英文のコーパス(ドキュメントの集まり)から 辞書,Bag of Words, Latent Semantic Indexing (LSI),Latent Dirichlet Allocation (LDA) を作る
次のページで公開されているプログラムを使い, 英語の文書(ドキュメント)についての,単語の切り出し,ストップワードの除去,頻出単語の抽出とIDの付与,Bag of Words の作成,LSI,LDA の作成を行う.
https://radimrehurek.com/gensim/auto_examples/core/run_core_concepts.html#core-concepts-document
【サイト内の関連ページ】
- 日本語文の場合について: 別ページ »で説明
謝辞:このページで使用しているソフトウェア類の作者に感謝します.
前準備
Python のインストールと必要なPythonライブラリのインストール(Windows上)
- Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements REM Python のパス設定 set "PYTHON_PATH=C:\Program Files\Python312" set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts" echo "%PATH%" | find /i "%PYTHON_PATH%" >nul if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
- AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
- 必要なPythonライブラリのインストール
【関連する外部ページ】
【サイト内の関連ページ】
日本語文書からの単語の切り出し,品詞の判定
Python 処理系の起動
Python 処理系として,Jupyter Qt Console を起動
jupyter qtconsole

Python プログラムを動かして,結果をビジュアルに見たい.
ここでは,Jupyter Qt Console を使っている. 他の開発環境(Spyder,PyCharm,PyScripter など)も便利である.
ここから先は,Jupyter Qt Console の画面で説明する.
コーパス
文書(ドキュメントの集まり)をコーパスという.
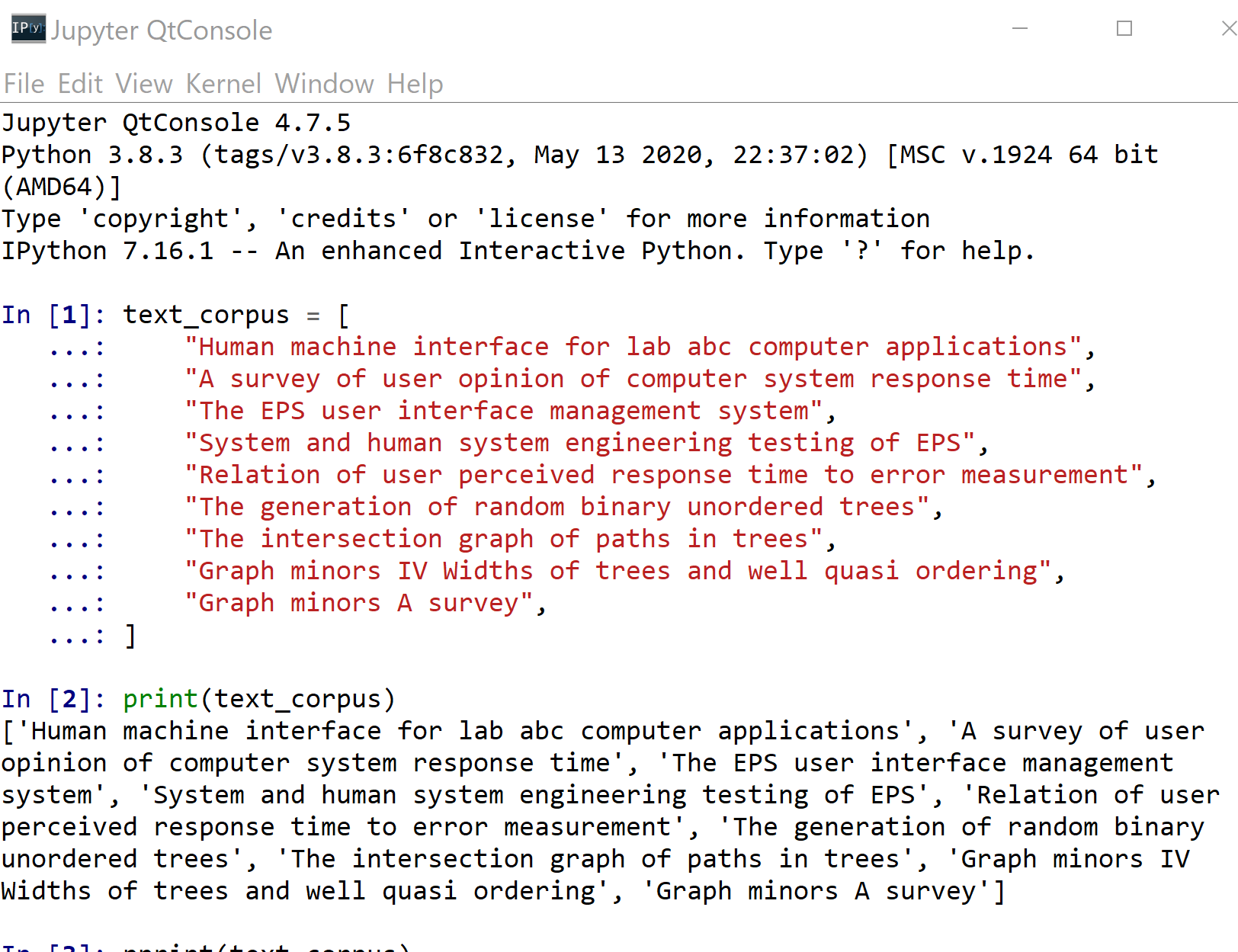
text_corpus = [
"Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey",
]
print(text_corpus)
単語の切り出し
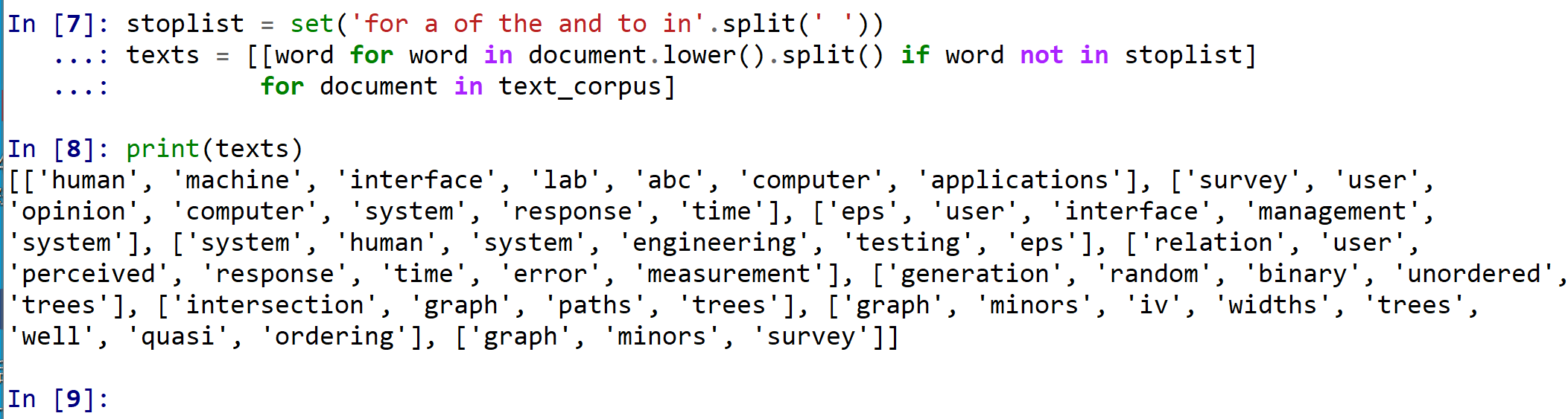
英語の文書から,単語を切り出す.切り出しには split() を用いる. このとき,次のことを行う.
- ストップワード(for, a, of, the, and, to, in)は除去する.
- 大文字は小文字に変える
stoplist = set('for a of the and to in'.split(' '))
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in text_corpus]
print(texts)
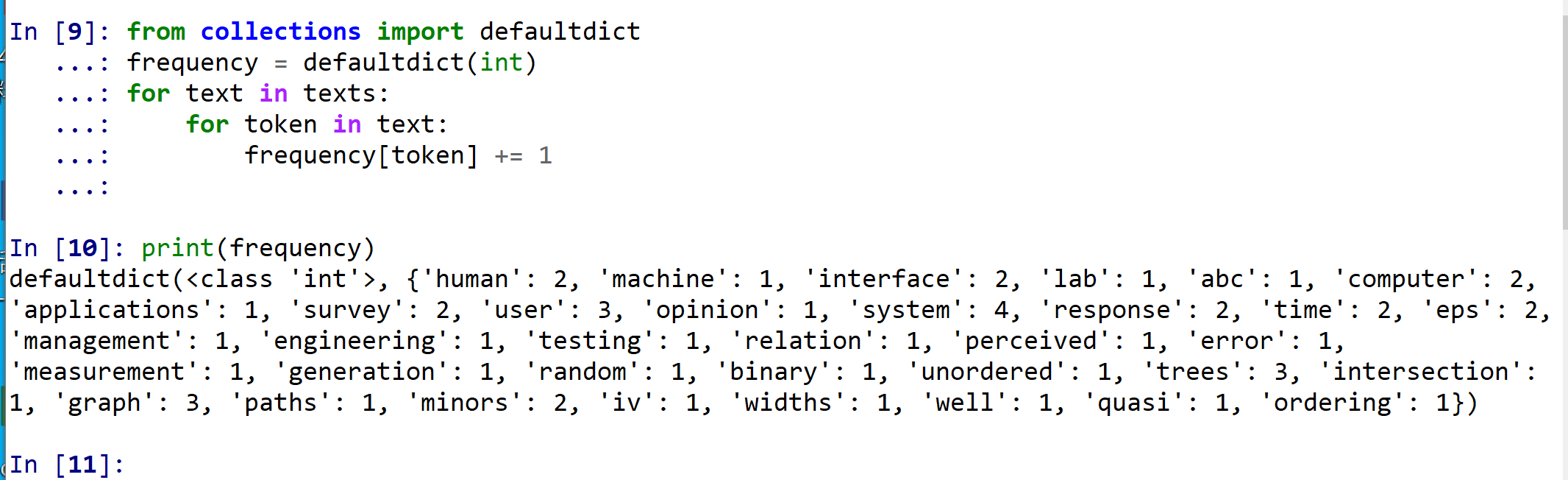
単語の出現数を数え上げ,単語の切り出し結果について頻出する単語のみを残す.
単語の出現数の数え上げは次で行う.
from collections import defaultdict
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
print(frequency)
単語の切り出し結果について,頻出する単語(出現回数 2回以上のみ)を残す.
processed_corpus = [[token for token in text if frequency[token] > 1] for text in texts]
print(processed_corpus)

単語の切り出し結果を使い,単語ごとに ID を割り振る
単語に,整数の ID を割り振る.
from gensim import corpora
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary.token2id)

Bag of Words
Bag of Words は,単語IDと出現回数のペアを文書(ドキュメント)ごとに作ったもの.
bow_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
print(bow_corpus)

TF/IDF コーパスの作成
先ほど作成した bow_corpus (Bag of Words) をTF/IDF値に変換する.
gensim の次のページで公開されている Python プログラムを使用
https://radimrehurek.com/gensim/auto_examples/core/run_topics_and_transformations.html#sphx-glr-auto-examples-core-run-topics-and-transformations-py
from gensim import models
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
for doc in corpus_tfidf:
print(doc)

Latent Semantic Indexing (LSI)
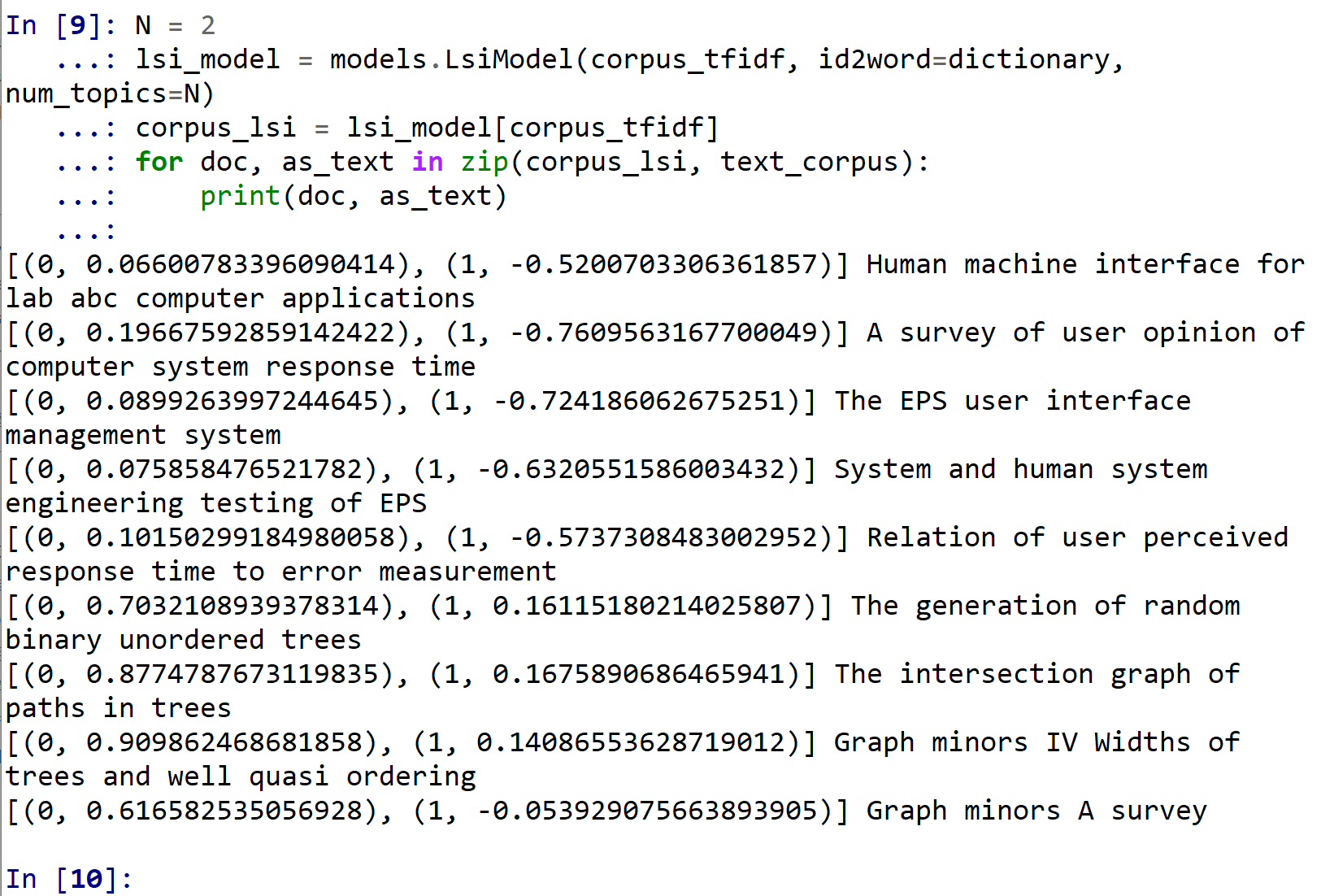
先ほど作成した corpus_tfidf (TF/IDF コーパス) をLatent Semantic Indexing に変換する. ここでは, トピックス数を 2 に設定.
gensim の次のページで公開されている Python プログラムを使用
https://radimrehurek.com/gensim/auto_examples/core/run_topics_and_transformations.html#sphx-glr-auto-examples-core-run-topics-and-transformations-py
N = 2
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=N)
corpus_lsi = lsi_model[corpus_tfidf]
for doc, as_text in zip(corpus_lsi, text_corpus):
print(doc, as_text)
Latent Dirichlet Allocation (LDA)
先ほど作成した bow_corpus (Bag of Words) をLatent Dirichlet Allocation (LDA) に変換する. ここでは, トピックス数を 100 に設定.
gensim の次のページで公開されている Python プログラムを使用
https://radimrehurek.com/gensim/auto_examples/core/run_topics_and_transformations.html#sphx-glr-auto-examples-core-run-topics-and-transformations-py
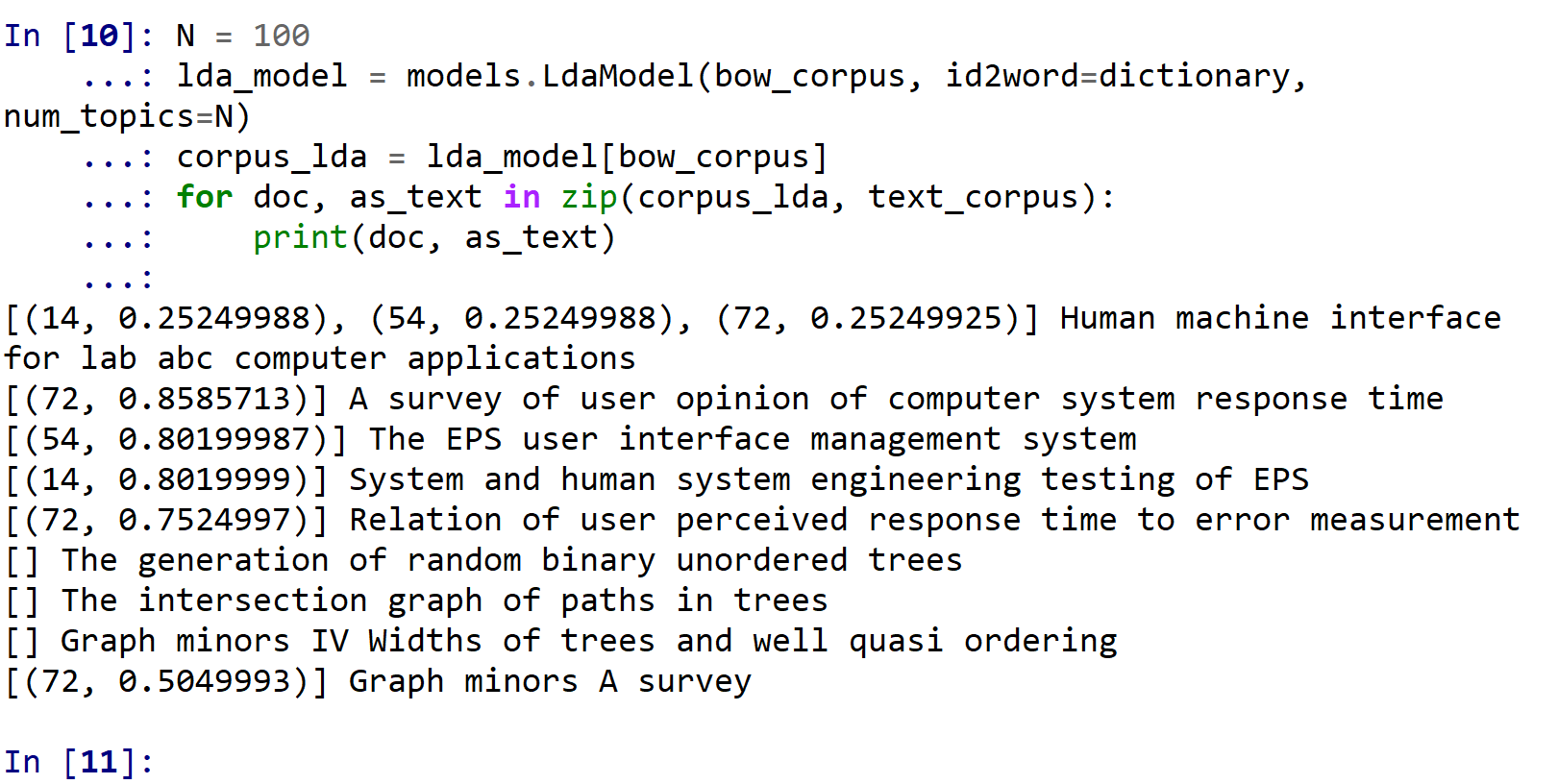
N = 100
lda_model = models.LdaModel(bow_corpus, id2word=dictionary, num_topics=N)
corpus_lda = lda_model[bow_corpus]
for doc, as_text in zip(corpus_lda, text_corpus):
print(doc, as_text)