郵便番号テーブル ken_all を 3つテーブル zips, kens, shichosons に分解(Ubuntu 上)
このページでは,日本郵政「ゆうびんホームページ」で公開されている 以下の2つの郵便番号データのCSV(カンマ区切り値)形式ファイルについて解説します.
- 住所の郵便番号(CSV形式)(ken_all.csv)
- 事業所の個別郵便番号(CSV形式)(JIGYOSYO.CSV)
これらのデータには,
潜在的な冗長性が存在します(「第三正規形」に準拠していないため,データ更新時に不整合が発生する可能性があります). この問題を解決するため,郵便番号データを3つのテーブルに分解し,冗長性を排除する手順を説明します.
前準備
使用するソフトウェア
- SQLite 3 コマンドラインシェルのインストールが完了していること.
あらかじめ決めておく事項
このページでは,SQLite 3 データベースの生成を実施します. まず,SQLite 3 データベースのデータベース名を決定する必要があります. 本解説では,以下のように設定します.
- データベース名: zipdb
データベース名は任意に設定可能ですが,半角文字(英字および英記号)のみを使用し,スペースを含まないようにしてください.
テーブルの準備
「郵便番号 CSV データを SQLite 3 にインポート(SQLite 3 を使用)」の Web ページの手順に従って,郵便番号テーブル ken_all の作成を完了してください.
郵便番号テーブル ken_all を 3 つのテーブル zips, kens, shichosons に分解
SQLプログラムを使用して, 郵便番号テーブル ken_allを以下の3つのテーブルに分解します.
- 郵便番号 ・・・ zips テーブル
- 県 ・・・ kens テーブル
- 市町村 ・・・ shichosons テーブル
郵便番号辞書には「町域」という要素が存在しますが, 本設計では町域に対応するテーブルは作成しません.その理由は, 「町域」テーブルを作成した場合,一意な「キー」が存在しない(より正確には,全属性を組み合わせなければキーとして機能しない)ためです. 「町域」には同一漢字で読み方が異なるケース(例:「上川」の「かみがわ」,「かみかわ」)が存在するため,一意なキーを設定できません.
zips, kens, shichosons のテーブル定義
◆ bash プログラム
#!/bin/bash
cat >/tmp/a.$$.sql <<-SQL
create table kens (
id INTEGER PRIMARY KEY autoincrement not null,
ken_kanji TEXT UNIQUE not null,
ken_kana TEXT UNIQUE not null );
create table shichosons (
jiscode INTEGER PRIMARY KEY not null CHECK (jiscode >= 1000 AND jiscode <= 50000),
ken_kanji TEXT not null,
shichoson_kanji TEXT not null,
shichoson_kana TEXT );
create table zips (
id INTEGER PRIMARY KEY autoincrement not null,
zipcode INTEGER not null,
zip_old INTEGER not null,
jiscode INTEGER not null REFERENCES shichosons(jiscode),
choiki_kanji TEXTL,
choiki_kana text,
flag10 TEXT not null,
flag11 INTEGER not null CHECK ( flag11 >= 0 AND flag11 <= 1 ),
flag12 INTEGER not null CHECK ( flag12 >= 0 AND flag12 <= 3 ),
flag13 INTEGER not null CHECK ( flag13 >= 0 AND flag13 <= 1 ),
info14 integer,
info15 INTEGER
);
SQL
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
zips, kens, shichosons テーブルの作成 (populate)
◆ bash プログラム
#!/bin/bash
# dump /tmp/ken_all.sql from mydb01
cat >/tmp/a.$$.sql <<-SQL
.output /tmp/ken_all.sql
.dump ken_all
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/mydb01
# load the dump result into zipdb
cat >/tmp/a.$$.sql <<-SQL
.read /tmp/ken_all.sql
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
#
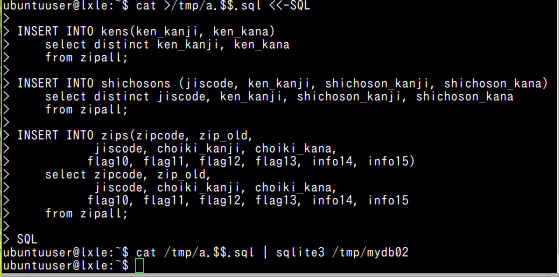
cat >/tmp/a.$$.sql <<-SQL
insert into kens(ken_kanji, ken_kana)
select distinct ken_kanji, ken_kana
from ken_all;
insert into shichosons (jiscode, ken_kanji, shichoson_kanji, shichoson_kana)
select distinct jiscode, ken_kanji, shichoson_kanji, shichoson_kana
from ken_all;
insert into zips(zipcode, zip_old,
jiscode, choiki_kanji, choiki_kana,
flag10, flag11, flag12, flag13, info14, info15)
select zipcode, zip_old,
jiscode, choiki_kanji, choiki_kana,
flag10, flag11, flag12, flag13, info14, info15
from ken_all;
vacuum;
SQL
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
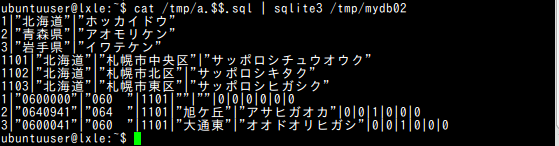
【各テーブルの中身の先頭部分】
#!/bin/bash
cat >/tmp/a.$$.sql <<-SQL
select * from kens limit 3;
select * from shichosons limit 3;
select * from zips limit 3;
SQL
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
◆ bash プログラム
#!/bin/bash
cat >/tmp/a.$$.sql <<-SQL
.output /tmp/kens.sql
.dump kens
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
cat >/tmp/a.$$.sql <<-SQL
.output /tmp/zips.sql
.dump zips
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
cat >/tmp/a.$$.sql <<-SQL
.output /tmp/shichosons.sql
.dump shichosons
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb
#
rm -f /tmp/zipdb
# load the dump result into zipdb
cat >/tmp/a.$$.sql <<-SQL
.read /tmp/kens.sql
.read /tmp/zips.sql
.read /tmp/shichosons.sql
vacuum;
.exit
SQL
#
cat /tmp/a.$$.sql | sqlite3 /tmp/zipdb