人工知能の実行(Google Colaboratory を使用)
画像分類、物体検出を見てみる
- ni-1. 画像分類 [PDF], [パワーポイント]
YouTube 動画: https://www.youtube.com/watch?v=pBJy3TjSxh8
- ni-2. 物体認識 [PDF], [パワーポイント]
YouTube 動画: https://www.youtube.com/watch?v=jlcAgLir1Vg
Google Colaboratory のページ: https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/object_detection.ipynb
YouTube 動画: https://www.youtube.com/watch?v=T8MPgNv1E5Y
人工知能による合成
- 超解像 (super-resolution) [PDF], [パワーポイント]
Google Colaboratory のページ: https://colab.research.google.com/drive/1oT69ts_qzr1xrPYguSepcl24QaQv5AYq#scrollTo=mlVW1_628s0G

- 顔のエンハンスメント (face enhancement)
Google Colaboratory のページ: https://colab.research.google.com/drive/1iXDAruObWanXwNq0ZPRmazRC_XuFSp3X#scrollTo=VLG5Fnvq2ZyS

- GAN の仕組み図解 [パワーポイント]
- 顔写真からの3次元再構成(3DFFA、学習済みモデルを使用)
https://colab.research.google.com/drive/1Ja_eTAJaIOdXOWXS6Nqz5Gw9_2QL9MNy?usp=sharing

人工知能とコンピュータビジョン
群衆の把握,理解 (crowd counting, crowd understanding)
- 群衆の数のカウントと位置の把握 (crowd counting)(FIDTM、学習済みモデルを使用)
トピックス: crowd counting, FIDTM
YouTube 動画: https://www.youtube.com/watch?v=eqCchBSqOdMA
Google Colaboratory のページ: https://colab.research.google.com/drive/1cmeI93PcRc20E70z6X_W3bvH2k1ge2v3?usp=sharing

姿勢推定 (pose estimation)
- 人体の3次元ランドマーク,3次元姿勢推定,セグメンテーション(MediaPipe Pose を使用)
MediaPipe Pose を使用して, 画像から,人体の3次元ランドマーク検出,人体の3次元姿勢推定,人体のセグメンテーションを行う.
- MediaPipe の公式 GitHub ページ
- BlazeFace GHUM 3D の arXiv のページ
- MediaPipe Pose のデモプログラム(Google Colaboratory)
https://colab.research.google.com/drive/13nOMSW0Dzx_LjN9XEG99jtvgMACl4m9V#scrollTo=qVuMcBVQ4CtX
Google Colaboratory のページ
https://colab.research.google.com/drive/13nOMSW0Dzx_LjN9XEG99jtvgMACl4m9V#scrollTo=qVuMcBVQ4CtX で公開されているプログラムを一部書き換えて使用.
https://colab.research.google.com/drive/13nOMSW0Dzx_LjN9XEG99jtvgMACl4m9V
- 人体の姿勢推定(MMPose、学習済みモデルを使用)
写真から,人体の骨格を,2次元,あるいは,3次元的に推定
Google Colaboratory のページ: https://colab.research.google.com/drive/1qzEYs38mF8CbaeOwX6zjsZPOrSv6uFy1?usp=sharing
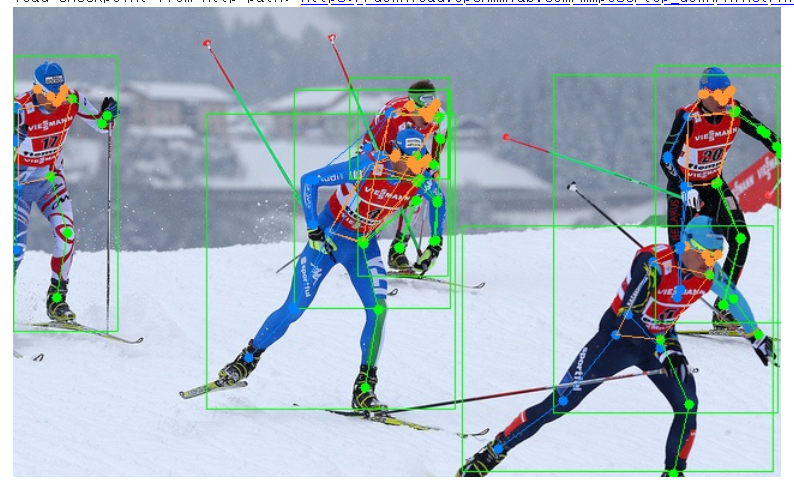


参考文献: Whole-Body Human Pose Estimation in the Wild, https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123540188.pdf
- DensePose 推定(Detectron2 の DensePose を使用)
https://colab.research.google.com/drive/1nQMCibYBrwTpQzVtoe1J_jj-WFghpOTb?usp=sharing
- 頭部のポーズの推定 (head pose estimation)(DeepGaze、学習済みモデルを使用)
DeepGaze のページ(GitHub): https://github.com/mpatacchiola/deepgaze
写真から,人体の頭部を検出. 検出されたポーズについて,3次元的な向きを推定する(頭部がどの向きにどれだけ回転しているかの情報が3次元的に得られる)
Google Colaboratory のページ: https://colab.research.google.com/drive/1dDTdZU8jaCEXHV3UUok05s-sDSgi-tb8?usp=sharing
3次元のボックス・ランドマーク (3D box landmark)
画像やビデオから 3次元の Box Landmark 検出を行う.
MediaPipe Objectron を使用
【関係する外部ページ】
- MediaPipe Objectron のページ
https://github.com/google-ai-edge/mediapipe/tree/master/mediapipe/modules/objectron
- MediaPipe の公式 GitHub ページ
- Objectron Dataset のページ
Google Colaboratory のページ
https://colab.research.google.com/drive/1bakykeEVwdwfZlRuWdgBgPW6iU8MNO3z?usp=sharing

複数の写真からの3次元再構成 (3D reconstruction)
YouTube 動画: https://www.youtube.com/embed/h4q0ote54M0
種々のセグメンテーション、物体検出
- 物体検出(YOLOv5 を使用)

https://colab.research.google.com/drive/1RsxKuJLQ7hHmHOr0p7QK7igI2AFkb608?usp=sharing
- インスタンス・セグメンテーション(instance segmentation) (Detectron2 を使用)
Detectron2 を使用. さまざまなモデルでインスタンス・セグメンテーションを実行.
- Mask R-CNN R50 FPN, COCO データセットで学習済み
- Mask R-CNN X101 FPN, COCO データセットで学習済み
- Mask R-CNN X152 FPN, COCO データセットで学習済み
- Mask R-CNN X101 FPN, LVIS データセットで学習済み
- Mask R-CNN R50 FPN, Cityscapes データセットで学習済み
- Faster R-CNN R50 C4, PASCAL VOC データセットで学習済み
Detectron2 の github のページ:
https://github.com/facebookresearch/detectron2
Google Colaboratory のページ
https://colab.research.google.com/drive/1ikWanuaLMM-dqCnS2SBRsPG1YW0UNzMR?usp=sharing


- パノプティック・セグメンテーション (panoptic segmentation) (MMDetection を使用)
パノプティック・セグメンテーションは,インスタンス・セグメンテーションと セマンティック・セグメンテーションの両立.
Google Colaboratory のページ: https://colab.research.google.com/drive/1xWaQuJt50LqYwyw9ohsYERZ_Ix1gy1rN?usp=sharing
- 物体検出,インスタンス・セグメンテーション,セマンティック・セグメンテーション (MMDetection, MMSegmentation を使用)
次を行う
- 物体検出(MMDetection,COCO データセットで学習済みの Faster RCNN を使用)**
- インスタンス・セグメンテーション(MMDetection,COCOデータセットで学習済みの Mask RCNN を使用)
- セマンティック・セグメンテーション(MMSegmentation, Cityscapes データセットで学習済みの Deeplabv3+ を使用)
Google Colaboratory のページ: https://colab.research.google.com/drive/1QpShUUrOdWHAjkbb-BBuwg8iXmHXv3ff?usp=sharing
- 画像のセマンティック・セグメンテーション (image semantic segmentation) (MMDetection, MMSegmentation, Cityscapes データセットで学習済みのモデルを使用)
- DeeplabV3+ (2017年) , R-101-B8, Cityscapes データセットで学習済み (https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segformer)
- OCRNet (2020年), HRNetV2p-W48, Cityscapes データセットで学習済み (https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet)
- SegFormer (2021年), MIT-B1, Cityscapes データセットで学習済み (https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segformer)
Google Colaboratory のページ: https://colab.research.google.com/drive/10Suuj4wdnFVNJBg82BihdqeO1wLrBIVt?usp=sharing
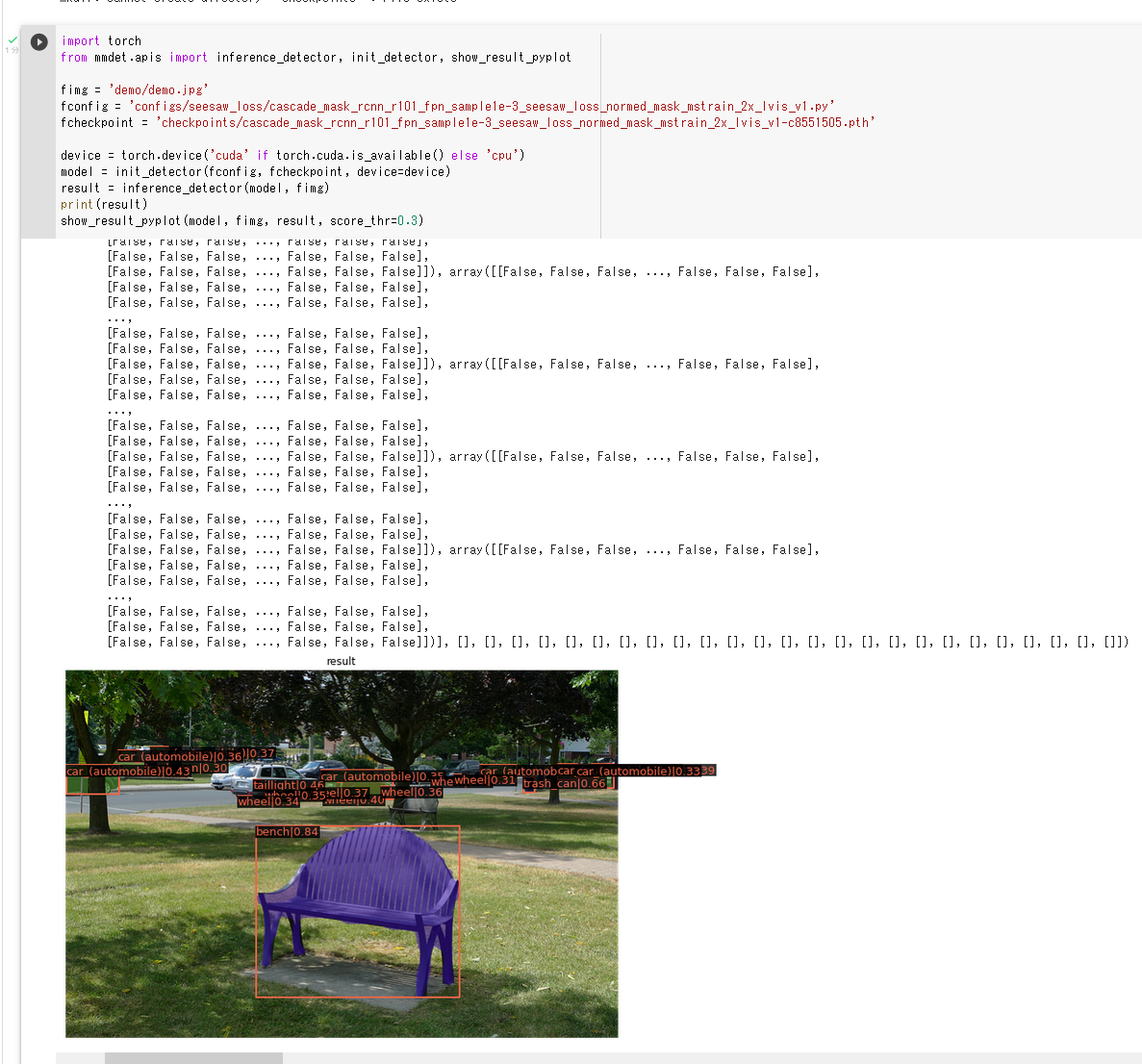
- 物体検出 (Object Detection) と,画像のセマンティック・セグメンテーション (image semantic segmentation) (MMDetection, COCO データセットで学習済みのモデルを使用)
- Seesaw Loss, Cascade Mask R-CNN, R-101-FPN, Lr schd = 2x, COCO データセットで学習済み
Google Colaboratory のページ: https://colab.research.google.com/drive/17W448FaNt3ahgQ0u6n8MQcVl5VfEE1jZ?usp=sharing
- 画像のセマンティック・セグメンテーション (image semantic segmentation) (MMSegmentation を使用)
トピックス: セマンティック・セグメンテーション, MMSegmentation
Cityscapes データセットのクラス:'road', 'sidewalk', 'building', 'wall', 'fence', 'pole', 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'
このページでは,MMSegmentation の作者による公式のプログラムおよび Cityscapes データセットで学習済みの DeepLabv3+ モデルを使用して,セマンティック・セグメンテーション (semantic segmentation) を行う手順を示している.
Google Colaboratory のページ: https://colab.research.google.com/drive/1NKmQfbDG0XCR0bO6vcFP304gy4iqeD7L?usp=sharing

- インスタンス・セグメンテーション (PixelLib を使用)
トピックス: インスタンス・セグメンテーション
このページでは,Pixel の作者による公式のプログラムおよび学習済みのモデルを使用して,インスタンス・セグメンテーションを行う手順を示している.
YouTube 動画: https://www.youtube.com/watch?v=FYzFdVEMBeU
Google Colaboratory のページ: https://colab.research.google.com/drive/1Ri1v_O4A5vXRSSEBgt4umKC1l3SoWp9U?usp=sharing

- TensorFlow 2 Object Detection API (オブジェクト検出 API)のインストールと一般物体検出(TensorFlow のチュートリアルのプログラムを使用)(Google Colab あるいは Ubuntu 上)
TensorFlow 2 Object Detection API (オブジェクト検出 API)による一般物体検出
画像
- Improved Adaptive Gamma Correction
画像の画質改善の一手法.
Google Colaboratory のページ
https://colab.research.google.com/drive/1QaXkXvwNMF_6VuaSI23vRwVDguX0Qb1-?usp=sharing

テキストエリアの検出
Google Colaboratory のページ:
https://colab.research.google.com/drive/16G5wGAHg_SKJ2FdM2SaIiVLinW2tTgkc?usp=sharing

音の処理
音源分離 (sound source seperation)
- 音源分離 (sound source seperation) (Demucs を使用,学習済みモデルを使用)
https://colab.research.google.com/drive/1KeKWclVD8OHkmusEIUolErIasyJZi7mR?usp=sharing
次のページで公開されているサウンドデータを使用
https://mirg.city.ac.uk/codeapps/vocal-source-separation-ismir2017
音源分離
顔情報処理
- 顔情報処理(Dlib、face_recognition、InsightFace、学習済みモデルを使用)
トピックス: 顔検出,顔のアラインメント,顔の68ランドマーク,顔のコード化,顔検証,顔からの性別や年齢の推定
Google Colaboratory のページ: https://colab.research.google.com/drive/1S55yEFiQpdIRdjWbdH0zzEYD5VAfklHd?usp=sharing
Windows による顔情報処理: 別ページに記載
ニューラルネットワークによる学習と分類
Iris データセットを用いた学習と分類
- 学習と検証、学習曲線(Iris データセット、2層の単純なニューラルネットワーク)
トピックス:分類を行うニューラルネットワーク、ニューラルネットワークの作成、ニューラルネットワークの学習、学習曲線、Iris データセット
Google Colaboratory のページ: https://colab.research.google.com/drive/18rj0Lyy7rL_JJS9flrGWJR04EuI8tnTm?usp=sharing
- ハイパーパラメータ(Iris データセット、2層の単純なニューラルネットワーク)
Keras の標準機能により,最適なニューロン数を探索.
Google Colaboratory のページ: https://colab.research.google.com/drive/1HJJfWyeS264l-C2ImIv7VJQB4Cvi9gC_?usp=sharing
小画像の分類
- 学習と検証、学習曲線(小画像、2層の単純なニューラルネットワーク)
トピックス:分類を行うニューラルネットワーク、ニューラルネットワークの作成、ニューラルネットワークの学習、学習曲線、学習不足、過学習
Google Colaboratory のページ: https://colab.research.google.com/drive/18Nf9FPFhOvx8_V30z8PdBD2kcyDap8b7?usp=sharing
- ハイパーパラメータ(小画像、2層の単純なニューラルネットワーク)
Keras の標準機能により,最適なニューロン数を探索.
Google Colaboratory のページ: https://colab.research.google.com/drive/1XyQKuEnqjlg_buD2YSiEA9uv9MfUCmXt?usp=sharing
MNIST データセットの分類
- MNIST データセットによる学習と画像分類(2層の単純なニューラルネットワークを使用)
トピックス:画素、画像、画像データ、画像分類システム、画像分類を行うニューラルネットワーク、ニューラルネットワークの作成、ニューラルネットワークの学習、MNIST データセット、Fashion-MNIST データセット
Google Colaboratory のページ: https://colab.research.google.com/drive/1uoxlVHhv3UcdsjC0VrFFoY4U4bxT0Z66?usp=sharing
- MNIST データセットによる学習と画像分類(CNN を使用)
トピックス:CNN、CNN による画像分類、ニューラルネットワークの作成、ニューラルネットワークの学習、MNIST データセット
Google Colaboratory のページ: https://colab.research.google.com/drive/1p98R2XpYcZsz-GZ84mFbw3v9H7AStz8e?usp=sharing
- MNIST データセットによる学習と画像分類,ハイパーパラメータ(2層の単純なニューラルネットワークを使用)
Keras の標準機能により,最適なニューロン数を探索.
Google Colaboratory のページ: https://colab.research.google.com/drive/1VjYDrdGRPHqKEJdIupASvcbOiH3Shd3u?usp=sharing
- ニューロン数と学習曲線(MNIST データセット,2層の単純なニューラルネットワークを使用)
ニューロン数を変えると分類精度や学習曲線はどのように変化するか確認してみる.
Google Colaboratory のページ: https://colab.research.google.com/drive/1-UWl-WEPmmNo-S_O17E5XPkF4tphE6xz?usp=sharing