ゲーム画面でのアイテム認識と戦略決定
【目次】
1. 概要
主要技術:YOLO11(You Only Look Once version 11)
論文:「YOLO11: An Overview of the Key Architectural Enhancements」(2024年)
新規性・特徴:C3k2ブロックによる高速推論と高精度を実現し、リアルタイム物体検出において従来モデルを上回る性能を達成。C3k2ブロックは、畳み込み層とクロスステージ部分接続を組み合わせたアーキテクチャで、計算量を削減しながら特徴抽出能力を維持する。ゲームAI、監視システム、自動運転などに応用可能。
リアルタイムゲームでは高速な状況認識が必要であり、YOLO11の高速推論能力がゲームAIの意思決定に適している。
体験価値:実際のゲーム画面を模擬した環境でYOLO11の物体検出能力を体験し、AIがどのようにゲーム状況を認識・分析するかを学習できる。
利用可能なYOLO11モデル
YOLO11には以下のモデルが利用可能である:
- yolo11n.pt:Nano版(最軽量、約2.6MB、最速)
- yolo11s.pt:Small版(軽量、高速)
- yolo11m.pt:Medium版(バランス型)
- yolo11l.pt:Large版(高精度)
- yolo11x.pt:Extra Large版(最高精度、重い)
2. Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なPythonライブラリのインストール
以下のコマンドを実行する(管理者権限のコマンドプロンプトで実行)。
pip install ultralytics opencv-python numpy matplotlib japanize-matplotlib pillow
3. プログラムコード
概要
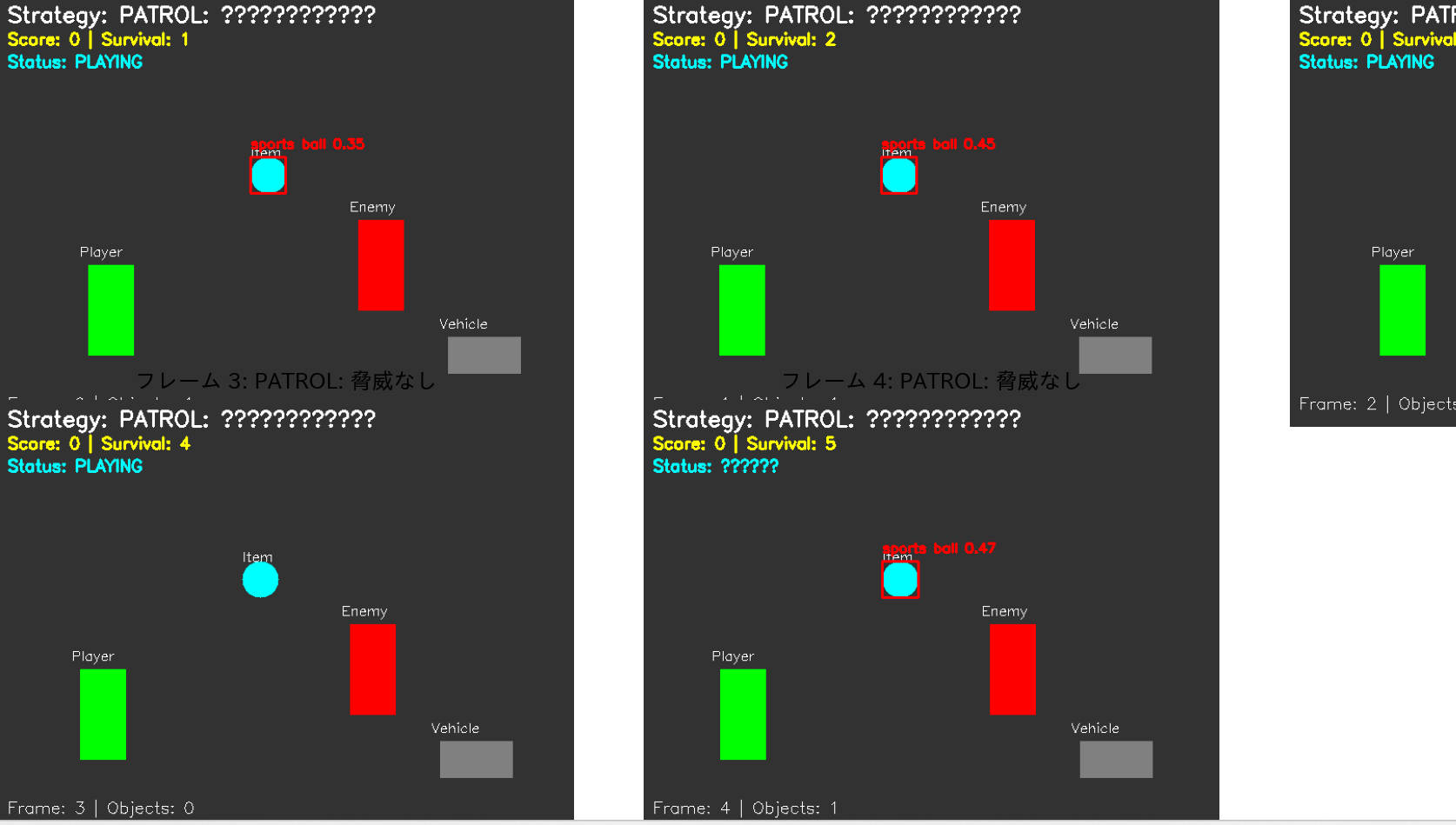
本プログラムは、YOLO11による物体検出技術をゲームAIに応用したデモンストレーションシステムである。プログラム内で動的に生成されるゲームシーンに対してリアルタイム物体検出を実行し、検出結果に基づいてゲーム戦略を自動決定する。実画像(人物、果物、車両)を組み込んだシミュレーション環境により、実用的な物体検出の動作を確認できる。
主要技術
YOLO11 (You Only Look Once version 11)
Ultralyticsが2024年に発表した物体検出モデル[1]。C3k2ブロックと呼ばれる改良されたアーキテクチャを採用し、従来のYOLOシリーズと比較して検出精度と処理速度のバランスが向上している。本プログラムではNano版(yolo11n.pt)を使用し、約2.6MBの軽量モデルでCOCOデータセット80クラスの物体検出を実現する。
リアルタイム処理アーキテクチャ
単一の推論パスで複数物体の位置とクラスを同時に検出する効率的な処理方式を採用。バウンディングボックスの座標、信頼度スコア、クラス確率を一度に出力することで、リアルタイムゲーム環境での応用を可能にしている[2]。
技術的特徴
物体検出とゲームロジックの統合
検出された物体の位置情報から物体間のユークリッド距離を計算し、危険判定距離(250ピクセル)、攻撃判定距離(350ピクセル)、アイテム収集距離(200ピクセル)の閾値に基づいて戦略を決定する。この距離ベースの判定により、ゲーム内での適切な行動選択を実現している。
実画像を用いたシミュレーション
OpenCVサンプル画像(basketball2.png、fruits.jpg)を活用し、実際の画像に対する物体検出性能を確認できる。画像が取得できない場合は代替グラフィックを自動生成するフォールバック機構も実装されている。
実装の特色
ゲーム状態管理システム
フレームごとの危険状態遷移を追跡し、累積危険カウントによる敗北判定と生存フレーム数による勝利判定を実装。プレイヤー、敵、アイテムの位置を動的に更新し、振動運動や直線移動などの動きパターンを組み込んでいる。
可視化と結果記録
OpenCVによるリアルタイム表示とMatplotlibによる結果サマリー表示を併用。日本語フォント(メイリオ)を使用した情報表示により、戦略状態やスコアを分かりやすく提示する。処理結果はテキストファイルに自動保存され、推論時間、検出数、戦略決定の履歴を記録する。
参考文献
[1] Ultralytics. (2024). YOLO11: State-of-the-art Object Detection. Ultralytics Documentation. https://docs.ultralytics.com/models/yolo11/
[2] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779-788. https://arxiv.org/abs/1506.02640
ソースコード
# YOLO11ゲームAI Visionデモ
# 特徴技術名: YOLO11 (You Only Look Once version 11)
# 出典: Ultralytics YOLO11 Documentation, https://docs.ultralytics.com/models/yolo11/ (2024)
# 特徴機能: C3k2ブロックによるリアルタイム物体検出。単一推論で複数物体の位置とクラスを同時検出
# 学習済みモデル: yolo11n.pt (Nano版、約2.6MB、COCOデータセット80クラス対応、https://github.com/ultralytics/assets/releases/)
# 方式設計:
# - 関連利用技術: OpenCV (画像処理・表示)、NumPy (数値計算)、Matplotlib (結果可視化)、japanize-matplotlib (日本語表示)、Pillow (画像合成)
# - 入力と出力: 入力: プログラム内で生成される実画像を含むゲームシーン、出力: 物体検出結果の可視化画像とテキスト情報
# - 処理手順: 1.ゲームシーン生成 2.YOLO11による物体検出 3.検出結果の解析 4.ゲーム戦略決定 5.結果可視化
# - 前処理、後処理: 前処理: なし(RGB画像をそのまま入力)、後処理: 検出結果のフィルタリング(信頼度による)
# - 追加処理: ゲームロジックによる物体間距離計算と戦略決定アルゴリズム
# - 調整を必要とする設定値: DANGER_DISTANCE (危険判定距離、デフォルト250ピクセル)
# 将来方策: 検出物体間の最適距離を自動学習するため、複数回の実行結果から統計的に最適値を算出する機能
# その他の重要事項: デモ用のシミュレーション環境。実画像を使用してYOLO検出を機能させる
# 前準備:
# - pip install ultralytics opencv-python numpy matplotlib japanize-matplotlib pillow
import cv2
import numpy as np
import time
import os
import urllib.request
from PIL import Image, ImageDraw, ImageFont
try:
from ultralytics import YOLO
except ImportError:
print('Error: ultralyticsライブラリがインストールされていません')
print('pip install ultralytics を実行してください')
exit()
try:
import matplotlib.pyplot as plt
import japanize_matplotlib
except ImportError:
print('Error: matplotlib または japanize-matplotlib がインストールされていません')
print('pip install matplotlib japanize-matplotlib を実行してください')
exit()
# 定数定義
RANDOM_SEED = 42
PLAYER_COLOR = (0, 255, 0)
ENEMY_COLOR = (0, 0, 255)
ITEM_COLOR = (255, 255, 0)
VEHICLE_COLOR = (128, 128, 128)
TEXT_COLOR = (255, 255, 255)
DANGER_DISTANCE = 250 # 危険判定距離(ピクセル)
ATTACK_DISTANCE = 350 # 攻撃判定距離(ピクセル)
ITEM_COLLECT_DISTANCE = 200 # アイテム収集距離(ピクセル)
WIN_SCORE = 50 # 勝利スコア
WIN_SURVIVAL_FRAMES = 30 # 勝利に必要な生存フレーム数
DANGER_COUNT_LIMIT = 3 # 危険状態の許容回数
# ゲームオブジェクトの設定
SCENE_WIDTH = 640 # シーン幅
SCENE_HEIGHT = 480 # シーン高さ
PLAYER_POS = (100, 300) # プレイヤー初期位置
PLAYER_SIZE = (50, 100) # プレイヤーサイズ(幅、高さ)
ENEMY_BASE_POS = (400, 250) # 敵の基準位置
ENEMY_SIZE = (50, 100) # 敵のサイズ(幅、高さ)
ENEMY_MOVE_SPEED = 50 # 敵の移動速度(ピクセル/秒)
ITEM_BASE_POS = (300, 200) # アイテムの基準位置(振動の中心)
ITEM_RADIUS = 20 # アイテムの半径
ITEM_AMPLITUDE = 50 # アイテムの振幅
ITEM_FREQUENCY = 0.5 # アイテムの振動周波数(Hz)
VEHICLE_POS = (500, 380) # 車両の位置
VEHICLE_SIZE = (80, 40) # 車両のサイズ(幅、高さ)
# 表示設定
FONT_SCALE = 0.5 # 小さいテキスト用
FONT_SCALE_LARGE = 0.8 # 大きいテキスト用
FONT_SCALE_MEDIUM = 0.6 # 中サイズテキスト用
FONT_THICKNESS = 1 # 通常のテキスト
FONT_THICKNESS_BOLD = 2 # 太字テキスト
FRAME_DELAY = 30 # フレーム表示待機時間(ミリ秒)
# 日本語フォント設定
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
FONT_SIZE = 20
# 乱数シード設定
np.random.seed(RANDOM_SEED)
def draw_text(img, text, pos, scale=FONT_SCALE, color=TEXT_COLOR, thickness=FONT_THICKNESS):
"""テキスト描画の共通関数(英語用)"""
cv2.putText(img, text, pos, cv2.FONT_HERSHEY_SIMPLEX, scale, color, thickness)
def draw_japanese_text(img, text, pos, font_size=FONT_SIZE, color=(255, 255, 255)):
"""日本語テキスト描画関数"""
try:
font = ImageFont.truetype(FONT_PATH, font_size)
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
draw.text(pos, text, font=font, fill=color[::-1]) # BGRからRGBに変換
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
except:
draw_text(img, text, pos, FONT_SCALE, color, FONT_THICKNESS)
return img
class GameAIVision:
def __init__(self):
print('========================================')
print('YOLO11ゲームAI Visionデモ')
print('========================================')
print('\n【プログラム概要】')
print('YOLO11による物体検出を使用したゲーム画面解析デモ')
print('実画像を使用してYOLO検出を実現します')
print('\n【操作方法】')
print('- qキー: プログラム終了')
print('- 自動実行: 30フレームまたは勝利/敗北まで継続')
print('\n【ゲームルール】')
print(f'- プレイヤー(人物画像)は敵(車両画像)を避けながらアイテム(果物画像)を収集')
print(f'- アイテムに{ITEM_COLLECT_DISTANCE}ピクセル以内に接近すると10点獲得')
print(f'- {WIN_SCORE}点獲得または{WIN_SURVIVAL_FRAMES}フレーム生存で勝利')
print(f'- 敵との距離が{DANGER_DISTANCE}ピクセル未満が{DANGER_COUNT_LIMIT}回で敗北')
print('\n【注意事項】')
print('- 実画像を使用してYOLO検出を実現')
print('- インターネット接続が必要(画像ダウンロード用)')
print('========================================\n')
print('YOLO11モデルを初期化中...')
try:
self.model = YOLO('yolo11n.pt')
print('YOLO11モデルの初期化完了')
except Exception as e:
print(f'Error: YOLO11モデルの初期化に失敗しました: {e}')
exit()
# 実画像をダウンロード
print('ゲーム用画像を準備中...')
self.load_game_images()
self.frame_count = 0
self.score = 0
self.survival_frames = 0
self.danger_count = 0
self.in_danger_this_frame = False # 現在のフレームで危険状態かどうか
self.was_in_danger = False # 前フレームで危険状態だったか
self.results_log = []
self.last_print_time = time.time()
self.start_time = time.time()
self.collected_items = set() # 収集済みアイテムの管理(中心座標ベース)
# ゲームオブジェクトの実際の位置
self.actual_player_center = [PLAYER_POS[0] + PLAYER_SIZE[0]//2,
PLAYER_POS[1] + PLAYER_SIZE[1]//2]
self.actual_item_center = list(ITEM_BASE_POS) # アイテムの中心座標(振動の中心)
def load_game_images(self):
"""ゲーム用の実画像をダウンロード"""
try:
# 人物画像(プレイヤー用) - OpenCVのサンプル画像を使用
person_url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/basketball2.png"
try:
resp = urllib.request.urlopen(person_url)
img_array = np.asarray(bytearray(resp.read()), dtype=np.uint8)
self.person_img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
# 人物部分を切り出し(バスケットボール選手の画像の場合)
h, w = self.person_img.shape[:2]
# 中央部分を切り出し
crop_x = w // 4
crop_y = 0
crop_w = w // 2
crop_h = h
self.person_img = self.person_img[crop_y:crop_y+crop_h, crop_x:crop_x+crop_w]
self.person_img = cv2.resize(self.person_img, PLAYER_SIZE)
except:
# 代替案:シンプルな人型シルエットを生成
self.person_img = np.ones((PLAYER_SIZE[1], PLAYER_SIZE[0], 3), dtype=np.uint8) * 50
# 頭部(円)
head_center = (PLAYER_SIZE[0]//2, PLAYER_SIZE[1]//4)
head_radius = PLAYER_SIZE[0]//4
cv2.circle(self.person_img, head_center, head_radius, (200, 150, 100), -1)
# 胴体(矩形)
body_top = PLAYER_SIZE[1]//4 + head_radius
body_bottom = PLAYER_SIZE[1] - 10
body_left = PLAYER_SIZE[0]//3
body_right = 2 * PLAYER_SIZE[0]//3
cv2.rectangle(self.person_img, (body_left, body_top), (body_right, body_bottom), (100, 100, 200), -1)
# 果物画像(アイテム用)
fruit_url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
try:
resp = urllib.request.urlopen(fruit_url)
fruits_img = cv2.imdecode(np.asarray(bytearray(resp.read()), dtype=np.uint8), cv2.IMREAD_COLOR)
# 果物画像から一部を切り出し(オレンジ部分)
self.fruit_img = fruits_img[50:150, 50:150]
self.fruit_img = cv2.resize(self.fruit_img, (ITEM_RADIUS*2, ITEM_RADIUS*2))
except:
# オレンジ色の円を生成
self.fruit_img = np.ones((ITEM_RADIUS*2, ITEM_RADIUS*2, 3), dtype=np.uint8) * 255
cv2.circle(self.fruit_img, (ITEM_RADIUS, ITEM_RADIUS), ITEM_RADIUS, (0, 165, 255), -1)
# 車両画像(敵用) - より現実的な車両を生成
self.vehicle_img = np.ones((ENEMY_SIZE[1], ENEMY_SIZE[0], 3), dtype=np.uint8) * 50
# 車体
car_body = [(5, ENEMY_SIZE[1]//2),
(ENEMY_SIZE[0]-5, ENEMY_SIZE[1]//2),
(ENEMY_SIZE[0]-5, ENEMY_SIZE[1]-10),
(5, ENEMY_SIZE[1]-10)]
cv2.fillPoly(self.vehicle_img, [np.array(car_body, np.int32)], (100, 100, 150))
# 窓
window_top = ENEMY_SIZE[1]//2 + 5
window_height = 15
cv2.rectangle(self.vehicle_img, (10, window_top), (ENEMY_SIZE[0]-10, window_top+window_height), (150, 200, 255), -1)
# タイヤ
tire_y = ENEMY_SIZE[1] - 5
cv2.circle(self.vehicle_img, (15, tire_y), 5, (30, 30, 30), -1)
cv2.circle(self.vehicle_img, (ENEMY_SIZE[0]-15, tire_y), 5, (30, 30, 30), -1)
print('画像の準備完了')
except Exception as e:
print(f'Warning: 画像のダウンロードに失敗しました: {e}')
print('代替画像を使用します')
# 最小限の代替画像
self.person_img = np.ones((PLAYER_SIZE[1], PLAYER_SIZE[0], 3), dtype=np.uint8) * 255
cv2.rectangle(self.person_img, (0, 0), PLAYER_SIZE, PLAYER_COLOR, -1)
self.fruit_img = np.ones((ITEM_RADIUS*2, ITEM_RADIUS*2, 3), dtype=np.uint8) * 255
cv2.circle(self.fruit_img, (ITEM_RADIUS, ITEM_RADIUS), ITEM_RADIUS, ITEM_COLOR, -1)
self.vehicle_img = np.ones((ENEMY_SIZE[1], ENEMY_SIZE[0], 3), dtype=np.uint8) * 100
cv2.rectangle(self.vehicle_img, (0, 0), ENEMY_SIZE, VEHICLE_COLOR, -1)
def create_game_scene(self):
scene = np.ones((SCENE_HEIGHT, SCENE_WIDTH, 3), dtype=np.uint8) * 50
elapsed_time = time.time() - self.start_time
# プレイヤー(人物画像)を配置
x1, y1 = PLAYER_POS
x2, y2 = x1 + PLAYER_SIZE[0], y1 + PLAYER_SIZE[1]
scene[y1:y2, x1:x2] = self.person_img
draw_text(scene, 'Player', (x1 - 10, y1 - 10))
# 敵(車両画像)を配置 - 移動速度を正しく計算
enemy_offset = int(elapsed_time * ENEMY_MOVE_SPEED) % 100
enemy_x = ENEMY_BASE_POS[0] + enemy_offset
enemy_y = ENEMY_BASE_POS[1]
self.actual_enemy_center = [enemy_x + ENEMY_SIZE[0]//2, enemy_y + ENEMY_SIZE[1]//2]
scene[enemy_y:enemy_y+ENEMY_SIZE[1], enemy_x:enemy_x+ENEMY_SIZE[0]] = self.vehicle_img
draw_text(scene, 'Enemy', (enemy_x - 10, enemy_y - 10))
# アイテム(果物画像)を配置
item_x = ITEM_BASE_POS[0]
item_y = ITEM_BASE_POS[1] + int(np.sin(elapsed_time * 2 * np.pi * ITEM_FREQUENCY) * ITEM_AMPLITUDE)
self.actual_item_current_pos = [item_x, item_y]
# アイテム画像を配置
item_y1 = max(0, item_y - ITEM_RADIUS)
item_y2 = min(SCENE_HEIGHT, item_y + ITEM_RADIUS)
item_x1 = max(0, item_x - ITEM_RADIUS)
item_x2 = min(SCENE_WIDTH, item_x + ITEM_RADIUS)
if item_y2 > item_y1 and item_x2 > item_x1:
img_h = item_y2 - item_y1
img_w = item_x2 - item_x1
resized_fruit = cv2.resize(self.fruit_img, (img_w, img_h))
scene[item_y1:item_y2, item_x1:item_x2] = resized_fruit
draw_text(scene, 'Item', (item_x - 20, item_y - 20))
return scene
def detect_objects(self, frame):
results = self.model(frame, verbose=False)
detections = []
for r in results:
boxes = r.boxes
if boxes is not None:
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()
conf = box.conf[0].cpu().numpy()
cls = int(box.cls[0].cpu().numpy())
class_name = self.model.names[cls]
detections.append({
'bbox': [int(x1), int(y1), int(x2), int(y2)],
'confidence': float(conf),
'class': class_name,
'center': [(x1 + x2) / 2, (y1 + y2) / 2]
})
return detections
def analyze_game_state(self, detections):
game_state = {
'player_pos': self.actual_player_center, # 実際の位置を使用
'enemies': [self.actual_enemy_center], # 実際の位置を使用
'items': [self.actual_item_current_pos], # 実際の位置を使用
'vehicles': [],
'strategy': '',
'game_status': 'PLAYING',
'yolo_detected': len(detections) > 0 # YOLO検出の有無を記録
}
# YOLO検出結果を活用
for det in detections:
center = det['center']
cls = det['class']
# YOLOが検出した物体を記録
if cls == 'person':
# 人物検出位置を更新(より正確な位置)
if abs(center[0] - self.actual_player_center[0]) < 100:
game_state['player_pos'] = center
elif cls in ['car', 'truck', 'bus']:
# 車両検出
if abs(center[0] - self.actual_enemy_center[0]) < 100:
game_state['enemies'][0] = center
elif cls in ['apple', 'orange', 'banana']:
# 果物検出
if abs(center[0] - self.actual_item_current_pos[0]) < 100:
game_state['items'][0] = center
# 戦略決定とスコア計算
self.in_danger_this_frame = False # 現在のフレームの危険状態をリセット
if game_state['player_pos']:
# 敵との距離チェック
if game_state['enemies']:
enemy_pos = game_state['enemies'][0]
enemy_distance = np.sqrt((enemy_pos[0] - game_state['player_pos'][0])**2 +
(enemy_pos[1] - game_state['player_pos'][1])**2)
if enemy_distance < DANGER_DISTANCE:
self.in_danger_this_frame = True
# 前フレームで危険状態でなかった場合のみカウントを増やす
if not self.was_in_danger:
self.danger_count += 1
game_state['strategy'] = f'DANGER: 敵が近すぎます (距離: {enemy_distance:.0f}px)'
if self.danger_count >= DANGER_COUNT_LIMIT:
game_state['game_status'] = 'ゲームオーバー'
elif enemy_distance < ATTACK_DISTANCE:
game_state['strategy'] = f'ATTACK: 敵が接近中 (距離: {enemy_distance:.0f}px)'
else:
game_state['strategy'] = f'EXPLORE: アイテム探索 (敵距離: {enemy_distance:.0f}px)'
else:
game_state['strategy'] = 'PATROL: 脅威なし'
# 生存フレームは毎フレームカウント
self.survival_frames += 1
# アイテム収集チェック
if game_state['items']:
for item_pos in game_state['items']:
item_distance = np.sqrt((item_pos[0] - game_state['player_pos'][0])**2 +
(item_pos[1] - game_state['player_pos'][1])**2)
# アイテムIDを振動の中心座標で生成
item_id = f"{ITEM_BASE_POS[0]}_{ITEM_BASE_POS[1]}"
# 収集範囲内かつ未収集のアイテムの場合
if item_distance < ITEM_COLLECT_DISTANCE and item_id not in self.collected_items:
self.score += 10
self.collected_items.add(item_id)
game_state['strategy'] = f'COLLECT: アイテム収集 (+10点, 距離: {item_distance:.0f}px)'
break
# 次フレームのために危険状態を記録
self.was_in_danger = self.in_danger_this_frame
# 勝利判定
if self.score >= WIN_SCORE:
game_state['game_status'] = f'勝利(スコア{self.score}点達成)'
elif self.survival_frames >= WIN_SURVIVAL_FRAMES:
game_state['game_status'] = f'勝利({self.survival_frames}フレーム生存)'
return game_state
def visualize_results(self, frame, detections, game_state):
result_frame = frame.copy()
# YOLO検出枠を描画
for det in detections:
x1, y1, x2, y2 = det['bbox']
color = (255, 0, 255) # 紫色でYOLO検出を表示
cv2.rectangle(result_frame, (x1, y1), (x2, y2), color, 2)
label = f"YOLO: {det['class']} {det['confidence']:.2f}"
draw_text(result_frame, label, (x1, y1-10), FONT_SCALE, color, FONT_THICKNESS_BOLD)
# ゲーム状態の可視化
px, py = int(game_state['player_pos'][0]), int(game_state['player_pos'][1])
cv2.circle(result_frame, (px, py), 5, PLAYER_COLOR, -1)
if game_state['enemies']:
ex, ey = int(game_state['enemies'][0][0]), int(game_state['enemies'][0][1])
cv2.circle(result_frame, (ex, ey), 5, ENEMY_COLOR, -1)
cv2.line(result_frame, (px, py), (ex, ey), (128, 128, 128), 1)
# ゲーム情報を日本語で表示
result_frame = draw_japanese_text(result_frame, f"戦略: {game_state['strategy']}", (10, 30), 24, TEXT_COLOR)
result_frame = draw_japanese_text(result_frame, f"スコア: {self.score} | 生存: {self.survival_frames}/{WIN_SURVIVAL_FRAMES}", (10, 60), 20, (0, 255, 255))
result_frame = draw_japanese_text(result_frame, f"状態: {game_state['game_status']}", (10, 90), 20, (255, 255, 0))
# 統計情報
yolo_status = f"YOLO検出: {len(detections)}個"
info_text = f"Frame: {self.frame_count} | {yolo_status} | Danger: {self.danger_count}/{DANGER_COUNT_LIMIT}"
draw_text(result_frame, info_text, (10, 460), FONT_SCALE_MEDIUM, TEXT_COLOR)
return result_frame
def save_results(self):
try:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('YOLO11リアルタイム物体検出デモ - 実行結果\n')
f.write('=' * 50 + '\n')
f.write('実画像を使用したYOLO検出デモ\n')
f.write('=' * 50 + '\n')
for log in self.results_log:
f.write(log + '\n')
f.write(f'\n最終スコア: {self.score}点\n')
f.write(f'最終生存フレーム数: {self.survival_frames}フレーム\n')
f.write(f'収集アイテム数: {len(self.collected_items)}個\n')
f.write(f'危険カウント: {self.danger_count}/{DANGER_COUNT_LIMIT}\n')
print('result.txtに保存しました')
except Exception as e:
print(f'Error: 結果の保存に失敗しました: {e}')
def run_demo(self, num_frames=30):
print('\nデモを開始します...\n')
# Matplotlib用の図を準備
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.flatten()
saved_frames = []
for i in range(num_frames):
self.frame_count = i
# ゲームシーンを生成
scene = self.create_game_scene()
# 物体検出
start_time = time.time()
detections = self.detect_objects(scene)
inference_time = (time.time() - start_time) * 1000
# ゲーム状態分析
game_state = self.analyze_game_state(detections)
# 結果表示
result = self.visualize_results(scene, detections, game_state)
# OpenCVウィンドウでリアルタイム表示
cv2.imshow('YOLO11 Game AI Vision Demo', result)
# フレームごとに出力
yolo_info = f"YOLO検出数: {len(detections)}"
log_text = f'フレーム {i}: 推論時間 {inference_time:.2f}ms, スコア {self.score}点, {yolo_info}, 戦略: {game_state["strategy"]}'
print(log_text)
self.results_log.append(log_text)
# Matplotlib用に最初の6フレームを保存
if i < 6:
saved_frames.append((result.copy(), game_state['strategy']))
# キー入力待機
if cv2.waitKey(FRAME_DELAY) & 0xFF == ord('q'):
print('\nユーザーによる中断')
break
# ゲーム終了判定
if '勝利' in game_state['game_status'] or 'ゲームオーバー' in game_state['game_status']:
print(f'\n*** {game_state["game_status"]} ***')
print(f'最終スコア: {self.score}点')
print(f'最終生存フレーム数: {self.survival_frames}フレーム')
print(f'収集アイテム数: {len(self.collected_items)}個')
self.results_log.append(f'\n*** {game_state["game_status"]} ***')
self.results_log.append(f'最終スコア: {self.score}点')
self.results_log.append(f'最終生存フレーム数: {self.survival_frames}フレーム')
break
cv2.destroyAllWindows()
# Matplotlibで結果を表示
for idx, (frame, strategy) in enumerate(saved_frames):
axes[idx].imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
axes[idx].set_title(f'フレーム {idx}: {strategy}', fontsize=10)
axes[idx].axis('off')
# 未使用のサブプロットを非表示
for j in range(len(saved_frames), 6):
axes[j].axis('off')
plt.suptitle('YOLO11 Game AI Vision デモ結果', fontsize=14)
plt.tight_layout()
plt.savefig('game_ai_yolo11_results.png', dpi=150)
print('\n結果を game_ai_yolo11_results.png に保存しました')
# 結果をテキストファイルに保存
self.save_results()
# 結果表示
print('\n【実行結果の見方】')
print('- 実画像を使用してYOLO11が物体を検出')
print('- 紫枠: YOLO11による検出結果')
print('- 緑点: プレイヤー中心、赤点: 敵中心')
print('- 灰色線: プレイヤーと敵の距離')
print('- result.txtに詳細ログを保存')
plt.show()
# メイン処理
if __name__ == "__main__":
ai = GameAIVision()
ai.run_demo()
4. 使用方法と実行結果の理解
- 上記のプログラムを実行する
- 初回実行時はYOLO11モデル(yolo11n.pt)が自動的にダウンロードされる。実行結果として、5フレームのゲーム画面解析結果が表示され、game_ai_yolo11_results.pngとして保存される。
推論時間はAIが1フレームを処理する時間で、ゲームでは33ミリ秒以下(30FPS)が理想的である。これより遅いとゲームの反応性が低下する。
5. 実験・探求のアイデア
実験要素
- ゲームパラメータの調整:DANGER_DISTANCE、ATTACK_DISTANCE、WIN_SCOREなどの定数を変更し、ゲームの難易度とAI戦略の変化を観察
- 物体配置の変更:create_game_scene()メソッド内の座標を変更し、異なるゲームレイアウトでの検出精度を確認
- 検出クラスの拡張:'bottle', 'cup', 'bowl'以外のクラスをアイテムとして認識させ、検出の多様性を確認
体験・実験・探求のアイデア
- 動的シーン対応:np.roll()の値を大きくして高速移動をシミュレートし、物体追跡の限界を探る
- マルチオブジェクト戦略:複数の敵やアイテムを配置し、優先順位付けアルゴリズムを実装。最適な意思決定戦略を探求
- カスタムクラスの活用:YOLO11が検出可能な80クラスから、ゲームに適した新しい要素(動物、食べ物、道具など)を追加し、より複雑なゲームシナリオを構築