社会ネットワーク分析(SNA: Social Network Analysis)
本記事は、社会ネットワーク分析(SNA)の基本概念と、Python の NetworkX ライブラリを用いた中心性分析の実装を解説する。題材として論文の引用ネットワークを取り上げ、有向・重み付きグラフに対する中心性指標の計算と、その結果の解釈までを示す。
本記事は重み付き有向グラフを主軸に扱う。各中心性指標はネットワーク内の異なる役割を測るものであり、指標が変われば最も値の高いノードも変わる。例えば後出のサンプルでは、被引用の中心は E、仲介役は B となる。値が指標ごとに食い違うのは矛盾ではなく、役割の違いを反映した結果である。SNA で複数の指標を併用するのはこのためである。
動作環境について。本記事のコードは Windows 上で動作し、GPU は不要で CPU のみで実行できる。Linux 等の追加知識も必要ない。導入はコマンドプロンプトまたは PowerShell で次のコマンドを実行する。
pip install networkx matplotlib1. 概要
社会ネットワーク分析(SNA: Social Network Analysis)は、グラフ理論を基盤として個体間の関係を定量的に分析する手法である。SNA ではネットワークをノード(node)とエッジ(edge)で表現する。ノードは人物・組織・論文などのアクターを表し、エッジはノード間の関係を表す。エッジには重み(weight)を付与でき、関係の強さや頻度を表現できる。
有向グラフを用いれば、引用関係や影響関係のような方向性のある関係を扱える。本記事ではこの有向・重み付きグラフを対象とする。
2. 他の分析手法との比較
従来の統計手法の多くは、個体の属性(年齢、性別、収入など)に着目し、サンプルの独立性を仮定する。これに対して SNA は、個体間のつながりの有無とつながり方そのものを分析対象とし、定量化する。なお、相関分析のように関係性を扱う統計手法も存在するが、SNA はネットワーク構造を明示的にモデル化する点で異なる。
3. 原理
3.1 基本構造:グラフ表現
ネットワークはグラフ G = (V, E) で表現する。V はノードの集合、E はエッジの集合である。
グラフには無向グラフと有向グラフがある。無向グラフはエッジに方向性がなく、友人関係のような双方向の関係を表す。有向グラフはエッジに方向性があり、引用関係や影響関係を表す。本記事では有向グラフを扱う。
エッジには重みを付与できる。重みは関係の強さや頻度を表す。例えば引用回数や影響の強さを重みとする。後出の指標のうち最短経路を用いるものでは、関係が強い(重みが大きい)ほど二者を近いと捉えるため、重みの逆数を距離として用いる。
3.2 主要な分析指標
以下の指標でネットワーク構造を評価する。指標によって重みの扱いが異なる。媒介中心性、近接中心性、PageRank は重みを考慮し、密度と次数中心性は考慮しない。
ネットワーク全体の指標
密度(Density)は、実際のエッジ数を最大エッジ数で割った値である。有向グラフでは A→B と B→A を別のエッジとして数える。最大エッジ数は N × (N-1)、密度は D = E / (N × (N-1)) である(N はノード数、E はエッジ数)。密度は重みを考慮しない。
ノードレベルの指標(中心性指標)
次数中心性(Degree Centrality)は、ノードに接続するエッジの数を基にした指標である。有向グラフでは入次数と出次数を区別する。値は接続ノード数を最大可能数(N-1)で割って正規化される(例:6 ノードのネットワークで 4 つのノードから引用されていれば 4 / 5 = 0.800)。次数中心性は重みを考慮しない。
入次数中心性(In-degree Centrality)は、そのノードに入るエッジの数を基にした指標である。被参照数やフォロワー数に相当し、受信者としての重要性を示す。
出次数中心性(Out-degree Centrality)は、そのノードから出るエッジの数を基にした指標である。参照数やフォロー数に相当し、発信者としての活発さを示す。
媒介中心性(Betweenness Centrality)は、他のノード間の最短経路上にそのノードが含まれる頻度である。仲介者としての重要性を示す。重み付きエッジの場合、重みの逆数を距離として計算する。出ていくエッジを持たない終端ノードは、どの最短経路の通過点にもならないため値が 0 になる。
近接中心性(Closeness Centrality)は、他のノードからそのノードへの平均最短距離の逆数である。値が高いほど、他のノードから短い距離で到達される。重み付きエッジの場合、重みの逆数を距離として計算する。入ってくるエッジが一つもないノードは到達されないため値が 0 になる。重みの逆数を距離に使うと距離が 1 未満になることがあり、その場合は逆数である近接中心性が 1 を超える。
近接中心性には方向の違いがある。NetworkX の closeness_centrality は、有向グラフに対してデフォルトで入方向(inward)、すなわち他のノードから対象ノードへ到達する距離を計算する。出方向(対象ノードから他へ到達する距離)で評価する場合は G.reverse() を適用する。本記事ではデフォルトの入方向で計算する。引用ネットワークでは A→B が「A が B を引用する」を意味するため、入方向の近接中心性が高いノードは、多くの論文から短い距離で引用される被引用の中心と解釈できる。
PageRank は、重要なノードからリンクされているノードほど値が高くなる指標である。入次数だけでなくリンク元の重要性も考慮する。重み付きエッジの場合、重みに応じてスコア配分が変わる。
3.3 重みがない場合
エッジに重みを設定しない場合、すべてのエッジの重みを 1 として扱う。この場合、媒介中心性と近接中心性はホップ数で経路長を計算し、PageRank はすべてのエッジを同等に扱う。重みがない場合は関係の有無のみを分析する。関係の強さを考慮しない場合や、重みのデータがない場合に用いる。以降の 4 章では、重みありのサンプルを用いて各指標を計算する。
4. 演習
演習1.引用ネットワークの中心性分析
テーマ
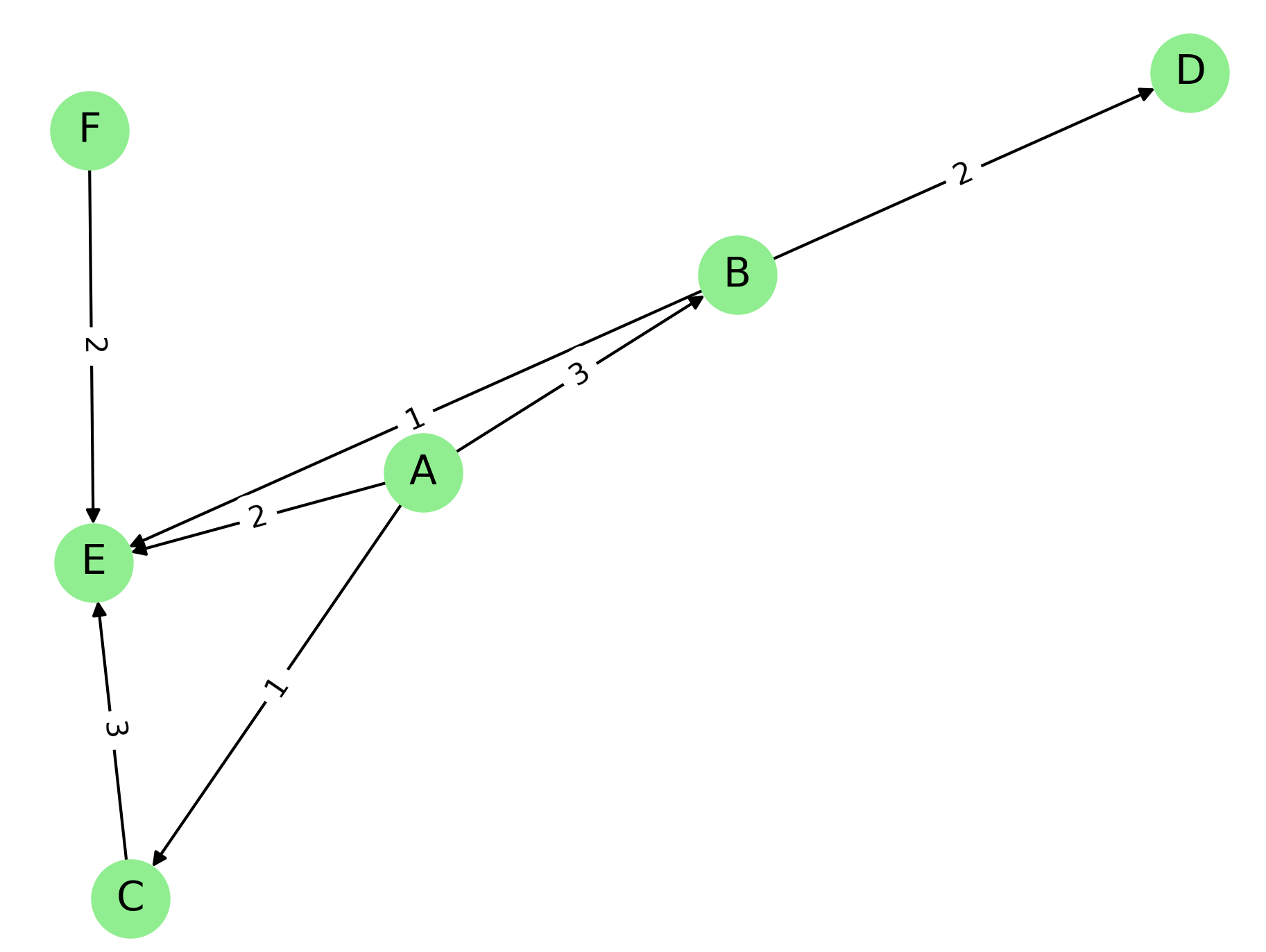
論文の引用ネットワークを有向・重み付きグラフとして構築し、各中心性指標を計算して、指標ごとに値の高いノードがどう変わるかを確認する。論文 A が論文 B を引用する場合、A→B のエッジを作成する。重みは引用の重要度を表し、値が大きいほど重要な引用である。
サンプルネットワーク(引用関係):
A → B → D
↓ ↘ ↓
C → E ← F
エッジと重み:
A → B (重み: 3)
A → C (重み: 1)
A → E (重み: 2)
B → D (重み: 2)
B → E (重み: 1)
C → E (重み: 3)
F → E (重み: 2)手順
コマンドプロンプトまたは PowerShell で pip install networkx matplotlib を実行し、ライブラリを導入する。次のコードをファイルに保存して実行する。実行すると、各中心性指標の値が表示され、続いてネットワーク図が表示される。
import networkx as nx
import matplotlib.pyplot as plt
# 有向グラフの構築(重み付き)
G = nx.DiGraph()
edges = [
('A', 'B', 3), ('A', 'C', 1), ('A', 'E', 2),
('B', 'D', 2), ('B', 'E', 1),
('C', 'E', 3),
('F', 'E', 2)
]
G.add_weighted_edges_from(edges)
# 重みの逆数を距離として設定(重みが大きいほど距離が近い)
for u, v, data in G.edges(data=True):
data['distance'] = 1 / data['weight']
# 入次数中心性と出次数中心性(重みは考慮されない)
in_degree_cent = nx.in_degree_centrality(G)
out_degree_cent = nx.out_degree_centrality(G)
# 媒介中心性(重みの逆数を距離として使用。引数名は weight)
betweenness_cent = nx.betweenness_centrality(G, weight='distance')
# 近接中心性(重みの逆数を距離として使用。引数名は distance。
# 有向グラフではデフォルトで入方向の距離を計算する)
closeness_cent = nx.closeness_centrality(G, distance='distance')
# PageRank(重みを考慮)
pagerank = nx.pagerank(G, weight='weight')
# 結果の表示
print("=== 入次数中心性 ===")
for node, cent in sorted(in_degree_cent.items()):
print(f" {node}: {cent:.3f}")
print("\n=== 出次数中心性 ===")
for node, cent in sorted(out_degree_cent.items()):
print(f" {node}: {cent:.3f}")
print("\n=== 媒介中心性(重み付き) ===")
for node, cent in sorted(betweenness_cent.items()):
print(f" {node}: {cent:.3f}")
print("\n=== 近接中心性(重み付き・入方向) ===")
for node, cent in sorted(closeness_cent.items()):
print(f" {node}: {cent:.3f}")
print("\n=== PageRank(重み付き) ===")
for node, cent in sorted(pagerank.items()):
print(f" {node}: {cent:.3f}")
# ネットワーク全体の指標
print("\n=== ネットワーク全体の指標 ===")
print(f" ノード数: {G.number_of_nodes()}")
print(f" エッジ数: {G.number_of_edges()}")
print(f" 密度: {nx.density(G):.3f}")
# ネットワークの可視化
pos = nx.spring_layout(G, seed=42)
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw(G, pos, with_labels=True, node_color='lightgreen', node_size=700, font_size=14, arrows=True)
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.show()実行結果は次のとおりである。
=== 入次数中心性 ===
A: 0.000
B: 0.200
C: 0.200
D: 0.200
E: 0.800
F: 0.000
=== 出次数中心性 ===
A: 0.600
B: 0.400
C: 0.200
D: 0.000
E: 0.000
F: 0.200
=== 媒介中心性(重み付き) ===
A: 0.000
B: 0.050
C: 0.000
D: 0.000
E: 0.000
F: 0.000
=== 近接中心性(重み付き・入方向) ===
A: 0.000
B: 0.600
C: 0.200
D: 0.600
E: 1.371
F: 0.000
=== PageRank(重み付き) ===
A: 0.101
B: 0.144
C: 0.116
D: 0.183
E: 0.355
F: 0.101
=== ネットワーク全体の指標 ===
ノード数: 6
エッジ数: 7
密度: 0.233ヒント
入次数中心性は接続ノード数を N-1(ここでは 5)で割った値である(例:E は 4 / 5 = 0.800)。近接中心性が 1 を超えるのは、重みの逆数を距離に使うためである(例:C→E は重み 3 なので距離 1 / 3 ≈ 0.333)。媒介中心性が 0 のノードは、最短経路の通過点になっていないノードである。
考察ポイント
入次数中心性と出次数中心性を比較し、E は受信側(被引用)で最大、A は発信側(引用)で最大であることを読み取る。媒介中心性では B のみが値を持つ。これは A から D への経路 A→B→D の唯一の通過点が B であるためである。一方、E は引用を多く受けるが出ていくエッジを持たない終端ノードのため、媒介中心性は 0 となる。近接中心性(入方向)と PageRank では E が最大であり、被引用の中心であることが確認できる。指標によって値の高いノードが E と B に分かれる点に着目し、各指標がネットワーク内のどの役割を測っているかを読み取る。
5. まとめ
SNA は個体間の関係を分析する手法である。中心性指標を用いて、ネットワーク内のアクターの位置づけや全体構造を評価する。方向性のある関係には有向グラフを用い、入次数中心性・出次数中心性・PageRank で発信と受信の重要性を分析する。エッジに重みを設定すれば、関係の強さを考慮した分析ができる。各指標が測る役割は異なるため、複数の指標を併用してアクターを多面的に評価する。