郵便番号テーブル ken_all を用いた演習
テーブルの分解
データベースにおけるテーブルの分解について説明します. 例えば,テーブル R(A,B,C) が存在する場合,以下のような分解が可能です.
- select A, B from R; の結果をテーブル S として定義する
- select A, C from R; の結果をテーブル T として定義する
S と T を組み合わせることで,元のテーブル R の情報を完全に表現することができます. このような操作を,「S と T は R の分解である」と定義します. このような分解は SQL プログラムで容易に実装できます.
ただし,分解には適切な基準と手順が必要です. 上記の例において,S と T の結合 (join) 操作によって R が完全に復元できること(無損失分解)が重要な要件となります. 具体的には,属性 A がテーブル R のキーである場合,S と T の結合によって R が確実に復元できることが保証されます.
異なり数
異なり数は,以下の SQL 文を用いて計算します.
select count(DISTINCT 属性名) FROM テーブル名;
という形での SQL で数えます.
SQL 演習
以下の演習では,Windows のコマンドプロンプトから SQLite3 コマンドラインツール(sqlite3.exe)を使用して SQL を実行します. データベースファイルのパスは C:\SQLiteDB\mydb01 とします.
- 「郵便番号CSVデータ作成プログラム」による自動編集前は「町域名漢字」に「一円」を含んでいたもの
sqlite3 C:\SQLiteDB\mydb01 "select count(*) FROM ken_all WHERE org_choiki_kanji LIKE '%一円%';"
- 「郵便番号CSVデータ作成プログラム」による自動編集前は「町域名漢字」に「以下に掲載がない場合」を含んでいたもの
sqlite3 C:\SQLiteDB\mydb01 "select count(*) FROM ken_all WHERE org_choiki_kanji LIKE '%以下に掲載がない場合%';"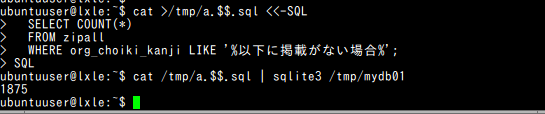
- 「全国地方公共団体コード」が「30207」であるもの
これは,全国地方公共団体コード 30207 において,郵便番号が 6470000 となるケースが「以下に掲載がない場合」に該当することを確認するためのクエリです.
sqlite3 -header -column C:\SQLiteDB\mydb01 "SELECT * FROM zips WHERE jiscode = 30207;"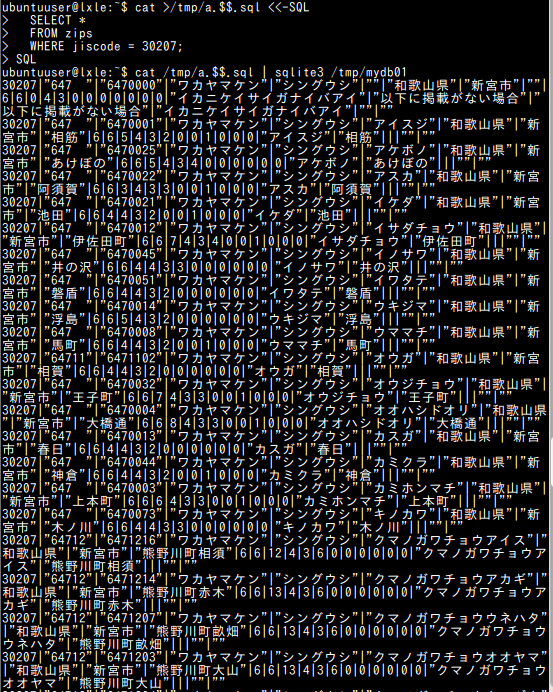
- 「以下に掲載がない場合」は,同一の「全国地方公共団体コード」に対しては1回しか現れないことの確認
sqlite3 C:\SQLiteDB\mydb01 "select count(*) FROM zips WHERE org_choiki_kanji LIKE '%以下に掲載がない場合%' group by jiscode ORDER BY COUNT(*) ASC;"
- 「郵便番号CSVデータ作成プログラム」による自動編集前は「町域名漢字」に「の次に番地がくる場合」を含んでいたもの
sqlite3 -header -column C:\SQLiteDB\mydb01 "SELECT * FROM zips WHERE org_choiki_kanji LIKE '%の次に番地がくる場合%';"
- 「全国地方公共団体コード」が「30401」であるもの
これは,白浜町における郵便番号の割り当てルールを確認するためのクエリです.白浜町の次に番地がくる場合は郵便番号が 6492211,番地がこない場合は 6492200 となります(ただし,以下の結果が示すように,町域が明示的に掲載されている場合は,それぞれに対応する郵便番号が割り当てられます).
sqlite3 -header -column C:\SQLiteDB\mydb01 "SELECT * FROM zips WHERE jiscode = 30401;"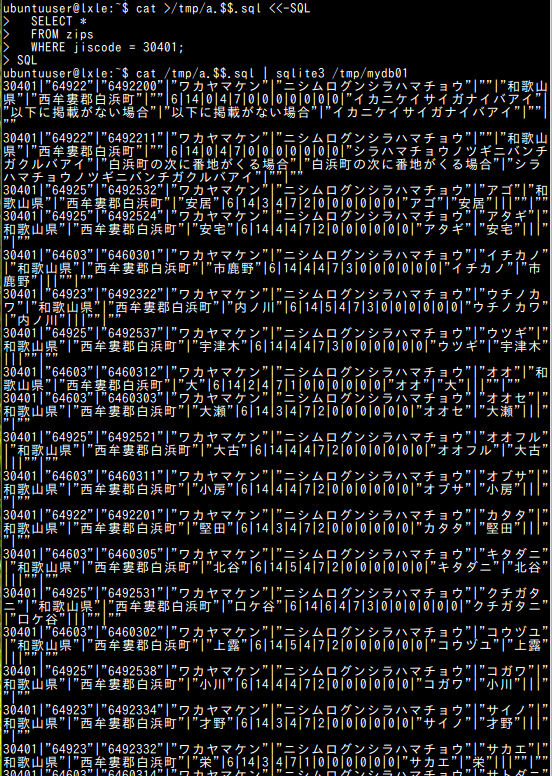
- 「郵便番号CSVデータ作成プログラム」による「町域名漢字」の変更に関する集計
sqlite3 C:\SQLiteDB\mydb01 "select count(*), comment_kanji FROM zips group by comment_kanji ORDER BY COUNT(*) DESC;"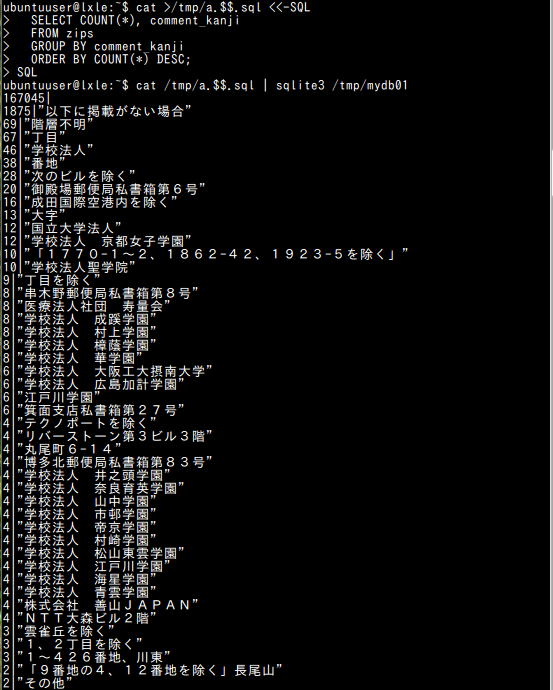
- 「町域名漢字」が「""」
sqlite3 C:\SQLiteDB\mydb01 "SELECT org_choiki_kanji, COUNT(*) FROM zips WHERE choiki_kanji = '\"\"' group by org_choiki_kanji ORDER BY COUNT(*) DESC, org_choiki_kanji ASC;"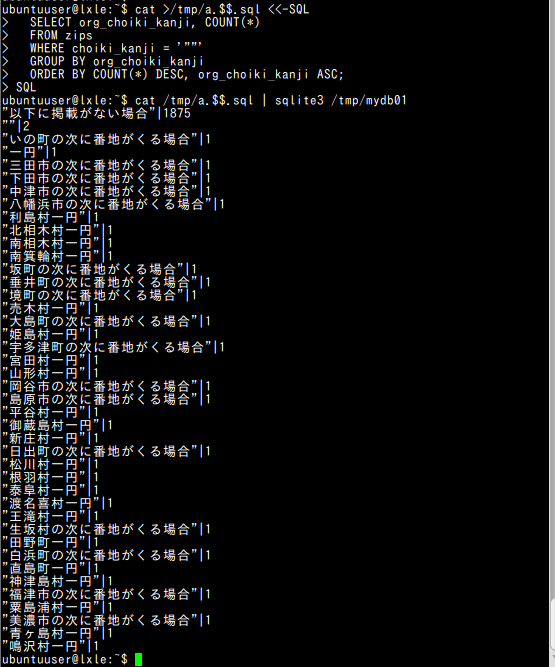
- 「以下に掲載がない場合」についての確認
sqlite3 -header -column C:\SQLiteDB\mydb01 "SELECT * FROM zips WHERE choiki_kanji = '\"\"' AND NOT org_choiki_kanji = '以下に掲載がない場合';"
候補キーに関する分析
- テーブル ken_all において,jiscode と choiki_kanji の組み合わせは候補キーとして機能しません.
以下のクエリで確認できます.
* jiscode と choiki_kanji が同一の値を持つレコードを検索する SQL
sqlite3 C:\SQLiteDB\mydb01 "select jiscode, choiki_kanji, count(*) from ken_all group by jiscode, choiki_kanji having count(*) > 1;"
- テーブル ken_all において,zipcode も候補キーとしては適切ではありません.
sqlite3 C:\SQLiteDB\mydb01 "select zipcode, count(*) from ken_all group by zipcode having count(*) > 1;"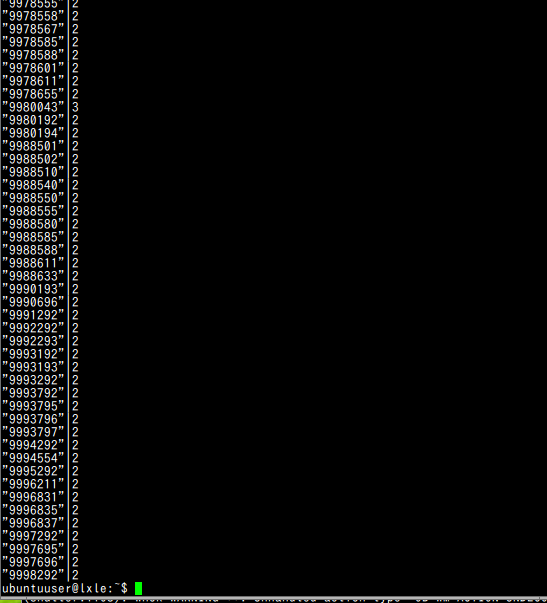
複数属性の関係の分析
属性間の関係を分析するために,以下のパターンの SQL クエリを頻繁に使用します.
select count(DISTINCT B), A, MAX(B), MIN(B) FROM T group by A ORDER BY COUNT(DISTINCT B) DESC, A ASC;
このクエリは,属性 A でグループ化(group by)を行い,各グループにおける「COUNT(DISTINCT B), A, MAX(B), MIN(B)」を計算します. 具体的には,同一の A 値を持つレコードについて,B の異なり数,最大値,最小値を集計します. また,「ORDER BY COUNT(DISTINCT B) DESC」により,B の異なり数が最大のグループが最上位に表示されます.
- 「一つの郵便番号で二以上の町域を表す場合の表示」が false である行について,同一郵便番号に対する全国地方公共団体コードの出現数を確認
「一つの郵便番号で二以上の町域を表す場合の表示」が false の場合,この問い合わせ結果は必ず「1」となるはずですが,データの整合性を確認するために実行します.
sqlite3 C:\SQLiteDB\mydb01 "select count(DISTINCT jiscode), zipcode, MAX(jiscode), MIN(jiscode) FROM ken_all WHERE flag13 = 0 group by zipcode ORDER BY COUNT(DISTINCT jiscode) ASC, zipcode ASC;"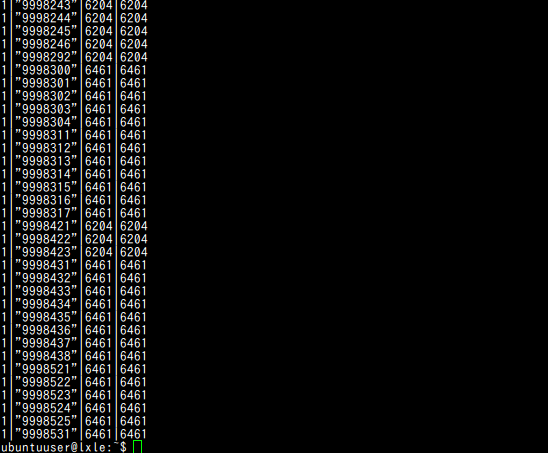
- 「一つの郵便番号で二以上の町域を表す場合の表示」が false である行について,同一の全国地方公共団体コードに対する異なる郵便番号の出現数を確認
この場合,結果が「1」以上となることは想定内ですが,データの傾向を把握するために実行します.
sqlite3 C:\SQLiteDB\mydb01 "select count(DISTINCT zipcode), jiscode, MAX(zipcode), MIN(zipcode) FROM ken_all WHERE flag13 = 0 group by jiscode ORDER BY COUNT(DISTINCT zipcode) DESC, jiscode ASC;"