Nano Banana 2 活用ガイド
Googleの画像生成AIモデル「Nano Banana 2」の基本操作、コア機能、活用法、および回避すべき注意点について解説する。

学習内容の構成
- 基本操作:Geminiアプリでの思考モード選択とプロンプト入力
- コア機能:思考モードによる意図の解釈、マルチリファレンスによる最大14枚の参照画像処理
- 活用法:論理的図解の生成、キャラクター一貫性の保持、対話による段階的編集、Google検索連携
- 注意点の回避:モード混同、過剰なプロンプト、否定指示の誤用への対策
- 前提:Webブラウザの基本操作、Googleアカウント
- 意義:画像生成AIの活用スキルの習得
【目次】
YouTube動画:https://youtu.be/b2VamyZnMcY
1. はじめに
Nano Banana 2は、Googleが提供する画像生成・編集AIモデルである。従来の画像生成AIで課題とされてきた「論理的な構成」「正確なテキスト描画」「複数画像の統合」に対応しているとされる。
2. 基本操作
2.1 操作手順
- Gemini(https://gemini.google.com/app?hl=ja)にアクセスし、Googleアカウントでログインする
- 画面下部の「+】をクリック、プルダウンから「画像を生成」を選択する
- テキスト入力欄に生成したい画像の説明を入力し、送信する
2.2 プロンプト例
森の中で本を読んでいる柴犬のイラスト。暖かい午後の光が差し込んでいる。
「営業部」と書かれた木製のドアプレート。シンプルで清潔感のあるデザイン。
添付の画像の人物が爆笑している。背景はハワイの海岸。

3. コア機能
3.1 思考モード
ユーザーの指示の意図と文脈を解釈してから画像を生成するモードである。複雑な指示でも意図に近い結果が得られやすい。
3.2 マルチリファレンス
最大14枚の参照画像を同時に処理できる機能である。複数の要素を組み合わせた画像の生成、および特定の人物やオブジェクトの特徴の維持に利用できる。内訳は次のとおりである。
- オブジェクト画像:最大10枚
- 人物画像:最大4名分
4. 活用法
4.1 論理的図解の生成
情報の階層構造とテキストを描画できる。
適用例:システム構成図、組織図、フローチャート
プロンプト例
左から右へのフローで、3つのボックスを配置。
ボックス1:「入力層」、ボックス2:「処理層」、ボックス3:「出力層」
各ボックスは矢印で接続。背景は白、文字は黒。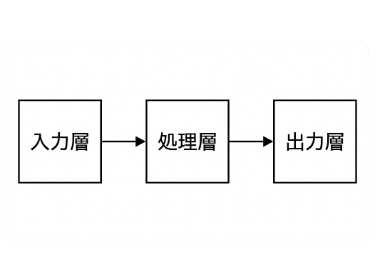
4.2 キャラクター一貫性の保持
参照画像を読み込むと、同一キャラクターを異なるシーンで描写できる。
適用例:絵コンテ作成、広告バナーの量産
プロンプト例
この人物が、カフェでノートPCを開いて作業している様子

4.3 対話による段階的編集
生成した画像を対話形式で修正できる。
例
- 初回:「写真の人物が、青空の下で満面の笑顔で踊りながら走っている」
- 2回目:「背景を夕焼けに変更」
- 3回目:「服装をカジュアルに変更」



4.4 Google検索連携
Google検索と連携し、最新の情報を画像に反映できる。
適用例:天気予報の視覚化、最新ニュースに基づく図解
プロンプト例
東京の今後5日間の天気予報をチャート形式で視覚化
5. 回避すべき注意点
5.1 モード混同
問題:高速モードで複雑な指示を実行すると、文字描画の崩れや構成の乱れが発生する場合がある。
対策:本番制作では「思考モード」を選択する。
5.2 過剰なプロンプト
問題:「4k, masterpiece, trending on artstation」等の定型キーワード(旧世代の画像生成AIで品質向上の効果があるとされた語句)は、本モデルでは効果が乏しい場合がある。
対策:自然な文章で記述する。
例1(自然な文章ではない):
beautiful girl, 4k, masterpiece, best quality
例2(自然な文章にしている):
窓際に座っている若い女性。柔らかい自然光が顔を照らしている。
5.3 否定指示について
問題:「~を描かないで」という指示よりも、何を描くかの指示を増やす。
悪い例:
商店街。たくさんの人通り。車を描かないで
良い例:
商店街。たくさんの人通り。歩行者や自転車などの自然な日本の商店街の風景。
6. 演習課題
課題1:思考モードで以下のプロンプトを実行し、テキストが正確に描画されるか確認せよ。
「会議中」と書かれたドアプレート課題2:3階層のシステム構成図(入力層→処理層→出力層)を生成せよ。