AIプログラミング実践ガイド:環境構築から探求へ
【概要】第1章では、Windows環境にPython、GPU計算基盤、AIエディタを導入し、開発環境を構築する。第2章では、構築した環境でAIプログラムを実行し、パラメータ変更による効果を観察する探求手法を学ぶ。たとえば学習率を0.1から0.01や0.5に変更し、損失の収束過程がどう変化するかをグラフで確認する。仮説を立て、プログラムを実行し、結果を観察するサイクルを通じて、AIの動作原理を体験的に理解する。第3章では、探求を研究に発展させる方法を扱う。探求対象の特定、仮説立案、結果観察、記録整理という4つのステップを学び、予想外の結果からも知見を得る柔軟な思考を身につける。さらに、再現性の確保や研究倫理の遵守といった、研究者としての基本も習得する。
概要プレゼン: パワーポイント

【目次】
本ガイドの読み方と前提
- 動作環境の前提:Windows 11 を前提とする。
- GPU の有無:本ガイドは NVIDIA GPU 搭載環境を前提とするが、GPU 非搭載環境でも第 2 章のサンプル(線形回帰)は CPU で実行できる。CPU のみで進める場合は、CUDA Toolkit のインストールを省略し、PyTorch を
--index-url https://download.pytorch.org/whl/cpuでインストールする。torch.cuda.is_available()の結果がFalse(GPU が利用できない状態を示す戻り値)でも、第 2 章のサンプルは動作する。 - 再現性の確保(実務上の最小事項):実験を再現可能にするため、乱数シード(疑似乱数の初期値)を固定する(例:
torch.manual_seed(0))。
重要概念
- winget (Windows Package Manager): Windowsの公式パッケージ管理ツール。管理者権限のコマンドプロンプトからコマンドを入力することで、Python、CUDA、VS Codeなどの環境構築に必要なソフトウェアを一括してシステムにインストールできる。
- AI駆動開発: AIがコード生成や修正を支援する開発手法。AI機能を統合した開発環境やVS Code拡張機能を活用し、コーディングと実験を行う。
- 勾配降下法: 機械学習において、損失関数(予測値と正解値の差を数値化する関数)の値を最小化するためにパラメータ(重みやバイアス)を逐次調整する最適化手法。本ガイドでは、学習率の変更がこの収束過程にどう影響するかを、Pythonプログラムを実行してグラフで確認する。
- 探求プロセス: 「探求対象の特定」「仮説の立案」「結果の観察」「記録と整理」の4ステップからなる学習プロセス。プログラムを動かすだけでなく、パラメータ変更による挙動の変化から動作原理を理解し、実験から得られた知見を研究へと発展させるための枠組み。
第1章 開発環境とビルドツールの準備
目標
本章の目標は、自身のパソコンでAIプログラミングの実行と実験が可能な環境を構築することである。本章を完了すると、AIプログラムを動作させ、ソースコードの確認や修正ができる環境が整う。
1.1 概要
Windows環境でAIプログラミングを始めるための開発環境を構築する。Python、GPU計算基盤、AIエディタを導入することで、機械学習モデルの実行や実験、AIによるコード生成支援を活用した開発が可能になる。各ソフトウェアはコマンドラインから一括でインストールでき、パスの設定も自動化される。
本ガイドでは以下のソフトウェアをインストールする。
開発環境とビルドツール
| ソフトウェア | 説明 | 用途 |
|---|---|---|
| Python 3.12 | 汎用プログラミング言語。3.12では型ヒント(変数や引数の型を明示する記法)の強化、インタープリタの最適化、サブインタープリタ(独立したPython実行環境)による並列処理の基盤を導入。 | AI開発、データ解析、Web開発 |
| Build Tools for Visual Studio 2026 | MSVC(Microsoft Visual C++コンパイラ)、リンカ、Windows SDKを含む。C/C++のビルドやPython拡張ライブラリのコンパイルに使用する。 | C/C++ビルド |
| Rust | システムプログラミング言語。所有権システム(メモリ管理機構)によりメモリ安全性をコンパイル時に保証する。Build Tools for Visual Studio が必要。 | システム開発、高速化 |
| Git | 分散型バージョン管理システム(ソースコードの変更履歴を管理するツール)。変更履歴をDAG(有向非巡回グラフ:履歴の分岐と統合を表現するデータ構造)として管理し、共同開発を支援する。 | ソースコード管理 |
| CMake | クロスプラットフォーム(複数のOSで動作する性質)のビルド自動化ツール。定義ファイルからOSやコンパイラに応じたビルド構成を生成する。 | ビルド構成の自動生成 |
| 7-Zip | 圧縮・解凍ツール。LZMA/LZMA2(高圧縮アルゴリズム)による.7z形式のほか、tar.gz等のUnix系形式にも対応する。 | ファイル圧縮・解凍 |
| CUDA | NVIDIA GPU用の並列計算基盤。GPUをGPGPU(汎用GPU計算:グラフィックス処理以外の計算にGPUを利用する技術)として活用し、行列演算などを高速に処理する。 | GPU並列計算 |
| PyTorch | pipでインストール。Metaが開発した機械学習フレームワーク。動的計算グラフ(実行時にグラフを構築する方式)による柔軟な記述ができる。 | 機械学習モデル開発 |
| Visual Studio Code | LSP(Language Server Protocol:エディタと言語解析機能を分離する規格)対応のコードエディタ。拡張機能により各種言語の開発環境として使用できる。 | コード編集 |
| Cline | VS Code拡張機能。AIによるファイル操作、ターミナル実行、複数ファイルの編集ができる。MCP(Model Context Protocol:AIと外部ツールの連携規格)に対応。 | AI駆動開発 |
| GitHub Copilot Free | AIによるコード補完ツール。既存のコードを基に、関数の実装や次の行を予測して提示する。 | コード補完 |
| JupyterLab | pipでインストール。対話的プログラミング環境。コードと実行結果を一つのノートブックに記録しながら分析できる。 | 対話的データ分析 |
1.2 実行前の確認事項
- ディスク空き容量が20GB以上あることを確認する
- すでにPythonがインストール済みの場合は、基本的にそのまま使用する
1.3 winget を用いたソフトウェアのインストール(Windows)
Windowsでは、winget(Windowsの公式パッケージ管理ツール)を用いて多くのソフトウェアをインストールできる。管理者権限で実行し、システム領域にインストールすることを推奨する。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Build Tools・CUDA Toolkit・PyTorch のインストール
本章では、C++ ビルドツール、NVIDIA CUDA Toolkit、PyTorch のインストールを行い、GPU を活用した機械学習プログラムを実行する環境を整える。扱う環境は、Windows 搭載パソコンである。
[Build Tools・CUDA Toolkit・PyTorch のインストール手順を見るには、ここをクリック]
Windows での Build Tools for Visual Studio 2026 のインストール
Build Tools for Visual Studio 2026 は、C++ ソースコードを Windows 用バイナリにコンパイルするための開発ツール群である。unsloth 等の一部 Python パッケージは、インストール時に C++ コードのビルドを必要とするため、これらのツールが必須となる。
以下のコマンドは、Build Tools が未インストールの場合は winget で新規インストールし、インストール済みの場合は setup.exe modify でコンポーネントを追加する(バージョンは変更しない)。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM ============================================================
REM Visual Studio Build Tools + Desktop development with C++
REM (VCTools、MSBuildTools、CMake連携、Clang、Windows 11 SDK)
REM ============================================================
REM 進行中のインストーラーを停止(ロック競合回避)
taskkill /F /IM vs_setup.exe /T >nul 2>&1
taskkill /F /IM vs_installer.exe /T >nul 2>&1
taskkill /F /IM vs_installerservice.exe /T >nul 2>&1
REM 未インストール時: winget で新規インストール
REM インストール済み時: setup.exe modify でコンポーネント追加(バージョンは変更しない)
winget list --id Microsoft.VisualStudio.BuildTools 2>nul | findstr /i "BuildTools" >nul 2>&1
if %ERRORLEVEL% EQU 0 (
for /f "usebackq delims=" %P in (`"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products Microsoft.VisualStudio.Product.BuildTools -property installationPath`) do start /wait "" "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" modify --installPath "%P" --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100 --includeRecommended --quiet --norestart --nocache
) else (
winget install --scope machine --id Microsoft.VisualStudio.BuildTools -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "--quiet --wait --norestart --nocache --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100"
)
REM 破損時の修復(任意、動作がおかしくなった場合)
REM "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" repair --installPath "C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools" --quiet --norestart
REM 導入確認(インストールパスが表示されれば正常)
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products * -requires Microsoft.VisualStudio.Workload.VCTools -property installationPath
上記のコマンドでは、Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし、続いて以下のコンポーネントを追加している。
- VCTools:C++ デスクトップ開発ワークロード(
--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる) - MSBuildTools:MSBuild によるビルドツールのワークロード
- VC.CMake.Project:Windows 向け C++ CMake ツール
- VC.Llvm.Clang:Windows 向け C++ Clang コンパイラ
- VC.Llvm.ClangToolset:MSBuild から Clang を使用するための clang-cl ツールセット
- Windows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
Windows での NVIDIA CUDA Toolkit のインストール
NVIDIA CUDA Toolkit は、NVIDIA GPU 上で計算を行うためのコンパイラ・ライブラリ群である。PyTorch や vLLM 等が GPU を利用するために必要となる。GPU を使用しない場合、この手順は不要である。
前提条件:NVIDIA GPU、NVIDIA ドライバ、Build Tools for Visual Studio もしくは Visual Studio が必要である。
インストール中の注意:他のウインドウは閉じておくこと。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール
winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n"
REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更)
mkdir C:\TEMP
setx TEMP "C:\TEMP" /M
setx TMP "C:\TEMP" /M
環境変数 TEMP および TMP を C:\TEMP に変更しているのは、後続のインストール処理で長いパス名や空白を含むパス名がエラーの原因となる場合があるためである。
Windows での PyTorch のインストール
https://pytorch.org のインストールガイドに従い、自環境の CUDA バージョンに対応したコマンドを取得して実行する。CUDA バージョンは以下で確認できる。
nvcc --versionPython 3.12、CUDA 12.6 以上の場合は、管理者権限でコマンドプロンプトを起動し、以下を実行する。cu128 は CUDA 12.8 用のタグである。CUDA バージョンが異なる場合は、上記公式サイトで該当するタグを確認し、URL 末尾の cu128 を置き換えること。
pip install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128以降の章では、必要に応じて題材に応じた必要なソフトウェアを追加する。
Rust のインストール(Windows 上)
管理者権限のコマンドプロンプトで以下を実行する。
REM Rust をシステム全体にインストール
curl -o rustup-init.exe https://static.rust-lang.org/rustup/dist/x86_64-pc-windows-msvc/rustup-init.exe
set "RUSTUP_HOME=C:\Rust\rustup"
set "CARGO_HOME=C:\Rust\cargo"
setx RUSTUP_HOME "%RUSTUP_HOME%" /M
setx CARGO_HOME "%CARGO_HOME%" /M
rustup-init.exe -y
powershell -NoProfile -Command "$p='C:\Rust\cargo\bin'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and $c -notlike \"*$p*\"){[Environment]::SetEnvironmentVariable('Path',\"$p;$c\",'Machine')}"
del rustup-init.exe
上記のコマンドでは、Rust のインストールに加えて、環境変数 RUSTUP_HOME と CARGO_HOME をシステム全体で共有するディレクトリ(C:\Rust 配下)に設定している。これにより、すべてのユーザが Rust ツールチェーン(Rust コンパイラとパッケージマネージャのセット)を利用できる。
Git のインストール(Windows 上)
管理者権限のコマンドプロンプトで以下を実行する。
REM Git をシステム領域にインストール
winget install --scope machine --id Git.Git -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/VERYSILENT /NORESTART /NOCANCEL /SP- /CLOSEAPPLICATIONS /RESTARTAPPLICATIONS /COMPONENTS=""icons,ext\reg\shellhere,assoc,assoc_sh"" /o:PathOption=Cmd /o:CRLFOption=CRLFCommitAsIs /o:BashTerminalOption=MinTTY /o:DefaultBranchOption=main /o:EditorOption=VIM /o:SSHOption=OpenSSH /o:UseCredentialManager=Enabled /o:PerformanceTweaksFSCache=Enabled /o:EnableSymlinks=Disabled /o:EnableFSMonitor=Disabled"
上記のコマンドでは、Git のインストールに加えて、システム環境変数 PATH に Git のコマンドパスを追加している。これにより、コマンドプロンプトから直接 git コマンドを実行できる。
CMake のインストール(Windows 上)
管理者権限のコマンドプロンプトで以下を実行する。
REM CMake をシステム領域にインストール
winget install --scope machine --id Kitware.CMake -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/qn /norestart ADD_CMAKE_TO_PATH=System"
上記のコマンドでは、CMake のインストールに加えて、システム環境変数 PATH に CMake のコマンドパスを追加している。CMake は、多くの C/C++ プロジェクトのビルドに使用されるビルドシステムジェネレータ(ビルド手順を自動生成するツール)である。
7-Zip のインストール(Windows 上)
管理者権限のコマンドプロンプトで以下を実行する。
REM 7-Zip をシステム領域にインストール
winget install --scope machine --id 7zip.7zip -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements
REM 7-Zip のパス設定
powershell -NoProfile -Command "$p='C:\Program Files\7-Zip'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and $c -notlike \"*$p*\"){[Environment]::SetEnvironmentVariable('Path',\"$p;$c\",'Machine')}"
上記のコマンドでは、7-Zip のインストールに加えて、システム環境変数 PATH に 7-Zip のコマンドパスを追加している。これにより、コマンドプロンプトから 7z コマンドで圧縮・展開操作を実行できる。
その他のソフトウェア
REM JupyterLab をインストール
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install -U jupyterlab
REM Microsoft VS Code をシステム領域にインストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM VS Code 拡張機能のインストール(Python環境、日本語化、Cline、GitHub Copilot)
if exist "C:\Program Files\Microsoft VS Code\bin" cd "C:\Program Files\Microsoft VS Code\bin"
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension ms-python.python
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension ms-python.vscode-pylance
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension MS-CEINTL.vscode-language-pack-ja
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension dongli.python-preview
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension saoudrizwan.claude-dev
if exist "C:\Program Files\Microsoft VS Code\bin" code --install-extension GitHub.copilot
echo セットアップ完了
実行時のヒント
- コマンドの途中で止まった場合は、まず Enter キーを 1 回押す。それでも進まない場合は、エラー内容を確認する
- Python のインストール時に「Modify Repair Uninstall」画面が出た場合は、Python がインストール済みであるため「Cancel」をクリックする
1.4 確認
次のプログラムを実行し、Python のバージョン、Git のバージョン、PyTorch のバージョン、GPU の動作を確認する。
import sys
import subprocess
import torch
print(sys.version)
print(subprocess.check_output(['git', '--version'], text=True).strip())
print(torch.__version__)
print(torch.cuda.is_available())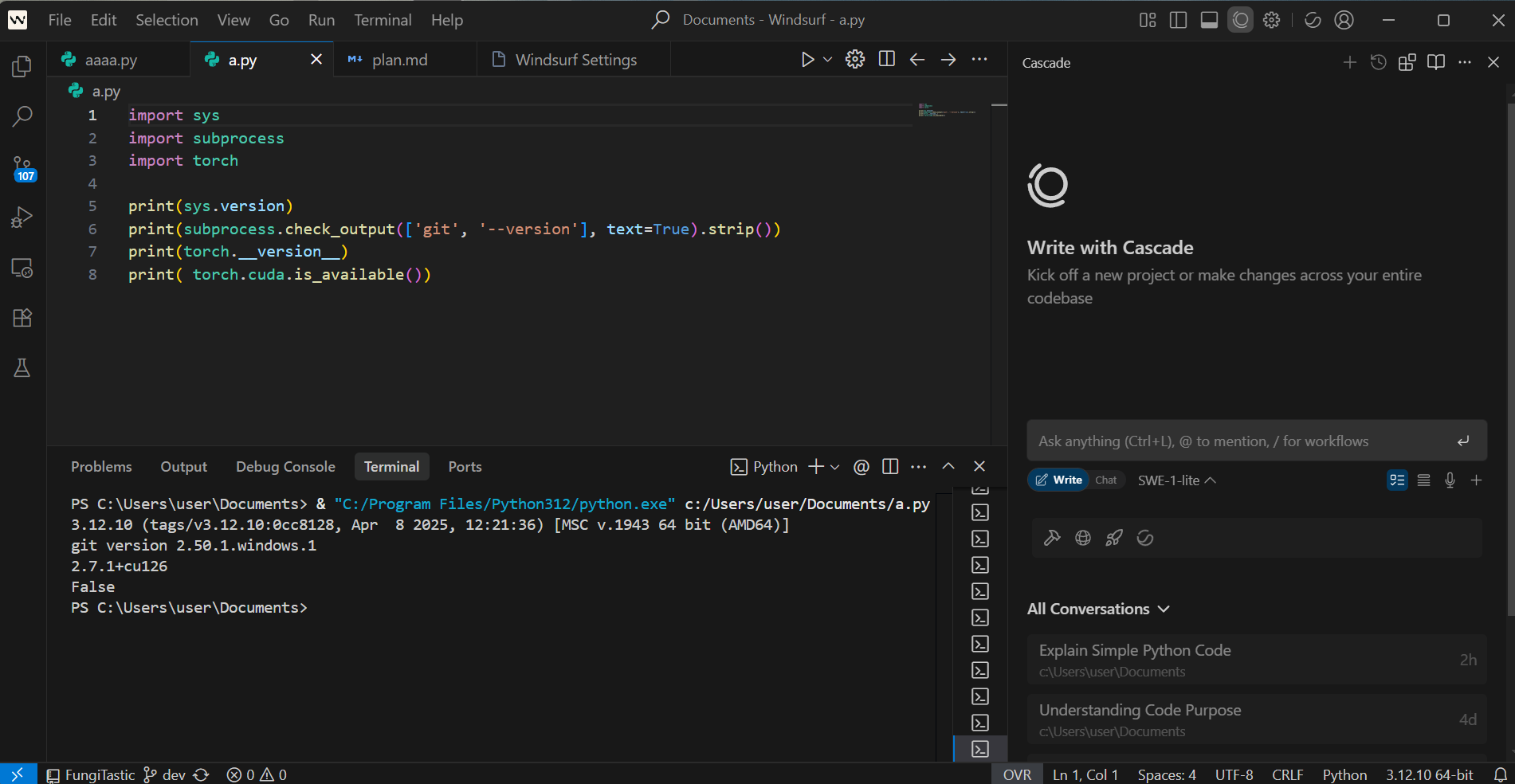
第2章 Pythonプログラム実行による探求
目標
第 1 章で構築した環境を使用して、AI プログラムを実行し、パラメータ変更による効果を観察する。本章では、pip を用いた Python ライブラリのインストール方法と、プログラム実行による探求手法を習得する。本章における「探求」とは、プログラムのパラメータを変更し、その結果を観察・考察するサイクルを指す。
2.1 VS Code でのプログラム実行手順
新規 Python ファイルの作成
- メニューから File → New File を選択する
- ファイル名を入力する(例:a.py)
- 保存先のフォルダ(ディレクトリ)を選び、保存する
左側のエクスプローラー(ファイル一覧を表示する領域)から既存のファイルを開くこともできる。
コードの入力と実行
- 作成したファイルの画面で、コードを入力および編集する
- 画面右上の実行ボタン(再生マークのアイコン)をクリックしてプログラムを実行する
- 実行結果は画面下部のターミナルに表示される
Python 実行環境(インタープリター)の設定確認
プログラムが正常に動作しない場合は、以下の手順で設定を確認する。
- Ctrl+Shift+P を押し、コマンドパレット(コマンド検索・実行用の入力欄)を開く
- 「Python: Select Interpreter」と入力し、表示される候補から選択する
- システムにインストールされた Python 3.12 が選択されていることを確認する(選択されていなければ変更する)
2.2 必要なライブラリのインストール
Python プログラムは、それぞれ異なるライブラリを必要とする場合がある(例:後述のプログラムは matplotlib ライブラリを必要とする)。必要なライブラリがインストールされていない場合は、以下の手順でインストールする。
手順
- 管理者権限でコマンドプロンプトを起動する
- Windows キーを押して
cmdと入力し、右クリックして「管理者として実行」を選択する
- Windows キーを押して
- pip コマンドでライブラリをインストールする
本ガイドではシステム領域にインストールした Python を使用するため、pip install も管理者権限のコマンドプロンプトから実行する。pip コマンドが見つからない場合は、"C:\Program Files\Python312\Scripts\pip" のようにフルパスで指定する。以下は代表的な例である。
pip install numpy pandas matplotlib pillow requestsインストール完了後、正常に終了したことを確認する。
主要な Python ライブラリ
Python には、さまざまな分野で利用できるライブラリがある。機械学習やデータサイエンス分野では、以下のライブラリが使用される。
- PyTorch:オープンソースの機械学習ライブラリ。Meta により開発が開始され、現在は Linux Foundation 傘下の PyTorch Foundation により運営されている。深層学習モデルの構築と訓練に使用され、自動微分(勾配を自動計算する仕組み)と GPU 計算をサポートする。後述のプログラムでも使用する
- timm:PyTorch 上で動作する画像モデルのライブラリ。多数の最先端(SOTA:State-of-the-Art)モデルが実装されており、転移学習(学習済みモデルを別のタスクに応用する手法)などに利用される
- NumPy:数値計算を行うためのライブラリ。多次元配列の操作が可能であり、科学計算の基盤として用いられる
- Pandas:データ分析を行うためのライブラリ。表形式データの操作や加工に用いられ、データの前処理に使用される
- Matplotlib:グラフ描画ライブラリ。データの可視化に利用され、後述のプログラムでも損失の推移をグラフで表示するために使用する
2.3 プログラム実行による探求の基本手順
プログラム実行による探求は、以下のサイクルで行う。
- 仮説の立案:プログラムの動作について予想を立てる
- コード変更:パラメータや値を変更する
- 実行:プログラムを実行して結果を得る
- 結果の観察:出力やグラフを観察する
- 考察:結果から何が分かったかを整理し、次の仮説を立てる
このサイクルを繰り返すことで、プログラムの動作原理を理解する。次節で扱う学習率の変更は探求の一例であり、さまざまなパラメータや設定を対象とした探求が可能である。
2.4 学習率の変更と効果
本節では、学習率がモデルの学習速度に与える影響を観察する。
用語説明
- 損失関数:予測値と正解値の差を数値化する関数。この値が小さいほど予測精度が高い
- 勾配降下法:損失を最小化するために、損失の傾き(勾配)を利用してパラメータを調整する最適化手法
- 学習率:勾配降下法において、各更新でパラメータを動かす量の大きさを決める係数
サンプルプログラム
import torch
import matplotlib.pyplot as plt
# 入力データと目標値を定義
x = torch.tensor([1., 2., 3., 4.])
y = torch.tensor([3., 5., 7., 9.])
# 学習する重み 'a' とバイアス 'b' を初期化。requires_grad=True により勾配計算を有効にする
a = torch.tensor(0.5, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
# 各反復での損失を記録するためのリスト
losses = []
# 勾配降下法による学習ループ
for _ in range(10):
# 予測値と目標値の差の二乗平均を損失として計算
loss = ((a * x + b - y) ** 2).mean()
# 損失値をリストに追加(.item() でテンソルからPythonの数値に変換)
losses.append(loss.item())
# 損失の勾配を計算
loss.backward()
# 勾配降下法による重み 'a' とバイアス 'b' の更新
# .data を直接変更することで、この操作が勾配計算に影響しないようにする
a.data -= 0.1 * a.grad
b.data -= 0.1 * b.grad
# 勾配をゼロにリセット(次の反復のために必要)
a.grad.zero_()
b.grad.zero_()
# 学習後の重み 'a'、バイアス 'b' と最終的な損失値を出力
print(f"a={a:.2f}, b={b:.2f}, loss={loss:.3f}")
# 損失の推移をグラフで表示
plt.plot(losses)
plt.xlabel('Iteration')
plt.ylabel('Loss')
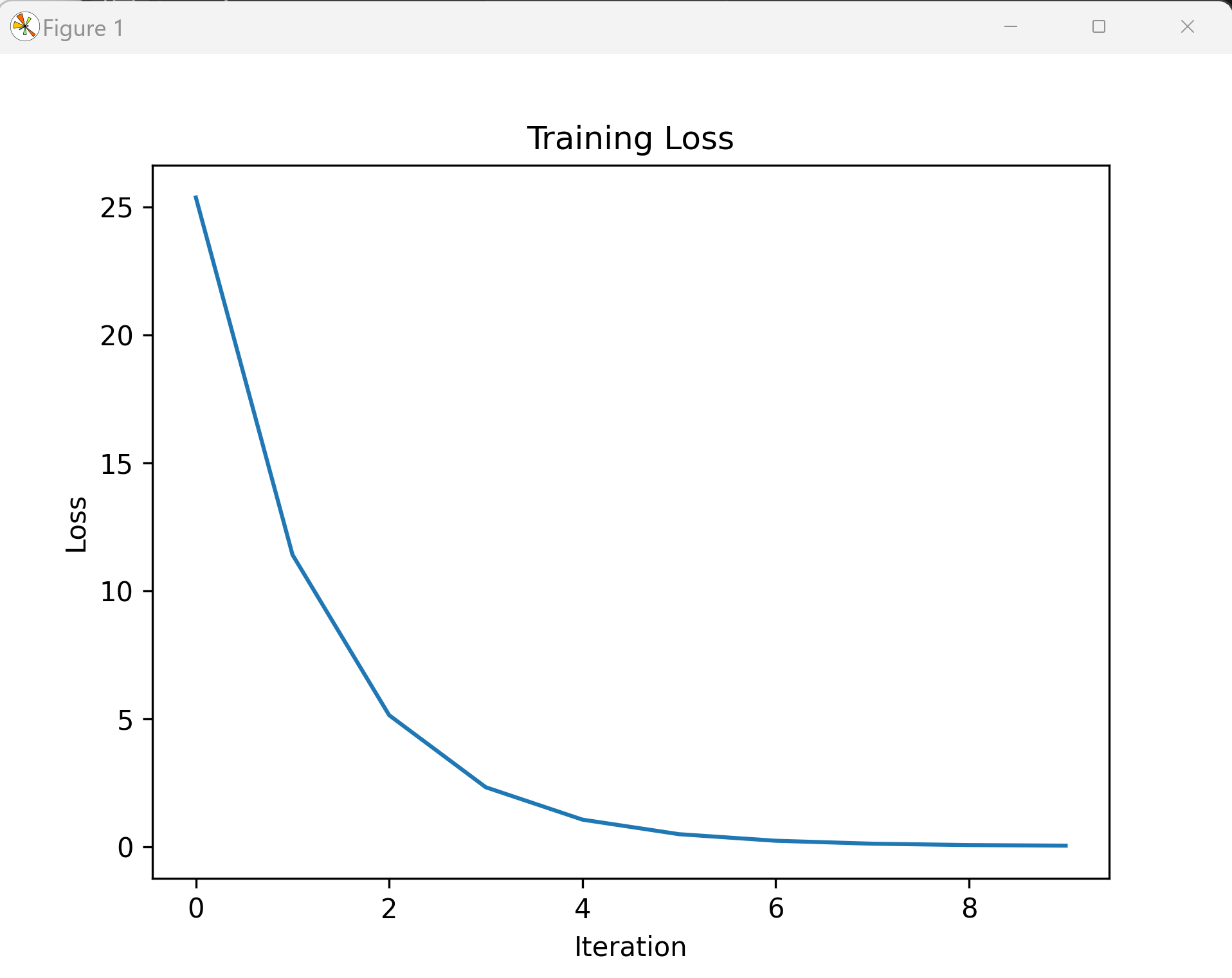
plt.title('Training Loss')
plt.show()このプログラムは、線形関数 y=ax+b(一次関数)の重み a とバイアス b を勾配降下法で学習する PyTorch の実装である。入力データ [1, 2, 3, 4] と目標値 [3, 5, 7, 9] から、初期値 a=0.5、b=0.0 を 10 回の反復で更新し、各反復の損失値をリストに記録してグラフ表示する。重み a やバイアス b の初期値、または学習率 0.1 を変更することで、収束過程の違いを観察できる。
入力データと目標値は y = 2x + 1 の関係を満たすため、十分な反復で a は 2 に、b は 1 に収束する。requires_grad=True は a・b を勾配計算の対象として登録する指定であり、loss.backward() によって勾配が計算される。.data への直接代入は、パラメータ更新自体を計算グラフに含めないための慣用手法である(with torch.no_grad(): ブロック内での更新と等価)。a.grad.zero_() は、PyTorch が勾配を加算する仕様であるため、次の反復のために 0 にリセットしている。
変更手順
- a.py ファイルを開き、コードを表示する
- 以下の行を探す
a.data -= 0.1 * a.grad b.data -= 0.1 * b.grad - この行の 0.1 を別の数値に書き換える
- 例:0.01(学習率を小さくする)
- 例:0.5(学習率を大きくする)
- 変更後、ファイルを保存する(Ctrl+S またはメニューの File → Save)
- 画面右上の実行ボタンをクリックしてプログラムを再実行する
なお、plt.show() はグラフウィンドウを閉じるまで処理が停止する。必要に応じて plt.savefig('loss.png') でファイルに保存することもできる。
期待される効果
学習率を変更すると、表示される損失のグラフに以下の違いが見られる。
- 学習率を小さくした場合(例:0.01):損失は緩やかに減少する。重み
aとバイアスbの更新量が小さいため、10 回の反復では損失が十分に下がらない場合がある - 学習率を大きくした場合(例:0.5):損失は急激に変化する。適切な範囲内であれば速やかに収束するが、学習率が大きすぎると更新量が過大となり、損失が振動または発散することがある
実行結果の確認方法
プログラムが正常に実行されると、以下の結果が得られる。
- コンソールに
a=..., b=..., loss=...の形式で、最終的な重み・バイアス・損失が表示される(学習率 0.1・10 反復では損失は小さくなるが 0 にはならず、aは 2 に、bは 1 に近づく途中の値となる) - 反復回数を増やす(例:
range(10)をrange(200)に変更する)と、a≈2.00、b≈1.00、loss≈0に近づく様子を観察できる - 損失のグラフが表示され、損失値が反復回数とともに減少する曲線が描かれる
グラフの横軸は反復回数(0 から 9 まで)、縦軸は損失値を表す。学習率が適切な場合、減少曲線を描き、反復回数を十分にとれば損失は 0 に近づく。学習率が大きすぎると振動や発散を示し、小さすぎると変化が緩慢になる。
演習
- 上記のプログラムを実行し、損失のグラフを確認する
- 学習率を 0.01 に変更して実行し、グラフの変化を観察する
- 学習率を 0.5 に変更して実行し、グラフの変化を観察する
- 各実行結果を比較し、学習率が収束過程に与える影響を考察する
この演習は一例である。内容に応じた考察、結果の記録、次の仮説の立案を行う。
別ページに多数の AI プログラムと説明を記載している。多数の AI プログラムの実行や探求が可能であり、本章の内容が参考となる。人工知能のプログラム実行体験と探求(Windows 上)のページを参照されたい。 https://www.kkaneko.jp/ai/labo/index.html
第3章 探求プロセス
3.1 学習目標
本章では、第 2 章で習得したプログラム実行による探求の手法を発展させ、研究計画の立案に応用できる汎用的なスキルを習得する。第 2 章の「探求」がパラメータ変更と結果観察のサイクルを指すのに対し、本章ではそれを基盤として、仮説の立案から研究成果の発表までを含む探求プロセスを扱う。
具体的な到達目標は以下のとおりである。
- 探求プロセスの全体像を理解する
- 具体的な探求手順を実践できる
- 研究計画の立案から実践までの一連のプロセスを理解する
- 失敗や予想外の結果を学習機会として活用できる柔軟な思考を身につける
3.2 探求プロセスの実践手法
第 2 章で示した「仮説の立案 → コード変更 → 実行 → 結果の観察 → 考察」のサイクルは、本章の 4 ステップのうち「仮説の立案」「結果の観察」「記録と整理」を 1 反復に圧縮したものに相当する。本章では、これを複数反復にわたって設計・記録するための枠組みとして 4 ステップを用いる。
探求プロセスの概要
探求は以下の 4 つのステップで構成される。
- 探求対象の特定:実装された Python プログラムの確認などを通して、調整や変更が可能な部分を特定する
- 仮説の立案:変更による影響を予測する
- 結果の観察:仮説検証に適した方法で結果を確認する
- 記録と整理:探求結果を整理し、次の探求に活用する
具体例:オープンボキャブラリ型物体検出を用いた探求
ここで取り上げるオープンボキャブラリ型物体検出(Open-Vocabulary Object Detection, OVD)は、4 ステップを具体的にイメージするための題材であり、本ガイドの範囲では実装までは行わない(実装には別途、専用モデルとデータセットの準備が必要となる)。読者は、第 2 章で扱った線形回帰の探求と同じ枠組みが、より大規模な研究テーマにも適用できることを確認する目的で読み進める。なお、文中の AP(Average Precision、平均適合率)は物体検出の評価指標であり、検出スコアの閾値を変えながら適合率(検出結果のうち正解の割合)と再現率(正解のうち検出できた割合)の関係をとり、その曲線下面積に基づいて算出される。COCO・LVIS は物体検出で広く用いられるベンチマークデータセット(評価用の標準データセット)、CLIP は画像とテキストを同じ埋め込み空間(数値ベクトル空間)で扱う視覚言語モデルである。
OVD は、事前に定義されたカテゴリを超えて、任意のテキスト入力で記述された物体を検出する技術である。従来手法では訓練時に使用した限定的なカテゴリ(例:COCO データセットの 80 クラス)のみを検出できたが、OVD では訓練時に使用したクラス(ベースクラス)に加え、訓練時に出現しないクラス(ノベルクラス)に対してもゼロショット検出(再学習なしでの検出)が可能である。この技術は、事前学習済みの視覚言語モデル(例:CLIP)を活用することで、視覚情報とテキスト記述を統合した物体検出を実現する。新しい物体カテゴリに対してモデルの再学習を必要とせず、テキストプロンプトによる柔軟な検索条件指定が可能である。
この技術を題材として、探求プロセスの各ステップを以下に示す。なお、プログラム中ではテキストプロンプトは英語の単語または文で指定する。
1. 探求対象の特定
調整や変更が可能な部分を特定する。
- テキストプロンプト(物体の名称、属性記述)(例:
car、red backpack、person wearing hat) - 信頼度閾値の設定(検出結果として採用するスコアの下限値。例:0.1、0.3、0.5、0.7)
2. 仮説の立案
変更による影響を予測し、検証可能な仮説を設定する。
- ベースクラスとノベルクラスの検出性能比較:「ベースクラスの方がノベルクラスより高い AP を示す」
- テキスト記述の抽象度による影響:「具体的記述(
bicycle)の方が抽象的記述(two-wheeled vehicle)より高い検出精度を示す」 - 信頼度閾値の最適化:「ベースクラスとノベルクラスでは最適な信頼度閾値が異なる」
3. 結果の観察
仮説検証に適した方法で結果を確認する。
- ベースクラスとノベルクラスの性能差:LVIS 等のベンチマークでベースクラス、ノベルクラス、全体の AP を比較する
- テキスト記述による検出精度変化:同一物体に対する異なる記述方法(
carとred sports car)での AP 比較を行う - 閾値変化による適合率-再現率トレードオフ:信頼度閾値を 0.1 から 0.9 まで変化させた際の Precision-Recall カーブ(適合率と再現率の関係を表す曲線)の変化を観察する
4. 記録と整理
探求結果を整理し、次の探求に活用する。
- テキストプロンプトと AP 値の対応記録(例:
bicycle→ AP 0.45、mountain bike→ AP 0.38) - ベースクラスとノベルクラス間の AP の差の定量化
- テキストプロンプトの記述方法がゼロショット検出性能に与える影響の分析
- 視覚言語モデルの特性や限界に関する知見の蓄積
探求から研究への発展
探求プロセスの発展段階として、プログラム実験を学術的研究に展開することができる。発展の段階は以下のとおりである。
- プログラム実験段階:個別のプログラムパラメータを変更し、結果を観察する
- パターン発見段階:複数の実験結果から規則性や傾向を特定する
- 仮説形成段階:観察されたパターンの背景にある原理を推測する
- 体系的検証段階:仮説を検証するための計画的な実験を設計する
- 学術的位置づけ段階:既存の学術研究との関連性を明確化する
探求成果を研究として位置づける際の指針は以下のとおりである。
- 単発の実験結果ではなく、複数の実験から導かれた知見であること
- 他の研究者が同じ条件で実験を行えば同じ結果が得られる再現性があること
- 技術分野や社会に対する貢献の可能性が説明できること
3.3 探求における柔軟な思考
探求プロセスでは、ある方法でうまくいかなかった場合に、別の方法で目的達成を試みる。ある方法の精度が低い場合でも、それは失敗ではなく、モデルの特性や限界を理解するための発見となりうる。
たとえば、OVD の探求において「抽象的記述の方が具体的記述より検出精度が高い」という予想に反する結果が得られたとする。この結果は、視覚言語モデルが視覚特徴と言語表現をどのように関連付けているかについての知見を与える。期待どおりでない結果からも、技術の限界、適用条件、改善の方向性などの知見を得ることができる。
3.4 研究計画の立案
研究計画の立案は、探求を進めるための準備段階である。自分の技術レベルや利用可能なリソースで解決可能な課題を設定し、現実的な目標設定を行う。
研究テーマの選定
- 興味と関心:自分が知りたいと思う問題を選ぶことが、継続的な取り組みの基盤となる
- 技術的実現可能性:現在の知識とスキルで取り組める範囲内の問題を設定する
研究目標の設定
目標設定においては、以下の点を確認する。
- 具体的:何を明らかにするかを明確に記述する
- 測定可能:達成度を客観的に評価できる指標を設定する
- 達成可能:現実的に実現可能な目標とする
目標の階層化として、最終目標までを段階的に達成できる中間目標を設定する。これにより、進捗を確認しながら進めることができる。
研究手法の選択
研究目標に適した手法を選択し、その手法を習得するための学習計画も含める。具体的な取り組み内容は以下のとおりである。
- 研究手法の調査:研究目標を達成するための技術や関連する先行事例を調査し、自分の研究に適用可能な手法を特定する
- 手法の選定:新しい手法の開発は慎重に検討し、まず既存手法の組み合わせや改良で目標達成が可能かを検討する
- 開発環境の構築:必要なソフトウェアやハードウェアを準備する
- 実験データの準備:プロトタイプ(試作実装)やサンプル実装を通じて、技術的な障壁を早期に発見する
- 実験の実施と記録:小さな発見でも探求成果となりうるため、実験過程を詳細に記録する
- 結果の分析と考察:実験結果を分析し、仮説との整合性を検討する
- 文書化:実験データ、実験手順説明、考察、参考文献リストを含む文書として整理する
研究計画の作成と共有
研究計画を文書化することで、研究の方向性を明確にし、指導教員や同僚との議論に役立てることができる。学期の中盤など適切な時期に仲間や教員と共有し、意見を求める。文書には以下の構成を含める。
- 背景
- 研究目標
- 取り組み
- 将来計画
- 参考文献
再現性の確保
研究の信頼性を担保するために、再現性の確保が必要である。実験環境(ソフトウェアのバージョン、ハードウェア仕様)を詳細に記録し、他の研究者が同じ条件で実験を再現できるようにする。また、関連する学術論文を調査して内容を整理し、自分の手法と既存手法の違いを説明できるようにしておく。
研究倫理の遵守
他者の研究成果を適切に引用し、実験データの捏造や改ざんを行わないことは、研究者としての基本的な責務である。
成果発表の計画
研究成果の発表形式には、ゼミ発表、卒業研究発表、学会発表(オプション)等がある。発表内容は、背景と目的、手法、結果、考察、結論の流れで構成する。
スケジュール管理とリスク対策
研究期間を複数の段階に分割し、スケジュールには余裕を持たせる。使用する技術やツールが期待どおりに動作しない可能性を考慮し、代替手法を想定しておく。
研究計画は固定的なものではなく、研究の進行とともに修正していく。
次のステップへ
統合開発環境と AI の支援により、プログラムの作成、バグの解決、機能変更などを効率的に行う。
【サイト内の関連ページ】
- Windows Python 開発環境とビルドツール構築ガイド

【概要】本ガイドでは、Windows 環境で AI プログラミングを始めるための開発環境を構築する。Python、GPU 計算基盤、ビルドツール、AI エディタを導入することで、機械学習モデルの実行や実験、AI によるコード生成支援を活用した開発が可能になる。各ソフトウェアのインストールとパスの設定は、コマンドラインから一括で行える。