人工知能,データサイエンス,データベース,3次元のまとめ
データ処理,データベース,ディープラーニング分野のための基礎用語. 項目を 0-9,a-z, あーん,漢字順に並べている.
【目次】
【関連する外部ページ】
- Papers with Code のページ: https://paperswithcode.com/
- fosswire.com の Unix/Linux コマンドリファランス: https://files.fosswire.com/2007/08/fwunixref.pdf
- Google Developer の機械学習用語集: https://developers.google.com/machine-learning/glossary
Python 関連
- 東京大学の「Pythonプログラミング入門」: https://utokyo-ipp.github.io/IPP_textbook.pdf
- ITmedia 社の「Python チートシート」の記事: https://atmarkit.itmedia.co.jp/ait/articles/2004/20/news015.html
- Python の公式サイト: https://www.python.org
【サイト内の関連ページ】
- 種々のまとめページ: [人工知能,データサイエンス,データベース,3次元], [Windows], [Ubuntu], [Python (Google Colaboratory を含む)], [C/C++言語プログラミング用語説明], [R システムの機能], [Octave]
Google Colaboratory の使い方
- Google Colaboratory は,オンラインの Python の開発環境.使い方などは: 別ページ »で説明
Windows のセットアップ
- Windows のまとめ: 別ページ »で説明
- GPU環境でのTensorFlow 2.10.1のインストールと活用(Windows 上): 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Windows での主要なソフトウェアのインストールと設定: 別ページ »で説明
0-9 (数字)
2to3
2to3 は,Python バージョン 2 用のソースコードを Python バージョン 3 用に変換するプログラム.
詳しくは: 別ページ »で説明
300W (300 Faces-In-The_Wild) データセット
顔のデータベース,顔の 68 ランドマークが付いている.
【文献】
C. Sagonas, G. Tzimiropoulos, S. Zafeiriou and M. Pantic, "300 Faces in-the-Wild Challenge: The First Facial Landmark Localization Challenge," 2013 IEEE International Conference on Computer Vision Workshops, 2013, pp. 397-403, doi: 10.1109/ICCVW.2013.59.
https://ibug.doc.ic.ac.uk/media/uploads/documents/sagonas_2016_imavis.pdf
【関連する外部ページ】
- 300 Faces In-The-Wild Challenge のページ: https://ibug.doc.ic.ac.uk/resources/300-W/
- OpenMMLab の 300W データセット: https://github.com/open-mmlab/mmpose/blob/master/docs/en/tasks/2d_face_keypoint.md#300w-dataset
【関連項目】 HELEN データセット, iBUG 300-W データセット, face alignment, 顔ランドマーク (facial landmark)の検出, 3次元の顔の再構成 (3D face reconstruction), OpenMMLab, 顔の 68 ランドマーク, 顔のデータベース
3DF Zephyr Free
3DF Zephyr Free は,フォトグラメトリのソフトウェア 3dF Zephyr の無料版
【関連項目】 フォトグラメトリ, Meshroom
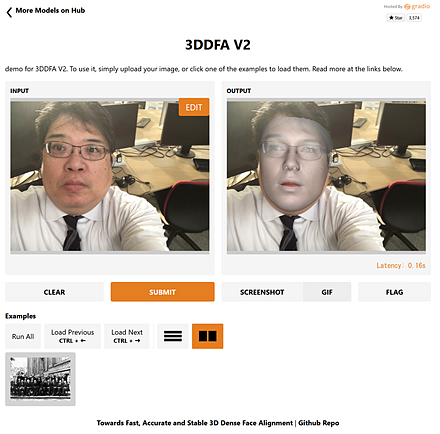
3DDFA_V2
3DDFA_V2 は, 3次元の顔の再構成 (3D face reconstruction) のうち dense vertices regression を行う一手法.論文は,2020年発表.
【文献】
Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, Stan Z. Li, Towards Fast, Accurate and Stable 3D Dense Face Alignment, ECCV 2020.
https://arxiv.org/pdf/2009.09960v2.pdf
【関連する外部ページ】
- GitHub のページ: https://github.com/cleardusk/3DDFA_V2
-
Hugging Face での 3DDFA_V2 のオンライン実行
URL: https://huggingface.co/spaces/PKUWilliamYang/3DDFA_V2
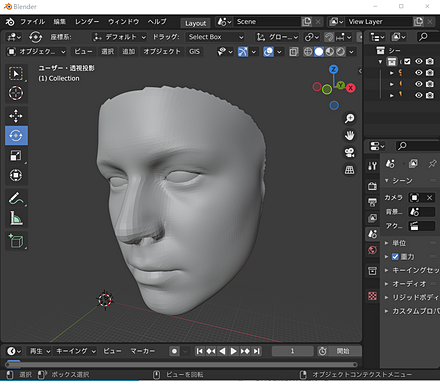
作成された3次元モデルを Blender にインポートした画面.
Google Colaboratory での 3DDFA_V2 のオンライン実行
次のページでは,Google Colaboratory で実行できるプログラムコード,プログラム利用ガイド,プログラムコードの説明など示している.
URL: https://www.kkaneko.jp/ai/intro/3ddfav2.html
【概要】本記事では、3DDFA_V2フレームワークを用いた3次元顔モデル生成プログラムについて解説する。単一の顔画像から3次元形状を復元し、OBJ/PLY形式で出力する技術をGoogle Colab環境で提供する。
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1fNfAdCRxnxxcxj9mH7lFVsP-uz4DAWoV?usp=sharing


3次元姿勢推定 (3D pose estimation)
画像から,物体検出を行うとともに,その3次元の向きの推定も行う.
【関連項目】 Objectron
3次元ゲームエンジン (3-D game engine)
3次元ゲームエンジン (3-D game engine) の機能を持つソフトウェアとしては, GoDot, Open 3D Engine, Unreal Engine, Panda3D などがある.
3次元の顔の再構成 (3D face reconstruction)
3次元の顔の再構成 (3D face reconstruction) は, 顔の写った画像から,元の顔の3次元の形を構成すること.
3次元の顔の再構成は,次の2つの種類がある.
- 3次元の変形可能な顔のモデル (3D Morphable Model) について,そのパラメータを,画像を使って推定すること. FaceRig などが有名である.
- dense vertices regression: dense は「密な」,vertices は「頂点」,regression は「回帰」.画像から,顔の3次元データであるポリゴンメッシュを推定する
3次元再構成 (3D reconstruction)
3次元再構成 (3D reconstruction) の機能をもつソフトウェアとしては, colmap, Meshroom がある.
【関連項目】 colmap, Meshroom, Multi View Stereo, OpenMVG, OpenMVS, Structure from Motion
3次元点群データ (3-D point cloud data)
3次元点群データ (3-D point cloud data) を扱うには,MeshLab や CloudCompare が便利である.
- Windows での MeshLab のインストール: 別ページ »で説明
- Windows での CloudCompare のインストール: CloudCompare のインストール(Windows 上)
7-Zip
ファイル圧縮・展開(解凍)ツール
winget を用いたインストールコマンド:
REM 7-Zip をシステム領域にインストール
winget install --scope machine --id 7zip.7zip -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements
REM 7-Zip のパス設定
powershell -NoProfile -Command "$p='C:\Program Files\7-Zip'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and $c -notlike \"*$p*\"){[Environment]::SetEnvironmentVariable('Path',\"$p;$c\",'Machine')}"
【関連する外部ページ】
- 7-Zip の公式ページ: https://7-zip.opensource.jp/
【関連項目】 7-Zip のインストール
7-Zip のインストール(Windows 上)
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM 7-Zip をシステム領域にインストール
winget install --scope machine --id 7zip.7zip -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements
REM 7-Zip のパス設定
powershell -NoProfile -Command "$p='C:\Program Files\7-Zip'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and $c -notlike \"*$p*\"){[Environment]::SetEnvironmentVariable('Path',\"$p;$c\",'Machine')}"
【関連する外部ページ】
- 7-Zip の公式ページ: https://7-zip.opensource.jp/
【サイト内の関連ページ】
【関連項目】 7-Zip
a-z (アルファベット)
Aachen Day-Night データセット
URL: https://www.visuallocalization.net/datasets/
Access
Access はリレーショナルデータベース管理の機能を持ったソフトウエア.
【サイト内の関連ページ】
AdaDelta 法
M.Zeiler の AdaDelta 法は,学習率をダイナミックに変化させる技術. 学習率をダイナミックに変化させる技術は,その他 Adam 法なども知られる.
確率的勾配降下法 (SGD 法) をベースとしているが, 確率的勾配降下法が良いのか,Adadelta 法が良いのかは,一概には言えない.
from tensorflow.keras.optimizers import Adadelta
optimizer = Adadelta(rh=0.95)
M. Zeiler, Adadelta An adaptive learning rate method, 2012.
Adam 法
Adam 法は,学習率をダイナミックに変化させる技術. 学習率をダイナミックに変化させる技術は,その他 AdaDelta 法なども知られる. Adam 法を使うプログラム例は次の通り.
m.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_crossentropy', 'accuracy']
)
Diederik Kingma and Jimmy Ba, Adam: A Method for Stochastic Optimization, 2014, CoRR, abs/1412.6980
ADE20K データセット
ADE20K データセット は, セマンティック・セグメンテーション,シーン解析(scene parsing), インスタンス・セグメンテーション (instance segmentation)についてのアノテーション済みの画像データセットである.
次の特色がある
- データの多様性
- 画素単位でのアノテーション
- オブジェクト(car や person など) も,背景領域も(grass, sky など) アノテーションされている.
- 腕や足などの,オブジェクトのパーツ (object parts) もアノテーションされている.
画像数,オブジェクト数などは次の通り.
- 画像数: 30,574 枚
うち学習用: 25,574 枚, うち検証用: 2,000 枚, うちテスト用: 3,000 枚.
- オブジェクト数: 707,868
- オブジェクトのカテゴリ数: 3,688
- アノテーションされたオブジェクトのパーツ (object parts) : 193,238
利用には,次の URL で登録が必要.
ADE20K データセットの URL: http://groups.csail.mit.edu/vision/datasets/ADE20K/
【文献】
- Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba, Scene Parsing Through ADE20K Dataset, CVPR 2017, also CoRR, abs/1608.05442, 2017.
- Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso and Antonio Torralba, Semantic Understanding of Scenes through ADE20K Dataset, International Journal on Computer Vision (IJCV), also CoRR, abs/1608.05442v2, 2016.
【関連する外部ページ】
- ADE20K データセットの URL: http://groups.csail.mit.edu/vision/datasets/ADE20K/
- CSAILVision の ADE20K のページ (GitHub のページ): https://github.com/CSAILVision/ADE20K
- CSAILVision の ADE20K スターターコード のページ (GitHub のページ):
https://github.com/CSAILVision/ADE20K/blob/main/notebooks/ade20k_starter.ipynb
このスターターコードは,画像1枚について元画像とアノテーションを表示するもの
- Papers With Code の ADE20K データセットのページ: https://paperswithcode.com/dataset/ade20k
【関連項目】 セマンティック・セグメンテーション (semantic segmentation), シーン解析(scene parsing), インスタンス・セグメンテーション (instance segmentation), Detectron2 CASILVision, MIT Scene Parsing Benchmark, 物体検出
AFLW (Annotated Facial Landmarks in the Wild) データセット
AFLW (Annotated Facial Landmarks in the Wild) データセットは, Flickr から収集された24,386枚の顔画像である. さまざまな表情,民族,年齢,性別,撮影条件,環境条件の顔が収集されている. それぞれの顔には,最大21個の顔ランドマークが付けられている.
- 24,386枚の画像.うち,59%が女性,41%が男性である.複数の顔を含む画像もある. ほとんどの画像がカラーだが,中には,濃淡画像もある.
- 約380,000 の顔について,顔ごとに 21 個の顔ランドマークが付いている.
- 顔で,左耳たぶが見えてないような場合,左耳たぶの顔ランドマークはアノテーションされていない(見えない場合はアノテーションされない)
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.tugraz.at/institute/icg/research/team-bischof/lrs-group/downloads
【文献】
M. Köstinger, P. Wohlhart, P. M. Roth and H. Bischof, "Annotated Facial Landmarks in the Wild: A large-scale, real-world database for facial landmark localization," 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), 2011, pp. 2144-2151, doi: 10.1109/ICCVW.2011.6130513.
【関連する外部ページ】
- Papers With Code の AFLW データセットのページ: https://paperswithcode.com/dataset/aflw
- open-mmplab での記事
https://github.com/open-mmlab/mmpose/blob/master/docs/en/tasks/2d_face_keypoint.md#aflw-dataset
AgeDB データセット
手作業で収集された,「in-the-wild」の顔と年齢のデータベース. 年号まで正確に記録された顔画像が含まれている.
次の URL で公開されているデータセット(オープンデータ)である.
https://ibug.doc.ic.ac.uk/resources/agedb/
【文献】
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia and S. Zafeiriou, "AgeDB: The First Manually Collected, In-the-Wild Age Database," 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1997-2005, doi: 10.1109/CVPRW.2017.250.
https://ibug.doc.ic.ac.uk/media/uploads/documents/agedb.pdf
【関連する外部ページ】
【関連項目】 顔認識 (face recognition), 顔のデータベース
AIM-500 (Automatic Image Matting-500) データセット
イメージ・マッティング (image matting) のデータセット. 3種類の前景(Salient Opaque, Salient Transparent/Meticulous, Non-Salient)を含む 500枚の画像について,元画像と alpha matte と Trimap のデータセットである.
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://drive.google.com/drive/folders/1IyPiYJUp-KtOoa-Hsm922VU3aCcidjjz
【文献】
Jizhizi Li, Jing Zhang, DaCheng Tao, Deep Automatic Natural Image Matting, CoRR, abs/2107.07235v1, 2021.
https://arxiv.org/pdf/2107.07235v1.pdf
【関連する外部ページ】
- 公式ページ の URL: https://github.com/JizhiziLi/AIM
- Papers with Code のページ: https://paperswithcode.com/dataset/aim-500
【関連用語】 イメージ・マッティング (image matting), オープンデータ (open data)
AlexeyAB darknet
AlexeyAB darknet は,YOLOv2, YOLOv3, YOLOv4 の機能などを持つ.
【文献】
Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao, Scaled-YOLOv4: Scaling Cross Stage Partial Network, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021, pp. 13029-13038, also CoRR, Scaled-YOLOv4: Scaling Cross Stage Partial Network, 2021.
https://arxiv.org/pdf/2011.08036v2.pdf
【サイト内の関連ページ】 AlexryAB/darknet のインストールと動作確認(Scaled YOLO v4 による物体検出)(Windows 上)
【関連する外部ページ】
- Alexey による darknet の実装(GitHub)ページ: https://github.com/AlexeyAB/darknet
- COCO データセットで事前学習済みモデルの重みのデータの URL: https://github.com/AlexeyAB/darknet
【関連項目】 YOLOv3, YOLOv4, RetinaNet, 物体検出
Alexnet
AlexNet の場合
input 3@224x224 conv 11x11 96@55x55 pooling conv 5x5 256@27x27 pooling 16@5x5 conv 3x3 384@13x13 conv 3x3 384@13xx13 conv 3x3 256@13x13 affine 4096 affine 4096 1000
参考文献: ch08/deep=cnvnet.py
AltCLIP
AltCLIP の特徴は, CLIP のテキストエンコーダ (text encoder) を 学習済みの多言語のテキストエンコーダ XLM-R で置き換えたこと.
【文献】
Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu, AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities, arXiv:2211.06679, 2022.
【関連項目】 CLIP
AP
機械学習による物体検出では, 「AP」は,「average precision」の意味である.
Apache Hadoop
- 巨大なファイル(ペタバイト規模)を格納し,処理できる機能を持つ
- クラスタ (cluster) 上にデータを分散させる.数千台のノードから構成されたクラスタでも動く.
- データが分散され,データが置かれているノード上で並行処理が行われる.
- データの複製 (multiple copies) が自動的に作られ,維持される.処理の失敗 (failure) 時には,自動的に再配置される.
Apache Hadoop は,並列処理のための MapReduce という機構を持つ.これは,Hadoop の分散ファイルシステム (Hadoop Distributed File System; HDFS) 上で動く.MapReduce とは,アプリケーションが,多数の小さな処理単位 (block) に分割するための機構である.分散ファイルシステムは, データブロック (data block) 単位での複製を作り,クラスタを構成するノード上に配置する.
Ubuntu での Apache Hadoop のインストール: 別ページ »で説明
Applications of Deep Neural Networks
「Applications of Deep Neural Networks」は,ディープラーニングに関するテキスト. ニューラルネットワーク, CNN (convolutional neural network), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Neural Networks), GAN (Generative Adversarial Network), 強化学習とその応用について学ぶことができる. Python, TensorFlow, Keras を使用している.
【関連する外部ページ】
- Papers with Code のページ: https://paperswithcode.com/paper/applications-of-deep-neural-networks
- PDF ファイル: https://arxiv.org/pdf/2009.05673v3.pdf
【関連項目】 CNN (convolutional neural network), GAN (Generative Adversarial Network), GRU (Gated Recurrent Neural Networks), Keras, LSTM (Long Short-Term Memory), TensorFlow, ディープラーニング ニューラルネットワーク, 強化学習
ArcFace 法
距離学習の1手法である. 分類モデルが特徴ベクトルを生成するための複数の層と,最終層の softmax から構成されているとき, その分類モデルでの,特徴ベクトルを生成するための複数の層の出力に対して, L2 正規化の処理と,Angular Magin Penalty 層による処理を追加し,softmax 層につなげる.
deepface, InsightFace などで実装されている.
【文献】
Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou, ArcFace: Additive Angular Margin Loss for Deep Face Recognition, CVPR 2019, also CoRR, abs/1801.07698v3, 2019.
https://arxiv.org/pdf/1801.07698v3.pdf
【関連する外部ページ】
- Papers with Code のページ: https://paperswithcode.com/method/arcface
【関連項目】 deepface, InsightFace, 顔検証 (face verification), 顔識別 (face identification), 顔認識 (face recognition), 顔に関する処理
asteroid
asteroid は,音源分離(audio source separation)のツールキット.
【文献】
Ryosuke Sawata, Stefan Uhlich, Shusuke Takahashi, Yuki Mitsufuji, All for One and One for All: Improving Music Separation by Bridging Networks, CoRR, abs/2010.04228v4, 2021.
PDF: https://arxiv.org/pdf/2010.04228v4.pdf
【関連する外部ページ】
- GitHub のページ: https://github.com/asteroid-team/asteroid
- Papers with Code のページ: https://paperswithcode.com/paper/all-for-one-and-one-for-all-improving-music
【関連用語】 audio source seperation, music source separation, speech enhancement
Windows での asteroid のインストールと動作確認(音源分離)
asteroid のインストールと動作確認(音源分離)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
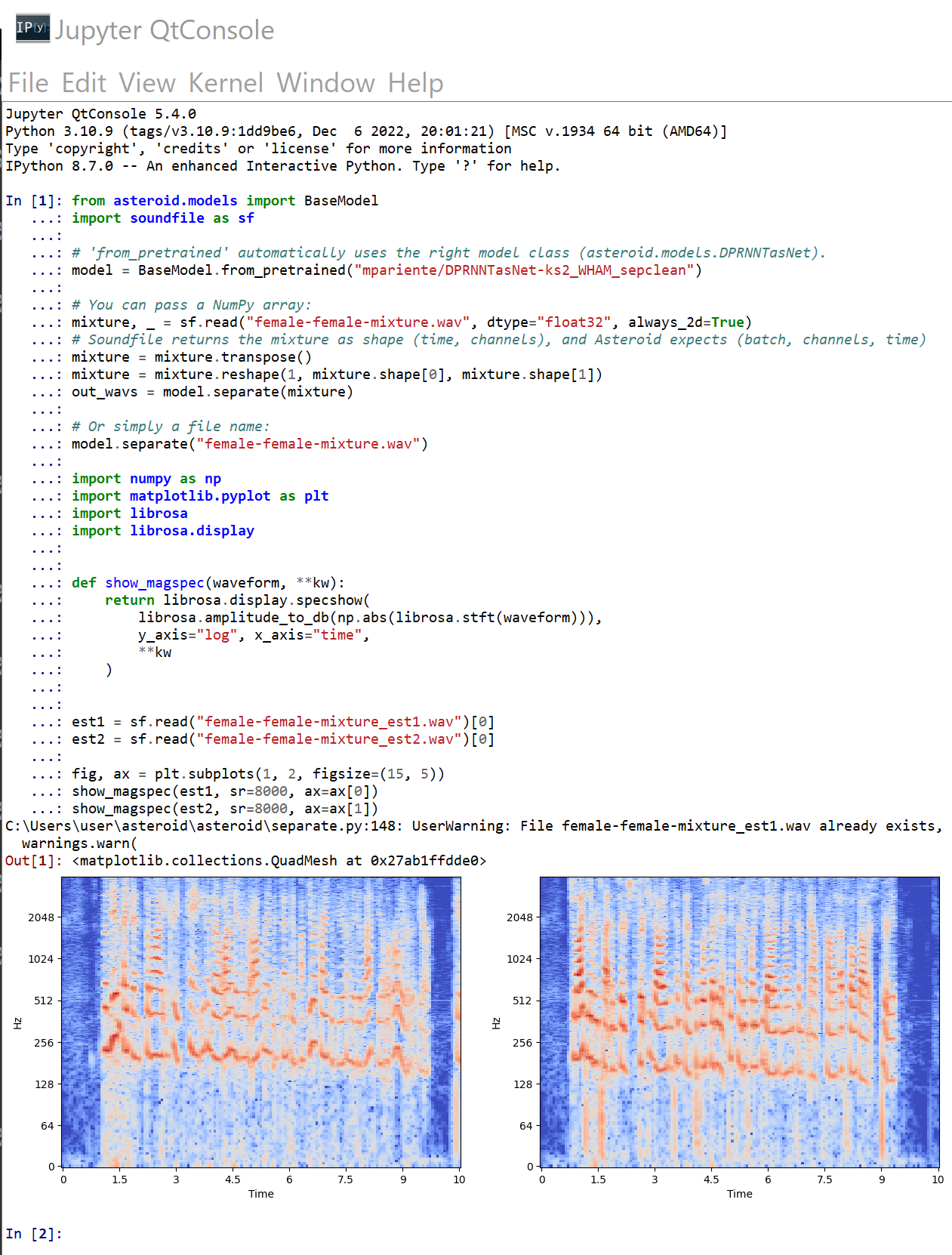
Google Colaboratory での asteroid のインストール
公式の手順 https://github.com/asteroid-team/asteroid による.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
%cd /content
!rm -rf asteroid
!git clone https://github.com/asteroid-team/asteroid
%cd asteroid
!python3 setup.py develop
!pip3 install -r requirements.txt
AVA
Spatio-Temporal Action Recognition の一手法.2016年発表
- 文献
Gu, Chunhui and Sun, Chen and Ross, David A and Vondrick, Carl and Pantofaru, Caroline and Li, Yeqing and Vijayanarasimhan, Sudheendra and Toderici, George and Ricco, Susanna and Sukthankar, Rahul and others, Ava: A video dataset of spatio-temporally localized atomic visual actions, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6047--6056, 2018.
- MMAction2 の AVA の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/detection/ava/README.md
【関連項目】 MMAction2, Spatio-Temporal Action Recognition, 動作認識 (action recognition)
Bark
Bark は Transformer ベースの音声合成の技術.多言語に対応.
【サイト内の関連ページ】
- 多言語の音声合成(Bark,Python,PyTorch を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- Bark の公式の GitHub のページ : https://github.com/suno-ai/bark
- Bark の Paper with Code のページ: https://paperswithcode.com/paper/neural-codec-language-models-are-zero-shot
【関連項目】 VALL-E X
BASNet (Boundary-Aware Salient object detection)
BASNet は, ディープラーニングにより,Salient Object Detection (顕著オブジェクトの検出)を行う一手法.2019年発表.
BASNet は次の2つのモジュールから構成される.
- Predict Module:
入力画像から saliency map を生成する. U-Net に類似の構造を持つ,教師有りの Encoder-Decoder ネットワークである. この段階での saliency map は,粗い (coarse) ものである.
- Residual Refinement Module:
Predict Module が生成した saliency map をリファイン (refine) する. Residual Refinement Module は Predict Module が生成した saliency map と,正解 (ground truth) との残差 (residuals) を学習する.
Salient Object Detection は, 視覚特性の異なるオブジェクトを,画素単位で切り出す. 前景と背景の分離に役立つ場合がある.人間がマスクの指定や塗り分け(Trimap など)を行うことなく実行される.
【文献】
Qin, Xuebin and Zhang, Zichen and Huang, Chenyang and Gao, Chao and Dehghan, Masood and Jagersand, Martin, BASNet: Boundary-Aware Salient Object Detection, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
【関連する外部ページ】
- 公式の GitHub のページ: https://github.com/xuebinqin/BASNet
- Papers With Code のページ: https://paperswithcode.com/paper/basnet-boundary-aware-salient-object
【関連用語】 U-Net, U2-Net, salient object detection, セマンティック・セグメンテーション (semantic segmentation)
Windows での BASNet のインストールとテスト実行(顕著オブジェクトの検出)
BASNet のインストールとテスト実行(顕著オブジェクトの検出)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明






Google Colaboratory での BASNet のインストールとオンライン実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
BASNet のテストプログラムのオンライン実行を行うまでの手順を示す.
- BASNet プログラムなどのダウンロード**
!git clone https://github.com/NathanUA/BASNet.git
- 学習済みモデルのダウンロード
公式ページ https://github.com/xuebinqin/BASNet の指示による. 学習済みモデル(ファイル名 basenet.pth)は,次で公開されている. ダウンロードし,saved_models/basnet_bsi の下に置く
https://drive.google.com/open?id=1s52ek_4YTDRt_EOkx1FS53u-vJa0c4nu
- テスト用の画像のダウンロードと確認表示
%cd BASNet !curl -L https://github.com/opencv/opencv/blob/master/samples/data/fruits.jpg?raw=true -o fruits.jpg !curl -L https://github.com/opencv/opencv/blob/master/samples/data/home.jpg?raw=true -o home.jpg !curl -L https://github.com/opencv/opencv/blob/master/samples/data/squirrel_cls.jpg?raw=true -o squirrel_cls.jpg from PIL import Image Image.open('fruits.jpg').show() Image.open('home.jpg').show() Image.open('squirrel_cls.jpg').show()

- BASNet の実行
%cd BASNet !python basnet_test.py
- 結果の表示

{kind=link}
BDD100K
物体検出, instance segmentaion, multi object tracking, segmentation trackling, セマンティック・セグメンテーション (semantic segmentation), lane marking, pose estimation 等の用途を想定したデータセット
- 文献 Yu, Fisher and Chen, Haofeng and Wang, Xin and Xian, Wenqi and Chen, Yingying and Liu, Fangchen and Madhavan, Vashisht and Darrell, Trevor, BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- 公式ページ: https://www.vis.xyz/bdd100k/
- 公式のドキュメント: https://doc.bdd100k.com/usage.html
- BDD100K のダウンロードの公式ページ: https://doc.bdd100k.com/download.html
- 公式の Model Zoo: https://github.com/SysCV/bdd100k-models/
- Papers with Code のページ: https://paperswithcode.com/dataset/bdd100k
【関連項目】 物体検出, instance segmentaion, multi object tracking, segmentation trackling, セマンティック・セグメンテーション (semantic segmentation), lane marking, pose estimation
Windows での BDD100K Images, Detection 2020 Labels, Pose Estimation Labels の展開
Windows での BDD100K Images, Detection 2020 Labels, Pose Estimation Labels の展開手順は次の通り.
BDD100K を image tagging, 物体検出 (object detection), pose estimation に用いることを想定.
BDD100K のデータセットの準備の説明ページ(公式): https://github.com/SysCV/bdd100k-models/blob/main/doc/PREPARE_DATASET.md
- BDD100K のダウンロードの公式ページから, BDD100K Images, Detection 2020 Labels, Pose Estimation Labels をダウンロード
- BDD100K のダウンロードの公式ページ: https://doc.bdd100k.com/download.html
- bdd100k_images_100k.zip がダウンロードされる
- 展開のため,次のコマンドを実行
copy bdd100k_images_100k.zip %LOCALAPPDATA% copy bdd100k_labels_release.zip %LOCALAPPDATA% copy bdd100k_pose_labels_trainval.zip %LOCALAPPDATA% cd %LOCALAPPDATA% powershell -command "Expand-Archive -DestinationPath . -Path bdd100k_images_100k.zip" powershell -command "Expand-Archive -DestinationPath . -Path bdd100k_labels_release.zip" powershell -command "Expand-Archive -DestinationPath . -Path bdd100k_pose_labels_trainval.zip" - ファイルの配置は次のようになる.
└─bdd100k | └── images ├── test ├── train └── val | └─labels ├──bdd_labels_images_train.json ├──bdd_labels_images_val.json └─ pose21
Ubuntu での BDD100K Images, Detection 2020 Labels, Pose Estimation Labels の展開
Ubuntu での BDD100K Images, Detection 2020 Labels, Pose Estimation Labels の展開手順は次の通り.
BDD100K を image tagging, 物体検出 (object detection), pose estimation に用いることを想定.
BDD100K のデータセットの準備の説明ページ(公式): https://github.com/SysCV/bdd100k-models/blob/main/doc/PREPARE_DATASET.md
- BDD100K のダウンロードの公式ページから, BDD100K Images, Detection 2020 Labels, Pose Estimation Labels をダウンロード
- BDD100K のダウンロードの公式ページ: https://doc.bdd100k.com/download.html
- bdd100k_images_100k.zip がダウンロードされる
- 展開のため,次のコマンドを実行
sudo cp bdd100k_images_100k.zip /usr/local sudo cp bdd100k_labels_release.zip /usr/local sudo cp bdd100k_pose_labels_trainval.zip /usr/local cd /usr/local sudo 7z x bdd100k_images_100k.zip sudo 7z x bdd100k_labels_release.zip sudo 7z x bdd100k_pose_labels_trainval.zip sudo chown -R $USER bdd100k - アノテーションファイルを,COCO 形式に変換する.
cd /usr/local sudo rm -rf bdd100k-models sudo git clone https://github.com/SysCV/bdd100k-models sudo chown -R $USER bdd100k-models cd bdd100k-models sed -i -e 's/git+git/git+https/g' requirements.txt sudo pip3 install -U -r requirements.txt sudo python3 det/setup.py install sudo python3 drivable/setup.py install sudo python3 ins_seg/setup.py install sudo python3 pose/setup.py install sudo python3 sem_seg/setup.py install sudo python3 tagging/setup.py install cd /usr/local mkdir bdd100k\jsons python3 -m bdd100k.label.to_coco -m pose \ -i bdd100k/labels/pose_21/pose_train.json \ -o bdd100k/jsons/pose_train_cocofmt.json python3 -m bdd100k.label.to_coco -m pose \ -i bdd100k/labels/pose_21/pose_val.json \ -o bdd100k/jsons/pose_val_cocofmt.json - ファイルの配置は次のようになる.
└─bdd100k | └── images ├── test ├── train └── val | └─labels ├──bdd_labels_images_train.json ├──bdd_labels_images_val.json └─ pose21
Big Tranfer ResNetV2
【関連項目】 Residual Networks (ResNets)
BioID 顔データベース (BioID Face Database)
BioID 顔データベースは,23名, 1521枚のモノクロの画像.解像度は 384x286 である.目の位置に関するデータを含む.
BioID 顔データベースは次の URL で公開されているデータセット(オープンデータ)である.
BLAS
BLAS の主な関数
- Level 1 ベクトルとベクトルの演算
- DOT : 内積
- AXPY : AXPY 演算 ( y <- ax + y の形など)
- NORM : ノルム など
- Level 2 行列とベクトルと計算
- 行列とベクトルの積 ( y <- Ax )
- 行列の rank-1 更新 ( A <- A + xy' )
- Level 3 行列同士の演算
- 行列と行列の積 ( Z <- XY )
Blender
Blenderは,3次元コンピュータグラフィックス・アニメーションソフトウェアである. 3次元モデルの編集,レンダリング,光源やカメラ等を設定しての3次元コンピュータグラフィックス・アニメーション作成機能がある.
- ファイル形式は,Stanford Triangle Format (ply), Wavefront OBJ (obj), 3D Studio Max (3ds), Stereo-Litography (stl) 等に対応.
- Windows 版, Linux 版, Max OS X 版などがある.
- Blender の URL: https://www.blender.org/
- Blender の便利な機能,演習教材,実演など: 別ページ »にまとめている.
【関連項目】 bpy (blenderpy), yuki-koyama の blender-cli-rendering
Windows での Blender のインストール
Windows での Blender のインストールは,複数の方法がある.
- 公式ページからダウンロードしてインストールする.その詳細は,別ページ »で説明
- Blender の最新版を検証,開発者に貢献したいなどの場合には, ソースコードからビルドして,インストールする. その詳細は,別ページ »で説明
Ubuntu での Blender のインストール
Ubuntu での Blender のインストールは,別ページ »で説明
Blender のモーショントラッキング機能
次の動画は,Blender のモーショントラッキング機能を用いた映像作成について説明している.
https://www.youtube.com/watch?v=lY8Ol2n4o4A
次の動画は,作成された映像,グリーンバックの映像である.
https://www.youtube.com/watch?v=FFJ_THGj72U
BM3D image denosing
BM3D image denosing の公式ソースコード(GitHub のページ): https://github.com/gfacciol/bm3d
【関連項目】 image denosing
Boost
Boost は, C++ のライブラリ.
Boost の URL: https://www.boost.org/
Windows での Boost のインストールとテスト実行
Windows での Boost 1_86 のインストールとテスト実行(ソースコードを使用): 別ページ »で説明
Ubuntu での Boost のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install libboost-all-dev
Boston housing price 回帰データセット
Boston housing price 回帰データセットは,次のプログラムでロードできる.
from tensorflow.keras.datasets import boston_housing
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
【関連項目】 Keras に付属のデータセット
Box Annotation
ディープラーニングによる物体検出のための学習と検証では, アノテーションとして,物体のバウンディングボックスが広く用いられている.
ディープラーニングによるインスタンス・セグメンテーション (instance segmentation)でも, Tian らの BoxInst (2021年発表) のように,画素単位でのアノテーションでなく, バウンディングボックスを用いる手法が登場している.
- 文献, Zhi Tian, Chunhua Shen, Xinlong Wang and Hao Chen, BoxInst: High-Performance Instance Segmentation with Box Annotations, CVPR 2021, also CoRR, abs/2012.02310, 2021.
【関連項目】 インスタンス・セグメンテーション (instance segmentation), バウンディングボックス, 物体検出,
bpy (blenderpy)
bpy (blenderpy) では,Blender がPython モジュールになっている.
【関連項目】 Blender yuki-koyama の blender-cli-rendering
Windows での bpy (blenderpy) のインストール(PyPI を使用)
https://pypi.org/project/bpy/ の記載により,PyPI の bpy (blenderpy) のインストールを行う.
- 次のページで,必要な Python のバージョンを確認する.
- いま確認したバージョンの Python がインストールされていないときは, Python のインストール: 別項目で説明している.を行う.
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
「-3.7」のところには, いま確認した Python のバージョンを指定する.
py -3.7 -m pip install numpy py -3.7 -m pip install bpy bpy_post_install - インストールできたことの確認
「-3.7」のところには, いま確認した Python のバージョンを指定する.
エラーメッセージが出ていなければ OK.
py -3.7 -c "import bpy"
Windows での bpy (blenderpy) のインストール(ソースコード を使用)
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- cmake のインストール: 別項目で説明している.
CMake の公式ダウンロードページ: https://cmake.org/download/
- svn のインストール: 別項目で説明している.
SlikSVN のページ: https://sliksvn.com/
- NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上)
- タグの確認
インストールしたい Blender のバージョンにあう Blender のタグを,次のページで探す.
- 以下のコマンドを管理者権限のx64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)で実行する (手順:スタートメニュー →Visual Studio 20xx」の下の「x64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)」 → 「管理者として実行」)。
- Blender のソースコードをダウンロード
「v3.0.1」のところには,使用したいバージョンの Blender のタグを指定すること.
cd /d c:%HOMEPATH% rmdir /s /q blender git clone -b v3.0.1 https://github.com/blender/blender - Blender のコンパイル済みのライブラリのダウンロード,Blender のビルド
Visual Studio Community 2022 を使うときは「make update 2022」,「make release 2022」 を実行.
終了まで時間がかかるので,しばらく待つ
cd /d c:%HOMEPATH% cd blender make update 2022b make release 2022b - Blender の Python モジュールのビルド
cd /d c:%HOMEPATH% cd blender rmdir /s /q build mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 -DWITH_PYTHON_INSTALL=OFF -DWITH_PYTHON_MODULE=ON .. cmake --build . --config Release --target INSTALL -- /m:4 - Python のバージョン, Python のインストールディレクトリを確認
- インストール
「c:\Program Files\Python39」のところは, Python のインストールディレクトリを指定すること.
python -m pip install numpy cd /d c:%HOMEPATH%\blender\build\release copy bin\bpy.pyd c:\Program Files\Python39\Lib\site-packages\ copy bin\*.dll c:\Program Files\Python39\Lib\site-packages\ del c:\Program Files\Python39\Lib\site-packages\python36.dll xcopy /E bin\3.0 c:\Program Files\Python39\ - インストールできたかの確認
コマンドプロンプトで次のコマンドを実行する.
エラーメッセージが出なければ OK.
python -c "import bpy; scene = bpy.data.scenes['Scene']; print(scene)"
Build Tools for Visual Studio 2019
Build Tools for Visual Studio 2019(ビルドツール for Visual Studio 2019)は,Windows で動くMicrosoft の C++ コンパイラーである.
- 64 ビット,32 ビットで動く.
- NVIDIA CUDA ツールキットの利用のときにも役立つ
- C++ のプログラムをコンパイルしたいときの手順概要:
- スタートメニューで「Visual Studio 2019」の下の「x64 Native Tools Command Prompt」
- cl コマンド(C++コンパイラー)でコンパイル
(例)cl hello.c
- .exe ファイルの確認
「cl hello.c」でコンパイルしたときは「hello.exe」ファイルができるので確認
- fopen 関数を使う場合には、C++ ソースコードの先頭に次を追加
#pragma warning(disable: 4996)
- 「x64 Native Tools Command Prompt」は、コマンドプロンプトとしての機能がある.
【サイト内の関連ページ】
- Build Tools for Visual Studio 2019 のインストール手順: 別ページ »で説明
【関連する外部ページ】
- Build Tools for Visual Studio 2019 の公式ダウンロードページ: https://visualstudio.microsoft.com/ja/downloads/
Build Tools for Visual Studio 2022(ビルドツール for Visual Studio 2022)
Build Tools for Visual Studio 2022(ビルドツール for Visual Studio 2022)は, Windows上で動作するMicrosoftのC++コンパイラーであり、プログラムのソースコードから実行可能なプログラムやライブラリを生成するためのツールである.
コンパイラ,リンカ,ランタイムライブラリなどが含まれており,32ビットと64ビットの両方で動作する. これらのツールはコマンドラインで使用される. NVIDIA CUDA ツールキットの利用時にも役立つ.
C++プログラムを64ビットでコンパイルする手順は以下の通りである.
- スタートメニューから「Visual Studio 2022」の下にある「x64 Native Tools Command Prompt」を開く
- clコマンド(C++コンパイラー)を使用してコンパイルする.例えば,「cl hello.c」のようにする..
- コンパイルが成功すると,hello.exeのような実行可能ファイルが生成されるので,確認する.
また,fopen関数を使用する場合は、C++ソースコードの先頭に「#pragma warning(disable: 4996)」を追加する必要がある.
x64 Native Tools Command Promptはコマンドプロンプトの機能も持っている. Visual Studioは機能が豊富だが,Visual Studioのビルドツール(Build Tools)の機能しか使用しない場合は,ビルドツール(Build Tools)だけを単独でインストールすることができる.
cabani の MaskedFace-Net データセット
正しくマスクが装着された状態の顔の写真 (CMFD) と, 正しくマスクが装着されていない状態の顔の写真 (IMFD) のデータセット.
- CMDD: 67,049 枚, 1024x1024
- IMFD: 66,734 枚, 1024x1024
文献
Adnane Cabani and Karim Hammoudi and Halim Benhabiles and Mahmoud Melkemi, MaskedFace-Net -- A Dataset of Correctly/Incorrectly Masked Face Images in the Context of COVID-19, Smart Health, 2020.
Science Direct: https://www.sciencedirect.com/science/article/pii/S2352648320300362
【サイト内の関連ページ】
chandrikadeb7 / Face-Mask-Detection のインストールと動作確認(マスク有り顔,マスクなし顔の検出)(Python,TensorFlow を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
公式 URL: https://github.com/cabani/MaskedFace-Net
【関連項目】 顔のデータベース, 顔検出 (face detection)
Caffe
- Caffe の URL: http://caffe.berkeleyvision.org/
Caffe2
【関連する外部ページ】
- URL: https://caffe2.ai
- github: https://github.com/caffe2/caffe2
- モデル zoo: https://caffe2.ai/docs/zoo.html https://github.com/caffe2/models
Caltech Pedestrian データセット (Caltech Pedestrian Dataset)
Caltech Pedestrian データセット は,都市部を走行中の車両から撮影したデータ. 機械学習による物体検出 の学習や検証に利用できるデータセットである.
- 640x480 30Hzのビデオ
- 約10時間分(約25万フレーム,約1分間のセグメントが137個)
- バウンディングボックス: 約35万個,約 2300人の歩行者がアノテーションされている.
- アノテーションは,バウンディングボックスの時間的な対応関係,オクルージョンラベルを含む
Caltech Pedestrian データセットは次の URL で公開されているデータセット(オープンデータ)である.
URL: http://www.vision.caltech.edu/datasets/
【関連情報】
- Papers With Code の Caltech Pedestrian データセットのページ: https://paperswithcode.com/dataset/caltech-pedestrian-dataset
- PyTorch の Caltech Pedestrian データセット: https://pytorch.org/vision/stable/datasets.html#caltech
Ceres ソルバ(Ceres Solver)
Ceres ソルバ(Ceres Solver)は,非線形の最適化の機能をもったソフトウェア.
公式ページ: http://ceres-solver.org/
【文献】
Agarwal, Sameer and Mierle, Keir and The Ceres Solver Team, Ceres Solver, https://github.com/ceres-solver/ceres-solver, 2022.
Windows での Ceres ソルバ(Ceres Solver)のインストール
Windows での Ceres ソルバ(Ceres Solver) のインストール: 別ページ »で説明
私がビルドしたもの,非公式,無保証, https://github.com/ceres-solver/ceres-solver で公開されているソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした. 作者が定めるライセンス https://github.com/ceres-solver/ceres-solver/blob/master/LICENSE による.
zip ファイルは C:\ 直下で展開し,C:\ceres-solver での利用を想定.
セキュリティに関する注意:非公式ビルドのバイナリを使用する際は,セキュリティリスクを理解した上で自己責任で使用すること.可能な限り,公式のビルド手順に従って自身でビルドすることを推奨する.
CASILVision
CASILVisionは、Places365データセットを用いた事前学習済みモデルと、それを利用した画像分類、image tagging、Class Activation Mapping (CAM) のプログラムを提供している。
- CASILVision の Places365
Places365 データセットを用いた事前学習済みモデルと、 それを利用した、画像分類、image tagging、Class Activation Mapping (CAM) のプログラムが公開されている。
【関連項目】 画像分類、 Class Activation Mapping (CAM)、 image tagging
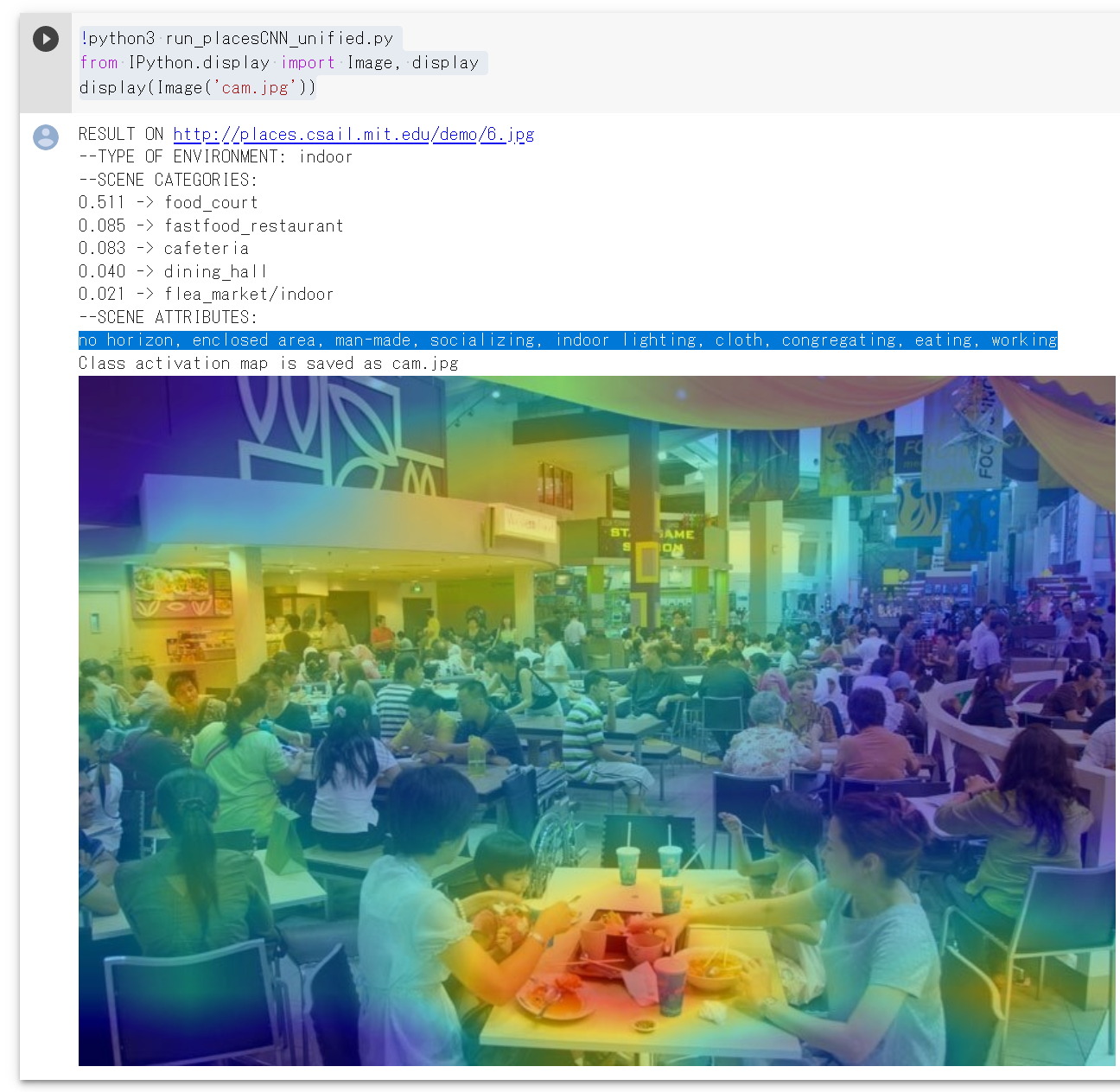
Google Colaboratory で 画像分類、image tagging、class activation map のプログラム実行(CASILVision の Places365 を使用)
CASILVision の Places365 を使用する。 公開されているプログラムは、次の手順で実行できる。
画像分類の結果は、 「0.511 -> food_court, 0.085 -> fastfood_restaurant, 0.083 -> cafeteria, 0.040 -> dining_hall, 0.021 -> flea_market/indoor」のように表示される。
image tagging では、 「no horizon, enclosed area, man-made, socializing, indoor lighting, cloth, congregating, eating, working」 のように、屋内であるか屋外であるかのタグなどが得られる。
!rm -rf places365
!git clone https://github.com/CSAILVision/places365
%cd places365
!python3 run_placesCNN_unified.py
from PIL import Image
Image.open('cam.jpg').show()
CelebA (Large-scale CelebFaces Attributes) データセットのダウンロード
Large-scale CelebFaces Attributes (CelebA) データセットは、顔画像とアノテーションのデータである。 機械学習による顔検出、顔ランドマーク (facial landmark)、顔認識、顔の生成などの学習や検証に利用できるデータセットである。
- 20万人以上の有名人の画像に、40の属性アノテーションを付けたもの
- 人数: 10,177
- 顔画像: サイズ 178×218 で、202,599枚
- 5つの顔ランドマーク
- 40の属性アノテーション(髪の色、性別、年齢などの顔属性)
Large-scale CelebFaces Attributes (CelebA) データセットは次の URL で公開されているデータセット(オープンデータ)である。
URL: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
【関連情報】
- 文献
Deep Learning Face Attributes in the Wild, Ziwei Liu, Ping Luo, Xiaogang Wang, Xiaoou Tang, ICCV 2015.
- Papers With Code の CelebA データセットのページ: https://paperswithcode.com/dataset/celeba
- PyTorch の CelebA データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.CelebA
- TensorFlow データセット の CelebA データセット: https://www.tensorflow.org/datasets/catalog/celeb_a
【関連項目】 顔のデータベース、顔ランドマーク (facial landmark)
Chain of Thought
マルチモーダル名前付きエンティティ認識(Multimodal Named Entity Recognition; MNER)およびマルチモーダル関係抽出(Multimodal Relation Extraction; MRE)の改善に注力し、これらの分野における精度向上を目指している。この目的のために、Chain of Thought(CoT)プロンプトを活用し、大規模言語モデル(LLM)から reasoning を抽出している。論文の手法は、名詞、文、マルチモーダルの観点からの多粒度の推論と、スタイル、エンティティ、画像を含むデータ拡張を網羅している。これにより、LLMからの reasoning をより効果的に抽出している。MNERの有効性を評価するために、Twitter2015、Twitter2017、SNAP、WikiDiverseという様々なデータセットを使用し、提案方法の効果を検証している。
【文献】
Feng Chen, Yujian Feng, Chain-of-Thought Prompt Distillation for Multimodal Named Entity Recognition and Multimodal Relation Extraction, arXiv:2306.14122v3, 2023.
https://arxiv.org/pdf/2306.14122v3.pdf
【関連する外部ページ】
- LangChain の GitHub のページ: https://github.com/langchain-ai/langchain
- LangChain の公式ドキュメント: https://python.langchain.com/v0.2/docs/introduction/
- LangChain の Paper with Code のページ: https://paperswithcode.com/paper/chain-of-thought-prompt-distillation-for
CityGML
CityGML は、3次元の都市、3次元の景観を扱う機能を持つデータフォーマットである。 次のようなモジュールがある。
Appearance、Bridge、Building、CityFurniture、LandUse、Relief、Transportation、Tunnel、Vegetation、 WaterBody、TexturedSurface

12-019_OGC_City_Geography_Markup_Language_CityGML_Encoding_Standard.pdf のページ 34から転載
CityGML の公式情報は、Open Geospatial Consortium のページで公開されている。
Open Geospatial Consortium の CityGML ページ: https://www.ogc.org/standards/citygml
CityGML の仕様書も、このページで公開されている。
CityGML のビューワには FZKViewer がある。 Windows での FZKViewer のインストールは 別ページ »で説明
【関連項目】 FZKViewer
CSAILVision
CSAILVision の公式デモ(GitHub のページ): https://colab.research.google.com/github/CSAILVision/semantic-segmentation-pytorch/blob/master/notebooks/DemoSegmenter.ip
【関連項目】 セマンティックセグメンテーション (semantic segmentation)
CGAL
Windows での CGAL のインストール
Windows での cgal のインストール(Windows 上): 別ページ »で説明
Ubuntu での CGAL のインストール
Ubuntu でインストールを行うには、次のコマンドを実行する。
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install libcgal-dev libcgal-qt5-dev
Chandrika Deb の顔マスク検出 (Chandrika Deb's Face Mask Detection) および顔のデータセット
写真やビデオから、マスクありの顔と、マスク無しの顔を検出する技術およびソフトウェアである。顔検出、マスク有りの顔とマスク無しの顔の分類を同時に行っている。MobileNetV2(ディープニューラルネットワーク)を使用している。
ソースコードは公開されており、画像を追加して学習をやり直すことも可能である。
Bing Search API、Kaggle dataset、RMDF dataset から収集された顔のデータセット(マスクあり: 2165 枚、マスクなし 1930 枚)が同封されている。
【関連する外部ページ】
- GitHub のページ: Chandrika Deb, https://github.com/chandrikadeb7/Face-Mask-Detection
- 正しくマスクをつけた顔と、正しくマスクをつけていない顔のデータセット: https://github.com/cabani/MaskedFace-Net
【関連項目】 cabani の MaskedFace-Net データセット、 Face Mask Detection、 マスク付き顔の処理、 顔検出 (face detection)
Google Colaboratory で、Chandrika Deb による顔マスク検出の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り、実行する)。
- インストール
!rm -rf Face-Mask-Detection !git clone https://github.com/chandrikadeb7/Face-Mask-Detection %cd Face-Mask-Detection !pip3 install -U -r requirements.txt
- 学習
Chandrika Deb の顔マスク検出に同封のデータセット(Bing Search API、Kaggle dataset、RMDF dataset から収集された顔のデータセット(マスクあり: 2165 枚、マスクなし 1930 枚))により学習を行う。
!python3 train_mask_detector.py --dataset dataset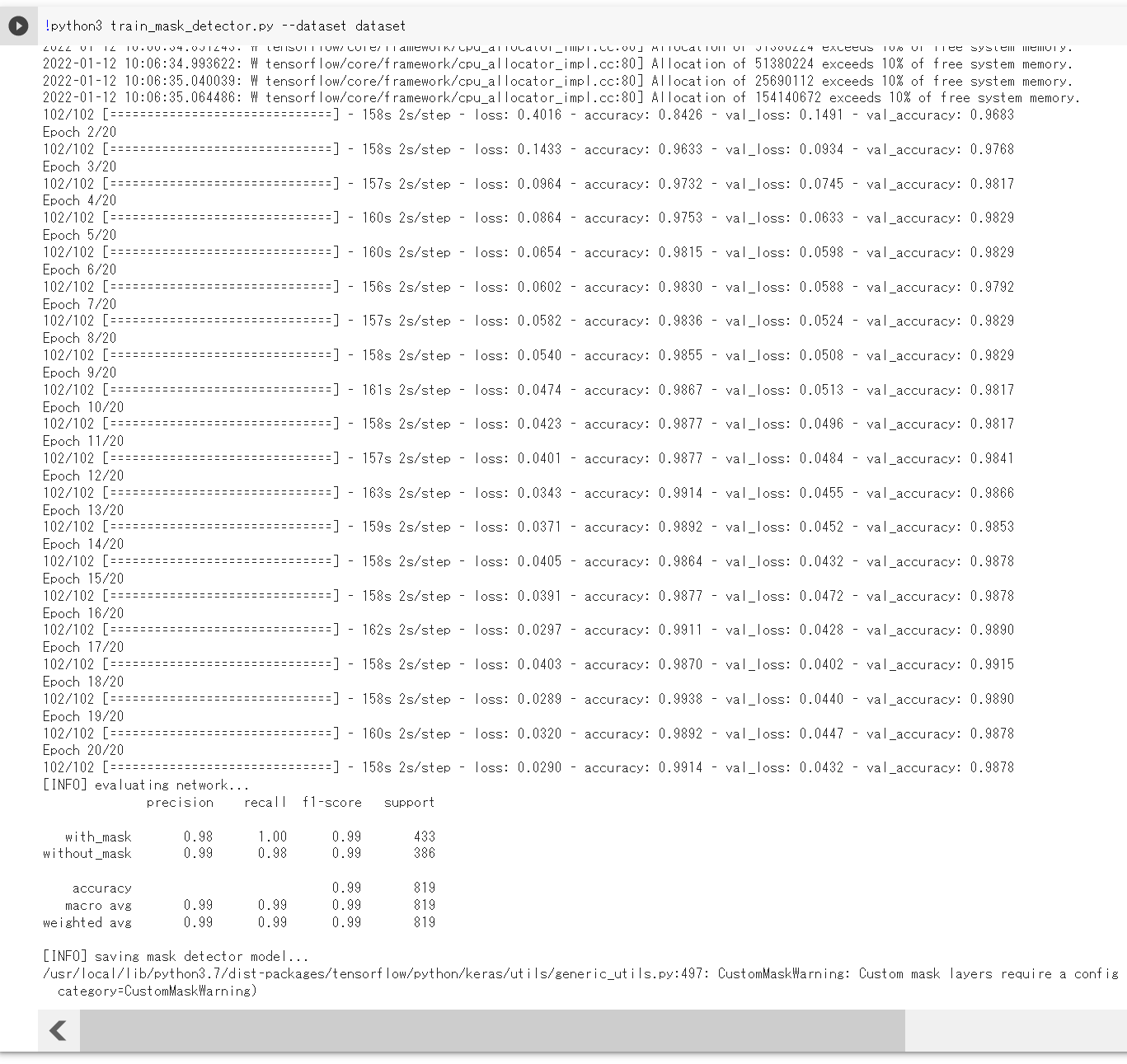
- 顔マスク検出の実行
!sed -i -e 's/cv2.imshow("Output", image)/cv2.imwrite("result.png", image)/g' detect_mask_image.py !sed -i -e 's/cv2.waitKey(0)//g' detect_mask_image.py !python3 detect_mask_image.py --image images/pic1.jpeg from PIL import Image Image.open('result.png').show()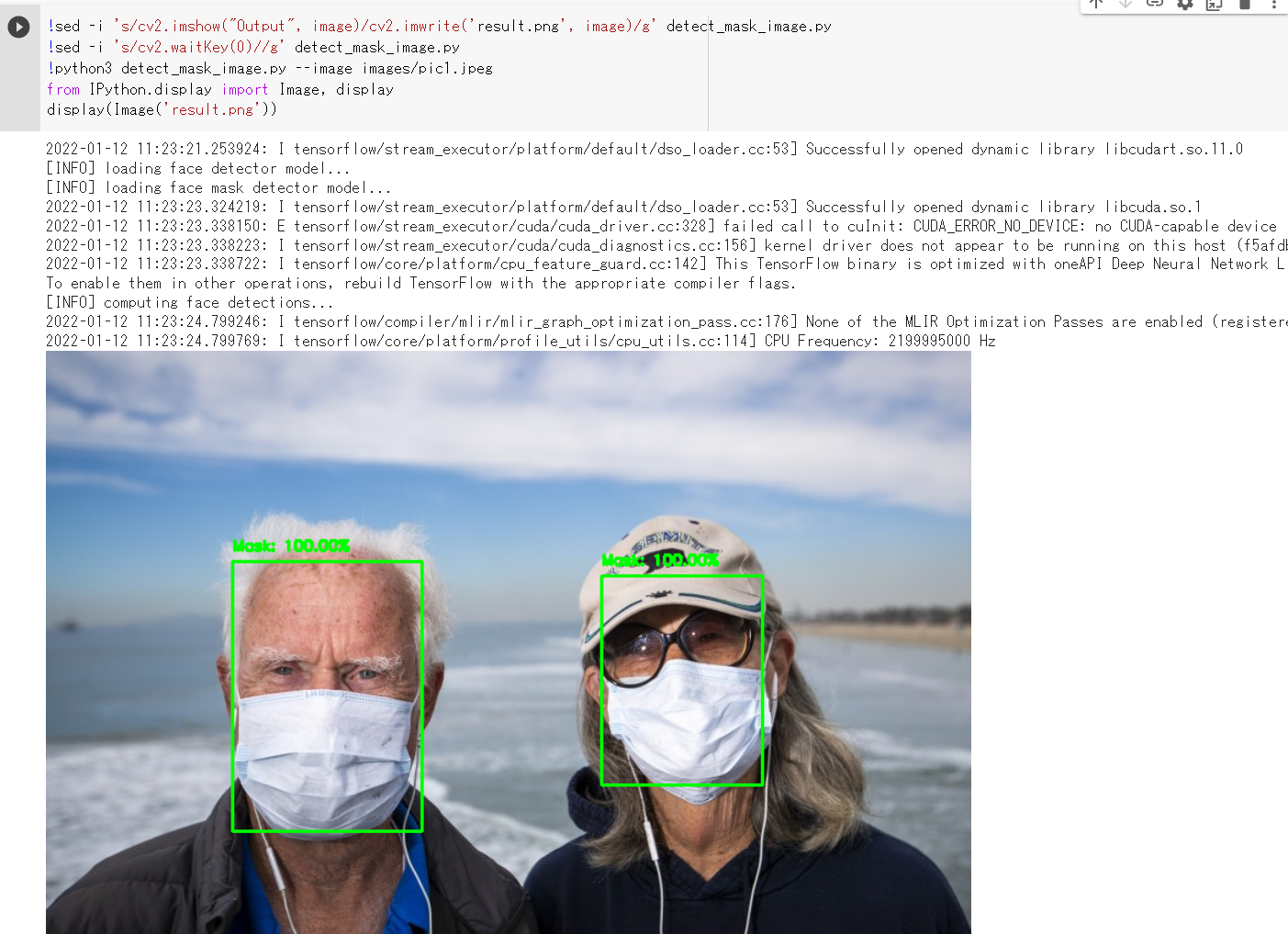
- 手持ちの画像で顔マスク検出の実行
curl は URL を指定して画像ファイルをダウンロードしている。
!curl -O https://www.kkaneko.jp/sample/face/3284.png !python3 detect_mask_image.py --image 3284.png from PIL import Image Image.open('result.png').show()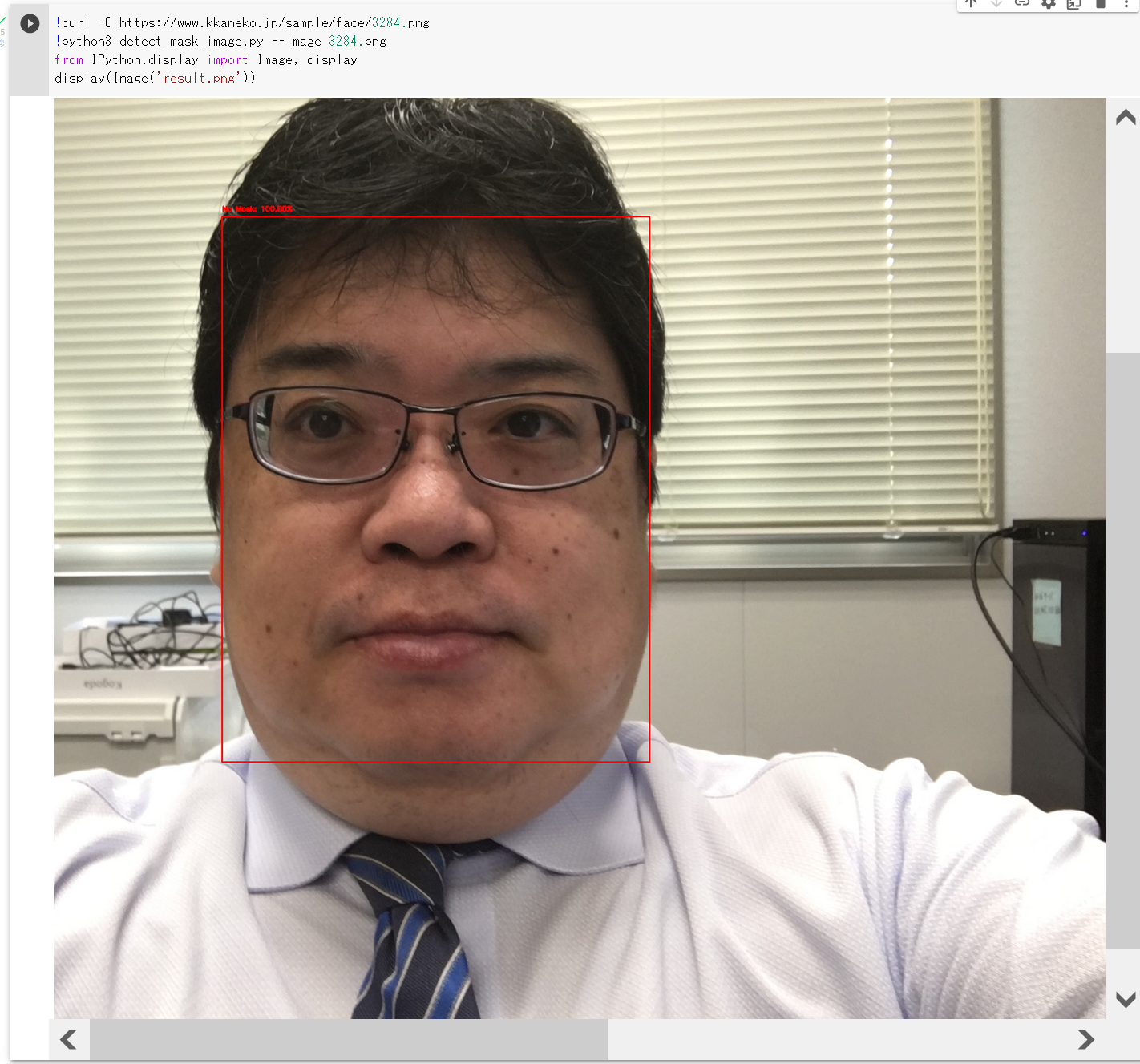
!curl -O https://www.kkaneko.jp/sample/face/3288.png !python3 detect_mask_image.py --image 3288.png from PIL import Image Image.open('result.png').show()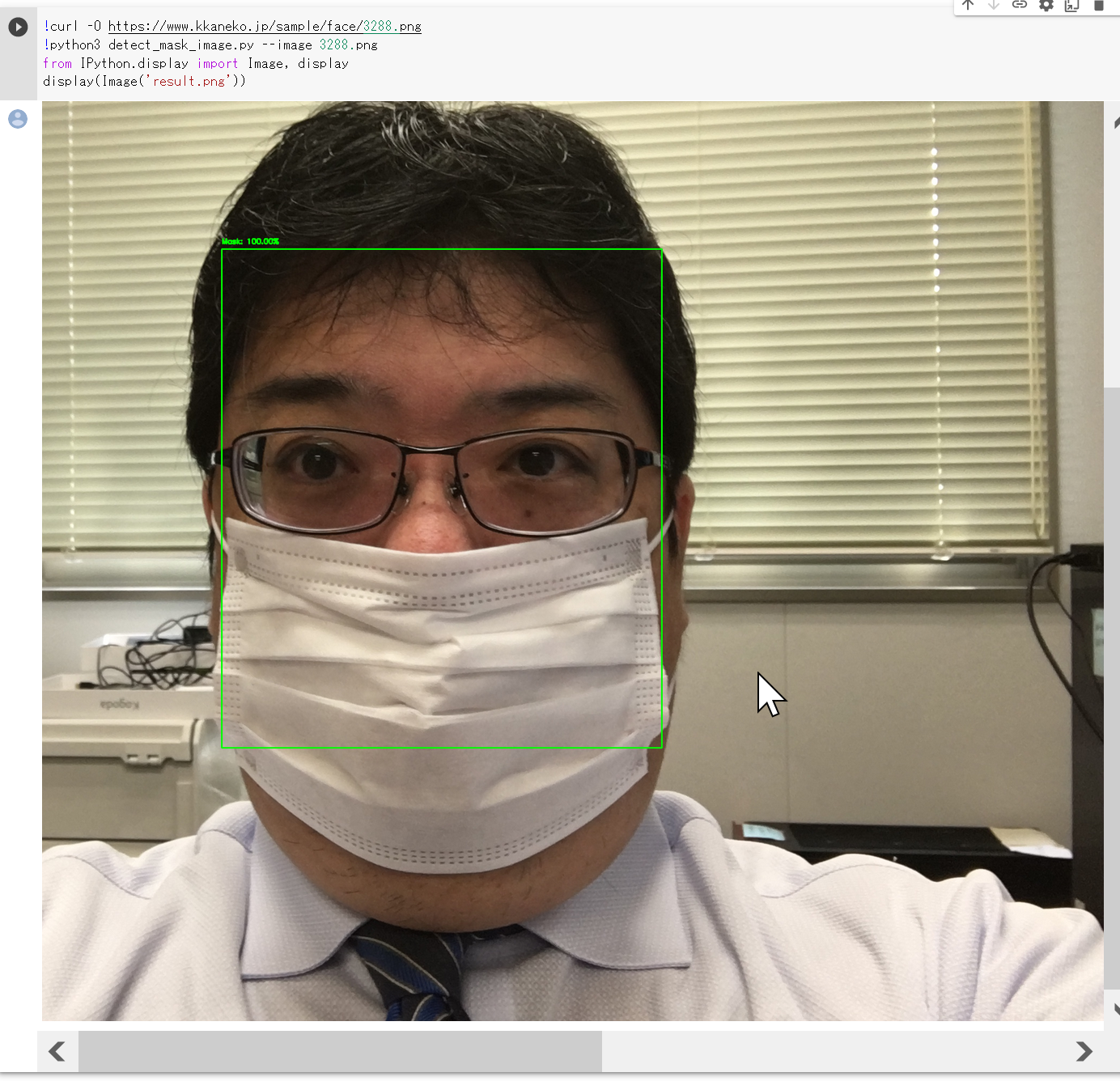
Windows での Chandrika Deb の顔マスク検出のインストールと学習と顔マスク検出
chandrikadeb7 / Face-Mask-Detection のインストールと動作確認(マスク有り顔、マスクなし顔の検出)(Python、TensorFlow を使用)(Windows 上): 別ページで説明
Ubuntu での Chandrika Deb の顔マスク検出のインストールと学習と顔マスク検出
前準備:事前に Python のインストール: 別項目で説明している。
- Ubuntu でインストールを行うには、次のコマンドを実行する。
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo rm -rf Face-Mask-Detection sudo git clone https://github.com/chandrikadeb7/Face-Mask-Detection sudo chown -R $USER Face-Mask-Detection # システム Python の環境とは別の Python の仮想環境(システム Python を使用)を作成 sudo apt -y update sudo apt -y install python3-venv python3 -m venv ~/a source ~/a/bin/activate cd /usr/local/Face-Mask-Detection pip install -U -r requirements.txt pip list - 学習
Chandrika Deb の顔マスク検出に同封のデータセット(Bing Search API、Kaggle dataset、RMDF dataset から収集された顔のデータセット(マスクあり: 2165 枚、マスクなし 1930 枚))により学習を行う。 その後、顔マスク検出を行う。
source ~/a/bin/activate cd /usr/local/Face-Mask-Detection python train_mask_detector.py --dataset dataset - 顔マスク検出の実行
「python detect_mask_video.py 」はカメラの顔マスク検出を行う。
python detect_mask_image.py --image images/pic1.jpeg python detect_mask_video.py
Chaudhury らの画像補正 (image rectification)
画像補正は、画像を射影変換することにより、斜め方向からの撮影画像を正面画像に変換する技術である。 意図しないカメラ回転(ロール、ピッチ、ヨー)を含む画像を正面画像に補正できる。
また、AIの事前学習は、通常、正面画像で行われることが多く、画像補正を使うことで、AIの推論をより精度よく行うことができると期待できる。


【文献】
Chaudhury, Krishnendu, Stephen DiVerdi, and Sergey Ioffe. "Auto-rectification of user photos." 2014 IEEE International Conference on Image Processing (ICIP). IEEE, 2014.
【資料】 PDFファイル、パワーポイントファイル
【サイト内の関連ページ】
【関連する外部ページ】
GitHub のページ: https://github.com/chsasank/Image-Rectification
CIFAR-10 データセット
CIFAR-10 データセット(Canadian Institute for Advanced Research, 10 classes)は、公開されているデータセット(オープンデータ)である。
CIFAR-10 データセット(Canadian Institute for Advanced Research, 10 classes) は、クラス数 10 の カラー画像と、各画像に付いたラベルから構成されるデータセットである。 機械学習での画像分類の学習や検証に利用できる。
- 画像の枚数:合計 60000枚
(内訳)60000枚の内訳は次の通りである。
50000枚:教師データ
10000枚:検証データ
- 画像のサイズ: 32×32 である。カラー画像。
- クラス数: 10(飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラック)(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck)。各画像に1つのラベル付けが行われている。
- 0: airplane(飛行機)
- 1: automobile(自動車)
- 2: bird(鳥)
- 3: cat(猫)
- 4: deer(鹿)
- 5: dog(犬)
- 6: frog(カエル)
- 7: horse(馬)
- 8: ship(船)
- 9: truck(トラック)
【文献】
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. 'Learning multiple layers of features from tiny images', Alex Krizhevsky, 2009.
【サイト内の関連ページ】
- CIFAR-10 データセットを扱う Python プログラム: 別ページ で説明している。
- CIFAR-10 データセットによる学習と分類(TensorFlow データセット、TensorFlow、Python を使用)(Windows 上、Google Colaboratory の両方を記載)
- CIFAR 10 の画像分類を行う畳み込みニューラルネットワーク (CNN) の学習、転移学習
【関連する外部ページ】
- CIFAR-10 データセットの URL: https://www.cs.toronto.edu/~kriz/cifar.html
- Papers With Code の CIFAR-10 データセットのページ: https://paperswithcode.com/dataset/cifar-10
- PyTorch の CIFAR-10: https://pytorch.org/vision/stable/datasets.html#cifar
- TensorFlow データセットの CIFAR-10 データセット: https://www.tensorflow.org/datasets/catalog/cifar10
【関連項目】 CIFAR-100 データセット(Canadian Institute for Advanced Research, 100 classes)、 Keras に付属のデータセット、 TensorFlow データセット、 オープンデータ、 画像分類
Python での CIFAR-10 データセットのロード(TensorFlow データセットを使用)
次の Python プログラムは、TensorFlow データセットから、CIFAR-10 データセットのロードを行う。 x_train、y_train が学習用のデータ、x_test、y_test が検証用のデータになる。
- x_train: サイズ 32×32 の 50000枚のカラー画像
- y_train: 50000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
- x_test: サイズ 32×32 の 10000枚のカラー画像
- y_test: 10000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
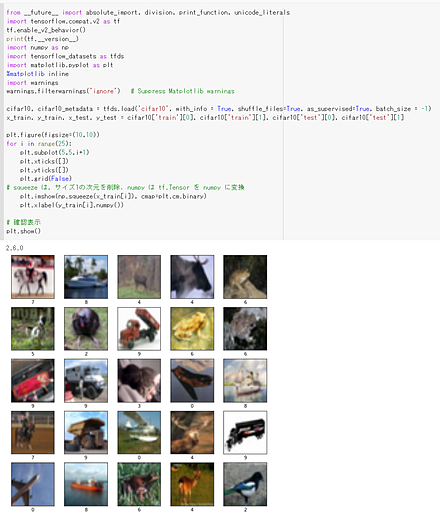
次のプログラムでは、x_train と y_train を 25枚分表示することにより、x_train と y_train が画像であることが確認できる。
tensorflow_datasets の loadで、 「batch_size = -1」を指定して、一括読み込みを行っている。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import tensorflow_datasets as tfds
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
# CIFAR-10 データセットのロード
cifar10, cifar10_metadata = tfds.load('cifar10', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1)
x_train, y_train, x_test, y_test = cifar10['train'][0], cifar10['train'][1], cifar10['test'][0], cifar10['test'][1]
plt.style.use('default')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# squeeze は、サイズ1の次元を削除。numpy は tf.Tensor を numpy に変換
plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary)
plt.xlabel(y_train[i].numpy())
# 確認表示
plt.show()
Python での CIFAR-10 データセットのロード(Keras を使用)
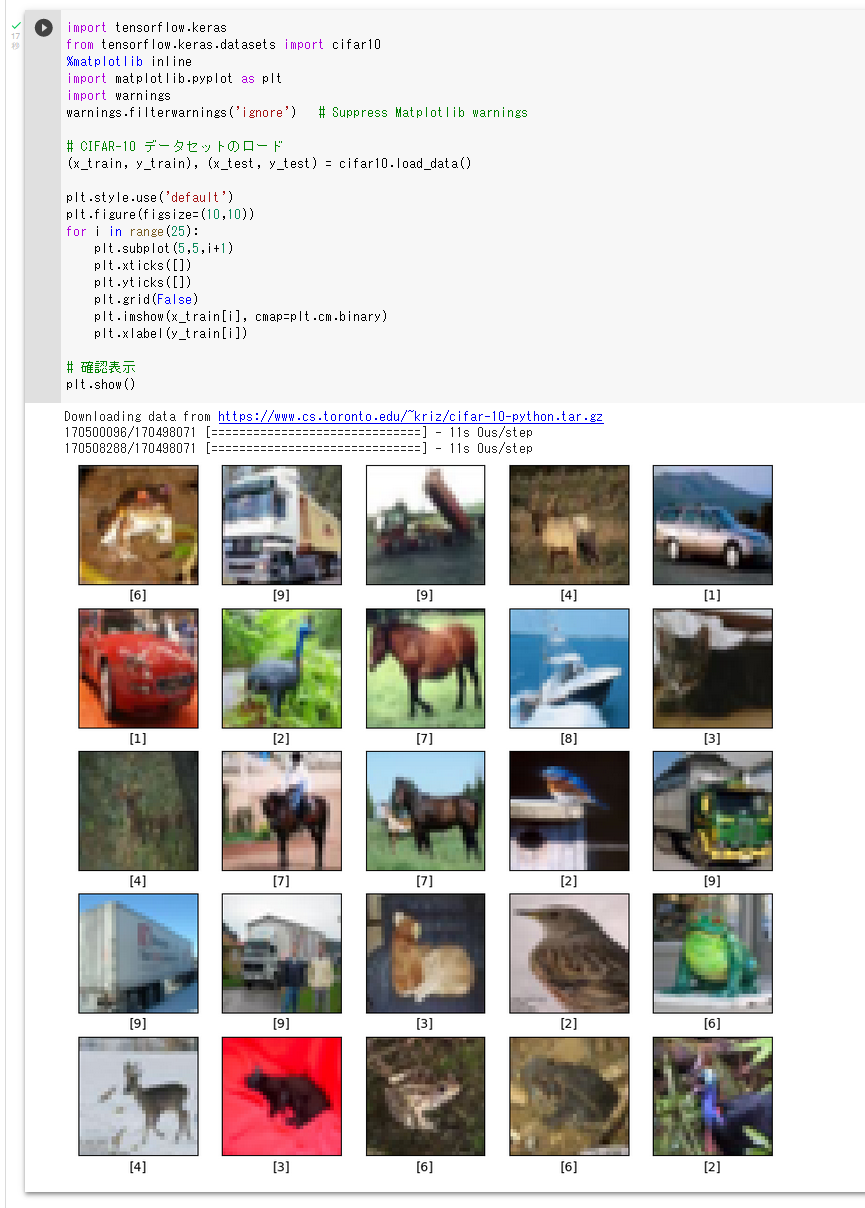
次の Python プログラムは、Keras に付属のデータセットの中にある CIFAR-10 データセットのロードを行う。 x_train、y_train が学習用のデータ、x_test、y_test が検証用のデータになる。
- x_train: サイズ 32×32 の 50000枚のカラー画像
- y_train: 50000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
- x_test: サイズ 32×32 の 10000枚のカラー画像
- y_test: 10000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
次のプログラムでは、x_train と y_train を 25枚分表示することにより、x_train と y_train がカラー画像であることが確認できる。
import tensorflow.keras
from tensorflow.keras.datasets import cifar10
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
# CIFAR-10 データセットのロード
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
plt.style.use('default')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(y_train[i])
# 確認表示
plt.show()
CIFAR-10 データセットのロードと正規化
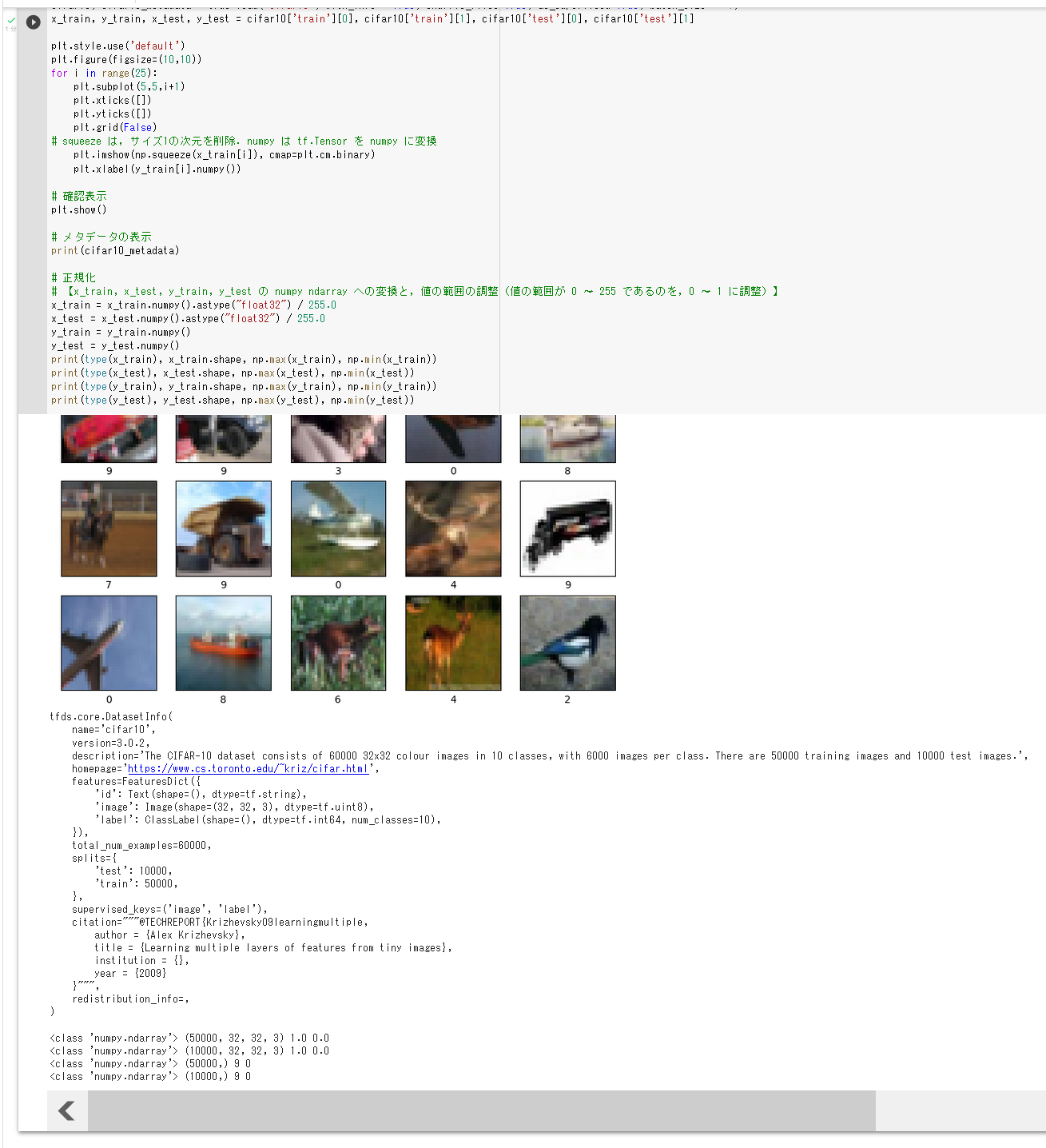
次の Python プログラムは、TensorFlow データセットから、CIFAR-10 データセットのロードを行う。 x_train、y_train が学習用のデータ、x_test、y_test が検証用のデータになる。
- x_train: サイズ 32×32 の 50000枚のカラー画像
- y_train: 50000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
- x_test: サイズ 32×32 の 10000枚のカラー画像
- y_test: 10000枚のカラー画像それぞれの種類番号(0 から 9 のどれか)
次のプログラムでは、x_train と y_train を 25枚分表示することにより、x_train と y_train が画像であることが確認できる。
tensorflow_datasets の loadで、 「batch_size = -1」を指定して、一括読み込みを行っている。
ロードの後、正規化を行う。type は型、shape はサイズ、np.max と np.min は最大値と最小値である。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import tensorflow_datasets as tfds
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
# CIFAR-10 データセットのロード
cifar10, cifar10_metadata = tfds.load('cifar10', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1)
x_train, y_train, x_test, y_test = cifar10['train'][0], cifar10['train'][1], cifar10['test'][0], cifar10['test'][1]
plt.style.use('default')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# squeeze は、サイズ1の次元を削除。numpy は tf.Tensor を numpy に変換
plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary)
plt.xlabel(y_train[i].numpy())
# 確認表示
plt.show()
# メタデータの表示
print(cifar10_metadata)
# 正規化
# 【x_train、x_test、y_train、y_test の numpy ndarray への変換と、値の範囲の調整(値の範囲が 0〜255 であるのを、0〜1 に調整)】
x_train = x_train.numpy().astype("float32") / 255.0
x_test = x_test.numpy().astype("float32") / 255.0
y_train = y_train.numpy()
y_test = y_test.numpy()
print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train))
print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test))
print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train))
print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))
CIFAR-100 データセット
CIFAR-100 データセット(Canadian Institute for Advanced Research, 100 classes)は、公開されているデータセット(オープンデータ)である。
CIFAR-100 データセット(Canadian Institute for Advanced Research, 100 classes) は、機械学習での画像分類の学習や検証に利用できるデータセットである。
- 画像の枚数:合計 60000枚
(内訳)60000枚の内訳は次の通りである。
50000枚:教師データ
10000枚:検証データ
- 画像のサイズ: 32×32 である。カラー画像。
- クラス数: 100。この100クラスは、20のスーパークラスに分類されている。 各画像には、画像が属するクラスである fine ラベルと、 画像が属するスーパークラスである coarse のラベルが付いている。 1クラスあたり、600枚の画像があり、うち500は学習用、うち100は検証用である。
【文献】
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Learning multiple layers of features from tiny images, Alex Krizhevsky, 2009.
【サイト内の関連ページ】
- CIFAR-100 データセットを扱う Python プログラム: 別ページ で説明している。
- CIFAR-100 データセットによる学習と分類(TensorFlow データセット、TensorFlow、Python を使用)(Windows 上、Google Colaboratory の両方を記載)
【関連する外部ページ】
- CIFAR-100 データセットの URL: https://www.cs.toronto.edu/~kriz/cifar.html
- Papers With Code の CIFAR-100 データセットのページ: https://paperswithcode.com/dataset/cifar-100
- PyTorch の CIFAR-100: https://pytorch.org/vision/stable/datasets.html#cifar
- TensorFlow データセットの CIFAR-100 データセット: https://www.tensorflow.org/datasets/catalog/cifar100
【関連項目】 CIFAR-10 データセット(Canadian Institute for Advanced Research, 10 classes)、 Keras に付属のデータセット、 TensorFlow データセット、 オープンデータ、 画像分類
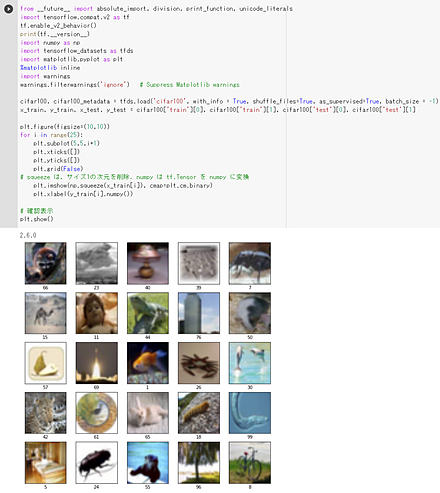
Python での CIFAR-100 データセットのロード(TensorFlow データセットを使用)
次の Python プログラムは、TensorFlow データセットから、CIFAR-100 データセットのロードを行う。 x_train、y_train が学習用のデータ、x_test、y_test が検証用のデータになる。
- x_train: サイズ 32×32 の 50000枚のカラー画像
- y_train: 50000枚のカラー画像それぞれの種類番号(0 から 99 のどれか)
- x_test: サイズ 32×32 の 10000枚のカラー画像
- y_test: 10000枚のカラー画像それぞれの種類番号(0 から 99 のどれか)
次のプログラムでは、x_train と y_train を 25枚分表示することにより、x_train と y_train が画像であることが確認できる。
tensorflow_datasets の loadで、 「batch_size = -1」を指定して、一括読み込みを行っている。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import tensorflow_datasets as tfds
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
# CIFAR-100 データセットのロード
cifar100, cifar100_metadata = tfds.load('cifar100', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1)
x_train, y_train, x_test, y_test = cifar100['train'][0], cifar100['train'][1], cifar100['test'][0], cifar100['test'][1]
plt.style.use('default')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# squeeze は、サイズ1の次元を削除。numpy は tf.Tensor を numpy に変換
plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary)
plt.xlabel(y_train[i].numpy())
# 確認表示
plt.show()
CIFAR-100 データセットのロードと正規化
次の Python プログラムは、TensorFlow データセットから、CIFAR-100 データセットのロードを行う。 x_train、y_train が学習用のデータ、x_test、y_test が検証用のデータになる。
- x_train: サイズ 32×32 の 50000枚のカラー画像
- y_train: 50000枚のカラー画像それぞれの種類番号(0 から 99 のどれか)
- x_test: サイズ 32×32 の 10000枚のカラー画像
- y_test: 10000枚のカラー画像それぞれの種類番号(0 から 99 のどれか)
次のプログラムでは、x_train と y_train を 25枚分表示することにより、x_train と y_train が画像であることが確認できる。
tensorflow_datasets の loadで、 「batch_size = -1」を指定して、一括読み込みを行っている。
ロードの後、正規化を行う。type は型、shape はサイズ、np.max と np.min は最大値と最小値である。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import tensorflow_datasets as tfds
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
# CIFAR-100 データセットのロード
cifar100, cifar100_metadata = tfds.load('cifar100', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1)
x_train, y_train, x_test, y_test = cifar100['train'][0], cifar100['train'][1], cifar100['test'][0], cifar100['test'][1]
plt.style.use('default')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# squeeze は、サイズ1の次元を削除。numpy は tf.Tensor を numpy に変換
plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary)
plt.xlabel(y_train[i].numpy())
# 確認表示
plt.show()
# メタデータの表示
print(cifar100_metadata)
# 正規化
# 【x_train、x_test、y_train、y_test の numpy ndarray への変換と、値の範囲の調整(値の範囲が 0〜255 であるのを、0〜1 に調整)】
x_train = x_train.numpy().astype("float32") / 255.0
x_test = x_test.numpy().astype("float32") / 255.0
y_train = y_train.numpy()
y_test = y_test.numpy()
print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train))
print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test))
print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train))
print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))
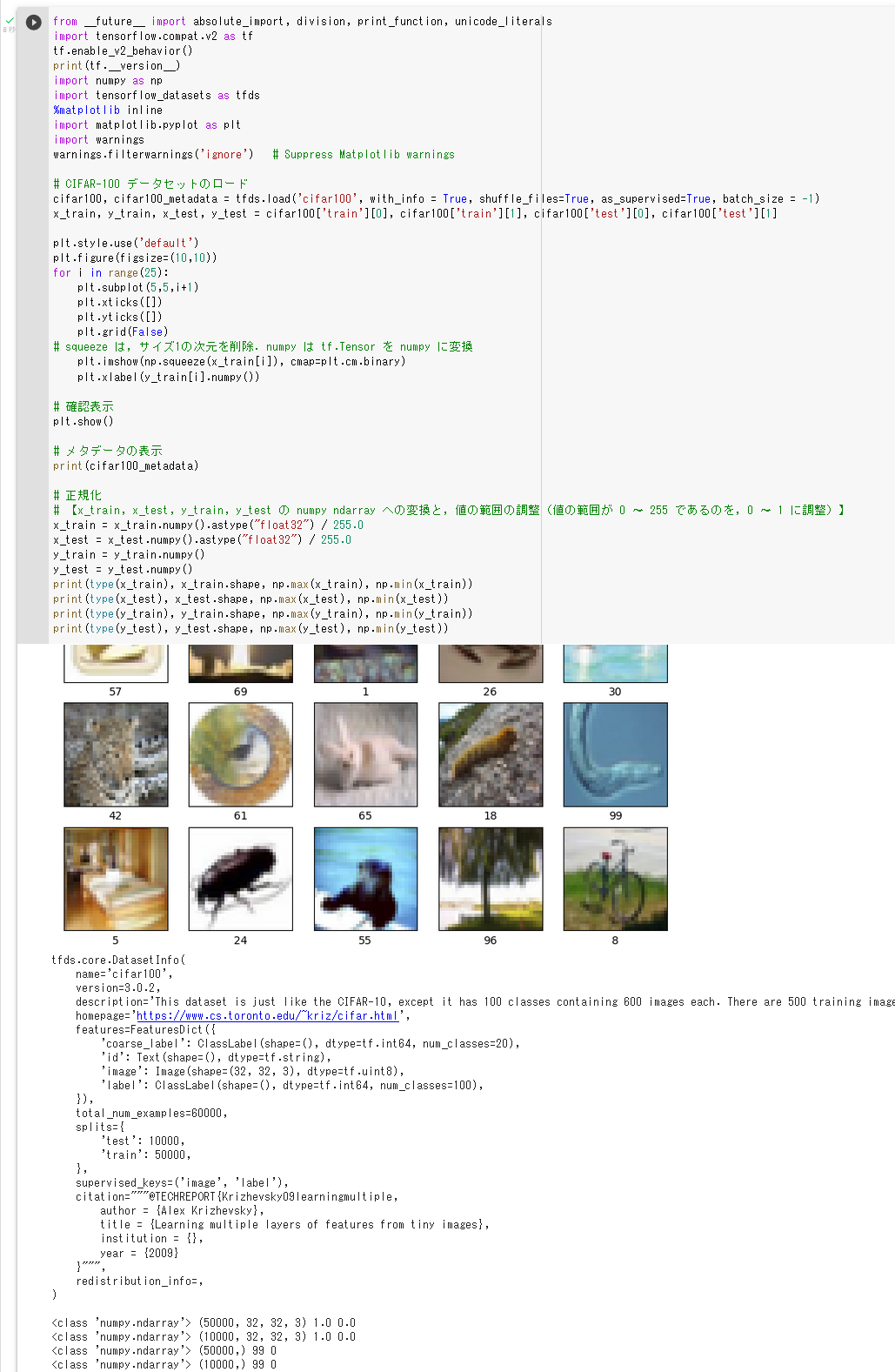
Cityscapes データセット
Cityscapes データセット は、車両と人が撮影されたアノテーション済の画像データである。 機械学習での セマンティックセグメンテーション (semantic segmentation)、 インスタンスセグメンテーション (instance segmentation) に利用できるデータセットである。
Cityscapes データセットは、 50都市の数ヶ月間(春、夏、秋)の日中、良好な/中程度の天候のもとで撮影、計測されたデータである。データの種類は次の通りである。
- Ground Truth(セグメンテーションの Ground Truth が、画素単位でアノテーションされたもの)
- leftImg8bit
- rightImg8bit
- leftImg16bit
- rightImg16bit
- disparity
- camera
- vehicle など
画像数は、合計で 24,998 枚であり、その内訳は次のとおりである。
- train and val: 3,475枚。アノテーション済み。うち学習用: 2,975 枚、うち検証用: 500 枚。
- test: テスト用: 1,525 枚。ダミーアノテーション
- extra: 19,998枚、粗いアノテーション済み。
クラスは次の通りである。これらクラス以外に「unlabeled」がある。
road、sidewalk、parking、rail track、 person、rider、 car、truck、bus、on rails、motorcycle、bicycle、caravan、trailer、 building、wall、fence、guard rail、bridge、tunnel、 pole、pole group、traffic sign、traffic light、 vegetation、terrain、 sky、 ground、dynamic、static
これらクラスは、次のようにグループ化されている。 (flat などがグループ名である)。
- flat: road、sidewalk、parking、rail track
- human: person、rider
- vehicle: car、truck、bus、on rails、motorcycle、bicycle、caravan、trailer
- construction: building、wall、fence、guard rail、bridge、tunnel
- object: pole、pole group、traffic sign、traffic light
- nature: vegetation、terrain
- sky: sky
- void: ground、dynamic、static
クラスの説明は次のページにある。
- 公式ページ: https://www.cityscapes-dataset.com/dataset-overview/#class-definitions
- mcordts の CityscapesScripts 内のプログラム: https://github.com/mcordts/cityscapesScripts/blob/25e802b9f8afe03e64c9c80f58dc96aed6b1f559/cityscapesscripts/helpers/labels.py#L62-L99
Cityscapes データセットは次の URL で公開されているデータセット(オープンデータ)である。利用には登録が必要である。
https://www.cityscapes-dataset.com/
【関連情報】
- 文献
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele、 The Cityscapes Dataset for Semantic Urban Scene Understanding, CVPR 2016, also CoRR abs/1604.01685, 2016.
- Cityscape データセットの説明(公式のドキュメント): https://www.cityscapes-dataset.com/dataset-overview/
- Papers With Code の Cityscapes データセットのページ: https://paperswithcode.com/dataset/cityscapes
- OpenMMLab の Cityscapes データセット: https://github.com/open-mmlab/mmdetection/blob/master/docs/en/1_exist_data_model.md
- PyTorch の Cityscapes データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.Cityscapes
- TensorFlow データセット の Cityscapes データセット: https://www.tensorflow.org/datasets/catalog/cityscapes
【関連項目】 Detectron2、 MMSegmentation、 OpenMMLab、 PANet
Cityscapes データセットの train and val と test のダウンロード
Cityscapes データセットの train and val と test は、合計で約 5,000枚(正確には 5,000枚:3,475 + 1,525)の画像と関連データである。
train and val と test の Ground Truth と画像のダウンロードのため、 gtFine、leftImg8bit のダウンロードを行うときは、 Cityscapes データセットのダウンロードのページで、次を選ぶ。 (必要最小限のダウンロードを行うこと)。
- gtFine_trainvaltest.zip (241MB) [md5]
- leftImg8bit_trainvaltest.zip (11GB) [md5]
Cityscape データセットのページ: https://www.cityscapes-dataset.com/
Clang
Clang は、LLVMのサブプロジェクトである。 C言語ファミリ(C、C++、Objective C/C++、OpenCL、CUDA、RenderScript)の機能、 GCC互換のコンパイラドライバ (clang) の機能、 MSVC互換のコンパイラドライバ (clang-cl.exe) の機能を持つ。
【関連する外部ページ】
- Clang の公式ページ: https://clang.llvm.org/
- Clang のインストールの公式ページ: https://clang.llvm.org/get_started.html
【サイト内の関連ページ】
【関連項目】 LLVM
clapack
clapack は、元々 FORTRAN で書かれていた LAPACK の、C言語版(C 言語に書き直されたもの)である。 lapack は、行列に関する種々の問題(連立1次方程式、固有値問題など多数)を解く機能を持つソフトウェアである。BLAS の機能を使う。
Windows での clapack のインストール
Windows での clapack のインストール(Windows 上): 別ページ »で説明
Class Activation Mapping (CAM)
Class Activation Mapping (CAM) は、 Bolei Zhou により、2016年に提案された。
- Bolei Zhou らの文献
Bolei Zhou Aditya Khosla Agata Lapedriza Aude Oliva Antonio Torralba, Learning Deep Features for Discriminative Localization, CVPR 2016, also CoRR, https://arxiv.org/abs/1512.04150v1, 2016.
- Bolei Zhou によるソースコードとモデル: https://github.com/zhoubolei/CAM
- Papers with Code のページ: https://paperswithcode.com/paper/learning-deep-features-for-discriminative
【関連項目】 CASILVision
CRAFT
CRAFT は,文字検出の一手法.

【文献】 Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, and Hwalsuk Lee, Character Region Awareness for Text Detection, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9365--9374, 2019.
【関連する外部ページ】
GitHub のページ: https://github.com/clovaai/CRAFT-pytorch
【関連項目】 EasyOCR
Windows で,CRAFT のインストールと動作確認(テキスト検出)
CRAFT のインストールと動作確認(テキスト検出)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
CREPE
CREPE(Convolutional Representation for Pitch Estimation)は、深層学習を用いたモノフォニック音声のピッチ推定手法です。以下に、CREPEの特徴と性能評価について説明します。
特徴
- CREPEは、時間領域の音声波形を直接入力とし、畳み込みニューラルネットワーク(CNN)を用いて360次元のピッチアクティベーションを出力します。
- ピッチアクティベーションは、6オクターブの音域を20セント間隔で分割した360個の音高候補に対する活性度を表す数値ベクトルです。
性能評価
- RWC-synthとMDB-stem-synthの2つのデータセットを用いて、従来手法であるpYINやSWIPEとの比較が行われました。
- 評価指標として、Raw Pitch Accuracy(RPA)とRaw Chroma Accuracy(RCA)が用いられました。
- ピッチ認識の閾値を変化させた場合や、ホワイトノイズ等を加えた場合のロバスト性も評価されました。
- 実験の結果、CREPEは多様な音色やノイズに対して従来手法よりもロバスト性に優れ、高精度なピッチ推定が可能であることが示されました。
応用分野
- CREPEは、旋律抽出やイントネーション分析など、ピッチ情報を必要とする様々な音声処理タスクに応用可能です。
- 音楽情報処理における音高推定や、言語学における韻律分析などにも活用できます。
文献
CREPE: A Convolutional Representation for Pitch Estimation Jong Wook Kim, Justin Salamon, Peter Li, Juan Pablo Bello. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), also arXiv:1802.06182v1 [eess.AS], 2018.
https://arxiv.org/pdf/1802.06182v1
CREPE の GitHub の公式ページ: https://github.com/marl/crepe
【サイト内の関連ページ】 CREPE のインストール,CREPE を用いた音声分析プログラム(音のピッチ推定)(Python,TensorFlow を使用)(Windows 上)
crowd counting (群衆の数のカウントと位置の把握)
crowd countingは, 画像内の人数を数えること. 監視等に役立つ. さまざま状況において, さまざまな大きさで画像内にある人物を数えることが課題であり, 画像からの物体検出とは研究課題が異なる.
【関連用語】 FIDTM, JHU-CROWD++ データセット, NWPU-Crowd データセット, ShanghaiTech データセット, UCF-QNRF データセット
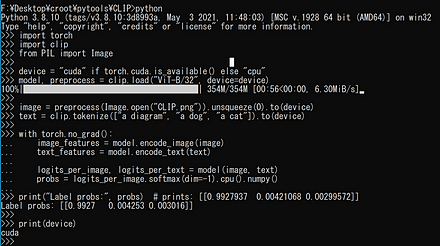
CLIP
CLIP(Contrastive Language-Image Pre-Training)では, テキスト画像のペアを用いて学習が行われる. GPT-2,GPT-3 のゼロショット学習 (zero-shot learning) のゼロショットと同様に, 画像に対して,テキストが結果として求まる. CLIP は,ImageNet データセット のゼロショットに対して, ResNet50と同等の性能があるとされる.
CLIP の GitHub のページ: https://github.com/openai/CLIP
CLIP のサンプルプログラムの実行結果は次の通り.
【関連項目】 AltCLIP
ビルドツール CMake
CMake は,ソフトウェアのビルドプロセスを自動化し,効率的に管理するためのツールである.Windows では,CMake のオプションを確認したい場合には,「cmake-gui」コマンドを使用して,CMake のグラフィカルユーザインタフェースを起動することにより確認ができる.このcmake-guiで,ビルドオプションの設定や,ビルドの実行も可能である.
CMakeの使用方法は次の通りである.
- CMakeを使用するプロジェクトのソースコードのディレクトリに移動する.
- そのディレクトリにある「CMakeLists.txt」ファイルが,CMakeのビルド設定として使用される.
- CMakeをジェネレータとして使用
次のコマンドでは,生成されるビルドファイルのタイプを Visual Studio 2022 に設定し,ターゲットアーキテクチャを64ビットに設定し,ビルドに使用するツールセットのアーキテクチャを64ビットに設定している.コマンドの実行により,Visual Studio 2022 用の64ビットビルドファイル(.slnファイルなど)が生成される.
cmake -A x64 -T host=x64 ..
- CMakeを用いたビルド
生成されたVisual Studio 2022 用の64ビットビルドファイルによるビルドは,次のコマンドで行う.ここではビルド構成を「Release」に設定している.
cmake --build . --config Release
ビルドツール CMake のインストール (Windows 上)
CMake は,ソフトウェアのビルドプロセスを自動化し,効率的に管理するためのツールである.Windows では,CMake のオプションを確認したい場合には,「cmake-gui」コマンドを使用して,CMake のグラフィカルユーザインタフェースを起動することにより確認ができる.このcmake-guiで,ビルドオプションの設定や,ビルドの実行も可能である.
Windows で CMake をインストールするには,公式ウェブサイト(https://cmake.org/download/)にアクセスし,"Windows x64 Installer" をダウンロードする.ダウンロードしたインストーラを実行し,インストールオプションで「Add CMake to the system PATH for all users」を選択する.他のオプションはデフォルトのままで構わない.
【サイト内の関連ページ】
【関連する外部ページ】
- CMake の公式ダウンロードページ: https://cmake.org/download/
Ubuntu での cmake のインストール
Ubuntu では,端末で,次のコマンドを実行して,cmake をインストールする.
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install cmake cmake-curses-gui cmake-gui
ソースコードからビルドする場合には,次のように操作する.
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install build-essential gcc g++ make
sudo apt -y install git cmake cmake-curses-gui cmake-gui
cd /tmp
curl -L -O https://github.com/Kitware/CMake/releases/download/v3.22.2/cmake-3.22.2.tar.gz
tar -xvzof cmake-3.22.2.tar.gz
cd cmake-3.22.2
./configure --prefix=/usr/local
make
sudo make install
C-MS-Celeb Cleaned データセット
C-MS-Celeb Cleaned データセット は, MS-Celeb-1M データセット を整えたもの.間違いの修正など.
人物数は 94,682 (94,682 identities), 画像数は 6,464,018 枚 (6,464,018 images)
次の URL で公開されているデータセット(オープンデータ)である.
https://github.com/EB-Dodo/C-MS-Celeb
- 文献
Chi Jin, Ruochun Jin, Kai Chen, and Yong Dou, “A Community Detection Approach to Cleaning Extremely Large Face Database,” Computational Intelligence and Neuroscience, vol. 2018, Article ID 4512473, 10 pages, 2018. doi:10.1155/2018/4512473
【関連項目】 顔のデータベース, MS-Celeb-1M データセット, 顔検出 (face detection)
CNN
CNN (convolutional neural network) は畳み込みニューラルネットワークのこと.
CNTK
- Web ページ:
https://github.com/microsoft/CNTK - github: https://github.com/Microsoft/CNTK
- チュートリアル: http://research.microsoft.com/en-us/um/people/dongyu/CNTK-Tutorial-NIPS2015.pdf
- ドキュメント: http://research.microsoft.com/apps/pubs/?id=226641
- Chainervr について: https://github.com/chainer/chainercv
- Python について: https://github.com/stitchfix/Algorithms-Notebooks
COCO (Common Object in Context) データセット
COCO(Common Object in Context)データセットは,物体検出やセグメンテーション,キーポイント検出,姿勢推定,画像分類,キャプショニング等の多様なタスクに対応可能な画像データセットとして,2014年にMicrosoftにより公開された.これは,人間や自動車,家具,食品等,多岐にわたるカテゴリのオブジェクトを含む数十万枚以上の画像から構成され,それぞれの画像は,80種類のカテゴリに対応する形でアノテーションが施されている. COCO は次の URL で公開されているデータセット(オープンデータ)である.
COCO は,以下の特徴がある.
- 328,000枚の画像,うち,200,000枚以上がラベル付け済み.
- 1,500,000 個のオブジェクト
- オブジェクトのカテゴリ数:80
- オブジェクトのバウンディングボックス,セグメンテーション結果
- 画像ごとのキャプション数: 5
- 250,000 名の人物に,キーポイントが付いている.(左目、鼻、右腰、右足首などの 17のキーポイント)
- 39,000枚以上の画像と56,000個以上の人物に対する Dense pose アノテーション.
- 2014, 2017 などの種類がある.2014 と比べると,2017 では,訓練,検証,テストの分割が異なる,panoptic segmenation についてのアノテーションが追加されているなどの違いがある.
COCO の 80 のクラスのラベルは次の通りである.
['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
【文献】
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollr, Microsoft COCO: Common Objects in Context, CoRR, abs/1405.0312, 2014.
https://arxiv.org/pdf/1405.0312v3.pdf
【サイト内の関連ページ】
COCO 2017 データセットのダウンロードとカテゴリ情報や画像情報の確認(Windows 上): 別ページ »で説明
【関連する外部ページ】
- Papers With Code の COCO データセットのページ: https://paperswithcode.com/dataset/coco
- PyTorch の COCO データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.CocoDetection
- TensorFlow データセット の COCO データセット: https://www.tensorflow.org/datasets/catalog/coco
【関連項目】 pycocotools, 物体検出, インスタンス・セグメンテーション (instance segmentation), keypoint detection, panoptic segmentation, セマンティック・セグメンテーション (semantic segmentation)
Windows での COCO 2014 データセットのダウンロードと展開
Windows での COCO 2014 のダウンロードと展開の手順は次の通り.
- COCO データセットの公式ページから,
2017 Train images, 2017 Val images, 2017 Train/Val annotations をダウンロード
COCO データセットの公式ページ: https://cocodataset.org/#home
コマンドプロンプトを管理者として開き ダウンロードのため,次のコマンドを実行
cd %LOCALAPPDATA% curl -O http://images.cocodataset.org/zips/train2017.zip curl -O http://images.cocodataset.org/zips/val2014.zip curl -O http://images.cocodataset.org/zips/test2017.zip curl -O http://images.cocodataset.org/annotations/annotations_trainval2014.zip - train2017.zip, val2014.zip, test2017.zip, annotations_trainval2014.zip がダウンロードされる
- 展開のため,次のコマンドを実行
cd %LOCALAPPDATA% powershell -command "Expand-Archive -DestinationPath . -Path train2014.zip" powershell -command "Expand-Archive -DestinationPath . -Path val2014.zip" powershell -command "Expand-Archive -DestinationPath . -Path test2014.zip" powershell -command "Expand-Archive -DestinationPath . -Path annotations_trainval2014.zip" - ファイルの配置は次のようになる.
└── COCO_DATASET_ROOT | ├── annotations ├── stuff_train2014.json (the original json files) ├── stuff_test2014.json (the original json files) ├── stuff_val2014.json (the original json files) ├── train2014 ├── test2014 └── val2014
Ubuntu での COCO 2017 データセットのダウンロードと展開
Ubuntu の場合.次により,/usr/local/mscoco2014, /usr/local/mscoco2017 にダウンロードされる.
`sudo mkdir cd /usr/local/coco2017
sudo chown -R $USER /usr/local/coco2017
cd /usr/local/coco2017
# labels
curl -O -L https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip
unzip coco2017labels-segments.zip
cd /usr/local/coco2017
# 19G, 118k images
curl -O http://images.cocodataset.org/zips/train2017.zip
unzip -d /usr/local/coco2017/coco train2017.zip
# 1G, 5k images
curl -O http://images.cocodataset.org/zips/val2017.zip
unzip -d /usr/local/coco2017/coco val2017.zip
# 7G, 41k images (optional)
curl -O http://images.cocodataset.org/zips/test2017.zip
unzip -d /usr/local/coco2017/coco test2017.zip
#
curl -O http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip -d annotations_trainval2017.zip
#
curl -O http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
unzip -d stuff_annotations_trainval2017.zip
#
curl -O http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip
unzip -d panoptic_annotations_trainval2017.zip
#
sudo mkdir cd /usr/local/coco2014
sudo chown -R $USER /usr/local/coco2014
cd /usr/local/coco2014
curl -O http://images.cocodataset.org/zips/train2014.zip
curl -O http://images.cocodataset.org/zips/val2014.zip
curl -O http://images.cocodataset.org/zips/test2014.zip
curl -O http://images.cocodataset.org/annotations/annotations_trainval2014.zip
unzip -d train2014.zip
unzip -d val2014.zip
unzip -d test2014.zip
unzip -d annotations_trainval2014.zip
ファイルの配置は次のようになる(現在確認中).
coco2014/
annotations/
images/
objectInfo150.txt
sceneCategories.txt
coco2017/
coco/
annotations/
images/
train2017/
val2017/
test2017/
labels/
objectInfo150.txt
sceneCategories.txt
Windows で COCO の Python API のインストール
cocoapi のインストールを行う. cocoapi は, COCO (Common Object in Context) データセット の Python API である.
- Windows では,コマンドプロンプトを管理者として実行
- pycocotools のインストール
python -m pip install -U cython python -m pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"
- COCO 2018 Panoptic Segmentation Task API のインストール
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
python -m pip install git+https://github.com/cocodataset/panopticapi.git
COCO の Keypoints 2014/2017 アノテーション
URL: https://cocodataset.org/#keypoints-2017
COCO の Keypoints 2014/2017 アノテーションは,次からダウンロードできる.
- https://drive.google.com/file/d/1jrxis4ujrLlkwoD2GOdv3PGzygpQ04k7/view
- https://drive.google.com/file/d/1YuzpScAfzemwZqUuZBrbBZdoplXEqUse/view
COLMAP
COLMAP は 3次元再構成の機能を持ったソフトウェア.
【文献】
Johannes L. Schonberger, Jan-Michael Frahm, Structure-From-Motion Revisited, CVPR 2016, 2016
【サイト内の関連ページ】
- COLMAP 3.8 のインストールと3次元再構成の実行(COLMAP 3.8 を使用)(Windows 上): 別ページ »で説明
- COLMAP のインストールと3次元再構成の実行(COLMAP のソースコード,vcpkgm, Visual Studio Community 2019 を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- Papers with Code の colmap のページ: https://paperswithcode.com/paper/structure-from-motion-revisited
- COLMAP の公式ページ(公式リリース,Vocabulary tree, データセットへのリンクなど): https://demuc.de/colmap
- COLMAP の公式の説明: https://colmap.github.io
- COLMAP を公開している公式ページ: https://github.com/colmap/colmap/releases
- Gerrard Hall, Craham Hall, Person Hall, South Building データセット: https://colmap.github.io/datasets.html
Coqui TTS
Coqui TTS は,音声合成および音声変換(Voice Changer)の研究プロジェクトならびに成果物.
Coqui の GitHub のページ: https://github.com/coqui-ai/TTS
- 文献
Rohan Badlani, Adrian Łancucki, Kevin J. Shih, Rafael Valle, Wei Ping, Bryan Catanzaro, One TTS Alignment To Rule Them All, CoRR, abs/2108.10447v1, 2021.
- Coqui TTS の公式の実装(GitHub)のページ: https://github.com/coqui-ai/TTS
- Papers with Code のページ: https://paperswithcode.com/paper/one-tts-alignment-to-rule-them-all
【関連項目】 音声合成 (Text To Speech; TTS)
Google Colaboratory で,Coqui TTS の顔マスク検出の実行
公式の手順(https://github.com/coqui-ai/TTS/tree/dev#install-tts)に従う.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
次のコマンドを実行することにより,Coqui TTS のインストール,日本語のモデル類のダウンロード, 音声合成の実行が行われる. 結果は,tts_output.wav にできる.
!pip3 install TTS[all]
!rm -rf TTS
!git clone https://github.com/coqui-ai/TTS
%cd TTS
!pip3 install -e .[all]
!make system-deps
!make install
!python3 setup.py install
!tts --list_models
!tts --text "日本国民は正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民と協和による成果と、わが国全土にわたって自由のもたらす恵沢を確保し、政府の行為によって再び戦争の惨禍が起こることのないようにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する.そもそも国政は国民の厳粛な信託によるものであって、その権威は国民に由来し、その権力は国民の代表者がこれを行使し、その福利は国民がこれを享受する.これは人類普遍の原理であり、この憲法は、かかる原理に基づくものである.われらはこれに反する一切の憲法、法令及び詔勅を排除する." --model_name "tts_models/ja/kokoro/tacotron2-DDC" --vocoder_name "vocoder_models/ja/kokoro/hifigan_v1"
Ubuntu での Coqui TTS のインストールとテスト実行
公式の手順(https://github.com/coqui-ai/TTS/tree/dev#install-tts)に従う.
次のコマンドを実行することにより,Coqui TTS のインストール,日本語のモデル類のダウンロード, 音声合成の実行が行われる. 結果は,tts_output.wav にできる.
cd /usr/local
sudo pip3 install TTS[all]
sudo rm -rf TTS
sudo git clone https://github.com/coqui-ai/TTS
cd TTS
sudo pip3 install -e .[all]
sudo make system-deps
sudo make install
sudo python3 setup.py install
tts --list_models
tts --text "日本国民は正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民と協和による成果と、わが国全土にわたって自由のもたらす恵沢を確保し、政府の行為によって再び戦争の惨禍が起こることのないようにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する.そもそも国政は国民の厳粛な信託によるものであって、その権威は国民に由来し、その権力は国民の代表者がこれを行使し、その福利は国民がこれを享受する.これは人類普遍の原理であり、この憲法は、かかる原理に基づくものである.われらはこれに反する一切の憲法、法令及び詔勅を排除する." --model_name "tts_models/ja/kokoro/tacotron2-DDC" --vocoder_name "vocoder_models/ja/kokoro/hifigan_v1"
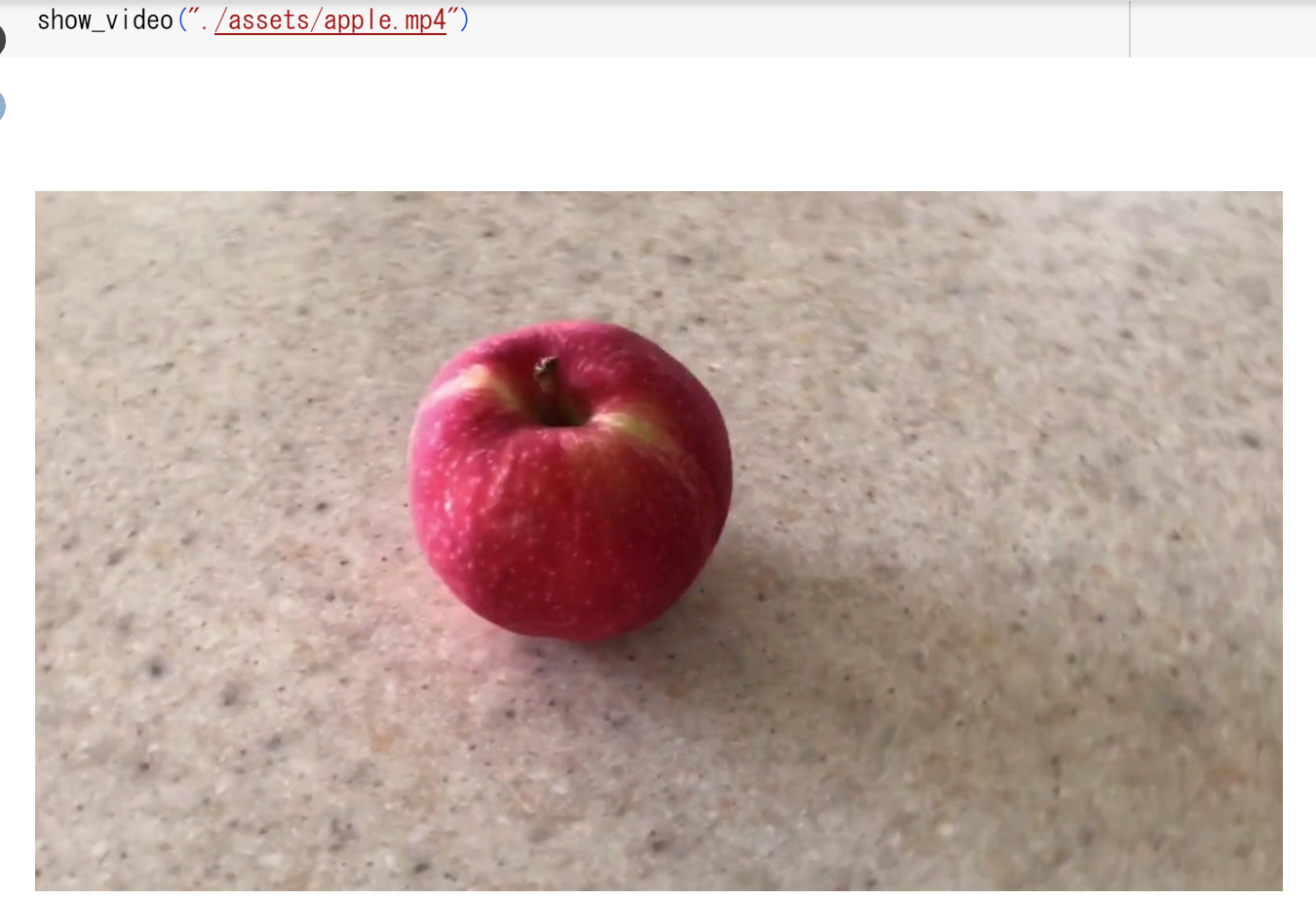
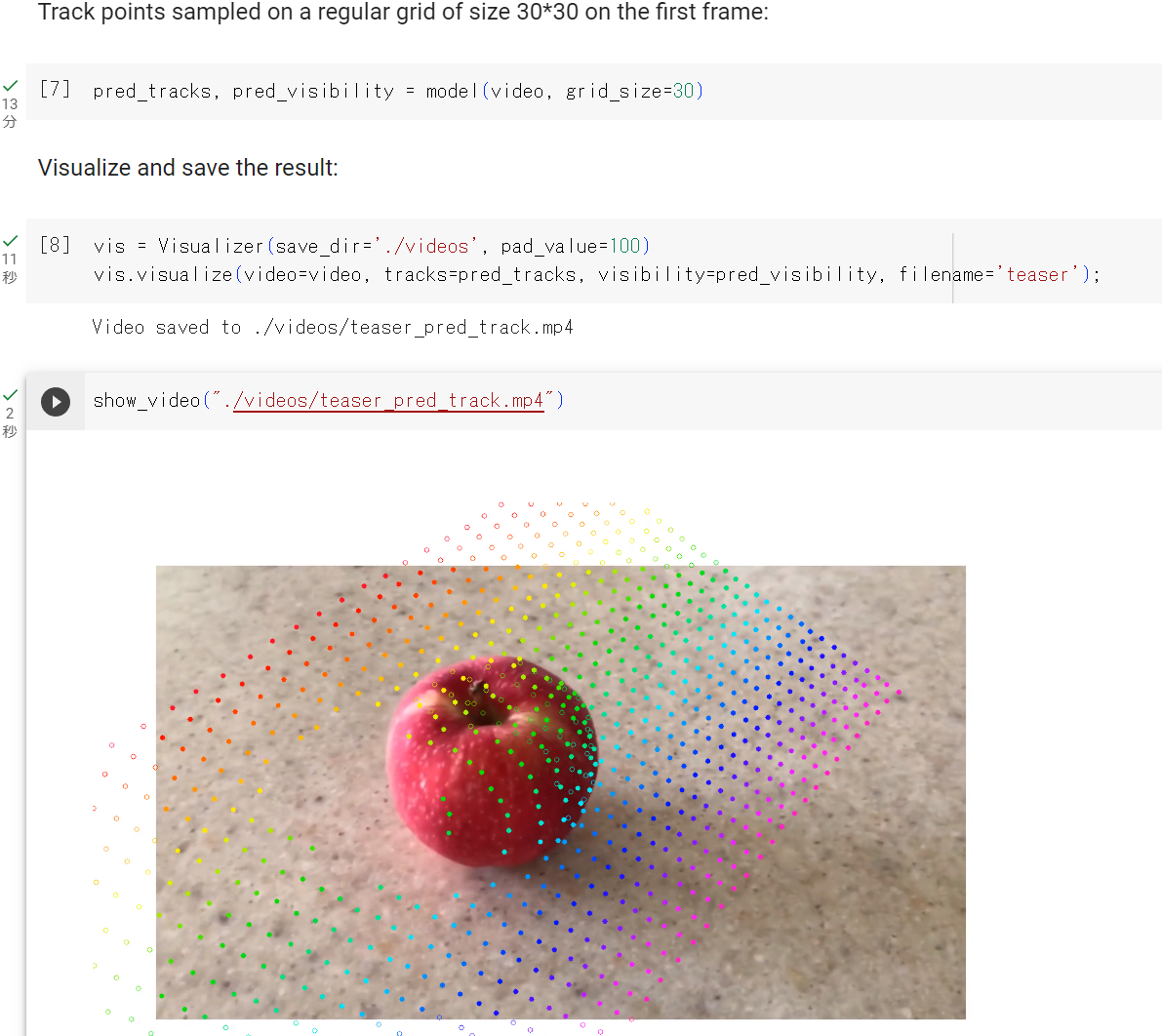
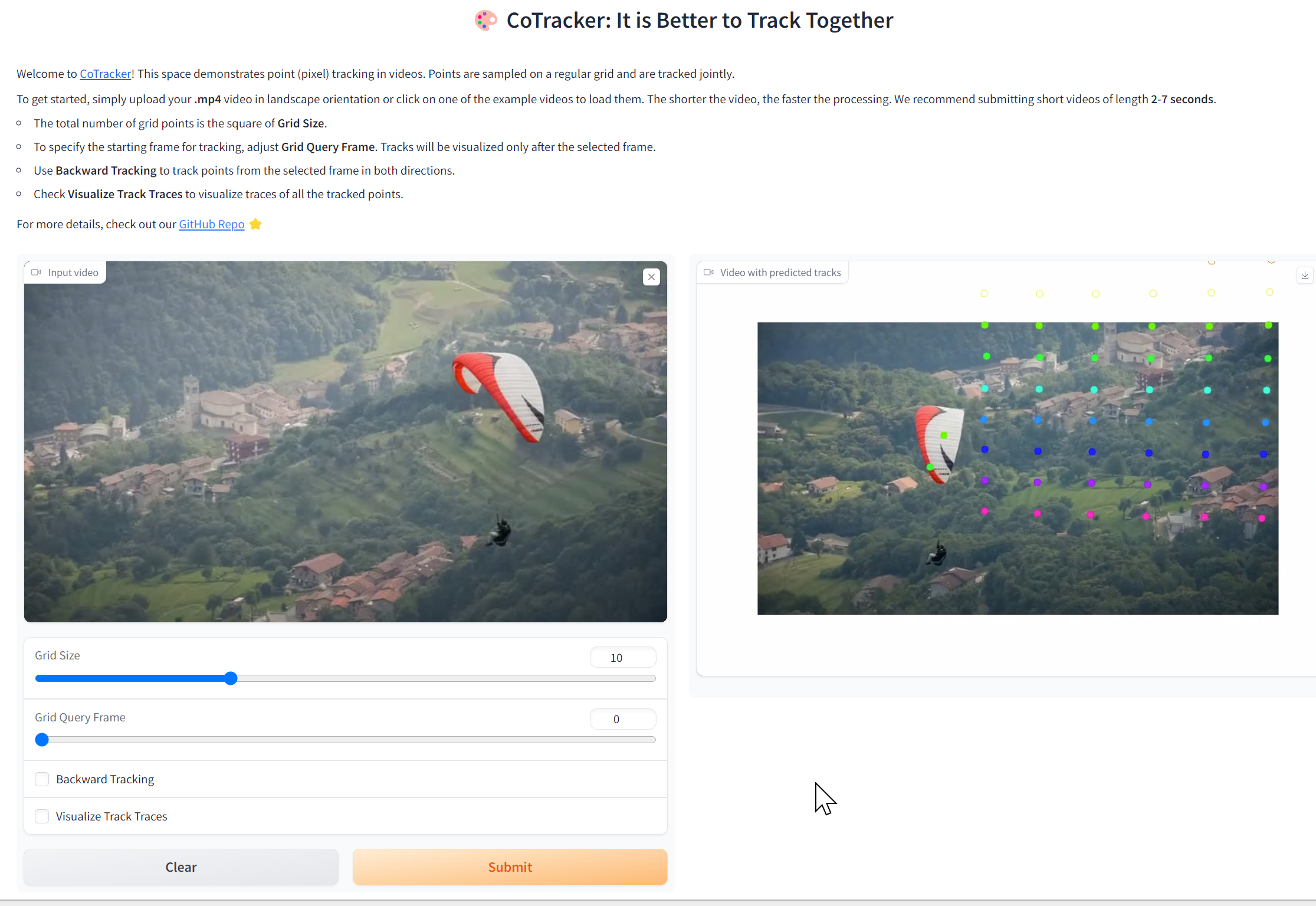
CoTracker
CoTracker は、動画のポイントトラッキングの一手法である. この手法は、長期間の追跡やオクルージョン(遮蔽)の取り扱いの難しさに対処するために開発された. CoTracker では、ポイントをグループとして追跡する方法、つまりグループベースのアプローチを採用しており、ポイント間の相互関係を活用する.さらに、時間的なスライディングウィンドウメカニズムを使用して、長期間にわたる追跡を行う.実験結果からは、co-trackingが既存の手法に比べて、オクルージョンや長期間のビデオに対する追跡の安定性が向上したことが示されている.
【文献】
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, Christian Rupprecht, CoTracker: It is Better to Track Together, arXiv:2307.07635v1, 2023.
https://arxiv.org/pdf/2307.07635v1.pdf
【関連する外部ページ】
- CoTracker のデモ(Google Colaboratory)
- CoTracker の Hugging Face のデモ
https://huggingface.co/spaces/facebook/cotracker
- GitHub のページ: https://github.com/facebookresearch/co-tracker
- Paper with Code のページ: https://paperswithcode.com/paper/cotracker-it-is-better-to-track-together
CSPNet (Cross Stage Parital Network)
CSPNet は,ステージの最初の特徴マップ (feature map) と最後の特徴マップ (feature map) を統合することを特徴とする手法.
CSPNet は, ResNet, ResNeXt, DenseNet などに適用でき, ImageNet データセットを用いた画像分類の実験では,計算コスト,メモリ使用量,推論の速度,推論の精度の向上ができるとされている. その結果として,物体検出 についても改善ができるとされている.
CSPNet の公式の実装 (GitHub) のページでは, 画像分類として, CSPDarkNet-53, CSPResNet50, CSPResNeXt-50, 物体検出として, CSPDarknet53-PANet-SPP, CSPResNet50-PANet-SPP, CSPResNeXt50-PANet-SPP 等の実装が公開されている.
Scaled YOLO v4 では,CSPNet の技術が使われている.
- 文献
Chien-Yao Wang, Hong-Yuan Mark Liao, I-Hau Yeh, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, CSPNet: A New Backbone that can Enhance Learning Capability of CNN, CoRR, abs/1911.11929v1, 2019.
- CSPNet の公式の実装 (GitHub) のページ: https://github.com/WongKinYiu/CrossStagePartialNetworks
- Ross Wightman の pytorch-image-models (GitHub) のページ: https://github.com/rwightman/pytorch-image-models
【関連用語】 AlexeyAB darknet, 画像分類, 物体検出, Scaled YOLO v4, pytorchimagemodels
csvkit
csvkit は,CSV ファイルを操作する機能を持ったソフトウェア.
csvkit の公式ドキュメント: https://csvkit.readthedocs.io/en/latest/
【主な機能】
- カラム名(列名)の表示: csvcut -n a.csv
- カラム名を指定して,取り出す: csvcut -c a1,a2,a3 a.csv
- カラムの並べ替え: csvcut -c a3,a2,a1 a.csv
- CSV ファイルの情報表示: csvstat a.csv
- Excel の xlsx ファイルを CSV ファイルに変換 (in2csv) : in2csv a.xlsx > a.csv
- CSV ファイルから JSON ファイルを生成 (csvjson) : csvjson a.csv > a.json
- CSV ファイルから,テーブル定義(SQL コマンド)を生成 (csvsql)
csvsql a.csv > a.sql csvsql --query "select * from a;" --insert a.csv > a.sql
csvkit 及び類似ソフトウェアのインストール
- 管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「
cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
python -m pip install -U pip setuptools pandas openpyxl csvkit
python -m pip install -e git+https://github.com/wireservice/agate-excel.git#egg=agate-excel
python -m pip install -U agate-dbf agate-sql six olefile
端末で,次のコマンドを実行
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install csvkit python3-pandas python3-csvkit
csvkit に同封されているデータファイル
csvkit に同封のデータは,次の URL で公開されている.
URL: https://github.com/wireservice/csvkit/tree/master/examples/realdata
上の URL をWebブラウザで開くか,次のコマンドでダウンロードできる.
curl -L -O https://raw.githubusercontent.com/wireservice/csvkit/master/examples/realdata/ne_1033_data.xlsx
CoRR
Computing Research Repository を,縮めて 「CoRR」という. URL は次の通り.
CoRR の URL: https://arxiv.org/corr
cudart64_100.dll
cudart64_100.dll は,NVIDIA CUDA 10.0 のファイル. NVIDIA CUDA 10.0 をインストールすることにより, cudart64_100.dll を得ることができる.
cudart64_101.dll
cudart64_101.dll は,NVIDIA CUDA 10.1 のファイル. NVIDIA CUDA 10.1 をインストールすることにより, cudart64_101.dll を得ることができる.
cudart64_110.dll
cudart64_110.dll は,NVIDIA CUDA 11 のファイル. NVIDIA CUDA 11 をインストールすることにより, cudart64_110.dll を得ることができる.
cudnn64_7.dll
cudnn64_7.dll は,NVIDIA cuDNN 7 のファイル. NVIDIA cuDNN 7 (例えば,NVIDIA cuDNN 7.6.5) をインストールすることにより, cudnn64_7.dll を得ることができる.
Windows では,次の操作により,cudnn64_7.dll にパスが通っていることを確認する.
Windows のコマンドプロンプトを開き,次のコマンドを実行する.エラーメッセージが出ないことを確認.
where cudnn64_7.dll
【関連情報】
- NVIDIA cuDNN のダウンロードページ: https://developer.nvidia.com/cudnn
- NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上)
- Ubuntu での NVIDIA CUDA ツールキット,NVIDIA cuDNN のインストール: 別ページ »で説明
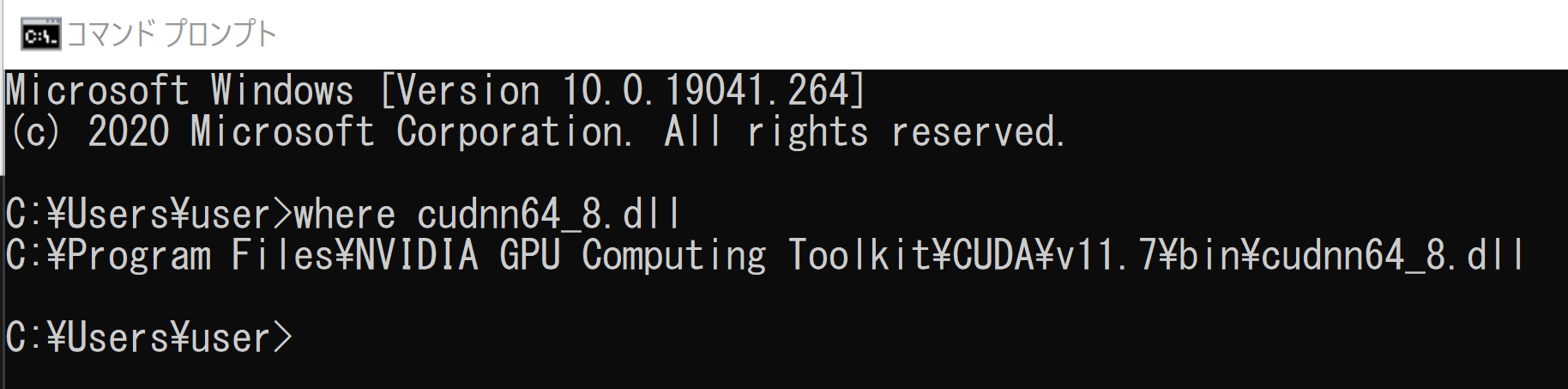
cudnn64_8.dll
cudnn64_8.dll は,NVIDIA cuDNN v8 のファイル. NVIDIA cuDNN v8 をインストールすることにより, cudnn64_8.dll を得ることができる.
Windows では,次の操作により,cudnn64_8.dll にパスが通っていることを確認する.
Windows のコマンドプロンプトを開き,次のコマンドを実行する.エラーメッセージが出ないことを確認.
where cudnn64_8.dll
【関連情報】
- NVIDIA cuDNN のダウンロードページ: https://developer.nvidia.com/cudnn
- NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上)
- Ubuntu での NVIDIA CUDA ツールキット,NVIDIA cuDNN のインストール: 別ページ »で説明
CuPy
CuPy は NumPyのGPU実装であり,CUDA対応GPUで高速な数値計算を行うためのPythonライブラリである.
【関連する外部ページ】
- CyPy の公式ページ: https://cupy.chainer.org/
- CyPy の公式のインストールページ: https://docs.cupy.dev/en/stable/install.html
【サイト内の関連ページ】
- CuPy 13.2 のインストール,CuPy のプログラム例(Windows 上): 別ページ »で説明
【関連項目】 NVIDIA CUDA
curl のインストール(Ubuntu 上)
curl の URL: https://curl.se/
- Windows での curl のインストール: curl は,Windows の標準機能にあるので,インストールしなくても使うことができる.
curl のインストールが必要な場合のため,インストール手順を別ページ »で説明
- Ubuntu での curl のインストール
# パッケージリストの情報を更新 sudo apt update sudo apt -y install curl
CuRRET データベース (Columbia-Utrecht Reflectance and Texture Database)
反射率とテクスチャに関するデータベース
- BRDF データベース: 60 以上のサンプルについて,反射率を計測したもの.
- BRDF パラメータデータベース: BRDF モデル(the Oren-Nayar model とthe Koenderink et al. representation の2つ)のフィッティングパラメータ (fitting parameter) を含む.
- BTF データベース: 60 以上のサンプルについての画像テクスチャに関する計測値
CuRRET データベース (Columbia-Utrecht Reflectance and Texture Database)は次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.cs.columbia.edu/CAVE/software/curet/html/about.php
DeepFace
DeepFace は,ArcFace 法による顔識別の機能や,顔検出,年齢や性別や表情の推定の機能などを持つ.
ArcFace 法は,距離学習の技術の1つである. 画像分類において,種類が不定個であるような画像分類に使うことができる技術である. 顔のみで動くということではないし, 顔の特徴を捉えて工夫されているということもない.
DeepFace の URL: https://github.com/serengil/deepface
ArcFace 法の概要は次の通り
- 顔のコード化:顔画像を,数値ベクトル(数値の並び)に変換する.
- 顔のコードについて,同一人物の顔のコードは近くになるように,違う人物の顔のコードは遠くなるように,顔のコードを作り直す.そのときディープラーニングを使う.これを「距離学習」という.
- 距離学習の学習済みモデルを使う.距離学習がなかったときと比べて,顔認識の精度の向上が期待できる.
【関連項目】 ArcFace 法, 顔検出, 顔識別 (face identification), 顔認識, 顔に関する処理
Google Colaboratory で,DeepFace による顔識別の実行,年齢,性別,表情の推定の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- ディレクトリ内の全画像ファイルを顔データベースとして,画像とかおデータベースを用いた顔認識 (face recognition)を行い,顔データベースの各画像との距離を表示.
- 年齢,性別,表情の推定.
- インストールと設定
!pip3 install deepface !git clone --recursive https://github.com/serengil/deepface from deepface import DeepFace import pandas as pd pd.set_option('display.max_rows', None) print(pd.get_option('display.max_rows'))
- 顔画像の準備
単一のディレクトリ ./deepface/tests/dataset に,処理したい顔画像をすべて入れておく
- 顔識別の実行
ディレクトリ内の全画像ファイルとの顔識別を行い,それぞれの顔画像ファイルとの距離を表示.
df = DeepFace.find(img_path="./deepface/tests/dataset/img38.jpg", db_path="./deepface/tests/dataset", distance_metric='euclidean') a = df.sort_values('VGG-Face_euclidean') print(a)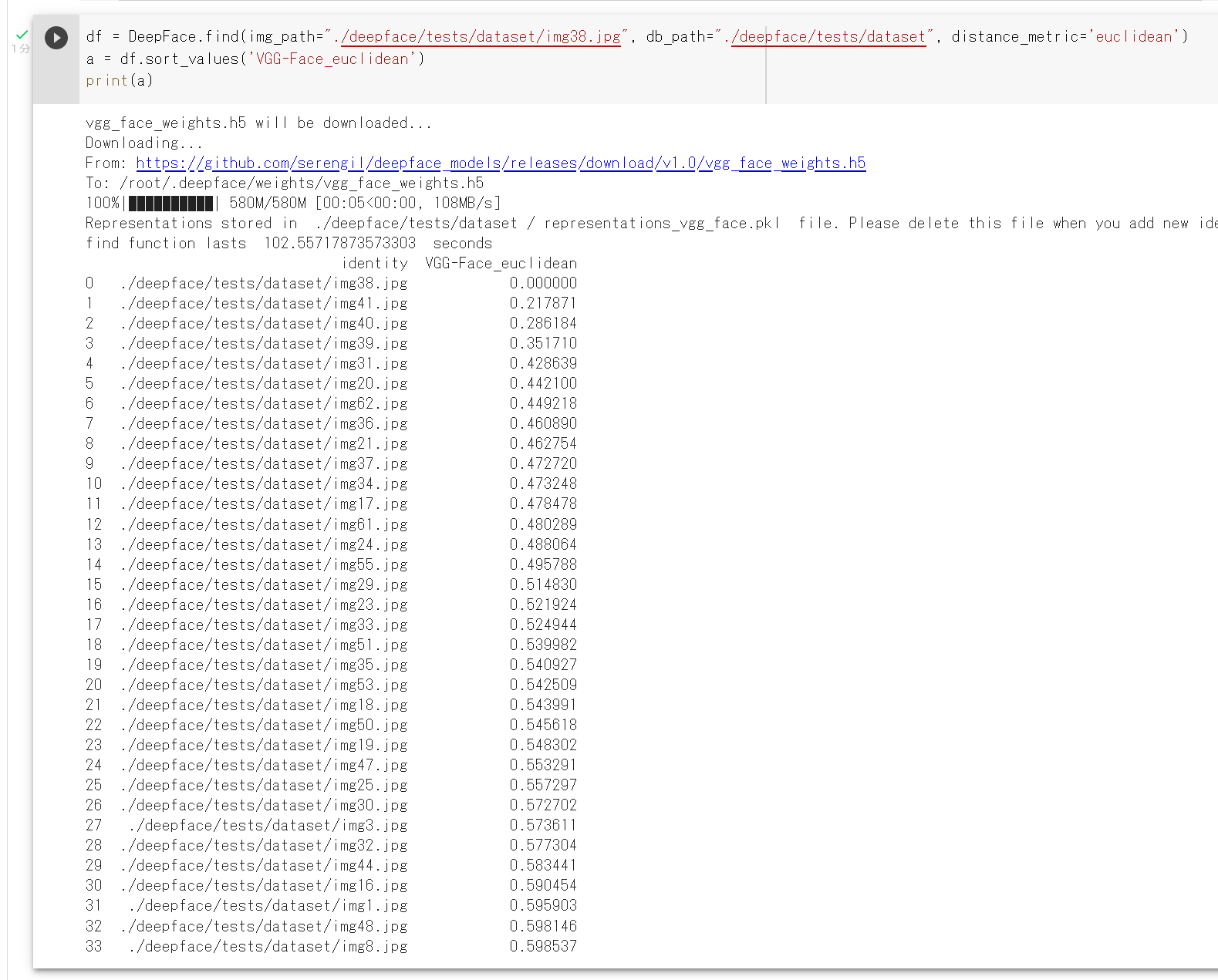
- 年齢,性別,表情の推定の実行
obj = DeepFace.analyze(img_path = "./deepface/tests/dataset/img38.jpg", actions = ['age', 'gender', 'emotion']) print(obj)
DeepForge
DeepForge は,ディープラーニングのソフトウェア一式.Webサーバも付属していて,Webブラウザからディープラーニングのソフトウェアの作成,実行,保存が簡単にできる.ソフトウェアの作成は,Webブラウザ上でのエディタでも,Webブラウザ上でのビジュアルなエディタでもできる.ディープラーニングでのニューラルネットワークの構造が図で簡単に確認できて便利
【サイト内の関連ページ】
- Windows での DeepForge のインストールとテスト実行: 別ページで説明してる
【関連する外部ページ】
- DeepForge の公式ページ: https://deepforge.org/
DeepLab2
DeepLab2 は,セグメンテーションの機能を持つ TensorFlow のライブラリである. DeepLab, Panoptic-DeepLab, Axial-Deeplab, Max-DeepLab, Motion-DeepLab, ViP-DeepLab を含む.
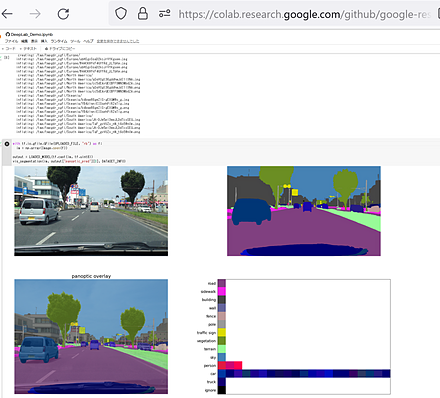
DeepLab2 の公式のデモ(Google Colaboratory のページ)の実行により,下図のように panoptic segmentation の結果が表示される.
そのデモのページの URL: https://colab.research.google.com/github/google-research/deeplab2/blob/main/DeepLab_Demo.ipynb#scrollTo=6552FXlAOHnX
【文献】
Mark Weber, Huiyu Wang, Siyuan Qiao, Jun Xie, Maxwell D. Collins, Yukun Zhu, Liangzhe Yuan, Dahun Kim, Qihang Yu, Daniel Cremers, Laura Leal-Taixe, Alan L. Yuille, Florian Schroff, Hartwig Adam, Liang-Chieh Chen, DeepLab2: A TensorFlow Library for Deep Labeling, CoRR, abs/2106.09748v1, 2021.
【サイト内の関連ページ】
Windows で動く人工知能関係 Pythonアプリケーション,オープンソースソフトウエア): 別ページ »で説明
【関連する外部ページ】
- https://arxiv.org/pdf/2106.09748v1.pdf
- DeepLab2 の GitHub のページ: https://github.com/google-research/deeplab2
- DeepLab2 の Google Colaboratory のページ: https://colab.research.google.com/github/google-research/deeplab2/blob/main/DeepLab_Demo.ipynb
【関連項目】 セマンティック・セグメンテーション (semantic segmentation), panoptic segmentation, depth estimation
Deeplab2 のインストール(Windows 上)
- プロトコル・バッファ・コンパイラ (protocol buffer compiler) のインストールを行っておく
- コマンドプロンプトを管理者として開く.
- Deeplab2 のダウンロード,前提ソフトウエアのインストール
Deeplab2 を動かすため,protobuf==3.19.6
cd c:\ rmdir /s /q c:\deeplab2 mkdir c:\deeplab2 cd c:\deeplab2 git clone https://github.com/google-research/deeplab2.git python -m pip install -U tensorflow==2.10.1 protobuf==3.19.6 - protoc を用いてコンパイル
cd c:\deeplab2 protoc deeplab2\*.proto --python_out=.
- Windows の システム環境変数 PYTHONPATHに,c:\deeplab2 を追加することにより,パスを通す.
Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。powershell -command "$oldpath = [System.Environment]::GetEnvironmentVariable(\"PYTHONPATH\", \"Machine\"); $oldpath += \";c:\deeplab2\"; [System.Environment]::SetEnvironmentVariable(\"PYTHONPATH\", $oldpath, \"Machine\")"
- 新しくコマンドプロンプトを開き,動作確認
cd c:\deeplab2\deeplab2\model python deeplab_test.py
Deeplab2 のインストール(Ubuntu 上)
ttps://github.com/google-research/deeplab2/blob/main/g3doc/setup/installation.md の記載による.
- protoc のインストール
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libprotobuf-dev protobuf-compiler protobuf-c-compiler python3-protobuf - pycocotools のインストール
sudo pip3 install tensorflow tf-models-official pillow matplotlib cython sudo pip3 install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI" # install pycocotools cd /usr/local sudo git clone https://github.com/cocodataset/cocoapi.git sudo chown -R $USER cocoapi cd ./cocoapi/PythonAPI make echo 'export PYTHONPATH=$PYTHONPATH:/usr/local/cocoapi/PythonAPI' >> ~/.bashrc - DeepLab2 のインストール
cd /usr/local sudo rm -rf deeplab2 sudo git clone https://github.com/google-research/deeplab2.git sudo chown -R $USER deeplab2 cd /usr/local protoc deeplab2/*.proto --python_out=. cd /usr/local bash deeplab2/compile.sh echo 'export PYTHONPATH=$PYTHONPATH:/usr/local' >> ~/.bashrc echo 'export PYTHONPATH=$PYTHONPATH:/usr/local/deeplab2' >> ~/.bashrc - TensorFlow モデルのインストール
cd /usr/local sudo rm -rf models sudo git clone https://github.com/tensorflow/models.git sudo chown -R $USER models cd /usr/local/models/research protoc object_detection/protos/*.proto --python_out=. protoc lstm_object_detection/protos/*.proto --python_out=. cd /usr/local/models/research\delf protoc delf/protos/*.proto --python_out=. echo 'export PYTHONPATH=$PYTHONPATH:/usr/local/models' >> ~/.bashrc - DeepLab2 の動作確認
source ~/.bashrc cd /usr/local # Model training test (test for custom ops, protobuf) python deeplab2/model/deeplab_test.py # Model evaluator test (test for other packages such as orbit, cocoapi, etc) python deeplab2/trainer/evaluator_test.py
DeepLabv3
セマンティック・セグメンテーションのモデル. 2017年発表.
- 文献
Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam, Rethinking Atrous Convolution for Semantic Image Segmentation
- 公式のソースコード: https://github.com/tensorflow/models/tree/master/research/deeplab
- MMSegmentation の DeepLabv3 のページ: https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3
【関連項目】 Residual Networks (ResNets) , モデル, セマンティック・セグメンテーション
DeepLabv3+
セマンティック・セグメンテーションのモデル. 2018年発表.
- 文献
Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam, Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, ECCV, 2018.
- 公式のソースコード: https://github.com/tensorflow/models/tree/master/research/deeplab
- MMSegmentation の DeepLabv3+ のページ: https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus
【関連項目】 Residual Networks (ResNets) , モデル, セマンティック・セグメンテーション
DeepL API の認証キー
DeepL API の認証キーの取得はオンラインで可能である.クレジットカード番号の登録などが必要になる.
【関連する外部ページ】
DeepL Pro のページ: https://www.deepl.com/pro#developer
DeepXi
- 文献 Nicolson Aaron, Paliwal Kuldip K., Deep Xi as a Front-End for Robust Automatic Speech Recognition, 2020.
- GitHub のページ: https://github.com/anicolson/DeepXi
- Papers with Code のページ: https://paperswithcode.com/paper/deep-xi-as-a-front-end-for-robust-automatic
【関連項目】 speech enhancement, speech recognition
Google Colaboratory での DeepXi のインストール
公式の手順 https://github.com/anicolson/DeepXi による.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
%cd /content
!rm -rf DeepXi
!git clone https://github.com/anicolson/DeepXi.git
%cd DeepXi
!pip3 install -r requirements.txt
Deformable DETR
物体検出の一手法.2021 年発表.
- 文献
Xizhou Zhu and Weijie Su and Lewei Lu and Bin Li and Xiaogang Wang and Jifeng Dai, Deformable DETR: Deformable Transformers for End-to-End Object Detection, International Conference on Learning Representations, also CoRR, abs/2010.04159v4, 2021.
- 公式の URL: https://openreview.net/forum?id=gZ9hCDWe6ke
- 公式のソースコード (GitHub): https://github.com/fundamentalvision/Deformable-DET
- Papers with Code のページ: https://paperswithcode.com/paper/deformable-detr-deformable-transformers-for-1
- MMDetection のモデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/deformable_detr/README.md
【関連項目】 DETR, MMDetection, 物体検出
Demucs
音源分離(music source separation)を行う 1手法.2019年発表.2021年に hybrid version が発表. 音声と楽器音の混合から,音声や楽器音を分離できる.
- 文献
Hybrid Spectrogram and Waveform Source Separation, Alexandre Défossez, Proceedings of the ISMIR 2021 Workshop on Music Source Separation, also CoRR, abs/2111.03600v1, 2021.
- 公式のページ (GitHub): https://github.com/facebookresearch/demucs
- 公式のオンラインデモ (Google Colaboratory): https://colab.research.google.com/drive/1dC9nVxk3V_VPjUADsnFu8EiT-xnU1tGH?usp=sharing
- 公式のオンラインデモ (HaggingFace 内): https://huggingface.co/spaces/akhaliq/demucs
【関連用語】 audio source seperation, music source separation
Google Colaboratory で,音声,楽曲の分離 (Demucs を使用)
公式の手順 https://github.com/facebookresearch/demucs による.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Demucs のインストール
!pip3 install -U git+https://github.com/facebookresearch/demucs#egg=demucs !pip3 show demucs
- 処理したいサウンドファイルの準備
ここでは,1.m4a をダウンロードしている.
%cd /content !curl -O https://www.kkaneko.jp/sample/audio/1.m4a
- Demucs の実行
!demucs 1.m4a
- 処理結果のダウンロード
「1」のところは,処理したサウンドファイルのファイル名にあわせること.
from google.colab import files %cd separated/mdx_extra_q/1 files.download('drums.wav') files.download('bass.wav') files.download('other.wav') files.download('vocals.wav')
DenseNet121, DenseNet169
CoRR, abs/1608.06993
Keras の DenseNet121 を用いて DenseNet121 を作成するプログラムは次のようになる. 「weights=None」を指定することにより,最初,重みをランダムに設定する.
m = tf.keras.applications.densenet.DenseNet121(input_shape=INPUT_SHAPE, weights=None, classes=NUM_CLASSES)
Keras の DenseNet169 を用いて DenseNet169 を作成するプログラムは次のようになる. 「weights=None」を指定することにより,最初,重みをランダムに設定する.
m = tf.keras.applications.densenet.DenseNet169(input_shape=INPUT_SHAPE, weights=None, classes=NUM_CLASSES)
Keras の応用のページ: https://keras.io/ja/applications/
PyTorch, torchvision の DenseNet121 学習済みモデルのロード,画像分類のテスト実行
Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのDenseNet121 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.densenet121(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)

- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
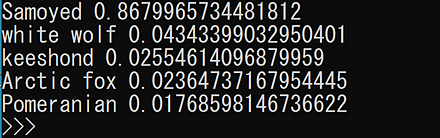
Linux での結果
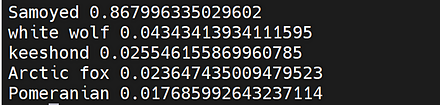
PyTorch, torchvision の DenseNet169 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_densenet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのDenseNet169 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.densenet169(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
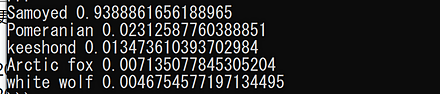
Linux での結果
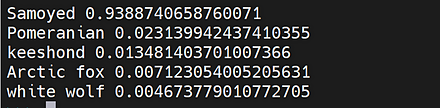
depthimage
depth image は遠近である depth を示す画像. 画素ごとの色や明るさで depth を表示する.
画像からの depth image の推定は,ステレオカメラや動画から視差を得る方法が主流である.
monodepth2 法
単一のカメラでの画像から depth image を推定する方法としては,ディープラーニングを用いる monodepth2 法 (2019 年発表) が知られる.
monodepth2 の GitHub のページ: https://github.com/nianticlabs/monodepth2
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- インストール
!pip3 install -U numpy pillow matplotlib torch torchvision opencv-python opencv-contrib-python scikit-image !git clone --recursive https://github.com/nianticlabs/monodepth2
- depth image プログラム実行
%cd monodepth2 !python3 test_simple.py --image_path assets/test_image.jpg --model_name mono+stereo_640x192
- 画像表示
from PIL import Image Image.open('assets/test_image.jpg').show() Image.open('assets/test_image_disp.jpeg').show()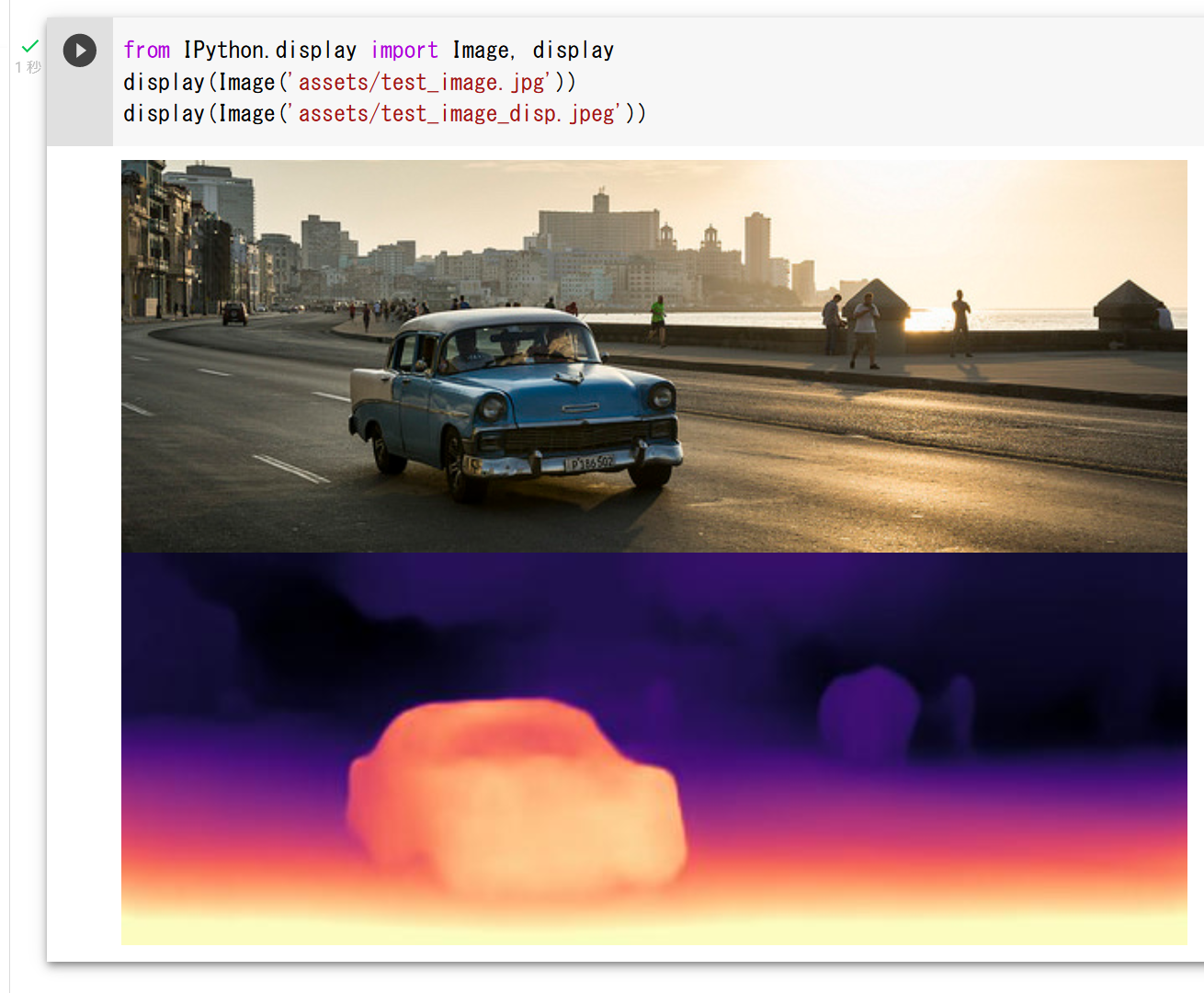
- 他の画像で試してみた場合


Detectron2
【文献】
Yuxin Wu and Alexander Kirillov and Francisco Massa and Wan-Yen Lo and Ross Girshick, Detectron2, https://github.com/facebookresearch/detectron2, 2019.
【サイト内の関連ページ】 物体検出,インスタンス・セグメンテーション,パノプティック・セグメンテーションの実行(Detectron2,PyTorch, Python を使用)(Windows 上)
【関連する外部ページ】
- GitHub のページ: https://github.com/facebookresearch/detectron2
- ドキュメント: https://detectron2.readthedocs.io/en/latest/tutorials/getting_started.html
- 関連プロジェクトのページ: https://github.com/facebookresearch/detectron2/tree/master/projects
【関連項目】 ADE20K データセット, インスタンス・セグメンテーション (instance segmentation)
Google Colaboratory で,Detectron2 のインスタンス・セグメンテーションの実行
インストールは次のページで説明されている.
https://github.com/facebookresearch/detectron2/releases
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する)
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- Detectron2 のインストール
NVIDIA CUDA ツールキット 11.1, PyTorch 1.10 の場合には,次のようになる
「cu111/torch1.10」のところは, NVIDIA CUDA ツールキット のバージョン, PyTorch のバージョンに合わせる
!pip3 install detectron2==0.6 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.10/index.html
- Detectron2 のソースコードをダウンロード
必要に応じて,中のファイルを利用できるように準備しておく.
!curl -LO https://github.com/facebookresearch/detectron2/archive/refs/tags/v0.6.tar.gz !tar -xvzof v0.6.tar.gz
- coco (common object in context) データセットの中の画像ファイルをダウンロード
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=FsePPpwZSmqt の記載による
!curl -O http://images.cocodataset.org/val2017/000000439715.jpg from PIL import Image Image.open('000000439715.jpg').show()
- インスタンス・セグメンテーションの実行
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=FsePPpwZSmqt の記載による
「im = cv2.imread('000000439715.jpg')」で,処理したい画像ファイルをロードしている.
import detectron2 from detectron2 import model_zoo from detectron2.engine import DefaultPredictor from detectron2.config import get_cfg from detectron2.utils.visualizer import Visualizer from detectron2.data import MetadataCatalog, DatasetCatalog cfg = get_cfg() # add project-specific config (e.g., TensorMask) here if you're not running a model in detectron2's core library cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")) cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model # Find a model from detectron2's model zoo. You can use the https://dl.fbaipublicfiles... url as well cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") predictor = DefaultPredictor(cfg) import cv2 im = cv2.imread('000000439715.jpg') outputs = predictor(im)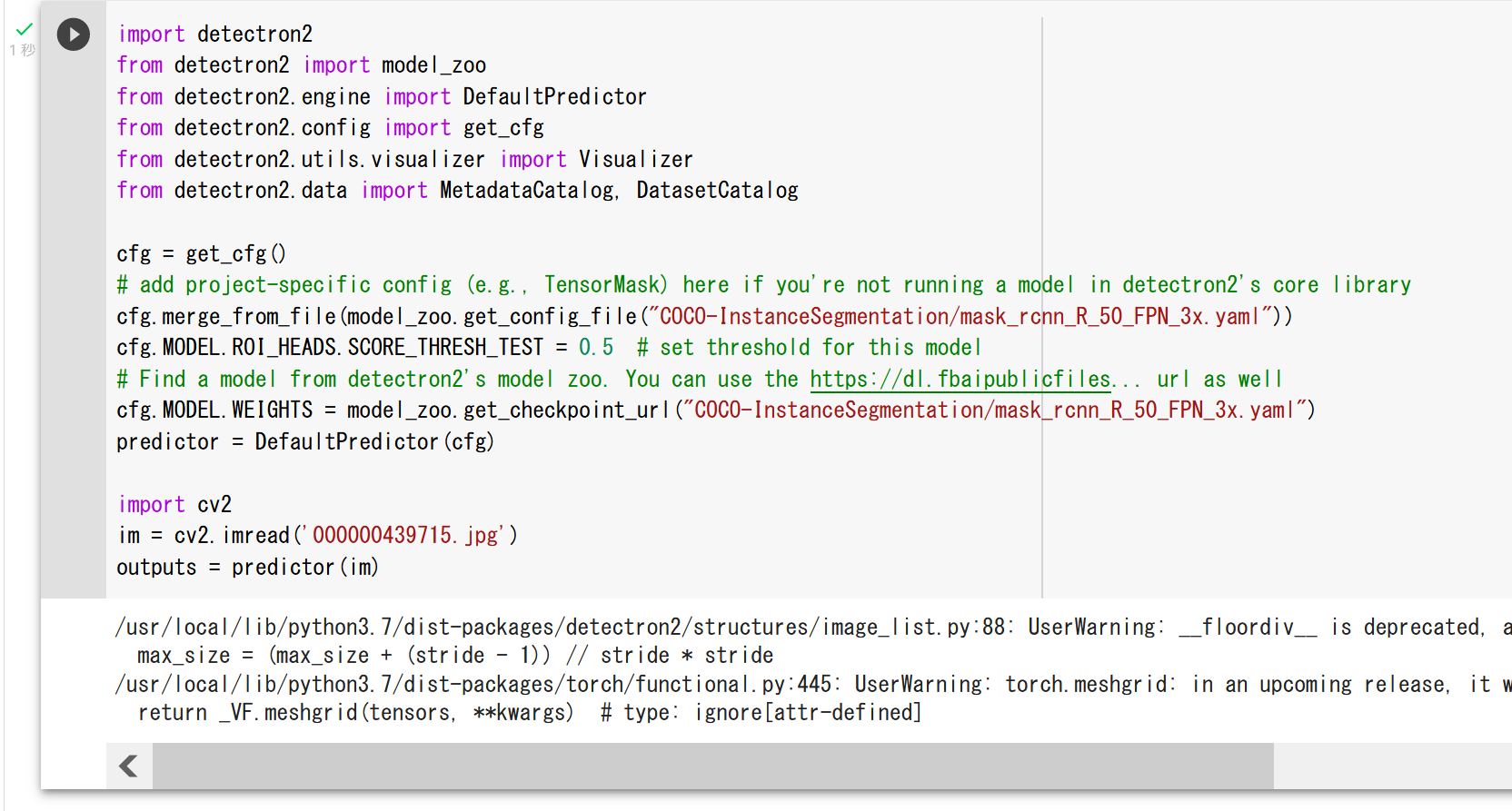
- インスタンス・セグメンテーションの結果の確認
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=FsePPpwZSmqt の記載による
# look at the outputs. See https://detectron2.readthedocs.io/tutorials/models.html#model-output-format for specification print(outputs["instances"].pred_classes) print(outputs["instances"].pred_boxes)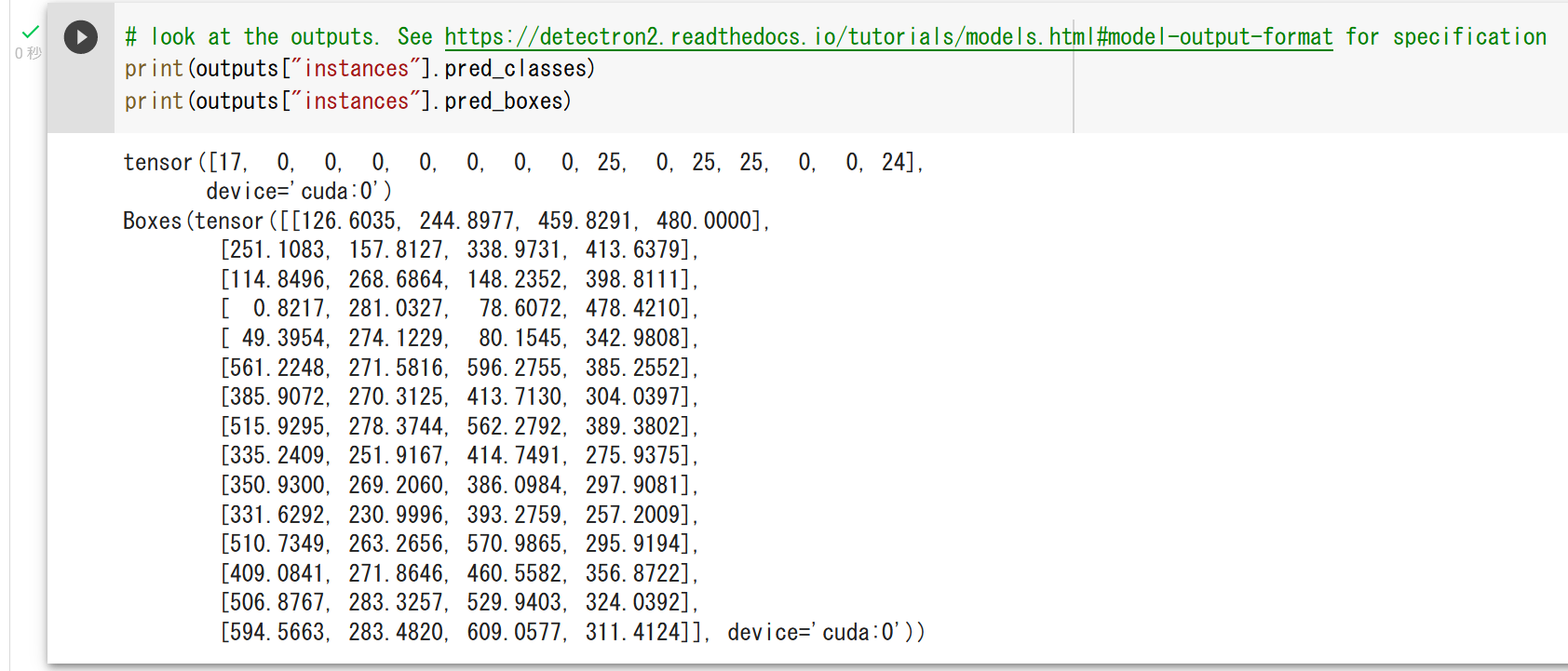
- インスタンス・セグメンテーションの結果の表示
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=FsePPpwZSmqt の記載による
# We can use `Visualizer` to draw the predictions on the image. v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2) out = v.draw_instance_predictions(outputs["instances"].to("cpu")) import matplotlib.pyplot as plt plt.imshow(out.get_image()[:, :, ::-1])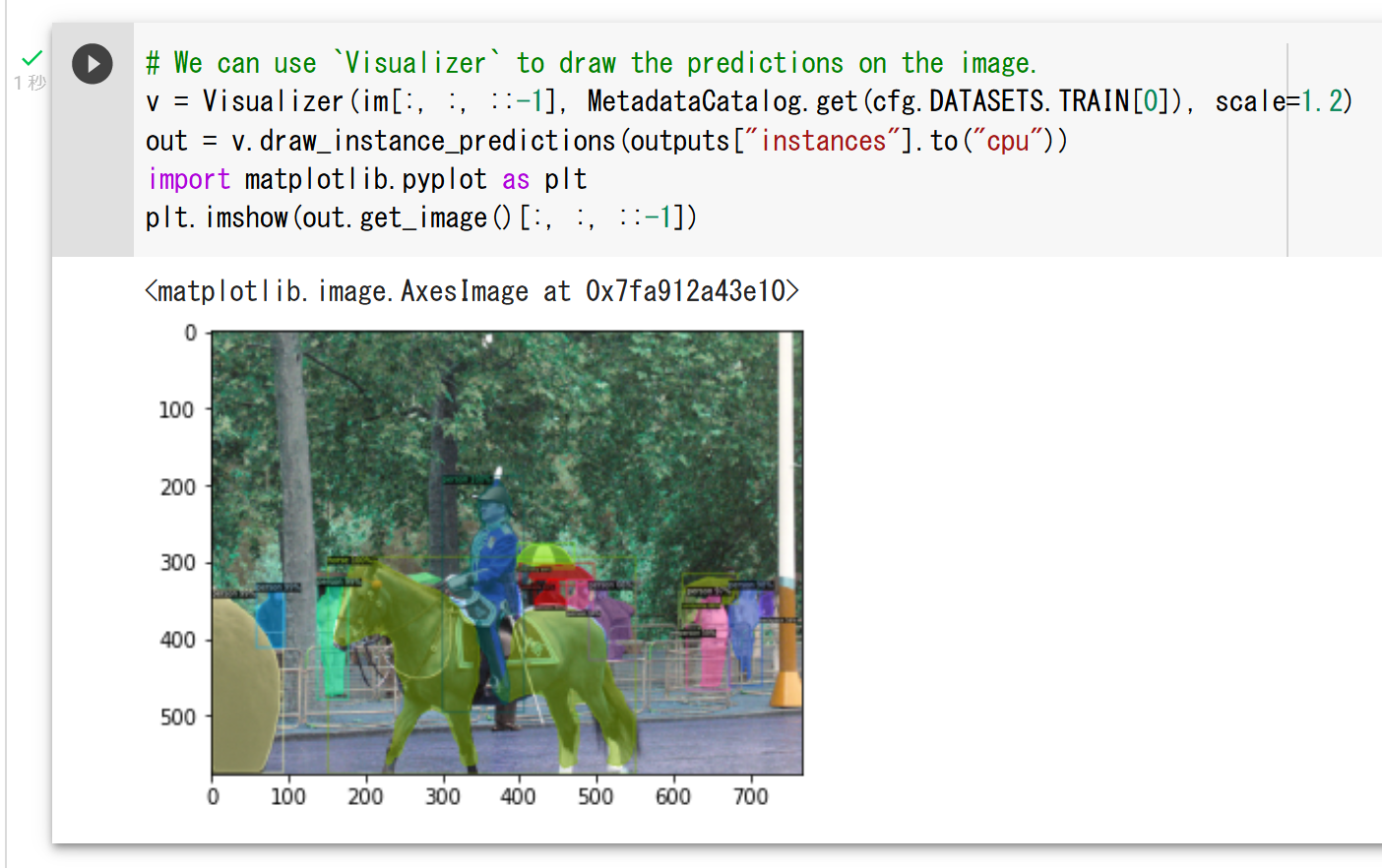
Windows での Detectron2 のインストールと動作確認
別ページ »で説明
Linux での Detectron2 のインストール
インストールは次のページで説明されている.https://github.com/facebookresearch/detectron2/releases
このページによれば,Linux マシンで,NVIDIA CUDA ツールキット 11.1, PyTorch 1.9 がインストール済みの場合には,次のような手順になる.
python -m pip install detectron2==0.5 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.9/index.htmlDETR
物体検出, panoptic segmentation の一手法.2020年発表.
- 文献
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko, End-to-End Object Detection with Transformers, ECCV 2020, also CoRR, abs/2005.12872v3, 2020.
- 公式のソースコード (GitHub): https://github.com/facebookresearch/detr
- 公式のデモ (Google Colaboratory): https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_demo.ipynb
- Papers with Code のページ: https://paperswithcode.com/paper/end-to-end-object-detection-with-transformers
- TensorFlow のモデル: https://github.com/tensorflow/models/tree/master/official/projects/detr
- MMDetection のモデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/detr/README.md
【関連項目】 Deformable DETR, MMDetection, panoptic segmentation, 物体検出,
DiffBIR
DiffBIRは画像復元の手法の一つである. 画像復元は、低品質または劣化した画像を元の高品質な状態に修復するタスクである. このタスクでは、ノイズや歪みなどの複雑な問題に対処する必要がある. DiffBIRは、2つの主要なステージから成り立っている. 最初のステージでは、画像復元が行われ、低品質な画像が高品質に修復される. そして、2番目のステージでは、事前に訓練されたStable Diffusionを使用して、高品質な画像が生成される. DiffBIRは他の既存の手法よりも優れた結果を得ることができることが実験によって示されている.【文献】
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Ben Fei, Bo Dai, Wanli Ouyang, Yu Qiao, Chao Dong, DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior, arXiv:2308.15070v1, 2023.
https://arxiv.org/pdf/2308.15070v1.pdf
【関連する外部ページ】
- 公式のデモページ(Google Colaboratory 上): https://colab.research.google.com/github/camenduru/DiffBIR-colab/blob/main/DiffBIR_colab.ipynb
- DiffBIR の公式の GitHub のページ: https://github.com/XPixelGroup/DiffBIR
- Paper with Code のページ: https://paperswithcode.com/paper/diffbir-towards-blind-image-restoration-with
diffusion model
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, Surya Ganguli, Deep Unsupervised Learning using Nonequilibrium Thermodynamics, arXiv:1503.03585 [cs.LG].
display
IPython の display は,画像表示の機能がある. display は,Jupyter Qt Console や Google Colaboratory などで動く
次の Python プログラムは,画像ファイルのダウンロードとロードと確認表示を行う.確認表示で display を用いている.
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
次の Python プログラムは,Iris データセットのロードと確認表示を行う. Pandas データフレームの df にロードしている. 確認表示で display を用いている.
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] display(df)Pandas データフレームのすべての行を表示したいときは,次のように 「pd.set_option('display.max_rows', None)」を使用する
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] pd.set_option('display.max_rows', None) display(df)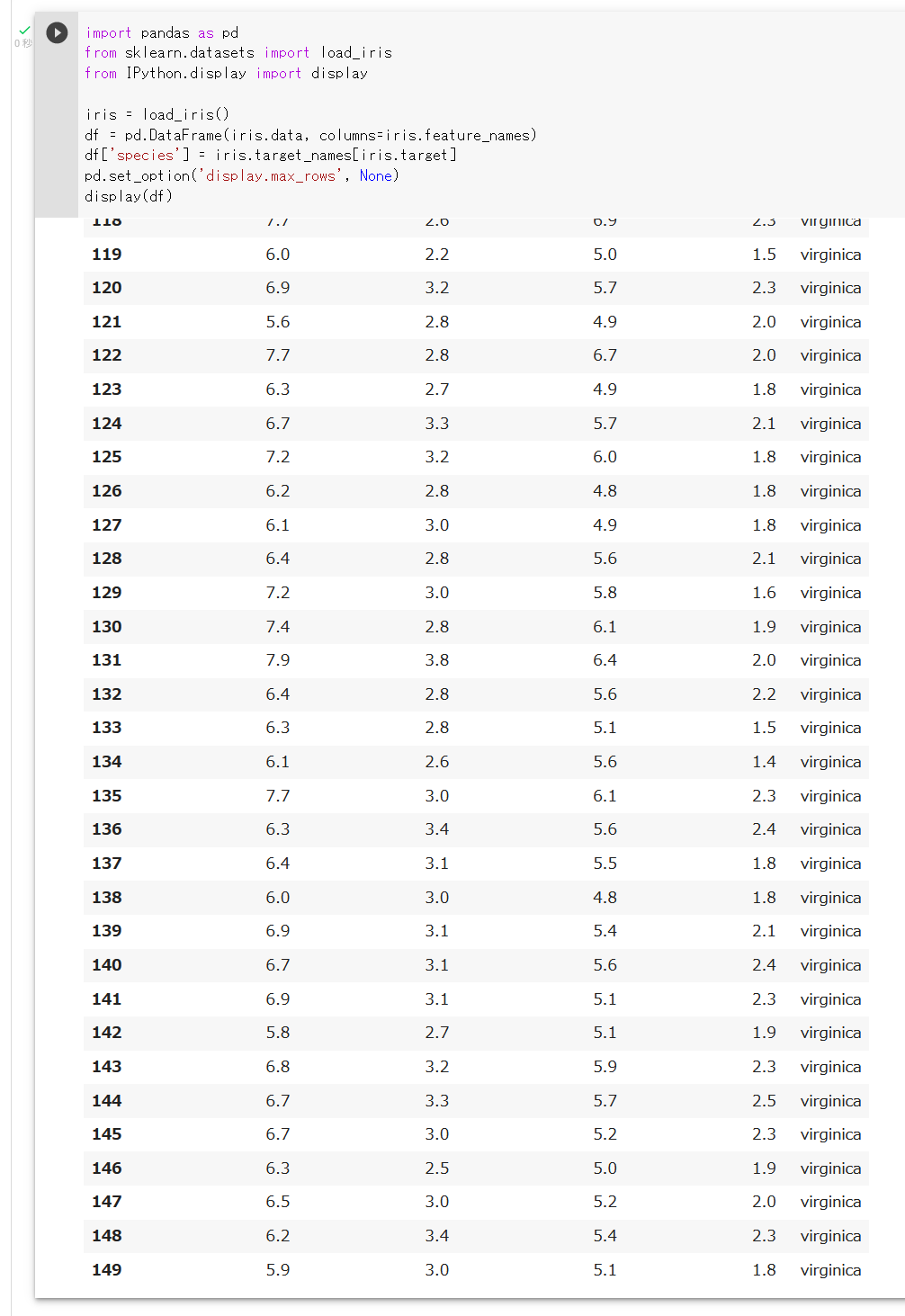
Dlib
Dlib は,数多くの機能を持つソフトウェア. Python, C++ のプログラムから使うためのインタフェースを持つ.
Dlib の機能には,機械学習,数値計算,グラフィカルモデル推論,画像処理,スレッド,通信,GUI,データ圧縮・一貫性,テスト,さまざまなユーティリティがある.
Dlib には,顔情報処理に関して,次の機能がある.
- 顔検出 (face detection)
- 顔ランドマーク (facial landmark)の検出
- 顔のアラインメント
- 顔のコード化
ディープニューラルネットワークの学習済みモデルも配布されている
Dlib の URL: http://dlib.net/
【関連項目】 FairFace, Max-Margin 物体検出 , 顔検出 (face detection), 顔ランドマーク (facial landmark), 顔のコード化
Windows での Dlib のインストール
Dlib のインストールは,複数の方法がある.
- Windows での Dlib,face_recognition のインストール(ソースコードを使用): 別ページ »で説明
- Windows での Python の Dlib ライブラリのインストール,Dlib のソースコード等と,Dlib の学習済みモデルのダウンロード: 別ページ »で説明
Dlib 19.24.99 の非公式ビルド: dlib.zip私がビルドしたもの,非公式,無保証, 公開されているDlib のソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした.NVIDIA CUDA は使用せずにビルドした. Eigen の MPL2 ライセンスによる.
zip ファイルは C:\ 直下で展開し,C:\dlib での利用を想定.
Ubuntu での Dlib のインストール
Dlib の顔検出
Dlib の顔検出 は次の仕組みで行われる.
Dlib には,ディープラーニングの CNN (convolutional neural network) を用いた物体検出 が実装されている. そこでは,Max-Margin 物体検出法が利用されている(文献は次の通り). それにより,Dlib の顔検出 が行われる.
Davis E. King, Max-Margin Object Detection, CoRR, abs/1502.00046, 2015
Dlib を用いた顔検出のプログラム例- 前準備として,パッケージのインストールと,学習済みモデルのダウンロードを行う.
ここでダウンロードしている mmod_human_face_detector.dat は,学習済みモデルのファイルである. ImageNet データセット, AFLW, , VGG, , face scrub 画像について, Dlib の作者がアノテーションしたものを用いて学習済みである. 詳細は https://github.com/davisking/dlib-models
Windows では, コマンドプロンプトを管理者として開き次のコマンドを実行する.
python -m pip install dlib opencv-python matplotlib curl -O http://dlib.net/files/mmod_human_face_detector.dat.bz2 "c:\Program Files\7-Zip\7z.exe" x mmod_human_face_detector.dat.bz2Linux では次のコマンドを実行する.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-matplotlib libopencv-dev libopencv-core-dev python3-opencv libopencv-contrib-dev opencv-data sudo pip3 install dlib curl -O http://dlib.net/files/mmod_human_face_detector.dat.bz2 bzip2 -d mmod_human_face_detector.dat.bz2 - Dlib を用いた顔検出の Python プログラムは次の通りである.
import dlib import cv2 %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import time import argparse # 使い方: 次のプログラムを a.py というファイル名で保存し,「python a.py」のように実行. # あるいは python a.py --image IMG_3264.png --model mmod_human_face_detector.dat のように. # --model は学習済みモデルのファイル名を指定できる ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", help="input image", default="a.png") ap.add_argument("-m", "--model", help="pre-trained model", default="python_examples/mmod_human_face_detector.dat") ap.add_argument("-u", "--upsample", type=int, default=1) args = vars(ap.parse_args()) # face_detector = dlib.cnn_face_detection_model_v1(args['model']) # 画像ファイル名を a.png のところに設定 bgr = cv2.imread(args['image']) if bgr is None: print("画像ファイルがない") exit() # 顔検出を行う. start = time.time() faces = face_detector(cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB), args['upsample']) end = time.time() print("秒数 : ", format(end - start, '.2f')) # 顔検出で得られた顔(複数あり得る)それぞれについて、赤い四角を書く for i, f in enumerate(faces): x = f.rect.left() y = f.rect.top() width = f.rect.right() - x height = f.rect.bottom() - y cv2.rectangle(bgr, (x, y), (x + width, y + height), (0, 0, 255), 2) print("%s, %d, %d, %d, %d" % (args['image'], x, y, x + width, y + height)) # 画面に描画 plt.style.use('default') plt.imshow(cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)) # ファイルに保存 cv2.imwrite("result.png", bgr) - 次のような結果が表示される.

次のページは,上のプログラム等を記載したGoogle Colaboratory のページである.ページを開き実行できる.
URL: https://colab.research.google.com/drive/1q-dGCfre8MT5Zet2O3xYoYMUP0sx_KLc?usp=sharing [Google Colaboratory]
Docker
Docker は,Windowsなどのオペレーティングシステムの中に, Docker コンテナ という Dockerのエリアを複数作ることができる. Docker コンテナの中には、ソフトもインストールしたりできるが、 それは、おおもとのWindows などのオペレーティングシステムや,他の Docker コンテナとは隔離される (つまり、Docker コンテナの中のアプリを起動するときは、Docker のコマンドも必要). いろんなソフトを試したいときに便利.「サーバ」を立てたいというとき、サーバのソフトを丸ごと Docker コンテナの中に入れておくと、サーバの運用保守(サーバを止めたりと、バージョンアップで入れ替えたりなど)が楽になる可能性がある
【サイト内の主な Docker 関連ページ】
- Docker Desktop のインストール,Ubuntu 22.04 コンテナとイメージの作成(Windows 上)
- Docker Engine,Docker Desktop のインストールと使用法,Docker Compose の「はじめよう」を実行(Ubuntu 22.04 上)
- Docker の概要: [PDF], [PPTX]
- Docker の基本機能: 別ページ »にまとめている.
【関連する外部ページ】
- Install Docker Engine のページ: https://docs.docker.com/engine/install/
Windows での Docker Engine, Docker Desktop のインストールと確認
Docker Desktop のインストール,Ubuntu 22.04 コンテナとイメージの作成(Windows 上)で説明している.
Ubuntu での Docker Engine, Docker Desktop のインストールと確認
Docker Engine,Docker Desktop のインストールと使用法,Docker Compose の「はじめよう」を実行(Ubuntu 22.04 上): 別ページ »で説明
Docker Compose
Docker Compose は, Docker を簡単に管理できるツール.環境変数を個々の Docker コンテナごとに変えるといったことも簡単にできるようになる.
【サイト内の主な Docker 関連ページ】
- Docker Desktop のインストール,Ubuntu 22.04 コンテナとイメージの作成(Windows 上)
- Docker Engine,Docker Desktop のインストールと使用法,Docker Compose の「はじめよう」を実行(Ubuntu 22.04 上)
- Docker の概要: [PDF], [PPTX]
- Docker の基本機能: 別ページ »にまとめている.
Docker を使い Ubuntu 22.04 の bash を使う
次のコマンドを実行する.exit で終了すると,コンテナは削除される(「--rm」を付けている)
docker run --rm -it --name myubuntu ubuntu:22.04 PS1='\h:\w\$ 'Docker の主なコマンド
- docker ps -a: コンテナの一覧表示
- docker ps: 実行中のコンテナの一覧表示
- docker images: イメージの一覧表示
- docker rm <コンテナID>: コンテナの削除
- docker rm <イメージID>: イメージの削除
- docker run ...: コンテナの作成(作成時に,イメージと,コンテナ名を指定できる)
- docker start <コンテナ名>: 起動
- docker exit <コンテナ名>: コンテナを用いてコマンドを実行
- docker system prune: イメージ,実行状態にないコンテナ等をすべて削除
DreamGaussian
DreamGaussianは3Dコンテンツ生成の新しいフレームワークであり、特に画像から3Dモデルを生成する(Image-to-3D)とテキストから3Dモデルを生成する(Text-to-3D)の二つの主要なタスクに対応しています.既存の手法であるNeural Radiance Fields(NeRF)は高品質な結果を出すものの、計算時間が長いという課題がありました.DreamGaussianの特長は、3Dガウススプラッティングモデルを用いることで、メッシュの抽出とUV空間でのテクスチャの精緻化が効率的に行える点です.この新しいアプローチにより、DreamGaussianは既存のNeRFベースの手法よりも高速な3Dコンテンツ生成を実現しています.さらに、実験結果では、DreamGaussianがImage-to-3DとText-to-3Dの両方のタスクで既存の方法よりも高速であることが確認されています.
【文献】
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, Gang Zeng, DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation, arXiv:2309.16653v1, 2023.
https://arxiv.org/pdf/2309.16653v1.pdf
【関連する外部ページ】
- 公式のオンラインデモ(Google Colaboratory): https://colab.research.google.com/drive/1sLpYmmLS209-e5eHgcuqdryFRRO6ZhFS?usp=sharing
- Image-to-3D の公式のオンラインデモ(Google Colaboratory): https://colab.research.google.com/drive/1sLpYmmLS209-e5eHgcuqdryFRRO6ZhFS?usp=sharing
元画像

中間結果(左),最終結果のスクリーンショット(右)


処理結果(3次元データ): b.obj, b.mtl, b_albedo.png
処理結果のスクリーンショット(動画):
- Text-to-3D の公式のオンラインデモ(Google Colaboratory): https://colab.research.google.com/github/camenduru/dreamgaussian-colab/blob/main/dreamgaussian_colab.ipynb

処理結果(3次元データ): icecream_mesh.obj, icecream_mesh.mtl, icecream_mesh_albedo.png, icecream_model.ply
処理結果のスクリーンショット(動画): icecream.mp4
- GitHub のページ: https://github.com/dreamgaussian/dreamgaussian
- Paper with Code のページ: https://paperswithcode.com/paper/dreamgaussian-generative-gaussian-splatting
DUTS データセット
DUTS データセットは,saliency detection のためのデータセットである. 10,553枚の訓練画像と5,019枚のテスト画像を含む.
- 訓練画像は ImageNet DET training/val set から収集された.
- テスト画像は ImageNet DET training/val set とSUN データセットから収集された.
いずれも手動でアノテーションされている.
次の URL で公開されているデータセット(オープンデータ)である.
URL: http://saliencydetection.net/duts/
- Papers with Code: https://paperswithcode.com/dataset/duts
- ImageNet データセットの文献
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, Imagenet: A large-scale hierarchical image database, CVPR, 2009.
- SUN データセットの文献
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, SUN database: Large-scale scene recognition from abbey to zoo, CVPR, 2010.
- DUTS データセットの文献
Lijun Wang, Huchuan Lu, Yifan Wang, Mengyang Feng, Dong Wang, Baocai Yin, and Xiang Ruan, Learning to detect salient objects with image-level supervision, CVPR, 2017.
https://openaccess.thecvf.com/content_cvpr_2017/papers/Wang_Learning_to_Detect_CVPR_2017_paper.pdf
Early Stopping
Early Stopping は, 正則化 (regularization) のための一手法である. training loss の減少が終わるのを待たずに,学習の繰り返しを打ち切る. このとき,検証用データでの検証において,validation loss が増加を開始した時点で,学習の繰り返しを打ち切る.Keras で Early Stopping を自動で行いたいとき,次のようにコールバックを書く.【Keras のプログラム】
from kernel.callbacks import EarlyStopping cb = EarlyStopping(monitor='var_loss', patience = 10)コールバックは,次のようにして使用する.
【Keras のプログラム】
history = m.fit(x_train, y_train, batch_size=32, epochs=50, validation_data=(x_test, y_test), callbacks=[cb])EasyOCR
EasyOCR は,多言語の文字認識のソフトウエア. テキスト検出に CRAFT を使用.

学習用のソースコードも公開されている.
【サイト内の関連ページ】
EasyOCR のインストールと動作確認(多言語の文字認識)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- 公式の GitHub のページ: https://github.com/JaidedAI/EasyOCR
- 公式のオンラインデモ: https://www.jaided.ai/easyocr/
【関連項目】 CRAFT, OCR
Google Colaboratory で,EasyOCR による日本語読み取りの実行
公式の手順 (https://github.com/JaidedAI/EasyOCR)による
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- EasyOCR のインストール
!pip3 install git+git://github.com/jaidedai/easyocr.git
- 処理したい画像ファイルを Google Colaboratory にアップロードする
- OCR の実行
「ja」は「日本語」の意味.
import easyocr reader = easyocr.Reader(['ja']) result = reader.readtext('1.png')
- 結果の確認
from IPython.display import display display(result)
JAIDED AI による EasyOCR のオンラインデモ
JAIDED AI による EasyOCR のオンラインデモの URL: https://www.jaided.ai/easyocr/

EdgeBoxes 法
エッジから,オブジェクトのバンディングボックス(包含矩形)を求める方法.
- 文献
C. L. Zitnick and P. Doll ́ar. Edge boxes: Locating object proposals from edges, ECCV, 2014.
- Papers with code の EdgeBoxes のページ: https://paperswithcode.com/method/edgeboxes
【関連項目】 物体検出
EfficientDet
zylo117 による EfficientDet の実装 (GitHub) のページ: https://github.com/zylo117
【関連項目】 物体検出
Google Colaboratory で,EfficientDet のインストール
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する)
# install requirements !pip3 install pycocotools numpy opencv-python opencv-contrib-python tqdm tensorboard tensorboardX pyyaml webcolors !pip3 install torch==1.4.0 !pip3 install torchvision==0.5.0 # run the simple inference script !rm -rf Yet-Another-EfficientDet-PyTorch !git clone https://github.com/zylo117/Yet-Another-EfficientDet-PyTorch !mkdir Yet-Another-EfficientDet-PyTorch/weights !(cd Yet-Another-EfficientDet-PyTorch/weights; curl -L -O https://github.com/zylo117/Yet-Another-Efficient-PyTorch/releases/download/1.0/efficientdet-d0.pth) !(cd Yet-Another-EfficientDet-PyTorch; python3 efficientdet_test.py)
Eigen 3
Eigen 3 は, 次の機能を持つ C++ テンプレートライブラリ.SSEを使うように最適化されている.
- 線形演算:行列,ベクトル,数値解析,その他関連のアルゴリズム
Ubuntu で Eigen のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libeigen3-dev【関連する外部ページ】
- Eigen 3 の公式ページ: https://eigen.tuxfamily.org/index.php
【サイト内の関連ページ】
ELSED
【文献】
Iago Suárez and José M. Buenaposada and Luis Baumela, ELSED: Enhanced Line SEgment Drawing, Pattern Recognition, vol. 127, pages 108619, arXiv:2108.03144, 2022. doi: https://doi.org/10.1016/j.patcog.2022.108619.
arXiv: https://arxiv.org/abs/2108.03144
https://arxiv.org/pdf/2108.03144.pdf
【サイト内の関連ページ】 ELSED のインストールと動作確認(線分検知)(Build Tools, Python を使用)(Windows 上)
【関連する外部ページ】
- ELSED の GitHub のページ: https://github.com/iago-suarez/ELSED
- Google Colab のデモ: https://colab.research.google.com/github/iago-suarez/ELSED/blob/main/Python_ELSED.ipynb
- Paper with Code のページ: https://paperswithcode.com/paper/elsed-enhanced-line-segment-drawing
【関連項目】 線分検知
Emotion-Investigator
SanjayMarreddi の Emotion-Investigator は,顔検出 (face detection)と,Happy, Sad, Disgust, Neutral, Fear, Angry, Surprise の表情推定を行う.
【サイト内の関連ページ】
- 顔検出と表情推定(SanjayMarreddi/Emotion-Investigator,Python,TensorFlow を使用)(Windows 上)別ページ »で説明
【関連する外部ページ】
- SanjayMarreddi/Emotion-Investigator の GitHub の公式ページ: https://github.com/SanjayMarreddi/Emotion-Investigator
ESRGAN
超解像 (super resolution) の一手法.2018 年発表.
- 文献
Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Loy, Chen Change, ESRGAN: Enhanced super-resolution generative adversarial networks, The European Conference on Computer Vision Workshops (ECCVW), 2018.
- 公式のソースコード: https://github.com/xinntao/ESRGAN
- Papers with Code のページ: https://paperswithcode.com/paper/esrgan-enhanced-super-resolution-generative
- 超解像に関する Google Colaboratory のノートブック: https://colab.research.google.com/github/AwaleSajil/ISR_simplified/blob/master/ISR_simplified(youtube).ipynb#scrollTo=yn2qU_Gstb12
【関連項目】 GAN (Generative Adversarial Network), image super resolution, video super resolution, 超解像 (super resolution)
Everything
Everything は,Windows で動くファイル検索のソフトウェア.
Everything のページ http://www.voidtools.com/
Windows での Everything のインストール
Windows での cmake のインストールには,複数の方法がある.次のいずれかによりインストールできる.
- wingetを用いてインストールする.
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「
cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。REM Everything をシステム領域にインストール winget install --scope machine --id voidtools.Everything -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/qn /norestart" winget install --scope machine --id stnkl.EverythingToolbar -e --silent --accept-source-agreements --accept-package-agreements winget install --scope machine --id QL-Win.QuickLook -e --silent --accept-source-agreements --accept-package-agreements REM Everything の設定(サービス登録,OS起動時の自動起動,更新確認の無効化) if exist "C:\Program Files\Everything\Everything.exe" "C:\Program Files\Everything\Everything.exe" -install-service -install-run-on-system-startup -disable-update-notification REM Everything のパス設定 powershell -NoProfile -Command "$p='C:\Program Files\Everything'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and $c -notlike \"*$p*\"){[Environment]::SetEnvironmentVariable('Path',\"$p;$c\",'Machine')}" - Everything のページ http://www.voidtools.com/ からダウンロードしてインストール:
詳しくは 別ページ »で説明
FaceForensics++ データセット
FaceForensics++ データセットは,自動合成された顔画像のデータセット
- FaceForensics++ は,977本のyoutube動画を使用.Deepfakes, Face2Face, FaceSwap and NeuralTextures を用いて顔データを操作.1000 個の動画を作成
- 動画は,オクルージョンのない,ほぼ正面の顔が含むように選択されている.
FaceForensics++ データセットは,次の URL で公開されているデータセット(オープンデータ)である.
URL: https://github.com/ondyari/FaceForensics
【関連情報】
- FaceForensics++: Learning to Detect Manipulated Facial Images, Andreas Rssler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Niener
- Papers With Code の FaceForensics++ データセットのページ: https://paperswithcode.com/dataset/faceforensics-1
FairFace (Face Arrtibute Dataset for Balanced Race, Gender, and Age)
性別,年齢,人種に関するバイアス (bias) 等の問題がないとされる顔データセットが発表された.2021年発表. 顔の性別,年齢等の予測の精度向上ができるとされている.
- Karkkainen, Kimmo and Joo, Jungseock, FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation, Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1548-1558, 2021
- GitHub のページ: https://github.com/dchen236/FairFace
【関連項目】 dlib, 顔のデータベース, 顔ランドマーク (facial landmark), 顔の性別,年齢等の予測
Google Colaboratory での FairFace デモプログラムの実行
顔の性別,年齢等の予測を行う.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- ソースコード等のダウンロード
!git clone https://github.com/dchen236/FairFace
- 公式の GitHub のページの記載により,事前学習済みモデルをダウンロードする
公式の GitHub のページ: https://github.com/dchen236/FairFace
2つのファイルをダウンロードする.

- いまダウンロードしたファイルについて.
Google Colaboratory 「fair_face_models」という名前のディレクトリを作る. そして,いまダウンロードしたファイルのファイル名を次のように変えて, 「fair_face_models」ディレクトリの下に置く. (ファイル名については,predict.py の中で指定されているファイル名にあわせる)
- 実行する
%cd FairFace !python3 predict.py --csv test_imgs.csv
test_imgs.csv には,次の画像ファイルのファイル名が設定されている.
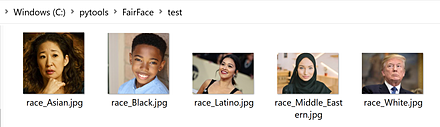 自前の画像で動作確認したいときは,画像ファイル名を書いた csv ファイルを準備する
自前の画像で動作確認したいときは,画像ファイル名を書いた csv ファイルを準備する - 実行結果の確認
性別,年齢などが推定されている.
!cat test_outputs.csv
Windows での FairFace デモプログラムの実行
顔の性別,年齢等の予測を行う.
- 前準備として pytorch, dlib のインストール,Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/を行っておくこと
- ソースコード等のダウンロード
git clone https://github.com/dchen236/FairFace - 公式の GitHub のページの記載により,事前学習済みモデルをダウンロードする
公式の GitHub のページ: https://github.com/dchen236/FairFace
2つのファイルをダウンロードする.
- いまダウンロードしたファイルについて.
「fair_face_models」という名前のディレクトリを作る. そして,いまダウンロードしたファイルのファイル名を次のように変えて, 「fair_face_models」ディレクトリの下に置く. (ファイル名については,predict.py の中で指定されているファイル名にあわせる)

- 実行する
cd FairFace python predict.py --csv test_imgs.csv
test_imgs.csv には,次の画像ファイルのファイル名が設定されている.
自前の画像で動作確認したいときは,画像ファイル名を書いた csv ファイルを準備する - 実行結果の確認
性別,年齢などが推定されている.
type test_outputs.csv
Fashion MNIST データセット
Fashion MNIST データセットは,公開されているデータセット(オープンデータ)である.
Fashion MNIST データセットは,10 種類のモノクロ画像と,各画像に付いた ラベル(10 種類の中の種類を示す)から構成されるデータセットである.
- 画像の枚数:合計 70000枚.
(内訳)70000枚の内訳は次の通りである
60000枚:教師データ
10000枚:検証データ
- 画像のサイズ: 28x28 である.
- ラベル
- 0: T-shirt/top
- 1: Trouser
- 2: Pullover
- 3: Dress
- 4: Coat
- 5: Sandal
- 6: Shirt
- 7: Sneaker
- 8: Bag
- 9: Ankle boot
- 画素はグレースケールであり,画素値は0~255である.0が白,255が黒.
【文献】
Han Xiao, Kashif Rasul, and Roland Vollgraf, Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms, arXiv:1708.07747 [cs.LG], 2017.
【サイト内の関連ページ】
- Fashion MNIST データセットを扱う Python プログラム: 別ページ で説明している.
- Fashion MNIST データセットによる学習と分類(TensorFlow データセット,TensorFlow,Python を使用)(Windows 上,Google Colaboratroy の両方を記載)
【関連する外部ページ】
- 公式ページ: https://github.com/zalandoresearch/fashion-mnist
- TensorFlow データセットの Fashion MNIST データセット: https://www.tensorflow.org/datasets/catalog/fashion_mnist
【関連項目】 Keras に付属のデータセット, MNIST データセット, TensorFlow データセット, オープンデータ, 画像分類
Python での Fashion MNIST データセットのロード(TensorFlow データセットを使用)
次の Python プログラムは,TensorFlow データセットから,Fashion MNIST データセットのロードを行う. x_train, y_train が学習用のデータ.x_test, y_test が検証用のデータになる.
- x_train: サイズ 28 × 28 の 60000枚の濃淡画像
- y_train: 60000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
- x_test: サイズ 28 × 28 の 10000枚の濃淡画像
- y_test: 10000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
次の Python プログラムでは,TensorFlow データセットから,Fashion MNIST データセットのロードを行う. x_train と y_train を 25枚分表示することにより,x_train と y_train が,モノクロ画像であることが確認できる.
tensorflow_datasets の loadで, 「batch_size = -1」を指定して,一括読み込みを行っている.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings # MNIST データセットのロード mnist, mnist_metadata = tfds.load('mnist', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1) x_train, y_train, x_test, y_test = mnist['train'][0], mnist['train'][1], mnist['test'][0], mnist['test'][1] plt.style.use('default') plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) # squeeze は,サイズ1の次元を削除.numpy は tf.Tensor を numpy に変換 plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary) plt.xlabel(y_train[i].numpy()) # 確認表示 plt.show()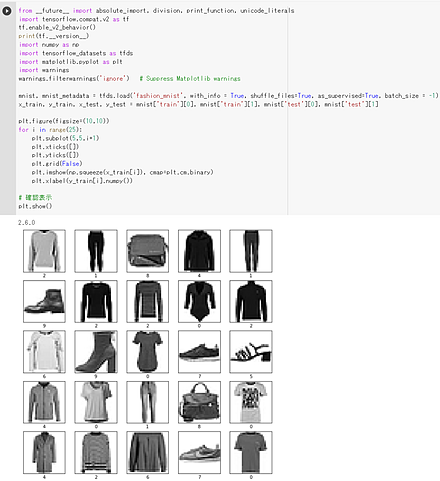
Python での Fashion MNIST データセットのロード(Keras を使用)
次の Python プログラムは,Keras に付属のデータセットの中にある Fashion MNIST データセットのロードを行う. x_train, y_train が学習用のデータ.x_test, y_test が検証用のデータになる.
- x_train: サイズ 28 × 28 の 60000枚の濃淡画像
- y_train: 60000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
- x_test: サイズ 28 × 28 の 10000枚の濃淡画像
- y_test: 10000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
from tensorflow.keras.datasets import fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()次の Python プログラムは,Keras に付属のデータセットの中にある Fashion MNIST データセットのロードを行う. x_train と y_train を 25枚分表示することにより,x_train と y_train が,モノクロ画像であることが確認できる.
import tensorflow.keras from tensorflow.keras.datasets import fashion_mnist %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings # Fashion MNIST データセットのロード (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data() plt.style.use('default') plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i], cmap=plt.cm.binary) plt.xlabel(y_train[i]) # 確認表示 plt.show()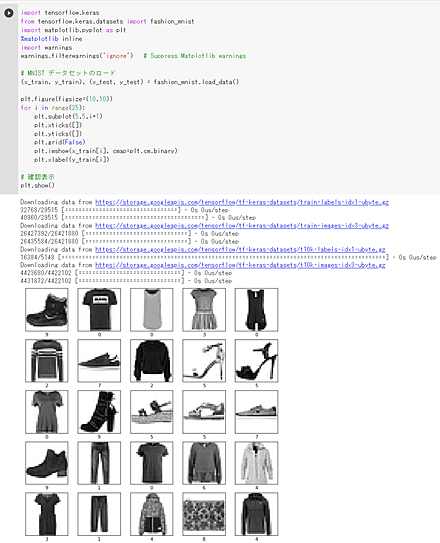
TensorFlow データセットからのロード,学習のための前処理
【TensorFlow データセット から Fashion MNIST データセット をロード】
- x_train: サイズ 28 × 28 の 60000枚の濃淡画像
- y_train: 60000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
- x_test: サイズ 28 × 28 の 10000枚の濃淡画像
- y_test: 10000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
結果は,TensorFlow の Tensor である.
type は型,shape はサイズ,np.max と np.mi は最大値と最小値.
tensorflow_datasets の loadで, 「batch_size = -1」を指定して,一括読み込みを行っている.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings # Fashion MNIST データセットのロード fashion_mnist, fashion_mnist_metadata = tfds.load('fashion_mnist', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1) x_train, y_train, x_test, y_test = fashion_mnist['train'][0], fashion_mnist['train'][1], fashion_mnist['test'][0], fashion_mnist['test'][1] print(fashion_mnist_metadata) # 【x_train, x_test, y_train, y_test の numpy ndarray への変換と,値の範囲の調整(値の範囲が 0 〜 255 であるのを,0 〜 1 に調整)】 x_train = x_train.numpy().astype("float32") / 255.0 x_test = x_test.numpy().astype("float32") / 255.0 y_train = y_train.numpy() y_test = y_test.numpy() print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train)) print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test)) print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train)) print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))Fast-Robust-ICP
ICP の一手法
Fast-Robust-ICP のページ(Git Hub): https://github.com/yaoyx689/Fast-Robust-ICP
【関連項目】 K 近傍探索 (K nearest neighbour), ICP
Google Colaboratory で,Fast-Robust-ICP の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- インストール
- Fast-Robust-ICP の実行
実行でのオプションについては,Fast-Robust-ICP のページ(Git Hub): https://github.com/yaoyx689/Fast-Robust-ICP
Windows での Fast-Robust-ICP のインストール
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- cmake のインストール: 別項目で説明している.
CMake の公式ダウンロードページ: https://cmake.org/download/
- Eigen 3 のインストール
-
コマンドプロンプトを管理者として開き次のコマンドを実行する.
c:\Fast-Robust-ICP にインストールされる.
cd /d c:%HOMEPATH% rmdir /s /q Fast-Robust-ICP git clone --recursive https://github.com/yaoyx689/Fast-Robust-ICP cd Fast-Robust-ICP rmdir /s /q build mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_INSTALL_PREFIX="c:/Fast-Robust-ICP" ^ -DEIGEN3_INCLUDE_DIRS="c:/eigen/include;c:/eigen/include/eigen3" ^ .. mklink c:\eigen\include\eigen c:\eigen\include\eigen3 cmake --build . --config Release del c:\eigen\include\eigen
FERET データベース
FERET データベースは顔のデータベース.詳細情報は,次のWebページにある.
https://www.nist.gov/itl/products-and-services/color-feret-database
【関連項目】 顔のデータベース
FFHQ (Flickr-Faces-HQ) データセット
FFHQ (Flickr-Faces-HQ) データセット は,70,000枚の顔画像データセット. 機械学習による顔の生成などの学習や検証に利用できるデータセットである.
- サイズ 1024×102,70,000枚の画像
- 年齢,民族,画像背景はさまざま
- 眼鏡,サングラス,帽子などもさまざま
- Flickr から取得.位置合わせとトリミング済み(Dlib を使用),画像の選別, 顔の彫刻や顔の絵画や顔の写真を除去(Amazon Mechanical Turk を使用)
FFHQ (Flickr-Faces-HQ) データセットは次の URL で公開されているデータセット(オープンデータ)である.
URL: https://github.com/NVlabs/ffhq-dataset
【関連情報】
- 文献
A Style-Based Generator Architecture for Generative Adversarial Networks, Tero Karras (NVIDIA), Samuli Laine (NVIDIA), Timo Aila (NVIDIA), CoRR, abs/1812.04948
- Papers With Code の FFHQ データセットのページ: https://paperswithcode.com/dataset/ffhq
【関連項目】 顔のデータベース
FFmpeg
FFmpeg は,動画のデコーダとエンコーダに関するソフトウェア.
【サイト内の関連ページ】
- 画像処理ソフト ImageMagick 7, 動画像処理ソフト FFmpeg のインストール(Windows 上): 別ページ »で説明
- FFmpeg のインストール(ビデオのエンコード・デコード)(Windows 上): 別ページ »で説明
【関連する外部ページ】
FFmpeg の公式ページ: https://ffmpeg.org/
FFTW
FFTW は, 離散フーリエ変換 (DFT) を行う C のプログラム集.1次元に限らず,より高次元でも動く.
【関連する外部ページ】
FFTW の公式ページ: https://www.fftw.org/
Windows での FFTW のインストール
Windows での FFTW3 のインストール(ソースコードを使用)(Build Tools for Visual Studio を利用)
FFTW 3.3.10 の非公式ビルド: fftw3.zip私がビルドしたもの,非公式,無保証, https://github.com/FFTW/fftw3 の ソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした. FFTW の GPL ライセンスによる.
zip ファイルは C:\ 直下で展開し,C:\fftw3 での利用を想定.
Ubuntu での FFTW のインストール
Ubuntu での FFTW3 のインストール(Ubuntu 上)
FIDTM (FIDT map)
FIDTM(Focal Inverse Distance Transform Map) は, crowd counting の一手法.2021年発表.
従来の density maps での課題を解決し,従来法よりも精度が上回るとされる. FIDT map を用いて頭部を得る LMDS もあわせて提案されている.
- 文献
Focal Inverse Distance Transform Maps for Crowd Localization and Counting in Dense Crowd, Liang, Dingkang and Xu, Wei and Zhu, Yingying and Zhou, Yu, arXiv preprint arXiv:2102.07925, 2021.
- FIDTM の公式のソースコード
- NWPU-Crowd データセットのダウンロード URL: https://drive.google.com/file/d/1drjYZW7hp6bQI39u7ffPYwt4Kno9cLu8/view
crowd coungting の結果の例

- Google Colaboratory のページ
群衆の数のカウントと位置の把握 (crowd counting) (FIDTM を使用)
このページでは,FIDTMの作者による公式のプログラムおよび学習済みモデルを使用して,群衆の数のカウントと位置の把握 (crowd counting) を行う手順を示している.
手順は,FIDTM 公式ページの説明通りに進める.難しい点はない.このページでは,Google Colaboratory で簡単に実行できるように,いくつかのコマンドを補っている.説明も補っている.
【関連用語】 crowd counting, JHU-CROWD++ データセット, NWPU-Crowd データセット, ShanghaiTech データセット, UCF-QNRF データセット
fine tuning (ファイン・チューニング)
学習済みモデルを使用する. 学習済みモデルの一部に新しいモデルを合わせた上で,追加のデータを使い学習を行う. このとき,学習済みモデルの部分と,新しいモデルの部分の両方について,パラメータ(重みなど)の調整を行う.
【関連項目】 画像分類 (image classification), 分類, 物体検出
画像分類のモデル DETR での添加学習(woctezuma の Google Colaboratory のページを使用)
woctezuma の Google Colaboratory のページを使用する
このプログラムは,物体検出等の機能を持つモデルである DETR を使い, fine tuning (ファイン・チューニング)と,物体検出を行う.
COCO データセットで学習済みの DETR について,確認のため, 物体検出を行ったあと, 風船(baloon)についてのfine tuning (ファイン・チューニング)を行い, 風船(baloon)が検出できるようにしている. 風船(baloon)は,COCO データセット には無い.
- woctezuma の Google Colaboratory のページを開く
- torch 1.8.0, torchvision 0.9.0, torchtext 0.9.0 を使うように書き換える
!pip3 uninstall -y torchtext !pip3 install torch==1.8.0 torchvision==0.9.0 torchtext==0.9.0 import torch, torchvision print(torch.__version__, torch.cuda.is_available()) torch.set_grad_enabled(False);
- ソースコードの要点を確認する.
COCO データセットのクラス名を確認する.
orange, apple, banana, doc, person などがある.baloon は無い.

detr_resnet50 の事前学習済みのモデルをダウンロードしている.

しきい値 0.9, 0.7, 0.0 の 3 通りで実行.しきい値を下げるほど,検出できる物体は増えるが,誤検知も増える傾向にある.

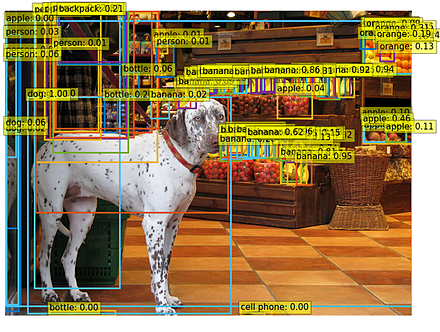
fine tuning を行うため,風船 (baloon) の画像,そして,風船の領域を示した情報(輪郭線,包含矩形)の情報を使う. 画像は複数.そのうち1枚は次の通り.

過学習は起きていないようである
fine tuning により,風船(baloon)を検出できるようになった. しきい値は 0.9, 0.7 の 2通り.

- 自前のデータでfine tuning を行いたいときは,このページの説明通り,COCO データのフォーマットでデータを準備する.
そのフォーマットは,/content/data/custom (Google Colaboratory の data/custom の下のファイル)が参考になる.
自前のデータが準備できたら,Google Colaboratory にアップロードし, 次のコードセルの「/content/data/custom」のところを書き換えて,再度実行する.
最初の物体検知(fine tuning の前)で,別の画像で試したいとき.画像ファイルをアップロード.プログラムは次のように書き換える.
fname = '/content/5m126sn2pov30qzu3pc49lampcp6.jpg' im = Image.open(fname) scores, boxes = detect(im, detr, transform)URL: https://github.com/woctezuma/finetune-detr
Flang
【サイト内の関連ページ】
【関連項目】 LLVM
flann
flann は近似近傍探索の機能を持ったソフトウェア
Windows での flann のインストール
Windows での flann のインストール(Windows 上): 別ページ »で説明
FlexGen
FlexGen は,大規模言語モデル (large language model)を用いた推論で必要とされる計算とメモリの要求を削減する技術. 実験では,大規模言語モデル OPT を,16GB の単一 GPU で実行したとき 100倍以上の高速化が可能であるとされている.
【文献】 Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Ce Zhang, Ion Stoica, Christopher Ré., High-throughput Generative Inference of Large Language Model with a Single GPU, 2023.
【サイト内の関連ページ】
- FlexGen のインストールと動作確認(大規模言語モデル,チャットボット)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
- Meta の言語モデルと日本語で対話できる chatBOT プログラム(chatBOT)(FlexGen, DeepL, Python を使用)(Windows 上): 別ページ »で説明
- 対話システム,chatBOT: PDFファイル, パワーポイントファイル
【関連する外部ページ】
FlexGen の GitHub のページ: https://github.com/FMInference/FlexGen
【関連項目】 OPT
FLIC (Frames Labeled In Cinema)データセット
FLIC は, 5003枚の画像(訓練データ: 3987枚,検証データ: 1016枚)で構成されている. 画像の上半身についてアノテーションが行われている. ほとんどの人物がカメラ正面を向いている.
ディープラーニングにより姿勢推定を行うためのデータとして利用できる.
次の URL で公開されているデータセット(オープンデータ)である. http://bensapp.github.io/flic-dataset.html
【関連情報】
- 文献
Sapp, B., Taskar, B.: Modec: Multimodal decomposable models for human pose estimation. In: Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, IEEE (2013) 3674–3681, https://www.cv-foundation.org/openaccess/content_cvpr_2013/papers/Sapp_MODEC_Multimodal_Decomposable_2013_CVPR_paper.pdf
- Papers With Code の FLIC データセットのページ: https://paperswithcode.com/dataset/flic
- TensorFlow データセットの FLIC データセット: https://www.tensorflow.org/datasets/catalog/flic
FordA データセット
FordA データセットは,時系列データである.
FordA データセットは,公開されているデータセット(オープンデータ)である.
URL: http://www.timeseriesclassification.com/description.php?Dataset=FordA
教師データ数:3601
テストデータ数: 1320
モーターセンサーにより計測されたエンジンノイズの計測値.
FSDnoisy18k データセット
20種類, 約 42.5 時間分のサウンドである.
次の URL で公開されているデータセット(オープンデータ)である.
http://www.eduardofonseca.net/FSDnoisy18k/
- 文献
Eduardo Fonseca, Manoj Plakal, Daniel P. W. Ellis, Frederic Font, Xavier Favory, and Xavier Serra, “Learning Sound Event Classifiers from Web Audio with Noisy Labels”, arXiv preprint arXiv:1901.01189, 2019
【関連項目】 sound data
FZKViewer
URL: https://www.iai.kit.edu/1302.php
Windows での FZKViewer のインストールは 別ページ »で説明
FZKViewer で CityGML のファイルを開くときは, File, Open, Open GML File... と操作する.
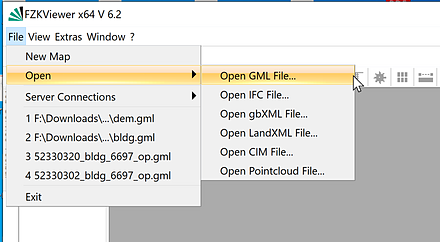
ファイルが読み込まれると,次のように表示される.
【関連項目】 CityGML
F 検定 (F test)
帰無仮説: 正規分布に従う2群の標準偏差が等しい . F 検定を,t 検定の行う前の等分散性の検定に使うのは正しくないという指摘もある.
R システム で,2群 s1, s2 の F 検定を行うプログラムvar.test(s1, s2)
【関連項目】 検定
GAN (generative adversarial network)
GAN (Generative Adversarial Network) では, 生成器 (generator) でデータを生成し, 識別機 (discriminator) で,生成されたデータが正当か正当でないかを識別する.
- 文献
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, Proceedings of the 27th International Conference on Neural Information Processing Systems 2014
- PyTorch-GAN のページ: https://github.com/eriklindernoren/PyTorch-GAN
- Keras-GAN のページ: https://github.com/eriklindernoren/Keras-GAN
- labmlai/annotated_deep_learning_paper_implementations のページ: https://github.com/labmlai/annotated_deep_learning_paper_implementations
【関連項目】 Applications of Deep Neural Networks, Real-ESRGAN, TecoGAN, Wasserstein GAN (WGAN), Wasserstein GAN with Fradient Penalty (WGAN-GP) ディープラーニング
バージョン管理システム Git
Git は、ソフトウェアの開発において使用されているバージョン管理システムである.git clone コマンドは、リモートリポジトリからソースコードをローカルマシンにコピー(クローン)するために使用される.シンプルなコマンドで,リモートリポジトリ全体のコピーや,リモートリポジトリとの同期を行えることが特徴である.
Windows 上で Git をインストールするには,公式ウェブサイト (https://git-scm.com/) から 64-bit Git for Windows Setup をダウンロードし,インストーラーの指示に従ってインストールを進める.ほとんどの設定は既定 (デフォルト) のままで問題ないが,PATH 環境変数の設定画面では 2 番目のオプションを選択することが推奨される.
次のコマンドの実行により,https://github.com/username/repository.git で指定されたリモートリポジトリを,現在のディレクトリにある repository というディレクトリにクローンできる.
git clone https://github.com/username/repository.git次のコマンドは,特定のブランチを指定してリポジトリをクローンしている.-b オプションは,クローンするブランチを指定する.この例では、v1.0 というブランチを指定している.
git -b v1.0 clone https://github.com/username/repository.git【サイト内の関連ページ】 Windows での Git のインストール: 別ページ »で説明
【関連する外部ページ】 Git の公式ページ: https://git-scm.com/
Ubuntu でのGit のインストール
Ubuntu での git のインストールは, 端末で,次のコマンドを実行する.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install gitGitHub からのファイルのダウンロード
GitHub からのファイルのダウンロードは, curl コマンドで, 次のように行う.
curl -L https://github.com/opencv/opencv/blob/master/samples/data/home.jpg?raw=true -o home.jpgGlueStick
GlueStick 法はイメージ・マッチングの一手法.2023年発表. 線分を使ったイメージ・マッチングは,照明条件や視点の変化,テクスチャのない領域でもマッチングできるメリットがある. GlueStick 法は,点と線分の両方を利用してイメージ・マッチングを行う. その際にCNNを利用.

【文献】
Rémi Pautrat, Iago Suárez, Yifan Yu, Marc Pollefeys, Viktor Larsson, GlueStick: Robust Image Matching by Sticking Points and Lines Together, ArXiv, 2023. ·
https://arxiv.org/pdf/2304.02008v1.pdf
【関連する外部ページ】
- GlueStick の GitHub のページ: https://github.com/cvg/GlueStick
- Google Colab のデモ: https://colab.research.google.com/github/cvg/GlueStick/blob/main/gluestick_matching_demo.ipynb
- Paper with Code のページ: https://paperswithcode.com/paper/gluestick-robust-image-matching-by-stickin
GNN (グラフニューラルネットワーク)
GNN は、グラフ構造を持つデータを用いた学習を可能とする技術である.
【関連項目】 PyTorch Geometric Temporal
GnuWin
GnuWin は, Win32 版の GNU ツールと,その他類似のオープンソースライセンスのツール
【関連する外部ページ】
- GnuWin の公式ページ: https://gnuwin32.sourceforge.net/index.html
- GnuWin プロジェクトのポータルページ: https://sourceforge.net/projects/getgnuwin32/
Google アカウント
Google アカウントは,Google のオンラインサービス等の利用のときに使うアカウント. Google オンラインサービスの利用条件などは,利用者で確認すること.
Google アカウントの取得: 別ページ »で説明Google Colaboratory
Google Colaboratory の利用により, オンラインで,Web ブラウザを用いて,次のことができる.
- Python のソースコード,説明文の編集.説明文には,リンク、添付ファイルを含めることができる.
- ノートブック内での Python プログラムの実行,実行結果の保存
- 「!pip」などの,システム操作
- 共同編集(相手先で、ソースコードの動作確認を行うなど).
Google Colaboratory は,オンラインで使用する. Google Colaboratory の使用には,Google アカウントの取得が必要.
詳しくは: 別ページ »で説明Google Colaboratory で TensorFlow, Keras のバージョン確認
Google Colaboratory のコードセルで,次の Python プログラムを実行
import tensorflow as tf print(tf.__version__) import keras print(keras.__version__)
Google Colaboratory で NVIDIA CUDA のバージョン確認
Google Colaboratory では,NVIDIA CUDA のバージョン確認のために,コードセルで,次の Python プログラムを実行
!nvcc -V
Google Colaboratory のコードセルで,次の Python プログラムを実行
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
Google Colaboratory で GPU の確認
!nvidia-smi --query-gpu=gpu_name,driver_version,memory.total --format=csv
Google Colaboratory を使用中であるかを判別する Python プログラム
try: from google.colab import drive USE_COLAB = True except: USE_COLAB = FalseGoogle Colaboratory での実行結果
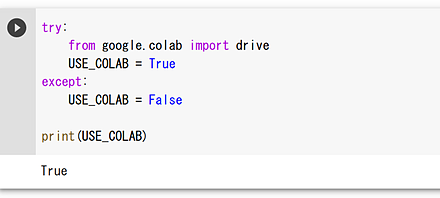
GPUとは
GPUは,グラフィックス・プロセッシング・ユニット(Graphics Processing Unit)の略です.その高い並列計算能力から,3次元コンピュータグラフィックス,3次元ゲーム,動画編集,科学計算,ディープラーニングなど,並列処理が必要な幅広い分野で活用されています.
.Graphviz
Graphviz はグラフデータ構造の機能を持ったソフトウェアである.
URL: https://graphviz.gitlab.io/
Windows での Graphviz のインストール
Windows での Graphviz のインストールには,複数の方法がある.次のいずれかによりインストールできる.
- winget をインストールしたのち,コマンドプロンプトを管理者として開き「winget install Graphviz」を実行
- Graphviz のページ GraphViz の URL: https://graphviz.gitlab.io/ からダウンロードしてインストール:
詳しくは 別ページ »で説明
インストールの終了後,C:\Program Files\Graphviz\bin にパスを通す.
Ubuntu での Graphviz のインストール
Ubuntu での graphviz のインストール
# パッケージリストの情報を更新 sudo apt update sudo apt -y install graphviz libgraphviz-dev python3-graphvizgrep
grep は,正規表現で,テキストファイルの中から行を選択する機能を持つソフトウェア.
Windows での grep のインストール
- GnuWin のページから grep for Windows をダウンロードし,インストール
- Windows のシステム環境変数 Path に次の値を追加し,パスを通す.
Windows での環境変数の設定は,マイコンピュータを右クリック → プロパティ→ 詳細設定 → 環境変数をクリック
Windows の画面の表示では、「\」(円マーク)が表示される
gsutil
gsutil は Google Cloud Strage のアクセス機能を持ったアプリケーション
公式ページは https://cloud.google.com/storage/docs/gsutil?hl=ja
Windows では, コマンドプロンプトを管理者として開き, 次のコマンドを実行することにより, gsutil のインストールを行うことができる.
cd /d c:%HOMEPATH% curl -L -O https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe .\GoogleCloudSDKInstaller.exeHe の初期値
He らの方法 (2015年) では,前層のユニット数(ニューロン数)を n とするとき, sqrt( 2 / n ) を標準偏差とする正規分布に初期化する. ただし,この方法は ReLU に特化した手法であるとされている. この方法を使うとき,層の入力は,正規化済みであること.
Kaiming He, Xiangyu hang, Shaoqing Ren and Jian Sun, Delving Deep into Rectifiers: Surpassing Human-Level, Performance on ImageNet Classification, pp. 1026^1-34.
HDF5
HDF5 は,階層データを扱うライブラリソフトウェア.
Suport th HDF Group の公式ページ: https://support.hdfgroup.org/
Windows での HDF5 のインストール
Windows での HDF5 のインストール(Windows 上): 別ページ »で説明
HELEN データセット
HELENデータセットは,顔画像と,顔のパーツの輪郭のデータセットである.
- 400×400 画素の顔画像2330枚
- 目,眉,鼻,唇,顎の輪郭を手動で作成.輪郭は,194個の顔ランドマークで扱う.
次の URL で公開されているデータセット(オープンデータ)である.
http://www.ifp.illinois.edu/~vuongle2/helen/
【関連情報】
- Le V., Brandt J., Lin Z., Bourdev L., Huang T.S. (2012) Interactive Facial Feature Localization. In: Fitzgibbon A., Lazebnik S., Perona P., Sato Y., Schmid C. (eds) Computer Vision ECCV 2012. ECCV 2012. Lecture Notes in Computer Science, vol 7574. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33712-3_49
- Papers With Code の Helen データセットのページ: https://paperswithcode.com/dataset/helen
【関連項目】 顔のデータベース
HierText データセット
HierTextは,文字認識,レイアウト解析,テキスト検出に利用できるデータセットである. このデータセットには,Open Imagesデータセットから選ばれた11639枚の画像が含まれており,これらの画像はテキストコンテンツとレイアウト構造が豊富である. さらに,約120万語の単語が提供されている. HierTextのアノテーションは,単語,行,段落のレベルを含んでいる. 訓練セットには8,281枚の画像が含まれ,検証セットには1,724枚の画像が含まれ,さらにテストセットには1,634枚の画像が含まれている.
【サイト内の関連ページ】 HierText データセットのインストール(テキスト検出,文字認識のデータセット)(Windows 上)
【関連する外部ページ】
公式のGitHub のページ https://github.com/google-research-datasets/hiertext
【関連項目】 Unified Scene Text Detection
HMDB51 (a large human motion database) データセット
HMDB51 (a large human motion database) データセット は,人間の行動データセット. 機械学習による行動分類,行動認識,ビデオ検索などの学習や検証に利用できるデータセットである.
- 主に映画から収集.その他,Prelinger archive,YouTube,Google video からも収集.
- 6849個のクリップ
- クリップは,アクションカテゴリ(「ジャンプ」,「キス」,「笑い」など)に分類済み.アクションカテゴリは 51種類.各アクションカテゴリは,最低でも 101個のクリップを含む.
- アクションカテゴリは,次の5つのタイプに分類されている. H.Kuehne,H.Jhuang,E.Garrote,T.Poggio,T.Serreの5種類である.
HMDB51 (a large human motion database) データセット >は次の URL で公開されているデータセット(オープンデータ)である.
https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#introduction
【関連情報】
- H. Kuehne, H. Jhuang, E. Garrote, T. Poggio and T. Serre, "HMDB: A large video database for human motion recognition," 2011 International Conference on Computer Vision, 2011, pp. 2556-2563, doi: 10.1109/ICCV.2011.6126543.
- Papers With Code の HMDB51 データセットのページ: https://paperswithcode.com/dataset/hmdb51
- PyTorch の HMDB51 データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.HMDB51
Hour Grass Network
Hour Grass Network は,stacked hourglass と呼ばれるアーキテクチャを特色とする CNN (convolutional neural network) である.
姿勢推定 (pose estimation) は,画像から,関節 (joint) の (x,y) 座標を得たり, ヒートマップを得る(ヒートマップでは,画素ごとに値を持ち,その値は,関節である確率が高いほど,高い値になる) 姿勢制御では,さまざまなスケールでの情報を扱うことが課題とされ, stacked hourglass で解決できるとされている. hougrass では,最初にプーリングを行い,その後アップサンプリングを行う. hougrass を直接に並べて stacked hourglass を構成する.
Hour Grass Network の文献は次の通りである.
A. Newell, K. Yang, and J. Deng. Stacked hourglass net- works for human pose estimation. In ECCV, 2016, CoRR, abs/1603.06937.
https://arxiv.org/pdf/1603.06937v2.pdf
【関連項目】 姿勢推定
Windows でのインストールと学習
Hour Grass Network を用いた姿勢推定については,次の文献がある.
qhttps://github.com/bearpaw/pytorch-pose
上の文献では,ディープラーニングにより,人体全身の姿勢推定を行っている. その学習は,次の手順で行う
- https://github.com/bearpaw/pytorch-pose の記載通りに,前もって行っておくこと).
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- Python 3.6, Scipy 1.1.0, pytorch で動く
git clone https://github.com/bearpaw/pytorch-pose py -3.6 -m pip install scipy==1.1.0 imutils easydict progress py -3.6 -m pip install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117 cd pytorch-pose mkdir .\checkpoint mkdir .\checkpoint\mpii mkdir .\checkpoint\mpii\hg_s1_b1 # MPII データセットを用いた学習 py -3.6 .\example\main.py --dataset mpii --arch hg --stack 1 --block 1 --features 256 --checkpoint .\checkpoint\mpii\hg_s1_b1 --anno-path .\data\mpii\mpii_annotations.json --image-path .\mpii\imagesHQ-SAM (Segment Anything in High Quality)
HQ-SAMは、既存のSAM(Segment Anything Model)を拡張し、より高精度なゼロショットセグメンテーションを実現する手法である.SAMは、プロンプト(点、バウンディングボックス、粗いマスクなど)を入力として、多様なオブジェクトや視覚構造のセグメンテーションを可能にするモデルである.しかし、SAMは細かい構造を持つオブジェクトに対するセグメンテーションが不十分で、その精度に限界がある.この問題を解決するために、HQ-SAMはSAMを拡張している.HQ-SAMでは、SAMのマスクデコーダに新しい学習可能な「HQ-Output Token」を導入している.さらに、グローバルなセマンティックコンテキストとローカルな境界(バウンダリ)の詳細を両方考慮する「Global-local Feature Fusion」も導入されている.複数のデータセットでの実験により、HQ-SAMが高精度なセグメンテーションマスクを生成できることが確認されている.
【文献】 Ke, Lei and Ye, Mingqiao and Danelljan, Martin and Liu, Yifan and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher, Segment Anything in High Quality, arXiv:2306.01567, 2023.
https://arxiv.org/pdf/2306.01567v1.pdf
【サイト内の関連ページ】
- ゼロショットのセグメンテーション(HQ-SAM,Light HQ-SAM,Python,PyTorch を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- 公式の GitHub ページ: https://github.com/SysCV/sam-hq
- HQ-SAM (ゼロショットのセグメンテーション)のオンラインデモ(Hugging Face上): https://huggingface.co/spaces/sam-hq-team/sam-hq
- HQ-SAM (ゼロショットのセグメンテーション)のオンラインデモ(Google Colaboratory 上): https://colab.research.google.com/drive/1QwAbn5hsdqKOD5niuBzuqQX4eLCbNKFL?usp=sharing
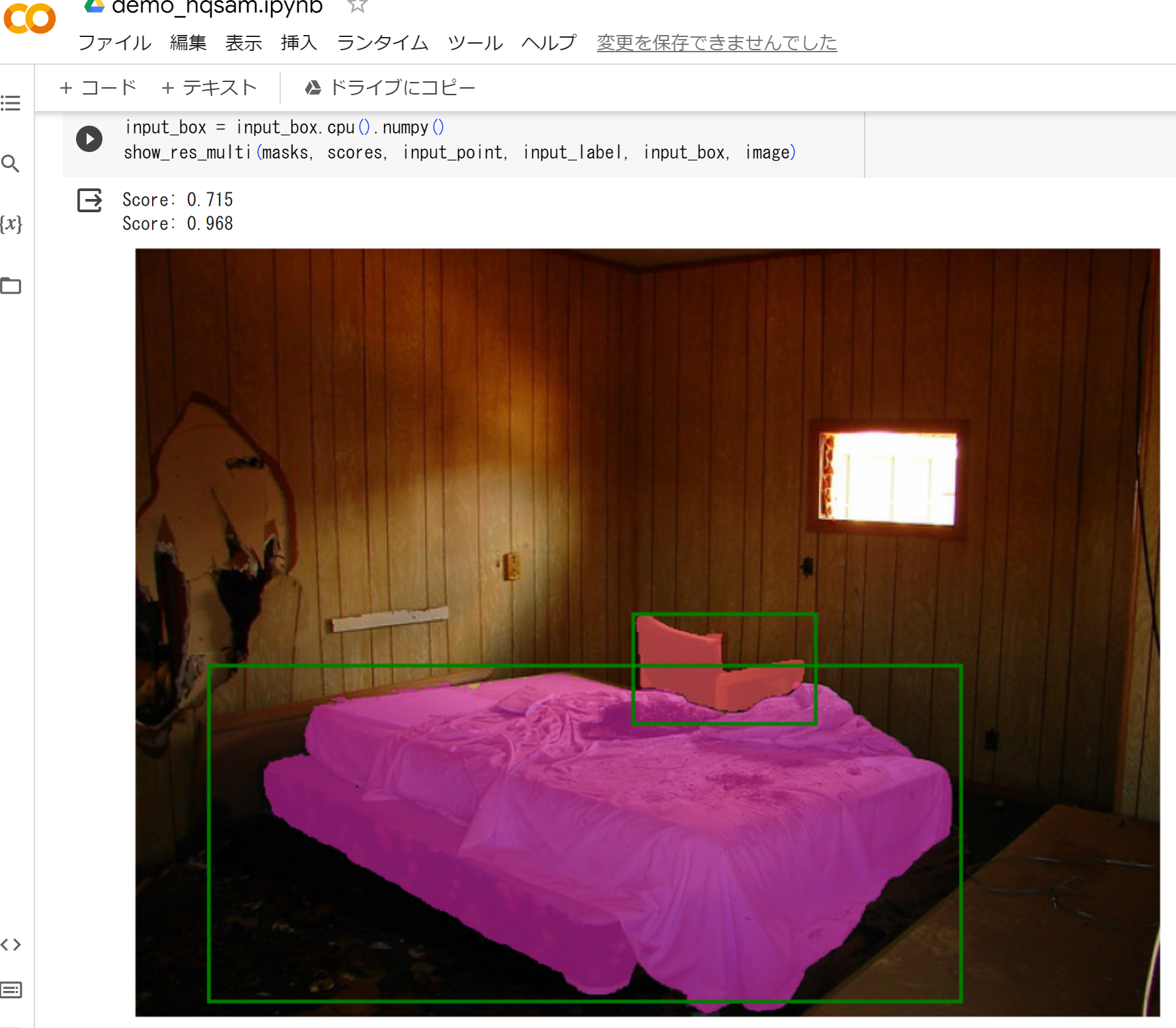
- Paper with Code のページ: https://paperswithcode.com/paper/segment-anything-in-high-quality
【関連項目】 SAM (Segment Anything Model)
HRNetw32
姿勢推定(pose estimation) の一手法.
【関連項目】 MMPose, 姿勢推定(pose estimation)
Human 3.6M データセット
ディープラーニングにより姿勢推定を行うためのデータとして利用できる.
利用には, https://vision.imar.ro/human3.6m/register.php での申請を必要とする.
http://vision.imar.ro/human3.6m/description.php
Catalin Ionescu, Dragos Papava, Vlad Olaru and Cristian Sminchisescu, Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, No. 7, July 2014
iBUG 300-W データセット
iBUG 300-W データセットは, 顔の 68 ランドマーク のデータである.7764枚の顔画像について,手作業で,顔の 68 ランドマークのアノテーションとラベル付が行われている.
顔ランドマーク (facial landmark)は,目,眉,鼻,口,あごのラインなど,顔のパーツの構造を特定でぃる形状予測器 (shape predictor) の学習に使うことができる.
iBUG 300-W データセットの URL: https://ibug.doc.ic.ac.uk/resources/300-W/
【関連項目】 顔の 68 ランドマーク, 顔ランドマーク (facial landmark), 顔のデータベース
image content removal(画像コンテンツの除去)
画像の中で,除去する対象となるオブジェクトの境界などを指定することにより, 指定されたオブジェクトを除去し,除去された部分の画素は, image completion and extrapolation で補う.
次の文献では, 除去する対象となるオブジェクトの境界を正確に指定しなくても, オブジェクトスコアマップ (object score map) を scene parsing network を用いて 推定することにより, image content removal(画像コンテンツの除去)ができるとされている.
- Huang JB, Kang SB, Ahuja N, Kopf J, Image completion using planar structure guidance, ACM Transactions on Graphics (TOG), 2014.
この論文の手法の SunkskyF による実装は,次のページで公開されている.https://github.com/SunskyF/StructCompletion-python
実行の前準備として,「pip install -U opencv-python opencv-contrib-python」を実行する.demo.py の実行結果は次のとおりである.


【関連項目】 image completion and extrapolation
ImageMagick
- 画像のサイズの例(幅のピクセル数を 100に指定)
「100x」のように x を付ける.
convert -resize 100x -unsharp -quality 100 fruits.jpg 1.jpg - 画像のサイズの例(幅のピクセル数を 100に指定)
「100x」のように x を付ける.
こちらは,元ファイルを上書き
mogrify -resize 100x -unsharp -quality 100 fruits.jpg - 画像の幅が 440 より大きい場合には,幅が 440 になるように縮小する.
for i in *.png; do if [ `identify -format "%[width]" $i` -gt 440 ]; then echo $i mogrify -resize 440x -unsharp 0x1+0.5+0 -quality 100 $i fi done
【関連項目】 画像データの形式変換, MagickWand
ImageMagick の主なコマンド
- display --画像の表示,変換
- animate --画像を連続表示してアニメーション
- convert --画像ファイル変換,エフェクト
- mogrify --連続画像の変換・エフェクト,一気に画像フォーマットを変換する.
- montage -- 1個の画像ファイルにたくさんの画像を詰め込む
- identify --画像フォーマットを調べる
- combine --画像を結合
Windows でのインストールは,別ページ »で説明Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install imagemagickimage matting
前景の色を F,背景の色を B とし,元画像の色は I = alpha * F + (1 - alpha) * B とする. 元画像 I は既知であり,F, B, alpha は未知であるとする. このとき alpha を推定することを image matting という(alpha image matting ともいう).
写真や動画の前景背景分離に用いることができる. 物体検出 や salient object detection との違いとしては, ガラスなどの半透明なもの,髪の毛や網のようなもの,そして,前景が必ずしも画面中央に集まっているとは限らず,画面全域にある(網越しに外を見るような場合)を想定していることがある.
【関連情報】
- Papers with Code の image matting のページ: https://paperswithcode.com/task/image-mattin
【関連項目】 GCA, IndexNet, DIM, AIM-500 (Automatic Image Matting-500) データセット
Trimap-based matting
trimap では,次の 3つを考える. 前景である画素は白,背景である画素は黒,transaction である画素は灰色の 3通りに 塗り分けた画像を trimap という.
- 前景 (foregdound)
- 背景 (background)
- transition: どちらであるか判断できないか,細かすぎて,塗分けが困難な領域
Trimap-based matting では, 元画像と,その trimap を用いて image matting を行う. ディープラーニングによる Trimap-based matting の手法としては,Xu らの Deep Image Matting (DIM) (2017年)(文献 [1]) などが知られている.
【関連情報】
- 文献 [1], Xu らの Deep Image Matting (DIM)
Ning Xu, Brian Price, Scott Cohen, Thomas Huang, Deep Image Matting CVPR 2017, CoRR, https://arxiv.org/abs/1703.03872v3
Backgroud matting
Backgroud matting は,image matting において背景画像を用いる. つまり,元画像と,追加の背景画像を用いて image matting を行う. 元画像での背景と,追加の背景画像は同一の場所で撮影されたものが想定されている.そのとき,全に一致しなくてもよい(わずかな位置のずれや照明条件の変化は許容される).
ディープラーニングによるbackground matting Shanchuan Lin らの Backgroud Matting (2021年)(文献 [2])などが知られる. Backbone に ResNet50, ASPP (Atrous Spatial Pyramid Pooling, DeepLabv3 のものに従う).
Background matting では,Trimap を必要としない. ZOOM などのビデオ会議などで,グリーンバックを使わずに,前景と背景を分離するとき, 背景の取得は容易であり, Background matting は有用である.
【関連情報】
- 文献 [2], Shanchuan Lin らの Backgroud Matting
Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian Curless, Steve Seitz, Ira Kemelmacher-Shlizerman, Real-Time High-Resolution Background Matting CVPR 2021, also CoRR, abs/2012.07810v1, 2021.
https://arxiv.org/pdf/2012.07810v1.pdf
Portrait matting
人物や動物に特化した image matting である. 人物や動物が写った写真や動画に対して,image matting を行う. このとき,Trimap や 背景画像などの追加の情報を準備することなく image matting を行う手法が種々提案されている.
Automatic image matting
Trimap や 背景画像などの追加の情報を必要とせず, 人物や動物など以外でも(例えば,半透明のコップ,網ごしの風景写真など) image matting を行うもの. Li らの GFM (文献 [3])(2020 年)は,ディープラーニングによる Trimap の推定が行われており, Li らの unified semantic model (文献 [4])(2021 年)は,Salient Opaque, Salient Transparent/Meticulous, Non-Salient の 3種類の画像を扱えるモデルであり,GGM の拡張により,unified semantic model の推定を行っている.
- 文献 [3]
Jizhizi Li, Jing Zhang, Stephen J Maybank, and Dacheng Tao. End-to-end animal image matting. arXiv preprint arXiv:2010.16188, 2020.
- 文献 [4]
Jizhizi Li , Jing Zhang and Dacheng Tao, Deep Automatic Natural Image Matting, 2021. https://arxiv.org/pdf/2107.07235v1.pdf
ImageNet データセット
ImageNet データセットは、画像分類や物体検出のタスクで利用されるデータセット. 機械学習における画像分類や物体検出のタスクで、学習、検証、テストに利用される. ImageNet-1K は ImageNet データセットのサブセットで、ImageNet Large Scale Visual Recognition Challenge(ILSVRC)でベンチマークで使用されている.
- 画像の総数: 14,197,122枚(ImageNet-1K では約120万枚)
- クラス数: 約20,000種類(ImageNet-1K では1000種類)、さまざまな種類を網羅
- ラベル付き画像:
画像が、ある特定のクラスのオブジェクトを含んでいるか(「有」、「無」の二値)
- 物体検出のアノテーション
画像内(ImageNet-1K では約45万枚)のオブジェクト(ImageNet-1K では約150万以上)の位置と大きさ(中心の座標、幅、高さ)、クラス
- 画像情報:画像のサムネイルとURL.URLを使用して画像をダウンロードする場合、各画像の利用条件を利用者が確認こと
【プログラム
ImageNet-1K の 1000クラスの表示
このプログラムはImageNet-1Kの1000クラスのデータファイル(クラス番号とクラス名のデータファイル)をダウンロードし、JSONに変換して保存した後、クラス番号とクラス名をすべて表示します.インターネット接続が必要で、requestsライブラリが必要です.
import requests import json def download_file(url, filename): """指定されたURLからファイルをダウンロードし、ローカルに保存する""" response = requests.get(url) with open(filename, 'wb') as file: file.write(response.content) def convert_txt_to_json(txt_file, json_file): """テキストファイルをJSON形式に変換し、保存する""" imagenet_classes = {} with open(txt_file, "r") as f: for i, line in enumerate(f): imagenet_classes[str(i)] = line.strip() with open(json_file, "w") as f: json.dump(imagenet_classes, f) def display_classes(json_file): """JSONファイルからクラス情報を読み込み、表示する""" with open(json_file) as f: imagenet_classes = json.load(f) for class_id, class_name in imagenet_classes.items(): print(f"Class ID: {class_id}, Class Name: {class_name}") # メイン処理 if __name__ == "__main__": url = "https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt" txt_filename = "imagenet_classes.txt" json_filename = "imagenet_class_index.json" # ファイルのダウンロード download_file(url, txt_filename) # テキストファイルをJSONに変換 convert_txt_to_json(txt_filename, json_filename) # クラス情報の表示 display_classes(json_filename)ImegeNet のクラス: 別ファイルに記載している.
ImageNet データセットは次の URL で公開されているデータセット(オープンデータ)である.
ImageNet データセットの URL: https://image-net.org/
【関連する外部ページ】
- 文献: abs/1409.0575
- Papers With Code の ImageNet データセットのページ: https://paperswithcode.com/dataset/imagenet
- PyTorch の ImageNet データセット: https://pytorch.org/vision/stable/datasets.html#imagenet
- TensorFlow データセットの imagenet2021 データセット: https://www.tensorflow.org/datasets/catalog/imagenet2012
IMDb データセット
IMDb の URL: https://www.imdb.com/
IMDb での映画の批評は,批評文とスコア(10点満点)である. IMDb データセットでは,7点以上の批評は positive,4点以下の批評は negative としている.つまり,2種類ある. そして,IMDb データセットには,positive か negative の批評のみが含まれている(中間の点数である 5点,6点のものは含まれていない).そして, positive,negative の批評が同数である. 学習用として,positive,negative がそれぞれ 25000. 検証用として,positive,negative がそれぞれ 25000.
IMDb データセットのURL: https://ai.stanford.edu/%7Eamaas/data/sentiment/
【関連項目】 Keras に付属のデータセット, TensorFlow データセット, オープンデータ,
Python での IMDb データセットのロード(TensorFlow データセットを使用)
次の Python プログラムは,TensorFlow データセットから,IMDb データセットのロードを行う. x_train, y_train が学習用のデータ.x_test, y_test が検証用のデータになる.
- x_train: 25000個のテキスト
- y_train: 25000個の数値
- x_test: 25000個のテキスト
- y_test: 25000個の数値
次のプログラムでは,そして確認表示を行う.
tensorflow_datasets の loadで, 「batch_size = -1」を指定して,一括読み込みを行っている.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings imdb_reviews, imdb_reviews_metadata = tfds.load('imdb_reviews', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1) x_train, y_train, x_test, y_test = imdb_reviews['train'][0], imdb_reviews['train'][1], imdb_reviews['test'][0], imdb_reviews['test'][1] # 確認表示 import pandas as pd display(pd.DataFrame(x_train[0:14], y_train[0:14]))
Python での IMDb データセットのロード(Keras を使用)
IMDb データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import imdb (x_train, y_train), (x_test, y_test) = imdb.load_data()Imm 顔データベース (IMM Face Database)
40種類の人間の顔を撮影した240枚の画像. 58個の顔ランドマークが付いている.
URL: http://www2.imm.dtu.dk/pubdb/pubs/3160-full.html
M. M. Nordstr{\o}m and M. Larsen and J. Sierakowski and M. B. Stegmann, The IMM Face Database - An Annotated Dataset of 240 Face Images
http://www2.imm.dtu.dk/pubdb/edoc/imm3160.pdf
【関連項目】 顔のデータベース
iNaturalist データセット
画像のデータセット.アノテーションとしてバウンディングボックスが付けられている.Imbalance の大きさを特徴とする.
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://github.com/visipedia/inat_comp/tree/master/2017
- クラス数:5,089
- 学習と検証 (validation) 用の 675,000 枚の画像.テスト用の 183,000 枚の画像.
- バウンディングボックス数: 183,000
- Imbalance 値: 453.44
- 文献 Grant Van Horn, Oisin Mac Aodha, Yang song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, Serge Belongie, The iNaturalist Species Classification and Detection Dataset CVPR 2018, 2018.
- Papers with Code のページ: https://paperswithcode.com/dataset/inaturalist
- TensorFlow のモデル: https://github.com/tensorflow/models
InsightFace
顔検出 (face detection),顔のアラインメント, 顔検証 (face verification), 顔識別 (face identification)の機能を持つ.
- 顔検出 (face detection): RetinaFace, SCRFD, blazeface_paddle をサポートしている.
InsightFace の GitHub のページ: https://github.com/deepinsight/insightface
【関連項目】 ArcFace 法, Chandrika Deb の顔マスク検出, Dlib の顔検出, face alignment, MobileFaceNets, 顔検出 (face detection)
Google Colaboratory で,InsightFace による顔検出及び年齢と性別の予測
公式ページ (https://github.com/deepinsight/insightface/tree/master/python-package) に記載の顔検出及び年齢と性別の予測のプログラムを変更して実行.
このプログラムは buffalo_l という名前の事前学習済みモデルを使用している.
- 顔検出のモデル: SCRFD-10GF
- 顔認識のモデル: ResNet50@WebFace600K
- 顔のアラインメント: 2d106, 3d68
- 属性: 年齢,性別
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- InsightFace のインストール
GPU を使わない場合には「onnxruntime-gpu」でなく,「onnxruntime」をインストールすること.
!pip3 install -U insightface onnxruntime-gpu opencv-python numpy
- 顔検出及び年齢と性別の予測の実行
動作確認のため,公式ページ (https://github.com/deepinsight/insightface/tree/master/python-package) に記載の,顔検出及び年齢と性別の予測のプログラムを実行する.
このプログラムは buffalo_l という名前の事前学習済みモデルを使用している.- 顔検出のモデル: SCRFD-10GF
- 顔認識のモデル: ResNet50@WebFace600K
- 顔のアラインメント: 2d106, 3d68
- 属性: 年齢,性別
このプログラムの実行により,result.jpg ファイルができる.
import cv2 import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import insightface from insightface.app import FaceAnalysis from insightface.data import get_image as ins_get_image app = FaceAnalysis(providers=['CUDAExecutionProvider', 'CPUExecutionProvider']) app.prepare(ctx_id=0, det_size=(640, 640)) img = ins_get_image('t1') faces = app.get(img) rimg = app.draw_on(img, faces) for i in faces: print("gender %s, age %d" % (('F' if i['gender'] == 0 else 'M'), i['age'])) plt.style.use('default') plt.imshow(cv2.cvtColor(rimg, cv2.COLOR_BGR2RGB)) plt.show() cv2.imwrite("./result.jpg", rimg)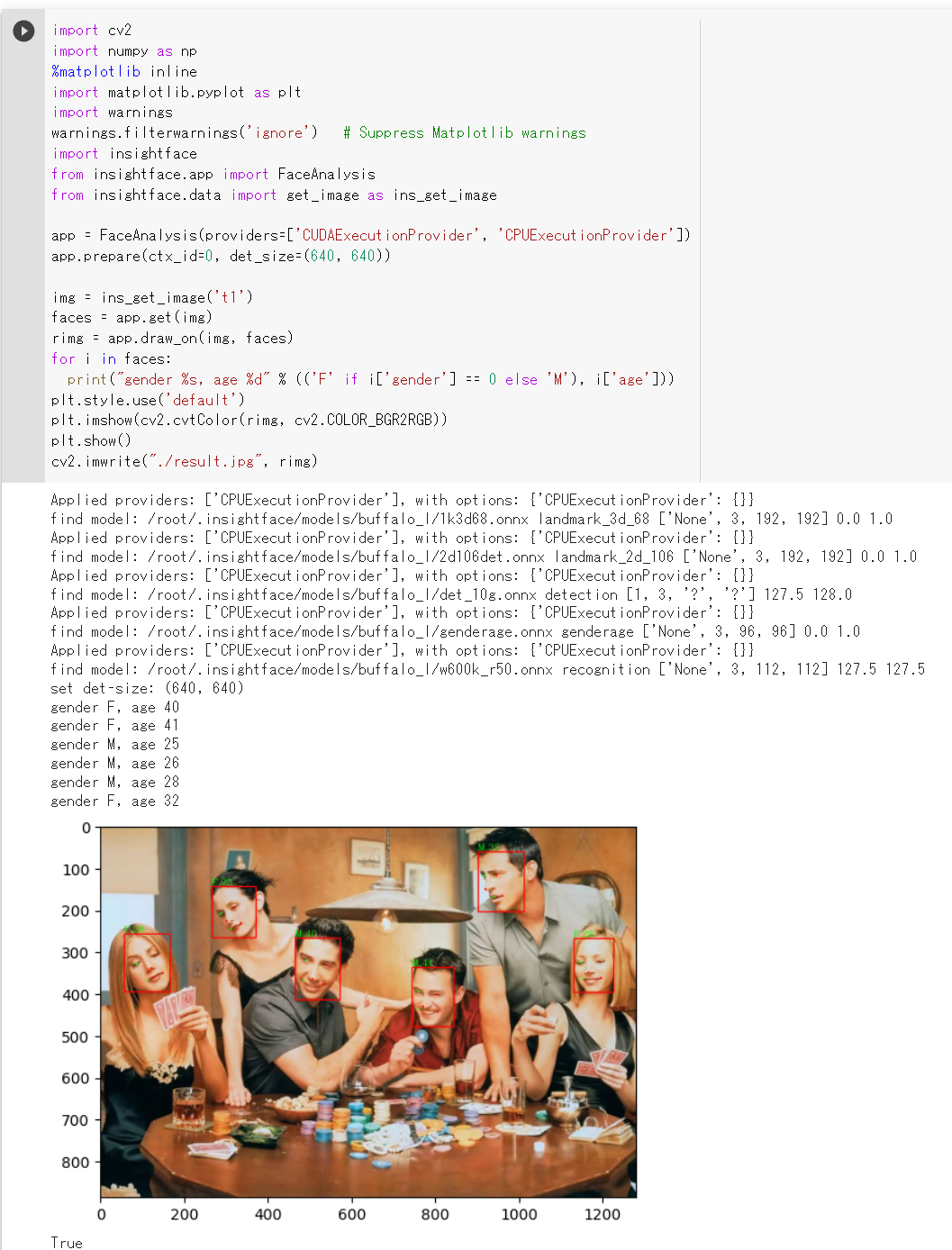
- 顔検出及び年齢と性別の予測の実行
顔の画像ファイルは何でも良いが,ここでは,画像ファイルをダウンロードしている.
!curl -O https://www.kkaneko.jp/sample/face/3284.png !curl -O https://www.kkaneko.jp/sample/face/3285.png !curl -O https://www.kkaneko.jp/sample/face/3287.png !curl -O https://www.kkaneko.jp/sample/face/3288.png !curl -O https://www.kkaneko.jp/sample/face/3289.png !curl -O https://www.kkaneko.jp/sample/face/3290.png
いま準備した画像ファイルについて,顔検出及び年齢と性別の予測の実行
import cv2 import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import insightface from insightface.app import FaceAnalysis from insightface.data import get_image as ins_get_image app = FaceAnalysis(providers=['CUDAExecutionProvider', 'CPUExecutionProvider']) app.prepare(ctx_id=0, det_size=(640, 640)) files = ['3284.png', '3285.png','3287.png', '3288.png', '3289.png', '3290.png'] for f in files: img = cv2.imread(f) faces = app.get(img) for i in faces: print("gender %s, age %d" % (('F' if i['gender'] == 0 else 'M'), i['age'])) rimg = app.draw_on(img, faces) plt.style.use('default') plt.imshow(cv2.cvtColor(rimg, cv2.COLOR_BGR2RGB)) plt.show()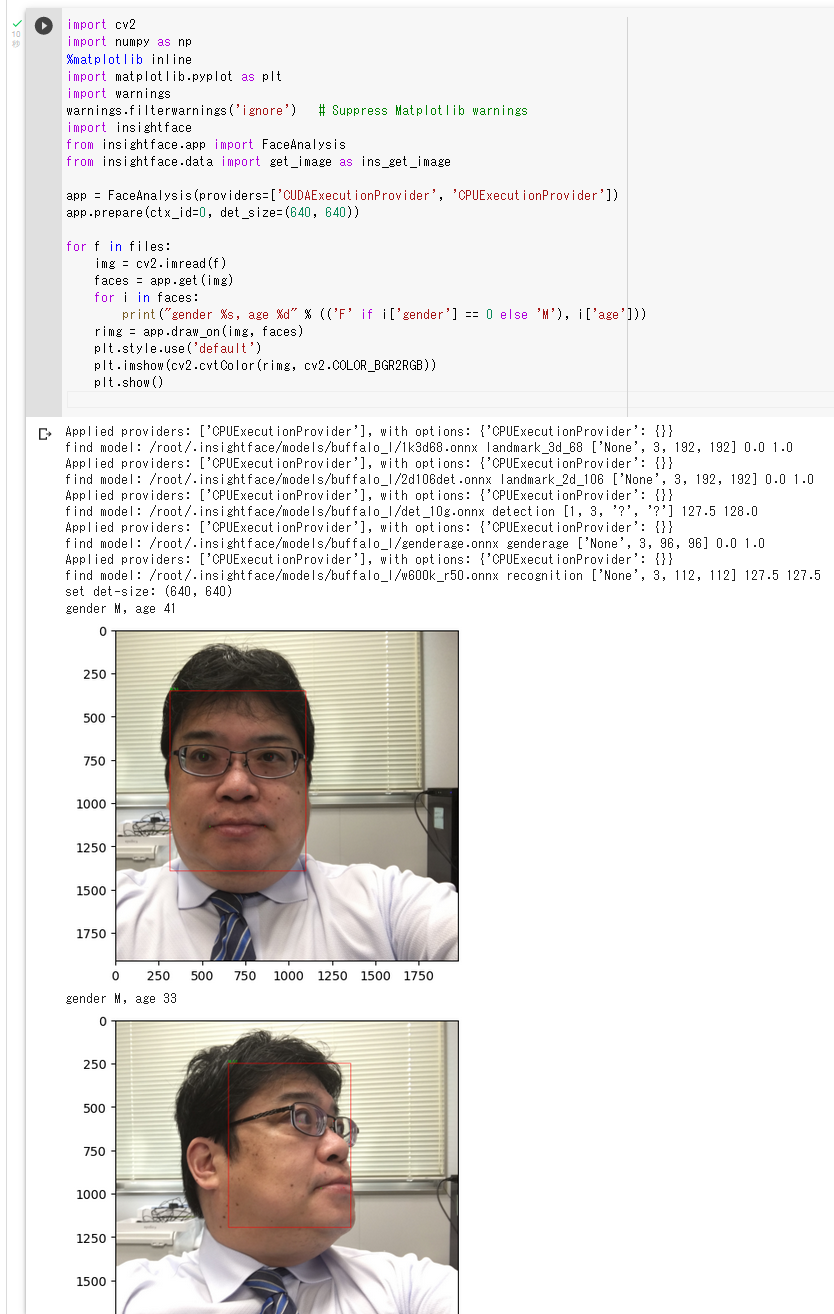


顔検出,年齢と性別の推定,顔識別,人体検出(InsightFace のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
別ページ »で説明
InsightFace のインストールと動作確認(顔検出,年齢と性別の推定)(Python, PyTorch を使用)(Ubuntu 上)
別ページ »で説明
Iris データセット
Iris データセットは公開されているデータセット(オープンデータ)である.
- 行数: 150行
- 属性: sepal length, sepal width, petal length, petal width, species
【文献】
R.A. Fisher, The use of multiple measurements in taxonomic problems, Annual Eugenics, 7, Part II, pp. 179-188, 1936.
【サイト内の関連ページ】
- Iris データセットについての説明資料: iris.pdf [PDF], [パワーポイント]
- Iris データセットを扱う Python プログラム: 別ページ で説明している.
【関連する外部ページ】
JAX: Autograd and XLA のインストール(Ubuntu 上)
URL: https://github.com/google/jax
Ubuntu でインストールを行うには,次のコマンドを実行.
sudo apt -y install python3-pip sudo pip3 install -U "jax[cuda111]" -f https://storage.googleapis.com/jax-releases/jax_releases.htmlJHU-CROWD++ データセット
画像数は 4822枚である. 各画像の人物数は 0 から 25791 である.
- 文献
Vishwanath A Sindagi, Rajeev Yasarla, and Vishal M Pa- tel. Jhu-crowd++: Large-scale crowd counting dataset and a benchmark method. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- 公式ページ: http://www.crowd-counting.com/
【関連用語】 crowd counting, FIDTM, オープンデータ
Johns Hopkins 大の COVID-19 データレポジトリ
国別,地域別の感染者データ
URL: https://github.com/CSSEGISandData/COVID-19
次の Python プログラムは, Johns Hopkins 大の COVID-19 データレポジトリからデータをダウンロードし,ロードし,表示する.
!curl -LO https://github.com/CSSEGISandData/COVID-19/raw/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv import pandas as pd df = pd.read_csv("./time_series_covid19_confirmed_global.csv") display(df) display(df.groupby(['Country/Region'], as_index=False).sum())【関連項目】 時系列データ
JupyterLab
Jupyter Lab は Python プログラム作成に関する種々の機能を持ったソフトウェア.
JupyterLab について:別ページ で説明している.
Jupyter Qt Console
Jupyter Qt Console は Python コンソールの機能を持ったソフトウェア.
Jupyter Qt Console について:別ページ で説明している.
Jupyter ノートブック (Jupyter Notebook)
Jupyter ノートブック (Jupyter Notebook)は,Pythonなどのプログラムのソースコード,実行結果などを1つのノートとして残す機能をもったノートブック.
Jupyter ノートブック について:別ページ で説明している.
Keras
Keras は 機械学習のAPI の機能を持つ. Python 言語から利用可能. TensorFlow, CNTK, Theano など,さまざまなディープラーニングのフレームワークの上で動く.
Keras の概要
- Keras のモデルは,複数の層が組み合わさったもの.単純に層を積み重ねたもの(シーケンシャル)や,複雑な構成のもの(グラフ)がある
- Keras の層には,活性化関数,層の種類(カーネル,バイアスなど)を設定できる
- Keras の層には,全結合層,畳み込み(コンボリューション)層などの種類がある
- 学習のために,オプティマイザの設定を行う
- Keras のモデルの構成やオプティマイザの設定は,保存できる
- 学習の結果は,重みになる. チェックポイントにより,重みも保存できる.
次のプログラムでは,損失関数を, categorical crossentropy, 最適化法を 確率的勾配降下法 (SGD 法), 尺度を accuracy に設定している.
m.compile(optimizer=tf.keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True), loss='sparse_categorical_crossentropy', metrics=['accuracy'])* 目的関数については: https://keras.io/ja/objectives/
【関連する外部ページ】
- URL: https://keras.io/ja/
- github: https://github.com/fchollet/keras
- Keras 応用: https://keras.io/api/applications/
【サイト内の関連ページ】
- Windows でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
- Ubuntu でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
【関連項目】 Applications of Deep Neural Networks, TensorFlow, ディープラーニング
Keras のインストール
- Windows でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
- Ubuntu でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
Keras-GAN のページ
Avatar Erik Linder-Norén により GitHub で公開されているKeras-GAN のページ.
URL は次の通り.
Keras-GAN のページ: https://github.com/eriklindernoren/Keras-GAN
Keras でのカーネルの初期化
次のプログラムの中の kernel_initializer の部分. 標準偏差を 0.01 になるように重みを設定している.
【Keras のプログラム】m.add(Dense(units=100, input_dim=len(768[0])), kernel.iniializer.TruncatedNormal(stddev=0.01))Keras での学習
教師データ x_train と y_train (x_train は入力データの numpy 配列もしくは numpy 配列のリスト,y_train はクラス番号の numpy 配列)を用いて, バッチサイズが 32,エポック数を 10 として学習したいときには,次のコマンドを用いる.
【Keras のプログラム】history = m.fit(x_train, y_train, batch_size=32, epochs=50, validation_data=(x_test, y_test))Keras での検証(バリデーション)
Keras での学習において,「validation_data」を付けることで,検証(バリデーション)が行われる.
このとき,検証(バリデーション)に使うデータ(x_test, y_test)をいろいろ変えながら,Kerasでの検証(バリデーション)を行う.
【Keras のプログラム】history = m.fit(x_train, y_train, batch_size=32, epochs=50, validation_data=(x_test, y_test))結果(上のプログラムでは history)を見て,過学習や学習不足を判断する.history は次のようなプログラムで表示できる.
【Keras のプログラム】import pandas as pd h = pd.DataFrame(history.history) h['epoch'] = history.epoch print(h)Keras でのコンパイル
Keras のモデルのコンパイルにおいては, オプティマイザ(最適化器)と 損失関数とメトリクスの指定を行う必要がある.
Keras でのモデル m のコンパイルのプログラムは「m.compile」のように書く.
Keras に付属のデータセット
データセットは,データの集まりのこと. Python の keras には,次のデータセットを簡単にダウンロードできる機能がある.
- CIFAR-10 データセット: カラー画像 60000枚, カテゴリーラベル (category label)
CIFAR-10 データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data()- CIFAR100 データセット: カラー画像 60000枚, カテゴリーラベル (category label)
CIFAR-100 データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import cifar100 (x_train, y_train), (x_test, y_test) = cifar100.load_data(label_mode='fine')- IMDb データセット: 25000 の映画レビュー
IMDb データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import imdb (x_train, y_train), (x_test, y_test) = imdb.load_data()- Reuters newswire topics データセット: ニュースワイヤ 11228, ラベル
Reuters newswire topics データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data()- MNIST データセット: 濃淡画像 70000枚, ラベル
MNIST データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()- Fashion MNIST データセット: 濃淡画像 70000枚, ラベル
Fashion MNIST データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()- Boston housing price 回帰データセット: 13属性
Boston housing price 回帰データセットは,次のプログラムでロードできる.
【Keras のプログラム】from tensorflow.keras.datasets import boston_housing (x_train, y_train), (x_test, y_test) = boston_housing.load_data()keras に付属のデータセットを取得するときのオプションについては, https://keras.io/ja/datasets/(日本語版), https://keras.io/api/datasets/(英語版) に説明されている.
【関連項目】 Boston housing price 回帰データセット, CIFAR-10 データセット, CIFAR100 データセット, IMDb データセット, Reuters newswire topics データセット, MNIST データセット, Fashion MNIST データセット
Keras の応用
Keras の応用としては, MobileNetV2, Inception-ResNet, ResNet50, DenseNet121, DenseNet169, NASNetなどの画像分類のモデルがある. (その詳細は,https://keras.io/ja/applications/)
Keras では,これらモデルについて,ImageNet データセット での学習済みモデルを,次のようなプログラムで,簡単に使えるようにすることができる.
【Keras のプログラム】from tensorflow.keras.applications.mobilenet_v3 import MobileNetV3 m = MobileNetV3(weights='imagenet')【関連項目】 ResNet50, ResNet101, ResNet152, その他の ResNet, Inception-ResNet, DenseNet121, DenseNet169, NASNet, MobileNetV2
Keras で利用可能な画像分類のモデルは,https://keras.io/api/applications/index.html で説明されている.
Kinetics Human Action Video Dataset (Kinetics Human Action Video データセット)
400/600/700 種類の人間の行動をカバーする最大65万のビデオクリップの URL リンク集とアノテーションである. それぞれのクリップには,1つの行動クラスがアノテーションされている. ビデオの長さは,約10秒である. 機械学習による行動分類,行動認識,ビデオ検索などの学習や検証に利用できるデータセットである.
ディープラーニングで,人間の行動推定に利用できる.
- 約65万のビデオクリップのURLリンク
- 楽器の演奏などの人間と物体のインタラクション,握手やハグなどの人間と人間のインタラクションを網羅
- 行動クラスの数は 400/600/700
- 各ビデオクリップには1つの行動クラスがアノテーションされている.
- 各ビデオクリップの長さは約10秒である.
Kinetics データセット >は次の URL で公開されているデータセット(オープンデータ)である.
https://deepmind.com/research/open-source/kinetics
【関連情報】
- URL: http://human-pose.mpi-inf.mpg.de/
- URL: https://deepmind.com/research/open-source/kinetics
- 文献
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017.
- Papers With Code の Kinetics データセットのページ: https://paperswithcode.com/dataset/kinetics
- PyTorch の Kinetics データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.Kinetics400
- 文献
Google Colaboratory で,Kinetics データセットのダウンロード
次のコマンドは Google Colaboratory で動く(コードセルを作り,実行する).
!curl -O https://storage.googleapis.com/deepmind-media/Datasets/kinetics700_2020.tar.gz !tar -xvzof kinetics700_2020.tar.gz !ls kinetics700_2020
Windows での Kinetics データセットのダウンロード
Windowsで次のように操作する.
mkdir /p c:\data mkdir /p c:\data\kinetics cd c:\data\kinetics curl -O https://storage.googleapis.com/deepmind-media/Datasets/kinetics700_2020.tar.gz "c:\Program Files\7-Zip\7z.exe" x kinetics700_2020.tar.gz "c:\Program Files\7-Zip\7z.exe" x kinetics700_2020.tarKITTI データセット
カラーのカメラ,モノクロのステレオカメラ,3次元レーザースキャナなどのさまざまなセンサーのデータから構成される.
- 数時間分の交通シナリオ
- セマンティック・セグメンテーションのグランドトゥルースが含まれているわけではない
http://www.cvlibs.net/datasets/kitti
【関連情報】
- A. Geiger, P. Lenz and R. Urtasun, "Are we ready for autonomous driving? The KITTI vision benchmark suite," 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3354-3361, doi: 10.1109/CVPR.2012.6248074.
- Papers With Code の KITTI データセットのページ: https://paperswithcode.com/dataset/kitti
- PyTorch の KITTI データセット: https://pytorch.org/vision/stable/datasets.html
- TensorFlow データセット の KITTI データセット: https://www.tensorflow.org/datasets/catalog/kitti
KITTY オドメトリデータセットのダウンロード
車両からの観測画像と車両の自己位置のデータ.ビジュアルオドメトリに使用.
URL: https://github.com/uoip/monoVO-python
- テスト用の画像データのダウンロードと展開(解凍)
テスト画像データをダウンロードしたい.再度,uoip / monoVO-python の Web ページを開く
- 「KITTY odometry data set (grayscale, 22 GB)」をクリック.

- 濃淡 (grayscale) 画像が欲しいので,「Download odometry data set (grayscale, 22GB)」をクリック.
これは,画像データの .zip ファイルである(多数の .png形式の画像ファイルを zip 形式に固めたものである).
- メールアドレスを登録し,「Request Download Link」をクリック.
- 電子メールで通知が送られてくるので確認の上,電子メールの中のリンクをクリックする.
- 件名を確認し,他のメールと勘違いしていないことをよく確認したうえでリンクをクリックすること.
- 通知が送られるまで,それほど時間はかからない.
- 電子メールの中身を他の人に見せる(他の人に代理作業を頼む)のはマナー違反
- リンクをクリックするので、ダウンロードが始まるので確認する.
* ダウンロードには時間がかかる
- いまダウンロードしたテスト用画像データの .zip ファイルを,分かりやすいディレクトリ(日本語を含まないこと)に展開(解凍)する.
この .zip ファイルは,C:\data_odometry_gray\dataset に展開(解凍)したものとして,説明を続けるので,適切に読み替えてください.
- 展開(解凍)してできたファイルを確認する.
- .png 形式のファイルが多数ある
- ファイル名は6桁の数字の連番になっている
- 多数のディレクトリに分かれている
KITTI データセットのビジュアライザ
https://github.com/navoshta/KITTI-Dataset
KITTI データセットの Python インタフェース
https://github.com/utiasSTARS/pykitti
K 近傍探索 (K nearest neighbour)
K 近傍探索 (K nearest neighbour)のアルゴリズムは,次の性質を持つ.
- 事前に、データを複数準備(事前データ).
- それぞれのデータに、ラベルがついている.
- 新しいデータが1つある.それを、事前データそれぞれすべてと類似度を計算する.
- 類似度が高いもの数個を選ぶ.そして、選ばれた数個のラベルについて多数決を取る
- その結果得られたラベルを識別結果とする
【関連項目】 Fast-Robust-ICP, libnabo, libpointmatcher
ks_1033_data
ks_1033_data は,次のページで CSV ファイルと Excel ファイルで公開されているデータセット(オープンデータ)である.
https://github.com/wireservice/csvkit/tree/master/examples/realdata
Google Colaboratory で,ks_1033_data データセットのダウンロード
次のコマンドは Google Colaboratory で動く(コードセルを作り,実行する).
!curl -O https://github.com/wireservice/csvkit/tree/master/examples/realdata/ks_1033_data.csv !ls -al ks_1033_data.csv
L2 正則化
正則化の一手法である. L2 正則化では,重みの二乗の合計に比例したペナルティを,重みに与える.
L2 正則化を行う Keras のプログラムL2 正則化を行いたいときは 次のようにする.
import tensorflow.compat.v2 as tf tf.keras.layers.Dense(128, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001))LabelMe インタフェース
LabelMe インタフェースは,アノテーションのツール.
- 文献
Russell BC, Torralba A, Murphy KP, Freeman WT, Labelme: a database and web-based tool for image annotation. Int’l Journal of Computer Vision, 2008.
- 公式ページ (GitHub のページ): https://github.com/wkentaro/labelme
【関連項目】 アノテーション (annotation)
Windows での LabelMe のインストールと確認
公式ページ https://github.com/wkentaro/labelmeの記載に従う.
- インストール
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
python -m pip install labelme - 確認のため「labelme」で起動
LAION
LAION-2B の画像数は約20億枚. LAION-5B の画像数は約50億枚.
【関連する外部ページ】
LAION の公式ページ: https://laion.ai/
LaMa
LaMa は,Image Inpainting (イメージ・インペインティング)のための技術である.2021年発表.
Image Inpainting (イメージ・インペインティング) 画像の欠落部分を補うことで,画像の中の不要な部分を消すときにも役立つ.
LaMa のデモページ
- LaMa のデモページの URL: https://colab.research.google.com/github/saic-mdal/lama/blob/master/colab/LaMa_inpainting.ipynb#scrollTo=-VZWySTMeGDM
- LaMa のデモページの実行結果の例


【関連項目】 image inpainting
Windows での Lama Cleaner のインストール
Windows での Lama Cleaner のインストール: 別ページで説明してリウ.
LAPACK
lapack は,行列に関する種々の問題(連立1次方程式,固有値問題,などなど多数)を解く機能を持つソフトウェア.BLAS の機能を使う.
netlib の lapack のページ: http://www.netlib.org/lapack
lapack 参照実装の Web ページ: https://github.com/Reference-LAPACK/lapack-release
【関連項目】 BLAS, clapack, OpenBLAS
Windows での LAPACK のインストール
Windows での LAPACK のインストール(Windows 上): 別ページ »で説明
Ubuntu での LAPACK のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libopenblas-dev liblapack-devLAPACK のプログラム例
dgeev()関数 (固有値と固有ベクトル)を使用.
#include<stdio.h> // CLAPACK ではなく LAPACK を直接呼び出す. // CLAPACK については,次の URL を見よ. // see http://www.netlib.org/clapack/clapack.h // ?geev : simple driver for eigenvalues/vectors // 決まり文句 (CLAPACK との互換用) #define doublereal double #define integer long int extern integer dgeev_(char *jobvl, char *jobvr, integer *n, doublereal *a, integer *lda, doublereal *wr, doublereal *wi, doublereal *vl, integer *ldvl, doublereal *vr, integer *ldvr, doublereal *work, integer *lwork, integer *info); integer eigenvalues( integer n, doublereal *a, doublereal *wr, doublereal *wi ) { /* LAPACK の _dgeev() を使って固有値(だけ)を求める */ integer n3 = n * n * n; integer info; doublereal *vl = (doublereal *)calloc(sizeof(doublereal), n * n); doublereal *vr = (doublereal *)calloc(sizeof(doublereal), n * n); doublereal *work = (doublereal *)calloc(sizeof(doublereal), n3); (void) dgeev_( /* char *jobvl */ "N", /* "N" なので左固有ベクトルを計算しない */ /* char *jobvr */ "N", /* "N" なので右固有ベクトルを計算しない */ /* integer *n */ &n, /* 正方行列の次数 */ /* doublereal *a, */ a, /* A */ /* integer *lda, */ &n, /* A 用の作業領域 */ /* doublereal *wr, */ wr, /* 固有値の実部 */ /* doublereal *wi, */ wi, /* 固有値の虚部 */ /* doublereal *vl, */ vl, /* 左固有値 */ /* integer *ldvl, */ &n, /* 左固有値の作業用 */ /* doublereal *vr, */ vr, /* 右固有値 */ /* integer *ldvr, */ &n, /* 左固有値の作業用 */ /* doublereal *work, */ work, /* 作業用 */ /* integer *lwork, */ &n3, /* 作業用の行列の次元 */ /* integer *info */ &info); free( work ); free( vr ); free( vl ); return info; } integer eigenvalues_rightvectors( integer n, doublereal *a, doublereal *wr, doublereal *wi, doublereal *vr ) { /* LAPACK の _dgeev() を使って固有値と右固有ベクトルを求める */ /* A * v(j) = lambda(j) * v(j), v(j) is the right eigen vector */ integer n3 = n * n * n; integer info; doublereal *vl = (doublereal *)calloc(sizeof(doublereal), n * n); doublereal *work = (doublereal *)calloc(sizeof(doublereal), n3); (void) dgeev_( /* char *jobvl */ "N", /* "N" なので左固有ベクトルを計算しない */ /* char *jobvr */ "V", /* "V" なので右固有ベクトルを計算する */ /* integer *n */ &n, /* 正方行列の次数 */ /* doublereal *a, */ a, /* A */ /* integer *lda, */ &n, /* A 用の作業領域 */ /* doublereal *wr, */ wr, /* 固有値の実部 */ /* doublereal *wi, */ wi, /* 固有値の虚部 */ /* doublereal *vl, */ vl, /* 左固有値 */ /* integer *ldvl, */ &n, /* 左固有値の作業用 */ /* doublereal *vr, */ vr, /* 右固有値 */ /* integer *ldvr, */ &n, /* 左固有値の作業用 */ /* doublereal *work, */ work, /* 作業用 */ /* integer *lwork, */ &n3, /* 作業用の行列の次元 */ /* integer *info */ &info); free( work ); free( vl ); return info; } int main( integer argc, char **argv ) { int i; integer n = 10; doublereal *a = (doublereal *)calloc(sizeof(doublereal), n * n); doublereal *wr = (doublereal *)calloc(sizeof(doublereal), n); doublereal *wi = (doublereal *)calloc(sizeof(doublereal), n); /* doublereal *vr = (doublereal *)calloc(sizeof(doublereal), n * n); */ eigenvalues( n, a, wr, wi ); for(i = 0; i < n; i++) { printf("%5d %15.7e %15.7e\n", i + 1, *(wr + i), *(wi + i)); } free(wi); free(wr); free(a); return 0; }Leeds Sports Pose Dataset (LSP データセット)
スポーツ選手を中心としで,Flickr から収集した2000枚の画像に, 姿勢(ポース)についてのアノテーションを行ったもの. 最も目立つ人物が,およそ150ピクセルになるようにスケーリングされている. 各画像には,14個のジョイント(関節)の位置がアノテーションされている. オリジナル画像の帰属 (attribution) とFlickrのURLは,各画像ファイルのJPEGコメントに記載されている.
ディープラーニングにより姿勢推定を行うためのデータとして利用できる.
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://dbcollection.readthedocs.io/en/latest/datasets/leeds_sports_pose_extended.html
【関連情報】
- 文献
Sam Johnson, and Mark Everingham. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. In Frédéric Labrosse, Reyer Zwiggelaar, Yonghuai Liu, and Bernie Tiddeman, editors, Proceedings of the British Machine Vision Conference, pages 12.1-12.11. BMVA Press, September 2010. doi:10.5244/C.24.12.
http://www.bmva.org/bmvc/2010/conference/paper12/paper12.pdf
- Papers With Code の LSP データセットのページ: https://paperswithcode.com/dataset/lsp
- open-mmlab での記事
https://github.com/open-mmlab/mmpose/blob/master/docs/en/tasks/3d_body_mesh.md#lsp
Google Colaboratory で,Leeds Sports Pose Dataset (LSP データセット)のダウンロード
次のコマンドは Google Colaboratory で動く(コードセルを作り,実行する).
!curl -O http://sam.johnson.io/research/lsp_dataset.zip !curl -O http://sam.johnson.io/research/lspet_dataset.zip !unzip lsp_dataset.zip -d lsp_dataset !unzip lspet_dataset.zip -d lspet_dataset !ls -la lspet_dataset
アノテーションファイルは,次の URL からダウンロードできる.
https://drive.google.com/file/d/1GZxlTLuMfA3VRvz2jyv8fhJDqElNrgKS/view
Windows での,Leeds Sports Pose Dataset (LSP データセット)のダウンロード
Windows の場合.次により c:\data\lsp にダウンロードされる.
mkdir /p c:\data mkdir /p c:\data\lsp mkdir /p c:\data\lsp\images cd c:\data\lsp\images curl -O http://sam.johnson.io/research/lsp_dataset.zip curl -O http://sam.johnson.io/research/lspet_dataset.zip powershell -command "Expand-Archive -DestinationPath . -Path lsp_dataset.zip" powershell -command "Expand-Archive -DestinationPath . -Path lspet_dataset.zip"アノテーションファイルは,次の URL からダウンロードできる.
https://drive.google.com/file/d/1GZxlTLuMfA3VRvz2jyv8fhJDqElNrgKS/view
Ubuntu での,Leeds Sports Pose Dataset (LSP データセット)のダウンロード
Ubuntu の場合.次により,/usr/local/data/lsp/images にダウンロードされる.
mkdir -p /usr/local/data/lsp/images cd /usr/local/data/lsp/images curl -O http://sam.johnson.io/research/lsp_dataset.zip curl -O http://sam.johnson.io/research/lspet_dataset.zip unzip lsp_dataset.zip -d lsp_dataset unzip lspet_dataset.zip -d lspet_datasetアノテーションファイルは,次の URL からダウンロードできる.
https://drive.google.com/file/d/1GZxlTLuMfA3VRvz2jyv8fhJDqElNrgKS/view
LFW データセット
LFWデータセットには,「in-the-wild」のラベル付きの顔のデータベースである. 合計で 13,233枚,5,749人の顔画像が含まれている.
機械学習による顔認識の学習や検証に利用できるデータセットである.
- 5749 人の顔について,IDが付いている.
- 1680 人については,2つ以上の画像に写っている.他の人は,1宇野画像ににも写っている.
- 文献
Gary B. Huang, Marwan Mattar, Tamara Berg, Eric Learned-Miller. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Erik Learned-Miller and Andras Ferencz and Frdric Jurie, Oct 2008, Marseille, France. inria-00321923
- E. Learned-Miller, G. B. Huang, A. RoyChowdhury, H. Li, and G. Hua. Labeled faces in the wild: A survey. In Advances in Face Detection and Facial Image Analysis, pages 189–248. Springer, 2016.
- Papers With Code の LFW データセットのページ: https://paperswithcode.com/dataset/lfw
- PyTorch のLFW データセット:
- TensorFlow データセットの LFW データセット: https://www.tensorflow.org/datasets/catalog/lfw
【関連項目】 顔認識 (face recognition), 顔のデータベース
libc++
libc++ は,C++ の標準ライブラリである.
【関連する外部ページ】
- libc++ の公式ページ: https://libcxx.llvm.org/
【関連項目】 LLVM
libiconv
Windows での libiconv のインストール
Windows での libiconv のインストール(Windows 上): 別ページ »で説明
libnabo
libnabo は,K 近傍探索 (K nearest neighbour) の機能を持つライブラリ.
ANN よりも高速だとされている.
- 文献
Elseberg, J. and Magnenat, S. and Siegwart, R. and N{\"u}chter, A., Comparison of nearest-neighbor-search strategies and implementations for efficient shape registration, Journal of Software Engineering for Robotics (JOSER), pages 2-12, vol. 3, no. 1, 2012.
- libnabo の URL: https://github.com/ethz-asl/libnabo
【関連項目】 K 近傍探索 (K nearest neighbour)
Windows での libnabo のインストール
https://github.com/CAOR-MINES-ParisTech/libpointmatcher/blob/master/doc/CompilationWindows.md の手順に従う.
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- Boost のインストール
- Eigen 3 のインストール
- grep のインストール
- インストール
以下のコマンドを管理者権限のx64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)で実行する (手順:スタートメニュー →Visual Studio 20xx」の下の「x64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)」 → 「管理者として実行」)。
c:\libnabo にインストールされる.
cd /d c:%HOMEPATH% rmdir /s /q libnabo git clone --recursive https://github.com/ethz-asl/libnabo cd libnabo rmdir /s /q build mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_BUILD_TYPE=Release ^ -DCMAKE_INSTALL_PREFIX="c:/libnabo" ^ -DEIGEN_INCLUDE_DIR="c:/eigen/include/eigen3" ^ -DLIBNABO_BUILD_PYTHON=OFF ^ -DCMAKE_BUILD_TYPE=RelWithDebInfo ^ .. msbuild /m:2 libnabo.sln -p:Configuration=Release - テストプログラムのビルド
以下のコマンドを管理者権限のx64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)で実行する (手順:スタートメニュー →Visual Studio 20xx」の下の「x64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)」 → 「管理者として実行」)。
c:\libnabo にインストールされる.
cd %LOCALAPPDATA%\libnabo\examples del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_BUILD_TYPE=Release ^ -DCMAKE_INSTALL_PREFIX="c:/libnabo" ^ -DEIGEN_INCLUDE_DIR="c:/eigen/include/eigen3" ^ -DLIBNABO_BUILD_PYTHON=OFF ^ -DCMAKE_BUILD_TYPE=RelWithDebInfo ^ .. msbuild /m:2 libnabo.sln -p:Configuration=Release
Ubuntu での libnabo のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
/usr/local/libnabo にインストールされる.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libboost-all-dev libeigen3-dev git cmake cmake-curses-gui cmake-gui cd /tmp sudo rm -rf libnabo sudo git clone --recursive https://github.com/ethz-asl/libnabo sudo chown -R $USER libnabo cd /tmp/libnabo mkdir build cd build cmake \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_INSTALL_PREFIX="/usr/local" \ -DCMAKE_BUILD_TYPE=RelWithDebInfo \ .. make sudo make install cd /tmp/libnabo/examples cmake \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_INSTALL_PREFIX="/usr/local" \ -DCMAKE_BUILD_TYPE=RelWithDebInfo \ .. make sudo make installliboctave
自分で,C++ のプログラムを書き,liboctave の機能を呼び出すことが簡単にできる.
liboctave の C++ プログラムの見本
「clock_t c = clock();」と「fprintf( stderr, "done, elapsed time = %f [sec]", ( (double)clock() - (double)c ) / CLOCKS_PER_SEC ); 」の2行は経過時間の測定のためです.
#include<stdio.h> #include<time.h> #include<octave/config.h> #include<octave/Matrix.h> // 正方行列のサイズを指定 #define DIM 2000 int main( int argc, char **argv ) { fprintf( stderr, "start, \n" ); clock_t c = clock(); // 行列の積と固有値/固有ベクトル Matrix X(DIM, DIM); Matrix Y(DIM, DIM, 1.0); Matrix Z = X * Y; EIG eig(X); fprintf( stderr, "done, elapsed time = %f [sec]", ( (double)clock() - (double)c ) / CLOCKS_PER_SEC ); return 0; }Octave の 関数 conv2 を用いて,2次元の畳み込み(コンボリューション)を行う.
関数 conv2 は,Octave ソースコードの DLD-FUNCTIONS/conv2.cc で定義されているので,「#include<octave/conv2.cc>」を含める.
「clock_t c = clock();」と「fprintf( stderr, "done, elapsed time = %f [sec]", ( (double)clock() - (double)c ) / CLOCKS_PER_SEC ); 」の2行は経過時間の測定のため.
// liboctave を用いた 2次元畳み込み(コンボリューション) #include<stdio.h> #include<time.h> #include<octave/config.h> #include<octave/Matrix.h> #include<octave/conv2.cc> // 正方行列のサイズを指定 #define DIM 2000 #define DIM2 21 int main( int argc, char **argv ) { printf( "start, \n" ); clock_t c = clock(); MArray2<double> a(DIM, DIM); MArray2<double> b(DIM2, DIM2); MArray<double> r(DIM, DIM); r = conv2(a, b, SHAPE_FULL); printf( "done, elapsed time = %f [sec]", ( (double)clock() - (double)c ) / CLOCKS_PER_SEC ); return 0; }libpointmatcher
Iterative Closest Point (ICP) の機能を持ち, 点群 (point cloud) のアラインメントを行うことができる. point-to-point の ICP と,point-to-plane ICP の機能を持つ. point-to-point の ICP では,剛体変換だけでなく,スケールの変更にも対応している.
- 文献
François Pomerleau, Francis Colas, Roland Siegwart, Stéphane Magnenat, Comparing ICP Variants on Real-World Data Sets, Autonomous Robots, vol. 34, no. 3, pages: 133-148, 2013.
- 文献
François Pomerleau, Stéphane Magnenat, Francis Colas, Ming Liu, Roland Siegwart, Tracking a Depth Camera: Parameter Exploration for Fast ICP, Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE Press, pages: 3824-3829, 2011.
- GitHub のページ: https://github.com/ethz-asl/libpointmatcher
【関連項目】 K 近傍探索 (K nearest neighbour), ICP
Windows での libpointmatcher のインストール
https://github.com/CAOR-MINES-ParisTech/libpointmatcher/blob/master/doc/CompilationWindows.md の手順に従う.
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- cmake のインストール: 別項目で説明している.
CMake の公式ダウンロードページ: https://cmake.org/download/
- Boost のインストール
- Boost のバージョンとインクルードディレクトリの確認
次のコマンドで確認する.ここで確認したことは,のちほど,使用する.
dir "c:\boost\build\include"
- Eigen 3 のインストール
- libnabo のインストール
- インストール
以下のコマンドを管理者権限のx64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)で実行する (手順:スタートメニュー →Visual Studio 20xx」の下の「x64 Native Tools コマンドプロンプト (x64 Native Tools Command Prompt)」 → 「管理者として実行」)。
エラーを回避するために「/bigobj」を設定.
c:\libpointmatcher にインストールされる.
「boost-1_86」のところは,先ほど確認したインクルードディレクトリに一致させること.
cd /d c:%HOMEPATH% rmdir /s /q libpointmatcher git clone --recursive https://github.com/ethz-asl/libpointmatcher cd libpointmatcher rmdir /s /q build mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_BUILD_TYPE=Release ^ -DCMAKE_INSTALL_PREFIX="c:/libpointmatcher" ^ -DEIGEN_INCLUDE_DIR="c:/eigen/include/eigen3" ^ -DBoost_USE_STATIC_LIBS=ON ^ -DBOOST_ROOT="c:/boost/build" ^ -DBoost_INCLUDE_DIR="c:/boost/build/include/boost-1_86" ^ -DBoost_DIR="c:/boost/build" ^ -Dlibnabo_DIR="%LOCALAPPDATA%/libnabo/build" ^ -DCMAKE_BUILD_TYPE=RelWithDebInfo ^ -DCMAKE_C_FLAGS="/DWIN32 /D_WINDOWS /W0 /utf-8 /bigobj" ^ -DCMAKE_CXX_FLAGS="/DWIN32 /D_WINDOWS /GR /EHsc /W0 /utf-8 /bigobj" ^ .. msbuild /m:2 libpointmatcher.sln -p:Configuration=Release
Ubuntu での libpointmatcher のインストール
公式ページの https://github.com/CAOR-MINES-ParisTech/libpointmatcher/blob/master/doc/CompilationWindows.md
- 前準備
libnabo のインストール が必要.
- インストール
Ubuntu でインストールを行うには,次のコマンドを実行.
/usr/local/libpointmatcher にインストールされる.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libboost-all-dev libeigen3-dev git cmake cmake-curses-gui cmake-gui cd /tmp sudo rm -rf libpointmatcher git clone --recursive https://github.com/ethz-asl/libpointmatcher sudo chown -R $USER libpointmatcher cd /tmp/libpointmatcher mkdir build cd build cmake \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_INSTALL_PREFIX="/usr/local" \ -DCMAKE_BUILD_TYPE=RelWithDebInfo \ .. make sudo make install
librosa
librosa は, 音声,音楽の機能をもった Python のパッケージである. 主な機能としては,音源分離(music source separation),スペクトログラム, 音声ファイルの読み込み,テンポ(tempo)の推定がある.
【文献】
McFee, Brian, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. “librosa: Audio and music signal analysis in python.” In Proceedings of the 14th python in science conference, pp. 18-25. 2015.
【関連する外部ページ】
- 公式のドキュメントのページ: https://librosa.org/doc/latest/index.html
- 公式の GitHub のページ: https://github.com/librosa/librosa
【関連項目】 short-time Fourier transform, 音声, 音楽, sound, 音データ(sound data)
Google Colaboratory で,パワースペクトログラムの表示(librosa を使用)
次のプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
次のプログラムは,librosa に付属の音声データである trumpet について,パワースペクトログラムを表示する. 次のプログラムでは,横軸は時間,縦軸は線形スケール(linear scale)で表された周波数である パワースペクトログラムを表示する. stft は short-time Fourier transform を行う. そして,その振幅により色をプロットする.
ここのプログラムのソースコードは, http://librosa.org/doc/main/auto_examples/plot_display.html#sphx-glr-auto-examples-plot-display-py のものを使用(ISC ライセンス).
import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import librosa import librosa.display y, sr = librosa.load(librosa.ex('trumpet')) D = librosa.stft(y) # STFT of y S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) plt.figure() librosa.display.specshow(S_db, x_axis='time', y_axis='linear', sr=sr) plt.colorbar()
Windows での librosa のインストール
librosa のインストールと動作確認(音声処理)(Python を使用)(Windows 上): 別ページ »で説明
Ubuntu での librosa のインストール
Ubuntu での librosa のインストールは,次のようなコマンドで行う.
sudo apt -y install ffmpeg sudo pip3 install -U numba librosaインストールするバージョンを指定する場合には,次のように操作する. 「==」のあとはバージョン指定であり,使用したいバージョンを指定する.
sudo apt -y install ffmpeg sudo pip3 install -U numba==0.48.0 librosa==0.7.0ソースコードを使用してインストールする場合には次のように操作する.
sudo apt -y install ffmpeg sudo pip3 install git+https://github.com/librosa/librosaLLD
LLD は,高速に動作するリンカーの機能を持つ.
【関連する外部ページ】
- LLD の公式ページ: https://lld.llvm.org/
【サイト内の関連ページ】
【関連項目】 LLVM
LLaMA (Large Language Model Meta AI)
LLaMA (Large Language Model Meta AI) は,Meta によって開発された大規模言語モデル (large language model) である. LLaMA には,パラメーター数が7B、13B、33B、65B(1Bは10億)の4つのバージョンがある.
【文献】
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample, LLaMA: Open and Efficient Foundation Language Models, https://arxiv.org/abs/2302.13971v1
【関連する外部ページ】
- GitHub の公式ページ: https://github.com/facebookresearch/llama
- Paper with Code のページ: https://paperswithcode.com/paper/llama-open-and-efficient-foundation-language-1
【関連項目】 大規模言語モデル
LLDB
LLDB は,デバッガの機能を持つ.
【関連する外部ページ】
- LLDB の公式ページ: https://lldb.llvm.org/
【サイト内の関連ページ】
【関連項目】 LLVM
LLVM
LLVM には,コンパイラ,ツールチェーンに関するさまざまなサブプロジェクトとして, LVM Core, Clang, LLD, LLDB, libc++ などのサブプロジェクトがある.
【サイト内の関連ページ】
- LLVM,Clang のインストール(winget を使用)(Windows 上)
- Clang, LLVM, LLD, LLDB のインストール(ソースコード,Build Tools for Visual Studio を使用)(Windows 上)
【関連する外部ページ】
- LLVM の公式ページ: https://llvm.org/
- LLVM のインストールの公式ページ: https://llvm.org/docs/GettingStarted.html
- Clang の公式ページ: https://clang.llvm.org/
【関連項目】 Clang, libc++, LLD, LLDB
Windows での LLVM のインストール
Windows での LLVM のインストールには,複数の方法がある.次のいずれかによりインストールできる.
- winget をインストールしたのち,コマンドプロンプトを管理者として開き「winget install LLVM」を実行
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
12.0.1 のところは,インストールしたいバージョン番号を指定すること.
curl -LO https://github.com/llvm/llvm-project/releases/download/llvmorg-12.0.1/LLVM-12.0.1-win64.exe .\LLVM-12.0.1-win64.exe
Ubuntu での LLVM のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install llvmlocate コマンド
Linux では,locate コマンドを用いてファイル検索を行うことができる.
- Ubuntu でのインストール: sudo apt -y install mlocate
mlocate に m が付いているのは書き間違いではない.
LoRA
LoRA は大規模言語モデルの学習の手法の1つである. LoRA は, 大規模言語モデルの学習において,ランク分解行列のペアを用いた学習を特徴とする. 学習可能なパラメータの数を削減を可能にしている. 具体的には,ランク分解行列のペアを用いることで,元の重み行列を低ランクな行列の積として近似することができ,これによって,元の重み行列の次元数を削減し,学習可能なパラメータ数を削減することができる.
【関連項目】 大規模言語モデル
LPIPS (Learned Perceptual Image Patch Similarity)
画像の類似尺度.Richard Zhang らにより 2018年に提案された.
- Windows でのインストール: python -m pip install lpips
- Ubuntu でのインストール: sudo pip3 install lpips
公式ページには,次の Python プログラムのソースコードが掲載されている.
import lpips loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization import torch img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1] img1 = torch.zeros(1,3,64,64) d = loss_fn_alex(img0, img1)このソースコードの Google Colaboratory での実行結果は次の通りである.
- 文献
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang, The Unreasonable Effectiveness of Deep Features as a Perceptual Metric, CVPR 2018, also CORR, abs/1801.03924v2
- Papers with Code のページ: https://paperswithcode.com/paper/the-unreasonable-effectiveness-of-deep
- GitHub のページ: https://github.com/richzhang/PerceptualSimilarity
【関連項目】 SSIM
LReLU (Leaky rectified linear unit)
LReLU (Leaky rectified linear unit) は,次の関数である.
f(x) = x (x>=0), alpha * x (x<0)
LReLUは,活性化関数としてよく使用されるもののうちの1つである. 活性化関数は,ニューロンの入力の合計から,そのニューロンの活性度の値を決めるためのもの. (他には,ReLU,シグモイド関数,ステップ関数,ソフトマックス関数などがある.
【Keras のプログラム】m.add(LeakyReLU(alpha=0.01)LS3D-W データセット
LS3D-W データセットは,3次元の顔ランドマーク (facial landmark)のデータセット.
これは,AFLW,300VW,iBUG 300-W,FDDB の顔画像から生成されたデータセットである.
利用には, https://www.adrianbulat.com/face-alignment での申請を必要とする.
生成手順については,次の文献に記載されている
Bulat, Adrian and Tzimiropoulos, Georgios, International Conference on Computer Vision, 2017, https://openaccess.thecvf.com/content_ICCV_2017/papers/Bulat_How_Far_Are_ICCV_2017_paper.pdf
【関連項目】 顔ランドマーク (facial landmark)
LSTM (Long Short-Term Memory)
LSTM 層を含むようなニューラルネットワークは,次の特徴を持つ
- リカレントニューラルネットワークの一種である
- 状態を維持することで,リカレントニューラルネットワークでの勾配消失問題の解決を目指している.
【関連項目】 Applications of Deep Neural Networks, ディープラーニング, リカレントニューラルネットワーク
LSTM 層(Long Short-Term Memory layer)
LSTM 層では,内部に「状態」を維持する. 状態は,ニューロンの動作のたびに変化するものである. (ふつうのニューロンでは,入力の値から出力が計算される.「状態」という考え方はない). LSTM 層のニューロンは,今の入力,1つ前の時間の入力,1つ前の時間での状態から出力を求める.
LSUN (Large-scale Scene UNderstanding Challenge) データセット
LSUN (Large-scale Scene UNderstanding Challenge) データセット は, ラベル付きの画像データセットである. 機械学習での画像分類や画像生成の学習や検証に利用できるデータセット.
- 約100万枚のラベル付き画像
- 10種類のシーンカテゴリ
- 20種類のオブジェクトカテゴリが含まれている.
【関連情報】
- 文献
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser and Jianxiong Xiao, LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop, arXiv:1506.03365
- Papers With Code の LSUN データセットのページ: https://paperswithcode.com/dataset/lsun
- PyTorch の LSUN データセット https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.LSUN
- TensorFlow データセットの LSUN データセット https://www.tensorflow.org/datasets/catalog/lsun
【関連項目】 顔のデータベース
LVIS データセット
シーン解析(scene parsing),インスタンス・セグメンテーション (instance segmentation)のデータセット
URL: https://www.lvisdataset.org/
【関連項目】 インスタンス・セグメンテーション (instance segmentation), オープンデータ, シーン解析(scene parsing)
MagickWand
MagickWand プログラムの実行
MagickWand のサイトから wand.c を入手.
このプログラムは,サムネイル画像を生成するプログラム.
- コンパイル
以下のコマンドを実行.
gcc `MagickWand-config --cflags --cppflags` -o wand.exe wand.c `MagickWand-config --ldflags --libs`
または
gcc -I/usr/include/ImageMagick -o wand.exe wand.c -L/usr/lib -L/usr/X11R6/lib -lMagickWand -lMagickCore -lfreetype -lz
- 実行
wand.c は,画像ファイルから,サムネイル(縮小画像)を作るプログラム.
次のコマンドにより実行.
./wand.exe <画像ファイル名> <サムネイル・ファイル名>
【関連項目】 ImageMagick
mallorbc の whisper_mic
Whisper でのマイクの使用を可能にする. 利用可能な言語モデルは,tiny,base,small,medium,large
- GitHub のページ: https://github.com/mallorbc/whisper_mic
【関連項目】 Whisper
mAP id="
機械学習による物体検出では, 「mAP」は,「mean average precision」の意味である.
Mapillary Vistas Dataset (MVD)
ストリート(街角)の25,000 枚の画像. インスタンスレベルのアノテーション, 124 のセマンティッククラス.
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.mapillary.com/dataset/vistas
- 文献
G. Neuhold, T. Ollmann, S. Rota Bulo, and P. Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. In ICCV, 2017.
【関連項目】 セマンティック・セグメンテーション (semantic segmentation), インスタンス・セグメンテーション (instance segmentation)
Mask R-CNN
セグメンテーション,物体検出,キーポイント検出等に使用されるモデル.
FPN (Feature Pyramid Network), ResNeXt101 や ResNeXt50 や ResNet101 や ResNet50 を使用.
COCO データセットで学習済みのモデル,Jupyter ノートブック (Jupyter Notebook) のデモ demo.ipynb が公開されている.
- 文献 Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick, Mask R-CNN, ICCV 2017, also, CoRR, abs/1703.06870v3 2017.
- 公式のソースコード (GitHub): https://github.com/BupyeongHealer/Mask_RCNN_tf_2.x
- Papers with Code のページ: https://paperswithcode.com/paper/mask-r-cnn
- TensorFlow のモデル: https://github.com/tensorflow/models
- Detectron2: https://github.com/facebookresearch/detectron2, Detectron2 のチュートリアル: https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5
- matterport の GitHub のページ: https://github.com/matterport/Mask_RCNN
【関連項目】 Detectron2, MMDetection, PANet (Path Aggregation Network), 物体検出, セグメンテーション (segmentation), keypoint detection
付属の Jupyter ノートブック (Jupyter Notebook) のデモ
Jupyter ノートブック (Jupyter Notebook) のデモが付属している.主なものは次の通り. 動作させるには,Mask R-CNN のインストールが終わっていること(下に記載). 学習: train_shapes.ipynb 仕組み: inspect_model.ipynb 重みの視覚化: inspect_weights.ipynb
Windows での Mask R-CNN のインストール
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
cd %LOCALAPPDATA% rmdir /s /q Mask_RCNN git clone --recursive https://github.com/matterport/Mask_RCNN cd Mask_RCNN python -m pip install -U -r requirements.txt python setup.py install
Ubuntu での Mask R-CNN のインストール
- Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo rm -rf Mask_RCNN sudo git clone --recursive https://github.com/matterport/Mask_RCNN sudo chown -R $USER Mask_RCNN # システム Python の環境とは別の Python の仮想環境(システム Python を使用)を作成 sudo apt -y update sudo apt -y install python3-venv python3 -m venv ~/a source ~/a/bin/activate cd /usr/local/Mask_RCNN sudo pip3 install -U -r requirements.txt sudo pip3 list python setup.py install
matplotlib
matplotlib は,オープンソースの Python のプロットライブラリ.
matplotlib を用いた散布図の描画は,別ページ »で説明
matplotlib を用いたグラフ描画の例は次の通り.
import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings x = np.linspace(0, 6, 100) plt.style.use('ggplot') plt.plot(x, np.sin(x))
matplotlib を用いて,OpenCV のカラー画像を表示する例は次の通り.
import cv2 %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings bgr = cv2.imread("126.png") plt.style.use('default') plt.imshow(cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)) plt.show()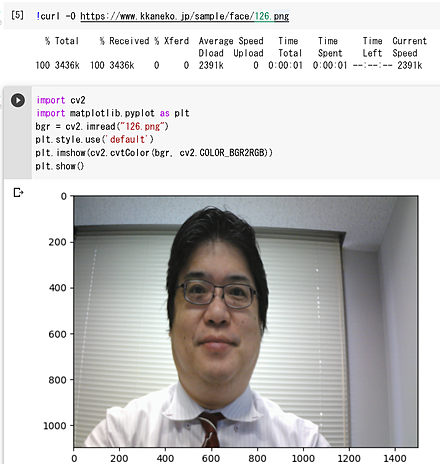
普通に Matplotlib を用いてOpenCV 画像の表示を表示すると,小さく表示される.
「plt.style.use('default')」の実行により,Matplotlib での OpenCV 画像の表示が大きくなる.
【サイト内の関連ページ】 Matplotlib(Python のまとめページ内)
【関連項目】 display
Windows での matplotlib のインストール
Windows での matplotlib, seaborn のインストールは, コマンドプロンプトを管理者として開き そのコマンドプロンプトで,次のコマンドを実行することで行う.
python -m pip install -U matplotlib seabornUbuntu での matplotlib のインストール
Ubuntu での matplotlib, seaborn のインストールは, 次のコマンドを実行することで行う.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-matplotlib python3-seabornMax-Margin 物体検出 (Max-Margin Object Detection)
画像からの物体検出 のための学習法である. 当時の,従来の,単純な物体検出 法よりも高速であり, 他の種々の物体検出 法よりも精度が劣らないとされている. サブサンプリングを行わずに,サブウインドウ(画像分類のために使用されるもの)の全体での最適化を行うことを特徴としている.
- 文献
Davis E. King, Max-Margin Object Detection, CoRR, abs/1502.00046, 2015.
- Papers with code のページ: https://paperswithcode.com/paper/max-margin-object-detection
【関連項目】 物体検出
MeCab
MeCab は,形態素解析の機能を持ったソフトウェア.
Windows での MeCab のインストール
公式ページからダウンロードしてインストールする.その詳細は,別ページ »で説明
Merkaartor
Merkaartor は, OpenStreetMap の編集ソフトウェア. OpenStreetMap,ESRI Shape データ,Bing,Spatialite を扱う機能がある. Windows 版,Linux 版,Mac OS X 版もある.ソースコードは公開されている.
【サイト内の関連ページ】
- Windows での Merkaartor のインストール,OpenStreetMap データのダウンロード(Windows 上): 別ページ »で説明
- Ubuntu での Merkaartor のインストール,OpenStreetMap データのダウンロード(Ubuntu 上): 別ページ »で説明
【関連する外部ページ】
Merkaartor の公式ページ: http://merkaartor.be
GitHub のページ: https://github.com/openstreetmap/merkaartor/
MeshLab
MeshLab は, 3次元データ(3次元点群データや,メッシュデータ)について表示, 簡易編集, データの間引き, 形式変換, 張り合わせ, 分割, 解析などが行えるソフトウェア
URL: http://meshlab.sourceforge.net/
【関連項目】 メッシュ簡略化 (Mesh Simplification) , メッシュ平滑化 (Mesh Smoothing)
Windows での MeshLab のインストール
Windows での MeshLab のインストールには,複数の方法がある.次のいずれかによりインストールできる.
- winget をインストールしたのち,コマンドプロンプトを管理者として開き「winget install MeshLab」を実行
- MeshLab のページ http://meshlab.sourceforge.net/ からダウンロードしてインストール:
詳しくは: 別ページ »で説明
Ubuntu での Meshlab のインストール
Ubuntu での MeshLab のインストール: 別ページ »で説明
Meshroom
Meshroom は フォトグラメトリ のソフトウェアである. Structure from Motion を,GUI を用いて簡単に行うことができる. 動作画面の一部は次の通りである. カメラの撮影位置と,オブジェクトの3次元形状が表示されている.
meshroom の URL (ここから Meshroom をダウンロード可能): https://alicevision.org/
【関連項目】 3次元再構成 (3D reconstruction), OpenMVG, OpenMMLab, Structure from Motion (SfM)
Metis
Windows での Metis のインストール
Windows での Metis のインストール: 別ページ »で説明 Ubuntu での Metis のインストール: 別ページ »で説明
SuiteSparse 5.4.0,Metis 5.1.0 の非公式ビルド: suitesparse.zip私がビルドしたもの,非公式,無保証, https://github.com/jlblancoc/suitesparse-metis-for-windows/releases で公開されているソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした. BSD ライセンスによる.
zip ファイルは C:\ 直下で展開し,C:\suitesparse での利用を想定.
MhLiao の DB
テキスト検知 (text detection), テキスト認識 (text recognition) の機能を持つ.
文献
Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang, Real-time Scene Text Detection with Differentiable Binarization, Proc. AAAI, 2020.
【関連項目】 テキスト検知 (text detection), テキスト認識 (text recognition)
Google Colaboratory でのインストール
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
%cd /content !rm -rf DB !git clone https://github.com/MhLiao/DB.git %cd DB !pip3 install -r requirement.txt %cd assets/ops/dcn/ !python3 setup.py build_ext --inplaceMIT Scene Parsing Benchmark
ADE20K データセット から派生した, シーン解析(scene parsing) のデータと, オブジェクトのパーツ (object parts) のセグメンテーションのデータ.
- 20,000 枚以上の画像
- ADE20K データセット のカテゴリのうち,150 のカテゴリを使用.人,車,ベッドなど,
- ピクセル単位で,オブジェクトとオブジェクトパーツのラベルがアノテーションされている.
次の URL で公開されているデータセット(オープンデータ)である.
http://sceneparsing.csail.mit.edu/
【関連情報】
- MIT Scene Parsing Benchmark: http://sceneparsing.csail.mit.edu/
- Instruction for the Instance Segmentation Task: https://github.com/CSAILVision/placeschallenge/tree/master/instancesegmentation
- TensorFlow データセットの scene parse 150 データセット: https://www.tensorflow.org/datasets/catalog/scene_parse150
【関連項目】 ADE20K データセット, CASILVision, セマンティック・セグメンテーション (semantic segmentation), シーン解析(scene parsing), インスタンス・セグメンテーション (instance segmentation)
Windows でのダウンロードと展開
c:\date 下にダウンロード,展開する.
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
mkdir /p c:\data cd c:\data curl -O http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip rmdir /s /q ADEChallengeData2016 powershell -command "Expand-Archive -DestinationPath . -Path ADEChallengeData2016.zip"ファイルの配置は次のようになる.
ADEChallengeData2016/ annotations/ images/ objectInfo150.txt sceneCategories.txt
MiVOS
MiVOSは、対話型のビデオオブジェクトセグメンテーション(interactive video object segmentation)の新しい手法として提案されている.このシステムはユーザーのインタラクションを取り入れつつ、特定のフレームでのセグメンテーション結果を他のフレームに効果的に伝搬させることができる.インタラクションと伝搬を分離するため、MiVOSはInteraction-to-Mask、Propagation、そしてDifference-Aware Fusionの3つの主要モジュールを採用している.2021年発表.
【文献】
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation, Cheng, Ho Kei and Tai, Yu-Wing and Tang, Chi-Keung, NeurIPS, also arXiv:2106.05210v2, 2021.
https://arxiv.org/pdf/2106.05210v2.pdf
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion, Cheng, Ho Kei and Tai, Yu-Wing and Tang, Chi-Keung, CVPR, also, arXiv:2103.07941v3, 2021.
https://arxiv.org/pdf/2103.07941v3.pdf
【サイト内の関連ページ】
【サイト内の関連ページ】
- MiVOS のインストールと動作(Windows 上)別ページ »で説明
【関連する外部ページ】
- GitHub の公式のページ(STCNバージョン) https://github.com/hkchengrex/MiVOS/tree/MiVOS-STCN
- GitHub の公式ページ: https://github.com/hkchengrex/MiVOS
- Paper with Code のページ: https://paperswithcode.com/paper/modular-interactive-video-object-segmentation
mixamo
キャラクタと動きのアセットを公開しているサイト.fbx形式でダウンロードできる.
【関連用語】 3次元コンピュータグラフィックス, human pose, human motion
MMAction2
MMAction2 は, OpenMMLab の構成物で,動作認識 (action recognition)の機能を提供する.
- 文献
MMAction2 Contributors, OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark, https://github.com/open-mmlab/mmaction2, 2020.
- MMAction2 の GitHub のページ: https://github.com/open-mmlab/mmaction2
- MMAction2 の公式ドキュメント: https://mmaction2.readthedocs.io/en/latest/
- MMAction2 の訓練,検証,推論の公式チュートリアル: https://colab.research.google.com/github/open-mmlab/mmaction2/blob/master/demo/mmaction2_tutorial.ipynb
- MMAction2 の公式の学習済みモデル: https://mmaction2.readthedocs.io/en/latest/model_zoo/recognition.html
- MMAction2 の公式のデモのドキュメント: https://github.com/open-mmlab/mmaction2/blob/master/demo/README.md#skeleton-based-action-recognition-demo
【関連項目】 AVA, MMCV, OpenMMLab, PoseC3D, Spatio-Temporal Action Recognition, Temporal Segment Networks (TSN), スケルトンベースの動作認識 (skelton-based action recognition), 動作認識 (action recognition)
Google Colaboratory で MMAction2 による動作認識 (action recognition),スケルトンベースの動作認識,Spatio-Temporal Action Recognition の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- MMCV 1.6.2 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())" - MIM, MMClassification, MMSegmentation, MMDetection, MMTracking, MMPose のインストール.MMPose のインストール後は numpy, scipy の更新も行う.
https://github.com/open-mmlab/mmpose/blob/master/docs/en/install.md#install-mmposeに記載の手順による.
MMCV 1.6.2 をインストールしたので,MMDetection は 2系列になる(3系列は動かない)(2023年4月時点).
!python -m pip install -U openmim opencv-python !python -m pip install -U mmcv-full==1.6.2 !python -m pip install -U git+https://github.com/open-mmlab/mmclassification.git !python -m pip install -U mmdet==2.28.2 !python -m pip install -U git+https://github.com/open-mmlab/mmsegmentation.git !python -m pip install -U git+https://github.com/open-mmlab/mmtracking.git !python -m pip install -U git+https://github.com/open-mmlab/mmpose.git !apt -y install python3-numpy !apt -y install python3-scipy !python -c "import mmcls; print(mmcls.__version__)" !python -c "import mmdet; print(mmdet.__version__)" !python -c "import mmseg; print(mmseg.__version__)" !python -c "import mmtrack; print(mmtrack.__version__)" !python -c "import mmpose; print(mmpose.__version__)" !pip3 install git+https://github.com/votchallenge/toolkit.git
- MMAction2 のインストール
!mim install mmaction2 -f https://github.com/open-mmlab/mmaction2.git !pip3 show mmaction2 %cd /content !rm -rf mmaction2 !git clone https://github.com/open-mmlab/mmaction2.git %cd mmaction2 !pip3 install -r requirements/optional.txt
- MMAction2 の学習済みモデルのダウンロード
Temporal Segment Networks (TSN), ResNet50, ImageNet, Kinetics-400 のものをダウンロード.
MMAction2 の Temporal Segment Networks (TSN) の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/recognition/tsn/README.md
!curl -O https://download.openmmlab.com/mmaction/recognition/tsn/tsn_r50_1x1x3_100e_kinetics400_rgb/tsn_r50_1x1x3_100e_kinetics400_rgb_20200614-e508be42.pth !mkdir checkpoints !mv tsn_r50_1x1x3_100e_kinetics400_rgb_20200614-e508be42.pth checkpoints
- Temporal Segment Networks (TSN) による動作認識 (action recognition)(MMAction2 を使用)
公式のチュートリアル: https://github.com/open-mmlab/mmaction2/blob/master/demo/mmaction2_tutorial.ipynb に記載のプログラムを使用
このプログラムは,Temporal Segment Networks (TSN), ResNet50, ImageNet, Kinetics-400 を使用
import torch from mmaction.apis import inference_recognizer, init_recognizer # Choose to use a config and initialize the recognizer config = 'configs/recognition/tsn/tsn_r50_video_inference_1x1x3_100e_kinetics400_rgb.py' # Setup a checkpoint file to load checkpoint = 'checkpoints/tsn_r50_1x1x3_100e_kinetics400_rgb_20200614-e508be42.pth' # Initialize the recognizer device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_recognizer(config, checkpoint, device=device) # Use the recognizer to do inference video = 'demo/demo.mp4' label = 'tools/data/kinetics/label_map_k400.txt' results = inference_recognizer(model, video) labels = open(label).readlines() labels = [x.strip() for x in labels] results = [(labels[k[0]], k[1]) for k in results] # Let's show the results for result in results: print(f'{result[0]}: ', result[1])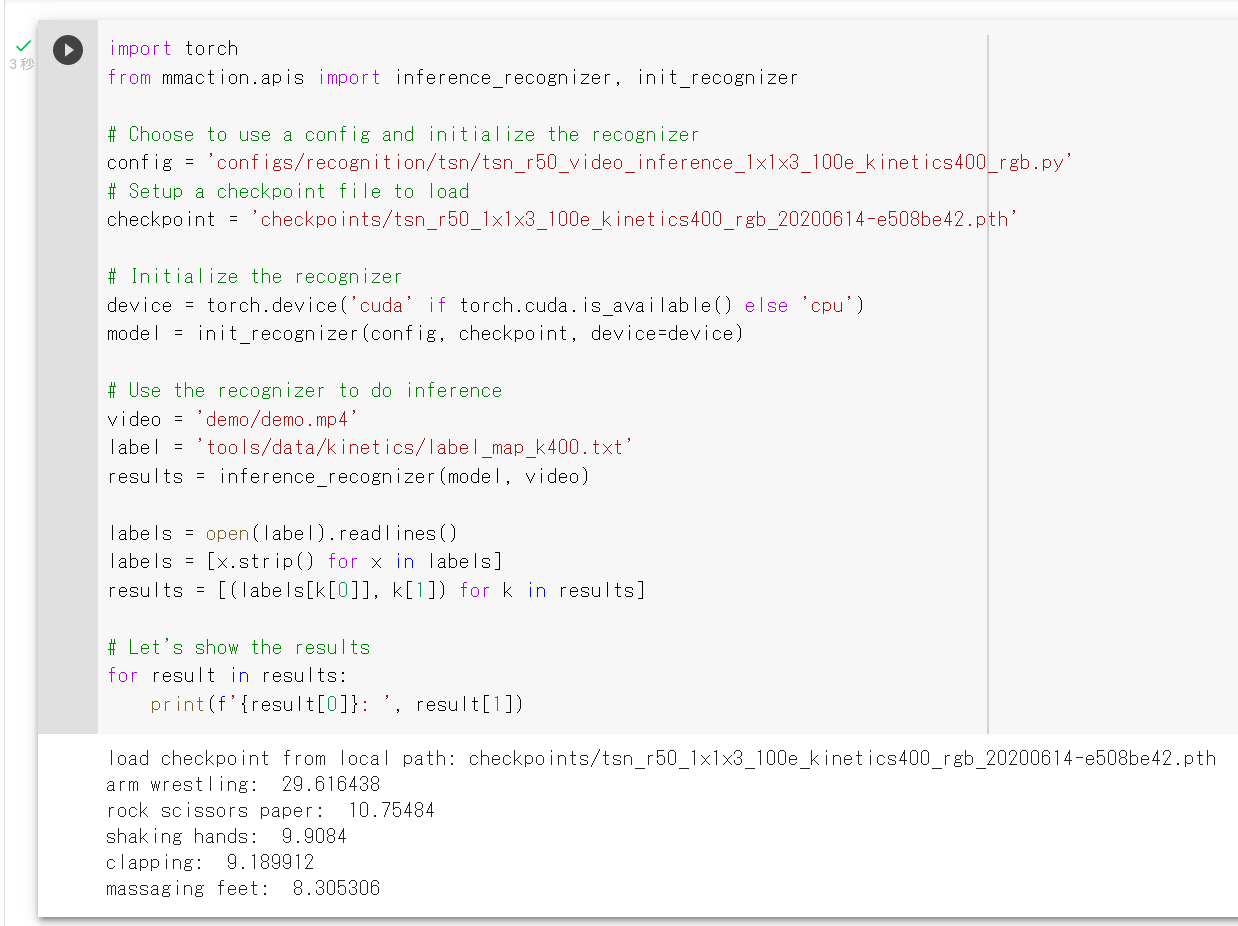
- MMAction2 の学習済みモデルのダウンロード
PoseC3D, SlowOnly-R50, NTU120_XSub のものをダウンロード.
MMAction2 の PoseC3D の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/skeleton/posec3d/README.md
!curl -O https://download.openmmlab.com/mmaction/skeleton/posec3d/slowonly_r50_u48_240e_ntu120_xsub_keypoint/slowonly_r50_u48_240e_ntu120_xsub_keypoint-6736b03f.pth !mkdir checkpoints !mv slowonly_r50_u48_240e_ntu120_xsub_keypoint-6736b03f.pth checkpoints
- PoseC3D によるスケルトンベースの動作認識 (skelton-based action recognition)(MMAction2 を使用)
MMAction2 の公式のデモのドキュメント: https://github.com/open-mmlab/mmaction2/blob/master/demo/README.md#skeleton-based-action-recognition-demo に記載のプログラムを使用
このプログラムは, 人物検出(human detection) に Faster RCNN を使用. 姿勢推定(pose estimation) に HRNetw32 を使用. スケルトンベースの動作認識 (skelton-based action recognition)に,PoseC3D, SlowOnly-R50, NTU120_XSub を使用.
!python3 demo/demo_skeleton.py demo/ntu_sample.avi demo/skeleton_demo.mp4 \ --config configs/skeleton/posec3d/slowonly_r50_u48_240e_ntu120_xsub_keypoint.py \ --checkpoint checkpoints/slowonly_r50_u48_240e_ntu120_xsub_keypoint-6736b03f.pth \ --det-config demo/faster_rcnn_r50_fpn_2x_coco.py \ --det-checkpoint http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth \ --det-score-thr 0.9 \ --pose-config demo/hrnet_w32_coco_256x192.py \ --pose-checkpoint https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \ --label-map tools/data/skeleton/label_map_ntu120.txt
mmaction/demo/skeleton_demo.mp4 を確認
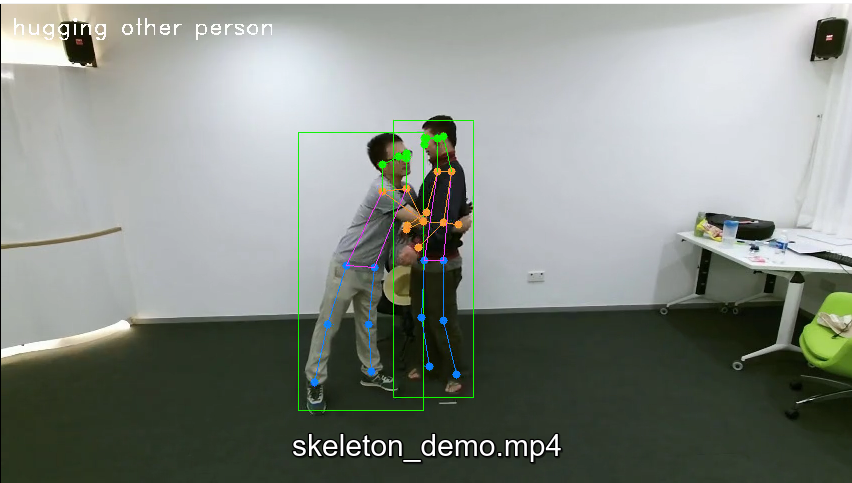
- MMAction2 の学習済みモデルのダウンロード
AVA, OmniSource, ResNet101 のものをダウンロード.
MMAction2 の AVA の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/detection/ava/README.md
!curl -O https://download.openmmlab.com/mmaction/detection/ava/slowonly_omnisource_pretrained_r101_8x8x1_20e_ava_rgb/slowonly_omnisource_pretrained_r101_8x8x1_20e_ava_rgb_20201217-16378594.pth !mkdir checkpoints !mv slowonly_omnisource_pretrained_r101_8x8x1_20e_ava_rgb_20201217-16378594.pth checkpoints
- AVA による Spatio-Temporal Action Recognition (MMAction2 を使用)
MMAction2 の公式のデモのドキュメント: https://github.com/open-mmlab/mmaction2/blob/master/demo/README.md#skeleton-based-action-recognition-demo に記載のプログラムを使用
このプログラムは, 人物検出(human detection) に Faster RCNN を使用. 動作認識 (action recognition)に,SlowOnly-8x8-R101 を使用. 8フレームごとに予測を行い,4フレームごとに1フレームを出力する.
!python3 demo/demo_spatiotemporal_det.py --video demo/demo.mp4 \ --config configs/detection/ava/slowonly_omnisource_pretrained_r101_8x8x1_20e_ava_rgb.py \ --checkpoint checkpoints/slowonly_omnisource_pretrained_r101_8x8x1_20e_ava_rgb_20201217-16378594.pth \ --det-config demo/faster_rcnn_r50_fpn_2x_coco.py \ --det-checkpoint http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth \ --det-score-thr 0.9 \ --action-score-thr 0.5 \ --label-map tools/data/ava/label_map.txt \ --predict-stepsize 8 \ --output-stepsize 4 \ --output-fps 6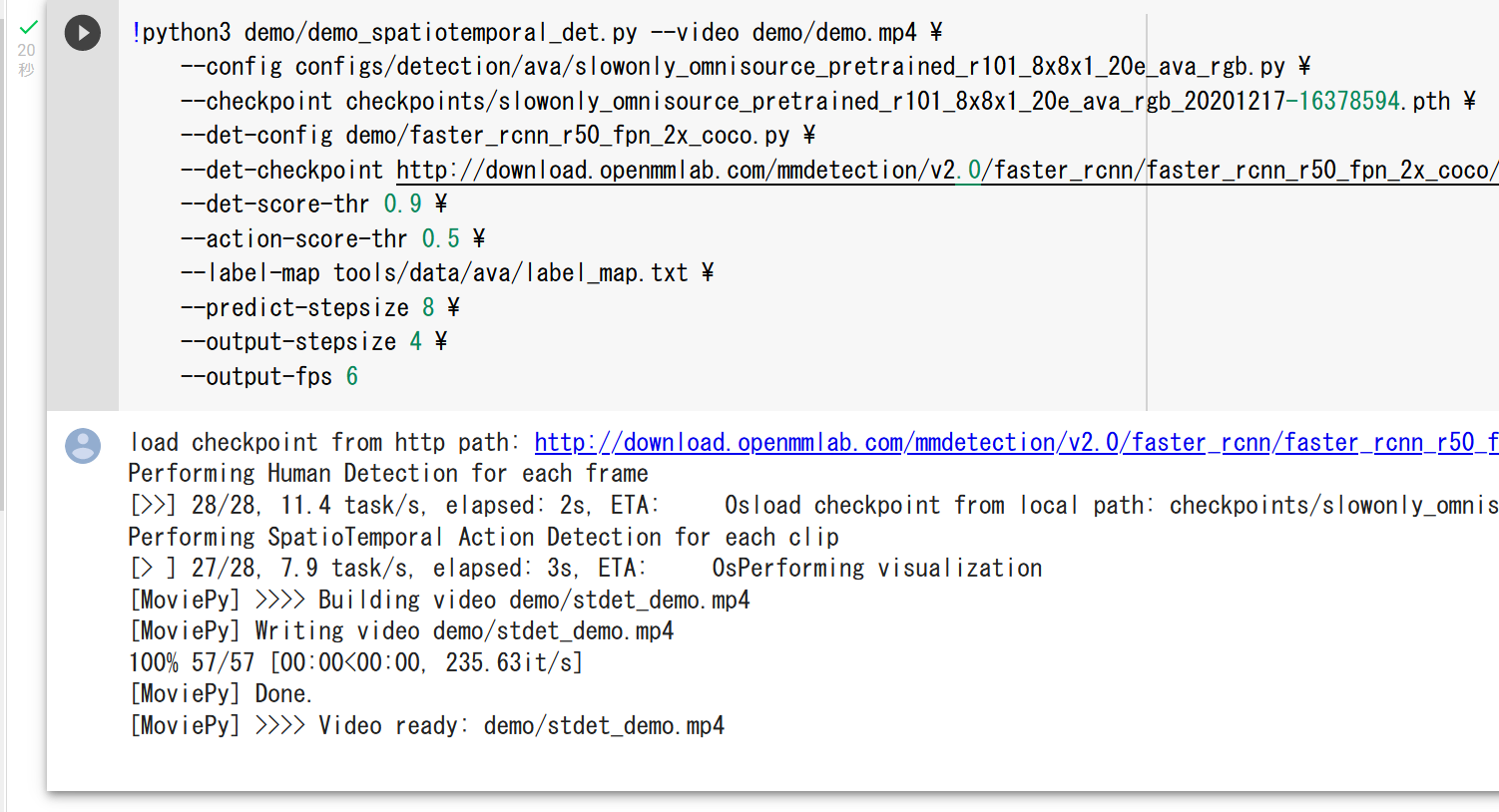
mmaction/demo/stdet_demo.mp4 を確認

MMPretrain
MMPretrain は, OpenMMLab の構成物で, 画像分類のツールボックスとベンチマークの機能を提供する.
【文献】
MMClassification Contributors, OpenMMLab's Image Classification Toolbox and Benchmark, https://github.com/open-mmlab/mmclassification, 2020.
【サイト内の関連ページ】 画像分類(MMPretrain のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
【関連する外部ページ】
- MMPretrain の GitHub のページ: https://github.com/open-mmlab/mmpretrain
- MMPretrain の公式ドキュメント: https://mmpretrain.readthedocs.io/en/latest/
- MMPretrain での訓練(公式ドキュメント): https://mmpretrain.readthedocs.io/en/latest/user_guides/train.html
- MMPretrain の公式の学習済みモデル: https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html
- MMPretrain の model zoo のページ: https://github.com/open-mmlab/mmpretrain/blob/master/docs/en/model_zoo.md
【関連項目】 OpenMMLab, MMCV, MMFewShot
Google Colaboratory で,MMClassification による画像分類の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- MIM のインストール
!pip3 install git+https://github.com/open-mmlab/mim.git - MMCV, MMClassification のインストール.
https://mmclassification.readthedocs.io/en/latest/install.html の記載の手順による
%cd /content !rm -rf mmclassification !git clone https://github.com/open-mmlab/mmclassification.git %cd mmclassification !git checkout dev !mim install -e . !pip3 show mmcls
- MMClassification の学習済みモデルのダウンロード
ResNet50, ImageNet-1k のものをダウンロード.
MMClassification の ResNet の説明ページ: https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet
!curl -O https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth !mkdir checkpoints !mv resnet50_8xb32_in1k_20210831-ea4938fc.pth checkpoints
- ResNet50による画像分類の実行(MMClassification を使用)
このプログラムは,ResNet50, ImageNet-1k を使用.
import torch from mmcls.apis import inference_model, init_model, show_result_pyplot fimg = 'demo/demo.JPEG' fconfig = 'configs/resnet/resnet50_8xb32_in1k.py' fcheckpoint = 'checkpoints/resnet50_8xb32_in1k_20210831-ea4938fc.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(fconfig, fcheckpoint, device=device) result = inference_model(model, fimg) print(result) show_result_pyplot(model, fimg, result)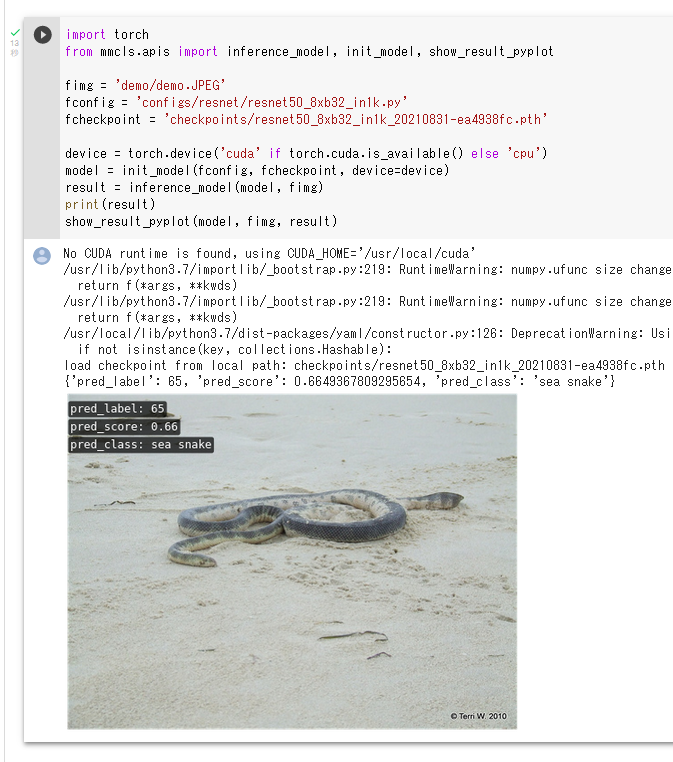
- 画像分類の実行(MMClassification, ResNet152,ImageNet データセットで事前学習済みモデルを使用)
- MMClassification のインストールを行う
- 画像分類の実行
「demo/demo.JPEG」のところに画像ファイル名を指定する.
import torch from mmcls.apis import inference_model, init_model, show_result_pyplot fimg = 'demo/demo.JPEG' fconfig = 'configs/resnet/resnet152_8xb32_in1k.py' fcheckpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_batch256_imagenet_20200708-ec25b1f9.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(fconfig, fcheckpoint, device=device) result = inference_model(model, fimg) print(result) show_result_pyplot(model, fimg, result)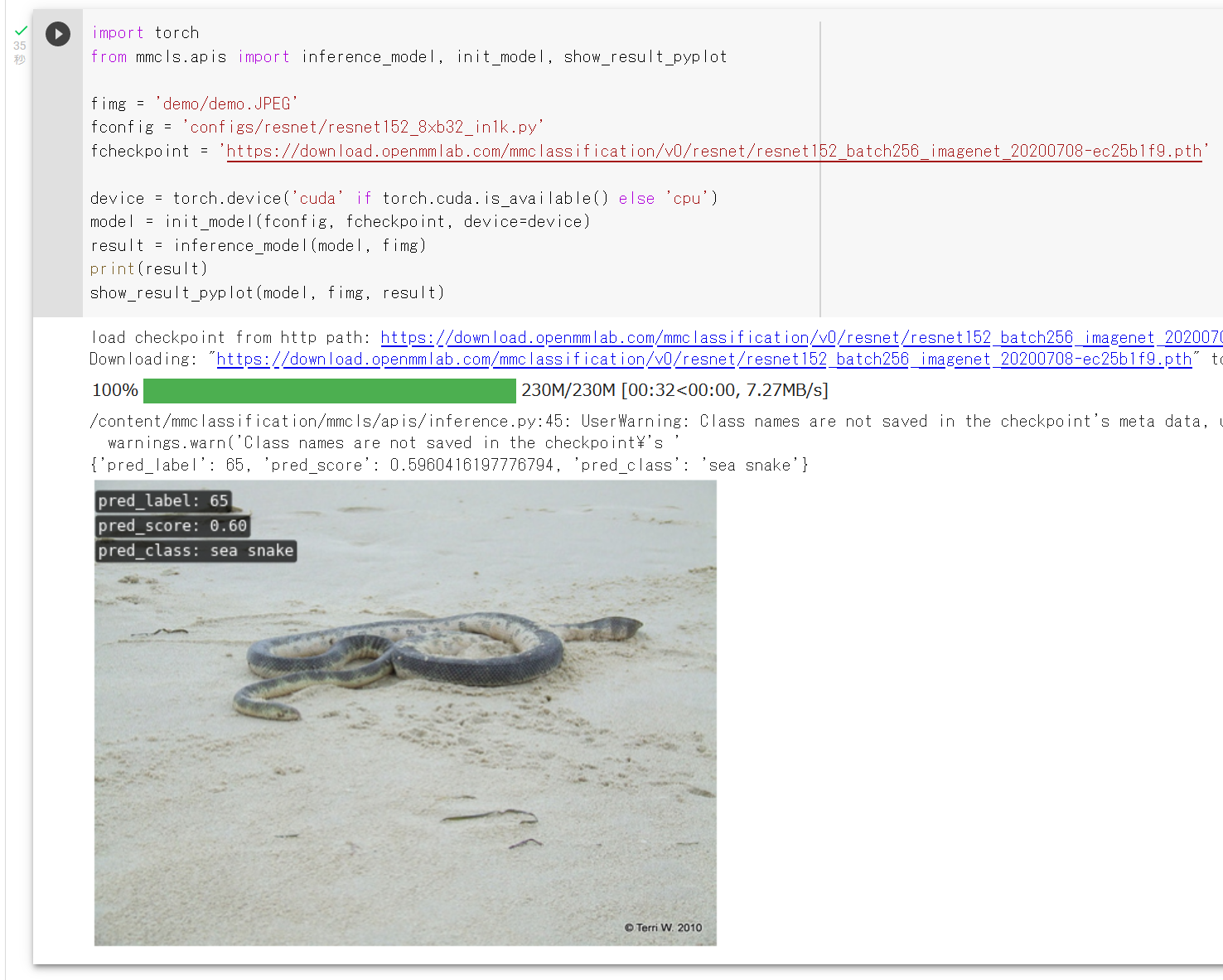
- 画像分類の実行(MMClassification, MobileNetV2,ImageNet データセットで事前学習済みモデルを使用)
- MMClassification のインストールを行う
- 画像分類の実行
「demo/demo.JPEG」のところに画像ファイル名を指定する.
import torch from mmcls.apis import inference_model, init_model, show_result_pyplot fimg = 'demo/demo.JPEG' fconfig = 'configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py' fcheckpoint = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(fconfig, fcheckpoint, device=device) result = inference_model(model, fimg) print(result) show_result_pyplot(model, fimg, result)
- 画像分類の実行(MMClassification, ResNeXt-32x4d-152,ImageNet データセットで事前学習済みモデルを使用)
- MMClassification のインストールを行う
- 画像分類の実行
「demo/demo.JPEG」のところに画像ファイル名を指定する.
import torch from mmcls.apis import inference_model, init_model, show_result_pyplot fimg = 'demo/demo.JPEG' fconfig = 'configs/resnext/resnext152-32x4d_8xb32_in1k.py' fcheckpoint = 'https://download.openmmlab.com/mmclassification/v0/resnext/resnext152_32x4d_b32x8_imagenet_20210524-927787be.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(fconfig, fcheckpoint, device=device) result = inference_model(model, fimg) print(result) show_result_pyplot(model, fimg, result)
- 画像分類の実行(MMClassification, ViT-B/32,ImageNet データセットで事前学習済みモデルを使用)
- MMClassification のインストールを行う
- 画像分類の実行
「demo/demo.JPEG」のところに画像ファイル名を指定する.
import torch from mmcls.apis import inference_model, init_model, show_result_pyplot fimg = 'demo/demo.JPEG' fconfig = 'configs/vision_transformer/vit-base-p32_ft-64xb64_in1k-384.py' fcheckpoint = 'https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(fconfig, fcheckpoint, device=device) result = inference_model(model, fimg) print(result) show_result_pyplot(model, fimg, result)
Windows で,MMClassification のインストールと,画像分類の実行
MMClassification のインストールと動作確認(画像分類)(PyTorch,Python を使用): 別ページ »で説明
MMCV
MMCV は, OpenMMLab の構成物で,基礎的な機能を提供する.
【文献】
MMCV Contributors, MMCV: OpenMMLab Computer Vision Foundation, https://github.com/open-mmlab/mmcv, 2018.
【関連する外部ページ】
- MMCV の GitHub のページ: https://github.com/open-mmlab/mmcv
- MMCV の公式ドキュメント: https://mmcv.readthedocs.io/en/latest/
【関連項目】 OpenMMLab, MMAction2, MMClassification MMDetection, MMFewShot, MMFlow, MMGen, MMPose, MMSegmentation, MMSegmentation3D, MMSelfSup, MMTracking
Google Colaboratory での MMCV のインストール
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)NVIDIA CUDA ツールキット のバージョンを確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMCV 1.6.2 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())"
Windows での MMCV のインストール
MMCV のインストールと動作確認(画像表示など)(PyTorch,Python を使用): 別ページ »で説明
Ubuntu での MMCV のインストール
MMCV 1.7.1 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
sudo apt install -y python3-terminaltables sudo apt install -y python3-opencv python3 -m pip uninstall -y mmcv mmcv-full python3 -m pip install mmcv==1.6.2MMDetection
MMDetection は, OpenMMLab の構成物で,物体検出, インスタンス・セグメンテーション (instance segmentation), パノプティック・セグメンテーション (panoptic segmentation) の機能を提供する.
【文献】
Chen, Kai and Wang, Jiaqi and Pang, Jiangmiao and Cao, Yuhang and Xiong, Yu and Li, Xiaoxiao and Sun, Shuyang and Feng, Wansen and Liu, Ziwei and Xu, Jiarui and Zhang, Zheng and Cheng, Dazhi and Zhu, Chenchen and Cheng, Tianheng and Zhao, Qijie and Li, Buyu and Lu, Xin and Zhu, Rui and Wu, Yue and Dai, Jifeng and Wang, Jingdong and Shi, Jianping and Ouyang, Wanli and Loy, Chen Change and Lin, Dahua, MMDetection: Open MMLab Detection Toolbox and Benchmark, arXiv:1906.07155, 2019.
【サイト内の関連ページ】 物体検出の実行(MMDetection,PyTorch,Python を使用)(Windows 上)
【関連する外部ページ】
- MMDetection の GitHub のページ: https://github.com/open-mmlab/mmdetection
- MMDetection の公式ドキュメント: https://mmdetection.readthedocs.io
- MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb
- MMDetection の公式の学習済みモデル: https://github.com/open-mmlab/mmdetection/blob/master/docs/en/model_zoo.md
【関連項目】 DETR, Deformable DETR, Mask R-CNN, MMCV, MMFewShot, MMPose, MMSegmentation, MMSegmentation3D, MMSelfSup, MMTracking, OpenMMLab, RetinaNet, Seesaw Loss, SSD, YOLOv3, YOLOv4, YOLOX, インスタンス・セグメンテーション (instance segmentation), パノプティック・セグメンテーション (panoptic segmentation) 物体検出
Google Colaboratory で,MMDetection による物体検出とセグメンテーションの実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- MIM のインストール
!pip3 install git+https://github.com/open-mmlab/mim.git - MMCV, MMDetection のインストール.
https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md に記載の手順による
!mim install mmdet !pip3 show mmdet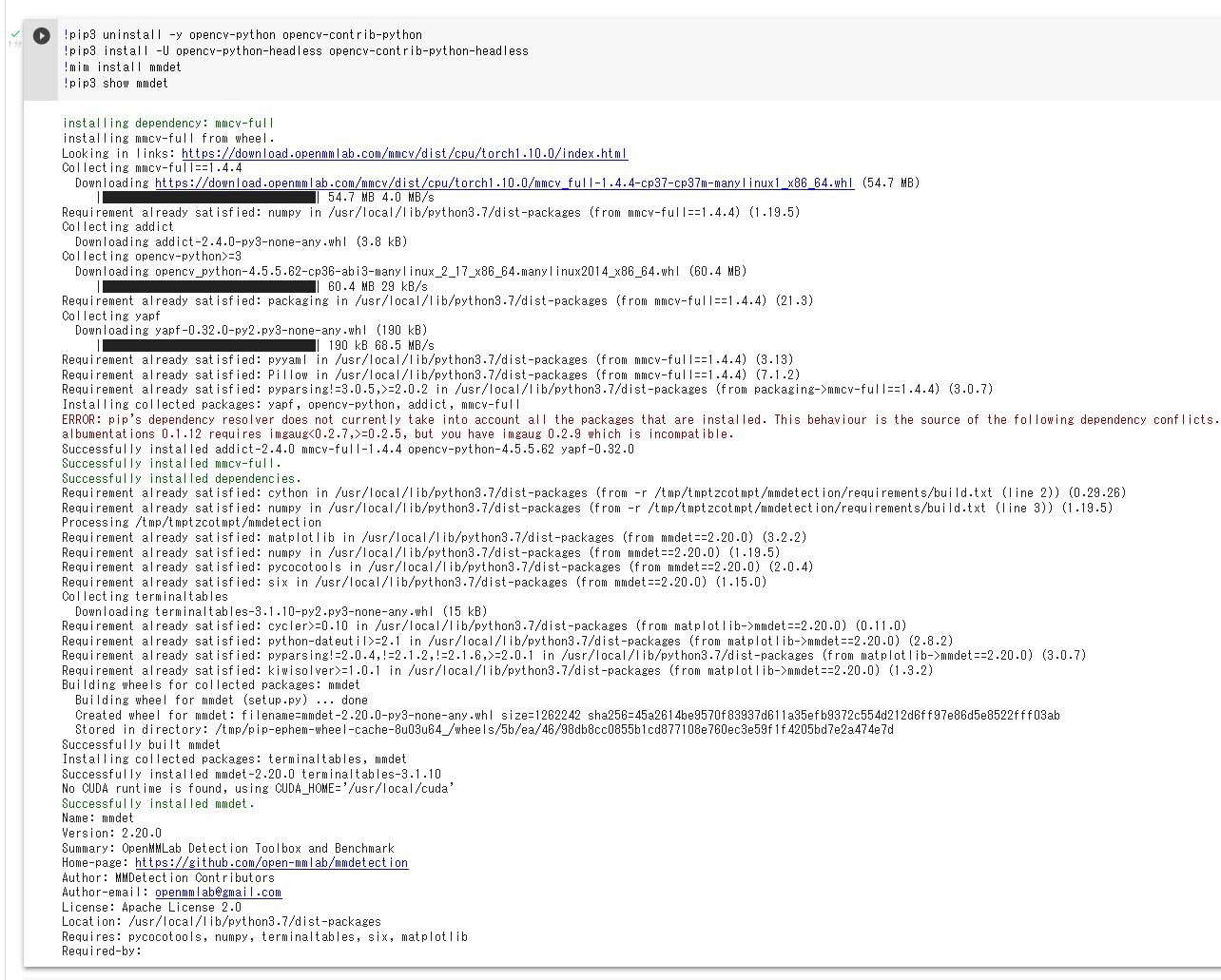
- MMDetection のソースコード等のダウンロード
あとで使用する
%cd /content !rm -rf mmdetection !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection
- MMDetection の学習済みモデルのダウンロード
Mask R-CNN, FPN (Feature Pyramid Network), Lr schd = 3x のものをダウンロード.
MMDetection の Mask R-CNN の説明ページ: https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn
!curl -O https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth !mkdir checkpoints !mv mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth checkpoints
- Mask R-CNN による 物体検出とセグメンテーションの実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,Mask R-CNN, FPN (Feature Pyramid Network), Lr schd = 3x を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco.py' fcheckpoint = 'checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)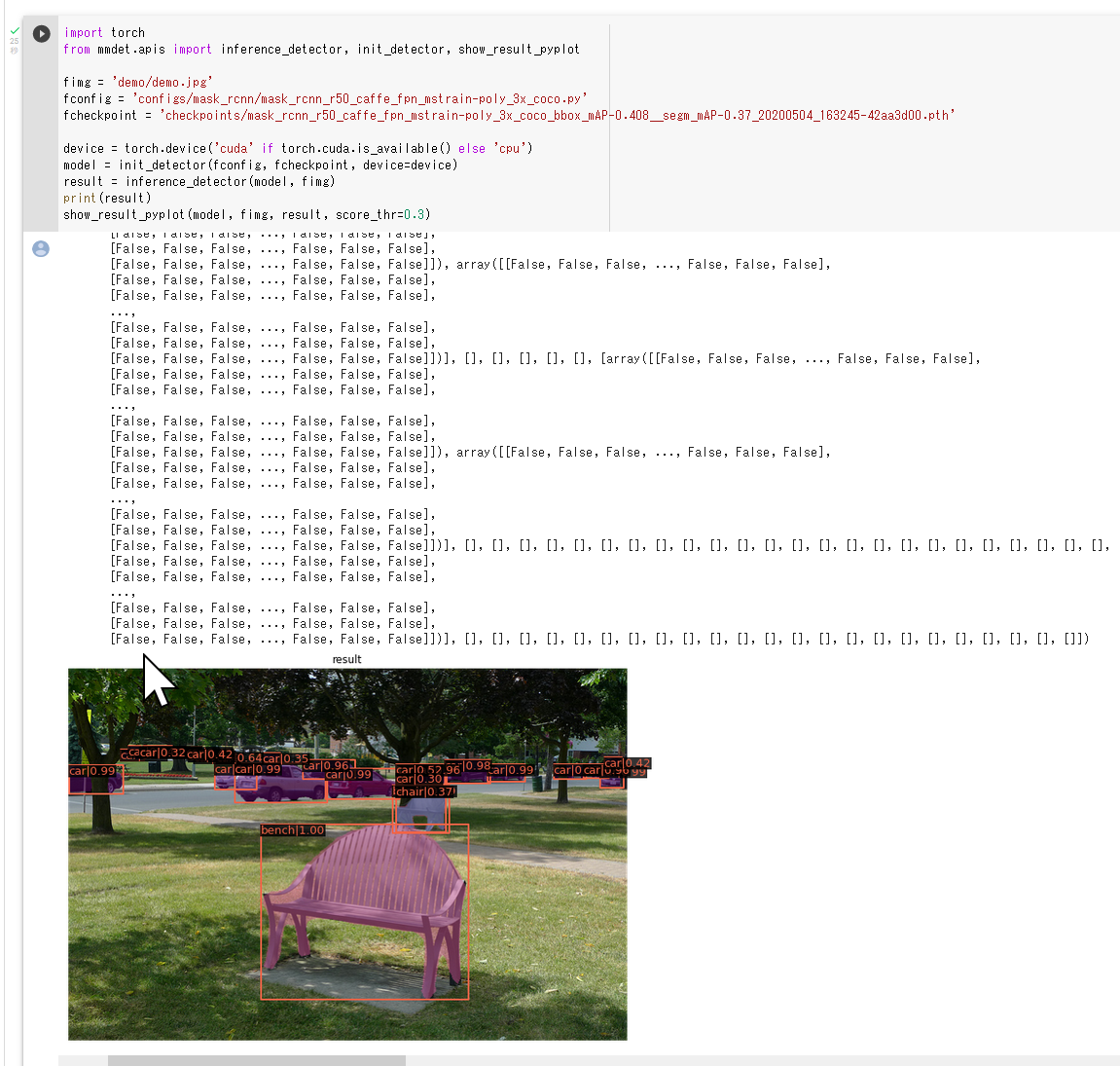
- RetinaNet による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
RetinaNet, R-50-FPN, Lr schd = 1x のものをダウンロード.
MMDetection の RetinaNet の説明ページ: https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet
!curl -O https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r50_caffe_fpn_1x_coco/retinanet_r50_caffe_fpn_1x_coco_20200531-f11027c5.pth !mkdir checkpoints !mv retinanet_r50_caffe_fpn_1x_coco_20200531-f11027c5.pth checkpoints
- RetinaNet による 物体検出の実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,RetinaNet, R-50-FPN, Lr schd = 1x を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/retinanet/retinanet_r50_caffe_fpn_1x_coco.py' fcheckpoint = 'checkpoints/retinanet_r50_caffe_fpn_1x_coco_20200531-f11027c5.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)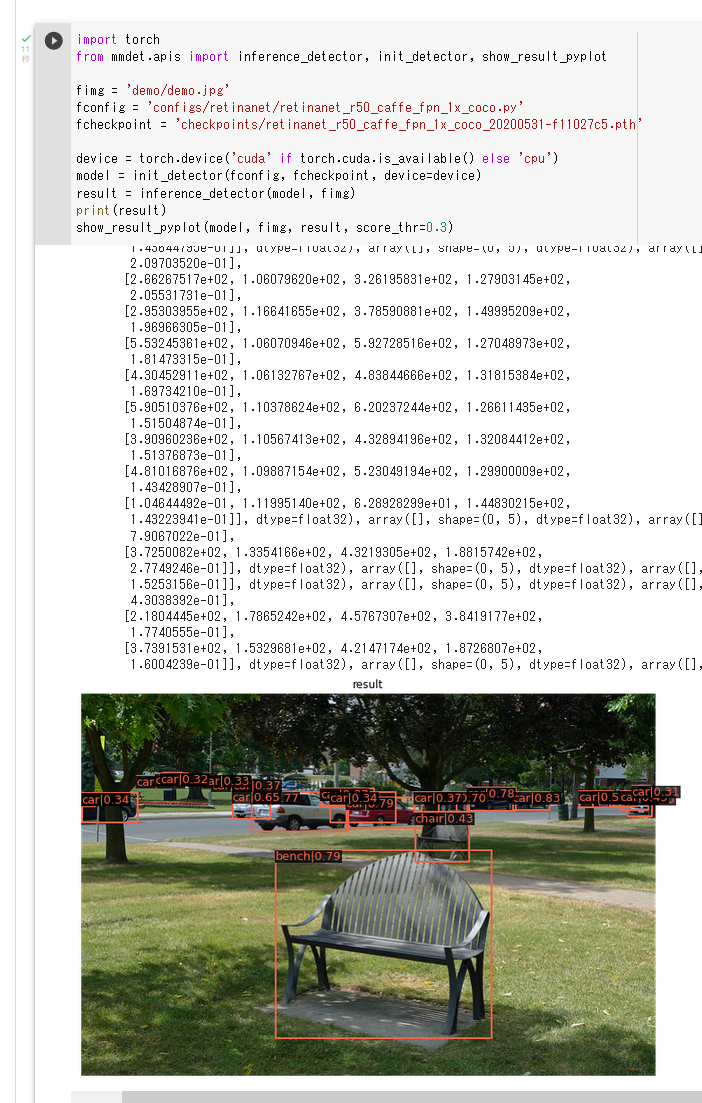
- MMDetection の学習済みモデルのダウンロード
- DETR による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
DETR, R-50, Lr schd = 150e のものをダウンロード.
MMDetection の DETR の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/detr/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/detr/detr_r50_8x2_150e_coco/detr_r50_8x2_150e_coco_20201130_194835-2c4b8974.pth !mkdir checkpoints !mv detr_r50_8x2_150e_coco_20201130_194835-2c4b8974.pth checkpoints
- DETR による 物体検出の実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,DETR, R-50, Lr schd = 150e を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/detr/detr_r50_8x2_150e_coco.py' fcheckpoint = 'checkpoints/detr_r50_8x2_150e_coco_20201130_194835-2c4b8974.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)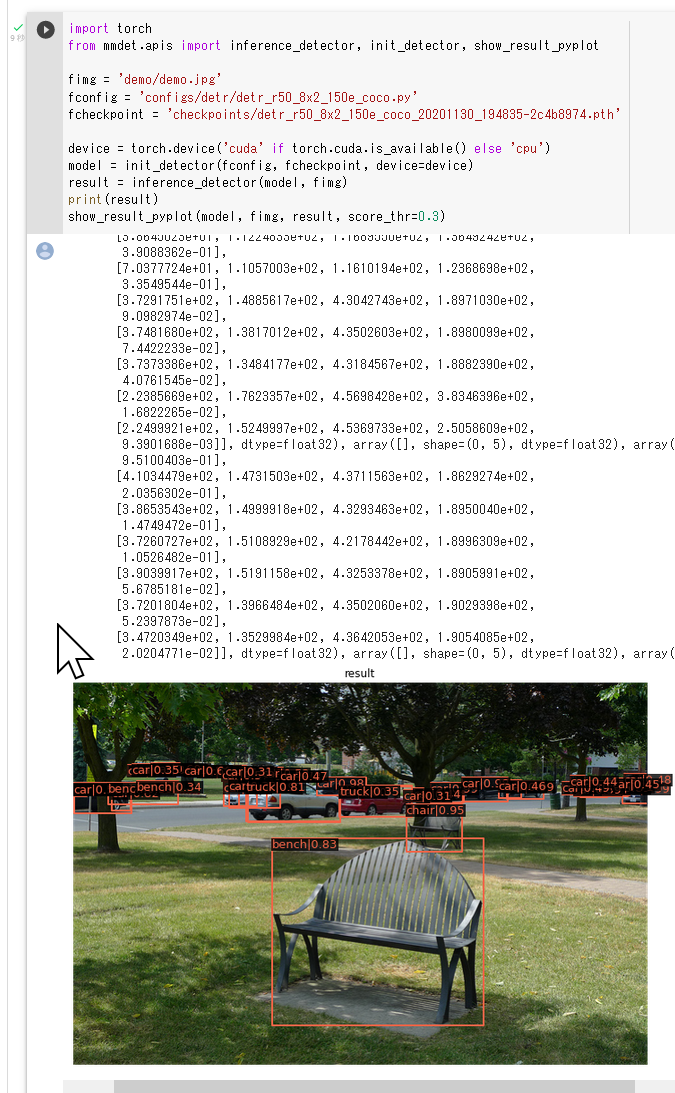
- MMDetection の学習済みモデルのダウンロード
- Deformable DETR による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
Deformable DETR, ++ two-stage Deformable DETR, R-50, Lr schd = 50e のものをダウンロード.
MMDetection の Deformable DETR の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/deformable_detr/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.pth !mkdir checkpoints !mv deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.pth checkpoints
- Deformable DETR による 物体検出の実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,Deformable DETR, ++ two-stage Deformable DETR, R-50, Lr schd = 50e を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco.py' fcheckpoint = 'checkpoints/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)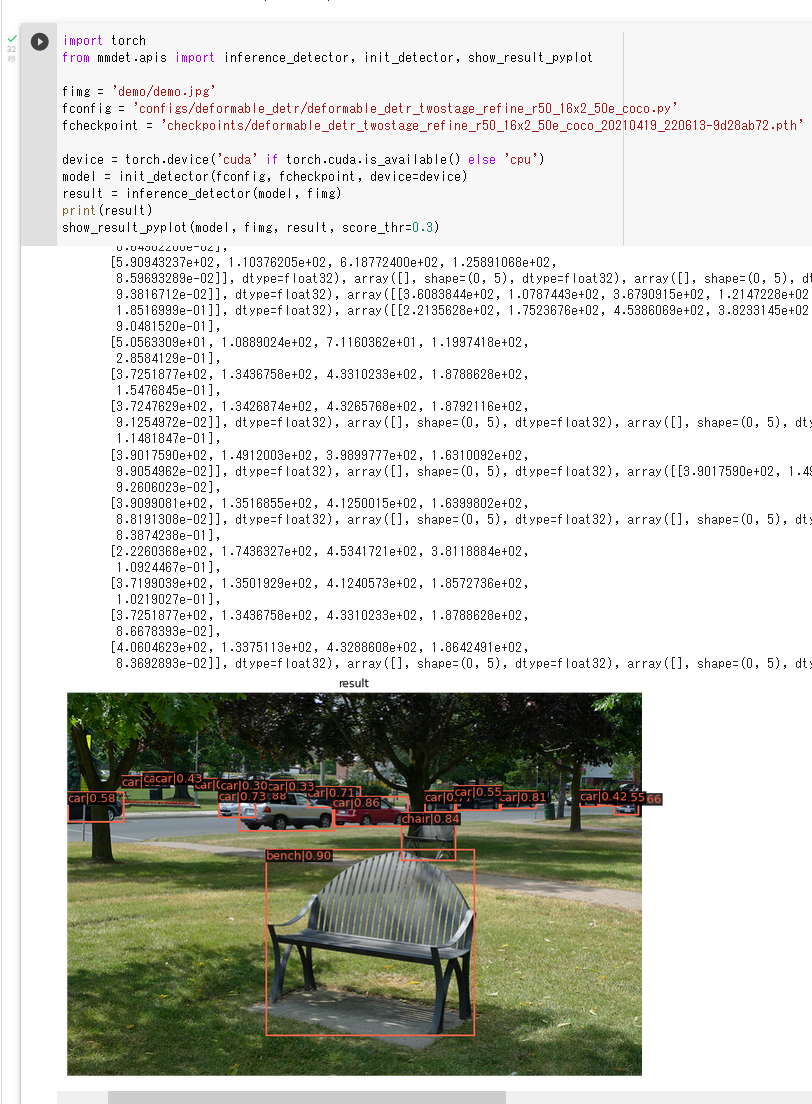
- MMDetection の学習済みモデルのダウンロード
- YOLOX による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
YOLOX のものをダウンロード.
MMDetection の YOLOX の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/yolox/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_x_8x8_300e_coco/yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth !mkdir checkpoints !mv yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth checkpoints
- YOLOX による 物体検出の実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,YOLOX を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/yolox/yolox_x_8x8_300e_coco.py' fcheckpoint = 'checkpoints/yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)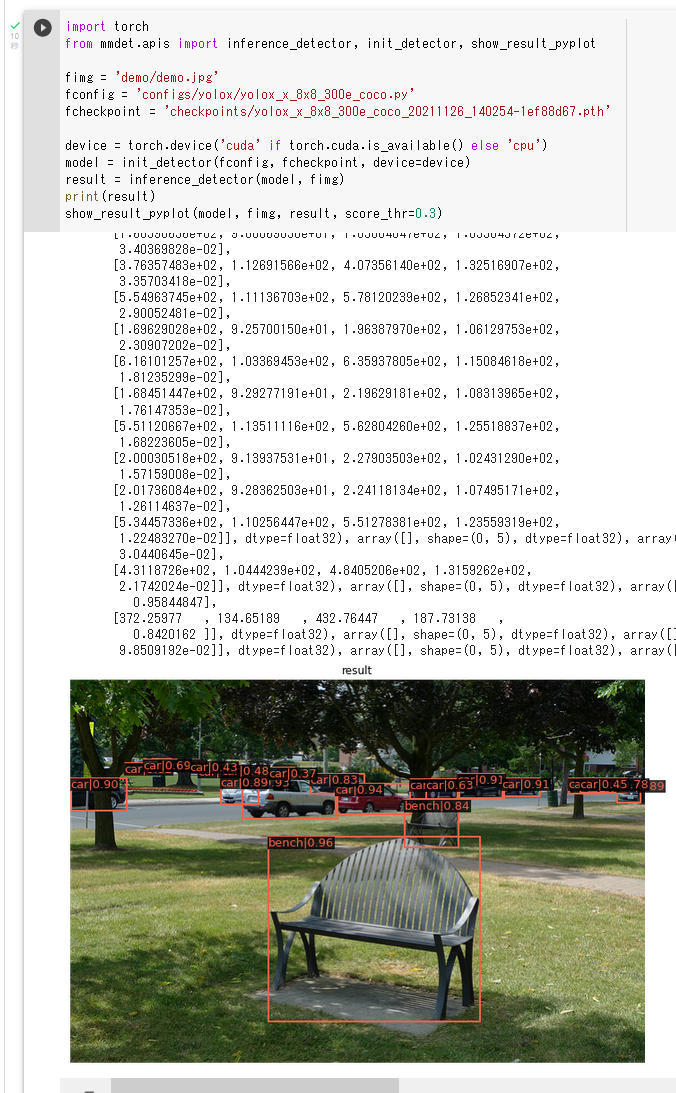
- MMDetection の学習済みモデルのダウンロード
- YOLOv3 による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
YOLOv3, DarkNet-53, Lr schd = 273e, with mixed precision training のものをダウンロード.
MMDetection の YOLOv3 の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/yolo/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/yolo/yolov3_d53_fp16_mstrain-608_273e_coco/yolov3_d53_fp16_mstrain-608_273e_coco_20210517_213542-4bc34944.pth !mkdir checkpoints !mv yolov3_d53_fp16_mstrain-608_273e_coco_20210517_213542-4bc34944.pth checkpoints
- YOLOv3 による 物体検出の実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,YOLOv3, DarkNet-53, Lr schd = 273e, with mixed precision training を使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/yolo/yolov3_d53_fp16_mstrain-608_273e_coco.py' fcheckpoint = 'checkpoints/yolov3_d53_fp16_mstrain-608_273e_coco_20210517_213542-4bc34944.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)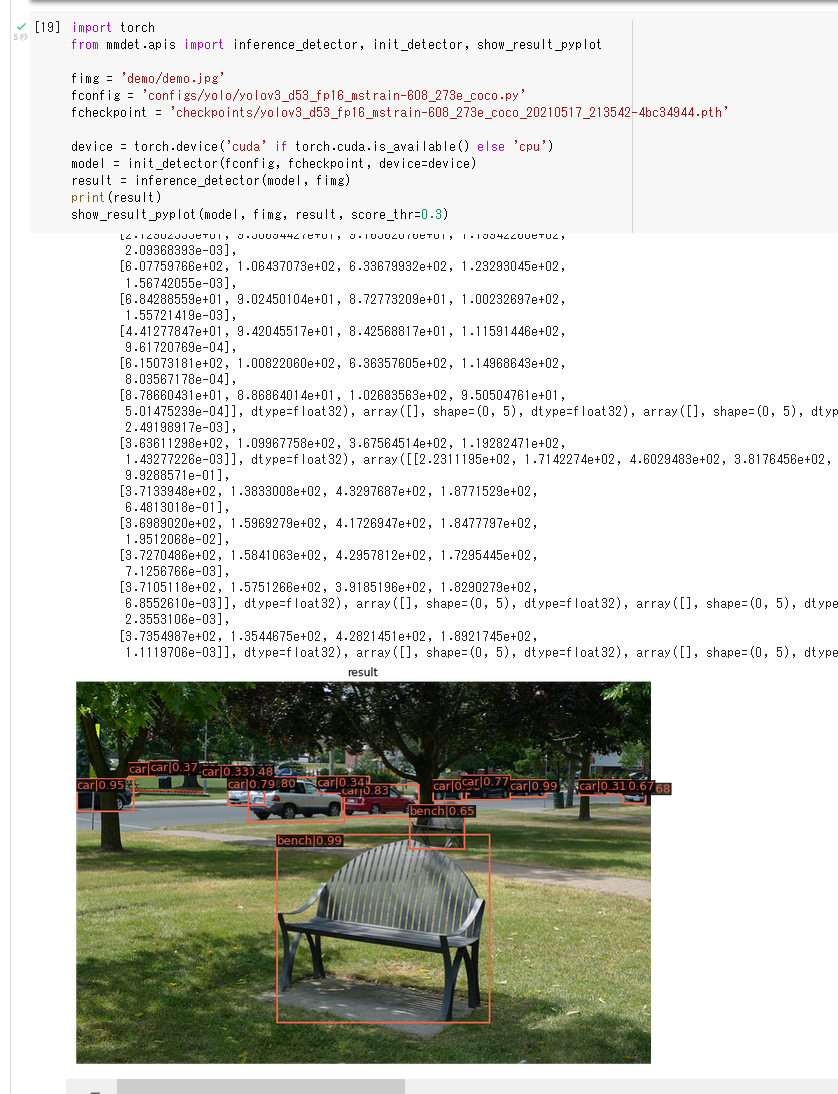
- MMDetection の学習済みモデルのダウンロード
- Seesaw Loss による物体検出とセグメンテーションの実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
Seesaw Loss,Cascade Mask R-CNN, R-101-FPN, Lr schd = 2x, LVIS v1 データセットのものをダウンロード.
MMDetection の Seesaw Loss の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/seesaw_loss/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1-c8551505.pth !mkdir checkpoints !mv cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1-c8551505.pth checkpoints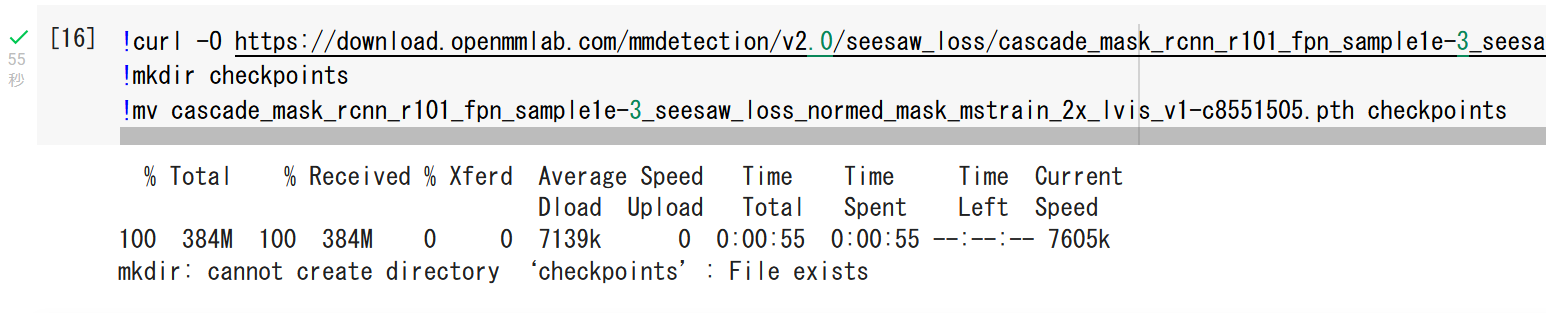
- Seesaw Loss による 物体検出とセグメンテーションの実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,Seesaw Loss,Cascade Mask R-CNN, R-101-FPN, Lr schd = 2x, LVIS v1 データセットを使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1.py' fcheckpoint = 'checkpoints/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1-c8551505.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)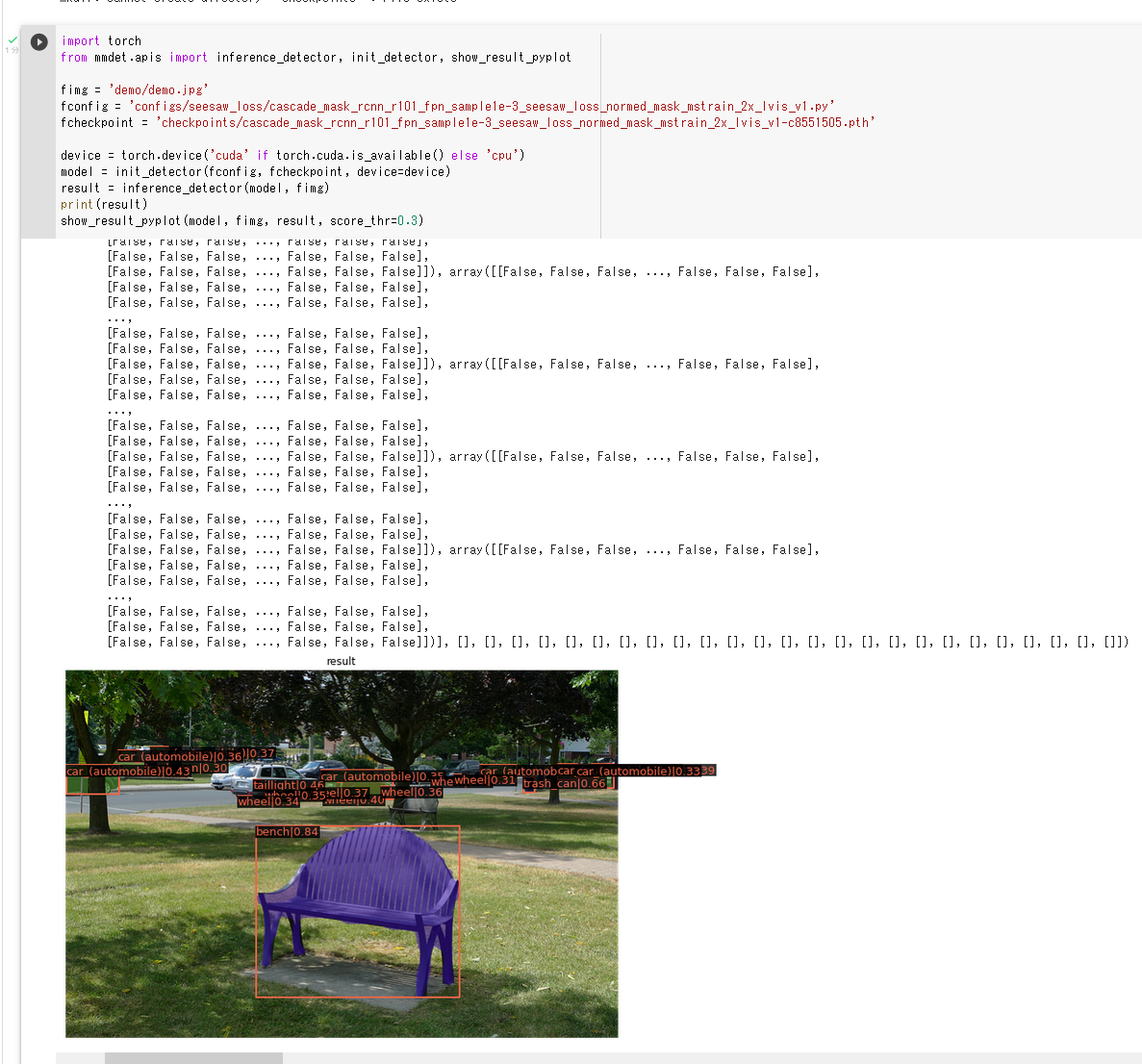
- MMDetection の学習済みモデルのダウンロード
- SSD による物体検出の実行(MMDetection を使用)
- MMDetection の学習済みモデルのダウンロード
SSD,size=512, Lr schd = 120x, COCO データセットのものをダウンロード.
MMDetection の SSD の説明ページ: https://github.com/open-mmlab/mmdetection/blob/master/configs/ssd/README.md
!curl -O https://download.openmmlab.com/mmdetection/v2.0/ssd/ssd512_coco/ssd512_coco_20210803_022849-0a47a1ca.pth !mkdir checkpoints !mv ssd512_coco_20210803_022849-0a47a1ca.pth checkpoints - SSD による 物体検出とセグメンテーションの実行(MMDetectionを使用)
MMDetection の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb に記載のプログラムを使用
このプログラムは,SSD,size=512, Lr schd = 120x, COCO データセットを使用.
import torch from mmdet.apis import inference_detector, init_detector, show_result_pyplot fimg = 'demo/demo.jpg' fconfig = 'configs/configs/ssd/ssd512_coco.py' fcheckpoint = 'checkpoints/ssd512_coco_20210803_022849-0a47a1ca.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_detector(fconfig, fcheckpoint, device=device) result = inference_detector(model, fimg) print(result) show_result_pyplot(model, fimg, result, score_thr=0.3)
- MMDetection の学習済みモデルのダウンロード
Windows で,MMDetection のインストールと,物体検出の実行
MMDetection のインストールと動作確認(物体検出)(PyTorch,Python を使用): 別ページ »で説明
Ubuntu での MMDetection のインストール
- インストール
「git checkout v0.14.0」は,バージョン 2.14.0 を指定している. これは,https://mmdetection3d.readthedocs.io/en/latest/get_started.html での2021/08 時点の説明による.将来はバージョン番号が変わる可能性があり,このページを確認してから,インストールを行うこと.
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo git clone https://github.com/open-mmlab/mmdetection.git sudo chown -R $USER mmdetection cd mmdetection git checkout v2.14.0 sudo pip3 install -r requirements\build.txt python3 setup.py develop pip3 install instaboostfast # for panoptic segmentation pip3 install git+https://github.com/cocodataset/panopticapi.git # for LVIS dataset pip3 install git+https://github.com/lvis-dataset/lvis-api.git - 動作確認
Ubuntu の場合は, mmcv のドキュメント: https://mmcv.readthedocs.io/en/latest/ の手順がそのまま使えそうである.
MMEditing
MMEditing は, OpenMMLab の構成物で, イメージ・インペインティング(image inpainting),画像のノイズ除去 (画像のノイズ除去 (image restoration)), イメージ・マッティング (image matting), 超解像 (super resolution), 画像生成の機能を持つ.
- 文献
MMEditing Contributors, OpenMMLab Editing Estimation Toolbox and Benchmark, https://github.com/open-mmlab/mmediting, 2020.
- MMEditing の GitHub のページ: https://github.com/open-mmlab/mmediting
- MMEditing の公式ドキュメント: https://mmediting-jm.readthedocs.io/en/latest/
- MMEditing の image matting の公式チュートリアル: https://github.com/open-mmlab/mmediting/blob/master/demo/matting_tutorial.ipynb
- MMEditing の 画像のノイズ除去 (image restoration) の公式チュートリアル: https://github.com/open-mmlab/mmediting/blob/master/demo/restorer_basic_tutorial.ipynb
- MMEditing の公式の学習済みモデル: https://mmediting-jm.readthedocs.io/en/latest/model_zoo.html
【関連項目】 MMCV, OpenMMLab, SRCNN, ESRGAN, EDvR, BasicVSR image inpainting, 画像のノイズ除去 (image restoration), イメージ・マッティング (image matting), 超解像 (super resolution), generation
Google Colaboratory で MMEditing の SRCNN, ESRGAN, EDVR, BasicVSR による超解像 (super resolution) の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMCV 1.7.1 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())" - MIM, MMEditing のインストール
!python -m pip install -U openmim opencv-python %cd /content !rm -rf mmediting !git clone https://github.com/open-mmlab/mmediting.git %cd mmediting !pip3 install -r requirements/build.txt !pip3 install .
- MMEditing のデモファイルのダウンロード
%cd /content/mmediting !curl -O https://download.openmmlab.com/mmediting/demo_files.zip !rm -rf demo_files !unzip demo_files
- 超解像 (super resolution) の実行
- SRCNN による画像の超解像 (super resolution) の実行
学習済みモデルを使用.
MMEditing の SRCNN の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/srcnn/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/restoration_demo.py ./configs/restorers/srcnn/srcnn_x4k915_g1_1000k_div2k.py https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth ./demo_files/lq_images/bird.png ./outputs/bird_SRCNN.png from PIL import Image Image.open('./demo_files/lq_images/bird.png').show() Image.open('./outputs/bird_SRCNN.png').show()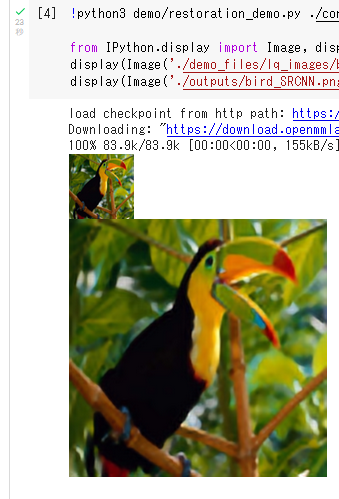
- ESRGAN による画像の超解像 (super resolution) の実行
学習済みモデルを使用.
MMEditing の ESRGAN の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/esrgan/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/restoration_demo.py ./configs/restorers/esrgan/esrgan_x4c64b23g32_g1_400k_div2k.py https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth ./demo_files/lq_images/bird.png ./outputs/bird_ESRGAN.png from PIL import Image Image.open('./demo_files/lq_images/bird.png').show() Image.open('./outputs/bird_ESRGAN.png').show()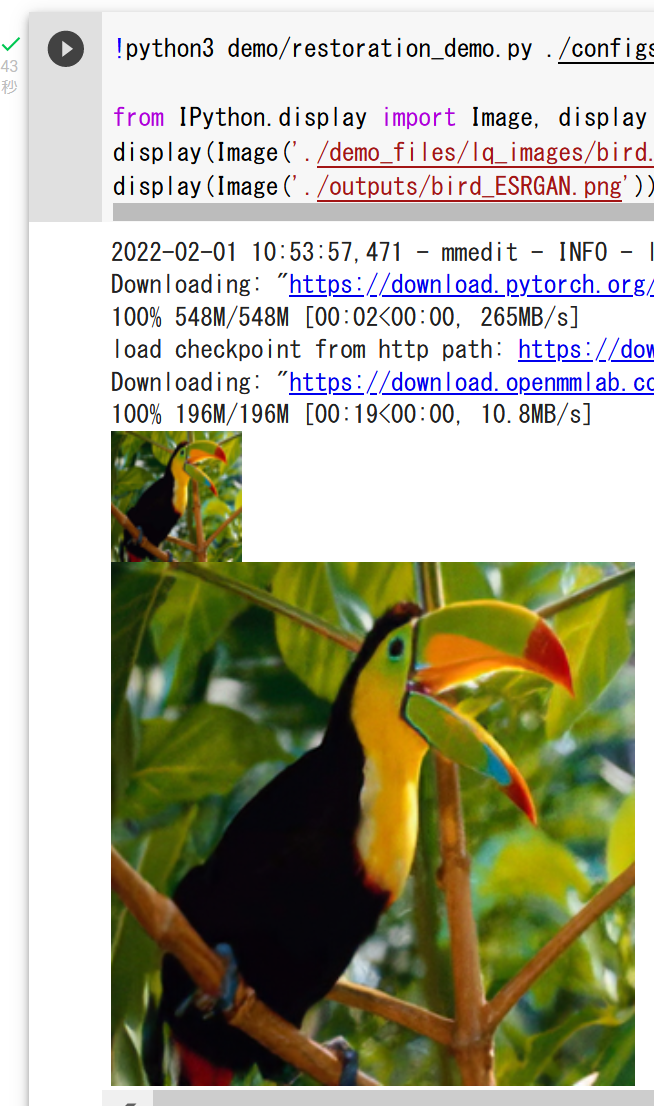
- EDVR による連続画像の超解像 (super resolution) の実行
学習済みモデルを使用.
MMEditing の EDVR の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/edvr/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/restoration_video_demo.py ./configs/restorers/edvr/edvrm_wotsa_x4_g8_600k_reds.py https://download.openmmlab.com/mmediting/restorers/edvr/edvrm_wotsa_x4_8x4_600k_reds_20200522-0570e567.pth demo_files/lq_sequences/city/ ./outputs/city_EDVR --window_size=5 from PIL import Image Image.open('./demo_files/lq_sequences/city/00000000.png').show() Image.open('./outputs/city_EDVR/00000000.png').show() Image.open('./demo_files/lq_sequences/city/00000001.png').show() Image.open('./outputs/city_EDVR/00000001.png').show() Image.open('./demo_files/lq_sequences/city/00000002.png').show() Image.open('./outputs/city_EDVR/00000002.png').show() Image.open('./demo_files/lq_sequences/city/00000003.png').show() Image.open('./outputs/city_EDVR/00000003.png').show() Image.open('./demo_files/lq_sequences/city/00000004.png').show() Image.open('./outputs/city_EDVR/00000004.png').show() Image.open('./demo_files/lq_sequences/city/00000005.png').show() Image.open('./outputs/city_EDVR/00000005.png').show()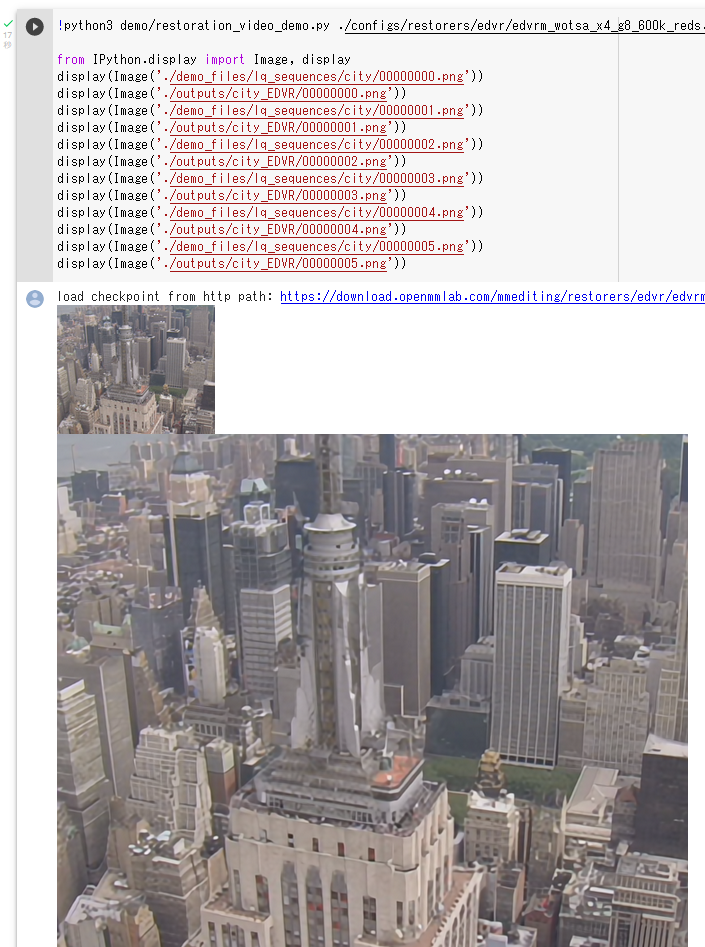

- BasicVSR (Recurrent framework) の実行
学習済みモデルを使用.
MMEditing の EDVR の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/edvr/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/restoration_video_demo.py ./configs/restorers/basicvsr/basicvsr_reds4.py https://download.openmmlab.com/mmediting/restorers/basicvsr/basicvsr_reds4_20120409-0e599677.pth demo_files/lq_sequences/city/ ./outputs/city_BasicVSR from PIL import Image Image.open('./demo_files/lq_sequences/city/00000000.png').show() Image.open('./outputs/city_BasicVSR/00000000.png').show() Image.open('./demo_files/lq_sequences/city/00000001.png').show() Image.open('./outputs/city_BasicVSR/00000001.png').show() Image.open('./demo_files/lq_sequences/city/00000002.png').show() Image.open('./outputs/city_BasicVSR/00000002.png').show() Image.open('./demo_files/lq_sequences/city/00000003.png').show() Image.open('./outputs/city_BasicVSR/00000003.png').show() Image.open('./demo_files/lq_sequences/city/00000004.png').show() Image.open('./outputs/city_BasicVSR/00000004.png').show() Image.open('./demo_files/lq_sequences/city/00000005.png').show() Image.open('./outputs/city_BasicVSR/00000005.png').show()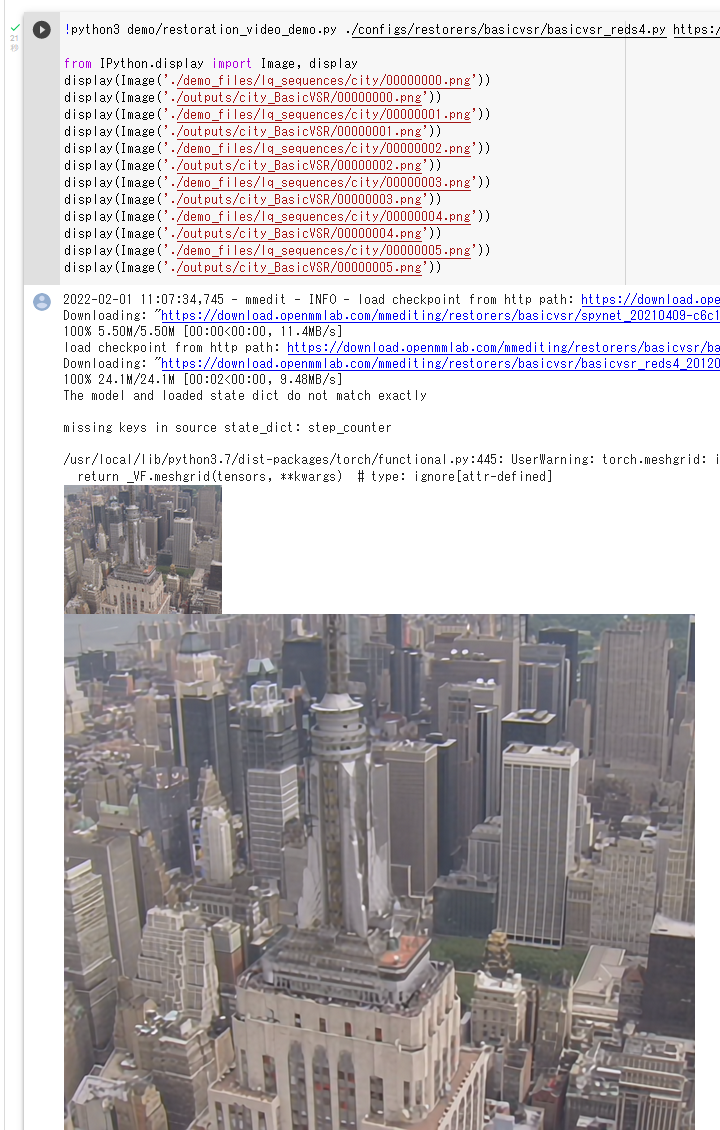

- SRCNN による画像の超解像 (super resolution) の実行
- image inpainting の実行
- DeepFillv2 による image impainting の実行
学習済みモデルを使用.
MMEditing の DeepFillv2 の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/inpainting/deepfillv2/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/inpainting_demo.py configs/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba.py https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_celeba_20200619-c96e5f12.pth tests/data/image/celeba_test.png tests/data/image/bbox_mask.png tests/data/pred/inpainting_celeba.png from PIL import Image Image.open('./tests/data/image/celeba_test.png').show() Image.open('./tests/data/pred/inpainting_celeba.png').show()
- Global&Local による image impainting の実行
学習済みモデルを使用.
MMEditing の Global&Local の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/inpainting/global_local/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/inpainting_demo.py configs/inpainting/global_local/gl_256x256_8x12_celeba.py https://download.openmmlab.com/mmediting/inpainting/global_local/gl_256x256_8x12_celeba_20200619-5af0493f.pth tests/data/image/celeba_test.png tests/data/image/bbox_mask.png tests/data/pred/inpainting_celeba.png from PIL import Image Image.open('./tests/data/image/celeba_test.png').show() Image.open('./tests/data/pred/inpainting_celeba.png').show()
- DeepFillv2 による image impainting の実行
- image matting の実行
- GCA による image matting の実行
学習済みモデルを使用.
MMEditing の GCA の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/mattors/gca/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/matting_demo.py configs/mattors/gca/gca_r34_4x10_200k_comp1k.py https://download.openmmlab.com/mmediting/mattors/gca/gca_r34_4x10_200k_comp1k_SAD-34.77_20200604_213848-4369bea0.pth tests/data/merged/GT05.jpg tests/data/trimap/GT05.png tests/data/pred/GT05.png from PIL import Image Image.open('./tests/data/merged/GT05.jpg')) Image.open('./tests/data/trimap/GT05.png').show() Image.open('./tests/data/pred/GT05.png').show()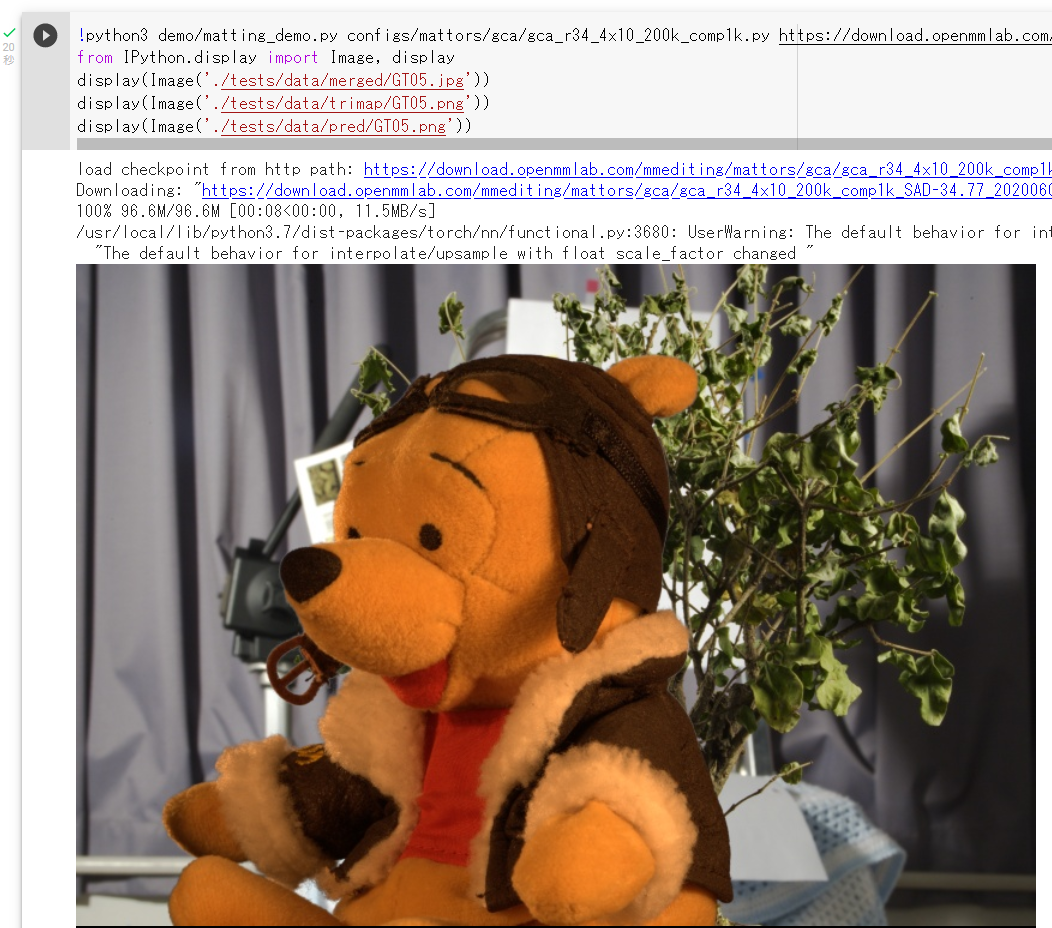


- IndexNet による image matting の実行
学習済みモデルを使用.
MMEditing の IndexNet の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/mattors/indexnet/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/matting_demo.py configs/mattors/indexnet/indexnet_mobv2_1x16_78k_comp1k.py https://download.openmmlab.com/mmediting/mattors/indexnet/indexnet_mobv2_1x16_78k_comp1k_SAD-45.6_20200618_173817-26dd258d.pth tests/data/merged/GT05.jpg tests/data/trimap/GT05.png tests/data/pred/GT05.png from PIL import Image Image.open('./tests/data/merged/GT05.jpg')) Image.open('./tests/data/trimap/GT05.png').show() Image.open('./tests/data/pred/GT05.png').show()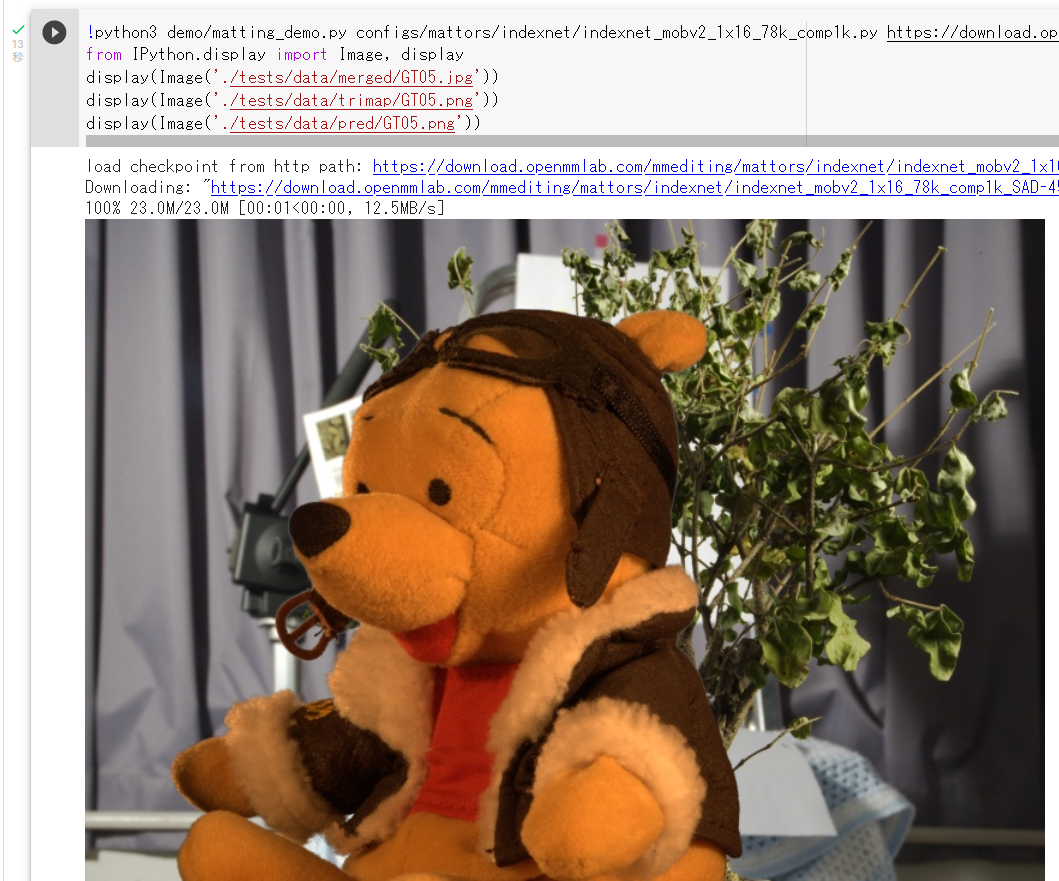


- DIM による image matting の実行
学習済みモデルを使用.
MMEditing の DIM の説明ページ: https://github.com/open-mmlab/mmediting/blob/master/configs/mattors/dim/README.md
コマンドの説明: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md
!python3 demo/matting_demo.py configs/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k.py https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth tests/data/merged/GT05.jpg tests/data/trimap/GT05.png tests/data/pred/GT05.png from PIL import Image Image.open('./tests/data/merged/GT05.jpg')) Image.open('./tests/data/trimap/GT05.png').show() Image.open('./tests/data/pred/GT05.png').show()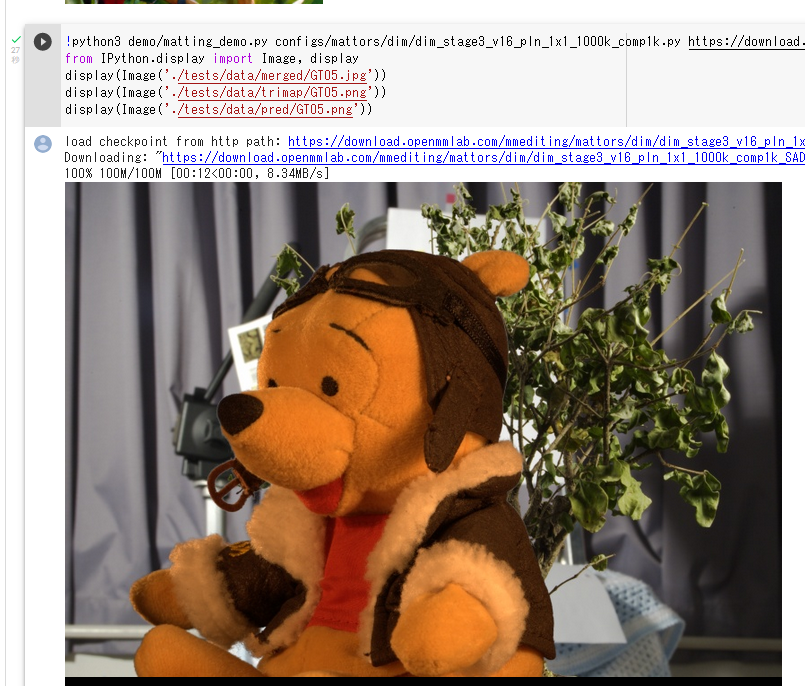


- GCA による image matting の実行
demos URL: https://github.com/open-mmlab/mmediting/blob/master/docs/en/getting_started.md!python3 demo/generation_demo.py configs/example_config.py work_dirs/example_exp/example_model_20200202.pth demo/demo.jpg demo/demo_out.jpg
!python3 demo/generation_demo.py configs/example_config.py work_dirs/example_exp/example_model_20200202.pth demo/demo.jpg demo/demo_out.jpg --unpaired_path demo/demo_unpaired.jpg
MMFewShot
MMFewShot は, OpenMMLab の構成物で, Few Shot Classification, Few Shot Detection の機能を提供する.
【文献】
mmfewshot Contributors, OpenMMLab Few Shot Learning Toolbox and Benchmark, https://github.com/open-mmlab/mmfewshot, 2021.
【関連する外部ページ】
- MMFewShot の公式ドキュメント: https://mmfewshot.readthedocs.io
- MMFewShot のデモの公式ドキュメント: https://github.com/open-mmlab/mmfewshot/blob/main/demo/README.md MMFewShot の公式の学習済みモデル: https://github.com/open-mmlab/mmfewshot/blob/main/docs/en/model_zoo.md
【関連項目】 Few Shot Detection, OpenMMLab, MMClassification, MMCV, MMDetection,
Google Colaboratory で,MMFewShot による Few Shot Detection の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- MIM のインストール
!pip3 install git+https://github.com/open-mmlab/mim.git - MMCV, MMDetection, MMClassification のインストール.
https://mmclassification.readthedocs.io/en/latest/install.html, https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md に記載の手順による
!mim install mmdet !pip3 show mmdet cd /content !rm -rf mmclassification !git clone https://github.com/open-mmlab/mmclassification.git %cd mmclassification !git checkout dev !mim install -e . !pip3 show mmcls
- MMFewShot のインストール
https://github.com/open-mmlab/mmfewshot/blob/main/docs/en/install.md に記載の手順による.
%cd /content !rm -rf mmfewshot !git clone https://github.com/open-mmlab/mmfewshot.git %cd mmfewshot !pip3 install -r requirements/build.txt !python3 setup.py develop !pip3 show mmfewshot
- Few Shot Detection の実行
%cd /content/mmfewshot import os from mmdet.apis import show_result_pyplot from mmfewshot.detection.apis import (inference_detector, init_detector, process_support_images) %matplotlib inline import matplotlib.pyplot as plt import torch import torchvision.models as models from IPython.display import display fconfig = 'configs/detection/attention_rpn/coco/attention-rpn_r50_c4_4xb2_coco_base-training.py' fcheckpoint = 'https://download.openmmlab.com/mmfewshot/detection/attention_rpn/coco/attention-rpn_r50_c4_4xb2_coco_base-training_20211102_003348-da28cdfd.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') fsupport_images_dir = 'demo/demo_detection_images/support_images' model = init_detector(fconfig,fcheckpoint, device=device) files = os.listdir(fsupport_images_dir) support_images = [ os.path.join(fsupport_images_dir, file) for file in files ] classes = [file.split('.')[0] for file in files] support_labels = [[file.split('.')[0]] for file in files] print("support_images") display(support_images) print("classes") display(classes) print("support_labels") display(support_labels) process_support_images(model, support_images, support_labels, classes=classes) # single image fimage = 'demo/demo_detection_images/query_images/demo_query.jpg' fscore_thr = 0.3 result = inference_detector(model, fimage) show_result_pyplot(model, fimage, result, score_thr=fscore_thr)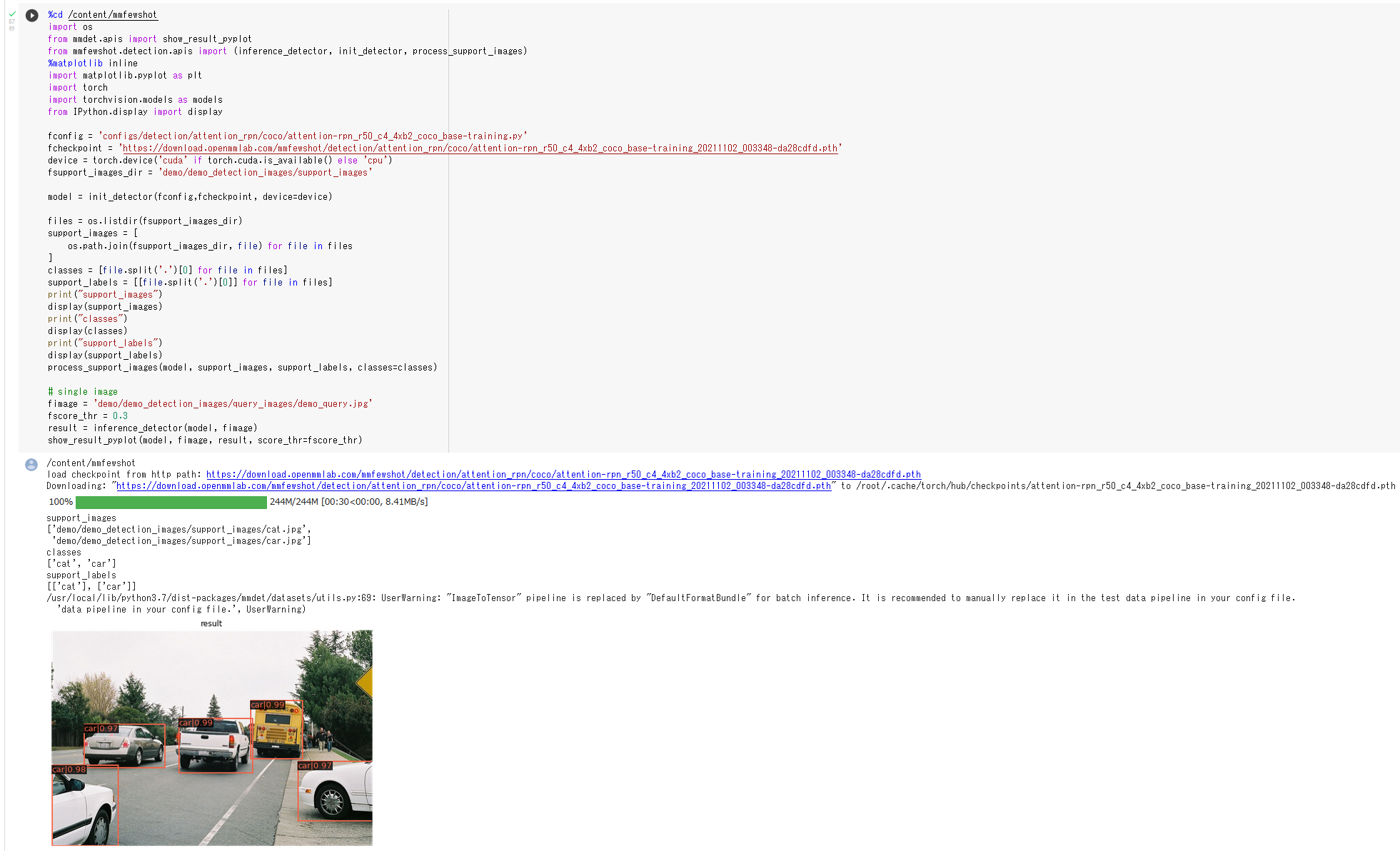
Windows で,MMFewShot のインストールと,物体検出の実行
MMCV 1.6.0, MMDetection 2.25.0,MMFewShot のインストールと動作確認(画像分類,物体検出)(PyTorch,Python を使用): 別ページ »で説明
MMFlow
MMFlow は, OpenMMLab の構成物で,オプティカルフローの機能を提供する.
【文献 】
MMFlow Contributors, MMFlow: OpenMMLab Optical Flow Toolbox and Benchmark, https://github.com/open-mmlab/mmflow, 2021.
【関連する外部ページ 】
- MMFlow の GitHub のページ: https://github.com/open-mmlab/mmflow
- MMFlow の公式ドキュメント: https://mmflow.readthedocs.io
- MMFlow の公式のデモ(プログラムやデータなど): https://github.com/open-mmlab/mmflow/tree/master/demo
- MMFlow の公式の学習済みモデル: https://github.com/open-mmlab/mmflow/blob/master/docs/en/model_zoo.md
【関連項目】 OpenMMLab, MMCV, optical flow
Windows で,MMFlow のインストールとオプティカルフローの実行
MMFlow のインストールと動作確認(オプティカルフロー)(PyTorch,Python を使用): 別ページ »で説明
Google Colaboratory で MMFlow によるオプティカルフローの算出
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMFlow のインストール
!rm -rf mmflow !git clone https://github.com/open-mmlab/mmflow.git %cd mmflow !pip3 install -r requirements/build.txt !pip3 install .
- 動画ファイルに対して,オプティカルフローを算出
学習済みモデルを使用.
!curl -O https://download.openmmlab.com/mmflow/raft/raft_8x2_100k_mixed_368x768.pth !python3 demo/video_demo.py demo/demo.mp4 \ configs/raft/raft_8x2_100k_mixed_368x768.py \ raft_8x2_100k_mixed_368x768.pth \ raft_demo.mp4 --gt demo/demo_gt.mp4
結果として raft_demo_gt.mp4 ができるので,ダウンロードして,表示して確認する.
MMGen
Google Colaboratory で MMGEN による StyleGAN の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMCV 1.7.1 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())" - MIM, MMGen のインストール
!python -m pip install -U openmim opencv-python !rm -rf mmgeneration !git clone https://github.com/open-mmlab/mmgeneration.git %cd mmgeneration !pip3 install -r requirements/build.txt !pip3 install .
- StyleGAN を実行
https://github.com/open-mmlab/mmgeneration/blob/master/docs/en/get_started.md に記載のプログラムを使用
学習済みモデルを使用.
from mmgen.apis import init_model, sample_uncoditional_model config_file = 'configs/styleganv2/stylegan2_c2_lsun-church_256_b4x8_800k.py' # you can download this checkpoint in advance and use a local file path. checkpoint_file = 'https://download.openmmlab.com/mmgen/stylegan2/official_weights/stylegan2-church-config-f-official_20210327_172657-1d42b7d1.pth' device = 'cuda:0' # init a generatvie model = init_model(config_file, checkpoint_file, device=device) # sample images fake_imgs = sample_uncoditional_model(model, 4) import numpy as np import matplotlib.pyplot as plt plt.style.use('default') for i in fake_imgs: plt.imshow(np.stack([i[2], i[1], i[0]], axis=2)) plt.show()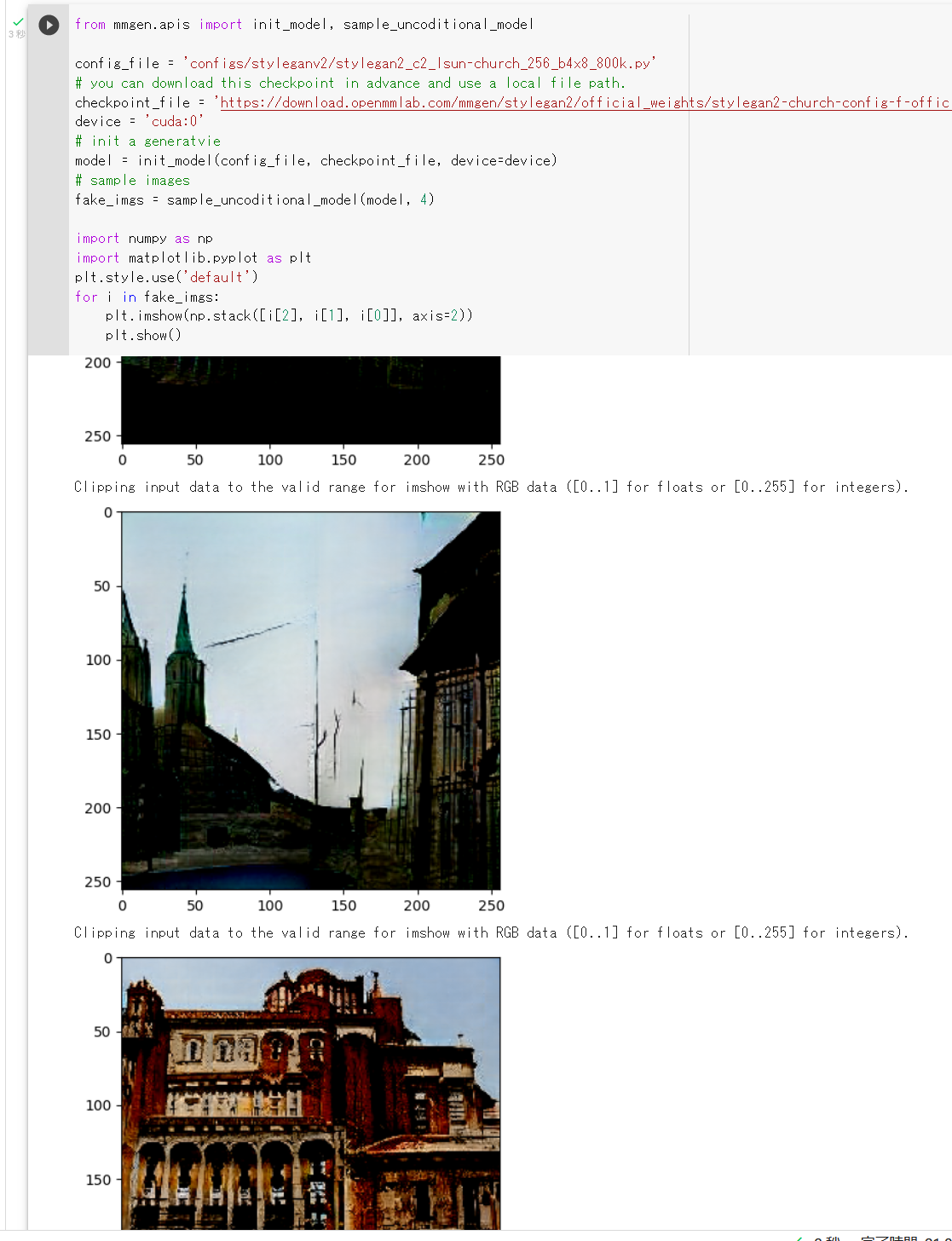
MMPose
MMPose は, OpenMMLab の構成物で,2次元の姿勢推定,3次元の姿勢推定の機能を提供する.
【関連項目】 OpenMMLab, MMCV, MMDetection, MMTracking, 物体検出 2次元の姿勢推定, 姿勢推定, 人体の姿勢推定, 手の姿勢推定,
Google Colaboratory で,MMPose による姿勢推定の実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- MMCV 1.7.1 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())" - MIM, MMClassification, MMSegmentation, MMDetection, MMTracking, MMPose のインストール.MMPose のインストール後は numpy, scipy の更新も行う.
https://github.com/open-mmlab/mmpose/blob/master/docs/en/install.md#install-mmposeに記載の手順による.
MMCV 1.6.2 をインストールしたので,MMDetection は 2系列になる(3系列は動かない)(2023年4月時点).
!python -m pip install -U openmim opencv-python !python -m pip install -U mmcv-full==1.6.2 !python -m pip install -U git+https://github.com/open-mmlab/mmclassification.git !python -m pip install -U mmdet==2.28.2 !python -m pip install -U git+https://github.com/open-mmlab/mmsegmentation.git !python -m pip install -U git+https://github.com/open-mmlab/mmtracking.git !python -m pip install -U git+https://github.com/open-mmlab/mmpose.git !apt -y install python3-numpy !apt -y install python3-scipy !python -c "import mmcls; print(mmcls.__version__)" !python -c "import mmdet; print(mmdet.__version__)" !python -c "import mmseg; print(mmseg.__version__)" !python -c "import mmtrack; print(mmtrack.__version__)" !python -c "import mmpose; print(mmpose.__version__)" !pip3 install git+https://github.com/votchallenge/toolkit.git
- 姿勢推定の実行
公式のデモプログラム(https://github.com/open-mmlab/mmpose/blob/master/demo/docs/2d_human_pose_demo.md)を使用.
- 人体の2次元姿勢推定
公式ページの https://github.com/open-mmlab/mmpose/blob/master/demo/docs/2d_human_pose_demo.md で説明されているプログラムを使用.
人体の検出 (human detection) に,MMDetection を使用し, 姿勢推定に,MMPoseを使用.
!python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ --img-root tests/data/coco/ \ --img 000000000785.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000000785.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ --img-root tests/data/coco/ \ --img 000000040083.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000040083.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ --img-root tests/data/coco/ \ --img 000000196141.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000196141.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ --img-root tests/data/coco/ \ --img 000000197388.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000197388.jpg').show()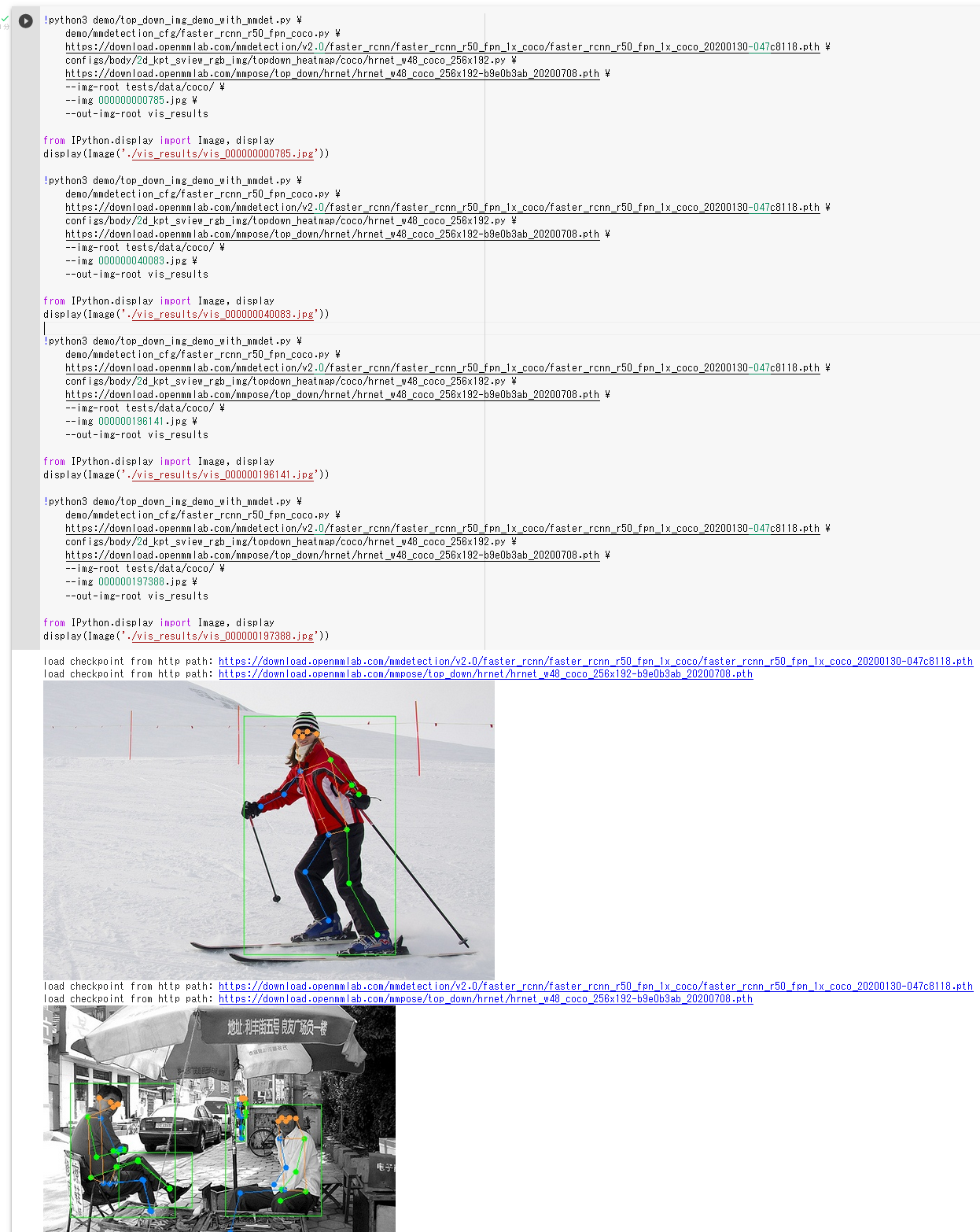
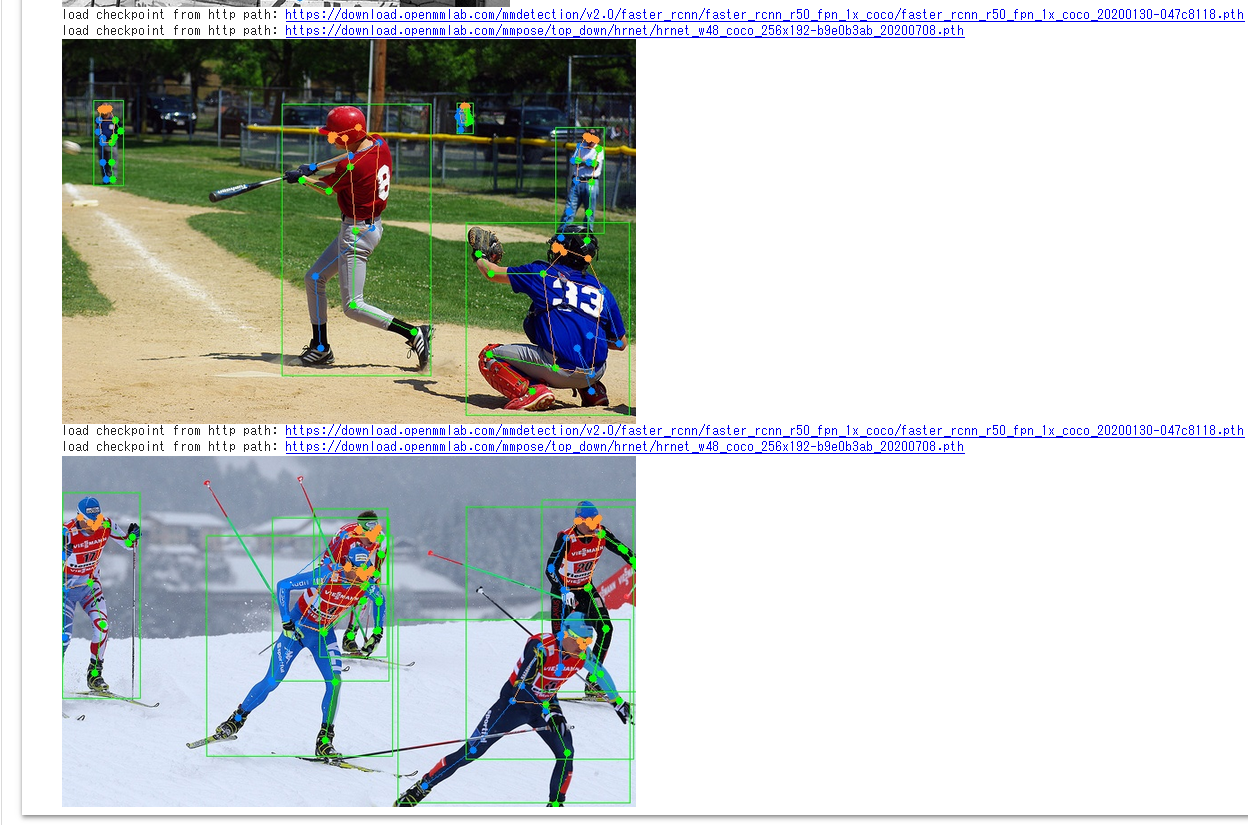
- 全身の2次元姿勢推定
公式ページの https://github.com/open-mmlab/mmpose/blob/master/demo/docs/2d_wholebody_pose_demo.md で説明されているプログラムを使用.
人体の検出 (human detection) に,MMDetection を使用し, 姿勢推定に,MMPoseを使用.
1つ上の結果(人体の2次元姿勢推定)と比べて,顔の部分に違いがある.
!python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --img-root tests/data/coco/ \ --img 000000000785.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000000785.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --img-root tests/data/coco/ \ --img 000000040083.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000040083.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --img-root tests/data/coco/ \ --img 000000196141.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000196141.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --img-root tests/data/coco/ \ --img 000000197388.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_000000197388.jpg').show()

- 手の2次元姿勢推定
公式ページの https://github.com/open-mmlab/mmpose/blob/master/demo/docs/2d_hand_demo.md で説明されているプログラムを使用.
人体の検出 (human detection) に,MMDetection を使用し, 姿勢推定に,MMPoseを使用.
!python3 demo/top_down_img_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ --img-root tests/data/onehand10k/ \ --img 1402.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_1402.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ --img-root tests/data/onehand10k/ \ --img 784.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_784.jpg').show() !python3 demo/top_down_img_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ --img-root tests/data/onehand10k/ \ --img 9.jpg \ --out-img-root vis_results from PIL import Image Image.open('./vis_results/vis_9.jpg').show()


- 顔のランドマーク検出
公式ページの https://github.com/open-mmlab/mmpose/blob/master/demo/docs/2d_face_demo.md で説明されているプログラムを使用.
顔検出 に,Dlib と ageitgey/face_recognition (https://github.com/ageitgey/face_recognition) を使用. 顔のランドマーク検出に,MMPoseを使用.

- 人体の3次元姿勢推定
公式ページの https://github.com/open-mmlab/mmpose/blob/master/demo/docs/3d_human_pose_demo.md で説明されているプログラムを使用.
!python3 demo/body3d_two_stage_video_demo.py \ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py \ https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \ --video-path demo/resources/demo.mp4 \ --out-video-root vis_results \ --rebase-keypoint-height
- 人体の2次元姿勢推定
Windows で,MMPose のインストールと人体の姿勢推定の実行
MMPose のインストールと動作確認(姿勢推定,関節角度の推定)(PyTorch,Python を使用)(Windows 上): 別ページ »で説明
MMSegmentation
MMSegmentation は, OpenMMLab の構成物で,セグメンテーションの機能を提供する.
【文献】
MMSegmentation Contributors, MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark, https://github.com/open-mmlab/mmsegmentation, 2020.
【サイト内の関連ページ】 セマンティック・セグメンテーション(MMSegmentation のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
【関連する外部ページ】
- MMSegmentation の公式ドキュメント: https://mmsegmentation.readthedocs.io
- MMSegmentation の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmsegmentation/blob/master/demo/MMSegmentation_Tutorial.ipynb
- MMSegmentation の公式の学習済みモデル: https://mmsegmentation.readthedocs.io/en/latest/model_zoo.html
【関連項目】 OpenMMLab, MMCV, MMSelfSup
Google Colaboratory でセマンティック・セグメンテーションの実行(MMSegmentation, DeepLabv3 を使用)
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMCV 1.7.1 のインストール
インストール手順は, https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
MMTracking が MMVC 1.6.2 に依存している (2023年4月時点). MMTracking の利用を想定して MMCV 1.6.2 をインストールする.
!python -c "import torch; print(torch.__version__)" !apt remove python3-pycocotools !pip uninstall -y pycocotools !pip install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip install mmcv-full==1.6.2 !python3 -c "from mmcv.ops import get_compiling_cuda_version, get_compiler_version; print(get_compiling_cuda_version(), get_compiler_version())" - MIM, MMDetection, MMSegmentation のインストール
MMCV 1.7.1 をインストールしたので,MMDetection は 2系列になる(3系列は動かない)(2023年4月時点).
!python -m pip install -U openmim opencv-python !python -m pip install -U mmcv-full==1.7.1 !python -m pip install -U mmdet==2.28.2 !python -m pip install -U git+https://github.com/open-mmlab/mmsegmentation.git !python -c "import mmdet; print(mmdet.__version__)" !python -c "import mmseg; print(mmseg.__version__)" - セマンティック・セグメンテーションの実行(MMSegmentation, Cityscapes データセットで学習済みのDeepLabv3+ を使用)
次のプログラムは,MMSegmentation の機能を利用して,DeepLabv3+ を用いたセマンティック・セグメンテーションを行う.
- Cityscapes データセットで学習済みのDeepLabv3+ を使用
詳しくは,MMSegmentation の DeepLabv3+ のページ: https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus
- 処理する画像の画像ファイル名は「fimg = 'demo/demo.png'」で設定
セマンティック・セグメンテーションの結果として得られる クラスが,色分けで表示される.
import torch from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot import mmcv fimg = 'demo/demo.png' # DeepLabv3 fconfig = 'configs/deeplabv3/deeplabv3_r101-d8_fp16_512x1024_80k_cityscapes.py' fcheckpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3/deeplabv3_r101-d8_fp16_512x1024_80k_cityscapes/deeplabv3_r101-d8_fp16_512x1024_80k_cityscapes_20200717_230920-774d9cec.pth' # DeepLabv3+ fconfig = 'configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py' fcheckpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes_20200717_230920-f1104f4b.pth' # OCRNet #fconfig = 'configs/ocrnet/ocrnet_hr48_512x1024_40k_cityscapes.py' #fcheckpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/ocrnet/ocrnet_hr48_512x1024_40k_cityscapes/ocrnet_hr48_512x1024_40k_cityscapes_20200601_033336-55b32491.pth' # SegFormer #fconfig = 'configs/segformer/segformer_mit-b2_8x1_1024x1024_160k_cityscapes.py' #fcheckpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b2_8x1_1024x1024_160k_cityscapes/segformer_mit-b2_8x1_1024x1024_160k_cityscapes_20211207_134205-6096669a.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_segmentor(fconfig, fcheckpoint, device=device) result = inference_segmentor(model, fimg) print(result) show_result_pyplot(model, fimg, result, opacity=0.5)
- Cityscapes データセットで学習済みのDeepLabv3+ を使用
セマンティック・セグメンテーション(MMSegmentation のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
別ページ »で説明
Ubuntu での MMSegmentation の実行
- インストール
「git checkout v0.14.1」は,バージョン 0.14.1 を指定している. これは,https://mmdetection3d.readthedocs.io/en/latest/get_started.html での2021/08 時点の説明による.将来はバージョン番号が変わる可能性があり,このページを確認してから,インストールを行うこと.
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo git clone https://github.com/open-mmlab/mmsegmentation.git sudo chown -R $USER mmsegmentation cd mmsegmentation git checkout v0.14.1 python3 setup.py develop - 動作確認
Ubuntu の場合は, MMCV のドキュメント: https://mmsegmentation.readthedocs.io/en/latest/get_started.html#verification の手順がそのまま使えそうである.
MMSegmentation3D
Google Colaboratory でのインストールは,次のような手順になるようである(未確認).
【関連項目】 OpenMMLab, MMCV, MMDetection, 物体検出%cd /content !rm -rf mmdetection3d.git !git clone https://github.com/open-mmlab/mmdetection3d.git %cd mmdetection3d !pip3 install importlib-metadata==4.2 !python3 setup.py develop !apt install -y python3-numba %cd mmdetection3d !python3 demo/pcd_demo.py demo/data/kitti/kitti_000008.bin configs/second/hv_second_secfpn_6x8_80e_kitti-3d-car.py checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-car_20200620_230238-393f000c.pthMMSelfSup
MMSelfSup は, OpenMMLab の構成物で, Self-Supervised Representation Learning の機能を提供する.
- 文献
MMSelfSup Contributors, MMSelfSup: OpenMMLab Self-Supervised Learning Toolbox and Benchmark, https://github.com/open-mmlab/mmselfsup, 2021.
- MMSelfSup の公式ドキュメント: https://mmselfsup.readthedocs.io/en/latest/
- MMSelfSup の公式の getting started: https://github.com/open-mmlab/mmselfsup/blob/master/docs/en/get_started.md MMSelfSup の公式の学習済みモデル: https://github.com/open-mmlab/mmselfsup/blob/master/docs/en/model_zoo.md
【関連項目】 MMCV, MMDetection, MMSegmentation, OpenMMLab, Self-Supervised Representation Learning, 物体検出
Google Colaboratory で,MMSelfSup のインストール
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
MMSelfSup のインストール(公式ページ): https://github.com/open-mmlab/mmselfsup/blob/master/docs/en/install.md
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- MIM のインストール
!pip3 install git+https://github.com/open-mmlab/mim.git - MMCV, MMDetection のインストール.
https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md に記載の手順による
!mim install mmdet !pip3 show mmdet
- MMSegmentation のインストール
次のプログラム実行により,MMSegmentation がインストールされる.
!rm -rf mmsegmentation.git !git clone https://github.com/open-mmlab/mmsegmentation.git %cd mmsegmentation !python3 setup.py develop
- MMSelfSup のインストール
%cd /content rm -rf mmselfsup !git clone https://github.com/open-mmlab/mmselfsup.git %cd mmselfsup !python3 setup.py develop
- インストールできたことの確認
公式ページ https://github.com/open-mmlab/mmselfsup/blob/master/docs/en/install.md に記載のプログラムを実行してみる.
エラーメッセージが出なければ OK.
import torch from mmselfsup.models import build_algorithm model_config = dict( type='Classification', backbone=dict( type='ResNet', depth=50, in_channels=3, num_stages=4, strides=(1, 2, 2, 2), dilations=(1, 1, 1, 1), out_indices=[4], # 0: conv-1, x: stage-x norm_cfg=dict(type='BN'), frozen_stages=-1), head=dict( type='ClsHead', with_avg_pool=True, in_channels=2048, num_classes=1000)) model = build_algorithm(model_config).cuda() image = torch.randn((1, 3, 224, 224)).cuda() label = torch.tensor([1]).cuda() loss = model.forward_train(image, label) print(loss)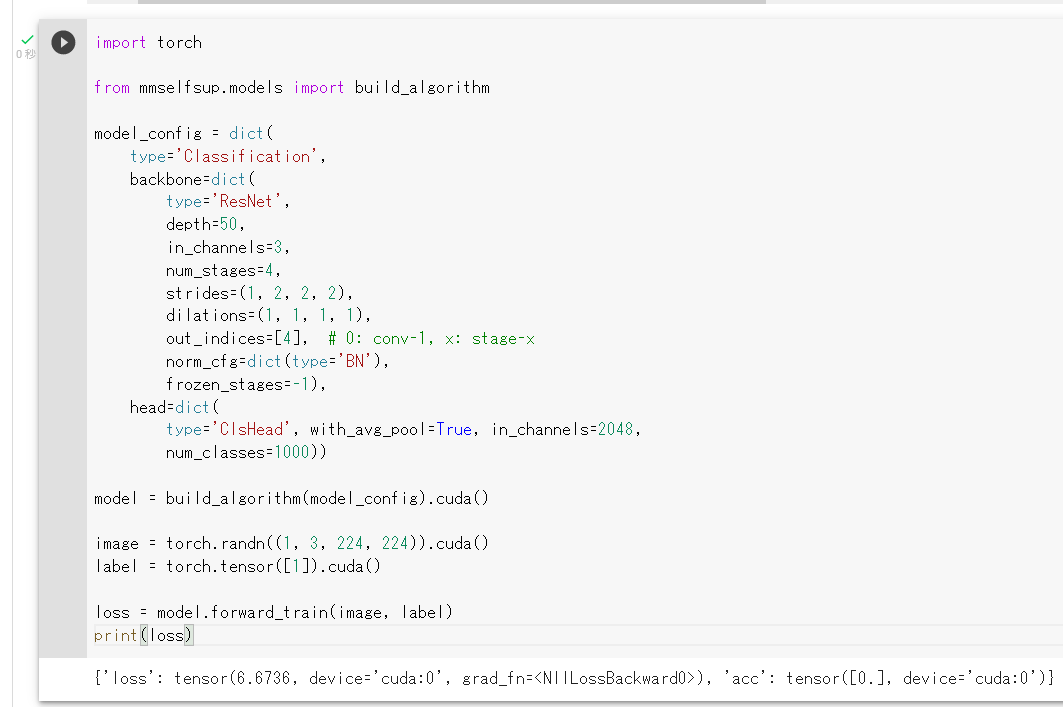
MMTracking
MMTracking は, OpenMMLab の構成物で,トラッキング・ビジョンの機能を提供する.
【関連項目】 OpenMMLab, MMCV, MMDetection, MMPose, 物体検出
Google Colaboratory で,MMTracking によるトラッキングの実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- MIM のインストール
!pip3 install git+https://github.com/open-mmlab/mim.git - MMCV, MMDetection のインストール.
https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md に記載の手順による
!mim install mmdet !pip3 show mmdet
- MMTracking のインストール
!rm -rf mmtracking !git clone https://github.com/open-mmlab/mmtracking.git %cd mmtracking !pip3 install -r requirements/build.txt !pip3 install . !pip3 show mmtrack !pip3 install git+https://github.com/votchallenge/toolkit.git
- トラッキングの実行
!python3 demo/demo_mot_vis.py configs/mot/deepsort/sort_faster-rcnn_fpn_4e_mot17-private.py --input demo/demo.mp4 --output mot.mp4
- 結果の確認
mot.mp4 というファイルができるので,ダウンロードして表示

Windows で,MMTracking のインストール
MMTracking のインストールと動作確認(トラッキングビジョン)(PyTorch,Python,MMCV,MMDetection を使用)(Windows 上): 別ページ »で説明
MNIST データセット
MNIST データセットは,公開されているデータセット(オープンデータ)である.
0 から 9 までの 10 種類の手書き文字についての, モノクロ画像と,各画像に付いた「0から9までの数値」のラベルから構成されるデータセットである.
- 画像の枚数:合計 70000枚.
(内訳)70000枚の内訳は次の通りである
60000枚:教師データ
10000枚:検証データ
- 画像のサイズ: 28x28 である.
- 画素はグレースケールであり,画素値は0~255である.0が白,255が黒.
【文献】
Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, Gradient-based learning applied to document recognition, vol. 86, no. 11, pp. 2278-2324, 1998.
【サイト内の関連ページ】
- MNIST データセットを扱う Python プログラム: 別ページ で説明している.
- MNIST データセットによる学習と分類(TensorFlow データセット,TensorFlow,Python を使用)(Windows 上,Google Colaboratroy の両方を記載)
【関連する外部ページ】
- MNIST データセット の詳細は, THE MNIST DATABASE of handwritten digits のページで説明されている.その URL は次の通り.
- TensorFlow データセットの MNIST データセット: https://www.tensorflow.org/datasets/catalog/mnist
【関連項目】 Keras に付属のデータセット, Fashion MNIST データセット, TensorFlow データセット, オープンデータ, 画像分類
MobileFaceNets
顔検証 (face verification) を,その当時の従来の mobile networks よりも高速で高精度で実行できるとされている.
InsightFace などで実装されている.
- 文献
Sheng Chen, Yang Liu, Xiang Gao, Zhen Han, MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices, CCBR 2018, also CoRR, abs/1804.07573v, 2018. https://arxiv.org/ftp/arxiv/papers/1804/1804.07573.pdf
【関連項目】 InsightFace, 顔検証 (face verification), 顔に関する処理
MobileNetV2
MobileNet は,separable convolution を特徴としている.ResNet の高速化が達成できたとされている.
MobileNetV2 は,conv 1x1, depthsise conv, conv 1x1 を特徴としている.高速化が達成できたとされている.
MobileNetV2 は,ディープラーニングでの画像分類などの高速化,精度向上のため Depthwise Separable Convolution という考え方が導入されていることが特徴である.
物体検出や セマンティック・セグメンテーションなどでのバックボーンでの利用も行われている.
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen, MobileNetV2: Inverted Residuals and Linear Bottlenecks, CVPR 2018
Keras の MobileNetV2 を用いて MobileNetV2 を作成するプログラムは次のようになる. 「weights=None」を指定することにより,最初,重みをランダムに設定する.
【Keras のプログラム】 Keras の応用のページ: https://keras.io/ja/applications/from tensorflow.keras.applications.mobilenet_v3 import MobileNetV3 m = MobileNetV3(input_shape=INPUT_SHAPE, weights=None, classes=NUM_CLASSES)【サイト内の関連ページ】
- MobileNetv2 を使い,Windows のパソコンや Google Colab などで画像分類することについては, 次のページで説明している.
MobileNetV3
物体検出や セマンティック・セグメンテーションなどでのバックボーンでの利用も行われている.
- 文献
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam, Searching for MobileNetV3, ICCV 2019
- Papers With Code の MobileNetV3 のページ: https://paperswithcode.com/paper/searching-for-mobilenetv3
- TensorFlow のモデルガーデン (model garden): https://github.com/tensorflow/models
- Google Colaboratory のページ: https://colab.research.google.com/github/tensorflow/models/blob/master/research/deeplab/deeplab_demo.ipynb
- DeepLab のページ: https://github.com/tensorflow/models/tree/master/research/deeplab
関連項目: 画像分類
PyTorch, torchvision の MobileNetV3 large 学習済みモデルのロード,画像分類のテスト実行
Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのMobileNetV3 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.mobilenet_v3_large(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
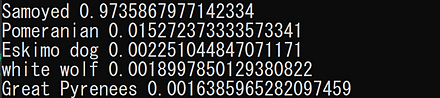
Linux での結果
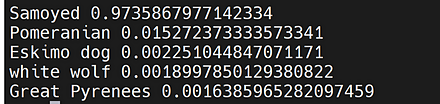
MongoDB
MongoDB は,ドキュメントデータモデルの機能をもつデータベース管理システム
【サイト内の関連ページ】
【関連する外部ページ】
- MongoDB の公式ページ: https://www.mongodb.com/ja-jp
- MongoDB のインストール手順(公式ページ): https://github.com/mongodb/mongo/blob/master/docs/building.md
MPII Human Pose データセット
MPII Human Pose データセット は, 人体全身の画像と姿勢のデータセットである. ディープラーニングにより姿勢推定を行うためのデータとして利用できる.
40,000人以上の人間を含む約25,000枚の画像が含まれている. (28,000 が訓練データ,11,000 が検証データである). 画像のアノテーションが行われている. 410 種類の人間の活動を網羅している. 各画像については,活動名のラベルが付いている. 画像はYouTubeの動画から抽出されたものである. テストデータセットでは,体のオクルージョン,胴体や頭の3次元での向きなど, より豊富なアノテーションが行われている.
次の URL で公開されているデータセット(オープンデータ)である.
URL: http://human-pose.mpi-inf.mpg.de/
ライセンス: BSD ライセンス.利用条件等は,利用者で確認すること.
【関連情報】
-
2D Human Pose Estimation: New Benchmark and State of the Art Analysis,
CVPR 2014,
Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, Bernt Schiele.
https://openaccess.thecvf.com/content_cvpr_2014/papers/Andriluka_2D_Human_Pose_2014_CVPR_paper.pdf
- Papers With Code の MPII Human Pose データセットのページ: https://paperswithcode.com/dataset/cifar-10
- open-mmlab の記事: https://github.com/open-mmlab/mmpose/blob/master/docs/en/tasks/2d_body_keypoint.md#mpii
次により c:\data\mpii にダウンロードされる.アノテーションファイルもダウンロードされる.mkdir /p c:\data mkdir /p c:\data\mpii cd c:\data\mpii curl -O https://datasets.d2.mpi-inf.mpg.de/andriluka14cvpr/mpii_human_pose_v1_u12_2.zip powershell -command "Expand-Archive -DestinationPath . -Path mpii_human_pose_v1_u12_2.zip" curl -O https://datasets.d2.mpi-inf.mpg.de/andriluka14cvpr/mpii_human_pose_v1.tar.gz "c:\Program Files\7-Zip\7z.exe" x mpii_human_pose_v1.tar.gz mkdir images cd images "c:\Program Files\7-Zip\7z.exe" x ..\mpii_human_pose_v1.tarMykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt, 2D Human Pose Estimation: New Benchmark and State of the Art Analysis, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, https://openaccess.thecvf.com/content_cvpr_2014/papers/Andriluka_2D_Human_Pose_2014_CVPR_paper.pdf
MS1M データセット
MS-Celeb-1M データセット を洗浄 (clean) したデータ. 画像サイズは 112x112. RetinaFace を用いて推定された,5点の顔ランドマーク (facial landmark)が付いている.
人物数は 94,682 (94,682 identities), 画像数は 6,464,018 枚 (6,464,018 images)
次の URL で公開されているデータセット(オープンデータ)である.
https://github.com/EB-Dodo/C-MS-Celeb
【関連項目】 InsightFace, MS-Celeb-1M データセット, RetinaFace, 顔のデータベース, 顔ランドマーク (facial landmark), 顔検出 (face detection)
MS-Celeb-1M データセット
MS-Celeb-1M は,顔のデータセット. このデータセットは,公開が撤回されている.
人物数は約 100,000 (100K identities), 画像数は約 8,000,000 枚 (8M images)
- 文献
Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, and Jianfeng Gao, MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition, In ECCV, 2016. arXiv:1607.08221
- URL: https://exposing.ai/msceleb/
- Papers with Code のページ: https://paperswithcode.com/paper/ms-celeb-1m-a-dataset-and-benchmark-for-large
- InsightFace のページ: https://github.com/deepinsight/insightface
【関連項目】 C-MS-Celeb Cleaned データセット , InsightFace, 顔のデータベース, 顔検出 (face detection)
MUCT 顔データベース
MUCT 顔データベースは,3755名の顔のデータベース.手作業で 76個の顔ランドマーク (facial landmark)が付けらている.
MUCT 顔データベースは次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.cs.columbia.edu/CAVE/software/curet/html/about.php
URL: http://www.milbo.org/muct/index.html
S. Milborrow and J. Morkel and F. Nicolls, The MUCT Landmarked Face Database, Pattern Recognition Association of South Africa, 2010.
次の手順でダウンロードできる.- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- ダウンロード操作
git clone https://github.com/StephenMilborrow/muct
【関連項目】 顔のデータベース, 顔ランドマーク (facial landmark)
Multi-PIE の 顔の 68 ランドマーク
顔の 68 ランドマーク は,顔ランドマーク (facial landmark)の一種であり,68 組の数値で構成されている.68 組のそれぞれは,(x, y) 座標値である.
- 文献
R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker, Multi-pie, Image and Vision Computing, 28(5):807–813, 2010.
【関連項目】 顔の 68 ランドマーク の検出, 顔ランドマーク (facial landmark)
Multi View Stereo (MVS)
Multi View Stereo は,オブジェクトの特徴点である低密度の3次元点群と,オブジェクトを周囲から撮影した多数の画像から,高密度の3次元点群を生成する. 色付き3次元点群を生成する場合もある.「Dense Recontruction」ともいう.
meshroom,OpenMVS などのソフトウェアがある. Ubuntu での OpenMVS のインストールは 別ページ »で説明
【関連用語】 3次元再構成 (3D reconstruction), meshroom, OpenMVS, Structure from Motion
MusicGen
MusicGen は, 単一ステージのトランスフォーマー言語モデル(transformer language model)を特徴とする. フレシェオーディオ距離 (FAD)、クルバック・ライブラーダイバージェンス (KL)、CLAPスコア (CLAP)という客観的指標ならびに、 全体的な品質および(ii)テキスト入力への関連性の主観的指標について、 baselines for text-to-music generation: Riffusion [Forsgren and Martiros] and Mousai [Schneider et al., 2023]をベースラインとして 評価が行われている.
【文献】
Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez, Simple and Controllable Music Generation, arXiv preprint arXiv:2306.05284, 2023.
https://arxiv.org/pdf/2306.05284v1.pdf
【サイト内の関連ページ】 MusicGen のインストールと動作確認(作曲)(Python,PyTorch を使用)(Windows 上)
【関連する外部ページ】
- arXiv のページ: https://arxiv.org/abs/2306.05284
- GitHub の公式ページ: https://github.com/facebookresearch/audiocraft
- HuggingFace のデモ: https://huggingface.co/spaces/facebook/MusicGen
NASNet
Keras の NASNet を用いて NASNet を作成するプログラムは次のようになる. 「weights=None」を指定することにより,最初,重みをランダムに設定する.
【Keras のプログラム】m = tf.keras.applications.nasnet.NASNetMobile(input_shape=INPUT_SHAPE, weights=None, classes=NUM_CLASSES)CoRR, abs/1707.07012
Keras の応用のページ: https://keras.io/ja/applications/
Nesterov モメンタム
参考文献: http://www.cs.toronto.edu/~fritz/absps/momentum.pdf
Ninja ビルドシステム
Ninja はビルドシステム.
主な機能:ビルドの実行,特定のターゲットのビルド,並列ビルド,ディレクトリの変更,ヘルプの表示,ツールの実行
winget を用いた Ninja と Meson のインストールコマンド: winget install --scope machine Ninja-build.Ninja mesonbuild.meson
【関連する外部ページ】
- Ninja の公式ページ: https://ninja-build.org/
【関連項目】 Ninja のインストール(Windows 上), Ninja の使用方法
NumPy
NumPy は,オープンソースの Python のライブラリ.数値計算,行列の機能を持つ.
配列では,添え字が複数になる. 下に,Python の numpy 配列のコンストラクタの例を示す.
import numpy as np M = np.array([[1, 2, 3], [4, 5, 6]]) print(M) print(M[0,], M[1,]) print(M[1,0], M[1,1], M[1,2])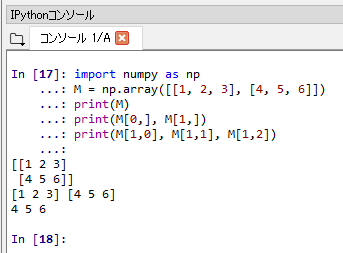
numpy 配列の形は shape 属性である. numpy 配列の次元は ndim 属性である.
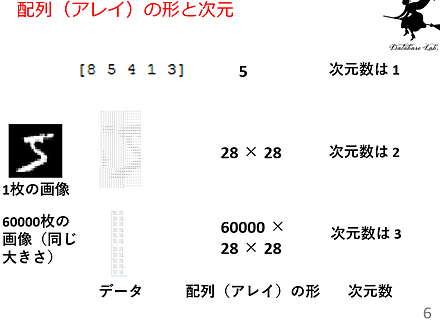
import numpy as np a = np.array([8,5,4,1,3]) print( a.shape ) print( a.ndim ) print(a) x = np.array([[1,2,3,4], [10,20,30,40], [100,200,300,400]]) print( x.shape ) print( x.ndim ) print(x)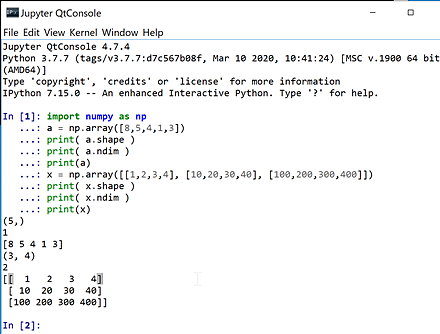
Windows での NumPy のインストール
Windows での numpy のインストールは, コマンドプロンプトを管理者として開き 次のコマンドを実行する.
python -m pip install -U numpyUbuntu での NumPy のインストール
Ubuntu での numpy のインストールは, 次のコマンドで行う.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-numpyNode.JS
【サイト内の関連ページ】
Nteract
Nteractは,Pythonなどのプログラムのソースコード,実行結果などを1つのノートとして残す機能をもったノートブック.
Nsight Systems がアンインストールできない
Windows で, コマンドプロンプトを管理者として開き次のようなコマンドを実行することにより, アンインストールできるようになる場合がある.
regsvr32.exe "C:\Program Files\NVIDIA Corporation\NVIDIA Nsight Systems 2019.3.7\Host-x86_64\msdia140.dll"NVIDIA CUDA ツールキット
NVIDIAのGPUを使用して並列計算を行うためのツールセット
主な機能: GPU を利用した並列処理,GPU のメモリ管理,C++をベースとした拡張言語とAPIとライブラリ
winget を用いたNVIDIA CUDA ツールキット 11.8のインストールコマンド: winget install --scope machine Nvidia.CUDA --version 11.8
【関連する外部ページ】
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA CUDA ツールキット の公式のドキュメント: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- NVIDIA CUDA ツールキットのインストールに関する,NVIDIA CUDA クイックスタートガイドの公式ページ: https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html
【関連項目】 NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上), NVIDIA CUDA ツールキット 11.8 のインストール(Windows 上), NVIDIA CUDA ツールキットのインストール時の注意点
NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上)
【NVIDIA CUDA ツールキットの動作に必要なもの】
- CUDA対応のNVIDIA GPUが必要.
そのために,NVIDIA グラフィックス・ボードを確認する. Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, 次のコマンドを実行することにより調べることができる.
wmic path win32_VideoController get name - NVIDIA ドライバのダウンロードとインストール
NVIDIA ドライバは,以下の NVIDIA 公式サイトからダウンロードできる. ダウンロードの際には,使用しているグラフィックス・ボードの型番とオペレーティングシステムを選択する.
- Windows では,インストール前に,Build Tools for Visual Studio もしくは Visual Studio をインストールしておくことが必要である.
【手順】
- Windows では,NVIDIA CUDA ツールキットのインストール中は,なるべく他のウインドウはすべて閉じておくこと.
- Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。 - 以下のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n" REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更) mkdir C:\TEMP set "TEMP_PATH=C:\TEMP" setx TEMP "%TEMP_PATH%" /M >nul setx TMP "%TEMP_PATH%" /M >nul【関連する外部ページ】
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA CUDA ツールキット の公式のドキュメント: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- NVIDIA CUDA ツールキットのインストールに関する,NVIDIA CUDA クイックスタートガイドの公式ページ: https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
【サイト内の関連ページ】
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8(CUDA のインストールで winget を使用),NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8(CUDA のインストールで winget を使用しない),NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Ubuntu での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8, NVIDIA cuDNN 8 のインストール: 別ページ »で説明
【関連項目】 NVIDIA CUDA ツールキット, NVIDIA CUDA ツールキット 11.8 のインストール(Windows 上), NVIDIA CUDA ツールキットのインストール時の注意点, NVIDIA ドライバ
NVIDIA CUDA ツールキット 11.8 のインストール(Windows 上)
【NVIDIA CUDA ツールキットの動作に必要なもの】
- CUDA対応のNVIDIA GPUが必要.
そのために,NVIDIA グラフィックス・ボードを確認する. Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, 次のコマンドを実行することにより調べることができる.
wmic path win32_VideoController get name - NVIDIA ドライバのダウンロードとインストール
NVIDIA ドライバは,以下の NVIDIA 公式サイトからダウンロードできる. ダウンロードの際には,使用しているグラフィックス・ボードの型番とオペレーティングシステムを選択する.
- Windows では,インストール前に,Build Tools for Visual Studio もしくは Visual Studio をインストールしておくことが必要である.
【手順】
- Windows では,NVIDIA CUDA ツールキットのインストール中は,なるべく他のウインドウはすべて閉じておくこと.
- 次のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - NVIDIA CUDA ツールキットのインストールが終わったら,ユーザ環境変数 TEMP の設定を行う.
Windows のユーザ名が日本語のとき,nvcc がうまく動作しないエラーを回避するためである.
ユーザ環境変数 TEMP に「C:\TEMP」を設定するために, コマンドプロンプトで,次のコマンドを実行する.
mkdir C:\TEMP powershell -command "[System.Environment]::SetEnvironmentVariable(\"TEMP\", \"C:\TEMP\", \"User\")"
次のコマンドは,NVIDIA GeForce Experience,NVIDIA CUDA ツールキット 11.8 をインストールするものである.
wmic path win32_VideoController get name winget install --scope machine Nvidia.CUDA --version 11.8 powershell -command "[System.Environment]::SetEnvironmentVariable(\"CUDA_HOME\", \"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\", \"Machine\")"【関連する外部ページ】
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA CUDA ツールキット の公式のドキュメント: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- NVIDIA CUDA ツールキットのインストールに関する,NVIDIA CUDA クイックスタートガイドの公式ページ: https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
【サイト内の関連ページ】
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8(CUDA のインストールで winget を使用),NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8(CUDA のインストールで winget を使用しない),NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Ubuntu での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8, NVIDIA cuDNN 8 のインストール: 別ページ »で説明
【関連項目】 NVIDIA CUDA ツールキット, NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上), NVIDIA CUDA ツールキットのインストール時の注意点, NVIDIA ドライバ
NVIDIA CUDA ツールキットのインストール時の注意点
【NVIDIA CUDA ツールキットの動作に必要なもの】
- CUDA対応のNVIDIA GPUが必要.
そのために,NVIDIA グラフィックス・ボードを確認する. Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, 次のコマンドを実行することにより調べることができる.
wmic path win32_VideoController get name - NVIDIA ドライバのダウンロードとインストール
NVIDIA ドライバは,以下の NVIDIA 公式サイトからダウンロードできる. ダウンロードの際には,使用しているグラフィックス・ボードの型番とオペレーティングシステムを選択する.
- Windows では,インストール前に,Build Tools for Visual Studio もしくは Visual Studio をインストールしておくことが必要である.
【Windows でインストールするときの注意点】
- Windows では, NVIDIA CUDA ツールキットのインストール中は,なるべく他のウインドウはすべて閉じておくこと.
- NVIDIA CUDA ツールキットのインストールが終わったら,ユーザ環境変数 TEMP の設定を行う.
Windows のユーザ名が日本語のとき,nvcc がうまく動作しないエラーを回避するためである.
ユーザ環境変数 TEMP に「C:\TEMP」を設定するために, コマンドプロンプトで,次のコマンドを実行する.
mkdir C:\TEMP powershell -command "[System.Environment]::SetEnvironmentVariable(\"TEMP\", \"C:\TEMP\", \"User\")"
【関連項目】 NVIDIA CUDA ツールキット, NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上), NVIDIA CUDA ツールキット 11.8 のインストール(Windows 上)
Windows でのメッセージで,「Could not locate zlibwapi.dll. Please make sure it is in your library path!」と表示されたときの対処
ZLIB DLL をインストールする.
NVIDIA ドライバ,NVIDIA CUDA ツールキット, NVIDIA cuDNN のインストールの要点と注意点
- Build Tools for Visual Studio 2022 のインストール
以下のコマンドを管理者権限のコマンドプロンプトで実行する (手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。REM VC++ ランタイム winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart" REM Build Tools + Desktop development with C++(VCTools)+ 追加コンポーネント(一括) winget install --id Microsoft.VisualStudio.2022.BuildTools --accept-source-agreements --accept-package-agreements ^ --override "--passive --wait --norestart --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.ComponentGroup.ClangCL --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.Windows11SDK.26100"--addで追加されるコンポーネント上記のコマンドでは,まず Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし,次に setup.exe を用いて以下のコンポーネントを追加している。
VCTools:C++ デスクトップ開発ワークロード(--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる)VC.Llvm.Clang:Windows 向け C++ Clang コンパイラClangCL:clang-cl ツールセットを含むコンポーネントグループ(MSBuild から Clang を使用するために必要)VC.CMake.Project:Windows 向け C++ CMake ツールWindows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
インストール完了の確認
winget list Microsoft.VisualStudio.2022.BuildTools上記以外の追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
- NVIDIA CUDA ツールキットのダウンロード:
NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- winimage の ZLIB DLL の公開ページ: http://www.winimage.com/zLibDll/
- NVIDIA cuDNN のダウンロード,
NVIDIA CUDA ツールキットに合致する NVIDIA cuDNN のバージョンの確認 (Windows, Linux):
NVIDIA cuDNN のページ: https://developer.nvidia.com/cudnn
必ず,使用する NVIDIA CUDA ツールキットにあう NVIDIA cuDNN を使うこと.
- Windows では,NVIDIA cuDNN のインストール後に,手動で,パスを通す必要がある.
- NVIDIA cuDNN の8.3 より前のバージョン:
zip ファイルを展開したら,展開先の下の bin にパスを通す.
- NVIDIA cuDNN v8.3 系列:
.exe ファイルの実行により「C:\Program Files\NVIDIA\CUDNN\v8.3 」にインストールされるので,C:\Program Files\NVIDIA\CUDNN\v8.3\bin に パスを通す.
- NVIDIA cuDNN の8.4 系列:
zip ファイルを展開したら,展開先の下の bin にパスを通す.
- NVIDIA cuDNN の8.3 より前のバージョン:
- NVIDIA cuDNN のインストール後に,必要に応じて,環境変数 CUDNN_PATH を設定する.
Windows での NVIDIA CUDA ツールキット,NVIDIA cuDNN のインストール
NVIDIA CUDA ツールキットのインストールは,公式ページからインストール用のプログラムをダウンロードして実行. NVIDIA cuDNN は,公式ページから ZIP ファイルをダウンロード,展開(解凍)し,パスを通す.
【サイト内の関連ページ】
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.5,NVIDIA cuDNN 8.3 のインストール: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 10.0,NVIDIA cuDNN 7.6.5 のインストール: 別ページ »で説明
関連 Web ページ- NVIDIA ドライバのダウンロードページ: https://www.nvidia.co.jp/Download/index.aspx?lang=jp
- NVIDIA CUDA ツールキットの URL: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA cuDNN のダウンロードページ: https://developer.nvidia.com/cudnn から cuDNN を入手
NVIDIA CUDA ツールキット,NVIDIA cuDNN のインストール(Ubuntu 上)
Ubuntu でのインストールは,次のページで説明している.
- NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.4,NVIDIA cuDNN v8 のインストール(Ubuntu 上): 別ページ »で説明
NVIDIA CUDA ツールキット のバージョンは何でも良いと言う場合には,apt を用いて,次の操作でインストールすることができる. Ubuntu 20.04 では,NVIDIA CUDA バージョン 10.1 がインストールされる.
NVIDIA CUDA バージョン 10.1 に対応する TensorFlow は,TensorFlow バージョン 2.3, 2.2, 2.1 である. NVIDIA CUDA バージョン 10.1 に対応する PyTorch は,PyTorch LTS (1.8.2) である. (いずれも,2022/03 時点).# パッケージリストの情報を更新 sudo apt update sudo apt -y install nvidia-cuda-dev nvidia-cuda-toolkit nvidia-cuda-toolkit-gccNVIDIA CUDA ツールキット,NVIDIA cuDNN の動作確認など
NVIDIA CUDA ツールキット,NVIDIA cuDNN については,次で情報を得ることができる.
- パソコンに載っているグラフィックス・カードが,NVIDIA CUDA ツールキット ,NVIDIA cuDNN 対応のものかを確認
次の公式ページを活用できる
- グラフィックス・カードドライバのバージョンは,nvidia-smi コマンドで確認できる.
- 次により TensorFlow を実際に動かし,TensorFlow から GPU を利用できているかを確認できる.
Windows の場合は,コマンドプロンプトを管理者として開き次のコマンドを実行する.
python -m pip install tensorflow python -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())"Ubuntu のシステム Python を使う場合は,次のコマンドを実行
sudo pip3 install tensorflow python3 -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())"
NVIDIA cuDNN
NVIDIA cuDNN は, NVIDIA CUDA ツールキット上で動作するディープラーニング・ライブラリである. 畳み込みニューラルネットワークや リカレントニューラルネットワークなど,さまざまなディープラーニングで利用されている.
Windows で,NVIDIA cuDNN の利用時に 「Could not locate zlibwapi.dll. Please make sure it is in your library path!」と表示されるときは, ZLIB DLL をインストールすること.
【関連する外部ページ】
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
- winimage の ZLIB DLL の公開ページ: http://www.winimage.com/zLibDll/
NVIDIA cuDNN のインストール時の注意点
【NVIDIA cuDNN の動作に必要なもの】
- NVIDIA ドライバ
Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, 次のコマンドを実行することにより調べることができる.
wmic path win32_VideoController get name【関連する外部ページ】
- 対応するバージョンのNVIDIA CUDA ツールキット
最新のNVIDIA CUDA ツールキットでは動かないということもあるので注意.
- Windows では,ZLIB DLL
ZLIB DLL は,データの圧縮と展開(解凍)の機能を持ったライブラリ.
ZLIB DLL のインストールを行うため, Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。次のコマンドを実行.
但し,「v11.8」のところは,実際にインストールされている NVIDIA CUDA ツールキットのバージョンを確認し,読み替えてください.
cd "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin" curl -O http://www.winimage.com/zLibDll/zlib123dllx64.zip powershell -command "Expand-Archive -DestinationPath . -Path zlib123dllx64.zip" copy zlib123dllx64\dll_x64\zlibwapi.dll . - NVIDIA Developer Program メンバーシップへの加入が必要.
NVIDIA Developer Program の公式ページ: https://developer.nvidia.com/developer-program
NVIDIA Developer Program メンバーシップ
NVIDIA Developer Program の公式ページ: https://developer.nvidia.com/developer-program
NVIDIA グラフィックスボード
NVIDIA ドライバ, NVIDIA CUDA ツールキット, NVIDIA cuDNN のインストールは, NVIDIA グラフィックスボードを搭載しているパソコンであることが前提である.
Windows で NVIDIA グラフィックスボード の有無を確認するための手順は次の通りである.
- 「デバイスマネージャー」を開く.
Window のスタートメニューを開き,検索窓に「デバイスマネージャー」と入れることでアクセスできる
- 「デバイスマネージャー」で,「ディスプレイアダプター」を展開する.
- 「ディスプレイアダプター」の下にあるリストを確認する.
ここに「NVIDIA」の名前が含まれる項目の有無により, NVIDIA グラフィックスボード の有無を確認する.
NVIDIA ドライバ
NVIDIA ドライバは,NVIDIA製GPUを動作させるための重要なソフトウェアである.このドライバをインストールすることにより,GPUの性能を引き出すことができ,グラフィックス関連のアプリ,AI関連のアプリの高速化が期待できる.
ドライバはNVIDIA公式サイトである https://www.nvidia.co.jp/Download/index.aspx?lang=jp からダウンロードできる.このサイトからダウンロードするときには,グラフィックスカードとオペレーティングシステムを選択する. なお,NVIDIA Geforce Experience を用いてインストールすることも可能である.
【インストールの手順】
- NVIDIA グラフィックス・ボードの確認
Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, 次のコマンドを実行することにより調べることができる.
wmic path win32_VideoController get name - NVIDIA ドライバのダウンロード
NVIDIA ドライバは,以下の NVIDIA 公式サイトからダウンロードできる.
- ダウンロードの際には,使用しているグラフィックス・ボードの型番とオペレーティングシステムを選択する.
NVIDIA ドライバのインストール法としては他に,NVIDIA GeForce Exprerience を使う方法もある.こちらは,グラフィックス・ボードの型番とオペレーティングシステムが自動判定される.
【関連する外部ページ】
【サイト内の関連ページ】
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Ubuntu での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8, NVIDIA cuDNN 8 のインストール: 別ページ »で説明
NWPU-Crowd データセット
画像数は 5019枚である.アノテーションされたインスタンスのインスタンス数は 2133375個である.
文献
Qi Wang, Junyu Gao, Wei Lin, and Xuelong Li. Nwpu- crowd: A large-scale benchmark for crowd counting and lo- calization. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2020.
【関連用語】 crowd counting, FIDTM, オープンデータ
Objectron
Objectron は,3次元姿勢推定 (3D pose estimation) の機能を持つ. Objectron は,次の公式ページで,プログラムとデータセットが配布されている.
https://github.com/google-research-datasets/Objectron
次は,Objectron の動作画面.

Objectron は,Google Colaboratory で動かすことができる. Google Colaboratory で動かすときは,コードセルに,次の3行を張り付けて実行. あとは,公式ページのプログラムのコピー&ペーストで動く.
!pip3 install frozendict !git clone --recursive https://github.com/google-research-datasets/Objectron %cd Objectron【関連項目】 Objectron データセット , 3次元姿勢推定 (3D pose estimation)
Objectron データセット
Objectron データセット は,15000のビデオと400万の画像を含む. これらはバイク,本,ボトル,カメラ,シリアルボックス,椅子,カップ,ラップトップ,靴といったカテゴリでアノテーションされている. Objectron データセットは,ビデオ,画像,オブジェクトの姿勢,カメラの姿勢,点群,平面のデータが含まれている. 各ビデオは同じオブジェクトを異なる角度から観察している.
【関連する外部ページ】
公式の GitHub のページ: https://github.com/google-research-datasets/Objectron
【関連項目】 Objectron
Objectron データセットのインストール(Windows 上)
- まず,gsutil のインストールを行う
cd /d c:%HOMEPATH% curl -L -O https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe .\GoogleCloudSDKInstaller.exe - Windows では,
コマンドプロンプトを管理者として開き,
次のコマンドを実行することにより,
gsutil のインストールを行うことができる.
cd /d c:%HOMEPATH% mkdir records_shuffled gsutil cp -r gs://objectron/v1/records_shuffled records_shuffled
Objects365 データセット
Objects365 データセットは,アノテーション済みの画像である. 機械学習での物体検出 の学習や検証に利用できるデータセット.
- 60,000枚の画像
- 365の物体カテゴリ
- オブジェクト検出結果をアノテーションした,1,000万個以上のバウンディングボックス
Objects365 データセットは次の URL で公開されているデータセット(オープンデータ)である.
https://www.objects365.org/overview.html
【関連情報】
- Objects365: A Large-Scale, High-Quality Dataset for Object Detection, ICCV 2019, Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, Jian Sun
- Papers With Code の Places365 データセットのページ: https://paperswithcode.com/dataset/objects365
OCRNet
セマンティック・セグメンテーションのモデル. 2020年発表.
- 文献
Yuhui Yuan and Xilin Chen and Jingdong Wang, Object-Contextual Representations for Semantic Segmentation, ECCV, 2020.
- 公式のソースコード: https://github.com/openseg-group/OCNet.pytorch
- MMSegmentation の OCRNet のページ: https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet
【関連項目】 モデル, セマンティック・セグメンテーション
Octave
Octave の公式ページ: https://www.gnu.org/software/octave/
【サイト内の関連ページ】
one-hot エンコーディング
one-hot エンコーディング (one-hot encodinng は,クラス番号を,長さがクラス数であるような数値ベクトルで,うち,1つだけが 1,残りが全て 0 になっているようなベクトルで表すこと. 1-of-k representation ともいう. クラス番号が 0, 1, 2, 3 の 4通りであるとき,one hot 表現では [1 0 0 0] [0 1 0 0] [0 0 1 0] [0 0 0 1] のように表す. Keras では,クラス番号を one hot 表現に変換するとき to_categorical 関数を用いる.
from tensorflow.keras.utils.np_utils import to_categorical print( to_categorical(0, 4) ) print( to_categorical(1, 4) ) print( to_categorical(2, 4) ) print( to_categorical(3, 4) )次の Python プログラムは,Iris データセットのロードを行う.配列 X, y にロードしている. その後,訓練用データと検証用データへの分割と,one-hot エンコーディングを行っている. 確認表示で display を用いている.
import pandas as pd import sklearn.model_selection from sklearn.datasets import load_iris import tensorflow as tf from IPython.display import display iris = load_iris() x = iris.data y = iris.target x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(x.reshape(x.shape[0], -1), y, train_size=0.5) y_train = tf.keras.utils.to_categorical(y_train) y_test = tf.keras.utils.to_categorical(y_test) display(x_train) display(y_train)
one-way ANOVA (One-way analysis of variance)
帰無仮説: パラメトリック検定.等分散である多群の検定.平均に差がない.
R システム で, one-way ANOVA (One-way analysis of variance) を行うプログラム.one-way (一元配置) と言っているように, x は必ず 1 つの数値である. y は 1つの数値(カテゴリカル変数など)である.
anova(aov(x ~ y))
【関連項目】 検定
ONNX
Windows での ONNX のインストール
ONNX のインストールは,複数の方法がある.
ここでは, vcpkg を使う方法を使う方法を説明する.
- 事前にvcpkg のインストールを行っておく.
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
c:\vcpkg\vcpkg search onnx c:\vcpkg\vcpkg install onnx[pybind11]:x64-windows c:\vcpkg\vcpkg install onnxruntime-gpu:x64-windows python -m pip install -U onnxruntime - (GPU を使い場合に限り)onnxruntime-gpu のインストール
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
- システムの環境変数 Path に,次を加える.
c:\vcpkg\installed\x64-windows\bin
Open3D
Open3D は,3次元データに関する種々の機能を Python, C から扱うことができるソフトウェア. 次の機能を持つ.
- 3次元再構成
- サーフェスのアラインメント
- 可視化
- PBR
- 3次元データに関する機械学習
- 文献 Qian-Yi Zhou and Jaesik Park and Vladlen Koltun Open3D: A Modern Library for 3D Data Processing, arXiv:1801.09847, 2018.
- Open3D の URL: http://www.open3d.org/
Windows で Open3D のインストール
http://www.open3d.org/docs/release/compilation.html に記載の手順による.
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - pip を用いて,Open3D のインストール
python -m pip install -U open3d関連ファイルのインストールを行いたいので,下に書いた手順を進める.
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- cmake のインストール: 別項目で説明している.
CMake の公式ダウンロードページ: https://cmake.org/download/
- Eigen 3 のインストール
- Python のインストール: 別項目で説明している.
- Open3D 関連ファイルのインストール
エラーを回避するために「/utf-8」を設定.
python -m pip install -U --ignore-installed numpy scikit-image cd /d c:%HOMEPATH% rmdir /s /q Open3D git clone --recursive https://github.com/isl-org/Open3D cd Open3D del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_C_FLAGS="/DWIN32 /D_WINDOWS /W0 /utf-8" ^ -DCMAKE_CXX_FLAGS="/DWIN32 /D_WINDOWS /GR /EHsc /W0 /utf-8" ^ -DCMAKE_INSTALL_PREFIX="c:/Open3D" . cmake --build . --config Release --target ALL_BUILD cmake --build . --config Release --target INSTALL - 確認のため Open3DViewer を起動してみる.
起動ができれば OK とする.
%LOCALAPPDATA%\Open3D\bin\Open3D\Release\Open3DViewer.exe
- Open3D-ML 関連ファイルのインストール
ここは書きかけ.動作未検証です.
cd %LOCALAPPDATA% rmdir /s /q Open3D-ML git clone --recursive https://github.com/isl-org/Open3D-ML cd Open3D-ML python -m pip install -r requirements.txt python -m pip install -r requirements-torch.txt python -m pip install -U numpy chumpy json-tricks munkres xtcocotools yapf cd ..\Open3D del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DBUILD_PYTORCH_OPS=ON ^ -DBUILD_TENSORFLOW_OPS=OFF ^ -DBUNDLE_OPEN3D_ML=ON ^ -DOPEN3D_ML_ROOT=%LOCALAPPDATA%\Open3D-ML ^ -DGLIBCXX_USE_CXX11_ABI=OFF ^ -DCMAKE_C_FLAGS="/DWIN32 /D_WINDOWS /W0 /utf-8" ^ -DCMAKE_CXX_FLAGS="/DWIN32 /D_WINDOWS /GR /EHsc /W0 /utf-8" ^ -DUSE_SYSTEM_EIGEN3=ON ^ -DEigen3_DIR="c:/eigen/share/eigen3" ^ -DCMAKE_INSTALL_PREFIX="c:/Open3D" . cmake --build . --config Release --target ALL_BUILD cmake --build . --config Release --target INSTALL - Open3D-ML 関連ファイルのインストールの続き.
前の手順でエラーメッセージを確認し,エラーメッセージが出ていないときは,続行することにして,次を実行する. (確認のときは,エラーメッセージを見落とさないように,表示を確認する.)
cmake --build . --config Release --target install-pip-package python -m pip show open3d - Open3D-ML 関連ファイルのインストール
次を実行し,エラーメッセージが出ないことを確認する.
エラーメッセージが出た場合には, Open3D-ML 関連ファイルのインストールは断念する.
python -c "import open3d.ml.torch"
Open 3D Engine
Open 3D Engine は,オープンソースの3次元ゲームエンジン.Amazon の Amazon Lumberyard の後継である.
o3de の URL: https://github.com/o3de/o3de
Windows での Open 3D Engine のインストール: 別ページ »で説明
OpenAI の APIキー
【関連する外部ページ】
- OpenAI の API キーのページ
- 料金の条件や利用履歴はこちらで確認.
OpenBLAS
OpenBLAS はオープンソースの BLAS(Basic Linear Algebra Subprograms)ライブラリである.行列演算や線形代数計算のための関数を提供する.
主な機能:行列乗算(DGEMM)などの関数,マルチスレッド対応,自動的にCPUを検出してコンパイル,
BLAS を用いたプログラムは, https://gist.github.com/xianyi/6930656 などで公開されている.その実行手順は,別ページ »で説明
【BLAS の主な関数】
- Level 1 ベクトルとベクトルの演算
- DOT : 内積
- AXPY : AXPY 演算 ( y <- ax + y の形など)
- NORM : ノルム など
- Level 2 行列とベクトルと計算
- 行列とベクトルの積 ( y <- Ax )
- 行列の rank-1 更新 ( A <- A + xy' )
- Level 3 行列同士の演算
- 行列と行列の積 ( Z <- XY )
【関連する外部ページ】
- OpenBLAS の Web ページ: https://www.openblas.net/
Windows での OpenBLAS のインストール
Windows での OpenBLAS (BLAS, CBLAS, LAPACK, LAPACKE)のインストール(ソースコードを使用)(Build Tools for Visual Studio を利用): 別ページ »で説明
Ubuntu での OpenBLAS のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libopenblas-dev liblapack-devOpenCLIP
OpenCLIP は,CLIP のオープンソース版である
【文献】
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, Jenia Jitsev, Reproducible scaling laws for contrastive language-image learning, arXiv:2212.07143, 2022.
【サイト内の関連ページ】
OpenCLIP のインストールと動作確認(Image-Text)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- OpenCLIP の GitHub のページ: https://github.com/mlfoundations/open_clip
- OpenCLIP の GoogleColab デモ: https://colab.research.google.com/github/mlfoundations/open_clip/blob/master/docs/Interacting_with_open_clip.ipynb
OpenCV
OpenCV は,実時間コンピュータビジョン (real time computer vision) の アルゴリズムと文書とサンプルコードの集まり.
- 2500 以上のアルゴリズム.
- 顔認識,物体認識,人間の動きの分類,カメラの動きの追跡,オブジェクトの動きの追跡,3次元モデルの抽出,ステレオカメラからの3次元点群の生成,イメージスティッチング,類似画像の検索,赤目の除去,眼球運動の追跡,ARの機能など
- ライセンス: BSD ライセンス
- インタフェース: C++, Python, Java, MATLAB
- マシン: Windows, Linux, Mac OS, iOS, Android
【関連する外部ページ】
- OpenCV の公式ページ: https://opencv.org
- GitHub の OpenCV のページ: https://github.com/opencv/opencv/releases
【サイト内の関連ページ】
【関連項目】 OpenCV Python, OpenCV のサンプルデータ , OpenCV のインストールと,C++ プログラムの実行,
OpenCV Python
Google Colaboratory での PythonのOpenCVライブラリのインストール
Google Colaboratory でのインストールは,コードセルで次を実行
不具合を避けるため,headless 版をインストールしている.
Windows での PythonのOpenCVライブラリのインストール
Windows でのインストールは,コマンドプロンプトを管理者として開き次を実行
python -m pip install -U opencv-python opencv-contrib-pythonUbuntu での PythonのOpenCVライブラリのインストール
Ubuntu でのインストールは,次を実行
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libopencxv-dev python3-opencvRaspberry Pi での PythonのOpenCVライブラリのインストール
Ubuntu でのインストールは,次を実行
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libopencv-dev python3-opencv python3-opencv-appsOpenCV サンプルプログラム
OpenCV の Python のサンプルプログラム
画像ファイルを準備しておく(ここでは,プログラム内でファイル名をfruits.jpg にしている).
import cv2 bgr = cv2.imread('fruits.jpg') cv2.imshow("", bgr) cv2.waitKey(0) cv2.destroyAllWindows()Windows では,次のように実行して,Python のプログラムファイル a.py を作り,実行する.
cd c:\opencv\sources\samples\data notepad a.py python a.pyUbuntu では,Python のプログラムファイル(ファイル名は /tmp/a.py とする)を作成したのち,次のような手順で実行する.
cd /usr/local/opencv/opencv-4.x/samples/data python /tmp/a.pyOpenCV の C++ のサンプルプログラム
画像ファイルを準備しておく(ここでは,プログラム内でファイル名をfruits.jpg にしている).
#include<opencv2/opencv.hpp> int main (int argc, char *argv[]) { cv::Mat bgr = cv::imread("c:/opencv/sources/samples/data/fruits.jpg"); cv::imshow("", bgr); cv::waitKey(0); cv::destroyAllWindows(); return 0; }- Windows での実行
別ページ »で説明
- Ubuntu での実行
Ubuntu では,C++ のプログラムファイル(ファイル名は /tmp/a.cpp とする)を作成したのち,次のような手順で実行する.
g++ -I/usr/include/opencv4 -o a.out a.cpp -lopencv_core -lopencv_highgui -lopencv_imgcodecs ./a.out
OpenCV のインストールと,C++ プログラムの実行
以下,Windows と Ubuntu について説明.
【関連項目】 OpenCV, OpenCV Python, OpenCV のサンプルデータ
Windows での OpenCV のインストール(GitHub の OpenCV のページからダウンロードしてインストール)
OpenCV 4.10.0 のインストール,動作確認(Windows 上): 別ページ »で説明
Windows での OpenCV のインストール(ソースコードを使用)
ソースコードからビルドして,インストールする.その詳細は: 別ページ »で説明公式ページhttps://docs.opencv.org/4.5.2/d3/d52/tutorial_windows_install.html に説明がある.
Ubuntu での OpenCV, opencv_contrib のインストール
インストールは複数の方法があるが,ここでは最も単純,確実な方法を案内する.
- 端末で,次のコマンドを実行する.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install build-essential gcc g++ make libtool texinfo dpkg-dev pkg-config sudo apt -y install libopencv-dev libopencv-core-dev python3-opencv libopencv-contrib-dev opencv-data - OpenCV を用いて動画表示を行う C++ プログラム
ファイル名 a.cpp で保存.
画像ファイルを準備しておく(ここでは,プログラム内でファイル名をfruits.jpg にしている).
#include<opencv2/opencv.hpp> int main (int argc, char *argv[]) { cv::Mat bgr = cv::imread("fruits.jpg"); cv::imshow("", bgr); cv::waitKey(0); cv::destroyAllWindows(); return 0; } - 次のコマンドで実行
g++ -I/usr/include/opencv4 -o a.out a.cpp -lopencv_core -lopencv_highgui -lopencv_imgcodecs ./a.out画像表示が行われる.画面をクリックし,なにかのキーを押して閉じる.

Ubuntu での OpenCV, opencv_contrib のインストール(ソースコードを利用)
ソースコードを用いてインストールすることにより, 最新版の機能を確認できる. ソースコードの中にはデモプログラムやデータが付属しており便利である. インストール時に,CUDA 対応などの設定ができる.
- ソースコードを用いたインストール
OpenCV, OpenCV Contrib のインストール,CUDA 対応可能(ソースコードを使用)(Ubuntu 上): 別ページ »で説明
- OpenCV を用いて動画表示を行う C++ プログラム
ファイル名 a.cpp で保存.
#include<opencv2/opencv.hpp> int main (int argc, char *argv[]) { cv::Mat bgr = cv::imread("/usr/local/share/opencv4/samples/data/fruits.jpg"); cv::imshow("", bgr); cv::waitKey(0); cv::destroyAllWindows(); return 0; }次のようなコマンドで実行
g++ -I/usr/local/include/opencv4 -o a.out a.cpp -L/usr/local/lib -lopencv_world ./a.outソースコードからビルドするときに「-D BUILD_opencv_world=ON」を付けなかったときは, 次のようなコマンドで実行
g++ -I/usr/local/include/opencv4 -o a.out a.cpp -L/usr/local/lib -lopencv_core -lopencv_highgui -lopencv_imgcodecs ./a.out画像表示が行われる.画面をクリックし,なにかのキーを押して閉じる.

OpenCV のサンプルデータ
OpenCV のサンプルデータ (samples/data) は,インターネットで公開されているデータセット(オープンデータ)である.(他のオープンデータと同様に,利用条件は利用者で確認すること).
curl を用いて,次のような操作でダウンロードできる.
curl -O https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg curl -O https://raw.githubusercontent.com/opencv/opencv/master/samples/data/home.jpgOpenCV による動画表示
Python プログラム例
次は,パソコンに接続された USB カメラなどのカメラ画像表示を行う Python プログラムである.
「cv2.VideoCapture(0)」の0は,カメラの意味.(動画ファイルを表示したいときは,0の変わりにファイル名を書く)
import os import cv2 v = cv2.VideoCapture(0) while(v.isOpened()): r, f = v.read() if ( r == False ): break cv2.imshow("", f) # Press Q to exit if cv2.waitKey(1) & 0xFF == ord('q'): break v.release() cv2.destroyAllWindows()カメラ画像表示が行われる.画面をクリックし「q」キーで終了.
OpenCV での画像表示
Python プログラム例
import os import cv2 bgr = cv2.imread("fruits.jpg") cv2.imshow("", bgr) cv2.waitKey(0) cv2.destroyAllWindows()次の CSV ファイルを作り,1.csv のようなファイル名で保存する.
100, 200 300, 300Python プログラム例 画像に CSV ファイル内の x, y 値をプロット.
import os import cv2 import pandas as pd bgr = cv2.imread("fruits.jpg") a = pd.read_csv("1.csv", names=['x', 'y']) for i, row in a.iterrows(): c = cv2.circle(bgr, (row['x'], row['y']), 3, (0, 0, 255), -1) cv2.imshow("", bgr) cv2.waitKey(0) cv2.destroyAllWindows()OpenFace
OpenFace の Web ページ: https://cmusatyalab.github.io/openface/
GitHub のページ: https://github.com/cmusatyalab/openface
OpenGV
OpenGV は Absolute camera pose computation, Relative camera-pose computation, Two methods for point-triangulation, Arun's method for aligning point clouds の機能を持つ. Matlab, Python のインタフェースを持つ.
URL: https://laurentkneip.github.io/opengv/
論文: L. Kneip, P. Furgale, “OpenGV: A unified and generalized approach to real-time calibrated geometric vision”, Proc. of The IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China. May 2014.
Ubuntu で OpenGV のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cmake cmake-curses-gui cmake-gui libeigen3-dev cd /usr/local sudo rm -rf opengv sudo git clone --recursive https://github.com/laurentkneip/opengv sudo chown -R $USER opengv cd opengv sudo rm -rf build mkdir build cd build cmake -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_INSTALL_PREFIX="/usr/local/opengv" \ -DBUILD_PYTHON=ON \ -DBUILD_TESTS=OFF .. cmake --build . --config Release --target INSTALL -- /m:4OpenMMLab
OpenMMLab の URL: https://openmmlab.com/
OpenMMLab の GitHub のページ: https://github.com/open-mmlab
関連項目: MMAction2, MMClassification, MMCV, MMDetection, MMFewShot, MMFlow, MMGen, MMPose, MMSegmentation, MMSegmentation3D MMSelfSup, MMTracking
OpenMVG
OpenMVG は Structure from Motion の機能を持つソフトウェアソフトウェア.
OpenMVG が持っている Structure from Motion (SfM) の機能に, Global Structure from Motion がある. Global Structure from Motion は, 多数の視点からの画像を使う SfM において,視点の位置と向きの推定を(当時の手法よりも)より頑健かつ正確に推定できるとされている. (その論文: P. Moulon, P. Monasse and R. Marlet, "Global Fusion of Relative Motions for Robust, Accurate and Scalable Structure from Motion," 2013 IEEE International Conference on Computer Vision, 2013, pp. 3248-3255, doi: 10.1109/ICCV.2013.403. https://www.researchgate.net/publication/261622957_Global_Fusion_of_Relative_Motions_for_Robust_Accurate_and_Scalable_Structure_from_Motion)
- OpenMVG の URL(GitHub): https://github.com/openMVG/openMVG
- 公式のドキュメント: https://openmvg.readthedocs.io/en/latest/software/SfM/GlobalSfM/
- OpenMVG の SfM の利用手順: https://github.com/openMVG/openMVG/wiki/OpenMVG-on-your-image-dataset
Windows で OpenMVG のインストール
Windows での OpenMVG のインストールは,複数の方法がある.
- vcpkg を使う.本項目の下で説明している.
- ソースコードからビルド.本項目の下で説明している.その詳細は: 別ページ »で説明
ここでは, vcpkg を使う方法と, ソースコードからビルドする方法を説明する.
- ソースコードからビルドする方法
前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/,
- cmake のインストール: 別項目で説明している.
CMake の公式ダウンロードページ: https://cmake.org/download/
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
c:\openmvg にインストールされる.
cd /d c:%HOMEPATH% rmdir /s /q openmvg git clone --recursive https://github.com/openMVG/openMVG.git cd openMVG cd src rmdir /s /q build mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_BUILD_TYPE=Release ^ -DCMAKE_INSTALL_PREFIX="c:/openmvg" ^ -DOpenMVG_BUILD_DOC=OFF ^ .. cmake --build . --config Release --target INSTALL -- /m:4 - vcpkg を使う方法
- 事前にvcpkg のインストールを行っておく.
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
c:\vcpkg\vcpkg search openmvg c:\vcpkg\vcpkg install openmvg[opencv,openmp,software]:x64-windows - システムの環境変数 Path に,次を加える.
c:\vcpkg\installed\x64-windows\bin
OpenMVG (2021/08/21 時点) Windows 10 64 ビット版の非公式ビルド: openMVG.zip私がビルドしたもの,非公式,無保証,ソースコードを改変せずにビルドした.OpenMVG の MPL2 ライセンスによる.
Ubuntu で OpenMVG のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cmake cmake-curses-gui cmake-gui libeigen3-dev cd /usr/local sudo rm -rf openmvg sudo git clone --recursive https://github.com/openMVG/openMVG.git sudo chown -R $USER openMVG cd openMVG cd src sudo rm -rf build mkdir build cd build cmake -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_INSTALL_PREFIX="/usr/local/openmvg" cmake --build . --config Release --target INSTALL -- /m:4デモプログラム
デモプログラムとして, 所定の画像データセットをダウンロードし,SfM を実行する Python プログラムが付属している.
Windows では次の手順で行う.
cdc:\openMVG\src python build\software\SfM\tutorial_demo.py デモプログラムの実行でできるファイルのうち,ply 形式ファイルの1つを MeshLabを用いて表示すると次のようになる.色付きの3次元点群である.
Global Structure from Motion を行う
いくつかのコマンドを順に実行する. Windows では次のような手順で行う.
# 画像の準備, ImageDataset_SceauxCastle\images に画像を置くためのプログラム cdc:\openMVG\src mkdir ImageDataset_SceauxCastle mkdir ImageDataset_SceauxCastle\images copy .\build\software\SfM\ImageDataset_SceauxCastle\images\*.JPG ImageDataset_SceauxCastle\images echo 1. Intrinsics analysis .\build\Windows-AMD64-Release\Release\openMVG_main_SfMInit_ImageListing -i ImageDataset_SceauxCastle/images/ -d openMVG/exif/sensor_width_database/sensor_width_camera_database.txt -o ImageDataset_SceauxCastle/matches/ echo 2. Compute features .\build\Windows-AMD64-Release\Release\openMVG_main_ComputeFeatures -i ImageDataset_SceauxCastle/matches/sfm_data.json -o ImageDataset_SceauxCastle/matches/ echo 3. Compute matches .\build\Windows-AMD64-Release\Release\openMVG_main_ComputeMatches -i ImageDataset_SceauxCastle/matches/sfm_data.json -o ImageDataset_SceauxCastle/matches/ -g e echo 4. Do Global reconstruction .\build\Windows-AMD64-Release\Release\openMVG_main_GlobalSfM -i ImageDataset_SceauxCastle/matches/sfm_data.json -m ImageDataset_SceauxCastle/matches/ -o ImageDataset_SceauxCastle/outReconstruction/ echo 5. Colorize Structure .\build\Windows-AMD64-Release\Release\openMVG_main_ComputeSfM_DataColor -i ImageDataset_SceauxCastle/outReconstruction/sfm_data.bin -o ImageDataset_SceauxCastle/outReconstruction/colorized.ply echo 6. compute final valid structure from the known camera poses, Structure from Known Poses (robust triangulation) .\build\Windows-AMD64-Release\Release\openMVG_main_ComputeStructureFromKnownPoses -i ImageDataset_SceauxCastle/outReconstruction/sfm_data.bin -m ImageDataset_SceauxCastle/matches/ -f ImageDataset_SceauxCastle/matches/matches.e.bin -o ImageDataset_SceauxCastle/outReconstruction/robust.bin .\build\Windows-AMD64-Release\Release\openMVG_main_ComputeSfM_DataColor -i ImageDataset_SceauxCastle/outReconstruction/robust.bin -o ImageDataset_SceauxCastle/outReconstruction/robust_colorized.ply 最後の処理でできた,色付きの3次元点群のファイル(ply 形式ファイル)を MeshLabを用いて表示すると次のようになる.
続けて,次を実行する.上の結果を,OpenMVS を用いて処理している.実行には OpenMVS のインストールが必要
参考ページ: https://openmvg.readthedocs.io/en/latest/software/MVS/OpenMVS/ (公式の資料)
.\build\Windows-AMD64-Release\Release\openMVG_main_openMVG2openMVS -i ImageDataset_SceauxCastle/outReconstruction/sfm_data.bin -d ImageDataset_SceauxCastle/outReconstruction/ -o ImageDataset_SceauxCastle/outReconstruction/scene.mvs DensifyPointCloud ImageDataset_SceauxCastle/outReconstruction/scene.mvs ReconstructMesh scene_dense.mvs TextureMesh scene_dense_mesh.mvsデモプログラムの実行でできるファイルのうち,ply 形式ファイルの1つを MeshLabを用いて表示すると次のようになる.色付きの3次元点群である.
OpenMVS
OpenMVS は,Multi View Stereo の機能を持ったソフトウェア
【関連項目】 meshroom, Multi View Stereo, OpenMVG, OpenMVS, Structure from Motion (SfM)
Windows で OpenMVS のインストール
Windows での OpenMVS のインストールは,複数の方法がある.
ここでは, vcpkg を使う方法を説明する.
- 事前にvcpkg のインストールを行っておく.
- コマンドプロンプトを管理者として開き次のコマンドを実行する.
c:\vcpkg\vcpkg search openmvs c:\vcpkg\vcpkg install openmvs[cuda,openmp]:x64-windows - システムの環境変数 Path に,次を加える.
c:\vcpkg\installed\x64-windows\bin
OpenStreetMap
OpenStreetMap のデータは,Node, Way, Relation の 2種類である.
- Node : 緯度経度の情報を持つ点要素
- Way: Node を相互に結んだ線要素
- Relation: 各要素をグループ分けしたもの.
PaddleOCR
テキスト検知 (text detection), テキスト認識 (text recognition) の機能を持つ.
- 文献
Yuning Du, Chenxia Li, Ruoyu Guo, Cheng Cui, Weiwei Liu, Jun Zhou, Bin Lu, Yehua Yang, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, Yanjun Ma, PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System, CoRR, abs/2109.03144v2, 2021.
- 公式のソースコード (GitHub): https://github.com/PaddlePaddle/PaddleOCR
- Papers with Code のページ: https://paperswithcode.com/paper/pp-ocrv2-bag-of-tricks-for-ultra-lightweight
【関連項目】 テキスト検知 (text detection), テキスト認識 (text recognition)
Google Colaboratory でのテキスト検知 (text detection), テキスト認識 (text recognition)
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- PaddlePaddle 2.0 GPU 版のインストール
!pip3 install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
- PaddleOCR のインストール
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/quickstart_en.md に記載の手順による.
!pip3 install "paddleocr>=2.0.1"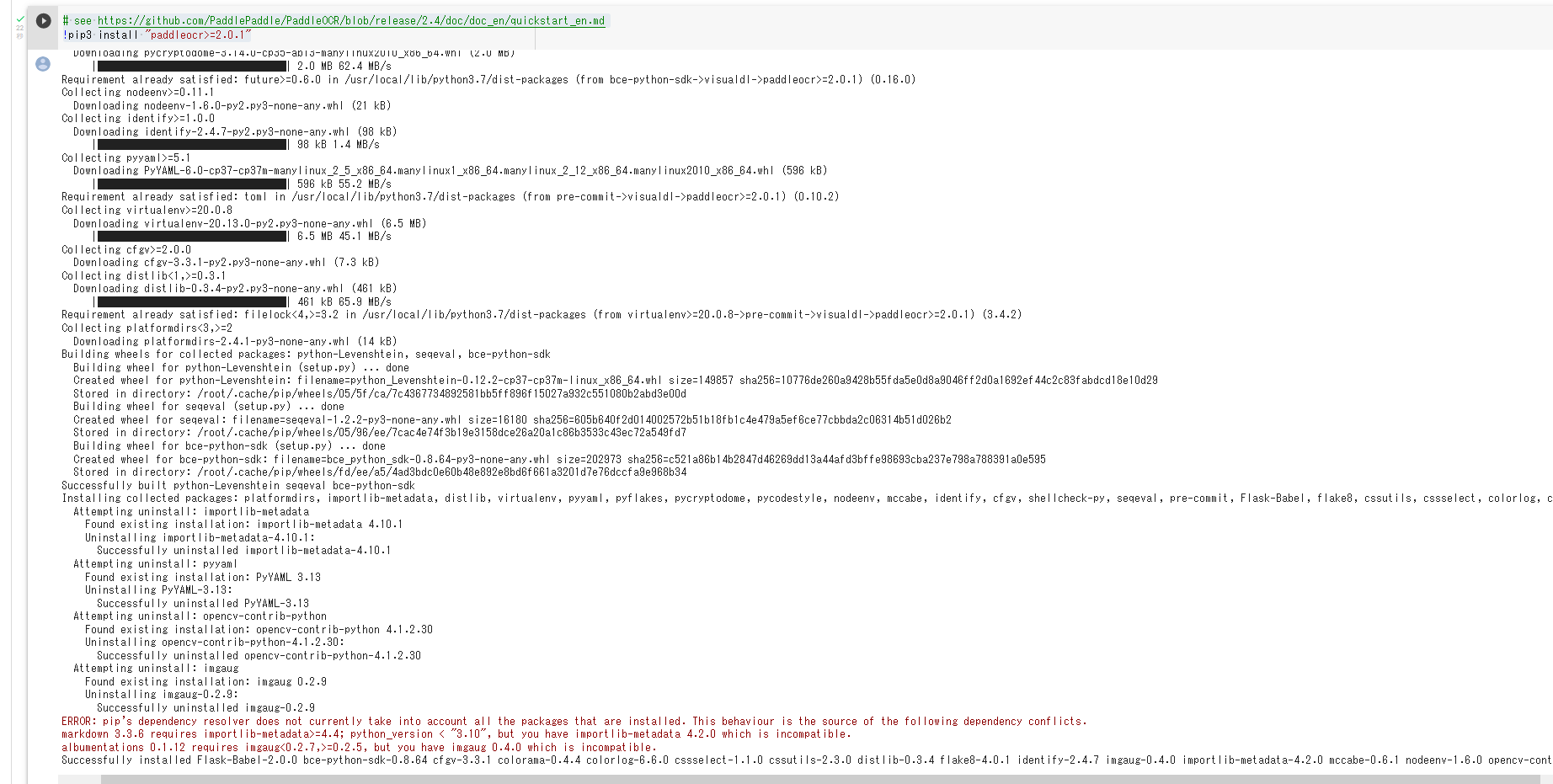
- layput parser のインストール
!pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl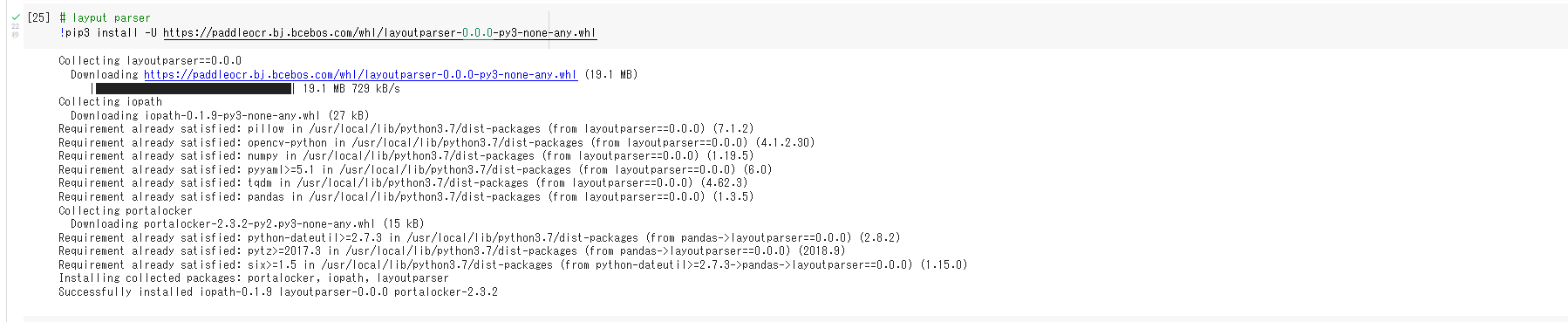
- PaddleOCR のソースコードやデータのダウンロード
あとで使用する.
%cd /content !rm -rf PaddleOCR !git clone https://github.com/PaddlePaddle/PaddleOCR %cd PaddleOCR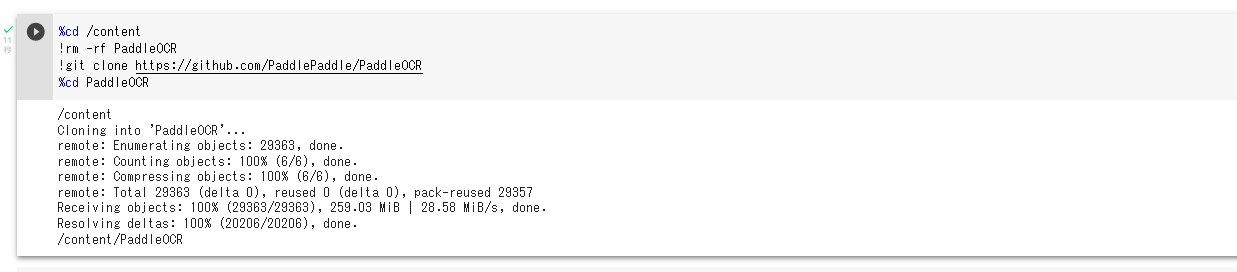
- 学習済みモデルのダウンロード
説明は https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/models_list_en.md
- ch_PP-OCRv2_det_infer.tar, テキスト検知のモデル, Moblile & Server 用
- ch_ppocr_server_v2.0_det_infer.tar, テキスト検知のモデル, Moblile & Server 用
- en_number_mobile_v2.0_rec_slim_infer.tar, テキスト認識のモデル, Slim pruned and quantized lightweight model, supporting English and number recognition
- japan_mobile_v2.0_rec_infer.tar, テキスト認識のモデル, Lightweight model for Japanese recognition
- ch_ppocr_mobile_v2.0_cls_infer.tar, テキスト角分類のモデル
!curl -O https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar !tar -xvf ch_PP-OCRv2_det_infer.tar !curl -O https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar !tar -xvf ch_ppocr_server_v2.0_det_infer.tar !curl -O https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/japan_mobile_v2.0_rec_infer.tar !tar -xvf japan_mobile_v2.0_rec_infer.tar !curl -O https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_infer.tar !tar -xvf en_number_mobile_v2.0_rec_slim_infer.tar !curl -O https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar !tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar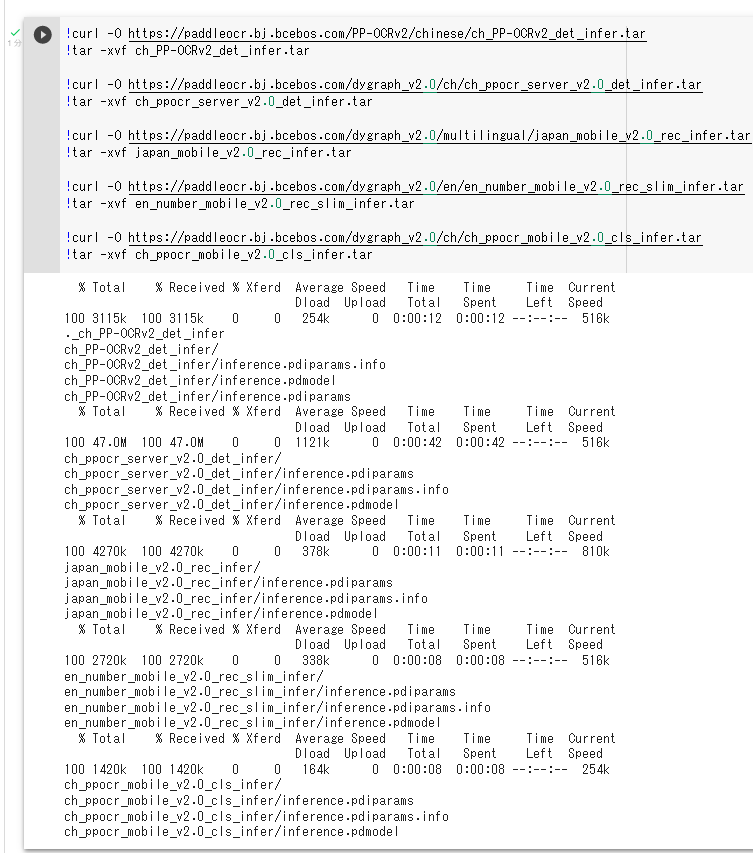
- 横書きの日本語のテキスト検知 (text detection) の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!rm -f 1.jpg !wget https://www.kkaneko.jp/sample/textimage/1.jpg !python3 tools/infer/predict_det.py --image_dir="1.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" !cat ./inference_results/det_results.txt from PIL import Image Image.open('inference_results/det_res_1.jpg').show()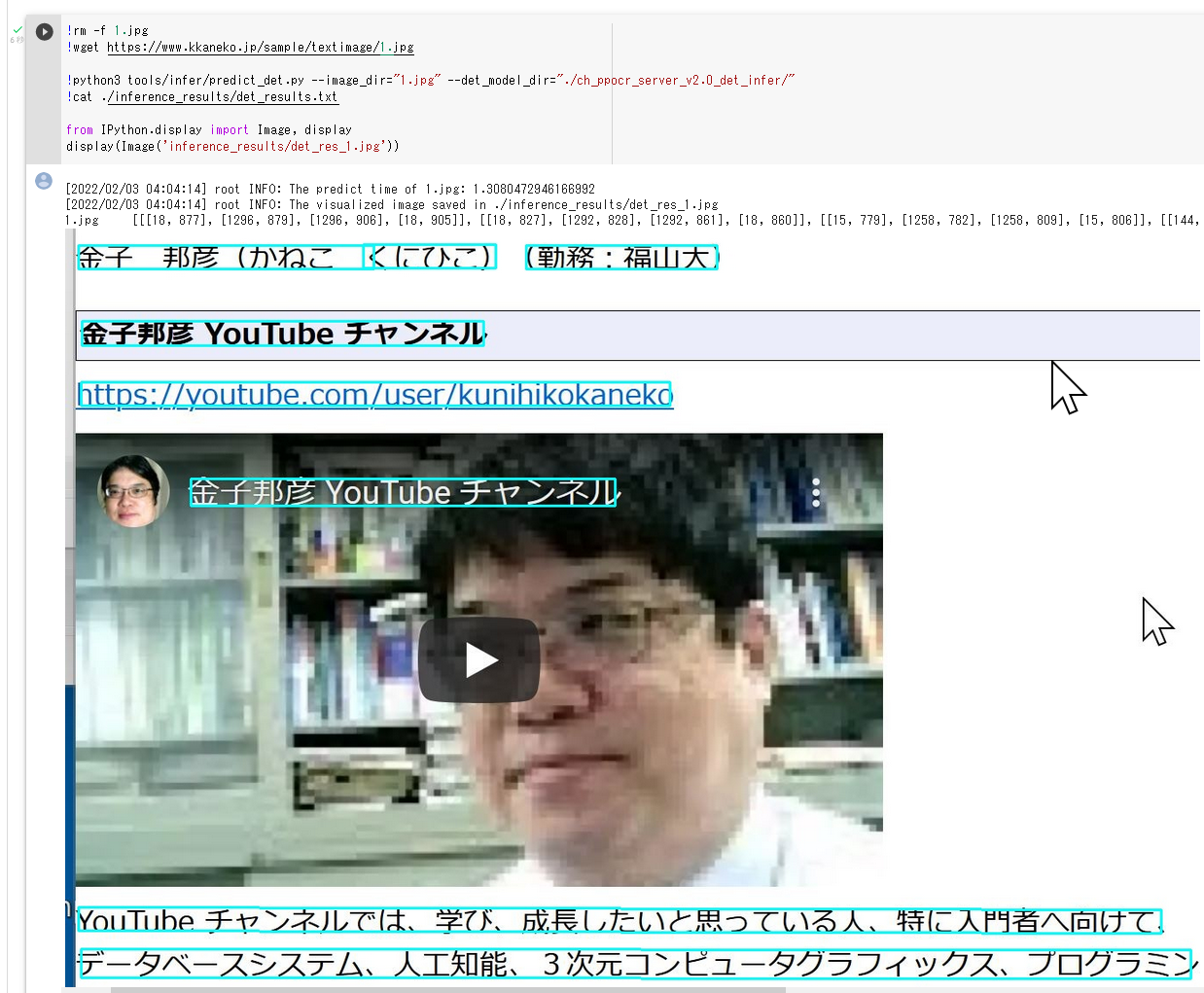
- 縦書きの日本語のテキスト検知 (text detection) の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!rm -f 2.jpg !wget https://www.kkaneko.jp/sample/textimage/2.jpg !python3 tools/infer/predict_det.py --image_dir="2.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" !cat ./inference_results/det_results.txt from PIL import Image Image.open('inference_results/det_res_2.jpg').show()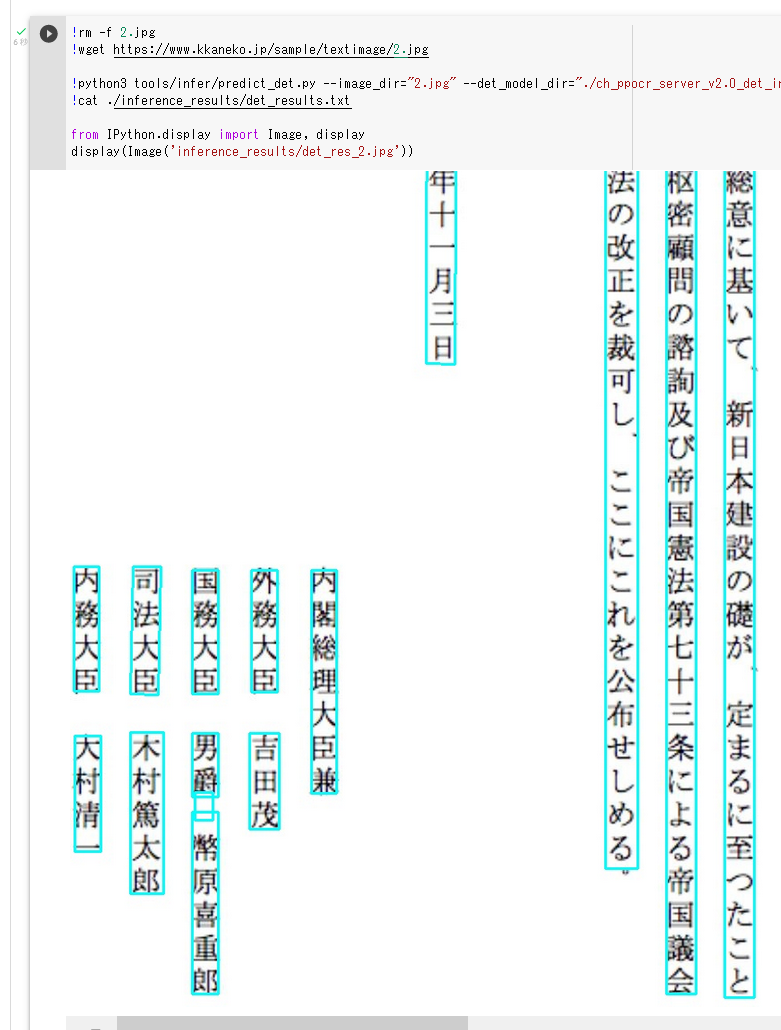
- 英語のテキスト検知 (text detection)の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_12.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" !cat ./inference_results/det_results.txt from PIL import Image Image.open('inference_results/det_res_img_12.jpg').show()
- 横書きの日本語のテキスト認識 (text recognition) の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!rm -f 1.jpg !wget https://www.kkaneko.jp/sample/textimage/1.jpg !python3 tools/infer/predict_system.py --image_dir="1.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" --cls_model_dir="./ch_ppocr_mobile_v2.0_cls_infer/" --rec_model_dir="japan_mobile_v2.0_rec_infer" --rec_char_dict_path="ppocr/utils/dict/japan_dict.txt" --vis_font_path="doc/fonts/japan.ttc" !cat ./inference_results/det_results.txt from PIL import Image Image.open('inference_results/1.jpg').show()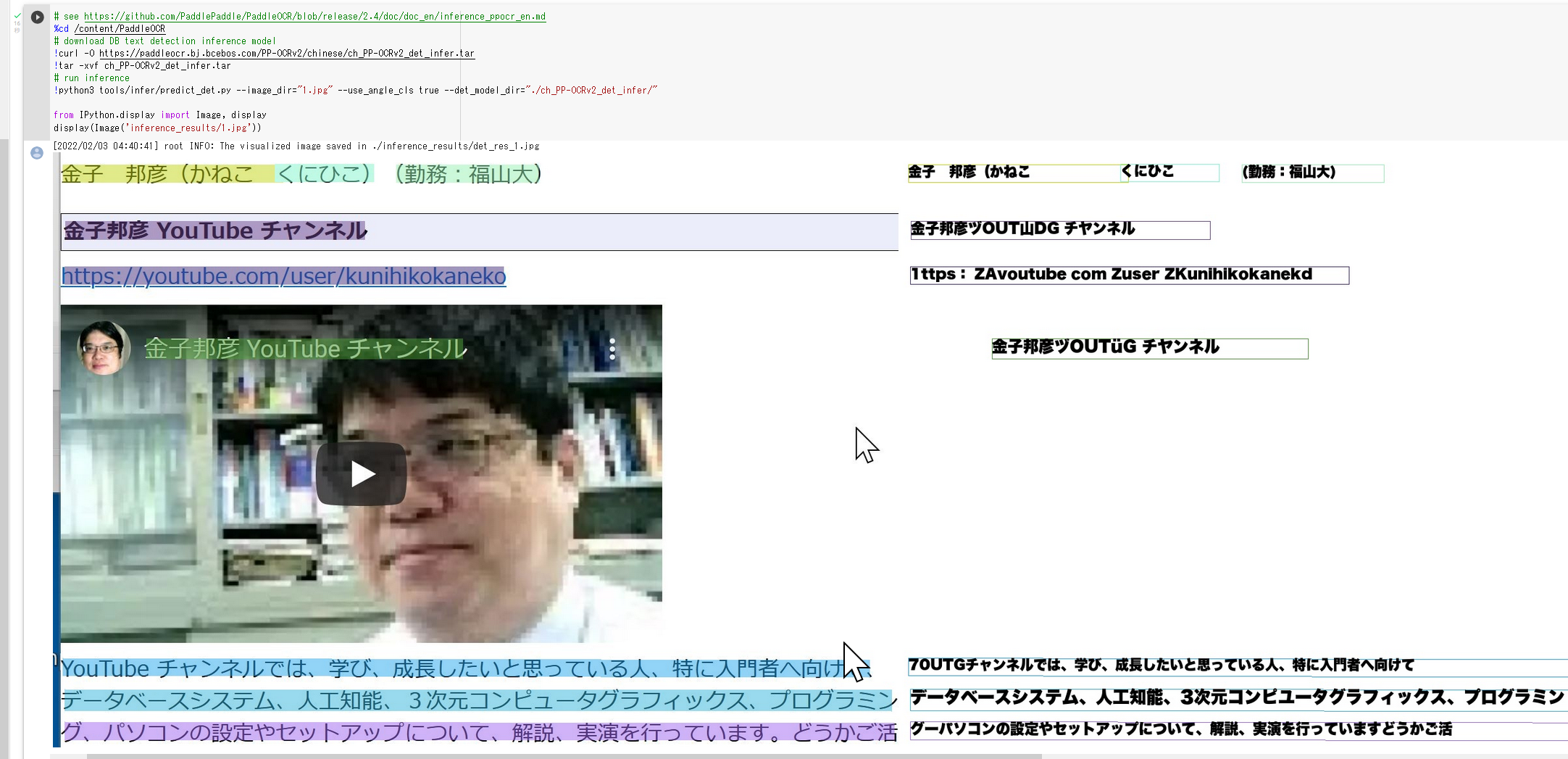
- 縦書きの日本語のテキスト認識 (text recognition) の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!rm -f 2.jpg !wget https://www.kkaneko.jp/sample/textimage/2.jpg !python3 tools/infer/predict_system.py --image_dir="2.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" --cls_model_dir="./ch_ppocr_mobile_v2.0_cls_infer/" --rec_model_dir="japan_mobile_v2.0_rec_infer" --rec_char_dict_path="ppocr/utils/dict/japan_dict.txt" --vis_font_path="doc/fonts/japan.ttc" !cat ./inference_results/det_results.txt from PIL import Image Image.open('inference_results/2.jpg').show()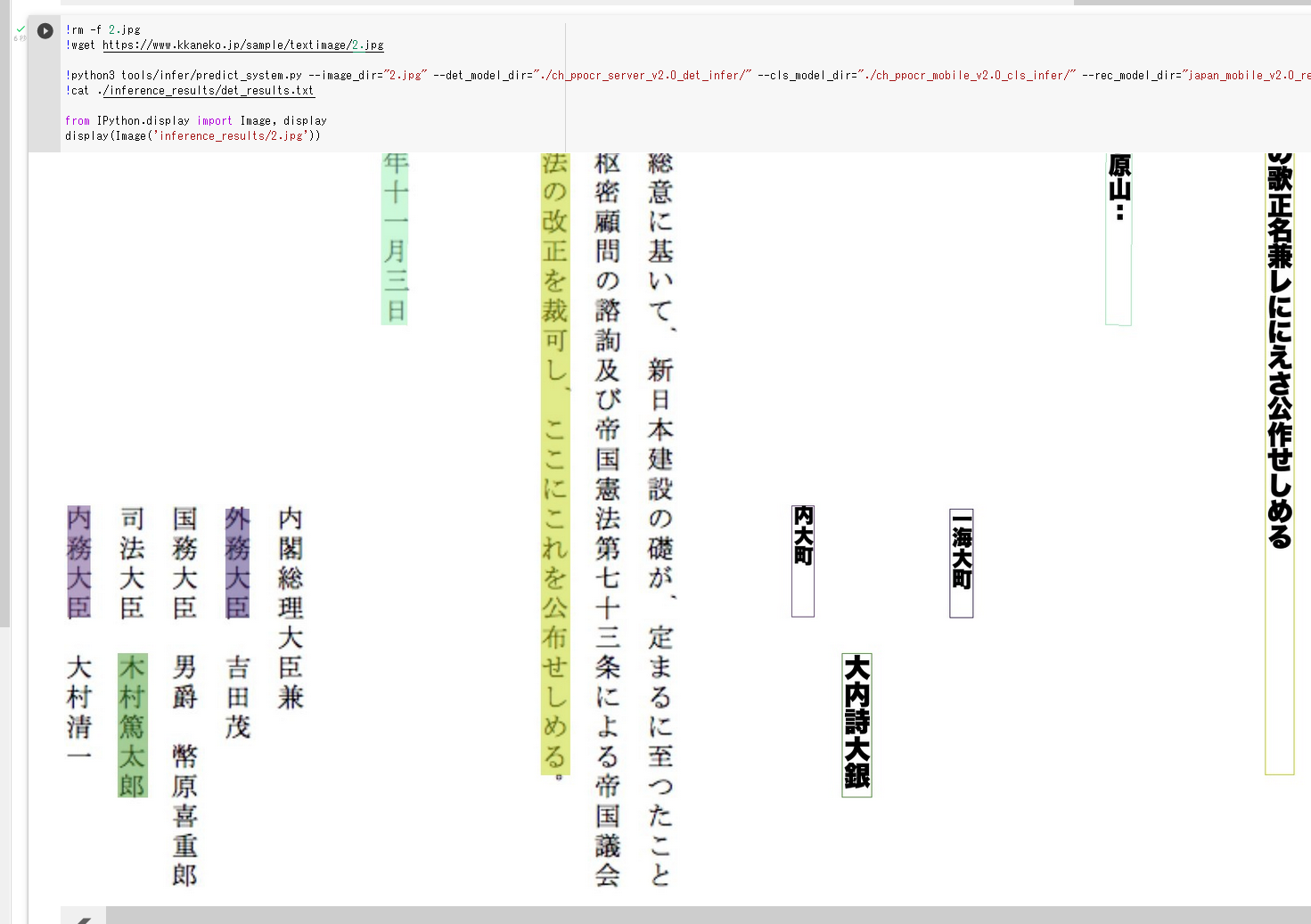
- 英語のテキスト認識 (text recognition) の実行
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/inference_ppocr_en.md で説明の手順による.
!python3 tools/infer/predict_system.py --image_dir="./doc/imgs_en/img_12.jpg" --det_model_dir="./ch_ppocr_server_v2.0_det_infer/" --cls_model_dir="./ch_ppocr_mobile_v2.0_cls_infer/" --rec_model_dir="en_number_mobile_v2.0_rec_slim_infer" --rec_char_dict_path="ppocr/utils/dict/en_dict.txt" from PIL import Image Image.open('inference_results/img_12.jpg').show()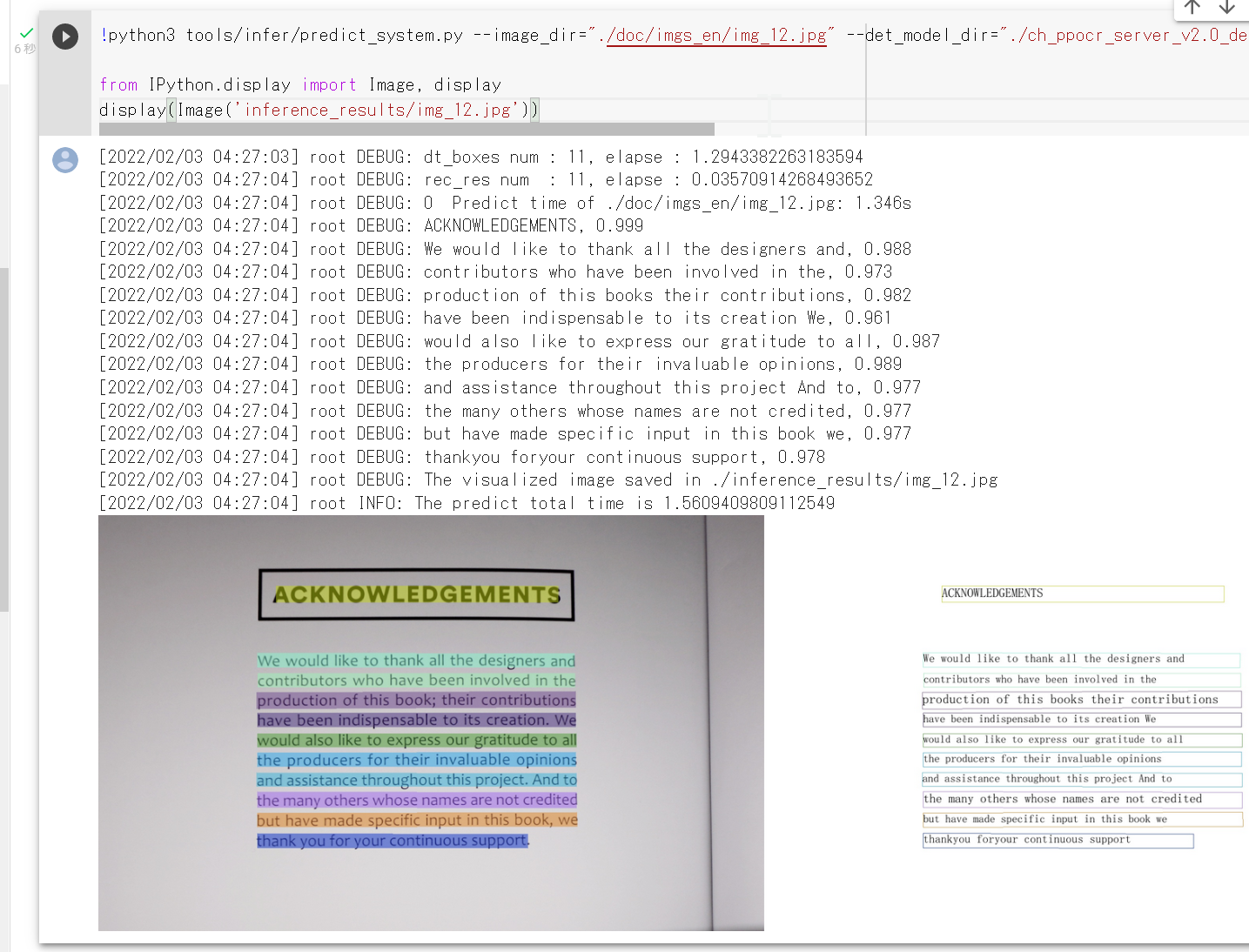
- 日本語のテキスト認識を行う Python プログラム
# see https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.4/doc/doc_en/quickstart_en.md from paddleocr import PaddleOCR,draw_ocr # Paddleocr supports Chinese, English, French, German, Korean and Japanese. # You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan` # to switch the language model in order. ocr = PaddleOCR(use_angle_cls=True, det_model_dir="./ch_ppocr_server_v2.0_det_infer/", cls_model_dir='./ch_ppocr_mobile_v2.0_cls_infer/', lang='japan') # need to run only once to download and load model into memory img_path = './2.jpg' result = ocr.ocr(img_path, cls=True) for line in result: print(line) # draw result from PIL import Image image = Image.open(img_path).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='./doc/fonts/japan.ttc') im_show = Image.fromarray(im_show) im_show.save('result.jpg') from PIL import Image Image.open('result.jpg').show()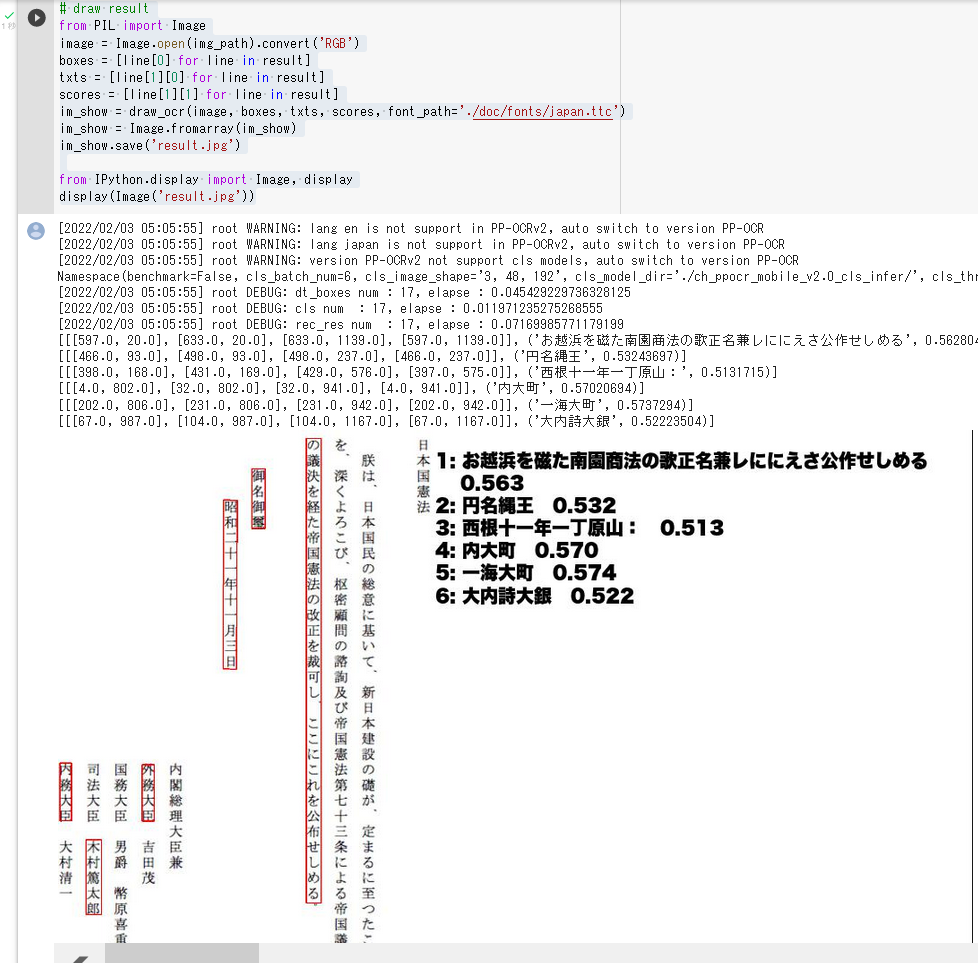
- テキスト検知 (text detection)の実行と,画像での結果の表示,英語の文書を使用
from paddleocr import PaddleOCR,draw_ocr # Paddleocr supports Chinese, English, French, German, Korean and Japanese. # You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan` # to switch the language model in order. ocr = PaddleOCR(use_angle_cls=True, lang='en') # need to run only once to download and load model into memory img_path = './doc/imgs_en/img_12.jpg' result = ocr.ocr(img_path, cls=True) for line in result: print(line) # draw result from PIL import Image image = Image.open(img_path).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='./doc/fonts/simfang.ttf') im_show = Image.fromarray(im_show) im_show.save('result.jpg') from PIL import Image Image.open('result.jpg').show()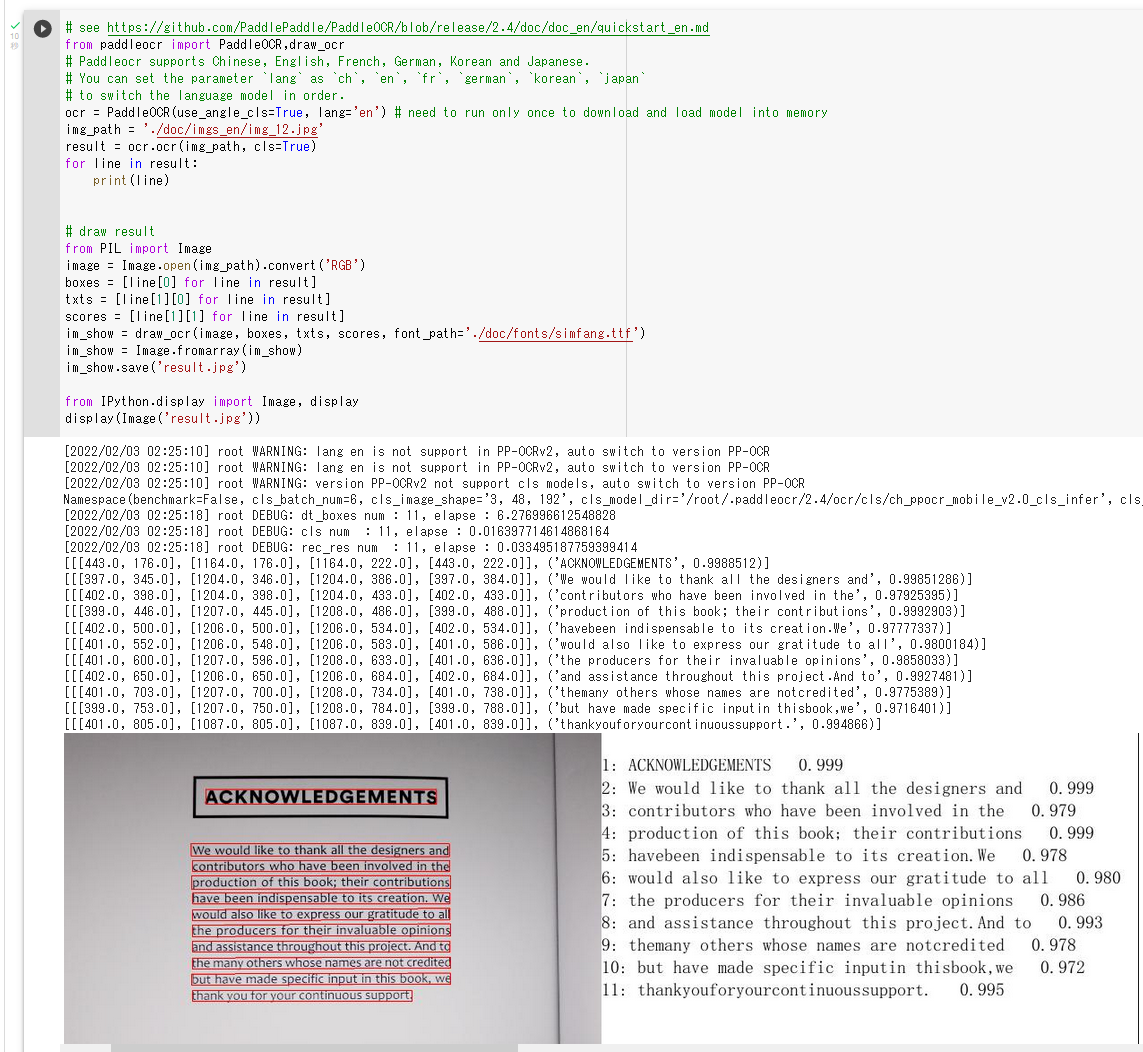
- 構造の読み取り
!paddleocr --image_dir ./doc/imgs_en/img_12.jpg --lang en --use_gpu false --type structure
OPT
OPT (Open Pre-Trained Transformer) は,事前学習済みの大規模言語モデル (large language model) である.GitHub のページでは,OPT-125M, OPT-350M, OPT-1.3B, OPT-2.7B, OPT-6.7B, OPT-13B, OPT-30B, OPT-66B, OPT-175B が公開されている.
【文献】
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, Luke Zettlemoyer, OPT: Open Pre-trained Transformer Language Models, arXiv:2205.01068, 2022.
https://arxiv.org/pdf/2205.01068.pdf
【関連する外部ページ】
GitHub のページ: https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
【関連項目】 FlexGen
Orbit
TensorFlow 2 で訓練ループのプログラムを書くときに利用できるソフトウェア.
Orbit の GitHub のページ: https://github.com/tensorflow/models/tree/master/orbit
関連項目: TensorFlow
Oxford-IIIT ペット データセット
Oxford-IIIT ペット データセットは、 は約200枚の画像と37の異なるカテゴリで構成されている. 主に犬と猫の画像とそれに対応するアノテーションデータが含まれており、 物体検出やセグメンテーションのタスクに利用できる.

【関連する外部ページ】
Windows でのダウンロード手順
cd /d c:%HOMEPATH% rmdir /s /q oxford3t mkdir oxford3t cd oxford3t curl -L -O https://thor.robots.ox.ac.uk/~vgg/data/pets/images.tar.gz curl -L -O https://thor.robots.ox.ac.uk/~vgg/data/pets/annotations.tar.gz "c:\Program Files\7-Zip\7z.exe" x images.tar.gz "c:\Program Files\7-Zip\7z.exe" x annotations.tar.gz "c:\Program Files\7-Zip\7z.exe" x images.tar "c:\Program Files\7-Zip\7z.exe" x annotations.tarPanda3D
Panda3D は,オープンソースのソフトウェア,3次元ゲームエンジン (3-D game engine),可視化,シミュレーションの機能を持つ.
Panda3D の URL: https://www.panda3d.org/
- Windows での Panda3D のインストール: 別ページ »で説明
- Ubuntu での Panda3D のインストール: 別ページ »で説明
- Panda3D の機能概要(説明資料)[PDF], [パワーポイント]
- 3次元のゲームエンジン Panda3D を使ってみる: 別ページ »にまとめている.
Panda3D のインストール
【サイト内の関連ページ】
- Panda3D SDK のインストール,サンプルプログラムの実行(3次元のゲームエンジン)(Python を使用)(Windows 上)
- 3次元ゲームエンジン Panda3D 1.11 SDK (dev 版) のインストール(Ubuntu 上)
Pandas
TensorFlow などの機械学習フレームワークでは,入力として pandas のデータ構造をサポートしていることが多い.
【関連項目】 Iris データセット
Pandas の表示
次のようなプログラムでは,displayを用いて,Pandas のデータフレームを整形して表示している.
from IPython.display import display display(df)Iris データセットを Pandas データフレームとしてロードし,画面表示するプログラム
次の Python プログラムは,Iris データセットのロードと確認表示を行う. Pandas データフレームの df にロードしている. 確認表示で display を用いている.
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] display(df)Pandas での列の選択
次の Python プログラムでは,次のことを行っている.
- 複数の列の選択: df.iloc[:,0:4] は,0列目から4列分を得る.
- 1列の選択: df.iloc[:,4] は,4列目を得る.
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] display(df.iloc[:,0:4]) display(df.iloc[:,4])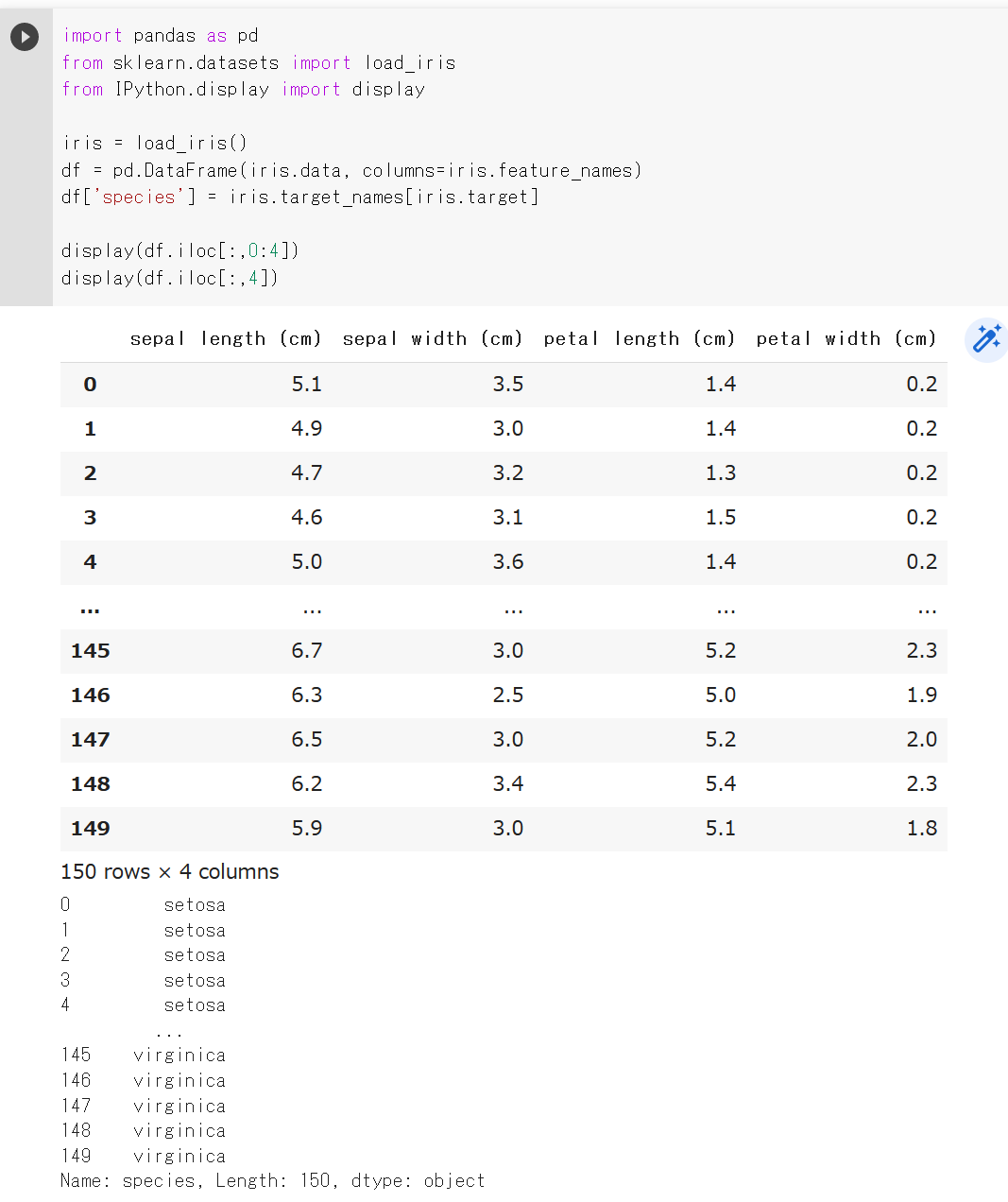
numpy.ndarray への変換
次の Python プログラムでは,to_numpy() を用いて, Pandas データフレームを numpy.ndarray へ変換している.
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] display(df.iloc[:,0:4].to_numpy())
Pandas での繰り返し処理,選択
Pandas のある特定の列(カラム)のデータについて,処理を繰り返したいときの書き方.iris は Iris データセットである.
import pandas as pd from sklearn.datasets import load_iris from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] display([x * 10 for x in df['sepal length (cm)']])
Pandas のある特定の列(カラム)のデータについて,処理を繰り返すとき,ある条件(例えば 7 より大)のものだけ処理対象にしたいときの書き方
[x * 10 for x in iris['sepal_length'] if x > 7]PANet (Path Aggregation Network)
物体検出とインスタンス・セグメンテーション (instance segmentation)のためのネットワーク. Mask R-CNN をもとに改善を行っている. PANet のネットワークは,FPN バックボーンののち, Bottom-up Path Augmentation を行い, Adaptive Feature Pooling を行っている.
COCO データセット, Cityscapes データセット, MVD データセットでの実験から,物体検出とインスタンス・セグメンテーション (instance segmentation)の精度が向上したとされている.
CSPNet の公式の実装 (GitHub) のページでは, PANetを用いた物体検出として, CSPDarknet53-PANet-SPP, CSPResNet50-PANet-SPP, CSPResNeXt50-PANet-SPP 等の実装が公開されている.
- 文献
Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, Jiaya Jia, Path Aggregation Network for Instance Segmentation, CVPR 2018, also CoRR, https://arxiv.org/abs/1803.01534v4,
- PANet の公式の実装 (GitHub) のページ: https://github.com/ShuLiu1993/PANet
- YOLOv5 の GitHub のページ: https://github.com/ultralytics/yolov5
【関連項目】 Mask R-CNN 物体検出, インスタンス・セグメンテーション (instance segmentation), YOLOv5
PARE
PARE は,3次元人体姿勢推定(3D human pose estimation)の技術である. オクルージョンの問題を解決するために, Part Attention REgressor (PARE) が提案されている. multi person tracker を用いて実装されており,画像の中に複数の人物がいても動くようになっている.
PARE のデモプログラムの実行結果を次に示す.


この実行結果を得るためのもととなる動画: kaneko_sample_video.mp4
実行結果の動画: kaneko_sample_video__result.mp4
- 文献
Kocabas, Muhammed and Huang, Chun-Hao P. and Hilliges, Otmar and Black, Michael J., PARE: Part Attention Regressor for {3D} Human Body Estimation, Proc. International Conference on Computer Vision (ICCV), also CoRR, abs/2104.08527v2, 2021.
- 公式のページ: https://pare.is.tue.mpg.de/
- 公式の GitHub のページ: https://github.com/mkocabas/PARE
- Papers with Code のページ: https://paperswithcode.com/paper/pare-part-attention-regressor-for-3d-human
【関連項目】 3D pose estimation, 3D human pose estimation, YOLOv3, multi person tracker
Google Colaboratory での PARE のインストールと事前学習済みモデルのダウンロードとデモの実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- 次を実行する.
!rm -rf PARE !git clone https://github.com/mkocabas/PARE.git %cd PARE !apt -y install libturbojpeg !pip3 uninstall -y torchtext panel datascience !pip3 install -U -r requirements.txt !source scripts/prepare_data.sh !python3 scripts/demo.py --vid_file data/sample_video.mp4 --output_folder logs/demo - 下図のように,/content/logs/demo/sample_video_ の下に結果ができる
Ubuntu での PARE のインストールとデモの実行
前準備:事前に Python のインストール: 別項目で説明している.
- Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo rm -rf PARE sudo git clone https://github.com/mkocabas/PARE.git sudo chown -R $USER PARE # システム Python の環境とは別の Python の仮想環境(システム Python を使用)を作成 sudo apt -y update sudo apt -y install python3-venv python3 -m venv ~/a source ~/a/bin/activate cd /usr/local/PARE sudo apt -y install libturbojpeg sed -i 's/opencv-python==4.1.1.26/opencv-python/g' requirements.txt pip install -U -r requirements.txt pip install -U numba - 事前学習済みモデルのダウンロード
source scripts/prepare_data.sh - デモの実行
python scripts/demo.py --vid_file data/sample_video.mp4 --output_folder logs/demo - 下のように,logs/demo/sample_video_ の下に結果ができる

出来た動画を表示すると,次のように表示される.

Pascal VOC (Pascal Visual Object Classes Challenge) データセット
Pascal VOC データセットは,アノテーション済みの画像データ. 機械学習での物体検出 ,画像分類,セマンテック・セグメンテーションに利用できるデータセットである. Pascal VOC 2007, Pascal VOC 2012 などいくつかの種類がある.
Pascal VOC 2012 データセット
- ピクセルレベルのセグメンテーションのアノテーション,バウンディングボックスのアノテーション,オブジェクトクラスのアノテーションが付いている.
- 学習用の1,464枚の画像,検証用の1,449枚の画像,その他のテストセットを含む
- オブジェクトのカテゴリ数: 20, その他,背景を表すカテゴリが 1.
vehicles, household, animals, and other: aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, TV/monitor, bird, cat, cow, dog, horse, sheep, person
Pascal VOC データセットは次の URL で公開されているデータセット(オープンデータ)である.
http://host.robots.ox.ac.uk/pascal/VOC/
【関連情報】
- 文献
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A., The Pascal Visual Object Classes (VOC) Challenge, International Journal of Computer Vision, 88(2), 303-338, 2010
- 文献
Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A., The Pascal Visual Object Classes Challenge: A Retrospective, International Journal of Computer Vision, 111(1), 98-136, 2015.
- Pascal VOC の公式ページ: http://host.robots.ox.ac.uk/pascal/VOC/index.html
- Papers With Code の Pascal VOC データセットのページ: https://paperswithcode.com/dataset/pascal-voc
- PyTorch の Pascal VOC データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.VOCSegmentation
【関連項目】 Detectron2, MMSegmentation, セマンティック・セグメンテーション (semantic segmentation), 画像分類, 物体検出
Windows での processed Pascal VOC 2007, 2012 データセットの展開
processed Pascal VOC 2007, 2012 データセットは,VOS の成果物.
VOS の GitHub のページ: https://github.com/deeplearning-wisc/vos
Windows での展開手順は次の通り.
- 次の URL から,processed Pascal VOC 2007, 2021 データセットをダウンロード.
https://drive.google.com/file/d/1n9C4CiBURMSCZy2LStBQTzR17rD_a67e/view
- VOC.zip がダウンロードされる.
- 次のコマンドを実行
copy VOC.zip %LOCALAPPDATA% cd %LOCALAPPDATA% powershell -command "Expand-Archive -DestinationPath . -Path VOC.zip" - ファイルの配置は次のようになる.
└── VOC_0712_converted | ├── JPEGImages ├── voc0712_train_all.json └── val_coco_format.json
Photo Tourism データセット
Photo Tourism データセットは次の URL で公開されているデータセット(オープンデータ)である.
http://phototour.cs.washington.edu/datasets/
【関連情報】
- 文献
Noah Snavely, Steven M. Seitz, Richard Szeliski, "Photo tourism: Exploring photo collections in 3D," ACM Transactions on Graphics (SIGGRAPH Proceedings), 25(3), 2006, 835-846.
- 公式ページ: http://phototour.cs.washington.edu/patches/default.htm
- PyTorch の PhotoTour データセットの説明: https://pytorch.org/vision/stable/datasets.html#phototour
Places365 データセット
Places365 データセットは,シーンクラスに分類済みの画像データ. 機械学習での画像分類の学習や検証に利用できるデータセット.
- 1000万枚の画像
- 434 のシーンクラス
- 2つのバージョン Places365-Standard と Places365-Challenge-2016 がある. Places365-Standardは,K=365個のシーンクラスからなる180万枚の学習画像と36000枚の検証画像. Places365-Challenge-2016は,新しい69個のシーンクラスを含む620万枚の学習画像が追加されている. (434個のシーンクラスからなる合計800万枚の学習画像).
Places365 データセットは次の URL で公開されているデータセット(オープンデータ)である.
【関連情報】
- B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, Places: A 10 million Image Database for Scene Recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017
- Papers With Code の Places365 データセットのページ: https://paperswithcode.com/dataset/places365
- PyTorch の Places365 データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.Places365
- TensorFlow データセットの Places365 データセット: https://www.tensorflow.org/datasets/catalog/places365_small
PointCloudLibrary の3次元点群データ
https://github.com/PointCloudLibrary/data では, 3次元点群データ (3-D point cloud data) が公開されている(オープンデータである).
Windows では,次のような手順でダウンロードできる.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- ダウンロード
mkdir /p c:\data cd c:\data mkdir PointCloudLibrary cd PointCloudLibrary git clone --recursive https://github.com/PointCloudLibrary/data echo git clone --recursive https://github.com/PointCloudLibrary/data > download.txt
Ubuntu では,次のようなコマンドでダウンロードできる.
cd /usr/local sudo mkdir PointCloudLibrary cd PointCloudLibrary sudo git clone --recursive https://github.com/PointCloudLibrary/data echo "git clone --recursive https://github.com/PointCloudLibrary/data" > download.sh3次元点群データ (3-D point cloud data) を扱うには,MeshLab や CloudCompare が便利である.
PoseC3D
スケルトンベースの動作認識 (skelton-based action recognition) の一手法.2021年発表
- 文献
Haodong Duan and Yue Zhao and Kai Chen and Dian Shao and Dahua Lin and Bo Dai, Revisiting Skeleton-based Action Recognition, arXiv, 2104.13586, 2021.
- MMAction2 の PoseC3D の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/skeleton/posec3d/README.md
【関連項目】 MMAction2, スケルトンベースの動作認識 (skelton-based action recognition), 動作認識 (action recognition)
PostgreSQL
【サイト内の主な PostgreSQL 関連ページ】
- Windows での,PostgreSQL 14.5,pgAdmin 4,PostGIS 3 のインストール,psql によるテーブル定義とレコード挿入: 別ページ »で説明
- Ubuntu での,PostgreSQL 14, pgAdmin 4, PostGIS 3 のインストール: 別ページ »で説明
- PostgreSQL の活用: 別ページ »にまとめている.
【関連する外部ページ】
- PostgreSQL 公式ページ: http://www.postgresql.org/
- カーネル設定: http://www.postgresql.jp/document/14/html/kernel-resources.html
- インストール: http://www.postgresql.jp/document/14/html/installation.html
PyCharm
PyCharm は Python プログラム作成に関する種々の機能を持ったソフトウェア.
PyCharm について:別ページ で説明している.
pycocotools
pycocotools は,COCO データセットを Python から扱う機能を持ったソフトウェア.
pycocotools の GitHub のページ: https://github.com/cocodataset/cocoapi/tree/master/PythonAPI/pycocotools
関連項目: COCO (Common Object in Context) データセット
pycocotools のレポジトリ
オリジナルの pycocotools から分岐 (fork) したレポジトリがある. Python 3 や Windows に対応.オリジナルの方は開発が休止しているようである.
pycocotools のインストール(Windows 上)
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- Python のインストール: 別項目で説明している.
- Windows では,コマンドプロンプトを管理者として実行
- pycocotools のインストール
python -m pip install -U cython python -m pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"
Ubuntu での pycocotools のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
sudo pip3 install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI関連項目: COCO (Common Object in Context) データセット
PyCUDA
PyCUDA は NVIDIA CUDA APIにアクセスできるようにするライブラリ
主な機能:
pip を用いたインストールコマンド: python -m pip install -U pycuda
【関連する外部ページ】
【サイト内の関連ページ】
- PyCUDA のインストール,PyCUDA のプログラム例(Windows 上): 別ページ »で説明
【関連項目】 NVIDIA CUDA
PyMVPA
PyMVPAは,大規模データセットに対する統計的学習解析の 機能を持つ Pythonのパッケージ
PyMVPA の URL: http://www.pymvpa.org/index.html
PyScripter
PyCharm は Python プログラム作成に関する種々の機能を持ったソフトウェア.
PyScripter について:別ページ で説明している.
Python
Pythonは,現在,人気の高いプログラミング言語の1つであり,読みやすく書きやすい文法と幅広い応用範囲を持つとされている.現在,様々な分野で使用され,豊富なライブラリがある.
インストールは次の手順で行うことができる.
- Pythonの公式サイト(https://www.python.org)にアクセスし,「Downloads」,「Windows」を選択する.
- 「Stable Releases」からインストールしたいバージョンを選ぶ(例:Python 3.10.10).
- 「Windows Installer (64-bit)」をダウンロードする.
- Windows上でPythonをインストールする際は,ユーザー名に日本語が含まれていると問題が生じる可能性がある.これは,既定(デフォルト)のインストール設定では,Pythonの関連ファイルのパスにユーザ名が含まれることが原因である.トラブルを避けるために,次の手順でインストールする.
- まず,ダウンロードしたインストーラを管理者権限で実行する.
- インストーラの最初の画面で,「Install launcher for all users (recommended)」と「Add Python.exe to PATH」をチェックし,「Customize installation」をクリックする.
- 次の画面でオプションの機能は既定のままで「Next」をクリックする.
- さらに次の画面で「Install Python 3.xx for all users」を選択し,インストールディレクトリを確認後,「Install」をクリックする.
- インストール中に「Disable path length limit」が表示された場合はクリックしてパス長の制限を解除します.
- インストール完了後,スタートメニューに「Python 3.10」が追加されていることを確認する.
【サイト内の関連ページ】
【関連する外部ページ】 Python の公式ページ: https://www.python.org/
【関連項目】 Anaconda3 のインストール(winget を使用)(Windows 上)
Python 3.6
Python 3.6 は scipy 1.1.0 が動く最新バージョン.
Python の公式ページ">https://www.python.org/
Python 3.7
Python 3.7 は TensorFlow 1.15,TensorFlow 1.14 が動く最新バージョン.
Python の公式ページ">https://www.python.org/
Python 3.8
Python の公式ページ">https://www.python.org/
Python の numpy ベクトル
ベクトルは,要素の並び.各要素の添字は 0, 1, 2... のようになる. 下に,Python の numpy ベクトルのコンストラクタの例を示す.
import numpy as np v = np.array([1, 2, 3]) print(v, v[0], v[1], v[2])
reshape の例は次の通り
X = X.reshape(len(X), 1)Python のインストール,pip と setuptools の更新
Python の公式ページ: https://www.python.org/
Windows でのPython のインストール,pip と setuptools の更新
Windows での Python 3.10 のインストール,pip と setuptools の更新: 別ページ »で説明
Ubuntu での Python のインストール,pip と setuptools の更新
Ubuntu のシステム Python,Ubuntu での Python のインストール,pip と setuptools の更新: 別ページ »で説明
Python の隔離された環境
Python の隔離された環境: 別ページ »で説明
Python 開発環境のインストール,起動
Windows での Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, spyder の起動
Python, pip, Python 開発環境,Python コンソールのコマンドでの起動: 別ページ »で説明
Ubuntu での Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, spyder の起動
Python, pip, Python 開発環境,Python コンソールのコマンドでの起動: 別ページ »で説明
Windows での Python 開発環境 のインストール
Windows での Python 開発環境として,Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, spyder のインストール: 別ページ »で説明
Ubuntu での Python 開発環境のインストール
Ubuntu での Python 開発環境として,Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, spyder のインストール: 別ページ »で説明
PyTorch
PyTorchは,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
【関連する外部ページ】
- PyTorch の Web ページ: http://pytorch.org/
- github: https://github.com/pytorch/pytorch
- github: https://github.com/hughperkins/pytorch
- PyTorch のデータセット, モデル: https://github.com/pytorch/vision/
【関連項目】 Python のインストール,pip と setuptools の更新, Python 開発環境
PyTorch Stable
PyTorch の Stable が対応している Python のバージョン:
https://pytorch.org/ の表示や, https://download.pytorch.org/whl/lts/1.8/torch_lts.html, https://download.pytorch.org/whl/cu117/torch_stable.html で確認できる.
2022年12月時点では次の通りである.
- PyTorch Stable (2022年12月時点では 1.13.1) の場合: Python は 3.10, 3.9, 3.8, 3.7 のいずれかを使う.
PyTorch 2.3 (NVIDIA CUDA ツールキット11.8 用)のインストール(Windows 上)
次のコマンドを実行することにより, PyTorch 2.3 (NVIDIA CUDA ツールキット 11.8 用)がインストールされる.
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - PyTorch の公式ページを確認
- 次のようなコマンドを実行(実行するコマンドは,PyTorch のページの表示されるコマンドを使う).
次のコマンドを実行することにより, PyTorch 2.3 (NVIDIA CUDA 11.8 用)がインストールされる. 但し,Anaconda3を使いたい場合には別手順になる.
事前に NVIDIA CUDA のバージョンを確認しておくこと(ここでは,NVIDIA CUDA ツールキット 11.8 が前もってインストール済みであるとする).
PyTorch で,GPU が動作している場合には,「torch.cuda.is_available()」により,True が表示される.
python -m pip install -U --ignore-installed pip python -m pip uninstall -y torch torchvision torchaudio torchtext xformers python -m pip install -U torch torchvision torchaudio numpy --index-url https://download.pytorch.org/whl/cu118 python -c "import torch; print(torch.__version__, torch.cuda.is_available())"
- Python プログラム実行により動作確認
動作確認のため,次のPythonプログラムを実行
このプログラムはPyTorchを使用して,GPUが利用可能な場合はGPUで,そうでない場合はCPUで計算を行う.-πからπまでの2000点の等間隔な点列を生成し,そこにランダムな傾きと切片を持つ一次関数を適用して結果を出力する.
import torch import math dtype = torch.float device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype) a = torch.randn((), device=device, dtype=dtype) b = torch.randn((), device=device, dtype=dtype) print(a + b * x)
【関連する外部ページ】
【サイト内の関連ページ】
- GPU対応PyTorch 2.3のセットアップと性能確認(Windows 上): 別ページ »で説明
- PyTorch の最新版を検証,開発者に貢献したいなどの場合には,ソースコードからビルドして,インストールする: 別ページ »で説明
【関連項目】 NVIDIA CUDA ツールキット, PyTorch
PyTorch のインストール(Ubuntu 上)
PyTorch のインストールは, 公式 (https://pytorch.org/) の手順で行う.
NVIDIA CUDA ツールキット を使うときは, NVIDIA ドライバは別途インストールすることと,CUDA のバージョン選択では「CUDA 同封の PyTorch を選択する」ことを心に留める.次の手順になる.
- NVIDIA ドライバのインストール: 別ページ »で説明
- PyTorch のインストール: 別ページ »で説明
PyTorch のバージョン確認
次の Python プログラムを実行
import torch print( torch.__version__ )"PyTorch で GPU が使用できるかの確認
次の Python プログラムを実行
python -c "import torch;print(torch.cuda.is_available())"PyTorch のサンプルプログラム
このプログラムはPyTorchを使用して,GPUが利用可能な場合はGPUで,そうでない場合はCPUで計算を行う.-πからπまでの2000点の等間隔な点列を生成し,そこにランダムな傾きと切片を持つ一次関数を適用して結果を出力する.
import torch import math dtype = torch.float device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype) a = torch.randn((), device=device, dtype=dtype) b = torch.randn((), device=device, dtype=dtype) print(a + b * x)PyTorch のモデルの保存
GPU マシン (cuda の動くマシン)で PyTorch を動かす可能性を想定している. GPU マシン (cuda の動くマシン)でも,そうでなくても,正しく動くようにしている.
- モデル m を CPU で動く形式で保存.ファイル名は「a.pth」とする
torch.save(m.to('cpu').state_dict(), 'a.pth') - モデルのロード.ファイル名「a.pth」からロードする.
ロード時に,デバイスは cuda あるいは cpu に自動設定する.
m.load_state_dict(torch.load('a.pth')) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = m.to(device)
torchsummary を用いたモデルの確認表示
前準備: torchsummary をインストールする. Windows ではコマンドプロンプトを管理者として開き次のコマンドを実行する.
python -m pip install torchsummaryResNet50 モデルのロードと確認表示
import torch import torchvision.models as models from torchsummary import summary device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.resnet50(pretrained=True).to(device).to(device) summary(m, (3, 224, 224))PyTorch3D
公式ページ(GitHub): https://github.com/facebookresearch/pytorch3d
Google Colaboratory で PyTorch3D のインストール
次のコマンドは Google Colaboratory で動く(コードセルを作り,実行する).
- PyTorch3D のインストール
!pip3 install pytorch3d
PyTorch-GAN のページ
Avatar Erik Linder-Norén により GitHub で公開されているPyTorch-GAN のページ.
URL は次の通り.
PyTorch-GAN のページ: https://github.com/eriklindernoren/PyTorch-GAN
PyTorch Geometric Temporal
【文献】
Benedek Rozemberczki and Paul Scherer and Yixuan He and George Panagopoulos and Alexander Riedel and Maria Astefanoaei and Oliver Kiss and Ferenc Beres and Guzman Lopez and Nicolas Collignon and Rik Sarkar, PyTorch Geometric Temporal: Spatiotemporal Signal Processing with Neural Machine Learning Models, Proceedings of the 30th ACM International Conference on Information and Knowledge Management, pp. 4564-4573, 2021.
【サイト内の関連ページ】
PyTorch Geometric Temporal のインストールと動作確認(予測)(Python,PyTorch を使用)(Windows 上)別ページ »で説明
【関連する外部ページ】
- GitHub のページ
https://github.com/benedekrozemberczki/pytorch_geometric_temporal
- 公式のドキュメント
https://pytorch-geometric-temporal.readthedocs.io/en/latest/
- 公式のサンプルプログラム
- 公式の Python ノートブックによるデモ
https://github.com/benedekrozemberczki/pytorch_geometric_temporal/tree/master/notebooks
【関連項目】 GNN (グラフニューラルネットワーク)
PyTorch, torchvision のモデル
URL: https://pytorch.org/vision/stable/models.html に説明がある.
【関連項目】 PyTorch, torchvision の DenseNet121 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の DenseNet169 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の MobileNetV3 large 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の ResNet50 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の ResNet101 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の ResNet152 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の ResNeXt51 32x4d 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の ResNeXt101 32x8d 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の Wide ResNet50 学習済みモデルのロード,画像分類のテスト実行, PyTorch, torchvision の Wide ResNet101 学習済みモデルのロード,画像分類のテスト実行, rwightman の PyTorch Image Models (TIMM)
RabbitToolBox
URL: https://github.com/ray-cast/RabbitToolbox
【関連用語】 MMD
Window で RabbitToolbox のインストール(書きかけ)
- Windows では,前準備として次を行う.
- Build Tools for Visual Studio 2022 のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- ソースコードからビルドして,インストールする.
cd /d c:%HOMEPATH% rmdir /s /q RabbitToolbox git clone --recursive https://github.com/ray-cast/RabbitToolbox cd RabbitToolbox mkdir build cd build del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCMAKE_TOOLCHAIN_FILE=C:/vcpkg/scripts/buildsystems/vcpkg.cmake -DVCPKG_TARGET_TRIPLET=x64-windows .. cmake --build . --config Release --target INSTALL -- /m:4
Ubuntu で RabbitToolbox のインストール(書きかけ)
ソースコードからビルドして,インストールする.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cmake cmake-curses-gui cmake-gui sudo apt -y install clang libopencl-clang-dev libclc-dev cd /usr/local sudo rm -rf RabbitToolbox sudo git clone --recursive https://github.com/ray-cast/RabbitToolbox sudo chown -R $USER RabbitToolbox cd RabbitToolbox rm -rf build mkdir build cd build cmake -G "Unix Makefiles" \ -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ \ -DCMAKE_C_FLAGS="-L/usr/lib/x86_64-linux-gnu" \ -DUSE_OPENCL=OFF \ .. cmake --build . --config Release --target INSTALL -- /m:4Recognize Anything Model
画像タグ付けの学習は画像とテキストのペアを訓練データとして使用する. Recognize Anything Model(RAM)は,画像タグ付けのためのモデルで,手動でのアノテーションではなく,テキストのセマンティック解析を自動化することでラベルを取得することを特徴とする. Recognize Anything Model(RAM)のラベルシステムは,6,449の一般的なラベルを含んでいる. また,データエンジンは,欠落しているラベルを追加し,誤ったラベルをクリーニングするために使用される. データエンジンは既存のモデルを用いて追加のタグを生成し,画像内の特定のカテゴリに対応する領域を特定します.その後,同じカテゴリ内の領域を処理し,異常値を排除します. さらに,Recognize Anything Model(RAM)は画像タグ付けとキャプションのタスクを統合し,その結果,ゼロショット画像タグ付けを可能にしている.これにより,未見のカテゴリについての処理が可能になる.また,学習のコストを抑制するために,Recognize Anything Model(RAM)はオープンソースでアノテーションフリーのデータセットを使用する.これらの特性により,Recognize Anything Model(RAM)はゼロショットの画像タグ付けだけでなく,学習済みモデルを用いた画像タグ付けでも高い性能を示すとされる.これは,OpenImages V6,COCO,ADE20kなどの一連のベンチマークデータセットでの評価により裏付けられている.
【文献】 Recognize Anything: A Strong Image Tagging Model 6 Jun 2023 · Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, Yandong Guo, Lei Zhang ·
https://arxiv.org/pdf/2306.03514v3.pdf
【サイト内の関連ページ】 Recognize Anything のインストールと動作確認(ゼロショットの画像タグ付け)(Python,PyTorch を使用)(Windows 上)
【関連する外部ページ】
- GitHub の公式ページ: https://github.com/xinyu1205/recognize-anything
- Paper with Code のページ: https://paperswithcode.com/paper/recognize-anything-a-strong-image-tagging
Raspberry Pi
Raspberry Pi は小型コンピュータ,Raspbian (Debian ベース) や Ubuntu が動く.
Rapberry Pi のパスワードリセット
Rapberry Pi のシステムは,SD カードに入っている. SD カードの所定のファイルを編集することで,パスワードを リセットできる. (このことからも,Raspberry Pi で大事なファイルを保持することは考えにくい
- 電源をオフ
- SD カードを取り出し,別のパソコンに入れる
- パソコンで,テキストファイル cmdline.txt を編集し, cmdline.txt の最後に「init=/bin/sh」を追加する.
- パソコンからSD カードを取り出し,Raspberry Pi に戻す
- Raspberry Pi を起動し,次のコマンドを実行
su mount -rw -o remount / passwd pi sync sync sync sync sync
Real-ESRGAN
超解像 (super resolution) の一手法.2021 年発表.
【文献】
Xintao Wang and Liangbin Xie and Chao Dong and Ying Shan, Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data, International Conference on Computer Vision Workshops (ICCVW), https://arxiv.org/abs/2107.10833, 2021.
【関連する外部ページ】
- Real-ESRGAN の GitHub のページ: https://github.com/xinntao/Real-ESRGAN
- Real-ESRGAN のデモページ: https://colab.research.google.com/drive/1k2Zod6kSHEvraybHl50Lys0LerhyTMCo?usp=sharing#scrollTo=7IMD5vhOYp68
処理前の画像

処理結果

【関連項目】 APA, GAN (Generative Adversarial Network), image super resolution, video restoration, video super resolution, 超解像 (super resolution),
Windows で,Real-ESRGAN のインストールと,超解像の実行
Real-ESRGAN のインストールと動作確認(超解像)(Python,PyTorch を使用)(Windows 上): 別ページ »で説明
Redis
Redis は,インメモリ・データストアである.文字列,リスト,集合,ハッシュなどを扱う機能を持つ.
【サイト内の関連ページ】
- キーバリューデータベースシステム Redis のインストールと基本操作,Python からの使用(Windows 上)
- キーバリューデータベースシステム Redis 7.0.4 のインストールと基本操作,Python からの使用(ソースコードを使用)(Ubuntu 上)
- Redis の利用
【関連する外部ページ】
Redis の公式ページ: https://redis.io/
Redis の GitHub のページ: https://github.com/redis/redis/tags
ReLU
ReLU (rectified linear unit) は,次の関数である.
f(x) = 0 for x < 0, f(x) = x for x >= 0
ReLUは,活性化関数としてよく使用されるもののうちの1つである. 活性化関数は,ニューロンの入力の合計から,そのニューロンの活性度の値を決めるためのもの. (他には,LReLU,シグモイド関数,ステップ関数,ソフトマックス関数などがある.
Residual Networks (ResNets)
residual function (残余関数)を特徴とするニューラルネットワーク
画像分類のための利用, 物体検出や セマンティック・セグメンテーションなどでのバックボーンでの利用などが行われている.
Residual Networks は DeepLabv3, Inception-v4, Inception-ResNet, ResNet50, ResNet101, ResNet152, その他の ResNet, ResNeXt, RetinaNet, SpineNet など,種々のモデルで使用されている.
- mask head アーキテクチャの論文
Vighnesh Birodkar, Zhichao Lu, Siyang Li, Vivek Rathod, Jonathan Huang, The surprising impact of mask-head architecture on novel class segmentation, 2021.
- SpineNet の論文
Xianzhi Du, Tsung-Yi Lin, Pengchong Jin, Golnaz Ghiasi, Mingxing Tan, Yin Cui, Quoc V. Le, Xiaodan Song, SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization, CVPR 2020, 2020.
- semi-supervised learning に関する論文
Meta Pseudo Labels, Hieu Pham, Zihang Dai, Qizhe Xie, Minh-Thang Luong, Quoc V. Le, CVPR 2021, 2021. https://arxiv.org/pdf/2003.10580v4.pdf
- DeepLabv3 に関する論文
Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam, Rethinking Atrous Convolution for Semantic Image Segmentation, 2017.
- RetinaNet に関する論文
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár, Focal Loss for Dense Object Detection, ICCV 2017, 2017.
- Inception-v4, Inception-ResNet に関する論文
Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi, Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 2016.
- ResNet18, ResNet34, ResNet50, ResNet101, ResNet152 に関する論文
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, CVPR 2016, 2016. https://arxiv.org/pdf/1512.03385v1.pdf
- Papers with Code のページ: https://paperswithcode.com/method/resnet
【関連項目】 DeepLabv3, ResNet50, ResNet101, ResNet152, その他の ResNet, ResNeXt, RetinaNet, セマンティック・セグメンテーション (semantic segmentation), 画像分類 物体検出,
ResNet50, ResNet101, ResNet152, その他の ResNet
Keras の ResNet50 を用いて ResNet50 のモデルを作成するプログラムは次のようになる. 「weights=one」を指定することにより,最初,重みをランダムに設定する.
【Keras のプログラム】m = tf.keras.applications.resnet50.ResNet50(input_shape=INPUT_SHAPE, weights=None, classes=NUM_CLASSES)CoRR, abs/1512.03385
Keras の応用のページ: https://keras.io/ja/applications/
【関連項目】 Residual Networks (ResNets), モデル, 画像分類
PyTorch, torchvision の ResNet50 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのResNet50 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.resnet50(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
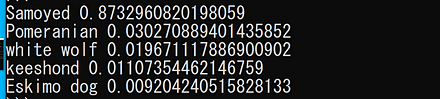
Linux での結果
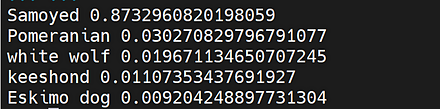
PyTorch, torchvision の ResNet101 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのResNet101 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.resnet101(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
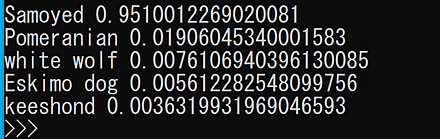
Linux での結果
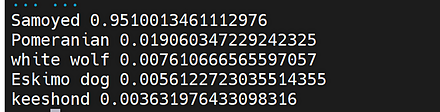
PyTorch, torchvision の ResNet152 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのResNet152 モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.resnet152(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
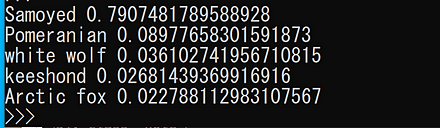
Linux での結果
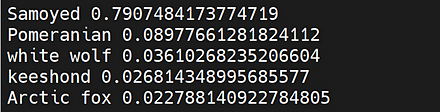
ResNeXt
ResNeXt は,ResNet の redidual unit で grouped conv3x3 を使うとともに,conv2x1 の次元削減率を抑制することにより,速度を低下させず,精度を向上させるものである.
物体検出や セマンティック・セグメンテーションなどでのバックボーンでの利用も行われている.
- 文献
Saining Xie, Ross B. Girshick, Piotr Doll{\'{a}}r, Zhuowen Tu, Kaiming He, Aggregated Residual Transformations for Deep Neural Networks, CoRR, abs/1611.05431, 2016.
- Papers with Code のページ: https://paperswithcode.com/model/resnext
- PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnext/
【関連項目】 PyTorch, torchvision のモデル, Residual Networks (ResNets), SE ResNeXt, モデル, 画像分類
PyTorch, torchvision の ResNeXt50 32x4d 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnext/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのResNeXt50 32x4d モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torchvision.models as models m = models.resnext50_32x4d(pretrained=True).to(device)
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果
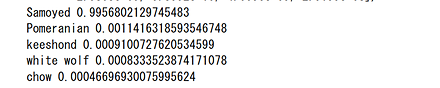
Windows での結果
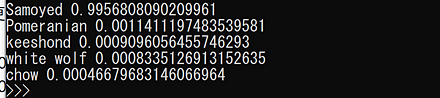
Linux での結果
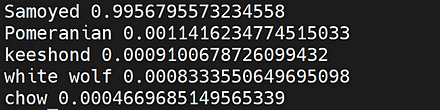
PyTorch, torchvision の ResNeXt101 32x8d 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_resnext/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのResNeXt101 32x8d モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.resnext101_32x8d(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
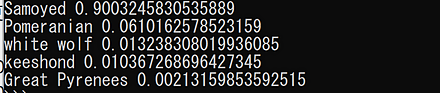
Linux での結果
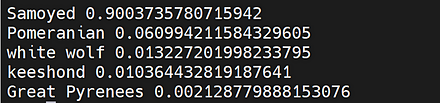
RetinaNet
focal loss 関数を特徴とする物体検出のモデルである.
- 文献
Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Doll\'ar, Piotr, Focal loss for dense object detection, Proceedings of the IEEE international conference on computer vision, also CoRR, abs/1708.02002v2 2017.
- 公式のソースコード (GitHub): https://github.com/facebookresearch/detectron
- Papers with Code のページ: https://paperswithcode.com/method/retinanet
- TensorFlow のモデル: https://github.com/tensorflow/models
- Detectron2: https://github.com/facebookresearch/detectron2, Detectron2 のチュートリアル: https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5
- OpenMMLab の mmdetection: https://github.com/open-mmlab/mmdetection
【関連項目】 AlexeyAB darknet, Detectron, Detectron2, OpenMMLab, MMDetection, Residual Networks (ResNets), SpineNet, TensorFlow, YOLOv3, モデル, 物体検出
Reuters newswire topics データセット
Reuters newswire topics データセットは,公開されているデータセット(オープンデータ)である.
Reuters newswire topics データセットは,次のプログラムでロードできる.
from tensorflow.keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data()【関連項目】 Keras に付属のデータセット,
RIB
RIB ファイルは,RenderMan で使用されているシーン記述ファイルである.
より詳しい説明は: 別ページ »で説明
RNN (recurrent neural network)
ある層でのニューロンでの結果を,1つ前の層が受け取ったり, その層が受け取ったりするようにニューラルネットワークを作る場合もある. そのようなニューラルネットワークを「リカレントニューラルネットワーク」という. リカレントニューラルネットワークは,フィードフォワードではない. リカレントニューラルネットワークでは,前回の実行時での結果の一部が,次の実行に反映される.
【関連項目】 GRU (Gated Recurrent Neural Networks), LSTM (Long Short-Term Memory), フィードフォワード
rwightman の PyTorch Image Models (TIMM)
rwightman の PyTorch Image Models (TIMM) は, 画像分類の機能を持つライブラリ. 300以上の事前学習済みの画像分類モデルを簡単に利用することができる. ImageNet などのデータセットを用いた学習を簡単に行えるためのスクリプトも提供される. 事前学習済みの画像分類モデルを,自分自身のデータを用いてファインチューニング (fine tuning)を行うことを簡単に行える スクリプトも提供される.学習,検証,推論を行うスクリプトは, https://github.com/rwightman/pytorch-image-models で説明が行われている.
- 公式の GitHub のページ: https://github.com/rwightman/pytorch-image-models
- rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm
- Paper with Code の URL: https://paperswithcode.com/lib/timm
【関連項目】 PyTorch, torchvision のモデル, モデル, 画像分類 (image classification)
Google Colaboratory での rwightman の PyTorch Image Models (TIMM) のインストール
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- rwightman の PyTorch Image Models (TIMM) のインストール
!rm -rf pytorch-image-models !git clone https://github.com/rwightman/pytorch-image-models.git %cd pytorch-image-models !python3 setup.py install - 確認のため,rwightman の PyTorch Image Models (TIMM) のモデルの一覧を表示
from IPython.display import display import timm model_names = timm.list_models(pretrained=True) display(model_names) - 確認のため,MobileNetV3の検証を行うプログラムを実行
m = timm.create_model('mobilenetv3_large_100', pretrained=True) m.eval() - 画像ファイルを置くためのディレクトリを作り,そこに画像ファイルを置く
画像ファイルは複数でも良い.下の図では,img を作り,そこに画像ファイルを1つ置いている.

- 推論を実行
画像分類の結果が表示される.
事前学習済みの MobileNetV3 を使用している.
!rm -f topk_ids.csv !python3 inference.py ./img --model mobilenetv3_large_100 --pretrained !cat topk_ids.csv
- 推論を実行
画像分類の結果が表示される.
事前学習済みの SE ResNeXt を使用している.
!rm -f topk_ids.csv !python3 inference.py ./img --model seresnext26t_32x4d --pretrained !cat topk_ids.csv
Windows での rwightman の PyTorch Image Models (TIMM) のインストール
- Windows では,前準備として次を行う.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/,
- NVIDIA CUDA ツールキット 12.6 のインストール(Windows 上)
- Python のインストール: 別項目で説明している.
- Git のインストール: 別項目で説明している.
- Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。 - PyTorch のインストール
PyTorch のページで確認ののち,次のようなコマンドを実行(実行するコマンドは,PyTorch のページの表示されるコマンドをそのまま使う).
PyTorch の公式ページ: https://pytorch.org/index.html
次のコマンドを実行することにより, PyTorch 2.3 (NVIDIA CUDA 11.8 用)がインストールされる. 但し,Anaconda3を使いたい場合には別手順になる.
事前に NVIDIA CUDA のバージョンを確認しておくこと(ここでは,NVIDIA CUDA ツールキット 11.8 が前もってインストール済みであるとする).
PyTorch で,GPU が動作している場合には,「torch.cuda.is_available()」により,True が表示される.
python -m pip install -U --ignore-installed pip python -m pip uninstall -y torch torchvision torchaudio torchtext xformers python -m pip install -U torch torchvision torchaudio numpy --index-url https://download.pytorch.org/whl/cu118 python -c "import torch; print(torch.__version__, torch.cuda.is_available())"
- rwightman の PyTorch Image Models (TIMM) のインストール
git clone https://github.com/rwightman/pytorch-image-models.git cd pytorch-image-models python setup.py install - 確認のため,rwightman の PyTorch Image Models (TIMM) のモデルの一覧を表示
python import timm model_names = timm.list_models(pretrained=True) print(model_names) exit()
- 確認のため,MobileNetV3の検証を行うプログラムを実行
python import timm m = timm.create_model('mobilenetv3_large_100', pretrained=True) m.eval() exit()
- 画像ファイルを置くためのディレクトリを作り,そこに画像ファイルを置く
画像ファイルは複数でも良い.下の図では,img を作り,そこに画像ファイルを1つ置いている.
- 推論を実行
画像分類の結果が表示される.
事前学習済みの MobileNetV3 を使用している.
del /s topk_ids.csv python inference.py ./img --model mobilenetv3_large_100 --pretrained type topk_ids.csv
- 推論を実行
画像分類の結果が表示される.
事前学習済みの SE ResNeXt を使用している.
del /s topk_ids.csv python inference.py ./img --model seresnext26t_32x4d --pretrained type topk_ids.csv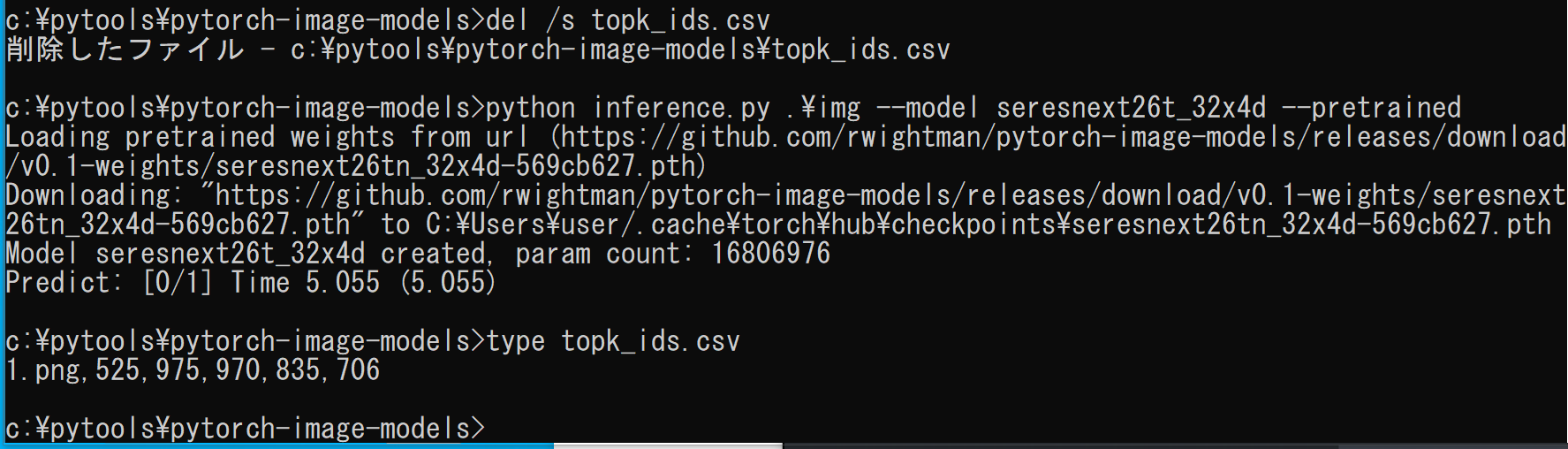
R システム
R システムは,統計計算とグラフィックスのソフトウェアで,多数の機能を持つ. R システムの詳細は,そのホームページ https://www.r-project.org/ に記載されている.
【関連する外部ページ】 R システムの CRAN の URL: https://cran.r-project.org/ 【サイト内の主な R 関連ページ】
- R システムの機能
- Windows での R システムのインストール: 別ページ »で説明
- Ubuntu での R システムのインストール: 別ページ »で説明
- R システムのプログラム例: 別ページ »にまとめ
- データシステム演習(R システム,Shiny を使用): 別ページ »にまとめ
- データサイエンス演習(R システムを使用): 別ページで説明している.
R システムの運用(パッケージのインストール,タスク・ビューのインストール,パッケージの更新など
- CRAN ミラーサイトの選択
chooseCRANmirror() - パッケージのインストール(メニューから指定)
utils:::menuInstallPkgs() - パッケージのインストール(パッケージ名を指定)
install.packages("<パッケージ名>") - タスク・ビュー Cluster のインストール
タスク・ビューの詳細については,CRAN Task View のページ: https://cran.r-project.org/web/views/
bioclite のインストールoptions(repos="http://cran.rstudio.com") install.packages("ctv", repos="http://cran.rstudio.com/") library(ctv) install.views("Cluster")source("http://bioconductor.org/biocLite.R") biocLite(groupName="all") - すべてのパッケージの更新
update.packages(checkBuilt=TRUE, ask=FALSE)
【関連項目】 R データセット
R データセット (Rdatasets)
R データセット (Rdatasets)は, 1700 を超えるデータセットの集まり.
R データセット (Rdatasets) の URL: https://vincentarelbundock.github.io/Rdatasets
Python で R データセット (Rdatasets)を用いる場合には, 次のように,データ名とパッケージを指定する. データ名とパッケージは,https://vincentarelbundock.github.io/Rdatasets で確認できる.
import statsmodels.api as sm df = sm.datasets.get_rdataset("Duncan", "carData") print(df.__doc__) print(df.data)Segment Anything Model (SAM)
Segment Anything(SA)は,画像セグメンテーションのための基盤モデルを構築することを目的としたプロジェクトである.このプロジェクトでは,新しいデータ分布とタスクに一般化できるプロンプト可能なセグメンテーションモデルSegment Anything Model(SAM)が開発された.Segment Anything Model(SAM)はゼロショットでのセグメンテーションが可能である.さらに,1100万枚以上の画像と,それらの画像に対する10億以上のマスクを含むセグメンテーションデータセットSA-1Bデータセットが構築された.
【文献】
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick, Segment Anything, arXiv:2304.02643, 2023.
https://arxiv.org/pdf/2304.02643v1.pdf
【サイト内の関連ページ】
- ゼロショットのセグメンテーション(Segment Anything Model,Python,PyTorch を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- 公式の GitHub ページ: https://github.com/facebookresearch/segment-anything
- Segment Anything のオンラインデモ: https://segment-anything.com/demo#
- Paper with Code のページ: https://paperswithcode.com/paper/segment-anything
【関連項目】 HQ-SAM (Segment Anything in High Quality)
SBU データセット
SBU データセットは,影画像に関するデータセットである. 機械学習での影検出の学習や検証に利用できるデータセット
SBU データセットは,次の URL で公開されているデータセット(オープンデータ)である.
SBU データセット の URL: https://www3.cs.stonybrook.edu/~cvl/projects/shadow_noisy_label/index.html
【関連情報】
- 文献
Large-scale Training of Shadow Detectors with Noisily-Annotated Shadow Examples, Vicente, T.F.Y., Hou, L., Yu, C.-P., Hoai, M., Samaras, D., Proceedings of European Conference on Computer Vision (ECCV), 2016.
- PyTorch の SBU データセット https://pytorch.org/vision/stable/datasets.html
scikit-learn
scikit-learnは,分類,会期,クラスタリング,次元削減,Model selection などの機械学習の 機能を持つ Pythonのパッケージ
scikit-learn の URL: https://scikit-learn.org/stable/
オープンソースの Python の機械学習プラットフォーム.URL は次のとおりである.
SCRFD (Sample and Computation Redistribution for Face Detection)
SCRFD は顔検出の手法である. TinaFace に対しては,画像が低解像度のとき速く処理できない,そして,一般の物体認識法である RetinaNet をベースに設計されているために,顔検出 (face detection)に用いるには冗長であったり,最適化しつくし切れていない という見解が示されているようである. WIDER FACE データセット の HARD レベルの顔は,78.83% の顔が 32x32 画素よりも小さいということも示されている. SCRFD では,探索空間の削減のために, sample redistribution と computation redistribution を 2段階で行う方法が提案されている. WIDER FACE データセット による実験結果では,TinaFace を精度と性能で上回るとされている.
- 文献
Jia Guo, Jiankang Deng, Alexandros Lattas, Stefanos Zafeiriou, Sample and Computation Redistribution for Efficient Face Detection, 2021. arXiv:2105.04714 [cs.CV]
- Papers with Code のページ:
- ソースコード: https://github.com/deepinsight/insightface
- SCRFD の事前学習済みモデル(InsightFace 内): https://github.com/deepinsight/insightface/tree/master/detection/scrfd
- SCRFD の実行については,InsightFace の項目で説明している.
【関連項目】 InsightFace, RetinaNet, TinaFace, 顔検出 (face detection)
Google Colaboratory で SCRFD のインストール
InsightFace の SCRFD のインストールは, 次のページで説明されている.
https://github.com/deepinsight/insightface/tree/master/detection/scrfd
このページの手順によりインストールを行う.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- まず,PyTorch のバージョンを確認
PyTorch は,ディープラーニングのフレームワークの 機能を持つ Pythonのパッケージ
次のプログラム実行により,PyTorch のバージョンが「1.10.0+cu111」のように表示される.
import torch print(torch.__version__) - NVIDIA CUDA ツールキット のバージョンを確認
(2)**NVIDIA CUDA ツールキット のバージョン**を確認
NVIDIA CUDA ツールキット は,NVIDIA社が提供している GPU 用のツールキットである.GPU を用いた演算のプログラム作成や動作のための各種機能を備えている.ディープラーニングでも利用されている.
次のプログラム実行により,NVIDIA CUDA ツールキットのバージョンが「cu111」のように表示される.
import torch CUDA_VERSION = torch.__version__.split("+")[-1] print(CUDA_VERSION)
- PyTorch のバージョンを確認
import torch TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) print(TORCH_VERSION)
- MMCV のインストール
https://mmcv.readthedocs.io/en/latest/get_started/installation.html に記載の手順による
NVIDIA CUDA ツールキット 11.1, PyTorch 1.10 の場合には,次のようになる
「cu111/torch1.10」のところは, NVIDIA CUDA ツールキット のバージョン, PyTorch のバージョンに合わせる
バージョンについては,公式のページ https://github.com/open-mmlab/mmcv に説明がある.
!apt remove python3-pycocotools !pip3 uninstall -y pycocotools !pip3 install mmpycocotools !apt install -y python3-terminaltables !apt install -y python3-opencv !pip3 install mmcv-full==1.3.3 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.10/index.html
- SCRFD のインストール
!git clone --recursive https://github.com/deepinsight/insightface %cd insightface/detection/scrfd !pip3 install dask==2022.01.0 !pip3 install -r requirements/build.txt !export CUDA_HOME='/usr/local/cuda' !python3 setup.py develop
SDL
SDL は,「Simple DirectMedia Layer」の略で, 次の機能などを持つ.
- オーディオ
- キーボード
- ジョイスティック
- 3次元グラフィックス・カード
- 2次元フレームバッファ
3次元グラフィックス・カードは,OpenGL を経由して使用する. SDL は,種々の OS (Linux, WInodws, MacOS, FreeBSD などなど)で動く. SDL は C 言語で書かれ,C++ からも使える.Java, Perl, PHP, Python 等等の種々の言語からも使える.
【関連する外部ページ】
SDL の公式ページ: https://www.libsdl.org/
Windows での SDL のインストール
Windows での SDL のインストール: 別ページ »で説明
Eigen 3.4 の非公式ビルド: sdl.zip私がビルドしたもの,非公式,無保証, 公式サイト https://github.com/libsdl-org/SDL で公開されているソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした. SDL のライセンスによる.
zip ファイルは C:\ 直下で展開し,C:\eigen での利用を想定.
SDL_image
SDL_image は, BMP, JPEG, PNG, PNM などの画像ファイルを扱う機能を持ったライブラリ.
GitHub のページ: https://github.com/libsdl-org/SDL_image
Windows での SDL2 のインストール: 別ページ »で説明
Ubuntu では,次のコマンドでインストール.
sudo apt -y install libsdl2-dev libsdl2-image-devStable Diffusion XL (SDXL)
Stable Diffusion XL (SDXL) は,Stability AIによって開発されたDiffusionベースの image-to-text の画像生成モデルである. SDXLはStable Diffusion with Larger UNet Backboneの略称である.
SDXLは,以前のStable Diffusionモデルと比較して,UNetバックボーンのサイズが3倍に増加している.この増加は,アテンションブロック数の増加とクロスアテンションコンテキストの拡大によるものである.また,SDXLはリファインメントモデルを導入している.このリファインメントモデルは,SDXLによって生成された画像の視覚的な精度を向上させるために使用される.
【文献】
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. CoRR abs/2307.01952, 2023.
https://arxiv.org/pdf/2307.01952v1.pdf
【サイト内の関連ページ】
- Stable Diffusion XL 1.0 (SDXL 1.0) のインストール,画像生成(img2txt),画像変換(img2img),APIを利用して複数画像を一括生成(AUTOMATIC1111,Python,PyTorch を使用)(Windows 上): 別ページ »で説明,
- Stable Diffusion XL を用いて複数の画像を一度に生成するアプリケーション(AUTOMATIC1111 の txt2img の API,Python,PyTorch を使用)(Windows 上): 別ページ »で説明,
【関連する外部ページ】
- Paper with Code のページ: https://paperswithcode.com/paper/sdxl-improving-latent-diffusion-models-for
- 公式のソースコード (GitHub のページ): https://github.com/Stability-AI/generative-models
- AUTOMATIC1111 の stable-diffusion-webui の GitHUb のページ: https://github.com/AUTOMATIC1111/stable-diffusion-webui
Seesaw Loss
セグメンテーション, 物体検出の一手法.2021 年に発表.
- 文献
Jiaqi Wang and Wenwei Zhang and Yuhang Zang and Yuhang Cao and Jiangmiao Pang and Tao Gong and Kai Chen and Ziwei Liu and Chen Change Loy and Dahua Lin, Seesaw Loss for Long-Tailed Instance Segmentation, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, also CoRR, abs/2008.10032v4 2021.
- Papers with Code のページ: https://paperswithcode.com/paper/seesaw-loss-for-long-tailed-instance
- MMDetection のモデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/seesaw_loss/README.md
【関連項目】 MMDetection, 物体検出, セグメンテーション
SegFormer
セマンティック・セグメンテーションのモデル. 2021年発表.
- 文献
Xie, Enze and Wang, Wenhai and Yu, Zhiding and Anandkumar, Anima and Alvarez, Jose M and Luo, Ping, SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers, arXiv preprint arXiv:2105.15203, 2021.
- 公式のソースコード: https://github.com/NVlabs/SegFormer
- MMSegmentation の SegFormer のページ: https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segformer
【関連項目】 モデル, セマンティック・セグメンテーション
SE ResNeXt
SE ResNeXt は, ResNeXt" からの派生であり, チャンネル単位での特徴の再キャリブレーションを可能にするための squeeze-and-excitation ブロックを特色とする.
- 文献
Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks, CoRR, abs/1709.01507v4
- 公式の実装: https://github.com/hujie-frank/SENet
- Papers With Code のページ: https://paperswithcode.com/paper/squeeze-and-excitation-networks
【関連項目】 PyTorch, torchvision のモデル, Residual Networks (ResNets), ResNeXt", モデル, 画像分類
Self-Instruct
Self-Instruct は,大規模言語モデルにおいて,事前学習されたモデルが指示に従う能力を調整するためのフレームワークである. 大規模言語モデルの自己学習では,大量のテキストデータを入力としてモデルをトレーニングし,生成されたテキストを再びモデルの入力として使用することが一般的である. Self-Instruct では,モデルが生成したテキストを正確な指示に変換し,それを再びモデルの入力として使用することで,自己学習の精度を向上させる.
【文献】
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi, Self-Instruct: Aligning Language Model with Self Generated Instructions, arXiv preprint arXiv:2212.10560, 2022.
https://arxiv.org/abs/2212.10560
【関連する外部ページ】
- GitHub のページ: https://github.com/yizhongw/self-instruct
- Paper with Code のページ: https://paperswithcode.com/paper/self-instruct-aligning-language-model-with
【関連項目】 Stanford Alpaca, 大規模言語モデル
ShanghaiTech データセット
ShanghaiTech データセットは,Part A と Part B がある. あわせて,画像数は 1198枚である.
文献
Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. Single-image crowd counting via multi-column convolutional neural network. In CVPR, 2016
【関連用語】 crowd counting, FIDTM, オープンデータ
Shap-E
Shap-e は,テクスチャ付きメッシュ (textured mesh)や neural radient fields としてレンダリングできる出力を生成 する能力を特徴とする. Point-E との比較では,高速,高品質の生成が可能であるとされている.
【文献】
Heewoo Jun, Alex Nichol, Shap-E: Generating Conditional 3D Implicit Functions, https://arxiv.org/abs/2305.02463, 2023.
https://arxiv.org/pdf/2305.02463v1.pdf
【サイト内の関連ページ】 Shap-E のインストールと動作確認(テキストや画像からの立体生成)(Python,PyTorch を使用)(Windows 上)
【関連する外部ページ】
- GitHub の公式ページ: https://github.com/openai/shap-e
- hysts による Hugging Face 上のデモ: https://huggingface.co/spaces/hysts/Shap-E
ShapeNet データセット
ShapeNet データセットは,3次元CADモデルのリポジトリである.
- 3億個以上の 3次元CADモデル
- 220,000個のモデルが,WordNetのにより,3,135のクラスに分類されている.
- ShapeNet Partsサブセットでは,31,693個のメッシュ形式データが,16のオブジェクトクラス(テーブル,椅子,飛行機など)に分類されている.
ShapeNet データセット は次の URL で公開されているデータセット(オープンデータ)である.
【関連情報】
- ShapeNet: An Information-Rich 3D Model Repository, Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qi-Xing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, Fisher Yu,
- Papers With Code の ShapeNet データセットのページ: https://paperswithcode.com/dataset/shapenet
Shiny のインストール
R システムで Shiny のインストールを行うには, R システムで次のコマンドを実行する.
install.packages("shiny")R システムの主な機能は,次の URL にまとめている. https://www.kkaneko.jp/pro/r/rintro.html
Shiny によるデータシステム演習は,次の URL にまとめている. https://www.kkaneko.jp/cc/shiny/index.html
short-time Fourier transform (STFT)
short-time Fourier transform (STFT) は, 短い区間のオーバーラッピングウインドウ (overlappig window) を 用いて離散フーリエ変換 (DFT) を行うことにより求める.
【関連項目】 librosa, 音データ(sound data)
softmax
分類モデルにおいて, クラスの確率を提供する関数.
Spleeter
音源分離(music source separation)を行う 1手法.2019年発表. 音声と楽器音等の混合から,音声とそれ以外を分離できる.
- 文献
Romain Hennequin and Anis Khlif and Felix Voituret and Manuel Moussallam,
Spleeter: a fast and efficient music source separation tool with pre-trained models,
Journal of Open Source Software,
vol. 5, no. 50, page 2154, 2020.
PDF: https://archives.ismir.net/ismir2019/latebreaking/000036.pdf
- GitHub のページ: https://github.com/deezer/spleeter
- 公式のオンラインデモ (Google Colaboratory): https://colab.research.google.com/github/deezer/spleeter/blob/master/spleeter.ipynb#scrollTo=HPjXH-IwtAi0
- Papers with Code のページ: https://paperswithcode.com/paper/spleeter-a-fast-and-state-of-the-art-music
【関連用語】 audio source seperation, music source separation
Google Colaboratory で,音声 (vocal) とそれ以外の分離 (Spleeter を使用)
公式の手順 https://github.com/deezer/spleeter による.
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- Spleeter のインストール
!apt install ffmpeg !pip3 install spleeter !pip3 show spleeter !spleeter separate --help
- 処理したいサウンドファイルの準備
ここでは,1.m4a をダウンロードしている.
%cd /content !curl -O https://www.kkaneko.jp/sample/audio/1.m4a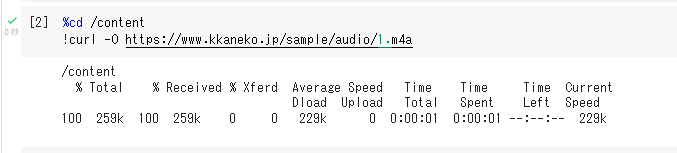
- Demucs の実行
!spleeter separate -p spleeter:2stems -o output/ 1.m4a
- 処理結果のダウンロード
「1」のところは,処理したサウンドファイルのファイル名にあわせること.
from google.colab import files %cd output/1 files.download('vocals.wav') files.download('accompaniment.wav')
SPP (Spatial Pyramid Pooling)
CNN (convolutional neural network) を用いた 画像分類において, 入力として固定サイズの画像(例えば 224x224)を要求していることを不要にできるための1手法. spatial pyramid pooling と呼ばれる pooling 戦略が導入されている. CNN を使用する画像分類全般に使える手法であるとされている.
CSPNet の公式の実装 (GitHub) のページでは, SPP を用いた物体検出として, CSPDarknet53-PANet-SPP, CSPResNet50-PANet-SPP, CSPResNeXt50-PANet-SPP 等の実装が公開されている.
- 文献
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, CoRR, abs/1406.4729
https://arxiv.org/pdf/1406.4729v4.pdf, 2014.
- CSPNet の公式の実装 (GitHub) のページ: https://github.com/WongKinYiu/CrossStagePartialNetworks
【関連項目】 画像分類
SQLite 3
SQLite 3は,リレーショナルデータベース管理システム
主な機能: リレーショナルデータベース管理システムとしての基本機能,設定不要での即時利用可能,単一ファイルでのデータベース管理,サーバレス運用(クライアント側のみで完結)
SQLite 3には以下の特徴がある.
- アカウント機能(ユーザ名やパスワード)が存在しない.
- 「クライアントサーバモデル」を採用していない.
- 設定不要で即座に利用可能である.
SQLite 3は主にローカルでの使用を想定しているため,クライアントサーバモデルで運用する場合(マルチユーザ環境やネットワーク越しの利用など),SQLite 3自体には並行処理制御やリモート通信の機能が備わっていない.そのため,これらの機能が必要な場合は,利用者側でアプリケーションレベルでの実装が必要となる.
また,SQLite 3はSQL標準(SQL-92やそれ以降)の全機能をサポートしているわけではなく,一部の機能は省略されている.
SQLite 3を対話的に使用するには,通常「sqlite3コマンド」を使用する.ただし,多くのプログラミング言語からライブラリとして利用することも可能である.
winget を用いたインストールコマンド: winget install --scope SQLite.SQLite
Windows での動作画面例
Ubuntu での動作画面例
【関連する外部ページ】
- SQLite 3 の公式ページ: https://www.sqlite.org/
- SQLite 3 の公式ダウンロードページ: https://www.sqlite.org/download.html
- SQLite 3 のコピーライト: https://www.sqlite.org/copyright.html
- SQLite 3の SQL に関する公式の説明: http://www.hwaci.com/sw/sqlite/lang.html
- SQLite 3のコマンドラインシェルの説明:https://www.sqlite.org/sqlite.html
【サイト内の関連ページ】
- Windows での SQLite 3 のインストール,データベース作成,テーブル定義,レコード挿入: 別ページ »で説明
- Ubuntu での SQLite 3 のインストール,データベース作成,テーブル定義,レコード挿入: 別ページ »で説明
- SQLite 3 入門(スライド資料と動画とプログラム例)(全3回): 別ページ »にまとめ
- SQLite 3 の使い方: 別ページ »にまとめている.
【関連項目】 SQLite 3 のインストール(Windows 上)
SQLiteman
SQLiteman は SQLite 3 のデータベースを操作する機能を持ったソフトウェア. Windows 版,Linux 版,Max OS X 版がある.ソースコードも配布されている. インストール,データベースの新規作成,SQLの編集と実行,データのブラウズの手順を演習する.
SQLiteman の URL: https://sourceforge.net/projects/sqliteman/
SRCNN
SRCNN は,image super resolution の一手法.2015年発表.
Dong, Chao and Loy, Chen Change and He, Kaiming and Tang, Xiaoou, Image super-resolution using deep convolutional networks, IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 2 pp. 295--307, 2015.
【関連項目】 MMEditing, 超解像 (super resolution)
SSD
MMDetection に実装された SSD を用いた物体検出については,別項目で説明している.
- 文献
Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C., SSD: Single Shot MultiBox Detector, ECCV, also CoRR, https://arxiv.org/abs/1512.02325v5 2016.
- 公式のソースコード (GitHub): https://github.com/weiliu89/caffe
- Papers with Code のページ: https://paperswithcode.com/paper/ssd-single-shot-multibox-detector
- MMDetection の SSD モデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/ssd/README.md
【関連項目】 MMDetection, モデル, 物体検出
SSIM (Structural Similarity)
SSIM は,動画や写真の品質を評価したり,類似性を判定するのに使用する. ImageMagick を用いて算出できる.
compare -metric SSIM 1.png 2.png NULL:【関連項目】 LPIPS (Learned Perceptual Image Patch Similarity)
Stable Diffision
【サイト内の関連ページ】
- Stable Diffusion XL 1.0 (SDXL 1.0) のインストール,画像生成(img2txt),画像変換(img2img),APIを利用して複数画像を一括生成(AUTOMATIC1111,Python,PyTorch を使用)(Windows 上)別ページで説明.
- ImaginAIry のインストールと動作確認(Text to Imge,画像編集,Prompt Based Masking,Image to Image)(Stable Diffusion,InstructPix2Pix,Stable Diffusion 2 Depth,Python を使用)(Windows 上)別ページで説明.
【関連する外部ページ】
- Stable Diffusion Online のページ,オンラインデモ
https://stablediffusionweb.com/
- Stable Diffusion 2-1 のページ(Hugging Face 上),オンラインデモ
https://huggingface.co/spaces/stabilityai/stable-diffusion

- stability-ai/stable-diffusion のページ(replicate 上),有料のサービス(登録を求められる)
- cjwbw/anything-v4.0 のページ(replicate 上),有料のサービス(登録を求められる)
https://replicate.com/cjwbw/anything-v4.0

- cjwbw/anything-v3.0 のページ(replicate 上),有料のサービス(登録を求められる)
https://replicate.com/cjwbw/anything-v3.0
- cjwbw/waifu-diffusion のページ(replicate 上),有料のサービス(登録を求められる)
- Scribble Diffusion のページ,オンラインデモ
https://scribblediffusion.com/

- andreasjansson/stable-diffusion-animation のページ (replicate 上),有料のサービス(登録を求められる)
https://replicate.com/andreasjansson/stable-diffusion-animation
Stanford Alpaca
Stanford Alpaca は, スタンフォード大学で開発された 大規模言語モデルである. このモデルは,52Kの指示に準拠したLLaMAモデルの7Bデータセットをベースにしており,Self-Instruct によるファインチューニングを行っている.
Stanford Alpacaの生成手順は公開されており,さまざまなプロジェクトで利用されている.
【文献】
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto, Stanford Alpaca: An Instruction-following LLaMA model, 2023.
【関連する外部ページ】
- Stanford Alpaca の GitHub のページ: https://github.com/tatsu-lab/stanford_alpaca
【関連項目】 LLaMA (Large Language Model Meta AI), Self-Instruct, 大規模言語モデル
statsmodels
PyPI の URL: https://pypi.org/project/statsmodels/
Ubuntu でのインストール
sudo apt install python3-statsmodelsStoop
Stoop は,金融に関するポータルサイト.
URL: https://stooq.pl/index.html
【関連項目】 株価データ
Structure from Motion (SfM)
SfM (Structure of Motion) は,オブジェクト(動かないもの)を, 周囲の複数の視点から撮影した多数の画像に対して次の処理を行う.
- それぞれの撮影での,視点の位置(3次元)と向きを推定する
- 画像の特徴点について,位置(3次元)を推定する.
その結果,各画像の撮影位置と方向が推定されるとともに,オブジェクトの3次元点群が構成される.
SfM (Structure of Motion) の機能を持ったソフトウエアとしては, meshroom,OpenMVG などがある.
Ubuntu での OpenMVG のインストールは 別ページ »で説明
【関連項目】 3次元再構成 (3D reconstruction), meshroom, Multi View Stereo, OpenMVG, OpenMVS
SuiteSparse
SuiteSparse は,下記の機能を持つソフトウェアである.
- AMD: symmetric approximate minimum degree
- CCOLAMD: constrained column approximate minimum degree
- COLAMD: column approximate minimum degree
- CHOLMOD: sparse supernodal Cholesky factorization and update/downdate
- CXSparse: an extended version of CSparse
- UMFPACK: 不完全 LU 分解 (sparse multifrontal LU factorization)
- UFconfig: common configuration for all but CSparse
UFconfig は,SuiteSparseQR, AMD, COLAMD, CCOLAMD, CHOLMOD, KLU, BTF, LDL, CXSparse, and UMFPACK のビルドに必要.
AMD は,疎行列の並び替えの機能を持ったソフトウェア. これは,Cholesky factorization や, 不完全 LU 分解 (LU factorization) の前処理として行うもの.
Windows での SuiteSparse のインストール
Windows での SuiteSparse のインストール: 別ページ »で説明
SuiteSparse 5.4.0,Metis 5.1.0 の非公式ビルド: suitesparse.zip私がビルドしたもの,非公式,無保証, https://github.com/jlblancoc/suitesparse-metis-for-windows/releases で公開されているソースコードを改変せずにビルドした. Windows 10, Visual Build Tools for Visual Studio 2022 を用いてビルドした. BSD ライセンスによる.
zip ファイルは C:\ 直下で展開し,C:\suitesparse での利用を想定.
Ubuntu での SuiteSparse のインストール
Ubuntu での SuiteSparse のインストール: 別ページ »で説明
Sunspot Number データセット(黒点数のデータセット)
太陽の黒点数の観測データである.
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.sidc.be/silso/datafiles
データは数種類ある. 毎日の黒点数のデータは, SN_d_tot_V2.0.csv というファイル名で公開されている. 属性は, (year, month, day, decimal year, SNvalue , SNerror, Nb observations) である
【関連項目】 time-series data
SVHN (The Street View House Numbers) データセット
SVHN データセット は,公開されているデータセット(オープンデータ)である.
SVHN データセット は,小さく切り取られた数字の画像で,ラベル付けがされている. 機械学習での画像分類の学習や検証に利用できる.
- 実写(自然風景の画像中の数字や数値の認識)に由来.Googleストリートビュー画像中の家の番号から得ている.
- 0から9までの数字が示されたカラー画像.
- 数字が切り取られ,中央にくるように調整されているが,近くにある他の数字や,妨げになるようなものは,そのまま残されている.
- 画像の枚数:合計 630420枚.
(内訳)
73257枚:教師データ
26032枚:検証データ
531131枚: extraのデータ
- 画像のサイズ: 32x32 である.
- RGB のカラー画像.
【文献】
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, Andrew Y. Ng, Reading Digits in Natural Images with Unsupervised Feature Learning, NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, 2011.
PDF ファイル:http://ufldl.stanford.edu/housenumbers/nips2011_housenumbers.pdf
【サイト内の関連ページ】
- SVHN データセットを扱う Python プログラム: 別ページ で説明している.
【関連する外部ページ】
- SVHN データセットの公式ページ: http://ufldl.stanford.edu/housenumbers/
- Papers With Code の SVHN データセットのページ: https://paperswithcode.com/dataset/svhn
- PyTorch の SVHN データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.SVHN
- TensorFlow データセットの SVHN データセット: https://www.tensorflow.org/datasets/catalog/svhn_cropped
【関連項目】 TensorFlow データセット, オープンデータ, 画像分類
svn
svn は,バージョン管理システム
Windows での svn のインストール
SlikSVN は,https://sliksvn.com/ から 64-bit 版をダウンロードして,インストール
Subversion for Windows (SlikSVN) については, https://sliksvn.com/ で確認すること. 利用条件についても,利用者で確認することSwinIR
SwinIRは,超解像,ノイズ除去の一手法
【文献】 Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu, SwinIR: Image Restoration Using Swin Transformer, arXiv preprint arXiv:2108.10257, 2021.
【関連する外部ページ】
GitHub のページ: https://github.com/JingyunLiang/SwinIR
SwinIR のインストールと動作確認(超解像,画像のノイズ除去)
JingyunLiang/SwinIR のインストールと動作確認(超解像,画像のノイズ除去)(Python,PyTorch を使用)(Windows 上)別ページ »で説明
TecoGAN
- 文献, Mengyu Chu, You Xie, Jonas Mayer, Laura Leal-Taixé, Nils Thuerey, Learning Temporal Coherence via Self-Supervision for GAN-based Video Generation, CoRR, abs/1811.09393v4, 2018.
- TecoGAN の GitHub のページ: https://github.com/thunil/TecoGAN
- 公式のデモページ(Google Colaboratory): https://colab.research.google.com/drive/1vgD2HML7Cea_z5c3kPBcsHUIxaEVDiIc
- PaperswithCode のページ: https://paperswithcode.com/paper/temporally-coherent-gans-for-video-super
関連項目 GAN (Generative Adversarial Network), image super resolution, video super resolution
Google Colaboratory での TecoGAN のインストールと動作確認
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
!pip3 install tensorflow==1.15.5 !pip3 install -U keras==2.3.1 !pip3 install git+https://www.github.com/keras-team/keras-contrib.git !rm -rf TecoGAN !git clone https://github.com/thunil/TecoGAN %cd TecoGAN !pip3 install -U -r requirements.txt !python3 runGan.py 0 !python3 runGan.py 1 from PIL import Image Image.open('LR/calendar/0001.png').show() Image.open('results/calendar/output_0001.png').show()
Ubuntu での TecoGAN のインストールと動作確認
前準備:事前に Python のインストール: 別項目で説明している.
- pyenv のダウンロードと更新
次のコマンドを実行.
cd /tmp git clone https://github.com/pyenv/pyenv.git ~/.pyenv cd ~/.pyenv git pull src/configure make -C src - pyenv の設定
次のコマンドを実行.
echo 'export PYENV_ROOT="${HOME}/.pyenv"' >> ~/.profile echo 'if [ -d "${PYENV_ROOT}" ]; then' >> ~/.profile echo ' export PATH=${PYENV_ROOT}/bin:$PATH' >> ~/.profile echo ' eval "$(pyenv init --path)"' >> ~/.profile echo 'fi' >> ~/.profile echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.profile exec $SHELL -l source ~/.profile - python 3.6 のインストールと有効化(pyenv を使用)
次のコマンドを実行.
「pyenv install -l | grep 3.6」でインストールできる最新バージョンを確認pyenv install -l | grep 3.6 pyenv install 3.6.15 pyenv shell 3.6.15 python -m pip install -U pip setuptools - TecoGAN をUbuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo rm -rf TecoGAN sudo git clone https://github.com/thunil/TecoGAN sudo chown -R $USER TecoGAN cd /usr/local/TecoGAN pip install -U tensorflow-gpu==1.15.5 pip install -U keras==2.3.1 pip install git+https://www.github.com/keras-team/keras-contrib.git pip install -U -r requirements.txt pip list - 学習済モデルのダウンロード
公式ページに記載の https://github.com/thunil/TecoGAN の手順に従う.
cd /usr/local/TecoGAN python runGan.py 0 - 確認のため実行してみる
公式ページに記載の https://github.com/thunil/TecoGAN の手順に従う.
python runGan.py 1
結果のうち一部を下に示す.画像は原寸で(拡大縮小せずに)表示している.
- 処理前

- 処理後

Temporal Segment Networks (TSN)
ビデオの動作認識 (action recognition) の一手法.2016年発表
- 文献
Wang, Limin and Xiong, Yuanjun and Wang, Zhe and Qiao, Yu and Lin, Dahua and Tang, Xiaoou and Van Gool, Luc, Temporal segment networks: Towards good practices for deep action recognition, European conference on computer vision, pp. 20--36, 2016.
- MMAction2 の Temporal Segment Networks (TSN) の説明ページ: https://github.com/open-mmlab/mmaction2/blob/master/configs/recognition/tsn/README.md
【関連項目】 MMAction2, 動作認識 (action recognition)
TensorFlow
TensorFlowは,Googleが開発した機械学習フレームワークである.Python,C/C++言語から利用可能で,CPU,GPU,TPU上で動作する.TensorFlowの特徴として「データフローグラフ」がある.これは,「データの流れ」を表現するもので,グラフの節点は演算(オペレーション)を,エッジはデータ(テンソル)の流れを表す.TensorFlowを使用することで,音声,画像,テキスト,ビデオなど多様なデータを扱う機械学習アプリケーションの開発が容易になる.2015年11月に初版がリリースされて以来,継続的にバージョンアップが続いている.◯ TensorFlow GPU 版の動作に必要なもの
- 最新のNVIDIA ドライバ
Windows で,NVIDIA グラフィックス・ボードの種類を調べたいときは, hwinfo (URL: https://www.hwinfo.com/) を使って調べることができる.
- cudart64_110.dll, cusolver64_11.dll, cudnn64_8.dll など
そのために, 最新の NVIDIA cuDNNと, それに対応した,NVIDIA CUDA ツールキット 11を使う. (NVIDIA CUDA ツールキット は,バージョン12 でなくバージョン11 の最新版を使うこと.Tensorflow 2.10.1 で実際に試したが,バージョン 12 は不可)
最新の NVIDIA cuDNNに対応するNVIDIA CUDA ツールキットのバージョンは, NVIDIA cuDNN のページ https://developer.nvidia.com/cudnn で確認
- 古いバージョンである2.4.4 あるいはそれ以前のバージョン のTensorFlow を使う場合は, 最新の NVIDIA cuDNNを使わないこと. 詳しくは,別ページ »で説明
TensorFlow で,GPU のメモリ不足でエラーメッセージがでて,プログラムが止まる場合, プログラムの先頭部分に次を追加すると解決する場合がある.メッセージ
Internal: Attempting to perform BLAS operation using StreamExecutor without BLAS support
解決策:Python プログラムの先頭部分に次を追加すると解決する場合がある.
import tensorflow as tf gpu = tf.config.list_physical_devices(device_type = 'GPU') if len(gpu) > 0: print("GPU:", gpus[0].name) tf.config.experimental.set_memory_growth(gpu[0], True)【文献】
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
https://arxiv.org/pdf/1603.04467v2.pdf
【関連する外部ページ】
- TensorFlow の URL: https://www.tensorflow.org
- Papers with Code のページ: https://paperswithcode.com/paper/tensorflow-large-scale-machine-learning-on
- TensorFlow のWeb ページ: http://tensorflow.org/
- github のページ: https://github.com/tensorflow/tensorflow
- TensorFlow 2.00 リリースノート: https://github.com/tensorflow/tensorflow/releases/tag/v2.0.0
- チュートリアル: http://tensorflow.org/tutorials, https://github.com/nlintz/TensorFlow-Tutorials
- whitepaper: http://download.tensorflow.org/paper/whitepaper2015.pdf
【サイト内の関連ページ】
- GPU環境でのTensorFlow 2.10.1のインストールと活用(Windows 上): 別ページ »で説明
- Ubuntu での TensorFlow のインストール: 別ページ »で説明
【関連項目】 Applications of Deep Neural Networks, Keras, ディープラーニング
TensorFlow, PyTorch が必要とするNVIDIA CUDA ツールキットとNVIDIA cuDNN のバージョン
現在,NVIDIA CUDA ツールキット 12 に対応する NVIDIA cuDNN が無い(2022年12月時点)ため, 古いバージョンであるNVIDIA CUDA ツールキット11.8 と, NVIDIA cuDNN 8.6 を使う.
その根拠:- TensorFlow GPU 版 2.10 の動作に cudart64_110.dll, cusolver64_11.dll, cudnn64_8.dll が必要である.
- そのために,最新の NVIDIA cuDNNを使う.
- そして,最新の NVIDIA cuDNNが対応している
NVIDIA CUDA ツールキットは,
NVIDIA cuDNN のページ https://developer.nvidia.com/cudnn で確認できる.
必ずしも,最新の NVIDIA CUDA ツールキット を使えるとは限らないので確認が必要.
2.4.4 あるいはそれ以前のバージョン のTensorFlow を使う場合
過去の TensorFlow は, 必ずしも, 新しいNVIDIA CUDA ツールキット, NVIDIA cuDNN で動くわけではないことに注意が必要.
TensorFlow のバージョンと, NVIDIA CUDA ツールキット,NVIDIA cuDNN のバージョンの関係- TensorFlow 2.10.1,
TensorFlow 2.9.3,
TensorFlow 2.8.4,
TensorFlow 2.7.4,
TensorFlow 2.6.5,
TensorFlow 2.5.3 の場合:
NVIDIA CUDA ツールキット11.8.0, 11.7.1, 11.6.1, 11.5.2, 11.4.4, 11.3.1, 11.2.2, 11.1.1を使う.(11.0 系列は不可(実際に試みて検証済み)).
使用するNVIDIA CUDA ツールキット に対応するNVIDIA cuDNN 8 の最新版を使う.
根拠: cudart64_110.dll, cusolver64_11.dll, cudnn64_8.dll が必要 - TensorFlow 2.4.4 の場合:
NVIDIA CUDA ツールキット11.0.3 を使う.(11.1 系列は不可(実際に試みて検証済み)).
使用するNVIDIA CUDA ツールキット に対応するNVIDIA cuDNN 8 の最新版を使う.
根拠: cudart64_110.dll, cusolver64_10.dll, cudnn64_8.dll が必要 - TensorFlow 2.3.4,
TensorFlow 2.2.3,
TensorFlow 2.1.4 の場合:
NVIDIA CUDA ツールキット10.1 update2を使う.(10.2 は不可(実際に試みて検証済み)).
NVIDIA cuDNN 7.6.5 を使う.(8系列は使わない).
NVIDIA CUDA ツールキット 10.1, NVIDIA cuDNN 7 の根拠: cudart64_101.dll, cudnn64_7.dll が必要 - TensorFlow 2.0.4,
TensorFlow 1.15.5,
TensorFlow 1.14.0,
tensorflow 1.13.2 の場合:
NVIDIA CUDA ツールキット 10.0 を使う.(10.2, 10.1 は不可(実際に試みて検証済み)).
NVIDIA cuDNN 7.6.5 を使う.(8系列はない).
NVIDIA CUDA ツールキット 10.0, NVIDIA cuDNN 7 の根拠: cudart64_100.dll, cudnn64_7.dll が必要PyTorch のバージョンと, NVIDIA CUDA ツールキットのバージョンの関係- PyTorch LTS (1.8.2): NVIDIA CUDA ツールキット は10.2 以上または11.1 以上を使う.
- PyTorch Stable (2022年10月時点では 1.13): NVIDIA CUDA ツールキット は11.3 以上を使う.
TensorFlow が必要とする Python のバージョン
TensorFlow のバージョンは,次ページで確認できる.
TensorFlow のタグのページ: https://github.com/tensorflow/tensorflow/tags で確認.
TensorFlow 2.7.1 や,それより前のバージョンは,Python 3.10 が対応していないので,古いバージョンの Python を使用する.
その根拠:https://pypi.org/project/tensorflow/#filesで確認することができる.
その内容をまとめると次の通りである.
- TensorFlow 2.11 の場合: Python 3.10, 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/#files)
- TensorFlow 2.10 の場合: Python 3.10, 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/#files)
- TensorFlow 2.9.1 の場合: Python 3.10, 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.9.1/#files)
- TensorFlow 2.8.0 の場合: Python 3.10, 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.8.0/#files)
- TensorFlow 2.7.1 の場合: Python 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.7.1/#files)
- TensorFlow 2.6.3 の場合: Python 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.6.3/#files)
- TensorFlow 2.5.3 の場合: Python 3.9, 3.8, 3.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.5.3/#files)
- TensorFlow 2.4.4 の場合: Python 3.8, 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.4.4/#files)
- TensorFlow 2.3.4 の場合: Python 3.8, 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.3.4/#files)
- TensorFlow 2.2.3 の場合: Python 3.8, 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.2.3/#files)
- TensorFlow 2.1.4 の場合: Python 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.1.4/#files)
- TensorFlow 2.0.4 の場合: Python 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/2.0.4/#files)
- TensorFlow 1.15.5 の場合: Python 3.7, 3.6 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/1.15.5/#files)
- TensorFlow 1.14.0 の場合: Python 3.7, 3.6, 3.5, 3.4, 3.3, 2.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/1.14.0/#files)
- TensorFlow 1.13.2 の場合: Python 3.7, 3.6, 3.5, 3.4, 3.3, 2.7 のいずれかを使う.(根拠: https://pypi.org/project/tensorflow/1.13.2/#files)
TensorFlow のインストール
前準備
- TensorFlow が必要とする NVIDIA CUDA ツールキットとNVIDIA cuDNN のバージョン を確認
- TensorFlow が必要とする Python のバージョン を確認
- Python のインストール
- NVIDIA CUDA ツールキット 11.8 のインストール(Windows 上)
- Windows でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
- Ubuntu でのインストール詳細(NVIDIA ドライバ,NVIDIA CUDA ツールキット,NVIDIA cuDNN, TensorFlow 関連ソフトウェアを含む): 別ページ »で説明
上に示した「別ページ」にあるように,TensorFlow バージョン 2 および関連ソフトウェア類のインストールは,コマンドで行うことができる. そのコマンドについて,ここに記しておく. インストールするときは,前準備や,前もって確認する事項があり,次のリンク先のページで,前準備,前もって確認する事項,インストール手順を説明している.
- Windows の場合
Windows で pip を実行するときは,管理者権限のコマンドプロンプトを使用し,システム領域へのインストールを行う.
次のコマンドを実行することにより,TensorFlow 2.10.1 および関連パッケージ(tf_slim,tensorflow_datasets,tensorflow-hub,Keras,keras-tuner,keras-visualizer)がインストール(インストール済みのときは最新版に更新)される. そして,Pythonライブラリ(Pillow, pydot, matplotlib, seaborn, pandas, scipy, scikit-learn, scikit-learn-intelex, opencv-python, opencv-contrib-python)がインストール(インストール済みのときは最新版に更新)される.
python -m pip uninstall -y protobuf tensorflow tensorflow-cpu tensorflow-gpu tensorflow-intel tensorflow-text tensorflow-estimator tf-models-official tf_slim tensorflow_datasets tensorflow-hub keras keras-tuner keras-visualizer python -m pip install -U protobuf tensorflow==2.10.1 tf_slim tensorflow_datasets==4.8.3 tensorflow-hub tf-keras keras keras_cv keras-tuner keras-visualizer python -m pip install git+https://github.com/tensorflow/docs python -m pip install git+https://github.com/tensorflow/examples.git python -m pip install git+https://www.github.com/keras-team/keras-contrib.git python -m pip install -U pillow pydot matplotlib seaborn pandas scipy scikit-learn scikit-learn-intelex opencv-python opencv-contrib-python
(途中省略)

(以下省略) - Ubuntu の場合
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo pip3 uninstall -y tensorflow tensorflow-cpu tensorflow-gpu tensorflow-intel tensorflow-text tensorflow-estimator tf-models-official tf_slim tensorflow_datasets tensorflow-hub keras keras-tuner keras-visualizer sudo pip3 uninstall -y six wheel astunparse tensorflow-estimator numpy keras-preprocessing absl-py wrapt gast flatbuffers grpcio opt-einsum protobuf termcolor typing-extensions google-pasta h5py tensorboard-plugin-wit markdown werkzeug requests-oauthlib rsa cachetools google-auth google-auth-oauthlib tensorboard tensorflow sudo apt -y install python3-six python3-wheel python3-numpy python3-grpcio python3-protobuf python3-termcolor python3-typing-extensions python3-h5py python3-markdown python3-werkzeug python3-requests-oauthlib python3-rsa python3-cachetools python3-google-auth sudo apt -y install python3-numpy python3-pil python3-pydot python3-matplotlib python3-keras python3-keras-applications python3-keras-preprocessing python3-opencv libopencv-dev libopencv-core-dev python3-opencv libopencv-contrib-dev opencv-data sudo pip3 install -U tensorflow tf-models-official tf_slim tensorflow_datasets tensorflow-hub keras keras-tuner keras-visualizer sudo pip3 install git+https://github.com/tensorflow/docs sudo pip3 install git+https://github.com/tensorflow/examples.git sudo pip3 install git+https://www.github.com/keras-team/keras-contrib.git
インストールされている TensorFlow のバージョン確認
import tensorflow as tf print(tf.__version__)TensorFlow が GPU を認識できているかの確認
- Windows の場合
python -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())" - Ubuntu のシステム Python を使う場合
python3 -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())"
TensorFlow の利用可能なデバイスを調べる
次のプログラムにより,利用可能なデバイスを確認することができる.
import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 0 = GPU use; -1 = CPU use from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
次のプログラムにより,TensorFlow で利用しているデバイスを確認することができる.
import tensorflow as tf print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU'))) print(tf.test.gpu_device_name())
TensorFlow 2 の上で,TensorFlow 1 のプログラムを動かす
TensorFlow 2 系列の上で TensorFlow 1 のプログラムを動かすときは, このサイトでは,次のように書くようにしている.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow.compat.v1 as tf # tf.enable_v1_behavior() import tensorflow.keras as keras import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 0 = GPU use; -1 = CPU use config = tf.compat.v1.ConfigProto( device_count = {'GPU': 1 , 'CPU': 3} ) sess = tf.compat.v1.Session(config=config) tf.keras.backend.set_session(sess)TensorFlow のベクトル
ベクトルは,要素の並び.各要素の添字は 0, 1, 2... のようになる. 下に,TensorFlow のベクトルのコンストラクタの例を示す.
import tensorflow as tf v1 = tf.constant([1, 2, 3]) print(v1) import numpy as np np.array([1, 2, 3]) v2 = tf.constant( np.array([1, 2, 3]) ) print(v2)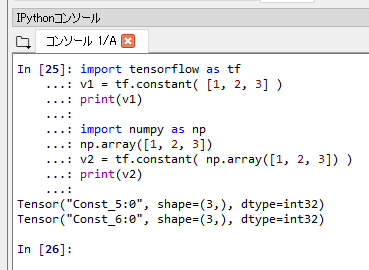
TensorFlow のレイヤ
TensorFlow のレイヤは,テンソルと設定オプションを入力とし,テンソルを出力とするような Python の関数である. TensorFlow を用いてニューラルネットワークを構築するときは, レイヤを組み立てていく. TensorFlow の Layers API は,以下のようなさまざまなタイプのレイヤを構築することができる.
- tf.layers.Dense: 全結合層
- tf.layers.Conv2D: 畳み込み層.
TensorFlow の Layers API は,Keras の layers API の書き方に準拠している. TensorFlow の Layers API と Keras の layers API で関数名は同じである. 接頭語「tf.」の部分が異なる.
【関連項目】 TensorFlow
TensorFlow の配列
配列では,添え字が複数になる. 下に,TensorFlow の配列のコンストラクタの例を示す.
import tensorflow as tf M1 = tf.constant([[1, 2, 3], [4, 5, 6]]) print(M1) import numpy as np np.array([1, 2, 3]) M2 = tf.constant( np.array([[1, 2, 3], [4, 5, 6]]) ) print(M2)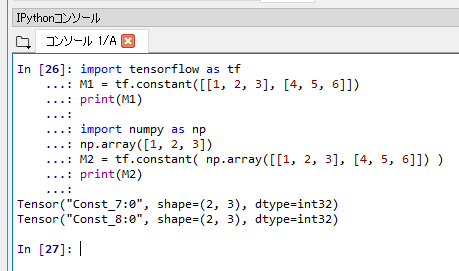
TensorFlow の Playground デモサイト
ニューラルネットワークのデモサイト: http://playground.tensorflow.org
【関連項目】 TensorFlow
TensorFlow 1.14
TensorFlow の URL: https://www.tensorflow.org/
TensorFlow 1.14 を使いたいとき,次の組み合わせになる.cuDNN 7.6.5 は,Windows で実際に試してみたことが根拠.
- Python 3.3 または 3.4 または 3.5 または Python 3.6 または Python 3.7(根拠は,https://pypi.org/project/tensorflow/1.14.0/#files)
- NVIDIA CUDA ツールキット 10.0
- NVIDIA cuDNN 7.6.5
【関連項目】 TensorFlow
TensorFlow 1.15.5
TensorFlow の URL: https://www.tensorflow.org/
TensorFlow 1.15.5 は Python 3.7, Python 3.6 で動く(Python 3.10 や Python 3.9 や Python 3.8 では動かない).
その根拠は,次のページである. https://pypi.org/project/tensorflow/1.15.5/#files
TensorFlow 1.15.5 は, NVIDIA CUDA ツールキット のバージョン 10.0 を必要とする.それより新しいバージョンでは動かない. NVIDIA cuDNN のバージョン 7 系列を必要とする.バージョン 8 系列では動かない.
以上から,TensorFlow 1.15.5 を使いたいとき,次の組み合わせになる.
- Python 3.6 または Python 3.7
- NVIDIA CUDA ツールキット 10.0
- NVIDIA cuDNN 7.6.5
【関連項目】 TensorFlow
Windows での TensorFlow 1.15.5 のインストール
Windows で TensorFlow 1.15.5 を使うためには,次を行う.
- Python 3.7 または Python 3.6 のインストール: それぞれ,Python 3.7 のインストール,Python 3.6 のインストールのページで説明している.
- NVIDIA ドライバ,NVIDIA CUDA ツールキット 10.0,NVIDIA cuDNN 7.6.5 のインストール: 別ページ »で説明
- TensorFlow 1.15.5 のインストール: 別ページ »で説明
このページでは,「すでにPython 3.9 あるいは Python 3.8 をインストールしている,あるいは,インストール予定」という場合を想定し, あとのトラブルが起きにくい,そして,簡単に運用できるように 「Python 3.7 をインストールし,その上に,TensorFlow 1.15.5 をインストールする」という手順を案内している.
Ubuntu での TensorFlow 1.15.5 のインストール
Ubuntu でのPython,TensorFlow 1.15 のインストール:別ページで案内している.Ubuntu のシステム Python に影響を与えないように,隔離された Python 3.6 仮想環境の新規作成し,その上にTensorFlow 1.15.5 をインストールするという手順(venv を使用)(Ubuntu 上)を案内している.
TensorFlow 1 で GPU を利用するように設定
import tensorflow.compat.v1 as tf # tf.enable_v1_behavior() import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 0 = GPU use; -1 = CPU use config = tf.compat.v1.ConfigProto( device_count = {'GPU': 1 , 'CPU': 3} ) sess = tf.compat.v1.Session(config=config) tf.keras.backend.set_session(sess)
【関連項目】 TensorFlow, TensorFlow 1.14, TensorFlow 1.15
TensorFlow Playground
TensorFlow Playground はオンラインで動く. ニューラルネットワークの ニューロン,結合,学習,重みの変化,学習率,活性化関数(ReLU など),正則化(L2 正則化など),バッチサイズ,データの分類,回帰,そして,ハイパーパラメータが,学習にどのように影響するかなどを簡単に確認できるオンラインのサービスである. URL は次の通り.
http://playground.tensorflow.org
【関連項目】 TensorFlow
TensorFlow-Slim
TensorFlow-Slimは,CNN (convolutional neural network) による画像分類のモデルで利用される学習や検証の機能を持つ. 微調整 (fine tuning)の機能も持つ.
TensorFlow-Slimは,TensorFlow, 1.14 から 2.2 で動くようである (根拠: https://github.com/google-research/tf-slim). 最新の TensorFlow で動くとは限らないので,利用者で確認すること.
- 出典
N. Silberman and S. Guadarrama, TensorFlow-Slim image classification model library, 2016.
- URL: https://github.com/tensorflow/models/tree/master/research/slim
関連項目: TensorFlow のモデルガーデン
【関連項目】 TensorFlow
TensorFlow-Slim のインストール
TensorFlow-Slim の公式ページ(https://github.com/tensorflow/models/tree/master/research/slim)の手順に従う.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- tf_slim のインストール
Windows での TensorFlow-Slim のインストールは, コマンドプロンプトを管理者として開き そのコマンドプロンプトで,次のコマンドを実行することで行う.
python -m pip install -U contextlib2 tf_slim - 確認
インストールできたかの確認は,次のコマンドで行う. エラーメッセージが出ないことを確認すること.
python -c "import tf_slim as slim; eval = slim.evaluation.evaluate_once"
- TensorFlow モデルガーデン(TensorFlow-Slim 画像分類モデルライブラリを含む)のダウンロード
「c:\Program Files\Python38」のところは,Python のインストールディレクトリを設定すること.
cd "c:\Program Files\Python38\Lib" git clone --recursive https://github.com/tensorflow/models mklink /D slim models\research\slim - 動作確認
インストールできたかの確認は,次のコマンドで行う. エラーメッセージが出ないことを確認すること.
python -c "from slim.nets import cifarnet; m = cifarnet.cifarnet"
【関連項目】 TensorFlow
TensorFlow データセット
TensorFlow データセットのカタログのページ: https://www.tensorflow.org/datasets/catalog/overview
「tfds.list_builders()」により,現在インストールされている TensorFlow データセットの データセットビルダーを確認できる.
TensorFlow データセットのロード時に分割を行うには,次のように書く.
「0%:50%」は先頭から 50 %, 「50%:100%」は末尾の 50% 部分.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings iris, iris_info = tfds.load('iris', split=['train[0%:50%]', 'train[50%:100%]'], with_info = True, shuffle_files=True, as_supervised=True) iris = {'train': iris[0], 'test': iris[1]}【関連項目】 CIFAR-10 データセット, CIFAR-100 データセット, Fashion MNIST データセット, IMDb データセット, MNIST データセット, くずし字 MNIST データセット(Kuzushiji-MNIST データセット)
【関連項目】 TensorFlow
TensorFlow データセットカタログ
TensorFlow データセットカタログ の URL: https://www.tensorflow.org/datasets/catalog/overview
【関連項目】 TensorFlow
TensorFlow のモデルガーデン
URL: https://github.com/tensorflow/models
Windows では,次のような手順でダウンロードできる.
「c:\Program Files\Python38」のところは,Python のインストールディレクトリを設定すること.
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- ダウンロード
cd "c:\Program Files\Python38\Lib" git clone --recursive https://github.com/tensorflow/models -
必要に応じて,次のようなコマンドで,シンボリックを作っておくと便利
cd "c:\Program Files\Python38\Lib" mklink /D slim models\research\slim
関連項目: TensorFlow-Slim
【関連項目】 TensorFlow
TensorFlow の最新バージョンの確認
TensorFlow のバージョン,TensorFlow のバージョンと Python のバージョンの関係は,次のページで確認するのが便利である.
https://pypi.org/project/tensorflow/#files
2022年10月時点では TensorFlow の最新版は 2.10 である
TensorFlow のインストールは 別の項目で説明している.
Tensorpack
Saliency Map
!pip3 install --upgrade git+https://github.com/tensorpack/tensorpack.git %tensorflow_version 1.x %cd /content !rm -rf tensorpack !git clone https://github.com/tensorpack/tensorpack %cd tensorpack %cd examples/Saliency !curl -O http://download.tensorflow.org/models/resnet_v1_50_2016_08_28.tar.gz !tar -xzvf resnet_v1_50_2016_08_28.tar.gz !curl -L https://github.com/opencv/opencv/blob/master/samples/data/squirrel_cls.jpg?raw=true -o squirrel_cls.jpg !python3 ./saliency-maps.py squirrel_cls.jpgTesseract OCR
Tesseract OCR は,文字認識ソフトウェアである.
【サイト内の関連ページ】
- Tesseract OCR の使い方: 別ページ »にまとめ
- Windows での Tesseract OCR 5.3.3 のインストールと動作確認(多言語の文字認識): 別ページ »で説明
- Ubuntu での Tesseract OCR のインストール: 別ページ »で説明
【関連する外部ページ】
GitHub の Tesseract OCR のページ: https://github.com/tesseract-ocr/tesseract
Theano
( 2017.9 に開発の停止がアナウンス)
- GitHub の公式ページ: https://github.com/Theano/
- チュートリアル: https://github.com/Newmu/Theano-Tutorials
- CoRR, abs/1605.02688
- Wikipedia のページ: https://en.wikipedia.org/wiki/Theano_(software)
TinaFace
TinaFace は顔検出法である. ResNet50 と Feature Pyramid Network (FPN) をベースとする顔検出法. FPN は 6 レベルあり,それを踏襲している. そうした仕組みになっていることから,さまざまなサイズの顔を検出できるとされている. WIDER FACE データセットを用いた検証により,当時の他の顔検出法よりも精度が優れているとされている.
- 文献
Yanjia Zhu, Hongxiang Cai, Shuhan Zhang, Chenhao Wang, Yichao Xiong, TinaFace: Strong but Simple Baseline for Face Detection, 2020, arXiv:2011.13183 [cs.CV],
- ResearchGate のページ: https://www.researchgate.net/publication/346475155_TinaFace_Strong_but_Simple_Baseline_for_Face_Detection
- Papers with Code のページ: https://paperswithcode.com/method/tinaface
【関連項目】 RetinaNet, SCRFD, モデル, 顔検出 (face detection)
Titanic データセット
Titanic データセットは,公開されているデータセット(オープンデータ)である.
- 行数: 1309行
- 属性: pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked, boat, body, home.dest, survived
【文献】
Frank E. Harrell Jr., Thomas Cason, Titanic dataset, 2002.
【サイト内の関連ページ】
- Titanic データセットについての説明資料: titanic.pdf [PDF], [パワーポイント]
- Titanic データセットを扱う Python プログラム: 別ページ で説明している.
【関連する外部ページ】
- TensorFlow データセットの titanic データセット: https://www.tensorflow.org/datasets/catalog/titanic
Torch 7
- Web ページ: http://torch.ch/
- github: https://github.com/torch/torch7
- チートシート: https://github.com/torch/torch7/wiki/Cheatsheet
- チュートリアル: http://torch.ch/docs/getting-started.html#_
Transformers
【関連項目】 GPT-2, text generation, テキスト特徴 (text feature)
Google Colaboratory で GPT を実行(huggingface の GPT-2 を使用)
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
- transformers のインストール
!pip3 install transformers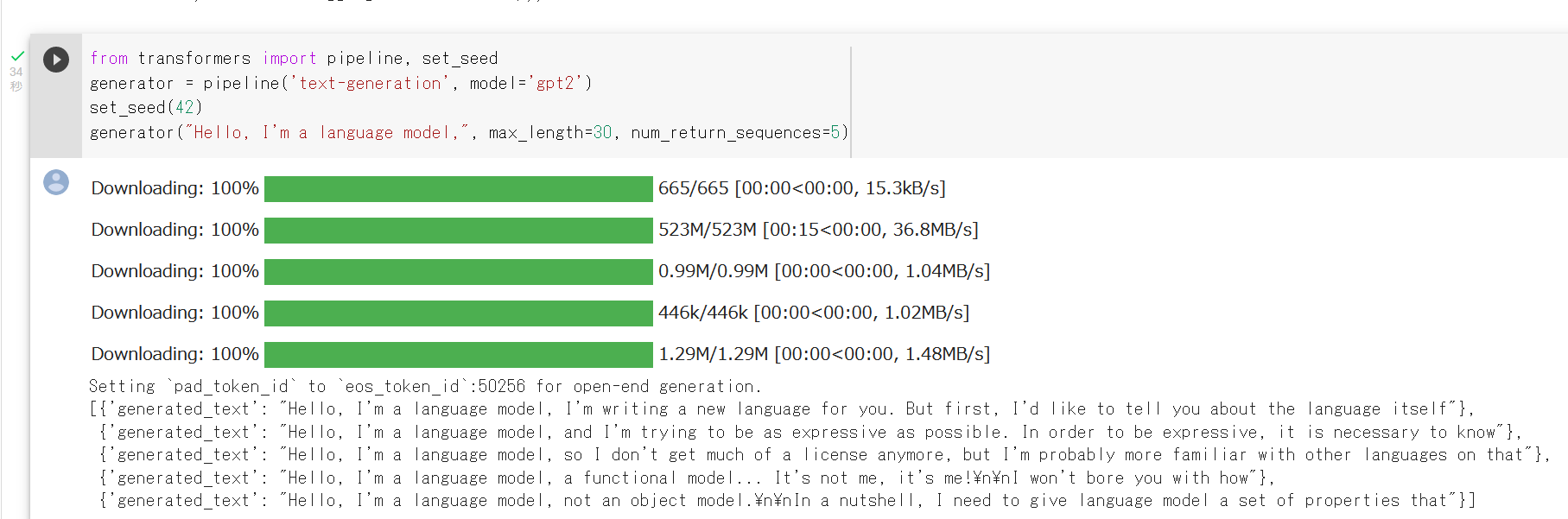
- huggingface の GPT-2 を用いて,open-end text generation を行ってみる.
from transformers import pipeline, set_seed generator = pipeline('text-generation', model='gpt2') set_seed(42) generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)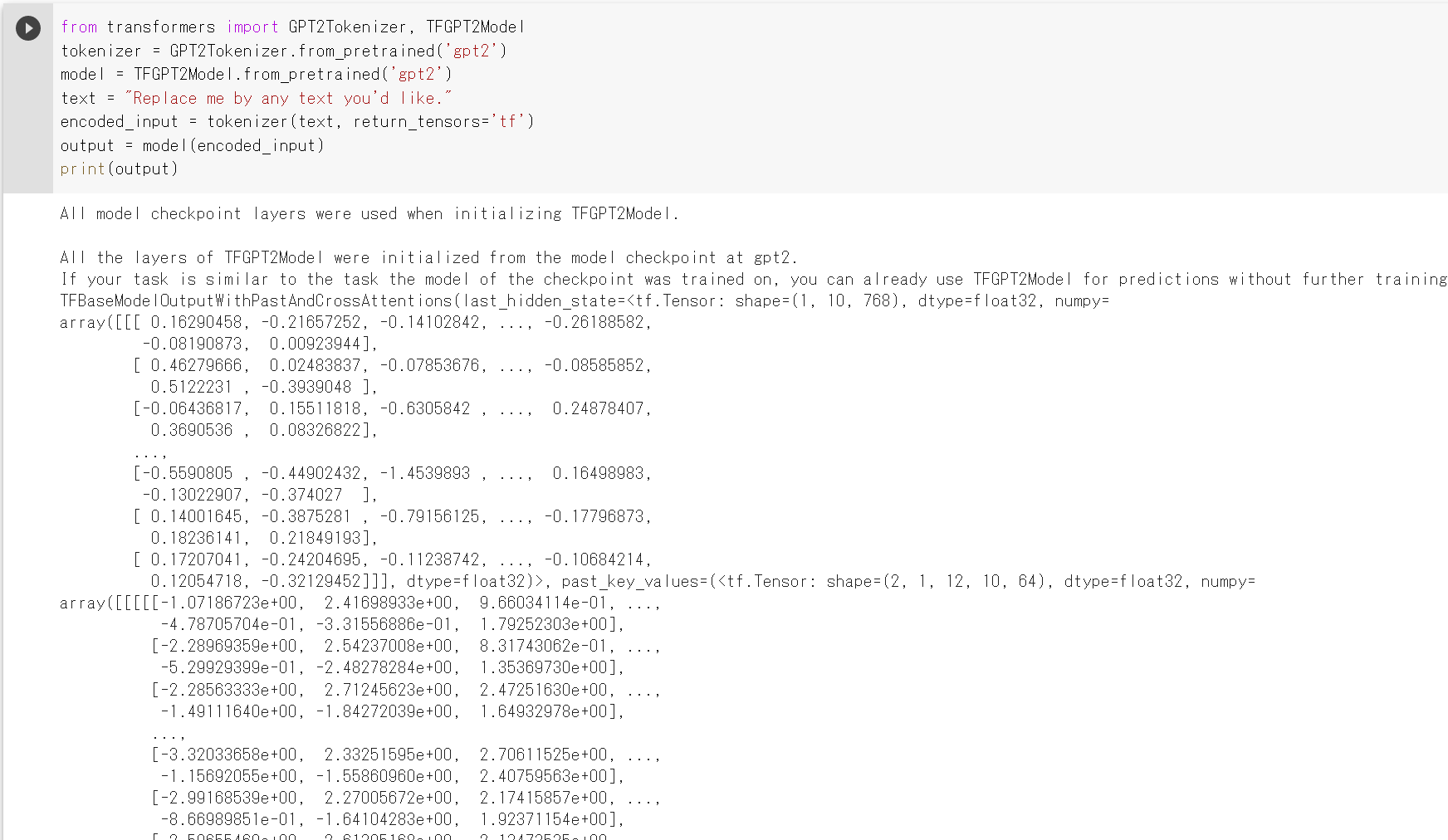
- huggingface の GPT-2 を用いて,テキストの特徴を取得する.
from transformers import GPT2Tokenizer, TFGPT2Model tokenizer = GPT2Tokenizer.from_pretrained('gpt2') model = TFGPT2Model.from_pretrained('gpt2') text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='tf') output = model(encoded_input) print(output)
Twinmotion
Twinmotion は,Unreal Engine を用いて実装されている. 3次元メッシュ(Wavefront OBJ, fbx)のインポート, 3次元点群データのインポート,高さマップ(r15, png)のインポート, OpenStreetMap との連携,人物の配置,波の表現,空の表現などの機能がある.
【関連項目】 Unreal Engine
t 検定 (t test)
- 正規分布に従う2群について,等分散性が成り立っていることが確実な場合には var.equal=TRUE,
- 正規分布に従う2群について,等分散性が成り立っていない可能性がある場合には, var.equal=FALSE を指定する.(等分散性を仮定しない t 検定を, ウェルチの検定ともいう)
R システム で,2群 s1, s2 の t 検定を行うプログラムt.test(s1, s2, var.equal=TRUE) t.test(s1, s2, var.equal=FALSE)
【関連項目】 検定
U2-Net
U2-Net は salient obeject detection の一手法. 【文献】
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R. Zaiane and Martin Jagersand, U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection, arXiv:2108.10257, 2021. 【サイト内の関連ページ】
rembg のインストールと動作確認(画像の背景除去)(Python を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- 公式の GitHub のページ: https://github.com/xuebinqin/U-2-Net
- Papers With Code のページ: https://paperswithcode.com/method/u2-net
【関連項目】 BASNet, U-Net, salient object detection, セマンティック・セグメンテーション (semantic segmentation)
UCF101 (UCF101 Human Actions dataset)
ビデオでのアクションの認識 UCF101 データセット は,101 のアクションカテゴリに分類済みの動画のデータセット.
UCF101 データセットは次の URL で公開されているデータセット(オープンデータ)である.
https://www.crcv.ucf.edu/data/UCF101.php
【関連情報】
- UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild, Khurram Soomro, Amir Roshan Zamir, Mubarak Shah
- Papers With Code の UCF101 データセットのページ: https://paperswithcode.com/dataset/ucf101
- PyTorch の UCF101 データセット: https://pytorch.org/vision/stable/datasets.html#torchvision.datasets.UCF101
- TensorFlow データセットの UCF101 データセット: https://www.tensorflow.org/datasets/catalog/ucf101
UCF-QNRF データセット
画像数は 1535枚. 各画像のアノテーションされたオブジェクト数は 49 から 12865 である.
- 文献
Haroon Idrees, Muhmmad Tayyab, Kishan Athrey, Dong Zhang, Somaya Al-Maadeed, Nasir Rajpoot, and Mubarak Shah. Composition loss for counting, density map estima- tion and localization in dense crowds. In ECCV, 2018.
- 公式ページ: https://www.crcv.ucf.edu/data/ucf-qnrf/
【関連用語】 crowd counting, FIDTM, オープンデータ
U-Net
- 文献
Olaf Ronneberger, Philipp Fischer, Thomas Brox, U-Net: Convolutional Networks for Biomedical Image Segmentation, CoRR, abs/1505.04597v1, 2015.
- U-Net のページ
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
- 実装されたソースコード等 (GitHub) のページ: https://github.com/milesial/PyTorch-UNet
【関連項目】 BASNet, セマンティック・セグメンテーション (semantic segmentation), salient object detection
Google Colaboratory での BASNet のインストールとオンライン実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
U-Net のテストプログラムのオンライン実行を行うまでの手順を示す.
- U-Net プログラムなどのダウンロード**
!rm -rf PyTorch-UNet !git clone https://github.com/milesial/PyTorch-UNet
- 学習済みモデルのダウンロード
https://github.com/milesial/PyTorch-UNet の指示通りに行う. 学習済みモデル(ファイル名 unet_carvana_scale0.5_epoch1.pth)を ダウンロードし,PyTorch-UNet の下に置く
- テスト用の画像のダウンロードと確認表示
%cd PyTorch-UNet !curl -L https://github.com/opencv/opencv/blob/master/samples/data/fruits.jpg?raw=true -o fruits.jpg !curl -L https://github.com/opencv/opencv/blob/master/samples/data/home.jpg?raw=true -o home.jpg !curl -L https://github.com/opencv/opencv/blob/master/samples/data/squirrel_cls.jpg?raw=true -o squirrel_cls.jpg from PIL import Image Image.open('fruits.jpg').show() Image.open('home.jpg').show() Image.open('squirrel_cls.jpg').show()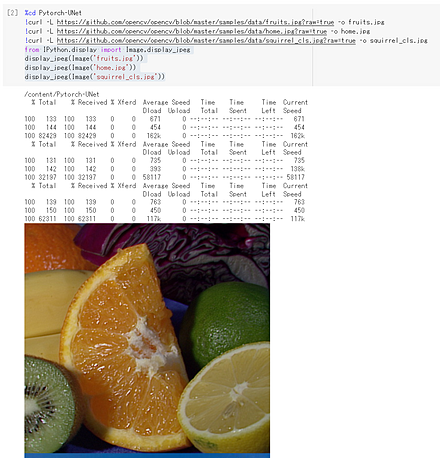

- U-Net の実行
!python3 predict.py --model unet_carvana_scale0.5_epoch1.pth -i fruits.jpg -o fruits_out.jpg !python3 predict.py --model unet_carvana_scale0.5_epoch1.pth -i home.jpg -o home_out.jpg !python3 predict.py --model unet_carvana_scale0.5_epoch1.pth -i squirrel_cls.jpg -o squirrel_cls_out.jpg from PIL import Image Image.open('fruits_out.jpg').show() Image.open('home_out.jpg').show() Image.open('squirrel_cls_out.jpg').show()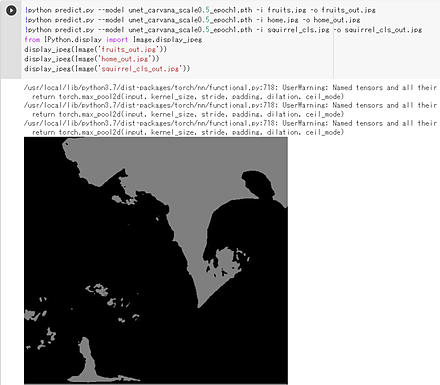

Unified Scene Text Detection
Unified Scene Text Detection は,テキスト検出(text detection),ドキュメントのレイアウト解析(layout analysis)を統合することにより,精度の改善を行っている. 2022年発表.
【文献】
Towards End-to-End Unified Scene Text Detection and Layout Analysis, Long, Shangbang and Qin, Siyang and Panteleev, Dmitry and Bissacco, Alessandro and Fujii, Yasuhisa and Raptis, Michalis, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
https://arxiv.org/abs/2203.15143
【サイト内の関連ページ】
Unified Scene Text Detection のインストールとテスト実行(テキスト検出)(Python,TensorFlow を使用)(Windows 上): 別ページ »で説明
【関連する外部ページ】
- Unified Scene Text Detection の GitHub の公式ページ: https://github.com/tensorflow/models/tree/master/official/projects/unified_detector
- Paper with Code のページ: https://paperswithcode.com/paper/towards-end-to-end-unified-scene-text
【関連項目】 HierText
Utah teapot
Utah teapot は,1975 年に University of Utah の Martin Newell により制作された3次元データ.
Utah teapot のデータは,common.wikimedia.prg の次のページからダウンロードすることができる.
https://commons.wikimedia.org/wiki/File:Utah_teapot_(solid).stl
UTKFace データセット
20000枚以上の顔画像,68ランドマーク,各種の属性(年齢,性別など)
次の URL で公開されているデータセット(オープンデータ)である.
UTKFace の URL: https://susanqq.github.io/UTKFace/
【関連項目】 顔のデータベース, 顔ランドマーク (facial landmark)
VALL-E X
VALL-E X は,音声合成(TTS),プロンプトとして音声を与えて音声合成(voice cloning)の技術である.
【サイト内の関連ページ】
- 顔検出と表情推定(SanjayMarreddi/Emotion-Investigator,Python,TensorFlow を使用)(Windows 上)別ページ »で説明
【関連する外部ページ】
- Plachtaa/VALL-E X の実装のGitHub のページ : https://github.com/Plachtaa/VALL-E-X
- Plachtaa/VALL-E X の実装のHuggingFace のデモページ, VALL E X - a Hugging Face Space by Plachta: https://huggingface.co/spaces/Plachta/VALL-E-X
【関連項目】 Bark
vcpkg
vcpkg は,C や C++ のライブラリを管理する機能を持ったソフトウェア.Windows, Linux, MacOS で動く. ダウンロードされたファイルは,downloads 下に保存される.
vcpkg の GitHub のページ: https://github.com/microsoft/vcpkg
vcpkg のインストール後, cmake から,vcpkg でインストールされたソフトウェアを認識できるようにするために, cmake の実行において,次のようなオプションを付ける場合がある.-DCMAKE_TOOLCHAIN_FILE=C:/vcpkg/scripts/buildsystems/vcpkg.cmake -DVCPKG_TARGET_TRIPLET=x64-windowsWindows での vcpkg のインストール
Windows での vcpkg のインストール: 別ページ »で説明
venv
venv は,Python の仮想環境を作成する機能を提供するモジュールである.Python の仮想環境は隔離されており,特定のバージョンのPythonや,特定のバージョンやPythonパッケージを管理するのに役立つ.
詳しい説明は: 別ページ »で説明
【Python のまとめ】 別ページ に Python の機能などをまとめている.【関連項目】 Python, Python, pip, Python 開発環境,Python コンソールのコマンドでの起動, Python のインストール,pip と setuptools の更新, Python の仮想環境, virtualenv
Python の隔離された環境を扱う(venv を使用)(Windows の場合)
venv を用いて,新しいPython の仮想環境の生成 Python の隔離された環境の新規作成,有効化,無効化を行う.
- Windows では,前準備として次を行う.
- Python のインストール: 別項目で説明している.
- 使用している Python のバージョンの確認は,次のコマンドで行うことができる.
python --version - Python の仮想環境の作成
ここでは,venv のためのディレクトリ名「%HOMEPATH%\.venv」を指定して,新しいPython の仮想環境を生成する.
python -m venv %HOMEPATH%\.venv dir /w %HOMEPATH%\.venv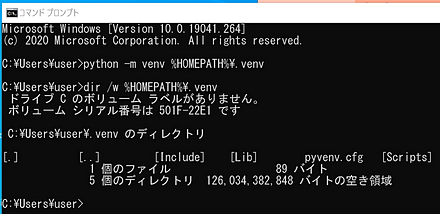
- Python の隔離された環境の有効化
%HOMEPATH%\.venv\Scripts\activate.bat
- パッケージを確認してみる
python -m pip list
- 現在使用している Python の隔離された環境の使用中止(無効化)
deactivate
Python の仮想環境を扱う(venv を使用)(Ubuntu の場合)
venv を用いて,新しいPython の仮想環境の生成 Python の隔離された環境の新規作成,有効化,無効化を行う.
Ubuntuでは,次の手順で行う.
- python3-venv のインストール
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-venv - 使用している システム Python のバージョンの確認は,次のコマンドで行うことができる.
python3 --version
- Python の仮想環境の作成
ここでは,venv のためのディレクトリ名「~/.venv」を指定して,新しいPython の仮想環境を生成する.
* システム Python と違うバージョンの Python を使いたいときは, pyenv を用いる.別ページ »で説明python3 -m venv ~/.venv ls -la .venv
- Python の隔離された環境の有効化
source ~/.venv/bin/activate
- パッケージを確認してみる
python -m pip list
- 現在使用している Python の隔離された環境の使用中止(無効化)
deactivate
VGGFace2 データセット
VGGFace2 データセットは,顔画像がクラス分けされたデータ.
- 画像は,約331万枚.訓練用と検証用に分かれ,うち検証用は約17万枚である.
- クラスは,9131 クラス.訓練用の画像は,8631クラス
- 平均解像度は 137x180 画素.32 画素以下の解像度のものは,全体の 1%未満である.
作者からは,社会的,性別的,人種的,その他の偏りに注意して使うように,注意が行われている.
次の URL で公開されているデータセット(オープンデータ)である.
https://www.robots.ox.ac.uk/~vgg/data/vgg_face/
- Qiong Cao, Li Shen, Weidi Xie, Omkar M. Parkhi, Andrew Zisserman, VGGFace2: A dataset for recognising faces across pose and age, CoRR, 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition, vol. 1, pages: 66-74, 2018.
- Papers With Code の VGGFace2 データセットのページ: https://paperswithcode.com/dataset/vggface2-1
【関連項目】 facial inpainting, 顔のデータベース, 顔認識
video
動画 (video) については,「動画」の項目で説明している.
【関連項目】 動画
vinta の awesome-python
Python のフレームワーク,ライブラリ,ソフトウェア等のリスト.
vinta の awesome-python: https://github.com/vinta/awesome-python
【関連項目】 Python
virtualenv
Ubuntu で,Python の仮想環境の作成
「test」のところは,Python の仮想環境の名前を指定. Python の仮想環境を削除するときは「rm -rf test」のように操作する.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install virtualenv python3-virtualenv virtualenv test source test/bin/activate【関連項目】 Python, Python, pip, Python 開発環境,Python コンソールのコマンドでの起動, Python のインストール,pip と setuptools の更新, Python の仮想環境, venv
Microsoft Build Tools 2015 (Microsoft Build Tools 2015 (マイクロソフト C++ ビルドツール 2015)
Windows での Microsoft Build Tools 2015 (Microsoft Build Tools 2015 (マイクロソフト C++ ビルドツール 2015)のインストール: 別ページ »で説明
Visual Studio Community 2019 のインストール,C++ ビルドツール (Build Tools) のインストール
ここでは,次の2つを説明する.- Visual Studio Community 2019 のインストール, C++ ビルドツール (Build Tools) のインストールを同時に行う.
- C++ ビルドツール (Build Tools) のみのインストール行う.
(1) Visual Studio Community 2019 のインストール, C++ ビルドツール (Build Tools) のインストールを同時に行う.
Visual Studio Community 2019 のインストールには,複数の方法がある. 次のいずれかによりインストールできる.
- wingetを用いてインストールする.本項目の下で説明している.
winget をインストールしたのち,コマンドプロンプトを管理者として開き「winget install Microsoft.VisualStudio.2019.Community」を実行
- 公式ページよりダウンロードしてインストール.
- Visual Studio Community 2019 (マイクロソフト C++ ビルドツール 2019 を含む)のインストールを行う場合: Visual Studio Community 2019 vesion 16.11 のインストール(Windows 上) で説明している.
- Visual Studio Community の全機能は必要なく,マイクロソフト C++ ビルドツール 2019 だけが必要な場合: マイクロソフト C++ ビルドツール 2019 (Build Tools for Visual Studio 2019) のインストール(Windows 上)で説明している.
ここでは,winget を用いてインストールする方法を説明する.
- 事前にwinget のインストールを行っておく.
- コマンドプロンプトを管理者として開き
そこで,次のコマンドを実行(winget を利用してインストール )
winget install Microsoft.VisualStudio.2019.Community - Visual Studio Installer の起動
スタートメニューの「Visual Studio Installer」を使うのが便利
- Visual Studio Community 2019 で「変更」を選ぶ.
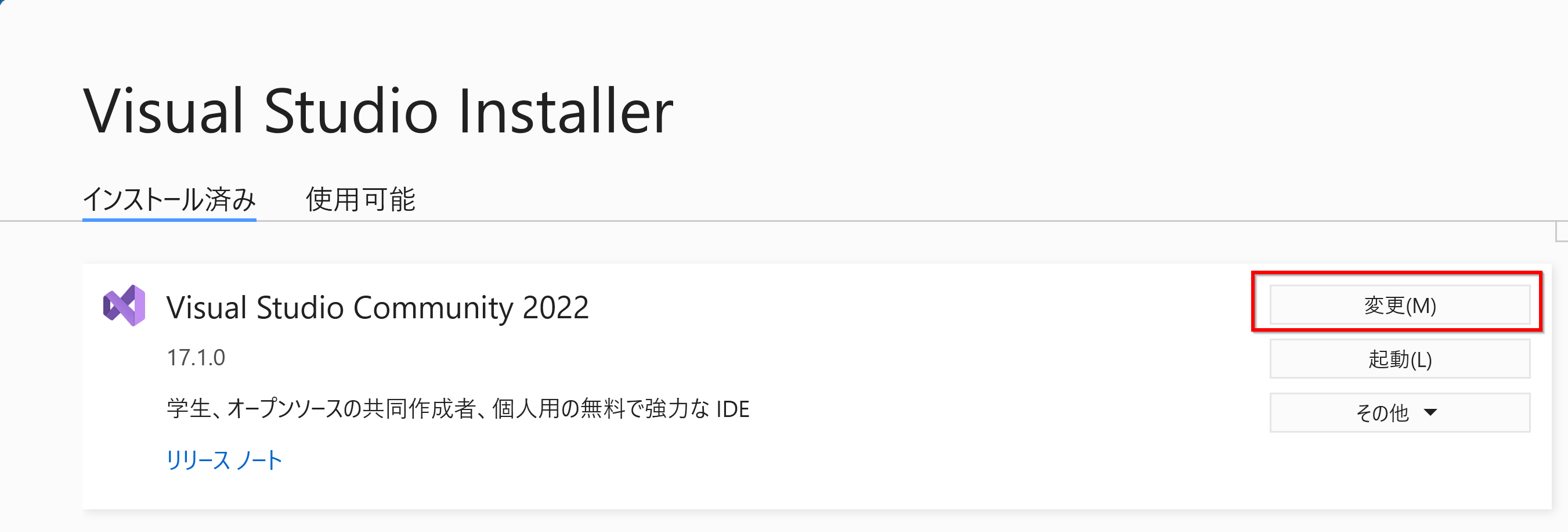
- 「C++ (v142) ユニバーサル Windows プラットフォーム」をチェックし,「変更」をクリック.
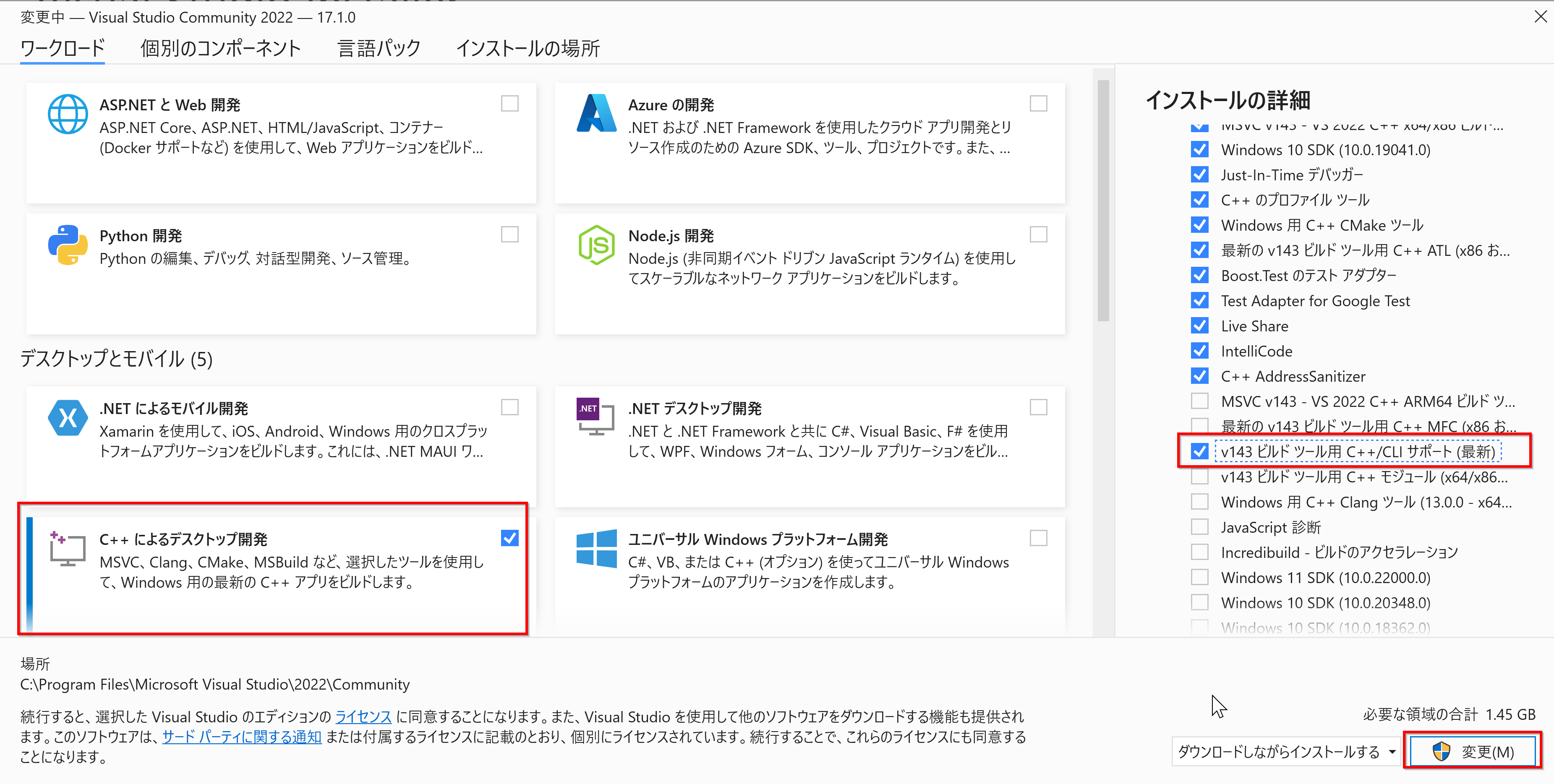
- Visual Studio の英語言語パックのインストール
今後は,「言語パック」で「英語」と「日本語」にチェックし,「変更」をクリック.
C++ ビルドツール (Build Tools) のみのインストール行う.
- Visual Studio のダウンロードの Web ページを開く
- 「Build Tools のダウンロード」をクリック

- ダウンロードが始まる
- ダウンロードした .exe ファイルを実行する
- 表示を確認し,「続行」をクリック
- 「C++ によるデスクトップ開発」をクリック.「インストール」をクリック.
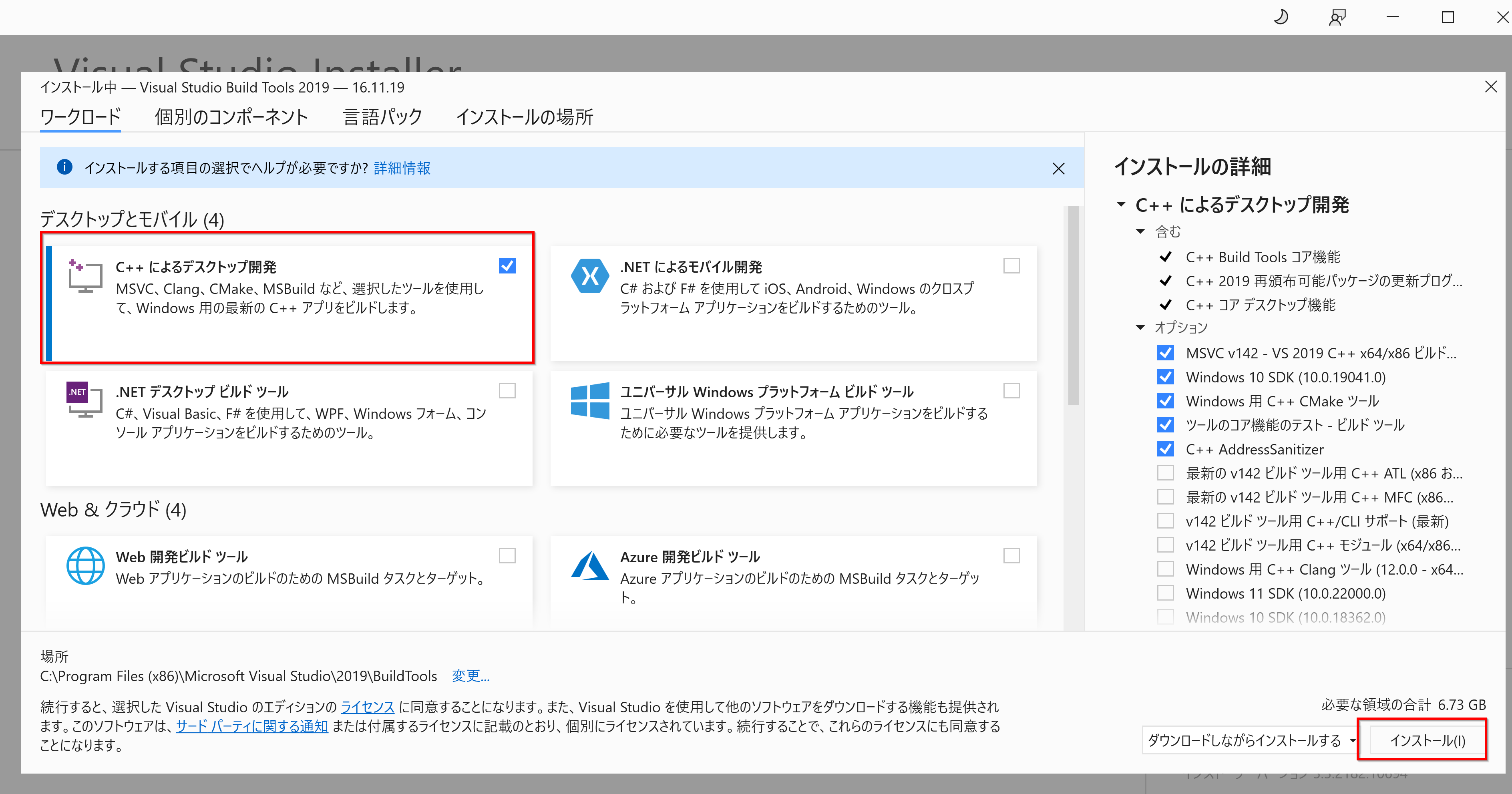
- ダウンロードとインストールが始まる
- インストール終了の確認
「再起動が必要です」と表示された場合には,指示に従う.
Vision Transformer
Vision Transformer は, 画像分類を,CNN よりも高速に,CNN よりも精度が落ちることなく実行できるとされる.
- 文献
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021, 2021.
【関連項目】 画像分類
非公式の PyTorch での ViT の実装
https://github.com/lucidrains/vit-pytorch
VMWare
VMware は仮想マシンソフトウエア
【サイト内の関連ページ】
- Windows での VMware Workstation Player 16.2.3 のインストール:
- Ubuntu での VMware Workstation Player バージョン 15 のインストール:
- VMWare Workstation Player のインストールと Ubuntu 仮想マシンの作成 [PDF], [パワーポイント]
- VMWare の活用: 別ページ »にまとめている.
VOICEVOX
VOICEVOX は,音声合成のソフトウェア.
VOICEVOX CORE の GitHub のページ: https://github.com/VOICEVOX/voicevox_core
【関連項目】 音声合成 (Text To Speech; TTS)
VoltDB
VoltDB Community エディションは, インメモリ SQL データベース,スナップショットによる永続性(persistence)の機能を持つ.
【サイト内の関連ページ】 VoltDB 11.4 のインストール(ソースコードを使用)(Ubuntu 上)
【関連する外部ページ】
VoltDB の GitHub のページ: https://github.com/VoltDB/voltdb
VoltDB の公式のチュートリアル: https://docs.voltdb.com/tutorial/
warning C4819 ファイルは,現在のコードページ (932) で表示できない文字を含んでいます.
「warning C4819 ファイルは,現在のコードページ (932) で表示できない文字を含んでいます. ファイルを Unicode 形式で保存してください」という警告が出る場合がある.
多くの場合,この警告は無視しても良さそうである.
警告のため,コンパイルを進めることができないという場合には, ファイルすべての文字コードを「UTF-8」に変換することで, この問題が解決できる場合がある. 文字コードの変換には,FileCode Checker などのソフトウェアを利用できる. 文字コードの変換は,バックアップを作成した後で実行すること.
FileCode Checker の 作者に感謝します.
FileCode Checker の Vector のページ: https://www.vector.co.jp/soft/winnt/util/se478635.html
Wasserstein GAN (WGAN)
Wasserstein GANでは, GAN (Generative Adversarial Network) での勾配消失問題の解決に取り組んでいる. GAN (Generative Adversarial Network) で用いられてきた Jensen-Shannon divergence (確率密度間の距離尺度の1つ) の代わりに Wasserstein 距離を用いる. 安定して学習ができるとされている
- 文献:
Martin Arjovsky, Soumith Chintala, Léon Bottou, Wasserstein GAN, 2017.
CoRR, abs/1701.07875v3
- Papers with Code のページ: https://paperswithcode.com/method/wgan
- PyTorch-GAN のページ: https://github.com/eriklindernoren/PyTorch-GAN
- Keras-GAN のページ: https://github.com/eriklindernoren/Keras-GAN
- labmlai/annotated_deep_learning_paper_implementations のページ: https://github.com/labmlai/annotated_deep_learning_paper_implementations
【関連項目】 GAN (Generative Adversarial Networks), image generation
Google Colaboratory での Wasserstein GAN (WGAN) のインストールとオンライン実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
実行時間の目安は,ハードウェアアクセラレータなしで 2時間
!rm -rf PyTorch-GAN !git clone https://github.com/eriklindernoren/PyTorch-GAN !python -m pip install -r PyTorch-GAN/requirements.txt !rm -rf PyTorch-GAN/implementations/wgan/images !python3 PyTorch-GAN/implementations/wgan/wgan.py結果は /content/PyTorch-GAN/images の下にある. その中の画像をダブルクリックすると,Webブラウザに画像の中身が表示される.
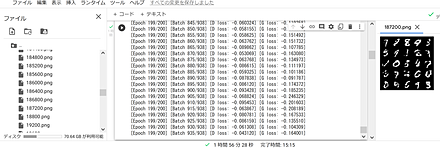
Windows での Wasserstein GAN (WGAN) のインストールと動作確認
PyTorch-GAN のページで公開されているプログラム等を使用
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
実行時間の目安は,GPU 搭載パソコンで数分.
cd %LOCALAPPDATA% rmdir /s /q PyTorch-GAN git clone https://github.com/eriklindernoren/PyTorch-GAN cd PyTorch-GAN python -m pip install -U -r requirements.txt cd implementations/wgan rmdir /s /q images python wgan.py結果は images の下に保存される.

Ubuntu での Wasserstein GAN (WGAN) のインストールと動作確認
PyTorch-GAN のページで公開されているプログラム等を使用
Ubuntu では,次のコマンドを実行.
実行時間の目安は,GPU 搭載パソコンで数分.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo git clone https://github.com/eriklindernoren/PyTorch-GAN sudo chown -R $USER PyTorch-GAN # システム Python の環境とは別の Python の仮想環境(システム Python を使用)を作成 sudo apt -y update sudo apt -y install python3-venv python3 -m venv ~/a source ~/a/bin/activate cd /usr/local/PyTorch-GAN pip install -U -r requirements.txt cd implementations/wgan rm -rf images python wgan.py結果は images の下に保存される.
Wasserstein GAN with Fradient Penalty (WGAN-GP)
- 文献: Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville, Improved Training of Wasserstein GANs, NeurIPS 2017, 2017.
- Papers with Code のページ: https://paperswithcode.com/paper/improved-training-of-wasserstein-gans
- PyTorch-GAN のページ: https://github.com/eriklindernoren/PyTorch-GAN
- Keras-GAN のページ: https://github.com/eriklindernoren/Keras-GAN
- labmlai/annotated_deep_learning_paper_implementations のページ: https://github.com/labmlai/annotated_deep_learning_paper_implementations
【関連項目】 GAN (Generative Adversarial Networks), image generation Wasserstein GAN (WGAN)
Google Colaboratory での Wasserstein GAN (WGAN) のインストールとオンライン実行
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する).
実行時間の目安は,ハードウェアアクセラレータなしで 2時間
!rm -rf PyTorch-GAN !git clone https://github.com/eriklindernoren/PyTorch-GAN !python -m pip install -r PyTorch-GAN/requirements.txt !rm -rf PyTorch-GAN/implementations/wgan_gp/images !python3 PyTorch-GAN/implementations/wgan_gp/wgan_gp.py結果は /content/PyTorch-GAN/images の下にある. その中の画像をダブルクリックすると,Webブラウザに画像の中身が表示される.
Windows での Wasserstein GAN with Gradient Penalty (WGAN-GP) のインストールと動作確認
PyTorch-GAN のページで公開されているプログラム等を使用
- Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/
- インストール
コマンドプロンプトを管理者として開き次のコマンドを実行する.
cd %LOCALAPPDATA% rmdir /s /q PyTorch-GAN git clone https://github.com/eriklindernoren/PyTorch-GAN cd PyTorch-GAN python -m pip install -U -r requirements.txt cd implementations/wgan_gp rmdir /s /q images python wgan_gp.py
Ubuntu での Wasserstein GAN with Gradient Penalty (WGAN-GP) のインストールと動作確認
PyTorch-GAN のページで公開されているプログラム等を使用
Ubuntu では,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install git cd /usr/local sudo git clone https://github.com/eriklindernoren/PyTorch-GAN sudo chown -R $USER PyTorch-GAN # システム Python の環境とは別の Python の仮想環境(システム Python を使用)を作成 sudo apt -y update sudo apt -y install python3-venv python3 -m venv ~/a source ~/a/bin/activate cd /usr/local/PyTorch-GAN pip install -U -r requirements.txt cd implementations/wgan_gp rm -rf images python wgan_gp.py結果は images の下に保存される.
WebFace260M, WebFace42M データセット
機械学習向けの大規模な顔画像のデータセット. 顔検出,顔の分類(年齢,性別など)の用途が想定されている.2021年時点では,研究者等が利用可能な,最大規模の顔画像のデータセットである. データは次の2種類がある.
- WebFace260M:
4M identities, 260M images, images/id 64, cleaning no, public
- WebFace42M
2M identities, 42M images, images/id 21, cleaning auto, 7 attributes 訓練データに適するとされている.年齢,人種,性別,シナリオ(controlled, in-the-wild, cross-scene)
次の URL で公開されているデータセット(オープンデータ)である.
URL: https://www.face-benchmark.org/index.html
詳細は,「the Masked Face Recognition challenge」の文献で説明されている.
- Papers with Code のページ: https://paperswithcode.com/dataset/webface260m
- 文献
Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jiwen Lu, Dalong Du, Jie Zhou, WebFace260M: A Benchmark Unveiling the Power of Million-scale Deep Face Recognition, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
- 文献
Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jia Guo, Jiwen, Lu, Dalong Du, and Jie Zhou. Masked face recognition challenge: The WebFace260M track report. arXiv:2108.07189, 2021.
【関連項目】 顔のデータベース
Wget のインストール(Windows 上)
- 次のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。
次のコマンドは,Wgetをインストールするものである.
winget install --scope machine GNU.Wget2wget2コマンドで使用.
【関連する外部ページ】
- Wget の公式ページ: https://www.gnu.org/software/wget/
- Wget のダウンロードページ: http://gnuwin32.sourceforge.net/packages/wget.htm からダウンロードしてインストール:
【関連項目】 Wget
Whisper
Whisperは,音声からの文字起こし,翻訳を行う. 訓練されたモデルが既存のデータセットにゼロショットで適用可能であり,データセット固有のファインチューニングを必要とせずに高品質な結果を達成することを特徴とする.
【文献】
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever, Robust Speech Recognition via Large-Scale Weak Supervision, CoRR abs/2212.04356, 2022.
https://cdn.openai.com/papers/whisper.pdf
【サイト内の関連ページ】
- マイクに話しかけた言葉を,リアルタイムにAIが認識(whisper, whisper_mic, Python を使用)(Windows 上)別ページ »で説明
- Whisper のインストール,Whisper を使う Python プログラム(音声からの文字起こし,翻訳)(Python,PyTorch を使用)(Windows 上)別ページ »で説明
【関連する外部ページ】
- Paper with Code のページ: https://paperswithcode.com/paper/robust-speech-recognition-via-large-scale-1
- Introducing Whisper のページ: https://openai.com/index/whisper/
- GitHub のページ: https://github.com/openai/whisper
【関連項目】 mallorbc の whisper_mic
Wide ResNet
【関連項目】 Residual Networks (ResNets), モデル, 画像分類
PyTorch, torchvision の Wide ResNet50 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_wide_resnet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのWide ResNet モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.wide_resnet50_2(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
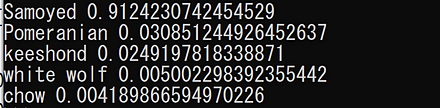
Linux での結果
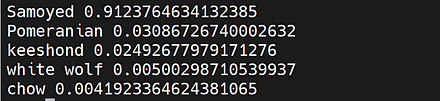
PyTorch, torchvision の Wide ResNet101 学習済みモデルのロード,画像分類のテスト実行
PyTorch HUB のページ: https://pytorch.org/hub/pytorch_vision_wide_resnet/ を参考にした.Google Colab あるいはパソコン(Windows あるいは Linux)を使用.
- 前準備
前準備として,Python のインストール: 別項目で説明している., PyTorch のインストール を行う.
Google Colaboratory では, Python, PyTorch はインストール済みなので,インストール操作は不要.次に,pip を用いて,pillow のインストールを行う.
pip install -U pillow - ImageNet データセット で学習済みのWide ResNet モデルのロード
PyTorch, torchvision のモデルについては: https://pytorch.org/vision/stable/models.html に説明がある.
import torch import torchvision.models as models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') m = models.wide_resnet101_2(pretrained=True).to(device)- 画像分類したい画像ファイルのダウンロードとロードと確認表示
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'https://github.com/pytorch/hub/raw/master/images/dog.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)
- 画像の前処理.PyTorch で扱えるようにするため.
from PIL import Image from torchvision import transforms img = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0)- 推論 (inference) の実行
「m.eval()」は,推論を行うときのためのもの.これを行わないと訓練(学習)が行われる.
import torch if torch.cuda.is_available(): input_batch = input_batch.to('cuda') m.eval() with torch.no_grad(): output = m(input_batch)- 結果の表示
import urllib url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt") try: urllib.URLopener().retrieve(url, filename) except: urllib.request.urlretrieve(url, filename) with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] # The output has unnormalized scores. To get probabilities, you can run a softmax on it. probabilities = torch.nn.functional.softmax(output[0], dim=0) print(probabilities) top5_prob, top5_catid = torch.topk(probabilities, 5) for i in range(top5_prob.size(0)): print(categories[top5_catid[i]], top5_prob[i].item())Google Colaboratory での結果

Windows での結果
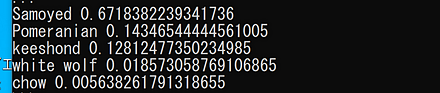
Linux での結果
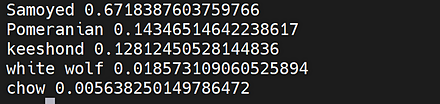
WIDER FACE データセット
WIDER FACE データセットは,32,203枚の顔画像のデータセットである. 機械学習での顔検出の学習や検証に利用できる.- 公開されている WIDERデータセットから,32,203枚の画像が選択された.
- その中の 393,703個の顔について,バウンディングボックスが付けられている.
- 顔のサイズ,ポース,occlusion,表情,照明,イベントはさまざまである.
- 61のシーンカテゴリ(scene category)が定めらている.各シーンカテゴリについて,40%/10%/50%の比率で,画像がランダムに選択され,訓練データ(training data),検証データ(validation data),テストデータ(test data)に分けられている.
- EdgeBoxes 法による検出率により,Easy, Medium, Hard の 3つの困難さのレベルが定められている.
- 訓練データと検証データの画像とアノテーションはオンラインで公開されているが,テストデータのアノテーションは公開されていない(結果はデータベースサーバーに送られ,精度とリコール曲線を受け取ることになっている).
WIDER FACE データセットは,次の URL で公開されているデータセット(オープンデータ)である.
URL: http://shuoyang1213.me/WIDERFACE/
【関連情報】
- Yang, Shuo and Luo, Ping and Loy, Chen Change and Tang, Xiaoou, WIDER FACE: A Face Detection Benchmark, IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016.
- PyTorch の WIDER FACE データセット: https://pytorch.org/vision/stable/datasets.html
- TensorFlow データセットの WIDER FACE データセット: https://www.tensorflow.org/datasets/catalog/wider_face
【関連項目】 顔のデータベース, 顔検出 (face detection)
Windows
【サイト内の主な Windows 関連ページ】
- Windows のまとめ: 別ページ »で説明
- GPU環境でのTensorFlow 2.10.1のインストールと活用(Windows 上): 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Windows での人工知能関係のソフトウエアのインストール: 別ページ »にまとめ
- Windows での主要なソフトウェアのインストールと設定: 別ページ »で説明
- winget を用いて,Windows での主要なソフトウェアのインストール,設定を行う(winget を使用): 別ページ »で説明
- Windows の種々のソフトウェアのインストール(目次): 別ページ »にまとめている.
Wine
Wine は,Windows の API の機能を提供することにより,Windows アプリケーションを Linux 上で動かすことを一部可能とするソフトウェア.
Linux でのインストールは,次のWebページに説明がある
https://wiki.winehq.org/Download
Wine のインストールの手順は,Linux ディストリビューションの種類によって違うので注意.
Ubuntu では,次のWebページの手順に従う
https://wiki.winehq.org/Ubuntu
WinPython のインストール
WinPython は,Window 用のPython 処理系と主要な Python パッケージを1つにまとめたソフトウェア.次のアプリケーションも同封されている
- MinGW の gcc
- qtconsole: コンソール.図などにも対応.
- spyder: Python 開発環境
- Anaconda Navigator: アプリケーションの起動や管理などができるアプリケーション
Windows での WinPython のインストールには,複数の方法がある.次のいずれかによりインストールできる.
- 公式ページからダウンロードしてインストールする.その詳細は,別ページ »で説明
- wingetを用いてインストールする.
winget をインストールしたのち,コマンドプロンプトを管理者として開き「winget install winpython」を実行.
【関連項目】 Python のインストール: 別項目で説明している.
XAMPP
XAMPP は, Apache Web サーバ, MySQL(もしくは MariaDB), PHP 及び関連のソフトウェアを一括でインストールするツール. 学習用に適すると考えている.実用で使うなら Linux を使い,パスワード,ファイヤウオール等を適切に設定する.バックアップも適切に行う.
【サイト内の関連ページ】
- XAMPP for Windows 8.2.4 のインストール,データベース作成,テーブル定義とレコード挿入,各種設定(Windows 上): 別ページ »で説明
- Apache Friends XAMPP for Linux 7.4.9 のインストール(Ubuntu 上): 別ページ »で説明
YOLOv3
- 文献
Redmon, Joseph and Farhadi, Ali, YOLOv3: An Incremental Improvement, CoRR, abs/1804.02767v1 2018.
- Papers with Code のページ: https://paperswithcode.com/paper/yolov3-an-incremental-improvement
- AlexeyAB darknet: https://github.com/AlexeyAB/darknet
- AlexeyAB darknet のアセット: https://github.com/AlexeyAB/darknet/releases/
- MMDetection のモデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/yolo/README.md
- MMDetection: https://github.com/open-mmlab/mmdetection
【関連項目】 AlexeyAB darknet, MMDetection, YOLOv4, YOLOX, モデル, 物体検出
Google Colaboratory で YOLOv3 による物体検出(AlexeyAB darknet を使用)
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する)
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- AlexeyAB darknet のビルド
%cd /content !rm -rf darknet !git clone https://github.com/AlexeyAB/darknet %cd darknet !make GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1
- 重みのダウンロード
AlexeyAB darknet のアセット: https://github.com/AlexeyAB/darknet/releases/
!curl -LO https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov3.weights
- YOLOv3 による物体検出
!rm -r predictions.jpg !./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg -dont_show from PIL import Image Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/giraffe.jpg -dont_show Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/horses.jpg -dont_show Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/person.jpg -dont_show Image.open('predictions.jpg').show()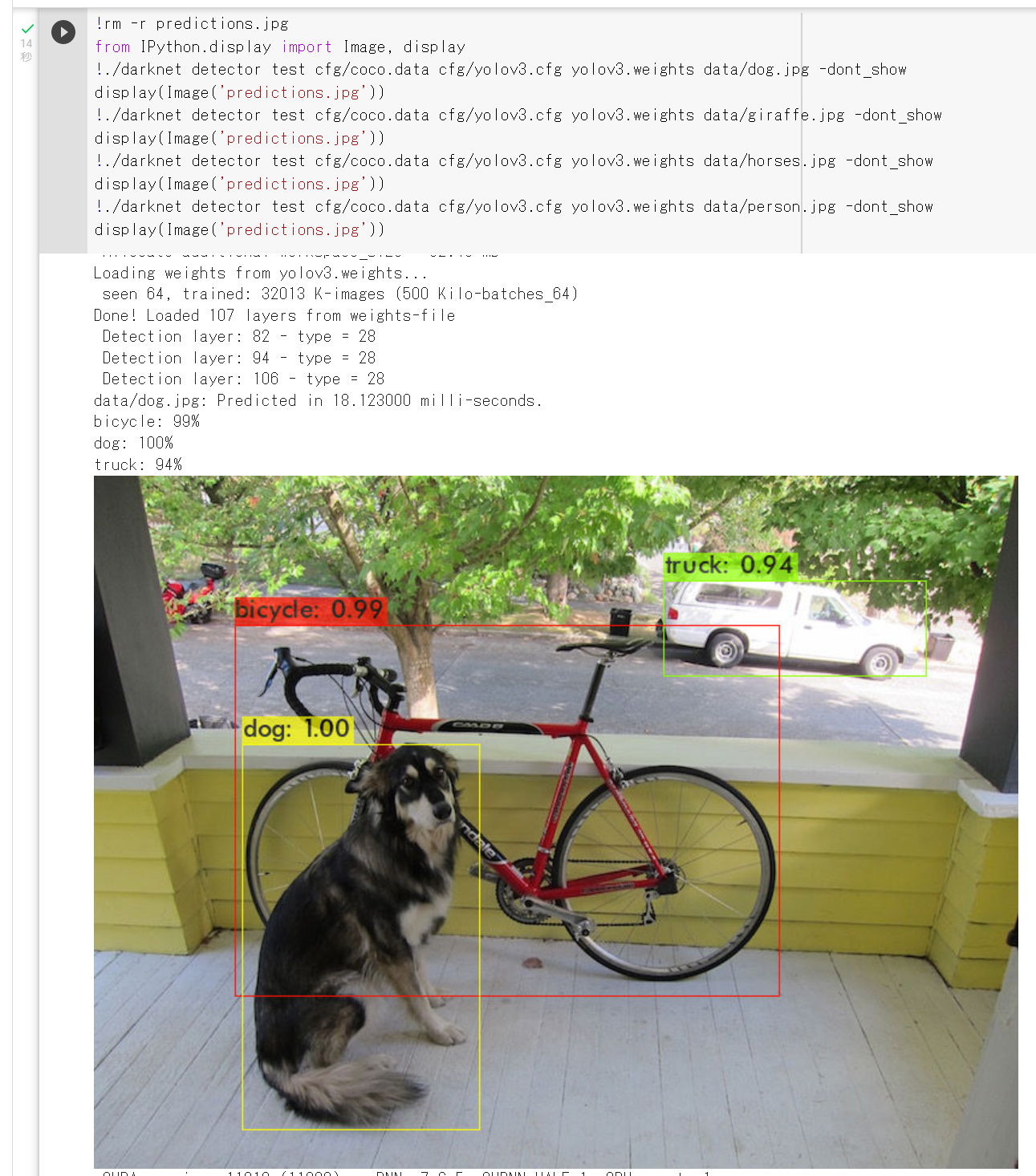



Google Colaboratory で AlexeyAB darknet のインストールと,YOLOv3 による物体検出(AlexeyAB darknet を使用)
書きかけ(動作チェック中)
cd %LOCALAPPDATA% rmdir /s /q darknet git clone https://github.com/AlexeyAB/darknet cd darknet del CMakeCache.txt rmdir /s /q CMakeFiles cmake -A x64 -T host=x64 ^ -DCUDA_BUILD_CUBIN=ON -DENABLE_CUDA=ON -DENABLE_CUDNN=ON -DENABLE_CUDNN_HALF=ON cmake --build . --config Release --target INSTALL -- /m:4 Windows では,システム環境変数 PATH に,次の2つを追加. %LOCALAPPDATA%\darknet\build\darknet\x64 %LOCALAPPDATA%\darknet\3rdparty\pthreads\bin cd %LOCALAPPDATA% cd darknet curl -LO https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov3.weights darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -ext_output darknet detect cfg/yolov3.cfg yolov3.weights data/giraffe.jpg -ext_output darknet detect cfg/yolov3.cfg yolov3.weights data/horses.jpg -ext_output darknet detect cfg/yolov3.cfg yolov3.weights data/person.jpg -ext_output curl -O https://www.kkaneko.jp/sample/video/samplevideo.mp4 ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights samplevideo.mp4 -i 0 -thresh 0.25
Avatar Erik Linder-Norén による YOLOv3 の実装の,Ubuntu でのインストールと実行
Avatar Erik Linder-Norén による YOLOv3 の実装: https://github.com/eriklindernoren/PyTorch-YOLOv3
- インストールとテスト実行
Ubuntu では,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install virtualenv python3-virtualenv cd ${HOME} virtualenv a source a/bin/activate pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html python -c "import torch; print(torch.__version__, torch.cuda.is_available())" pip install pytorchyolo # ソースコード等をダウンロード(後の作業で使うため) cd /usr/local sudo git clone https://github.com/eriklindernoren/PyTorch-YOLOv3 sudo chown -R ${USER} PyTorch-YOLOv3 # 事前学習の重み (pretrained weight) yolov3.weights, yolov3-tiniy.weights, darknet53.conv.74 のダウンロード cd /usr/local/PyTorch-YOLOv3/weights bash ./download_weights.sh # COCO データセット train2014.zip, val2014.zip, instances_train-val2014,zip, 5k.part, trainvalno5k.part, labels.tgz のダウンロード cd /usr/local/PyTorch-YOLOv3/data bash ./get_coco_dataset.sh # テスト実行 cd /usr/local/PyTorch-YOLOv3 yolo-test --weights weights/yolov3.weightsテスト実行の結果,COCO test データセットでの,AP と mAP が表示される.
- 推論
Ubuntu では,次のコマンドを実行.
cd /usr/local/PyTorch-YOLOv3 yolo-detect --images data/samples/推論の結果が表示される. 推論の結果としては,data/samples 下にある画像ファイルについての物体検出の結果である,クラス名と確信度 (confidence) が得られる. あわせて,output の下に,物体検出の画像ファイルができる.

- 学習
ImageNet で事前学習済みの Darknet-53 バックエンドを用いて, COCO データセットによる学習を行う手順が, https://github.com/eriklindernoren/PyTorch-YOLOv3 で説明されている.
yolo-train --data config/coco.data --pretrained_weights weights/darknet53.conv.74
YOLOv4
物体検出のモデルである.
【関連項目】 AlexeyAB darknet, YOLOX, モデル, 物体検出
Google Colaboratory で YOLOv4 による物体検出(AlexeyAB darknet を使用)
次のコマンドやプログラムは Google Colaboratory で動く(コードセルを作り,実行する)
- Google Colaboratory で,ランタイムのタイプを GPU に設定する.
- AlexeyAB darknet のビルド
%cd /content !rm -rf darknet !git clone https://github.com/AlexeyAB/darknet %cd darknet !make GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1
- 重みのダウンロード
AlexeyAB darknet のアセット: https://github.com/AlexeyAB/darknet/releases/
!curl -LO https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights - YOLOv4 による物体検出
!rm -r predictions.jpg !./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/dog.jpg -dont_show from PIL import Image Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/giraffe.jpg -dont_show Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/horses.jpg -dont_show Image.open('predictions.jpg').show() !./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/person.jpg -dont_show Image.open('predictions.jpg').show()



YOLOX
DarkNet53 バックボーンとするYOLOv3 に修正を行たもの.
物体検出のモデルである. single-stage である. DarkNet53 バックボーンとするYOLOv3 に修正を行たものである.
- 文献
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun, YOLOX: Exceeding YOLO Series in 2021, CoRR, abs/2107.08430v2, 2021.
- 公式のソースコード: https://github.com/Megvii-BaseDetection/YOLOX
- Papers with Code のページ: https://paperswithcode.com/method/yolox
- MMDetection のモデル: https://github.com/open-mmlab/mmdetection/blob/master/configs/yolox/README.md
【関連項目】 MMDetection, YOLOv3, YOLOv4, モデル, 物体検出
Google Colab での YOLOX のインストールとオンライン実行
公式のソースコードを使用.
- cython, pycocotools, YOLOX のインストール
!pip3 install cython !pip3 install git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI !rm -rf YOLOX !git clone https://github.com/Megvii-BaseDetection/YOLOX !pip3 install -U pip !pip3 install -r YOLOX/requirements.txt !(cd YOLOX; python3 setup.py develop) - 重みのダウンロード.
!(cd YOLOX; curl -L -O https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_x.pth) - 物体検出の実行
GPU を使うときは「cpu」のところを「GPU」に変える
!(cd YOLOX; python tools/demo.py image -n yolox-x -c ./yolox_x.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device cpu)./YOLOX_outputs/yolox_x/vis_res の下に結果ができるので確認

- 別の画像で物体検出の実行
GPU を使うときは「cpu」のところを「GPU」に変える
次のプログラムでは,curl は,画像ファイルのダウンロードのために用いている(コマンドを使わずに,手作業で画像ファイルを置く場合には,この部分は不要)
画像ファイル名には「../img.png」のように「../」を付けていることに注意.「../」は,「1つ上のレベルのディレクトリ」という意味.
!curl -O https://raw.githubusercontent.com/zylo117/Yet-Another-EfficientDet-PyTorch/master/test/img.png !curl -O https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg !curl -O https://raw.githubusercontent.com/opencv/opencv/master/samples/data/home.jpg !(cd YOLOX; python tools/demo.py image -n yolox-x -c ./yolox_x.pth --path ../img.png --conf 0.25 --nms \ 0.45 --tsize 640 --save_result --device cpu) !(cd YOLOX; python tools/demo.py image -n yolox-x -c ./yolox_x.pth --path ../fruits.jpg --conf 0.25 --n\ ms 0.45 --tsize 640 --save_result --device cpu) !(cd YOLOX; python tools/demo.py image -n yolox-x -c ./yolox_x.pth --path ../home.jpg --conf 0.25 --nms\ 0.45 --tsize 640 --save_result --device cpu)./YOLOX_outputs/yolox_x/vis_res の下に結果ができるので確認



yuki-koyama の blender-cli-rendering
bpy (blenderpy)を使うときに便利なソフトウェアのライブラリと,そのサンプルプログラムと,各種のアセット.
- 前準備
Git のインストール: 別項目で説明している.
Git の公式ページ: https://git-scm.com/ が必要.
- yuki-koyama の blender-cli-rendering のダウンロード
mkdir c:\pytools cd c:\pytools rmdir /s /q blender-cli-rendering-master git clone https://github.com/yuki-koyama/blender-cli-rendering - 確認のため Blender の Cycles レンダラーを用いてレンダリングを行う.
Windows で Python のバージョン指定したいときは, 「python 」でなく「py -3.7」のように実行すること. 「-3.7」のところには,使用する Python のバージョンを指定(バージョンが分からないときは「py -0」で調べる).
cd c:\pytools cd blender-cli-rendering-master python - その後,次の Python プログラムを実行
import bpy import utils # scene utils.clean_objects() scene = bpy.data.scenes["Scene"] monkey = utils.create_smooth_monkey(location=(0, 0, 1)) plane = utils.create_plane(size=20.0) camera = utils.create_camera(location=(5, -3, 3)) utils.add_track_to_constraint(camera, monkey) # light light = utils.create_sun_light(rotation=(0.3, -1.5, 1.2)) # rendering utils.set_output_properties(scene, 20, 'c:/pytools/02') utils.set_cycles_renderer(scene, camera, 16) bpy.ops.render.render(write_still=True)次の画像ができる.

- その後,次の Python プログラムを実行
import os import bpy import utils # scene utils.clean_objects() scene = bpy.data.scenes["Scene"] monkey = utils.create_smooth_monkey(location=(0, 0, 1)) plane = utils.create_plane(size=20.0) camera = utils.create_camera(location=(5, -3, 3)) utils.add_track_to_constraint(camera, monkey) # light working_dir_path = os.path.abspath('.') hdri_path = os.path.join(working_dir_path, "assets\HDRIs\green_point_park_2k.hdr") utils.build_environment_texture_background(scene.world, hdri_path) # rendering utils.set_output_properties(scene, 20, 'c:/pytools/03') utils.set_cycles_renderer(scene, camera, 16) bpy.ops.render.render(write_still=True)
謝辞:この項目に記載のソースコードは, https://github.com/yuki-koyama/blender-cli-rendering/ で公開されているものを改変して使用している.
【関連項目】 bpy (blenderpy), Blender
あ〜ん (ひらがな,カタカナ)
zlib データ圧縮ライブラリ
zlib はデータ圧縮ライブラリ
主な機能: データの圧縮と展開(解凍),メモリ内での圧縮と展開(解凍)処理
【関連する外部ページ】
- zlib の公式ページ: https://www.zlib.net/
【関連項目】 zlib のインストール(Windows 上)
zlib のインストール(Windows 上)
- 次のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。
次のコマンドは,zlibをインストールし,パスを通すものである.
cd /d c:%HOMEPATH% rmdir /s /q zlib git clone https://github.com/madler/zlib cd zlib del CMakeCache.txt rmdir /s /q CMakeFiles cmake . -G "Visual Studio 17 2022" -A x64 -T host=x64 -DCMAKE_INSTALL_PREFIX=c:/zlib cmake --build . --config Release --target INSTALL powershell -command "$oldpath = [System.Environment]::GetEnvironmentVariable(\"Path\", \"Machine\"); $oldpath += \";c:\zlib\bin\"; [System.Environment]::SetEnvironmentVariable(\"Path\", $oldpath, \"Machine\")" powershell -command "[System.Environment]::SetEnvironmentVariable(\"ZLIB_HOME\", \"C:\zlib\", \"Machine\")"【関連する外部ページ】
- zlib の公式ページ: https://www.zlib.net/
【関連項目】 zlib
イテレーション (iteration)
モデルの学習において, モデルの重みを更新することを繰り返すが, その各々1回をイテレーション (iteration) という. 「反復」ともいう. 1回のイテレーションで,データの 1つのバッチに対する損失についてのパラメータの勾配が計算される.
インスタンス・セグメンテーション (instance segmentation)
インスタンス・セグメンテーション (instance segmentation) は, 物体検出 を行うだけでなく, 検出されたオブジェクトについて, オブジェクトのセグメンテーションマスクを画素単位で生成する.
セマンティック・セグメンテーション との違いは次の通りである. セマンティック・セグメンテーションでは,「インスタンス」という概念がないため, シーン内に複数の人物 (person) がいるような場合,人物の領域に person をいうラベルを付ける. インスタンス・セグメンテーションは, シーン内に複数の人物 (person) がいるような場合,それぞれの人物を分離する. 【関連項目】 セマンティック・セグメンテーション (semantic segmentation), シーン解析(scene parsing), CASILVision, MIT Scene Parsing Benchmark, 物体検出
ウエルチの方法による一元配置分散分析 (One-way analysis of means)
パラメトリック検定.等分散を仮定しない場合と仮定する場合がある.多群の検定.
R システム で,x, y についての ウエルチの方法による一元配置分散分析 (One-way analysis of means) を行うプログラム.なお,群数が2の場合には t 検定(R の t.test)と同じ結果が得られる.
oneway.test(x ~ y)
等分散 のときは,「var=T」を付ける.
oneway.test(x ~ y, var=T)
なお,群数が2の場合には,等分散での t 検定(R の t.test(var.equal=TRUE))と同じ結果が得られる.
【関連項目】 検定
ウィルコクソンの符号順位検定 (Wilcoxon signed-rank test)
帰無仮説: ノンパラメトリック検定の1つ.対応のある2標本で,2群の差が 0 である.
【関連項目】 検定
エポック
教師データを全て使い終わったら 1エポックである.
ミニバッチ学習を行うとき, 教師データのサイズを N とすると, N 割るバッチサイズの回数のイテレーション (iteration) が実行される. バッチサイズが 100,教師データのサイズが 800であるとすると, 8回のイテレーション (iteration) で 1エポックである.
オープンデータ (open data)
このサイトでは,「オープンデータは,インターネットで公開されているデータ,もしくは,インターネット等を用いて利用申込みができるデータ」の意味で用いている.
オープンデータには次のようなものがある.
- Aachen Day-Night データセット
- ADE20K データセット,セグメンテーション
- AFLW (Annotated Facial Landmarks in the Wild) データセット: 顔画像,21の顔ランドマーク,in-the-wild
- AIM-500 (Automatic Image Matting-500) データセット, イメージ・マッティング (image matting)
- AgeDB データセット, 顔データ,年齢, in-the-wild
- BioID 顔データベース (BioID Face Database), 顔画像,目の位置
- Caltech Pedestrian データセット,物体検出
- CelebA (Large-scale CelebFaces Attributes) データセットのダウンロード,顔検出,顔ランドマーク (facial landmark),顔認識,顔の生成
- CIFAR-10 データセット, 画像分類
- CIFAR-100 データセット, 画像分類
- Cityscapes データセット, セマンティック・セグメンテーション (semantic segmentation)
- CuRRET データベース (Columbia-Utrecht Reflectance and Texture Database), 反射率とテクスチャに関するデータベース
- COCO データセット, 物体検出 ,オブジェクトのセグメンテーション(パノプティックを含む),キーポイント,姿勢推定
- COCO の Keypoints 2014/2017 データセット, 姿勢推定
- DUTS データセット, saliency detection, salient object detection
- FaceForensics++ データセット, 画像分類
- Fashion MNIST データセット, 画像分類
- FFHQ (Flickr-Faces-HQ) データセット,顔の生成など
- FLIC (Frames Labeled In Cinema)データセット, 姿勢推定
- FordA データセット, 時系列
- FSDnoisy18k データセット, 20種類のサウンドデータ
- HELEN データセット, 顔画像,194個の顔ランドマーク
- HMDB51 (a large human motion database) データセット,行動分類,行動認識,ビデオ検索
- JHU-CROWD++ データセット, crowd counting
- ImageNet データセット, 画像分類,物体検出
- IMM 顔データベース (IMM Face Database), 顔,58個の顔ランドマーク
- iNaturalist データセット, 画像分類, 物体検出
- Iris データセット, データフレーム
- Kinetics Human Action Video データセット, ビデオでのアクション
- KITTI データセット,3次元のセグメンテーション
- ks_1033_data, データフレーム
- LFW データセット: 顔データ,人物のID,顔認識 (face recognition),in-the-wild
- LSP データセット, 姿勢推定
- LSUN (Large-scale Scene UNderstanding Challenge) データセット, 画像分類,画像生成
- Mapillary Vistas Dataset (MVD), セマンティック・セグメンテーション (semantic segmentation), インスタンス・セグメンテーション (instance segmentation)
- MIT Scene Parsing Benchmark, セマンティック・セグメンテーション (semantic segmentation), シーン解析(scene parsing),インスタンス・セグメンテーション (instance segmentation)
- LVIS データセット, シーン解析(scene parsing),インスタンス・セグメンテーション (instance segmentation)
- MNIST データセット, 画像分類
- MPII Human Pose データセット, 姿勢推定
- MUCT 顔データベース, 顔と 76 顔ランドマークのデータベース
- NWPU-Crowd データセット, crowd counting
- Objects365 データセット,物体検出
- OpenCV のサンプルデータ, 画像など
- Pascal VOC (Pascal Visual Object Classes Challenge) データセット,物体検出 ,セグメンテーション,画像分類 2
- PointCloudLibrary の3次元点群データ,3次元点群
- Photo Tourism データセット,Structure from Motion
- Places365 データセット,画像分類
- Reuters newswire topics データセット, ドキュメント
- SBU データセット,影検出
- ShapeNet データセット,3次元CADモデル
- ShanghaiTech データセット, crowd counting
- SVHN (The Street View House Numbers) データセット,画像分類
- Titanic データセット, データフレーム
- UCF101 (UCF101 Human Actions dataset) , ビデオでのアクション
- UCF-QNRF データセット, crowd counting
- VGGFace2 データセット,顔データ,人物のID
- WebFace260M, WebFace42M データセット,顔画像,属性付き
- WIDER FACE データセット: 顔検出
- くずし字 MNIST データセット(Kuzushiji-MNIST データセット),画像分類
- 国土数値情報,バス停留所データなど
次のデータはオープンデータではない.(ダウンロードには,申請を必要とする).
- FERET データベース, 顔画像
- Human 3.6M データセット, 姿勢推定
- iBUG 300-W データセット, 顔の 68 ランドマーク
- LS3D-W データセット, 顔ランドマーク (facial landmark)
【関連情報】
- Wiki Pedia の「List of datasets for machine-learning research」: https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
- Pagers with code のデータセットのページ: https://paperswithcode.com/datasets
【関連項目】 R データセット (Rdatasets) を用いる場合には,
オプティカルフロー
オプティカルフローは MMFlow で算出できる.
【関連項目】 MMFlow
オプティマイザ(最適化器, optimizer)
オプティマイザは, 勾配降下法を実装したものである. 最適化器には,次のようなものがある.
- AdaGrad: ADAptive GRADient descent
- Adam: ADAptive with Momentum
TensorFlow の最適化器のベースクラスは tf.train.Optimizer クラスである.
勾配降下法の効果を高めるために,次のような手法が考案されている.
- モメンタム (momentum)
- 更新頻度 (update frequency)
- スパース性 (sparsity)
- 正則化 (Follow The (Prox-imally) Regularized Leade)
論文: An overview of gradient descent optimization algorithms, CoRR, abs/1609.04747.
http://sebastianruder.com/optimizing-gradient-descent/
Keras のオプティマイザのページ: https://keras.io/api/optimizers/
エントロピー (entropy)
確率分布 [1/2, 1/2] からエントロピーを求める Python プログラム. 「base = 2」で log の底を 2 としてエントロピーを求めているprint(scipy.stats.entropy([1/2, 1/2], base=2))
参考ページ: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.entropy.html
確率分布 c(1/2, 1/2) からエントロピーを求める R のプログラム. 「unit="log2"」で log の底を 2 としてエントロピーを求めているlibrary(entropy) entropy(c(1/2, 1/2), unit="log2")

参考資料: https://cran.r-project.org/web/packages/entropy/entropy.pdf
オートエンコーダ
Undercomplete Autoencoder, Sparse Autoencoder, Convolutional Autoencoder, Stacked Autoencoder, Variational Autoencoder (VAE), VQ-VAE(Vector Quantised) などの種類がある.
キーポイント
キーポイントは,画像の中での,ある特定の特徴の座標. 「ランドマーク」ともいう.
くずし字 MNIST データセット(Kuzushiji-MNIST データセット)
くずし字 MNIST データセットは,公開されているデータセット(オープンデータ)である.
【文献】 CODH:Center for Open Data in the Humanities), KMNISTデータセット(機械学習用くずし字データセット), arXiv:1812.01718 [cs.CV], 2018.
【サイト内の関連ページ】
【関連する外部ページ】
- くずし字 MNIST データセットの公式ページ:
https://github.com/rois-codh/kmnist
Kuzushiji-MNIST, Kuzushiji-49, Kuzushiji-Kanji の 3種類が公開されている(オープンデータ).
【関連項目】 MNIST データセット, TensorFlow データセット, オープンデータ, 画像分類
Python での くずし字 MNIST データセットのロード(TensorFlow データセットを使用)
次の Python プログラムは,TensorFlow データセットから,くずし字 MNIST データセットのロードを行う. x_train, y_train が学習用のデータ.x_test, y_test が検証用のデータになる.
- x_train: サイズ 28 × 28 の 60000枚の濃淡画像
- y_train: 60000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
- x_test: サイズ 28 × 28 の 10000枚の濃淡画像
- y_test: 10000枚の濃淡画像それぞれの,種類番号(0 から 9 のどれか)
次のプログラムでは,くずし字 MNIST データセットのロードを行う.x_train と y_train を 25枚分表示することにより,x_train と y_train が,手書き文字のモノクロ画像であることが確認できる.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings kmnist, kmnist_metadata = tfds.load('kmnist', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1) x_train, y_train, x_test, y_test = kmnist['train'][0], kmnist['train'][1], kmnist['test'][0], kmnist['test'][1] plt.style.use('default') plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) # squeeze は,サイズ1の次元を削除.numpy は tf.Tensor を numpy に変換 plt.imshow(np.squeeze(x_train[i]), cmap=plt.cm.binary) plt.xlabel(y_train[i].numpy()) # 確認表示 plt.show()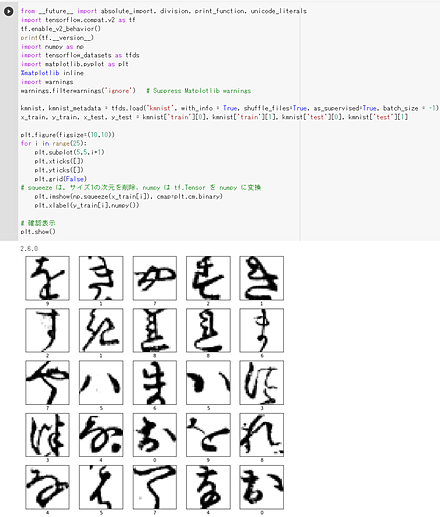
クラス
クラスはオブジェクトの種類,もしくは,同一種類のオブジェクトの集まりの意味である.
クラス番号
クラス番号は, クラスを示す番号.クラスカル・ウォリス検定 ( Kruskal-Wallis rank sum test)
帰無仮説: ノンパラメトリック検定の1つ.対応の無い多群の差の検定
群数が2の場合には,マン・ホイットニーの U 検定と同じ結果が得られる.
* R システム で,クラスカル・ウォリス検定 ( Kruskal-Wallis rank sum test) を行うプログラム.kruskal.test(length ~ group)
【関連項目】 検定
コルモゴロフ–スミルノフ検定 (Kolmogorov-Smirnov test)
帰無仮説: ノンパラメトリック検定の1つ.2標本に対して使う場合には,2標本が,同一の母集団である.検定では,各標本の累積確率分布を使用.
R システム で,2群 s1, s2 のコルモゴロフ–スミルノフ検定 (Kolmogorov-Smirnov test) を行うプログラムks.test(s1, s2)
【関連項目】 検定
コンピュータビジョンのタスク
コンピュータビジョンのタスクは種々があるが,次のようなものをあげることができる.
- シーン
- シーン理解 (scene parsing)
- 画像分類 (image classification)
- image tagging (weather tagging, scene tagging などがある)
- Class Activation Mapping (CAM)
- セマンティック・セグメンテーション (semantic segmentation), pixelwise classification ともいう
- インスタンス・セグメンテーション (instance segmentation)
- パノプティックセグメンテーション (panoptic segmentation)
- 物体検出 (object detection)
- salient object detection
- シーン解析(scene parsing)
- Few Shot Segmentation
- 動画像の処理
- multi object tracking
- segmentation tracking
- optical flow
- 画像や動画の編集
- image inpainteing
- 画像のノイズ除去 (image restoration)
- イメージ・マッティング (image matting)
- 超解像 (super resolution)
- generation
- image content removal(画像コンテンツの除去)
- 人物検出,姿勢推定
- 人物検出(human detection)
- 姿勢推定(pose estimation)
- 頭部姿勢推定(head pose estimation)
- 顔情報処理
- 動作認識
- スケルトンベースの動作認識 (skelton-based action recognition)
- Spatio-Temporal Action Recognition,
- ビデオの動作認識 (action recognition)
- 3次元再構成
- テキスト
- テキスト検知 (text detection)
- テキスト認識 (text recognition)
シーン解析(scene parsing)
シーン解析(scene parsing) では,画像全体の画素をクラスに分類する.各画素にクラスのラベルが割り当てられる. セマンティック・セグメンテーション (semantic segmentation) との違いとしては,画像全体の画素を何らかのクラスに分類する(クラスが不明な画素が無い)ことである.
【関連項目】 セマンティック・セグメンテーション (semantic segmentation)
システム Python
Ubuntu のシステム Python を用いるとき, python, pip は,次のコマンドで起動できる.
- python3 (Ubuntu のシステム Python)
- sudo pip3 (pip 3)
Ubuntu のシステム Python を用いるとき, venv の実行は次のようになる.
python3 -m venv <ディレクトリ名>【関連項目】 Python, Python, pip, Python 開発環境,Python コンソールのコマンドでの起動
シグモイド関数 (sigmoid function)
シグモイド関数 (sigmoid function) は,次の関数である.
f(x) = 1 / (1 + exp(-x))
シグモイド関数は,活性化関数としてよく使用されるもののうちの1つである. 活性化関数は,ニューロンの入力の合計から,そのニューロンの活性度の値を決めるためのもの. (他には,ReLU,LReLU,ステップ関数,ソフトマックス関数などがある.
シャピロ・ウィルク検定 (Shapiro Wilk test)
帰無仮説: 標本の母集団は正規分布である
R システム で, Iris データセットの Sepal.Length についてのシャピロ・ウィルク検定を行うプログラムs1 <- iris[iris$Species=='setosa',]$Sepal.Length s2 <- iris[iris$Species=='versicolor',]$Sepal.Length s3 <- iris[iris$Species=='virginica',]$Sepal.Length shapiro.test( s1 ) shapiro.test( s2 ) shapiro.test( s3 )
【関連項目】 検定
ステップ関数 (step function)
ステップ関数は,次の関数である.
f(x) = x (x < 0 のとき), 1 (x > = 0 のとき)
セマンティック・セグメンテーション (semantic segmentation)
セマンティック・セグメンテーション (semantic segmentation)では, 画像内に人物 (person) がいるような場合,人物の領域に person というラベルを付ける. このとき,人物は複数いても問題ない.
学習のときには,'road', 'slidewalk', 'building' のようなクラスについての学習を行う. 学習データでは,画像の画素に,'road', 'slidewalk', 'building' のようなクラス名(あるいはクラス番号)がラベルとして付いている. 学習済みデータで推論を行うと,画素に 'road', 'slidewalk', 'building' のようなラベルが付く.
Cityscapes データセットのクラスは次の通りである(これらクラス以外に「unlabeled」がある).road, sidewalk, parking, rail track, person, rider, car, truck, bus, on rails, motorcycle, bicycle, caravan, trailer, building, wall, fence, guard rail, bridge, tunnel, pole, pole group, traffic sign, traffic light, vegetation, terrain, sky, ground, dynamic, static
【関連項目】 ADE20K データセット, BASNet (Boundary-Aware Salient object detection), BDD100K, CSAILVision, Cityscapes データセット, COCO (Common Object in Context) データセット, DeepLab2, DeepLabv3, DeepLabv3+, Mapillary Vistas Dataset (MVD), MIT Scene Parsing Benchmark, MMSegmentation, OCRNet, Pascal VOC (Pascal Visual Object Classes Challenge) データセット, Residual Networks (ResNets), SegFormer, U-Net, インスタンス・セグメンテーション (instance segmentation), コンピュータビジョンのタスク, シーン解析(scene parsing), 物体検出
ソースコード
ソースコードは,コンピュータのプログラムを,プログラミング言語で書いたもの.
ソースコードからのビルド
プログラムのソースコードを書き換えた場合,ソースコードからビルドしなおす.
プログラムが,あるライブラリを使うとき, ライブラリの特定のバージョンのためにビルドされたプログラムが, そのライブラリの別のバージョンでは動かないことがある.そうした場合でも,ソースコードからビルドしなおす.
プログラムが公開されているとき, ビルド済みの状態(実行可能な形式など)で配布されていることもあれば, ソースコードが公開されている場合もある. そして,それら両方が配布されている場合もある.そうした場合,ソースコードからのビルドを行う利点としては, 次のようなものがある.
- ソースコードを確認しながらビルドできるので情報セキュリティ面でのリスクを下げることができること,
- ソースコードを変更して使いたい場合にはビルドが必要であること.
- ビルド済みの状態では,特定のバージョンのライブラリに依存していたり,あるいは,あるライブラリを使えていなかったする.自分自身でビルドすることで,そうしたことを調整できること
ソフトマックス関数 (softmax function)
次元数 n のベクトル x に対するソフトマックス関数 (softmax function) は,f(x[k]) = exp(x[k]) / (exp(x[1]) + exp(x[2]) + ... exp(x[n]))
ニューラルネットワークの,ある層(レイヤ)の出力が one-hot 表現の出力であるときによく使用される.
チェックポイント
ある特定の時点での,モデルの変数の状態を表したデータのこと. チェックポイントにより,ニューラルネットワークの重み (weight) をエクスポートすることができるようになる.
データサイエンス
データサイエンスというとき,データを数理的に処理(事前に定義された数式に当てはめて処理)することにより, 処理された結果が,どのようにして算出されたかが明らかであり,算出に再現性があるという意味合いに加えて, その数理的処理において,体系だった学問があるという意味がある.
データサイエンスでは,次のようなものを扱う.
記述統計量,分布,相関,正規化,外れ値,クラスタリング,統計処理
データの前処理
TensorFlowでは,入力の値が 0 から 1 の範囲の浮動小数点数にスケールする必要がある.
データフレーム
データフレームでは,データのデータ型は,列ごとに同じである. 列に属性名がある.
【関連項目】 Iris データセット, ks_1033_data, titanic データセット, ポケモンデータセット
データ拡張 (data augmentation)
データ拡張 (data augmentation)では,すでに存在するデータを利用して,データを変換することにより,データを増量する.
ディープラーニング
ディープラーニングは,層の浅いニューラルネットワークの組み合わせによる多層性の実現により勃興した分野. ジェフ・ヒントンらが見出したオートエンコーダやディープ・ビリーフ・ネットワークが基礎である.
【関連項目】 applications of deep neural networks, cnn (convolutional neural network), gan (generative adversarial network), gru (gated recurrent neural networks), keras, lstm (long short-term memory), pytorch tensorflow, ニューラルネットワーク, 強化学習, 層構造のニューラルワーク,
ディープニューラルネットワーク
ディープラーニングを行う ニューラルネットワーク. 「ディープモデル (deep model)」ともいう.
ドロップアウト
学習の途中で, ニューラルネットワークを構成するニューロンを無作為(ランダム)に「あたかも存在しない状態」すること. 過学習の防止に効果がある場合があるとされる.
参考文献: dropout: a simple way to prevent neural networks from overfitting, https://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
参考文献: improving neural networks by preventing co-adaptation of feature detectors, corr, abs/1207.0580
ニューラルネットワーク
ニューラルネットワークは,人間の脳細胞を,信号が流れるネットワークと見立てたうえで, 個々の脳細胞を, 次の簡単な数理で組み立てるもの.
ニューラルネットワークは,入力を与えると, 出力が出てくる. この仕組みにより,質問が与えられたときに,多数の選択肢の中から 1つを選ぶことなどもできる. 例えば,コンピュータに画像を見せて「男か女か」の答えを出す,年齢を「0から120の中から」答えるということができる.
ニューラルネットワークは層で構成されている.隠れ層を持つのがふつうである. ニューロンには非線形性がある.
ニューラルネットワークでは, 前もって,入力とそれに対する正解についての学習を行うことによって, 入力に対して,適切な出力が出てくるにようになる.
ニューラルネットワークは 1980年内に登場した. ニューラルネットワークの技術革新としては,次のようなものがある.
- ドロップアウトや正規化などによる過学習の防止
- relu法により,ニューラルネットワークの本質的課題であった勾配消失問題の解決
- gpuプロセッサの活用
- early stoppingなどの正則化のための手法
以上の背景から,ディープニューラルネットワークが広く使われるようになった.
【関連項目】 applications of deep neural networks, ディープラーニング
ニューラルネットワークのビジュアライズ
keras visualizer を用いて keras のニューラルネットワークをビジュアライズするプログラムは次の通り.
from keras_visualizer import visualizer visualizer(m, format='png') from PIL import Image Image.open('graph.png').show()windows の場合は,コマンドプロンプトを管理者として開き次のコマンドを実行する.
python -m pip install git+https://github.com/lordmahyar/keras-visualizergoogle colaboratory では「!pip3 install git+https://github.com/lordmahyar/keras-visualizer」を実行
!pip3 install git+https://github.com/lordmahyar/keras-visualizerニューラルネットワークの種類
ニューラルネットワークの種類には,次のようなものがある. 「教師あり」は,教師データを用いての 学習の機能があるもの. 「教師なし」は,そうでないものである.
- 教師あり
- 教師なし
オートエンコーダ (autoencoder)
ニューラルネットワークのビジュアライズ
keras のモデルのビジュアライズについては: https://keras.io/ja/visualization/
ニューラルネットワーク m のビジュアライズを行う keras のプログラムimport pydot plot_model(m)ニューロン (neuron)
ニューロンは, 複数の入力の総和に,バイアス (bias)を足したのち,ニューロンに設定された活性化関数を適用して得られた値を出力する. ニューロンの入力と出力の間には 重みがある. ニューロンの出力には,重みが掛け合わされたのちに,次のニューロンの入力になる.
1つのニューロンは,複数の入力を取ることができる.出力は1つである.これら入力と出力は,次のいずれかの条件を満たす
- ある特定のニューロンを見ると,すべての入力は,1つの数である.出力も1つの数である.
- ある特定のニューロンを見ると,すべての入力は,数のベクトルである.出力も数のベクトルである.そして,それらの次元数がすべて等しい.
層構造のニューラルワークでは, バイアスは,ニューロンごとに違い, 活性化関数は,同じ層(レイヤ)のニューロンでは同じものとするのが通例.
ニューロンの発火
ニューロンの発火は, 1 あるいは 1 に近い高い値を出力すること.
パーセプトロン (perceptron)
パーセプトロンは,1つまたは複数の入力を取り,入力値の加重和に対して関数を実行し,1つの出力値を計算するシステムである. 機械学習では,関数として,relu,シグモイド関数などの非線形関数を用いることが多い, 例えば,以下のパーセプトロンでは,x1, x2, x3, x4, x5 の加重和に対してシグモイド関数を実行し,出力値を得るものである. f(x1, x2, x3, x4, x5) = sigmoid(w1x1 + w2x2 + w3x3 + w4x4+ w5x5)
パーセプトロンは, ニューラルネットワークは, 複数のパーセプトロンを接続したネットワークであり, バックプロパゲーションによりフィードバックを行う.
バイアス (bias)
次の式では,b はバイアスである.
y = b + w1 * x1 + w2 * x2 + ... + wn * xn
ニューラルネットワークでのバイアスは個々のニューロンが持つ値.ニューロンの発火のしやすさを表す値とされる.
ハイパーパラメータ (hyper parameter)
ハイパーパラメータは,次の 2つである.
- モデルパラメータ
層(レイヤ)の数,各層のニューロンの数など
- アルゴリズムパラメータ
学習アルゴリズムに関するパラメータ
ハイパーパラメータチューニング
最適なハイパーパラメータを探索すること.
ハイパーパラメータチューニングを行うモデルの定義
ハイパーパラメータチューニングを行うモデルの定義では, ハイパーパラメータの探索を行う探索空間を定義する.
iris データセット を,3種類に分類する keras プログラムの例は次の通り.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf from tensorflow.keras import layers import numpy as np from sklearn.datasets import load_iris import sklearn.model_selection from sklearn.preprocessing import normalize from IPython.display import display gpu = tf.config.list_physical_devices(device_type = 'GPU') if len(gpu) > 0: print("GPU:", gpus[0].name) tf.config.experimental.set_memory_growth(gpu[0], True) # データ num_classes = 3 iris = load_iris() x = iris.data y = iris.target x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(x.reshape(x.shape[0], -1), y, train_size=0.5) m = tf.keras.Sequential( [ layers.Dense(units=64, input_dim=len(x_train[0]), activation='relu'), layers.Dropout(0.5), layers.Dense(num_classes, activation="softmax"), ] ) print(m.summary()) batch_size = 4 epochs = 300 m.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_crossentropy', 'accuracy'] ) history = m.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test)) score = m.evaluate(x_test, y_test, verbose=0) print("Test loss:", score[0]) print("Test accuracy:", score[1]) # 分類 predictions = m.predict(x_test) print(predictions.argmax(axis=1)) # 正解の表示 print(y_test) import pandas as pd h = pd.DataFrame(history.history) h['epoch'] = history.epoch print(h) # 学習曲線 # https://www.tensorflow.org/tutorials/keras/overfit_and_underfit?hl=ja で公開されているプログラムを使用 %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings def plot_history(histories, key='binary_crossentropy'): plt.figure(figsize=(16,10)) for name, history in histories: val = plt.plot(history.epoch, history.history['val_'+key], '--', label=name.title()+' Val') plt.plot(history.epoch, history.history[key], color=val[0].get_color(), label=name.title()+' Train') plt.xlabel('Epochs') plt.ylabel(key.replace('_',' ').title()) plt.legend() plt.xlim([0,max(history.epoch)]) plot_history([('history', history)], key='sparse_categorical_crossentropy')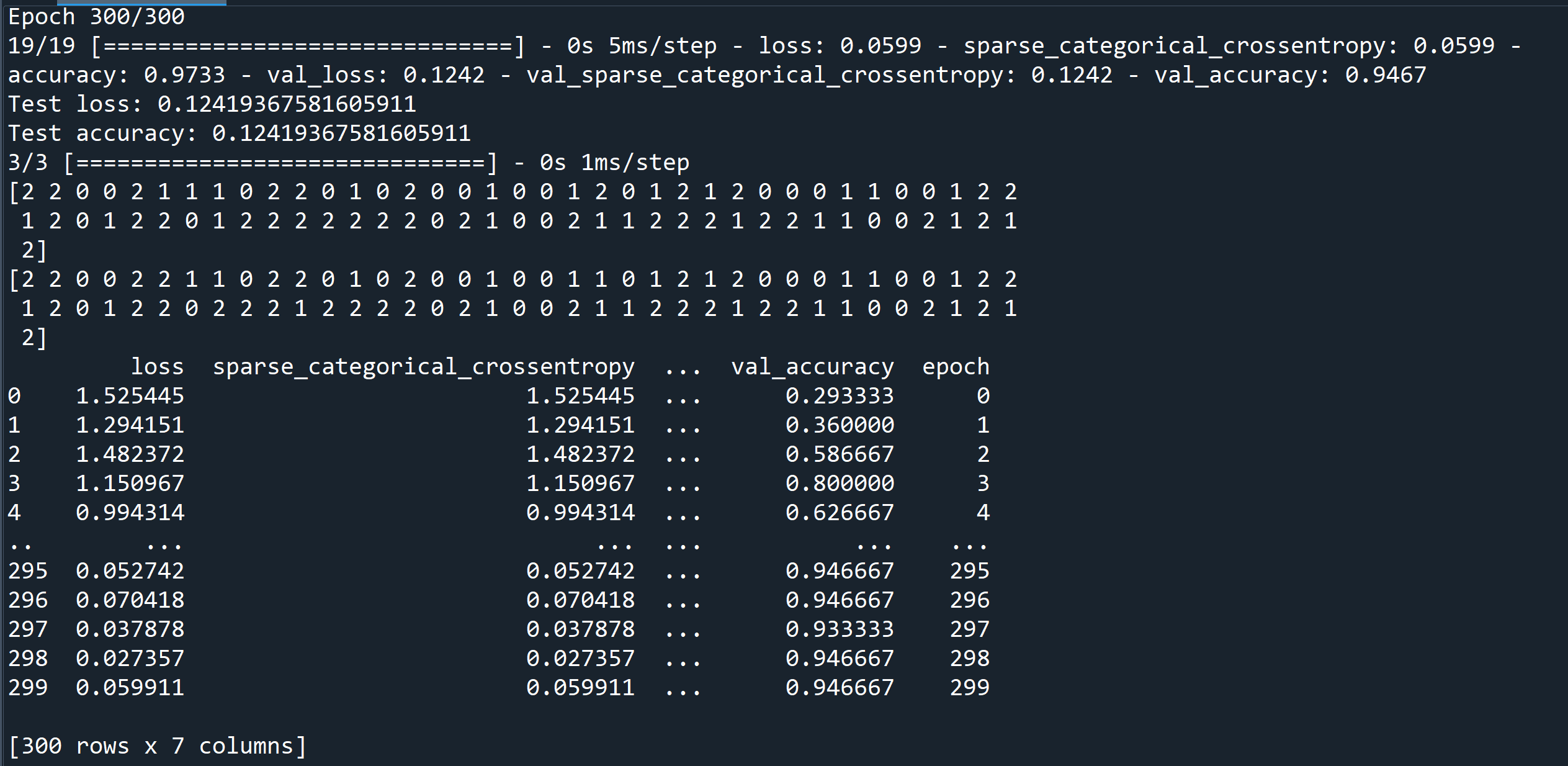
バウンディングボックス (bounding box)
写真やビデオの中での,対象領域を示す矩形. 取り扱いたい対象を囲むような矩形を作ることが多いことから「バウンディング」と呼ばれる.
バッチ (batch)
バッチ (batch) は, ミニバッチ学習 での 学習の1回のイテレーション (iteration) で使われるデータ集合などのこと.
バウンディングボックス (bounding box)
バウンディングボックス (bounding box) は, 画像で,オブジェクトなどを囲む四角形のこと.
パッケージ (package)
パッケージ (モジュール,インクルードファイルなどともいう) 複数のプログラムが共有して使えるような機能を持ったソースコード
バックプロパゲーション (backpropagation)
バックプロパゲーション (backpropagation) は, ニューラルネットワークで,勾配降下法 (gradient descent) を実行するためのアルゴリズムである. パラメータと損失の偏微分を算出することにより,バックプロパゲーションが実行される.
バッチサイズ (batch size)
1つのバッチ (batch) の中のデータ等の数のこと. 確率的勾配降下法 (sgd 法) のバッチサイズは 1 である. ミニバッチ学習 でのバッチサイスは普通 10 から 100 である.
バッチ正規化 (batch normalization)
バッチ正規化 (batch normalization) は, ミニバッチ学習を行うとき,ミニバッチごとに, 隠れ層 (hidden layer) の活性化関数の入力や出力を, 正規化すること. 過学習 (overfitting) の緩和などの効果がある.
バッチ正規化 (batch normalization) の代替とされる手法(adaptive gradient clipping 法など)も登場しつつある.
keras で バッチ正規化 (batch normalization) を行うときは,次のように全結合を示す「dense」の直後に,「m.add(batchnormalization)」を入れる.【keras のプログラム】
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf m = tf.keras.sequential() m.add(tf.keras.layers.flatten(input_shape=(28, 28))) m.add(tf.keras.layers.dense(units=128, activation='relu')) m.add(tf.keras.layers.batchnormalization()) m.add(tf.keras.layers.dropout(0.5)) m.add(tf.keras.layers.dense(units=10, activation='softmax'))ソフトマックス関数 (softmax function)を活性化関数とするような層(レイヤ)では,batchnormalization は行わないようです.
- batch normalization: accelerating deep network training by reducing internal covariate shift, corr, abs/1502.03167
パラメータ (parameter)
機械学習でのパラメータは, モデルの変数のうち,機械学習のシステムでの学習の対象になっているもの. モデルの変数でも,学習の対象になっていないものはハイパーパラメータである.
ビルド
ビルドは,プログラムのソースコードを,実行可能な形式や中間言語の形式に変換すること. 実行可能な形式のファイルは windows では .exe や .dll の拡張子が付いていることが多い.
プーリング (pooling)
直前の畳み込み層で生成された1つの行列(あるいは複数の行列)を,より小さな行列に縮小すること
フィードフォワード (feed forward)
ある層のニューロンでの結果を,次の層のニューロンが受け取る (それ以外にはない)ような構造になっているような ニューラルネットワークを「フィードフォワード」という.
フォトグラメトリ
フォトグラメトリ (Photogrammetry) は写真測量のこと.
プロトコル・バッファ(protocol buffer)
プロトコル・バッファ(protocol buffer)は,次のような proto ファイルを書き,様々なプログラミング言語のプログラムや機器の間でデータ交換等を行うためのもの.
message Person { required string name = 1; required int32 id = 2; optional string email = 3; }- Protobuf のページ: https://developers.google.com/protocol-buffers
- GitHub の Protobuf のページ: https://github.com/protocolbuffers/protobuf
- チュートリアル: https://developers.google.com/protocol-buffers/docs/tutorials
【関連項目】 プロトコル・バッファ・コンパイラ (protocol buffer compiler)
プロトコル・バッファ・コンパイラ (protocol buffer compiler)
インストールの公式ページ: https://grpc.io/docs/protoc-installation/
【関連項目】 Protobuf
プロトコル・バッファ・コンパイラ (protocol buffer compiler) のインストール(Windows 上)
- コマンドプロンプトを管理者として開く.
- protoc のダウンロードと展開(解凍)
「23.3」のところにはバージョンを指定すること.
https://github.com/protocolbuffers/protobuf/releases
python -m pip install -U protobuf==3.19.6c:\protoc cd c:\protoc curl -L -O https://github.com/protocolbuffers/protobuf/releases/download/v23.3/protoc-23.3-win64.zip powershell -command "Expand-Archive -DestinationPath . -Path protoc-23.3-win64.zip"
- Windows の システム環境変数 Pathに,c:\protoc\bin を追加することにより,パスを通す.
Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。powershell -command "$oldpath = [System.Environment]::GetEnvironmentVariable(\"Path\", \"Machine\"); $oldpath += \";c:\protoc\bin\"; [System.Environment]::SetEnvironmentVariable(\"Path\", $oldpath, \"Machine\")"
Ubuntu でのプロトコル・バッファ・コンパイラ (protocol buffer compiler) のインストール
Ubuntu でインストールを行うには,次のコマンドを実行.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install libprotobuf-dev protobuf-compiler protobuf-c-compiler python3-protobufボクセル化 (voxelize)
ボクセル化は,3次元データをボクセル形式に変換すること.
ボクセル化のソフトウェアとしては,binvox, cuda_voxelizer がある.
binbox のURL: https://www.patrickmin.com/binvox/
binbox の文献: Fakir S. Nooruddin and Greg Turk, Simplification and Repair of Polygonal Models Using Volumetric Techniques, IEEE Transactions on Visualization and Computer Graphics, vol. 9, no. 3, pp. 191--205, 2003.
cuda_voxelizer の GitHub のページ: https://github.com/Forceflow/cuda_voxelizer
.binbox 形式ファイルのボクセルデータを,STL 形式のデータに変換するソフトウェアとしては, binvox2mesh が知られる.
binbox2mesh の GitLab のページ: https://gitlab.com/mandries/binvox2mesh
ポケモンデータセット
ポケモンデータセットの url: https://gist.github.com/armgilles
次の Python プログラムは,ポケモンデータセットの主成分分析を行い,第1主成分,第2主成分,第3主成分,ポケモンデータセットの属性 Type 1 で3次元の散布図を表示する.
次の Python プログラムでは,3次元の散布図のために, plotly の scatter_3d を用いている.
!git clone https://gist.github.com/armgilles/194bcff35001e7eb53a2a8b441e8b2c6 !mv 194bcff35001e7eb53a2a8b441e8b2c6/pokemon.csv . import numpy as np import pandas as pd from sklearn.datasets import load_iris import sklearn.decomposition %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import plotly.express as px from IPython.display import display pokemon = pd.read_csv("pokemon.csv") display(pokemon) x = pokemon.iloc[:,4:11].to_numpy() type1 = pokemon.iloc[:,2] pca = sklearn.decomposition.PCA(n_components=4) r = pca.fit_transform(x) fig = px.scatter_3d(x=r[:,0], y=r[:,1], z=r[:,2], color=type1, symbol=type1, opacity=0.4, labels={'x': '1', 'y': '2', 'z': '3', 'color': 'Type 1', 'symbol': 'Type 1'}) fig.show()
マイクロソフト C++ ビルドツール (Microsoft C++ Build Tools)
URL: https://visualstudio.microsoft.com/visual-cpp-build-tools/
マスク付き顔の処理
マスク付き顔の処理には次のようなものがある.
- マスク付き顔の顔検知
- マスク付き顔の顔検知,マスクなし顔の顔検知を同時に行うもの: Chandrika Deb の顔マスク検出 (Chandrika Deb's Face Mask Detection)
【関連項目】 cabani の MaskedFace-Net データセット, Chandrika Deb の顔マスク検出 (Chandrika Deb's Face Mask Detection)
マスターフェイス (master face)
マスターフェイス (master face)は,顔認識 (face recognition)のシステムにおいて, そこに登録された顔のテンプレートの複数にマッチ (match) するような顔.
顔認識のシステムは,他人の顔を間違って認識したり,あるいは人工知能が合成した顔を間違って認識したりすることがありえるものである.
近年,種々の研究があり, 「Dlib, FaceNet, SphereFace の 3つの顔認識システムについて, 10未満のマスターフェイスが,LFW データセットの 40 パーセント以上にマッチする」という報告もある. (コメント:Dlib, FaceNet, SphereFace の優劣や評価ではなく,現行の顔認識システム全般の脆弱性の指摘であると受け止めることができると,本サイト作成者は考えています).
- 文献
Huy H. Nguyen, Sébastien Marcel, Junichi Yamagishi, Isao Echizen, Master Face Attacks on Face Recognition Systems, CoRR, abs/2109.03398v1, 2021.
- 文献
Ron Shmelkin, Tomer Friedlander, Lior Wolf, Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution, CoRR, abs/2108.01077v3, 2021.
【関連項目】 顔識別 (face identification), 顔認識 (face recognition), 顔に関する処理
マン・ホイットニーの U 検定 (Mann-Whitney U test, Wilcoxon rank sum test)
帰無仮説: ノンパラメトリック検定の1つ.独立な2標本で,2標本が同じ母集団から得られた標本である.
R システム で,2群 s1, s2 のマン・ホイットニーの U 検定を行うプログラムwilcox.test(s1, s2)
なお,correct=F を付けると,連続性の修正(continuity correction)を行わないようになる.
wilcox.test(s1, s2, correct=F)
【関連項目】 検定
ミニバッチ (mini-batch)
学習の繰り返しのうち,各々の繰り返しで使用されるバッチ全体の中からランダムに選ばられた部分集合である. ミニバッチのバッチサイズは,ふつう,10 から 1000 である. ミニバッチの使用により,損失の計算を高速化できるとされている.
ミニバッチ学習
ミニバッチ学習は,教師データの中から,「バッチ」あるいは「ミニバッチ」と呼ばれる少数を無作為に(ランダムに)選び出し,それを使って学習を行うこと.
ミニバッチ確率勾配降下法 (mini-batch stochastic gradient descent)
ミニバッチを使用する確率勾配降下法である. 学習データのミニバッチを用いて,勾配が算出される. 通常の確率的勾配降下法は,サイズ1のミニバッチを使用するミニバッチ確率勾配降下法と同じである.
メッシュ簡略化 (Mesh Simplification)
メッシュ簡略化は,メッシュの頂点数とポリゴン数の削減を行う.
MeshLab を用いて,次の手順で, メッシュ簡略化 を行うことができる.
- MeshLab を使用.
- MeshLab で 「File」, 「Import Mesh...」.そして,ファイルを選ぶ.
- 「Filters」, 「Remashing, Simplification and Reconstruction」,「Simplification: Quadric Edge Collapse Decimation (with texture)」と操作.
- 設定し「Apply」.
【関連項目】 MeshLab, メッシュ平滑化 (Mesh Smoothing)
メッシュ平滑化 (Mesh Smoothing)
メッシュ平滑化は,メッシュをなめらかにする.
MeshLab を用いて,次の手順で, メッシュ平滑化 を行うことができる.
- MeshLab を使用.
- MeshLab で 「File」, 「Import Mesh...」.そして,ファイルを選ぶ.
- 「Filters」, 「Smoothing, Fairing and Deformation」,「Laplacian Smooth」と操作.
- 設定し「Apply」.
【関連項目】 MeshLab, メッシュ簡略化 (Mesh Simplification)
メトリクス(metrics)
メトリクスは,モデルの性能を判定するための関数である. メトリクスは,損失関数とは違い,学習時には使用されない.
Keras では,メトリクスは,関数のリストである.そして,Keras では,任意の損失関数をメトリクスとして使うことができる.
Keras のメトリクスのページ: https://keras.io/api/losses/index.html
モデル
機械学習での「モデル」は, 機械学習のシステムが教師データを用いて学習した内容を表現したものである.
TensorFlowでは,「モデル」は次のような意味でつかわれる場合がある. ・TensorFlow グラフは,ニューラルネットワークによる予測がどのように計算されるかの構造を表現したもの. ・TensorFlow グラフの重みとバイアスの値は,学習により決定される.
ディープニューラルネットワークのモデルには,次のようなものがある.
- DeepLab2
- DeepLabv3
- DenseNet121, DenseNet169: 画像分類
- Hour Grass Network
- Inception-v4: 画像分類
- Inception-ResNet: 画像分類
- MixConv
- MobileNetV2: 画像分類
- MobileNetV3: 画像分類
- NASNet: 画像分類
- ResNet50, ResNet101, ResNet152, その他の ResNet: 画像分類
- ResNeXt: 画像分類
- RetinaNet
- SpineNet
- TinaFace
- Wide ResNet: 画像分類
- Xception
- YOLOv3: 物体検出
【関連項目】 PyTorch, torchvision のモデル, rwightman の PyTorch Image Models (TIMM)
モメンタム (momentum)
ある学習ステップは,現在のステップでの勾配だけでなく, その直前のステップの勾配にも依存するという考え方による勾配降下法. モメンタムでは,時間経過に伴いながら,勾配の指数加重移動平均を算出する.
ライブラリ (library)
ライブラリは,複数のプログラムが共有して使えるような機能を持ったプログラムのこと. 多くの場合,プログラムの実行時にリンク(結合)される
ラベル (label)
ラベルは,クラスの番号やクラス名など,クラスを識別できる番号や文字列などのこと.
リレーショナルデータベース管理システム
リレーショナルデータベースシステムは,リレーショナルデータベースとリレーショナルデータベース管理システムから構成される.
ロジット
分類の結果として得られる数値ベクトルで,正規化されていないもの. ロジットに対しては,正規化が行われるのが普通である.
多クラスの分類では,ロジットを正規化するために ソフトマックス関数 (softmax function)を用いるのが普通である. ソフトマックス関数 (softmax function)により,数値ベクトルが生成されるが,そのそれぞれの値が1クラスに対応する.
ロジットの別の意味として,ロジットという言葉を,ロジット関数(シグモイド関数 (sigmoid function))という意味で使うことがある.
あ〜ん (漢字)
音データ(sound data)
ffmpeg を用いて,m4a (mp4 audio) のファイルを 16 ビット 整数RAW big endian モノラルに変換
ffmpeg -y -vn -sn -ar 44100 -i "sample.m4a" -ac 1 -ar 48000 -f s16be "output.raw"ffmpeg を用いて,16 ビット 整数RAW big endian モノラルのファイルを m4a (mp4 audio) に変換
ffmpeg -y -vn -sn -ar 48000 -f u16be -i "output2.raw" -ac 1 -ar 48000 -acodec flac -f flac "output2.flac"【関連項目】 librosa, ffmpeg
重み (weight)
線形モデルでの特徴での係数である. ニューラルネットワークで,あるニューロンとニューロンが結合しているとき, 個々の結合には重みがある. 重みが大きいほど,当ニューロンの出力が強く,次のニューロンに渡される. 例えば, あるニューロンが,別の2つのニューロンと結合していて,それら2つの出力を受け取るとき, そのニューロンの入力は,w[1] * x[1] + w[2] * x[2] のよになる. w[1], w[2] は重み, x[1], x[2] は2つのニューロンの出力である.
重みの初期化
重みの初期化 (weights initialization)
重みの方向ベクトル
重みが複数あるとき,それらは重みの方向ベクトルをなす. 重みが複数あり,それら重みをそれぞれ増やしたり減らしたりする量は,重みの方向ベクトルをなす.
音声処理のタスク
音声処理のタスクには次のようなものがある.
- audio source seperation
- music source separation
- speech enhancement
- Speech synthesis
- 音声合成 (Text To Speech; TTS)
音声合成 (Text To Speech; TTS)
人間の音声を合成すること.
【関連項目】 Coqui TTS, Speech synthesis, VALL-E X, VOICEVOX, 自然言語処理のタスク
解釈可能性 (interpretability)
モデルを用いた予測について,それが容易に説明できるかの度合い.
顔に関する処理
顔に関する処理には,次のようなものがある.
- 3次元の顔の再構成 (3D face reconstruction)
- 顔検証 (face verification)
- 顔検出 (face detection)
- 顔識別 (face identification)
- 顔認識 (face recognition)
- 顔の 68 ランドマーク の検出
- 顔のコード化
- 顔の性別,年齢等の予測
- 顔ランドマーク (facial landmark)の検出
- 顔ランドマークの3次元化
顔のコード化
顔のコード化では,顔を数値(複数の数値)に置き換える. このとき,同一人物の顔は,近い値の数値に, 違う人物の顔は,離れた値の数値になるようにコード化を行う.
顔のデータベース
顔のデータベースの有名なものには,
- AgeDB データセット, 顔データ,年齢, in-the-wild
- AFLW (Annotated Facial Landmarks in the Wild) データセット: 顔画像,21の顔ランドマーク,in-the-wild
- CelebA (Large-scale CelebFaces Attributes) データセットのダウンロード
- FFHQ (Flickr-Faces-HQ) データセット(顔認識),
- LFW データセット: 顔データ,人物のID,顔認識 (face recognition),in-the-wild
- LSUN (Large-scale Scene UNderstanding Challenge) データセット
- UTKFace データセット
- WebFace260M, WebFace42M データセット,in-the-wild を含む
- WIDER FACE データセット: 顔検出
などがある.これらの中には,シナリオが「in-the-wild」であるもの,顔が部分しか見えていないものを含むようなデータセットもある.
その他,マスク付きの顔のデータセットには, cabani の MaskedFace-Net データセット, Chandrika Deb の顔マスク検出 (Chandrika Deb's Face Mask Detection) および顔のデータセット などがある.
その他,顔のデータセットは, 300W (300 Faces-In-The_Wild) データセット, AgeDB データセット, C-MS-Celeb Cleaned データセット , FERET データベース, HELEN データセット, iBUG 300-W データセット, IMM 顔データベース (IMM Face Database), MS-Celeb-1M データセット, MUCT 顔データベース, VGGFace2 データセットなどがある.
【関連項目】 オープンデータ
顔の性別,年齢等の予測
画像から顔の性別,年齢等の予測を行う.
顔検出 (face detection)
顔検出 (face detection)は,写真やビデオの中の顔を検出すること.顔とそれ以外のオブジェクトを区別することも行う.
顔検出 (face detection)の結果は, バウンディングボックスで得られるのが普通である.
【関連項目】 Chandrika Deb の顔マスク検出, Dlib の顔検出, Emotion-Investigator, InsightFace, RetinaFace, SCRFD (Sample and Computation Redistribution for Face Detection), TinaFace, WIDER FACE データセット 顔検証 (face verification), 顔識別 (face identification), 顔認識 (face recognition), 顔に関する処理, 物体検出
顔検証 (face verification)
顔検証 (face verification)は, 顔と顔とを比べてマッチするか(同一人物であるか)を調べること. 本人確認などで 顔検証 (face verification) が行われる.
【関連項目】 ArcFace 法, MobileFaceNets, マスターフェイス (master face), 顔検出 (face detection), 顔識別 (face identification), 顔認識 (face recognition), 顔に関する処理
顔識別 (face identification)
顔識別 (face identification)では,ある顔と,データベースの中の多数の顔についての情報を用いて, 顔が誰であるのかの個人の特定を行う. このとき,データベースの中の多数の顔とのマッチングが行われる.
【関連項目】 ArcFace 法, マスターフェイス (master face), 顔検証 (face verification), 顔検出 (face detection), 顔認識 (face recognition), 顔に関する処理
顔認識 (face recognition)
顔認識 (face recognition)は, 写真やビデオについて顔検出 (face detection)を行い, その結果として得られた顔について(複数の顔が得られた場合にはそれぞれについて), 顔識別 (face identification) を(データベースの中の多数の顔についての情報を用いての,個人の特定)を行う.
【関連項目】 ArcFace 法, LFW データセット, マスターフェイス (master face), 顔検証 (face verification), 顔検出 (face detection), 顔識別 (face identification), 顔に関する処理
顔ランドマーク (facial landmark)
顔ランドマーク (facial landmark)は, 顔について,目,眉,鼻,口,あごのラインなどのアノテーションを行ったもの. 目,眉,鼻,口,あごのラインなど,顔のパーツの構造を特定できる形状予測器 (shape predictor) の学習に使うことができる.
【関連項目】 AFLW (Annotated Facial Landmarks in the Wild) データセット, UTKFace データセット, 顔に関する処理, 顔の 68 ランドマーク, 顔ランドマークの3次元化
顔ランドマークの3次元化
ディープラーニングを用いて 顔ランドマーク (facial landmark)の3次元化する学習済みモデルは,次のページで公開されている.
https://www.adrianbulat.com/face-alignment
【関連項目】 顔ランドマーク(facial landmark)
過学習 (overfitting)
教師データにはよく適合しているが,新しいデータに対しては,正しい予測ができないようなモデルを生成すること.
過学習では, 訓練データでは精度が高く,損失が少ないが, 検証データでは精度が低く,損失が多いというように,訓練データと検証データでの乖離が起きている.
学習 (learning)
学習は,より正しい出力が得られるように, ニューラルネットワークの重みとバイアスを修正すること. あるいは, 最適な出力が得られるように, 重みとバイアスを最適化すること.
そのために,教師データのうち,入力を使い, ニューラルネットワークを動かす. そして,正解の出力を使い, 損失関数の値ができるだけ小さくなるように, オプティマイザ(最適化器)を用いて, ニューラルネットワークを構成するニューロンの重みとバイアスなど, ニューラルネットワークのパラメータを修正する.
学習曲線 (learning curve)
学習済みモデル (trained model)
学習不足 (underfitting)
学習不足の原因は種々あり得る.
学習率 (learning rate)
勾配降下法を用いてモデルの学習を行うときに使用される値である. 勾配降下法では,イテレーションごとに,勾配と学習率の掛け算を行う. その結果として得られる積を「gradient step」と言う. 学習率は,ハイパーパラメータの1つである.
学習率をダイナミックに変化させる技術には, AdaDelta 法,Adam 法などが知られる.
確率勾配降下法 (SGD, stochastic gradient descent)
バッチサイズが 1として,勾配降下法を実行すること. これは,教師データから,ランダムに1つのを選び,勾配を算出して,学習を行う.
確率的勾配降下法 (SGD 法) は,次の方法で行う勾配降下法である.
- ミニバッチ学習を行う.
- 次の手順により,損失関数の値ができるだけ小さくなるように,ニューラルネットワークの重みの値を定める
m.compile( optimizer=tf.keras.optimizers.SGD(learning_rate=0.0001, momentum=0.9, nesterov=True), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_crossentropy', 'accuracy'] )隠れ層 (hidden layer)
ニューラルネットワークで,入力層と出力層の間の層.
画素
MNIST データセットは,濃淡画像 70000枚である.その画素は 0 から 255 の値になっている.
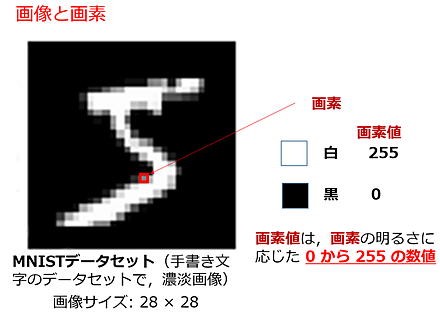
画像全体は配列として扱うことが多い.
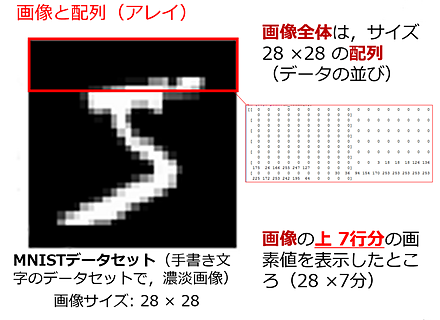
画像
【関連項目】 動画については,「動画」の項目で説明している.
画像データの形式変換
画像の形式変換は,ImageMagickを用いて行うことができる.
convert a.png a.jpg画像のサイズ変更 (image resize)
次の Python プログラムは,画像ファイル http://images.cocodataset.org/train2017/000000310645.jpg のダウンロードとロードを行ったのち, 画像のサイズ変更を行う.画像の表示も行う.
from PIL import Image import requests # ダウンロードとロード url = 'http://images.cocodataset.org/train2017/000000310645.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # サイズ変更と確認表示 img2 = img.resize((400, 200), Image.ANTIALIAS) display(img2)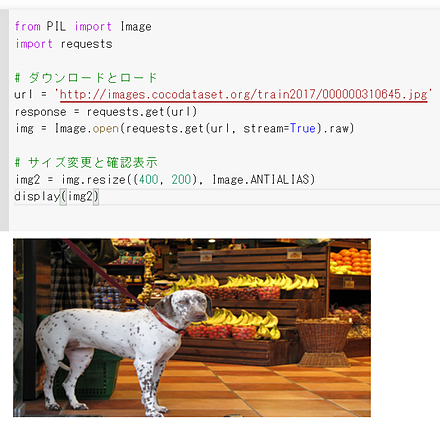
画像の切り出し (image crop)
次の Python プログラムは,画像ファイル http://images.cocodataset.org/train2017/000000310645.jpg のダウンロードとロードを行ったのち, 画像を正方形に切り出す.画像の表示も行う.
from PIL import Image import requests def square(img): width, height = img.size if height > width: e = (height - width) / 2 region = (0, e, width, width + e) else: e = (width - height) / 2 region = (e, 0, height + e, height) return img.crop(region) # ダウンロードとロード url = 'http://images.cocodataset.org/train2017/000000310645.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 切り出しと確認表示 display(square(img))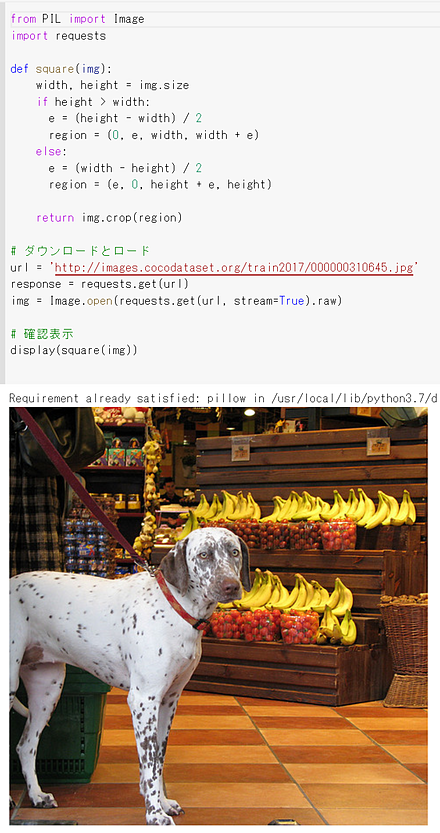
画像ファイルのダウンロードとロード
- ダウンロード: URLを指定してファイルをダウンロード
- ロード:ファイルの中身を読み込み
次の Python プログラムは,画像ファイル http://images.cocodataset.org/train2017/000000310645.jpg のダウンロードとロードを行う.画像の表示も行う.
- 前準備
pip install pillow - プログラムのソースコードと実行結果
from PIL import Image import requests from IPython.display import display # ダウンロードとロード url = 'http://images.cocodataset.org/train2017/000000310645.jpg' response = requests.get(url) img = Image.open(requests.get(url, stream=True).raw) # 確認表示 display(img)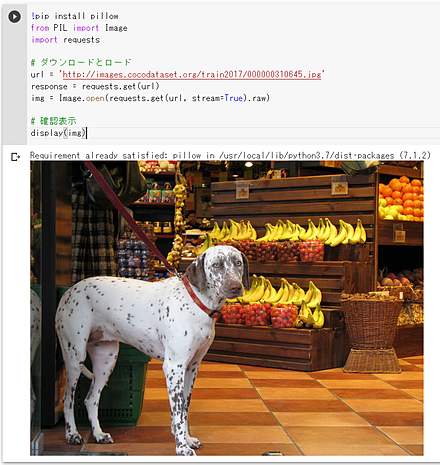
画像データのデータ拡張 (image data augmentation)
CIFAR-10 データセットについて,データ拡張のために フリップと回転を行う Keras のプログラムは次の通りである.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np import tensorflow_datasets as tfds # CIFAR-10 データセットのロード cifar10, cifar10_metadata = tfds.load('cifar10', with_info = True, shuffle_files=True, as_supervised=True, batch_size = -1) x_train, y_train, x_test, y_test = cifar10['train'][0], cifar10['train'][1], cifar10['test'][0], cifar10['test'][1] print(cifar10_metadata) # 増量 INPUT_SHAPE = [32, 32, 3] data_augmentation = tf.keras.Sequential() data_augmentation.add(tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal", input_shape=INPUT_SHAPE)) data_augmentation.add(tf.keras.layers.experimental.preprocessing.RandomRotation(0.1)) def f(x): tf.reshape(data_augmentation(tf.reshape(x, (1, INPUT_SHAPE[0], INPUT_SHAPE[1], INPUT_SHAPE[2]))), (INPUT_SHAPE[0], INPUT_SHAPE[1], INPUT_SHAPE[2])) display([*map(f, x_train)])画像分類 (image classification)
画像分類は,画像からそのクラス名を求めるもの.
Big Tranfer ResNetV2, CSPNet, MobileNetV2, MobileNetV3, Inception-Resnet, ResNet50, ResNet101, ResNet152, ResNeXt, DenseNet121, DenseNet169, NASNet, Vision Transformer, Wide ResNet などの画像分類のモデルがある.
CSPNet, 文献: CSPNet: A New Backbone that can Enhance Learning Capability of CNN - https://arxiv.org/abs/1911.11929 公式の実装: https://github.com/WongKinYiu/CrossStagePartialNetworks rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/csp-resnet CSPResNet is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to ResNet. The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network. import timm m = timm.create_model('cspresnet50', pretrained=True) m.eval() MobileNetV3, 文献: Searching for MobileNetV3 - https://arxiv.org/abs/1905.02244 公式の実装: https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/mobilenet-v3 MobileNetV3 is a convolutional neural network that is designed for mobile phone CPUs. The network design includes the use of a hard swish activation and squeeze-and-excitation modules in the MBConv blocks. import timm m = timm.create_model('mobilenetv3_large_100', pretrained=True) m.eval() Inception-Resnet, 文献: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning - https://arxiv.org/abs/1602.07261 実装: https://github.com/Cadene/pretrained-models.pytorch rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/inception-resnet-v2 Inception-ResNet-v2 is a convolutional neural architecture that builds on the Inception family of architectures but incorporates residual connections (replacing the filter concatenation stage of the Inception architecture). import timm m = timm.create_model('inception_resnet_v2', pretrained=True) m.eval() ResNet152, 文献: Deep Residual Learning for Image Recognition - https://arxiv.org/abs/1512.03385 実装: https://github.com/pytorch/vision/tree/master/torchvision/models rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/resnet Residual Networks, or ResNets, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack residual blocks ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks. import timm m = timm.create_model('resnet152', pretrained=True) m.eval() ResNeXt, 文献: Aggregated Residual Transformations for Deep Neural Networks - https://arxiv.org/abs/1611.05431 実装: Code: https://github.com/pytorch/vision/tree/master/torchvision/models rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/resnext A ResNeXt repeats a building block that aggregates a set of transformations with the same topology. Compared to a ResNet, it exposes a new dimension, cardinality (the size of the set of transformations) , as an essential factor in addition to the dimensions of depth and width. import timm m = timm.create_model('resnext50_32x4d', pretrained=True) m.eval() DenseNet169, 文献: Densely Connected Convolutional Networks - https://arxiv.org/abs/1608.06993 実装: https://github.com/pytorch/vision/tree/master/torchvision/models rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/densenet DenseNet is a type of convolutional neural network that utilises dense connections between layers, through Dense Blocks, where we connect all layers (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers. import timm m = timm.create_model('densenet169', pretrained=True) m.eval() NASNet, 文献: Learning Transferable Architectures for Scalable Image Recognition - https://arxiv.org/abs/1707.07012 実装: https://github.com/Cadene/pretrained-models.pytorch rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/nasnet NASNet is a type of convolutional neural network discovered through neural architecture search. The building blocks consist of normal and reduction cells. import timm m = timm.create_model('nasnetalarge', pretrained=True) m.eval() Big Tranfer ResNetV2, 文献: Big Transfer (BiT): General Visual Representation Learning - https://arxiv.org/abs/1912.11370 公式の実装: https://github.com/google-research/big_transfer rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/big-transfer Big Transfer (BiT) is a type of pretraining recipe that pre-trains on a large supervised source dataset, and fine-tunes the weights on the target task. Models are trained on the JFT-300M dataset. The finetuned models contained in this collection are finetuned on ImageNet. import timm m = timm.create_model('resnetv2_101x1_bitm', pretrained=True) m.eval() related resnetv2 Vision Transformer, 文献: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale - https://arxiv.org/abs/2010.11929 公式の実装: https://github.com/google-research/vision_transformer rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://paperswithcode.com/lib/timm/vision-transformer The Vision Transformer is a model for image classification that employs a Transformer-like architecture over patches of the image. This includes the use of Multi-Head Attention, Scaled Dot-Product Attention and other architectural features seen in the Transformer architecture traditionally used for NLP. import timm m = timm.create_model('vit_large_patch16_224', pretrained=True) m.eval() Wide ResNet 文献: https://arxiv.org/abs/1605.07146v4 rwightman の PyTorch Image Models (TIMM) の画像分類モデルの説明(Papers With Code 内): https://github.com/rwightman/pytorch-image-models Wide Residual Networks are a variant on ResNets where we decrease depth and increase the width of residual networks. This is achieved through the use of wide residual blocks. import timm m = timm.create_model('wide_resnet169_2', pretrained=True) m.eval()
【関連項目】 Big Tranfer ResNetV2, CSPNet, MobileNetV2, MobileNetV3, Inception-Resnet, ResNet50, ResNet101, ResNet152, ResNeXt, rwightman の PyTorch Image Models (TIMM) DenseNet121, DenseNet169, NASNet, Vision Transformer, Wide ResNet Residual Networks (ResNets), SPP (Spatial Pyramid Pooling)
活性化関数
活性化関数は,ニューロンの入力の合計から,そのニューロンの出力(活性度の値)を求めるための関数である. 活性化関数には,次のようなものがある.
- ReLU (rectified linear unit)
- LReLU (Leaky rectified linear unit)
- シグモイド関数 (sigmoid function)
- ステップ関数
- ソフトマックス関数 (softmax function) など
- ReLU (Rectified linear units improve restricted boltzmann machines)
- LReLU (leaky-ReLU)
https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
株価データ
pandas_datareader を用いて Stoop から,株価のデータをダウンロードし,mplfinance を用いて確認表示する.
- pandas_datareader, mplfinance のインストール
pip を用いて pandas_datareader, mplfinance をインストールする
- 次の Python プログラムは,
pandas_datareader を用いて Stoop から,株価のデータをダウンロードし,mplfinance を用いて確認表示(ろうそく足,出来高,移動平均線のプロット)する.
import pandas_datareader.data as pdrdata import mplfinance name = "1301.JP" a = pdrdata.DataReader(name,"stooq") mplfinance.plot(a, type='candle', volume=True, mav=(5, 50))
【関連項目】 Pandas, Python, Stoop, オープンデータ
教師あり学習 (supervised learning)
教師データ
教師データは,次の2つのセット.
- ニューラルネットワークの入力データ
- 正解データ
「訓練データ」などともいう.
教師なし学習 (unsupervised learning)
正解となるラベルのないデータを用いて学習を行うこと.クラスタリングなどがある.
距離学習
距離学習は,同一クラスであれば距離が小さく, 違うクラスであれば距離が遠くなるような数値ベクトル(数値の並び)を,機械学習によって得ることである.
距離学習は,2つの顔画像が同一人物であるかを判定したり,顔画像が既知の人物の誰であるかを特定したり(あるいは,既知の人物ではないと判定しあり)する場合に役立つ.
距離学習と分類は違う.分類は,全クラスに属するデータを事前に得て学習させることを行う. 距離学習は,全クラスに属するデータを事前に得ることができないことを前提とする. 距離学習は,推論のときに,未知のクラスのデータが与えられる可能性があるなど,クラス数が不定である場合に有用である.
訓練
検証 (validation)
学習のときに,機械学習のモデルの品質を,検証用のデータを用いて評価する. 検証用のデータは,教師データとは独立したものである必要がある.検定
検定には次のようなものがある.検定のときに,度数分布(ヒストグラム)をあわせて作成しておくことは,良い手がかりになる.
- パラメトリック検定
母集団は正規分布である.母平均,母分散を考える場合もある.
t 検定 (t test),F 検定 (F test), シャピロ・ウィルク検定 (Shapiro Wilk test), one-way ANOVA (One-way analysis of variance), ウエルチの方法による一元配置分散分析 (One-way analysis of means)
- ノンパラメトリック検定
母集団は正規分布とは限らない.
ウィルコクソンの符号順位検定 (Wilcoxon signed-rank test), マン・ホイットニーの U 検定 (Mann-Whitney U test, Wilcoxon rank sum test), コルモゴロフ–スミルノフ検定 (Kolmogorov-Smirnov test), クラスカル・ウォリス検定 ( Kruskal-Wallis rank sum test)
交差エントロピー
多クラスの交差エントロピーは,
- yi : ニューラルネットワークの出力 (yi の総和は,1 であること.例えば,ソフトマックス関数の場合は,総和は 1 になる.
- ti : 正解の出力.one-hot エンコーディングのクラス番号になっている.
のとき,次の通り.
-sigma_i( t[i] * log( y[i] ) )
2クラスの交差エントロピーは,
- yi : ニューラルネットワークの出力.{0, 1} の 2値ベクトルになっていること.
- ti : 正解の出力.{0, 1} の 2値ベクトルになっていること.
のとき,次の通り.
-sigma_i( t[i] * log( y[i] + (1 - t[i]) * (1 - log( y[i]) )
勾配 (gradient)
勾配は,すべての自由変数について偏微分を行った結果として得られる ベクトルである.
機械学習では,モデル関数の偏微分を行った結果として得られるベクトルである. 重みに関する損失関数の勾配は,損失関数の値を最も減らすような重みの方向ベクトルである.
勾配消失問題 (vanishing gradient problem)
ニューラルネットワークの入力層に近い隠れ層について,その勾配が 0 に近くなる傾向のこと. 勾配が 0 に近くなると,学習における重みの変化が小さくなり,学習がうまく行えなくなる. LSTM (Long Short-Term Memory) は勾配消失問題を解決できるとされている.
国土数値情報
- バス停留所データ: https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-P11.html
- 行政区域データ: https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N03-v2_3.html
混合行列 (confusion matrix)
分類モデル (classification model) での分類結果について集計した N かける N の表. N はクラス数である. 分類モデルでの分類として得られたクラスと, 実際のクラス(正解のクラス)とを,縦方向と横方向にする.
勾配降下法 (gradient descent)
モデルのパラメータについて,損失の 勾配を算出することにより, 損失を最小化する方法の1つ. 損失を最小化するような重みとバイアスの最適な組み合わせに徐徐に近づけるために,パラメータの調整を繰り返す.
最小全域木 (minimum spanning tree)
最小全域木 (minimum spanning tree) を作成する R システムのプログラムは, 別ページ »で説明
散布図
散布図(縦軸のラベル,横軸のラベル,凡例の表示付き)の作成を行う Python プログラムを紹介する. plotly を使うものと,Seaborn を使うものと,Matplotlib を使うものを紹介する.
plotly を用いた散布図の例
次の Python プログラムは,Iris データセットの散布図を表示する.
次の Python プログラム は Iris データセットの 'sepal length (cm)', 'sepal width (cm)' を横軸と縦軸の値として散布図を書く. 'species' を使って色を付けるとともに,形を変える. 縦軸のラベル,横軸のラベル,凡例の表示も行う. Pandas データフレームから散布図を作成しているのは,このプログラムの末尾の2行である.
import numpy as np import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import plotly.express as px from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] fig = px.scatter(df, x="sepal width (cm)", y="sepal length (cm)", color='species', symbol='species', opacity=0.4) fig.show()
次の Python プログラムは,Iris データセットの散布図を表示する.
次の Python プログラムの関数 scatter_plot_matplotlib は x, y を横軸と縦軸の値として散布図を書く. target を使って色を付けるとともに,形を変える. このプログラムは,numpy ndarray のデータを散布図にしたいときの見本として作成した. 散布図を作成しているのは,このプログラムの末尾の2行である.
import numpy as np import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import plotly.express as px from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] x = df['sepal length (cm)'].to_numpy() y = df['sepal width (cm)'].to_numpy() target = df['species'] fig = px.scatter(x=x, y=y, color=target, symbol=target, opacity=0.4, labels={'x': 'sepal length (cm)', 'y': 'sepal width (cm)', 'color': 'species', 'symbol': 'species'}) fig.show()
plotly とDash の連携の例
【関連する外部ページ】 https://dash.plot.ly/getting-started
import dash import dash_table import dash_core_components as dcc import dash_html_components as html import pandas as pd import seaborn as sns import plotly.graph_objs as go X = sns.load_dataset('iris') external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div(children=[ html.H1(children='Iris DataSet'), html.Div(children=''' Iris DataSet Display '''), dcc.Graph( id='example-graph', figure={ 'data': [ go.Scatter( x = X[X.iloc[:,4]==i].iloc[:,0], y = X[X.iloc[:,4]==i].iloc[:,1], mode = 'markers', marker={ 'size': 10, 'line': {'width': 0.5, 'color': 'white'} }, opacity = 0.5, name=i ) for i in X.iloc[:,4].unique() ], 'layout': { 'title': 'Iris DataSet Graph' } } ) ])Seaborn を用いた散布図の例
次の Python プログラムは,Iris データセットの散布図を表示する.
次の Python プログラム は Iris データセットの 'sepal length (cm)', 'sepal width (cm)' を横軸と縦軸の値として散布図を書く. 'species' を使って色を付ける. 縦軸のラベル,横軸のラベル,凡例の表示も行う. Pandas データフレームから散布図を作成しているのは,このプログラムの末尾の3行である.
import numpy as np import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import seaborn as sns from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] nump = np.max(pd.factorize(df['species'])[0] + 1) plt.style.use('ggplot') sns.scatterplot(x='sepal length (cm)', y='sepal width (cm)', hue='species', data=df, palette=sns.color_palette("hls", nump), legend="full", alpha=0.4)
次の Python プログラムは,Iris データセットの散布図を表示する.
次の Python プログラムの関数 scatter_plot_matplotlib は x, y を横軸と縦軸の値として散布図を書く. target を使って色を付ける. xlabel, ylabel, target_name は,横軸の名前,縦軸の名前,凡例のタイトルをグラフに表示させるためのもの. このプログラムは,numpy ndarray のデータを散布図にしたいときの見本として作成した.
import numpy as np import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import seaborn as sns from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] def scatter_plot_sns(x, y, xlabel, ylabel, target, target_name, alpha): # x, y, target は同じ長さの1次元の numpy.ndarray df = pd.DataFrame(np.stack([x, y, target], 1), columns=[xlabel, ylabel, target_name]) nump = np.max(pd.factorize(df['species'])[0] + 1) g = sns.scatterplot(x=xlabel, y=ylabel, hue=target_name, data=df, palette=sns.color_palette("hls", nump), legend="full", alpha=alpha) plt.show() plt.style.use('ggplot') scatter_plot_sns(df['sepal length (cm)'].to_numpy(), df['sepal width (cm)'].to_numpy(), 'sepal length (cm)', 'sepal width (cm)', df['species'], 'species', 0.4)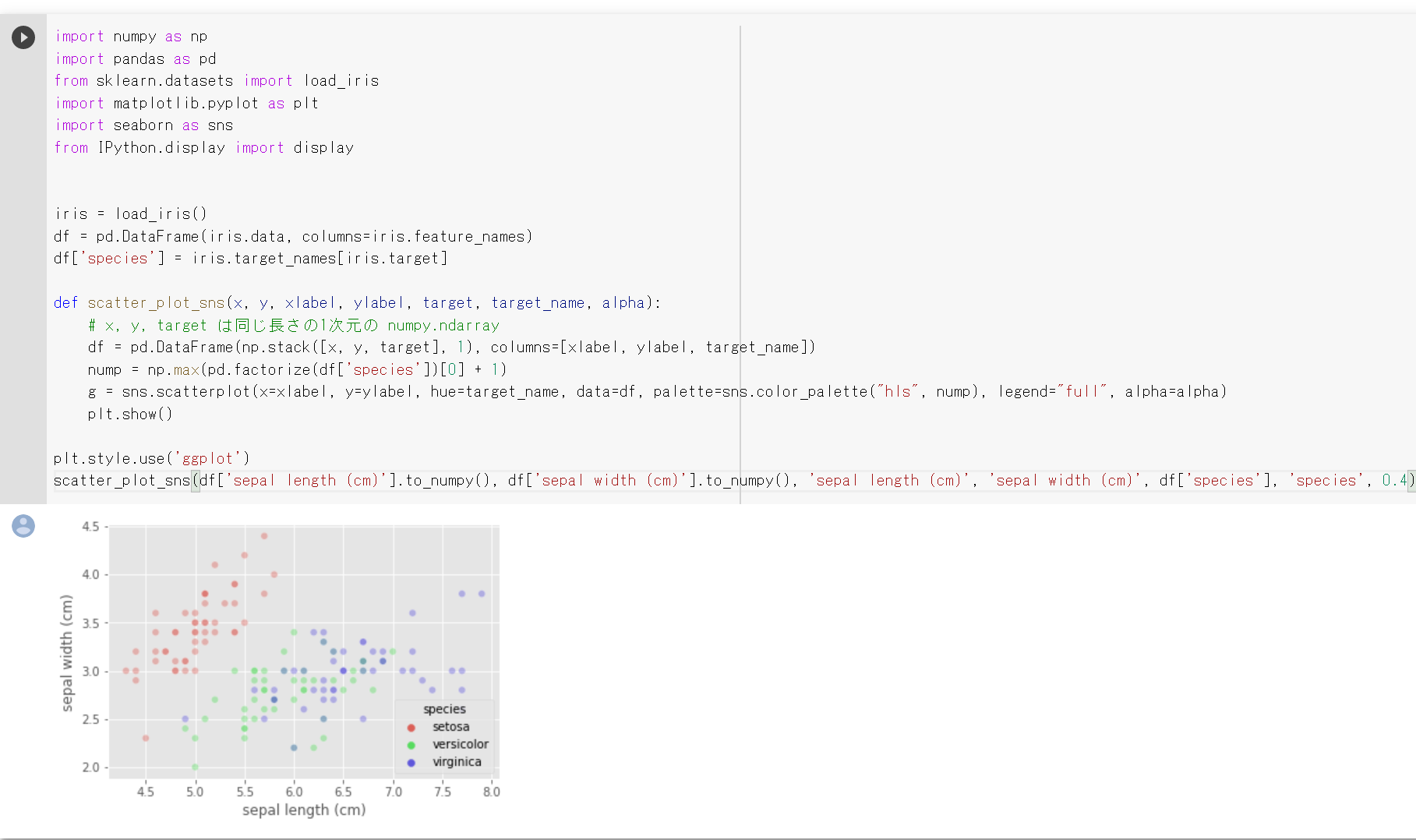
次のプログラムも M の最初の2列を横軸と縦軸の値として散布図を書く. b を使って色を付ける.今度は,seaborn の lmplot を使用
def scatter_plot(M, b, alpha): a12 = pd.DataFrame( M[:,0:2], columns=['a1', 'a2'] ) a12['target'] = b sns.lmplot(x='a1', y='a2', data=a12, hue='target', scatter_kws={'alpha': alpha}, fit_reg=False)Matplotlib を用いた散布図の例
次の Python プログラムは,Iris データセットの散布図を表示する.
次の Python プログラムの関数 scatter_plot_matplotlib は x, y を横軸と縦軸の値として散布図を書く. target を使って色を付ける. xlabel, ylabel, target_name は,横軸の名前,縦軸の名前,凡例のタイトルをグラフに表示させるためのもの.
import numpy as np import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] def scatter_plot_matplotlib(x, y, xlabel, ylabel, target, target_name, alpha): # x, y, target は同じ長さの1次元の numpy.ndarray f = pd.factorize(target) plt.style.use('ggplot') fig, ax = plt.subplots() for i in range(np.min(f[0]), np.max(f[0]) + 1): ax.scatter(x=x[f[0] == i], y=y[f[0] == i], alpha=alpha, label=target[np.where(f[0] == i)[0][0]]) ax.legend(title = target_name) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.show() plt.style.use('ggplot') scatter_plot_matplotlib(df['sepal length (cm)'].to_numpy(), df['sepal width (cm)'].to_numpy(), 'sepal length (cm)', 'sepal width (cm)', df['species'], 'species', 0.4)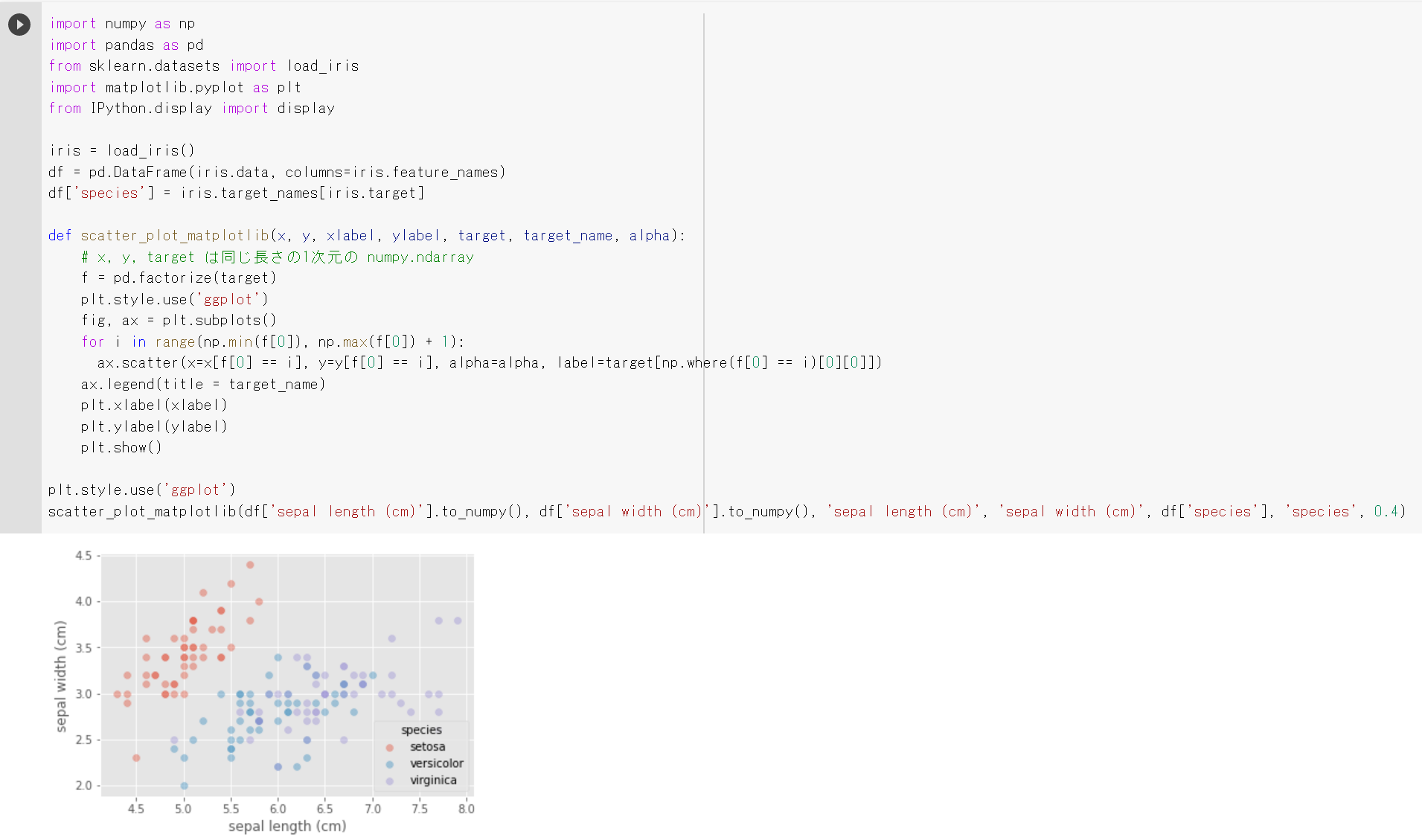
次の Python プログラムは,Iris データセットの散布図を表示する.
データフレーム df について, は 'sepal length(cm)', 'sepal width(cm)' を横軸と縦軸の値として散布図を書く. 'species' の値を使って色を付ける. 横軸の名前,縦軸の名前を表示させる. 上のプログラムとは違って凡例は表示しない.プログラムは簡単になっている.
import pandas as pd from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] df['plot_color'] = pd.factorize(df['species'])[0] plt.style.use('ggplot') plt.scatter(x='sepal length (cm)', y='sepal width (cm)', c='plot_color', data=df, alpha=0.4) plt.xlabel('sepal length (cm)') plt.ylabel('sepal width (cm)') plt.show()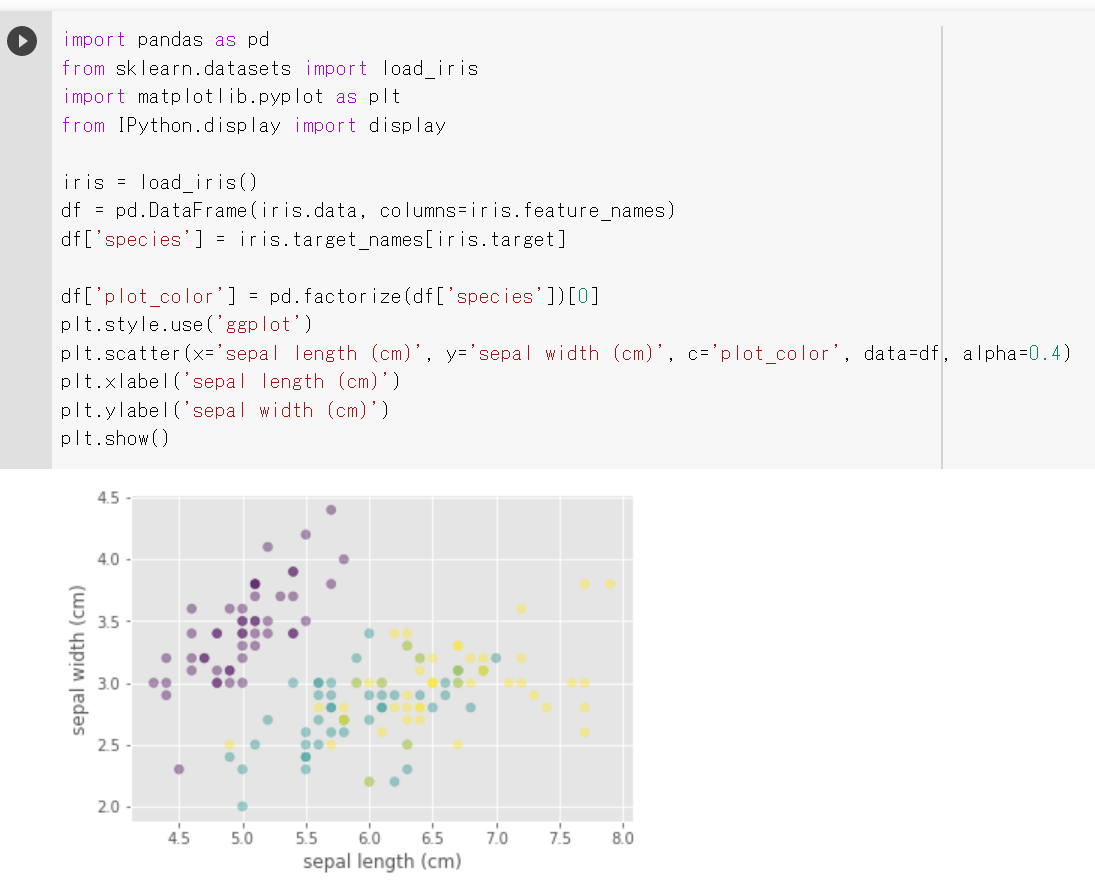
時系列データ(time series data)
時系列データは,「昨日の気温は15度,今日の気温が13度」のように,時間とともに,値が変化するようなデータである.
【関連項目】 Johns Hopkins 大の COVID-19 データレポジトリ
時系列データのニューラルネットワークでの扱い
時系列データをニューラルネットワークで扱うとき, 前回の推論時でのニューロンの出力の一部を,次の推論に反映させることが役立つ. 例えば,10月23日のデータでの推論時のでの ニューロンの出力の一部を,10月24日のデータでの推論に反映させるようなことである.
前回の推論時での出力の一部を,次の推論に反映させるために, 前回の推論時でのニューロンの出力が, 次の推論時で,同じニューロンの入力の一部になるようにするなどで,ニューラルネットワークを作る場合がある. そのようなニューラルネットワークには, リカレントニューラルネットワークがある. リカレントニューラルネットワークには, LSTM (Long Short-Term Memory), GRU (Gated Recurrent Neural Networks) などのバリエーションがある.
【関連項目】 GRU (Gated Recurrent Neural Networks), LSTM (Long Short-Term Memory), リカレントニューラルネットワーク
次元削減 (dimension reduction)
特徴ベクトルの特定の属性を表現するのに用いられる次元の数を削減すること.
収束
収束は, 学習において, 学習を繰り返したのち, 学習を 1回行うごとの training loss と validation loss の変化がとても少なくなっているか,そうでないかの判断を場合に関係する.
主成分分析 (principal component alalysis)
次の Python プログラムは,Iris データセットの主成分分析を行い,第1主成分,第2主成分,Iris データセットの属性 species で散布図を表示する.
次の Python プログラム では Iris データセットの主成分分析の第1主成分,第2主成分を横軸と縦軸の値として散布図を書く. 'species' を使って色を付けるとともに,形を変える. 縦軸のラベル,横軸のラベル,凡例の表示も行う.
import numpy as np import pandas as pd from sklearn.datasets import load_iris import sklearn.decomposition %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import plotly.express as px from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] pca = sklearn.decomposition.PCA(n_components=4) r = pca.fit_transform(df.iloc[:,0:4].to_numpy()) fig = px.scatter(x=r[:,0], y=r[:,1], color=df['species'], symbol=df['species'], opacity=0.4, labels={'x': '1', 'y': '2', 'color': 'species', 'symbol': 'species'}) fig.show()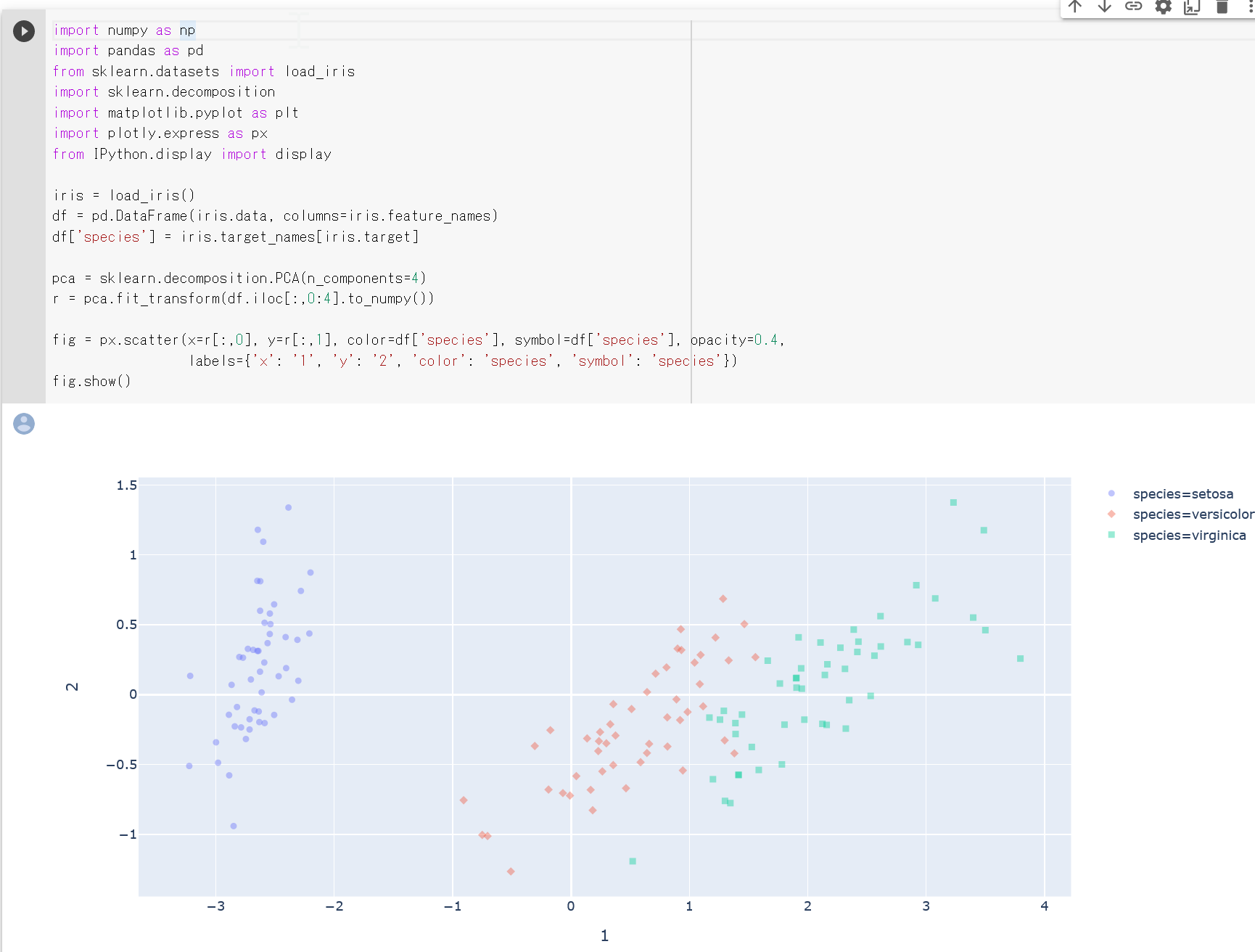
次の Python プログラムは,Iris データセットの主成分分析を行い,第1主成分,第2主成分,第3主成分,Iris データセットの属性 species で3次元の散布図を表示する.
次の Python プログラムでは,3次元の散布図のために, plotly の scatter_3d を用いている.
import numpy as np import pandas as pd from sklearn.datasets import load_iris import sklearn.decomposition %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings import plotly.express as px from IPython.display import display iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target_names[iris.target] pca = sklearn.decomposition.PCA(n_components=4) r = pca.fit_transform(df.iloc[:,0:4].to_numpy()) fig = px.scatter_3d(x=r[:,0], y=r[:,1], z=r[:,2], color=df['species'], symbol=df['species'], opacity=0.4, labels={'x': '1', 'y': '2', 'z': '3', 'color': 'species', 'symbol': 'species'}) fig.show()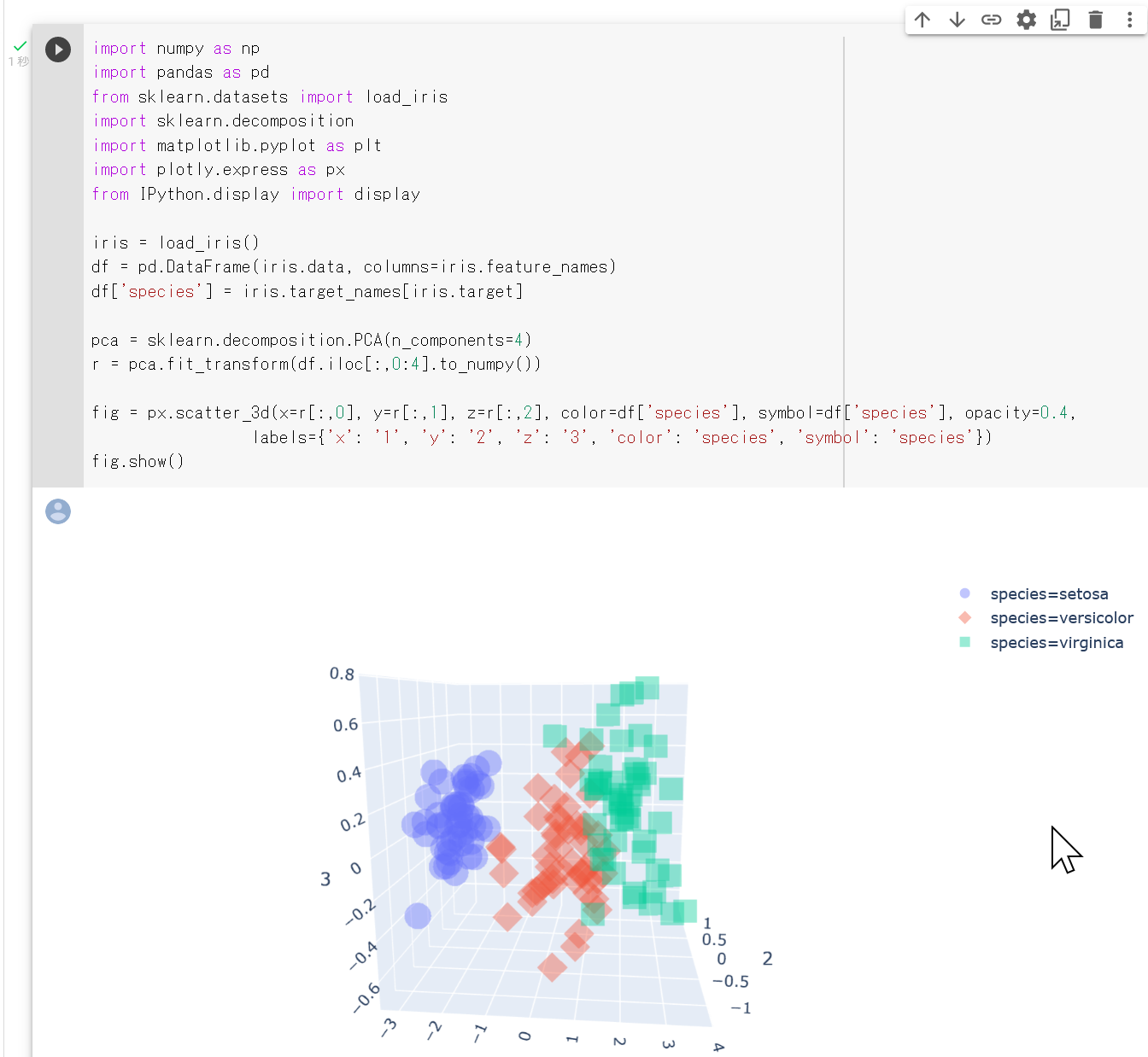
出力層 (output layer)
ニューラルネットワークの最終の層のこと.
正規化
正規化は, 値の範囲を,標準的な値の範囲に変換すること. 次のような意味がある.
- 複数のデータがあるとき,分布を保ちながら「データの範囲を0から1の間に収める」ようなデータ変換操作.
Python のプログラムは次の通り.
import numpy as np from sklearn.preprocessing import scale, minmax_scale scale(np.array([1, 3, 4, 5, 2])) - 複数のデータがあるとき,分布を保ちながら「平均 0,標準偏差1になる」ようなデータ変換操作.
Python のプログラムは次の通り.
import numpy as np from sklearn.preprocessing import scale, minmax_scale minmax_scale(np.array([1, 3, 4, 5, 2])) - 数値ベクトルがあるとき,そのベクトルの向きを保ちながら,長さを1にするようなデータ変換操作
Python のプログラムは次の通り.
import numpy as np from sklearn.preprocessing import normalize a = np.array([[1, 2, 0], [11, 12, 0]]) a.shape normalize(a, axis=0) normalize(a, axis=1)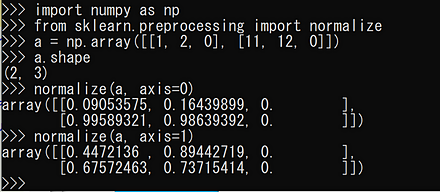
推論 (inference)
ニューラルネットワークを教師あり学習で使用する場合での推論は,学習済みのモデルに対して,入力を与え,出力を得ること. このとき,ニューラルネットワークの重みは変化しない.
ニューラルネットワークの重みが変化可能に設定したままの状態で推論を行うと,精度よく推論が出来ないなどの問題がある.PyTorch では,eval メソッドの実行により, ニューラルネットワークの重みが変化しないように設定した上で推論を行う.
出力は分類結果であったり,分類結果の確率分布であったり,さまざまありえる.
生成モデル (generative model)
生成モデルは,データ X とクラス C の結合確率をモデル化し, そのモデルのパラメータと,データ X の同時確率を最大化したもの.
あるいは,生成モデルのことを,データ X を生成するための確率モデルという意味でいうこともある.
正則化 (regularization)
正則化は,モデルの複雑さに対するペナルティととらえることができる. 正則化は過学習の防止,緩和に役立つとされる. 正則化には次のような種類がある.
参考文献: http://research.microsoft.com/en-us/um/people/jingdw/pubs/cvpr16-disturblabel.pdf
生成的 AI (generatve AI)
生成的 AI (generatve AI) は,大量のデータによる学習により,要求に応じた文章や画像や音声などを生成する能力に上達する能力を持った人工知能である.
【関連項目】 リカレントニューラルネットワーク,
正則化率 (regularization rate)
重みと比べたときの,正則化関数の相対的な重要性を指定する数値である. 正則化率を上げると,過学習が減少するが,モデルの精度が低下する可能性がある. 正則化率を「lambda」と書くことが多い.
全結合 (Dense)
全結合は,多層パーセプトロン (MLP)で,である層のニューロンすべてと,隣の層のニューロンすべてを結合すること.
全結合層
ニューラルネットワークの 層(レイヤ)のうち, 後続の層(レイヤ)と 全結合されている層(レイヤ)のことを 全結合層という.
「Fully-connected Layer」と言ったり,「Dense Layer」と言ったり,「Affine レイヤ」と言ったりもする.
層(レイヤ)
ニューラルネットワークは, 層(レイヤ)の積み重ねで構成されると考えることができる.
ニューラルネットワークの1つの層(レイヤ)は, コンピュータの中に作るとき,全結合層 (fully-connected layer), 活性化関数層 (activation layer) いう複数の層(レイヤ)に分かれることが普通である. さらに Dropout のような,新しい層(レイヤ)が加わることもある.
【Keras のプログラム】入力の次元数が 784,ニューロン数 100, 100, 100の3層,クラス数 10,ドロップアウト 0.05 であるような分類モデル">のプログラムは次のようになる.
m.add(Dense(units=100, input_dim=len(768[0]))) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=100)) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=100)) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=クラス数)) m.add(Activation('softmax'))層構造のニューラルネットワーク
この資料で, 「層構造のニューラルネットワーク」というときは, ニューラルネットワークが層構造をなしていて,さらに,ある層(レイヤ)のニューロンは, 次の層(レイヤ)のみにつながる(つながりでは,飛び越しや後戻りがない)という場合のことをいう. Keras では,「Sequential」という.
例えば,次のような 10層からなる層構造のニューラルネットワークを考えることができる.
- 全結合層 (fully-connected layer)
- 活性化関数層 (activation layer) として ReLu
- 全結合層 (fully-connected layer)
- 活性化関数層 (activation layer) として ReLu
- 全結合層 (fully-connected layer)
- 活性化関数層 (activation layer) として ReLu
- 全結合層 (fully-connected layer)
- 活性化関数層 (activation layer) として Softmax
【Keras のプログラム】m.add(Dense(units=100, input_dim=len(768[0]))) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=100)) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=100)) m.add(Activation('relu')) m.add(Dropout('0.05')) m.add(Dense(units=クラス数)) m.add(Activation('softmax'))相互情報量 (mutual information)
相互情報量を求める R のプログラム.library(entropy) X <- c(1,2,1,2,3,2,1) Y <- c(4,5,5,4,6,5,4) a <-discretize2d(X, Y, 3, 3) mi.plugin(a) chi2indep.plugin(a)
参考資料: https://cran.r-project.org/web/packages/entropy/entropy.pdf
相対度数分布 (relative frequency histgram)
度数分布のうち,データの個数を数え上げる普通の度数分布の他に, 比率(全体を 1 をする)を数え上げる相対度数分布(relative frequency histgram), 累積値を数え上げる累積度数分布(cumulative frequency histogram)がある.
相対度数分布を数える Python プログラム.numbins で帯数を指定.scipy.stats.relfreq([0, 1, 1, 0, 0, 0, 1, 0, 0], numbins = 2)
参考ページ: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.relfreq.html
相対度数分布を数える R のプログラム.numBins で帯数を指定.library(entropy) a = c(0, 1, 1, 0, 0, 0, 1, 0, 0) discretize(a, numBins=2)/length(a)

参考資料: https://cran.r-project.org/web/packages/entropy/entropy.pdf
損失 loss)
ニューラルネットワークの出力と正解との差. つまり,損失は,モデルにより予測された値が,正解とどれだけ離れているかを示す. 損失の値を算出するために,損失関数が必要である.
損失関数
損失を算出するための関数のこと. 平均二乗誤差 (MSE, Mean Squared Error), カルバック-ライブラー情報量などがある. 「誤差関数」ともいうこともある.
ニューラルネットワークの学習においては,損失関数の値が最小になるように探索が行われる.
Keras の損失関数のページ: https://keras.io/api/losses/index.html
-
交差エントロピー(binary_crossentropy )
2クラスの 交差エントロピー(binary_crossentropy )を, 学習 (training)での,損失関数として使うことがある. logloss ともいう.
-
categorical crossentropy
多クラスの 交差エントロピーを, 学習 (training)での,損失関数として使うこと. マルチクラス logloss ともいう.
Keras の categorical crossentropy を使う場合には, ラベルのデータがバイナリ配列であり,その形状が (n_sample, nb_classes) であること. 2クラスの交差エントロピーを使いたいときは,binary_crossentropy を用いる.
大規模言語モデル (large language model)
大規模言語モデル は,自然言語処理を機械学習で行うためのモデルの一種であり,その中でも数億〜数十億以上のパラメーターを持ち,膨大な量の自然言語データによる訓練を受けたものを指す. 大規模言語モデルは,文章の生成,要約,翻訳,対話システムなどの自然言語処理において有用性が示されつつあります. 代表的な大規模言語モデルには,OpenAI の GPT,Google の BERT,Meta の LLaMA,Stanford Alpaca などがある.
【関連項目】 FlexGen, LLaMA (Large Language Model Meta AI), LoRA, OPT, Stanford Alpaca, Whisper
多クラス
「多クラス」は,クラス数が3以上であること.クラス数が2の場合には「2クラス」という.
多クラスの分類 (multi-class classification)
2つ以上のクラスに分類すること. 2クラスに分類するときは binary classication という.
畳み込みニューラルネットワーク (CNN, Convolutional Neural Network)
畳み込みニューラルネットワーク (Convolutional Neural Network) は,畳み込み層 (convolutional layer) を含むような ニューラルネットワークである.
畳み込みニューラルネットワーク (Convolutional Neural Network) は, 次の 3種類の層を含むように構成するのが普通である.
- 畳み込み層 (convolutional layer)
参考文献: Non-linear Convolution Filters for CNN-based Learning, CoRR, abs/1708.07038
- プーリング層 (pooling layer)
参考文献: A new kind of pooling layer for faster and sharper convergence, https://github.com/singlasahil14/sortpool2d
- 全結合層 (fully-connected layer)
【関連項目】 Applications of Deep Neural Networks, Keras, ディープラーニング
畳み込みニューラルネットワーク (Convolutional Neural Network) を作成する Python プログラム(Keras を使用)
例えば,次のような 5層からなる層構造のニューラルネットワークの作成を行う.
- 2次元の畳み込み層 (convolutional layer)
- 2次元の畳み込み層 (convolutional layer)
- プーリング層 (pooling layer)
- 全結合層 (fully-connected layer).ニューロン数は 128.
- 全結合層 (fully-connected layer).ニューロン数は 10
その Python プログラムは次のようになる.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf from tensorflow.keras import layers from tensorflow.keras import backend as K gpu = tf.config.list_physical_devices(device_type = 'GPU') if len(gpu) > 0: print("GPU:", gpus[0].name) tf.config.experimental.set_memory_growth(gpu[0], True) # 畳み込みニューラルネットワークの作成 num_classes = 10 img_rows, img_cols = 28, 28 if K.image_data_format() == 'channels_first': input_shape = (1, img_rows, img_cols) else: input_shape = (img_rows, img_cols, 1) m = tf.keras.Sequential( [ tf.keras.Input(shape=input_shape), layers.Conv2D(32, kernel_size=(3, 3), activation="relu"), layers.Conv2D(64, kernel_size=(3, 3), activation="relu"), layers.MaxPooling2D(pool_size=(2, 2)), layers.Dropout(0.25), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dropout(0.5), layers.Dense(num_classes, activation="softmax"), ] ) m.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) print(m.summary())補足説明は次の通りである.
- TensorFlow, Keras の機能を使用している.プログラム中の add, compile, Conv2D, MaxPooling2D, Dropout, Flatten, Dense は,TensorFlow, Keras の機能である.
- Keras では, 活性化関数層 (activation layer) , ドロップアプト層 (dropout layer) も考慮する.
- 損失関数は categorical cross entropy に設定
- 最適化手法は ADAM を使用
多層パーセプトロン (MLP)
超解像 (super resolution)
超解像 (super resolution) は,低解像度のものを入力として受け取り, 高解像度のものを出力する. その結果,解像度が高まる.
- アルゴリズムによる方法 bicubic など
- 人工知能による方法 Real-ESRGAN, ESRGAN, SRGAN など
下図の左は ESRGAN (RRDN GANS) 法の結果, 下図の右は bicubic 法の結果.
【関連項目】 Real-ESRGAN, ESRGAN
転移学習 (transfer learning)
ある機械学習のタスクから別のタスクに情報を転移すること.
ニューラルネットワークの転移学習では,学習済みモデル を使い,新しい分類を行う.新しい分類のための教師データを十分に準備できないときに効果を期待できる. 転移学習では, 学習済みモデルについて,重みを凍結(フリーズ)する. 学習済みモデルに新しい層(レイヤ)を追加して, 新しい分類を行えるようにする. 学習済みモデルは,新しい分類のための特徴抽出のために使うと考えることができる
動画 (video)
動画の情報確認
動画のサイズ,縦横比,コーデックなどの確認は,mediainfo コマンドで行うことができる.
- Windows での mediainfo のインストールは,日本語版のページを利用できる: https://mediaarea.net/ja/MediaInfo
- Ubuntu での mediainfo のインストール: sudo apt install mediainfo
avi ファイルでの実行結果例
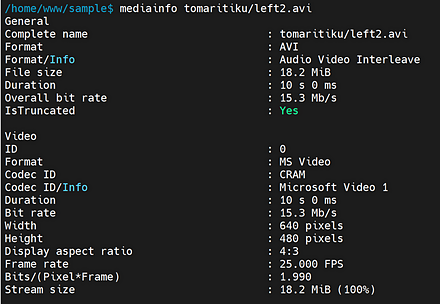
mp4 ファイルでの実行結果例
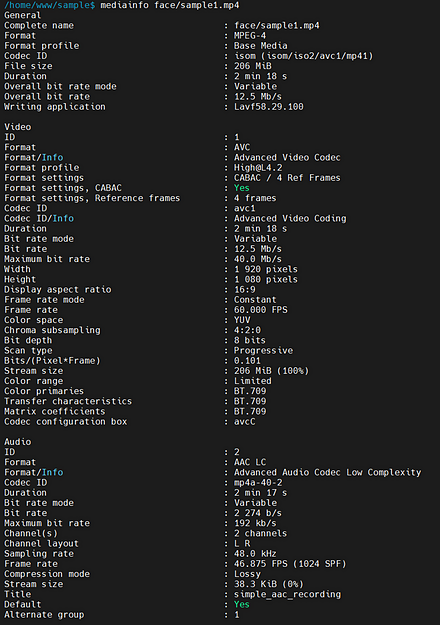
動画の形式変換
動画の形式変換は,ffmpeg を用いて行うことができる.
- Windows での ffmpeg のインストール: 別ページ »で説明
- Ubuntu での ffmpeg のインストール: sudo apt -y install ffmpeg
- VOB 形式を mp4 形式に変換する
- -an : オーディオの記録を無効にする
- -sn : サブタイトルの記録を無効にする
- -vcodec : コーデックの指定.「-vcodec copy」,「-vcodec libx264」,「-vcodec mpeg2video」など.
ffpmeg -i VTS_01_1.VOB -an -sn -vcodec copy VTS_01_1.mp4 - VOB 形式を avi 形式に変換する
- -an : オーディオの記録を無効にする
- -sn : サブタイトルの記録を無効にする
- -vcodec : コーデックの指定.「-vcodec copy」,「-vcodec libx264」,「-vcodec mpeg2video」など.
ffpmeg -i VTS_01_1.VOB -an -sn -vcodec copy VTS_01_1.avi - mp4 形式を avi 形式に変換する
- -an : オーディオの記録を無効にする
- -sn : サブタイトルの記録を無効にする
- -vcodec : コーデックの指定.「-vcodec copy」,「-vcodec libx264」,「-vcodec mpeg2video」など.
ffmpeg -i kaneko_sample_video.mp4 -an -sn -vcodec copy kaneko_sample_video.mp4.avi
動画から連番画像の作成
- -i : 連番画像を作成したい動画ファイル
- -r : 1秒あたり何枚の画像を作るか
- -f image2: ffmpeg の image2 コーデックを使用して画像を作成する
- img%06d.png: 連番画像のファイル名と形式.jpeg 画像が欲しいときは「img%06d.jpg」.
- 画像サイズを指定したいときは,次のように「-s」を使う. 「ffmpeg -i kaneko_sample_video.mp4 -r 4 -f image2 -s 320x240 img%06d.png 」
ffmpeg -i kaneko_sample_video.mp4 -r 4 -f image2 img%06d.png動画の編集
動画の形式変換は,OpenShot などを用いて行うことができる.
- Windows での OpenShot のインストール: 別ページ »で説明
- Ubuntu での OpenShot のインストール: sudo apt install openshot-qt
動画のストリーミング配信,録画,リアルタイム合成
OBS (Open Broadcaster Software) は, 動画のストリーミング配信,録画,リアルタイム合成の機能を持つ. 例えば,FaceRig の動画と,パソコンの画面との合成も簡単にできる.
OBS の公式ページ(日本語版): https://obsproject.com/ja/
統計的機械学習 (Statistical Machine Learning)
統計的機械学習には,次のようなものがある.
- 変分オートエンコーダ(Variational Auto Encoder; VAE)
- 敵対的生成ネットワーク(GAN)など
特徴ベクトル (feature vector)
特徴値 (feature value) のベクトル.
度数分布(ヒストグラム)
度数分布のうち,データの個数を数え上げる普通の度数分布の他に, 比率(全体を 1 をする)を数え上げる相対度数分布(relative frequency histgram), 累積値を数え上げる累積度数分布(cumulative frequency histogram)がある.
度数分布を数える R のプログラム.numBins で帯数を指定.library(entropy) a = c(0, 1, 1, 0, 0, 0, 1, 0, 0) discretize(a, numBins=2)
参考資料: https://cran.r-project.org/web/packages/entropy/entropy.pdf
Iris データセットの度数分布(ヒストグラム)をプロットする R のプログラム.
library(ggplot2) p <- ggplot( iris[iris$Species=='setosa',]$Sepal.Length ) p + stat_bin(aes(hoge, ..count..))
凸最適化 (convex optimization)
凸最適化 (convex optimization) には, 凸関数 (convex function) での最小を発見する勾配降下法 (gradient descent) などがある.
入力層 (input layer)
ニューラルネットワークの最初の層.
入力の次元数
ニューロンの入力が数のベクトルであるとき,そのベクトルの次元数を「入力の次元数」という.
非公式ビルド
オープンソースのソフトウェアを,非公式にビルドしたもの.
白色化
白色化 (whitening) とは,ニューラルネットワークの入力である数値ベクトルについて, 次のことを行う処理のこと.
- 平均が 0,標準偏差が 1 になるように変換する
- 数値ベクトルの成分の間の相関を除去する
微調整 (fine tuning)
2度めの最適化を実施することで, すでに学習済みモデルのパラメーターを, 新しい問題に適合するように調整すること.
「教師なしのニューラルネットワークで学習済みのものについて, 重みを調整することで,教師ありのニューラルネットワークとして使えるようにする」という意味もある.
転移学習では,モデル全体もしくはモデルの一部の凍結(フリーズ)を解除し,新しいデータで学習を行う.このとき,十分な量のデータを準備すること,そして,学習率を低く設定するなので,モデルの改善を行う.
半教師あり学習 (semi-supervised learning)
教師データとして,正解の付いているデータと,正解の付いていないデータを使う. 正解の付いているデータを使い,ニューラルネットワークの学習を使い. そして,このニューラルネットワークに,正解の付いていないデータを与え,出力を得る. この出力を正解とみなして,正解の付いていないデータと合わせて,教師データとして使う.
深さ (depth)
深さ (depth) は,ニューラルネットワークの層(レイヤ) のうち, 重み (weight) についての学習を行う層(レイヤ)の数のこと.
物体検出
物体検出は,写真やビデオの中から,ある特定の種類の物体を検出すること.種類は複数ありえ,その場合には,物体検出 が行われるともに,その種類が判別される.
物体検出の結果は, バウンディングボックスで得られるのが普通である.
【関連項目】 ADE20K データセット Box Annotation, COCO (Common Object in Context) データセット, DETR, Deformable DETR, EfficientDet, ImageNet データセット, Mask R-CNN, Max-Margin 物体検出 (Max-Margin Object Detection), MMDetection, MMPose, MMSegmentation3D, MMSelfSup, MMTracking, PANet (Path Aggregation Network), Pascal VOC (Pascal Visual Object Classes Challenge) データセット, RetinaNet, Seesaw Loss, SSD, YOLOv3, YOLOX, 顔検出 (face detection) セマンティック・セグメンテーション (semantic segmentation), インスタンス・セグメンテーション (instance segmentation)
分類 (classification)
分類は, データから,そのクラス名,もしくは,クラスについての確率分布を求めること. 「クラス分類」ともいう.
多くの場合には,ベクトルデータの集合を, オブジェクトをクラス(カテゴリ)に分けたり, クラスに属する確率を求める.
ディープラーニングによる分類は,事前に,教師データを用いて訓練(学習)を行う.
分類モデル (classification model)
Iris データセット を,3種類に分類する Keras プログラムの例は次の通り.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import numpy as np from sklearn.datasets import load_iris import sklearn.model_selection from sklearn.preprocessing import normalize from IPython.display import display iris = load_iris() x = iris.data y = iris.target x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(x.reshape(x.shape[0], -1), y, train_size=0.5) NUM_CLASSES = 3 m = tf.keras.Sequential() m.add(tf.keras.layers.Dense(units=64, input_dim=len(x_train[0]), activation='relu')) m.add(tf.keras.layers.Dropout(0.5)) m.add(tf.keras.layers.Dense(units=NUM_CLASSES, activation='softmax')) print(m.summary()) m.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_crossentropy', 'accuracy'] ) EPOCHS = 300 history = m.fit(x_train, y_train, batch_size=32, epochs=EPOCHS, validation_data=(x_test, y_test)) # 分類 predictions = m.predict(x_test) print(predictions.argmax(axis=1)) # 正解の表示 print(y_test) import pandas as pd h = pd.DataFrame(history.history) h['epoch'] = history.epoch print(h) # 学習曲線 # https://www.tensorflow.org/tutorials/keras/overfit_and_underfit?hl=ja で公開されているプログラムを使用 %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings def plot_history(histories, key='binary_crossentropy'): plt.figure(figsize=(16,10)) for name, history in histories: val = plt.plot(history.epoch, history.history['val_'+key], '--', label=name.title()+' Val') plt.plot(history.epoch, history.history[key], color=val[0].get_color(), label=name.title()+' Train') plt.xlabel('Epochs') plt.ylabel(key.replace('_',' ').title()) plt.legend() plt.xlim([0,max(history.epoch)]) plot_history([('history', history)], key='sparse_categorical_crossentropy')- 出力層のニューロン数は,クラス数と同じ one-hot エンコーディングのクラス番号を出力する
- 損失関数が categorical_crossentropy である
- 確率的勾配降下法 (SGD 法) を使う
- 確率的勾配効果法の学習率 (learning rate) は 0.01,Nesterov momentum を適用する.
- 「metrics=['accuracy'])」は accuracy を求めよという指示.
上のプログラムの実行結果は下の図の通り.
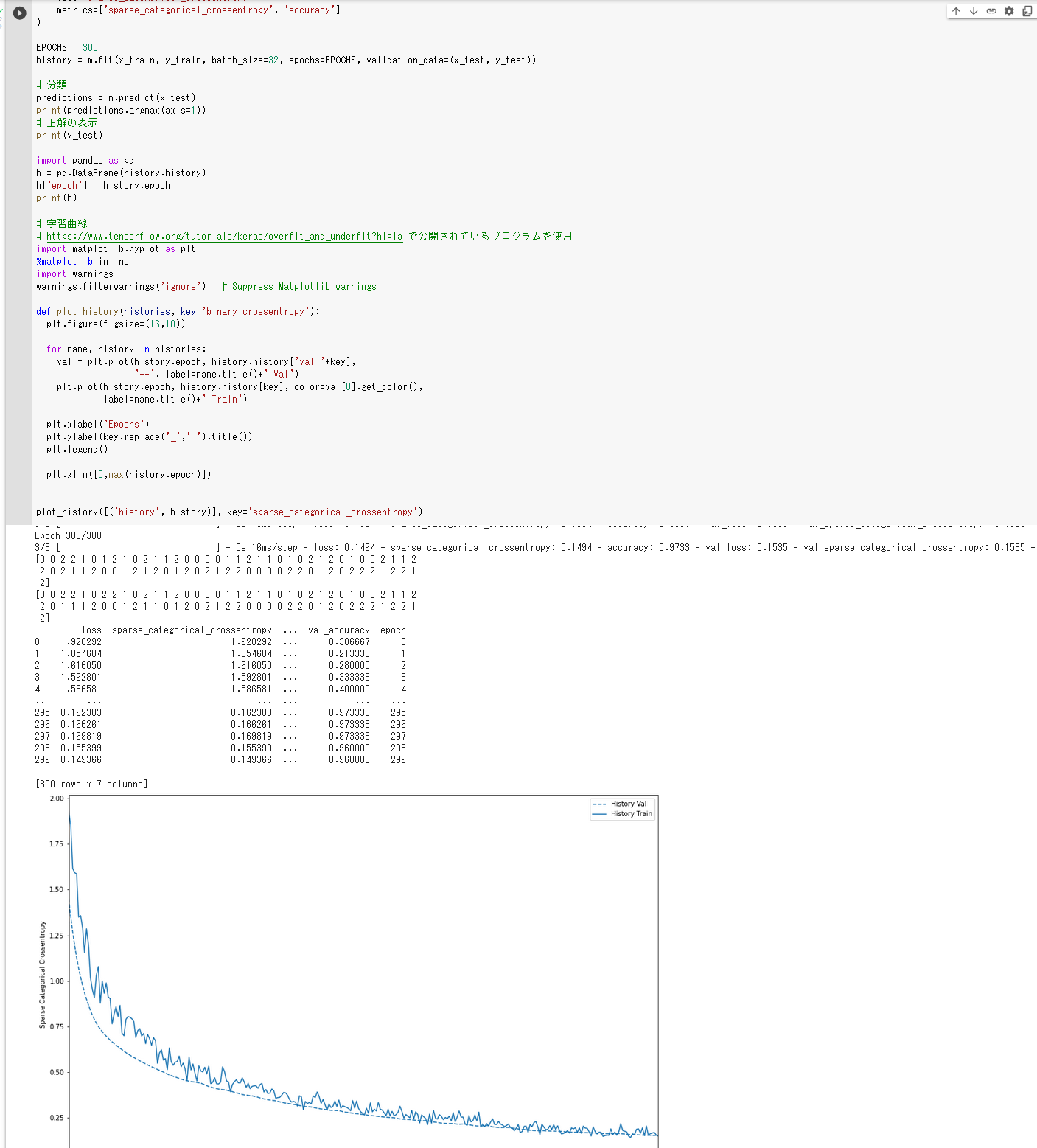
上のプログラムで作成される分類モデルは,次の通り.

学習に追加に使うデータ: x_test と y_test のペア
- x_test:
全部で75行
入力の次元数は「4」なので,入力として一度に受け取るデータが4個(それを1行分).
- y_test:
正解データ. 全部で75行
print(x_train) print(y_train)

学習のあと,別のデータを使って分類してみる
まず分類したいデータの確認
print(x_test)
分類結果の確認
m.predict(x_test)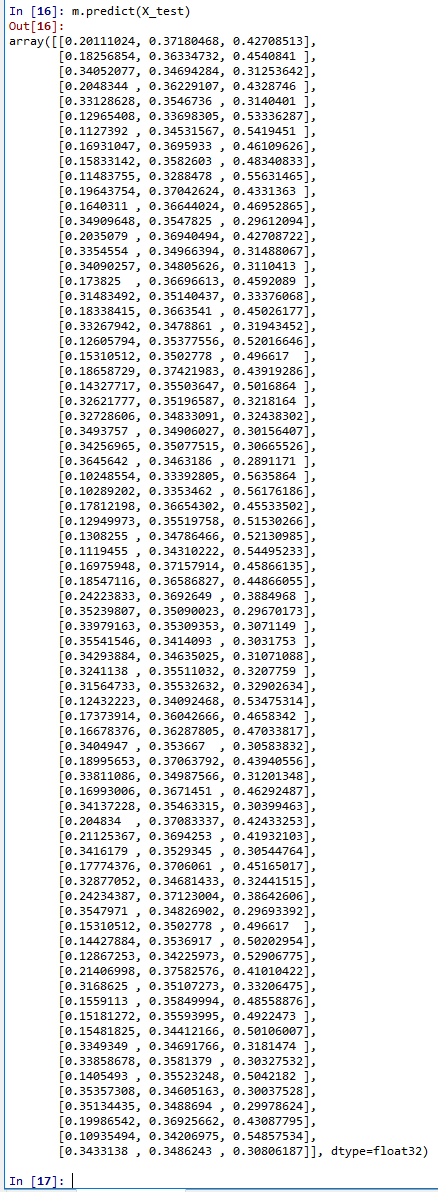
偏微分 (partial derivative)
変数が複数あるとき,ある特定の1変数を除くすべての変数を定数とみなした導関数のこと. 例えば,x に関する f(x, y) の偏微分では,y を定数に保ちながら微分を行う. x に対する f の偏導関数は,x がどのように変化するかのみに注目するもので,方程式内の x 以外のすべての変数を無視する.
変分オートエンコーダ(Variational Auto Encoder; VAE)
変分オートエンコーダ(Variational Auto Encoder; VAE) は,エンコーダとデコーダから構成される. 学習によって,エンコーダとデコーダのパラメータが決定されるもので,デコーダは,生成モデルになっている.
変分オートエンコーダ(Variational Auto Encoder; VAE) は,オートエンコーディング変分ベイズアルゴリズム(Auto-Encoding VB algorithm; AEVB algorithm)を用いた学習を行う. オートエンコーディング変分ベイズアルゴリズムは, 確率的勾配降下法を用いて,確率的勾配変分ベイズ推定量 (Stochastic Gradient Variational Bayes estimator) を極大化するような,エンコーダとデコーダのパラメータを求める.
その構造は,オートエンコーダに類似するが, 次の違いがある.
- オートエンコーダでの推論 (inference)は,入力と同じ出力を得ること.
- 変分オートエンコーダ(Variational Auto Encoder; VAE) での推論は,潜在変数の分布(ふつうは,単純な正規分布である)から,元データの分布を求めること.
変分オートエンコーダ(Variational Auto Encoder; VAE) は,CVAE と関連する.
- 文献
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2013.
連番画像
次のコマンドは,動画ファイルから連判画像を生成する.
rm *.png ffmpeg -i IMG_0581.MOV -vcodec png 0581_%06d.png ffmpeg -i IMG_0596_Trim.mp4 -vcodec png 0596_%06d.png - 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- CIFAR100 データセット: カラー画像 60000枚, カテゴリーラベル (category label)
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
- 画像分類したい画像ファイルのダウンロードとロードと確認表示
{kind=link}
{kind=link}
{kind=link}