LangChain + Gemini 2.5対話型AIツール(画像アップロード可能)(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install langchain-google-genai pillow langchain-core
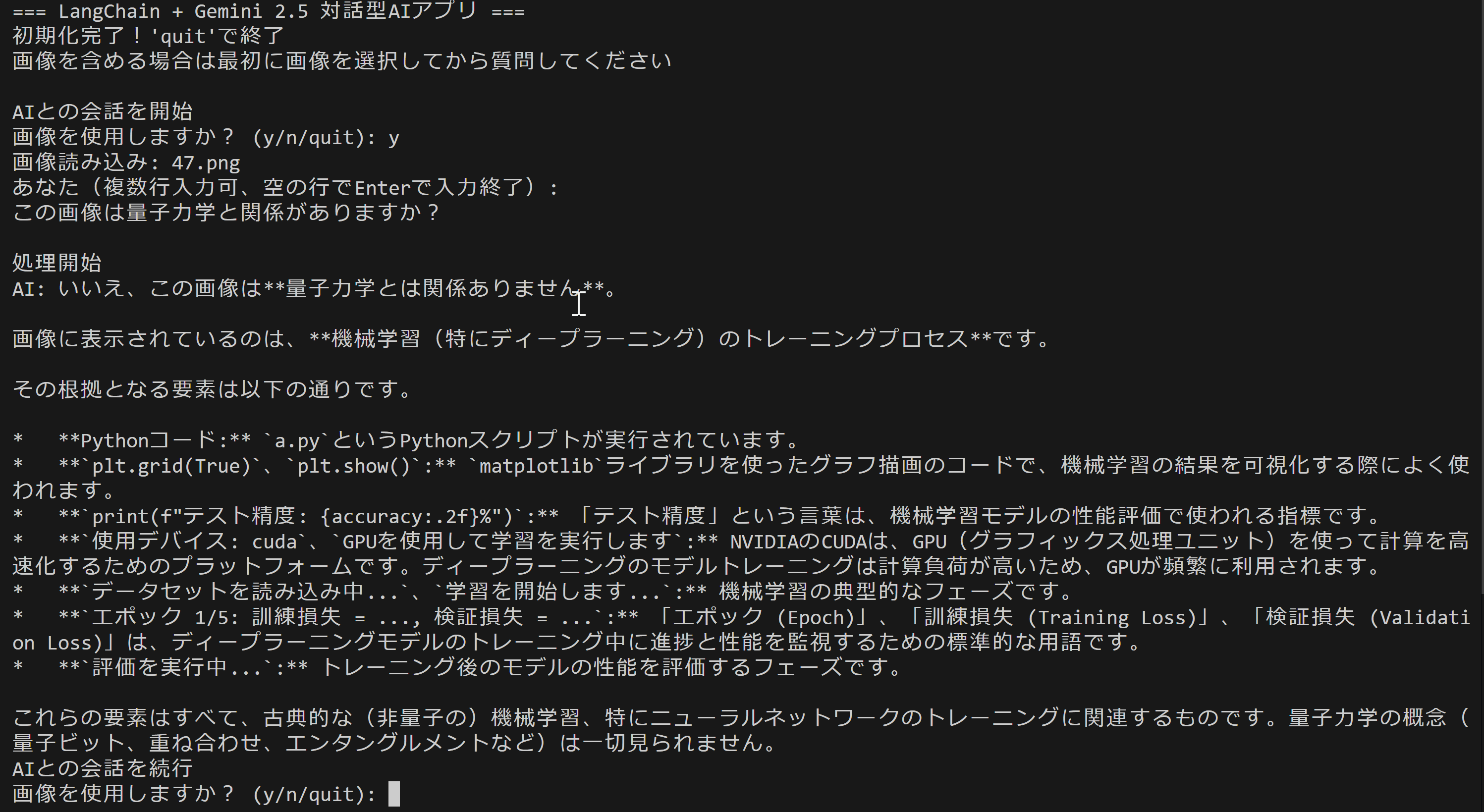
LangChain + Gemini 2.5対話型AIツール(画像アップロード可能)(ソースコードと実行結果)
概要
本プログラムは、LangChainフレームワークとGemini 2.5 Flash APIを組み合わせた対話型AIアプリケーションである。テキストと画像の両方を入力として受け付けることが可能なマルチモーダル処理の機能を持つ。会話型インターフェースである。Gemini 2.5 Flash 思考機能による推論処理、問題解決を実現している。
主要技術
Gemini 2.5 Flash API
Google DeepMindが2025年に開発した思考機能付き言語モデルAPI [1][2]。推論プロセスを経た内部思考により、問題解決を可能とする。
LangChain
Harrison Chaseが2022年に開発した大規模言語モデル統合フレームワーク [3][4]。LLMを活用したアプリケーション開発を支援する。
技術的特徴
本実装では、複数の技術的工夫が施されている。マルチモーダルメッセージ構築にはLangChainのHumanMessageクラスを使用し、テキストと画像データを処理する。画像データはBase64エンコーディングによってテキスト形式に変換され、APIリクエストに組み込まれる。APIキー管理については、環境変数と.envファイルの双方からの自動取得機能を実装している。
実装の特色
GUI機能として、tkinterライブラリを用いたファイル選択ダイアログを実装し、画像ファイル選択を可能としている。複数行テキスト入力機能により、長文の質問や複雑な指示を受け付けることができる。対話の継続性を維持し、セッション内でのコンテキストを保持する。
参考文献
[1] Google DeepMind Team. (2025). Gemini 2.5: Our newest Gemini model with thinking. Google DeepMind Blog. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/
[2] Google AI for Developers. (2025). Gemini 2.5 Flash API Documentation. Google AI for Developers. https://ai.google.dev/gemini-api/docs/models
[3] Chase, H. (2022). LangChain: Building applications with LLMs through composability. GitHub. https://github.com/langchain-ai/langchain
[4] LangChain Development Team. (2025). LangChain Documentation. LangChain Inc. https://python.langchain.com/docs/introduction/
ソースコード
# LangChain + Gemini 2.5 Flash対話型AIアプリケーション
# 特徴技術名: Gemini 2.5 Flash API
# 出典: Gemini Team, Google. (2025). Gemini 2.5: Our newest Gemini model with thinking. Google DeepMind. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/
# 特徴機能: 思考機能による文脈理解推論(推論プロセスを経た思考により、単純な応答生成ではなく複雑な問題解決と文脈理解を実現)
# 学習済みモデル: 使用なし(Gemini 2.5 Flash APIによる直接呼び出し)
# 方式設計:
# 関連利用技術: LangChain(LLMフレームワーク)、tkinter(ファイル選択GUI)、PIL(画像処理)、base64(画像エンコーディング)、pathlib(ファイル操作)
# 入力と出力: 入力: テキスト(複数行対応、空行で終了)、画像(オプション、tkinterでファイル選択可能)、出力: AI応答テキストをコンソール表示
# 処理手順: APIキー取得→LangChain初期化→会話ループ(画像選択→テキスト入力→API呼び出し→結果表示)
# 前処理、後処理: 前処理: 画像のBase64エンコーディング、マルチモーダルメッセージ構築、後処理: 応答内容の表示処理
# 追加処理: マルチモーダル対応(テキスト+画像同時処理)、複数行入力機能、会話状態管理
# 調整を必要とする設定値: GEMINI_API_KEY(Gemini APIアクセスキー)、temperature(応答の一貫性制御、デフォルト0.1)
# 将来方策: APIキー自動設定機能(.env設定の自動化、環境変数設定支援)
# その他の重要事項: Windows環境対応、Python 3.10以上、Google AI Studio APIキー必要
# 前準備: pip install langchain-google-genai pillow langchain-core
import os
import re
import base64
from pathlib import Path
from datetime import datetime
from PIL import Image
import tkinter as tk
from tkinter import filedialog
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import HumanMessage
# 設定定数
TEMPERATURE = 0.1
MODEL_NAME = "gemini-2.5-flash"
def load_api_key():
# 環境変数から取得
for var_name in ['GEMINI_API_KEY', 'GOOGLE_API_KEY']:
if api_key := os.getenv(var_name):
return api_key
# .envファイルから取得
for env_file in ['.env', '.env.development']:
if Path(env_file).exists():
try:
content = Path(env_file).read_text()
for var_name in ['GEMINI_API_KEY', 'GOOGLE_API_KEY']:
if match := re.search(rf'^\s*{var_name}\s*=(.+)$', content, re.M):
return match.group(1).strip().strip('"\'')
except Exception:
continue
return None
def encode_image(image_path):
try:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode()
except Exception as e:
print(f"画像読み込みエラー: {e}")
return None
def select_image():
root = tk.Tk()
root.withdraw()
return filedialog.askopenfilename(
title="画像を選択(キャンセルでテキストのみ)",
filetypes=[("画像", "*.jpg *.jpeg *.png *.gif *.bmp"), ("全て", "*.*")]
)
def generate_filename():
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
return f"conversation_log_{timestamp}.txt"
def main():
print("=== LangChain + Gemini 2.5 対話型AIアプリ ===")
# APIキー取得
api_key = load_api_key()
if not api_key:
# APIキー取得手順を表示
print("=" * 60)
print("Gemini APIキーが見つかりません")
print("=" * 60)
print()
print("このプログラムを使用するには、Gemini APIキーが必要です。")
print()
print("APIキー取得手順:")
print("1. または手動でAPIキーを取得:")
print(" - https://aistudio.google.com/app/apikey にアクセス")
print(" - Googleアカウントでログイン")
print(" - 'Get API key' → 'Create API key' をクリック")
print(" - 'Create API key in new project' を選択")
print(" - 生成されたAPIキーをコピー")
print()
print("参考: 「Gemini APIキー取得支援ツール」を用意しています")
print(" https://www.kkaneko.jp/ai/labo/geminiapikey.html")
print()
print("2. 設定")
print(" **1. 環境変数での設定**")
print(" - `GEMINI_API_KEY` または `GOOGLE_API_KEY` を環境変数に設定")
print(" **2. .envファイルでの設定**")
print(" - プログラムと同じフォルダに `.env` ファイルを作成し、以下のように記述:")
print(" GEMINI_API_KEY=your_api_key_here")
print(" または")
print(" GOOGLE_API_KEY=your_api_key_here")
print()
print("3. 設定後、このプログラムを再実行してください")
print("=" * 60)
# LangChainでGemini初期化
try:
llm = ChatGoogleGenerativeAI(
model=MODEL_NAME,
google_api_key=api_key,
temperature=TEMPERATURE
)
print("初期化完了!'quit'で終了")
print("\n=== 使用ガイド ===")
print("1. テキスト質問: 複数行入力可能(空行でEnter押下で入力終了)")
print("2. 画像付き質問: 最初に画像を選択してからテキストを入力")
print("3. 使用例:")
print(" - 'この画像の内容を説明してください'")
print(" - 'コードのレビューをお願いします'")
print(" - '文章の要約をしてください'")
print("画像を含める場合は最初に画像を選択してから質問してください\n")
except Exception as e:
print(f"初期化エラー: {e}")
return
conv_count = 0
while True:
try:
# 会話状態表示
if conv_count == 0:
print("AIとの会話を開始")
else:
print("AIとの会話を続行")
conv_count += 1
# 設定確認表示
print(f"\n=== 設定確認 ===")
print(f"使用モデル: {MODEL_NAME}")
print(f"温度設定: {TEMPERATURE}")
print("=" * 30)
# 画像選択オプション
use_image = input("画像を使用しますか? (y/n/quit): ").lower()
if use_image == 'quit':
break
image_data = None
if use_image == 'y':
if image_path := select_image():
image_data = encode_image(image_path)
print(f"画像読み込み: {Path(image_path).name}")
# ユーザー入力
print("あなた(複数行入力可、空の行でEnterで入力終了):")
lines = []
while True:
line = input()
if line == "":
break
lines.append(line)
user_input = "\n".join(lines)
if user_input.lower() in ['quit', 'exit', '終了']:
break
if not user_input.strip():
print("入力が空です。再入力してください。")
continue
print("処理開始")
# メッセージ構築と送信
if image_data:
# マルチモーダル対応
message = HumanMessage(
content=[
{"type": "text", "text": user_input},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{image_data}"}
]
)
response = llm.invoke([message])
else:
# テキストのみ
response = llm.invoke(user_input)
print(f"AI: {response.content}")
except KeyboardInterrupt:
print("\n\nプログラムを終了します")
break
except Exception as e:
print(f"エラーが発生しました: {e}")
print("別の質問で再試行してください。")
print("お疲れ様でした!")
if __name__ == "__main__":
main()