SQLによるテーブルの関数従属性の確認、分解と結合(SQLite 3を使用)
【概要】SQLiteを使用して、テーブルの属性間における関数従属性をSQLで確認する方法、およびテーブルを分解して結合する手法について、具体的な事例を用いて解説する。情報無損失分解の概念についても扱う。
【目次】
はじめに
属性間の関数従属性をSQLで確認する方法について、具体的な事例を用いて解説する。
テーブルRが属性a1, a2, ..., am, b1, b2, ..., bnおよびその他の属性を持ち、関数従属性a1, a2, ..., am -> b1, b2, ..., bnが存在する場合、以下のSQLの実行結果において、1番目の属性値が「1」となる。
create table S AS
select distinct a1, a2, ..., am, b1, b2, ..., bn
from R;
select count(*), a1, a2, ..., am
from S
group by a1, a2, ..., am;
SQLite 3のSQL文法の詳細については、http://www.hwaci.com/sw/sqlite/lang.html(英語Webページ)を参照されたい。
前準備
SQLite 3に関する詳細は別ページ »を確認されたい。
関数従属性の確認
- SQLite 3の起動
本例では、インメモリ・データベースを使用するため、データベース名の指定は不要である。
sqlite3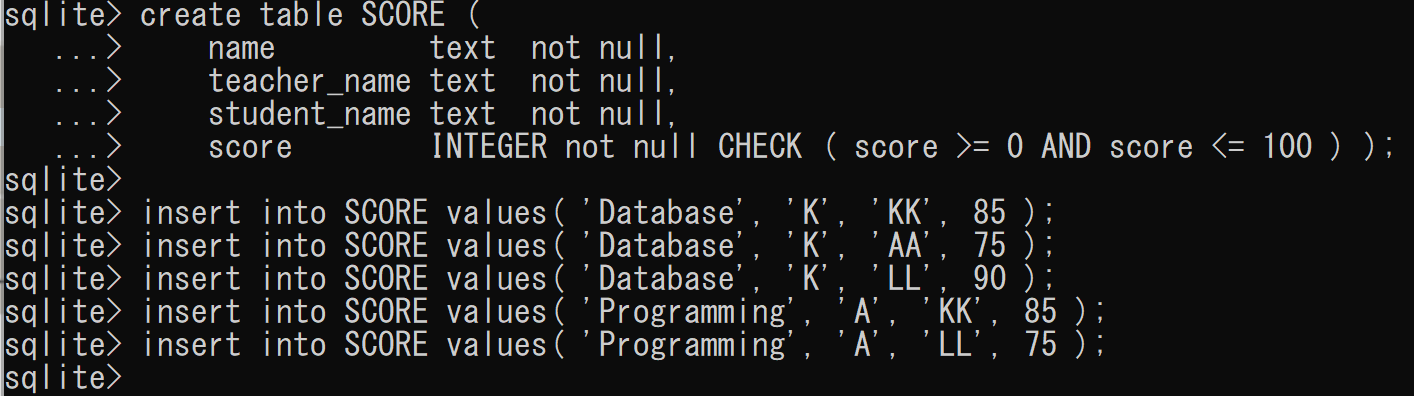
- テーブルの作成
create table SCORE ( name text not null, teacher_name text not null, student_name text not null, score INTEGER not null CHECK ( score >= 0 AND score <= 100 ) ); insert into SCORE values( 'Database', 'K', 'KK', 85 ); insert into SCORE values( 'Database', 'K', 'AA', 75 ); insert into SCORE values( 'Database', 'K', 'LL', 90 ); insert into SCORE values( 'Programming', 'A', 'KK', 85 ); insert into SCORE values( 'Programming', 'A', 'LL', 75 );
- 確認表示
select * from SCORE;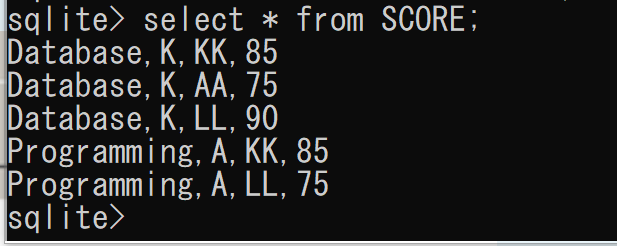
- 関数従属性 name -> teacher_name の確認
実行結果において、1番目の属性値が「1」となることを確認する。
create table S AS select distinct name, teacher_name from SCORE; select count(*), name from S group by name;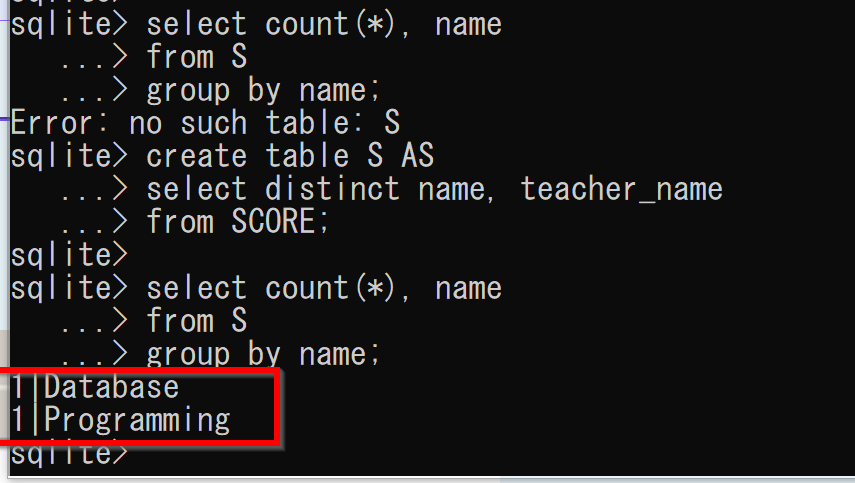
- 関数従属性 name, student_name -> score の確認
実行結果において、1番目の属性値が「1」となることを確認する。
drop table S; create table S AS select distinct name, student_name, score from SCORE; select count(*), name, student_name from S group by name, student_name;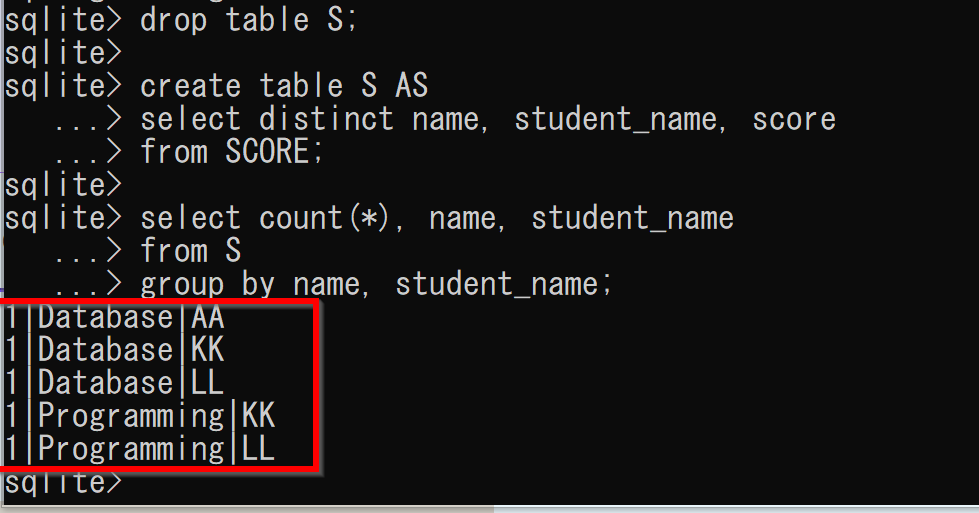
- SQLite 3の終了
.exit
テーブルの分解と結合
- SQLite 3の起動
本例では、インメモリ・データベースを使用するため、データベース名の指定は不要である。
sqlite3 - テーブルの作成
create table SCORE ( name text not null, teacher_name text not null, student_name text not null, score INTEGER not null CHECK ( score >= 0 AND score <= 100 ) ); insert into SCORE values( 'Database', 'K', 'KK', 85 ); insert into SCORE values( 'Database', 'K', 'AA', 75 ); insert into SCORE values( 'Database', 'K', 'LL', 90 ); insert into SCORE values( 'Programming', 'A', 'KK', 85 ); insert into SCORE values( 'Programming', 'A', 'LL', 75 );
- 確認表示
select * from SCORE;
- 2つのテーブルに分解
SCORE(name, teacher_name, student_name, score)を2つのテーブル
- A(name, teacher_name)
- B(name, student_name, score)
に分解する。テーブルを分解する際は重複行を除去するという規則に従い、DISTINCTを使用する。
create table A as select distinct name, teacher_name from SCORE; create table B AS select distinct name, student_name, score from SCORE;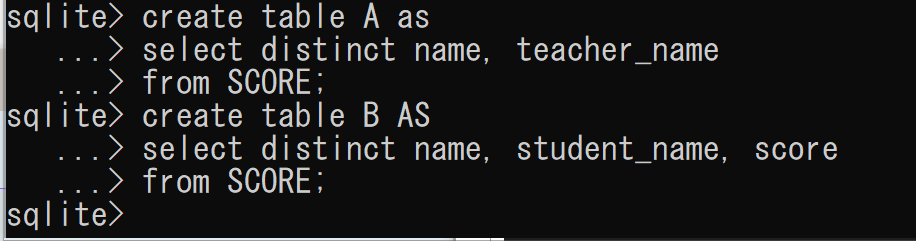
- 確認表示
select * from A;
select * from B;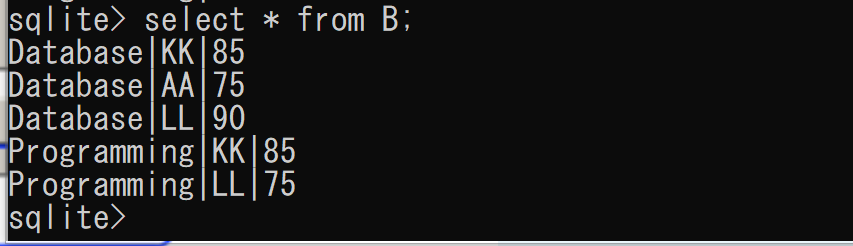
- 元のテーブルSCOREが、分解後の2つのテーブルA、Bから復元可能であることを確認する
select A.name, A.teacher_name, B.student_name, B.score from A, B where A.name = B.name;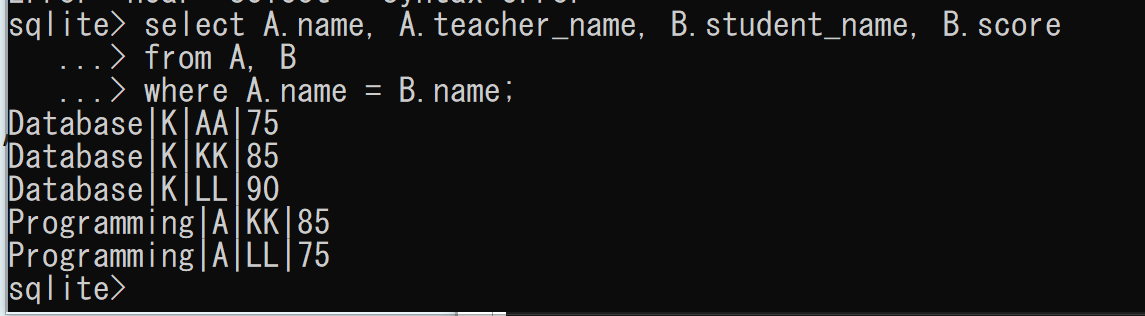
テーブルSCOREはテーブルAとBから復元可能であるため、データベース設計において、次の2つの選択肢を検討できる。
- テーブルSCOREをデータベースに格納する
- テーブルSCOREではなく、テーブルAとBをデータベースに格納する
- 情報無損失分解
ここでは、テーブルの分解方法を変更する。分解後のテーブルから、元のテーブルを復元できない場合があることを確認する。
create table C AS select distinct name, student_name from SCORE; create table D AS select distinct teacher_name, student_name, score from SCORE;
select * from C; select * from D;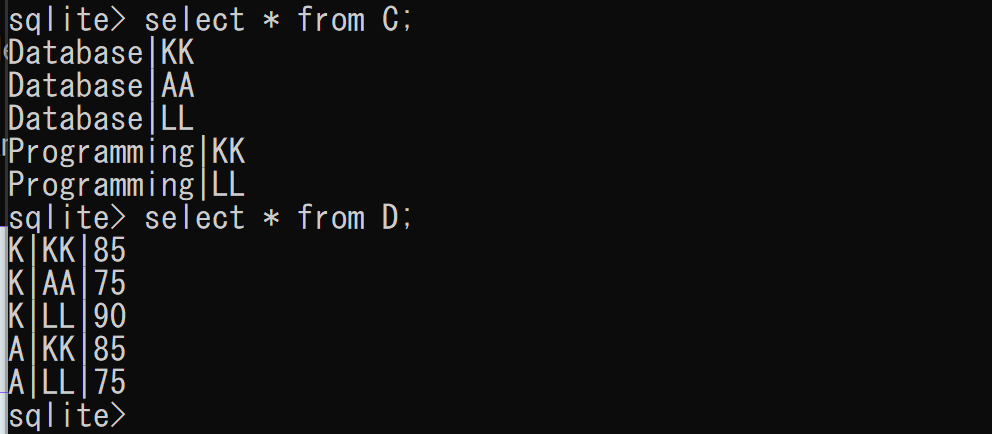
テーブルC、DからはテーブルSCOREを再構築することができない。
SELECT C.name, D.teacher_name, C.student_name, D.score FROM C, D WHERE C.student_name = D.student_name;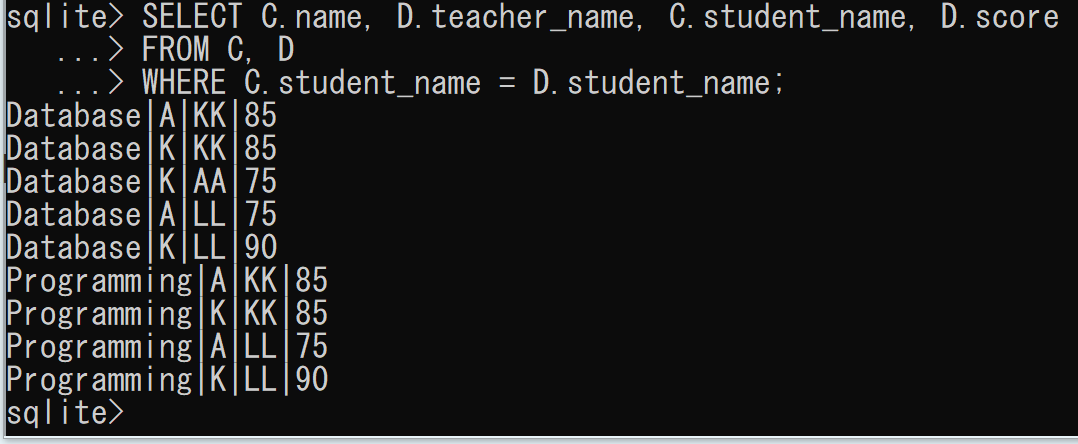
演習問題と解答例
以下の問題に取り組み、解答例を参照して理解を深められたい。
問題
次のPTABLEテーブルに関する問題である。
name | type | color ------------------------------ apple | fruit | red apple | fruit | blue rose | flower | white rose | flower | red rose | flower | yellow
- 次のSQLの実行結果を考えよ。
SELECT DISTINCT name, type FROM PTABLE;
- 次のSQLの実行結果を考えよ。
SELECT DISTINCT name FROM PTABLE;
- PTABLEテーブルを、2つのテーブルE(name, type)とF(name, color)に分解した場合の結果を示せ。
- テーブルE、Fに対する、次のSQLの実行結果を考えよ。
SELECT E.name, E.type, F.color FROM E, F where E.name = F.name;
解答例
問合せ結果は1つのテーブルとなり、属性名には元のテーブル名と属性名をドットで連結したドット記法を使用する。
-
select distinct name, type FROM PTABLE; name | type ------------------ apple | fruit rose | flower
-
select distinct name FROM PTABLE; name -------- apple rose
-
E name | type ------------------ apple | fruit rose | flower F name | color ------------------ apple | red apple | blue rose | white rose | red rose | yellow
-
name | type | color ------------------------------ apple | fruit | red apple | fruit | blue rose | flower | white rose | flower | red rose | flower | yellow