scikit-learn, seaborn のデータセット(Python,scikit-learn, seaborn を使用)
【概要】
この資料では,Python のライブラリである seaborn と scikit-learn に同梱されているサンプルデータセットの一覧と,それらを pandas の DataFrame として読み込み,CSV ファイルとして保存するプログラム例を示す。機械学習や統計の練習に使えるデータをすぐに利用できるようにすることが目的である。
【目次】
【関連する外部ページ】
- seaborn 公式ドキュメント: https://seaborn.pydata.org/generated/seaborn.load_dataset.html
- scikit-learn 公式データセット: https://scikit-learn.org/stable/datasets
【サイト内の関連情報】
第1章 前準備
scikit-learn, seaborn のインストール
- 管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 そして,次のコマンドを実行する.Windows で pip を実行するときは,管理者権限のコマンドプロンプトを使用し,システム領域へのインストールを行う.--no-userはシステム領域へのインストールを指定するオプションである.python -m pip install -U --no-user scikit-learn scikit-learn-intelex seaborn - Ubuntu の場合は,パッケージリストを更新してから以下を実行する。
sudo apt update sudo apt -y install python3-sklearn python3-seaborn
第2章 seaborn のデータセット
seaborn の load_dataset 関数で読み込めるサンプルデータセットには,次のようなものがある(カッコ内は主な列名)。
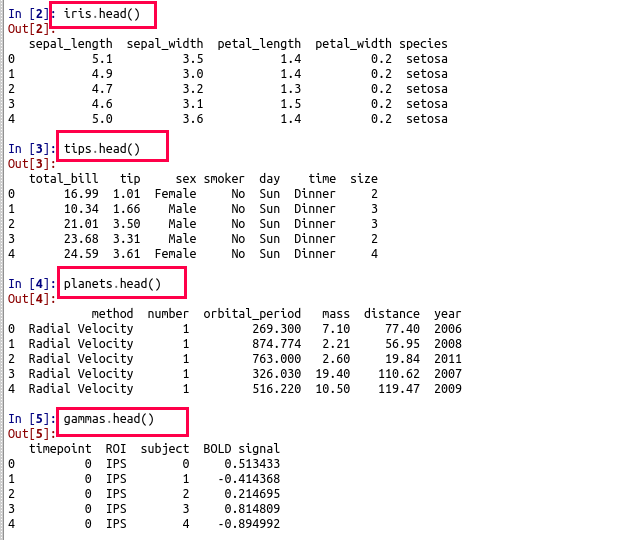
- iris(sepal_length, sepal_width, petal_length, petal_width, species)
- tips(total_bill, tip, sex, smoker, day, time, size)
- planets(method, number, orbital_period, mass, distance, year)
- fmri(subject, timepoint, event, region, signal)
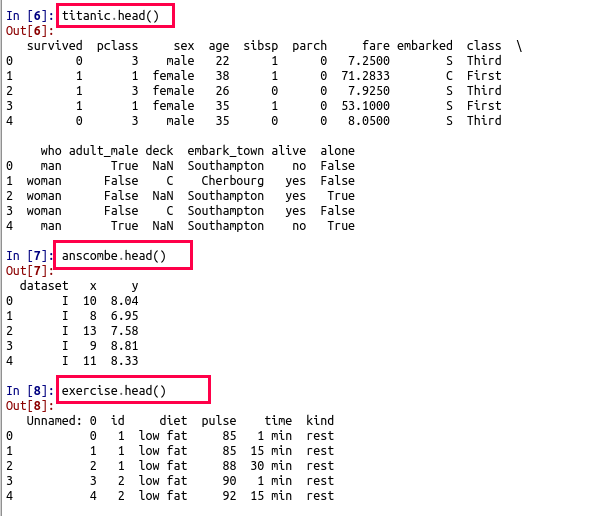
- titanic(survived, pclass, sex, age, sibsp, parch, fare, embarked, class, who, adult_male, deck, embark_town, alive, alone)
- anscombe(dataset, x, y)
- exercise(id, diet, pulse, time, kind)
次のプログラムは,iris, tips, planets, fmri, titanic, anscombe, exercise を CSV ファイルとして保存し,それぞれの先頭部分を確認表示する。
import seaborn
iris = seaborn.load_dataset('iris')
tips = seaborn.load_dataset('tips')
planets = seaborn.load_dataset('planets')
fmri = seaborn.load_dataset('fmri')
titanic = seaborn.load_dataset('titanic')
anscombe = seaborn.load_dataset('anscombe')
exercise = seaborn.load_dataset('exercise')
iris.to_csv('iris.csv', encoding='utf-8', index_label='id')
tips.to_csv('tips.csv', encoding='utf-8', index_label='id')
planets.to_csv('planets.csv', encoding='utf-8', index_label='id')
fmri.to_csv('fmri.csv', encoding='utf-8', index_label='id')
titanic.to_csv('titanic.csv', encoding='utf-8', index_label='id')
anscombe.to_csv('anscombe.csv', encoding='utf-8', index_label='id')
exercise.to_csv('exercise.csv', encoding='utf-8', index_label='id')
print(iris.head())
print(tips.head())
print(planets.head())
print(fmri.head())
print(titanic.head())
print(anscombe.head())
print(exercise.head())
第3章 scikit-learn のデータセット
公式ページ: https://scikit-learn.org/stable/datasets
- diabetes(data, target): diabetes データセット(回帰)。
- 'data', 学習に使う特徴量。
- 'target', 各サンプルのラベル(目的変数)。
- digits(data, target): digits データセット(分類)。
- 'data', 学習に使う特徴量。
- 'target', 各サンプルの分類ラベル。
- iris(sepal_length, sepal_width, petal_length, petal_width, species_number, species): iris データセット(分類)。
- linnerud(chins, situps, jumps, weight, waist, pulse): linnerud データセット(多出力回帰)。chins, situps, jumps が運動データ(data),weight, waist, pulse が生理データ(target)である。
次のプログラムは,diabetes, digits, iris, linnerud を CSV ファイルとして保存する。
import numpy as np
import pandas as pd
import sklearn.datasets
a = sklearn.datasets.load_diabetes()
diabetes = pd.DataFrame(pd.Series(map(list, a.data)), columns=["data"])
diabetes["target"] = pd.Series(a.target)
a = sklearn.datasets.load_digits()
digits = pd.DataFrame(pd.Series(map(list, a.data)), columns=["data"])
digits["target"] = pd.Series(a.target)
a = sklearn.datasets.load_iris()
iris = pd.DataFrame(a.data, columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
iris["species_number"] = pd.Series(a.target)
iris["species"] = pd.Series(a.target_names[a.target])
a = sklearn.datasets.load_linnerud()
linnerud = pd.DataFrame(np.hstack((a.data, a.target)), columns=['chins', 'situps', 'jumps', 'weight', 'waist', 'pulse'])
diabetes.to_csv('diabetes.csv', encoding='utf-8', index_label='id')
digits.to_csv('digits.csv', encoding='utf-8', index_label='id')
iris.to_csv('iris.csv', encoding='utf-8', index_label='id')
linnerud.to_csv('linnerud.csv', encoding='utf-8', index_label='id')
次のプログラムは,digits データセットの 0 番目のデータを 8×8 の画像として表示する。
import numpy as np
import sklearn.datasets
import matplotlib.pyplot as plt
a = sklearn.datasets.load_digits()
plt.gray()
plt.matshow(np.array(a.data[0]).reshape(8, 8))
plt.show()