Web ページのダウンロード,単語に切り分け,形態素解析(Python, Mecab, BeautifulSoap を使用)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
必要なライブラリをシステム領域にインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install -U mecab-python3
pip install -U ipadic unidic-lite
pip install -U html5lib bs4
日本語文書からの単語の切り出し,品詞の判定
- Python プログラムの実行
日本語の文章から,単語を切り出し,品詞を自動判定する Python プログラム
import sys import MeCab import unidic_lite m = MeCab.Tagger("") print(m.parse ("日本国民は、正当に選挙された国会における代表者を通じて行動し"))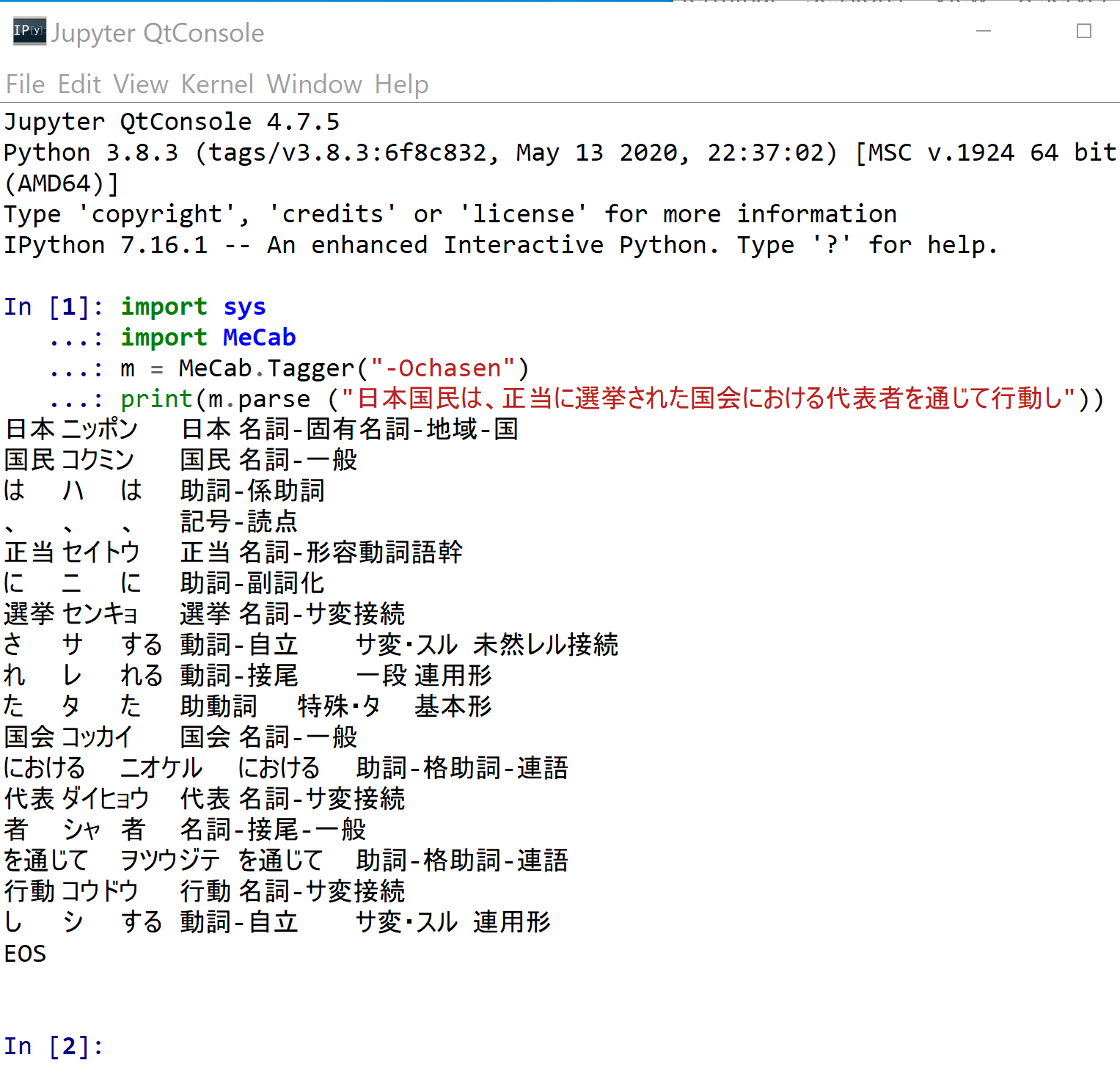
Web ページのダウンロードと単語の切り出し
- Web ページのダウンロード
URL を指定して,Web ページをダウンロード.そして,確認表示を行う Python プログラム.
import urllib.request r = urllib.request.urlopen('https://www.kkaneko.jp') html = r.read() print(html.decode())
- HTML タグの除去
いまダウンロードした Web ページについて,BeautifulSoap を用いて,HTML タグを取り除く Python プログラム.テキストと JavaScript が残る.
from bs4 import BeautifulSoup soup = BeautifulSoup(html,'html5lib') t = soup.get_text() print(t)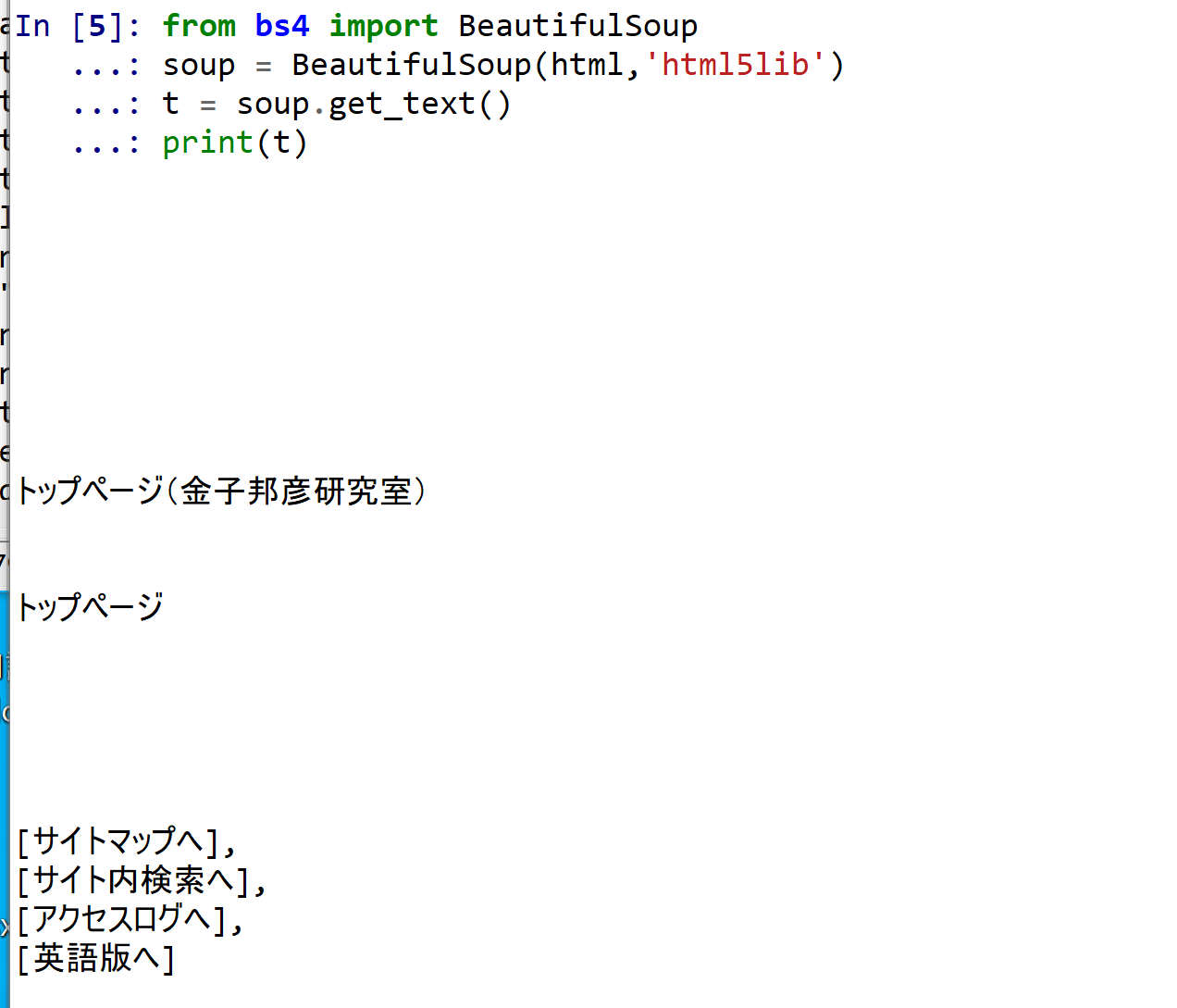
- プログラムの実行
いまダウンロードした日本語の Web ページについて,MeCab を用いて,単語を切り出す Python プログラム
import sys import MeCab import unidic_lite m = MeCab.Tagger("") a = m.parse(t) words = [i.split()[0] for i in a.splitlines()] print(words)