FastText日本語単語ベクトル演算
【目次】
1. Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なPythonライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install gensim numpy scikit-learn matplotlib japanize-matplotlib
2. プログラムコード
# プログラム名: FastText日本語単語ベクトル演算デモ
# 特徴技術名: FastText
# 出典: Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135-146.
# 特徴機能: サブワード情報を利用した単語埋め込み - 文字n-gramベースで単語を表現し、未知語にも対応可能な単語ベクトル生成
# 学習済みモデル: Common Crawl日本語FastTextモデル(cc.ja.300.vec.gz)- 157言語対応、300次元ベクトル、Common Crawlコーパスで学習済み、URL: https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz
# 方式設計:
# - 関連利用技術: Gensim(単語ベクトル操作・類似度計算)、scikit-learn(PCAによる次元削減)、matplotlib/japanize-matplotlib(可視化)
# - 入力と出力: 入力: なし(プログラム内で定義された単語を使用)、出力: コンソールへの類似度・演算結果表示、2次元可視化グラフ、result.txtファイル
# - 処理手順: 1)学習済みモデルのダウンロード・読み込み、2)単語ベクトル演算(加減算)、3)類似語検索、4)PCAによる2次元可視化、5)コサイン類似度計算
# - 前処理、後処理: 前処理: モデルファイルの存在確認とダウンロード、後処理: 可視化結果の表示と結果ファイル保存
# - 追加処理: 日本語フォント設定(japanize-matplotlib)による可視化の日本語対応
# - 調整を必要とする設定値: RANDOM_SEED(PCAの再現性制御、デフォルト42)、TOPN(類似語表示数、デフォルト5)
# 将来方策: インタラクティブな単語入力機能を追加し、ユーザが任意の単語でベクトル演算を実行可能にする
# その他の重要事項: 初回実行時は約2GBのモデルファイルをダウンロードするため時間がかかる
# 前準備: pip install gensim numpy scikit-learn matplotlib japanize-matplotlib
import os
import urllib.request
import gensim
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import japanize_matplotlib
# 定数定義
RANDOM_SEED = 42 # 再現性のための乱数シード
MODEL_URL = 'https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz'
MODEL_FILE = 'cc.ja.300.vec.gz'
RESULT_FILE = 'result.txt'
TOPN = 5 # 類似語検索の表示数
# 可視化設定
FIG_SIZE = (10, 8)
SCATTER_SIZE = 200
FONT_SIZE_ANNOTATION = 16
FONT_SIZE_TITLE = 18
FONT_SIZE_LABEL = 14
# 演算対象の単語設定
VECTOR_CALC_WORDS = [
(['王様', '女性'], ['男性'], '王様 - 男性 + 女性 = ?'),
(['東京', 'アメリカ'], ['日本'], '東京 - 日本 + アメリカ = ?')
]
SIMILAR_TARGET = 'コンピュータ'
VISUALIZATION_WORDS = ['王様', '女王', '男性', '女性', '王子', '王女']
SIMILARITY_PAIRS = [('王様', '女王'), ('男性', '女性'), ('コンピュータ', 'ソフトウェア')]
# 乱数シード設定
np.random.seed(RANDOM_SEED)
# 結果記録用関数
def log_result(message, results_list):
print(message)
results_list.append(message)
# プログラム開始時の説明
print('FastText日本語単語ベクトル演算デモ')
print('このプログラムは日本語の単語ベクトルを使用して、単語の演算や類似度計算を行います。')
print('初回実行時は約2GBのモデルファイルをダウンロードします。')
print()
# 処理結果を保存するためのリスト
results = []
results.append('FastText日本語単語ベクトル演算デモ - 実行結果')
results.append('')
# モデルのダウンロードと読み込み
log_result('日本語FastText学習済みモデルをダウンロード中...', results)
if not os.path.exists(MODEL_FILE):
try:
urllib.request.urlretrieve(MODEL_URL, MODEL_FILE)
log_result('ダウンロード完了', results)
except Exception as e:
print(f'モデルのダウンロードに失敗しました: {MODEL_URL}')
print(f'エラー: {e}')
exit()
log_result('モデルを読み込み中...', results)
try:
model = gensim.models.KeyedVectors.load_word2vec_format(MODEL_FILE, binary=False)
log_result('読み込み完了', results)
except Exception as e:
print(f'モデルの読み込みに失敗しました: {MODEL_FILE}')
print(f'エラー: {e}')
exit()
# メイン処理
log_result('', results)
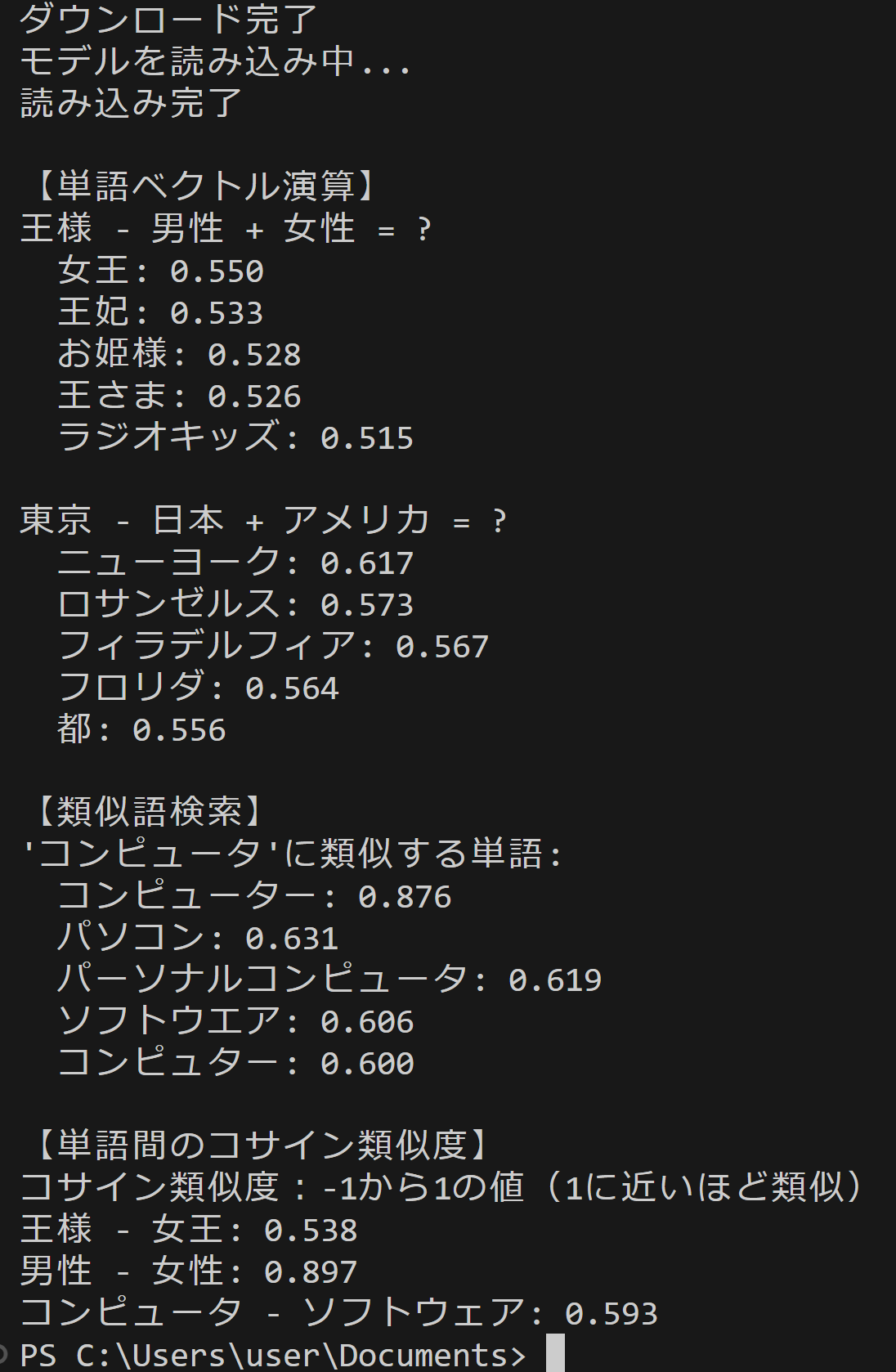
log_result('【単語ベクトル演算】', results)
# ベクトル演算
for positive, negative, description in VECTOR_CALC_WORDS:
if all(word in model for word in positive + negative):
result = model.most_similar(positive=positive, negative=negative, topn=TOPN)
log_result(description, results)
for word, score in result:
log_result(f' {word}: {score:.3f}', results)
log_result('', results)
# 類似語検索
log_result('【類似語検索】', results)
if SIMILAR_TARGET in model:
similar_words = model.most_similar(SIMILAR_TARGET, topn=TOPN)
log_result(f"'{SIMILAR_TARGET}'に類似する単語:", results)
for word, score in similar_words:
log_result(f' {word}: {score:.3f}', results)
# ベクトル空間の可視化
word_vectors = []
valid_words = []
for word in VISUALIZATION_WORDS:
if word in model:
word_vectors.append(model[word])
valid_words.append(word)
if len(word_vectors) > 1:
pca = PCA(n_components=2, random_state=RANDOM_SEED)
vectors_2d = pca.fit_transform(word_vectors)
plt.figure(figsize=FIG_SIZE)
for i, word in enumerate(valid_words):
plt.scatter(vectors_2d[i, 0], vectors_2d[i, 1], s=SCATTER_SIZE)
plt.annotate(word, (vectors_2d[i, 0], vectors_2d[i, 1]),
xytext=(5, 5), textcoords='offset points', fontsize=FONT_SIZE_ANNOTATION)
plt.title('日本語単語ベクトルの2次元可視化', fontsize=FONT_SIZE_TITLE)
plt.xlabel('第1主成分', fontsize=FONT_SIZE_LABEL)
plt.ylabel('第2主成分', fontsize=FONT_SIZE_LABEL)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 単語間のコサイン類似度
log_result('', results)
log_result('【単語間のコサイン類似度】', results)
log_result('コサイン類似度:-1から1の値(1に近いほど類似)', results)
for w1, w2 in SIMILARITY_PAIRS:
if w1 in model and w2 in model:
similarity = model.similarity(w1, w2)
log_result(f'{w1} - {w2}: {similarity:.3f}', results)
# 結果をファイルに保存
with open(RESULT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(results))
print(f'\n{RESULT_FILE}に保存しました')
3. 使用方法
- 上記のプログラムを実行する
- 初回実行時は学習済みモデル(約4GB)のダウンロードに時間がかかる。2回目以降は読み込みのみとなる。
4. 実験・探求のアイデア
AIモデル選択
FastText以外に以下の日本語単語ベクトルモデルが利用可能である:
- 東北大学日本語Wikipediaモデル(entity_vector.model.bin):200次元、日本語特化
- 白ヤギコーポレーション日本語モデル:50次元、軽量モデル
追加実験
1. 単語ベクトル演算の組み合わせ変更:
- 「医者 - 男性 + 女性」で性別による職業表現の違いを観察
- 「パリ - フランス + 日本」で首都の関係性を検証
- 「寿司 - 日本 + イタリア」で文化的要素の変換を試行
2. 類似度の閾値実験:
- topnパラメータを1〜20に変更し、類似語の広がりを観察
- 異なるカテゴリの単語間の類似度を測定
3. 可視化する単語群の変更:
- 動物:['犬', '猫', '鳥', '魚', '馬', '牛']
- 色:['赤', '青', '緑', '黄', '白', '黒']
- 感情:['喜び', '悲しみ', '怒り', '恐れ', '驚き', '嫌悪']
体験・実験・探求のアイデア
未知語への対応検証:造語や新語を入力し、FastTextの処理を観察する。
時代による意味変化の推測:古語と現代語の類似度を考察する。
専門用語の関係性発見:特定分野の専門用語群を入力し、専門用語間の関連性を分析する。