Tesseract OCR 5 で新しいフォントを用いた学習(Ubuntu 上)
- 学習に使うための日本語テキストファイルを作成する.
- 学習では、学習に用いるフォント名を指定する。
- Tesseract OCR で配布されている日本語の学習済みデータに対して、以上を用いたFine Tuning を行い、認識精度の向上を試す.
手順は、次のページの記載による
https://tesseract-ocr.github.io/tessdoc/#training-for-tesseract-4
新しいフォント、新しい文字を学習させたいときの基礎として説明している. 精度の向上のみが目的の場合は、より高い解像度の画像を使う、あるいは、 バージョン 5 でなく、安定版を使うほうがよい可能性がある。
ここでは、日本語テキストファイルを次のように設定している.
00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
-00 -01 -02 -03 -04 -05 -06 -07 -08 -09 -10 -11 -12 -13 -14 -15 -16 -17 -18 -19 -20 -21 -22 -23 -24 -25 -26 -27 -28 -29 -30 -31 -32 -33 -34 -35 -36 -37 -38 -39 -40 -41 -42 -43 -44 -45 -46 -47 -48 -49 -50 -51 -52 -53 -54 -55 -56 -57 -58 -59 -60 -61 -62 -63 -64 -65 -66 -67 -68 -69 -70 -71 -72 -73 -74 -75 -76 -77 -78 -79 -80 -81 -82 -83 -84 -85 -86 -87 -88 -89 -90 -91 -92 -93 -94 -95 -96 -97 -98 -99
00- 01- 02- 03- 04- 05- 06- 07- 08- 09- 10- 11- 12- 13- 14- 15- 16- 17- 18- 19- 20- 21- 22- 23- 24- 25- 26- 27- 28- 29- 30- 31- 32- 33- 34- 35- 36- 37- 38- 39- 40- 41- 42- 43- 44- 45- 46- 47- 48- 49- 50- 51- 52- 53- 54- 55- 56- 57- 58- 59- 60- 61- 62- 63- 64- 65- 66- 67- 68- 69- 70- 71- 72- 73- 74- 75- 76- 77- 78- 79- 80- 81- 82- 83- 84- 85- 86- 87- 88- 89- 90- 91- 92- 93- 94- 95- 96- 97- 98- 99
a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
・
さ す せ そ た ち つ て と な に ぬ ね の は ひ ふ ほ ま み む め も や ゆ よ ら り る ろ れ わ
あ い う え か き く け こ を
いわき つくば とちぎ なにわ 愛媛 旭川 伊豆 一宮 宇都宮 越谷 奄美 横浜 岡崎 岡山 沖縄 下関 会津 岩手 岐阜 久留米 宮崎 宮城 京都 金沢 釧路 熊谷 熊本 群馬 郡山 広島 香川 高崎 高知 佐賀 佐世保 堺 札幌 三河 三重 山形 山口 山梨 滋賀 鹿児島 室蘭 秋田 習志野 春日井 春日部 所沢 庄内 松本 沼津 湘南 新潟 神戸 諏訪 水戸 杉並 世田谷 成田 盛岡 青森 静岡 石川 仙台 千葉 川越 川口 川崎 前橋 倉敷 相模 足立 袖ヶ浦 多摩 帯広 大宮 大阪 大分 筑豊 長岡 長崎 長野 鳥取 土浦 島根 徳島 奈良 那須 柏 函館 八王子 八戸 飛騨 尾張小牧 姫路 品川 浜松 富山 富士山 富士山 福井 福岡 福山 福島 平泉 豊橋 豊田 北九州 北見 名古屋 野田 鈴鹿 練馬 和歌山 和泉
学習に用いるフォント名を次のように設定している.
'TRMフォント JB' 'FZナンバープレートゴシック Ver.10' \
'Noto Sans CJK JP' 'Noto Serif CJK JP Bold' 'Noto Serif CJK JP Heavy' 'Noto Serif CJK JP Light' 'Noto Serif CJK JP Medium' 'Noto Serif CJK JP Semi-Bold' 'Noto Serif CJK JP Ultra-Light'
前準備
Tesseract OCR 最新版のインストール
Ubuntu での Tesseract OCR のインストール手順: 別ページで説明
Tesseract OCR のテスト実行
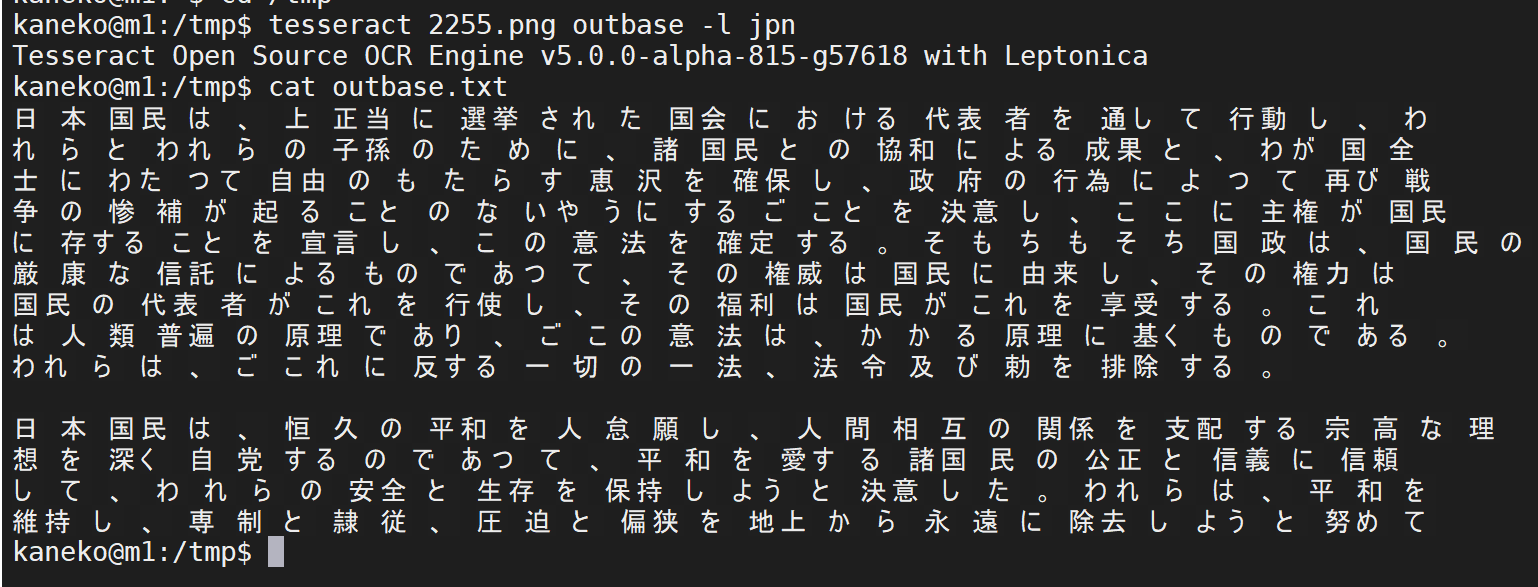
最初に、画像ファイルを用意し、テスト実行してみる
tesseract 2255.png outbase -l jpn
cat outbase.txt
{kind=link}
フォントの追加
フォントのファイルを /usr/share/fonts に置く。そして、確認する。手順を次に示す。
- フォントリストを作成しておく
あとで確認のために使う
text2image --list_available_fonts --fonts_dir /usr/share/fonts &> /tmp/fontlist1
- フォントファイルを準備し、/usr/share/fonts に置く
Ubuntu では、ttf や otf は、/usr/share/fonts に置くと使えるようになる。 フォントファイルのライセンスは利用者で確認すること。
以下、説明のために、TRM フォント(http://dc-crafts.main.jp/trm/f/trm-font.php で公開されている), FZナンバープレートゴシック(https://expwyandstamps.web.fc2.com/sozai/fontproject.htm ) を使うことにする。 これらフォントの作者に感謝する。 以下の手順を試す場合でも、これらフォントの利用条件は利用者が確認すること。 なお、以下の手順のついての質問を、これらフォントの作者に送るようなことはしないこと。
- 再度、フォントリストを作成
text2image --list_available_fonts --fonts_dir /usr/share/fonts &> /tmp/fontlist2
- フォントリストの差分を得る
これで、フォント名を確認(あとで、フォント名を使う).
diff /tmp/fontlist1 /tmp/fontlist2 - Tesseract OCT に、フォントを追加したいので、
/usr/local/share/langdata/font_properties を編集
次の行を、フォントの種類数だけ追加.「フォント名」のところには、いま確認したフォントを設定
<フォント名> 0 0 0 0 0
Tesseract OCR の学習手順(Ubuntu 上)
- 学習に用いる日本語ファイルの準備
/usr/local/share/langdata/jpn/jpn.training_text を編集する。
このとき、このファイルの文字コードが変わらないようにすること(ファイルの上書きコピーを行うと、文字コードが変わってしまっても気づきにくい。必ず確認すること)。
エディタを管理者の権限で実行して編集する。ここでは、次のように編集したとして説明を続ける。
00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 -00 -01 -02 -03 -04 -05 -06 -07 -08 -09 -10 -11 -12 -13 -14 -15 -16 -17 -18 -19 -20 -21 -22 -23 -24 -25 -26 -27 -28 -29 -30 -31 -32 -33 -34 -35 -36 -37 -38 -39 -40 -41 -42 -43 -44 -45 -46 -47 -48 -49 -50 -51 -52 -53 -54 -55 -56 -57 -58 -59 -60 -61 -62 -63 -64 -65 -66 -67 -68 -69 -70 -71 -72 -73 -74 -75 -76 -77 -78 -79 -80 -81 -82 -83 -84 -85 -86 -87 -88 -89 -90 -91 -92 -93 -94 -95 -96 -97 -98 -99 00- 01- 02- 03- 04- 05- 06- 07- 08- 09- 10- 11- 12- 13- 14- 15- 16- 17- 18- 19- 20- 21- 22- 23- 24- 25- 26- 27- 28- 29- 30- 31- 32- 33- 34- 35- 36- 37- 38- 39- 40- 41- 42- 43- 44- 45- 46- 47- 48- 49- 50- 51- 52- 53- 54- 55- 56- 57- 58- 59- 60- 61- 62- 63- 64- 65- 66- 67- 68- 69- 70- 71- 72- 73- 74- 75- 76- 77- 78- 79- 80- 81- 82- 83- 84- 85- 86- 87- 88- 89- 90- 91- 92- 93- 94- 95- 96- 97- 98- 99 a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z ・ さ す せ そ た ち つ て と な に ぬ ね の は ひ ふ ほ ま み む め も や ゆ よ ら り る ろ れ わ あ い う え か き く け こ を いわき つくば とちぎ なにわ 愛媛 旭川 伊豆 一宮 宇都宮 越谷 奄美 横浜 岡崎 岡山 沖縄 下関 会津 岩手 岐阜 久留米 宮崎 宮城 京都 金沢 釧路 熊谷 熊本 群馬 郡山 広島 香川 高崎 高知 佐賀 佐世保 堺 札幌 三河 三重 山形 山口 山梨 滋賀 鹿児島 室蘭 秋田 習志野 春日井 春日部 所沢 庄内 松本 沼津 湘南 新潟 神戸 諏訪 水戸 杉並 世田谷 成田 盛岡 青森 静岡 石川 仙台 千葉 川越 川口 川崎 前橋 倉敷 相模 足立 袖ヶ浦 多摩 帯広 大宮 大阪 大分 筑豊 長岡 長崎 長野 鳥取 土浦 島根 徳島 奈良 那須 柏 函館 八王子 八戸 飛騨 尾張小牧 姫路 品川 浜松 富山 富士山 富士山 福井 福岡 福山 福島 平泉 豊橋 豊田 北九州 北見 名古屋 野田 鈴鹿 練馬 和歌山 和泉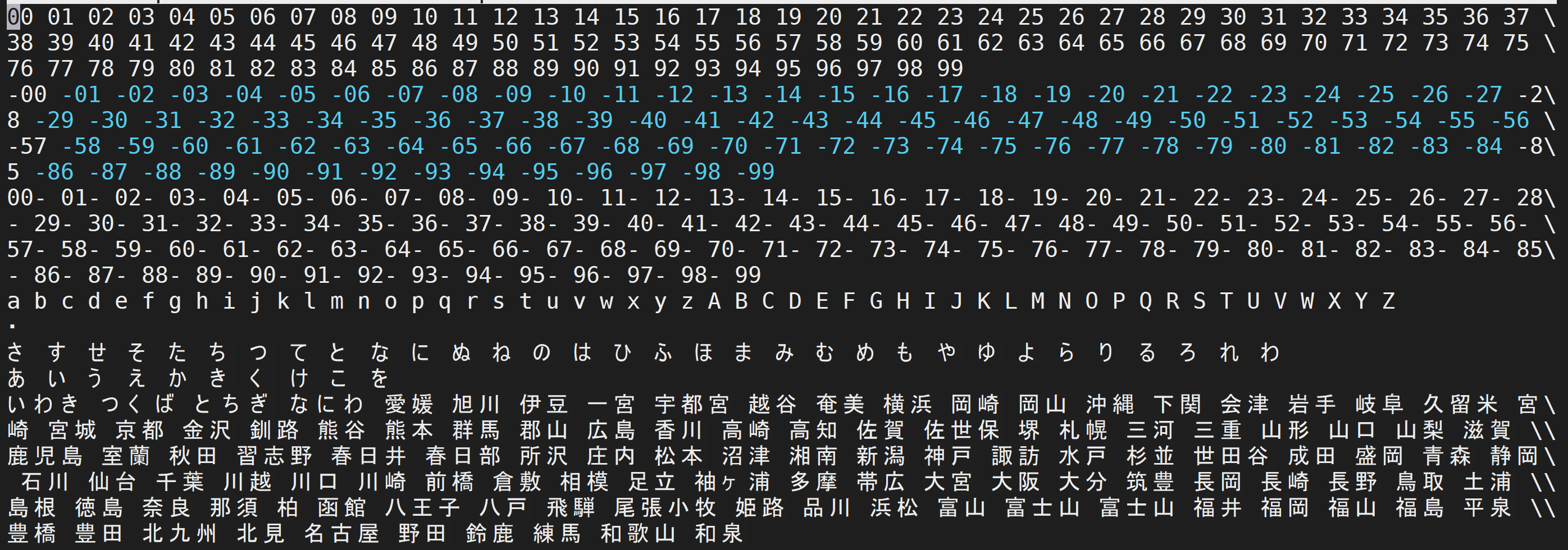
- 検証に用いる日本語ファイルの準備
/usr/local/share/langdata/jpn/jpn.eval_text を編集する。
このとき、このファイルの文字コードは、 /usr/local/share/langdata/jpn/jpn.eval_text と同じにすること.
エディタを管理者の権限で実行して編集する。ここでは、次のように編集したとして説明を続ける。
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 あいうえお
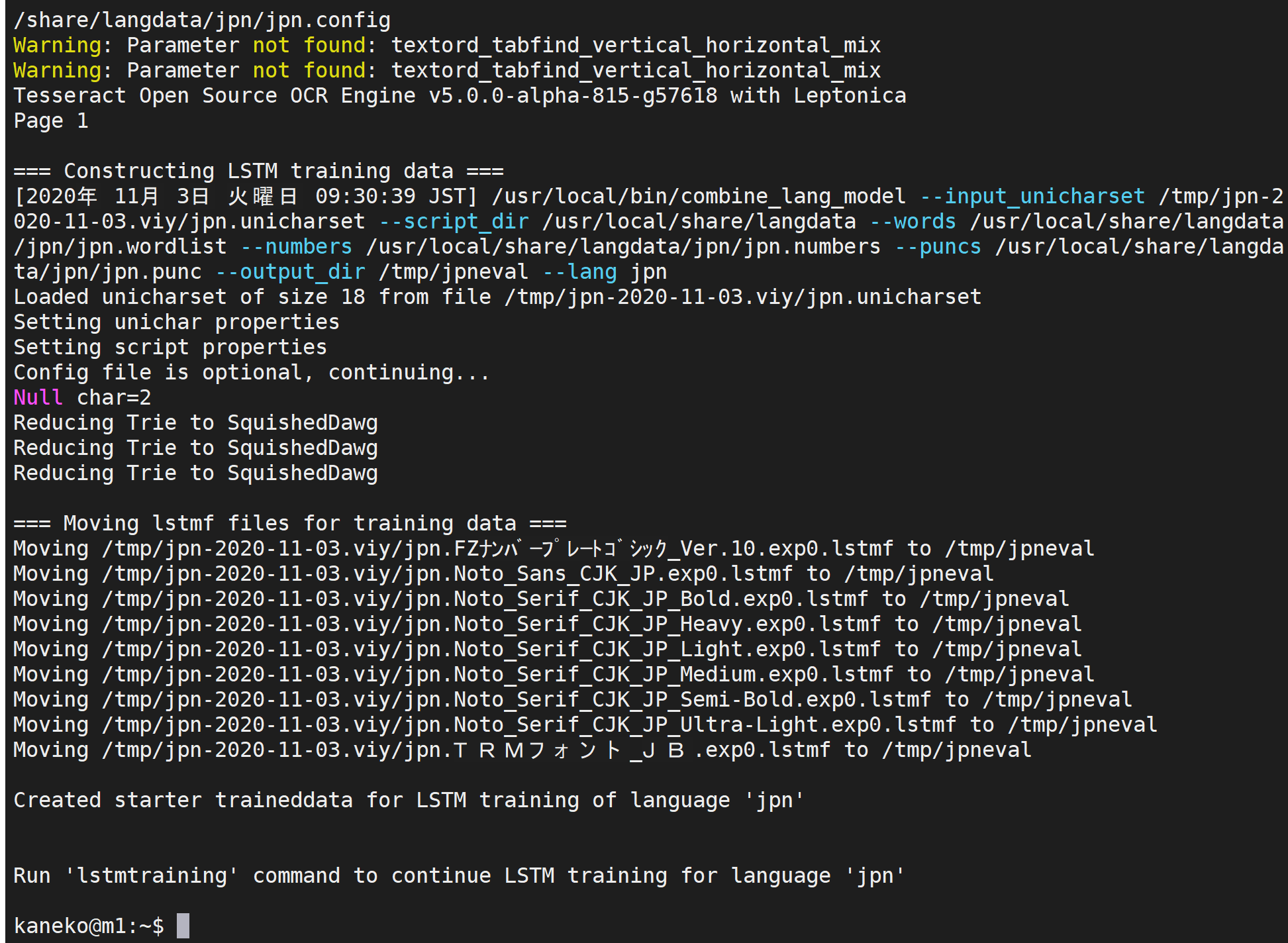
- 教師データの生成、訓練データの生成(tesstrain.sh を使用)
終了までしばらく待つ.(学習に用いる日本語ファイルが長いなどの場合は、時間がかかる)
「--linedata_only 」は、LSTM での学習のための設定
「--fontlist 」のところに、使用する日本語フォント名を書く。
rm -rf /tmp/jpntrain rm -rf /tmp/jpneval tesstrain.sh --fonts_dir /usr/share/fonts --lang jpn --linedata_only \ --noextract_font_properties --langdata_dir /usr/local/share/langdata \ --tessdata_dir /usr/local/share/tessdata --output_dir /tmp/jpntrain \ --training_text /usr/local/share/langdata/jpn/jpn.training_text \ --fontlist 'TRMフォント JB' 'FZナンバープレートゴシック Ver.10' \ 'Noto Sans CJK JP' 'Noto Serif CJK JP Bold' 'Noto Serif CJK JP Heavy' 'Noto Serif CJK JP Light' 'Noto Serif CJK JP Medium' 'Noto Serif CJK JP Semi-Bold' 'Noto Serif CJK JP Ultra-Light' tesstrain.sh --fonts_dir /usr/share/fonts --lang jpn --linedata_only \ --noextract_font_properties --langdata_dir /usr/local/share/langdata \ --tessdata_dir /usr/local/share/tessdata --output_dir /tmp/jpneval \ --training_text /usr/local/share/langdata/jpn/jpn.eval_text \ --fontlist 'TRMフォント JB' 'FZナンバープレートゴシック Ver.10' \ 'Noto Sans CJK JP' 'Noto Serif CJK JP Bold' 'Noto Serif CJK JP Heavy' 'Noto Serif CJK JP Light' 'Noto Serif CJK JP Medium' 'Noto Serif CJK JP Semi-Bold' 'Noto Serif CJK JP Ultra-Light'
(以下省略) - 終了の確認
エラーメッセージが出ていないこと
- ファイルができるので確認
ls -al /tmp/jpntrain ls -al /tmp/jpntrain/jpn ls -al /tmp/jpneval ls -al /tmp/jpneval/jpn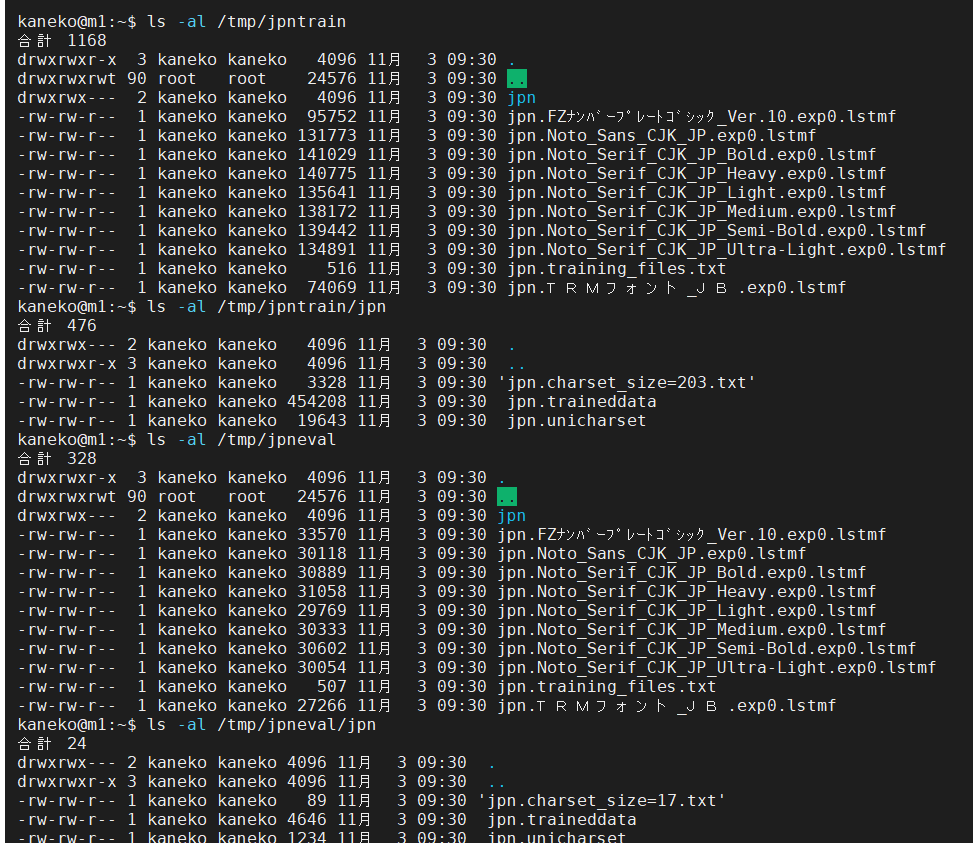
- Fine Tuning の実行
まず、コマンドで、配布・公開されている jpn.traineddata のファイルから、モデルのファイルを生成
combine_tessdata -e /usr/local/share/tessdata/jpn.traineddata /tmp/jpntrain/jpn.lstm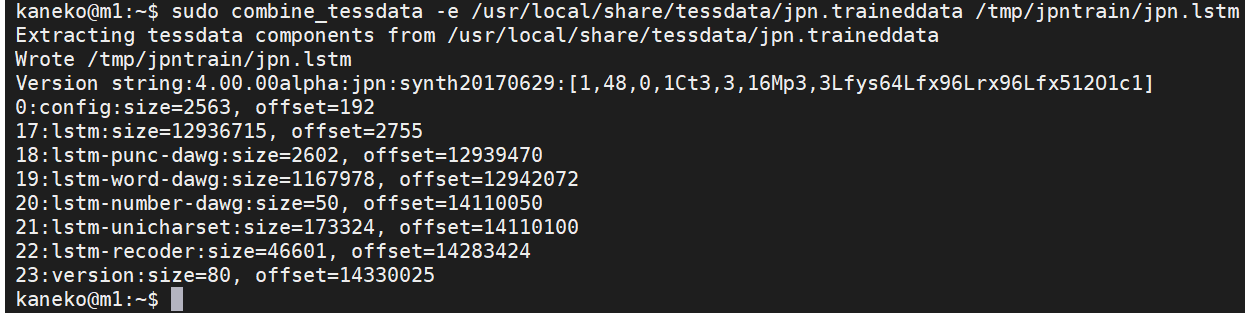
いま生成したモデルのファイルを、先ほど生成した教師データを使って FineTuning する.
「--max_iterations 400」は、過剰な学習の抑止のための設定。
終了までしばらく待つ.
cd rm lstmtrain* lstmtraining --model_output lstmtrain \ --continue_from /tmp/jpntrain/jpn.lstm \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --train_listfile /tmp/jpntrain/jpn.training_files.txt \ --max_iterations 400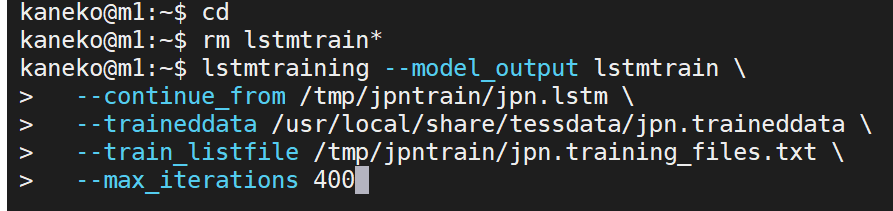
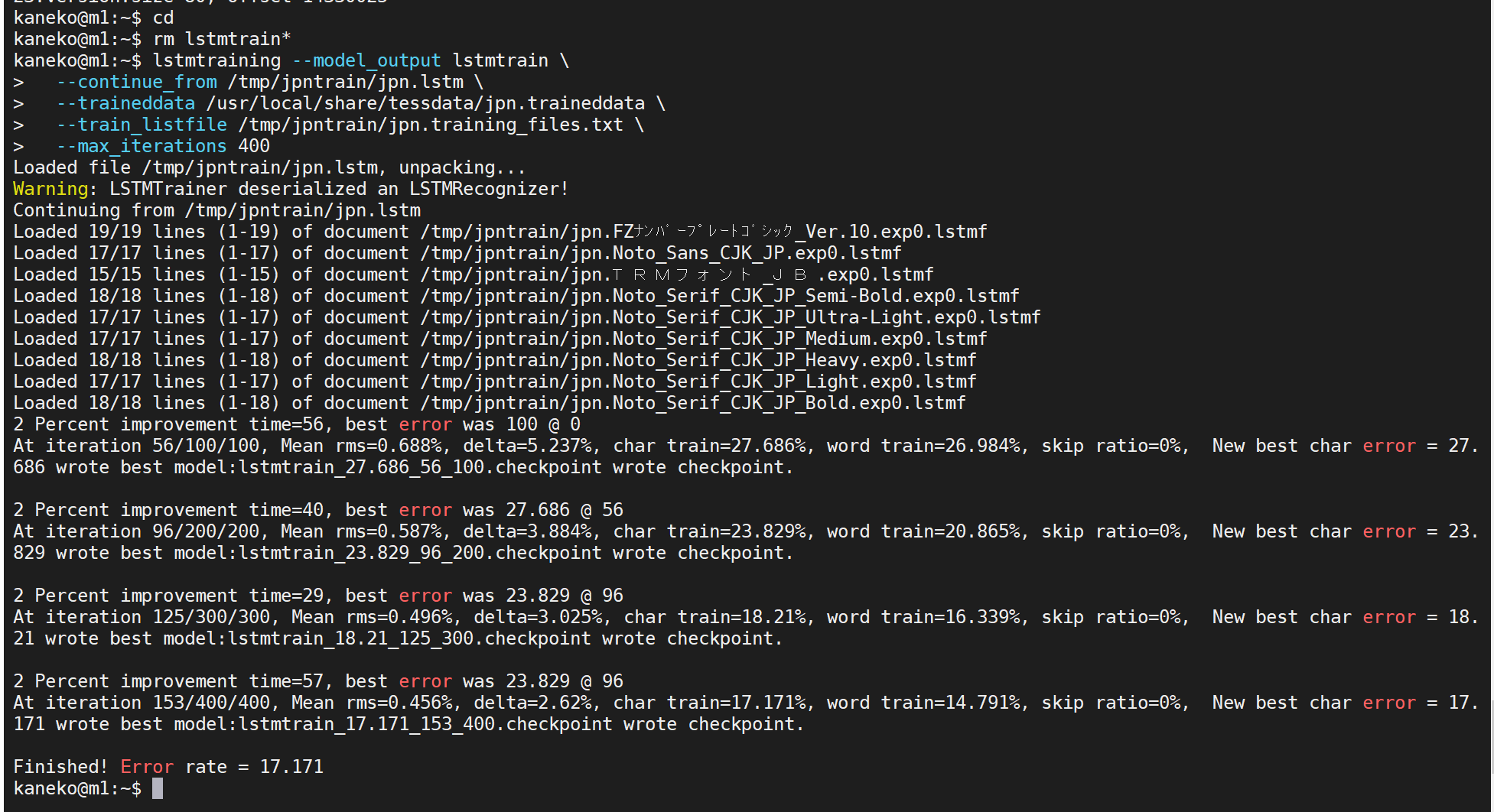
- 終了の確認
エラーメッセージが出ていないこと.
- 検証の実施
lstmeval --model lstmtrain_checkpoint \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --eval_listfile /tmp/jpntrain/jpn.training_files.txt lstmeval --model lstmtrain_checkpoint \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --eval_listfile /tmp/jpneval/jpn.training_files.txt - モデルのファイルを生成、所定の場所にコピー
cd lstmtraining --stop_training \ --continue_from lstmtrain_checkpoint \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --train_listfile /tmp/jpntrain/jpn.training_files.txt \ --model_output jpn.traineddata sudo cp /usr/local/share/tessdata/jpn.traineddata /usr/local/share/tessdata/jpn.traineddata.$$ sudo cp jpn.traineddata /usr/local/share/tessdata/jpn.traineddata
- テスト実行し、動作確認
tesseract 2255.png outbase -l jpn cat outbase.txt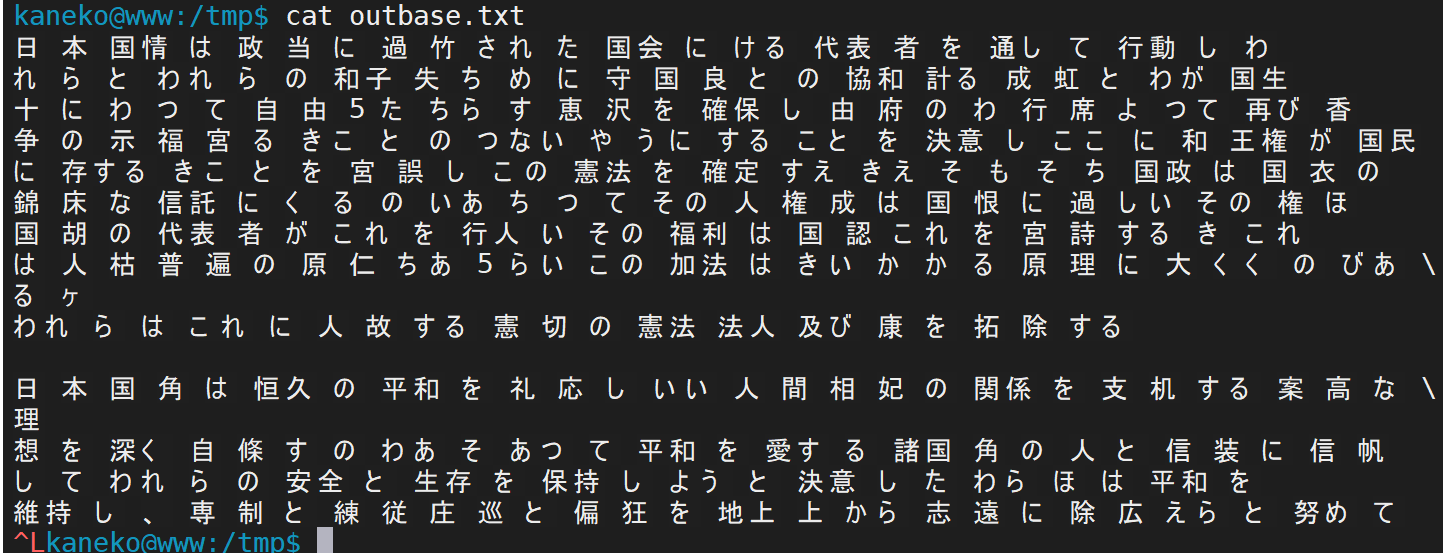
これで分かるように、学習を重ねたとき、精度が落ちるということは十分にありえる