SQL 入門演習
【概要】 SQLは,リレーショナルデータベースの標準的言語である.テーブル定義,問い合わせ(クエリ),データ操作などを行う.LIKE演算子を用いたパターンマッチングでは,「%」や「_」のワイルドカード文字と組み合わせることで,「typeの値に'AA'を含む行」や「先頭がBである行」などの柔軟な検索が可能となる.GROUP BY句を用いたデータをグループ化,各グループの行数をCOUNT関数でカウントするなどの集計処理も重要である.例えば,product_nameの値ごとにグループ化して各グループの行数を集計できる.また,HAVING句を用いてグループ化後の集計結果に対して条件を適用することができ,「行数が24を超えるグループのみを抽出」といった処理が可能である.SQLを用いてデータの効率的な抽出と分析ができる.
演習で行うこと
- LIKE と % の組み合わせ: 文字列のパターンマッチ
- ORDER BY と COUNT の組み合わせ: ソート
- group by と COUNT の組み合わせ: グループごとの数え上げ
- group by と COUNT と HAVING の組み合わせ: COUNT で数えたタップル数に関して条件を指定し,タップルを絞り込む.
Sqliteman で既存のデータベースを開く
すでに作成済みのデータベースを,下記の手順で開くことができる.
以下の手順で,既存のデータベースファイルを開く.
- 「File」→
「Open」
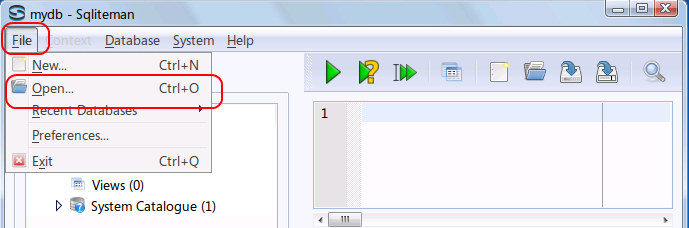
- データベースファイルを開く
* Ubuntu での実行例(「/home/ubuntuuser/mydb」を開く場合)
データベースファイル /home/ubuntuuser/mydb を選び, 「開く」をクリック
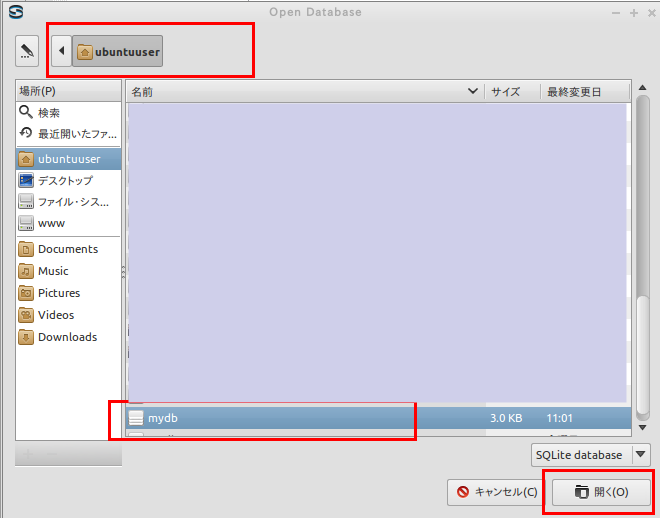
* Windows での実行例(「C:\SQLite\mydb」を開く場合)
データベースファイル C:\SQLite\mydb を選び, 「開く」をクリック
要するに,/home/<ユーザ名>/SQLite 3の下の mydb を選ぶ.
SQL を用いたテーブル定義と一貫性制約の記述
以前の授業で定義した products テーブルを使う. products テーブルのテーブル定義が残っている場合には,ここの操作は必要ない. products テーブルのテーブル定義が残っていない場合には,次の手順で定義する.
SQL を用いて,products テーブルを定義し,一貫性制約を記述する.
- products テーブルの定義
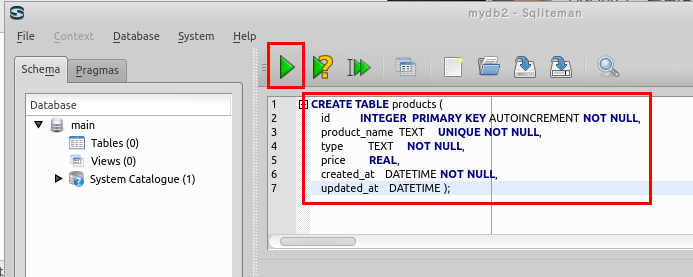
次の SQL を入力し,「Run SQL」のアイコンをクリック
create table products ( id INTEGER PRIMARY KEY autoincrement not null, product_name TEXT UNIQUE not null, type TEXT not null, price real, created_at DATETIME not null, updated_at DATETIME );* 「SQL Editor」のウインドウには,SQL プログラムを書くことができる. .
- コンソールの確認
エラーメッセージが出ていないことを確認する.
テーブルへの行の挿入
以前の授業で定義した products テーブルを使う.
下記の操作により,演習用のデータ(1000行)を,products テーブルに格納する.
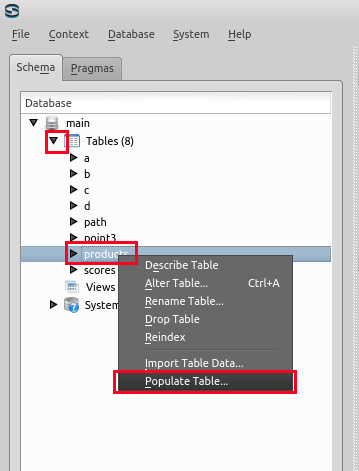
- Sqliteman で,products を右クリック (right click) し,「Populate Table...」を選ぶ.
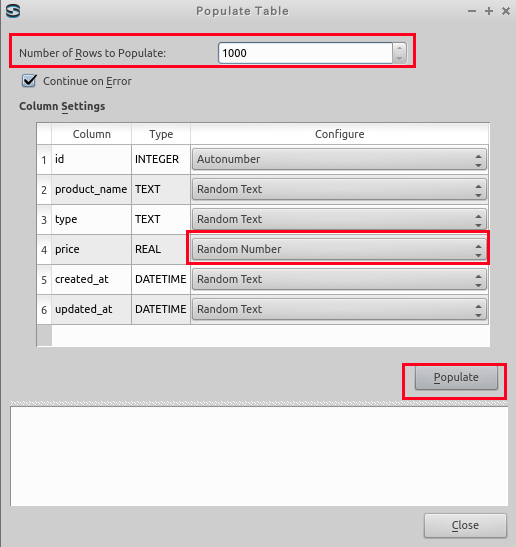
- Number of Rows to Populate に「1000」を設定,
ecost の行は「Random Number」に設定し,
「Populate」をクリックする.
- 「Close」をクリックする.
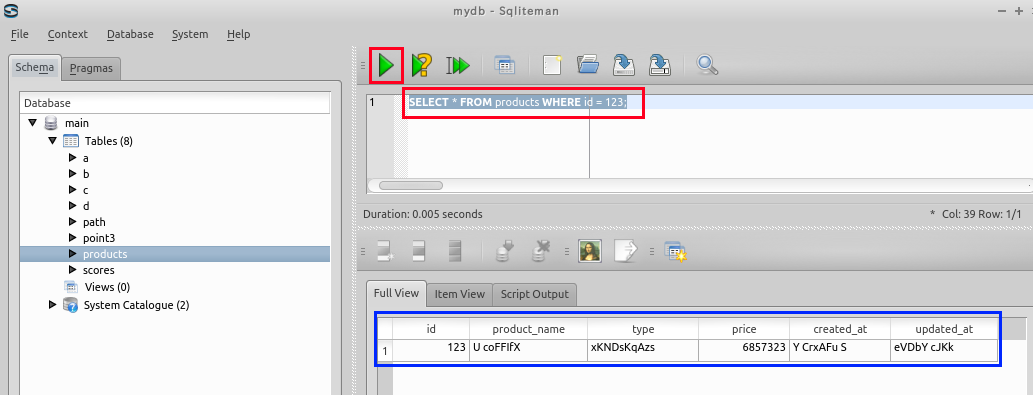
条件を満足する行のみの表示
SELECT * FROM products WHERE id = 123;
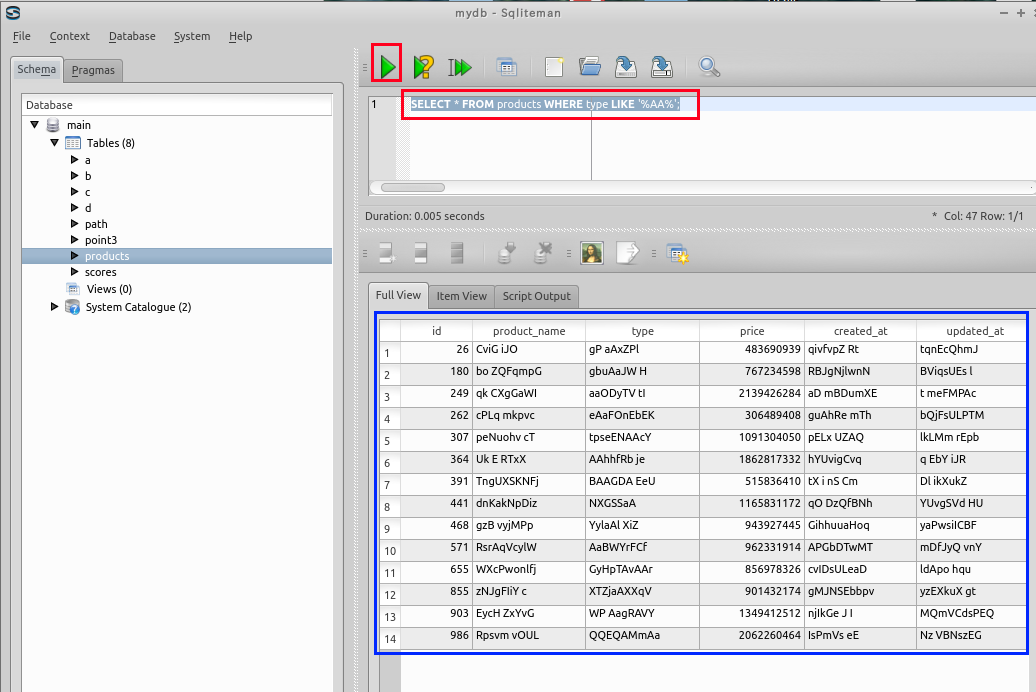
LIKE と % の組み合わせ: 文字列のパターンマッチ
「aa」あるいは「aA」あるいは「Aa」あるいは「AA」を含むという条件での検索. 検索条件では「'%AA%'」と書いている. 大文字と小文字の両方が検索条件にマッチする.
SELECT * FROM products WHERE type LIKE '%AA%';
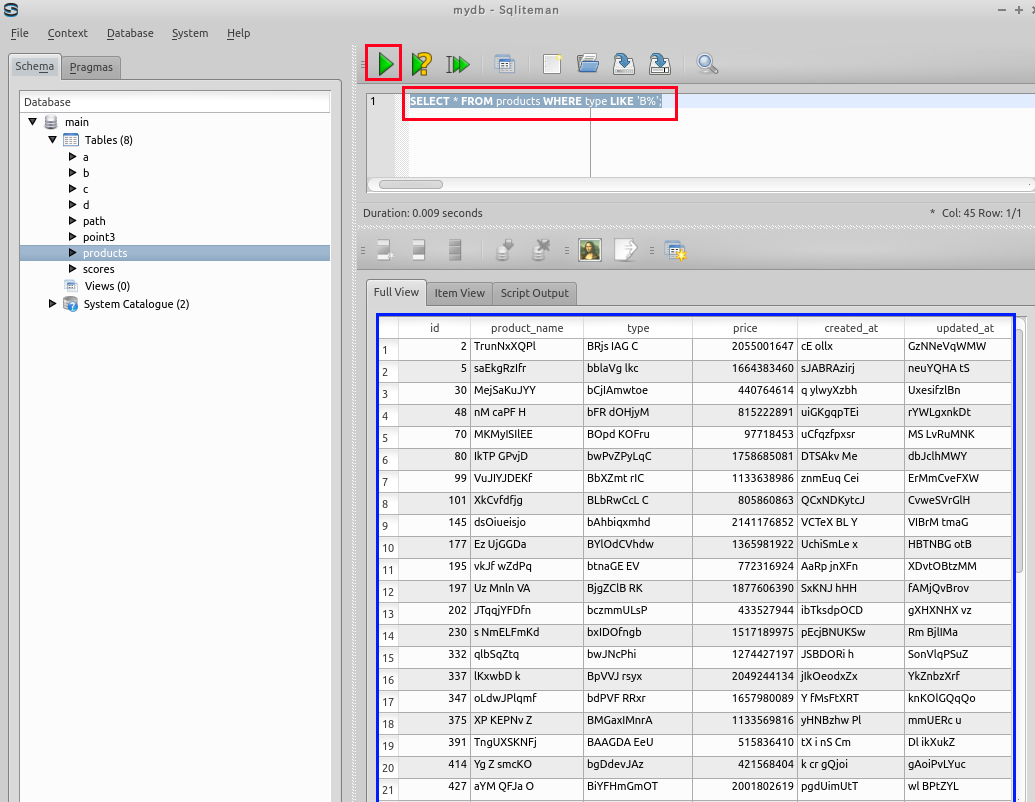
先頭が「B」あるいは「b」であるという条件での検索. 検索条件では「'B%'」と書いている. 大文字と小文字の両方が検索条件にマッチする.
SELECT * FROM products WHERE type LIKE 'B%';
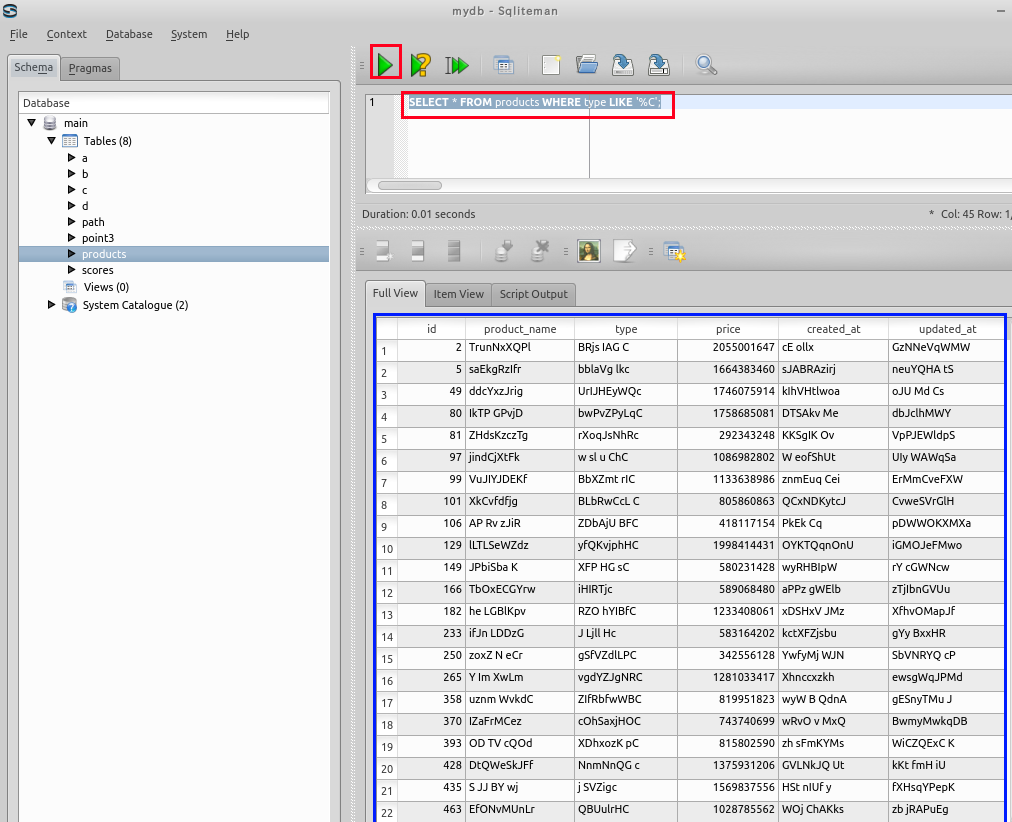
末尾が「C」あるいは「c」であるという条件での検索. 検索条件では「'%C'」と書いている. 大文字と小文字の両方が検索条件にマッチする.
SELECT * FROM products WHERE type LIKE '%C';
ORDER BY を用いたソート
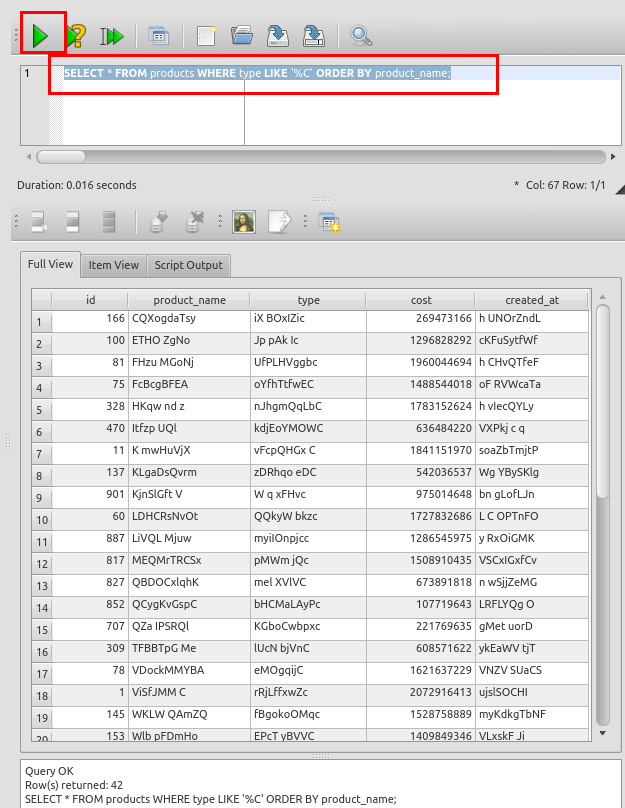
末尾が「C」あるいは「c」であるという条件での検索. 検索条件では「'%C'」と書いている. 検索結果を 「ORDER BY product_name」でソートする.
SELECT * FROM products WHERE type LIKE '%C' ORDER BY product_name;
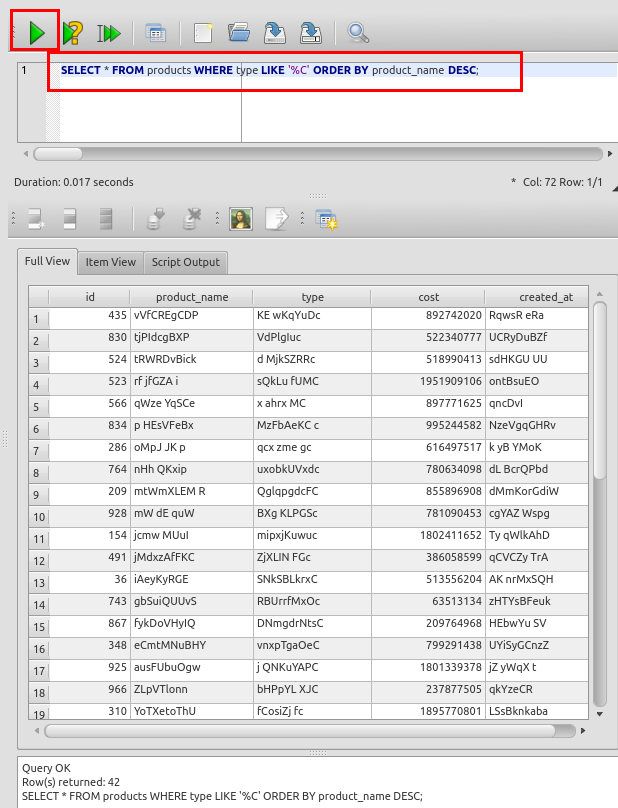
今度は,「ORDER BY product_name DESC」でソートする.末尾に「DESC」を付けることにより, 結果が降順になる.
SELECT * FROM products WHERE type LIKE '%C' ORDER BY product_name DESC;
group by と COUNT の組み合わせ: グループごとの数え上げ
「substr(<属性名>, X, Y)」は,X文字列目から,Y文字分取り出すという意味である. 例えば, 「substr(procuct_name, 1, 1)」は,先頭文字を(文字を1個だけ)取り出すという意味である.
group by はグループ化である.
SELECT substr(product_name, 1, 1), COUNT(*) FROM products group by substr(product_name, 1, 1);
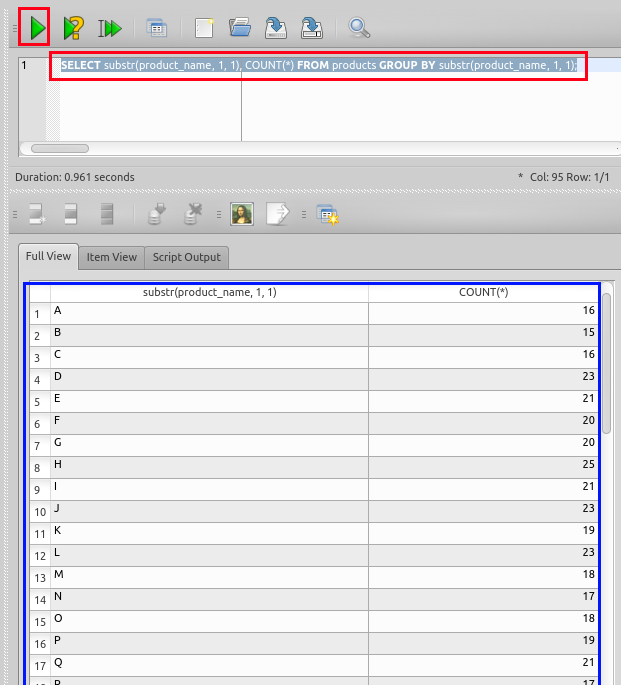
上の図では,「先頭がAのものが16行,先頭がBのものが15行,先頭がCのものが1行」という意味になる.
procuct_name の先頭文字は aからz, AからZの 52 通りある.
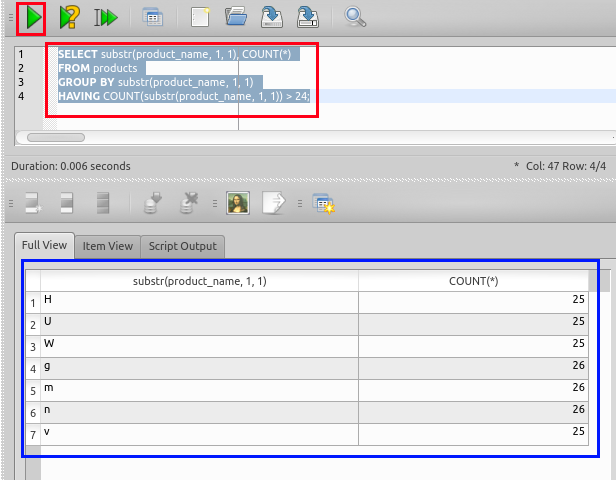
今後は,行数で絞り込む.次のSQLでは,行数が24を超えるものに絞り込んでいる.
SELECT substr(product_name, 1, 1), COUNT(*)
FROM products
group by substr(product_name, 1, 1)
HAVING COUNT(substr(product_name, 1, 1)) > 24;