Self-Attentionメカニズムの確認
【目次】
概要
技術名:Self-Attention
出典:Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
従来手法との比較:RNN(回帰型ニューラルネットワーク)/CNN(畳み込みニューラルネットワーク)は長距離依存関係の捕捉が困難で逐次処理が必要である。Self-Attentionは系列内の任意の位置間で直接的に関係性を計算し、並列処理が可能である。
基本概念:Self-AttentionはTransformerの中核技術で、同一系列内での注意計算を行う。Query(何を探すか)、Key(何を持つか)、Value(実際の情報)の3要素で構成され、入力系列内の各要素間の関係性を直接計算する。
数学的定義:Attention(Q,K,V) = softmax(QK^T/√d_k)V。スケーリングファクター√d_kは内積値の分散を制御し学習を安定化する。ソフトマックス関数(確率分布を生成する関数)は重みを正規化する。
応用例:機械翻訳、文書要約、画像認識、音声認識などの自然言語処理・画像認識分野で活用される。
学習効果:Self-Attentionの計算過程を段階的に確認し、各トークンが他のトークンに注意を向ける仕組みを理解する。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM PyTorch をインストール(GPU対応版)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%
プログラムコード
ソースコード
# Self-Attentionメカニズム体験プログラム
# PyTorchによるSelf-Attentionの基本動作を可視化
# 論文: "Attention Is All You Need" (Vaswani et al., NIPS 2017)
# GitHub: https://github.com/pytorch/pytorch
# 特徴: Transformerの中核技術、Q・K・V変換による重み付き平均計算
# 自然言語処理・画像認識分野で広く活用
# 前準備: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
import torch
import torch.nn.functional as F
# 定数定義
TOKEN_COUNT = 3 # トークン数
FEATURE_DIM = 4 # 特徴次元数
RANDOM_SEED = 42 # 乱数シード(再現性確保)
# メイン処理
torch.manual_seed(RANDOM_SEED)
# 入力データ定義(3つのトークンの特徴ベクトル)
input_data = torch.tensor([[1.0, 0.0, 1.0, 0.0],
[0.0, 2.0, 0.0, 2.0],
[1.0, 1.0, 1.0, 1.0]])
# 線形変換層初期化(バイアスなし)
torch.manual_seed(RANDOM_SEED)
query_weight = torch.nn.Linear(FEATURE_DIM, FEATURE_DIM, bias=False)
key_weight = torch.nn.Linear(FEATURE_DIM, FEATURE_DIM, bias=False)
value_weight = torch.nn.Linear(FEATURE_DIM, FEATURE_DIM, bias=False)
# Self-Attention計算
# Q, K, V生成(それぞれ独立した重み行列を使用)
query_matrix = query_weight(input_data)
key_matrix = key_weight(input_data)
value_matrix = value_weight(input_data)
# スケーリングドット積アテンション計算
raw_attention_scores = torch.matmul(query_matrix, key_matrix.T)
# スケーリング: 勾配消失を防ぐため√d_kで正規化
scaled_scores = raw_attention_scores / torch.sqrt(torch.tensor(query_matrix.size(-1), dtype=torch.float32))
# ソフトマックス: 各行の合計が1になるよう正規化
attention_weights = F.softmax(scaled_scores, dim=-1)
# 重み付き平均: アテンション重みでValueを統合
attention_output = torch.matmul(attention_weights, value_matrix)
# 結果出力
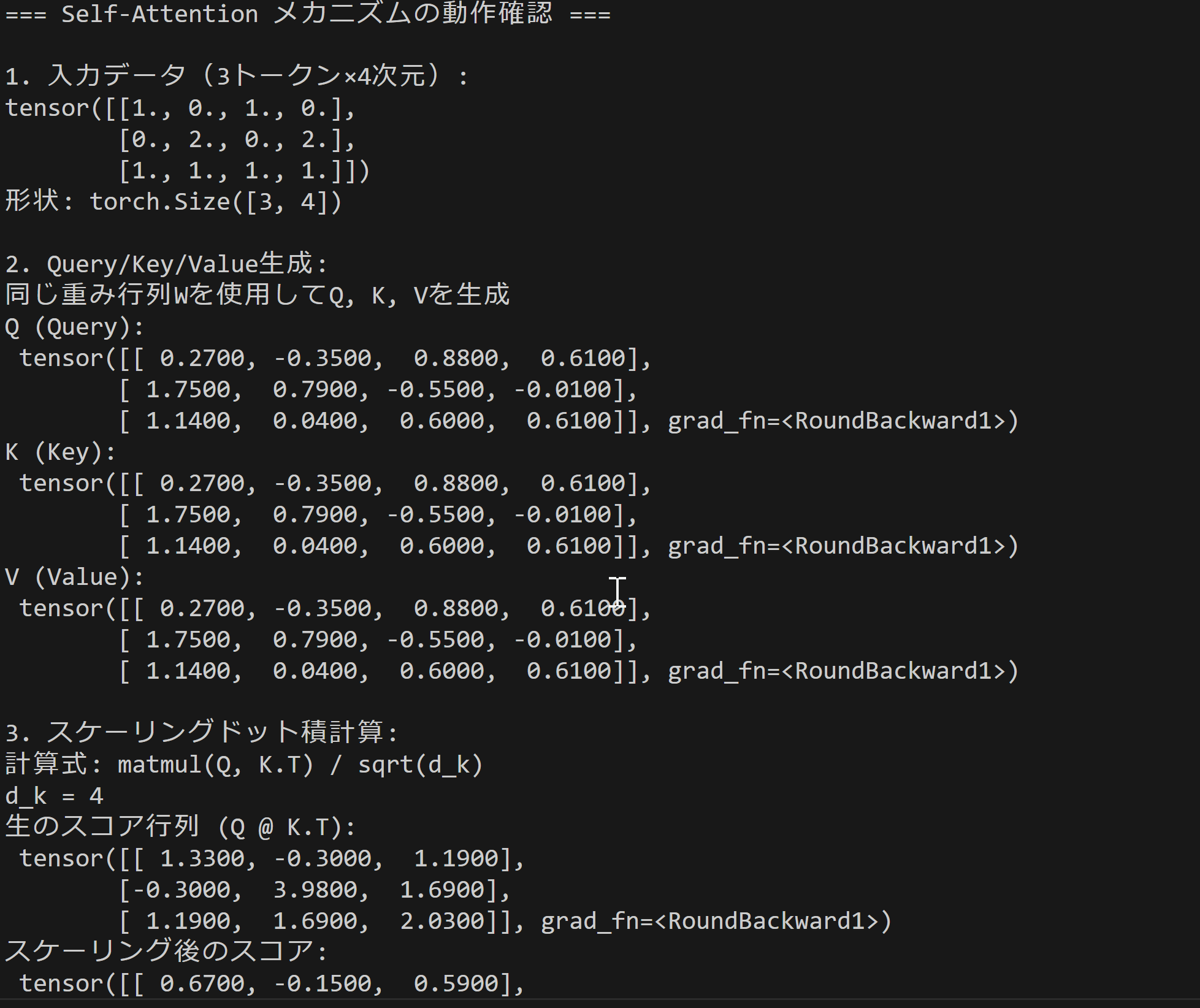
print("=== Self-Attention メカニズムの動作確認 ===")
print(f"\n1. 入力データ({TOKEN_COUNT}トークン×{FEATURE_DIM}次元):")
print(input_data)
print(f"形状: {input_data.shape}")
print("\n2. Query/Key/Value生成:")
print("それぞれ独立した重み行列を使用してQ, K, Vを生成")
print("Q (Query):\n", query_matrix.round(decimals=2))
print("K (Key):\n", key_matrix.round(decimals=2))
print("V (Value):\n", value_matrix.round(decimals=2))
print("\n3. スケーリングドット積計算:")
print("計算式: matmul(Q, K.T) / sqrt(d_k)")
print(f"d_k = {query_matrix.size(-1)}")
print("生のスコア行列 (Q @ K.T):\n", raw_attention_scores.round(decimals=2))
print("スケーリング後のスコア:\n", scaled_scores.round(decimals=2))
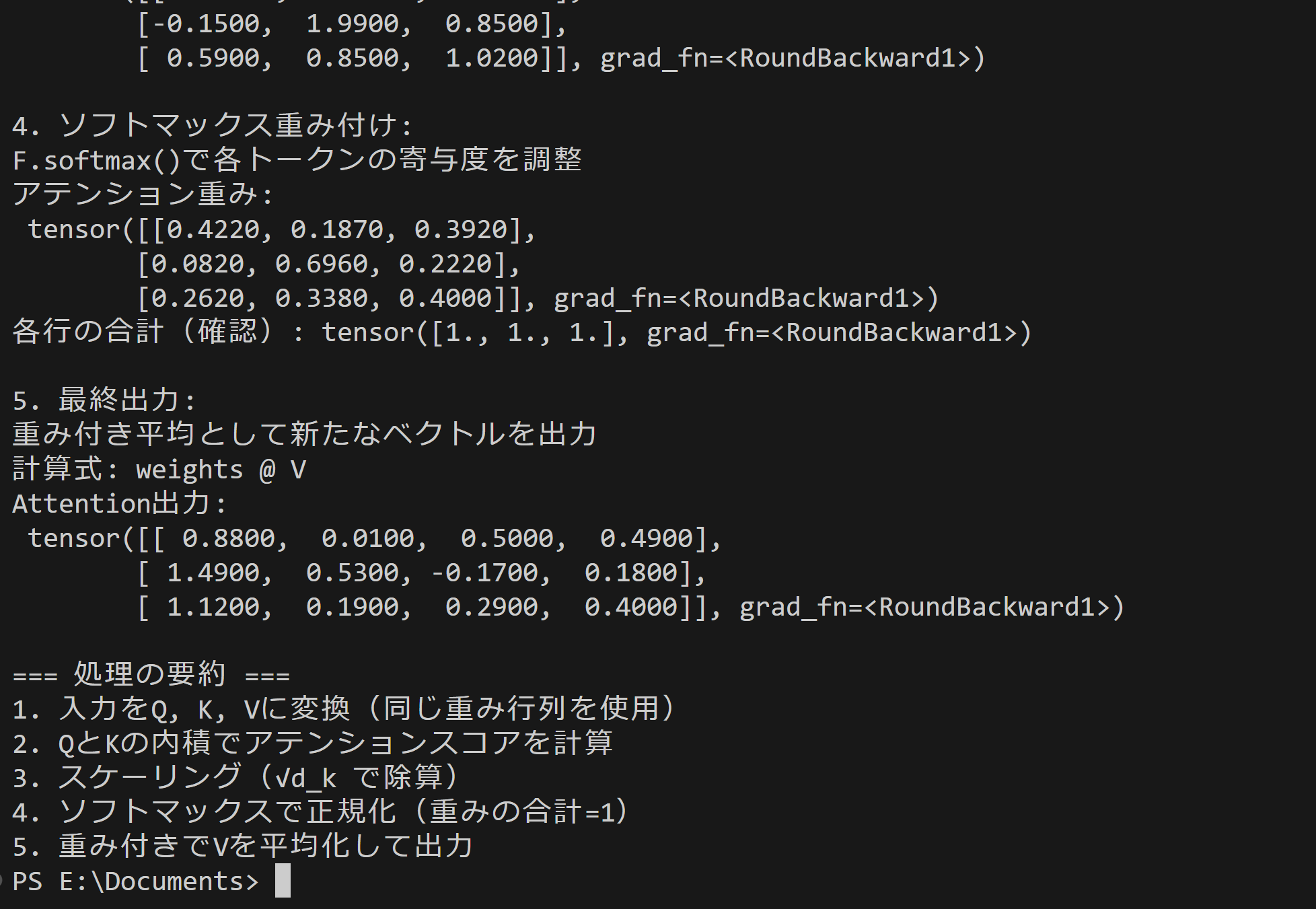
print("\n4. ソフトマックス重み付け:")
print("F.softmax()で各トークンの寄与度を調整")
print("アテンション重み:\n", attention_weights.round(decimals=3))
print("各行の合計(確認):", attention_weights.sum(dim=-1).round(decimals=3))
print("\n5. 最終出力:")
print("重み付き平均として新たなベクトルを出力")
print("計算式: weights @ V")
print("Attention出力:\n", attention_output.round(decimals=2))
print("\n=== 処理の要約 ===")
print("1. 入力をQ, K, Vに変換(それぞれ独立した重み行列を使用)")
print("2. QとKの内積でアテンションスコアを計算")
print("3. スケーリング(√d_k で除算)")
print("4. ソフトマックスで正規化(重みの合計=1)")
print("5. 重み付きでVを平均化して出力")
使用方法
- 上記のプログラムを実行する
実行結果として、Self-Attentionの各計算段階が順次表示される。
実験・探求のアイデア
設定変更実験
- 異なる重み行列の初期化(
SEEDの値を変更) - 入力次元数の変更(
Dを8, 16, 32に変更) - トークン数の変更(
Nを5, 10に変更)
実験要素
- 入力データパターンの変更(すべて同じ値、交互パターン、ランダム値)
- スケーリング係数の変更(
sqrt(D)を固定値に変更) - 表示精度の変更(
round(decimals=2)の値を1や4に変更)
探求のアイデア
- 入力データを類似度の高いトークンに変更し、アテンション重みの変化を観察する
- 特定のトークンを極端な値に設定し、他のトークンへの影響度を確認する
- アテンション重みの分布から、どのトークンが影響力を持つかを分析する