ONNX機械学習モデル変換・推論

【目次】
概要
背景と課題
機械学習フレームワーク(TensorFlow、PyTorch、scikit-learn等)は独自のモデル形式を持つため、フレームワーク間でのモデル共有には互換性の課題が存在する。学習環境と推論環境が異なる場合、モデルの移行が困難になる。
ONNX(Open Neural Network Exchange)の役割
ONNXは異なる機械学習フレームワーク間でのモデル相互運用を可能にするオープンスタンダード形式である。モデルを計算グラフ(ノードとエッジで表現される処理の流れ図)として表現し、標準化されたオペレーター(数学的演算処理)と型システム(データ型の定義体系)を使用してモデル構造を定義する。
出典: Bai, J., Lu, F., Zhang, K., et al. (2019). ONNX: Open Neural Network Exchange. GitHub repository. https://github.com/onnx/onnx
技術的制約
全てのモデルタイプがサポートされるわけではなく、フレームワーク固有の機能は変換時に制限される場合がある。scikit-learnでは主要な分類・回帰アルゴリズムがサポートされている。
応用分野
クラウドで学習したモデルをエッジデバイスで実行、Webブラウザでの機械学習推論、異なる開発チーム間でのモデル共有、モバイルアプリケーションへのモデルデプロイメント、リアルタイム推論システムでの活用が可能である。
学習目標
scikit-learnで学習したモデルをONNX形式に変換し、推論速度と精度の変化を測定することで、モデル変換技術の特性を理解する。
事前準備
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なPythonライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install scikit-learn skl2onnx onnxruntime numpy
プログラムコード
# ONNX変換による機械学習モデル動作確認プログラム
# 特徴技術名: ONNX (Open Neural Network Exchange)
# 出典: Bai, J., Lu, F., Zhang, K., et al. (2019). ONNX: Open Neural Network Exchange. arXiv preprint arXiv:1712.03213.
# 特徴機能: クロスプラットフォーム・クロスフレームワークでのモデル相互運用性。異なる機械学習フレームワーク間でモデルを共有・実行可能にする標準フォーマット
# 学習済みモデル: なし(プログラム内でRandomForestClassifierを学習)
# 方式設計:
# - 関連利用技術: scikit-learn (機械学習ライブラリ、RandomForestClassifierを提供)、skl2onnx (scikit-learnモデルのONNX変換ツール)、ONNX Runtime (推論エンジン)
# - 入力と出力: 入力: Irisデータセット(プログラム内で自動読み込み)、出力: モデル変換と推論結果の確認
# - 処理手順: 1) Irisデータセットの読み込みと分割、2) RandomForestClassifierの学習、3) scikit-learnモデルでの推論、4) ONNXフォーマットへの変換、5) ONNX Runtimeでの推論、6) 両モデルの推論結果比較
# - 前処理、後処理: 前処理: データ型をfloat32に変換(ONNX推論時)、後処理: 推論結果の一致確認
# - 追加処理: なし
# - 調整を必要とする設定値: N_ESTIMATORS (RandomForestの決定木数、デフォルト10)、RANDOM_SEED (再現性のための乱数シード、デフォルト42)
# 将来方策: N_ESTIMATORSの最適値を決定するため、複数の値で精度評価する機能の実装
# その他の重要事項: Windows環境での動作確認済み
# 前準備: pip install scikit-learn skl2onnx onnxruntime numpy
import numpy as np
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
import onnxruntime as ort
# 定数定義
RANDOM_SEED = 42 # 再現性のための乱数シード
N_ESTIMATORS = 10 # RandomForestの決定木数
TEST_SIZE = 0.25 # テストデータの割合
TARGET_OPSET = 12 # ONNX opsetバージョン
# プログラム開始時の概要表示
print('=== ONNX変換による機械学習モデル動作確認プログラム ===')
print('scikit-learnのRandomForestClassifierをONNX形式に変換し、')
print('両形式での推論結果の一致を確認します。')
print()
print('操作方法: プログラムは自動実行されます。')
print('注意事項: 必要なライブラリがインストールされていることを確認してください。')
print()
# データセット読み込みと分割
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=TEST_SIZE, random_state=RANDOM_SEED
)
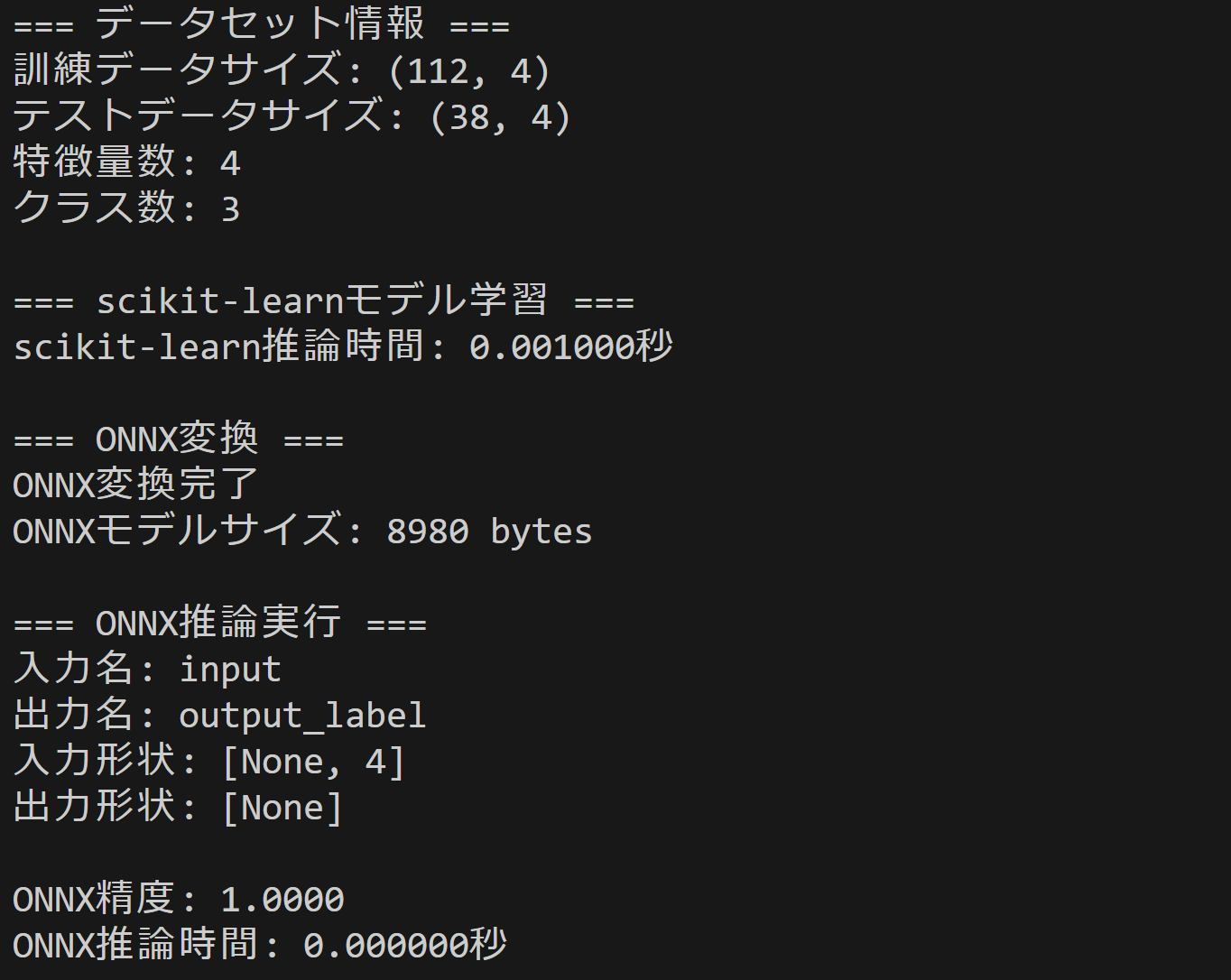
print('=== データセット情報 ===')
print(f'訓練データサイズ: {X_train.shape}')
print(f'テストデータサイズ: {X_test.shape}')
print(f'特徴量数: {X.shape[1]}')
print(f'クラス数: {len(np.unique(y))}')
print()
# メイン処理
print('=== scikit-learnモデル学習 ===')
sklearn_model = RandomForestClassifier(
n_estimators=N_ESTIMATORS, random_state=RANDOM_SEED
)
sklearn_model.fit(X_train, y_train)
# scikit-learn推論
sklearn_pred = sklearn_model.predict(X_test)
print(f'scikit-learn予測結果の形状: {sklearn_pred.shape}')
print(f'scikit-learn予測結果のデータ型: {sklearn_pred.dtype}')
# 精度計算(正確性のため明示的にint型に変換)
sklearn_pred = sklearn_pred.astype(np.int64)
y_test = y_test.astype(np.int64)
sklearn_accuracy = np.sum(sklearn_pred == y_test) / len(y_test)
print(f'scikit-learn精度: {sklearn_accuracy:.4f}')
print()
print('=== ONNX変換 ===')
initial_types = [('input', FloatTensorType([None, X.shape[1]]))]
onnx_model = convert_sklearn(
sklearn_model,
initial_types=initial_types,
target_opset=TARGET_OPSET
)
print('ONNX変換完了')
print(f'ONNXモデルサイズ: {len(onnx_model.SerializeToString())} bytes')
print(f'ONNX opsetバージョン: {TARGET_OPSET}')
print()
print('=== ONNX推論実行 ===')
# CPUプロバイダーを明示的に指定
onnx_session = ort.InferenceSession(
onnx_model.SerializeToString(),
providers=['CPUExecutionProvider']
)
# 入出力情報の詳細確認
input_name = onnx_session.get_inputs()[0].name
print(f'入力名: {input_name}')
print(f'入力形状: {onnx_session.get_inputs()[0].shape}')
print(f'入力データ型: {onnx_session.get_inputs()[0].type}')
# 出力情報の確認
print(f'出力数: {len(onnx_session.get_outputs())}')
for i, output in enumerate(onnx_session.get_outputs()):
print(f'出力[{i}]名: {output.name}')
print(f'出力[{i}]形状: {output.shape}')
print(f'出力[{i}]データ型: {output.type}')
print(f'実行プロバイダー: {onnx_session.get_providers
使用方法
- 上記のプログラムコードを実行する
実験・探求のアイデア
機械学習モデル選択の実験
- RandomForestClassifier: 決定木アンサンブル手法(複数の決定木を組み合わせた分類器)
- SVM: サポートベクターマシン(データを分離する最適な境界面を見つける分類器)
- LogisticRegression: 線形分類器(線形関数を用いた確率的分類器)
- MLPClassifier: 多層パーセプトロン(複数の層からなるニューラルネットワーク)
各モデルでONNX変換時の速度変化を比較し、モデルの種類による違いを観察する。
追加実験
- データセット変更: Iris以外のデータセット(Wine、Breast Cancer等)での性能比較
- モデルサイズ変更: n_estimatorsを10、50、100に変更し、モデル複雑度と変換効果の関係を調査
- 推論回数増加: 1000回の推論を実行し、累積時間での性能差を測定
研究のアイデア
- 変換精度の検証: 異なるデータセットでの精度保持率を調査し、ONNX変換の信頼性を確認
- モデル保存・読み込み: ONNXモデルをファイル保存し、別のプログラムで読み込む実験