二次索引の基礎
【概要】 データベース処理の性能向上には,二次索引と問い合わせ計画の理解が重要である.二次索引は主索引のキー以外の属性に対して作成される索引で,検索処理を高速化する.一つのテーブルに対して任意の数の二次索引を作成でき,「CREATE INDEX <索引名> ON <テーブル名> (<列名の並び>)」という形式のSQL文で二次索引を作成する.例えば「CREATE INDEX idx1 ON point3(x)」はpoint3テーブルのx列に対する二次索引idx1を作成する.また,「EXPLAIN」を付加したSQL文を実行することでSQL問い合わせ計画を確認でき,SQLite3の問い合わせ計画はOpenRead,Rewind,Column,Nextなどのオペコードから構成され,SQLite3の内部処理を示すものである.二次索引によるデータベース処理の性能向上は,問い合わせ計画で確認できる.
リレーショナルデータベースの基礎であるテーブル定義,一貫性制約,SQL,結合と分解,トランザクション,埋め込みSQL,実行計画,二次索引を学ぶ.SQLite 3 を用いて,SQL についての演習も行う.

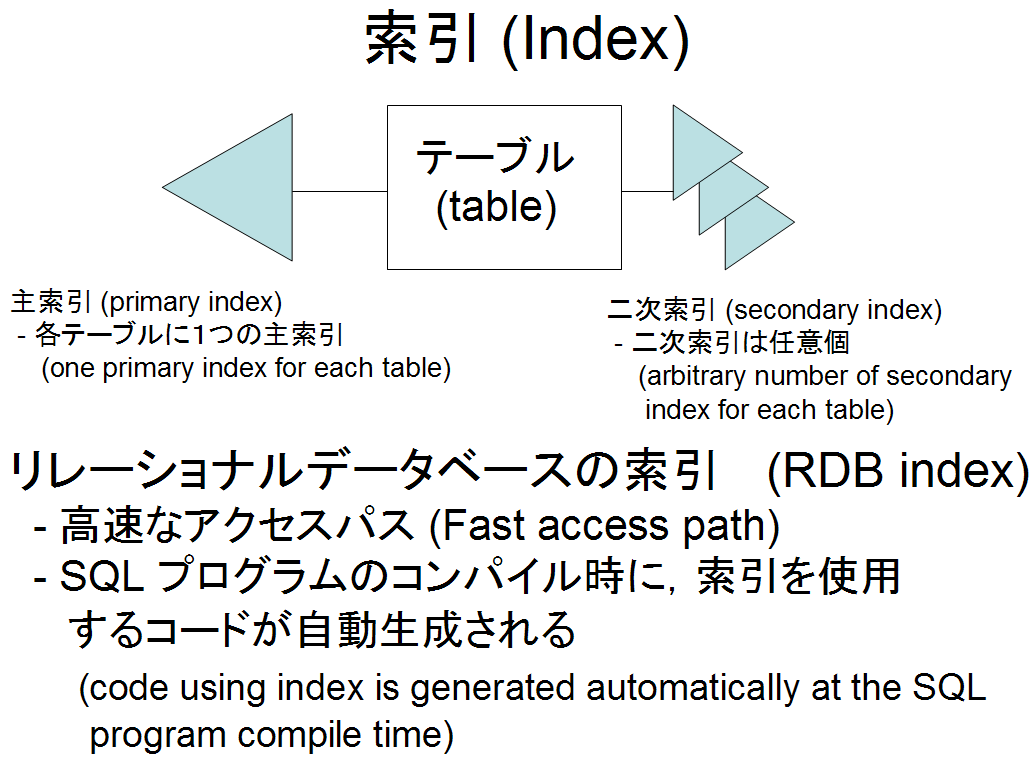


- 索引 (index)
索引を用いることで,レコードを効率よく検索することができる.
但し,レコードデータの更新時には,索引の維持 (maintenance) を行わなければならないので,索引を増やしすぎるのは良くない.
- 主索引 (primary index)
主キー (Key Primary) の値とレコードとを直接結びつけているような索引構造のことを,この資料では「主索引」と呼ぶことにする.
各テーブルに,1つの主索引がある(1つのテーブルに2個以上の主索引はありえない).
テーブル定義において「primary key」と指定した属性が,主キーになるのが普通である.
「primary key」を指定しなかったときは, テーブル定義が「primary key」を含まないなどの場合には,データベース管理システムが,テーブルの各行を識別する識別番号を自動生成し,それを主索引のキーとして使うのが普通である.
- 二次索引 (secondary index)
主索引のキー以外の属性による索引構造.
二次索引は,1つのテーブルに対して任意個作ることができる.二次索引は自由に追加,削除できるのが普通である.
【SQLite 3 の主要なオペコード (Opcode) の要点】
- OpenRead: ルート・ページが P2 であるようなテーブル(または二次索引)のカーソルを作る. P1 にはカーソル番号を設定する. P4 には、テーブルの列数を設定するか, KeyInfo 構造体 (KeyInfo 構造体)と呼ばれる構造体へのポインタを設定する.
- Rewind: 将来の Column, Rowid, Next 命令の実行に備えて,カーソル P1 をテーブルの先頭(または二次索引のルートノード)を指し示すようにする.テーブル(または二次索引)が空の場合には,アドレス P2 にジャンプする.o
- Column: カーソル P1 (cursor P1) が指し示すレコードの P2 番目の桁 (P2-th column) からデータを取り出して,レジスタ P3 に格納する.(列番号は 0 から始まる)
- Rowid: カーソル P1 (cursor P1) が指し示すレコードの主キーの値を,レジスタ P2 に格納する.
- MakeRecord:
レジスタP1 から レジスタ(P1+P2-1) までの値を,テーブルの1行、あるいは索引のキー (key) として使うことを示す.
P4には column affinity を文字列として指定できる.column affinity の各文字は,SQLite バージョン 3.7.9 では次のように定義されている.
#define SQLITE_AFF_TEXT 'a' #define SQLITE_AFF_NONE 'b' #define SQLITE_AFF_NUMERIC 'c' #define SQLITE_AFF_integer 'd' #define SQLITE_AFF_real 'e'
- IdxInsert: IdxInsert命令を実行すると,索引P1にデータを挿入する.
- ResultRow: レジスタP1 から レジスタ(P1+P2-1) までの値を1行として出力する
- SeekGe カーソルP1がテーブルを指し示しているときは,レジスタP3の値を検索キーとして使う。 カーソルP1が索引を指し示すときは,レジスタP3からレジスタ(P3+P4-1)までを使う. カーソルP1の位置を,検索キーに等しいか検索キーよりも大きいという条件を満足するなかで最小の要素を指し示すように動かす.そのような要素がない場合にはP2にジャンプする.
- IdxGE レジスタP3からレジスタ(P3+P4-1)までを検索キーとして使う.検索キーの値を,現在P1が指し示している索引を使って比較する. もし,P1が指し示す索引エントリ (index entry) が,検索キーの値1と等しいか大きければ P2 にジャンプする.さもなければ次に進む.
- Eq: レジスタP1 の値とレジスタ P3 の値が等しいときに限り,アドレス P2 (address P2) にジャンプする.
- Ne: レジスタP1 の値とレジスタ P3 の値が等しくないときに限り,アドレス P2 (address P2) にジャンプする.
- Next: もし,カーソル P1 (cursor P1) が指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソル P1 (cursor P1) が指し示すレコードが末端レコードでなければ、カーソル P1 (cursor P1) を1つ進めて、アドレス P2 (address P2) にジャンプする.
- Goto: アドレス P2 (address P2) にジャンプする.
* SQLite 3 のオペコードの説明は http://www.hwaci.com/sw/sqlite/opcode.html にある.
* SQLite 3の SQL の説明は http://www.hwaci.com/sw/sqlite/lang.html (English Web Page) にある.
演習で行うこと
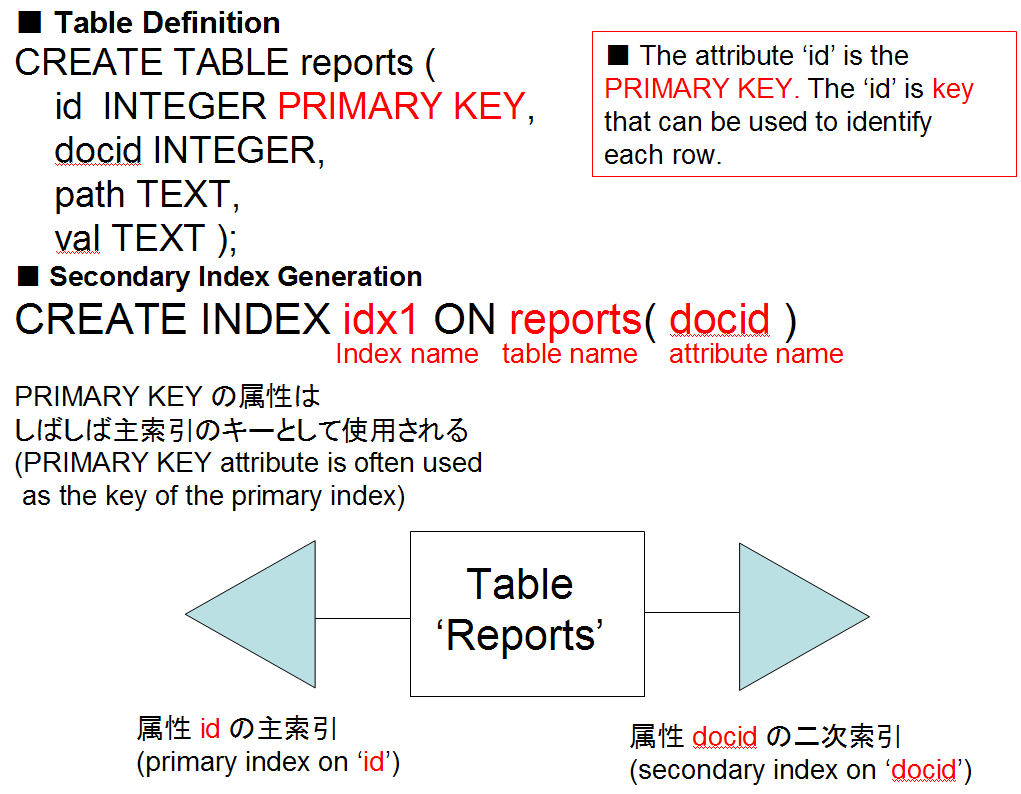
- 二次索引の生成
CREATE INDEX <index-name> ON <table-name> ( <column-name の並び> )
テーブル名と属性名を指定して,二次索引を生成する.「index-name」とあるのは二次索引の名前のことで,後で二次索引を削除したいときなどに使う.
SQLite 3 の SQL 演習に関連する部分
SQLite 3の SQL の説明は http://www.hwaci.com/sw/sqlite/lang.html (English Web Page) にある.
- CREATE INDEX <index-name> ON <table-name> ( <column-name の並び> )
テーブル名と属性名を指定して,二次索引を生成する.「index-name」とあるのは二次索引の名前のことで,後で二次索引を削除したいときなどに使う.
- DROP INDEX <index-name>;
索引名を指定して二次索引を削除する.
Sqliteman で既存のデータベースを開く
すでに作成済みのデータベースを,下記の手順で開くことができる.
以下の手順で,既存のデータベースファイルを開く. (Open an existing database file)
- 「File」→
「Open」
- データベースファイルを開く
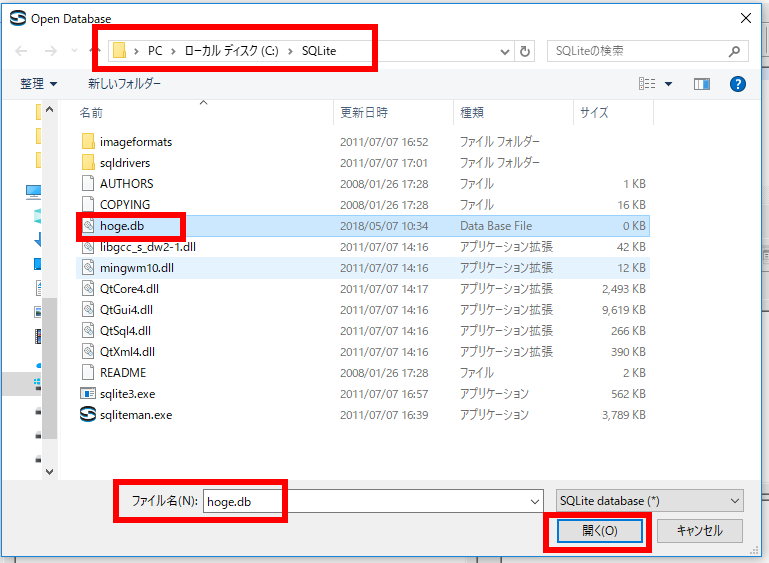
* Ubuntu での実行例(「/home/ubuntuuser/mydb」を開く場合)
データベースファイル /home/ubuntuuser/mydb を選び, 「開く」をクリック
* Windows での実行例(「C:\SQLite\mydb」を開く場合)
データベースファイル C:\SQLite\mydb を選び, 「開く」をクリック
要するに,/home/<ユーザ名>/SQLite 3の下の mydb を選ぶ.
SQL を用いたテーブル定義と一貫性制約の記述
SQL を用いて,point3 テーブルを定義し,一貫性制約を記述する.
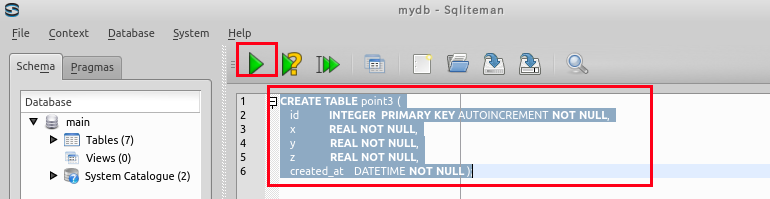
リレーショナル・スキーマ (relational schema): point3(id, x, y, z, created_at)
- point3 テーブルの定義 (Define a table)
次の SQL を入力し,「Run SQL」のアイコンをクリック
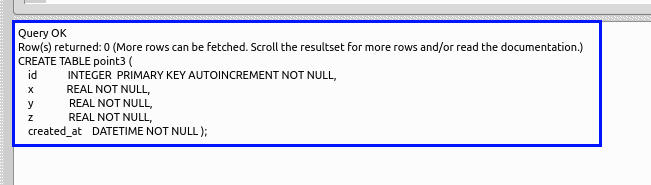
create table point3 ( id integer primary key autoincrement not null, x real not null, y real not null, z real not null, created_at datetime not null );* 「SQL Editor」のウインドウには,SQL プログラムを書くことができる. In the 'SQL string' window, you can write down SQL program(s).
- コンソールの確認
エラーメッセージが出ていないことを確認
SQL を用いたテーブルへの行の挿入
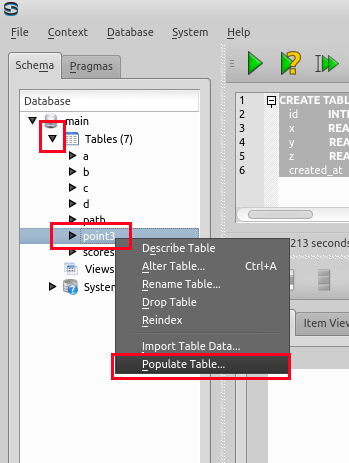
以前の授業で定義した point3 テーブルを使う。
下記の操作により、演習用のデータ(1000行)を、point3 テーブルに格納する。
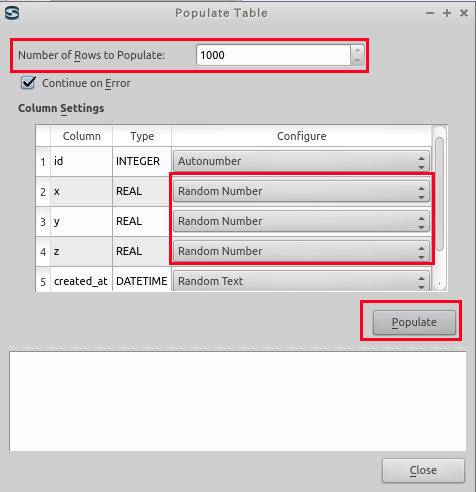
- Sqliteman で、point3 を右クリック (right click) し、「Populate Table...」を選ぶ.
- Number of Rows to Populate に「1000」を設定する。
x の行, y の行, z の行は「Random Number」に設定し、
「Populate」をクリック
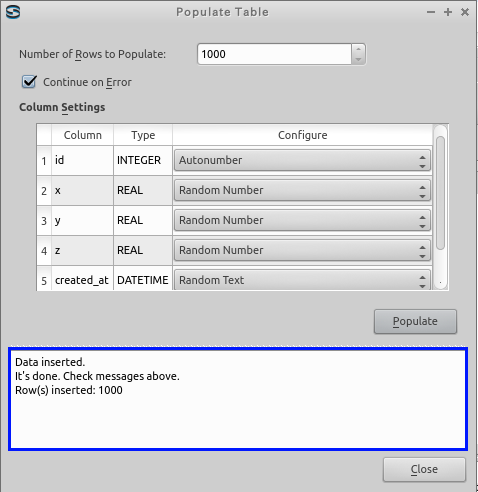
- 確認
エラーメッセージが出ていないことを確認
- 「Close」をクリック
データベースの構造の確認
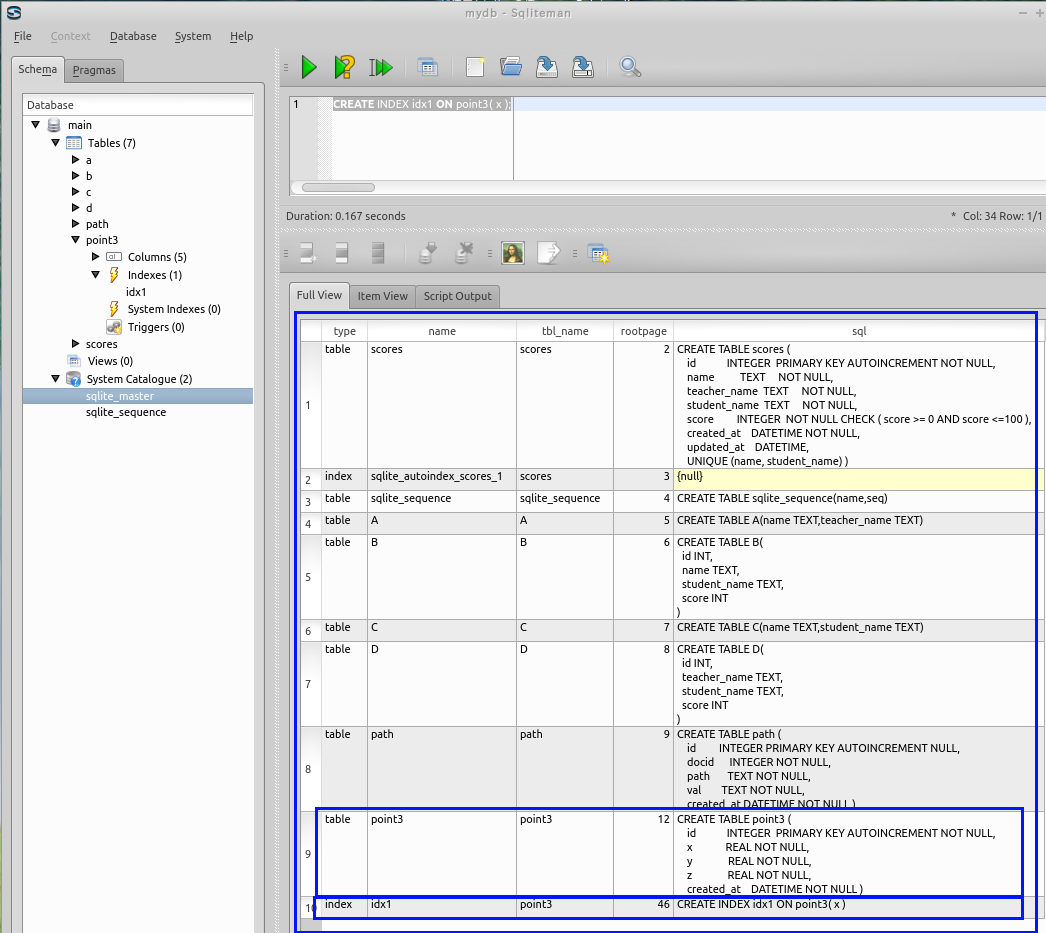
- sqlite_master をダブルクリック
- テーブル point3 のルート・ページ番号が分かる
下の図では、point3 テーブルのルートページ (root page) 番号は 12 になっている。 ルート・ページ番号は,SQLite 3 システムが決める値である。 ルート・ページ番号が 12 以外の値になっていても問題はない。
* この資料では, point3 テーブルのルートページ (root page) は,12 になっているものとして、説明を続ける。
Sqliteman を用いた SQL 問い合わせ計画の表示
単一テーブルに対する問い合わせの SQL 問い合わせ計画の表示例
ここでは 条件を満足する行のみの表示する SQL のSQL 問い合わせ計画の表示例を示す.
データベース管理システムは, SQL 文をコンパイルし,SQL 問い合わせ計画を作る. SQL 問い合わせ計画とは,データベースに関する基本的なオペレータの並びである.
SQLite 3の問い合わせ計画については,SQLite Virtual Machine Opcodes の Web ページなどを見てください.
- SQL の問い合わせの発行と評価結果の確認
SELECT * FROM point3 WHERE x < 1000000000;
*「1000000000」では、0 は 9個
- SQL 問い合わせ計画の表示
SQL 文の前に「EXPLAIN」を付ける.
EXPLAIN SELECT * FROM point3 WHERE x < 1000000000;
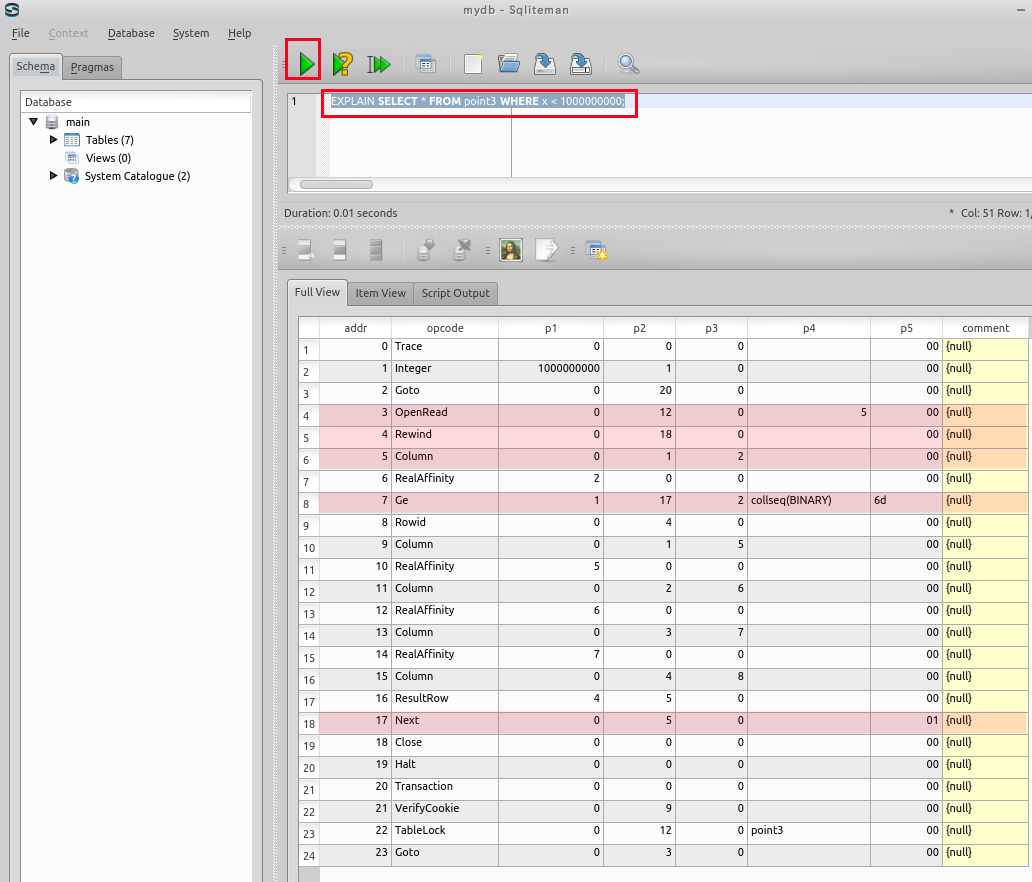
【表示された問い合わせ計画の要点】
アドレス (addr) オペコード 主なオペランド 1 Integer P1 = 1000000000, P2 = 1 レジスタ1に,値1000000000をセットする 3 OpenRead P2 = 12 ルート・ページが 12 であるようなテーブル 4 Rewind P2 = 18 カーソルを,テーブル point3 の先頭を指し示すようにする.テーブルが空の場合には,アドレス 18 (「Close」の行)にジャンプする 5 Column P2 = 1, P3 = 2 列番号1の値 (つまり x の値) を,レジスタ 2 に格納する. - 列番号 0 : id
- 列番号 1 : x
- 列番号 2 : y
- 列番号 3 : z
- 列番号 4 : created_at
7 Ge P1 = 1, P2 = 17, P3 = 2 条件付きジャンプ. レジスタ 1 の値とレジスタ 2 を比較.P1 の値 ≧ P2 の値のときに限り,アドレス 17 にジャンプする. 8 から 15 Columnなど id, x, y, z, created_at の値を,それぞれ、レジスタ 4, 5, 6, 7, 8 に格納 16 ResultRow P1 = 4, P2 = 5 レジスタ 4 からレジスタ 8 までの値 (レジスタの個数は,P2 に指定した5個) を1行として出力する 17 Next P2 = 5 もし,カーソルが指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソルが指し示すレコードが末端レコードでなければ、カーソルを1つ進めて、アドレス5 (「Column 0 1 2」のところ) にジャンプする.
Sqliteman を用いた二次索引の追加
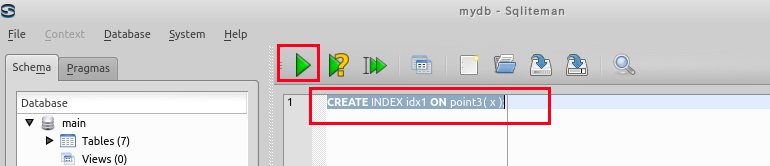
ここでは,テーブル point3 の属性 xの二次索引を作る.- CREATE INDEX を用いた二次索引の生成
CREATE INDEX idx1 ON point3( x );
「idx1は索引名である.索引の管理(索引の削除など)に使用される.
索引は数秒以内で生成される.
- コンソールの確認
エラーメッセージが出ていないことを確認
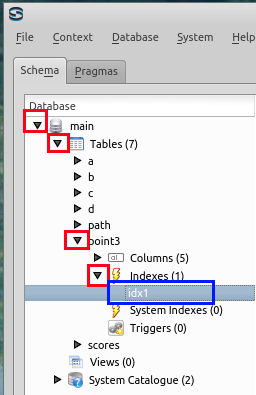
- Sqliteman での二次索引の確認
下の図のように、テーブルpoint3の「indexes」を展開して、idx1 が出来ていることを確認する。
二次索引による問い合わせ計画の変化
* データベースの構造の確認
- sqlite_master をダブルクリック
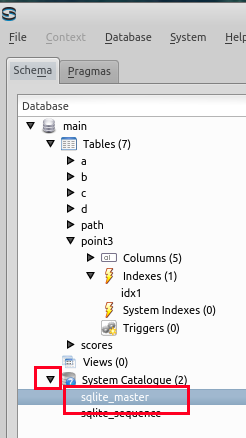
- テーブル point3 と二次索引 idx1 のルート・ページ番号が分かる
二次索引 idx1 のルート・ページ番号(上の図では「46」)を確認しておく.ルート・ページ番号は,データベース管理システムが決める値なので,違う値になっているはずである.
* SQL 問い合わせ計画の表示
- 先ほどと同じ SQL 問い合わせを評価させる.
SQL 文の前に「EXPLAIN」を付けている.
EXPLAIN SELECT * FROM point3 WHERE x < 1000000000;
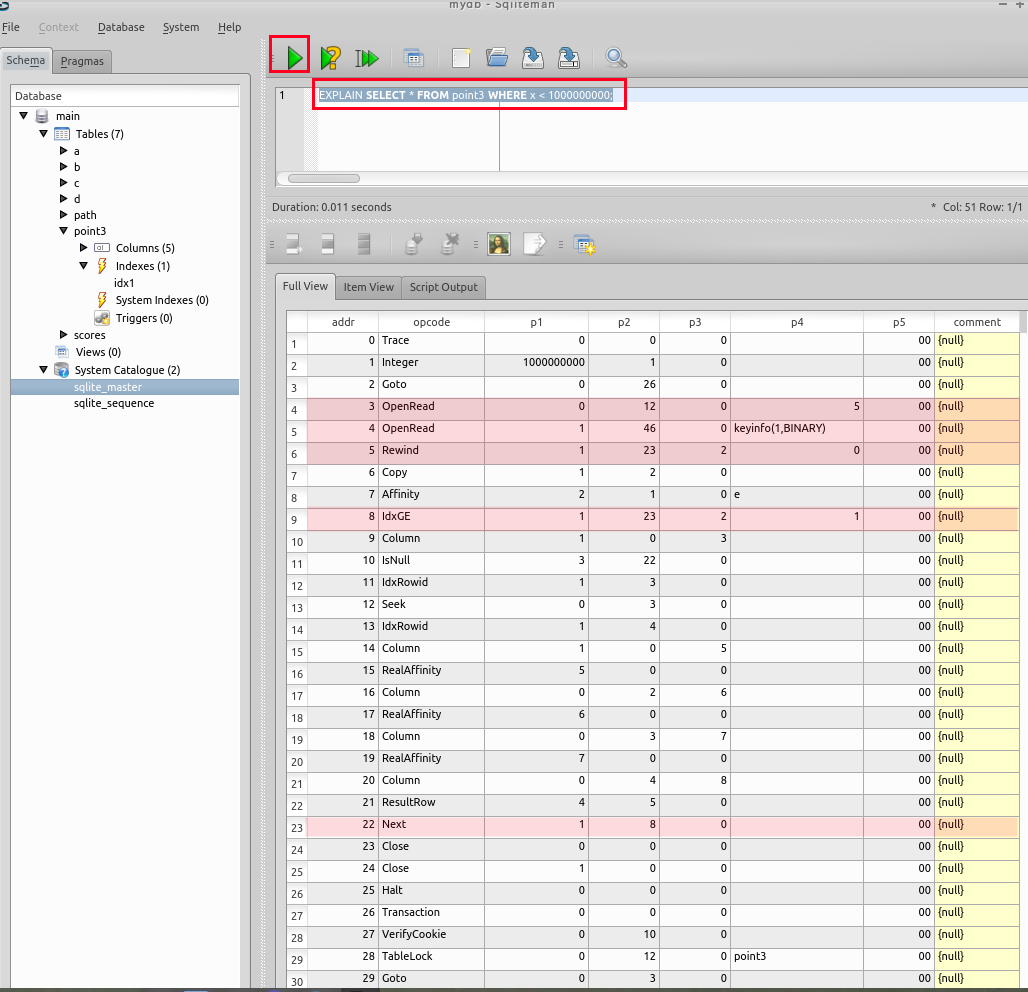
【問い合わせ計画の要点】
上の図から、二次索引が使われていることが確認できる。
二次索引は事前に作成済み。二次索引は多数の索引エントリから構成され、個々の索引エントリは、元のテーブルの各行に対応する。 最初,カーソル番号1のカーソルは二次索引のルートノードにセットされる.(ルートノードとは、個々の二次索引の管理情報を含むノードである)。 次に、「x < 1000000000」という条件式を満たす最小の x を含む行の 索引エントリが、二次索引の中から検索される。この処理は高速である。カーソル番号1のカーソルは、いま検索された索引エントリを指し示すように動く。 その後、カーソル番号1のカーソルを使って、 テーブル point3 の行を取り出しながら、 カーソル番号1のカーソルが,二次索引の中だけを動く. 「x < 1000000000」という条件式を満たすすべての行が取り出し終えたら、処理を終える。
- 二次索引のサイズは,テーブル本体のサイズよりずっと小さい
- 二次索引は,高速処理に向いたデータ構造になっている
二次索引がないとき,テーブルの本体が1行ずつ処理される.テーブルの全ての行について処理が繰り返される. (このことを「tuple at a time」ともいう)。
二次索引を使うとき、「テーブルの本体が1行ずつ処理される」わけではない。このことで、データベース処理がより高速になることが期待できる。
【表示された問い合わせ計画の要点】
| アドレス (addr) | オペコード | 主なオペランド | |
| 1 | Integer | P1 = 1000000000, P2 = 1 | レジスタ1に,値1000000000をセットする |
| 3 | OpenRead | P1 = 0, P2 = 12 | ルート・ページが 12 であるようなテーブル (この場合は,テーブル point3) のカーソルを作る. カーソル番号は0 |
| 4 | OpenRead | P1 = 1, P2 = 46 | ルート・ページが 46 であるような二次索引 (この場合は idx1 ) のカーソルを別に作る. カーソル番号は1 |
| 6 | Rewind | P1 = 1, P2 = 23 | P1 = 1 なので、カーソル番号1のカーソルを使う. カーソルを,二次索引 idx のルートノードを指し示すようにする.二次索引が空の場合には,アドレス 23 (「Close」の行)にジャンプする |
| 7 | IdxGE | P1 = 1, P2 = 23 | P1 = 1 なので、カーソル番号1のカーソルを使う. 検索キーの値(この場合は、レジスタ1に入っている「1000000000」)と、 カーソルが指し示している値を比較する。 もし、 「カーソルが指し示している値」 ≧ 「検索キーの値」のときは、アドレス 23 にジャンプする. |
| 11 から 12 | Seekなど | 二次索引を使って、カーソル0を動かす。 | |
| 14 から 20 | Columnなど | id, x, y, z, created_at の値を,それぞれ、レジスタ 4, 5, 6, 7, 8 に格納 | |
| 21 | ResultRow | P1 = 4, P2 = 5 | レジスタ 4 からレジスタ 8 までの値 (レジスタの個数は,P2 に指定した5個) を1行として出力する |
| 22 | Next | P1 = 1, P2 = 8 | もし,カーソルが指し示す二次索引ノードが末端ならば、次の命令に進む. もし,カーソルが指し示す二次索引ノードが末端でなければ、カーソルを1つ進めて、アドレス8 にジャンプする. |