librosa による音声スペクトログラムと CREPE によるF0時間変化(ソースコードと実行結果)
プログラム利用ガイド
1. このプログラムの利用シーン
人の声や楽器の演奏といった音声データの「音の高さ(基本周波数)」と「周波数成分(スペクトログラム)」を手軽に可視化・分析するためのものです。自身の発声練習におけるピッチの安定性を確認したり、音楽のフレーズを音響的に分析したり、機械音の周波数特性を調査したりといった用途に利用できます。
2. 主な機能
- 多様な入力に対応: ローカルの音声・動画ファイル、PCに接続されたマイクからのリアルタイム録音から分析対象を選択できます。
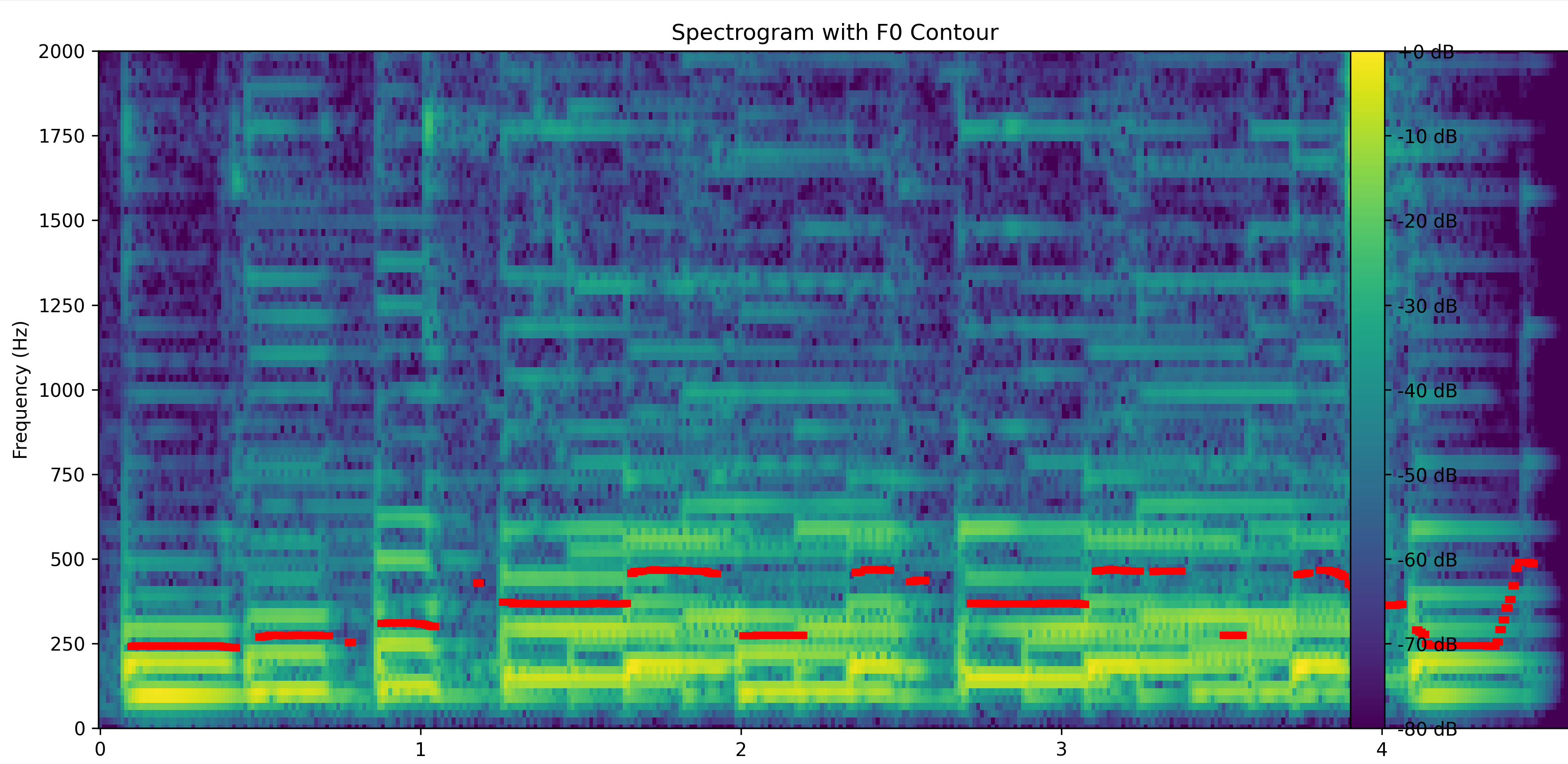
- 音声特徴の可視化: 音声の周波数成分の時間変化を示すスペクトログラムと、音の高さの推移を示す基本周波数(F0)の軌跡を、一つのグラフに重ねて分かりやすく表示します。
- F0統計情報の算出: 分析区間におけるF0の平均値、標準偏差、最大値、最小値などを自動で計算し、コンソールに表示します。
- 結果の自動保存: 分析日時、入力ソースの情報、F0統計情報、1秒ごとのF0値などを、
result.txtというファイル名で自動的に記録します。
3. 基本的な使い方
- プログラムの実行と入力ソースの選択:
プログラムを実行すると、コンソール画面に「入力ソースを選択してください:」というメッセージが表示されます。キーボードで
0(ファイル)、1(マイク)、2(サンプル音声) のいずれかの数字を入力し、Enterキーを押します。0を選択した場合は、ファイル選択ダイアログが開くので、分析したい音声ファイルまたは動画ファイルを選択してください。 - 分析結果の確認:
分析処理が自動で実行され、完了するとコンソールにF0の統計情報が表示されます。その後、スペクトログラムとF0軌跡が描画されたグラフウィンドウがポップアップで表示されます。
- プログラムの終了:
グラフウィンドウを閉じると、コンソールに音声再生を行うかどうかの選択肢が表示されます。
y(再生)またはn(終了)を入力すると、プログラムが終了します。
4. 便利な機能
- 動画ファイルからの音声分析: MP4やMOVなどの動画ファイルを指定すると、プログラムが自動的に音声トラックだけを抽出して分析対象とします。映像コンテンツの音声を簡単に分析できます。
- パラメータの調整: プログラム冒頭の「設定値」セクションを編集することで、F0推定モデルの種類(
CREPE_MODEL_CAPACITY)や分析の時間解像度(HOP_LENGTH)などを変更し、分析の精度や処理速度を調整できます。 - 分析結果のテキスト保存: グラフには表示されない詳細な数値データ(1秒ごとのF0値と実際の測定時刻など)が
result.txtに記録されるため、表計算ソフトなどで後のデータ分析に活用できます。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install crepe librosa matplotlib numpy scipy sounddevice japanize-matplotlib tensorflow moviepy
librosa による音声スペクトログラムと CREPE によるF0時間変化プログラム
概要
このプログラムは、音声信号からスペクトログラムと基本周波数(F0)を算出し、結果を可視化およびファイルに保存する分析ツールである。音声・動画ファイル、マイク入力、インターネット上のサンプル音声など、多様な入力ソースに対応する。信号処理ライブラリと深層学習モデルを組み合わせ、音声の時間-周波数特性とピッチの変動を分析する機能を提供する。
主要技術
CREPE (Convolutional Representation for Pitch Estimation)
深層畳み込みニューラルネットワーク(CNN)を用いて音声波形から直接F0を推定する[1]。従来の周波数領域に基づく手法と比較して、ノイズに対する頑健性が高いという特徴を持つ。
Short-Time Fourier Transform (STFT)
STFTは、信号を短時間のフレームに分割し、各フレームでフーリエ変換を適用することで、信号の時間-周波数表現を得る信号解析手法である。本プログラムでは、音声・音楽信号分析ライブラリであるlibrosa[2]を用いてSTFTを計算し、その結果からスペクトログラムを得る。
技術的特徴
本プログラムは、F0推定に深層学習モデルであるCREPEを採用している。CREPEが出力する推定の信頼度(confidence)を利用し、信頼度が閾値未満の区間のF0データを除去するフィルタリング処理を実装している。これにより、無音区間やノイズが支配的な区間における誤ったF0のプロットを防ぎ、分析結果の信頼性を高めている。さらに、推定されたF0軌跡に対してメディアンフィルタを適用することで、突発的な変動を平滑化し、滑らかなピッチ輪郭を得る後処理も行っている。
実装の特色
本プログラムは、多様な入力形式への対応(ファイル、マイク、URL)、分析結果の自動ファイル保存、Windows環境におけるライブラリのキャッシュディレクトリ問題への対策など、実用性も考慮した機能が実装されている。moviepyライブラリを用いて動画ファイルから音声トラックを自動抽出する機能もあり、映像コンテンツの音声分析を容易にしている。
参考文献
- [1] J. W. Kim, J. Salamon, P. Li, and J. P. Bello, "CREPE: A Convolutional Representation for Pitch Estimation," in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 161-165. https://doi.org/10.1109/ICASSP.2018.8461329
- [2] B. McFee, et al., "librosa: Audio and music signal analysis in python," in Proceedings of the 14th Python in Science Conference, 2015, pp. 11-17. https://doi.org/10.25080/Majora-7b98e3ed-003
ソースコード
# プログラム名: librosa による音声スペクトログラムと CREPE による基本周波数(F0)時間変化解析プログラム
# 特徴技術名: CREPE (Convolutional Representation for Pitch Estimation)
# 出典: Kim, J. W., Salamon, J., Li, P., & Bello, J. P. (2018). CREPE: A convolutional representation for pitch estimation. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 161-165). IEEE. doi:10.1109/ICASSP.2018.8461329
# 特徴機能: 時間領域音声波形からの直接的ピッチ推定。深層畳み込みニューラルネットワークが音声波形を直接入力として受け取り、前処理なしに基本周波数推定を実現。従来の周波数領域解析手法と比較してノイズ耐性が高く、複雑な音響環境でも安定した性能を発揮
# 学習済みモデル: CREPE tiny/small/medium/large/full モデル(容量:tiny-0.9MB、small-1.8MB、medium-3.3MB、large-5.9MB、full-12MB)。GitHub公式リポジトリ(https://github.com/marl/crepe)から提供。TensorFlow SavedModel形式で、初回実行時にPython crepeライブラリを通じて自動ダウンロード
# 方式設計:
# - 関連利用技術: librosa(音声読み込み・STFT・スペクトログラム変換)、matplotlib(可視化)、numpy(数値計算)、scipy(信号処理・フィルタリング)、sounddevice(音声再生・録音)、tkinter(ファイル選択GUI)、urllib(サンプルファイルダウンロード)、moviepy(動画音声抽出)
# - 入力と出力: 入力: 音声・動画ファイル、マイク入力、サンプル音声(ユーザは「0:音声・動画ファイル,1:マイク,2:サンプル音声」のメニューで選択)、出力: スペクトログラムとF0軌跡の重ね合わせ表示、F0統計情報のコンソール出力、1秒間隔でのF0値表示、result.txtファイルへの結果保存、音声再生機能
# - 処理手順: 1.入力ソース選択(ファイル/マイク/サンプル) 2.音声データ取得 3.ハイパスフィルタ適用(scipy.butter, 50Hz以下除去) 4.音声信号正規化 5.STFT計算(librosa.stft) 6.スペクトログラム変換(amplitude_to_db) 7.CREPE F0推定(crepe.predict, Viterbiデコーディング適用) 8.信頼度フィルタリング 9.メディアンフィルタによるスムージング 10.F0統計計算 11.可視化・出力・保存
# - 前処理、後処理: 前処理: バターワースハイパスフィルタ(5次、50Hz以下除去)による低域ノイズ除去、最大振幅による正規化、後処理: 5点メディアンフィルタによるF0軌跡平滑化、信頼度0.5未満の区間をNaN設定による無音区間処理
# - 追加処理: 統計情報算出(平均・標準偏差・最小・最大・中央値・範囲)、1秒間隔サンプリングによる時系列F0値出力、結果の自動ファイル保存、処理日時記録、音声再生機能、CREPE推定範囲の明示
# - 調整を必要とする設定値: CREPE_MODEL_CAPACITY(モデルサイズ選択、精度と計算時間のトレードオフ)、CREPE_STEP_SIZE(時間解像度、デフォルト10ms)、HOP_LENGTH(STFT解像度、デフォルト512サンプル)、CONF_THRESH(無音判定閾値、デフォルト0.5)、MED_FILTER_SIZE(スムージング強度、デフォルト5)、HIGHPASS_CUTOFF(ノイズ除去周波数、デフォルト50Hz)、RECORDING_DURATION(マイク録音時間、デフォルト10秒)
# 将来方策: 音声長に応じたHOP_LENGTHの動的調整機能実装(短時間音声では高解像度、長時間音声では処理効率を優先した自動パラメータ調整)
# その他の重要事項: Windows環境でのNumba/librosaキャッシュディレクトリ問題対応のため環境変数設定実装。CREPEモデルは初回のみダウンロード、以降はローカルキャッシュ使用。処理結果は日時付きでresult.txtに自動保存。動画ファイルの場合は音声トラックを自動抽出
# 前準備: pip install crepe librosa matplotlib numpy scipy sounddevice japanize-matplotlib tensorflow moviepy
import os
# Windowsでのキャッシュディレクトリ設定
os.environ['NUMBA_CACHE_DIR'] = os.path.join(os.path.expanduser('~'), '.numba_cache')
os.environ['LIBROSA_CACHE_DIR'] = os.path.join(os.path.expanduser('~'), '.librosa_cache')
import crepe
import librosa
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
from scipy.signal import medfilt, butter, filtfilt
import tkinter as tk
from tkinter import filedialog
import urllib.request
import sounddevice as sd
from datetime import datetime
import tempfile
# 設定値(必要に応じて調整してください)
CREPE_MODEL_CAPACITY = 'tiny' # CREPEモデルサイズ: 'tiny', 'small', 'medium', 'large', 'full'
CREPE_STEP_SIZE = 10 # CREPEの時間ステップ(ミリ秒)
HOP_LENGTH = 512 # 時間解像度(サンプル数):小さいほど時間解像度が高い
N_FFT = 2048 # FFTウィンドウサイズ
WINDOW_TYPE = 'hann' # 窓関数の種類
CONF_THRESH = 0.5 # 無音判定の信頼度閾値(0.0-1.0)
MED_FILTER_SIZE = 5 # メディアンフィルタのカーネルサイズ
SAMPLE_AUDIO_URL = 'https://github.com/librosa/librosa-test-data/raw/main/test1_44100.wav'
SPECTROGRAM_MAX_FREQ = 2000 # スペクトログラム表示の最大周波数(Hz)
F0_MAX_FREQ = 800 # F0表示の最大周波数(Hz)
HIGHPASS_CUTOFF = 50 # ハイパスフィルタのカットオフ周波数(Hz)
FILTER_ORDER = 5 # バターワースフィルタの次数
RESULT_FILENAME = 'result.txt' # 結果保存ファイル名
RECORDING_DURATION = 10 # マイク録音時間(秒)
RECORDING_SAMPLERATE = 44100 # マイク録音サンプリングレート(Hz)
# 表示関連定数
FIGURE_SIZE_WIDTH = 12
FIGURE_SIZE_HEIGHT = 6
LINE_WIDTH = 4
PRINT_INTERVAL_SEC = 1 # 1秒間隔表示用
# ファイル選択関連
AUDIO_FILE_TYPES = [
('Audio/Video Files', '*.wav *.mp3 *.flac *.m4a *.ogg *.mp4 *.avi *.mov *.mkv *.webm'),
('Audio Files', '*.wav *.mp3 *.flac *.m4a *.ogg'),
('Video Files', '*.mp4 *.avi *.mov *.mkv *.webm'),
('All Files', '*.*')
]
FILE_DIALOG_TITLE = '音声・動画ファイルを選択'
TEMP_FILENAME = 'sample_audio.wav'
# プログラムの説明表示
print('=== 音声スペクトログラムとF0時間変化表示プログラム ===')
print('このプログラムは音声から以下の処理を行います:')
print('1. スペクトログラム(周波数成分の時間変化)の計算')
print('2. 基本周波数(F0/ピッチ)の推定')
print('3. スペクトログラムとF0の重ね合わせ表示')
print('4. F0統計情報の計算と表示')
print('5. 結果をresult.txtに自動保存')
print()
print('【入力ソース】')
print('- 音声ファイル(WAV, MP3, FLAC, M4A, OGG)')
print('- 動画ファイル(MP4, AVI, MOV, MKV, WEBM)から音声抽出')
print('- マイクからのリアルタイム録音')
print('- サンプル音声のダウンロード')
print()
# 入力ソース選択
print('入力ソースを選択してください:')
print('0: 音声ファイル・動画ファイル')
print('1: マイク')
print('2: サンプル音声ファイル')
choice = input('選択: ')
temp_file = None
temp_audio_file = None
result_data = [] # 結果保存用
try:
if choice == '0':
# ファイル選択
root = tk.Tk()
root.withdraw()
file_path = filedialog.askopenfilename(
title=FILE_DIALOG_TITLE,
filetypes=AUDIO_FILE_TYPES
)
root.destroy()
if not file_path:
print('ファイルが選択されませんでした。')
exit()
print(f'選択されたファイル: {file_path}')
# 動画ファイルかどうかチェック
video_extensions = ['.mp4', '.avi', '.mov', '.mkv', '.webm']
if any(file_path.lower().endswith(ext) for ext in video_extensions):
print('動画ファイルを検出しました。音声トラックを抽出中...')
try:
from moviepy.editor import VideoFileClip
video = VideoFileClip(file_path)
if video.audio is None:
print('エラー: この動画ファイルには音声トラックがありません。')
exit()
# 一時ファイルに音声を保存
temp_audio_file = tempfile.NamedTemporaryFile(suffix='.wav', delete=False)
temp_audio_file.close()
video.audio.write_audiofile(temp_audio_file.name, logger=None)
video.close()
audio_path = temp_audio_file.name
print('音声トラックの抽出が完了しました。')
except ImportError:
print('エラー: moviepyがインストールされていません。')
print('pip install moviepy を実行してください。')
exit()
except Exception as e:
print(f'動画ファイルの処理に失敗しました: {e}')
exit()
else:
audio_path = file_path
elif choice == '1':
# マイク録音
print(f'\nマイクから{RECORDING_DURATION}秒間録音します。')
print('録音開始の準備ができたらEnterキーを押してください...')
input()
print(f'録音中... ({RECORDING_DURATION}秒間)')
try:
# 録音実行
audio_recording = sd.rec(int(RECORDING_DURATION * RECORDING_SAMPLERATE),
samplerate=RECORDING_SAMPLERATE,
channels=1, dtype='float32')
sd.wait() # 録音完了まで待機
print('録音が完了しました。')
# 一時ファイルに保存
temp_audio_file = tempfile.NamedTemporaryFile(suffix='.wav', delete=False)
temp_audio_file.close()
import scipy.io.wavfile
# float32を16bit整数に変換して保存
audio_int16 = np.int16(audio_recording * 32767)
scipy.io.wavfile.write(temp_audio_file.name, RECORDING_SAMPLERATE, audio_int16)
audio_path = temp_audio_file.name
print(f'録音データを一時ファイルに保存しました。')
except Exception as e:
print(f'マイク録音に失敗しました: {e}')
print('マイクが正しく接続されているか確認してください。')
exit()
elif choice == '2':
# サンプル音声ダウンロード
url = SAMPLE_AUDIO_URL
filename = TEMP_FILENAME
try:
print('サンプル音声をダウンロードしています...')
urllib.request.urlretrieve(url, filename)
temp_file = filename
audio_path = filename
print('サンプル音声のダウンロードが完了しました。')
except Exception as e:
print(f'音声のダウンロードに失敗しました: {url}')
print(f'エラー: {e}')
exit()
else:
print('無効な選択です')
exit()
# 結果データの記録開始
result_data.append(f'処理日時: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}')
if choice == '0':
result_data.append(f'入力ソース: 音声・動画ファイル')
result_data.append(f'ファイルパス: {file_path}')
elif choice == '1':
result_data.append(f'入力ソース: マイク録音')
result_data.append(f'録音時間: {RECORDING_DURATION}秒')
else:
result_data.append(f'入力ソース: サンプル音声')
result_data.append('')
# 音声ファイル読み込み
print('音声ファイル読み込み中...')
print(f'ファイルパス: {audio_path}')
try:
audio, sr = librosa.load(audio_path, sr=None, mono=True)
print(f'読み込み成功: サンプリングレート={sr}Hz, 長さ={len(audio)/sr:.1f}秒')
result_data.append(f'サンプリングレート: {sr} Hz')
result_data.append(f'音声長: {len(audio)/sr:.1f} 秒')
except Exception as e:
print(f'音声ファイルの読み込みに失敗しました: {e}')
exit()
# 音声信号の前処理
print('音声信号前処理中...')
# ハイパスフィルタの適用(50Hz以下をカット)
nyquist = sr / 2
if HIGHPASS_CUTOFF >= nyquist:
print(f'警告: ハイパスフィルタのカットオフ周波数({HIGHPASS_CUTOFF}Hz)がナイキスト周波数({nyquist}Hz)以上です。フィルタを適用しません。')
audio_filt = audio
else:
normal_cutoff = HIGHPASS_CUTOFF / nyquist
b, a = butter(FILTER_ORDER, normal_cutoff, btype='high', analog=False)
audio_filt = filtfilt(b, a, audio)
# 正規化
if np.max(np.abs(audio_filt)) > 0:
audio_norm = audio_filt / np.max(np.abs(audio_filt))
else:
print('警告: 音声信号の振幅が0です。')
audio_norm = audio_filt
# スペクトログラム計算
print('スペクトログラム計算中...')
# librosaによるSTFT計算
D = librosa.stft(audio_norm, n_fft=N_FFT, hop_length=HOP_LENGTH, window=WINDOW_TYPE)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
# CREPEによるF0推定
print('F0推定中...')
print(f'音声データ: shape={audio_norm.shape}, sr={sr}')
try:
time, frequency, confidence, activation = crepe.predict(
audio_norm, sr, viterbi=True,
model_capacity=CREPE_MODEL_CAPACITY,
step_size=CREPE_STEP_SIZE
)
print('F0推定完了')
# 配列長の整合性チェック
if len(time) != len(frequency) or len(time) != len(confidence):
print(f'警告: CREPE出力配列の長さが不一致です。time:{len(time)}, frequency:{len(frequency)}, confidence:{len(confidence)}')
min_len = min(len(time), len(frequency), len(confidence))
time = time[:min_len]
frequency = frequency[:min_len]
confidence = confidence[:min_len]
# CREPE推定範囲を記録
crepe_start_time = time[0] if len(time) > 0 else 0
crepe_end_time = time[-1] if len(time) > 0 else 0
result_data.append(f'CREPE推定範囲: {crepe_start_time:.2f}秒 - {crepe_end_time:.2f}秒')
result_data.append('')
if crepe_end_time < len(audio)/sr - 0.5: # 0.5秒以上の差がある場合
print(f'注意: CREPE推定範囲({crepe_end_time:.2f}秒)は音声全体({len(audio)/sr:.2f}秒)をカバーしていません。')
except Exception as e:
print(f'CREPE F0推定に失敗しました: {e}')
print('初回実行時はモデルのダウンロードが必要です。ネットワーク接続を確認してください。')
exit()
# 無音区間のF0をNaNに設定(グラフで不連続表示)
frequency[confidence < CONF_THRESH] = np.nan
# F0のスムージング(メディアンフィルタ、NaNは保持)
freq_smooth = frequency.copy()
valid_mask = ~np.isnan(frequency)
if np.any(valid_mask):
# 有効な値のみでメディアンフィルタを適用
valid_indices = np.where(valid_mask)[0]
for i in valid_indices:
start = max(0, i - MED_FILTER_SIZE // 2)
end = min(len(frequency), i + MED_FILTER_SIZE // 2 + 1)
window_data = frequency[start:end]
valid_window = window_data[~np.isnan(window_data)]
if len(valid_window) > 0:
freq_smooth[i] = np.median(valid_window)
# F0統計情報の計算(不偏標準偏差を使用)
valid_f0 = freq_smooth[~np.isnan(freq_smooth)]
if len(valid_f0) > 0:
stats = {
'平均F0': np.mean(valid_f0),
'標準偏差': np.std(valid_f0, ddof=1) if len(valid_f0) > 1 else '計算不可',
'最小F0': np.min(valid_f0),
'最大F0': np.max(valid_f0),
'中央値': np.median(valid_f0)
}
stats['F0範囲'] = stats['最大F0'] - stats['最小F0']
else:
stats = {'平均F0': 0, '標準偏差': '計算不可', '最小F0': 0, '最大F0': 0, '中央値': 0, 'F0範囲': 0}
# グラフ描画
fig, ax1 = plt.subplots(figsize=(FIGURE_SIZE_WIDTH, FIGURE_SIZE_HEIGHT))
# スペクトログラム表示
freqs = librosa.fft_frequencies(sr=sr, n_fft=N_FFT)
times = librosa.frames_to_time(np.arange(S_db.shape[1]), sr=sr, hop_length=HOP_LENGTH)
img = ax1.pcolormesh(times, freqs, S_db, shading='auto', cmap='viridis')
ax1.set_ylim(0, SPECTROGRAM_MAX_FREQ)
# F0グラフの重ね合わせ
ax2 = ax1.twinx()
# === ▼ 修正箇所 ▼ ===
# F0軌跡を効率的に描画(NaN値は自動的に線が途切れる)
ax2.plot(time, freq_smooth, 'r-', linewidth=LINE_WIDTH)
# === ▲ 修正箇所 ▲ ===
ax2.set_ylabel('Frequency (Hz)', color='r')
ax2.tick_params(axis='y', labelcolor='r')
ax2.set_ylim(0, F0_MAX_FREQ)
# タイトルとラベル
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Frequency (Hz)')
plt.title('Spectrogram with F0 Contour')
# カラーバー追加
cbar = plt.colorbar(img, ax=ax1, format='%+2.0f dB')
# F0統計情報の出力と記録
duration = len(audio) / sr
print(f'\n音声長: {duration:.1f}秒')
print(f'CREPE推定範囲: {crepe_start_time:.2f}秒 - {crepe_end_time:.2f}秒')
print('\nF0統計情報:')
result_data.append('F0統計情報:')
for key, value in stats.items():
if isinstance(value, str):
print(f'{key}: {value}')
result_data.append(f'{key}: {value}')
else:
print(f'{key}: {value:.1f} Hz')
result_data.append(f'{key}: {value:.1f} Hz')
result_data.append('')
# 1秒ごとのF0値出力と記録
print('\n1秒ごとのF0値:')
result_data.append('1秒ごとのF0値:')
# time配列の最大値を取得
max_time = time[-1] if len(time) > 0 else 0
for t in range(0, int(min(duration, max_time)) + 1, PRINT_INTERVAL_SEC):
# time配列の範囲内でのみ処理
if t <= max_time:
# 指定時刻に最も近いインデックスを取得
idx = np.argmin(np.abs(time - t))
# インデックスの範囲チェック
if 0 <= idx < len(freq_smooth):
if not np.isnan(freq_smooth[idx]):
actual_time = time[idx] # 実際の測定時刻
print(f'{t:3d}秒: {freq_smooth[idx]:.1f} Hz (実測定時刻: {actual_time:.2f}秒)')
result_data.append(f'{t:3d}秒: {freq_smooth[idx]:.1f} Hz (実測定時刻: {actual_time:.2f}秒)')
else:
print(f'{t:3d}秒: 無音')
result_data.append(f'{t:3d}秒: 無音')
else:
print(f'{t:3d}秒: データなし')
result_data.append(f'{t:3d}秒: データなし')
else:
# CREPEの推定範囲外
print(f'{t:3d}秒: 推定範囲外(CREPE推定終了: {max_time:.2f}秒)')
result_data.append(f'{t:3d}秒: 推定範囲外(CREPE推定終了: {max_time:.2f}秒)')
# 結果をファイルに保存
try:
with open(RESULT_FILENAME, 'w', encoding='utf-8') as f:
f.write('\n'.join(result_data))
print(f'\n結果を {RESULT_FILENAME} に保存しました')
except Exception as e:
print(f'結果ファイルの保存に失敗しました: {e}')
print('保存内容:')
print('- 処理日時と入力ソース情報')
print('- CREPE推定範囲')
print('- F0統計情報(平均、標準偏差、最小、最大、中央値、範囲)')
print('- 1秒ごとのF0値と実測定時刻')
plt.tight_layout()
plt.show()
# 音声再生(すべての入力ソースで可能)
if choice == '1':
print('\n録音した音声を再生しますか?')
else:
print('\n音声を再生しますか?')
print('y: 再生')
print('n: 終了')
play_choice = input('選択: ')
if play_choice.lower() == 'y':
print('音声再生中... (Ctrl+Cで中断)')
try:
sd.play(audio, sr)
sd.wait()
print('再生完了')
except KeyboardInterrupt:
sd.stop()
print('\n再生を中断しました')
except Exception as e:
print(f'音声再生エラー: {e}')
except Exception as e:
print(f'予期しないエラーが発生しました: {e}')
finally:
# 一時ファイルの削除
if temp_file and os.path.exists(temp_file):
try:
os.remove(temp_file)
print('一時ファイルを削除しました。')
except OSError:
print('一時ファイルの削除に失敗しました。')
if temp_audio_file and os.path.exists(temp_audio_file.name):
try:
os.remove(temp_audio_file.name)
print('音声一時ファイルを削除しました。')
except OSError:
print('音声一時ファイルの削除に失敗しました。')