ニューラルネットワークと機械学習の基礎:概念からPyTorchによる実装まで
【概要】
ニューラルネットワークは、ニューロンを処理単位として構成される機械学習モデルである。各ニューロンは、入力の重みづけ、重み付き和とバイアスの加算、活性化関数の適用を行う。PyTorchを用いた実装では、訓練データによる学習を通じて、ニューロン間の結合の重みとバイアスを最適化し、データの特徴やパターンを獲得する。学習では、バックプロパゲーションによる誤差の逆伝播と、勾配降下法による誤差の最小化が中心的な役割を担う。
【本資料の読み方】
第2章で機械学習とMNISTの概要を示し、第3章では完成プログラム(演習1)を実行する。これは本資料が最終的に到達する内容のデモであり、ここで用いる用語やコードの細部(バッチ、エポック、損失関数など)がこの時点で分からなくても差し支えない。第4章以降で、ニューロン、活性化関数、フォワードプロパゲーション、バックプロパゲーションを順に説明する。これらを理解したうえで第3章のプログラムに戻ると、全体像が把握できる構成である。
ニューラルネットワークの学習では、出力と正解のずれを測る損失関数をタスクに応じて使い分ける。分類タスク(MNISTなど、入力をいずれかのクラスに振り分ける問題)では交差エントロピーを、第8章の手計算例のような単純な数値合わせでは二乗誤差を用いる。用語は以下のように使い分ける。損失(loss)は損失関数が出力する1つの数値で、出力全体のずれを集約した値である。誤差(error)は出力と正解の各要素のずれを指す。勾配(gradient)は、損失を小さくするために各重み・バイアスをどの向きにどれだけ変えればよいかを示す量であり、バックプロパゲーションで計算される。
【目次】
1. PythonとPyTorchのインストール(Windows上)
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。Windows 版の PyTorch がサポートする Python は 3.10〜3.14 であり、本資料では Python 3.12 を用いる。
方法1:winget によるインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
続いて、以下を実行する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定すると、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、Windows 用の Python 3.12 系インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れないと、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.12 for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
PyTorch のインストール
本資料で使用するのは PyTorch(torch)と、画像データセットを扱う torchvision である。NVIDIA 製 GPU を搭載しているかどうかにより、以下の2通りからいずれかを選んでインストールする。どちらを選んでも本資料のコードはそのまま動作する(コード内で GPU が利用可能なら GPU を、なければ CPU を使用する)。
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
GPU(NVIDIA 製)を搭載している場合:CUDA 対応版をインストールする。下記は CUDA 13.0 対応版(cu130)であり、Windows + Python 3.12 向けの安定版 wheel が配布されている。
pip install -U --no-user torch torchvision --index-url https://download.pytorch.org/whl/cu130GPU を搭載していない場合(CPU のみ):CPU 専用版をインストールする。
pip install -U --no-user torch torchvision --index-url https://download.pytorch.org/whl/cpu数値計算ライブラリの numpy は torch の依存として自動的にインストールされるため、個別の指定は不要である。インストール後、以下を実行して PyTorch の導入と GPU の利用可否を確認できる。
import torch
print(torch.__version__) # PyTorch のバージョン
print(torch.cuda.is_available()) # GPU が利用可能なら True、CPU のみなら FalseCPU のみの環境では、第3章の MNIST 学習プログラムの実行に数分程度かかることがある。実行中に出力が止まって見えても異常ではないため、エポックごとの表示が出るまで待つ。
【関連する外部ページ】
- Python 公式サイト:https://www.python.org/
- PyTorch 公式インストールガイド:https://pytorch.org/get-started/locally/
2. 機械学習の概要とPyTorchによる実装例
機械学習は、訓練データを用いて学習し、分類や予測などの能力を獲得する技術である。訓練データは、学習に使用するデータである。学習の手順は以下のとおりである。
- データの準備(目的に応じた訓練データを準備する)
- 学習の実行(データからパターンを学習し、モデルを構築する)
- タスクの実行(新しいデータを処理する)
機械学習の特徴は以下のとおりである。
- データを用いて性能を向上させる
- データのパターンを自動で抽出する
- 人手による規則の記述が不要である
応用事例には、画像認識、自然言語処理、予測などがある。
MNISTデータセットは、手書き数字(0〜9)の画像データセットであり、機械学習の入門用に使用される。
- 訓練用60,000枚、テスト用10,000枚で構成される
- 各画像は28×28ピクセルのグレースケールである
- 各画像に正解ラベル(0〜9)が付与されている
次章の演習では、MNIST を用いて手書き数字を分類するニューラルネットワークを学習・評価するプログラムを実行する。GPU がある環境では GPU を、ない環境では CPU を使用する。
プログラムで用いる用語を以下に示す(詳しい仕組みは第4章以降で説明する)。
- バッチ:訓練データを少数ずつまとめた単位(演習のプログラムでは1バッチ64枚)。1枚ずつではなくまとめて処理することで学習が効率化される
- エポック:訓練データ全体を1巡すること(演習のプログラムでは5エポック繰り返す)
- データローダー(DataLoader):データセットをバッチに分割し、順に供給する仕組み
- 損失関数:出力と正解のずれを1つの数値で表す関数(ここでは分類向けの交差エントロピー
CrossEntropyLossを用いる)
出力層に活性化関数を適用しない理由:演習のモデルでは、中間層には ReLU を適用するが、出力層には活性化関数を適用せず、生の出力値(ロジット)をそのまま返す。これは、CrossEntropyLoss が内部で Softmax 相当の処理(出力を確率に変換する処理)を含むため、出力層で別途 Softmax を適用する必要がないからである。第6章の「最も高い活性度を示すニューロンに対応するクラスが分類結果となる」という考え方はここでも適用され、評価時には torch.max によって最大の出力値を持つニューロンの番号を予測クラスとしている。
学習率0.1は、学習の進み方を調整する設定値の例である。値が大きすぎると学習が不安定になり、小さすぎると収束が遅くなる。
3. 演習1.MNISTの学習と正解率の確認
テーマ:MNIST データセットを用いた手書き数字分類モデルの学習と評価
手順
- 下記のプログラムを実行する(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)。
- エポックごとに表示される訓練損失と、最後に表示されるテストデータの正解率を記録する。
epochsの値を5から10に変更し、再度実行して結果を記録する。
ヒント:epochs は学習の実行部分で定義されている。CPU環境では実行に数分かかることがある。
考察ポイント:エポック数を増やすと訓練損失とテスト正解率がどのように変化するか。損失の減少と正解率の向上が対応しているかを確認する。
import torch
from torch import nn, optim
from torchvision import datasets, transforms
# デバイスの設定(GPUが使えればGPU、なければCPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# データセットの準備(MNIST)
# ToTensor()によりピクセル値は0〜1に正規化される
transform = transforms.Compose([transforms.ToTensor()])
train_data = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_data = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# データローダーの設定(データをバッチに分割して供給する)
# batch_size=64: 1バッチ64枚 shuffle=True: 訓練時は順序をランダム化
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=False)
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
# 入力層784(=28×28)→中間層128→中間層64→出力層10(=クラス数0〜9)
# 中間層のニューロン数128・64は設計者が選ぶ値(ハイパーパラメータ)である
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
# 出力層には活性化関数を適用しない(理由は本資料の第2章を参照)
x = self.fc3(x)
return x
# モデルをデバイスに移動
model = SimpleNN().to(device)
criterion = nn.CrossEntropyLoss() # 分類向けの損失関数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 勾配降下法(学習率0.1)
# 学習の実行
epochs = 5
for epoch in range(epochs):
model.train() # 訓練モード(ドロップアウト等を訓練用に切り替える)
running_loss = 0.0
for images, labels in train_loader:
# 28×28の画像を784次元の1次元ベクトルに変換し、データをデバイスに移動
images = images.view(images.shape[0], -1).to(device)
labels = labels.to(device)
optimizer.zero_grad() # 勾配の初期化
output = model(images) # フォワードプロパゲーション
loss = criterion(output, labels) # 損失の計算
loss.backward() # バックプロパゲーション(勾配計算)
optimizer.step() # 重みとバイアスの更新
running_loss += loss.item()
print(f"エポック {epoch+1}/{epochs}, 訓練損失: {running_loss/len(train_loader):.4f}")
# モデルの評価
model.eval() # 評価モード(ドロップアウト等を評価用に切り替える)
correct = 0
total = 0
with torch.no_grad(): # 勾配計算を止めてメモリと計算を節約(評価時は更新しないため)
for images, labels in test_loader:
images = images.view(images.shape[0], -1).to(device)
labels = labels.to(device)
outputs = model(images)
# 最も大きい出力値を持つニューロンの番号を予測クラスとする
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"テストデータにおける正解率: {100 * correct / total:.2f}%")
4. ニューラルネットワークの基本構造と仕組み
ニューラルネットワークは、機械学習の手法の一つであり、ニューロンと呼ばれる処理単位から構成される。各ニューロンは複数の入力信号を受け取り、以下の処理を行う。
- 入力の重みづけ:各入力信号に重み係数を乗算する。重みは各入力の重要度を表し、学習により調整される
- 重み付き和とバイアスの加算:重みづけされた入力値の総和にバイアス値を加算する。バイアスはニューロンの発火しやすさを調整する
- 活性化関数の適用:加算結果に活性化関数を適用し、出力値を決定する
この出力は、次層のニューロンへの入力として伝播される。
以下に、単一ニューロンの順伝播計算のプログラム例を示す。
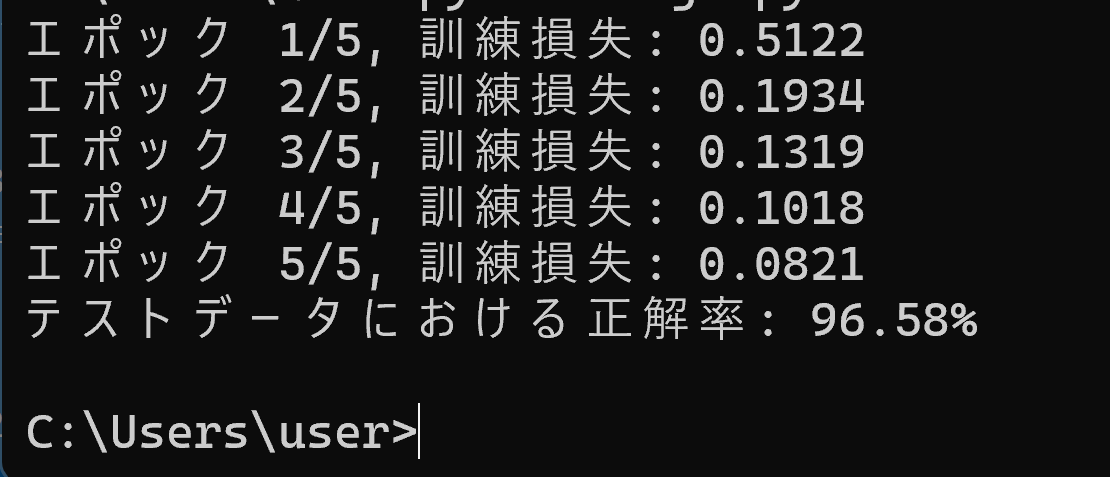
# 単一ニューロンの順伝播計算
# 入力、重み、バイアスから出力値を計算する
inputs = [0.3, -0.5, 0.2] # 入力値
weights = [0.1, 0.8, -0.5] # 重み
bias = 0.2 # バイアス
# 重み付き和の計算(各入力に対応する重みを掛けて合計)
weighted_sum = 0
for i in range(len(inputs)):
weighted_sum += inputs[i] * weights[i]
# バイアスを加算
weighted_sum += bias
# ReLU活性化関数による出力計算(0以下なら0、そうでなければそのまま出力)
output = max(0, weighted_sum)
print(f"{inputs} -> {output}")
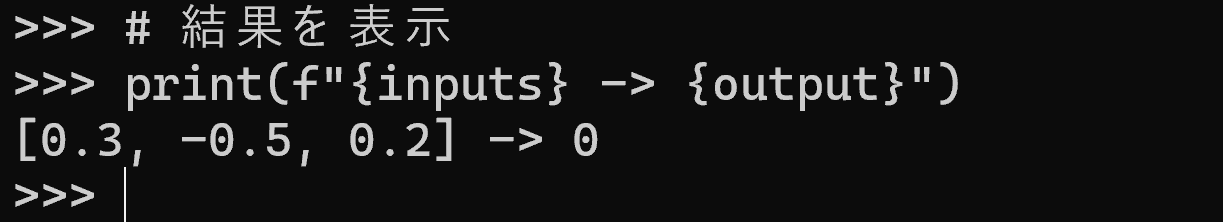
5. 活性化関数とその役割
活性化関数は、ニューロンの出力値を決定する関数であり、重み付き和とバイアスの加算結果に適用される。代表的な活性化関数として、ReLUとシグモイド関数がある。
ReLU(Rectified Linear Unit)は、以下の特徴を持つ。
- 入力が0未満の場合は0を出力する
- 入力が0以上の場合は、その値をそのまま出力する
- ディープラーニングで使用される
シグモイド関数は、入力値を0から1の範囲の実数に変換する。
以下に、ReLUとシグモイド関数のプログラム例を示す。
import math
def relu(x):
# ReLU活性化関数(0以下なら0、そうでなければそのまま出力)
return max(0, x)
def sigmoid(x):
# シグモイド活性化関数(入力を0〜1の範囲に変換)
return 1 / (1 + math.exp(-x))
x1 = 1
x2 = -1
x3 = 0
print(f"{x1} -> {relu(x1)}") # ReLU(正の入力)
print(f"{x2} -> {relu(x2)}") # ReLU(負の入力)
print(f"{x3} -> {sigmoid(x3)}") # シグモイド
6. ニューラルネットワークの構造とフォワードプロパゲーション
ニューラルネットワークは、複数の層から構成される。各層は複数のニューロンで構成され、層間はニューロン同士の結合で接続される。入力層のニューロン数は入力データの大きさ(MNISTでは28×28=784)に、出力層のニューロン数は分類するクラス数(MNISTでは0〜9の10)に対応する。中間層(隠れ層)のニューロン数は設計者が選ぶ値(ハイパーパラメータ)であり、タスクに応じて調整する。
フォワードプロパゲーションでは、入力データが入力層から出力層へと順方向に伝播する。各層のニューロンは、前層からの入力を処理し、その結果を次層へ伝達する。
分類タスクにおける出力層の構造は以下のとおりである。
- 出力層のニューロン数は、分類対象のクラス数に対応する
- 各出力ニューロンは活性度(実数値)を出力する
- 最も高い活性度を示すニューロンに対応するクラスが分類結果となる
以下のプログラムは、2入力3出力のニューラルネットワークによる3クラス分類を実装している。
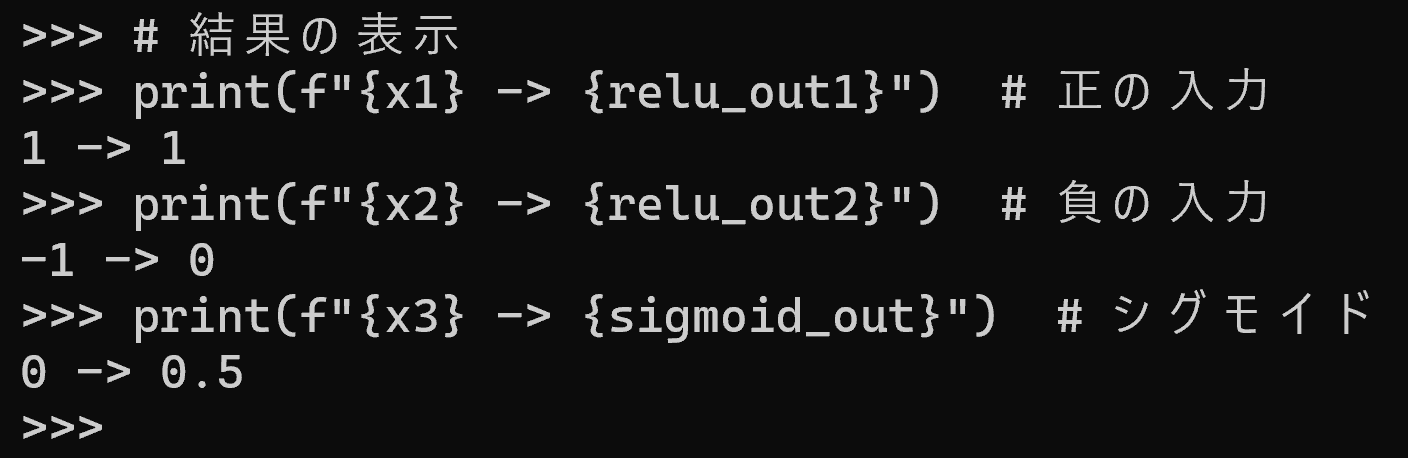
# 2入力3出力のニューラルネットワークによる3クラス分類
# 入力層(2ニューロン)から出力層(3ニューロン)への順伝播計算を行う
inputs = [0.2, 0.8] # 入力値
# 入力層から出力層への重み係数(2×3)
layer_weights = [
[0.1, 0.4, 0.7], # 入力1からの重み
[0.2, 0.5, 0.8] # 入力2からの重み
]
layer_bias = [0.1, 0.1, 0.1] # 出力層の各ニューロンのバイアス
# 出力層の各ニューロンの出力を計算
output = [0] * 3
for j in range(3): # 出力層の各ニューロンについて
s = 0
for i in range(2): # 入力層の各ニューロンからの入力を合計
s += inputs[i] * layer_weights[i][j]
s += layer_bias[j] # バイアスを加算
output[j] = max(0, s) # ReLU活性化関数
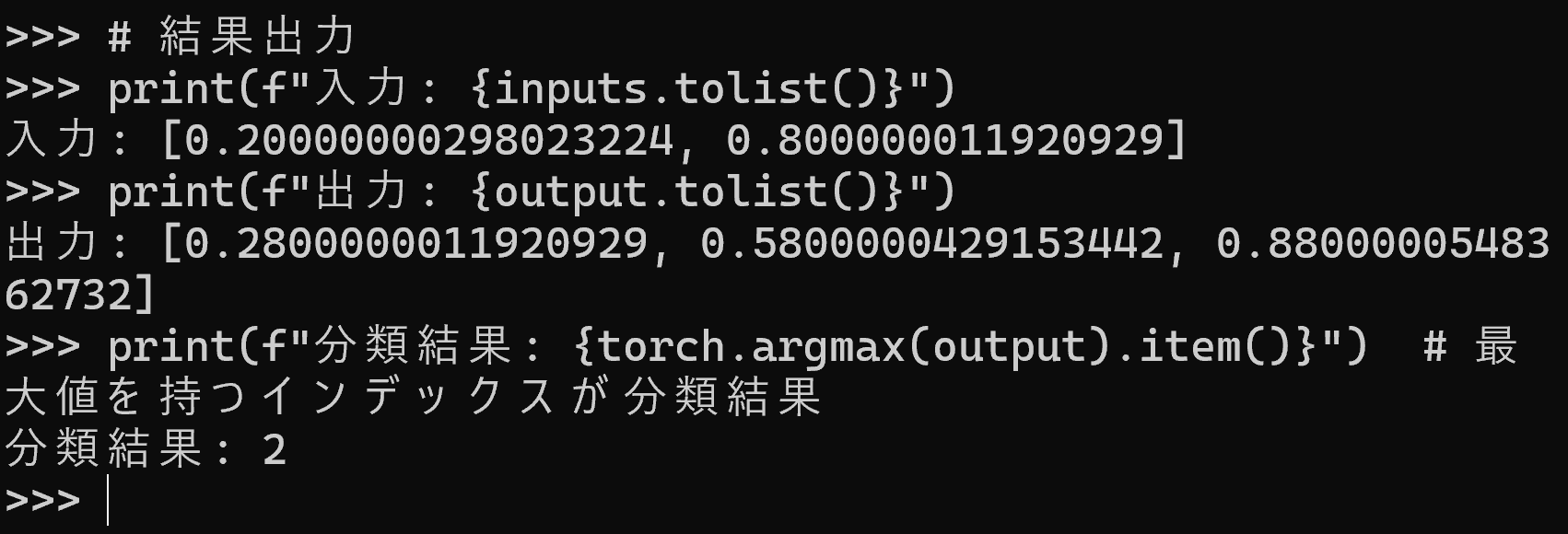
print(f"入力: {inputs}")
print(f"出力: {output}")
print(f"分類結果: {output.index(max(output))}") # 最大出力を持つニューロンの番号
PyTorchによる実装
PyTorchを用いると、上記と同等の計算を簡潔に記述できる。
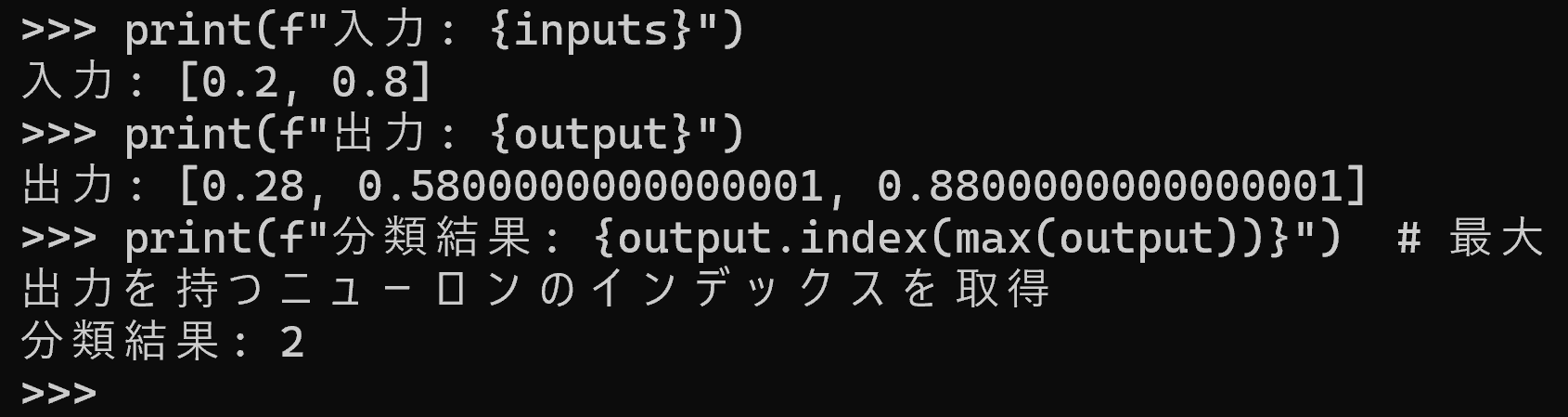
# 2入力3出力のニューラルネットワークによる3クラス分類(PyTorch版)
import torch
inputs = torch.tensor([0.2, 0.8]) # 入力データ(2ニューロン)
# 重み行列(入力2×出力3)
layer_weights = torch.tensor([
[0.1, 0.4, 0.7], # 入力1からの重み
[0.2, 0.5, 0.8] # 入力2からの重み
])
layer_bias = torch.tensor([0.1, 0.1, 0.1]) # 出力層の3ニューロン分のバイアス
# フォワードプロパゲーション
# 1. 入力と重みの行列積で重み付き和を計算
# 2. バイアスを加算
# 3. ReLU活性化関数を適用
output = torch.relu(torch.matmul(inputs, layer_weights) + layer_bias)
print(f"入力: {inputs.tolist()}")
print(f"出力: {output.tolist()}")
print(f"分類結果: {torch.argmax(output).item()}") # 最大値を持つ番号
7. バックプロパゲーションと学習メカニズム
バックプロパゲーションは、ニューラルネットワークの学習アルゴリズムである。出力誤差を基に、出力層から入力層へと逆方向に誤差を伝播させ、各層の重みとバイアスを更新する。
学習の手順は以下のとおりである。
- 訓練データを用いてフォワードプロパゲーションを行い、出力を得る
- 出力と正解(教師信号)を損失関数で比較し、損失を計算する。損失関数は問題の種類により使い分け、第2章で扱ったような分類タスクでは交差エントロピーを、第8章の手計算例のような単純な数値合わせでは二乗誤差を用いる
- 損失の勾配を計算し、勾配降下法により重みとバイアスを更新する。勾配は、損失を小さくするために各重み・バイアスをどう変えればよいかを示す量である
- 訓練データを繰り返し使用し、損失を低減する
次章の演習では、二乗誤差を用いた重みの更新を、計算過程を明示した基本的な実装(プログラム1)と、PyTorchの自動微分機能を活用した実装(プログラム2)の2つの方法で示す。
8. 演習2.二乗誤差による重みの更新
テーマ:二乗誤差を損失関数とした重みとバイアスの更新(手計算実装と自動微分実装の比較)
手順
- 下記のプログラム1を実行し(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)、誤差と更新後の重みを記録する。
- 同じ入力で下記のプログラム2を実行し、誤差と更新後の重みを記録する。
- 2つのプログラムの出力を比較する。
ヒント:両プログラムは同じ入力値、同じ初期重み、同じ学習率を用いている。プログラム1は更新式を明示的に記述し、プログラム2は自動微分で同じ計算を行う。
考察ポイント:手計算による更新(プログラム1)と自動微分による更新(プログラム2)で、更新後の重みが一致するかを確認する。
本演習では仕組みを理解しやすくするため、損失関数として二乗誤差を用いる。プログラム1は計算過程を明示した基本的な実装、プログラム2はPyTorchの自動微分機能を活用した実装である。
プログラム1:基本的な実装
# 入力層(2)→出力層(3)のニューラルネットワークの学習
# ReLU活性化関数を使用し、二乗誤差により重みとバイアスを更新する
inputs = [0.2, 0.8]
target = [1, 0, 0] # 正解ラベル(3クラス分類の1番目)
learning_rate = 0.1
# 初期重みとバイアス
layer_weights = [
[0.1, 0.4, 0.7], # 入力1からの重み
[0.2, 0.5, 0.8] # 入力2からの重み
]
layer_bias = [0.1, 0.1, 0.1] # 出力層の各ニューロンのバイアス
# フォワードプロパゲーション
output = [0, 0, 0]
for j in range(3):
s = 0
for i in range(2):
s += inputs[i] * layer_weights[i][j]
s += layer_bias[j]
output[j] = max(0, s) # ReLU活性化関数
# 誤差の計算(教師信号と出力の差)
errors = [target[j] - output[j] for j in range(3)]
# 勾配降下法による重みとバイアスの更新
# 二乗誤差 L = Σ(target - output)^2 の勾配は -2(target - output)*入力 となるため、
# 更新式の係数に 2 が現れる
for j in range(3):
if output[j] > 0: # ReLUの勾配は出力が正のときのみ1
for i in range(2):
layer_weights[i][j] += 2 * learning_rate * errors[j] * inputs[i]
layer_bias[j] += 2 * learning_rate * errors[j]
print(f"誤差: {errors}")
print(f"更新後の重み: {layer_weights}")

プログラム2:PyTorchによる実装
PyTorchの自動微分機能では、勾配を手計算せずに求められる。requires_grad=True を指定したテンソルに対して行った計算は記録され、loss.backward() を呼ぶと各テンソルの勾配が .grad に格納される。勾配は backward() を呼ぶたびに加算されるため、更新後に zero_() でゼロに戻し、次回の計算に前回の勾配が混ざらないようにする。
# 入力層(2)→出力層(3)のニューラルネットワークの学習(PyTorch版)
import torch
inputs = torch.tensor([0.2, 0.8])
target = torch.tensor([1.0, 0.0, 0.0]) # 正解ラベル(3クラス分類の1番目)
learning_rate = 0.1
# 重みとバイアスの初期化(requires_gradを設定して勾配計算を有効化)
layer_weights = torch.tensor([
[0.1, 0.4, 0.7],
[0.2, 0.5, 0.8]
], requires_grad=True)
layer_bias = torch.tensor([0.1, 0.1, 0.1], requires_grad=True)
# フォワードプロパゲーション
output = torch.relu(torch.matmul(inputs, layer_weights) + layer_bias)
# 二乗誤差による損失の計算(出力と正解のずれの二乗の総和)
loss = torch.sum((target - output) ** 2)
# 更新前に誤差を記録(detach()で勾配計算の対象から外す)
errors = (target - output).detach().tolist()
# バックプロパゲーション(各テンソルの.gradに勾配が格納される)
loss.backward()
# 勾配降下法による重みとバイアスの更新(更新操作は勾配計算の対象外にする)
with torch.no_grad():
layer_weights -= learning_rate * layer_weights.grad
layer_bias -= learning_rate * layer_bias.grad
# 次回の計算に前回の勾配が加算されないよう、勾配をクリア
layer_weights.grad.zero_()
layer_bias.grad.zero_()
print(f"誤差: {errors}")
print(f"更新後の重み: {layer_weights.tolist()}")

9. 過学習の概念と対策
過学習は、訓練データへの過剰な適合により発生する現象である。訓練データに含まれるノイズや偶発的なパターンまで学習し、未知のデータに対する性能が低下する。訓練データが少ない場合や、モデルのパラメータ数が多い場合に発生しやすい。
対策は以下のとおりである。
- 訓練データの増加
- モデルの複雑さの抑制(層数やニューロン数の調整)
- 検証データによる過学習の検出
- ドロップアウト:学習時にランダムにニューロンを無効化する手法。第3章のコードで
model.train()とmodel.eval()を切り替えていたのは、こうした学習時のみ有効な処理を、評価時には無効にするためである - 正則化(L1、L2):重みの大きさに制約を加える手法
10. ディープラーニングの概要
ディープラーニングは、多層のニューラルネットワークを使用する機械学習の手法である。「ディープ」という名称は、多層構造に由来する。
ディープラーニングは、画像認識、自然言語処理、音声認識などのタスクで使用される。これを支える要素には、活性化関数(ReLUなど)、ドロップアウトなどの正則化手法、大規模データ、高性能な計算機環境(GPUなど)がある。
11. まとめ
ニューラルネットワークは、ニューロンによる入力の重みづけ、重み付き和とバイアスの加算、活性化関数の適用を基本とする。フォワードプロパゲーションにより入力から出力へデータが伝播し、バックプロパゲーションにより重みとバイアスが更新される。学習では、出力と正解のずれを損失関数で数値化し、その勾配にもとづいて勾配降下法でパラメータを更新する。損失関数は問題の種類により使い分け、分類では交差エントロピーを、単純な数値合わせでは二乗誤差を用いる。訓練データを繰り返し使用することで損失を低減し、目的のタスクを実行できるようになる。