Gemini API による回答添削、画像理解(ソースコードと実行結果)
【目次】
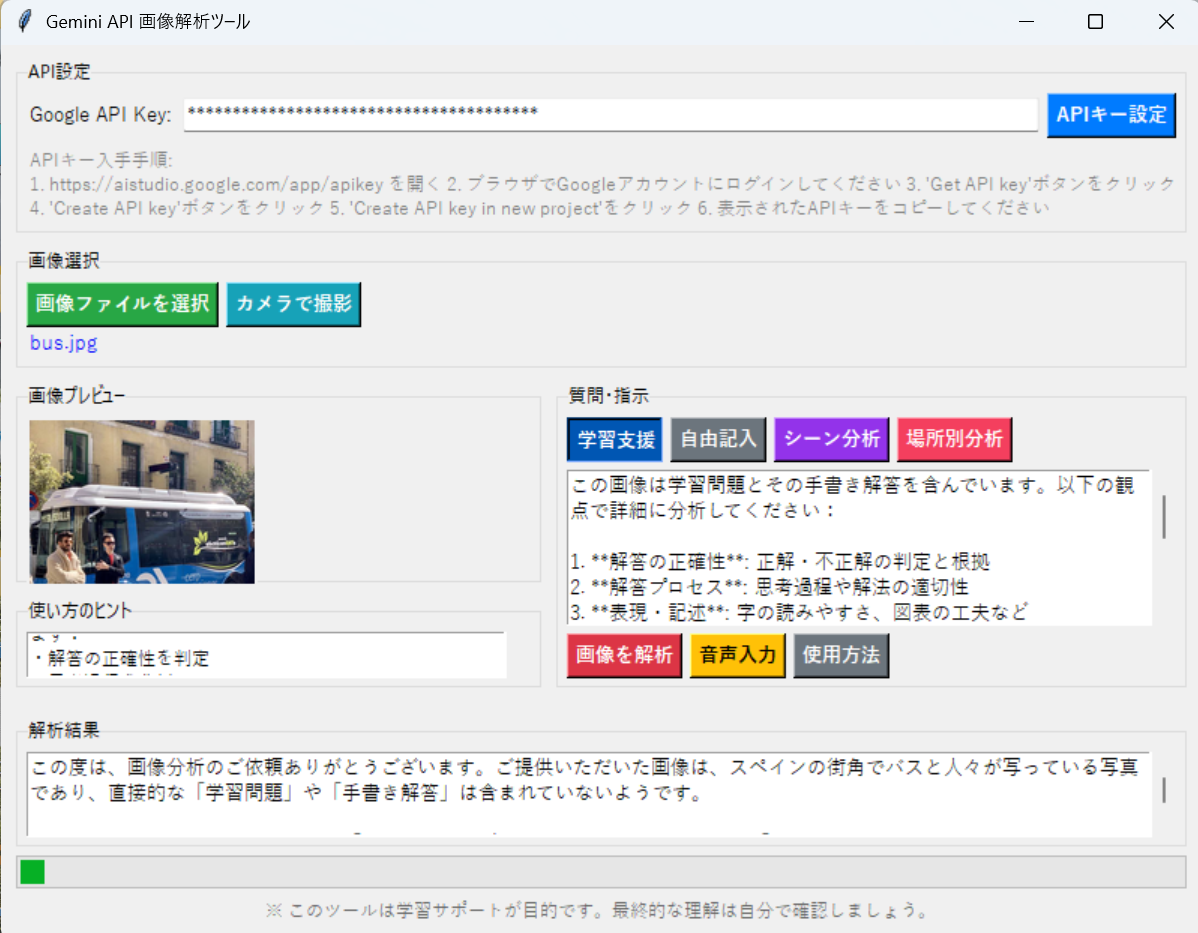
プログラム利用ガイド
1. このプログラムの利用シーン
学習問題の添削支援、画像内の文字情報の読み取り、場所や施設の案内情報の分析などの用途に適する。学習場面では手書き解答の評価とフィードバック生成に活用でき、日常場面では標識や案内板の内容理解を支援できる。
2. 主な機能
- 画像入力機能:ファイル選択またはWebカメラ撮影により画像を取得する。対応形式はJPEG、PNG、WebP、HEIC、HEIF。
- 質問入力機能:テキスト入力欄への直接入力、または音声入力ボタンによる日本語音声認識を利用できる。
- プロンプトテンプレート:学習支援、自由記入、シーン分析、場所別分析の4種類のテンプレートが用意されている。
- 解析結果表示:画面内のテキスト領域に結果を表示し、同時にresult.txtファイルへタイムスタンプ付きで保存する。
- 画像プレビュー:選択または撮影した画像の縮小表示により、入力内容を確認できる。
3. 基本的な使い方
- APIキーの設定:
Google AI Studioから取得したAPIキーを入力欄に貼り付け、「APIキー設定」ボタンを押す。.envファイルにGEMINI_API_KEY=の形式で記述しておくと、起動時に自動的に読み込まれる。
- 画像の選択:
「画像ファイルを選択」ボタンでローカルファイルを指定するか、「カメラで撮影」ボタンでWebカメラを起動する。カメラ使用時はスペースキーで撮影、Qキーで終了する。
- 質問の入力:
テキスト入力欄に質問を入力するか、「音声入力」ボタンを押してマイクに向かって話す。プロンプトテンプレートボタンを使用すると、定型的な質問が自動入力される。
- 解析の実行:
「画像を解析」ボタンを押すと、入力された画像と質問がGemini APIへ送信され、解析結果が表示される。処理中はプログレスバーが動作する。
4. 便利な機能
- プロンプトテンプレートの活用:学習支援モードは解答の正確性と改善点を含む詳細な添削を提供する。シーン分析モードは画像内の重要情報と安全性の確認を提供する。場所別分析モードは施設の案内情報と文字情報の翻訳を提供する。各モードの使い方はヒント表示欄に示される。
- 解析結果の履歴保存:result.txtファイルには解析結果がタイムスタンプ、使用モデル名、質問内容とともに記録される。ファイルは追記形式で保存されるため、過去の解析履歴を参照できる。
- 音声入力の利用:質問の音声入力機能を使用すると、マイクからの音声が日本語テキストへ変換される。音声認識中はステータス表示欄に進行状況が表示される。
- 画像の自動処理:選択した画像は送信前に長辺1600ピクセル以内へ自動的にリサイズされる。HEIC/HEIF形式の画像は自動的にJPEG形式へ変換されるため、iOS端末で撮影した画像をそのまま使用できる。
Python開発環境、ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているため、必要に応じて参照されたい。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install opencv-python pillow pillow-heif langchain-google-genai SpeechRecognitionプログラムコードの説明
1. 概要
このプログラムは、Google Gemini 2.5 Flash APIを利用して画像の内容を解析し、ユーザーの質問に応答するGUIアプリケーションである。画像ファイルの選択またはWebカメラからの撮影により画像を取得し、テキストまたは音声による質問入力を受け付ける。解析結果は画面表示と同時にテキストファイルへ保存される。
2. 主要技術
Google Gemini 2.5 Flash API
Google DeepMindが開発したマルチモーダルAIモデルのAPI[1]。テキストと画像を同時に入力として受け付け、画像の内容理解とテキスト生成を統合的に処理する。モデルは推論時に思考プロセスを実行することで、複雑な質問への応答精度を向上させる。APIはクラウド経由でモデルにアクセスし、ローカル環境へのモデルダウンロードを必要としない。
LangChain Expression Language(LCEL)
LangChain開発チームが実装したパイプライン構成フレームワーク[2]。Runnableインターフェースに基づき、プロンプト生成、モデル実行、出力解析の各処理を宣言的に接続する。パイプ演算子(|)による記述により、同期・非同期実行、ストリーミング、バッチ処理の機能が自動的に提供される[2]。
3. 技術的特徴
- マルチモーダル入力処理
画像とテキストを統合したHumanMessageオブジェクトを生成し、単一のAPI呼び出しで処理する。画像をBase64エンコード形式でData URLとして埋め込み、MIMEタイプの自動判定により複数の画像形式に対応する。
- 適応的画像前処理
送信前に画像の長辺を1600ピクセル以内にリサイズし、API制限とネットワーク負荷に配慮する。HEIC/HEIF形式の画像はJPEG形式へ変換され、RGBA画像はRGB形式へ変換される。
- LCELパイプライン構成
RunnableLambdaによる入力変換、ChatGoogleGenerativeAIによるモデル実行、StrOutputParserによる出力抽出を、パイプ演算子で接続する。各コンポーネントはRunnableインターフェースを実装し、統一的な実行制御を可能にする。
- 音声入力統合
SpeechRecognitionライブラリのrecognize_google関数を使用し、音声認識を実行する[3]。この関数は内部でGoogle Speech Recognition APIと通信する。マイクからの音声取得と日本語認識処理を別スレッドで実行し、GUI応答性を維持する。
4. 実装の特色
プログラムは以下の機能を統合する。
- 学習支援、シーン分析、場所別分析のプロンプトテンプレート機能
- JPEG、PNG、WebP、HEIC、HEIFの画像形式対応
- OpenCVによるWebカメラ制御(CAP_DSHOWモードでの初期化とフォールバック機構)
- 解析結果の履歴保存機能(タイムスタンプ付きテキスト形式)
- .envファイルからのAPIキー自動読み込み
- Tkinterによる視覚的なGUI設計(カラーコーディングされたボタン配置)
5. 参考文献
[1] Google DeepMind. (2025). Gemini 2.5 Flash. https://deepmind.google/models/gemini/flash/
[2] LangChain. (2023). LangChain Expression Language (LCEL). https://python.langchain.com/docs/concepts/lcel/
[3] Zhang, A. (Uberi). (2016). SpeechRecognition: Library for performing speech recognition. https://pypi.org/project/SpeechRecognition/
ソースコード
"""
プログラム名: Gemini API 画像解析ツール
特徴技術名: Google Gemini API (Gemini 2.5 Flash)
出典: Google AI Studio Documentation (2024). Gemini API. https://ai.google.dev/docs
特徴機能: マルチモーダル画像理解機能 - 画像とテキストを同時に理解し、画像の内容について詳細な説明、分析、質問への回答を生成
学習済みモデル: Gemini 2.5 Flash (クラウドAPI経由で使用、ダウンロード不要)
方式設計:
- 関連利用技術:
- LangChain(LCEL: Runnableを用いたパイプライン構成)
- OpenCV(Webカメラからの画像キャプチャ)
- Tkinter(GUIフレームワーク)
- SpeechRecognition(Google Web Speech API(SpeechRecognitionのrecognize_google)による音声入力)
- PIL/Pillow(画像のリサイズとプレビュー表示)
- pillow-heif(HEIC/HEIFの読み込み対応)
- 入力と出力: 入力: 静止画像(ファイル選択またはカメラ撮影)+ テキスト指示。出力: テキスト形式の解析結果(GUI表示・result.txtに保存)
- 処理手順: 1.画像を長辺1600px以内に自動リサイズ、2.Base64エンコードとMIME判定、3.LCELでHumanMessage生成→Gemini API呼び出し→文字列化、4.GUI表示と履歴保存
- 追加処理: プロンプトテンプレート機能(学習支援、シーン分析、場所別分析)
- 調整パラメータ: temperature(0-2、現在0)
将来方策: temperatureの自動調整機能
その他の重要事項: APIキーは.envまたはGUI入力で設定。無料枠の制限あり
前準備:
- pip install opencv-python pillow pillow-heif langchain-google-genai SpeechRecognition
"""
import tkinter as tk
from tkinter import ttk, filedialog, scrolledtext
import base64
import os
import cv2
from PIL import Image, ImageTk
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableLambda
from langchain_core.output_parsers import StrOutputParser
import datetime
import threading
import speech_recognition as sr
import io
# HEIC/HEIF対応(pillow-heif)
try:
from pillow_heif import register_heif_opener
register_heif_opener()
except Exception as e:
print(f'HEIC/HEIF読み込みサポートの初期化に失敗しました(pillow-heif未導入の可能性): {str(e)}')
# 設定定数
# ウィンドウ設定
WINDOW_WIDTH = 800
WINDOW_HEIGHT = 700
PREVIEW_MAX_WIDTH = 250
PREVIEW_MAX_HEIGHT = 200
QUESTION_HEIGHT = 8
QUESTION_WIDTH = 40
RESULT_HEIGHT = 15
RESULT_WIDTH = 80
API_ENTRY_WIDTH = 50
# 画像処理設定
MAX_LONG_SIDE = 1600 # 送信前の最大長辺ピクセル
# ファイル設定
TEMP_IMAGE_FILE = 'temp_captured_image.jpg'
RESULT_FILE = 'result.txt'
ENV_FILE = '.env'
# 色設定(ボタンの背景色)
COLOR_PRIMARY = '#007bff' # 青(学習支援)
COLOR_SECONDARY = '#6c757d' # グレー(自由記入、使用方法)
COLOR_SUCCESS = '#28a745' # 緑(画像選択)
COLOR_DANGER = '#dc3545' # 赤(画像解析)
COLOR_WARNING = '#ffc107' # 黄(音声入力)
COLOR_INFO = '#17a2b8' # 水色(カメラ)
COLOR_PURPLE = '#9333ea' # 紫(シーン分析)
COLOR_PINK = '#f43f5e' # ピンク(場所別分析)
# ボタンの押下時の色
COLOR_PRIMARY_DARK = '#0056b3'
COLOR_SECONDARY_DARK = '#495057'
COLOR_PURPLE_DARK = '#a855f7'
COLOR_PINK_DARK = '#e11d48'
# API設定
TEMPERATURE = 0
MODEL_NAME = 'gemini-2.5-flash' # 指示により現状のまま使用
# グローバル変数
api_key = ''
llm = None
chain = None
img_path = ''
root = None
api_key_var = None
img_path_var = None
img_path_label = None
image_label = None
q_text = None
r_text = None
v_button = None
v_status_var = None
progress = None
recognizer = None
microphone = None
hint_text = None
learning_button = None
free_button = None
scene_button = None
location_button = None
# .envファイルからAPIキー読み込み
if os.path.exists(ENV_FILE):
try:
with open(ENV_FILE, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line and not line.startswith('#'):
if line.startswith('GEMINI_API_KEY='):
api_key = line.split('=', 1)[1].strip()
except Exception as e:
print(f'.envファイルの読み込みに失敗しました: {str(e)}')
# 音声認識の初期化(Google Web Speech API / SpeechRecognition の recognize_google)
try:
recognizer = sr.Recognizer()
microphone = sr.Microphone()
except Exception as e:
print(f'音声認識の初期化に失敗しました: {str(e)}')
recognizer = None
microphone = None
# プロンプト定義
prompt_learn = '''この画像は学習問題とその手書き解答を含んでいます。以下の観点で詳細に分析してください:
1. 解答の正確性: 正解・不正解の判定と根拠
2. 解答プロセス: 思考過程や解法の適切性
3. 表現・記述: 字の読みやすさ、図表の工夫など
4. 評価とフィードバック:
- 良い点(具体的に褒める部分)
- 改善点(1つの重要なアドバイス)
- 理解度の推定
5. 教育的補足: 問題に関する解説や関連知識
学習者のモチベーション向上を重視し、建設的で温かい添削をお願いします。'''
prompt_scene = '''この画像を詳細に分析し、以下の観点で情報を提供してください:
1. 場所・シーンの特定: 画像に写っている場所やシーンの種類
2. 重要な情報: 標識、表示、文字情報など
3. 安全性の確認: 危険箇所、注意すべき点
4. 状態の評価: 設備や環境の状態
5. その他の観察事項: 特筆すべき点や気づいたこと
実用的で具体的な情報を提供してください。'''
prompt_location = '''この画像について、場所の種類(駅、空港、ショッピングモール、その他)を特定し、以下の観点で詳細に分析してください:
1. 場所の特定と基本情報:
- 場所の種類(屋内/屋外、建物の種類、具体的な場所名)
- プラットフォーム番号、ゲート番号、店舗名など場所固有の識別情報
- 営業時間、運行情報などの時間に関する情報
2. 案内・方向情報:
- 出口案内、階段、エスカレーター、エレベーターの位置
- フロアガイド、施設配置図
- 行き先表示、方向指示
3. 施設・サービス情報:
- トイレ、売店、レストラン、休憩所などの位置
- 特別なサービス(ラウンジ、免税店、コインロッカーなど)
- バリアフリー設備
4. 重要な表示・告知:
- 時刻表、フライト情報、セール情報
- 注意事項、警告表示
- イベント情報、臨時案内
5. 文字情報の翻訳と解説:
- 看板、標識、標示に書かれている文字情報(英語表記は日本語に翻訳)
- 時間帯、天候、混雑状況などの状況
- その他の特徴的で有用な情報
必ず日本語で回答し、実用的な情報を提供してください。'''
# ヒントテキスト
hint_learn = '''【学習問題の添削機能】
本モードは学習問題と手書き解答の添削に適する。
【画像の準備】
・問題文と手書き解答が両方写る画像を使用
・文字が読み取りやすい解像度で撮影
・影や反射を避ける'''
hint_free = '枠に自由に記入できる。'
hint_scene = '''【シーン分析の撮影のコツ】
・全体が明瞭に写るように撮影
・標識や表示が読み取れる解像度を確保'''
hint_location = '''【場所別分析の撮影のコツ】
・案内板や標識を含めて撮影
・方向や位置関係が分かる構図で撮影'''
# ヒント更新
def update_hint(text):
hint_text.config(state=tk.NORMAL)
hint_text.delete('1.0', tk.END)
hint_text.insert('1.0', text)
hint_text.config(state=tk.DISABLED)
# プロンプトとボタン状態
def set_prompt(prompt_text, active_btn, active_color, hint):
q_text.delete('1.0', tk.END)
q_text.insert('1.0', prompt_text)
buttons = [
(learning_button, COLOR_PRIMARY),
(free_button, COLOR_SECONDARY),
(scene_button, COLOR_PURPLE),
(location_button, COLOR_PINK)
]
for btn, color in buttons:
btn.config(relief=tk.RAISED, bg=color)
active_btn.config(relief=tk.SUNKEN, bg=active_color)
update_hint(hint)
# 画像の送信用前処理(長辺1600pxリサイズ、フォーマット別処理)
def prepare_image_bytes_for_api(path, max_long_side=MAX_LONG_SIDE):
"""
画像を開き、必要に応じて長辺をmax_long_sideに収めて再エンコードし、バイト列とMIMEタイプを返す。
対応拡張子: .jpg/.jpeg, .png, .webp, .heic, .heif
HEIC/HEIFは読み込み後JPEGに変換して送信。
"""
ext = os.path.splitext(path)[1].lower()
allowed = {'.jpg', '.jpeg', '.png', '.webp', '.heic', '.heif'}
if ext not in allowed:
raise ValueError('サポートされていない画像形式である')
im = Image.open(path)
if max(im.size) > max_long_side:
im.thumbnail((max_long_side, max_long_side), Image.Resampling.LANCZOS)
if ext in ('.jpg', '.jpeg'):
save_format, mime = 'JPEG', 'image/jpeg'
if im.mode in ('RGBA', 'P'):
im = im.convert('RGB')
elif ext == '.png':
save_format, mime = 'PNG', 'image/png'
elif ext == '.webp':
save_format, mime = 'WEBP', 'image/webp'
elif ext in ('.heic', '.heif'):
save_format, mime = 'JPEG', 'image/jpeg'
if im.mode in ('RGBA', 'P'):
im = im.convert('RGB')
else:
save_format, mime = 'JPEG', 'image/jpeg'
if im.mode in ('RGBA', 'P'):
im = im.convert('RGB')
buf = io.BytesIO()
im.save(buf, format=save_format)
data = buf.getvalue()
return data, mime
# LCEL: 入力辞書からHumanMessageを生成するRunnable
def build_human_message(inputs):
return [
HumanMessage(
content=[
{"type": "text", "text": inputs["question"]},
{"type": "image_url", "image_url": {"url": inputs["image_data_url"]}}
]
)
]
def build_chain():
"""LLM作成後にLCELのパイプラインを構築"""
global chain
if llm is None:
chain = None
return
chain = RunnableLambda(build_human_message) | llm | StrOutputParser()
# APIキー設定処理
def set_api_key():
"""APIキーを設定し、LLMとLCELチェーンを初期化"""
global api_key, llm
api_key = api_key_var.get().strip()
if not api_key:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', 'APIキーが入力されていない。')
return
try:
os.environ['GOOGLE_API_KEY'] = api_key
llm = ChatGoogleGenerativeAI(
model=MODEL_NAME,
temperature=TEMPERATURE
)
build_chain()
r_text.delete('1.0', tk.END)
r_text.insert('1.0', 'APIキーが設定された。')
except Exception as e:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', f'APIキーの設定に失敗した: {str(e)}')
# カメラ撮影処理
def capture_from_camera():
"""Webカメラから画像を撮影"""
global img_path
try:
# 指定の初期化手順(CAP_DSHOW → 通常Openのフォールバック)
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
if not cap.isOpened():
r_text.delete('1.0', tk.END)
r_text.insert('1.0', 'カメラを開けない。')
return
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
while True:
# る
cap.grab()
ret, frame = cap.retrieve()
if not ret:
break
cv2.imshow('Camera - Press SPACE to capture, Q to quit', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
cv2.imwrite(TEMP_IMAGE_FILE, frame)
img_path = TEMP_IMAGE_FILE
img_path_var.set('撮影した画像')
image = Image.open(TEMP_IMAGE_FILE)
image.thumbnail((PREVIEW_MAX_WIDTH, PREVIEW_MAX_HEIGHT), Image.Resampling.LANCZOS)
photo = ImageTk.PhotoImage(image)
image_label.configure(image=photo, text='')
image_label.image = photo
break
elif key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
except Exception as e:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', f'カメラ撮影エラー: {str(e)}')
# 画像ファイル選択
def select_image():
"""画像ファイルを選択"""
global img_path
filetypes = [
('画像ファイル', '*.jpg *.jpeg *.png *.webp *.heic *.heif'),
('JPEG files', '*.jpg *.jpeg'),
('PNG files', '*.png'),
('WebP files', '*.webp'),
('HEIC files', '*.heic'),
('HEIF files', '*.heif'),
('すべてのファイル', '*.*')
]
filename = filedialog.askopenfilename(
title='画像ファイルを選択',
filetypes=filetypes,
initialdir=os.getcwd()
)
if filename:
img_path = filename
img_path_var.set(os.path.basename(filename))
try:
image = Image.open(filename)
image.thumbnail((PREVIEW_MAX_WIDTH, PREVIEW_MAX_HEIGHT), Image.Resampling.LANCZOS)
photo = ImageTk.PhotoImage(image)
image_label.configure(image=photo, text='')
image_label.image = photo
except Exception as e:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', f'画像の読み込みエラー: {str(e)}')
# プロンプト設定(個別)
def set_learning_support():
set_prompt(prompt_learn, learning_button, COLOR_PRIMARY_DARK, hint_learn)
def set_free_input():
set_prompt('', free_button, COLOR_SECONDARY_DARK, hint_free)
def set_scene_analysis():
set_prompt(prompt_scene, scene_button, COLOR_PURPLE_DARK, hint_scene)
def set_location_analysis():
set_prompt(prompt_location, location_button, COLOR_PINK_DARK, hint_location)
# 音声入力(別スレッド)
def voice_input_thread():
"""Google Web Speech API / SpeechRecognition の recognize_google を使用"""
try:
root.after(0, lambda: v_status_var.set('音声を聞いている...'))
root.after(0, lambda: v_button.config(state='disabled'))
with microphone as source:
recognizer.adjust_for_ambient_noise(source, duration=1)
audio = recognizer.listen(source, timeout=10)
root.after(0, lambda: v_status_var.set('音声を認識中...'))
text = recognizer.recognize_google(audio, language='ja-JP')
root.after(0, lambda: q_text.delete('1.0', tk.END))
root.after(0, lambda: q_text.insert('1.0', text))
root.after(0, lambda: v_status_var.set('認識完了'))
except sr.UnknownValueError:
root.after(0, lambda: v_status_var.set('音声を認識できなかった'))
except sr.RequestError as e:
root.after(0, lambda: v_status_var.set(f'音声認識エラー: {str(e)}'))
except sr.WaitTimeoutError:
root.after(0, lambda: v_status_var.set('タイムアウト:音声が検出されなかった'))
except Exception as e:
root.after(0, lambda: v_status_var.set(f'エラー: {str(e)}'))
finally:
root.after(0, lambda: v_button.config(state='normal'))
root.after(3000, lambda: v_status_var.set(''))
def voice_input():
if not recognizer or not microphone:
v_status_var.set('音声認識が利用できない')
root.after(3000, lambda: v_status_var.set(''))
return
thread = threading.Thread(target=voice_input_thread)
thread.daemon = True
thread.start()
# 使用方法ガイド
def show_usage_guide():
guide_window = tk.Toplevel(root)
guide_window.title('使用方法ガイド')
guide_window.geometry('700x600')
guide_text = '''
Gemini API 画像解析ツール 使用ガイド
【初期設定】
1. パッケージのインストール
- pip install opencv-python pillow pillow-heif langchain-google-genai SpeechRecognition
2. Google AI StudioでAPIキーを取得
- https://aistudio.google.com/app/apikey
3. APIキーの設定
- APIキー入力欄に貼り付けて「APIキー設定」
【画像の準備】
- 対応形式: JPEG, PNG, WEBP, HEIC, HEIF
- カメラ撮影: スペースで撮影、Qでキャンセル
【画像処理】
- 送信前に長辺1600px以内へ自動リサイズ
【入力】
- テキスト入力または音声入力(Google Web Speech API / recognize_google)
【解析結果】
- 画面表示とresult.txtへの保存(時刻付き履歴)
'''
text_widget = scrolledtext.ScrolledText(guide_window, wrap=tk.WORD, font=('Yu Gothic', 10))
text_widget.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
text_widget.insert(tk.END, guide_text)
text_widget.config(state=tk.DISABLED)
# 画像解析
def analyze_image():
"""画像を解析し、結果を表示"""
if llm is None:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', 'APIキーが設定されていない。')
return
if not img_path:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', '画像が選択されていない。')
return
question = q_text.get('1.0', tk.END).strip()
if not question:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', '質問・指示が入力されていない。')
return
if chain is None:
build_chain()
progress.start()
r_text.delete('1.0', tk.END)
r_text.insert('1.0', '解析中...')
root.update()
try:
# 送信用画像を準備
processed_bytes, mime_type = prepare_image_bytes_for_api(img_path, MAX_LONG_SIDE)
encoded_image = base64.b64encode(processed_bytes).decode('utf-8')
data_url = f'data:{mime_type};base64,{encoded_image}'
# LCELチェーンで推論
inputs = {"question": question, "image_data_url": data_url}
response_text = chain.invoke(inputs)
r_text.delete('1.0', tk.END)
r_text.insert('1.0', response_text)
# 履歴保存
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
history_entry = f'''
{'='*80}
解析日時: {timestamp}
画像ファイル: {os.path.basename(img_path)}
使用モデル: {MODEL_NAME}
{'='*80}
質問:
{question}
{'-'*80}
解析結果:
{response_text}
{'='*80}
'''
with open(RESULT_FILE, 'a', encoding='utf-8') as f:
f.write(history_entry)
except Exception as e:
r_text.delete('1.0', tk.END)
r_text.insert('1.0', f'解析エラー: {str(e)}')
progress.stop()
# ウィンドウ終了処理
def on_closing():
current_result = r_text.get('1.0', tk.END).strip()
if current_result and current_result != '解析中...':
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
session_end = f'''
{'='*80}
セッション終了: {timestamp}
{'='*80}
'''
with open(RESULT_FILE, 'a', encoding='utf-8') as f:
f.write(session_end)
if os.path.exists(TEMP_IMAGE_FILE):
try:
os.remove(TEMP_IMAGE_FILE)
except:
pass
root.destroy()
# GUI作成
root = tk.Tk()
root.title('Gemini API 画像解析ツール')
root.geometry(f'{WINDOW_WIDTH}x{WINDOW_HEIGHT}')
root.protocol('WM_DELETE_WINDOW', on_closing)
main_frame = ttk.Frame(root, padding='10')
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# API設定
api_frame = ttk.LabelFrame(main_frame, text='API設定', padding='5')
api_frame.grid(row=0, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 10))
ttk.Label(api_frame, text='Google API Key:', font=('Yu Gothic', 10)).grid(row=0, column=0, sticky=tk.W)
api_key_var = tk.StringVar()
if api_key:
api_key_var.set(api_key)
api_entry = ttk.Entry(api_frame, textvariable=api_key_var, width=API_ENTRY_WIDTH, show='*', font=('Yu Gothic', 10))
api_entry.grid(row=0, column=1, padx=(5, 0), sticky=(tk.W, tk.E))
api_button = tk.Button(api_frame, text='APIキー設定', command=set_api_key,
bg=COLOR_PRIMARY, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
api_button.grid(row=0, column=2, padx=(5, 0))
api_help_text = '''APIキー入手手順:
1. https://aistudio.google.com/app/apikey を開く
2. Googleアカウントにログイン
3. 'Get API key'→'Create API key'→'Create API key in new project'
4. 表示されたAPIキーをコピー'''
api_help_label = ttk.Label(api_frame, text=api_help_text, foreground='gray', font=('Yu Gothic', 9))
api_help_label.grid(row=1, column=0, columnspan=3, sticky=tk.W, pady=(5, 0))
# 画像選択
image_frame = ttk.LabelFrame(main_frame, text='画像選択', padding='5')
image_frame.grid(row=1, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 10))
select_button = tk.Button(image_frame, text='画像ファイルを選択', command=select_image,
bg=COLOR_SUCCESS, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
select_button.grid(row=0, column=0)
camera_button = tk.Button(image_frame, text='カメラで撮影', command=capture_from_camera,
bg=COLOR_INFO, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
camera_button.grid(row=0, column=1, padx=(5, 0))
img_path_var = tk.StringVar()
img_path_label = ttk.Label(image_frame, textvariable=img_path_var, foreground='blue', font=('Yu Gothic', 10))
img_path_label.grid(row=1, column=0, columnspan=2, padx=(0, 0), sticky=tk.W)
# プレビュー
preview_frame = ttk.LabelFrame(main_frame, text='画像プレビュー', padding='5')
preview_frame.grid(row=2, column=0, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10))
image_label = ttk.Label(preview_frame, text='画像が選択されていない', font=('Yu Gothic', 10))
image_label.grid(row=0, column=0)
# ヒント
hint_frame = ttk.LabelFrame(main_frame, text='使い方のヒント', padding='5')
hint_frame.grid(row=3, column=0, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10))
hint_text = scrolledtext.ScrolledText(hint_frame, height=8, width=30, font=('Yu Gothic', 9), wrap=tk.WORD)
hint_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 質問・指示
question_frame = ttk.LabelFrame(main_frame, text='質問・指示', padding='5')
question_frame.grid(row=2, column=1, rowspan=2, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10), padx=(10, 0))
prompt_button_frame = ttk.Frame(question_frame)
prompt_button_frame.grid(row=0, column=0, pady=(0, 5), sticky=(tk.W, tk.E))
learning_button = tk.Button(prompt_button_frame, text='学習支援', command=set_learning_support,
bg=COLOR_PRIMARY, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2', relief=tk.SUNKEN)
learning_button.pack(side=tk.LEFT, padx=(0, 5))
free_button = tk.Button(prompt_button_frame, text='自由記入', command=set_free_input,
bg=COLOR_SECONDARY, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2', relief=tk.RAISED)
free_button.pack(side=tk.LEFT, padx=(0, 5))
scene_button = tk.Button(prompt_button_frame, text='シーン分析', command=set_scene_analysis,
bg=COLOR_PURPLE, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2', relief=tk.RAISED)
scene_button.pack(side=tk.LEFT, padx=(0, 5))
location_button = tk.Button(prompt_button_frame, text='場所別分析', command=set_location_analysis,
bg=COLOR_PINK, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2', relief=tk.RAISED)
location_button.pack(side=tk.LEFT)
q_text = scrolledtext.ScrolledText(question_frame, height=QUESTION_HEIGHT, width=QUESTION_WIDTH, font=('Yu Gothic', 10))
q_text.grid(row=1, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
q_text.insert('1.0', prompt_learn)
button_frame = ttk.Frame(question_frame)
button_frame.grid(row=2, column=0, pady=(5, 0), sticky=(tk.W, tk.E))
analyze_button = tk.Button(button_frame, text='画像を解析', command=analyze_image,
bg=COLOR_DANGER, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
analyze_button.pack(side=tk.LEFT, padx=(0, 5))
v_button = tk.Button(button_frame, text='音声入力', command=voice_input,
bg=COLOR_WARNING, fg='black', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
v_button.pack(side=tk.LEFT)
guide_button = tk.Button(button_frame, text='使用方法', command=show_usage_guide,
bg=COLOR_SECONDARY, fg='white', font=('Yu Gothic', 10, 'bold'),
cursor='hand2')
guide_button.pack(side=tk.LEFT, padx=(5, 0))
v_status_var = tk.StringVar()
v_status_label = ttk.Label(button_frame, textvariable=v_status_var, foreground='green', font=('Yu Gothic', 10))
v_status_label.pack(side=tk.LEFT, padx=(10, 0))
# 解析結果
result_frame = ttk.LabelFrame(main_frame, text='解析結果', padding='5')
result_frame.grid(row=4, column=0, columnspan=2, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(10, 0))
r_text = scrolledtext.ScrolledText(result_frame, height=RESULT_HEIGHT, width=RESULT_WIDTH, font=('Yu Gothic', 10))
r_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
progress = ttk.Progressbar(main_frame, mode='indeterminate')
progress.grid(row=5, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(5, 0))
# 注意書き
notice_label = ttk.Label(main_frame,
text='※ このツールは学習サポートが目的である。最終的な理解は自分で確認すること。',
foreground='#666666',
font=('Yu Gothic', 9))
notice_label.grid(row=6, column=0, columnspan=2, pady=(5, 0))
# グリッド設定
main_frame.columnconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
main_frame.rowconfigure(2, weight=1)
main_frame.rowconfigure(3, weight=1)
main_frame.rowconfigure(4, weight=2)
api_frame.columnconfigure(1, weight=1)
result_frame.columnconfigure(0, weight=1)
result_frame.rowconfigure(0, weight=1)
question_frame.columnconfigure(0, weight=1)
question_frame.rowconfigure(1, weight=1)
hint_frame.columnconfigure(0, weight=1)
hint_frame.rowconfigure(0, weight=1)
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
# APIキー自動設定
if api_key:
set_api_key()
# 初期ヒント表示
update_hint(hint_learn)
# 使用方法表示(標準出力)
env_status = ''
if api_key:
env_status = '\n※.envファイルからAPIキーが自動読み込みされた'
print('Gemini API 画像解析ツール')
print('1. Google AI StudioでAPIキーを取得する')
print('2. APIキーを入力して「APIキー設定」をクリック')
print(' (.envにGEMINI_API_KEY=を設定すると自動読み込み)')
print('3. 画像を選択またはカメラで撮影')
print('4. 質問や指示を入力(音声入力も可:Google Web Speech API / recognize_google)')
print('5. 「画像を解析」をクリックして結果を確認')
print('')
print('対応画像形式: JPEG, PNG, WEBP, HEIC, HEIF')
print('送信前に長辺1600pxへ自動リサイズ')
if env_status:
print(env_status)
root.mainloop()
実験・研究スキルの基礎:Windowsで学ぶ画像解析実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは画像ファイルと質問テキストが実験用データである。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- プロンプトの記述方法が解析結果の詳細度に与える影響を確認する
- 画像の解像度や形式が認識精度に与える影響を確認する
- 学習問題の添削において、具体的な改善提案を引き出すプロンプトを見つける
- 場所や施設の案内情報を正確に抽出するための質問方法を探る
- 異なる種類の画像(手書き文字、標識、風景など)に対する認識精度を比較する
1.3 プログラム
実験を実施するためのツールである。このプログラムはGoogle Gemini 2.5 Flash APIとLangChain Expression Languageを使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムは画像とテキストを入力として受け付け、AIによる解析結果を出力する。
入力パラメータ。
- 画像:ファイル選択またはカメラ撮影により取得(JPEG、PNG、WebP、HEIC、HEIF対応)
- 質問テキスト:直接入力、音声入力、またはプロンプトテンプレートを使用
- プロンプトテンプレート:学習支援、シーン分析、場所別分析の3種類
出力情報。
- 画像プレビュー:選択または撮影した画像の縮小表示
- 解析結果:テキスト形式でGUI画面に表示
- 履歴保存:タイムスタンプ付きでresult.txtファイルに記録
プログラムの動作。
- 画像を選択し、質問を入力して「画像を解析」ボタンを押すと、APIによる解析が実行される
- 解析中はプログレスバーが動作し、完了後に結果が表示される
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、入力条件の影響を考察する。
基本認識:
- 質問の記述方法を変えると解析結果が変わる。その変化を観察することが実験である
- 「良い結果」「悪い結果」は目的によって異なる
観察のポイント:
- 解析結果の詳細度はどう変化するか
- 誤検出(存在しない情報の記述)は発生しているか
- 見逃し(存在する情報の未検出)は発生しているか
- 質問の具体性が結果に与える影響はどうか
- プロンプトテンプレートと自由記述で結果は異なるか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する。
- 原因:APIキーが設定されていない、必要なライブラリがインストールされていない
- 対処方法:エラーメッセージを確認し、APIキーが設定されているか、ライブラリがインストールされているかを確認する
画像が表示されない。
- 原因:対応していない画像形式、またはファイルパスが正しくない
- 対処方法:対応形式(JPEG、PNG、WebP、HEIC、HEIF)の画像を使用し、ファイルの存在を確認する
解析に時間がかかる。
- 原因:画像サイズが大きい、またはAPI応答に時間がかかっている
- 対処方法:これは正常な動作である。画像は自動的に1600ピクセル以内にリサイズされるが、APIの処理時間は制御できない
2.2 期待と異なる結果が出る場合
質問を変えても解析結果が変化しない。
- 原因:質問の変更が十分に明確でない、または画像内容が限定的である
- 対処方法:質問の具体性を大きく変えて観察する。例:「何が写っていますか」と「この画像の文字情報をすべて抽出してください」を比較する
明らかに存在する情報が解析結果に含まれない。
- 原因:質問が抽象的すぎる、または画像が不鮮明である
- 対処方法:質問をより具体的に記述する。例:「画像に何がありますか」ではなく「画像内の看板に書かれている文字を読み取ってください」とする
解析結果に誤った情報が含まれる。
- 原因:画像が不鮮明、または類似した対象が存在する
- 対処方法:より鮮明な画像を使用する。質問に「確信度の低い情報は除外してください」などの指示を追加する。これはAIの限界を理解する機会である
手書き文字が正しく認識されない。
- 原因:文字が不鮮明、または極端に崩れている
- 対処方法:画像の明るさとコントラストを調整して再撮影する。どの程度の文字であれば認識可能か記録する
3. 実験レポートのサンプル
プロンプトの具体性が学習問題添削の詳細度に与える影響
実験目的:
手書き数学問題の解答画像に対して、プロンプトの記述方法を変化させることで、添削結果の詳細度と有用性がどのように変化するかを明らかにする。
実験計画:
同一の画像に対して、異なる4種類のプロンプトを使用し、解析結果を比較する。
実験方法:
プログラムを実行し、以下の4種類のプロンプトで同じ画像を解析する。
- プロンプトA:「この画像を説明してください」(最も抽象的)
- プロンプトB:「この問題の解答を添削してください」(やや具体的)
- プロンプトC:学習支援テンプレート(詳細な指示を含む)
- プロンプトD:「解答の誤りを指摘し、正しい解法を段階的に説明してください」(最も具体的)
実験結果:
| プロンプト | 解答の正誤判定 | 誤りの指摘 | 改善提案 | 詳細度評価 |
|---|---|---|---|---|
| A | xxxx | xxxx | xxxx | xxxx |
| B | xxxx | xxxx | xxxx | xxxx |
| C | xxxx | xxxx | xxxx | xxxx |
| D | xxxx | xxxx | xxxx | xxxx |
考察:
- (例文)プロンプトAでは画像の物理的な特徴のみが記述され(手書き文字の存在、数式の記述など)、添削としての機能を果たさなかった
- (例文)プロンプトBでは正誤判定は得られたが、誤りの具体的な箇所や改善方法については簡潔な記述に留まった
- (例文)プロンプトC(学習支援テンプレート)では、解答プロセスの評価、具体的な改善点、理解度の推定など、多角的な添削結果が得られた
- (例文)プロンプトDでは、誤りの指摘が詳細であり、正しい解法が段階的に説明されたため、学習者にとって理解しやすい結果となった
- (例文)プロンプトの具体性が高いほど、解析結果の詳細度と教育的価値が向上することが確認できた
結論:
(例文)学習問題の添削において、抽象的な質問では表面的な記述しか得られないが、具体的な指示を含むプロンプトを使用することで、詳細かつ有用な添削結果を得られることが確認できた。(例文)学習支援テンプレートまたはそれに準じる詳細なプロンプトを使用することが推奨される。(例文)ただし、プロンプトが長くなりすぎると本質的でない情報が増える可能性がある。(例文)目的に応じた適切な具体性のバランスを取ることが重要である。