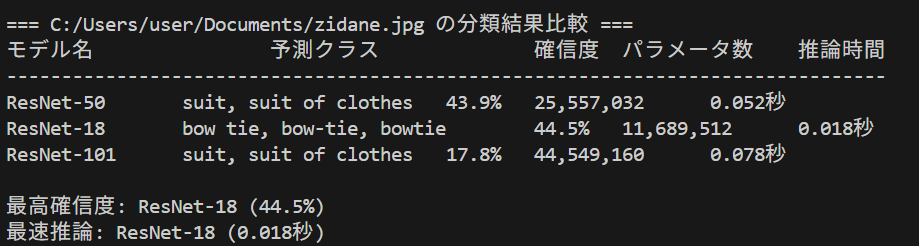
ResNet(Residual Network)による画像分類の複数モデル比較実験である。ResNet-18、ResNet-50、ResNet-101の3つのモデルで同一画像を分類し、予測精度と処理速度を比較できる。AIモデルを動かすことで、モデルサイズと性能のトレードオフを体験的に理解できる。

事前準備
上記「共通事前準備」を参照。
プログラムの実行手順
- プログラムを実行する
- 選択肢から実験方法を選択
- 各モデルの分類結果と処理時間を確認する
- 最終的な比較結果を分析する
モデル選択による実験要素
ResNet-18: 最軽量モデル(約1100万パラメータ)。高速だが精度は相対的に低い。
ResNet-50: バランス型モデル(約2500万パラメータ)。精度と速度のバランスが良い。
ResNet-101: 高精度モデル(約4400万パラメータ)。高精度だが処理時間が長い。
体験・実験のアイデア
- 精度と速度の関係発見:同じ画像で3つのモデルを比較し、パラメータ数と精度・速度の関係を確認する
- 画像による性能差の発見:異なる画像で実験を繰り返し、モデルごとの得意・不得意分野を発見する
- 確信度の分析:同じ予測クラスでもモデルによって確信度が異なることを確認し、その理由を考察する
使用技術の原論文
ResNet: He, K., et al. "Deep residual learning for image recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016.ViT-Baseによる画像分類
Pythonプログラム
# ViT画像分類プログラム
# Vision Transformerによる画像分類システム
# 論文: "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" (ICLR 2021)
# GitHub: https://github.com/google-research/vision_transformer
# 特徴: ViTは畳み込みを使わずTransformerのみで画像認識を実現、ImageNet分類で高精度
# パッチベースの画像処理により計算効率が良く、大規模データセットでの学習に適している
# 学習済モデル: google/vit-base-patch16-224 (ImageNet-21k事前学習、ImageNet-1k微調整)
# 前準備: pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install transformers pillow requests matplotlib japanize-matplotlib
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
import tkinter as tk
from tkinter import filedialog
import matplotlib.pyplot as plt
import japanize_matplotlib
import os
# 定数定義
MODEL_NAME = "google/vit-base-patch16-224"
SAMPLE_IMAGE_URL = "http://images.cocodataset.org/val2017/000000039769.jpg"
TOP_K = 5
print("=== ViT画像分類システム ===")
print("1: サンプル画像で試す")
print("2: ローカル画像ファイルを選択")
choice = input("選択してください (1 or 2): ")
# モデル読み込み
print(f"\n読み込み中: {MODEL_NAME}")
processor = ViTImageProcessor.from_pretrained(MODEL_NAME)
model = ViTForImageClassification.from_pretrained(MODEL_NAME)
# 画像取得
if choice == "1":
response = requests.get(SAMPLE_IMAGE_URL, stream=True)
image = Image.open(response.raw)
image_source = "サンプル画像"
print("サンプル画像を使用")
else:
root = tk.Tk()
root.withdraw()
file_paths = filedialog.askopenfilenames(
title="画像ファイルを選択してください",
filetypes=[("画像ファイル", "*.jpg *.jpeg *.png *.bmp *.gif"), ("すべてのファイル", "*.*")]
)
if not file_paths:
print("画像が選択されませんでした。プログラムを終了します。")
exit()
image = Image.open(file_paths[0])
image_source = os.path.basename(file_paths[0])
print(f"選択画像: {image_source}")
# メイン処理
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_idx = outputs.logits.argmax(-1).item()
confidence = outputs.logits.softmax(dim=-1).max().item()
predicted_class = model.config.id2label[predicted_idx]
probabilities = outputs.logits.softmax(dim=-1)[0]
top_indices = probabilities.topk(TOP_K).indices
top_probs = probabilities.topk(TOP_K).values
# 結果出力
total_params = sum(p.numel() for p in model.parameters())
print(f"\n=== モデル情報 ===")
print(f"モデル: ViT-Base")
print(f"パラメータ数: {total_params:,}")
print(f"入力サイズ: 224x224 pixels")
print(f"\n=== 予測結果 ===")
print(f"最有力候補: {predicted_class}")
print(f"確信度: {confidence:.1%}")
print(f"\n=== トップ{TOP_K}予測 ===")
for i, (idx, prob) in enumerate(zip(top_indices, top_probs)):
class_name = model.config.id2label[idx.item()]
print(f"{i+1}. {class_name}: {prob:.1%}")
print(f"\n画像サイズ: {image.size}")
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.axis('off')
plt.title(f"処理対象画像: {image_source}")
plt.tight_layout()
plt.show()
print("分析完了")
概要
Vision Transformer(ViT)による画像分類をWindows環境で体験できる。従来のCNNとは異なるTransformerアーキテクチャによる画像認識の性能を直接確認し、様々な画像での予測精度を実験できる。

事前準備
上記「共通事前準備」を参照。
使用方法
- プログラムを実行
- 選択肢から実験方法を選択
- 選択肢1:サンプル画像(猫の画像)で動作確認
- 選択肢2:ローカル画像ファイルを選択(複数選択可能、最初の画像を使用)
モデル仕様
- アーキテクチャ: ViT-Base/16
- パラメータ数: 約8,600万個
- 入力解像度: 224×224ピクセル
- パッチサイズ: 16×16ピクセル
- 分類クラス数: ImageNet 1,000クラス
体験・実験のアイデア
- 動物、建物、乗り物など異なるカテゴリの画像での精度比較
- 高解像度画像と低解像度画像での認識性能差
- 背景がシンプルな画像と複雑な画像での認識精度
- 複数の物体が写った画像での最優先認識対象
- 季節や時間帯の違いによる同一対象の認識変化
これらの実験を通じて、Transformerベースの画像認識モデルの特性と限界を体験的に理解できる。CNNとは異なる認識パターンや、予想外の分類結果から新たな考察が期待できる。
使用技術の原論文
Vision Transformer: Dosovitskiy, A., et al. "An image is worth 16x16 words: Transformers for image recognition at scale." International Conference on Learning Representations (ICLR) 2021.EVA-02による画像分類
Pythonプログラム
# EVA-02による高精度画像分類プログラム
# ローカル画像またはサンプル画像の分類とTop-K予測結果表示
# 論文: "EVA-02: A Visual Representation for Neon Genesis" (arXiv 2023)
# GitHub: https://github.com/baaivision/EVA/tree/master/EVA-02
# 特徴: EVA-02は大規模Vision Transformer、MIM事前学習による高精度分類
# ImageNet-1Kで90.0%超の精度、448×448解像度対応
# 学習済モデル: eva02_large_patch14_448 (パラメータ数約300M、ImageNet-22K事前学習)
# 前準備: pip install torch timm pillow requests matplotlib japanize-matplotlib
import torch
import timm
from PIL import Image
import requests
import tkinter as tk
from tkinter import filedialog
import matplotlib.pyplot as plt
import japanize_matplotlib
from pathlib import Path
# 定数定義
MODEL_NAME = "eva02_large_patch14_448.mim_m38m_ft_in22k_in1k"
TOP_K = 5
SAMPLE_IMAGE_URL = "https://images.cocodataset.org/val2017/000000039769.jpg"
IMAGENET_CLASSES_URL = "https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
print("=== EVA-02画像分類システム ===")
print("1: サンプル画像で試す")
print("2: ローカル画像ファイルを選択")
choice = input("選択してください (1 or 2): ")
print(f"\nモデル読み込み中: {MODEL_NAME}")
# モデルの読み込み
model = timm.create_model(MODEL_NAME, pretrained=True)
model.eval()
# 画像変換の設定
config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**config, is_training=False)
# ImageNetクラスラベルの取得
response = requests.get(IMAGENET_CLASSES_URL)
classes = response.text.strip().split('\n')
# 画像の取得
if choice == "1":
response = requests.get(SAMPLE_IMAGE_URL, stream=True)
response.raw.decode_content = True
image = Image.open(response.raw)
source = "サンプル画像"
print("サンプル画像を使用")
else:
root = tk.Tk()
root.withdraw()
paths = filedialog.askopenfilenames(
title="画像ファイルを選択してください",
filetypes=[("画像ファイル", "*.jpg *.jpeg *.png *.gif *.bmp")]
)
if not paths:
print("画像が選択されませんでした。プログラムを終了します。")
exit()
image = Image.open(paths[0])
source = Path(paths[0]).name
print(f"選択画像: {source}")
# メイン処理
tensor = transforms(image).unsqueeze(0)
with torch.no_grad():
output = model(tensor)
probs = torch.softmax(output, dim=1) * 100
top_prob, top_idx = torch.topk(probs, k=TOP_K)
# 結果出力
params = sum(p.numel() for p in model.parameters())
print(f"\n=== モデル情報 ===")
print(f"モデル: {MODEL_NAME}")
print(f"パラメータ数: {params:,}")
print(f"入力解像度: {config['input_size']}")
print(f"\n=== 予測結果 (Top {TOP_K}) ===")
for i in range(TOP_K):
idx = top_idx[0][i].item()
prob = top_prob[0][i].item()
class_name = classes[idx]
print(f"{i+1}. {class_name}: {prob:.2f}%")
print(f"\n画像サイズ: {image.size[0]}x{image.size[1]}ピクセル")
# 画像表示
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.axis('off')
plt.title(f"処理対象画像: {source}")
plt.tight_layout()
plt.show()
print("分析完了")
概要
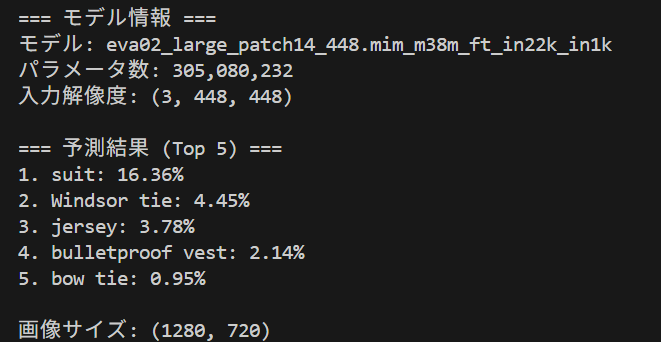
EVA-02(Efficient Vision Transformer)は、Meta社が開発した画像認識モデルである。本プログラムでは、3億400万パラメータの大規模モデルを使用して、日常的な画像に対する高精度な分類を体験できる。従来のCNNとは異なるTransformerアーキテクチャによる画像理解の特徴を確認できる。
事前準備
上記「共通事前準備」を参照。追加で以下を実行する:
pip install timm
使用方法
- プログラムを実行すると、サンプル画像またはローカル画像ファイルの選択画面が表示される
- 選択肢1:サンプル画像(猫の画像)を自動的にダウンロードして分析
- 選択肢2:ローカル画像ファイルを選択(複数選択可能、最初の画像を使用)
- モデル情報と上位5つの予測結果が表示される
- 各予測結果には、クラス名と確信度(%)が表示される
モデル選択・実験要素
利用可能なEVA-02モデル
プログラム冒頭のMODEL_NAMEを変更することで、異なるサイズのモデルを比較できる:
- eva02_tiny_patch14_336.mim_in22k_ft_in1k - 小型モデル(高速)
- eva02_small_patch14_336.mim_in22k_ft_in1k - 小型モデル
- eva02_base_patch14_448.mim_in22k_ft_in1k - 標準モデル
- eva02_large_patch14_448.mim_m38m_ft_in22k_in1k - 大型モデル(高精度)
画像の変更
IMAGE_URLを変更することで、任意のオンライン画像を分析できる:
IMAGE_URL = "https://example.com/your-image.jpg"
体験・実験のアイデア
1. モデルサイズ比較実験
- 同じ画像に対して、tiny、small、base、largeの各モデルで予測結果を比較
- パラメータ数と精度の関係を観察
- 処理時間の違いを測定
2. 画像種別による認識特性
- 動物、建物、食べ物、自然風景など異なるカテゴリの画像で実験
- EVA-02が得意とする画像種別を発見
- 予想外の分類結果から、AIの認識特性を理解
3. 確信度分析
- 明確な被写体の画像と曖昧な画像での確信度比較
- 上位予測と下位予測の確信度差を観察
4. 解像度の影響
- 同じ画像の異なる解像度版で予測精度を比較
これらの実験を通じて、Vision Transformerの能力と限界を体験し、AI画像認識技術の理解を深めることができる。
使用技術の原論文
EVA-02: Fang, Y., et al. "EVA-02: A Visual Representation for Neon Genesis." arXiv:2303.11331, 2023. TIMM: Wightman, R. "PyTorch Image Models." GitHub repository, 2019.ConvNeXtによる画像分類
Pythonプログラム
# ConvNeXtによる画像分類
import torch
from transformers import AutoImageProcessor, ConvNextForImageClassification
from PIL import Image
import requests
import tkinter as tk
from tkinter import filedialog
import matplotlib.pyplot as plt
import japanize_matplotlib
print("=== ConvNeXt画像分類システム ===")
print("1: サンプル画像で試す")
print("2: ローカル画像ファイルを選択")
choice = input("選択してください (1 or 2): ")
# モデル設定
model_name = "facebook/convnext-tiny-224"
default_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
print("モデルを読み込み中...")
processor = AutoImageProcessor.from_pretrained(model_name)
model = ConvNextForImageClassification.from_pretrained(model_name)
# 画像の取得
if choice == "1":
# サンプル画像
image = Image.open(requests.get(default_url, stream=True).raw)
image_source = "サンプル画像"
print("サンプル画像を使用")
else:
# ローカル画像選択
root = tk.Tk()
root.withdraw()
file_paths = filedialog.askopenfilenames(
title="画像ファイルを選択してください",
filetypes=[("画像ファイル", "*.jpg *.jpeg *.png *.gif *.bmp"), ("すべてのファイル", "*.*")]
)
if not file_paths:
print("画像が選択されませんでした。プログラムを終了します。")
exit()
# 最初の選択画像を使用
image = Image.open(file_paths[0])
image_source = file_paths[0].split('\\')[-1]
print(f"選択画像: {image_source}")
# 推論実行
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# 結果取得
predicted_idx = outputs.logits.argmax(-1).item()
confidence = outputs.logits.softmax(dim=-1).max().item()
predicted_class = model.config.id2label[predicted_idx]
# 結果表示
print(f"\n=== 分類結果 ===")
print(f"予測クラス: {predicted_class}")
print(f"確信度: {confidence:.1%}")
print(f"モデル: {model_name}")
print(f"パラメータ数: {sum(p.numel() for p in model.parameters()):,}")
print(f"画像サイズ: {image.size}")
# 処理した画像を表示
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.axis('off')
plt.title(f"処理対象画像: {image_source}")
plt.tight_layout()
plt.show()
print("分析完了")
概要
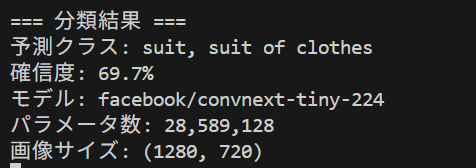
ConvNeXtは2022年に発表された画像分類AIモデルである。従来のCNNアーキテクチャを現代的に改良し、Vision Transformerに匹敵する性能を実現した。このプログラムでは、事前学習済みConvNeXtモデルを使用して、任意の画像に対する物体分類を体験できる。
事前準備
上記「共通事前準備」を参照。
使用方法
- プログラムを実行する
- 選択肢から実験方法を選択
- 選択肢1:サンプル画像(猫の画像)で動作確認
- 選択肢2:ローカル画像ファイルを選択(複数選択可能、最初の画像を使用)
- 分類結果が表示される
モデル選択・実験要素
利用可能なConvNeXtモデル
以下のモデルに変更して性能を比較できる:
- facebook/convnext-tiny-224 (28M parameters)
- facebook/convnext-small-224 (50M parameters)
- facebook/convnext-base-224 (89M parameters)
- facebook/convnext-large-224 (198M parameters)
実験アイデア
- model_name変数を変更してモデルサイズの違いを体験
- 同じ画像で異なるモデルの予測結果を比較
- 曖昧な画像での各モデルの確信度を比較
- モデル間差異の観察:同一画像に対する異なるサイズモデルの予測比較
使用技術の原論文
ConvNeXt: Liu, Z., et al. "A ConvNet for the 2020s." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2022.第6章:最新動向
2024-2025年の技術動向
効率化の進展
- エッジAI:デバイス上でのリアルタイム処理。例:スマートフォンでの画像認識、クラウド通信不要で低遅延を実現。2025年には多くのモバイルデバイスで標準化予定。
- 軽量化技術:大規模モデルの知識を小規模モデルに転移する手法(知識蒸留)。GPT-4レベルの性能を1/10のサイズで実現する研究が進行中。
- ハイブリッドアーキテクチャ:CNNとTransformerの統合。CNNの効率性とTransformerの表現力を併用し、両者の利点を活用。
応用分野の拡大
- マルチモーダル学習:画像-テキスト統合モデル。例:CLIP、DALL-E等により画像生成・検索が文章指示で可能に。2024年以降、創作・デザイン分野で実用化加速。
- 自己教師あり学習:ラベルなしデータの活用。人手によるラベル付けが不要となり、学習コストが大幅削減。医療・科学分野での応用が期待される。
参考文献
主要技術の原論文
- Transformer: Vaswani, A., et al. "Attention is all you need." Advances in Neural Information Processing Systems (NIPS) 2017.
- Vision Transformer (ViT): Dosovitskiy, A., et al. "An image is worth 16x16 words: Transformers for image recognition at scale." International Conference on Learning Representations (ICLR) 2021.
- ResNet: He, K., et al. "Deep residual learning for image recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016.
- EVA-02: Fang, Y., et al. "EVA-02: A Visual Representation for Neon Genesis." arXiv:2303.11331, 2023.
- ConvNeXt: Liu, Z., et al. "A ConvNet for the 2020s." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2022.
実装ライブラリ
- Transformers: Wolf, T., et al. "Transformers: State-of-the-art natural language processing." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) 2020 System Demonstrations.
- TIMM: Wightman, R. "PyTorch Image Models." GitHub repository, 2019.
その他の重要技術
- CLIP: Radford, A., et al. "Learning transferable visual representations from natural language supervision." Proceedings of the 38th International Conference on Machine Learning (ICML) 2021.
- AlexNet: Krizhevsky, A., et al. "ImageNet classification with deep convolutional neural networks." Advances in Neural Information Processing Systems (NIPS) 2012.