LangChain + Gemini 2.5 画像解析ツール(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install langchain-google-genai langchain-core opencv-python pillow SpeechRecognition pyaudio pillow-heif
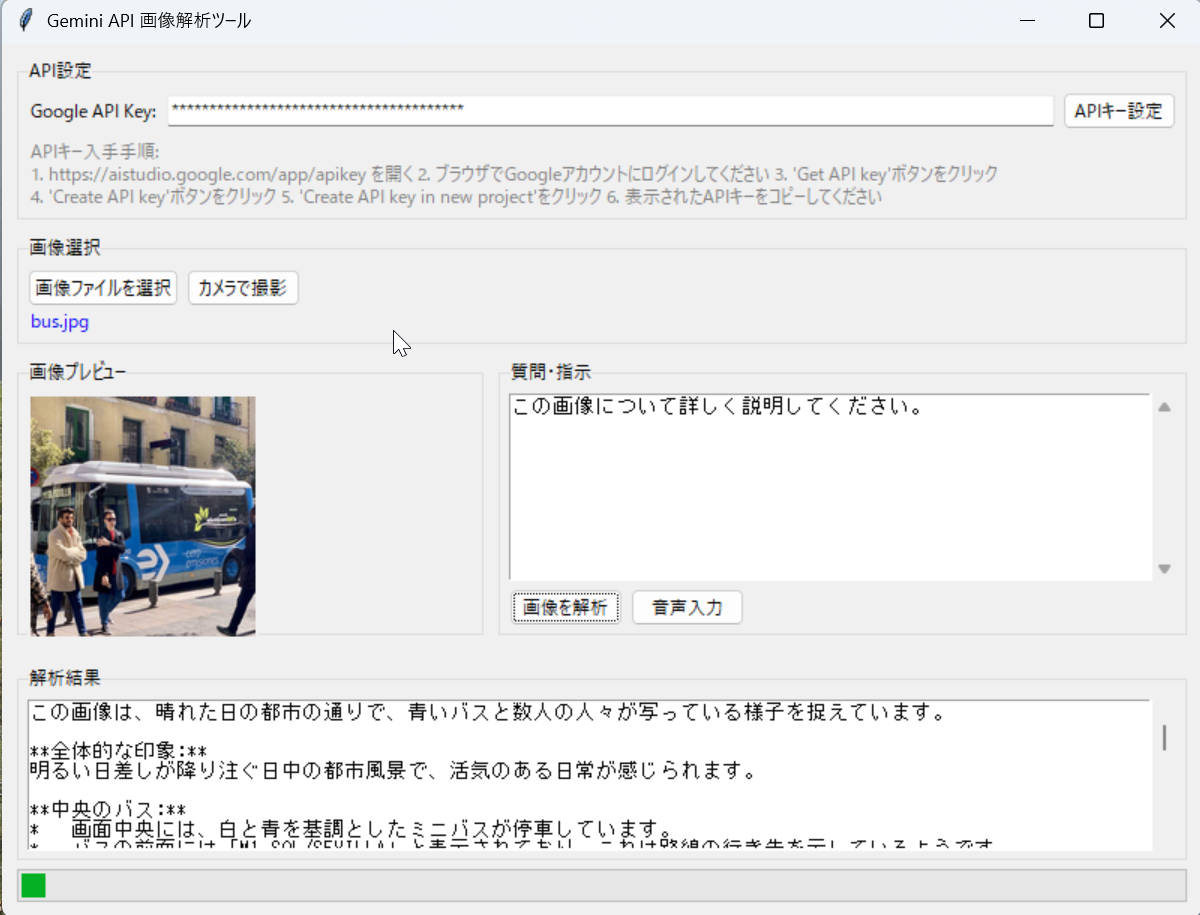
LangChain + Gemini 2.5 画像解析ツール
概要
このプログラムは、Google Gemini 2.5 FlashのAIを使って画像を解析するGUIアプリケーションである。画像ファイルの選択,カメラで撮影の機能がある.質問を入力(音声入力も可能)して「画像を解析」ボタンを押すと、AIが画像の内容を説明する。APIキーは.envファイルから自動読み込み可能であり,画面から入れることもできる.解析結果は画面表示と同時にresult.txtファイルに自動保存される。
ソースコード
"""
プログラム名: LangChain + Gemini 2.5 画像解析ツール
特徴技術名: Google Gemini API (gemini-2.5-flash)
出典: Google AI Studio (2024). Gemini API Documentation. https://ai.google.dev/
特徴機能: マルチモーダル画像理解機能 - 画像とテキストプロンプトを同時に処理し、画像の内容を自然言語で詳細に説明
学習済みモデル: なし(クラウドベースAPIを使用)
方式設計:
- 関連利用技術:
- LangChain/LCEL: LLM統合フレームワーク。RunnableLambda → ChatGoogleGenerativeAI → StrOutputParser による推論チェーンを構成
- OpenCV: カメラ制御と画像キャプチャ(cap.grab() と cap.retrieve() を使用)
- SpeechRecognition: Google Web Speech API(recognize_google)による音声入力
- Tkinter: クロスプラットフォームGUI
- Pillow: 画像読み込み・リサイズ・EXIF回転補正
- pillow-heif: HEIC/HEIF読み込み対応(任意)
- 入力と出力:
- 入力: 静止画像(「画像ファイルを選択」または「カメラで撮影」)、質問テキスト(手入力または音声入力)
- 出力: テキスト(解析結果)
- 処理手順:
1) 画像取得
2) 前処理(EXIF回転補正、長辺1600px以内へのリサイズ、必要に応じた再エンコード、Base64エンコード)
3) LCELでマルチモーダルメッセージを生成し、Gemini APIに送信
4) 解析結果の表示および履歴への保存
- 前処理、後処理:
- 前処理: EXIF回転補正、任意リサイズ(長辺1600px以内)、画像のBase64エンコード
- 後処理: 解析結果テキストのファイル保存(追記)
- 追加処理: LCELによる推論チェーン化
- 調整を必要とする設定値:
- GOOGLE_API_KEY(実行時の環境変数)
- .envのGEMINI_API_KEYから自動読み込み可(内部でGOOGLE_API_KEYに設定)
将来方策:
- APIキーの自動検証機能を実装し、無効なキーの場合に即時フィードバックを行う
その他の重要事項:
- 対応画像形式: JPEG, PNG, GIF, WebP, HEIC, HEIF
- HEIC/HEIFの読み込み・プレビューには pillow-heif の導入が必要である
- Windows環境での動作を想定
- .envファイルからのAPIキー自動読み込みに対応(GEMINI_API_KEYを設定)
前準備:
- pip install langchain-google-genai を実行してください
- pip install langchain-core を実行してください
- pip install opencv-python を実行してください
- pip install pillow を実行してください
- pip install SpeechRecognition を実行してください
- pip install pyaudio を実行してください
- pip install pillow-heif を実行してください(HEIC/HEIF対応時)
"""
import base64
import datetime
import os
import threading
import tkinter as tk
from tkinter import ttk, filedialog, scrolledtext
from io import BytesIO
import cv2
import numpy as np
import speech_recognition as sr
from PIL import Image, ImageTk, ImageOps, ImageDraw, ImageFont
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableLambda
from langchain_core.output_parsers import StrOutputParser
# HEIC/HEIF対応(pillow-heifが導入されている場合のみ有効)
try:
from pillow_heif import register_heif_opener
register_heif_opener()
HEIF_SUPPORTED = True
except Exception:
HEIF_SUPPORTED = False
# 設定定数
WINDOW_WIDTH = 800
WINDOW_HEIGHT = 700
PREVIEW_MAX_WIDTH = 250
PREVIEW_MAX_HEIGHT = 200
QUESTION_HEIGHT = 8
QUESTION_WIDTH = 40
RESULT_HEIGHT = 15
RESULT_WIDTH = 80
API_ENTRY_WIDTH = 50
TEMP_IMAGE_FILE = 'temp_captured_image.jpg'
# リサイズ設定(Pillowで開ける場合のみ適用)
RESIZE_ENABLED = True
RESIZE_MAX_WIDTH = 1600
RESIZE_MAX_HEIGHT = 1600
JPEG_QUALITY = 90
WEBP_QUALITY = 90
# Geminiモデル(ご指定どおり維持)
GEMINI_MODEL = 'gemini-2.5-flash'
# ファイル名定数
RESULT_FILE = 'result.txt'
ENV_FILE = '.env'
API_KEY_PREFIX = 'GEMINI_API_KEY=' # .envではGEMINI_API_KEY、実際の環境変数はGOOGLE_API_KEY
# メッセージ定数
ANALYZING_MESSAGE = '解析中...'
IMAGE_NOT_SELECTED = '画像が選択されていません'
CAPTURED_IMAGE_TEXT = '撮影した画像'
# 画面描画用フォント
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
# 解析に許可する拡張子(運用方針)
ALLOWED_MIME_EXTS_FOR_GEMINI = {'.jpg', '.jpeg', '.png', '.webp'}
# グローバル変数
api_key = ''
llm = None
chain = None
img_path = ''
root = None
api_key_var = None
img_path_var = None
img_path_label = None
image_label = None
q_text = None
r_text = None
v_button = None
v_status_var = None
progress = None
recognizer = None
microphone = None
# .envファイルからAPIキー読み込み
if os.path.exists(ENV_FILE):
try:
with open(ENV_FILE, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line and not line.startswith('#'):
if line.startswith(API_KEY_PREFIX):
api_key = line.split('=', 1)[1].strip()
except Exception as e:
print(f'{ENV_FILE}ファイルの読み込みに失敗しました: {str(e)}')
# 対応MIMEタイプ(Geminiの想定範囲に合わせる)
MIME_TYPES = {
'.jpg': 'image/jpeg',
'.jpeg': 'image/jpeg',
'.png': 'image/png',
'.gif': 'image/gif',
'.webp': 'image/webp',
'.heic': 'image/heic',
'.heif': 'image/heif'
}
PIL_FORMATS = {
'.jpg': 'JPEG',
'.jpeg': 'JPEG',
'.png': 'PNG',
'.gif': 'GIF',
'.webp': 'WEBP',
'.heic': 'HEIC', # pillow-heifが必要
'.heif': 'HEIF' # pillow-heifが必要
}
# LCEL: 入力辞書からHumanMessageを組み立てるRunnable
def _build_multimodal_message(inputs):
question = inputs['question']
mime_type = inputs['mime_type']
b64 = inputs['b64']
# image_url は文字列のデータURIで渡す
return [
HumanMessage(
content=[
{'type': 'text', 'text': question},
{'type': 'image_url', 'image_url': f'data:{mime_type};base64,{b64}'}
]
)
]
# APIキー設定処理(LLMおよびLCELチェーンの構築)
def set_api_key():
global api_key, llm, chain
api_key = api_key_var.get().strip()
if not api_key:
return
os.environ['GOOGLE_API_KEY'] = api_key
llm = ChatGoogleGenerativeAI(model=GEMINI_MODEL, temperature=0)
chain = RunnableLambda(_build_multimodal_message) | llm | StrOutputParser()
# 画像プレビュー更新
def update_image_preview(image_path):
try:
image = Image.open(image_path)
image.thumbnail((PREVIEW_MAX_WIDTH, PREVIEW_MAX_HEIGHT), Image.Resampling.LANCZOS)
photo = ImageTk.PhotoImage(image)
image_label.configure(image=photo, text='')
image_label.image = photo
except Exception:
message = 'プレビューを表示できません(HEIC/HEIFはpillow-heifが必要)' if (os.path.splitext(image_path)[1].lower() in ['.heic', '.heif'] and not HEIF_SUPPORTED) else 'プレビューを表示できません'
image_label.configure(image='', text=message)
image_label.image = None
#
def _capture_from_camera_thread():
global img_path
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
if not cap.isOpened():
return
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
while True:
cap.grab()
ret, frame = cap.retrieve()
if not ret:
break
# OpenCV画面にテキスト表示(Pillow+Meiryo)
try:
font = ImageFont.truetype(FONT_PATH, 20)
img_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
draw.text((20, 20), 'SPACE: 撮影 / Q: 終了', font=font, fill=(0, 255, 0))
frame = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
except Exception:
pass
cv2.imshow('Camera - Press SPACE to capture, Q to quit', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
cv2.imwrite(TEMP_IMAGE_FILE, frame)
img_path = TEMP_IMAGE_FILE
root.after(0, lambda: img_path_var.set(CAPTURED_IMAGE_TEXT))
root.after(0, lambda: update_image_preview(TEMP_IMAGE_FILE))
break
elif key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def capture_from_camera():
thread = threading.Thread(target=_capture_from_camera_thread, daemon=True)
thread.start()
# 画像の読み込み+任意リサイズ(Pillowで開けないときは原寸)
def load_image_bytes_with_optional_resize(path):
ext = os.path.splitext(path)[1].lower()
mime_type = MIME_TYPES.get(ext, 'image/jpeg')
if not RESIZE_ENABLED:
with open(path, 'rb') as f:
return f.read(), mime_type
try:
img = Image.open(path)
img = ImageOps.exif_transpose(img)
w, h = img.size
scale = min(RESIZE_MAX_WIDTH / w, RESIZE_MAX_HEIGHT / h, 1.0)
if scale < 1.0:
new_size = (max(1, int(w * scale)), max(1, int(h * scale)))
img = img.resize(new_size, Image.Resampling.LANCZOS)
buf = BytesIO()
fmt = PIL_FORMATS.get(ext, 'JPEG')
save_params = {}
if fmt == 'JPEG':
save_params['quality'] = JPEG_QUALITY
save_params['optimize'] = True
elif fmt == 'WEBP':
save_params['quality'] = WEBP_QUALITY
save_params['method'] = 6
try:
img.save(buf, format=fmt, **save_params)
data = buf.getvalue()
return data, mime_type
except Exception:
with open(path, 'rb') as f:
return f.read(), mime_type
except Exception:
with open(path, 'rb') as f:
return f.read(), mime_type
# 画像ファイル選択(対応形式はGemini想定範囲)
def select_image():
global img_path
filetypes = [
('画像ファイル', '*.jpg *.jpeg *.png *.gif *.webp *.heic *.heif'),
('JPEG files', '*.jpg *.jpeg'),
('PNG files', '*.png'),
('GIF files', '*.gif'),
('WebP files', '*.webp'),
('HEIC files', '*.heic'),
('HEIF files', '*.heif')
]
filename = filedialog.askopenfilename(title='画像ファイルを選択', filetypes=filetypes, initialdir=os.getcwd())
if filename:
img_path = filename
img_path_var.set(os.path.basename(filename))
update_image_preview(filename)
# 音声入力(Google Web Speech API:SpeechRecognitionのrecognize_google)
def voice_input_thread():
try:
root.after(0, lambda: v_status_var.set('音声を聞いています...'))
root.after(0, lambda: v_button.config(state='disabled'))
with microphone as source:
recognizer.adjust_for_ambient_noise(source, duration=1)
audio = recognizer.listen(source, timeout=10)
root.after(0, lambda: v_status_var.set('音声を認識中...'))
text = recognizer.recognize_google(audio, language='ja-JP')
root.after(0, lambda: q_text.delete('1.0', tk.END))
root.after(0, lambda: q_text.insert('1.0', text))
root.after(0, lambda: v_status_var.set('認識完了'))
except sr.WaitTimeoutError:
root.after(0, lambda: v_status_var.set('タイムアウト:音声が検出されませんでした'))
except sr.UnknownValueError:
root.after(0, lambda: v_status_var.set('音声を認識できませんでした'))
except sr.RequestError as e:
root.after(0, lambda: v_status_var.set(f'音声認識エラー: {str(e)}'))
except Exception as e:
root.after(0, lambda: v_status_var.set(f'エラー: {str(e)}'))
finally:
root.after(0, lambda: v_button.config(state='normal'))
root.after(3000, lambda: v_status_var.set(''))
def voice_input():
global recognizer, microphone
if recognizer is None:
recognizer = sr.Recognizer()
microphone = sr.Microphone()
thread = threading.Thread(target=voice_input_thread)
thread.daemon = True
thread.start()
# 画像解析(LCELチェーンを使用)
def analyze_image():
if not llm or not chain:
return
if not img_path:
return
question = q_text.get('1.0', tk.END).strip()
if not question:
return
# 形式制限の確認(JPEG/PNG/WebPのみ許可)
ext = os.path.splitext(img_path)[1].lower()
if ext not in ALLOWED_MIME_EXTS_FOR_GEMINI:
msg = '現在はJPEG/PNG/WebPのみ対応しています(選択された画像形式は未対応です)'
print(msg)
r_text.delete('1.0', tk.END)
r_text.insert('1.0', msg)
return
progress.start()
r_text.delete('1.0', tk.END)
r_text.insert('1.0', ANALYZING_MESSAGE)
root.update()
try:
image_bytes, mime_type = load_image_bytes_with_optional_resize(img_path)
encoded_image = base64.b64encode(image_bytes).decode('utf-8')
result_text = chain.invoke({'question': question, 'mime_type': mime_type, 'b64': encoded_image})
r_text.delete('1.0', tk.END)
r_text.insert('1.0', result_text)
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
history_entry = f"""
{'='*80}
日時: {timestamp}
画像ファイル: {os.path.basename(img_path) if img_path else '未選択'}
質問: {question}
{'='*80}
解析結果:
{result_text}
"""
with open(RESULT_FILE, 'a', encoding='utf-8') as f:
f.write(history_entry)
except Exception as e:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', f'エラー: {str(e)}')
print(f'Gemini API呼び出しに失敗しました: {str(e)}')
finally:
progress.stop()
# ウィンドウ終了処理
def on_closing():
current_result = r_text.get('1.0', tk.END).strip()
if current_result and current_result != ANALYZING_MESSAGE:
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
session_end = f"""
{'='*80}
セッション終了: {timestamp}
{'='*80}
"""
with open(RESULT_FILE, 'a', encoding='utf-8') as f:
f.write(session_end)
if os.path.exists(TEMP_IMAGE_FILE):
os.remove(TEMP_IMAGE_FILE)
root.destroy()
# GUI作成
root = tk.Tk()
root.title('Gemini API 画像解析ツール')
root.geometry(f'{WINDOW_WIDTH}x{WINDOW_HEIGHT}')
root.protocol('WM_DELETE_WINDOW', on_closing)
main_frame = ttk.Frame(root, padding='10')
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# API設定
api_frame = ttk.LabelFrame(main_frame, text='API設定', padding='5')
api_frame.grid(row=0, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 10))
ttk.Label(api_frame, text='Google API Key:').grid(row=0, column=0, sticky=tk.W)
api_key_var = tk.StringVar(value=api_key if api_key else '')
api_entry = ttk.Entry(api_frame, textvariable=api_key_var, width=API_ENTRY_WIDTH, show='*')
api_entry.grid(row=0, column=1, padx=(5, 0), sticky=(tk.W, tk.E))
ttk.Button(api_frame, text='APIキー設定', command=set_api_key).grid(row=0, column=2, padx=(5, 0))
api_help_text = """APIキー入手手順:
1. https://aistudio.google.com/app/apikey を開く
2. ブラウザでGoogleアカウントにログインしてください
3. 'Get API key'ボタンをクリック
4. 'Create API key'ボタンをクリック
5. 'Create API key in new project'をクリック
6. 表示されたAPIキーをコピーしてください"""
api_help_label = ttk.Label(api_frame, text=api_help_text, foreground='gray')
api_help_label.grid(row=1, column=0, columnspan=3, sticky=tk.W, pady=(5, 0))
# 画像選択
image_frame = ttk.LabelFrame(main_frame, text='画像選択', padding='5')
image_frame.grid(row=1, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 10))
ttk.Button(image_frame, text='画像ファイルを選択', command=select_image).grid(row=0, column=0)
ttk.Button(image_frame, text='カメラで撮影', command=capture_from_camera).grid(row=0, column=1, padx=(5, 0))
img_path_var = tk.StringVar()
img_path_label = ttk.Label(image_frame, textvariable=img_path_var, foreground='blue')
img_path_label.grid(row=1, column=0, columnspan=2, padx=(0, 0), sticky=tk.W)
# プレビュー
preview_frame = ttk.LabelFrame(main_frame, text='画像プレビュー', padding='5')
preview_frame.grid(row=2, column=0, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10))
image_label = ttk.Label(preview_frame, text=IMAGE_NOT_SELECTED)
image_label.grid(row=0, column=0)
# 質問・指示
question_frame = ttk.LabelFrame(main_frame, text='質問・指示', padding='5')
question_frame.grid(row=2, column=1, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10), padx=(10, 0))
q_text = scrolledtext.ScrolledText(question_frame, height=QUESTION_HEIGHT, width=QUESTION_WIDTH)
q_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
q_text.insert('1.0', 'この画像について詳しく説明してください。')
button_frame = ttk.Frame(question_frame)
button_frame.grid(row=1, column=0, pady=(5, 0), sticky=(tk.W, tk.E))
ttk.Button(button_frame, text='画像を解析', command=analyze_image).pack(side=tk.LEFT, padx=(0, 5))
v_button = ttk.Button(button_frame, text='音声入力', command=voice_input)
v_button.pack(side=tk.LEFT)
v_status_var = tk.StringVar()
v_status_label = ttk.Label(button_frame, textvariable=v_status_var, foreground='green')
v_status_label.pack(side=tk.LEFT, padx=(10, 0))
# 結果
result_frame = ttk.LabelFrame(main_frame, text='解析結果', padding='5')
result_frame.grid(row=3, column=0, columnspan=2, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(10, 0))
r_text = scrolledtext.ScrolledText(result_frame, height=RESULT_HEIGHT, width=RESULT_WIDTH)
r_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
progress = ttk.Progressbar(main_frame, mode='indeterminate')
progress.grid(row=4, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(5, 0))
# グリッド設定
main_frame.columnconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
main_frame.rowconfigure(2, weight=1)
main_frame.rowconfigure(3, weight=2)
api_frame.columnconfigure(1, weight=1)
result_frame.columnconfigure(0, weight=1)
result_frame.rowconfigure(0, weight=1)
question_frame.columnconfigure(0, weight=1)
question_frame.rowconfigure(0, weight=1)
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
# APIキー自動設定
if api_key:
set_api_key()
# 使用方法表示
env_status = ''
if api_key:
env_status = f'\n※{ENV_FILE}ファイルからAPIキーが自動読み込みされました'
print('Gemini API 画像解析ツール')
print('1. Google AI StudioでAPIキーを取得してください')
print('2. APIキーを入力して「APIキー設定」をクリック')
print(f' ({ENV_FILE}ファイルに{API_KEY_PREFIX}を設定すると自動読み込み)')
print('3. 「画像ファイルを選択」で解析したい画像を選択、または')
print(' 「カメラで撮影」でカメラから画像を撮影')
print('4. 質問や指示を入力(デフォルトの内容でも可)')
print(' - 音声入力は Google Web Speech API(SpeechRecognitionのrecognize_google)を利用')
print('5. 「画像を解析」をクリックして結果を確認')
print('')
print('対応画像形式: JPEG, PNG, WebP(当面の運用)')
print('カメラプレビュー: SPACE で撮影, Q で終了')
if not HEIF_SUPPORTED:
print('※HEIC/HEIFのプレビューとリサイズには pillow-heif のインストールが必要です')
print(f'※解析履歴は自動的に{RESULT_FILE}に保存されます')
if env_status:
print(env_status)
root.mainloop()