郵便番号テーブル ken_all を 3つテーブル zips, kens, shichosons に分解(Ubuntu 上)
このページでは,日本郵政「ゆうびんホームページ」で公開されている 以下の2つの郵便番号データのCSV(カンマ区切り値)形式ファイルについて解説します.
- 住所の郵便番号(CSV形式)(ken_all.csv)
- 事業所の個別郵便番号(CSV形式)(JIGYOSYO.CSV)
これらのデータには, 潜在的な冗長性が存在します(「第三正規形」を満たしていないため,データ更新時に不整合が発生する可能性があります). この問題を解決するため,郵便番号データを3つのテーブルに分解し,冗長性を排除する手順を説明します.
前準備
使用するソフトウェア
- Python 3(標準ライブラリの
sqlite3モジュールを使用)がインストール済みであること.
あらかじめ決めておく事項
このページでは,SQLite 3 データベースの生成を実施します. まず,SQLite 3 データベースのデータベース名を決定する必要があります. 本解説では,以下のように設定します.
- データベース名: zipdb
データベース名は任意に設定可能ですが,半角文字(英字および英記号)のみを使用し,スペースを含まないようにしてください.
テーブルの準備
「郵便番号 CSV データを SQLite 3 にインポート(SQLite 3 を使用)」の Web ページの手順に従って,郵便番号テーブル ken_all の作成を完了してください.
郵便番号テーブル ken_all を 3 つのテーブル zips, kens, shichosons に分解
Pythonプログラムを使用して, 郵便番号テーブル ken_allを以下の3つのテーブルに分解します.
- 郵便番号 ・・・ zips テーブル
- 県 ・・・ kens テーブル
- 市町村 ・・・ shichosons テーブル
郵便番号辞書には「町域」という要素が存在しますが, 本設計では町域に対応するテーブルは作成しません.その理由は, 「町域」テーブルを作成した場合,一意な「キー」が存在しない(より正確には,全属性を組み合わせなければキーとして機能しない)ためです. 「町域」には同一漢字で読み方が異なるケース(例:「上川」の「かみがわ」,「かみかわ」)が存在するため,一意なキーを設定できません.
zips, kens, shichosons のテーブル定義
◆ Python プログラム
import sqlite3
con = sqlite3.connect("/tmp/zipdb")
cur = con.cursor()
cur.executescript("""
CREATE TABLE kens (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
ken_kanji TEXT UNIQUE NOT NULL,
ken_kana TEXT UNIQUE NOT NULL
);
CREATE TABLE shichosons (
jiscode INTEGER PRIMARY KEY NOT NULL CHECK (jiscode >= 1000 AND jiscode <= 50000),
ken_kanji TEXT NOT NULL,
shichoson_kanji TEXT NOT NULL,
shichoson_kana TEXT
);
CREATE TABLE zips (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
zipcode INTEGER NOT NULL,
zip_old INTEGER NOT NULL,
jiscode INTEGER NOT NULL REFERENCES shichosons(jiscode),
choiki_kanji TEXT,
choiki_kana TEXT,
flag10 TEXT NOT NULL,
flag11 INTEGER NOT NULL CHECK (flag11 >= 0 AND flag11 <= 1),
flag12 INTEGER NOT NULL CHECK (flag12 >= 0 AND flag12 <= 3),
flag13 INTEGER NOT NULL CHECK (flag13 >= 0 AND flag13 <= 1),
info14 INTEGER,
info15 INTEGER
);
""")
con.commit()
con.close()
zips, kens, shichosons テーブルの作成 (populate)
◆ Python プログラム
import sqlite3
# mydb01 から ken_all テーブルのデータを読み出し,zipdb にコピーする
src_con = sqlite3.connect("/tmp/mydb01")
dst_con = sqlite3.connect("/tmp/zipdb")
# mydb01 の ken_all テーブルを zipdb に複製する
dump_sql = "\n".join(src_con.iterdump())
dst_con.executescript(dump_sql)
src_con.close()
# kens, shichosons, zips テーブルにデータを投入する
cur = dst_con.cursor()
cur.execute("""
INSERT INTO kens (ken_kanji, ken_kana)
SELECT DISTINCT ken_kanji, ken_kana
FROM ken_all
""")
cur.execute("""
INSERT INTO shichosons (jiscode, ken_kanji, shichoson_kanji, shichoson_kana)
SELECT DISTINCT jiscode, ken_kanji, shichoson_kanji, shichoson_kana
FROM ken_all
""")
cur.execute("""
INSERT INTO zips (zipcode, zip_old,
jiscode, choiki_kanji, choiki_kana,
flag10, flag11, flag12, flag13, info14, info15)
SELECT zipcode, zip_old,
jiscode, choiki_kanji, choiki_kana,
flag10, flag11, flag12, flag13, info14, info15
FROM ken_all
""")
dst_con.commit()
cur.execute("VACUUM")
dst_con.close()
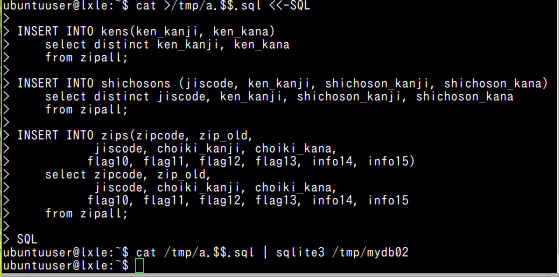
【各テーブルの中身の先頭部分】
import sqlite3
con = sqlite3.connect("/tmp/zipdb")
cur = con.cursor()
print("--- kens ---")
for row in cur.execute("SELECT * FROM kens LIMIT 3"):
print(row)
print("--- shichosons ---")
for row in cur.execute("SELECT * FROM shichosons LIMIT 3"):
print(row)
print("--- zips ---")
for row in cur.execute("SELECT * FROM zips LIMIT 3"):
print(row)
con.close()
(オプション) 再構成
◆ Python プログラム
import sqlite3
import os
# 各テーブルの SQL ダンプを取得する
con = sqlite3.connect("/tmp/zipdb")
# テーブルごとにダンプを取得する関数
def dump_table(connection, table_name):
"""指定テーブルに関連する SQL 文のみを抽出して返す"""
lines = []
for line in connection.iterdump():
if table_name in line:
lines.append(line)
return "\n".join(lines)
kens_sql = dump_table(con, "kens")
shichosons_sql = dump_table(con, "shichosons")
zips_sql = dump_table(con, "zips")
# ダンプ結果をファイルに保存する
with open("/tmp/kens.sql", "w") as f:
f.write(kens_sql)
with open("/tmp/shichosons.sql", "w") as f:
f.write(shichosons_sql)
with open("/tmp/zips.sql", "w") as f:
f.write(zips_sql)
con.close()
# 既存の zipdb を削除する
if os.path.exists("/tmp/zipdb"):
os.remove("/tmp/zipdb")
# ダンプファイルから zipdb を再構成する
con = sqlite3.connect("/tmp/zipdb")
with open("/tmp/kens.sql", "r") as f:
con.executescript(f.read())
with open("/tmp/shichosons.sql", "r") as f:
con.executescript(f.read())
with open("/tmp/zips.sql", "r") as f:
con.executescript(f.read())
con.execute("VACUUM")
con.close()