CPUでもGPUでも動かせるローカルLLM ーWindowsでの学習・推論ツール導入
Windows環境で大規模言語モデル(LLM)を扱うための主要な7つのツール(transformers、unsloth、llama.cpp、Ollama、LM Studio、vLLM、LLaMA Factory)について、その役割と関係を整理し、概要・用途・セットアップ手順を示す。これらのツールはLLMの学習と推論の2つの段階で用いられ、それぞれ異なる役割を持つ。学習はtransformers、unsloth、LLaMA Factoryが担い、推論はllama.cpp系(GGUF形式・CPU可)とvLLM(HF形式・GPU必須)が担う(transformersは推論にも利用できる)。用途別の選び方としては、手軽に試すならLM Studio、APIサーバとしての軽量な運用ならOllama、高負荷な推論や複数同時リクエストにはvLLM、学習の入門にはunslothのColabノートブックが適する。本記事では軽量モデルLFM2.5-1.2Bを用い、各ツールの導入と動作確認の手順を具体的に示す。セットアップと動作確認はWindows 11上での実行を前提とし、GPUを搭載した機種でもCPUのみの機種でも動作するが、unslothとvLLMはGPU(CUDA)が必須である。
【目次】
前提知識:基礎用語と動作確認用モデル
本記事を読み進める上で前提となる用語を整理する。各ツールの説明と手順では、以下の用語を断りなく用いる。
- LLM(大規模言語モデル):大量のテキストで事前学習された、文章生成・対話・要約などを行うニューラルネットワーク。入力テキストをトークン(文字や単語の断片に相当する単位)に分割し、次に来るトークンを確率的に予測することで応答を生成する。モデルの規模はパラメータ数(例:1.2B=12億)で表される。
- 学習と推論:学習はモデルのパラメータを更新する工程、推論は学習済みモデルに入力を与えて出力(応答)を得る工程である。学習はさらに、ゼロから大規模データで行う事前学習と、既存モデルを追加データで微調整するファインチューニング(FT)に分かれる。LoRA(Low-Rank Adaptation)はFTの代表的な手法で、元モデルの重みを凍結し、少量の追加パラメータのみを学習することでメモリと時間を削減する。
- 量子化とGGUF:量子化はモデルの重みを低ビット(例:16bitから4bit)に圧縮し、ファイルサイズと必要メモリを削減する技術である。精度はある程度低下するが、CPUや少VRAMのGPUでも実行可能になる。GGUF(GGML Universal File)はllama.cpp系ツールで用いる量子化済みモデルの標準ファイル形式である。Q4_K_Mは4bit量子化の代表的な品質設定で、サイズと精度のバランスが取れている。
- Hugging Face (HF) Hub:モデルとデータセットの共有プラットフォーム。モデルは「組織名/モデル名」の形式(例:
LiquidAI/LFM2.5-1.2B-Instruct)で識別される。本記事のコマンドおよびコード中に登場するモデルIDはすべてHF Hub上のものである。 - PyTorch / CUDA:PyTorchはLLMの学習・推論に広く用いられる機械学習フレームワークである。CUDAはNVIDIA GPU上で計算を行うための実行環境であり、PyTorchはCUDA経由でGPUを利用する。
- WSL(Windows Subsystem for Linux):Windows上でLinux環境を動作させるWindows公式機能。Linux前提のツール(vLLM、LLaMA Factory等)はWSL上で実行する。WSL2はNVIDIA GPUにも対応する。
- APIサーバ / OpenAI互換API:HTTP経由でモデルに問い合わせる仕組みを提供するサーバをAPIサーバと呼ぶ。OpenAI互換APIはOpenAI社のAPI仕様に揃えたインターフェースであり、これを採用するサーバには既存のOpenAIクライアント(Pythonの
openaiライブラリ等)をそのまま利用できる。
ハードウェア要件の目安:本記事で動作確認に用いるLFM2.5-1.2Bはパラメータ数約1.2Bの軽量モデルで、Q4_K_M量子化(約731MB)では約1〜2GBのVRAMで動作する。GPUを持たないPCでも、llama.cpp、Ollama、LM StudioによるCPU推論は可能である。一方、unslothとvLLMはGPU(CUDA)が必須である。
動作確認用モデル:LFM2.5-1.2B
本記事では、ツールの動作確認にLiquid AI社のLFM2.5-1.2Bを使用する。パラメータ数約1.2Bと軽量で動作が速く、日本語を含む多言語(英語、アラビア語、中国語、フランス語、ドイツ語、日本語、韓国語、スペイン語)に対応する。本記事では、対話用に調整されたLFM2.5-1.2B-Instructを基本に用いる。
用途は会話・要約・翻訳などの軽量な多言語タスク全般である。少VRAMのGPUやCPUのみのPCでも動作する点が、本記事の動作確認用モデルとして適している。
公式情報: https://www.liquid.ai/blog/introducing-lfm2-5-the-next-generation-of-on-device-ai
各ツールの概要と関係
学習ツール
transformers:機械学習ライブラリ。事前学習済みモデルの読み込み、推論、ファインチューニングを実行する。他のツールの基盤となる。本記事ではv5系を用いる。
unsloth:transformersをベースとするファインチューニング高速化ライブラリ。少ないメモリで高速にモデルを学習できる。すぐに試せるColab(Googleが提供するブラウザ上のPython実行環境)向けノートブックが提供されている。Windows環境でも動作する。
LLaMA Factory:Web UIとCLIを提供するファインチューニングプラットフォーム。コードを書かずにモデルを学習でき、内部でtransformersやunsloth等を利用する。Windows環境ではWSLまたはDockerが必要である。
推論ツール
llama.cpp:C++実装の推論エンジン。量子化(GGUF形式)によりモデルサイズを削減し、CPUでも実行できる。後述のOllamaとLM Studioの基盤となる。
Ollama:llama.cppを基盤とする推論プラットフォーム。モデルの自動ダウンロードと管理、ローカルAPIサーバ機能を持ち、Pythonからも数行で利用できる。APIサーバは既定でポート11434で待ち受ける。軽量な単一モデル運用に向く。複数同時リクエストや高スループット(単位時間あたりの処理量)が必要な場合はvLLMを選ぶ。
LM Studio:llama.cppを基盤とするGUIツール。コマンドライン操作が不要で、マウス操作でモデルを選択・実行できる。
vLLM:PyTorch/CUDA上で動作する高スループット推論エンジン。ローカルGPU上でLLMをAPIサーバとして起動し、OpenAI互換のインターフェースを提供する。llama.cpp系とは別系統で、HF形式(safetensors:モデルの重みを安全かつ高速に読み書きするためのファイル形式)のモデルを直接読み込む。Windows環境ではWSLで使用する。GPU(CUDA)が必須である。
ツール間の関係
【基盤】PyTorch + transformers
【学習フェーズ】
transformers → 学習・推論の基本機能を提供
unsloth → transformersをラップしFTを高速化・省メモリ化
LLaMA Factory → Web UI/CLIによる統合FTプラットフォーム
(内部でtransformers/unsloth等を利用)
【推論フェーズ】
◆ llama.cpp系(GGUF形式・CPU/GPU対応)
llama.cpp → 推論エンジン本体
Ollama → llama.cpp系。ローカルAPIサーバ+モデル管理
LM Studio → llama.cpp系。GUIアプリ
◆ PyTorch系(HF形式・GPU必須)
vLLM → 高スループット推論サーバ。OpenAI互換API代表的なワークフロー
学習:transformers / unsloth / LLaMA Factory
│
├─(GGUF変換)→ llama.cpp / Ollama / LM Studio で推論
└─(HF形式のまま)→ vLLM / transformers で推論状況別のツール選択
モデルを学習したい場合
初めてモデルを学習する
unslothのColabノートブックを使う。Googleアカウントがあればブラウザだけで学習を開始でき、環境構築が不要である。
コードを書かずに学習したい
LLaMA Factoryを使う。Web UIでモデルとデータセットを選択し、ボタンをクリックして学習する。Windows環境ではWSLまたはDockerのセットアップが必要である。
自分のWindows PCで学習したい
unslothを使う。Windows環境でネイティブに動作し、GPUがあれば高速に学習できる。
モデルを実行したい場合
コマンドラインが苦手な場合
LM Studioを使う。アプリを起動し、モデルを選択してクリックして実行する。
Pythonプログラムから利用したい場合
Ollamaを使う。数行のPythonコードでモデルを呼び出せ、モデルは自動的にダウンロードされる。OllamaはローカルAPIサーバとしても動作し、軽量な単一モデル運用に向く。複数同時リクエストや高スループットが必要な場合はvLLMを選ぶ。
APIサーバとして利用したい場合
vLLMを使う。OpenAI互換のAPIサーバを起動できる。
推論パラメータを細かく調整したい場合
llama.cppを使う。コマンドラインオプションで詳細な設定が可能で、性能測定にも適する。
状況の組み合わせ
デモやプレゼンテーションでモデルを見せたい場合
LM Studioを使う。視覚的に確認でき、操作も簡単である。
研究でモデルの性能を詳細に測定したい場合
llama.cppを使う。実行時間やメモリ使用量を詳細に計測できる。
簡単な方法でモデルを試したい場合
学習:unslothのColabノートブック(環境構築不要)
推論:LM Studio(インストール後すぐに実行可能)
Windowsでのセットアップ
前提環境
- Windows 11
- CUDA対応NVIDIA GPU(GPU訓練を行う場合)
- 管理者権限のコマンドプロンプト(環境構築時)
インストール全体の流れ
- Python 3.12
- Build Tools for Visual Studio 2026
- NVIDIA CUDA Toolkit
- PyTorch(CUDAバージョンに合わせて選択)
- Ollama・モデル・Open WebUI(LFM2.5-1.2B-Instruct、gemma4:e2b-it-qat、gemma4:12b-it-qat、bge-m3 を一括導入)
- transformers v5(LFM2.5で動作確認)
- unsloth(LFM2.5で動作確認)
- llama.cpp(LFM2.5 GGUFで動作確認)
- LM Studio(LFM2.5で動作確認)
- vLLM(オプション、WSL環境)
- LLaMA Factory(オプション、WSL環境)
上記の番号はインストールの推奨順序を示す。本記事では作業を効率化するため、項番1〜4を「環境構築」、項番5を「Ollama・モデル・Open WebUI のインストール」としてまとめ、項番6〜9(transformers、unsloth、llama.cpp、LM Studio)は「ツールのインストールと動作確認」の章で一括インストールと個別の動作確認に分け、項番10・11(vLLM、LLaMA Factory)は同じ章の中でそれぞれWSL環境のセットアップとして扱う。Ollama本体および動作確認用の各モデルは項番5で導入・取得するため、項番6〜9の一括インストールではOllamaを扱わない。
本記事では、各ツールに共通する作業として「管理者権限のコマンドプロンプトを開く」操作が頻出する。手順は次のとおりである。Windowsキーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。以降の各節では、この操作を「管理者権限のコマンドプロンプトで実行する」とのみ記す。各手順のコマンドは、コマンド全体をコマンドプロンプトにコピー&ペーストして実行すればよい。なお、wingetの --scope machine オプションでシステム全体(全ユーザー向け)にインストールするには、管理者権限が必要である。
Python 3.12 のインストール
本章では、Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
以降の章では、必要に応じて題材に応じたソフトウェアを追加する。
Build Tools・CUDA Toolkit・PyTorch のインストール
本章では、C++ ビルドツール、NVIDIA CUDA Toolkit、PyTorch のインストールを行い、GPU を活用した機械学習プログラムを実行する環境を整える。扱う環境は、Windows 搭載パソコンである。
[Build Tools・CUDA Toolkit・PyTorch のインストール手順を見るには、ここをクリック]
Windows での Build Tools for Visual Studio 2026 のインストール
Build Tools for Visual Studio 2026 は、C++ ソースコードを Windows 用バイナリにコンパイルするための開発ツール群である。unsloth 等の一部 Python パッケージは、インストール時に C++ コードのビルドを必要とするため、これらのツールが必須となる。
以下のコマンドは、Build Tools が未インストールの場合は winget で新規インストールし、インストール済みの場合は setup.exe modify でコンポーネントを追加する(バージョンは変更しない)。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM ============================================================
REM Visual Studio Build Tools + Desktop development with C++
REM (VCTools、MSBuildTools、CMake連携、Clang、Windows 11 SDK)
REM ============================================================
REM 進行中のインストーラーを停止(ロック競合回避)
taskkill /F /IM vs_setup.exe /T >nul 2>&1
taskkill /F /IM vs_installer.exe /T >nul 2>&1
taskkill /F /IM vs_installerservice.exe /T >nul 2>&1
REM 未インストール時: winget で新規インストール
REM インストール済み時: setup.exe modify でコンポーネント追加(バージョンは変更しない)
winget list --id Microsoft.VisualStudio.BuildTools 2>nul | findstr /i "BuildTools" >nul 2>&1
if %ERRORLEVEL% EQU 0 (
for /f "usebackq delims=" %P in (`"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products Microsoft.VisualStudio.Product.BuildTools -property installationPath`) do start /wait "" "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" modify --installPath "%P" --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100 --includeRecommended --quiet --norestart --nocache
) else (
winget install --scope machine --id Microsoft.VisualStudio.BuildTools -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "--quiet --wait --norestart --nocache --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100"
)
REM 破損時の修復(任意、動作がおかしくなった場合)
REM "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" repair --installPath "C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools" --quiet --norestart
REM 導入確認(インストールパスが表示されれば正常)
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products * -requires Microsoft.VisualStudio.Workload.VCTools -property installationPath
上記のコマンドでは、Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし、続いて以下のコンポーネントを追加している。
- VCTools:C++ デスクトップ開発ワークロード(
--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる) - MSBuildTools:MSBuild によるビルドツールのワークロード
- VC.CMake.Project:Windows 向け C++ CMake ツール
- VC.Llvm.Clang:Windows 向け C++ Clang コンパイラ
- VC.Llvm.ClangToolset:MSBuild から Clang を使用するための clang-cl ツールセット
- Windows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
Windows での NVIDIA CUDA Toolkit のインストール
NVIDIA CUDA Toolkit は、NVIDIA GPU 上で計算を行うためのコンパイラ・ライブラリ群である。PyTorch や vLLM 等が GPU を利用するために必要となる。GPU を使用しない場合、この手順は不要である。
前提条件:NVIDIA GPU、NVIDIA ドライバ、Build Tools for Visual Studio もしくは Visual Studio が必要である。
インストール中の注意:他のウインドウは閉じておくこと。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール
winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n"
REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更)
mkdir C:\TEMP
setx TEMP "C:\TEMP" /M
setx TMP "C:\TEMP" /M
環境変数 TEMP および TMP を C:\TEMP に変更しているのは、後続のインストール処理で長いパス名や空白を含むパス名がエラーの原因となる場合があるためである。
Windows での PyTorch のインストール
https://pytorch.org のインストールガイドに従い、自環境の CUDA バージョンに対応したコマンドを取得して実行する。CUDA バージョンは以下で確認できる。
nvcc --versionPython 3.12、CUDA 12.6 以上の場合は、管理者権限でコマンドプロンプトを起動し、以下を実行する。cu128 は CUDA 12.8 用のタグである。CUDA バージョンが異なる場合は、上記公式サイトで該当するタグを確認し、URL 末尾の cu128 を置き換えること。
pip install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128以降の章では、必要に応じて題材に応じた必要なソフトウェアを追加する。
Ollama・モデル・Open WebUI のインストール
[Windows でのインストール・設定手順を見るには、ここをクリック]
本章では、Ollama、3 つのモデル(LFM2.5-1.2B-Instruct、gemma4:e2b-it-qat、gemma4:12b-it-qat)、埋め込みモデルbge-m3、Open WebUI、Gitのインストール手順を示す。
設定としては、Ollama の動作パラメータを Machine スコープの環境変数として設定しており、その内容は、Flash Attention の有効化(OLLAMA_FLASH_ATTENTION=1)、KV キャッシュの 8bit 量子化(OLLAMA_KV_CACHE_TYPE=q8_0)、コンテキスト長をデフォルトの 4096 から 262144 への拡張(OLLAMA_CONTEXT_LENGTH=262144)、モデル保存先の C:\Ollama\models への変更(OLLAMA_MODELS)である。Flash Attention は KV キャッシュの量子化に必要な高速化機能である。その他、gemma4:e2b-it-qat 起動用のスタートメニュー ショートカット作成を行う。
ハードウェアの前提
- ディスク空き容量 20GB 以上、メモリ搭載量 16GB 以上を推奨(モデル 3 種で合計約 12GB + Open WebUI 等)。少 VRAM の GPU や CPU のみの PC でも動作するが、gemma4:12b-it-qat は時間がかかる場合がある。
- 推論時のメモリ占有は 1 モデル分(モデル切替時に Ollama が自動でアンロードおよびロードを行う)。
ハードウェア要件の事前確定は難しい。新規に PC を準備する前に、現有の機器で本手順を試行し、性能面の問題の有無を確認したうえで、本格運用のハードウェアを決定する。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。winget の --scope machine オプションでシステム全体にインストールするには、管理者権限が必要である。実行時はコマンド全体をコマンドプロンプトにコピー&ペーストする。
REM ============================================================
REM 管理者権限チェック
net session >nul 2>&1
if errorlevel 1 ( echo [エラー] 管理者権限で実行してください & pause & exit /b 1 )
REM winget パッケージ一覧のローカルキャッシュを更新
winget source update
REM === 1. Ollama 環境変数を Machine スコープで事前設定 ===
REM インストール前に設定することで、Ollama 起動時から正しい設定が読み込まれる
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_FLASH_ATTENTION', '1', 'Machine')"
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_KV_CACHE_TYPE', 'q8_0', 'Machine')"
REM コンテキスト長:Ollama のデフォルトは 4096。
REM ここでは gemma4:12b-it-qat の上限 262144 に設定する
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_CONTEXT_LENGTH', '262144', 'Machine')"
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_MODELS', 'C:\Ollama\models', 'Machine')"
set "OLLAMA_FLASH_ATTENTION=1"
set "OLLAMA_KV_CACHE_TYPE=q8_0"
set "OLLAMA_CONTEXT_LENGTH=262144"
set "OLLAMA_MODELS=C:\Ollama\models"
REM === 2. 既存の Ollama プロセスを停止(ファイルロック解除のため) ===
taskkill /IM ollama.exe /F >nul 2>&1
taskkill /IM "ollama app.exe" /F >nul 2>&1
REM === 3. モデルフォルダの作成と権限設定 ===
if not exist "C:\Ollama\models" mkdir "C:\Ollama\models"
icacls "C:\Ollama\models" /grant *S-1-5-32-545:(OI)(CI)(M) /T /C
REM === 4. 既存モデルの移動(ユーザープロファイルに残っている場合) ===
REM Ollama 停止状態で実行するためファイルロックが起きない
if exist "%USERPROFILE%\.ollama\models" robocopy "%USERPROFILE%\.ollama\models" "C:\Ollama\models" /E /MOVE
if exist "%USERPROFILE%\.ollama\models" rd /s /q "%USERPROFILE%\.ollama\models"
REM === 5. winget パッケージ一覧のローカルキャッシュを更新 ===
winget source update
REM === 6. Ollama のインストール(Inno Setup) ===
winget uninstall --id Ollama.Ollama -e --silent --disable-interactivity --accept-source-agreements
REM uninstall 後にプロセスが残ることがあるため再度停止
taskkill /IM ollama.exe /F >nul 2>&1
taskkill /IM "ollama app.exe" /F >nul 2>&1
winget install --id Ollama.Ollama -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/DIR=C:\Ollama"
winget upgrade --id Ollama.Ollama -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/DIR=C:\Ollama"
REM === 7. Ollama のパス設定(システム PATH に未登録の場合のみ追加) ===
powershell -NoProfile -Command "$p='C:\Ollama'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\")){[Environment]::SetEnvironmentVariable('Path',\"$c;$p\",'Machine')}"
REM Ollama のパスを現在のセッションに反映
set "PATH=C:\Ollama;%PATH%"
REM === 8. Ollama サービスの起動(モデルダウンロードの前に必要) ===
where ollama >nul 2>&1
if errorlevel 1 echo Ollama のパスが見つかりません。再起動後に再実行してください。 & exit /b 1
tasklist /fi "imagename eq ollama.exe" | find "ollama.exe" 2>&1
if errorlevel 1 start "" "C:\Ollama\ollama.exe" serve & timeout /t 10 /nobreak
REM === 9. モデルのダウンロード ===
REM 動作確認用(テキスト専用、約 731MB)。
echo LFM2.5-1.2B-Instruct モデルをダウンロード中...
ollama pull LiquidAI/lfm2.5-1.2b-instruct
REM 画像入力対応(軽量、約 4.3GB)
echo gemma4:e2b-it-qat モデルをダウンロード中...
ollama pull gemma4:e2b-it-qat
REM 画像入力対応(上位、約 7.2GB)
echo gemma4:12b-it-qat モデルをダウンロード中...
ollama pull gemma4:12b-it-qat
echo モデルダウンロード完了
REM === 10. 埋め込みモデルのダウンロード(RAG 演習で使用) ===
echo bge-m3 埋め込みモデルをダウンロード中...
ollama pull bge-m3
echo 埋め込みモデルダウンロード完了
REM === 11. Open WebUI のインストール ===
REM open-webui パッケージにより、依存パッケージ(FastAPI、ChromaDB、
REM sentence-transformers 等)が一括インストールされる
python -m pip install --no-user --upgrade pip
python -m pip install --no-user --upgrade open-webui
python -m pip uninstall -y open-webui
python -m pip install --user --upgrade open-webui
REM === 12. Git のインストール ===
winget install --scope machine --id Git.Git -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/VERYSILENT /NORESTART /NOCANCEL /SP- /CLOSEAPPLICATIONS /RESTARTAPPLICATIONS /COMPONENTS=""icons,ext\reg\shellhere,assoc,assoc_sh"" /o:PathOption=Cmd /o:CRLFOption=CRLFCommitAsIs /o:BashTerminalOption=MinTTY /o:DefaultBranchOption=main /o:EditorOption=VIM /o:SSHOption=OpenSSH /o:UseCredentialManager=Enabled /o:PerformanceTweaksFSCache=Enabled /o:EnableSymlinks=Disabled /o:EnableFSMonitor=Disabled"
REM Git のパスを現在のセッションに反映
set "PATH=C:\Program Files\Git\cmd;%PATH%"
REM === 13. スタートメニュー ショートカット作成 ===
REM gemma4:e2b-it-qat 起動ショートカット(CUI で質問・応答を行う)
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $l=$s.CreateShortcut([Environment]::GetFolderPath('CommonPrograms')+'\Ollama Gemma4 e2b.lnk'); $l.TargetPath='cmd.exe'; $l.Arguments='/k \"start cmd /k ollama serve ^& timeout /t 3 /nobreak ^>nul ^& ollama run gemma4:e2b-it-qat\"'; $l.Save()"
echo インストール完了
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
本章では、Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
以降の章では、必要に応じて題材に応じた必要なソフトウェアを追加する。
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


演習 1.基本動作確認(CUI)
Ollama 自体が動作することを確認する。本演習のみコマンドプロンプト(CUI)で行い、LLM のローカル実行(外部サーバへの送信を伴わず、手元のマシン内で完結する推論)を体験する。以降の演習はすべてブラウザ(Open WebUI)で行う。
手順
- Ollama でモデル LFM2.5-1.2B-Instruct を実行する
- コマンドプロンプトを開き、Ollama を起動する(
ollama serve)。次のメッセージが出た場合は、すでに Ollama が起動中なので、問題ない。続行する。
- 別のコマンドプロンプトで、モデル LFM2.5-1.2B-Instruct を選んで実行する(
ollama run LiquidAI/lfm2.5-1.2b-instruct)。
- コマンドプロンプトを開き、Ollama を起動する(
- プロンプト記号
>>>が表示されたら、質問を入力する(例:「日本の首都はどこですか?」)。
- 応答が返ることを確認する。
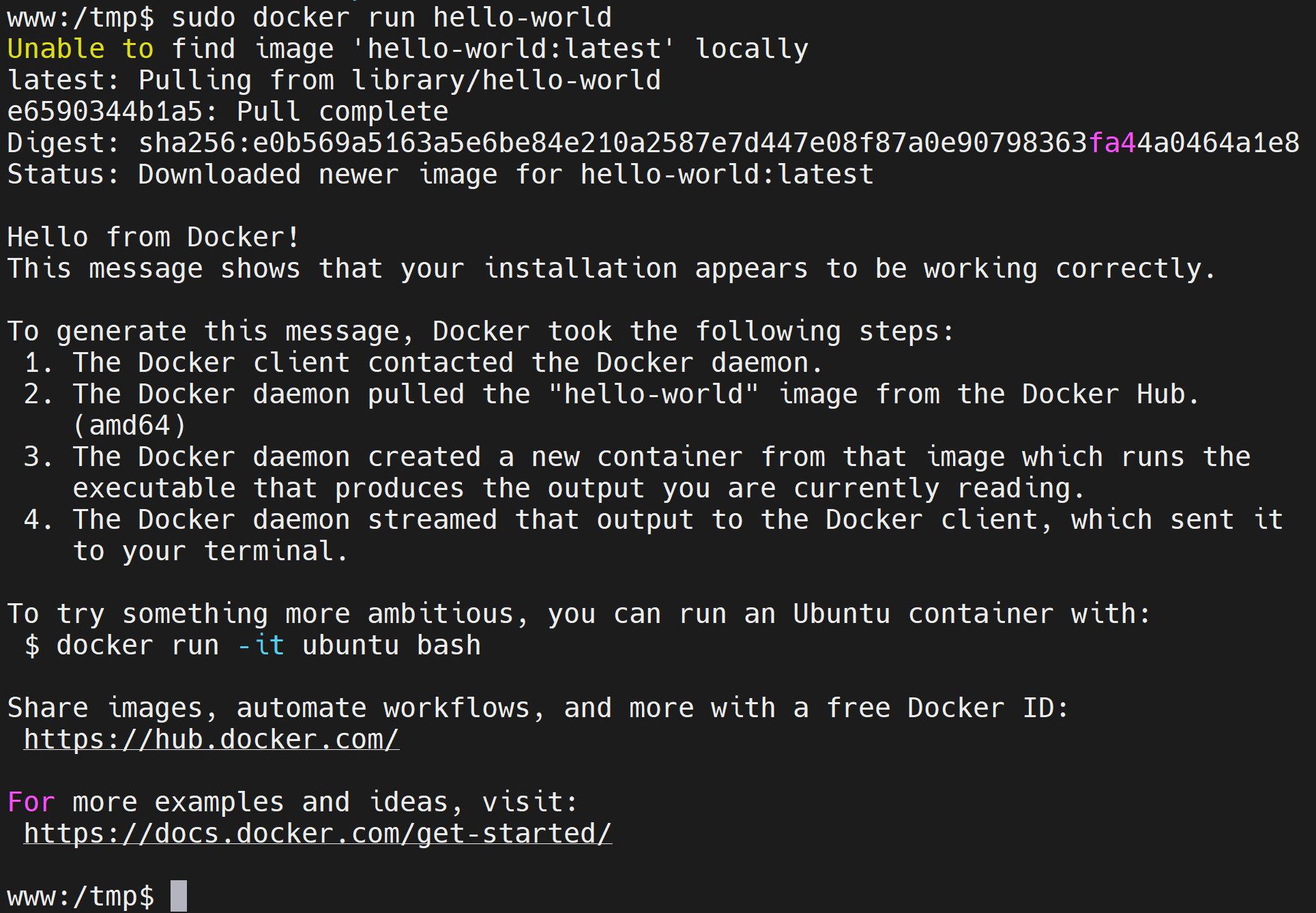
/byeを入力して終了する。
ヒント
- 初回起動時は、モデルのメモリへのロードに時間を要する(LFM2.5-1.2B-Instruct は軽量のため比較的短時間で完了する)。
- 応答の生成中に中断する場合は Ctrl+C を押す。
ollama serve用ウィンドウは閉じずに残しておく。サーバに接続できない場合は、別のコマンドプロンプトでollama serveを実行してサーバを起動してから、再度モデルを実行する。- 登録済みモデルの一覧は別のコマンドプロンプトで
ollama listで確認できる(LFM2.5-1.2B-Instruct、gemma4:e2b-it-qat、gemma4:12b-it-qat、bge-m3 が表示される)。
考察ポイント
- モデルが質問に対して応答を返すか(本演習の目的は応答経路の動作確認であり、応答内容の正確性は問わない)。
- 応答が返るまでの時間が、初回ロードと 2 回目以降でどう異なるか。
ollama listに 3 つの LLM と埋め込みモデル(テキストを数値ベクトルに変換するモデル。検索などに用いる)bge-m3 が登録されているか。
ツールのインストールと動作確認
WSLを必要としない4つのツール(transformers、unsloth、llama.cpp、LM Studio)のインストールを、以下の1つの手順としてまとめて実行する。管理者権限のコマンドプロンプトで以下を実行する。Visual Studio Build Tools(C++ワークロード、Clang、CMake、Windows SDK)のインストールが完了していることが前提である。なお、Ollamaは前章「Ollama・モデル・Open WebUI のインストール」で導入済みのため、本手順では扱わない。インストール後の各ツールの動作確認は、続く「動作確認」の各節で個別に行う。
REM transformers v5 のインストール
pip install -U transformers
REM unsloth のインストール(動作にはGPUが必要)
pip install -U unsloth
REM llama.cpp のセットアップ(CPU版・バージョン7966。最新版に置き換えること。NVIDIA GPU版を使う場合は「cpu」を「cuda」に置き換える)
cd "C:\Program Files"
curl -L -o llama-cpp.zip https://github.com/ggml-org/llama.cpp/releases/download/b7966/llama-b7966-bin-win-cpu-x64.zip
mkdir llama-cpp
tar -xf llama-cpp.zip -C llama-cpp
REM LM Studio のインストール
winget install ElementLabs.LMStudio --scope machine
各ツールのインストールには、次の代替手段もある。llama.cppはリリースページ(https://github.com/ggml-org/llama.cpp/releases)から最新版のWindows用ビルド済みバイナリを手動でダウンロードして展開してもよい。CPU版のファイル名の形式は llama-b{バージョン番号}-bin-win-cpu-x64.zip、NVIDIA GPU版は llama-b{バージョン番号}-bin-win-cuda-x64.zip である。LM Studioは https://lmstudio.ai/download から、Windows用インストーラーを入手してインストールしてもよい。
動作確認
1. transformers v5の動作確認
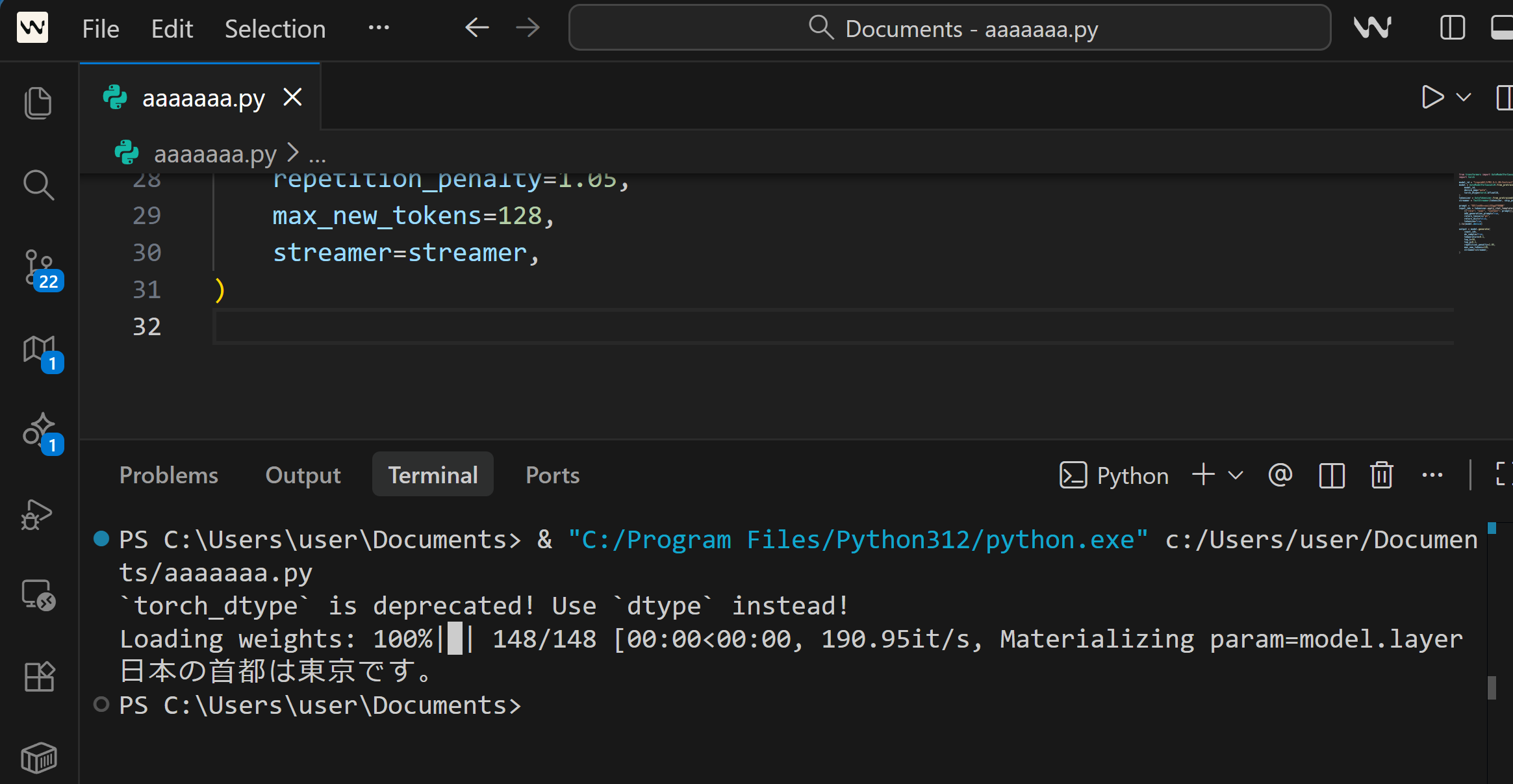
LFM2.5-1.2B-Instructモデルで動作確認を行う。以下のPythonコードを実行する。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_id = "LiquidAI/LFM2.5-1.2B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
dtype="bfloat16",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "日本の首都はどこですか?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(model.device)
output = model.generate(
input_ids,
do_sample=True,
temperature=0.1,
top_k=50,
repetition_penalty=1.05,
max_new_tokens=128,
streamer=streamer,
)初回実行時にモデルのダウンロード(約2.4GB)が行われる。応答テキストが表示されれば、transformersのインストールは正常に完了している。エラーが発生する場合は公式ドキュメント(https://huggingface.co/docs/transformers)を参照する。
2. unslothの動作確認
LFM2.5をunslothで読み込んで動作確認を行う。動作にはGPUが必要である。
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="LiquidAI/LFM2.5-1.2B-Instruct",
max_seq_length=2048,
dtype=None,
load_in_4bit=True,
)
prompt = "日本の首都はどこですか?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(model.device)
FastLanguageModel.for_inference(model)
output = model.generate(
input_ids,
do_sample=True,
temperature=0.1,
repetition_penalty=1.05,
max_new_tokens=128,
)
print(tokenizer.decode(output[0], skip_special_tokens=True))4bit量子化でモデルが読み込まれ、応答が得られれば正常である。
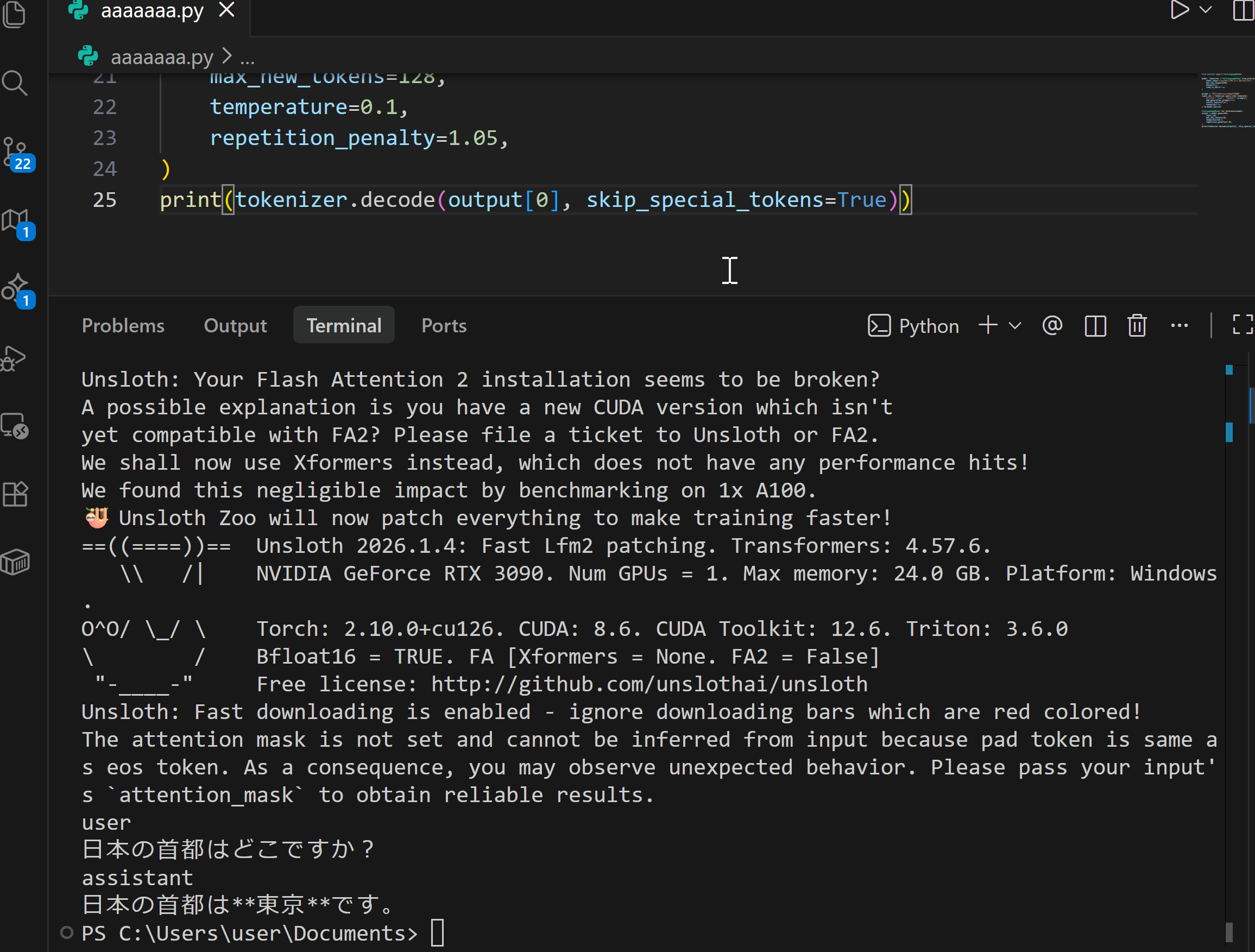
エラーが発生する場合は、公式ドキュメント(https://docs.unsloth.ai/get-started/install-and-update/windows-installation)を参照する。
3. llama.cppの動作確認
LFM2.5のGGUF版で動作確認を行う。管理者権限のコマンドプロンプトで以下を実行する。-hfオプションにより、初回実行時にHugging FaceからGGUFファイル(Q4_K_M: 731MB)が自動的にダウンロードされる。
cd "C:\Program Files\llama-cpp"
llama-cli -hf LiquidAI/LFM2.5-1.2B-Instruct-GGUF:Q4_K_M -cnv --temp 0.1 --repeat-penalty 1.05「>」が表示されたら、例えば「日本の首都はどこですか?」のように入力する。応答が表示されれば正常である。終了するには Ctrl+C を押す。エラーが発生する場合は公式ドキュメント(https://github.com/ggml-org/llama.cpp)を参照する。
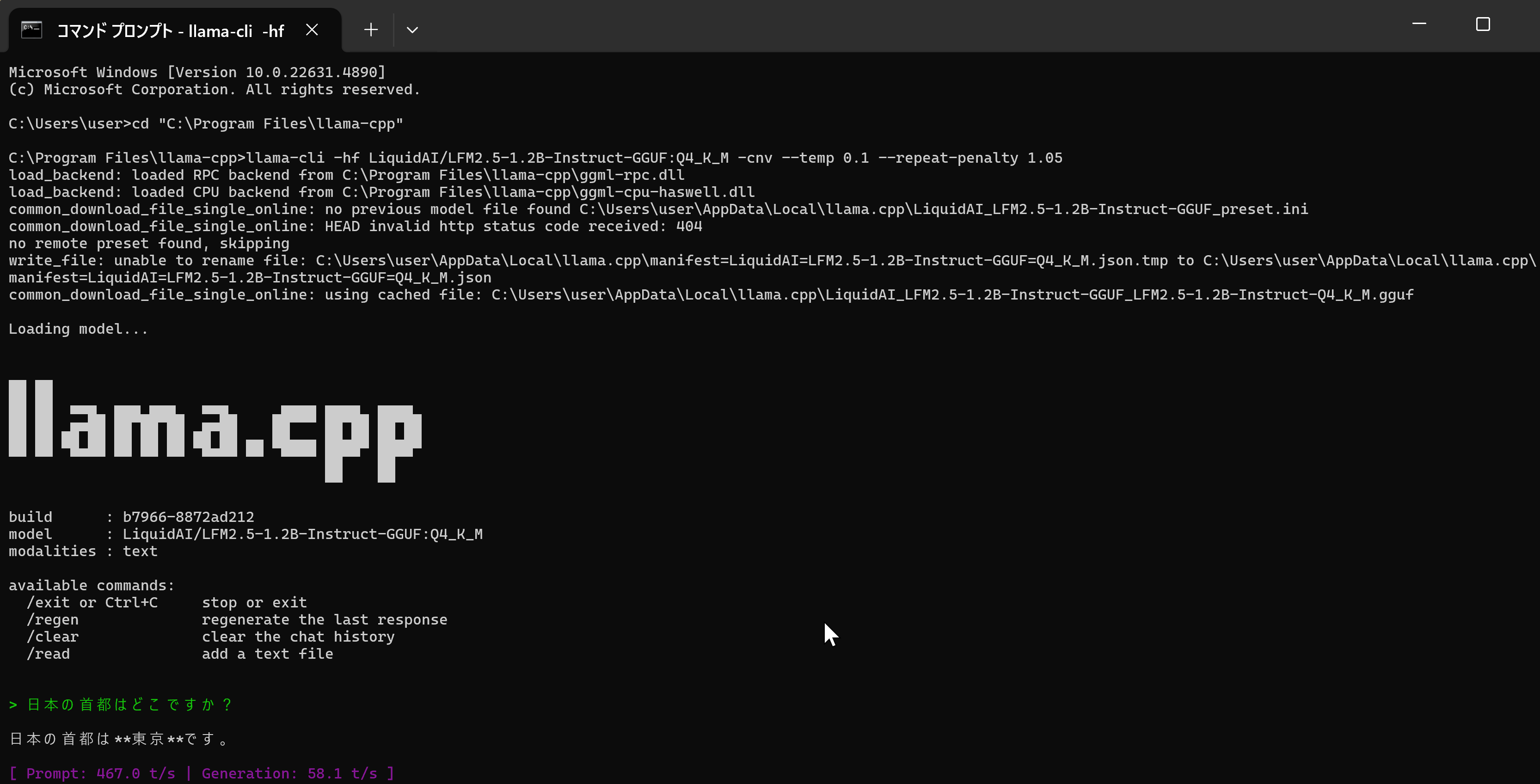
4. Ollamaの動作確認
Ollamaの導入と動作確認は、前章「Ollama・モデル・Open WebUI のインストール」および「演習 1.基本動作確認(CUI)」で行う。LFM2.5-1.2B-Instruct を用いたコマンドライン上の動作確認手順は、そちらを参照すること。なお、OllamaはローカルAPIサーバとしても動作し、既定ではポート11434で待ち受ける。
5. LM Studioの動作確認
モデルのダウンロード
LFM2.5で動作確認を行う。LM Studio を起動し、モデル管理画面(
Ctrl+Shift+Mで開く)の検索バーで「LFM2.5」と検索し、LFM2.5-1.2B-Instruct-GGUF(Q4_K_M推奨、約731MB)をダウンロードする。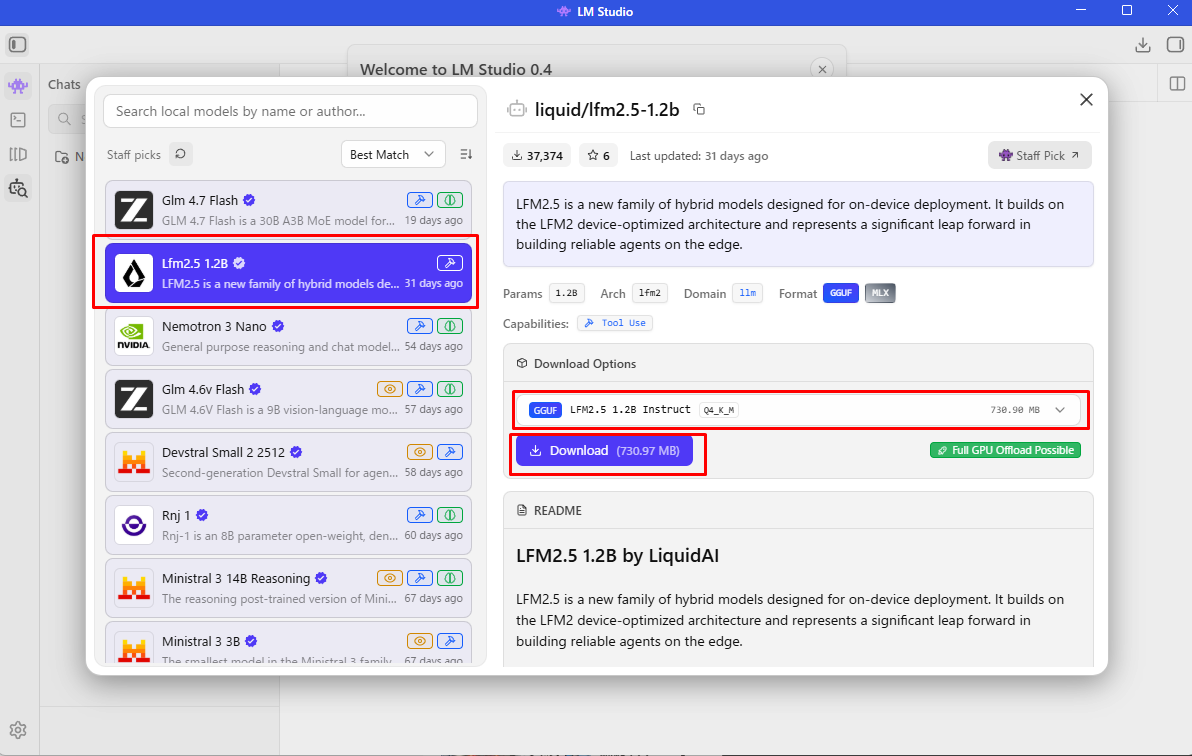
チャットの開始と設定
ダウンロードが終了したら、チャット画面に切り替える。「New Chat」と表示されたときは、クリックする。
チャット画面でモデルを選択する。
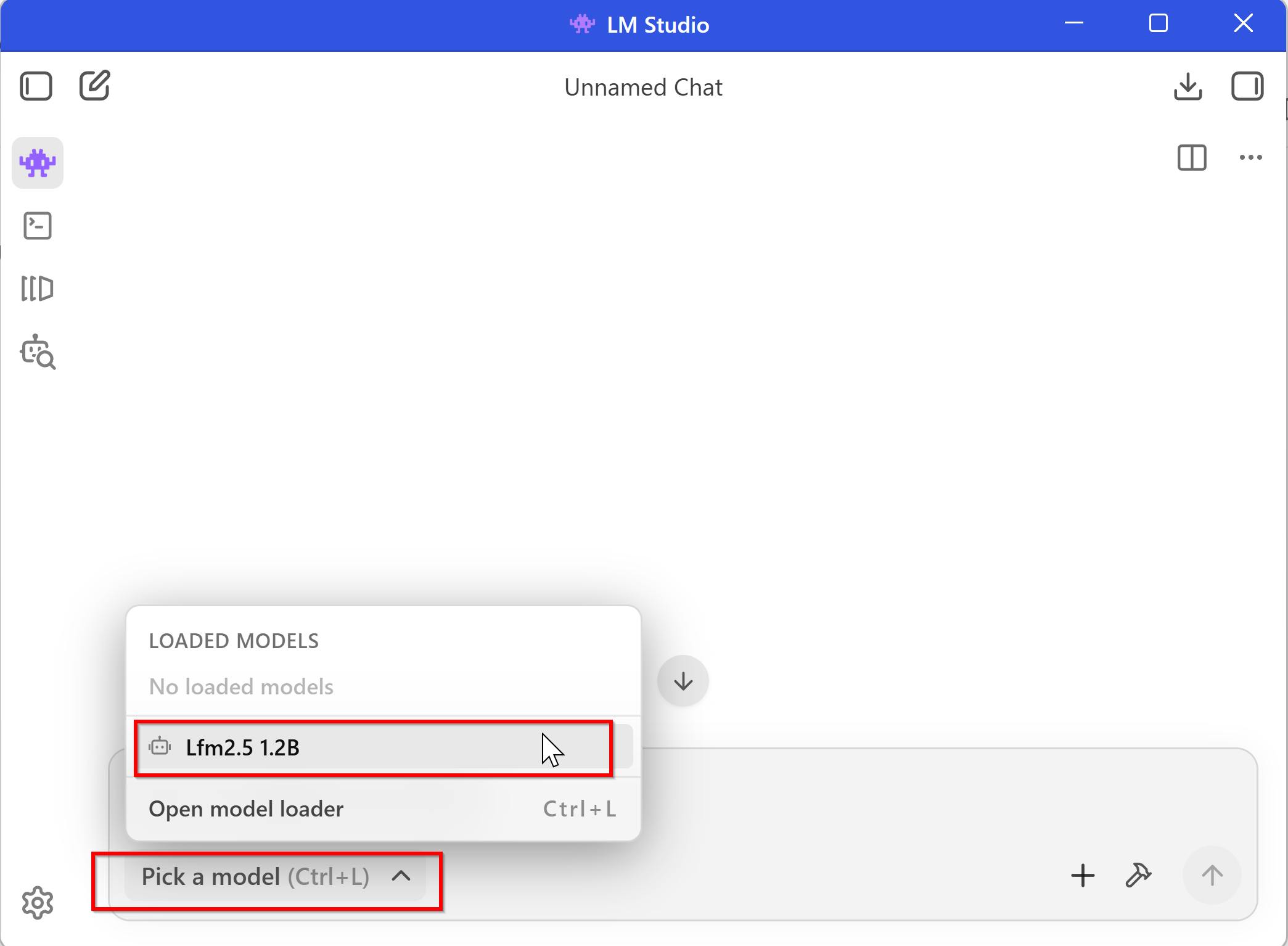
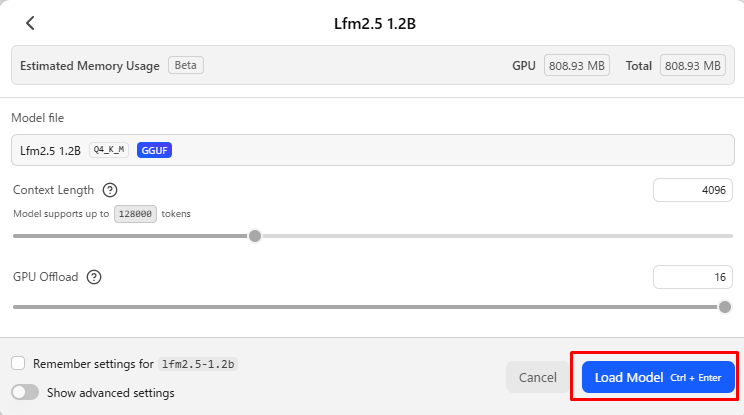
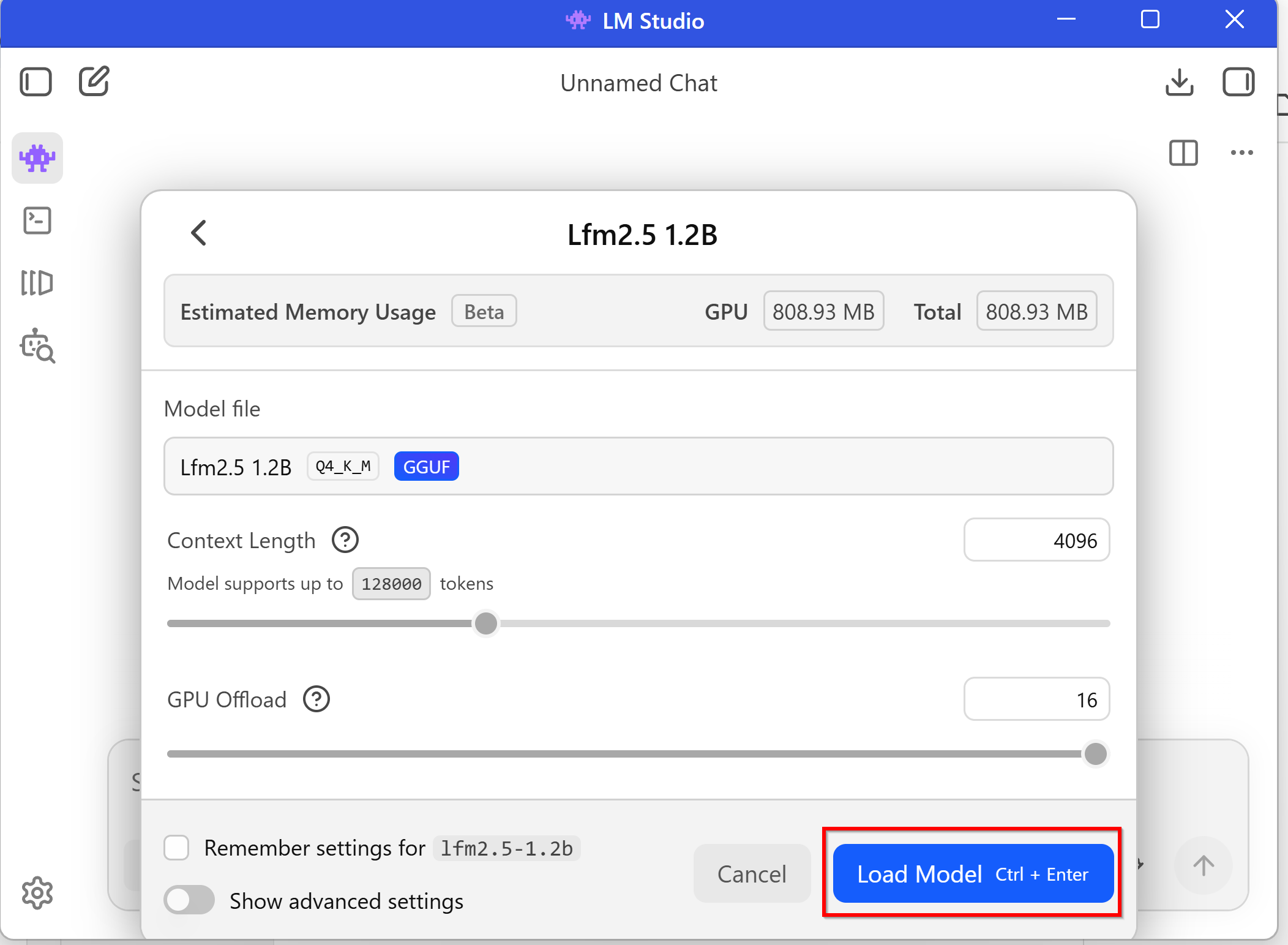
モデルの設定画面が開いたときは、必要であれば設定変更を行い「Load Model」をクリックする。
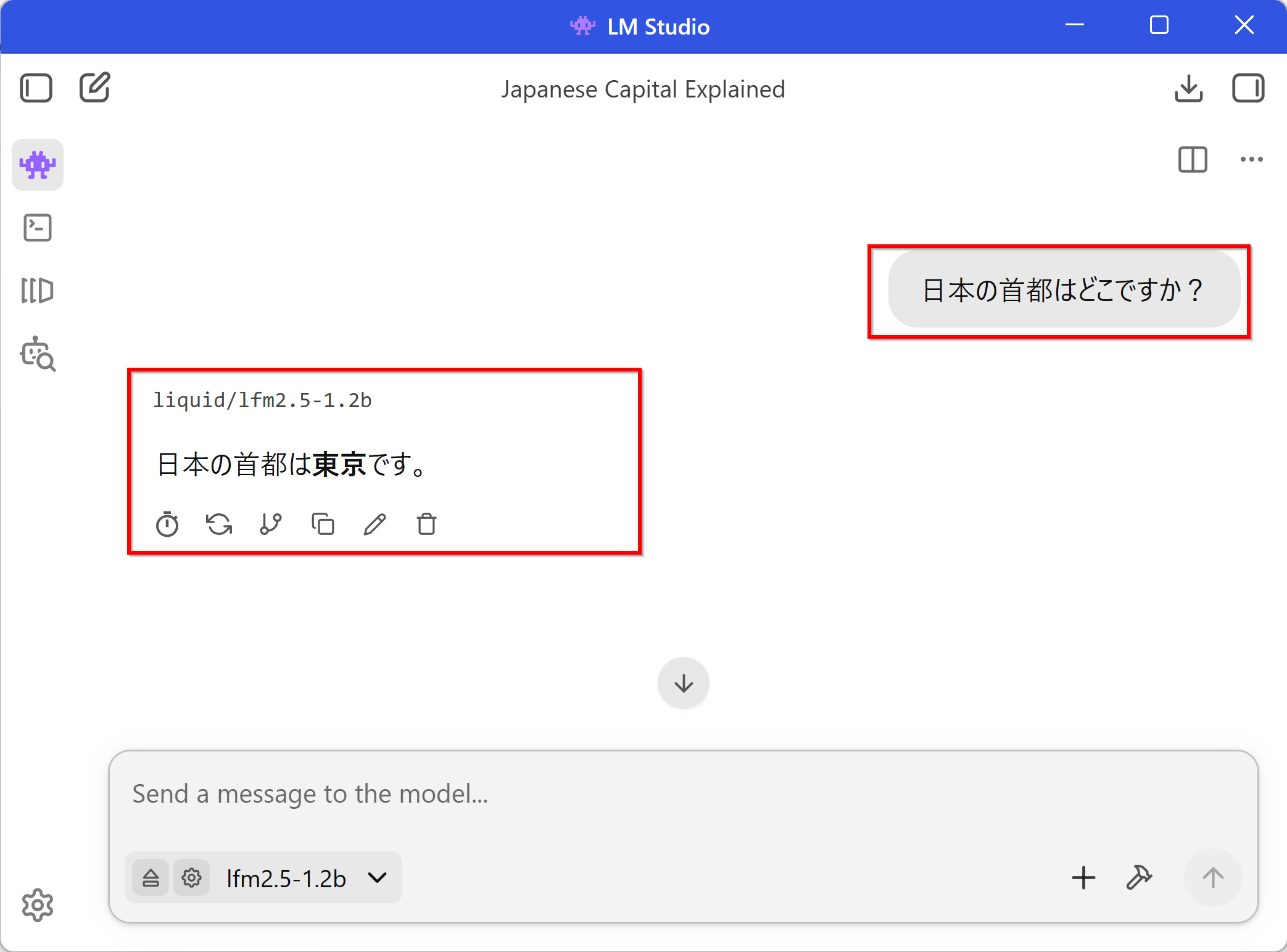
動作確認
任意の質問を入力する(例:「日本の首都はどこですか?」)。応答が表示されれば正常である。エラーが発生する場合は公式ドキュメント(https://lmstudio.ai/docs)を参照する。
10. vLLMのセットアップと動作確認(WSL環境)
vLLMはローカルでLLMをAPIサーバとして動かし、OpenAI互換のインターフェースで利用するためのツールである。Windows環境ではWSLで使用する。GPU(CUDA)が必要である。
WSLの準備とvLLMのインストール・APIサーバ起動
WSLの準備からvLLMのインストール、OpenAI互換APIサーバの起動までを、以下の手順でまとめて行う。最初の wsl --install と wsl nvidia-smi はWindowsのコマンドプロンプトで実行し、wsl bash 以降はWSL内のbash(Linuxの標準シェル)で実行する。先頭の wsl bash は、WindowsのコマンドプロンプトからWSL内のbashを起動するためのものである。WSLが未導入の場合は wsl --install 実行後に再起動し、Ubuntuのセットアップ(ユーザー名・パスワードの設定。これはWSL内のLinuxユーザーのものであり、Windowsのアカウントとは別である)を済ませてから残りを実行する。Windows側にNVIDIAドライバがインストールされていれば、wsl nvidia-smi でGPU情報が表示され、WSL2からGPUを利用できる状態を確認できる。vLLMの初回実行時にはモデルのダウンロードが自動で行われる。
REM ① WSLのインストール(未導入の場合のみ。実行後に再起動が必要)
wsl --install
REM ② WSLからGPUを利用できることの確認
wsl nvidia-smi
REM ③ WSL内でvLLMをインストールし、OpenAI互換APIサーバを起動
wsl bash
python3 -m venv vllm-env
source vllm-env/bin/activate
pip install -U vllm
vllm serve LiquidAI/LFM2.5-1.2B-Instruct --host 0.0.0.0 --port 8000 --dtype auto
サーバが起動すると、ポート8000で待ち受け状態になる。次の動作確認では、このサーバへのリクエスト送信を別のコマンドプロンプトから行う。
動作確認(curl)
コマンドプロンプトを別に開き、以下を実行し、応答が返れば正常である。エラーが発生する場合は公式ドキュメント(https://docs.vllm.ai)を参照する。
wsl bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "LiquidAI/LFM2.5-1.2B-Instruct",
"messages": [{"role": "user", "content": "日本の首都はどこですか?"}],
"temperature": 0.1,
"max_tokens": 128
}'
動作確認(Python)
OpenAI互換APIのため、PythonからはOpenAIライブラリを使用してアクセスできる。api_key はローカルサーバでは認証に使用されないため、任意の文字列(例:"dummy")でよい。
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy",
)
response = client.chat.completions.create(
model="LiquidAI/LFM2.5-1.2B-Instruct",
messages=[{"role": "user", "content": "日本の首都はどこですか?"}],
temperature=0.1,
max_tokens=128,
)
print(response.choices[0].message.content)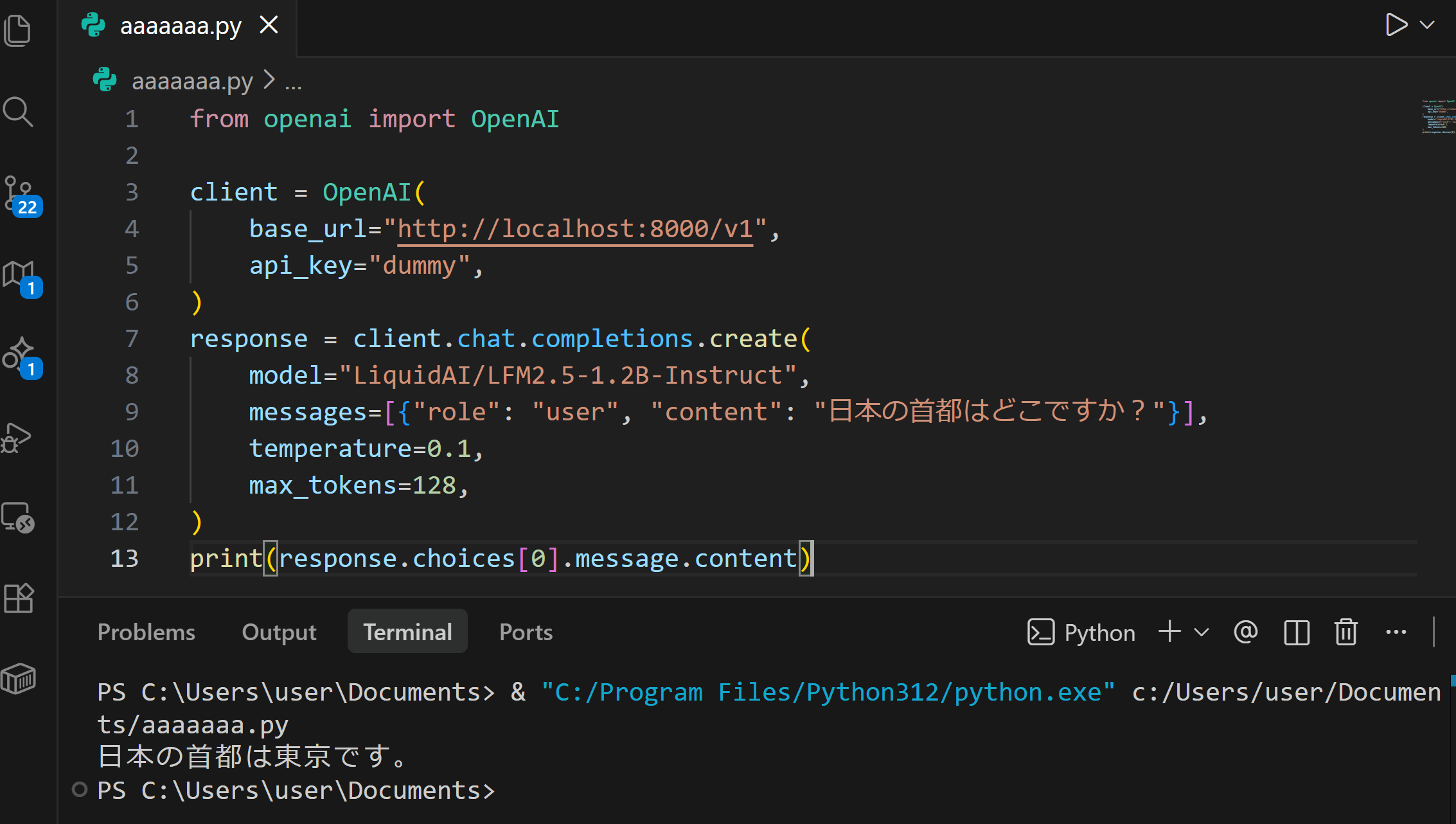
11. LLaMA Factoryのセットアップ(WSL環境)
LLaMA FactoryはLinux環境を前提とする機能が多いため、WSL環境で動作させる。以下はWSL上のUbuntuでの手順である。WSL環境のセットアップ(wsl --install)およびGPU利用の確認(wsl nvidia-smi)は「10. vLLMのセットアップ」と同じであり、未導入の場合はそちらを参照すること。
WSL内でのインストールからWeb UI起動までを、以下の手順でまとめて行う(先頭の wsl bash の役割は手順10と同じである)。
wsl bash
# Python環境の準備
sudo apt update && sudo apt install -y python3-pip python3-venv git
# 仮想環境の作成と有効化
python3 -m venv ~/llamafactory-env
source ~/llamafactory-env/bin/activate
# LLaMA Factoryのインストール
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# Web UI起動
llamafactory-cli webuiブラウザで表示されるURL(通常 http://localhost:7860)にWindows側からアクセスする。Web UIが表示されれば、インストールは正常に完了している。エラーが発生する場合は公式ドキュメント(https://llamafactory.readthedocs.io)を参照する。
代替:Dockerによるセットアップ
WSLを使用せず、Docker環境でも動作させられる。GPU対応のコンテナ起動方法を含む詳細は、公式ドキュメント(https://llamafactory.readthedocs.io)を参照する。
docker pull hiyouga/llamafactory:latest演習
本記事の最初の演習として、Ollama 自体の基本動作を確認する「演習 1.基本動作確認(CUI)」を「Ollama・モデル・Open WebUI のインストール」章の末尾に置いている。以下では、各推論ツールを横断して比較する演習を扱う。
演習2:CPU推論で軽量モデルを動かす
テーマ名:llama.cppによるCPU推論
手順:上記「3. llama.cppの動作確認」に従い、LFM2.5-1.2B-Instruct-GGUF(Q4_K_M)を対話モードで起動し、「日本の首都はどこですか?」と入力して応答を得る。
ヒント:-hf オプションを付けると初回にモデルが自動ダウンロードされる。終了は Ctrl+C。
考察ポイント:CPUのみで応答が返るまでの体感速度を確認する。同じモデルをGPU版バイナリで実行した場合と比べ、応答開始までの時間がどう変わるかを読み取る。
演習3:同一モデルを推論方式の異なるツールで比較する
テーマ名:transformers・Ollama・vLLMの応答比較
手順:同じ質問「日本の首都はどこですか?」を、「1. transformers」の動作確認手順、「演習 1.基本動作確認(CUI)」のOllama手順、「10. vLLM」の動作確認手順でそれぞれ実行し、各応答を記録する。
ヒント:transformersとvLLMは生成パラメータを temperature=0.1 に揃えてある。Ollamaはllama.cpp系(GGUF)、transformersとvLLMはHF形式である。
考察ポイント:同じモデル・同じ質問でも、量子化の有無や推論エンジンの違いによって応答内容や速度に差が出るかを読み取る。
発展:他のモデルを試す
本記事では、ダウンロード容量が小さく動作確認が容易な LFM2.5-1.2B を共通の動作確認用モデルとして用いてきた。Ollama を使うと、モデル名を差し替えるだけで他のモデルも同じ手順で試せる。ここでは一段上の選択肢として、「Ollama・モデル・Open WebUI のインストール」章で LFM2.5-1.2B とあわせて導入済みの、Google DeepMind が公開しているオープンモデル gemma4:e2b-it-qat を紹介する。
gemma4:e2b-it-qat は、Gemma 4 シリーズのうちエッジデバイス向けに設計された E2B モデルを、量子化を考慮した学習(QAT: Quantization-Aware Training)によって軽量化したものである。「E」は有効パラメータ(effective parameters)を表し、E2B は有効 2.3B(埋め込みを含めると 5.1B)、35 層、語彙数 262K、コンテキスト長(一度に扱える入力の長さ)128K、ライセンスは Apache 2.0 である。テキストに加えて画像入力にも対応し、思考モード(reasoning)を備える。Ollama のベンチマーク表では、E2B の MMLU Pro(幅広い分野の知識と推論力を測るベンチマーク)が 60.0%、多言語ベンチマーク MMMLU が 67.4% と報告されており、小型ながら一定の総合性能を示す。
このモデルは導入済みであるため、Ollama で gemma4:e2b-it-qat を試すには、次のコマンドをコマンドプロンプトで実行するだけでよい(初回導入時のダウンロードは「Ollama・モデル・Open WebUI のインストール」章で完了している)。
ollama run gemma4:e2b-it-qat実行すると対話が始まる。動作確認用の問いかけとして、これまでと同じ「日本の首都はどこですか?」を入力してみるとよい。対話を終了するには /bye と入力する。サーバに接続できない場合は、別のコマンドプロンプトで ollama serve を実行してサーバを起動してから、再度上のコマンドを実行する。
ただし gemma4:e2b-it-qat を選ぶ際は、リソース要求が LFM2.5-1.2B とは異なる点に注意したい。LFM2.5-1.2B の GGUF(Q4_K_M 量子化)が約 731MB、VRAM 目安が 1〜2GB であるのに対し、Ollama 上の gemma4:e2b-it-qat はダウンロード容量が約 4.3GB あり、必要な VRAM/メインメモリもその分大きくなる。QAT による軽量化版とはいえサイズに差があるため、手元のマシンの空き容量とメモリに余裕があるかを確認したうえで運用するとよい。さらに上位の gemma4:12b-it-qat(約 7.2GB)も同章で導入済みであり、ollama run gemma4:12b-it-qat で同様に試せる。
このように、Ollama では ollama run <モデル名> のモデル名を変えるだけで、用途やマシンの能力に応じてさまざまなモデルを試すことができる。
追加リソース
公式ドキュメント
- transformers: https://huggingface.co/docs/transformers
- unsloth: https://docs.unsloth.ai
- llama.cpp: https://github.com/ggml-org/llama.cpp
- Ollama: https://docs.ollama.com
- Open WebUI: https://docs.openwebui.com
- LM Studio: https://lmstudio.ai/docs
- vLLM: https://docs.vllm.ai
- LLaMA Factory: https://llamafactory.readthedocs.io
- Liquid AI LFM2.5: https://docs.liquid.ai
- LFM2.5 Hugging Face: https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct
- bge-m3 Hugging Face: https://huggingface.co/BAAI/bge-m3