4. Python のデータフレーム,集計・集約,ソー<ト/h1>

概要
この演習では,Python によるデータ処理を実習する。MySQL Employees Sample データベースのデータを SQLite3 に格納し,サンプルデータセットとして使用する。
この演習を通じて,以下の操作を習得する。
- データベースのテーブルをデータフレームに読み込む
- データフレームの内容を確認する
- 集計・集約を行う
- ソートを行う
- 頻度分布を求める
Python の pandas パッケージ
Python の pandas パッケージは,以下の機能を持つ。
- データフレーム (DataFrame) と呼ばれる表形式データの処理
- 時系列データの処理
- 集計・集約
- CSV ファイルや Excel ファイルなどの読み書き
- リレーショナルデータベースとの連携
本演習では,このうちデータフレームへの読み込み,集計・集約,ソートを扱う。
Python のデータフレームの例
以下は dept_emp テーブルから読み込んだデータフレームの例である。
| emp_no | dept_no | from_date | to_date |
|---|---|---|---|
| 10001 | d005 | 2025-04-01 | 9999-01-01 |
| 10002 | d007 | 2025-04-15 | 9999-01-01 |
| 10003 | d004 | 2025-05-01 | 9999-01-01 |
| 10004 | d004 | 2025-06-01 | 2026-01-31 |
| 10005 | d003 | 2025-04-01 | 9999-01-01 |
| 10006 | d005 | 2025-07-01 | 9999-01-01 |
| 10007 | d008 | 2025-08-01 | 9999-01-01 |
| 10008 | d005 | 2025-04-10 | 2026-02-15 |
| 10009 | d006 | 2025-09-01 | 9999-01-01 |
| 10010 | d004 | 2025-05-15 | 2026-01-10 |
SQLite の GLOB
SQLite の GLOB は,文字列のパターンマッチを行う。GLOB は大文字・小文字を区別する。
*— 任意の文字列と一致する?— 任意の1文字と一致する[a-z]— a, b, …, z のいずれか1文字と一致する
例えば,以下の SQL 文では,列 A に文字列 "9999" を含む行を取得する。
SELECT * FROM R WHERE A GLOB '*9999*'演習準備
以下のやり方が分からない場合は,先に「Windows環境でのPython:基本とプログラムの作成・実行」を参照すること。
この演習では Python を使用する。Python がインストールされていない場合は,下記の「Python 3.12 のインストール(Windows 上)」を展開し,手順に従いインストールすること。下記の「必要なライブラリのインストール」を実施すること。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
必要なライブラリのインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install -U pandas matplotlib演習
Employees Sample データベース(SQLite版)
このデータベースは,MySQL Employees Sample Database を SQLite 形式に変換したものであり,GitHub 上の bytebase/employee-sample-database リポジトリで公開されている。出典と著作権表示は以下のとおりである。
データの出典: MySQL Employees Sample Database(原著者: Fusheng Wang, Carlo Zaniolo。リレーショナルスキーマ: Giuseppe Maxia。データ変換: Patrick Crews)
This work is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA.
SQLite adaptation: bytebase/employee-sample-database (MIT License)
ステップ1:Employees Sample データベースのダウンロード
以下の手順で,Employees Sample データベース(SQLite版)をダウンロードする。
このデータベースは,MySQL Employees Sample Database を SQLite 形式に変換したものであり,GitHub 上の bytebase/employee-sample-database リポジトリで公開されている。
コマンドプロンプトで以下のコマンドを実行し,データベースファイルをカレントディレクトリにダウンロードする。python -c は,引用符内の Python コードをコマンドライン上で直接実行するオプションである。urllib.request.urlretrieve は,第1引数に指定した URL からファイルを取得し,第2引数に指定したファイル名で保存する関数である。
python -c "import urllib.request; urllib.request.urlretrieve('https://raw.githubusercontent.com/bytebase/employee-sample-database/main/sqlite/dataset_small/employee.db', 'employee.db')"
ステップ2:Emplyees Sample データベースの確認
Pythonの対話型シェルを使って,SQLによるデータ操作を実行する。
① コマンドプロンプトを開き,python と入力してPythonの対話型シェルを起動する。
python
② 次のPythonプログラムを実行し,SQLite3データベースに接続する。この演習で使用するデータベースファイルは,ステップ1でカレントディレクトリにダウンロードした employee.db である。
import sqlite3
c = sqlite3.connect('employee.db')
③ データベースに含まれるテーブルの一覧を確認する。sqlite_master は SQLite が内部的に保持するシステムテーブルであり,データベース内のテーブルやインデックスなどの定義情報が格納されている。type='table' の条件を指定することで,テーブル名のみを取得できる。
result = c.execute("select * from department").fetchall()
for row in result:
print(row)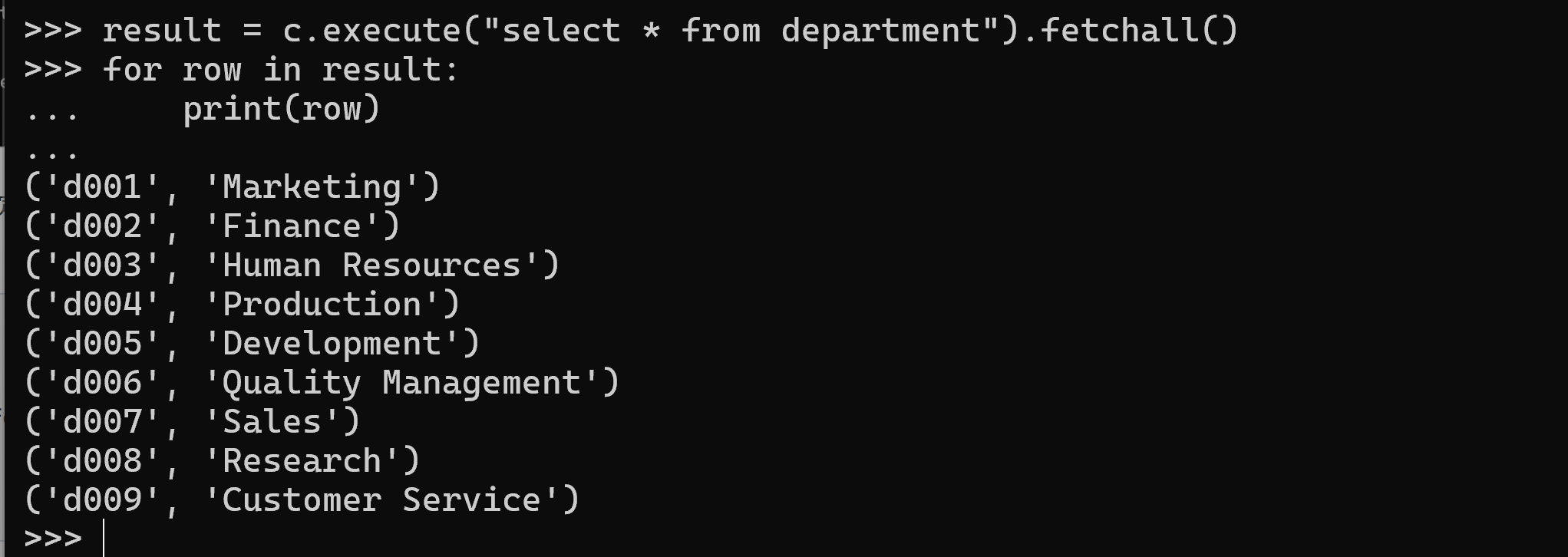
④ 各テーブルの列情報を確認する。PRAGMA table_info(テーブル名) は,指定したテーブルの列名,データ型,主キーの有無などの構造情報を返す SQLite 固有のコマンドである。
for table_name in ['department', 'dept_manager', 'dept_emp', 'employee', 'title', 'salary']:
print(table_name)
result = c.execute(f"PRAGMA table_info({table_name})").fetchall()
for row in result:
print(row)
print()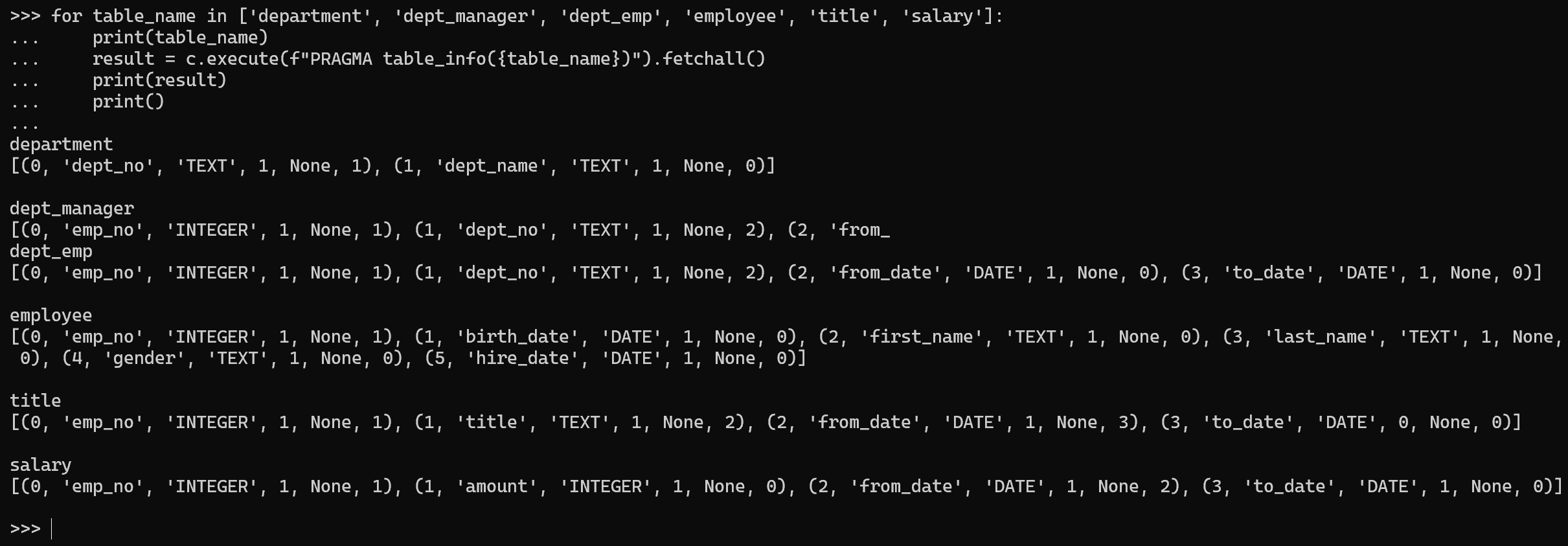
ステップ 3:テーブルをデータフレームに読み込む
pandas を使い,データベースのテーブルをデータフレームに読み込む。以下のコードでは,ステップ2で作成した接続オブジェクト c を使用し,テーブルの内容を変数 df に読み込んでいる。
import pandas
df = pandas.read_sql("SELECT * FROM dept_emp", c)
ステップ 4:データフレームの確認と分析
4-1. データフレームの確認
データフレームの内容を確認する。df.describe(include='all') を実行すると,各列の統計項目が表示される。
文字列型の列に対しては,以下の項目が表示される。
count— 行数unique— 異なる値の数top— 最頻値freq— 最頻値の出現回数
数値型の列に対しては,以下の項目が表示される。
count— 行数mean— 平均値std— 標準偏差min— 最小値25%— 第1四分位数50%— 中央値75%— 第3四分位数max— 最大値
df.describe(include='all')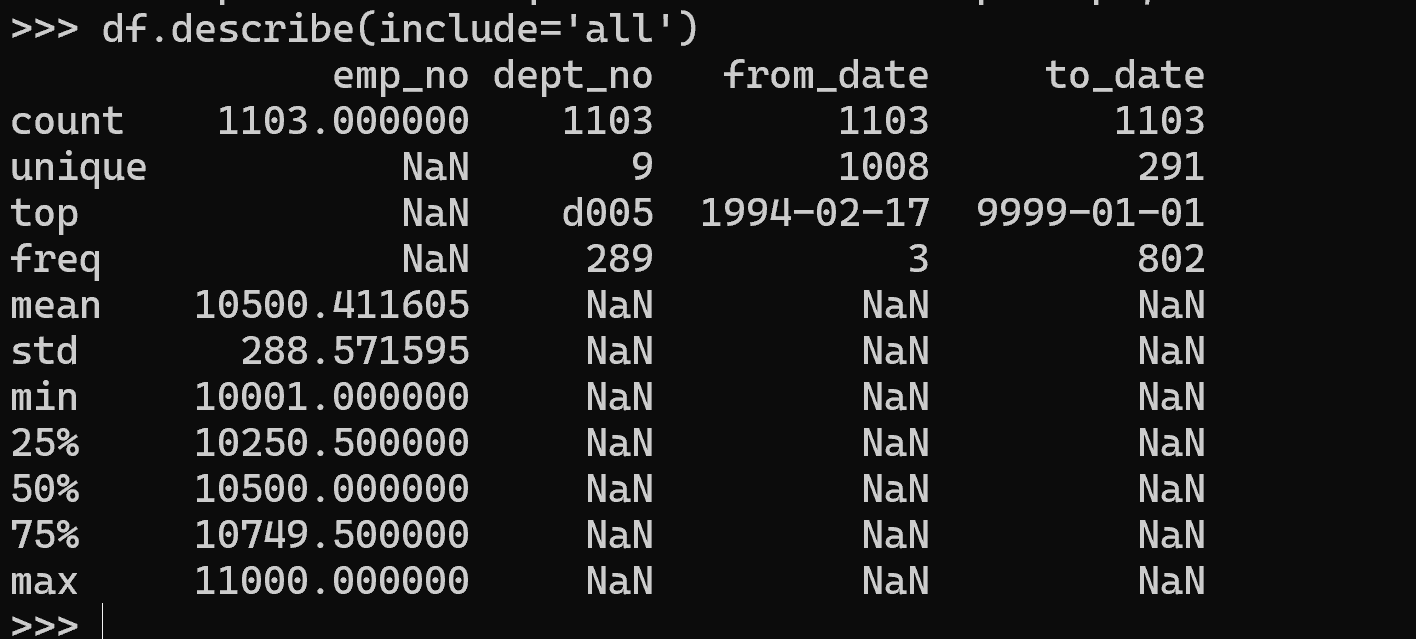
4-2. 集計
データフレームの集計を行う。
df.count()
df['dept_no'].value_counts()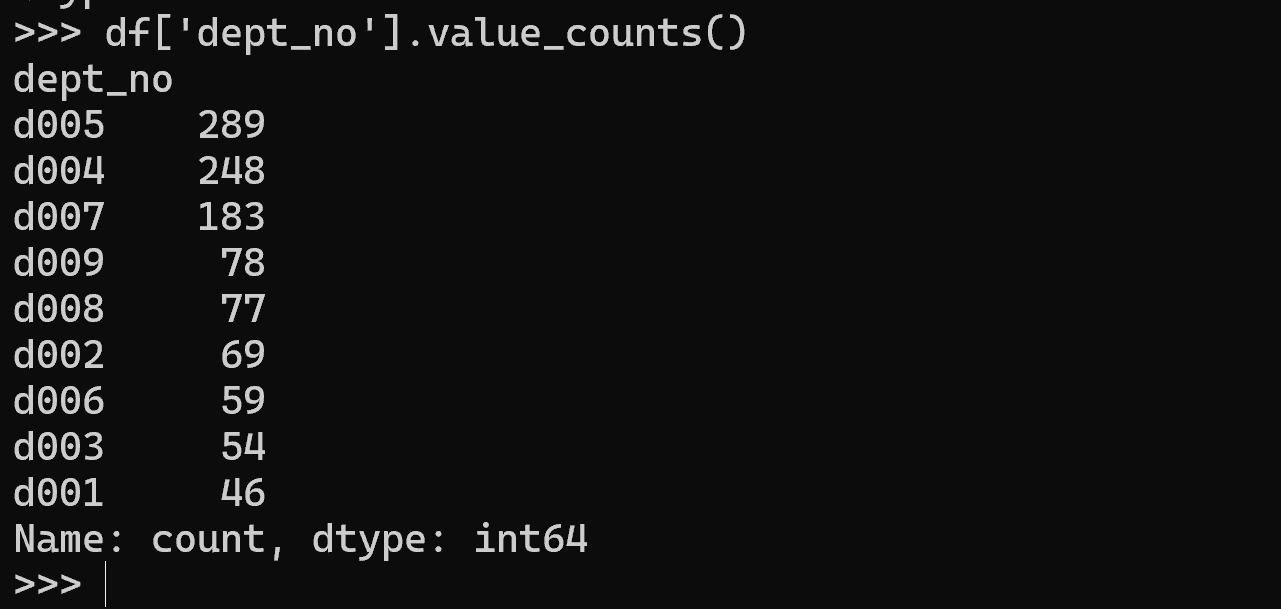
4-3. ソート
昇順:
df.sort_values(by='emp_no', ascending=True)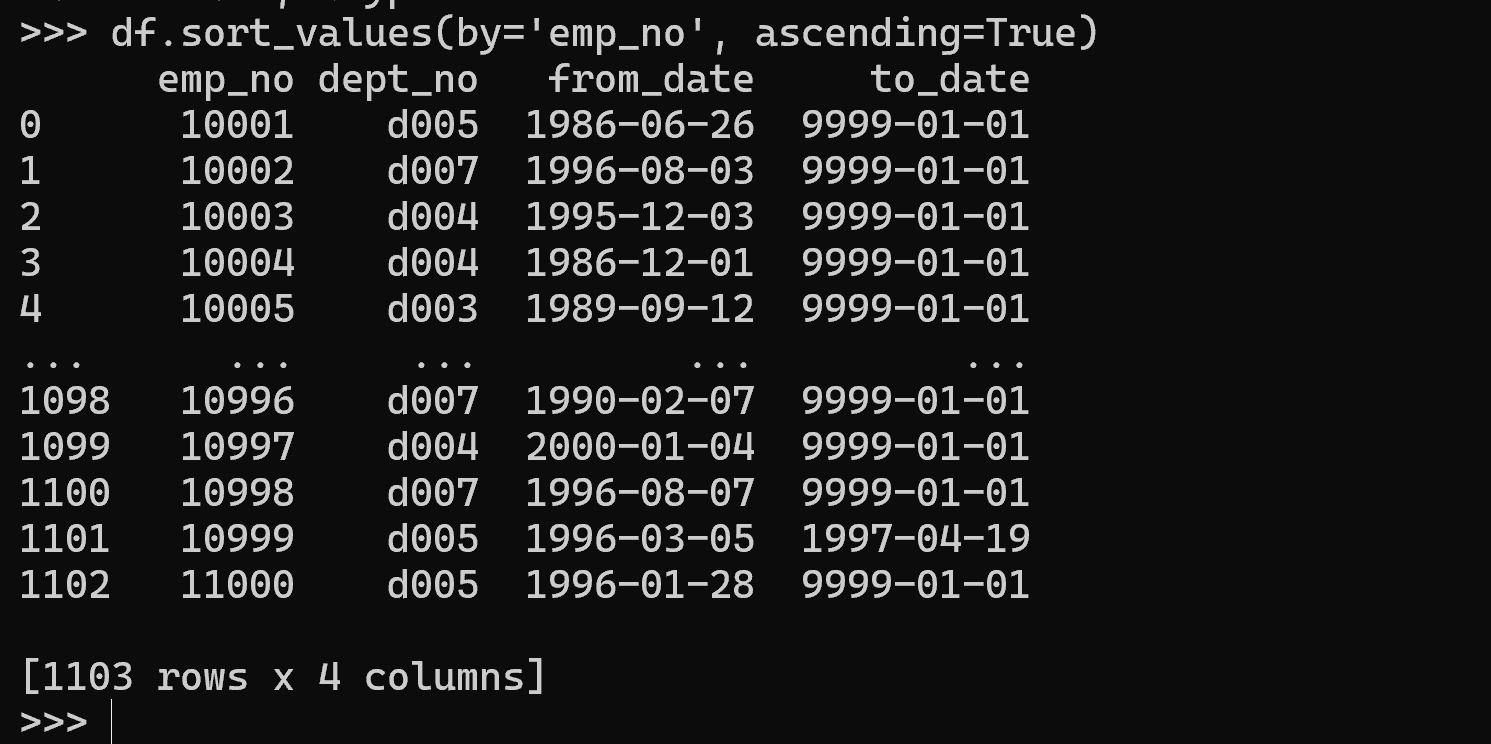
降順:
df.sort_values(by='emp_no', ascending=False)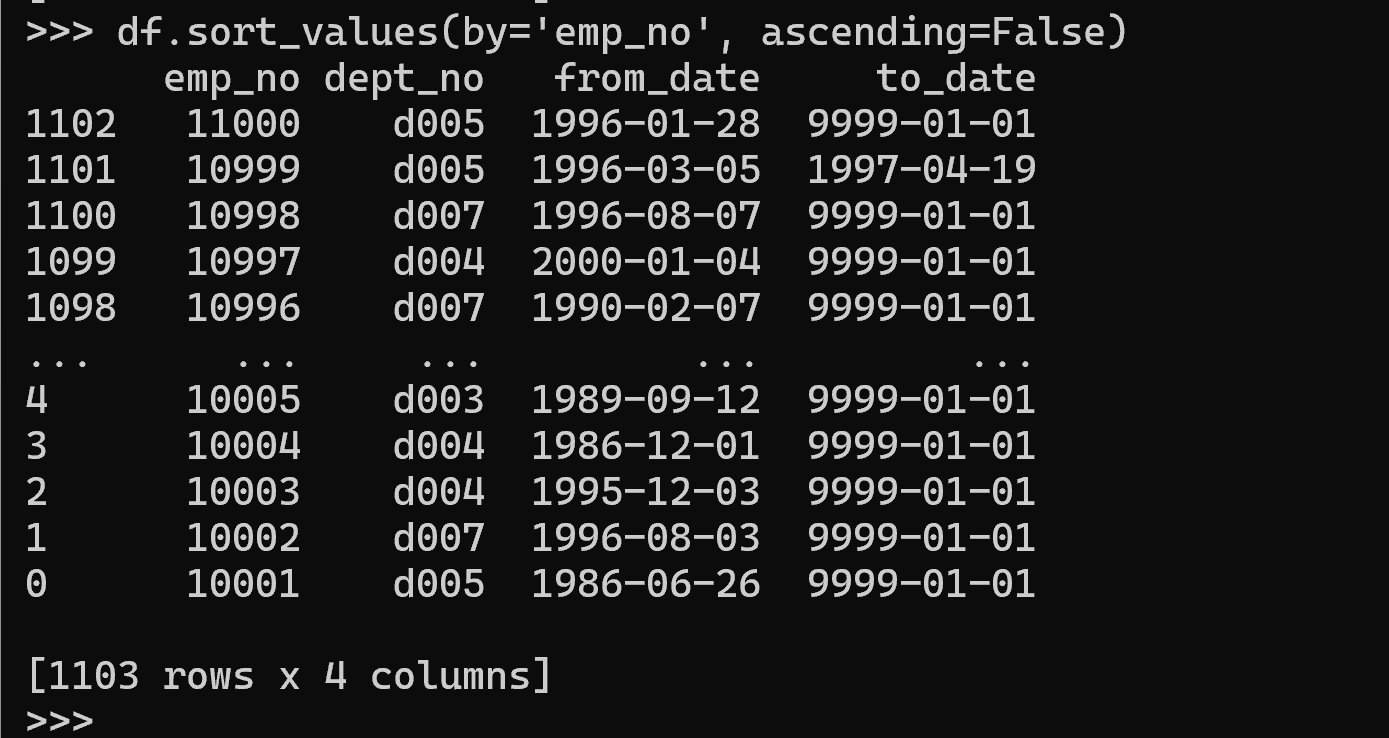
複数列によるソート:
df.sort_values(by=['dept_no', 'emp_no'], ascending=[True, True])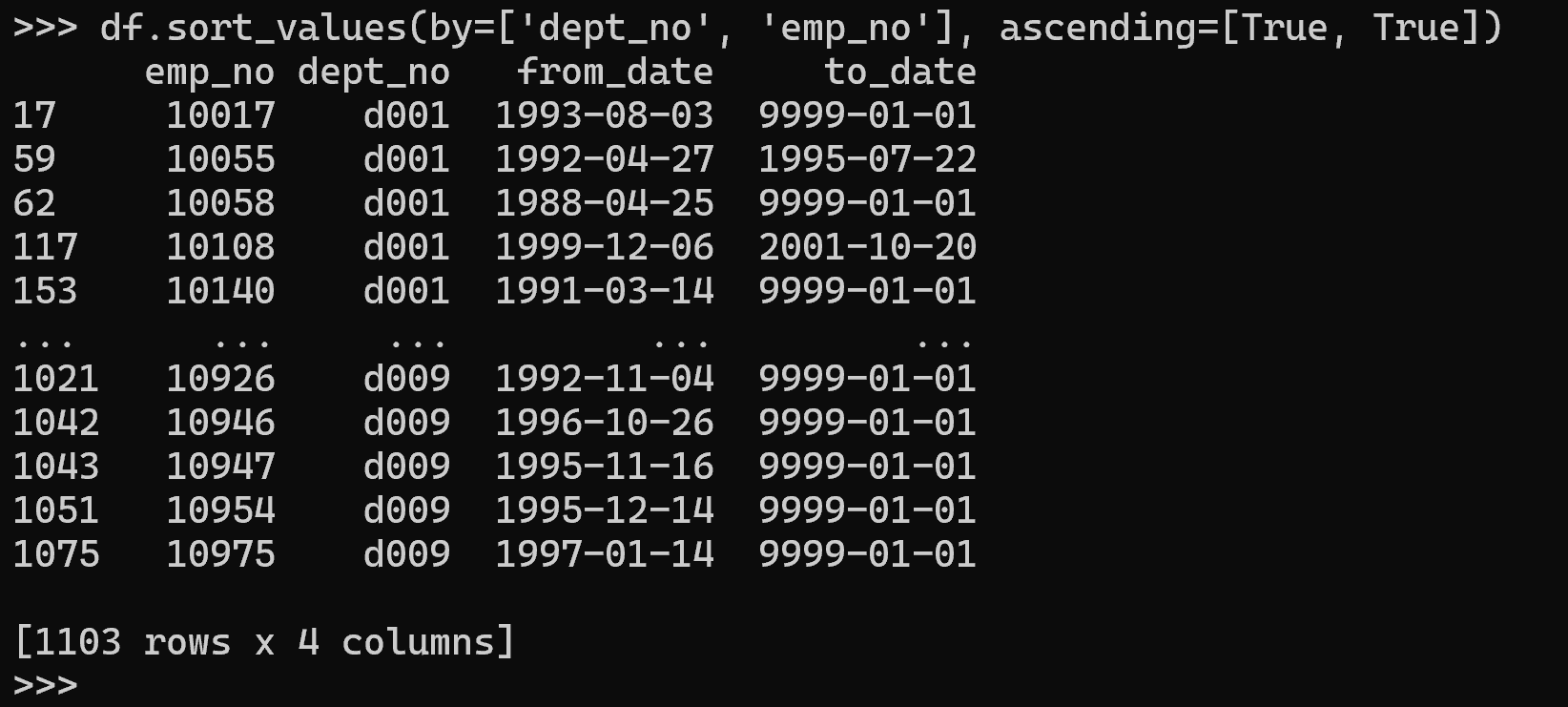
4-4. 頻度分布
データフレームの列の頻度分布を求める。
df['dept_no'].value_counts()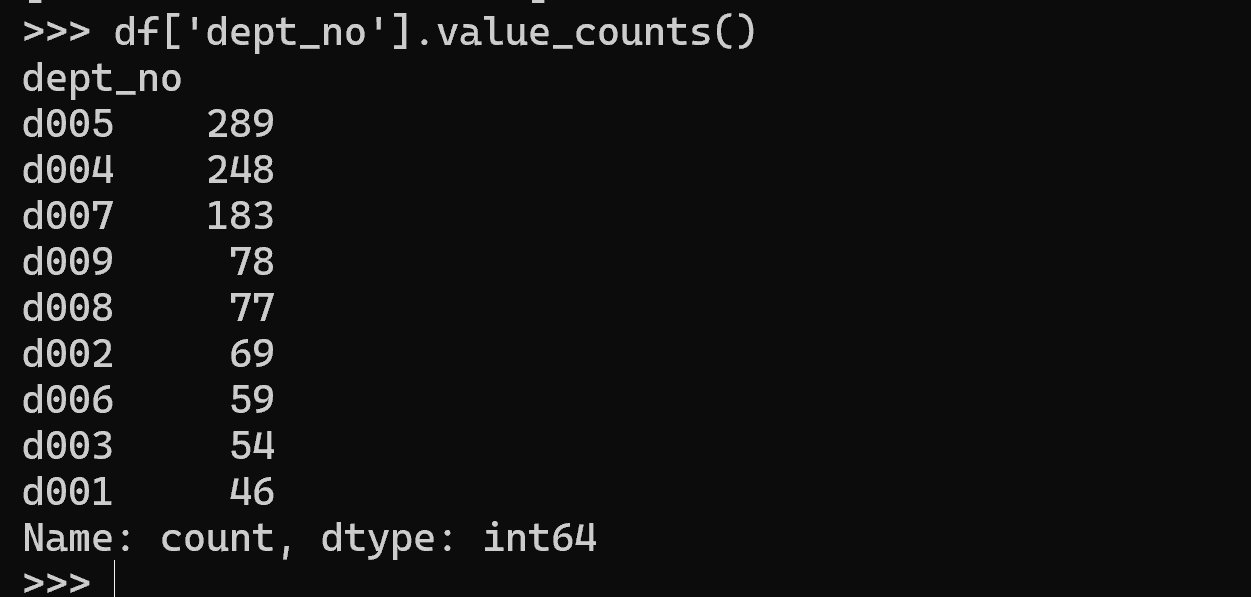
4-5. 集約
groupby() を使用して,特定の列でグループ化し,集約を行う。
df.groupby('dept_no').count()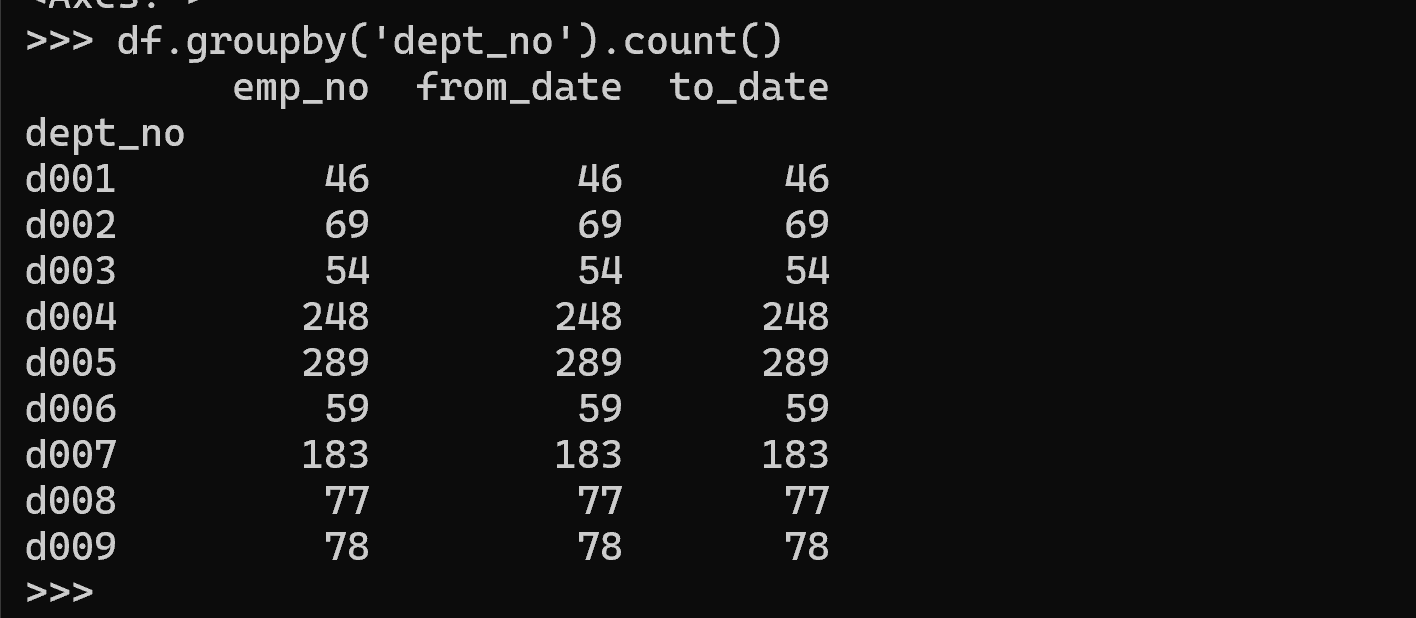
df.groupby('dept_no')['emp_no'].count()4-6. 接続を閉じる
c.close()