Optunaによるハイパーパラメータ最適化
目次
概要
技術名: Optuna(ハイパーパラメータ最適化フレームワーク)
出典: T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, "Optuna: A Next-generation Hyperparameter Optimization Framework," in Proc. 25th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, 2019.
新規性・特徴: TPE(Tree-structured Parzen Estimator:木構造パルツェン推定器)によるベイズ最適化(確率モデルを用いて効率的に最適解を探索する手法)を採用し、過去の試行結果を学習して有望な領域を優先的に探索する(良い結果が得られた領域の周辺を重点的に調べる)。従来のグリッドサーチ(全組み合わせ探索)やランダムサーチ(無作為探索)と比較して少ない試行回数で最適解に到達する。
応用例: 深層学習モデルの学習率・バッチサイズ最適化、機械学習競技での特徴量選択、強化学習のハイパーパラメータ調整
学習目標: 最適化過程をリアルタイムで観察し、従来手法との効率性の違いを理解する。最適解への収束過程を分析する。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する:
pip install optuna scikit-learn
プログラムコード
# Optuna TPEアルゴリズムによるハイパーパラメータ最適化
# 特徴技術名: Optuna TPE (Tree-structured Parzen Estimator)
# 出典: Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. (2019). Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 2623-2631).
# 特徴機能: TPEアルゴリズムによる効率的なハイパーパラメータ探索。過去の試行結果から良好なパラメータ領域を学習し、有望な領域を優先的に探索することで、グリッドサーチやランダムサーチより少ない試行回数で最適解に到達
# 学習済みモデル: 使用なし(RandomForestClassifierをscikit-learnで訓練)
# 方式設計:
# - 関連利用技術: scikit-learn(機械学習ライブラリ、RandomForestClassifierによる分類器構築とcross_val_scoreによる交差検証)
# - 入力と出力: 入力: Irisデータセット(プログラム内で自動読み込み)、出力: 最適化結果のテキスト表示
# - 処理手順: 1)Irisデータセット読み込み、2)ベースライン性能測定、3)TPEサンプラーによる最適化study作成、4)試行でパラメータ探索、5)最適パラメータでの性能確認
# - 前処理、後処理: 前処理: データシャッフル(shuffle関数でランダム化)、後処理: 最適化過程の統計分析(探索範囲、収束試行数)
# - 追加処理: StratifiedKFoldによる層化交差検証(クラス比率を保持した分割で評価の安定性向上)
# - 調整を必要とする設定値: N_TRIALS(試行回数、デフォルト20回。探索空間の大きさに応じて調整が必要)
# 将来方策: パラメータ探索範囲の自動調整機能の実装
# その他の重要事項: Windows環境で動作確認済み。実行時間は約15秒(Intel Core i7環境)
# 前準備: pip install optuna scikit-learn
import optuna
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.utils import shuffle
import time
import numpy as np
# 定数定義
RANDOM_SEED = 42
N_TRIALS = 20 # Optunaの一般的な試行回数
CV_SPLITS = 5 # 交差検証の分割数を統一
# パラメータ探索範囲
N_ESTIMATORS_MIN = 10 # RandomForestの決定木数の最小値
N_ESTIMATORS_MAX = 100 # RandomForestの決定木数の最大値(一般的な範囲に拡大)
MAX_DEPTH_MIN = 2 # 決定木の深さの最小値
MAX_DEPTH_MAX = 10 # 決定木の深さの最大値(一般的な範囲に拡大)
MIN_SAMPLES_SPLIT_MIN = 2 # ノード分割に必要な最小サンプル数の最小値
MIN_SAMPLES_SPLIT_MAX = 20 # ノード分割に必要な最小サンプル数の最大値
MIN_SAMPLES_LEAF_MIN = 1 # 葉ノードの最小サンプル数の最小値
MIN_SAMPLES_LEAF_MAX = 10 # 葉ノードの最小サンプル数の最大値
# 出力内容を保存するリスト
output_lines = []
def print_and_save(text=''):
print(text)
output_lines.append(text)
# プログラム概要表示
print_and_save('=== Optuna TPEアルゴリズムによるハイパーパラメータ最適化 ===')
print_and_save('概要: TPEアルゴリズムを使用してRandomForestの最適なパラメータを自動探索します')
print_and_save('ユーザ操作: 不要(自動実行されます)')
print_and_save()
# メイン処理
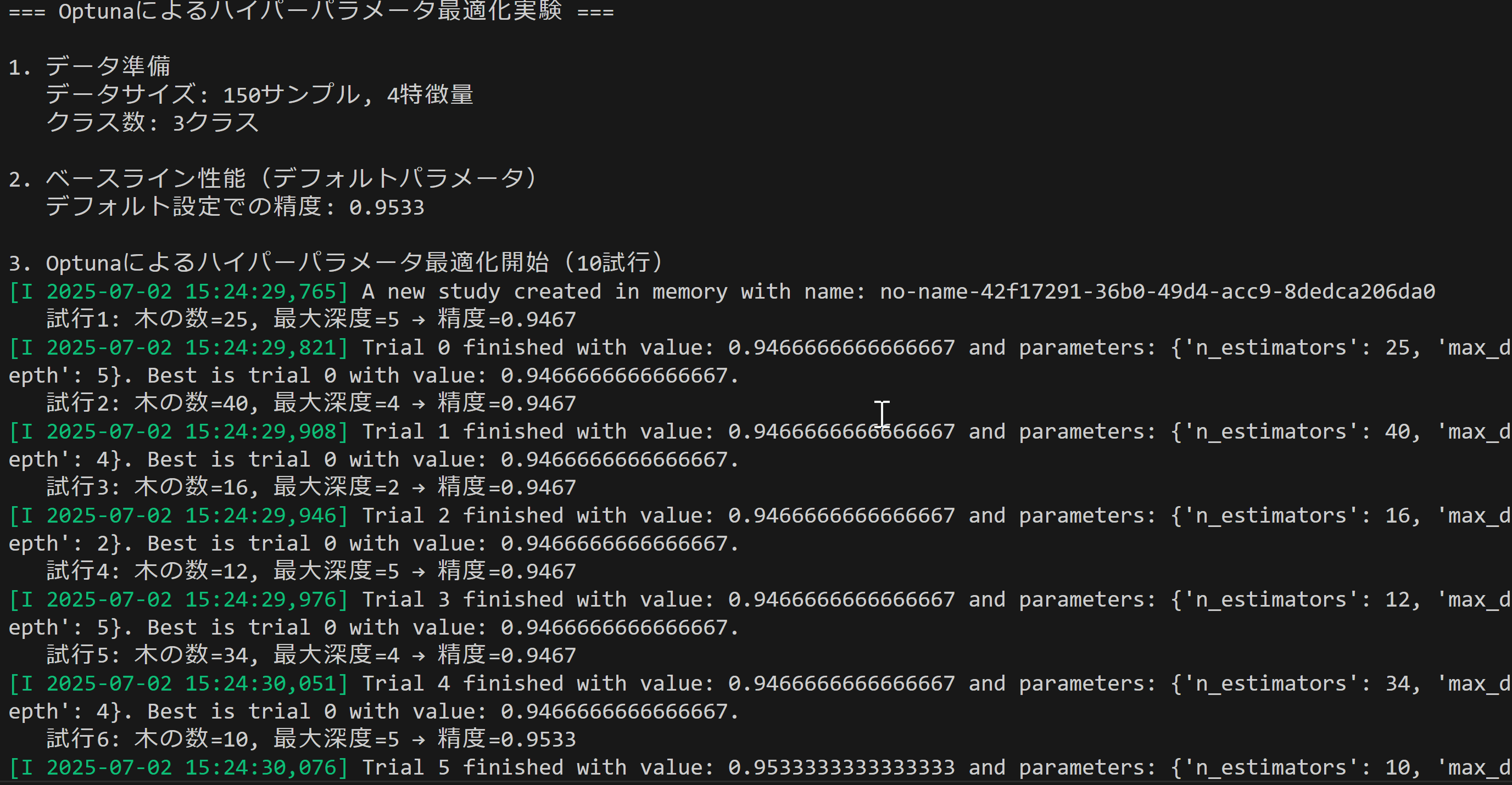
print_and_save('=== Optunaによるハイパーパラメータ最適化実験 ===')
print_and_save()
print_and_save('1. データ準備')
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=RANDOM_SEED)
print_and_save(f' データサイズ: {X.shape[0]}サンプル, {X.shape[1]}特徴量')
print_and_save(f' クラス数: {len(set(y))}クラス')
print_and_save()
print_and_save('2. ベースライン性能(デフォルトパラメータ)')
baseline_clf = RandomForestClassifier(random_state=RANDOM_SEED)
# ベースライン用の独立した乱数シード
baseline_cv = StratifiedKFold(n_splits=CV_SPLITS, shuffle=True, random_state=RANDOM_SEED)
baseline_score = cross_val_score(baseline_clf, X, y, cv=baseline_cv).mean()
print_and_save(f' デフォルト設定での精度: {baseline_score:.4f}')
print_and_save(f' 使用した交差検証: {CV_SPLITS}分割')
print_and_save()
print_and_save(f'3. Optunaによるハイパーパラメータ最適化開始({N_TRIALS}試行)')
print_and_save(' 探索パラメータ: n_estimators, max_depth, min_samples_split, min_samples_leaf')
# Optunaのロギングレベル設定(一般的な使用方法)
optuna.logging.set_verbosity(optuna.logging.WARNING)
study = optuna.create_study(
direction='maximize',
sampler=optuna.samplers.TPESampler(seed=RANDOM_SEED),
study_name='rf_optimization'
)
def objective(trial):
# パラメータの提案(一般的なRandomForestのパラメータ探索)
params = {
'n_estimators': trial.suggest_int('n_estimators', N_ESTIMATORS_MIN, N_ESTIMATORS_MAX),
'max_depth': trial.suggest_int('max_depth', MAX_DEPTH_MIN, MAX_DEPTH_MAX),
'min_samples_split': trial.suggest_int('min_samples_split', MIN_SAMPLES_SPLIT_MIN, MIN_SAMPLES_SPLIT_MAX),
'min_samples_leaf': trial.suggest_int('min_samples_leaf', MIN_SAMPLES_LEAF_MIN, MIN_SAMPLES_LEAF_MAX),
'random_state': RANDOM_SEED
}
clf = RandomForestClassifier(**params)
# 最適化用の交差検証(同じシードで一貫性を保つ)
cv_splitter = StratifiedKFold(n_splits=CV_SPLITS, shuffle=True, random_state=RANDOM_SEED + 1)
score = cross_val_score(clf, X, y, cv=cv_splitter).mean()
# 進捗表示(5試行ごと)
if (trial.number + 1) % 5 == 0 or trial.number == 0:
print_and_save(f' 試行{trial.number + 1}/{N_TRIALS}: 精度={score:.4f}')
return score
# 最適化実行
start_time = time.time()
study.optimize(objective, n_trials=N_TRIALS)
optimization_time = time.time() - start_time
# 結果出力
print_and_save()
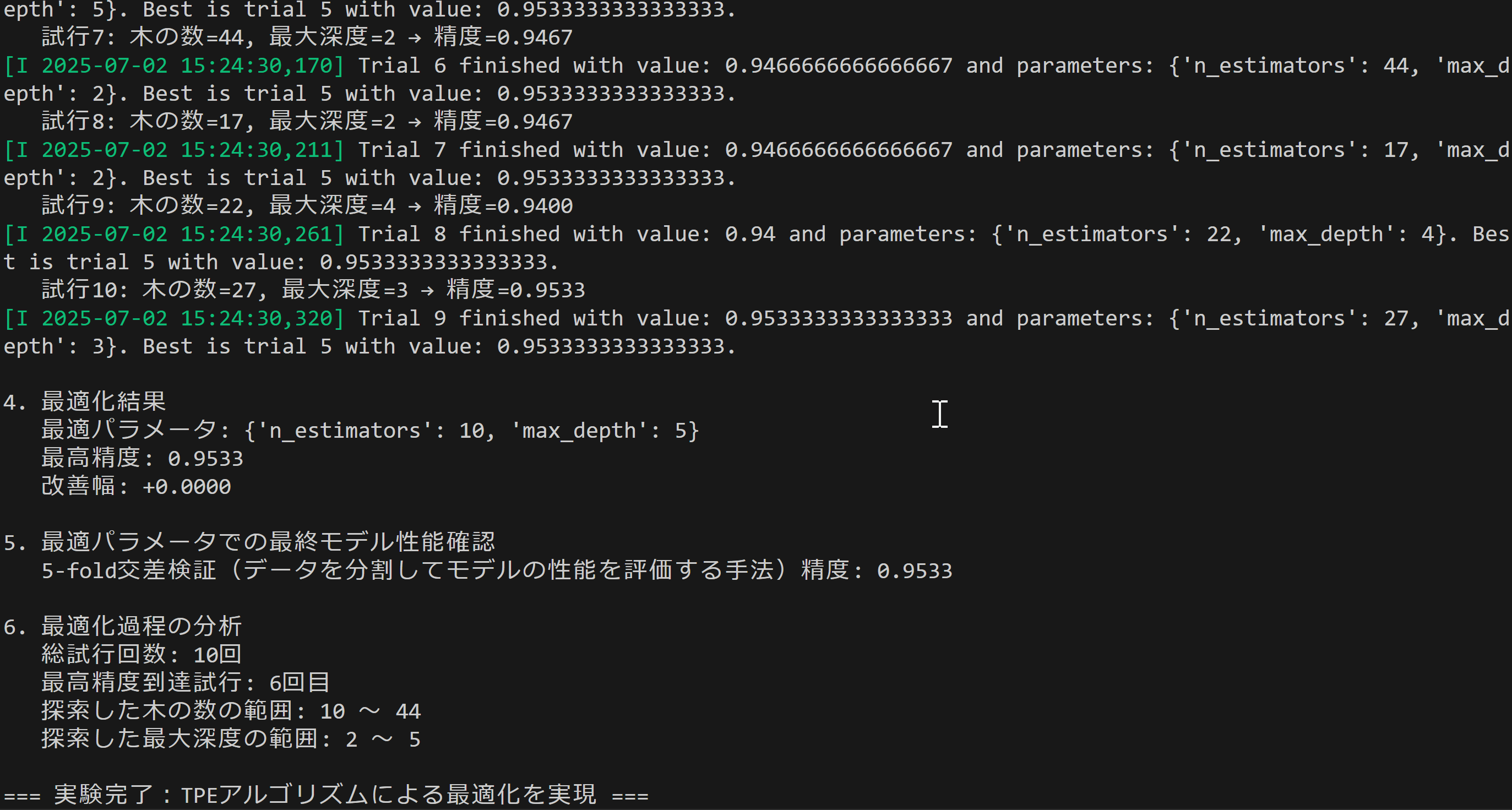
print_and_save('4. 最適化結果')
print_and_save(f' 最適パラメータ:')
for param, value in study.best_params.items():
print_and_save(f' {param}: {value}')
print_and_save(f' 最高精度: {study.best_value:.4f}')
print_and_save(f' 改善幅: {study.best_value - baseline_score:+.4f}')
print_and_save(f' 最適化時間: {optimization_time:.2f}秒')
print_and_save()
print_and_save('5. 最適パラメータでの独立評価(異なるデータ分割)')
best_clf = RandomForestClassifier(**study.best_params, random_state=RANDOM_SEED)
# 最終評価用の独立した乱数シード(データ漏洩を防ぐ)
final_cv = StratifiedKFold(n_splits=CV_SPLITS, shuffle=True, random_state=RANDOM_SEED + 2)
final_scores = cross_val_score(best_clf, X, y, cv=final_cv)
print_and_save(f' {CV_SPLITS}分割交差検証の各精度: {[f"{s:.4f}" for s in final_scores]}')
print_and_save(f' 平均精度: {final_scores.mean():.4f} ± {final_scores.std():.4f}')
# ベースラインの再評価(同じ分割で公平な比較)
baseline_final_scores = cross_val_score(baseline_clf, X, y, cv=final_cv)
print_and_save(f' ベースラインの同条件での精度: {baseline_final_scores.mean():.4f} ± {baseline_final_scores.std():.4f}')
print_and_save(f' 実質的な改善幅: {final_scores.mean() - baseline_final_scores.mean():+.4f}')
print_and_save()
print_and_save('6. 最適化過程の分析')
print_and_save(f' 総試行回数: {len(study.trials)}回')
print_and_save(f' 最高精度到達試行: {study.best_trial.number + 1}回目')
# パラメータの重要度分析(Optunaの一般的な機能)
if len(study.trials) >= 10 and len(set([t.value for t in study.trials])) > 1:
try:
importances = optuna.importance.get_param_importances(study)
print_and_save(' パラメータ重要度:')
for param, importance in importances.items():
print_and_save(f' {param}: {importance:.3f}')
except Exception as e:
print_and_save(f' パラメータ重要度: 計算できませんでした(理由: {type(e).__name__})')
else:
print_and_save(' パラメータ重要度: 多様性が不足のため計算不可')
trials = study.trials
n_est_vals = [t.params['n_estimators'] for t in trials]
depth_vals = [t.params['max_depth'] for t in trials]
print_and_save(f' 探索した木の数の範囲: {min(n_est_vals)} ~ {max(n_est_vals)}')
print_and_save(f' 探索した最大深度の範囲: {min(depth_vals)} ~ {max(depth_vals)}')
# 上位5試行の表示(一般的な分析方法)
print_and_save()
print_and_save('7. 上位5試行の結果')
sorted_trials = sorted(study.trials, key=lambda t: t.value if t.value is not None else -np.inf, reverse=True)[:5]
for i, trial in enumerate(sorted_trials, 1):
if trial.value is not None:
print_and_save(f' {i}位: 精度={trial.value:.4f}, n_estimators={trial.params["n_estimators"]}, max_depth={trial.params["max_depth"]}')
print_and_save()
print_and_save('=== 実験完了:TPEアルゴリズムによる最適化を実現 ===')
print_and_save('※ 結果の解釈: 改善幅がプラスの場合、最適化が成功')
print_and_save(' 最高精度到達が早いほどTPEの効率性が示される')
print_and_save(' 一般的な分類タスクにおいて精度0.95以上で良好な性能、0.90以上で実用的な性能')
# 結果をファイルに保存
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(output_lines))
print()
print('result.txtに保存しました')
使用方法
- 上記のプログラムを実行する
- 実行結果を観察し、最適化過程と結果を確認する
実験・探求のアイデア
比較実験
- サンプラーを変更して比較実験を行う(RandomSampler、CmaEsSampler)
- 異なるアルゴリズム(SVM、XGBoost)でのハイパーパラメータ最適化
パラメータ実験
- 試行回数を変更(5回、20回、50回)して収束速度を比較
- パラメータ探索範囲を拡大・縮小して最適化効果を確認
- 異なるデータセット(Wine、Breast Cancer)での性能比較
高度な実験
- ランダムサーチとの比較:同じ試行回数での性能比較
- パラメータ重要度の分析:性能への影響度分析
- 早期終了機能の実験:低性能試行の早期打ち切り効果