OpenAI Whisperによる日本語の音声・動画ファイル文字起こし・pyannoteによる話者特定
事前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする
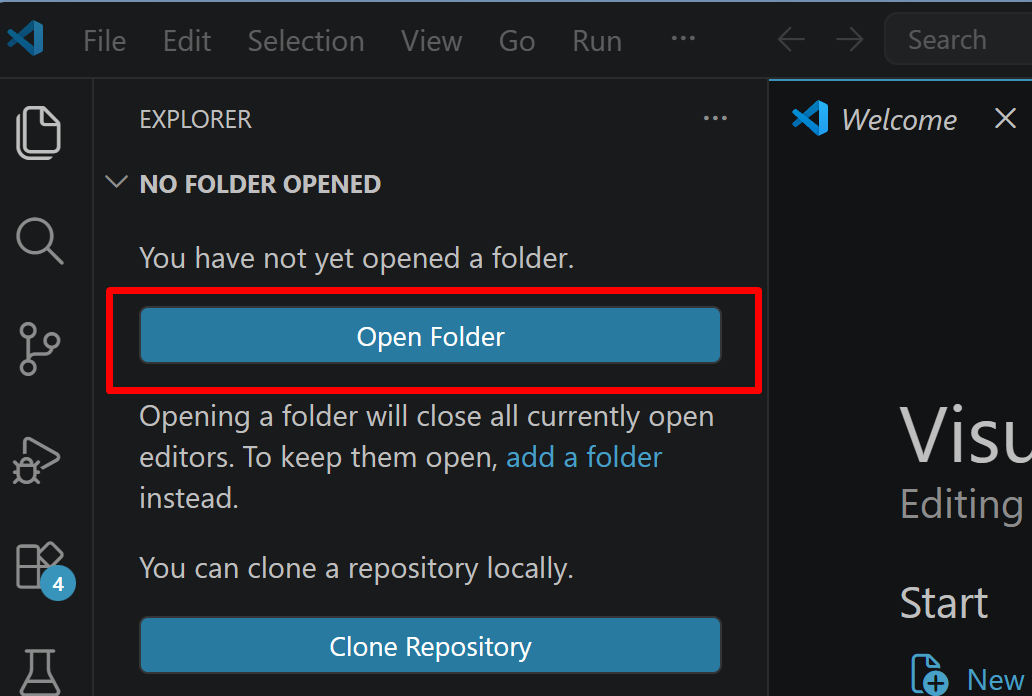
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
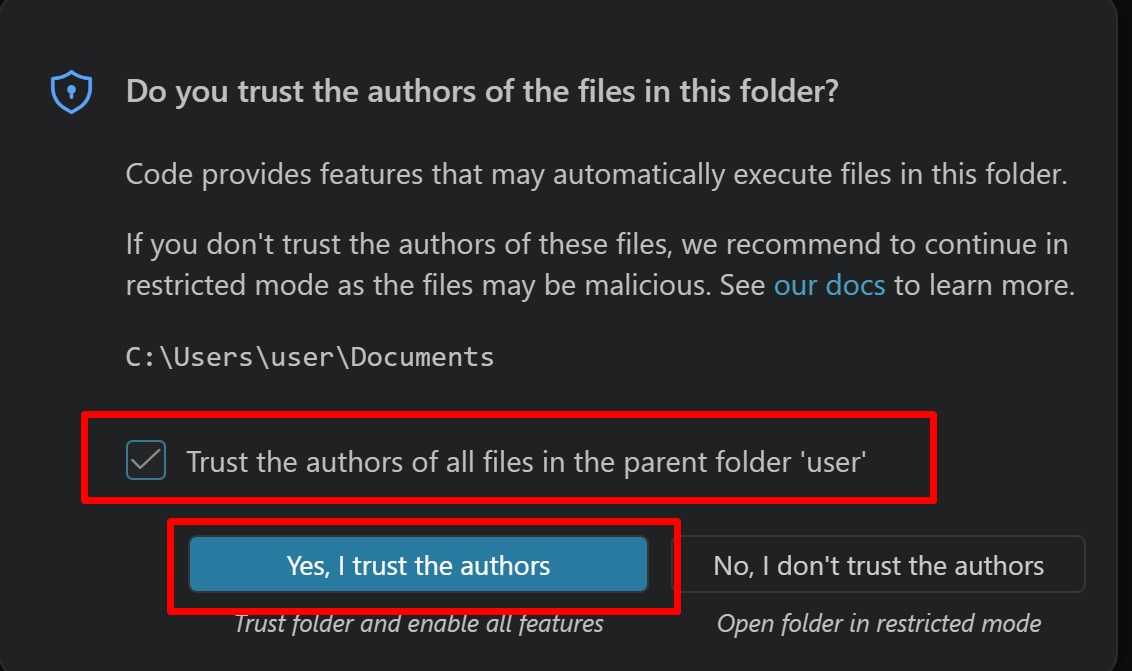
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


Windows での FFmpeg インストール手順(手動インストール)
公式ビルド版を使用
-
ダウンロード
- https://www.gyan.dev/ffmpeg/builds/ にアクセス
- 「release builds」セクションの「full」版をダウンロード
- ファイル名例:
ffmpeg-release-full.7z - essentials版ではなくfull版を選択(ffprobeも含まれる)
- ファイル名例:
-
解凍
- ダウンロードした7zファイルを右クリック
- 7-Zip等で解凍(Windows標準では7z非対応のため、7-Zipが必要)
- 7-Zipダウンロード: https://www.7-zip.org/
- 解凍先を
C:\ffmpegにする(推奨)- フォルダ構造:
C:\ffmpeg\bin\ffmpeg.exeとなるように配置
- フォルダ構造:
-
環境変数PATHの設定
- Windowsキー + R → 「sysdm.cpl」と入力してEnter
- 「詳細設定」タブ → 「環境変数」ボタンをクリック
- 「システム環境変数」の「Path」を選択 → 「編集」
- 「新規」をクリック →
C:\ffmpeg\binを追加 - 「OK」を3回クリックして設定を保存
-
動作確認
- コマンドプロンプトを新規で開く(既存のものは閉じる)
- 以下のコマンドを実行:
ffmpeg -version ffprobe -version - バージョン情報が表示されれば成功
必要なライブラリのインストール
管理者権限で起動したコマンドプロンプト(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)。で以下を実行
REM PyTorch をインストール(GPU対応版)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%
pip install openai-whisper transformers sounddevice numpy
HugggingFace トークン取得
https://huggingface.co/settings/tokens にアクセス. HugggingFace トークンの設定.保存の支援ツールは別ページ (https://www/kkaneko.jp/ai/labo/hf.html)で紹介.
プログラムコード
# OpenAI Whisperによる日本語の音声・動画ファイル文字起こし・pyannoteによる話者特定
import sys
import os
import threading
import time
from pathlib import Path
import tkinter as tk
from tkinter import filedialog, messagebox, scrolledtext, ttk
import torch
from faster_whisper import WhisperModel
import torchaudio
import subprocess
import tempfile
# 対応ファイル形式
VIDEO_EXTENSIONS = {'.mp4', '.avi', '.mov', '.mkv', '.flv', '.m4v'}
AUDIO_EXTENSIONS = {'.wav', '.mp3', '.aac', '.ogg', '.wma', '.flac', '.webm', '.3gp'}
SUPPORTED_EXTENSIONS = VIDEO_EXTENSIONS | AUDIO_EXTENSIONS
# 文の終端として扱う記号(結合の判定に使用)
END_PUNCTUATIONS = ('。', '!', '?', '.', '!', '?')
# 結合の上限(長すぎを回避)
MAX_MERGE_DURATION_S = 30.0
MAX_MERGE_CHARS = 150
def detect_best_device():
"""最適なデバイスを自動検出"""
if torch.cuda.is_available():
return "cuda", "float16"
else:
return "cpu", "int8"
def format_srt_timestamp(seconds: float) -> str:
"""SRT形式のタイムスタンプに変換(丸め誤差に強い)"""
total_ms = int(round(seconds * 1000))
hours, rem = divmod(total_ms, 3600 * 1000)
minutes, rem = divmod(rem, 60 * 1000)
secs, millis = divmod(rem, 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
class TranscriptionGUI:
def __init__(self, root):
self.root = root
self.root.title("音声・動画ファイル文字起こしツール")
self.root.geometry("800x600")
self.auto_device, self.auto_compute_type = detect_best_device()
self.model = None
self.setup_gui()
def setup_gui(self):
main_frame = ttk.Frame(self.root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
self.token_frame = ttk.Frame(main_frame)
self.token_frame.pack(fill=tk.X, pady=(0, 10))
self.token_frame.columnconfigure(1, weight=1)
token_label = ttk.Label(self.token_frame, text="Hugging Face Token(発話者特定に必要):")
token_label.grid(row=0, column=0, sticky=tk.W, padx=(0, 5))
self.hf_token = tk.StringVar()
token_entry = ttk.Entry(self.token_frame, textvariable=self.hf_token, show="*")
token_entry.grid(row=0, column=1, sticky=tk.EW)
token_info_text = (
"1) アクセストークン作成: https://hf.co/settings/tokens でRead権限のトークンを作成\n"
"2) 同意1: https://hf.co/pyannote/speaker-diarization-3.1 を開き、利用条件に同意\n"
"3) 同意2: https://hf.co/pyannote/segmentation を開き、同様に同意(パイプライン内部で使用)"
)
token_info_label = ttk.Label(self.token_frame, text=token_info_text, font=("", 8), foreground="blue", justify=tk.LEFT)
token_info_label.grid(row=1, column=0, columnspan=2, sticky=tk.W, pady=(4, 0))
file_frame = ttk.LabelFrame(main_frame, text="ファイル選択", padding="5")
file_frame.pack(fill=tk.X, pady=(0, 10))
self.file_path = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.file_path, width=60).pack(side=tk.LEFT, padx=(0, 5), fill=tk.X, expand=True)
ttk.Button(file_frame, text="選択", command=self.select_file).pack(side=tk.LEFT)
model_frame = ttk.LabelFrame(main_frame, text="設定", padding="5")
model_frame.pack(fill=tk.X, pady=(0, 10))
ttk.Label(model_frame, text="モデル:").pack(side=tk.LEFT)
self.model_var = tk.StringVar(value="medium")
ttk.Combobox(
model_frame, textvariable=self.model_var,
values=["tiny", "base", "small", "medium", "large-v3", "large-v3-turbo"],
state="readonly", width=15
).pack(side=tk.LEFT, padx=(5, 20))
ttk.Label(model_frame, text="デバイス:").pack(side=tk.LEFT)
device_text = "GPU (CUDA)" if self.auto_device == "cuda" else "CPU"
ttk.Label(model_frame, text=device_text, foreground="blue").pack(side=tk.LEFT, padx=(5, 20))
self.speaker_diarization = tk.BooleanVar(value=False)
ttk.Checkbutton(model_frame, text="発話者特定", variable=self.speaker_diarization).pack(side=tk.LEFT)
self.transcribe_button = ttk.Button(main_frame, text="文字起こし実行", command=self.start_transcription)
self.transcribe_button.pack(pady=10)
self.result_text = scrolledtext.ScrolledText(main_frame, height=20, wrap=tk.WORD, font=("Consolas", 10))
self.result_text.pack(fill=tk.BOTH, expand=True, pady=(0, 10))
self.context_menu = tk.Menu(self.result_text, tearoff=0)
self.context_menu.add_command(label="コピー", command=lambda: self.result_text.event_generate("<<Copy>>"))
self.context_menu.add_separator()
self.context_menu.add_command(label="すべて選択", command=lambda: self.result_text.tag_add("sel", "1.0", "end"))
self.result_text.bind("<Button-3>", self.show_context_menu)
ttk.Button(main_frame, text="SRTファイルで保存", command=self.save_result).pack()
def show_context_menu(self, event):
"""右クリックメニューを表示し、選択状態に応じて「コピー」を有効/無効化"""
try:
self.result_text.get("sel.first", "sel.last")
self.context_menu.entryconfig(0, state=tk.NORMAL)
except tk.TclError:
self.context_menu.entryconfig(0, state=tk.DISABLED)
self.context_menu.tk_popup(event.x_root, event.y_root)
def select_file(self):
filetypes = [("対応ファイル", " ".join(f"*{ext}" for ext in SUPPORTED_EXTENSIONS)), ("すべて", "*.*")]
filename = filedialog.askopenfilename(title="音声・動画ファイルを選択", filetypes=filetypes)
if filename:
self.file_path.set(filename)
def update_result(self, text: str):
def _update():
self.result_text.insert(tk.END, text)
self.result_text.see(tk.END)
self.root.after(0, _update)
def start_transcription(self):
file_path = self.file_path.get()
if not file_path or not os.path.exists(file_path):
messagebox.showerror("エラー", "有効なファイルを選択してください")
return
self.transcribe_button.config(state="disabled")
self.result_text.delete(1.0, tk.END)
threading.Thread(target=self.transcribe_worker, daemon=True).start()
def transcribe_worker(self):
audio_file_to_process = None
temp_wav_file = None
try:
original_file_path = self.file_path.get()
file_ext = Path(original_file_path).suffix.lower()
if file_ext in VIDEO_EXTENSIONS:
self.update_result(f"動画ファイル {Path(original_file_path).name} を検出。音声抽出を開始します...\n")
temp_wav_file = tempfile.mktemp(suffix=".wav")
command = [
"ffmpeg", "-y", "-i", original_file_path,
"-vn", "-ar", "16000", "-ac", "1", "-f", "wav", temp_wav_file
]
proc = subprocess.run(command, capture_output=True, text=True, encoding='utf-8', errors='ignore')
if proc.returncode != 0:
error_message = proc.stderr or f"ffmpegがエラーコード {proc.returncode} で終了しました。"
self.update_result(f"音声抽出に失敗しました: {error_message}\n")
return
self.update_result("音声抽出が完了しました。文字起こしを開始します...\n")
audio_file_to_process = temp_wav_file
else:
audio_file_to_process = original_file_path
model_size = self.model_var.get()
want_diarization = self.speaker_diarization.get()
token = self.hf_token.get().strip()
self.model = WhisperModel(model_size, device=self.auto_device, compute_type=self.auto_compute_type)
diarization = None
if want_diarization and token:
try:
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token=token)
if torch.cuda.is_available():
pipeline.to(torch.device("cuda"))
diarization = pipeline(audio_file_to_process)
except Exception as e:
self.update_result(f"注: 発話者特定をスキップした(理由: {str(e)})\n")
elif want_diarization and not token:
self.update_result("注: トークン未入力のため発話者特定をスキップした\n")
segments_gen, _ = self.model.transcribe(
audio_file_to_process, language="ja", beam_size=5, temperature=0.0,
condition_on_previous_text=True,
initial_prompt="以下は日本語の音声である。文は意味のまとまりで区切り、適切に句読点「、」「。」を付ける。",
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=2800, speech_pad_ms=400, max_speech_duration_s=3600.0),
)
srt_index, buf_text, buf_start, buf_end = 0, "", None, None
def pick_speaker_id(start, end):
if not diarization: return None
mid = (start + end) / 2.0
for turn, _, speaker in diarization.itertracks(yield_label=True):
if turn.start <= mid <= turn.end:
try: return str(int(speaker.split("_")[-1]) + 1)
except: return None
return None
def flush():
nonlocal srt_index, buf_text, buf_start, buf_end
if not buf_text: return
srt_index += 1
speaker_id = pick_speaker_id(buf_start, buf_end)
line_text = f"({speaker_id}){buf_text}" if speaker_id else buf_text
srt_entry = f"{srt_index}\n{format_srt_timestamp(buf_start)} --> {format_srt_timestamp(buf_end)}\n{line_text}\n\n"
self.update_result(srt_entry)
buf_text, buf_start, buf_end = "", None, None
for seg in segments_gen:
text = (seg.text or "").strip()
if not text: continue
if buf_start is None: buf_start = seg.start
buf_end, buf_text = seg.end, buf_text + text
if text.endswith(END_PUNCTUATIONS) or (buf_end - buf_start) >= MAX_MERGE_DURATION_S or len(buf_text) >= MAX_MERGE_CHARS:
flush()
if buf_text: flush()
except Exception as e:
self.update_result(f"エラー: {str(e)}\n")
finally:
if temp_wav_file and os.path.exists(temp_wav_file):
try:
os.remove(temp_wav_file)
except OSError as e:
self.update_result(f"注: 一時ファイルの削除に失敗しました: {e}\n")
self.root.after(0, self.transcription_finished)
def transcription_finished(self):
self.transcribe_button.config(state="normal")
def save_result(self):
content = self.result_text.get(1.0, tk.END).strip()
if not content:
messagebox.showwarning("警告", "保存する内容がありません")
return
filename = filedialog.asksaveasfilename(defaultextension=".srt", filetypes=[("SRT字幕ファイル", "*.srt")])
if filename:
with open(filename, 'w', encoding='utf-8') as f: f.write(content)
messagebox.showinfo("完了", "SRTファイルで保存しました")
def main():
root = tk.Tk()
app = TranscriptionGUI(root)
root.mainloop()
if __name__ == "__main__":
main()
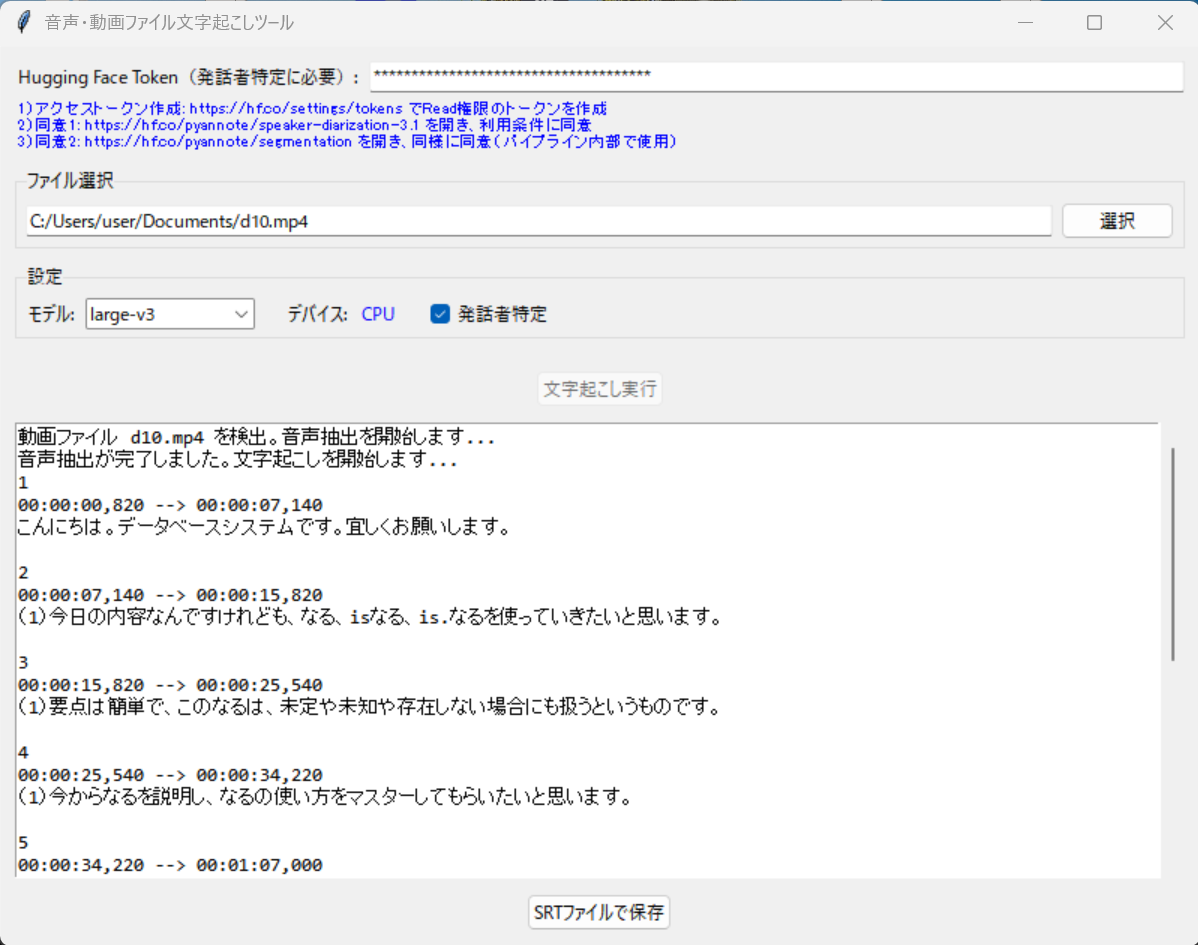
使用方法
- 上記のコードを whisper_transcribe.py として保存する
- コマンドラインで実行する:
python whisper_transcribe.py
モデルサイズの選択と特徴
プログラム内の load_model() で指定するモデルサイズを変更することで、認識精度と処理速度の違いを体験できる。各モデルの特徴は以下の通りである:
- tiny:39MB、低精度だが高速処理が可能
- base:74MB、中程度の精度で高速処理が可能
- small:244MB、中程度の精度で標準的な処理速度
- medium:769MB、高精度で標準的な処理速度
- large:1550MB、最高精度だが低速処理
体験・実験のアイデア
- 異なるモデルサイズで、結果を比較する
- 雑音のある環境での音声認識性能を検証する
- 早口や方言での認識能力を実験する