TimeSformer による人物動作認識(ソースコードと説明と利用ガイド)

プログラム利用ガイド
1. このプログラムの利用シーン
動画に映る人物の動作をリアルタイムで認識し分類するためのソフトウェアである。スポーツ動作の分析、監視システムでの行動検出、動画コンテンツの自動タグ付け、人間の行動研究等の用途に適用できる。400種類の動作クラスに対応し、楽器演奏や握手等の多様な人物動作を認識する。
2. 主な機能
- リアルタイム動作認識:動画再生と同時に人物動作を分析し、結果を画面に表示する
- 多様な入力対応:動画ファイル、ウェブカメラ、サンプル動画の3つの入力モードを選択可能
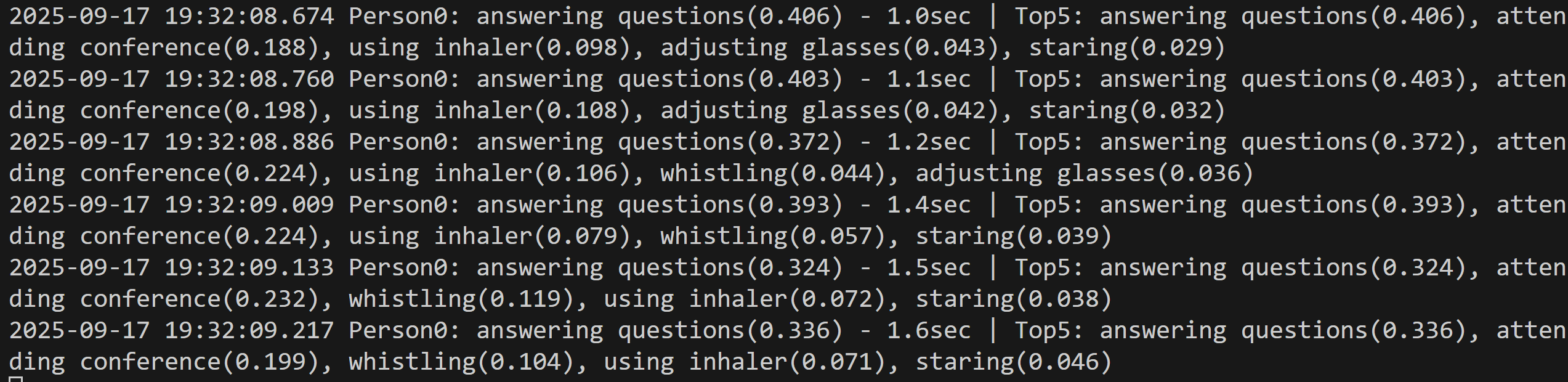
- 信頼度表示:認識結果の上位5クラスを信頼度とともに表示し、予測精度を把握できる
- 動作継続時間追跡:同一動作の継続時間を測定し、動作の持続性を分析する
- 結果保存機能:全ての認識結果をテキストファイル(result.txt)に自動保存する
- フレーム数設定:8フレームまたは16フレームの処理単位を選択可能(モデル設定に応じて自動調整)
3. 基本的な使い方
- プログラム起動:事前にPyTorchとTransformersライブラリをインストールし、プログラムを実行する
- フレーム数選択:0(8フレーム)または1(16フレーム)を入力してEnterキーを押す
- 入力モード選択:0(動画ファイル)、1(カメラ)、2(サンプル動画)のいずれかを選択する
- 動画処理開始:選択したモードに応じて動画処理が開始され、認識結果が表示される
- プログラム終了:qキーを押してプログラムを終了する
4. 便利な機能
- 処理統計表示:総処理フレーム数、使用デバイス、GPU情報等をファイルに記録する
- 時刻情報付与:カメラ入力時には認識結果に時刻情報を付与し、時系列分析を支援する
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリのインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM PyTorch をインストール(GPU対応版)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%
pip install transformers opencv-python pillow
人物動作認識プログラム(TimeSformer)
概要
このプログラムは、TimeSformerアーキテクチャを使用した動画からの人物動作認識システムである。動画ファイル、ウェブカメラ、またはサンプル動画から入力を受け取り、リアルタイムで人物の動作を400種類のクラスから分類する。
主要技術
TimeSformer (Time-Space Transformer)
TimeSformerは時空間分離注意機構を採用したTransformerベースの動画理解モデルである[1]。自己注意機構のみで動画分類を行う。空間注意と時間注意を分離して適用することで、動画フレーム間の時間的依存関係を学習する。
Kinetics-400データセット
事前訓練に使用される大規模動作認識データセットである[2]。400の人物動作クラスを含み、各クラスに最低400の動画クリップが含まれる。楽器演奏などの人物-物体間相互作用や握手などの人物間相互作用を幅広くカバーする。
実装の特色
- OpenCVとHuggingFace Transformersライブラリの統合
- フレームバッファ管理によるリアルタイム処理
- 動作継続時間の追跡機能
- Top-5予測結果の信頼度表示
- 処理結果の自動ファイル保存機能
- 3つの入力モード(動画ファイル、カメラ、サンプル動画)への対応
処理方式
入力動画から8フレームまたは16フレームのシーケンスを抽出し、224×224ピクセルにリサイズして正規化を行う。TimeSformerモデルがフレームシーケンスから時空間特徴を抽出し、400クラスの動作分類を実行する。softmax関数により各クラスの確率を算出し、上位5クラスを信頼度とともに出力する。
参考文献
[1] Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the International Conference on Machine Learning (ICML), 139, 4102-4112. https://arxiv.org/abs/2102.05095
[2] Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., ... & Zisserman, A. (2017). The Kinetics Human Action Video Dataset. arXiv preprint arXiv:1705.06950. https://arxiv.org/abs/1705.06950
ソースコード
# TimeSformer + RT-DETRv2 統合人物動作認識プログラム
# 特徴技術名: TimeSformer + RT-DETRv2
# 出典:
# - TimeSformer: Bertasius, G., Wang, H., & Torresani, L. (2021). Is space-time attention all you need for video understanding? Proceedings of the International Conference on Machine Learning (ICML)
# - RT-DETRv2: W. Lv, Y. Zhao, Q. Chang, K. Huang, G. Wang, and Y. Liu, "RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer," arXiv preprint arXiv:2407.17140, 2024.
# 特徴機能: RT-DETRv2による複数人物検出とTimeSformerによる各人物個別動作認識の統合システム
# 学習済みモデル:
# - TimeSformer: facebook/timesformer-base-finetuned-k400(Kinetics-400、8フレーム)または facebook/timesformer-base-finetuned-k600(Kinetics-600、8フレーム)
# - RT-DETRv2: PekingU/rtdetr_v2_r50vd(COCO 2017、人物検出)
# 方式設計:
# 関連利用技術: RT-DETRv2(人物検出)、TimeSformer(動作認識)、OpenCV(動画処理)、transformers(モデル)、torch(深層学習)、PIL(画像変換)
# 入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択);出力: OpenCV画面で複数人物のMBR表示と各人物の動作認識結果、各人物個別の処理結果をprint()表示、result.txtファイルに保存
# 処理手順: 1.RT-DETRv2による複数人物検出→2.各人物のクロップとフレームバッファ蓄積→3.16フレーム蓄積後に各人物個別TimeSformer推論→4.動作クラス分類→5.結果表示
# 前処理、後処理: 前処理:人物領域クロップ、フレームリサイズ(224x224)、正規化、テンソル変換;後処理:softmax確率計算、上位5クラス抽出
# 追加処理: 複数人物のフレームバッファ個別管理、人物ID追跡、検出失敗時の動作認識スキップ
# 調整を必要とする設定値: フレーム数(8フレーム固定)、人物検出信頼度閾値(デフォルト0.5)、最小人物サイズ(デフォルト20px)
# 将来方策: 人物追跡機能、動作履歴管理、複数人物間の相互作用解析
# その他の重要事項: GPU使用推奨、複数人物対応のため処理負荷増加、精度重視設計
# 前準備: pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install transformers opencv-python pillow
import cv2
import torch
import numpy as np
from transformers import TimesformerForVideoClassification, AutoImageProcessor
from transformers import RTDetrV2ForObjectDetection, RTDetrImageProcessor
from PIL import Image
import tkinter as tk
from tkinter import filedialog
import urllib.request
import time
from datetime import datetime
from collections import defaultdict, deque
# 設定値の明示化
PERSON_CONFIDENCE_THRESHOLD = 0.5 # 人物検出信頼度閾値
MIN_PERSON_SIZE = 20 # 最小人物サイズ(ピクセル)
PERSON_CLASS_ID = 0 # COCOデータセットにおけるPersonクラスのID
PERSON_TRACKING_THRESHOLD = 100 # 人物追跡のための距離閾値(ピクセル)
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# モデル選択
print("TimeSformerモデルを選択してください:")
print("0: facebook/timesformer-base-finetuned-k400 - Kinetics-400データセット(8フレーム、400動作クラス)")
print("1: facebook/timesformer-base-finetuned-k600 - Kinetics-600データセット(8フレーム、600動作クラス)")
model_choice = input("選択: ")
if model_choice == '1':
model_name = "facebook/timesformer-base-finetuned-k600"
print("選択: Kinetics-600モデル(600動作クラス)")
else:
model_name = "facebook/timesformer-base-finetuned-k400"
print("選択: Kinetics-400モデル(400動作クラス)")
# TimeSformerモデル読み込み
print('TimeSformerモデル読み込み中...')
try:
timesformer_model = TimesformerForVideoClassification.from_pretrained(model_name)
timesformer_processor = AutoImageProcessor.from_pretrained(model_name)
timesformer_model.to(device)
timesformer_model.eval()
print('TimeSformerモデル読み込み完了')
except Exception as e:
print(f'TimeSformerモデル読み込み失敗: {e}')
exit(1)
# RT-DETRv2モデル読み込み
print('RT-DETRv2モデル読み込み中...')
try:
rtdetr_model = RTDetrV2ForObjectDetection.from_pretrained("PekingU/rtdetr_v2_r50vd")
rtdetr_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_v2_r50vd")
rtdetr_model.to(device)
rtdetr_model.eval()
print('RT-DETRv2モデル読み込み完了')
except Exception as e:
print(f'RT-DETRv2モデル読み込み失敗: {e}')
exit(1)
# モデル設定の取得
try:
MODEL_NUM_FRAMES = getattr(timesformer_model.config, "num_frames", 8)
print(f'TimeSformerモデル設定のフレーム数: {MODEL_NUM_FRAMES}')
except Exception as e:
print(f'モデル設定取得エラー: {e}')
MODEL_NUM_FRAMES = 8
# モデル設定に合わせる
TIMESFORMER_FRAMES = MODEL_NUM_FRAMES
print(f"設定フレーム数: {TIMESFORMER_FRAMES}")
# フレームバッファの初期化(正しいフレーム数で)
def create_person_buffer():
return deque(maxlen=TIMESFORMER_FRAMES)
# グローバル変数(フレーム数設定後に初期化)
frame_count = 0
results_log = []
person_frame_buffers = defaultdict(create_person_buffer)
person_action_states = defaultdict(lambda: {'current_action': None, 'action_start_time': None})
previous_persons = []
next_person_id = 0
def calculate_person_distance(person1, person2):
"""2つの人物間の中心点距離を計算(改良版)"""
# person1とperson2のbboxから中心点を計算
x1_center = (person1['bbox'][0] + person1['bbox'][2]) / 2
y1_center = (person1['bbox'][1] + person1['bbox'][3]) / 2
x2_center = (person2['bbox'][0] + person2['bbox'][2]) / 2
y2_center = (person2['bbox'][1] + person2['bbox'][3]) / 2
# ユークリッド距離
distance = np.sqrt((x1_center - x2_center)**2 + (y1_center - y2_center)**2)
# サイズ変化も考慮(オプション)
area1 = (person1['bbox'][2] - person1['bbox'][0]) * (person1['bbox'][3] - person1['bbox'][1])
area2 = (person2['bbox'][2] - person2['bbox'][0]) * (person2['bbox'][3] - person2['bbox'][1])
size_ratio = abs(area1 - area2) / max(area1, area2)
# サイズ変化が大きすぎる場合は距離にペナルティ
if size_ratio > 0.5: # 50%以上のサイズ変化
distance *= (1 + size_ratio)
return distance
def assign_person_ids(detected_persons):
"""人物IDの割り当て(簡易追跡機能付き)"""
global previous_persons, next_person_id
if not previous_persons:
# 初回検出時
for i, person in enumerate(detected_persons):
person['person_id'] = next_person_id
next_person_id += 1
else:
# 前フレームとの対応付け
assigned_ids = set()
for person in detected_persons:
best_match_id = None
min_distance = float('inf')
# 前フレームの各人物との距離を計算
for prev_person in previous_persons:
if prev_person['person_id'] not in assigned_ids:
distance = calculate_person_distance(person, prev_person)
if distance < PERSON_TRACKING_THRESHOLD and distance < min_distance:
min_distance = distance
best_match_id = prev_person['person_id']
if best_match_id is not None:
person['person_id'] = best_match_id
assigned_ids.add(best_match_id)
else:
# 新しい人物
person['person_id'] = next_person_id
next_person_id += 1
previous_persons = detected_persons.copy()
return detected_persons
def detect_persons_rtdetr(frame):
"""RT-DETRv2による複数人物検出"""
try:
# 画像前処理
frame_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
inputs = rtdetr_processor(images=frame_pil, return_tensors='pt')
inputs = {k: v.to(device) for k, v in inputs.items()}
# 物体検出の実行
with torch.no_grad():
outputs = rtdetr_model(**inputs)
# 結果処理(修正:正しい形状でtarget_sizesを作成)
h, w = frame.shape[:2]
target_sizes = torch.tensor([[h, w]], dtype=torch.float32).to(device)
results = rtdetr_processor.post_process_object_detection(
outputs, target_sizes=target_sizes, threshold=PERSON_CONFIDENCE_THRESHOLD
)[0]
persons = []
if len(results['labels']) > 0:
boxes = results['boxes'].cpu().numpy()
scores = results['scores'].cpu().numpy()
labels = results['labels'].cpu().numpy()
# Personクラスのみフィルタリング
person_indices = labels == PERSON_CLASS_ID
if np.any(person_indices):
person_boxes = boxes[person_indices]
person_scores = scores[person_indices]
# 信頼度でソート(降順)
sorted_indices = np.argsort(person_scores)[::-1]
person_boxes = person_boxes[sorted_indices]
person_scores = person_scores[sorted_indices]
# 各人物の処理
for i, (box, score) in enumerate(zip(person_boxes, person_scores)):
x1, y1, x2, y2 = map(int, box[:4])
# 最小サイズチェック
if (x2 - x1) >= MIN_PERSON_SIZE and (y2 - y1) >= MIN_PERSON_SIZE:
persons.append({
'bbox': (x1, y1, x2, y2),
'confidence': float(score)
})
# 人物ID割り当て(追跡機能付き)
persons = assign_person_ids(persons)
return persons
except Exception as e:
print(f"人物検出エラー: {e}")
return []
def preprocess_person_frames(video_frames):
"""TimeSformer用の前処理(5次元テンソル形状に修正)"""
# AutoImageProcessorでフレームリストを処理
inputs = timesformer_processor(images=video_frames, return_tensors="pt")
# pixel_valuesの形状確認と修正
pixel_values = inputs['pixel_values']
# 4次元テンソルの場合、5次元に変換
if pixel_values.dim() == 4:
# (num_frames, channels, height, width) -> (1, num_frames, channels, height, width)
pixel_values = pixel_values.unsqueeze(0)
elif pixel_values.dim() == 5:
# 既に正しい形状
pass
else:
raise ValueError(f"Unexpected pixel_values shape: {pixel_values.shape}")
# GPU転送
inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
inputs['pixel_values'] = pixel_values.to(device)
return inputs
def recognize_action_for_person(person_frames, person_id, current_time):
"""個別人物の動作認識"""
try:
# 前処理
inputs = preprocess_person_frames(person_frames)
# 推論実行
with torch.no_grad():
outputs = timesformer_model(**inputs)
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
# 上位5クラス取得
top5_prob, top5_indices = torch.topk(probabilities, 5)
# 結果整形
top5_predictions = []
for i in range(5):
class_idx = top5_indices[0][i].item()
confidence = top5_prob[0][i].item()
class_name = timesformer_model.config.id2label[class_idx]
top5_predictions.append((class_name, confidence))
# Top-1動作取得
top1_action, top1_confidence = top5_predictions[0]
# 動作継続時間管理
person_state = person_action_states[person_id]
if person_state['current_action'] != top1_action:
person_state['current_action'] = top1_action
person_state['action_start_time'] = current_time
duration = 0.0
else:
duration = current_time - person_state['action_start_time'] if person_state['action_start_time'] else 0.0
# 結果文字列作成
predicted_actions = [f"{name}({conf:.3f})" for name, conf in top5_predictions]
result = f"Person{person_id}: {top1_action}({top1_confidence:.3f}) - {duration:.1f}sec | Top5: {', '.join(predicted_actions)}"
return {
'person_id': person_id,
'top1_action': top1_action,
'top1_confidence': top1_confidence,
'duration': duration,
'top5_predictions': top5_predictions,
'result_text': result
}
except Exception as e:
error_result = f"Person{person_id}: 動作認識エラー - {str(e)[:30]}"
return {
'person_id': person_id,
'top1_action': "エラー",
'top1_confidence': 0.0,
'duration': 0.0,
'top5_predictions': [],
'result_text': error_result
}
def video_frame_processing(frame):
global frame_count
current_time = time.time()
frame_count += 1
# RT-DETRv2による人物検出
detected_persons = detect_persons_rtdetr(frame)
# 人物検出結果の表示
result_texts = []
action_results = []
if not detected_persons:
# 人物検出失敗時は動作認識スキップ
result_texts.append(f"フレーム{frame_count}: 人物検出なし - 動作認識スキップ")
# フレームに検出状況を表示
cv2.putText(frame, "No Person Detected", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
else:
# 各人物の処理
for person in detected_persons:
person_id = person['person_id']
x1, y1, x2, y2 = person['bbox']
# 人物領域をクロップ
padding = 20
h, w = frame.shape[:2]
crop_x1 = max(0, x1 - padding)
crop_y1 = max(0, y1 - padding)
crop_x2 = min(w, x2 + padding)
crop_y2 = min(h, y2 + padding)
cropped_person = frame[crop_y1:crop_y2, crop_x1:crop_x2]
if cropped_person.shape[0] > 0 and cropped_person.shape[1] > 0:
# フレームを224x224にリサイズ
resized_frame = cv2.resize(cropped_person, (224, 224))
rgb_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
rgb_frame = rgb_frame.astype(np.uint8) # データ型保証
pil_frame = Image.fromarray(rgb_frame)
# 人物別フレームバッファに追加
person_frame_buffers[person_id].append(pil_frame)
# デバッグ用: 現在のバッファ状況を確認
current_buffer_size = len(person_frame_buffers[person_id])
# バウンディングボックス描画(緑色)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# Person ID と信頼度表示
cv2.putText(frame, f"Person{person_id}",
(x1, y1-30), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
cv2.putText(frame, f"Conf:{person['confidence']:.2f}",
(x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 正確なフレーム数蓄積後に動作認識実行
if current_buffer_size == TIMESFORMER_FRAMES:
person_frames = list(person_frame_buffers[person_id])
action_result = recognize_action_for_person(person_frames, person_id, current_time)
action_results.append(action_result)
result_texts.append(action_result['result_text'])
# 動作認識結果を常に表示(フレーム蓄積完了後)
if current_buffer_size == TIMESFORMER_FRAMES and action_results:
latest_action = action_results[-1]
# Top-1動作認識結果を画面に表示(青色、大きめフォント)
top1_text = f"{latest_action['top1_action']}"
conf_text = f"({latest_action['top1_confidence']:.2f})"
cv2.putText(frame, top1_text, (x1, y1-50), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)
cv2.putText(frame, conf_text, (x1, y1-25), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
else:
# フレーム蓄積中表示
buffer_text = f"Loading {current_buffer_size}/{TIMESFORMER_FRAMES}"
cv2.putText(frame, buffer_text, (x1, y1-25), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1)
buffer_status = f"Person{person_id}: {current_buffer_size}/{TIMESFORMER_FRAMES}フレーム蓄積中"
result_texts.append(buffer_status)
# 全体の検出状況表示
cv2.putText(frame, f"Detected: {len(detected_persons)} person(s)",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# デバッグ用:フレーム数表示
cv2.putText(frame, f"Frames: {TIMESFORMER_FRAMES}",
(10, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 0), 1)
# 結果文字列の結合
if result_texts:
combined_result = " | ".join(result_texts)
else:
combined_result = f"フレーム{frame_count}: 処理中"
return frame, combined_result, current_time
print("TimeSformer + RT-DETRv2 統合人物動作認識プログラム")
print(f"設定フレーム数: {TIMESFORMER_FRAMES}")
print(f"人物検出信頼度閾値: {PERSON_CONFIDENCE_THRESHOLD}")
print(f"最小人物サイズ: {MIN_PERSON_SIZE}px")
print(f"人物追跡閾値: {PERSON_TRACKING_THRESHOLD}px")
print("\n動画ソースを選択してください:")
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
try:
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
except Exception as e:
print(f'サンプル動画ダウンロードエラー: {e}')
exit()
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = f"TimeSformer + RT-DETRv2 統合システム"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== TimeSformer + RT-DETRv2 統合結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用フレーム数: {TIMESFORMER_FRAMES}\n')
f.write(f'人物検出閾値: {PERSON_CONFIDENCE_THRESHOLD}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')