ipazc/MTCNN のインストールと動作確認(顔検出)(Python を使用)(Windows 上)
ソフトウェア等の利用条件等は,利用者で確認すること.
【サイト内の関連ページ】
謝辞:MTCNN の考案者、そして、プログラムの作者に感謝します
MTCNN のWebページ: https://www.github.com/ipazc/mtcnn
前準備
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
- 必要なPythonライブラリのインストール
【関連する外部ページ】
【サイト内の関連ページ】
このページで説明のために使用するビデオ、写真
必要であればダウンロードして使ってください.
- ここで使用する mp4 形式動画ファイル: sample1.mp4
- ここで使用する顔写真: 126.png, 127.png

{kind=link}
{kind=link}
顔検出(ipazc/MTCNN を使用)
- ipazc/MTCNN のインストール
python -m pip install -U mtcnn - mtcnn の factory.py を書き換える.
現在の TensorFlow で動くようにするための変更
次のようなコマンドで,エディタを起動.
notepad c:\program files\python39\lib\site-packages\mtcnn\network\factory.py先頭部分を次のように書き換える.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow.compat.v1 as tf # tf.enable_v1_behavior() import tensorflow.keras as keras import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 0 = GPU use; -1 = CPU use config = tf.compat.v1.ConfigProto( device_count = {'GPU': 1 , 'CPU': 3} ) sess = tf.compat.v1.Session(config=config) tf.keras.backend.set_session(sess) from tensorflow.keras.applications.resnet50 import ResNet50 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions from tensorflow.keras.utils import plot_model from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D, Input, Conv2D, MaxPooling2D, PReLU, Flatten, Softmax import numpy as np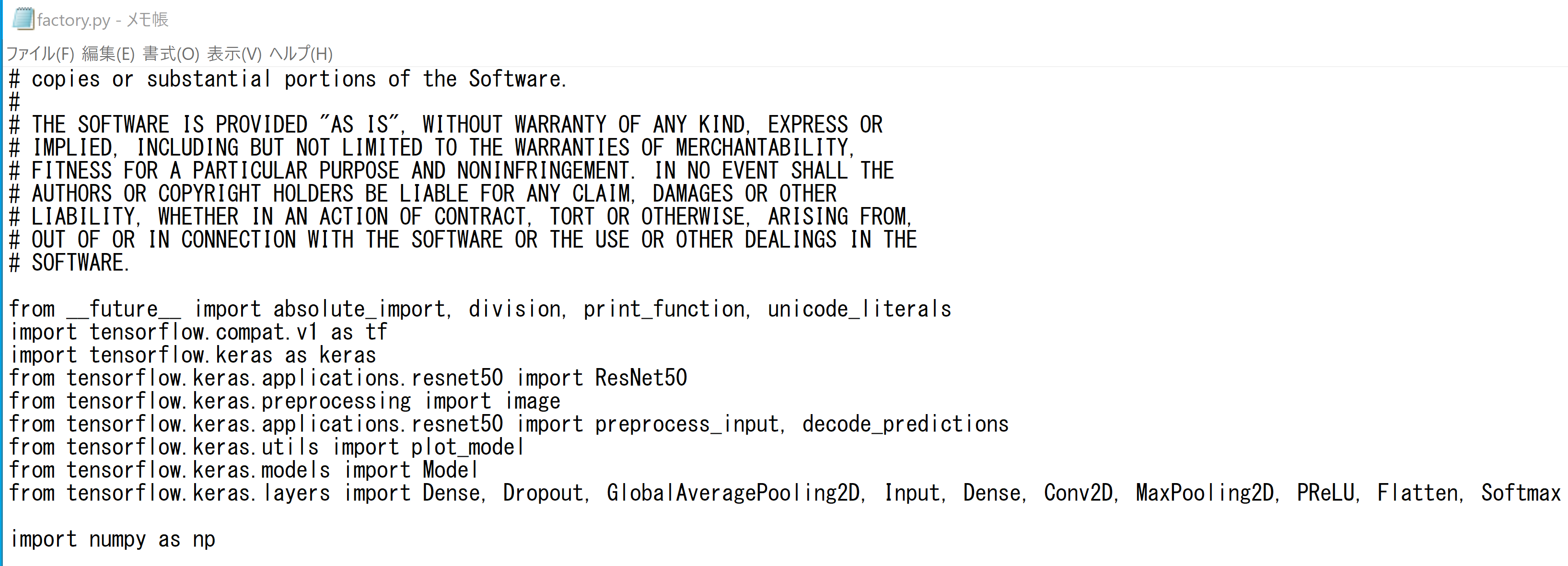
- C:\face-image のような作業用のディレクトリ(フォルダ)を作る
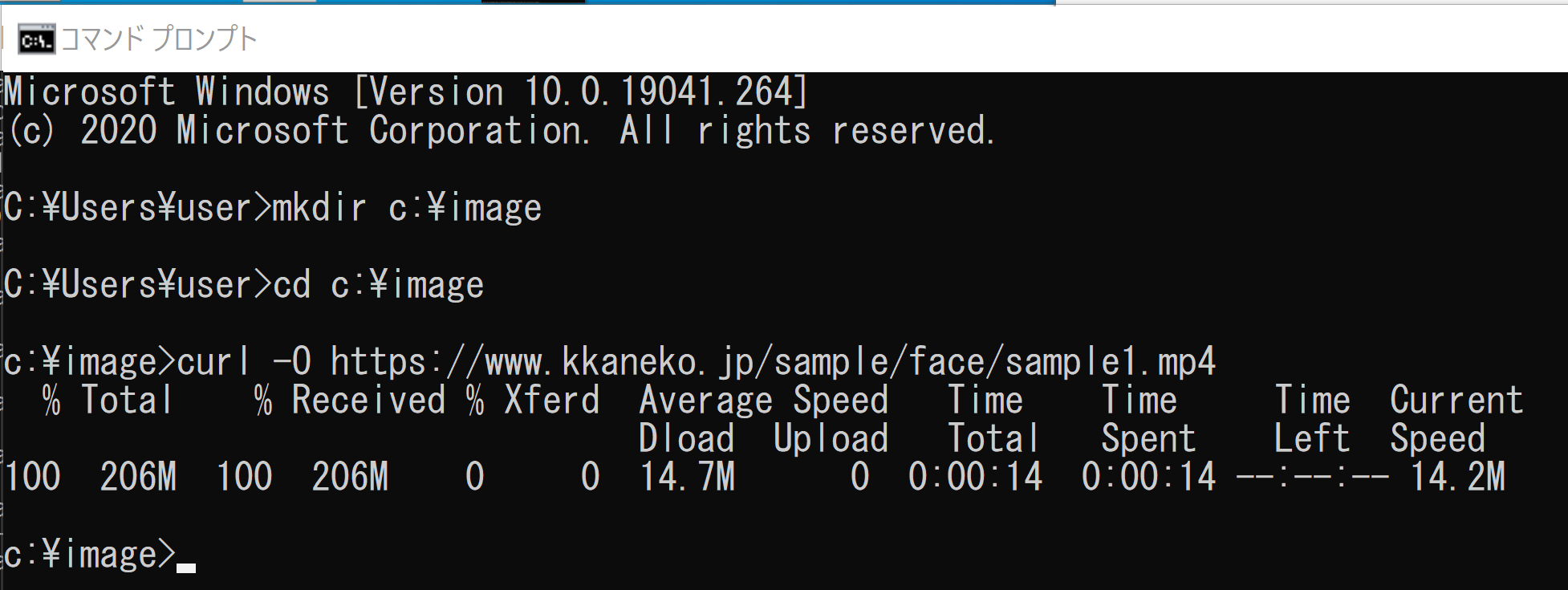
- このディレクトリに、顔写真: 126.png, 127.png をダウンロード

- 次の Python プログラムを実行する
https://github.com/ipazc/mtcnn で公開されているプログラムを変更して使用
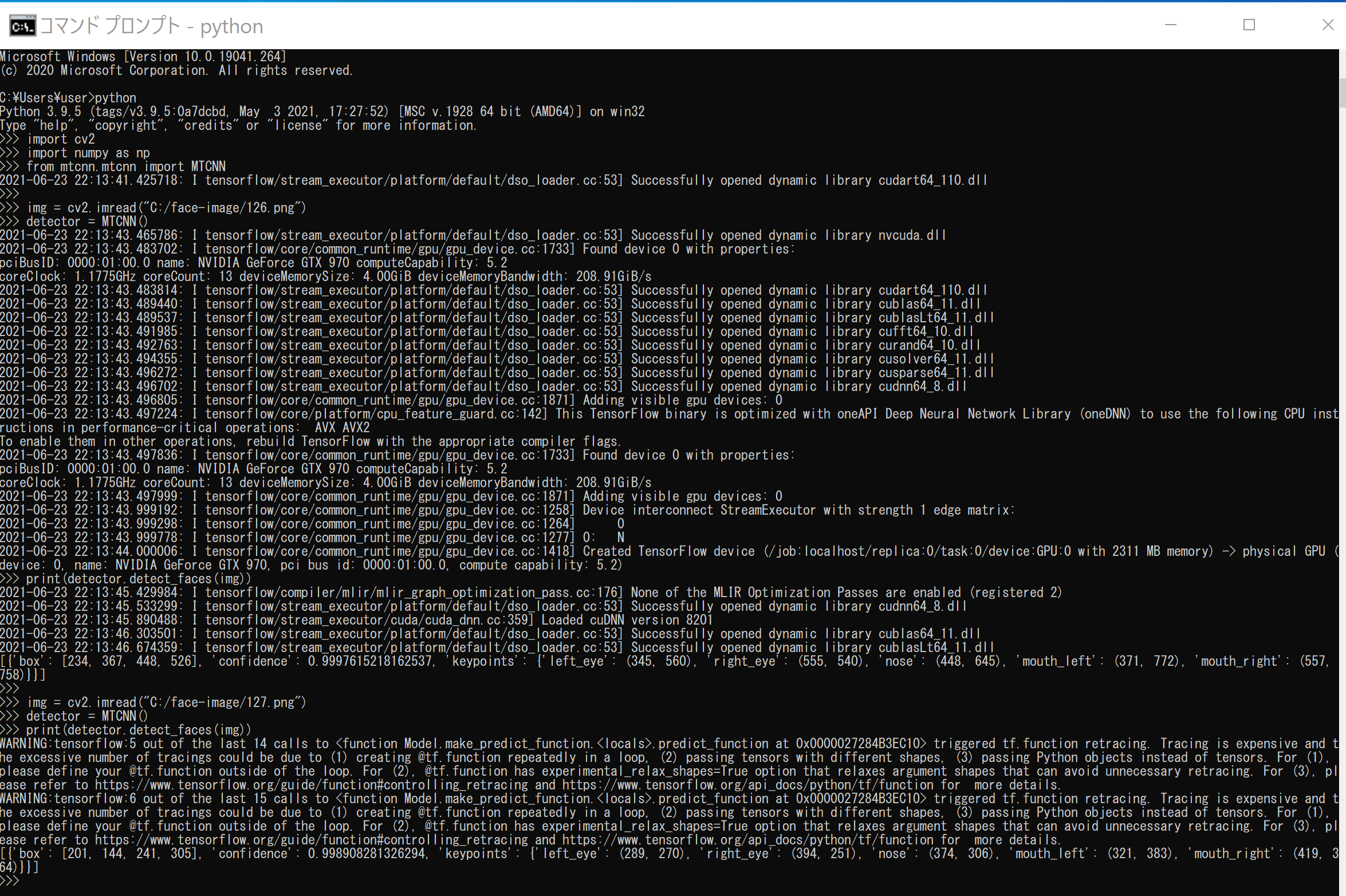
import cv2 import numpy as np from mtcnn.mtcnn import MTCNN img = cv2.imread("c:/image/126.png") detector = MTCNN() print(detector.detect_faces(img)) img = cv2.imread("c:/image/127.png") detector = MTCNN() print(detector.detect_faces(img))顔検出と、5点(左目、右目、鼻、口の左、口の右)の検出結果が表示されるので確認する
-
矩形(四角形)を書き、情報を表示する関数 box_label
これは,顔検出は行っていない. 画像の上に矩形(四角形)を書き,情報を表示する関数 box_label をテスト実行するもの.
Python プログラムを実行する
import cv2 import numpy as np bgr = cv2.imread("c:/image/127.png") def box_label(bgr, x1, y1, x2, y2, label): cv2.rectangle(bgr, (x1, y1), (x2, y2), (255, 0, 0), 1, 1) cv2.rectangle(bgr, (int(x1), int(y1-25)), (x2, y1), (255,255,255), -1) cv2.putText(bgr, label, (x1, int(y1-5)), cv2.FONT_HERSHEY_COMPLEX, 0.7, (0,0,0), 1) box_label(bgr, 100, 300, 200, 400, "hello") cv2.imshow('', bgr) cv2.waitKey(0) cv2.destroyAllWindows()画像が表示されるので確認. このあと,ウインドウの右上の「x」をクリックしない.画面の中をクリックしてから,何かのキーを押して閉じる

-
顔検出と、5点(左目、右目、鼻、口の左、口の右)の検出結果を、グラフィックスで表示
Python プログラムを実行する
import cv2 import numpy as np from mtcnn.mtcnn import MTCNN def box_label(bgr, x1, y1, x2, y2, label): cv2.rectangle(bgr, (x1, y1), (x2, y2), (255, 0, 0), 1, 1) cv2.rectangle(bgr, (int(x1), int(y1-25)), (x2, y1), (255,255,255), -1) cv2.putText(bgr, label, (x1, int(y1-5)), cv2.FONT_HERSHEY_COMPLEX, 0.7, (0,0,0), 1) bgr = cv2.imread("c:/image/127.png") detector = MTCNN() a1 = detector.detect_faces(bgr) for i, d in enumerate(a1): x1, y1 = tuple( d['box'][0:2] ) x2, y2 = tuple( np.array( d['box'][0:2] ) + np.array( d['box'][2:4] ) ) box_label(bgr, x1, y1, x2, y2, '{:0.2f}'.format(d['confidence'])) left_eye = d['keypoints']['left_eye'] if len(left_eye) == 2: cv2.circle(bgr, left_eye, 6, (255,255,255), -1) right_eye = d['keypoints']['right_eye'] if len(right_eye) == 2: cv2.circle(bgr, right_eye, 6, (255,255,255), -1) nose = d['keypoints']['nose'] if len(nose) == 2: cv2.circle(bgr, nose, 6, (255,255,255), -1) mouth_left = d['keypoints']['mouth_left'] if len(mouth_left) == 2: cv2.circle(bgr, mouth_left, 6, (255,255,255), -1) mouth_right = d['keypoints']['mouth_right'] if len(mouth_right) == 2: cv2.circle(bgr, mouth_right, 6, (255,255,255), -1) cv2.imshow('', bgr) cv2.waitKey(0) cv2.destroyAllWindows()画像が表示されるので確認. このあと,ウインドウの右上の「x」をクリックしない.画面の中をクリックしてから,何かのキーを押して閉じる

動画ファイルで動かしてみる
- C:\face-image のような作業用のディレクトリ(フォルダ)に、mp4 形式動画ファイル: sample1.mp4 をダウンロード
- 次の Python プログラムを実行
「c:/image/sample1.mp4」のところは、実際のファイル名に置き換えること
OpenCV による動画表示を行う.
Python プログラムを実行する
import cv2 import numpy as np from mtcnn.mtcnn import MTCNN def box_label(bgr, x1, y1, x2, y2, label): cv2.rectangle(bgr, (x1, y1), (x2, y2), (255, 0, 0), 1, 1) cv2.rectangle(bgr, (int(x1), int(y1-25)), (x2, y1), (255,255,255), -1) cv2.putText(bgr, label, (x1, int(y1-5)), cv2.FONT_HERSHEY_COMPLEX, 0.7, (0,0,0), 1) detector = MTCNN() v = cv2.VideoCapture("c:/image/sample1.mp4") while(v.isOpened()): r, bgr = v.read() if ( r == False ): break a1 = detector.detect_faces(bgr) for i, d in enumerate(a1): x1, y1 = tuple( d['box'][0:2] ) x2, y2 = tuple( np.array( d['box'][0:2] ) + np.array( d['box'][2:4] ) ) box_label(bgr, x1, y1, x2, y2, '{:0.2f}'.format(d['confidence'])) left_eye = d['keypoints']['left_eye'] if len(left_eye) == 2: cv2.circle(bgr, left_eye, 6, (255,255,255), -1) right_eye = d['keypoints']['right_eye'] if len(right_eye) == 2: cv2.circle(bgr, right_eye, 6, (255,255,255), -1) nose = d['keypoints']['nose'] if len(nose) == 2: cv2.circle(bgr, nose, 6, (255,255,255), -1) mouth_left = d['keypoints']['mouth_left'] if len(mouth_left) == 2: cv2.circle(bgr, mouth_left, 6, (255,255,255), -1) mouth_right = d['keypoints']['mouth_right'] if len(mouth_right) == 2: cv2.circle(bgr, mouth_right, 6, (255,255,255), -1) cv2.imshow("", bgr) # Press Q to exit if cv2.waitKey(1) & 0xFF == ord('q'): break v.release() cv2.destroyAllWindows()* 途中で止めたいとき,右上の「x」をクリックしない.画面の中をクリックしてから,「q」のキーを押して閉じる
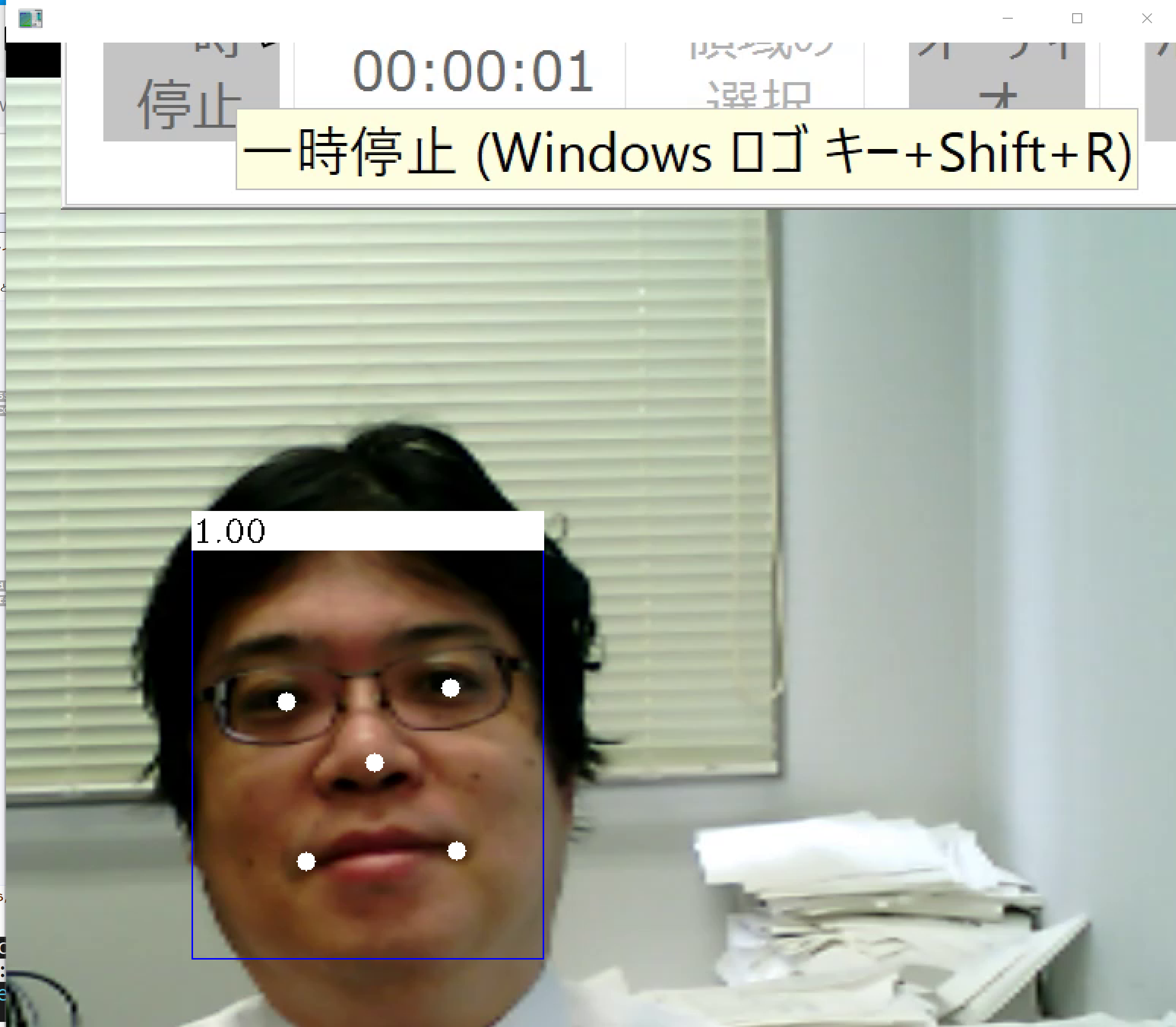
パソコンの USB カメラで動かしてみる
「v = cv2.VideoCapture(0) 」は、USB カメラを使うためのもの。他の部分は、上のプログラムと同じ。
Python プログラムを実行する
import cv2
import numpy as np
from mtcnn.mtcnn import MTCNN
def box_label(bgr, x1, y1, x2, y2, label):
cv2.rectangle(bgr, (x1, y1), (x2, y2), (255, 0, 0), 1, 1)
cv2.rectangle(bgr, (int(x1), int(y1-25)), (x2, y1), (255,255,255), -1)
cv2.putText(bgr, label, (x1, int(y1-5)), cv2.FONT_HERSHEY_COMPLEX, 0.7, (0,0,0), 1)
detector = MTCNN()
v = cv2.VideoCapture(0)
while(v.isOpened()):
r, bgr = v.read()
if ( r == False ):
break
a1 = detector.detect_faces(bgr)
for i, d in enumerate(a1):
x1, y1 = tuple( d['box'][0:2] )
x2, y2 = tuple( np.array( d['box'][0:2] ) + np.array( d['box'][2:4] ) )
box_label(bgr, x1, y1, x2, y2, '{:0.2f}'.format(d['confidence']))
left_eye = d['keypoints']['left_eye']
if len(left_eye) == 2:
cv2.circle(bgr, left_eye, 6, (255,255,255), -1)
right_eye = d['keypoints']['right_eye']
if len(right_eye) == 2:
cv2.circle(bgr, right_eye, 6, (255,255,255), -1)
nose = d['keypoints']['nose']
if len(nose) == 2:
cv2.circle(bgr, nose, 6, (255,255,255), -1)
mouth_left = d['keypoints']['mouth_left']
if len(mouth_left) == 2:
cv2.circle(bgr, mouth_left, 6, (255,255,255), -1)
mouth_right = d['keypoints']['mouth_right']
if len(mouth_right) == 2:
cv2.circle(bgr, mouth_right, 6, (255,255,255), -1)
cv2.imshow("", bgr)
if cv2.waitKey(1) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
* 途中で止めたいとき,右上の「x」をクリックしない.画面の中をクリックしてから,「q」のキーを押して閉じる
