ロジスティック回帰による分類性能の確認
【目次】
概要
主要技術: ロジスティック回帰(Logistic Regression)
出典: Hosmer, D. W., & Lemeshow, S. (2013). Applied Logistic Regression (3rd ed.). Wiley.
理論的背景: ロジスティック回帰は線形回帰をシグモイド関数(σ(z) = 1/(1+e^(-z)))で変換した確率的分類手法である。線形結合z = β₀ + β₁x₁ + β₂x₂ + ...を0-1の確率値に変換し、最尤推定法によりパラメータを学習する。
特徴: 特徴量の係数から判断根拠を解釈でき、確率値を出力するため閾値調整が可能である。医療診断システム、マーケティング予測、品質管理の分野で活用される。
データセット選択理由: Irisデータセットは特徴量が明確で二値分類の学習に適したデータセットである。
学習目標: 混同行列、AUC-ROC、分類レポートによる多角的な性能評価を通じて、分類器の強みと弱点を定量的に把握する。異なる評価指標の違いを理解し、分類問題における評価手法の選択基準を確認する。
評価指標
混同行列: [[TN, FP], [FN, TP]]形式。正解率 = (TP+TN)/(TP+TN+FP+FN)
Precision(適合率): TP/(TP+FP) - 予測陽性の正解率
Recall(再現率): TP/(TP+FN) - 実際陽性の検出率
F1-score: 2×(Precision×Recall)/(Precision+Recall) - 両者の調和平均
AUC-ROC: 0.5=ランダム、0.7=実用下限、0.8=良好、0.9=優秀の判断基準
実務判断基準: 医療診断では再現率重視(見逃し回避)、スパム検出では適合率重視(誤判定回避)。AUC≥0.8で実用化検討、AUC≥0.9で高精度システムとして運用可能。
事前準備
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要パッケージのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する:
pip install scikit-learn matplotlib seaborn japanize-matplotlib numpy
プログラムコード
概要
このプログラムは、Irisデータセットを用いてロジスティック回帰による二値分類を実行し、分類性能を多角的に評価するシステムである。3クラスのIrisデータセットから2クラス(versicolor対virginica)を抽出し、訓練データとテストデータに分割した後、ロジスティック回帰モデルを学習させる。評価段階では、混同行列、ROC-AUC、分類レポートなど複数の指標を算出し、結果を可視化する。
主要技術
ロジスティック回帰(Logistic Regression)
ロジスティック回帰は、線形回帰をシグモイド関数で変換することで確率的な二値分類を実現するアルゴリズムである[1]。scikit-learnのLogisticRegressionクラスは、L-BFGS、SAG、SAGAなど複数の最適化アルゴリズムを提供し、正則化パラメータの調整により過学習を制御できる[2]。本プログラムでは、predict_proba()メソッドを用いてクラス所属確率を推定し、ROC曲線やAUC値の算出に活用している。
技術的特徴
本実装では、Irisデータセットの150サンプル(3クラス各50サンプル)から、setosaクラスを除外してversicolorとvirginicaの2クラス100サンプルに変換している。この前処理により、線形分離が困難な二値分類問題を構成し、ロジスティック回帰の性能を適切に評価できる環境を整えている。
評価指標として、混同行列による正解率の算出、ROC曲線とAUC値による確率的予測性能の測定、適合率・再現率・F1スコアを含む分類レポートの生成を実装している。これらの指標を組み合わせることで、モデルの性能を包括的に評価できる[3]。
実装の特色
- タイムスタンプ付きログ記録:処理の各段階で時刻付きメッセージを記録し、実行過程を追跡可能にしている
- 可視化機能:seabornによる混同行列のヒートマップ表示とmatplotlibによるROC曲線描画を同一図内に配置し、視覚的な性能評価を実現
- 結果保存機能:評価結果をテキストファイルに自動保存し、後続の分析や報告書作成に活用できる
- 再現性の確保:乱数シード(RANDOM_SEED)の固定により、実行結果の再現性を保証
参考文献
[1] Hosmer, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied Logistic Regression (3rd ed.). John Wiley & Sons. https://doi.org/10.1002/9781118548387
[2] Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830. https://jmlr.org/papers/v12/pedregosa11a.html
[3] Fawcett, T. (2006). An Introduction to ROC Analysis. Pattern Recognition Letters, 27(8), 861-874. https://doi.org/10.1016/j.patrec.2005.10.010
ソースコード
# プログラム名: ロジスティック回帰による二値分類性能評価システム
# 特徴技術名: scikit-learn LogisticRegression
# 出典: Pedregosa, F., et al. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825-2830.
# 特徴機能: 確率的二値分類と多角的性能評価(LogisticRegressionのpredict_proba()により確率出力が可能で、ROC-AUC等の確率ベース評価指標と混同行列による詳細な分類性能分析を実現)
# 学習済みモデル: なし(Irisデータセットで新規学習)
# 方式設計:
# - 関連利用技術:
# - matplotlib (グラフ描画、混同行列とROC曲線の可視化)
# - seaborn (統計的可視化、ヒートマップ表示)
# - numpy (数値計算、配列操作)
# - japanize-matplotlib (日本語表示対応)
# - 入力と出力: 入力: なし(内蔵Irisデータセット使用)、出力: 分類性能評価結果のテキスト表示とグラフ表示
# - 処理手順: 1)Irisデータセットから2クラス抽出、2)訓練・テストデータ分割、3)ロジスティック回帰学習、4)予測と確率推定、5)混同行列・AUC・分類レポート計算、6)結果可視化
# - 前処理、後処理: 前処理: 3クラスから2クラスへの変換(クラス0を除外)、後処理: 混同行列ヒートマップとROC曲線の描画
# - 追加処理: なし
# - 調整を必要とする設定値: RANDOM_SEED (再現性のための乱数シード、デフォルト42)、TEST_SIZE (テストデータの割合、デフォルト0.25)
# 将来方策: RANDOM_SEEDを複数値で実行し、性能の安定性を評価する交差検証機能の実装
# その他の重要事項: Irisデータセットの3クラスから2クラス(versicolor vs virginica)に制限して二値分類を実施
# 前準備: pip install scikit-learn matplotlib seaborn japanize-matplotlib numpy
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score, roc_curve
import time
# 定数定義
RANDOM_SEED = 42 # 再現性のための乱数シード
TEST_SIZE = 0.25 # テストデータの割合
FIGURE_SIZE = (12, 4) # グラフサイズ
ENCODING = 'utf-8' # ファイルエンコーディング
RESULT_FILE = 'result.txt' # 結果保存ファイル名
COLOR_ROC = 'darkorange' # ROC曲線の色
COLOR_BASELINE = 'navy' # ベースライン(ランダム分類)の色
COLOR_HEATMAP = 'Blues' # ヒートマップのカラーマップ
# プログラム開始時の表示
print('='*60)
print('ロジスティック回帰による二値分類性能評価システム')
print('='*60)
print('概要: Irisデータセットを用いてロジスティック回帰の分類性能を評価します')
print('処理内容: データ準備→学習→評価→可視化')
print('='*60)
print()
# 結果記録用リスト
results = []
def record_result(message):
"""結果を記録し、表示"""
timestamp = time.strftime('%H:%M:%S')
line = f'[{timestamp}] {message}'
results.append(line)
print(line)
# データセット準備
record_result('データセット準備開始')
X, y = load_iris(return_X_y=True)
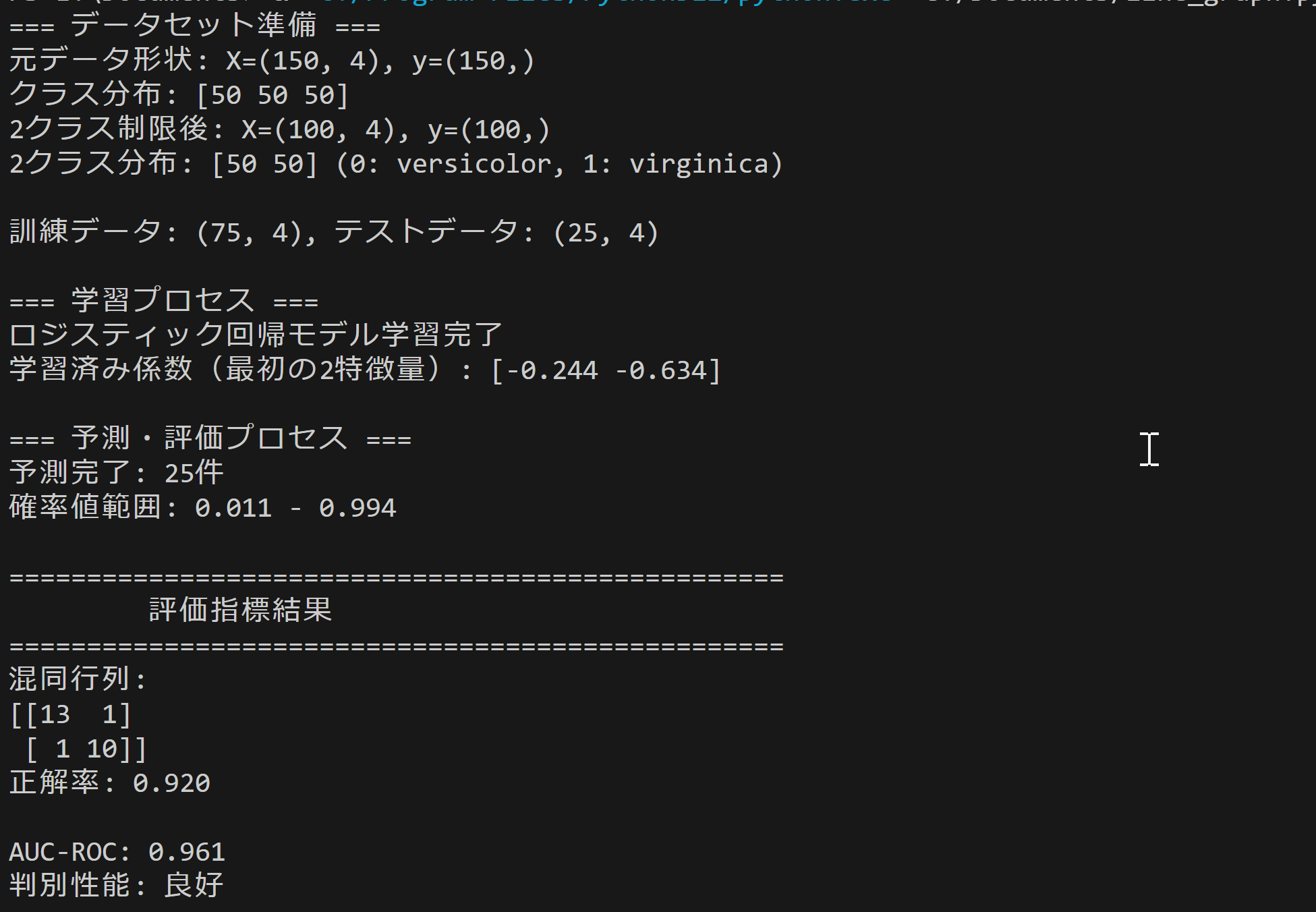
record_result(f'元データ形状: X={X.shape}, y={y.shape}')
record_result(f'クラス分布: {np.bincount(y)}')
# 2クラス制限(versicolor vs virginica)
mask = y != 0
X, y = X[mask], y[mask]
y = y - 1
record_result(f'2クラス制限後: X={X.shape}, y={y.shape}')
record_result(f'2クラス分布: {np.bincount(y)} (0: versicolor, 1: virginica)')
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=RANDOM_SEED)
record_result(f'訓練データ: {X_train.shape}, テストデータ: {X_test.shape}')
# メイン処理
record_result('学習プロセス開始')
model = LogisticRegression(random_state=RANDOM_SEED)
model.fit(X_train, y_train)
record_result('ロジスティック回帰モデル学習完了')
record_result(f'学習済み係数(最初の2特徴量): {model.coef_[0][:2].round(3)}')
record_result('予測・評価プロセス開始')
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
record_result(f'予測完了: {len(y_pred)}件')
record_result(f'確率値範囲: {y_prob.min():.3f} - {y_prob.max():.3f}')
# 評価指標計算
cm = confusion_matrix(y_test, y_pred)
auc = roc_auc_score(y_test, y_prob)
report = classification_report(y_test, y_pred)
accuracy = (cm[0,0] + cm[1,1]) / cm.sum()
# 結果出力
record_result('評価指標計算完了')
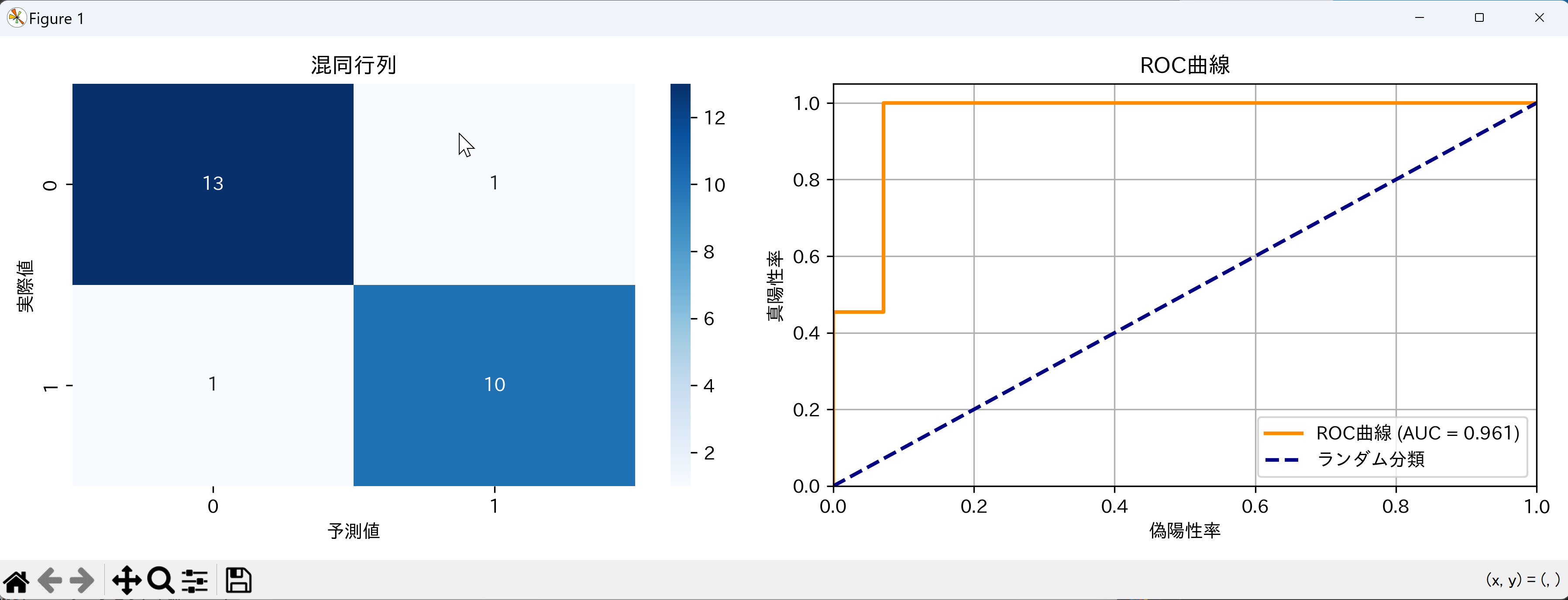
record_result(f'混同行列: [[{cm[0,0]}, {cm[0,1]}], [{cm[1,0]}, {cm[1,1]}]]')
record_result(f'正解率: {accuracy:.3f}')
record_result(f'AUC-ROC: {auc:.3f}')
perf_level = '0.7以下' if auc <= 0.7 else '0.7-0.8' if auc <= 0.8 else '0.8以上'
record_result(f'AUC範囲: {perf_level}')
# 詳細レポート
print('\n' + '='*50)
print(' 詳細評価レポート')
print('='*50)
print('分類レポート:')
print(report)
# 総合評価
record_result('総合評価')
record_result(f'データ: {len(y_test)}件のテストデータで評価')
record_result(f'正解率: {accuracy:.1%} ({cm[0,0] + cm[1,1]}/{cm.sum()}件正解)')
record_result(f'AUC値: {auc:.3f} ({perf_level}範囲)')
# 可視化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=FIGURE_SIZE)
sns.heatmap(cm, annot=True, fmt='d', cmap=COLOR_HEATMAP, ax=ax1)
ax1.set_title('混同行列')
ax1.set_xlabel('予測値')
ax1.set_ylabel('実際値')
fpr, tpr, _ = roc_curve(y_test, y_prob)
ax2.plot(fpr, tpr, color=COLOR_ROC, lw=2, label=f'ROC曲線 (AUC = {auc:.3f})')
ax2.plot([0, 1], [0, 1], color=COLOR_BASELINE, lw=2, linestyle='--', label='ランダム分類')
ax2.set_xlim([0.0, 1.0])
ax2.set_ylim([0.0, 1.05])
ax2.set_xlabel('偽陽性率')
ax2.set_ylabel('真陽性率')
ax2.set_title('ROC曲線')
ax2.legend(loc='lower right')
ax2.grid(True)
plt.tight_layout()
plt.show()
record_result('可視化完了: 混同行列ヒートマップ + ROC曲線')
# 結果表示
print('\n結果表示:')
for i, line in enumerate(results):
print(f'{i+1}: {line}')
# 結果をファイルに保存
with open(RESULT_FILE, 'w', encoding=ENCODING) as f:
for line in results:
f.write(line + '\n')
print(f'\n{RESULT_FILE}に保存しました')
使用方法
- 上記のプログラムを実行する
- 実行結果として以下が表示される:
- データセット情報とクラス分布
- 学習プロセスの進行状況
- 評価指標(混同行列、AUC-ROC、分類レポート)
- 混同行列とROC曲線のグラフ
実験・探求のアイデア
基本実験
- 正則化パラメータ(過学習を防ぐための調整値)であるC値を変更した性能の変化観察
応用実験
- データセット変更:他のクラス組み合わせ(setosa vs versicolor)での性能比較
- 訓練データ比率:TEST_SIZEを0.1、0.3、0.5に変更した時の安定性検証
発展的探求
- 閾値調整実験:predict_proba()の結果を使い、0.3、0.7の異なる閾値(分類判定の境界値)で分類した場合の精度・再現率の変化を観察
- 係数解釈実験:model.coef_を全て表示し、どの特徴量が分類に最も影響するかを特定
- 学習曲線実験:訓練データ量を段階的に増加させ、性能がどの時点で収束するかを検証
- 外れ値影響実験:意図的に極値データを追加した場合の性能劣化度合いを測定
- アルゴリズム比較実験:異なる分類アルゴリズム(SVM:サポートベクターマシン、決定木、ランダムフォレスト)との性能比較