1. テーブル定義,テーブル生成,問い合わせ(SQLite3, Python を使用)
概要
Python言語からリレーショナルデータベースを操作する方法について説明する.リレーショナルデータベースは,複数のテーブルから構成される.テーブルは,数値,テキスト,日時などの情報を行と列の形式で格納するデータ構造である.リレーショナルデータベースの操作を記述する言語の世界標準がSQL(Structured Query Language)である.ここでは,PythonとSQLを組み合わせてデータベース操作を行う.なお,データベースへの接続時には,データベース名を指定する.

テーブル
リレーショナルデータベースでは,データベースをテーブルの集まり(collection of tables)として表現する.各テーブルにはテーブル名があり,テーブル内の各列には列名がある.これらの名前はテーブルや列を識別するために用いられる.
テーブルの例
| id | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
リレーションスキーマ
リレーションスキーマ(スキーマともいう,relation schema)とは,テーブルの構造を形式的に表現したものである.Rをテーブル名,A1, A2, …, Anを属性名とするとき,リレーションスキーマを「R(A1, A2, …, An)」のように記述する.例えば,本教材で使用するirisテーブルのリレーションスキーマは「iris(id, sepal_length, sepal_width, petal_length, petal_width, species)」である.
テーブル定義
テーブル定義とは,テーブル名,属性名の並び,各属性のデータ型,各属性の制約(例:主キー)などを記述することである.
SQLのデータ型
SQLiteにおける代表的なデータ型を以下に示す.
| データ型 | 説明 |
|---|---|
INTEGER | 符号付き整数(signed integer) |
REAL | 浮動小数点数(floating point value) |
TEXT | 文字列(text string) |
主キー
テーブルのタプルを一意に識別できる属性または属性の組のうち,極小なものを候補キー(candidate key)という.候補キーの中から,データベース管理者が管理上最も適切と判断し,かつ空値(NULL)をとる可能性がないものを,リレーションスキーマの設計時に選定したものが主キー(primary key)である.
SQLの集約関数
SQLiteの代表的な集約関数には次がある.
| 集約関数 | 説明 |
|---|---|
SUM() | 指定した属性の合計値 |
AVG() | 指定した属性の平均値 |
COUNT() | 行数 |
MAX() | 指定した属性の最大値 |
MIN() | 指定した属性の最小値 |
CSVファイル(CSV File)
CSV(Comma-Separated Values)ファイルとは,値をカンマで区切って並べたテキスト形式のデータファイルである.CSVファイルの列名は,データベースのテーブル定義における列名と異なる場合がある.
本教材では,Irisデータセットを使用する.このデータセットは Kaggle(https://www.kaggle.com/datasets/uciml/iris)から入手できる.ファイルの内容は以下のとおりである.
Id,SepalLengthCm,SepalWidthCm,PetalLengthCm,PetalWidthCm,Species
1,5.1,3.5,1.4,0.2,Iris-setosa
2,4.9,3.0,1.4,0.2,Iris-setosa
3,4.7,3.2,1.3,0.2,Iris-setosa
4,4.6,3.1,1.5,0.2,Iris-setosa
5,5.0,3.6,1.4,0.2,Iris-setosa
6,5.4,3.9,1.7,0.4,Iris-setosa
7,4.6,3.4,1.4,0.3,Iris-setosa
8,5.0,3.4,1.5,0.2,Iris-setosaPythonの繰り返し処理
Pythonでは,データの集まりに対して for 文で各要素を順に処理できる.以下の例では,変数 row が t の各要素を順に参照する.
for row in t:
print(row)PythonのSQLプレースホルダー
SQL文の中にプレースホルダーを示す記号「?」を記述し,実行時に指定した値で置き換えることができる.これはPythonの sqlite3 モジュールが提供する機能である.以下の例では,「?」の部分が値 4 で置き換えられ,"select * from iris where id = 4" に相当するSQL文が実行される.プレースホルダーを使用することで,SQLインジェクション(外部からの入力を利用してSQL文を改ざんする攻撃)を防止できる.
# cur は c.cursor() で取得したカーソルオブジェクト
sql = "select * from iris where id = ?"
cur.execute(sql, (4,))演習準備
以下のやり方が分からない場合は,先に「Windows環境でのPython:基本とプログラムの作成・実行」を参照すること。
この演習では Python を使用する。Python がインストールされていない場合は,下記の「Python 3.12 のインストール(Windows 上)」を展開し,手順に従いインストールすること。下記の「必要なライブラリのインストール」を実施すること。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
必要なライブラリのインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install -U pandas演習
① コマンドプロンプトを開き,python と入力してPythonの対話型シェルを起動する。
python
② カレントディレクトリの確認
python
os モジュールを使用してカレントディレクトリ(現在の作業ディレクトリ)を取得する.このパスは,データベースファイルやCSVファイルの保存場所となる.
import os
os.getcwd()
③ iris.csv をダウンロードし保存
Python の標準ライブラリである urllib.request を使用して,GitHub 上で公開されている Iris データセットの CSV ファイルをダウンロードする.urllib.request.urlretrieve は,第1引数に指定した URL からファイルを取得し,第2引数に指定したファイル名でカレントディレクトリに保存する関数である.この方法により,外部サイトへのアカウント登録なしにデータを取得できる.
import urllib.request
url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv"
urllib.request.urlretrieve(url, "iris.csv")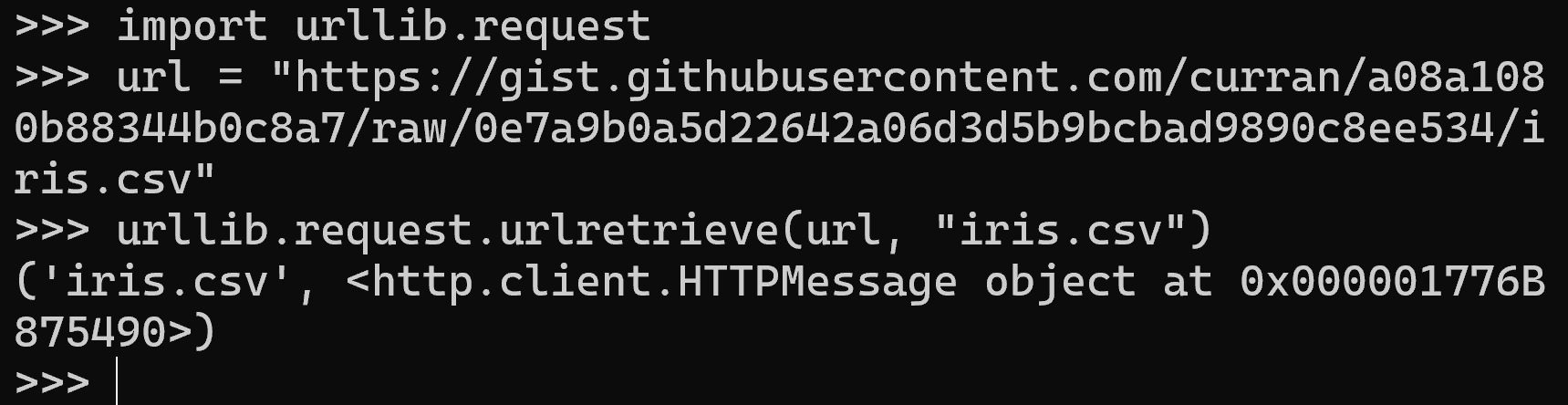
実行後,カレントディレクトリに iris.csv が保存される.このファイルには 150 件の Iris(アヤメ)のデータが含まれており,ヘッダー行の列名は sepal_length,sepal_width,petal_length,petal_width,species である.
④ データベースのテーブル定義を行う
以下のプログラムでは,sqlite3.connect でSQLite3データベースに接続し,接続オブジェクト c を取得する.SQLite3はファイルベースのデータベースであるため,接続時にはデータベースファイルのパス(ここでは 'hoge.sqlite')を指定する.接続オブジェクトは,SQL文の実行やトランザクション(一連のデータベース操作をまとめて確定または取り消す仕組み)の管理に用いる.create table 文でテーブル iris を定義し,各列にデータ型を指定する.id 列には主キー制約(primary key)を設定する.トリプルクォート(""" … """)を用いることで,複数行のSQL文を見やすく記述している.なお,ここでは接続オブジェクト c の execute メソッドでSQL文を直接実行している.(これは sqlite3 モジュールが提供するショートカットであり,内部的にはカーソルが自動生成される.)
import sqlite3
c = sqlite3.connect('hoge.sqlite')
sql = """
create table iris (
id integer primary key,
sepal_length real,
sepal_width real,
petal_length real,
petal_width real,
species text );
"""
c.execute(sql)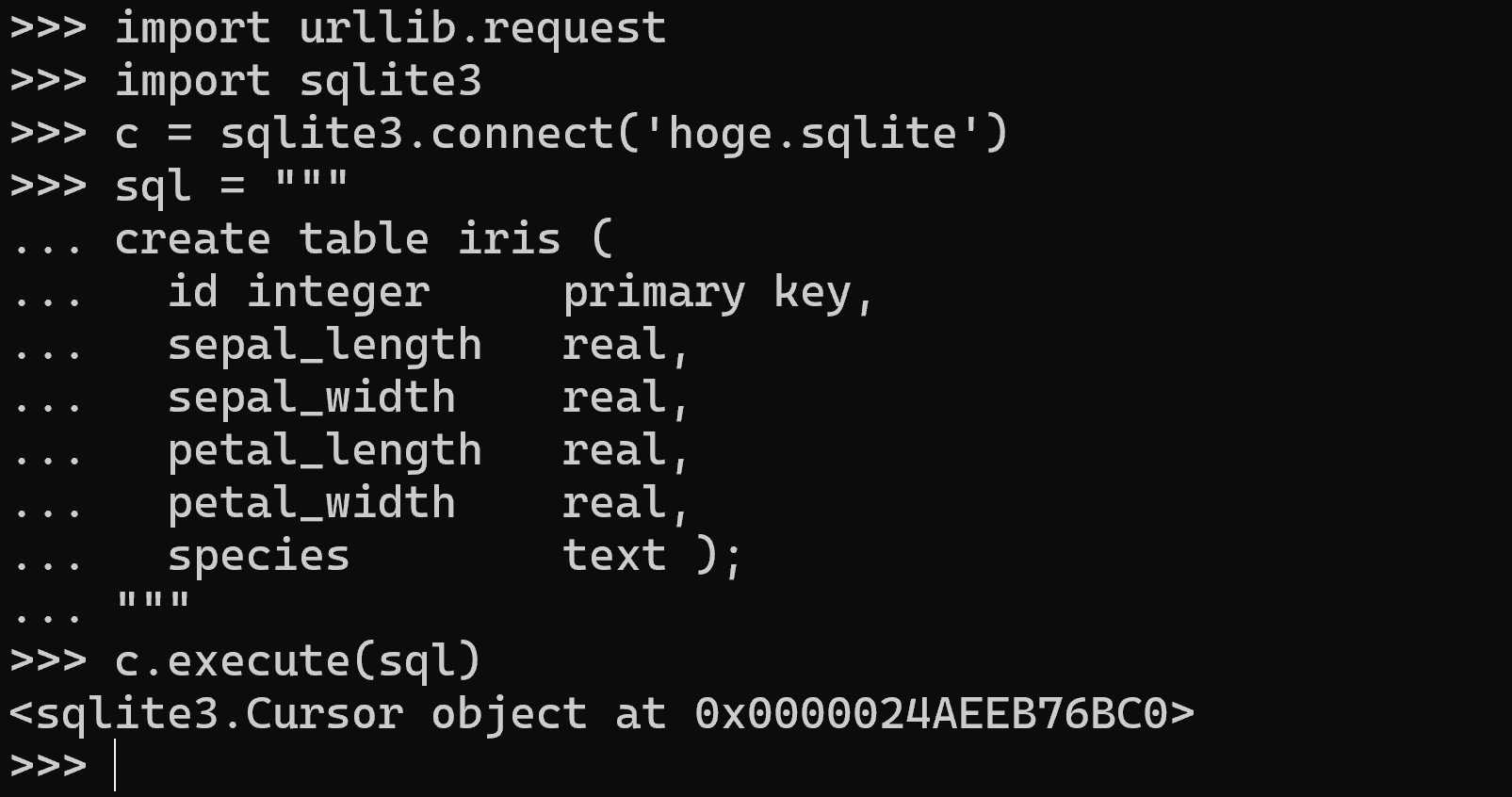
⑤ テーブル生成(空のテーブルにレコードを挿入する)
以下のプログラムでは,pandasの pd.read_csv でCSVファイルを読み込み,SQLプレースホルダー(?)と iterrows() を組み合わせて,各行をSQLiteテーブルに挿入する.
(1) オブジェクト x にCSVファイルを読み込む
読み込むCSVファイルにヘッダー行がない場合は header=None を指定する.今回使用するCSVファイルには sepal_length,sepal_width,petal_length,petal_width,species というヘッダー行があるため,header=0(先頭行をヘッダーとして扱う)を指定している.なお,このCSVファイルには id 列が含まれていないため,挿入時には DataFrame のインデックス(0始まり)に1を加えた値を id として使用する.
import pandas as pd
x = pd.read_csv('iris.csv', header=0)
(2) オブジェクト x に格納されたデータを iris テーブルに挿入する
for index, r in x.iterrows(): は,DataFrameオブジェクト x の各行について繰り返す構文である.insert into iris values は,テーブルに1行挿入するSQL文である.「?」はSQLプレースホルダーである.CSVファイルに id 列は含まれていないため,index + 1(DataFrame のインデックスに1を加えた値)を id として使用している.r['sepal_length'] 等は CSV ファイルの各列の値に対応する.最後に c.commit() を実行し,挿入したデータをデータベースに確定(コミット)させる.c.commit() を実行しない場合,挿入したデータは保存されない.
for index, r in x.iterrows():
sql = "insert into iris values (?, ?, ?, ?, ?, ?)"
c.execute(sql, (index + 1, r['sepal_length'], r['sepal_width'], r['petal_length'], r['petal_width'], r['species']))
c.commit()
⑥ テーブルの全データを読み出す
select * from iris は,iris テーブルの全行・全列を取得するSQL問い合わせである.問い合わせ結果を取得し,print で表示する.
result = c.execute("select * from iris").fetchall()
print(result)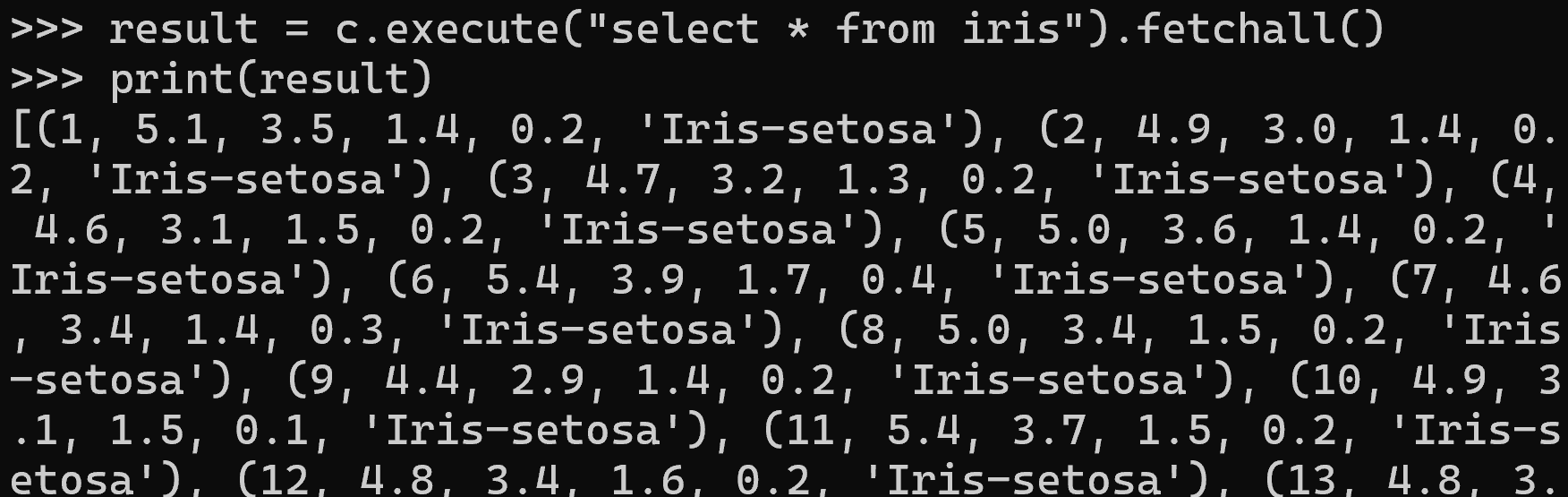
⑦ SQL集約関数による合計・平均の取得
SUM() と AVG() はSQLの集約関数(Aggregate Function)と呼ばれ、複数行のデータをまとめて1つの値を返す。次の例では sepal_length(がく片の長さ)を対象としている。sepal_width や petal_length など他の数値属性に置き換えることも可能である。
なお、species のような文字列型の属性に対して SUM() や AVG() を使うと、意味のある結果は得られないため注意すること。集約関数の対象は数値型の属性に限定する必要がある。
result = c.execute("select sum(sepal_length), avg(sepal_length) from iris").fetchall()
print(result)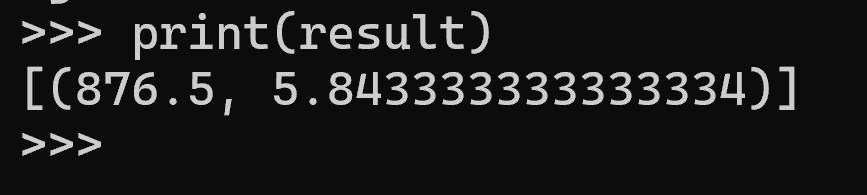
⑧ 接続を閉じる
データベース操作の終了後は c.close() で接続を閉じる.
c.close()
⑨ Pythonの終了
exit() でPythonを終了する.
exit()
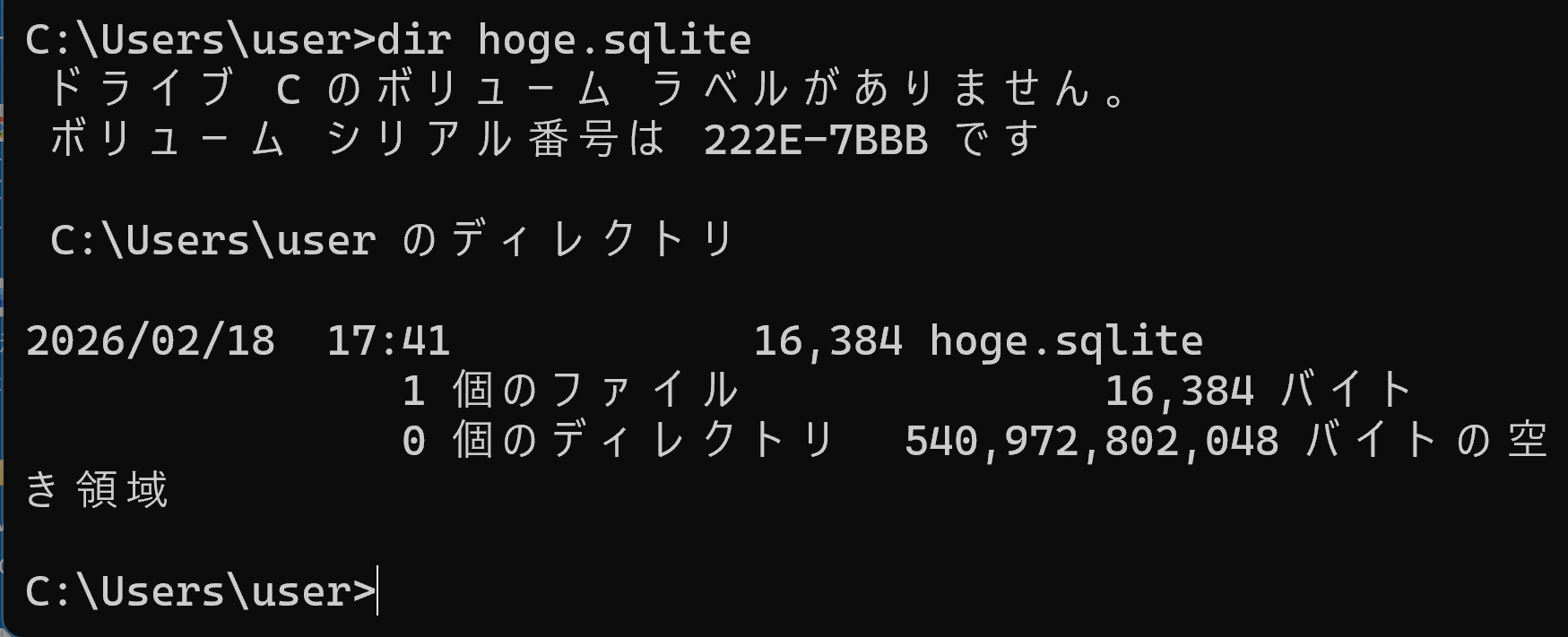
⑩ データベースファイルの確認
手順②で確認したカレントディレクトリに,データベースファイル hoge.sqlite が生成されていることを確認する.
dir hoge.sqlite