U-2-Net (U Square Net) による動画用オブジェクト顕著性検出(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM PyTorch をインストール(GPU対応版)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%
pip install opencv-python pillow numpy requests
事前学習済みモデルのダウンロード
次のURLからダウンロード
https://drive.google.com/file/d/1ao1ovG1Qtx4b7EoskHXmi2E9rp5CHLcZ/view
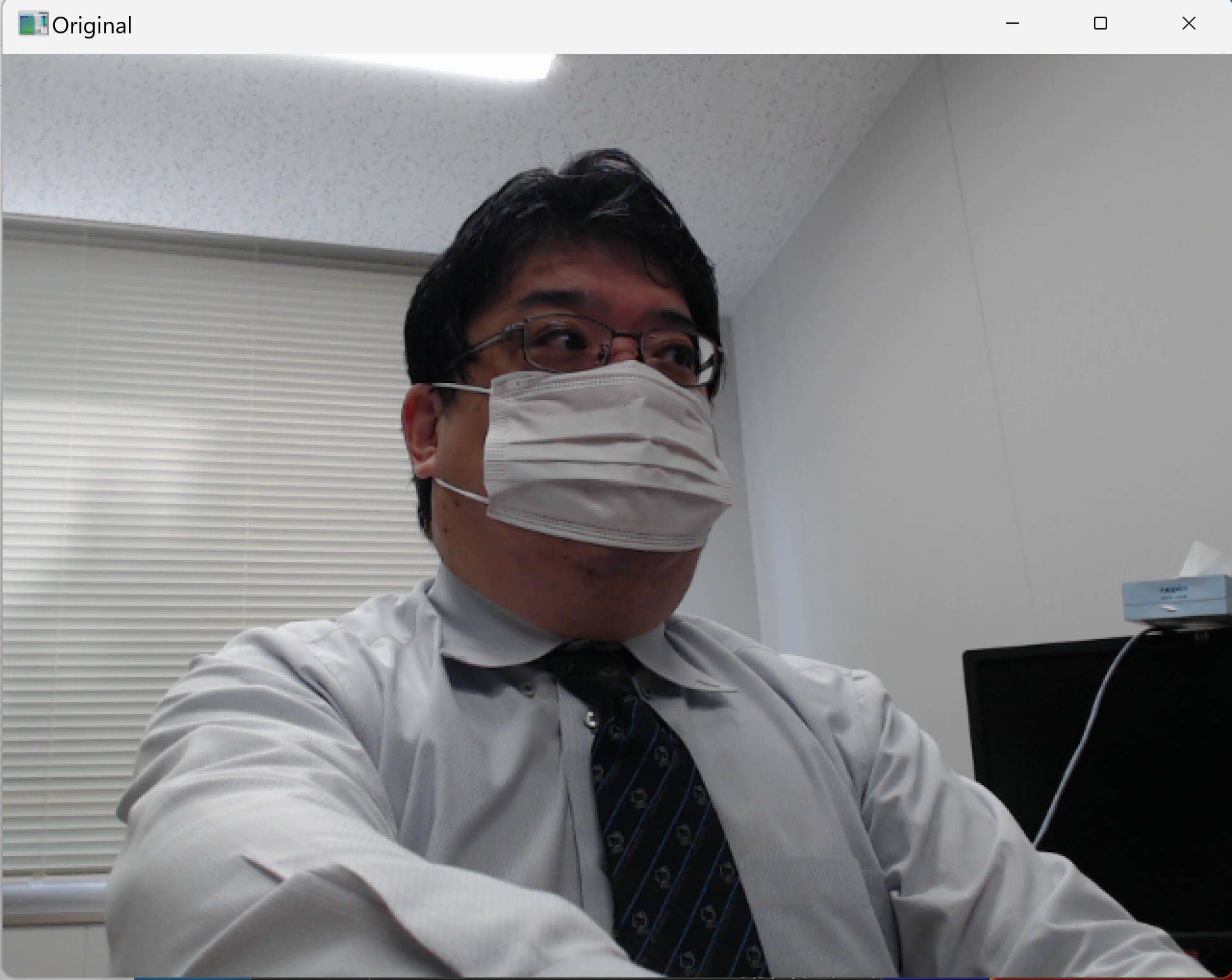
U-2-Net (U Square Net) による動画用オブジェクト顕著性検出プログラム
概要
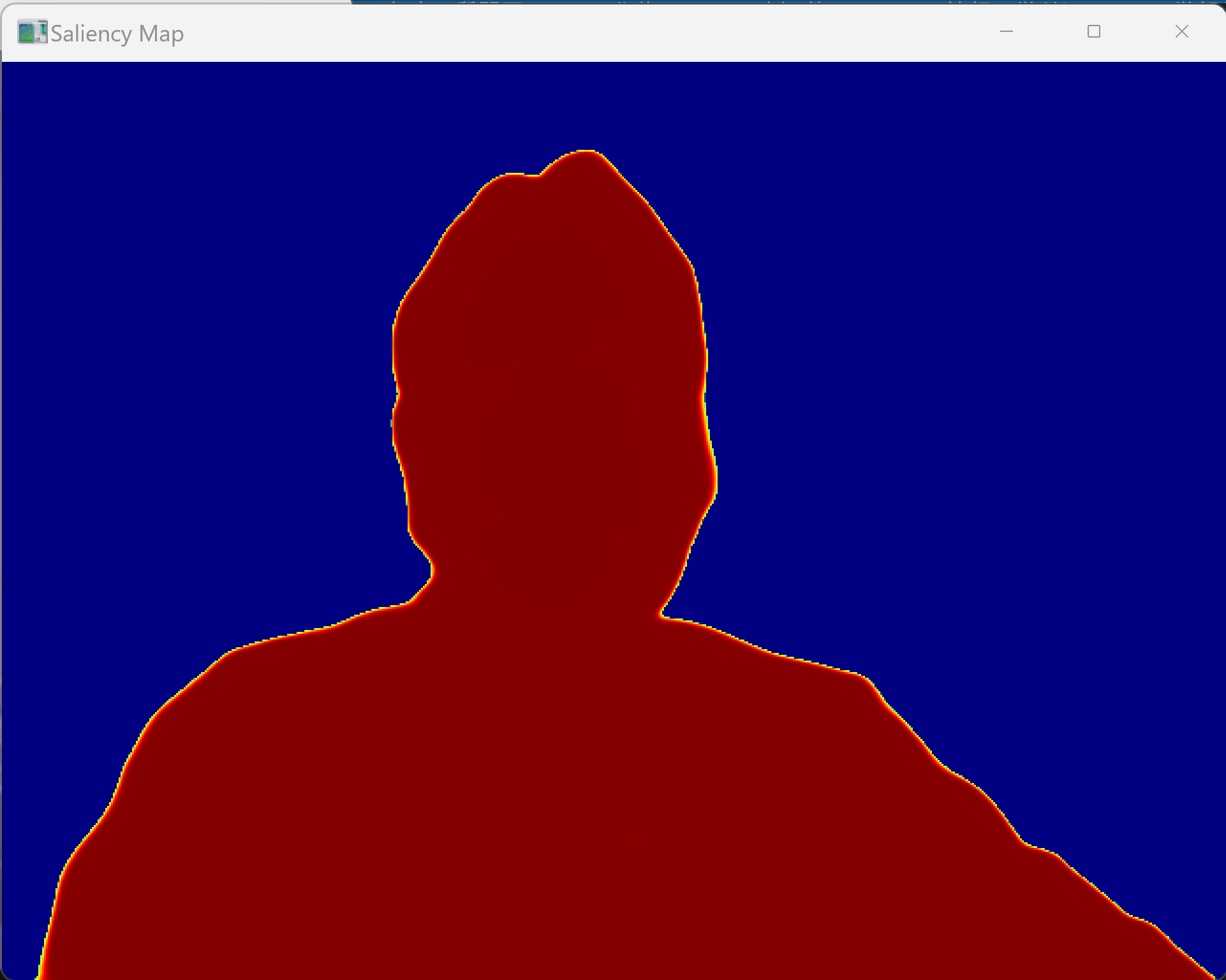
動画像中の各フレームから人間の視覚的注意を引く領域を自動的に検出する能力を持つ。U-2-Netの深層学習モデルにより、物体の境界を高精度に認識し、背景から主要な物体を分離する。時間的フィルタリングにより、フレーム間の一貫性を保ちながら動画全体で安定した顕著性検出を実現する。
主要技術
- U-2-Net(U Square Net)
入れ子状のU構造(Nested U-Structure)による顕著性物体検出である[1]。従来のU-Netと異なり、各段階で異なる深さのU構造を組み合わせることで、多スケールの特徴を扱う。RSU(Residual U-blocks)と呼ばれる基本ブロックを使用し、浅い層では高解像度の詳細情報を、深い層では意味的な情報を学習する。
- 時間的フィルタリング
指数移動平均(Exponential Moving Average)を用いて連続するフレーム間の顕著性マップを平滑化する。現在フレームと前フレームの顕著性マップを重み付き平均することで、動画における急激な変化を抑制し、視覚的に安定した出力を生成する。
参考文献
[1] Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O., & Jagersand, M. (2020). U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognition, 106, 107404.
[2] Borji, A., Cheng, M. M., Jiang, H., & Li, J. (2015). Salient object detection: A benchmark. IEEE Transactions on Image Processing, 24(12), 5706-5722.
ソースコード
# プログラム名: U-2-Net (U Square Net) による動画用オブジェクト顕著性検出プログラム
# 特徴技術名: U-2-Net (U Square Net)
# 出典: Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O., & Jagersand, M. (2020). U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognition, 106, 107404
# 特徴機能: Nested U-Structure with ReSidual U-blocks (RSU)による多スケール特徴抽出。2レベルのネストしたU構造により、異なる深さとスケールの特徴を効果的に統合し、高解像度を維持しながら計算コストを抑制
# 学習済みモデル: u2net.pth(176.3MB)- DUTS-TR(10,553枚)で学習済み、顕著性検出性能、https://drive.google.com/file/d/1ao1ovG1Qtx4b7EoskHXmi2E9rp5CHLcZ/view
# 方式設計:
# 関連利用技術: OpenCV(動画処理・表示、BGR形式画像処理)、PyTorch(深層学習推論エンジン)、PIL(画像形式変換、日本語フォント描画)、NumPy(配列演算)
# 入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.2の場合はhttps://github.com/opencv/opencv/blob/master/samples/data/vtest.aviを使用)、出力: 処理結果が画像化できる場合にはOpenCV画面でリアルタイムに表示.OpenCV画面内に処理結果をテキストで表示.さらに,各フレームごとに,print()で処理結果を表示.プログラム終了時にprint()で表示した処理結果をresult.txtファイルに保存し,「result.txtに保存」したことをprint()で表示.プログラム開始時に,プログラムの概要,ユーザが行う必要がある操作(もしあれば)をprint()で表示
# 処理手順: フレーム取得→前処理(320x320リサイズ・正規化)→U-2-Net推論(6段階エンコーダ・5段階デコーダ・顕著性マップ融合)→後処理(Sigmoid活性化・正規化)→顕著性マップ生成→カラーマップ適用→表示
# 前処理、後処理: 前処理: 320x320固定サイズリサイズ・0-1正規化、後処理: Sigmoid活性化・最大最小値正規化・カラーマップ適用
# 追加処理: フレーム間の時間的一貫性を保つための指数移動平均フィルタリング(α=0.7)
# 調整を必要とする設定値: CONFIDENCE_THRESHOLD(顕著性閾値、0.0-1.0、デフォルト0.5)
# 将来方策: Otsuの閾値法による自動閾値決定機能の実装
# その他の重要事項: U-2-Netモデルが利用できない場合はOpenCVのStaticSaliencyFineGrainedを代替使用
# 前準備: pip install -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install opencv-python pillow numpy requests
import sys
import io
import os
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageDraw, ImageFont
import requests
import time
import urllib.request
from datetime import datetime
# 設定値(利用者が調整可能)
CONFIDENCE_THRESHOLD = 0.5 # 顕著性閾値(0.0-1.0)- 物体検出の感度調整
COLOR_MAP = cv2.COLORMAP_JET # カラーマップ(JET, HOT, COOL等)- 顕著性の可視化色
FILTER_ALPHA = 0.7 # 時間的フィルタリング強度(0.0-1.0)- 値が大きいほど現在フレームの影響が強い
MODEL_PATH = 'u2net.pth' # モデルファイルパス
MODEL_URL = 'https://drive.usercontent.google.com/download?id=1ao1ovG1Qtx4b7EoskHXmi2E9rp5CHLcZ&export=download&authuser=0'
# Windows文字エンコーディング設定
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', line_buffering=True)
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
def _upsample_like(src, tar):
"""アップサンプリング関数"""
src = F.interpolate(src, size=tar.shape[2:], mode='bilinear', align_corners=False)
return src
class REBNCONV(nn.Module):
"""ReLU-BatchNorm-Conv基本ブロック"""
def __init__(self, in_ch=3, out_ch=3, dirate=1):
super(REBNCONV, self).__init__()
self.conv_s1 = nn.Conv2d(in_ch, out_ch, 3, padding=1*dirate, dilation=1*dirate)
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self, x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
class RSU7(nn.Module):
"""U-2-Netの基本ブロック RSU-7"""
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU7, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv7 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv6d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv5d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx = self.pool5(hx5)
hx6 = self.rebnconv6(hx)
hx7 = self.rebnconv7(hx6)
hx6d = self.rebnconv6d(torch.cat((hx7, hx6), 1))
hx6dup = _upsample_like(hx6d, hx5)
hx5d = self.rebnconv5d(torch.cat((hx6dup, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
class RSU6(nn.Module):
"""U-2-Netの基本ブロック RSU-6"""
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU6, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv5d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx6 = self.rebnconv6(hx5)
hx5d = self.rebnconv5d(torch.cat((hx6, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
class RSU5(nn.Module):
"""U-2-Netの基本ブロック RSU-5"""
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU5, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv4d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx5 = self.rebnconv5(hx4)
hx4d = self.rebnconv4d(torch.cat((hx5, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
class RSU4(nn.Module):
"""U-2-Netの基本ブロック RSU-4"""
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
class RSU4F(nn.Module):
"""U-2-Netの基本ブロック RSU-4F"""
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4F, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=4)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=8)
self.rebnconv3d = REBNCONV(mid_ch*2, mid_ch, dirate=4)
self.rebnconv2d = REBNCONV(mid_ch*2, mid_ch, dirate=2)
self.rebnconv1d = REBNCONV(mid_ch*2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx2 = self.rebnconv2(hx1)
hx3 = self.rebnconv3(hx2)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx2d = self.rebnconv2d(torch.cat((hx3d, hx2), 1))
hx1d = self.rebnconv1d(torch.cat((hx2d, hx1), 1))
return hx1d + hxin
class U2NET(nn.Module):
"""U-2-Net メインネットワーク"""
def __init__(self, in_ch=3, out_ch=1):
super(U2NET, self).__init__()
self.stage1 = RSU7(in_ch, 32, 64)
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage2 = RSU6(64, 32, 128)
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage3 = RSU5(128, 64, 256)
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage4 = RSU4(256, 128, 512)
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage5 = RSU4F(512, 256, 512)
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage6 = RSU4F(512, 256, 512)
# decoder
self.stage5d = RSU4F(1024, 256, 512)
self.stage4d = RSU4(1024, 128, 256)
self.stage3d = RSU5(512, 64, 128)
self.stage2d = RSU6(256, 32, 64)
self.stage1d = RSU7(128, 16, 64)
self.side1 = nn.Conv2d(64, out_ch, 3, padding=1)
self.side2 = nn.Conv2d(64, out_ch, 3, padding=1)
self.side3 = nn.Conv2d(128, out_ch, 3, padding=1)
self.side4 = nn.Conv2d(256, out_ch, 3, padding=1)
self.side5 = nn.Conv2d(512, out_ch, 3, padding=1)
self.side6 = nn.Conv2d(512, out_ch, 3, padding=1)
self.outconv = nn.Conv2d(6*out_ch, out_ch, 1)
def forward(self, x):
hx = x
# stage 1
hx1 = self.stage1(hx)
hx = self.pool12(hx1)
# stage 2
hx2 = self.stage2(hx)
hx = self.pool23(hx2)
# stage 3
hx3 = self.stage3(hx)
hx = self.pool34(hx3)
# stage 4
hx4 = self.stage4(hx)
hx = self.pool45(hx4)
# stage 5
hx5 = self.stage5(hx)
hx = self.pool56(hx5)
# stage 6
hx6 = self.stage6(hx)
hx6up = _upsample_like(hx6, hx5)
# -------------------- decoder --------------------
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
# side output
d1 = self.side1(hx1d)
d2 = self.side2(hx2d)
d2 = _upsample_like(d2, d1)
d3 = self.side3(hx3d)
d3 = _upsample_like(d3, d1)
d4 = self.side4(hx4d)
d4 = _upsample_like(d4, d1)
d5 = self.side5(hx5d)
d5 = _upsample_like(d5, d1)
d6 = self.side6(hx6)
d6 = _upsample_like(d6, d1)
d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1))
return torch.sigmoid(d0), torch.sigmoid(d1), torch.sigmoid(d2), torch.sigmoid(d3), torch.sigmoid(d4), torch.sigmoid(d5), torch.sigmoid(d6)
def normPRED(d):
"""予測結果の正規化"""
ma = torch.max(d)
mi = torch.min(d)
dn = (d - mi) / (ma - mi)
return dn
def preprocess_frame(frame):
"""フレーム前処理"""
# 320x320にリサイズ
frame_resized = cv2.resize(frame, (320, 320))
# RGB変換と正規化
frame_rgb = cv2.cvtColor(frame_resized, cv2.COLOR_BGR2RGB)
frame_normalized = frame_rgb.astype(np.float32) / 255.0
# テンソル変換
frame_tensor = torch.from_numpy(frame_normalized).permute(2, 0, 1).unsqueeze(0)
return frame_tensor
def postprocess_saliency(saliency_map, original_shape):
"""顕著性マップ後処理"""
# CPU、NumPy変換
sal_map = saliency_map.squeeze().cpu().data.numpy()
# 元のサイズにリサイズ
sal_map_resized = cv2.resize(sal_map, (original_shape[1], original_shape[0]))
# 平均顕著性を計算(閾値適用前の全体的な顕著性)
mean_saliency = np.mean(sal_map_resized)
# 閾値適用
sal_map_thresholded = np.where(sal_map_resized > CONFIDENCE_THRESHOLD,
sal_map_resized, 0)
# 0-255スケール変換
sal_map_scaled = (sal_map_thresholded * 255).astype(np.uint8)
# カラーマップ適用
sal_map_colored = cv2.applyColorMap(sal_map_scaled, COLOR_MAP)
return sal_map_colored, mean_saliency
def download_model():
"""学習済みモデルの自動ダウンロード"""
if not os.path.exists(MODEL_PATH):
print('U-2-Netモデルをダウンロード中...')
print('ファイルサイズ: 約176MB')
response = requests.get(MODEL_URL, stream=True)
total_size = int(response.headers.get('content-length', 0))
with open(MODEL_PATH, 'wb') as f:
downloaded = 0
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
downloaded += len(chunk)
if total_size > 0:
percent = (downloaded / total_size) * 100
print(f'\rダウンロード進捗: {percent:.1f}%', end='')
print('\nダウンロード完了')
# ファイルサイズ確認
file_size = os.path.getsize(MODEL_PATH)
if file_size < 100 * 1024 * 1024: # 100MB未満の場合は異常
os.remove(MODEL_PATH)
print('ダウンロードに失敗しました。ファイルサイズが異常です。')
print('手動でダウンロードしてください。')
return False
return True
return True
def download_model_guide():
"""学習済みモデルのダウンロード案内"""
if not os.path.exists(MODEL_PATH):
print('=' * 60)
print('U-2-Netモデルの手動ダウンロードが必要です')
print('=' * 60)
print('以下の手順でモデルをダウンロードしてください:')
print('1. ブラウザで以下のURLにアクセス:')
print(' https://drive.google.com/file/d/1ao1ovG1Qtx4b7EoskHXmi2E9rp5CHLcZ/view')
print("2. 'ダウンロード'ボタンをクリック")
print("3. ダウンロードした'u2net.pth'ファイルをこのPythonファイルと同じフォルダに配置")
print('4. プログラムを再実行')
print('=' * 60)
print('注意: モデルファイルサイズは約176MBです')
print('=' * 60)
return False
return True
def load_model():
"""U-2-Netモデルのロード"""
# 自動ダウンロード試行
if not download_model():
# 自動ダウンロード失敗時は手動案内
if not download_model_guide():
return None
# モデルロード
model = U2NET(3, 1)
if torch.cuda.is_available():
model.cuda()
model.load_state_dict(torch.load(MODEL_PATH, weights_only=False))
else:
model.load_state_dict(torch.load(MODEL_PATH, map_location='cpu', weights_only=False))
model.eval()
return model
def opencv_saliency_process(frame):
"""OpenCV組み込み顕著性検出"""
# Fine Grained静的顕著性検出器を使用
saliency = cv2.saliency.StaticSaliencyFineGrained_create()
(success, saliency_map) = saliency.computeSaliency(frame)
if success:
# 平均顕著性を計算(閾値適用前の全体的な顕著性)
mean_saliency = np.mean(saliency_map)
# 閾値適用
saliency_thresholded = np.where(saliency_map > CONFIDENCE_THRESHOLD,
saliency_map, 0)
# 0-255スケール変換
saliency_scaled = (saliency_thresholded * 255).astype(np.uint8)
# カラーマップ適用
saliency_colored = cv2.applyColorMap(saliency_scaled, COLOR_MAP)
return saliency_colored, mean_saliency
else:
return np.zeros_like(frame), 0.0
def draw_japanese_text(img, text, position, font_size=20, color=(255, 255, 255)):
"""OpenCV画像に日本語テキストを描画"""
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
# フォント設定
try:
font = ImageFont.truetype(FONT_PATH, font_size)
except:
# フォントが見つからない場合は英語表示にフォールバック
cv2.putText(img, text, position, cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2)
return img
# OpenCV画像をPIL画像に変換
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
# テキスト描画
draw.text(position, text, font=font, fill=color)
# PIL画像をOpenCV画像に戻す
img_with_text = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
return img_with_text
frame_count = 0
results_log = []
prev_saliency = None
def video_frame_processing(frame):
"""動画フレーム処理関数"""
global frame_count, prev_saliency
current_time = time.time()
frame_count += 1
# 推論実行
if use_u2net:
# U-2-Net処理
# 前処理
input_tensor = preprocess_frame(frame)
if torch.cuda.is_available():
input_tensor = input_tensor.cuda()
# 推論
with torch.no_grad():
d0, d1, d2, d3, d4, d5, d6 = model(input_tensor)
pred = d0[:, 0, :, :]
pred = normPRED(pred)
# 後処理
saliency_colored, mean_saliency = postprocess_saliency(pred, frame.shape)
else:
# OpenCV顕著性検出
saliency_colored, mean_saliency = opencv_saliency_process(frame)
# 時間的フィルタリング処理(初期フレームの場合はフィルタリングをスキップ)
if prev_saliency is not None:
saliency_colored = cv2.addWeighted(
saliency_colored, FILTER_ALPHA,
prev_saliency, 1 - FILTER_ALPHA, 0
)
prev_saliency = saliency_colored.copy()
# 統計情報を画像に追加
elapsed_time = current_time - start_time
fps = frame_count / elapsed_time if elapsed_time > 0 else 0
info_text = f'FPS: {fps:.1f} | 平均顕著性: {mean_saliency:.3f}'
processed_frame = draw_japanese_text(saliency_colored, info_text, (10, 30))
result = f'フレーム: {frame_count}, FPS: {fps:.1f}, 平均顕著性: {mean_saliency:.3f}'
return processed_frame, result, current_time
# プログラム開始時の概要表示
print('=' * 60)
print('U-2-Net動画用オブジェクト顕著性検出プログラム')
print('=' * 60)
print('【概要】')
print('U-2-Netディープラーニングモデルを使用して、')
print('動画中の顕著なオブジェクトをリアルタイムで検出します。')
print('')
print('【操作方法】')
print('1. 入力ソース選択メニューから選択')
print('2. 処理中の操作:')
print(' - qキー: プログラム終了')
print('3. 処理結果の表示:')
print(' - U-2-Net顕著性検出: 顕著性マップ(赤色が顕著な領域)')
print('')
print('【注意事項】')
print('- 初回実行時はモデルファイル(176MB)のダウンロードが必要です')
print('- GPUがある場合は自動的にGPU処理を行います')
print('=' * 60)
# メイン処理
print('U-2-Netモデルをロード中...')
model = load_model()
if model is None:
print('U-2-Netが利用できません。OpenCV顕著性検出を使用します。')
use_u2net = False
else:
print('U-2-Netモデルロード完了')
use_u2net = True
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# 処理統計用変数
start_time = time.time()
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "U-2-Net顕著性検出"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')